-
首先启动一个Git Bash窗口(非Windows用户直接打开终端)
-
执行:
cd ~/.ssh
如果返回“… No such file or directory”,说明没有生成过SSH Key,直接进入第4步。否则进入第3步备份!
stonegao
/ dive_into_ethereum.md
Created
June 15, 2021 03:18
— forked from cryptowen/dive_into_ethereum.md
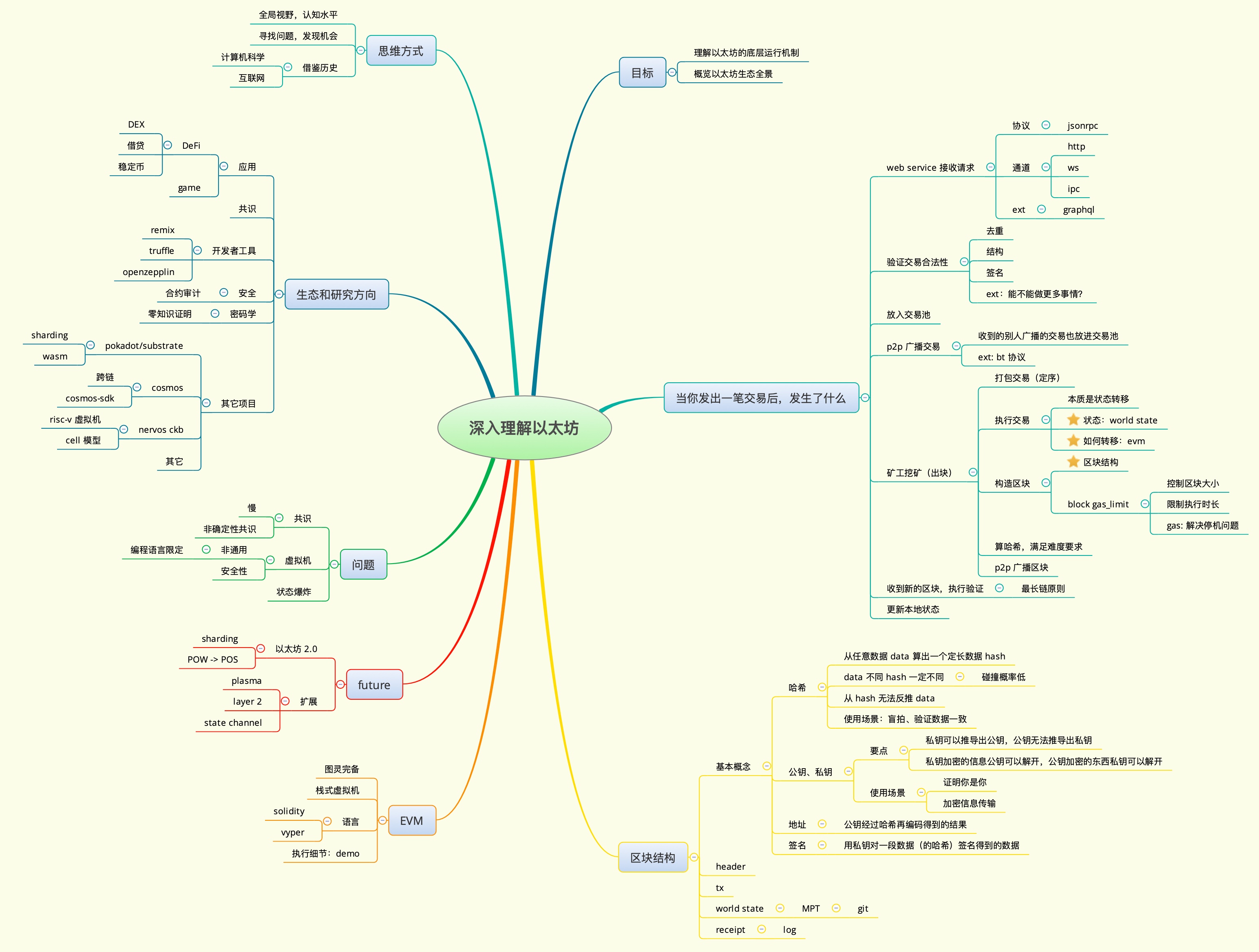
Dive Into Ethereum
CRITICAL! Almost all USDC liquidity on the REKT/USDC uniswap pool can be stolen, due to an authorization issue with burnFrom() on the REKT token.
Uniswap v2 pools get the prices for their swaps by comparing the relative amounts of each of the two tokens that they hold. If the pool holds very little of token A, and a lot of token B, then it only takes a little of token A to buy a lot of token B.
Currently REKT and USDC are fairly priced in the pool. If there were to suddenly be very little REKT in the pool, but the same amount of USDC, then very little REKT would be able to buy a lot of USDC.
A pattern for building personal knowledge bases using LLMs.
This is an idea file, it is designed to be copy pasted to your own LLM Agent (e.g. OpenAI Codex, Claude Code, OpenCode / Pi, or etc.). Its goal is to communicate the high level idea, but your agent will build out the specifics in collaboration with you.
Most people's experience with LLMs and documents looks like RAG: you upload a collection of files, the LLM retrieves relevant chunks at query time, and generates an answer. This works, but the LLM is rediscovering knowledge from scratch on every question. There's no accumulation. Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up. NotebookLM, ChatGPT file uploads, and most RAG systems work this way.