First let’s load in the movies data set:
Michael Hunger jexp
🐉
jexp
/ moviesByDecade.adoc
Last active
August 29, 2015 14:03
— forked from mneedham/moviesByDecade.cyp
jexp
/ WorldCup2014.adoc
Last active
August 29, 2015 14:03
— forked from mneedham/WorldCup2014.adoc
jexp
/ oscon.adoc
Created
July 15, 2014 20:33
— forked from peterneubauer/oscon.adoc
At Neo4j, we love going to
This year, there is a DYI Schedule page that we are very intrigued by, so let’s build a — graph of the conference!
jexp
/ network_test.adoc
Last active
August 29, 2015 14:06
— forked from mattkaar/network_test_20140803.cypher
shortest path test
jexp
/ test.adoc
Last active
August 29, 2015 14:06
— forked from CliffordAnderson/test.adoc
CREATE (you:Person {name:"You"})-[like:LIKE]->(us:Database:NoSql:Graph {name:"Neo4j" }),
(him:Person {name:"He"})-[l:LIKE]->(us)
RETURN you, like, usAnd render as a graph.
jexp
/ post.md
Last active
August 29, 2015 14:10
— forked from ikwattro/post.md
Graph databases are now the heart of a lot of running companies dealing with high connected data.
Business graphs, social graphs, economic graphs are daily encountered words when browsing the web.
Neo4j, the world's leading graph database developed by NeoTechnology, has proven her natural ability to deal with massive amount of high connected data.
The recent use cases from TomTom and Ebay's Shuttle demonstrated the value she will bring allowing your company to provide fantastic customer experience and processing complex queries in no time.
jexp
/ post.md
Last active
August 29, 2015 14:10
— forked from ikwattro/post.md
Graph databases are now one of the core technologies of companies dealing with highly connected data.
Business graphs, social graphs, knowledge graphs, interest graphs and media graphs are frequently in the (technology) news. And for a reason. The graph model represents a very flexible way of handling relationships in your data. And graph databases provide fast and efficient storage, retrieval and querying for it.
Neo4j, the most popular graph database, has proven that ability to deal with massive amount of high connected data in many use-cases.
jexp
/ gotographgist.adoc
Last active
August 29, 2015 14:23
— forked from rvanbruggen/gotographgist.adoc
This gist is a graph version of the GOTO Amsterdam Schedule that I imported into Neo4j.
jexp
/ RoomDoorKey.adoc
Last active
August 26, 2015 18:48
— forked from blackslate/RoomDoorKey.adoc
Imagine a maze with rooms (nodes) and doors (relationships) between the rooms. The doors to some rooms are locked and their keys are held in other rooms (as properties).
In this gist model of the maze, you can reach room D by following the path A→B→C→A, picking up the key for room D in room B. However it is not possible to reach room F, since the key to room F is in room E, and the key to room E is in room D, and there is no way back from room D to room A, so room E is inaccessible. (Finding the HIDDEN door from room D to room C would make this possible.)
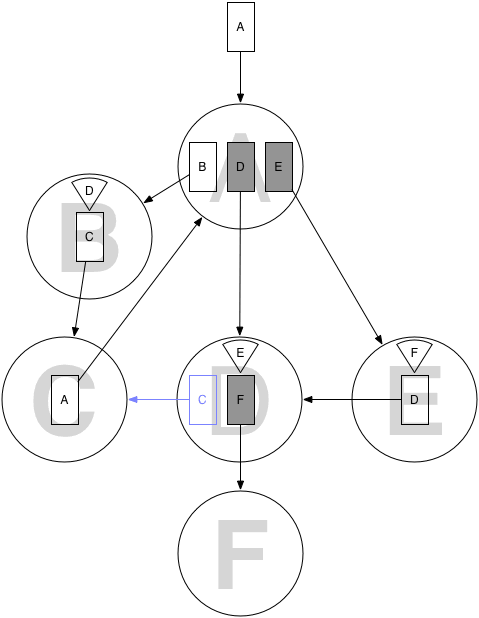
Is it possible to create queries which take into account the keys that can be picked up on the way? For example:
jexp
/ small-query-obscured.txt
Last active
September 16, 2015 22:31
http://stackoverflow.com/questions/32582128/neo4j-merge-chain-unexpectedly-slow
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| profile merge (en:Entity { id: "SensitiveData" }) merge (et:Entity { id: "SensitiveData" }) merge (en)-[:SensitiveData]->(et) merge (ept0:Entity { id: "SensitiveData" }) merge (et)-[rtept0:`SensitiveData`]->(ept0) on create set rtept0.SensitiveData = "SensitiveData" on match set rtept0.SensitiveData = rtept0.SensitiveData merge (epv0x0:Entity { id: "SensitiveData" }) merge (epv0x0)-[:SensitiveData]->(ept0) merge (en)-[:`SensitiveData`]->(epv0x0) merge (ept1:Entity { id: "SensitiveData" }) merge (et)-[rtept1:`SensitiveData`]->(ept1) on create set rtept1.SensitiveData = "SensitiveData" on match set rtept1.SensitiveData = rtept1.SensitiveData merge (epv1x0:Entity { id: "SensitiveData" }) merge (epv1x0)-[:SensitiveData]->(ept1) merge (en)-[:`SensitiveData`]->(epv1x0) merge (ept2:Entity { id: "SensitiveData" }) merge (et)-[rtept2:`SensitiveData`]->(ept2) on create set rtept2.SensitiveData = "SensitiveData" on match set rtept2.SensitiveData = rtept2.SensitiveData merge (epv2x0:Entity { id: "SensitiveData" }) set e |