Created
October 1, 2018 16:35
-
-
Save chiragjn/3636a897ef2e28b077d7edab3249c19f to your computer and use it in GitHub Desktop.
Notebook for my Intro to NLP talk for undergraduates
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "code", | |
| "execution_count": 30, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "[nltk_data] Downloading package punkt to /Users/chirag/nltk_data...\n", | |
| "[nltk_data] Package punkt is already up-to-date!\n", | |
| "[nltk_data] Downloading package reuters to /Users/chirag/nltk_data...\n", | |
| "[nltk_data] Package reuters is already up-to-date!\n", | |
| "[nltk_data] Downloading package averaged_perceptron_tagger to\n", | |
| "[nltk_data] /Users/chirag/nltk_data...\n", | |
| "[nltk_data] Package averaged_perceptron_tagger is already up-to-\n", | |
| "[nltk_data] date!\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "True" | |
| ] | |
| }, | |
| "execution_count": 30, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "import nltk\n", | |
| "nltk.download('punkt')\n", | |
| "nltk.download('reuters')\n", | |
| "nltk.download('averaged_perceptron_tagger')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Loading Data\n", | |
| "\n", | |
| "### Our data is news type corpus\n", | |
| "### N samples of (document, class)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 75, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "from sklearn.datasets import fetch_20newsgroups\n", | |
| "newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))\n", | |
| "newsgroups_test = fetch_20newsgroups(subset='test', remove=('headers', 'footers', 'quotes'))\n", | |
| "print(list(newsgroups_train.target_names))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 73, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([7, 4, 4, ..., 3, 1, 8])" | |
| ] | |
| }, | |
| "execution_count": 73, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "newsgroups_train.target" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 131, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "['I was wondering if anyone out there could enlighten me on this car I saw\\nthe other day. It was a 2-door sports car, looked to be from the late 60s/\\nearly 70s. It was called a Bricklin. The doors were really small. In addition,\\nthe front bumper was separate from the rest of the body. This is \\nall I know. If anyone can tellme a model name, engine specs, years\\nof production, where this car is made, history, or whatever info you\\nhave on this funky looking car, please e-mail.',\n", | |
| " \"A fair number of brave souls who upgraded their SI clock oscillator have\\nshared their experiences for this poll. Please send a brief message detailing\\nyour experiences with the procedure. Top speed attained, CPU rated speed,\\nadd on cards and adapters, heat sinks, hour of usage per day, floppy disk\\nfunctionality with 800 and 1.4 m floppies are especially requested.\\n\\nI will be summarizing in the next two days, so please add to the network\\nknowledge base if you have done the clock upgrade and haven't answered this\\npoll. Thanks.\",\n", | |
| " 'well folks, my mac plus finally gave up the ghost this weekend after\\nstarting life as a 512k way back in 1985. sooo, i\\'m in the market for a\\nnew machine a bit sooner than i intended to be...\\n\\ni\\'m looking into picking up a powerbook 160 or maybe 180 and have a bunch\\nof questions that (hopefully) somebody can answer:\\n\\n* does anybody know any dirt on when the next round of powerbook\\nintroductions are expected? i\\'d heard the 185c was supposed to make an\\nappearence \"this summer\" but haven\\'t heard anymore on it - and since i\\ndon\\'t have access to macleak, i was wondering if anybody out there had\\nmore info...\\n\\n* has anybody heard rumors about price drops to the powerbook line like the\\nones the duo\\'s just went through recently?\\n\\n* what\\'s the impression of the display on the 180? i could probably swing\\na 180 if i got the 80Mb disk rather than the 120, but i don\\'t really have\\na feel for how much \"better\" the display is (yea, it looks great in the\\nstore, but is that all \"wow\" or is it really that good?). could i solicit\\nsome opinions of people who use the 160 and 180 day-to-day on if its worth\\ntaking the disk size and money hit to get the active display? (i realize\\nthis is a real subjective question, but i\\'ve only played around with the\\nmachines in a computer store breifly and figured the opinions of somebody\\nwho actually uses the machine daily might prove helpful).\\n\\n* how well does hellcats perform? ;)\\n\\nthanks a bunch in advance for any info - if you could email, i\\'ll post a\\nsummary (news reading time is at a premium with finals just around the\\ncorner... :( )\\n--\\nTom Willis \\\\ [email protected] \\\\ Purdue Electrical Engineering',\n", | |
| " \"\\nDo you have Weitek's address/phone number? I'd like to get some information\\nabout this chip.\\n\",\n", | |
| " \"From article <[email protected]>, by [email protected] (Tom A Baker):\\n\\n\\nMy understanding is that the 'expected errors' are basically\\nknown bugs in the warning system software - things are checked\\nthat don't have the right values in yet because they aren't\\nset till after launch, and suchlike. Rather than fix the code\\nand possibly introduce new bugs, they just tell the crew\\n'ok, if you see a warning no. 213 before liftoff, ignore it'.\"]" | |
| ] | |
| }, | |
| "execution_count": 131, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "newsgroups_train.data[:5]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 77, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "train_data = []\n", | |
| "test_data = []\n", | |
| "\n", | |
| "for doc, label in zip(newsgroups_train.data, newsgroups_train.target):\n", | |
| " train_data.append((doc, label, newsgroups_train.target_names[label]))\n", | |
| "\n", | |
| "for doc, label in zip(newsgroups_test.data, newsgroups_test.target):\n", | |
| " test_data.append((doc, label, newsgroups_train.target_names[label]))\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 78, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import pandas as pd\n", | |
| "train_df = pd.DataFrame(train_data, columns=['body', 'label', 'label_str'])\n", | |
| "test_df = pd.DataFrame(test_data, columns=['body', 'label', 'label_str'])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 79, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "11314\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/html": [ | |
| "<div>\n", | |
| "<style scoped>\n", | |
| " .dataframe tbody tr th:only-of-type {\n", | |
| " vertical-align: middle;\n", | |
| " }\n", | |
| "\n", | |
| " .dataframe tbody tr th {\n", | |
| " vertical-align: top;\n", | |
| " }\n", | |
| "\n", | |
| " .dataframe thead th {\n", | |
| " text-align: right;\n", | |
| " }\n", | |
| "</style>\n", | |
| "<table border=\"1\" class=\"dataframe\">\n", | |
| " <thead>\n", | |
| " <tr style=\"text-align: right;\">\n", | |
| " <th></th>\n", | |
| " <th>body</th>\n", | |
| " <th>label</th>\n", | |
| " <th>label_str</th>\n", | |
| " </tr>\n", | |
| " </thead>\n", | |
| " <tbody>\n", | |
| " <tr>\n", | |
| " <th>0</th>\n", | |
| " <td>I was wondering if anyone out there could enli...</td>\n", | |
| " <td>7</td>\n", | |
| " <td>rec.autos</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>1</th>\n", | |
| " <td>A fair number of brave souls who upgraded thei...</td>\n", | |
| " <td>4</td>\n", | |
| " <td>comp.sys.mac.hardware</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>2</th>\n", | |
| " <td>well folks, my mac plus finally gave up the gh...</td>\n", | |
| " <td>4</td>\n", | |
| " <td>comp.sys.mac.hardware</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>3</th>\n", | |
| " <td>\\nDo you have Weitek's address/phone number? ...</td>\n", | |
| " <td>1</td>\n", | |
| " <td>comp.graphics</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>4</th>\n", | |
| " <td>From article <[email protected]>, by to...</td>\n", | |
| " <td>14</td>\n", | |
| " <td>sci.space</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>5</th>\n", | |
| " <td>\\n\\n\\n\\n\\nOf course. The term must be rigidly...</td>\n", | |
| " <td>16</td>\n", | |
| " <td>talk.politics.guns</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>6</th>\n", | |
| " <td>There were a few people who responded to my re...</td>\n", | |
| " <td>13</td>\n", | |
| " <td>sci.med</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>7</th>\n", | |
| " <td>...</td>\n", | |
| " <td>3</td>\n", | |
| " <td>comp.sys.ibm.pc.hardware</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>8</th>\n", | |
| " <td>I have win 3.0 and downloaded several icons an...</td>\n", | |
| " <td>2</td>\n", | |
| " <td>comp.os.ms-windows.misc</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>9</th>\n", | |
| " <td>\\n\\n\\nI've had the board for over a year, and ...</td>\n", | |
| " <td>4</td>\n", | |
| " <td>comp.sys.mac.hardware</td>\n", | |
| " </tr>\n", | |
| " </tbody>\n", | |
| "</table>\n", | |
| "</div>" | |
| ], | |
| "text/plain": [ | |
| " body label \\\n", | |
| "0 I was wondering if anyone out there could enli... 7 \n", | |
| "1 A fair number of brave souls who upgraded thei... 4 \n", | |
| "2 well folks, my mac plus finally gave up the gh... 4 \n", | |
| "3 \\nDo you have Weitek's address/phone number? ... 1 \n", | |
| "4 From article <[email protected]>, by to... 14 \n", | |
| "5 \\n\\n\\n\\n\\nOf course. The term must be rigidly... 16 \n", | |
| "6 There were a few people who responded to my re... 13 \n", | |
| "7 ... 3 \n", | |
| "8 I have win 3.0 and downloaded several icons an... 2 \n", | |
| "9 \\n\\n\\nI've had the board for over a year, and ... 4 \n", | |
| "\n", | |
| " label_str \n", | |
| "0 rec.autos \n", | |
| "1 comp.sys.mac.hardware \n", | |
| "2 comp.sys.mac.hardware \n", | |
| "3 comp.graphics \n", | |
| "4 sci.space \n", | |
| "5 talk.politics.guns \n", | |
| "6 sci.med \n", | |
| "7 comp.sys.ibm.pc.hardware \n", | |
| "8 comp.os.ms-windows.misc \n", | |
| "9 comp.sys.mac.hardware " | |
| ] | |
| }, | |
| "execution_count": 79, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "print(len(train_df))\n", | |
| "train_df.head(10)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 80, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "7532\n" | |
| ] | |
| }, | |
| { | |
| "data": { | |
| "text/html": [ | |
| "<div>\n", | |
| "<style scoped>\n", | |
| " .dataframe tbody tr th:only-of-type {\n", | |
| " vertical-align: middle;\n", | |
| " }\n", | |
| "\n", | |
| " .dataframe tbody tr th {\n", | |
| " vertical-align: top;\n", | |
| " }\n", | |
| "\n", | |
| " .dataframe thead th {\n", | |
| " text-align: right;\n", | |
| " }\n", | |
| "</style>\n", | |
| "<table border=\"1\" class=\"dataframe\">\n", | |
| " <thead>\n", | |
| " <tr style=\"text-align: right;\">\n", | |
| " <th></th>\n", | |
| " <th>body</th>\n", | |
| " <th>label</th>\n", | |
| " <th>label_str</th>\n", | |
| " </tr>\n", | |
| " </thead>\n", | |
| " <tbody>\n", | |
| " <tr>\n", | |
| " <th>0</th>\n", | |
| " <td>I am a little confused on all of the models of...</td>\n", | |
| " <td>7</td>\n", | |
| " <td>rec.autos</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>1</th>\n", | |
| " <td>I'm not familiar at all with the format of the...</td>\n", | |
| " <td>5</td>\n", | |
| " <td>comp.windows.x</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>2</th>\n", | |
| " <td>\\nIn a word, yes.\\n</td>\n", | |
| " <td>0</td>\n", | |
| " <td>alt.atheism</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>3</th>\n", | |
| " <td>\\nThey were attacking the Iraqis to drive them...</td>\n", | |
| " <td>17</td>\n", | |
| " <td>talk.politics.mideast</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>4</th>\n", | |
| " <td>\\nI've just spent two solid months arguing tha...</td>\n", | |
| " <td>19</td>\n", | |
| " <td>talk.religion.misc</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>5</th>\n", | |
| " <td>\\nElisabeth, let's set the record straight for...</td>\n", | |
| " <td>13</td>\n", | |
| " <td>sci.med</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>6</th>\n", | |
| " <td>Dishonest money dwindles away, but he who gath...</td>\n", | |
| " <td>15</td>\n", | |
| " <td>soc.religion.christian</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>7</th>\n", | |
| " <td>A friend of mine managed to get a copy of a co...</td>\n", | |
| " <td>15</td>\n", | |
| " <td>soc.religion.christian</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>8</th>\n", | |
| " <td>Hi,\\n\\n We have a requirement for dynamicall...</td>\n", | |
| " <td>5</td>\n", | |
| " <td>comp.windows.x</td>\n", | |
| " </tr>\n", | |
| " <tr>\n", | |
| " <th>9</th>\n", | |
| " <td>: \\n: well, i have lots of experience with sc...</td>\n", | |
| " <td>1</td>\n", | |
| " <td>comp.graphics</td>\n", | |
| " </tr>\n", | |
| " </tbody>\n", | |
| "</table>\n", | |
| "</div>" | |
| ], | |
| "text/plain": [ | |
| " body label \\\n", | |
| "0 I am a little confused on all of the models of... 7 \n", | |
| "1 I'm not familiar at all with the format of the... 5 \n", | |
| "2 \\nIn a word, yes.\\n 0 \n", | |
| "3 \\nThey were attacking the Iraqis to drive them... 17 \n", | |
| "4 \\nI've just spent two solid months arguing tha... 19 \n", | |
| "5 \\nElisabeth, let's set the record straight for... 13 \n", | |
| "6 Dishonest money dwindles away, but he who gath... 15 \n", | |
| "7 A friend of mine managed to get a copy of a co... 15 \n", | |
| "8 Hi,\\n\\n We have a requirement for dynamicall... 5 \n", | |
| "9 : \\n: well, i have lots of experience with sc... 1 \n", | |
| "\n", | |
| " label_str \n", | |
| "0 rec.autos \n", | |
| "1 comp.windows.x \n", | |
| "2 alt.atheism \n", | |
| "3 talk.politics.mideast \n", | |
| "4 talk.religion.misc \n", | |
| "5 sci.med \n", | |
| "6 soc.religion.christian \n", | |
| "7 soc.religion.christian \n", | |
| "8 comp.windows.x \n", | |
| "9 comp.graphics " | |
| ] | |
| }, | |
| "execution_count": 80, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "print(len(test_df))\n", | |
| "test_df.head(10)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 132, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import re\n", | |
| "def clean(text):\n", | |
| " text = text.lower()\n", | |
| " text = text.replace('\\n', ' ')\n", | |
| " text = text.replace(\"'\", '')\n", | |
| " text = text.replace(\",\", '')\n", | |
| " text = re.sub(r'&[a-z]+;', ' ', text)\n", | |
| " text = re.sub(r'[^a-zA-Z0-9]+', ' ', text)\n", | |
| " text = re.sub(r'\\d+', ' ', text)\n", | |
| " text = ' '.join(text.split())\n", | |
| " return text" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 82, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'I was wondering if anyone out there could enlighten me on this car I saw\\nthe other day. It was a 2-door sports car, looked to be from the late 60s/\\nearly 70s. It was called a Bricklin. The doors were really small. In addition,\\nthe front bumper was separate from the rest of the body. This is \\nall I know. If anyone can tellme a model name, engine specs, years\\nof production, where this car is made, history, or whatever info you\\nhave on this funky looking car, please e-mail.'" | |
| ] | |
| }, | |
| "execution_count": 82, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "train_df.iloc[0].body" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 133, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'i was wondering if anyone out there could enlighten me on this car i saw the other day it was a door sports car looked to be from the late s early s it was called a bricklin the doors were really small in addition the front bumper was separate from the rest of the body this is all i know if anyone can tellme a model name engine specs years of production where this car is made history or whatever info you have on this funky looking car please e mail'" | |
| ] | |
| }, | |
| "execution_count": 133, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "clean(train_df.iloc[0].body)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 134, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "train_df['processed_body'] = train_df['body'].apply(clean)\n", | |
| "test_df['processed_body'] = test_df['body'].apply(clean)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## We will use Nearest Neighbors as our classifier\n", | |
| "### 1. Define some similarity metric between two docs\n", | |
| "### 2. To predict, Get top K = 5 most similar documents according to the similarity metric\n", | |
| "### 3. Assign the class that is majority among the classes for 5 nearest neighbors" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 85, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "def tokenize(text):\n", | |
| " return text.split(' ')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Simplest way to define similarity would be Jaccard similarity\n", | |
| "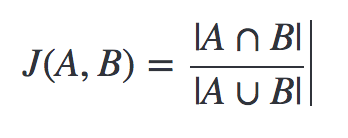" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 86, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "0.11382113821045674\n", | |
| "0.12328767123231377\n", | |
| "0.05128205128139382\n", | |
| "0.09606986899521368\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "def jaccard_similarity(text1, text2):\n", | |
| " A = set(tokenize(text1))\n", | |
| " B = set(tokenize(text2))\n", | |
| " return float(len(A & B)) / (len(A | B) + 1e-9)\n", | |
| "\n", | |
| "print(jaccard_similarity(train_df.iloc[0].processed_body, train_df.iloc[1].processed_body))\n", | |
| "print(jaccard_similarity(train_df.iloc[0].processed_body, train_df.iloc[2].processed_body))\n", | |
| "print(jaccard_similarity(train_df.iloc[0].processed_body, train_df.iloc[3].processed_body))\n", | |
| "print(jaccard_similarity(train_df.iloc[1].processed_body, train_df.iloc[2].processed_body))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 135, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'rec.autos'" | |
| ] | |
| }, | |
| "execution_count": 135, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "import collections\n", | |
| "from sklearn.metrics import accuracy_score\n", | |
| "\n", | |
| "def predict(text):\n", | |
| " scores = []\n", | |
| " for row in train_df.itertuples():\n", | |
| " scores.append((jaccard_similarity(row.processed_body, text), row.label))\n", | |
| " scores = sorted(scores, reverse=True)[:5]\n", | |
| " return collections.Counter(scores).most_common(1)[0][0][1]\n", | |
| "\n", | |
| "\n", | |
| "newsgroups_train.target_names[predict(train_df.iloc[0].processed_body)]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 67, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "ename": "KeyboardInterrupt", | |
| "evalue": "", | |
| "output_type": "error", | |
| "traceback": [ | |
| "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", | |
| "\u001b[0;31mKeyboardInterrupt\u001b[0m Traceback (most recent call last)", | |
| "\u001b[0;32m<ipython-input-67-8038b27cc7cf>\u001b[0m in \u001b[0;36m<module>\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mtest_df\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m'predicted_labels'\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mtest_df\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m'processed_body'\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mapply\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mpredict\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m", | |
| "\u001b[0;32m~/venv3/lib/python3.6/site-packages/pandas/core/series.py\u001b[0m in \u001b[0;36mapply\u001b[0;34m(self, func, convert_dtype, args, **kwds)\u001b[0m\n\u001b[1;32m 2549\u001b[0m \u001b[0;32melse\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2550\u001b[0m \u001b[0mvalues\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0masobject\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 2551\u001b[0;31m \u001b[0mmapped\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mlib\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmap_infer\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mvalues\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mf\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mconvert\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mconvert_dtype\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 2552\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2553\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mlen\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmapped\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;32mand\u001b[0m \u001b[0misinstance\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmapped\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m0\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mSeries\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n", | |
| "\u001b[0;32mpandas/_libs/src/inference.pyx\u001b[0m in \u001b[0;36mpandas._libs.lib.map_infer\u001b[0;34m()\u001b[0m\n", | |
| "\u001b[0;32m<ipython-input-66-d79d4b452671>\u001b[0m in \u001b[0;36mpredict\u001b[0;34m(text)\u001b[0m\n\u001b[1;32m 4\u001b[0m \u001b[0mscores\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mrow\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mtrain_df\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mitertuples\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 6\u001b[0;31m \u001b[0mscores\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mappend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mjaccard_similarity\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mrow\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mprocessed_body\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtext\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mrow\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mlabel\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 7\u001b[0m \u001b[0mscores\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0msorted\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mscores\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mreverse\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0;32mTrue\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;36m10\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 8\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0mcollections\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mCounter\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mscores\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmost_common\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m0\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m0\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n", | |
| "\u001b[0;32m<ipython-input-61-b6437c6b874e>\u001b[0m in \u001b[0;36mjaccard_similarity\u001b[0;34m(text1, text2)\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0mA\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mset\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtokenize\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtext1\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3\u001b[0m \u001b[0mB\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mset\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtokenize\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtext2\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 4\u001b[0;31m \u001b[0;32mreturn\u001b[0m \u001b[0mfloat\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlen\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mA\u001b[0m \u001b[0;34m&\u001b[0m \u001b[0mB\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;34m/\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0mlen\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mA\u001b[0m \u001b[0;34m|\u001b[0m \u001b[0mB\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;34m+\u001b[0m \u001b[0;36m1e-9\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 5\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 6\u001b[0m \u001b[0mjaccard_similarity\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtrain_df\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0miloc\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m0\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mprocessed_body\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtrain_df\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0miloc\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mprocessed_body\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n", | |
| "\u001b[0;31mKeyboardInterrupt\u001b[0m: " | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "test_df['predicted_labels'] = test_df['processed_body'].apply(predict)\n", | |
| "\n", | |
| "print(accuracy_score(test_df['labels'], test_df['predicted_labels']))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "- Above method is very slow because it involves expensive hashing and set operations\n", | |
| "- We iterate through the entire corpus!\n", | |
| "- We are still not using any numbers which computers are very good at handling\n", | |
| "- We need to work with vector space\n", | |
| "\n", | |
| "### One idea is to count words\n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 136, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer\n", | |
| "# list(nltk.ngrams(tokenize(train_df.iloc[0].processed_body), n=2))\n", | |
| "cv = CountVectorizer(ngram_range=(1, 1))\n", | |
| "Xv = cv.fit_transform(train_df.processed_body)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 138, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "83" | |
| ] | |
| }, | |
| "execution_count": 138, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "sum(Xv[0].todense().tolist()[0])\n", | |
| "# print(Xv.shape)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# For similarity we can use cosine similarity\n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 112, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='cosine',\n", | |
| " metric_params=None, n_jobs=1, n_neighbors=5, p=2,\n", | |
| " weights='uniform')" | |
| ] | |
| }, | |
| "execution_count": 112, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "from sklearn.neighbors import KNeighborsClassifier\n", | |
| "nn = KNeighborsClassifier(n_neighbors=5, metric='cosine')\n", | |
| "nn.fit(Xv, train_df.label.values)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 113, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([7])" | |
| ] | |
| }, | |
| "execution_count": 113, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "nn.predict(cv.transform([test_df.iloc[0].processed_body]))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 116, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "test_df['predicted_labels'] = nn.predict(cv.transform(test_df.processed_body))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 119, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "0.2258364312267658" | |
| ] | |
| }, | |
| "execution_count": 119, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "accuracy_score(test_df['label'], test_df['predicted_labels'])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "In a large text corpus, some words will be very present (e.g. “the”, “a”, “is” in English)\n", | |
| "hence carrying very little meaningful information about the actual contents of the document. \n", | |
| "If we were to feed the direct count data directly to a classifier those very frequent terms would shadow the frequencies of rarer yet more interesting terms.\n", | |
| "\n", | |
| "In order to re-weight the count features into floating point values suitable for usage by a classifier it is very common to use the tf–idf transform.\n", | |
| "Tf means term-frequency while tf–idf means term-frequency times inverse document-frequency: \n", | |
| "# tfidf(t, d) = tf(t, d) * idf(t)\n", | |
| "\n", | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 139, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='cosine',\n", | |
| " metric_params=None, n_jobs=1, n_neighbors=5, p=2,\n", | |
| " weights='uniform')" | |
| ] | |
| }, | |
| "execution_count": 139, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "tv = TfidfVectorizer(ngram_range=(1, 1), smooth_idf=True, sublinear_tf=True)\n", | |
| "Xv = tv.fit_transform(train_df.processed_body)\n", | |
| "nn = KNeighborsClassifier(n_neighbors=5, metric='cosine')\n", | |
| "nn.fit(Xv, train_df.label.values)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 140, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "array([4])" | |
| ] | |
| }, | |
| "execution_count": 140, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "nn.predict(tv.transform([test_df.iloc[0].processed_body]))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 122, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "test_df['predicted_labels'] = nn.predict(tv.transform(test_df.processed_body))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 123, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "0.6046202867764207" | |
| ] | |
| }, | |
| "execution_count": 123, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "accuracy_score(test_df['label'], test_df['predicted_labels'])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 53, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from nltk.corpus import wordnet, stopwords\n", | |
| "\n", | |
| "stopwords = set(stopwords.words('english'))\n", | |
| "stemmer = nltk.SnowballStemmer('english')\n", | |
| "lemmatizer = nltk.stem.WordNetLemmatizer()\n", | |
| "\n", | |
| "def get_wordnet_pos(treebank_tag):\n", | |
| "\n", | |
| " if treebank_tag.startswith('J'):\n", | |
| " return wordnet.ADJ\n", | |
| " elif treebank_tag.startswith('V'):\n", | |
| " return wordnet.VERB\n", | |
| " elif treebank_tag.startswith('N'):\n", | |
| " return wordnet.NOUN\n", | |
| " elif treebank_tag.startswith('R'):\n", | |
| " return wordnet.ADV\n", | |
| " else:\n", | |
| " return 'n'" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 141, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "Stemmed\n", | |
| "--------\n", | |
| "the men were happi they were sing their life had never been better\n", | |
| "--------\n", | |
| "POS Tags\n", | |
| "--------\n", | |
| "[('the', 'DT'), ('men', 'NNS'), ('were', 'VBD'), ('happy', 'JJ'), ('they', 'PRP'), ('were', 'VBD'), ('singing', 'VBG'), ('their', 'PRP$'), ('life', 'NN'), ('had', 'VBD'), ('never', 'RB'), ('been', 'VBN'), ('better', 'JJR')]\n", | |
| "--------\n", | |
| "Lemmatized\n", | |
| "--------\n", | |
| "the men were happy they were singing their life had never been better\n", | |
| "--------\n", | |
| "Lemmatized with pos tags\n", | |
| "--------\n", | |
| "the men be happy they be sing their life have never be good\n", | |
| "--------\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "test_doc = clean('The men were happy. They were singing. Their life had never been better')\n", | |
| "print('Stemmed')\n", | |
| "print('--------')\n", | |
| "print(' '.join([stemmer.stem(token) for token in test_doc.split(' ')]))\n", | |
| "print('--------')\n", | |
| "print('POS Tags')\n", | |
| "print('--------')\n", | |
| "print(nltk.pos_tag(test_doc.split(' ')))\n", | |
| "print('--------')\n", | |
| "print('Lemmatized')\n", | |
| "print('--------')\n", | |
| "print(' '.join([lemmatizer.lemmatize(token) for token in test_doc.split(' ')]))\n", | |
| "print('--------')\n", | |
| "print('Lemmatized with pos tags')\n", | |
| "print('--------')\n", | |
| "print(' '.join([lemmatizer.lemmatize(token, get_wordnet_pos(tag))\n", | |
| " for token, tag in nltk.pos_tag(test_doc.split(' '))]))\n", | |
| "print('--------')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 47, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "name": "stdout", | |
| "output_type": "stream", | |
| "text": [ | |
| "computer terminal said sedio also ha the right to buy additional share and increase it total holding\n" | |
| ] | |
| } | |
| ], | |
| "source": [ | |
| "print(' '.join([lemmatizer.lemmatize(token) for token in test_doc.split(' ')]))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## We can do much better with word vectors\n", | |
| "### \"You shall know a word by the company it keeps\" - J. Firth\n", | |
| "\n", | |
| "- can i pay for this flight using amazon pay balance\n", | |
| "- can i pay tickets price with tez\n", | |
| "- can i pay using amazon pay\n", | |
| "- can i pay using freecharge\n", | |
| "- can i pay using mobikwik\n", | |
| "- can i pay you through paytm\n", | |
| "\n", | |
| "\n", | |
| "\n", | |
| "\n", | |
| "\n", | |
| "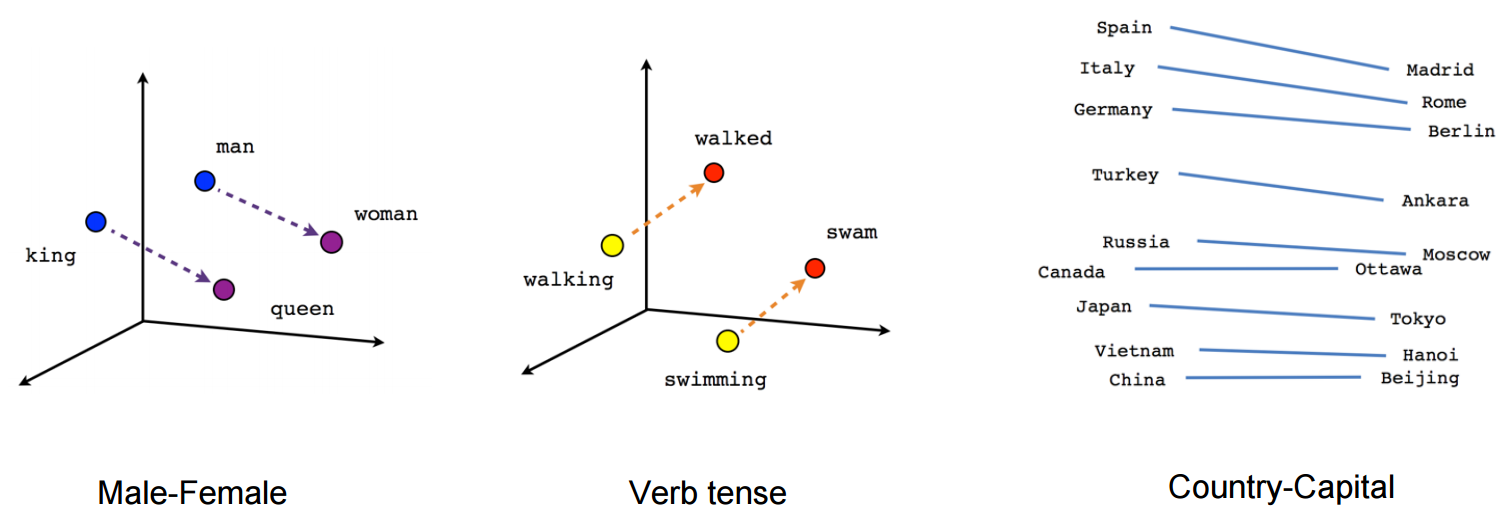\n", | |
| "(Taken from tensorflow.org)\n", | |
| "\n", | |
| "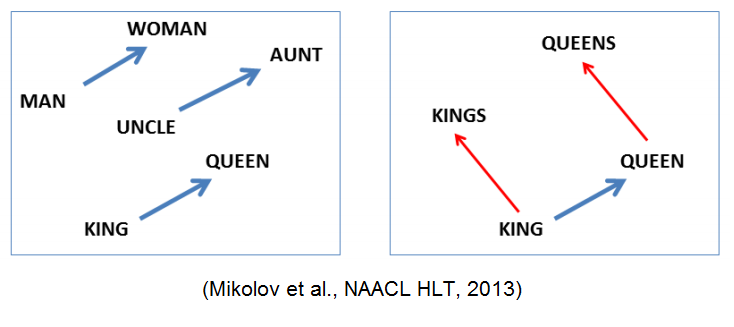\n", | |
| "\n", | |
| "### Cool Demo at https://projector.tensorflow.org/" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python 3", | |
| "language": "python", | |
| "name": "python3" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.6.2" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 2 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Requirements: