Created
July 24, 2021 09:47
-
-
Save johnleung8888/5739c7e6e6bc2fb37c9abc0a008d27a7 to your computer and use it in GitHub Desktop.
Multi-class classification with MNIST.ipynb
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "nbformat": 4, | |
| "nbformat_minor": 0, | |
| "metadata": { | |
| "colab": { | |
| "name": "Multi-class classification with MNIST.ipynb", | |
| "private_outputs": true, | |
| "provenance": [], | |
| "collapsed_sections": [], | |
| "include_colab_link": true | |
| }, | |
| "kernelspec": { | |
| "name": "python3", | |
| "display_name": "Python 3" | |
| } | |
| }, | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "view-in-github", | |
| "colab_type": "text" | |
| }, | |
| "source": [ | |
| "<a href=\"https://colab.research.google.com/gist/johnleung8888/5739c7e6e6bc2fb37c9abc0a008d27a7/multi-class-classification-with-mnist.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "wDlWLbfkJtvu" | |
| }, | |
| "source": [ | |
| "#@title Copyright 2020 Google LLC. Double-click here for license information.\n", | |
| "# Licensed under the Apache License, Version 2.0 (the \"License\");\n", | |
| "# you may not use this file except in compliance with the License.\n", | |
| "# You may obtain a copy of the License at\n", | |
| "#\n", | |
| "# https://www.apache.org/licenses/LICENSE-2.0\n", | |
| "#\n", | |
| "# Unless required by applicable law or agreed to in writing, software\n", | |
| "# distributed under the License is distributed on an \"AS IS\" BASIS,\n", | |
| "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n", | |
| "# See the License for the specific language governing permissions and\n", | |
| "# limitations under the License.\n", | |
| "\n", | |
| "# Yann LeCun and Corinna Cortes hold the copyright of MNIST dataset,\n", | |
| "# which is a derivative work from original NIST datasets. \n", | |
| "# MNIST dataset is made available under the terms of the \n", | |
| "# Creative Commons Attribution-Share Alike 3.0 license." | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "TL5y5fY9Jy_x" | |
| }, | |
| "source": [ | |
| "# Multi-Class Classification\n", | |
| "\n", | |
| "This Colab explore multi-class classification problems through the classic MNIST dataset." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "XuKlphuImFSN" | |
| }, | |
| "source": [ | |
| "## Learning Objectives:\n", | |
| "\n", | |
| "After doing this Colab, you'll know how to do the following:\n", | |
| "\n", | |
| " * Understand the classic MNIST problem.\n", | |
| " * Create a deep neural network that performs multi-class classification.\n", | |
| " * Tune the deep neural network.\n", | |
| "\n", | |
| "This exercise introduces image classification with machine learning." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "cxj8yVh4mFl5" | |
| }, | |
| "source": [ | |
| "## The Dataset\n", | |
| " \n", | |
| "This MNIST dataset contains a lot of examples:\n", | |
| "\n", | |
| "* The MNIST training set contains 60,000 examples.\n", | |
| "* The MNIST test set contains 10,000 examples.\n", | |
| "\n", | |
| "Each example contains a pixel map showing how a person wrote a digit. For example, the following images shows how a person wrote the digit `1` and how that digit might be represented in a 14x14 pixel map (after the input data is normalized). \n", | |
| "\n", | |
| "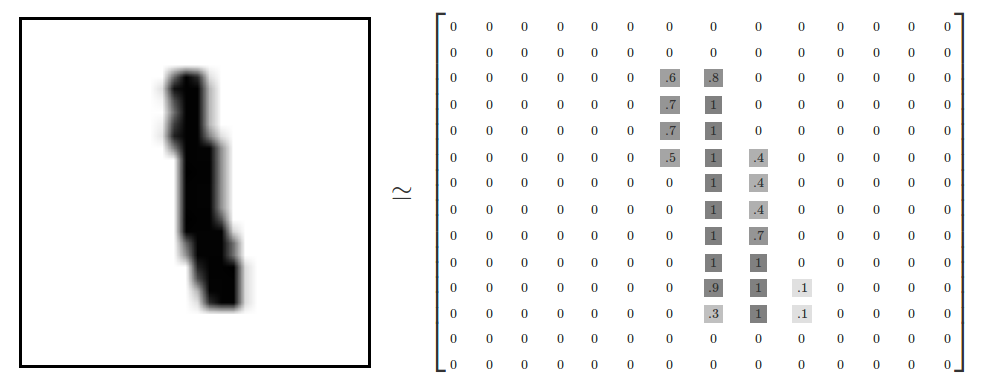\n", | |
| "\n", | |
| "Each example in the MNIST dataset consists of:\n", | |
| "\n", | |
| "* A label specified by a [rater](https://developers.google.com/machine-learning/glossary/#rater). Each label must be an integer from 0 to 9. For example, in the preceding image, the rater would almost certainly assign the label `1` to the example.\n", | |
| "* A 28x28 pixel map, where each pixel is an integer between 0 and 255. The pixel values are on a gray scale in which 0 represents white, 255 represents black, and values between 0 and 255 represent various shades of gray. \n", | |
| "\n", | |
| "This is a multi-class classification problem with 10 output classes, one for each digit." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "tX_umRMMsa3z" | |
| }, | |
| "source": [ | |
| "## Use the right version of TensorFlow\n", | |
| "\n", | |
| "The following hidden code cell ensures that the Colab will run on TensorFlow 2.X." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "lM75uNH-sTv2" | |
| }, | |
| "source": [ | |
| "#@title Run on TensorFlow 2.x\n", | |
| "%tensorflow_version 2.x\n", | |
| "from __future__ import absolute_import, division, print_function, unicode_literals" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "xchnxAsaKKqO" | |
| }, | |
| "source": [ | |
| "## Import relevant modules\n", | |
| "\n", | |
| "The following hidden code cell imports the necessary code to run the code in the rest of this Colaboratory." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "9n9_cTveKmse" | |
| }, | |
| "source": [ | |
| "#@title Import relevant modules\n", | |
| "import numpy as np\n", | |
| "import pandas as pd\n", | |
| "import tensorflow as tf\n", | |
| "from tensorflow.keras import layers\n", | |
| "from matplotlib import pyplot as plt\n", | |
| "\n", | |
| "# The following lines adjust the granularity of reporting. \n", | |
| "pd.options.display.max_rows = 10\n", | |
| "pd.options.display.float_format = \"{:.1f}\".format\n", | |
| "\n", | |
| "# The following line improves formatting when ouputting NumPy arrays.\n", | |
| "np.set_printoptions(linewidth = 200)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "X_TaJhU4KcuY" | |
| }, | |
| "source": [ | |
| "## Load the dataset\n", | |
| "\n", | |
| "`tf.keras` provides a set of convenience functions for loading well-known datasets. Each of these convenience functions does the following:\n", | |
| "\n", | |
| "* Loads both the training set and the test set.\n", | |
| "* Separates each set into features and labels.\n", | |
| "\n", | |
| "The relevant convenience function for MNIST is called `mnist.load_data()`:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "JZlvdpyYKx7V" | |
| }, | |
| "source": [ | |
| "(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()\n" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "SfQkr3hxJGXU" | |
| }, | |
| "source": [ | |
| "Notice that `mnist.load_data()` returned four separate values:\n", | |
| "\n", | |
| "* `x_train` contains the training set's features.\n", | |
| "* `y_train` contains the training set's labels.\n", | |
| "* `x_test` contains the test set's features.\n", | |
| "* `y_test` contains the test set's labels.\n", | |
| "\n", | |
| "**Note:** The MNIST .csv training set is already shuffled." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "71vsSUM7pdmu" | |
| }, | |
| "source": [ | |
| "## View the dataset\n", | |
| "\n", | |
| "The .csv file for the California Housing Dataset contains column names (for example, `latitude`, `longitude`, `population`). By contrast, the .csv file for MNIST does not contain column names. Instead of column names, you use ordinal numbers to access different subsets of the MNIST dataset. In fact, it is probably best to think of `x_train` and `x_test` as three-dimensional NumPy arrays: \n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "IoOhpjkeCL8Q" | |
| }, | |
| "source": [ | |
| "# Output example #2917 of the training set.\n", | |
| "x_train[2917]" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "LNJrJKUwvZMR" | |
| }, | |
| "source": [ | |
| "Alternatively, you can call `matplotlib.pyplot.imshow` to interpret the preceding numeric array as an image. " | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "siRC8a1hJvmq" | |
| }, | |
| "source": [ | |
| "# Use false colors to visualize the array.\n", | |
| "plt.imshow(x_train[2917])" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "V-he9IcihDxb" | |
| }, | |
| "source": [ | |
| "# Output row #10 of example #2917.\n", | |
| "x_train[2917][10]" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "DUEWipalhQ8J" | |
| }, | |
| "source": [ | |
| "# Output pixel #16 of row #10 of example #2900.\n", | |
| "x_train[2917][10][16]" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "8ldP-5z1B2vL" | |
| }, | |
| "source": [ | |
| "## Task 1: Normalize feature values\n", | |
| "\n", | |
| "Complete the following code cell to map each feature value from its current representation (an integer between 0 and 255) to a floating-point value between 0 and 1.0. Store the floating-point values in `x_train_normalized` and `x_test_normalized`." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "4YQljE-wizDw" | |
| }, | |
| "source": [ | |
| "x_train_normalized = x_train/255.0\n", | |
| "x_test_normalized = x_test/255.0\n", | |
| "print(x_train_normalized[2900][10]) # Output a normalized row" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "g8HC-TDgB1D1" | |
| }, | |
| "source": [ | |
| "#@title Double-click to see a solution to Task 1. \n", | |
| "\n", | |
| "x_train_normalized = x_train / 255.0\n", | |
| "x_test_normalized = x_test / 255.0\n", | |
| "print(x_train_normalized[2900][12]) # Output a normalized row" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "ZBWRF6CStuNA" | |
| }, | |
| "source": [ | |
| "## Define a plotting function\n", | |
| "\n", | |
| "The following function plots an accuracy curve:" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "QF0BFRXTOeR3" | |
| }, | |
| "source": [ | |
| "#@title Define the plotting function\n", | |
| "def plot_curve(epochs, hist, list_of_metrics):\n", | |
| " \"\"\"Plot a curve of one or more classification metrics vs. epoch.\"\"\" \n", | |
| " # list_of_metrics should be one of the names shown in:\n", | |
| " # https://www.tensorflow.org/tutorials/structured_data/imbalanced_data#define_the_model_and_metrics \n", | |
| "\n", | |
| " plt.figure()\n", | |
| " plt.xlabel(\"Epoch\")\n", | |
| " plt.ylabel(\"Value\")\n", | |
| "\n", | |
| " for m in list_of_metrics:\n", | |
| " x = hist[m]\n", | |
| " plt.plot(epochs[1:], x[1:], label=m)\n", | |
| "\n", | |
| " plt.legend()\n", | |
| "\n", | |
| "print(\"Loaded the plot_curve function.\")" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "3014ezH3C7jT" | |
| }, | |
| "source": [ | |
| "## Create a deep neural net model\n", | |
| "\n", | |
| "The `create_model` function defines the topography of the deep neural net, specifying the following:\n", | |
| "\n", | |
| "* The number of [layers](https://developers.google.com/machine-learning/glossary/#layer) in the deep neural net.\n", | |
| "* The number of [nodes](https://developers.google.com/machine-learning/glossary/#node) in each layer.\n", | |
| "* Any [regularization](https://developers.google.com/machine-learning/glossary/#regularization) layers.\n", | |
| "\n", | |
| "The `create_model` function also defines the [activation function](https://developers.google.com/machine-learning/glossary/#activation_function) of each layer. The activation function of the output layer is [softmax](https://developers.google.com/machine-learning/glossary/#softmax), which will yield 10 different outputs for each example. Each of the 10 outputs provides the probability that the input example is a certain digit.\n", | |
| "\n", | |
| "**Note:** Unlike several of the recent Colabs, this exercise does not define feature columns or a feature layer. Instead, the model will train on the NumPy array." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "pedD5GhlDC-y", | |
| "cellView": "both" | |
| }, | |
| "source": [ | |
| "def create_model(my_learning_rate):\n", | |
| " \"\"\"Create and compile a deep neural net.\"\"\"\n", | |
| " \n", | |
| " # All models in this course are sequential.\n", | |
| " model = tf.keras.models.Sequential()\n", | |
| "\n", | |
| " # The features are stored in a two-dimensional 28X28 array. \n", | |
| " # Flatten that two-dimensional array into a a one-dimensional \n", | |
| " # 784-element array.\n", | |
| " model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))\n", | |
| "\n", | |
| " # Define the first hidden layer. \n", | |
| " model.add(tf.keras.layers.Dense(units=32, activation='relu'))\n", | |
| " \n", | |
| " # Define a dropout regularization layer. \n", | |
| " model.add(tf.keras.layers.Dropout(rate=0.1))\n", | |
| "\n", | |
| " # Add a new test and dropout layer .\n", | |
| " model.add(tf.keras.layers.Dense(units=32, activation='relu'))\n", | |
| " model.add(tf.keras.layers.Dropout(rate=0.1))\n", | |
| "\n", | |
| " # Define the output layer. The units parameter is set to 10 because\n", | |
| " # the model must choose among 10 possible output values (representing\n", | |
| " # the digits from 0 to 9, inclusive).\n", | |
| " #\n", | |
| " # Don't change this layer.\n", | |
| " model.add(tf.keras.layers.Dense(units=10, activation='softmax')) \n", | |
| " \n", | |
| " # Construct the layers into a model that TensorFlow can execute. \n", | |
| " # Notice that the loss function for multi-class classification\n", | |
| " # is different than the loss function for binary classification. \n", | |
| " model.compile(optimizer=tf.keras.optimizers.Adam(lr=my_learning_rate),\n", | |
| " loss=\"sparse_categorical_crossentropy\",\n", | |
| " metrics=['accuracy'])\n", | |
| " \n", | |
| " return model \n", | |
| "\n", | |
| "\n", | |
| "def train_model(model, train_features, train_label, epochs,\n", | |
| " batch_size=None, validation_split=0.1):\n", | |
| " \"\"\"Train the model by feeding it data.\"\"\"\n", | |
| "\n", | |
| " history = model.fit(x=train_features, y=train_label, batch_size=batch_size,\n", | |
| " epochs=epochs, shuffle=True, \n", | |
| " validation_split=validation_split)\n", | |
| " \n", | |
| " # To track the progression of training, gather a snapshot\n", | |
| " # of the model's metrics at each epoch. \n", | |
| " epochs = history.epoch\n", | |
| " hist = pd.DataFrame(history.history)\n", | |
| "\n", | |
| " return epochs, hist " | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "D-IXYVfvM4gD" | |
| }, | |
| "source": [ | |
| "## Invoke the previous functions\n", | |
| "\n", | |
| "Run the following code cell to invoke the preceding functions and actually train the model on the training set. \n", | |
| "\n", | |
| "**Note:** Due to several factors (for example, more examples and a more complex neural network) training MNIST might take longer than training the California Housing Dataset. Be patient." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "nj3v5EKQFY8s", | |
| "cellView": "both" | |
| }, | |
| "source": [ | |
| "# The following variables are the hyperparameters.\n", | |
| "learning_rate = 0.003\n", | |
| "epochs = 50\n", | |
| "batch_size = 4000\n", | |
| "validation_split = 0.2\n", | |
| "\n", | |
| "# Establish the model's topography.\n", | |
| "my_model = create_model(learning_rate)\n", | |
| "\n", | |
| "# Train the model on the normalized training set.\n", | |
| "epochs, hist = train_model(my_model, x_train_normalized, y_train, \n", | |
| " epochs, batch_size, validation_split)\n", | |
| "\n", | |
| "# Plot a graph of the metric vs. epochs.\n", | |
| "list_of_metrics_to_plot = ['accuracy']\n", | |
| "plot_curve(epochs, hist, list_of_metrics_to_plot)\n", | |
| "\n", | |
| "# Evaluate against the test set.\n", | |
| "print(\"\\n Evaluate the new model against the test set:\")\n", | |
| "my_model.evaluate(x=x_test_normalized, y=y_test, batch_size=batch_size)" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "id": "Y5IKmk7D49_n" | |
| }, | |
| "source": [ | |
| "## Task 2: Optimize the model\n", | |
| "\n", | |
| "Experiment with the following:\n", | |
| "\n", | |
| "* number of hidden layers \n", | |
| "* number of nodes in each layer\n", | |
| "* dropout regularization rate\n", | |
| "\n", | |
| "What trends did you discover? Can you reach at least 98% accuracy against the test set? \n", | |
| "\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "metadata": { | |
| "id": "wYG5qXpP5a9n" | |
| }, | |
| "source": [ | |
| "#@title Double-click to view some possible answers.\n", | |
| "\n", | |
| "# It would take much too long to experiment \n", | |
| "# fully with topography and dropout regularization \n", | |
| "# rate. In the real world, you would\n", | |
| "# also experiment with learning rate, batch size, \n", | |
| "# and number of epochs. Since you only have a \n", | |
| "# few minutes, searching for trends can be helpful.\n", | |
| "# Here is what we discovered:\n", | |
| "# * Adding more nodes (at least until 256 nodes) \n", | |
| "# to the first hidden layer improved accuracy.\n", | |
| "# * Adding a second hidden layer generally \n", | |
| "# improved accuracy.\n", | |
| "# * When the model contains a lot of nodes, \n", | |
| "# the model overfits unless the dropout rate \n", | |
| "# is at least 0.5. \n", | |
| "\n", | |
| "# We reached 98% test accuracy with the \n", | |
| "# following configuration:\n", | |
| "# * One hidden layer of 256 nodes; no second \n", | |
| " hidden layer.\n", | |
| "# * dropout regularization rate of 0.4\n", | |
| "\n", | |
| "# We reached 98.2% test accuracy with the \n", | |
| "# following configuration:\n", | |
| "# * First hidden layer of 256 nodes; \n", | |
| "# second hidden layer of 128 nodes.\n", | |
| "# * dropout regularization rate of 0.2\n" | |
| ], | |
| "execution_count": null, | |
| "outputs": [] | |
| } | |
| ] | |
| } |
Author
how would I add to the dataset
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()
In TensorFlow, it provide an efficient way for us to load and split the mnist dataset into training set, testing set, training labels and testing labels in just one code.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
how would I add to the dataset