Last active
November 27, 2019 23:29
-
-
Save douglasrizzo/99437e0ea9f36a1f07a0c61181090e9e to your computer and use it in GitHub Desktop.
grafo_computacional.ipynb
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "nbformat": 4, | |
| "nbformat_minor": 0, | |
| "metadata": { | |
| "colab": { | |
| "name": "grafo_computacional.ipynb", | |
| "provenance": [], | |
| "collapsed_sections": [], | |
| "toc_visible": true, | |
| "machine_shape": "hm", | |
| "include_colab_link": true | |
| }, | |
| "kernelspec": { | |
| "name": "python3", | |
| "display_name": "Python 3" | |
| }, | |
| "accelerator": "GPU" | |
| }, | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "view-in-github", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "<a href=\"https://colab.research.google.com/gist/douglasrizzo/99437e0ea9f36a1f07a0c61181090e9e/grafo_computacional.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "fd3eO5tt4FPA", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "# Grafos computacionais\n", | |
| "\n", | |
| "Grafos computacionais permitem paralelizar uma sequência de operações matemáticas, assim como aproveitar valores já computados. Antes de ser uma biblioteca para realização de _deep learning_, o TensorFlow é uma biblioteca para processamento de grafos computacionais.\n", | |
| "\n", | |
| "Por exemplo, as seguintes operações [(fonte)](http://colah.github.io/posts/2015-08-Backprop/):\n", | |
| "\n", | |
| "$$ c = a + b $$\n", | |
| "$$ d = b + 1 $$\n", | |
| "$$ e = c * d $$\n", | |
| "\n", | |
| "Formam este grafo computacional:\n", | |
| "\n", | |
| "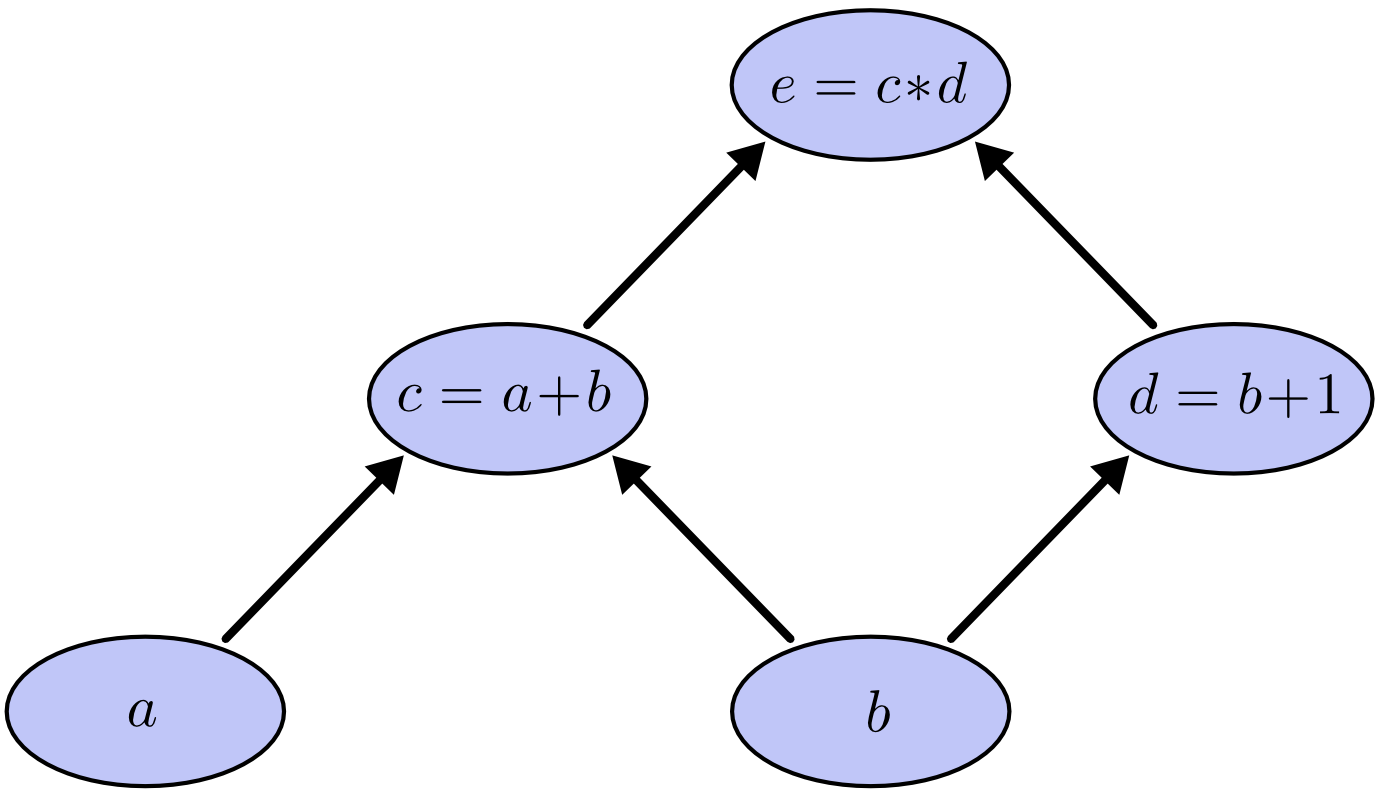\n", | |
| "\n", | |
| "O valor de $d$ pode ser calculado antes, ou ao mesmo tempo, que o valor de $c$. O grafo computacional organiza as chamadas às operações de forma a paralelizá-las e distribuí-las.\n", | |
| "\n", | |
| "Ao trabalhar com redes neurais, o grafo computacional permite calcular as derivadas das variáveis com relação a suas antecessoras, utilizando [derivação automática](https://en.wikipedia.org/wiki/Automatic_differentiation).\n", | |
| "\n", | |
| "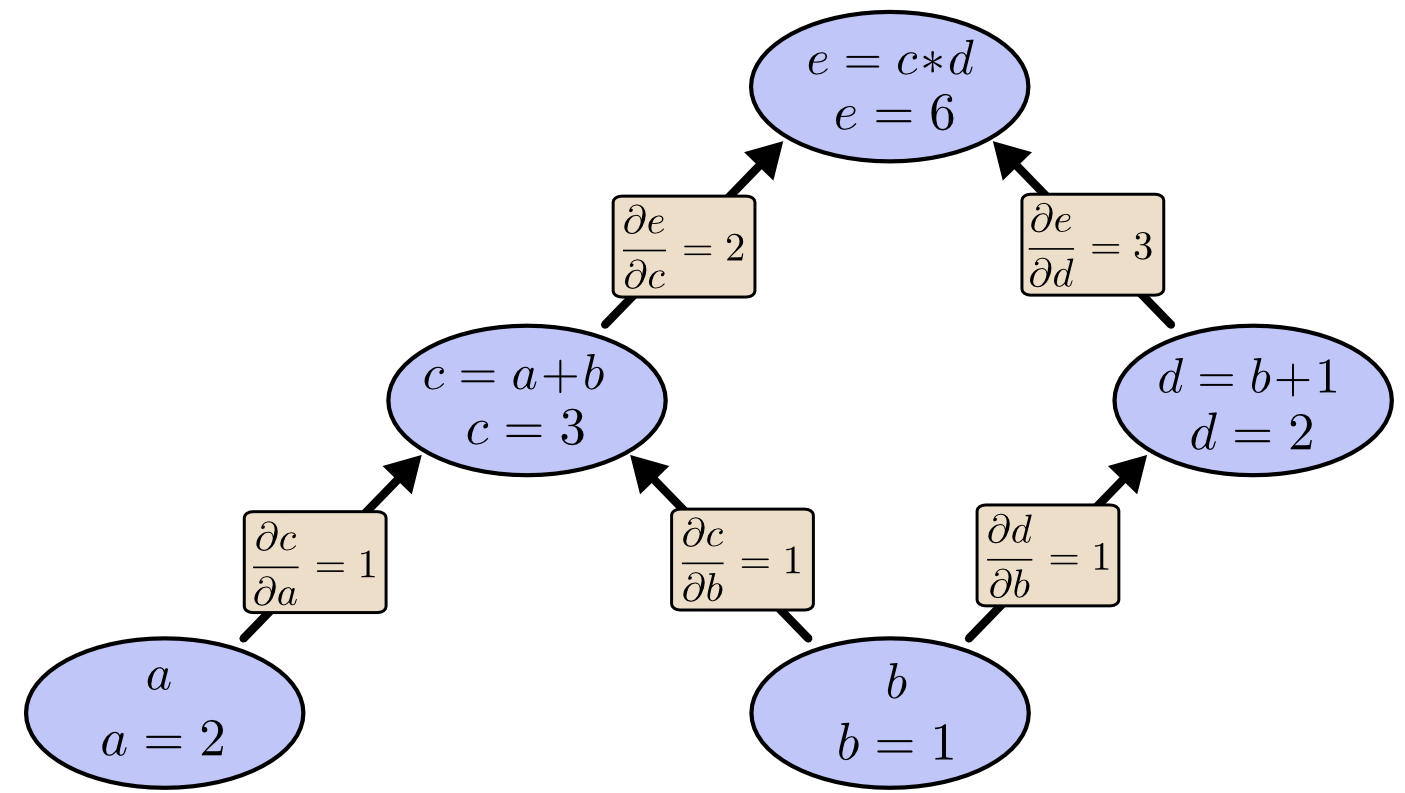" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "8FigI3ZoDFAy", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "## No TensorFlow 1\n", | |
| "\n", | |
| "1. o grafo computacional é declarado (nenhuma operação matemática é realizada);\n", | |
| "2. uma sessão do TensorFlow é iniciada;\n", | |
| "3. o grafo computacional é enviado para um processado de baixo nível (em C) e executado de uma vez);\n", | |
| "4. o resultado da operação é retornado." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "1_YUa69JE7Yl", | |
| "colab_type": "code", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 89 | |
| }, | |
| "outputId": "8b8b11b2-71f1-4716-fbe0-64c526e4ccaf" | |
| }, | |
| "source": [ | |
| "import os\n", | |
| "import pprint\n", | |
| "%tensorflow_version 1.x\n", | |
| "import tensorflow as tf\n", | |
| "print('TensorFlow {}'.format(tf.__version__))\n", | |
| "from tensorflow.python.client import device_lib\n", | |
| "\n", | |
| "has_cpu = any([x.device_type == 'CPU' for x in device_lib.list_local_devices()])\n", | |
| "has_gpu = any([x.device_type == 'GPU' for x in device_lib.list_local_devices()])\n", | |
| "has_tpu = 'COLAB_TPU_ADDR' in os.environ\n", | |
| "\n", | |
| "print('CPU: {}\\nGPU: {}\\nTPU: {}'.format(has_cpu, has_gpu, has_tpu))\n", | |
| "\n", | |
| "cpu_address = None if not has_cpu else [x.name for x in device_lib.list_local_devices() if x.device_type == 'CPU'][0]\n", | |
| "gpu_address = None if not has_gpu else [x.name for x in device_lib.list_local_devices() if x.device_type == 'GPU'][0]\n", | |
| "tpu_address = None if not has_tpu else 'grpc://' + os.environ['COLAB_TPU_ADDR']\n", | |
| "\n", | |
| "n = int(1E8)" | |
| ], | |
| "execution_count": 1, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "TensorFlow 1.15.0\n", | |
| "CPU: True\n", | |
| "GPU: True\n", | |
| "TPU: False\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "V8zyzZUesOMN", | |
| "colab_type": "code", | |
| "outputId": "9ef0c12f-441b-4ad7-f332-83e941619b8d", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 53 | |
| } | |
| }, | |
| "source": [ | |
| "def tf_velho_lazy_exec(verbose=False):\n", | |
| " x = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " y = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " n_in = x * x + y * y < 1\n", | |
| " n_in = tf.reduce_sum(tf.cast(n_in, dtype=tf.int32))\n", | |
| " pi = 4 * n_in / n\n", | |
| " \n", | |
| " if verbose:\n", | |
| " print('isso não é um valor: {}'.format(pi))\n", | |
| "\n", | |
| " with tf.Session() as sess:\n", | |
| " pi_value = sess.run(pi)\n", | |
| " if verbose:\n", | |
| " print('isso é um valor: {}'.format(pi_value))\n", | |
| "\n", | |
| "tf_velho_lazy_exec(True)" | |
| ], | |
| "execution_count": 2, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "isso não é um valor: Tensor(\"truediv:0\", shape=(), dtype=float64)\n", | |
| "isso é um valor: 3.14148488\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "NNYFO68_DlfY", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "É possível apontar explicitamente em qual hardware cada operação do grafo computacional será realizada, permitindo paralelizar e distribuir as operações manualmente.\n", | |
| "\n", | |
| "É importante saber quais operações cada hardware executa melhor:\n", | |
| "* CPUs: inicialização de variáveis, leitura e desserialização de arquivos\n", | |
| "* GPUs e TPUs: operações com matrizes\n", | |
| "\n", | |
| "Mas cuidado! A passagem de valores entre dispositivos, assim como entre computadores pela rede, pode aumentar consideravelmente o tempo para processamento do grafo computacional." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "colab_type": "code", | |
| "outputId": "edc56f89-be82-456a-e8b0-2d6bc6530b4c", | |
| "id": "MOCSCQXP5z2g", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 35 | |
| } | |
| }, | |
| "source": [ | |
| "def tf_velho_lazy_exec_devices(verbose=False):\n", | |
| " with tf.device(cpu_address):\n", | |
| " x = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " y = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " with tf.device(gpu_address):\n", | |
| " n_in = x * x + y * y < 1\n", | |
| " n_in = tf.reduce_sum(tf.cast(n_in, dtype=tf.int32))\n", | |
| " pi = 4 * n_in / n\n", | |
| "\n", | |
| " with tf.Session() as sess:\n", | |
| " pi_value = sess.run(pi)\n", | |
| " if verbose:\n", | |
| " print(pi_value)\n", | |
| "\n", | |
| "if has_cpu and has_gpu:\n", | |
| " tf_velho_lazy_exec_devices(True)" | |
| ], | |
| "execution_count": 2, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "3.14144112\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "colab_type": "code", | |
| "id": "3iqfiCwyIi5v", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "def tf_velho_lazy_exec_device(d):\n", | |
| " with tf.device(d):\n", | |
| " x = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " y = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " n_in = x * x + y * y < 1\n", | |
| " n_in = tf.reduce_sum(tf.cast(n_in, dtype=tf.int32))\n", | |
| " pi = 4 * n_in / n\n", | |
| "\n", | |
| " with tf.Session() as sess:\n", | |
| " pi_value = sess.run(pi)\n", | |
| "\n", | |
| "if has_cpu:\n", | |
| " tf_velho_lazy_exec_device(cpu_address) \n", | |
| "if has_gpu:\n", | |
| " tf_velho_lazy_exec_device(gpu_address) " | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "lH-o4GOkF3dV", | |
| "colab_type": "code", | |
| "colab": {} | |
| }, | |
| "source": [ | |
| "if has_tpu:\n", | |
| " def tf_velho_lazy_exec_tpu():\n", | |
| " x = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " y = tf.random.uniform([n], minval=0., maxval=1.)\n", | |
| " n_in = x * x + y * y < 1\n", | |
| " n_in = tf.reduce_sum(tf.cast(n_in, dtype=tf.int32))\n", | |
| " pi = 4 * n_in / n\n", | |
| "\n", | |
| " with tf.Session(tpu_address) as sess:\n", | |
| " pi_value = sess.run(pi)\n", | |
| "\n", | |
| " tf_velho_lazy_exec_tpu()" | |
| ], | |
| "execution_count": 0, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "PllcBwF580ac", | |
| "colab_type": "code", | |
| "outputId": "512ee396-22f7-4f61-a9dd-c9f800e3143f", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 35 | |
| } | |
| }, | |
| "source": [ | |
| "%timeit -n 30 tf_velho_lazy_exec()" | |
| ], | |
| "execution_count": 6, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "30 loops, best of 3: 172 ms per loop\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "hLi3P9K69LhP", | |
| "colab_type": "code", | |
| "outputId": "c583f335-7ad3-46b5-9273-af0d6c7e21bb", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 35 | |
| } | |
| }, | |
| "source": [ | |
| "%timeit -n 30 tf_velho_lazy_exec_devices()" | |
| ], | |
| "execution_count": 7, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "30 loops, best of 3: 240 ms per loop\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "colab_type": "code", | |
| "outputId": "00cd80cc-e224-4e23-bf07-5b3f55cd86ee", | |
| "id": "LuuQxqL0I_Qd", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 35 | |
| } | |
| }, | |
| "source": [ | |
| "if has_cpu:\n", | |
| " %timeit -n 30 tf_velho_lazy_exec_device(cpu_address)" | |
| ], | |
| "execution_count": 8, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "30 loops, best of 3: 331 ms per loop\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "colab_type": "code", | |
| "outputId": "5e45e2fa-a3fe-4d47-b0d7-bf52382e032d", | |
| "id": "LrdYKKlLI_Z8", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 35 | |
| } | |
| }, | |
| "source": [ | |
| "if has_gpu:\n", | |
| " %timeit -n 30 tf_velho_lazy_exec_device(gpu_address)" | |
| ], | |
| "execution_count": 4, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "30 loops, best of 3: 109 ms per loop\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "colab_type": "code", | |
| "outputId": "5ed18c88-a30b-44df-c172-b8b8a5b1333a", | |
| "id": "JX3zrUSbIcHn", | |
| "colab": { | |
| "base_uri": "https://localhost:8080/", | |
| "height": 35 | |
| } | |
| }, | |
| "source": [ | |
| "if has_tpu:\n", | |
| " %timeit -n 30 tf_velho_lazy_exec_tpu()" | |
| ], | |
| "execution_count": 10, | |
| "outputs": [ | |
| { | |
| "output_type": "stream", | |
| "text": [ | |
| "30 loops, best of 3: 514 ms per loop\n" | |
| ], | |
| "name": "stdout" | |
| } | |
| ] | |
| } | |
| ] | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment