Last active
October 5, 2019 14:59
-
-
Save caiomoura1994/5c522ca4a48f2d064f74d03809f090b1 to your computer and use it in GitHub Desktop.
NLTP trabalho de IA 2019.2
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "nbformat": 4, | |
| "nbformat_minor": 0, | |
| "metadata": { | |
| "colab": { | |
| "name": "NLTP trabalho de IA 2019.2", | |
| "provenance": [], | |
| "collapsed_sections": [], | |
| "include_colab_link": true | |
| }, | |
| "kernelspec": { | |
| "display_name": "Python 3", | |
| "name": "python3" | |
| } | |
| }, | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "view-in-github", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "<a href=\"https://colab.research.google.com/gist/caiomoura1994/5c522ca4a48f2d064f74d03809f090b1/welcome-to-colaboratory.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "YLuONDgkq3op", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Processamento de Linguagem Natural\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "2oAiGUTSraGu", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Vamos ver hoje\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "z8MMFO1UrqZg", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "\n", | |
| "\n", | |
| "> * Evolução da Linguagem do Homem\n", | |
| "* O que e Processamento Natural de Linguagem\n", | |
| "* Aplicação para NLP\n", | |
| "* Componentes da NLP\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "f1qIOJWir5AR", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Evolução da linguagem do Homem\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "OIeN54B-sejg", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Evolução da linguagem do Homem\n", | |
| "\n", | |
| "> * Idiomas\n", | |
| "* Alfabetos\n", | |
| "* Juntos formam palavras\n", | |
| "* E palavras juntas formam sentenças\n", | |
| "* Regras \n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "W6qaD_dWtVPm", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# A final o que e NLP?\n", | |
| "\n", | |
| "* É a parte da ciência da computação e da inteligência artificial, que lida com linguagens humanas" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "f_1E7kRwtqod", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Como NPL pode ser util de verdade?\n", | |
| "> * Corrigindo a fala de alguem\n", | |
| "* Gerando respostas\n", | |
| "* Monitorando midias sociais\n", | |
| "* Encontrando similaridade em textos\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "a8SlyhQptyC_", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Aplicações de NLP \n", | |
| "\n", | |
| "\n", | |
| "\n", | |
| "> * Soletrando\n", | |
| "* Encontrando palavras\n", | |
| "* Extraindo informacoes\n", | |
| "* Conversao de Anuncios\n", | |
| "* Analise de Sentimentos\n", | |
| "* Capacidade de identificar a voz e fazer alguma acao\n", | |
| "* ChatBots\n", | |
| "* Tradutor\n", | |
| "\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "NtrO3cbCvwdb", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Componentes do NLP\n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "_IlTKBkNwR_G", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "lKM-RKjOv5xm", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# NLTK\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "a8TcIMF_wMW6", | |
| "colab_type": "code", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "#@title Importando o NLTK\n", | |
| "\n", | |
| "import nltk\n", | |
| "# nltk.download('punkt')\n", | |
| "# nltk.download('brown')\n", | |
| "# nltk.download('gutenberg')\n", | |
| "stopwords = nltk.corpus.stopwords.words('portuguese')" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "GFsZ7Hk-yt6L", | |
| "colab_type": "code", | |
| "outputId": "211916e7-f24e-478f-f3b4-21421c8fcebd", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 54 | |
| } | |
| }, | |
| "source": [ | |
| "#@title Conhecendo o corpus\n", | |
| "\n", | |
| "import nltk.corpus\n", | |
| "from nltk.corpus import brown\n", | |
| "\n", | |
| "brown.words()\n", | |
| "hamlet = nltk.corpus.gutenberg.words(\"shakespeare-hamlet.txt\")\n", | |
| "\n", | |
| "for word in hamlet[:500]:\n", | |
| " print(word, sep=' ', end=' ')" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "[ The Tragedie of Hamlet by William Shakespeare 1599 ] Actus Primus . Scoena Prima . Enter Barnardo and Francisco two Centinels . Barnardo . Who ' s there ? Fran . Nay answer me : Stand & vnfold your selfe Bar . Long liue the King Fran . Barnardo ? Bar . He Fran . You come most carefully vpon your houre Bar . ' Tis now strook twelue , get thee to bed Francisco Fran . For this releefe much thankes : ' Tis bitter cold , And I am sicke at heart Barn . Haue you had quiet Guard ? Fran . Not a Mouse stirring Barn . Well , goodnight . If you do meet Horatio and Marcellus , the Riuals of my Watch , bid them make hast . Enter Horatio and Marcellus . Fran . I thinke I heare them . Stand : who ' s there ? Hor . Friends to this ground Mar . And Leige - men to the Dane Fran . Giue you good night Mar . O farwel honest Soldier , who hath relieu ' d you ? Fra . Barnardo ha ' s my place : giue you goodnight . Exit Fran . Mar . Holla Barnardo Bar . Say , what is Horatio there ? Hor . A peece of him Bar . Welcome Horatio , welcome good Marcellus Mar . What , ha ' s this thing appear ' d againe to night Bar . I haue seene nothing Mar . Horatio saies , ' tis but our Fantasie , And will not let beleefe take hold of him Touching this dreaded sight , twice seene of vs , Therefore I haue intreated him along With vs , to watch the minutes of this Night , That if againe this Apparition come , He may approue our eyes , and speake to it Hor . Tush , tush , ' twill not appeare Bar . Sit downe a - while , And let vs once againe assaile your eares , That are so fortified against our Story , What we two Nights haue seene Hor . Well , sit we downe , And let vs heare Barnardo speake of this Barn . Last night of all , When yond same Starre that ' s Westward from the Pole Had made his course t ' illume that part of Heauen Where now it burnes , Marcellus and my selfe , The Bell then beating one Mar . Peace , breake thee of : Enter the Ghost . Looke where it comes againe Barn . In the same figure , like the King that ' s dead Mar . Thou art a Scholler ; speake to it Horatio Barn . Lookes it not like the King ? Marke it Horatio Hora . Most like : It harrowes me with fear & wonder Barn . It would be spoke too Mar . Question it Horatio Hor . What art " | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "QeR6W2BL1yss", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Tokenization\n", | |
| "* Separar frases em palavras\n", | |
| "* Entender a importância de cada palavra na frase\n", | |
| "* Bigrams\n", | |
| "* Trigrams\n", | |
| "* Ngrams\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "K8i7-WbUyyOB", | |
| "colab_type": "code", | |
| "outputId": "1532c7f5-28b6-418b-87c0-93b50cfb59fe", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 34 | |
| } | |
| }, | |
| "source": [ | |
| "#@title Conhecendo o word_tokenize\n", | |
| "sentence = \"Apresentação de procesamento natual de linguagem\"\n", | |
| "tokens = nltk.word_tokenize(sentence)\n", | |
| "tokens" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "execute_result", | |
| "data": { | |
| "text/plain": [ | |
| "['Apresentação', 'de', 'procesamento', 'natual', 'de', 'linguagem']" | |
| ] | |
| }, | |
| "metadata": { | |
| "tags": [] | |
| }, | |
| "execution_count": 13 | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "3dQEq_8823sR", | |
| "colab_type": "code", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "bigrams_tokens = list(nltk.bigrams(tokens))\n", | |
| "bigrams_tokens" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "bstK72Pz3SWh", | |
| "colab_type": "code", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "trigrams_tokens = list(nltk.trigrams(tokens))\n", | |
| "trigrams_tokens" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "PLQLZvWU3TaR", | |
| "colab_type": "code", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "ngrams = list(nltk.ngrams(tokens, 4))\n", | |
| "ngrams" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "svPsiSRd31QC", | |
| "colab_type": "code", | |
| "outputId": "e15b8502-caff-40f7-9849-4a8550fb2261", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 102 | |
| } | |
| }, | |
| "source": [ | |
| "from nltk.probability import FreqDist\n", | |
| "fdist= FreqDist()\n", | |
| "for word in tokens:\n", | |
| " fdist[word.lower()]+=1\n", | |
| "fdist" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "execute_result", | |
| "data": { | |
| "text/plain": [ | |
| "FreqDist({'apresentação': 1,\n", | |
| " 'de': 2,\n", | |
| " 'linguagem': 1,\n", | |
| " 'natual': 1,\n", | |
| " 'procesamento': 1})" | |
| ] | |
| }, | |
| "metadata": { | |
| "tags": [] | |
| }, | |
| "execution_count": 32 | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "aVjY9dwR4YyB", | |
| "colab_type": "code", | |
| "outputId": "01046b8d-ac2b-4d4f-b874-4b566f887db0", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 34 | |
| } | |
| }, | |
| "source": [ | |
| "from nltk.tokenize import blankline_tokenize\n", | |
| "\n", | |
| "ia_blank = blankline_tokenize(\"\"\"Test blankline_tokenize\n", | |
| "\n", | |
| "Quebrou uma linha aí\n", | |
| "\n", | |
| "Valeu.\"\"\")\n", | |
| "ia_blank" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "execute_result", | |
| "data": { | |
| "text/plain": [ | |
| "['Test blankline_tokenize', 'Quebrou uma linha aí', 'Valeu.']" | |
| ] | |
| }, | |
| "metadata": { | |
| "tags": [] | |
| }, | |
| "execution_count": 56 | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "2KwXtZyq7aQw", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Stemming\n", | |
| "\n", | |
| "> * Normaliza as palavras em sua forma base ou raiz" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "FlX_eabT7i1y", | |
| "colab_type": "code", | |
| "outputId": "0d6a6ba0-64cd-4bc0-b89c-1f3f9befdead", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 85 | |
| } | |
| }, | |
| "source": [ | |
| "#@title Conhecendo PorterStemmer\n", | |
| "from nltk.stem import PorterStemmer, LancasterStemmer, SnowballStemmer\n", | |
| "pst = PorterStemmer()\n", | |
| "lst = LancasterStemmer()\n", | |
| "sbst = SnowballStemmer('english')\n", | |
| "\n", | |
| "words_to_stem = ['give', 'giving', 'given', 'gave']\n", | |
| "\n", | |
| "stemmer = pst.stem\n", | |
| "stemmer = lst.stem\n", | |
| "stemmer = sbst.stem\n", | |
| "\n", | |
| "for words in words_to_stem:\n", | |
| " print(words + \":\"+ stemmer(words))\n", | |
| "\n", | |
| "\n", | |
| "# stopwords = nltk.corpus.stopwords.words('portuguese')\n", | |
| "# stemmer = nltk.stem.RSLPStemmer()\n", | |
| "# stemmer.stem(\"tentando\")\n" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "give:give\n", | |
| "giving:give\n", | |
| "given:given\n", | |
| "gave:gave\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "KhImDpyY9fFe", | |
| "colab_type": "code", | |
| "outputId": "7881fd27-4477-4ea7-9215-24b218b02c24", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 85 | |
| } | |
| }, | |
| "source": [ | |
| "from nltk.stem import wordnet\n", | |
| "from nltk.stem import WordNetLemmatizer\n", | |
| "word_lem= WordNetLemmatizer()\n", | |
| "\n", | |
| "word_lem.lemmatize('corpora')\n", | |
| "\n", | |
| "for words in words_to_stem:\n", | |
| " print(words + \":\" + word_lem.lemmatize(words))" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "give:give\n", | |
| "giving:giving\n", | |
| "given:given\n", | |
| "gave:gave\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "QQaA6y7RCnAf", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Stop Words\n", | |
| "* de\n", | |
| "* a\n", | |
| "* o\n", | |
| "* que\n", | |
| "* e\n", | |
| "* do\n", | |
| "* da\n", | |
| "* em\n", | |
| "* ..." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "gQrBQh3uC7xA", | |
| "colab_type": "code", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "from nltk.corpus import stopwords" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "tWF13m4EDBnG", | |
| "colab_type": "code", | |
| "outputId": "d708f5b4-c9bd-43ea-fd17-2acd9e69dcf1", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 34 | |
| } | |
| }, | |
| "source": [ | |
| "#@title Removendo StopWords\n", | |
| "stop_words = stopwords.words('portuguese')\n", | |
| "\n", | |
| "[word for word in tokens if word not in stop_words]" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "execute_result", | |
| "data": { | |
| "text/plain": [ | |
| "['Apresentação', 'procesamento', 'natual', 'linguagem']" | |
| ] | |
| }, | |
| "metadata": { | |
| "tags": [] | |
| }, | |
| "execution_count": 117 | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "C8uyceXBEdyn", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# POS: Parts of Speech\n", | |
| "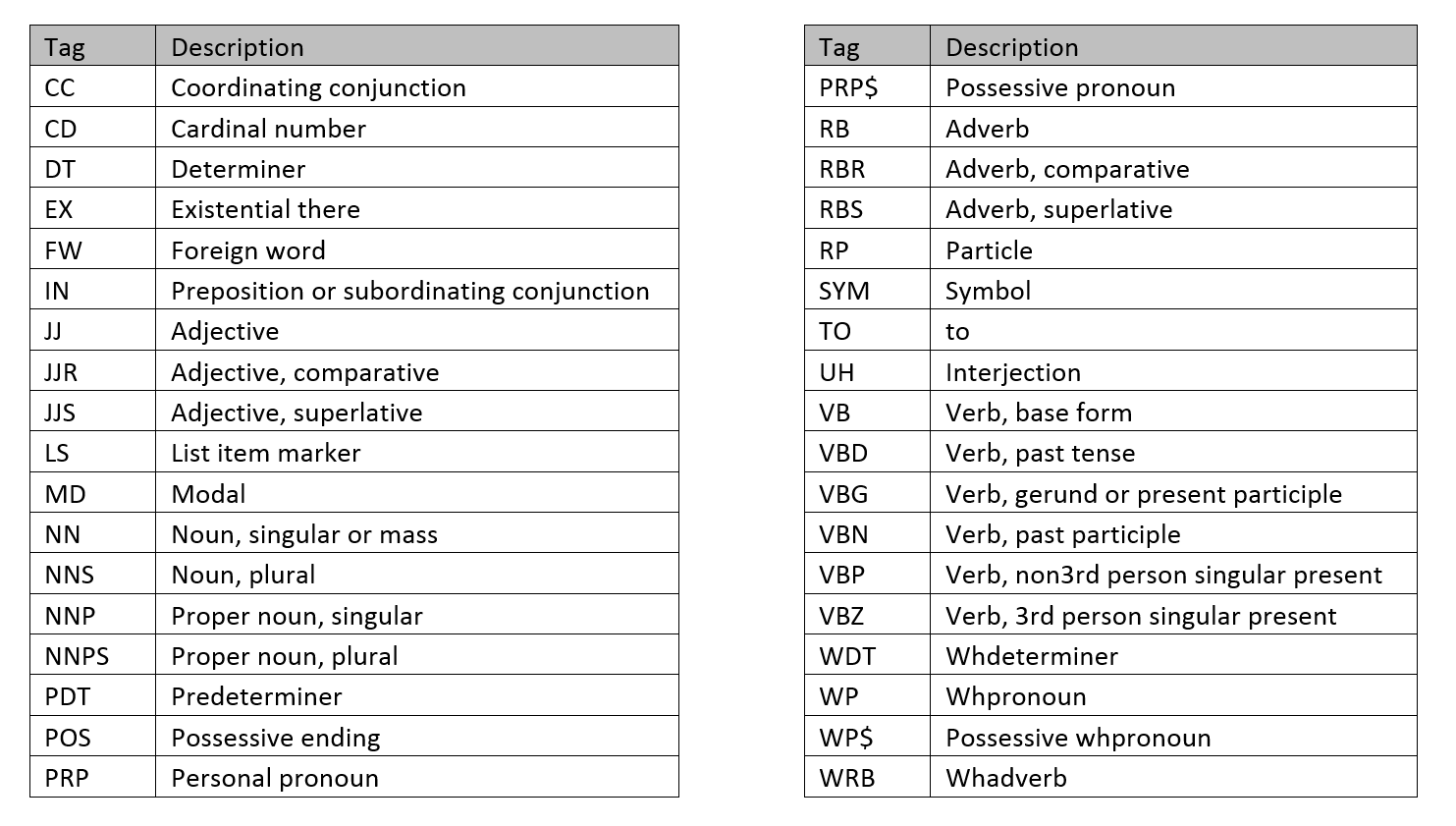\n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "vS-U1GI3FNMO", | |
| "colab_type": "code", | |
| "outputId": "e6117e23-c6bb-484a-d346-4b757fd2308e", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 119 | |
| } | |
| }, | |
| "source": [ | |
| "# some_text = \"Caio is student in Unifacs University\"\n", | |
| "some_text = \"Caio is eating a delicious cake\"\n", | |
| "\n", | |
| "some_tokens = nltk.word_tokenize(some_text)\n", | |
| "for token in some_tokens:\n", | |
| " print(nltk.pos_tag([token]))" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "[('Caio', 'NN')]\n", | |
| "[('is', 'VBZ')]\n", | |
| "[('eating', 'VBG')]\n", | |
| "[('a', 'DT')]\n", | |
| "[('delicious', 'JJ')]\n", | |
| "[('cake', 'NN')]\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "UP1G-VLiG7Tx", | |
| "colab_type": "code", | |
| "cellView": "both", | |
| "outputId": "c4ac9c59-dd18-4cd2-fc10-8fb54999e95d", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 221 | |
| } | |
| }, | |
| "source": [ | |
| "#@title NER: Named Entity Recognition (Reconhecimento de entidade nomeada)\n", | |
| "from nltk import ne_chunk\n", | |
| "\n", | |
| "some_text = \"The Jusbrasil CTO Tupi introduct the new Pixel at Minnesota Roi Centre Event \"\n", | |
| "\n", | |
| "some_tokens = nltk.word_tokenize(some_text)\n", | |
| "NE_tags = nltk.pos_tag(some_tokens)\n", | |
| "ne_ner = ne_chunk(NE_tags)\n", | |
| "\n", | |
| "print(ne_ner)" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "(S\n", | |
| " The/DT\n", | |
| " (ORGANIZATION Jusbrasil/NNP)\n", | |
| " CTO/NNP\n", | |
| " Tupi/NNP\n", | |
| " introduct/VBP\n", | |
| " the/DT\n", | |
| " new/JJ\n", | |
| " Pixel/NNP\n", | |
| " at/IN\n", | |
| " (ORGANIZATION Minnesota/NNP Roi/NNP Centre/NNP)\n", | |
| " Event/NNP)\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "PgPmhf5KIm9V", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
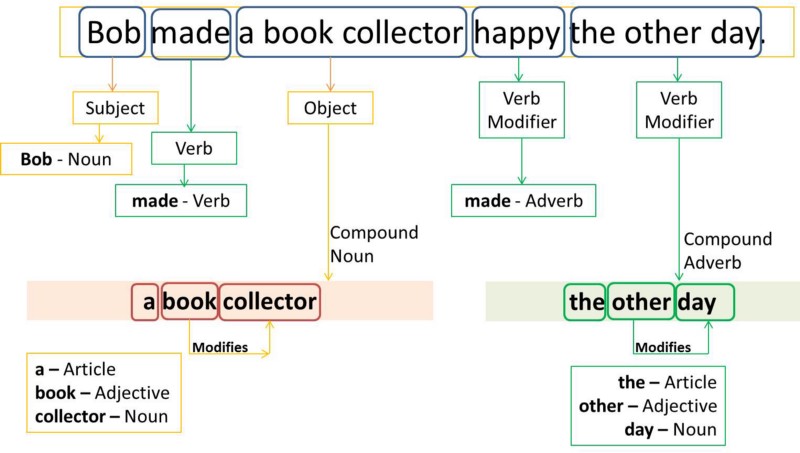
| "# Syntax Tree\n", | |
| "> * É a arvore de representação sintatica da estrutura das frases ou textos\n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "dmHIzfvsOx3R", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Casos de Fracasso\n", | |
| "\n", | |
| "> * A Leme militar tentou automatizar o processo de baixa de contas a pagar a partir de imagens de um telefone celular\n", | |
| "* Cadastro automatico de CFOP de acordo com o nome do produto\n", | |
| "* Jusbrasil tentativa de fazer similaridade entre jurisprudencias de nivel 1\n", | |
| "\n", | |
| "\n", | |
| "# Casos de Sucesso\n", | |
| "\n", | |
| "> * Jusbrasil tem uma ferramenta para dizer se um caso é quente ou não com intensão de indicar esse caso para mais advogados\n", | |
| "* Google\n", | |
| "* Operaçao serenata de amor\n", | |
| "* Identificador de Gemidão do whatsapp\n", | |
| "* [Lin Robô que lê o Twitter e identifica o sentimento](http://g1.globo.com/Noticias/Tecnologia/0,,MUL1271047-6174,00-MENSAGENS+NO+TWITTER+MOVIMENTAM+ROBO+DE+PAPELAO.html)\n", | |
| "* [Facebook Api para identificar intenção do usuario no chat](https://developers.facebook.com/docs/messenger-platform/built-in-nlp/?translation)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "_Y2CqDTgJ_Pr", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Referências\n", | |
| "\n", | |
| "[Documentacao do NLTK](https://www.nltk.org/)\n", | |
| "\n", | |
| "[Algumas pesquisas no Wikipedia](https://pt.wikipedia.org)\n", | |
| "\n", | |
| "https://medium.com/botsbrasil/o-que-%C3%A9-o-processamento-de-linguagem-natural-49ece9371cff\n", | |
| "\n", | |
| "https://www.nltk.org/book/ch02.html\n", | |
| "\n", | |
| "https://minerandodados.com.br/\n", | |
| "\n", | |
| "[Filipe Deschamps](https://www.youtube.com/channel/UCU5JicSrEM5A63jkJ2QvGYw)\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "yWUXXJbCJZDi", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Google vision AI\n", | |
| "\n", | |
| ">* https://translate.google.com/\n", | |
| "* https://cloud.google.com/vision/" | |
| ] | |
| } | |
| ] | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment