2018.9 @AlloVince
数据搜索/ETL/可视化的开源技术栈
- 2000 Elasticsearch (Lucene)
- 2012 ELK Stack
- 2015 Elastic company -> ELK 5.0
- 2017 ECE (Elastic Cloud Enterprise)
- 2018 X-Pack open source
- Elasticsearch
- Logstash
- Kibaba
- Beats
- X-Pack


- Searching
- Log Analytics
- APM / Tracing
- Metrics Monitoring
- Business Analytics
Demo: [Flights] Global Flight Dashboard
Docker一键安装全家桶
git clone https://github.com/elastic/stack-docker.git
docker-compose -f setup.yml up
全部使用RESTFul接口, 使用Curl即可调试
GET localhost:9200
{
"name" : "-BRIEeP",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "WN9OpZpbR6iqmyfSCqn3gQ",
"version" : {
"number" : "6.4.0",
...
},
"tagline" : "You Know, for Search"
}
services:
elastic:
image: docker.elastic.co/elasticsearch/elasticsearch:6.4.0
container_name: elastic
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- ./elastic/elastic:/usr/share/elasticsearch/data
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:6.4.0
container_name: kibana
environment:
ELASTICSEARCH_URL: http://elastic:9200
volumes:
- ./elastic/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- 5601:5601
depends_on:
- elastic- Cluster <--> 集群
- Node <--> 节点
- Index <--> 类比数据表
- Type <--> 对Index归类,已废弃
- Document <--> 类比单行数据
- Mapping <--> 映射, 关联原始数据与Elastic类型
- Field <--> 字段, 一个mapping可以有多个fields
- Shards <--> 分片
InnoDB主索引

InnoDB辅助索引

数据库:
侧重数据精确查找和范围筛选, 读写比较均衡
- 正排索引(ForwardIndex): fast indexing, less efficient query's
- 倒排索引(InvertIndex): fast query, slower indexing


倒排索引的特点
- 多个词叠加AND/OR搜索只需要合并链表
- 容易支持跨字段搜索
- 索引建立后可重复使用
- 空间占用大
- 建立索引慢
Elastic:
侧重数据的搜索, 牺牲写入换取较快的读取
PUT cn/article/1
{
"title": "中国人民万岁"
}
GET cn
GET cn/_search
POST _bulk
{ "index": { "_index": "cn", "_type": "article", "_id": 1 } }
{ "title": "中国人民万岁" }
{ "index": { "_index": "cn", "_type": "article", "_id": 2 } }
{ "title": "全世界都有中国人" }
{ "index": { "_index": "cn", "_type": "article", "_id": 3 } }
{ "title": "国与国关系" }
{ "index": { "_index": "cn", "_type": "article", "_id": 4 } }
{ "title": "中国人口多" }
{ "index": { "_index": "cn", "_type": "article", "_id": 5 } }
{ "title": "中国地大物博" }
GET cn/article/_search
{
"query" : { "match" : { "title" : "中国人" }}
}
GET cn/article/_search
{
"explain": true,
"query" : { "match" : { "title" : "中国人" }}
}
通用搜索引擎Workflow

安装语法分析
elasticsearch-plugin install analysis-icu
重启检查分词器安装
POST _analyze
{
"tokenizer": "icu_tokenizer",
"text": "中国人"
}
语法分析器构成
- Analyzer
- Character filter * N (字符过滤)
- Tokenizer * 1 (分词)
- Token filter * N (词过滤)


对索引字段配置分词
PUT cn
{
"settings": {
"analysis": {
"analyzer": {
"cn_analyzer": {
"type": "custom",
"tokenizer": "icu_tokenizer"
}
}
}
},
"mappings": {
"article": {
"properties": {
"title": {
"type": "text",
"analyzer":"cn_analyzer"
}
}
}
}
}
Elastic字段类型
- String: text, keyword
- Numeric: long, integer, short, byte, double, float, half_float, scaled_float
- Date
- Boolean
- Binary
- Range: integer_range, float_range, long_range, double_range, date_range
检查字段分词已经生效
POST cn/_analyze
{
"field": "title",
"text": "中国人"
}
Keep schema free
PUT cn
{
"settings": {
"number_of_shards": 1,
"analysis": {
"analyzer": {
"cn_analyzer": {
"type": "custom",
"tokenizer": "icu_tokenizer"
}
}
}
},
"mappings": {
"article": {
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "cn_analyzer",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
]
}
}
}
GET cn/article/_search
{
"query" : { "term": { "title.raw": "国与国关系" }}
}
multi_match: {
query: keyword,
type: 'cross_fields',
operator: 'and',
fields: ['title', 'tags', 'summary^0.5']
}
query: {
bool: {
filter: {
term: {
'termKeywords.raw': keyword
}
},
should: ...
}
}
function_score: {
query: {
multi_match: {
....
}
},
functions: [
{
exp: {
timestamp: {
origin: Datetime.now(),
offset: 86400 * 60,
scale: 86400 * 60
}
}
}
],
boost_mode: 'multiply'
}
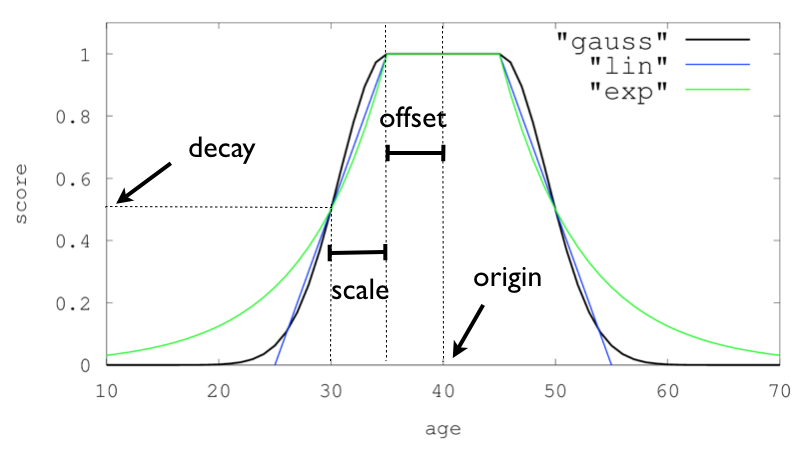
- 全文检索
- match: 基本单字段and/or搜索
- multi_match: 多字段匹配
- match_phrase: 短语匹配, 搜索的所有词必须存在且顺序一致
- 精确匹配
- term
- terms
- range
- wildcard
- pregexp
- 组合检索
- Bool
- must
- filter
- should
- must_not
- Function Score
- Bool
- TF/IDF
- Cosine Similarity (余弦近似度)
- Kafka Connector
- Logstash Plugin
- Custom script
Logstash Plugins
- Input plugin
- Output plugin
Logstash JDBC
- 下载JDBC库
- Docker进入Logstash容器运行
yum install mysql-connector-java - 复制 /usr/share/java/mysql-connector-java.jar
- 后续可以挂载运行
- 配置Logstash
input {
jdbc {
jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://docker.for.mac.localhost:3306/accounts"
jdbc_user => "root"
jdbc_password => "password"
schedule => "* * * * *"
statement => "SELECT * FROM accounts WHERE id >= :sql_last_value"
use_column_value => true
tracking_column_type => "numeric"
tracking_column => "id"
last_run_metadata_path => "syncpoint_table"
}
}
output {
elasticsearch {
hosts => [ 'elasticsearch' ]
user => 'elastic'
password => "${ELASTIC_PASSWORD}"
index => 'wxmp'
document_id => "%{id}"
document_type => 'accounts'
ssl => true
cacert => '/usr/share/logstash/config/certs/ca/ca.crt'
}
}
简单数据同步并没有意义
- 无法直接用于搜索
- 数据增删改
- 出错重试
准实时数据ETL
- 数据库端
- Iterator API
- Single Item Read API
- Binlog -> Message Queue
- ES端
- Iterator All Items
- Pull Single Item (Upsert)
- ETL
- Receive notify
- Security: 角色及权限
- Alerting: 根据日志数据创建报警
- Monitoring: ELK栈CPU、内存、磁盘等使用状况
- Reporting: 导出Kibana数据表为PDF
- Graph: 数据可视化高阶图表
- Machine Learning: 非监督学习发现数据异常
- SQL: 使用SQL语法查询数据
POST /_xpack/sql?format=txt
{
"query": "SHOW tables"
}
POST /_xpack/sql?format=txt
{
"query": "SELECT title FROM cn"
}
< 6.3: 闭源, 作为独立组件安装>= 6.3: 开源, 强制集成, 提供30天试用, License只能申请
- Logstash (Golang)
- Filebeat (Java)
- Filebeat + Logstash

优点:
- 技术栈全面, 仍然是最好的搜索和日志分析解决方案
- RESTFul接口, 理解上手容易
- SDK齐全,开发简单
- 集群自动连接, 门槛低
缺点:
- 细节屏蔽多, 深入有难度
- 资源占用较大
- 商业化导致免费版本不友好
- JSON作为Query格式比较啰嗦