Created
November 21, 2017 18:11
-
-
Save fformenti/a4fde51413254aa7493306fdbffefae7 to your computer and use it in GitHub Desktop.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Pré Requisitos" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## 0.1 Bias / Variance Tradeoff" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
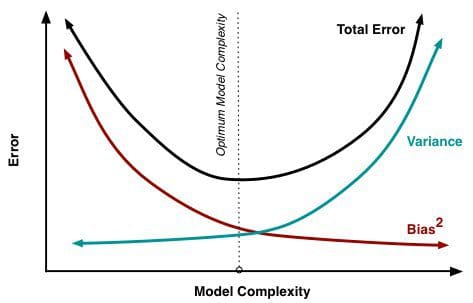
| "_O que quer dizer um modelo com um viés muito alto?_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_O que quer dizer um modelo com a variância muito alta?_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Objetivo:__ \n", | |
| "\n", | |
| "- Puxar para baixo a curva preta da figura 1.\n", | |
| "- Alternativamente podemos pensar em sair do cenário de High Variance/Low Bias para o cenário de Low Variance/Low Bias representado na figura 2\n", | |
| "\n", | |
| "__Como:__\n", | |
| "- Ao tiramos a média de todos os modelos, conseguimos diminuir a variância sem alterar o viés." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## 0.2 The Bootstrap" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Suponha que eu tenha uma amostra aleatória gerada por uma distribuição desconhecida, como faço para construir o intervalo de confiança para a média?_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Como posso gerar um intervalo de confiança da inclinação da reta de uma regressão linear?_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "O Bootstrap nos permite construir o intervalo de confiança de um parâmetro do qual não sabemos a distriuição usando apenas a amostra que temos em mão.\n", | |
| "\n", | |
| "Pseudo código:\n", | |
| "1. Pegue N amostras com reposição.\n", | |
| "2. Calcule a estatística desejada desta amostra.\n", | |
| "3. Repita os passos (1 e 2) k vezes\n", | |
| "4. Orderne os valores do parâmetro estimado.\n", | |
| "5. Pegue os percentis que representam seu intervalo de confiança" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import numpy as np" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "statistics = []\n", | |
| "data = np.array([1, 2, 1, 4, 1, 6, 8, 3, 9, 7])\n", | |
| "#data = np.concatenate([np.random.exponential(size=200), np.random.normal(size=100)])\n", | |
| "bootstraps = 1000\n", | |
| "for i in range(bootstraps):\n", | |
| " sample = np.random.choice(data, size=data.shape, replace=True)\n", | |
| " stat = sample.mean()\n", | |
| " statistics.append(stat)\n", | |
| "statistics.sort()\n", | |
| "np.percentile(statistics, [2.5, 97.5])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Ensemble Methods" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Quando não dever ser usado:__\n", | |
| "\n", | |
| "- Quando é preciso um entendimento mais claro de como a variável de respota se comporta perante as variáveis explanatórias. (Na área médica por exemplo)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## 1.1 Bagging (Bootstrap Aggregating)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Motivação:__\n", | |
| "- Reduzir a variância deixando o modelo menos sensível as dados de entrada.\n", | |
| "\n", | |
| "__Como:__\n", | |
| "\n", | |
| "- Vamos tirar proveito da técnica de Bootstrap para alimentar vários modelos auxiliares com dados de entrada diferentes entre si.\n", | |
| "- Usaremos todos esses modelos auxiliares para criar um modelo único." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Pseudo Algoritmo:**\n", | |
| "1. Retire N amostras com reposição\n", | |
| "2. Treine diferentes modelos com inputs diferentes\n", | |
| "3. Tire a média do resultado (Regressão) / Votação (Classificação)\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Prós:**\n", | |
| "- Reduz a variância sem alterar o viéz.\n", | |
| "- É paralelizável.\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Quando não Funciona:**\n", | |
| "\n", | |
| "\n", | |
| "- Quando seu modelo inicial já tiver um viéz alto (modelo errado).\n", | |
| "- Quando seu modelo for muito simplista e pouco sensível ao dados de entrada. As permutações feitas durante o bagging não surtiram nenhum efeito.\n", | |
| "- Esse procedimento não funciona para modelos lineares (Regressão Linear) já que a média final de todas elas será apenas mais um regressor linear.\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Para quem quiser ver uma implementação de Bagging usando Decision Trees: __[bagging_from_scratch](https://machinelearningmastery.com/implement-bagging-scratch-python/)__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Bagging na prática_\n", | |
| "\n", | |
| "Vamos usar o dataset de câncer de mama que está disponivel neste __[link](https://www.kaggle.com/uciml/breast-cancer-wisconsin-data/data)__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import pandas as pd\n", | |
| "import matplotlib.pyplot as plt\n", | |
| "\n", | |
| "pd.options.mode.chained_assignment = None # default='warn'\n", | |
| "%matplotlib inline " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn import metrics\n", | |
| "\n", | |
| "from sklearn.model_selection import train_test_split, cross_val_score\n", | |
| "from sklearn.ensemble import BaggingClassifier, VotingClassifier\n", | |
| "from sklearn.neighbors import KNeighborsClassifier\n", | |
| "from sklearn.tree import DecisionTreeClassifier" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "breast = pd.read_csv('../data/breast_cancer.csv')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "breast.info()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# Isolate Response variable and Drop unwanted columns\n", | |
| "X_drop = ['id', 'Unnamed: 32']\n", | |
| "response_variable = 'diagnosis'\n", | |
| "X_drop.append(response_variable)\n", | |
| "X = breast.drop(X_drop, axis = 1)\n", | |
| "y = breast[response_variable]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=28)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Usando KNN como modelo__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "knn = KNeighborsClassifier(n_neighbors=2)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "bag = BaggingClassifier(base_estimator = knn, oob_score=True, random_state = 28)\n", | |
| "bag.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Alguem sabe me dizer o motivo desse warning acima?_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Out of Bag Score (OOB) **\n", | |
| "\n", | |
| "Este valor é calculado usando as oberservações que ficaram de fora da amostra de treino. Cada um dos X (no caso mil) modelos gerados tem seu set específico de amostras que não foram usadas. Então para os modelos essas amostars servem como teste, possibilitando assim calcularmos o Out-of-bag-error e o Out-of-bag-score. \n", | |
| "Se por acaso uma observação estiver presente em todos os \"bags\" então não é possível calcular um out-of-bag-error para esta observação. É isso que o warning acima está se referindo." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "bag = BaggingClassifier(base_estimator = knn, n_estimators = 100, oob_score=True, random_state = 28)\n", | |
| "bag.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "bag.predict(X_test)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "print(bag.oob_score_)\n", | |
| "print(bag.score(X_test, y_test))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Usando Decision Trees como modelo__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "dtc = DecisionTreeClassifier(criterion = \"gini\", random_state = 28, max_depth=3)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "bag = BaggingClassifier(base_estimator = dtc, n_estimators = 100, oob_score=True, random_state = 28)\n", | |
| "bag.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "print(bag.oob_score_)\n", | |
| "print(bag.score(X_test, y_test))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "No exemplo que dei acima estamos usando um mesmo modelo múltiplas vezes e estamos mudando apenas os dados de entrada fornecidos a ele. Porém isso pode ser problemático especialmente quando as amostras de cada modelo forem muito homogêneas.\n", | |
| "Isso porque se os modelos recebem inputs similares eles darão respostas similares, frustando a idéia inicial de diversidade. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Podemos resolver este problema alterando algumas parâmetros pré definidos na função BaggingClassifier, eles são:\n", | |
| "- max_samples\n", | |
| "- max_features\n", | |
| "- bootstrap\n", | |
| "- bootstrap_features" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "#### Destinado aos alunos - Exercício de aula #####\n", | |
| "bootstrap = \n", | |
| "max_features =\n", | |
| "max_samples =\n", | |
| "bootstrap_features = " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "bag = BaggingClassifier(base_estimator= dtc, max_samples=max_samples, max_features=max_features, bootstrap=bootstrap, \n", | |
| " bootstrap_features=bootstrap_features, n_estimators=100, oob_score=True, random_state=28)\n", | |
| "bag.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "print(bag.oob_score_)\n", | |
| "print(bag.score(X_test, y_test))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Desta forma ao invés de termos K árvores iguais, teremos K árvores com apenas alguns regressores escolhidos de forma randômica.\n", | |
| "\n", | |
| "Foi dessa forma que surgiu a ideia para a criação do algoritmo Random Forest que vamos discutir na sessão seguinte." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## 1.1.1 Random Forest" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Pseudo Algoritmo__\n", | |
| "\n", | |
| "_Repetir n vezes (onde n é o número de árvores):_\n", | |
| "1. Tire uma amostra por aleatória de obrservações(Faça Bootstrap das observações, com reposição)\n", | |
| "2. Escolha aleatóriamente p variáveis possíveis para uma árvore.\n", | |
| "3. Repita os passos abaixo até que a árvore atinja sua profundidade máxima\n", | |
| "\t\t1. Das p variáveis escolha m variáveis aleatóriamente.\n", | |
| "\t\t2. Das m variáveis, escolha a que possuir o melhor divisão usando um dos critérios (Entropy, Gini Coef, Information gain)\n", | |
| "4. Calcule o Out-of-bag-error\n", | |
| "\t\t1. Use as observações que não foram escolhidas para testar o erro desta árvore\n", | |
| "\t\t2. Calcule a importâncias das variáveis.\n", | |
| "5. Selecione da previsão mais comum entre todas as árvores (para Classificação) ou tire a média (para Regressão)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Prós:__\n", | |
| "- Ótima alternativa para casos onde temos mais variáveis do que observações (small n big p problems)\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### 1.1.1.1 Random Forest Classifier" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Principais argumentos que o Random Forest Classifier recebe__\n", | |
| "- n_estimador: Número de árvores. (Tipicamente quanto maior melhor)\n", | |
| "- max_features: Número máximo de váriaveis escolhidas aleatóriamente.\n", | |
| "- max_depth: Profundidade da árvore como critério de parada. Se deixado como vazio continua té que as folhas sejam puras ou até bater na condição min_samples_split. (Eu costumo usar valores menores do que o max_features)\n", | |
| "- min_samples_split: Quantidade mínima necessária para que o nó posso ser divido.\n", | |
| "- min_sample_leaf: Número mínimo de observações que se deve ter na nova folha que será criada. Funciona como uma condição de parada na criação das árvores. (Tente [1,2,3] se 3 for o melhor tente valores maiores)\n", | |
| "- class_weight: Peso atribuído para cada classe. É usado quando algumas classes pussuem mais ocorrência do que as outras (Exemplo: detecção de fraude)\n", | |
| "- criterion: Medida de pureza para fazer o split" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Random Forest na Prática_\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.ensemble import RandomForestClassifier" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "kobe = pd.read_csv('../data/kobe.csv')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "kobe.info()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "kobe.head(3)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "kobe.period.unique()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "##### Data Treatment" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Removing NA's_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "df = kobe[pd.notnull(kobe['shot_made_flag'])]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Label Encoding_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# # Scikit Learn Approach\n", | |
| "# from sklearn.preprocessing import LabelEncoder\n", | |
| "\n", | |
| "# le = LabelEncoder()\n", | |
| "# df[\"shot_zone_range_code\"] = le.fit_transform(df[\"shot_zone_range\"])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# Pandas Approach\n", | |
| "df[\"shot_zone_range\"] = df[\"shot_zone_range\"].astype('category')\n", | |
| "df[\"shot_zone_range_code\"] = df[\"shot_zone_range\"].cat.codes" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Binarization_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# Pandas Approach\n", | |
| "df = pd.get_dummies(df, columns=[\"combined_shot_type\"], prefix = '', prefix_sep='')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| " Atenção! Certifique-se que todas as categorias de uma váriavel estejam presentes tanto no set de treino quanto no set de teste. Caso contrário podemos ter problemas se no teste o algoritmo encontrar uma categoria nunca vista antes." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "##### Feature Engineering" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "def get_minutes_remaing(period, minutes):\n", | |
| " if period < 5:\n", | |
| " return 12*(4-period) + minutes\n", | |
| " else:\n", | |
| " return minutes" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "df['game_minutes_remaing'] = df.apply(lambda x: get_minutes_remaing(x['period'], x['minutes_remaining']), axis=1)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Treinando o Modelo__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# Isolate Response variable and Drop unwanted columns\n", | |
| "X_keep = ['shot_distance','seconds_remaining','game_minutes_remaing','playoffs','shot_zone_range_code','Bank Shot','Dunk', 'Hook Shot', 'Jump Shot', 'Layup', 'Tip Shot']\n", | |
| "response_variable = 'shot_made_flag'\n", | |
| "\n", | |
| "X = df[X_keep]\n", | |
| "y = df[response_variable]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# Create a random forest Classifier\n", | |
| "rfc = RandomForestClassifier(n_estimators=10, max_features = 4, max_depth = 6, random_state=28)\n", | |
| "\n", | |
| "rfc.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Testando o Modelo__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "aux = rfc.predict_proba(X_test)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "aux[0:3,:]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "| shot_id | Missed Prob | Made Prob |\n", | |
| "| ------------- |:-------------:| -----:|\n", | |
| "| 1 | 0.594 | 0.405 |\n", | |
| "| 2 | 0.565 | 0.434 |\n", | |
| "| 3 | 0.588 | 0.411 |" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "y_pred_prob = rfc.predict_proba(X_test)[:,1]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "def plot_prob_hist(prob_array, bins = 8):\n", | |
| " # histogram of predicted probabilities\n", | |
| " plt.hist(prob_array, bins = bins)\n", | |
| " plt.xlim(0,1)\n", | |
| " plt.title('Histogram of predicted probabilities')\n", | |
| " plt.xlabel('Predicted probability Kobe makes the shot')\n", | |
| " plt.ylabel('Frequency')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "plot_prob_hist(y_pred_prob, bins = 10)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "y_pred = rfc.predict(X_test)\n", | |
| "accuracy = metrics.accuracy_score(y_test, y_pred)\n", | |
| "accuracy" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "roc_auc_score = metrics.roc_auc_score(y_test, y_pred_prob)\n", | |
| "FPR_array, TPR_array, thresholds_array = metrics.roc_curve(y_test, y_pred_prob)\n", | |
| "roc_auc_score" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Buscando melhor parâmetro (Parameters Tuning)__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Melhor número de Árvores_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# find the best n_estimators for RandomForestClassifier\n", | |
| "max_acc = 0.0\n", | |
| "best_n = 0\n", | |
| "accuracy_n = []\n", | |
| "range_n = [1,10,50,100,300,500]\n", | |
| "for n in range_n:\n", | |
| " print(\"the number of trees : {0}\".format(n))\n", | |
| " rfc_acc = 0.\n", | |
| " n_folds = 10\n", | |
| " \n", | |
| " \n", | |
| " rfc = RandomForestClassifier(n_estimators=n, max_features = 4, max_depth = 6, random_state=28)\n", | |
| " rfc_acc = cross_val_score(rfc, X_train, y_train, cv=5).mean()\n", | |
| " accuracy_n.append(rfc_acc)\n", | |
| " if rfc_acc > max_acc:\n", | |
| " max_acc = rfc_acc\n", | |
| " best_n = n\n", | |
| " \n", | |
| "print(best_n, max_acc)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "plt.figure(figsize=(10,5))\n", | |
| "plt.subplot(121)\n", | |
| "plt.plot(range_n, accuracy_n)\n", | |
| "plt.ylabel('accuracy')\n", | |
| "plt.xlabel('number of trees')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Melhor Quantidade de Variáveis_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "## find the best n_estimators for RandomForestClassifier\n", | |
| "max_acc = 0.0\n", | |
| "best_m = 0\n", | |
| "accuracy_m = []\n", | |
| "range_m = [2,4,6]\n", | |
| "for m in range_m:\n", | |
| " print(\"maximum features : {0}\".format(m))\n", | |
| " rfc_acc = 0.\n", | |
| " n_folds = 10\n", | |
| " \n", | |
| " rfc = RandomForestClassifier(n_estimators=best_n, max_features = m, max_depth=4, random_state=28)\n", | |
| " rfc_acc = cross_val_score(rfc, X_train, y_train, cv=5).mean()\n", | |
| " accuracy_m.append(rfc_acc)\n", | |
| " if rfc_acc > max_acc:\n", | |
| " max_acc = rfc_acc\n", | |
| " best_m = m\n", | |
| " \n", | |
| "print(best_m, max_acc)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "plt.subplot(122)\n", | |
| "plt.plot(range_m, accuracy_m)\n", | |
| "plt.ylabel('score')\n", | |
| "plt.xlabel('max features')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "_Modelo Escolhido_" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "params = {'n_estimators': best_n, 'max_depth': 4, 'max_features': best_m ,'random_state': 28}\n", | |
| "rfc = RandomForestClassifier(**params)\n", | |
| "rfc.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "__Variable Importance__" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "importances = rfc.feature_importances_\n", | |
| "feature_names = X_test.columns\n", | |
| "n = 10" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "def plot_feature_importance(importances, feature_names, n):\n", | |
| " indices = np.argsort(importances)[::-1][:n]\n", | |
| " fig, ax = plt.subplots(1,1)\n", | |
| " fig.set_size_inches(10,6)\n", | |
| " plt.title(\"Feature importances\", fontsize = 16)\n", | |
| " xlabels = [feature_names[int(i)] for i in indices]\n", | |
| " plt.bar(range(n), importances[indices],\n", | |
| " color=\"#799DBB\", align=\"center\")\n", | |
| " plt.grid()\n", | |
| " plt.xticks(range(n), xlabels, rotation=90)\n", | |
| " plt.xlim([-1, n])\n", | |
| " plt.ylim([0, min(1, max(importances[indices]+0.0005))])\n", | |
| " plt.xlabel('Features', fontsize = 14)\n", | |
| " plt.ylabel('Feature Importance', fontsize = 14)\n", | |
| " plt.title(' Variable Importance')\n", | |
| " plt.show()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "plot_feature_importance(importances, feature_names, n)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "y_pred_prob = rfc.predict_proba(X_test)[:,1]\n", | |
| "plot_prob_hist(y_pred_prob, bins = 10)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "y_pred = rfc.predict(X_test)\n", | |
| "accuracy = metrics.accuracy_score(y_test, y_pred)\n", | |
| "accuracy" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "roc_auc_score = metrics.roc_auc_score(y_test, y_pred_prob)\n", | |
| "roc_auc_score" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "### 1.1.1.2 Random Forest Regression" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.ensemble import RandomForestRegressor" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "#### Destinado aos alunos - Exercício de aula #####\n", | |
| "breast = pd.read_csv('../data/breast_cancer.csv')\n", | |
| "\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## 1.1.2 Voting Classifier" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "from sklearn.linear_model import LogisticRegression\n", | |
| "from sklearn.naive_bayes import GaussianNB\n", | |
| "\n", | |
| "from sklearn.ensemble import VotingClassifier" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "clf1 = LogisticRegression(random_state=28)\n", | |
| "clf2 = rfc\n", | |
| "clf3 = KNeighborsClassifier(n_neighbors=3)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "eclf = VotingClassifier(estimators=[('lr', clf1), ('rfc', clf2), ('knn', clf3)],\n", | |
| " voting='soft',\n", | |
| " weights=[1, 1, 1])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "eclf.fit(X_train, y_train)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "eclf.score(X_test, y_test)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# predict class probabilities for all classifiers\n", | |
| "probas = [c.fit(X_test, y_test).predict_proba(X) for c in (clf1, clf2, clf3, eclf)]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "# get class probabilities for the first sample in the test set\n", | |
| "class1_1 = [pr[0, 0] for pr in probas]\n", | |
| "class2_1 = [pr[0, 1] for pr in probas]\n", | |
| "\n", | |
| "\n", | |
| "# plotting\n", | |
| "\n", | |
| "N = 4 # number of groups\n", | |
| "ind = np.arange(N) # group positions\n", | |
| "width = 0.35 # bar width\n", | |
| "\n", | |
| "fig, ax = plt.subplots()\n", | |
| "\n", | |
| "# bars for classifier 1-3\n", | |
| "p1 = ax.bar(ind, np.hstack(([class1_1[:-1], [0]])), width,\n", | |
| " color='green', edgecolor='k')\n", | |
| "p2 = ax.bar(ind + width, np.hstack(([class2_1[:-1], [0]])), width,\n", | |
| " color='lightgreen', edgecolor='k')\n", | |
| "\n", | |
| "# bars for VotingClassifier\n", | |
| "p3 = ax.bar(ind, [0, 0, 0, class1_1[-1]], width,\n", | |
| " color='blue', edgecolor='k')\n", | |
| "p4 = ax.bar(ind + width, [0, 0, 0, class2_1[-1]], width,\n", | |
| " color='steelblue', edgecolor='k')\n", | |
| "\n", | |
| "# plot annotations\n", | |
| "plt.axvline(2.8, color='k', linestyle='dashed')\n", | |
| "ax.set_xticks(ind + width)\n", | |
| "ax.set_xticklabels(['LogisticRegression',\n", | |
| " 'KNN',\n", | |
| " 'RandomForestClassifier',\n", | |
| " 'VotingClassifier\\n(average probabilities)'],\n", | |
| " rotation=40,\n", | |
| " ha='right')\n", | |
| "plt.ylim([0, 1])\n", | |
| "plt.title('Class probabilities for sample 1 by different classifiers')\n", | |
| "plt.legend([p1[0], p2[0]], ['class 1', 'class 2'], loc='upper left')\n", | |
| "plt.show()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "probas[0]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "probas[1]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "probas[2]" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python 3", | |
| "language": "python", | |
| "name": "python3" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.6.3" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 2 | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment