Created
September 30, 2021 15:43
-
-
Save AxoyTO/2a69838a8e6b4abd526f467f0b991c53 to your computer and use it in GitHub Desktop.
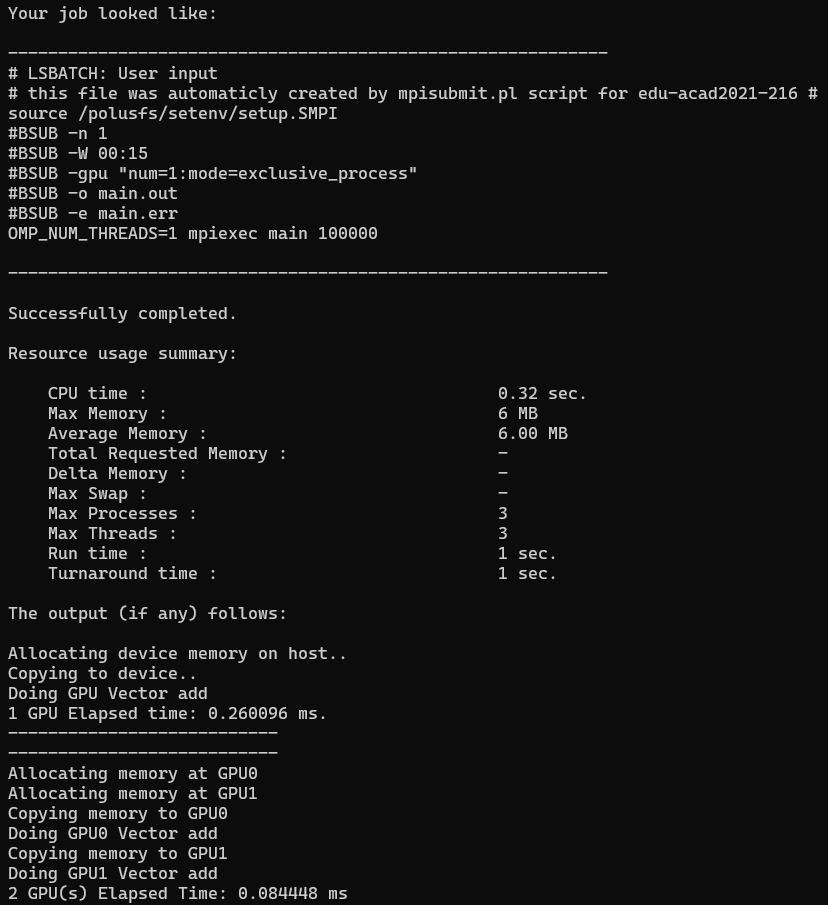
CUDA MultiGPU (TASK_11)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <cuda.h> | |
| #include <cuda_runtime.h> | |
| #include <device_launch_parameters.h> | |
| #include <stdio.h> | |
| #include <cstdlib> | |
| #include <iostream> | |
| __global__ void vectorAddGPU(float* a, float* b, float* c, int N) { | |
| int idx = blockIdx.x * blockDim.x + threadIdx.x; | |
| if (idx < N) { | |
| c[idx] = a[idx] + b[idx]; | |
| } | |
| } | |
| void multiGPU(int size = 1000000) { | |
| int n = size; | |
| int work_per_gpu = (n - 1) / 2 + 1; | |
| int nBytes = n * sizeof(float); | |
| int nBytes_per_gpu = work_per_gpu * sizeof(float); | |
| int devices_count = 2; | |
| float *h_a, *h_b, *h_c; | |
| h_a = (float*)malloc(nBytes); | |
| h_b = (float*)malloc(nBytes); | |
| h_c = (float*)malloc(nBytes); | |
| cudaHostRegister(h_a, nBytes, 0); | |
| cudaHostRegister(h_b, nBytes, 0); | |
| cudaHostRegister(h_c, nBytes, 0); | |
| for (int i = 0; i < n; i++) { | |
| h_a[i] = i; | |
| h_b[i] = i + 1; | |
| } | |
| float *d_a1, *d_b1, *d_c1; | |
| float *d_a2, *d_b2, *d_c2; | |
| cudaSetDevice(0); | |
| printf("Allocating memory at GPU0\n"); | |
| cudaMalloc(&d_a1, nBytes_per_gpu); | |
| cudaMalloc(&d_b1, nBytes_per_gpu); | |
| cudaMalloc(&d_c1, nBytes_per_gpu); | |
| cudaSetDevice(1); | |
| printf("Allocating memory at GPU1\n"); | |
| cudaMalloc(&d_a2, nBytes_per_gpu); | |
| cudaMalloc(&d_b2, nBytes_per_gpu); | |
| cudaMalloc(&d_c2, nBytes_per_gpu); | |
| cudaSetDevice(0); | |
| cudaEvent_t start, stop; | |
| cudaEventCreate(&start); | |
| cudaEventCreate(&stop); | |
| const int BLOCK_SIZE = 1024; | |
| const int GRID_SIZE = (work_per_gpu - 1) / BLOCK_SIZE + 1; | |
| cudaEventRecord(start); | |
| printf("Copying memory to GPU0\n"); | |
| cudaSetDevice(0); | |
| cudaMemcpyAsync(d_a1, &h_a[0], nBytes_per_gpu, cudaMemcpyHostToDevice); | |
| cudaMemcpyAsync(d_b1, &h_b[0], nBytes_per_gpu, cudaMemcpyHostToDevice); | |
| printf("Doing GPU0 Vector add\n"); | |
| vectorAddGPU<<<GRID_SIZE, BLOCK_SIZE>>>(d_a1, d_b1, d_c1, n); | |
| cudaMemcpyAsync(&h_c[0], d_c1, nBytes_per_gpu, cudaMemcpyDeviceToHost); | |
| cudaSetDevice(1); | |
| printf("Copying memory to GPU1\n"); | |
| cudaMemcpyAsync(d_a2, &h_a[work_per_gpu], nBytes_per_gpu, | |
| cudaMemcpyHostToDevice); | |
| cudaMemcpyAsync(d_b2, &h_b[work_per_gpu], nBytes_per_gpu, | |
| cudaMemcpyHostToDevice); | |
| printf("Doing GPU1 Vector add\n"); | |
| vectorAddGPU<<<GRID_SIZE, BLOCK_SIZE>>>(d_a2, d_b2, d_c2, n); | |
| cudaMemcpyAsync(&h_c[work_per_gpu], d_c2, nBytes_per_gpu, | |
| cudaMemcpyDeviceToHost); | |
| cudaDeviceSynchronize(); | |
| cudaSetDevice(0); | |
| cudaDeviceSynchronize(); | |
| cudaEventRecord(stop); | |
| cudaEventSynchronize(stop); | |
| float msecs = 0; | |
| cudaEventElapsedTime(&msecs, start, stop); | |
| printf("%d GPU(s) Elapsed Time: %f ms\n", devices_count, msecs); | |
| cudaFree(d_a1); | |
| cudaFree(d_b1); | |
| cudaFree(d_c1); | |
| cudaSetDevice(1); | |
| cudaFree(d_a2); | |
| cudaFree(d_b2); | |
| cudaFree(d_c2); | |
| cudaSetDevice(0); | |
| cudaHostUnregister(h_a); | |
| cudaHostUnregister(h_b); | |
| cudaHostUnregister(h_c); | |
| free(h_a); | |
| free(h_b); | |
| free(h_c); | |
| } | |
| void singleGPU(int size = 1000000) { | |
| int n = size; | |
| int nBytes = n * sizeof(float); | |
| float *h_a, *h_b, *h_c; | |
| h_a = (float*)malloc(nBytes); | |
| h_b = (float*)malloc(nBytes); | |
| h_c = (float*)malloc(nBytes); | |
| float *d_a, *d_b, *d_c; | |
| dim3 block(256); | |
| dim3 grid((unsigned int)ceil(n / (float)block.x)); | |
| for (int i = 0; i < n; i++) { | |
| h_a[i] = rand() / (float)RAND_MAX; | |
| h_b[i] = rand() / (float)RAND_MAX; | |
| h_c[i] = 0; | |
| } | |
| printf("Allocating device memory on host..\n"); | |
| cudaMalloc((void**)&d_a, n * sizeof(float)); | |
| cudaMalloc((void**)&d_b, n * sizeof(float)); | |
| cudaMalloc((void**)&d_c, n * sizeof(float)); | |
| printf("Copying to device..\n"); | |
| cudaEvent_t start, stop; | |
| cudaEventCreate(&start); | |
| cudaEventCreate(&stop); | |
| cudaEventRecord(start); | |
| cudaMemcpy(d_a, h_a, n * sizeof(float), cudaMemcpyHostToDevice); | |
| cudaMemcpy(d_b, h_b, n * sizeof(float), cudaMemcpyHostToDevice); | |
| printf("Doing GPU Vector add\n"); | |
| vectorAddGPU<<<grid, block>>>(d_a, d_b, d_c, n); | |
| cudaEventRecord(stop); | |
| cudaEventSynchronize(stop); | |
| float msecs = 0; | |
| cudaEventElapsedTime(&msecs, start, stop); | |
| printf("1 GPU Elapsed time: %f ms.\n", msecs); | |
| cudaFree(d_a); | |
| cudaFree(d_b); | |
| cudaFree(d_c); | |
| free(h_a); | |
| free(h_b); | |
| free(h_c); | |
| } | |
| int main(int argc, char** argv) { | |
| singleGPU(atoi(argv[1])); | |
| std::cout << "---------------------------\n---------------------------\n"; | |
| multiGPU(atoi(argv[1])); | |
| return 0; | |
| } |
Author
AxoyTO
commented
Sep 30, 2021
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment