随着时间增长, 看事情的思路也会产生一些变化。回顾之前作安全架构评审时的一些思路和细节, 同现在对比来看, 又有了些许思考。记录于此, 以飨读者。
你可能会下面列的东西觉得有点虚, 但是根据经验总结来看, 一个称职的安全架构师确实需要具备这些能力。当然这并不意味着你需要在一开始就具备所有的知识。但如果你遇到的安全架构师不具有这些知识并且没有去了解的欲望, 那么很大程度上, 他并不会是一个合格的安全架构师。当然这些也只是一家之言, 权作参考。如有不同,亦可邮件交流。
| #!/usr/bin/env python | |
| """Simple HTTP Server With Upload. | |
| This module builds on BaseHTTPServer by implementing the standard GET | |
| and HEAD requests in a fairly straightforward manner. | |
| """ |
| /* | |
| * A PTRACE_POKEDATA variant of CVE-2016-5195 | |
| * should work on RHEL 5 & 6 | |
| * | |
| * (un)comment correct payload (x86 or x64)! | |
| * $ gcc -pthread c0w.c -o c0w | |
| * $ ./c0w | |
| * DirtyCow root privilege escalation | |
| * Backing up /usr/bin/passwd.. to /tmp/bak | |
| * mmap fa65a000 |
视图和表的区别和联系
上篇博客我说,最近可能是突破瓶颈期了,然后应该会陷入新的瓶颈。然后突然发现其实不然.本篇博客将浅显得讨论一下反入侵体系的建设。
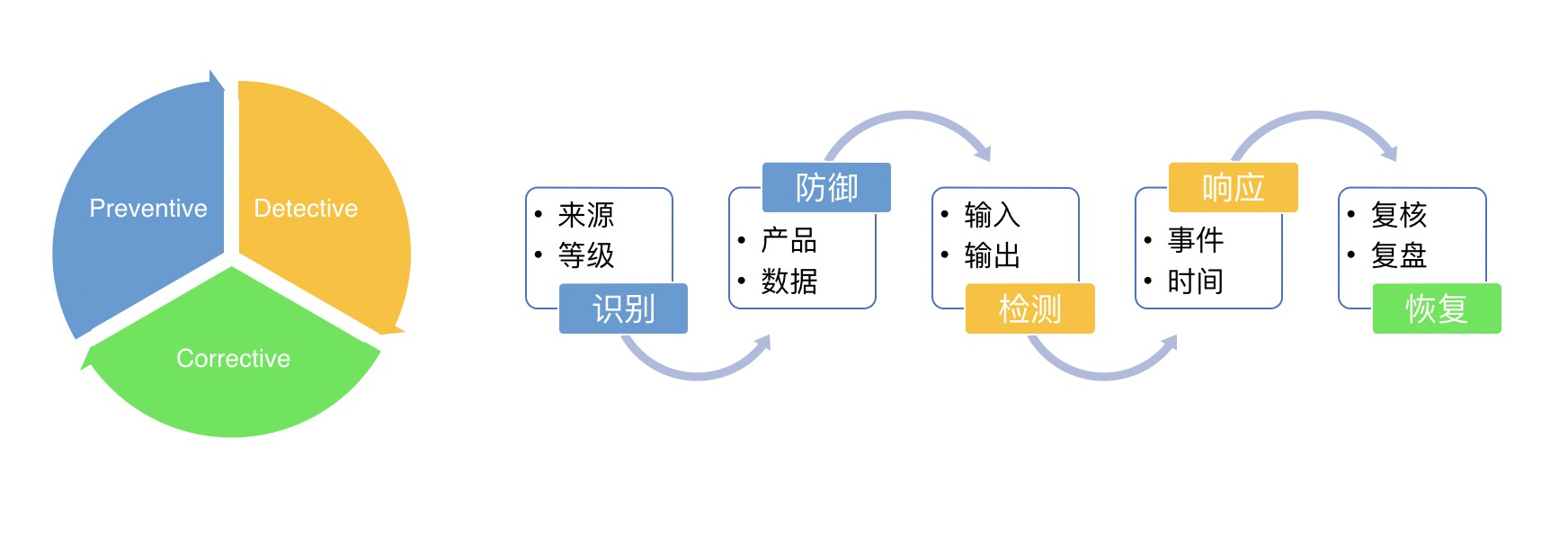
所谓的道术器,即治理的方向,方法,依赖工具。打个比方: 骑x向x走。 骑就是治理方法,治理方向就是向哪走,骑的那个东西就是依赖的工具。反入侵的治理过程的道术器一言以蔽之就是:通过安全产品分别从数据安全和产品安全角度进行识别、防御、检测、响应、恢复。其中识别、防御属于阻止Preventive,响应、恢复属于校正Corrective,还有一部分就是Detective。一个完整的治理就应该是从预防到检测最后到校正的阶段。同时在每一个阶段中继续采用这种方向方法依赖的模型去进行思考。
| # +TLS | |
| SESSION = smtplib.SMTP_SSL() | |
| SESSION.connect(SMTPADDR, 465) | |
| SESSION.login(SENDER, password) | |
| MAILMSG = MIMEMultipart() | |
| MAILMSG['Subject'] = SUBJECT | |
| MAILMSG['From'] = SENDER | |
| MAILMSG['To'] = toaddrs |
git clone https://github.com/facebook/osquerycd osquerytools\make-win64-dev-env.batnote:
run cmd from admin
check your script path
https://osquery.readthedocs.io/en/stable/development/windows-provisioning/
| ##TCP FLAGS## | |
| Unskilled Attackers Pester Real Security Folks | |
| ============================================== | |
| TCPDUMP FLAGS | |
| Unskilled = URG = (Not Displayed in Flag Field, Displayed elsewhere) | |
| Attackers = ACK = (Not Displayed in Flag Field, Displayed elsewhere) | |
| Pester = PSH = [P] (Push Data) | |
| Real = RST = [R] (Reset Connection) | |
| Security = SYN = [S] (Start Connection) |
| import numpy as np | |
| from hmmlearn import hmm | |
| from sklearn.datasets import load_iris,load_diabetes | |
| from sklearn.metrics import accuracy_score | |
| from sklearn.model_selection import train_test_split | |
| CLASSES = 4 | |
| ITERATIONS = 100000 | |
| iris = load_iris() |