//@Entity
//@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@MappedSuperclass
public class AbstractResume {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String externalId;
private String rawJSON;
}
@Entity
public class AvitoResume extends AbstractResume {
private String description;
private Boolean isPurchased;
}
@Entity
public class HHResume extends AbstractResume {
private String ownerId;
private String getWithContactsUrl;
}
public void test() {
AvitoResume avitoResume = new AvitoResume();
avitoResume.setRawJSON("raw json avito");
avitoRepository.save(avitoResume);
HHResume hhResume = new HHResume();
hhResume.setRawJSON("raw json from hh");
hhRepository.save(hhResume);
abstractRepository.findAll().forEach(r -> System.out.println(r.getRawJSON()));
//List<AbstractResume> resumes = new ArrayList<>();
//resumes.addAll(avitoRepository.findAll());
//resumes.addAll(hhRepository.findAll());
//resumes.forEach(r -> System.out.println(r.getRawJSON()));
}
Статья на основе которой я делал: https://www.baeldung.com/hibernate-inheritance
Теперь по порядку по каждой из предложенных схем
В БД это превращается в
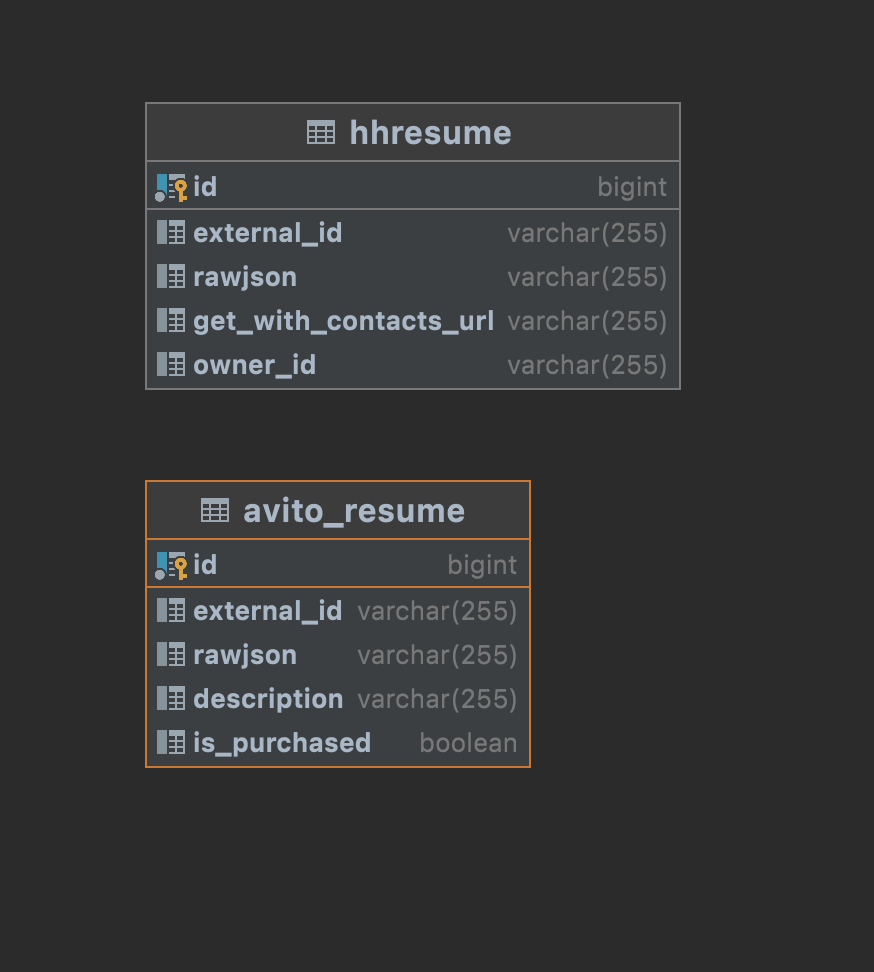
Из минусов - мы не можем использовать репозиторий
Repository extends JpaRepository<AbstractResume, Long>{}
потому что AbstractResume не является entity. Есть смысл использовать @MappedSuperclass только если мы вдругм решим отказаться от Spring Data JPA и будем писать чисто на hibernate
Таблица в БД
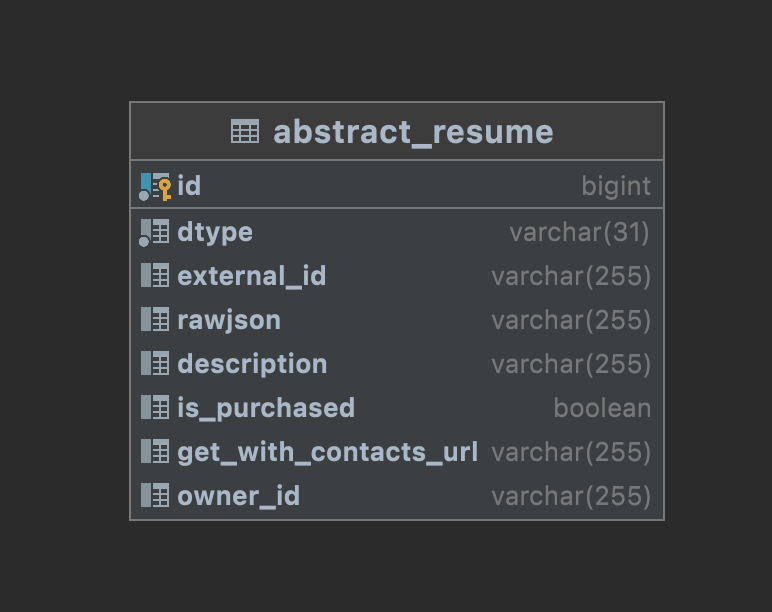
Какие будут запросы в тестовом методе:
Hibernate: insert into abstract_resume (external_id, rawjson, description, is_purchased, dtype) values (?, ?, ?, ?, 'AvitoResume')
Hibernate: insert into abstract_resume (external_id, rawjson, get_with_contacts_url, owner_id, dtype) values (?, ?, ?, ?, 'HHResume')
Hibernate: select abstractre0_.id as id2_0_, abstractre0_.external_id as external3_0_, abstractre0_.rawjson as rawjson4_0_, abstractre0_.description as descript5_0_, abstractre0_.is_purchased as is_purch6_0_, abstractre0_.get_with_contacts_url as get_with7_0_, abstractre0_.owner_id as owner_id8_0_, abstractre0_.dtype as dtype1_0_ from abstract_resume abstractre0_
То есть в БД создается дополнительный столбец, чтобы понимать в какой класс мапить, и мы можем работать с любым классом-наследником вот так:
abstractRepository.findAll().forEach(r -> System.out.println(r.getRawJSON()));
где
abstractRepository = AbstractRepository extends JpaRepository<AbstractResume, Long>{}
Из минусов - не получится на поля в наследниках вещать not null ограничение
Таблицы в БД
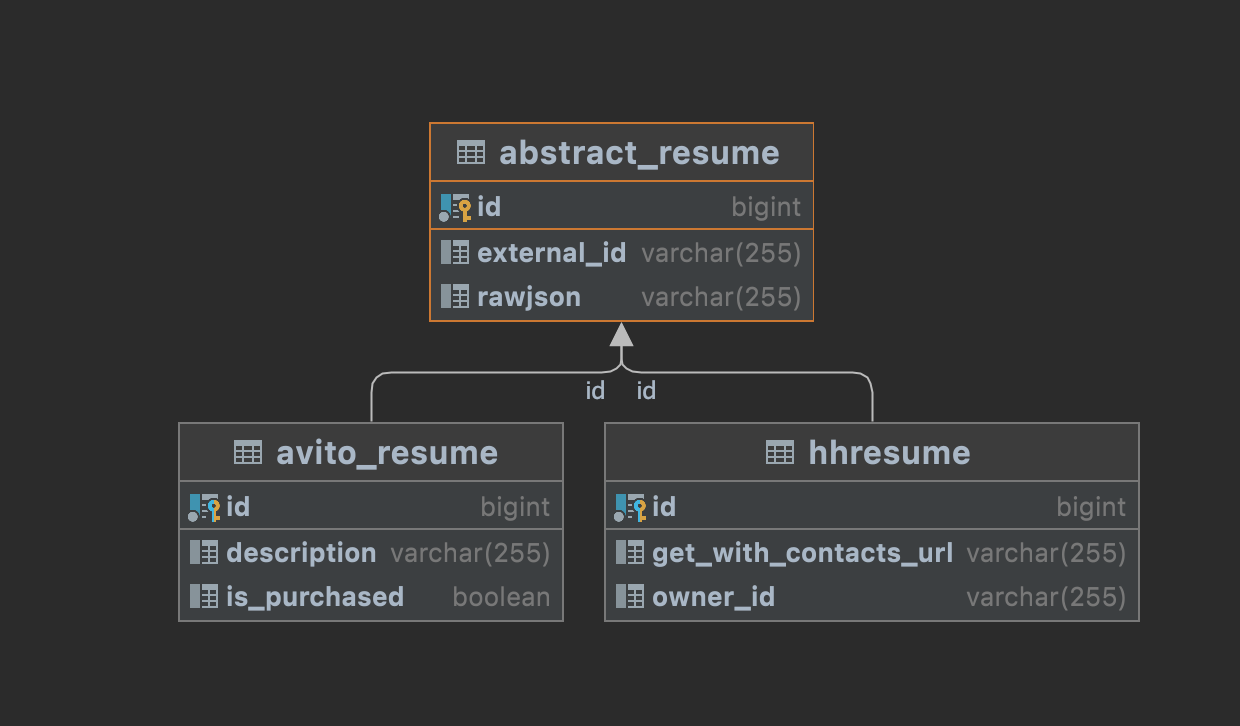
Какие будут запросы в тестовом методе:
Hibernate: insert into abstract_resume (external_id, rawjson) values (?, ?)
Hibernate: insert into hhresume (get_with_contacts_url, owner_id, id) values (?, ?, ?)
Hibernate: select abstractre0_.id as id1_0_, abstractre0_.external_id as external2_0_, abstractre0_.rawjson as rawjson3_0_, abstractre0_1_.description as descript1_1_, abstractre0_1_.is_purchased as is_purch2_1_, abstractre0_2_.get_with_contacts_url as get_with1_2_, abstractre0_2_.owner_id as owner_id2_2_, case when abstractre0_1_.id is not null then 1 when abstractre0_2_.id is not null then 2 when abstractre0_.id is not null then 0 end as clazz_ from abstract_resume abstractre0_ left outer join avito_resume abstractre0_1_ on abstractre0_.id=abstractre0_1_.id left outer join hhresume abstractre0_2_ on abstractre0_.id=abstractre0_2_.
Получается в одном Select происходит несколько join.
Таблицы в БД
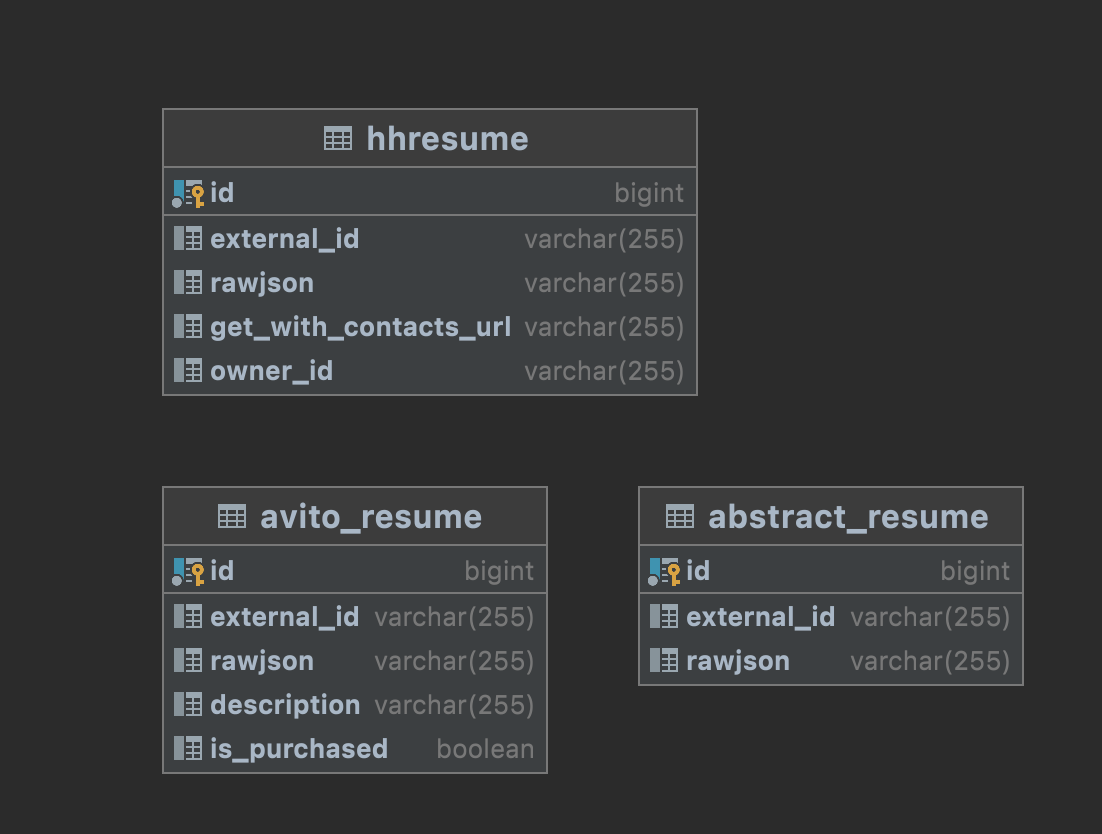
Немного страшненький запрос:
Hibernate: insert into avito_resume (external_id, rawjson, description, is_purchased, id) values (?, ?, ?, ?, ?)
Hibernate: insert into hhresume (external_id, rawjson, get_with_contacts_url, owner_id, id) values (?, ?, ?, ?, ?)
Hibernate: select abstractre0_.id as id1_0_, abstractre0_.external_id as external2_0_, abstractre0_.rawjson as rawjson3_0_, abstractre0_.description as descript1_1_, abstractre0_.is_purchased as is_purch2_1_, abstractre0_.get_with_contacts_url as get_with1_2_, abstractre0_.owner_id as owner_id2_2_, abstractre0_.clazz_ as clazz_ from ( select id, external_id, rawjson, null::varchar as description, null::boolean as is_purchased, null::varchar as get_with_contacts_url, null::varchar as owner_id, 0 as clazz_ from abstract_resume union all select id, external_id, rawjson, description, is_purchased, null::varchar as get_with_contacts_url, null::varchar as owner_id, 1 as clazz_ from avito_resume union all select id, external_id, rawjson, null::varchar as description, null::boolean as is_purchased, get_with_contacts_url, owner_id, 2 as clazz_ from hhresume )
Получается дублирование информации в БД плюс запрос с подселектами и union
Для хранения поиска кажется можно использовать SingleTable, пусть все и хранится в одной таблице, но там не так много полей, не нужна какая-то огромная аналитика и кучей запросов, по производительности один селект лучше, чем куча join
Для хранения сырых резюме с джобордов можно использовать формат вообще кастомный. Поскольку все таблицы мы все равно создаем руками через миграции, то можно сделать структуру таблиц как в MappedSuperclass, а работу с пачкой резюме разных форматов проводть примерно так:
List<AbstractResume> resumes = new ArrayList<>();
resumes.addAll(avitoRepository.findAll());
resumes.addAll(hhRepository.findAll());
resumes.forEach(r -> System.out.println(r.getRawJSON()));
Почему так предлагаю - у нас будет на каждую JobBoard своя таблица, независимая от других, и мы всегда можем вынести поиск на конкретной JobBoard в отдельный сервис без больших трудозатрат (в части БД)