Created
September 30, 2021 18:28
-
-
Save AxoyTO/7ab90fa89a05766acb9c15ea4a26624b to your computer and use it in GitHub Desktop.
CUDA Streams (TASK_10)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // | |
| // main.cpp | |
| // | |
| // | |
| // Created by Elijah Afanasiev on 25.09.2018. | |
| // | |
| // | |
| // System includes | |
| #include <assert.h> | |
| #include <stdio.h> | |
| #include <chrono> | |
| #include <cstdlib> | |
| #include <iostream> | |
| // CUDA runtime | |
| #include <cuda.h> | |
| #include <cuda_runtime.h> | |
| #include <device_launch_parameters.h> | |
| #ifndef MAX | |
| #define MAX(a, b) (a > b ? a : b) | |
| #endif | |
| __global__ void vectorAddGPU(float* a, float* b, float* c, int N, int offset) { | |
| int idx = blockIdx.x * blockDim.x + threadIdx.x; | |
| if (idx < N) { | |
| c[offset + idx] = a[offset + idx] + b[offset + idx]; | |
| } | |
| } | |
| void sample_vec_add(int size = 1048576) { | |
| int n = size; | |
| int nBytes = n * sizeof(int); | |
| float *a, *b, *c; | |
| a = (float*)malloc(nBytes); | |
| b = (float*)malloc(nBytes); | |
| c = (float*)malloc(nBytes); | |
| float *d_A, *d_B, *d_C; | |
| dim3 block(256); | |
| dim3 grid((unsigned int)ceil(n / (float)block.x)); | |
| for (int i = 0; i < n; i++) { | |
| a[i] = rand() / (float)RAND_MAX; | |
| b[i] = rand() / (float)RAND_MAX; | |
| c[i] = 0; | |
| } | |
| cudaMalloc((void**)&d_A, n * sizeof(float)); | |
| cudaMalloc((void**)&d_B, n * sizeof(float)); | |
| cudaMalloc((void**)&d_C, n * sizeof(float)); | |
| cudaEvent_t start, stop; | |
| cudaEventCreate(&start); | |
| cudaEventCreate(&stop); | |
| cudaEventRecord(start); | |
| cudaMemcpy(d_A, a, n * sizeof(float), cudaMemcpyHostToDevice); | |
| cudaMemcpy(d_B, b, n * sizeof(float), cudaMemcpyHostToDevice); | |
| vectorAddGPU<<<grid, block>>>(d_A, d_B, d_C, n, 0); | |
| cudaEventRecord(stop); | |
| cudaEventSynchronize(stop); | |
| float milliseconds = 0; | |
| cudaEventElapsedTime(&milliseconds, start, stop); | |
| printf("Streams Used: 0\nGPU Elapsed time: %f ms\n", milliseconds); | |
| cudaDeviceSynchronize(); | |
| cudaFree(d_A); | |
| cudaFree(d_B); | |
| cudaFree(d_C); | |
| } | |
| void streams_vec_add(int size = 1048576) { | |
| int n = size; | |
| int nBytes = n * sizeof(float); | |
| cudaEvent_t start, stop; | |
| cudaEventCreate(&start); | |
| cudaEventCreate(&stop); | |
| float *a, *b, *c; | |
| cudaHostAlloc((void**)&a, nBytes, cudaHostAllocDefault); | |
| cudaHostAlloc((void**)&b, nBytes, cudaHostAllocDefault); | |
| cudaHostAlloc((void**)&c, nBytes, cudaHostAllocDefault); | |
| float *d_A, *d_B, *d_C; | |
| for (int i = 0; i < n; i++) { | |
| a[i] = rand() / (float)RAND_MAX; | |
| b[i] = rand() / (float)RAND_MAX; | |
| c[i] = 0; | |
| } | |
| cudaMalloc((void**)&d_A, nBytes); | |
| cudaMalloc((void**)&d_B, nBytes); | |
| cudaMalloc((void**)&d_C, nBytes); | |
| cudaEventRecord(start); | |
| const int stream_count = 4; | |
| const int stream_size = n / stream_count; | |
| cudaStream_t Stream[stream_count]; | |
| for (int i = 0; i < stream_count; i++) | |
| cudaStreamCreate(&Stream[i]); | |
| dim3 block(1024); | |
| dim3 grid((stream_size - 1) / 1024 + 1); | |
| for (int i = 0; i < stream_count; i++) { | |
| int offset = i * stream_size; | |
| cudaMemcpyAsync(&d_A[offset], &a[offset], stream_size * sizeof(float), | |
| cudaMemcpyHostToDevice, Stream[i]); | |
| cudaMemcpyAsync(&d_B[offset], &b[offset], stream_size * sizeof(float), | |
| cudaMemcpyHostToDevice, Stream[i]); | |
| cudaMemcpyAsync(&d_C[offset], &c[offset], stream_size * sizeof(float), | |
| cudaMemcpyHostToDevice, Stream[i]); | |
| vectorAddGPU<<<grid, block>>>(d_A, d_B, d_C, stream_size, offset); | |
| cudaMemcpyAsync(&a[offset], &d_A[offset], stream_size * sizeof(float), | |
| cudaMemcpyDeviceToHost, Stream[i]); | |
| cudaMemcpyAsync(&b[offset], &d_B[offset], stream_size * sizeof(float), | |
| cudaMemcpyDeviceToHost, Stream[i]); | |
| cudaMemcpyAsync(&c[offset], &d_C[offset], stream_size * sizeof(float), | |
| cudaMemcpyDeviceToHost, Stream[i]); | |
| } | |
| cudaEventRecord(stop); | |
| cudaEventSynchronize(stop); | |
| float msecs = 0; | |
| cudaEventElapsedTime(&msecs, start, stop); | |
| std::cout << "Streams Used: " << stream_count | |
| << "\nGPU Elapsed Time : " << msecs << " ms.\n"; | |
| cudaDeviceSynchronize(); | |
| cudaFree(d_A); | |
| cudaFree(d_B); | |
| cudaFree(d_C); | |
| cudaFreeHost(a); | |
| cudaFreeHost(b); | |
| cudaFreeHost(c); | |
| } | |
| int main(int argc, char** argv) { | |
| sample_vec_add(atoi(argv[1])); | |
| std::cout << "---------------------\n---------------------\n"; | |
| streams_vec_add(atoi(argv[1])); | |
| return 0; | |
| } |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
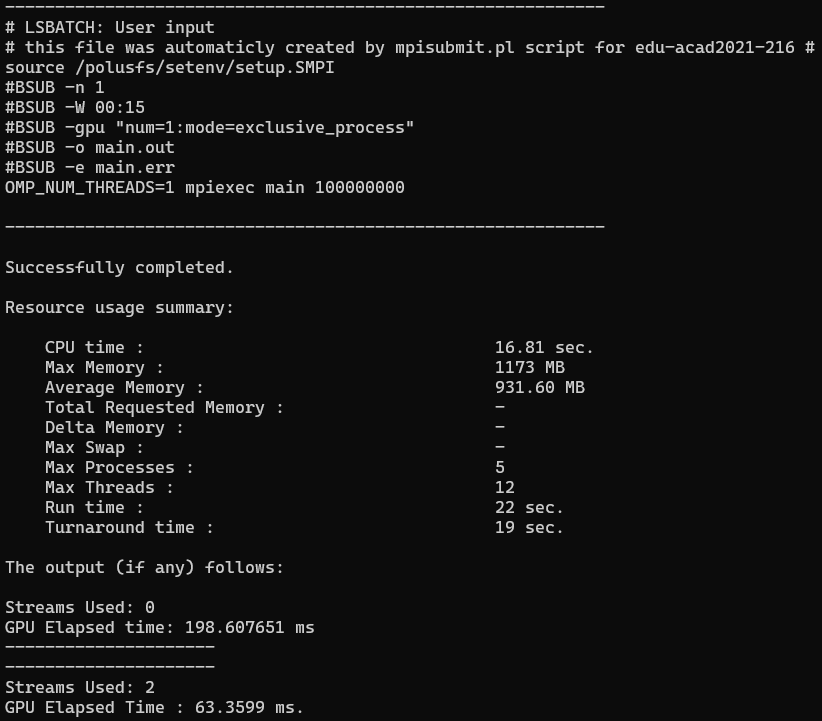
ЗАПУСК С 2 ПОТОКАМИ
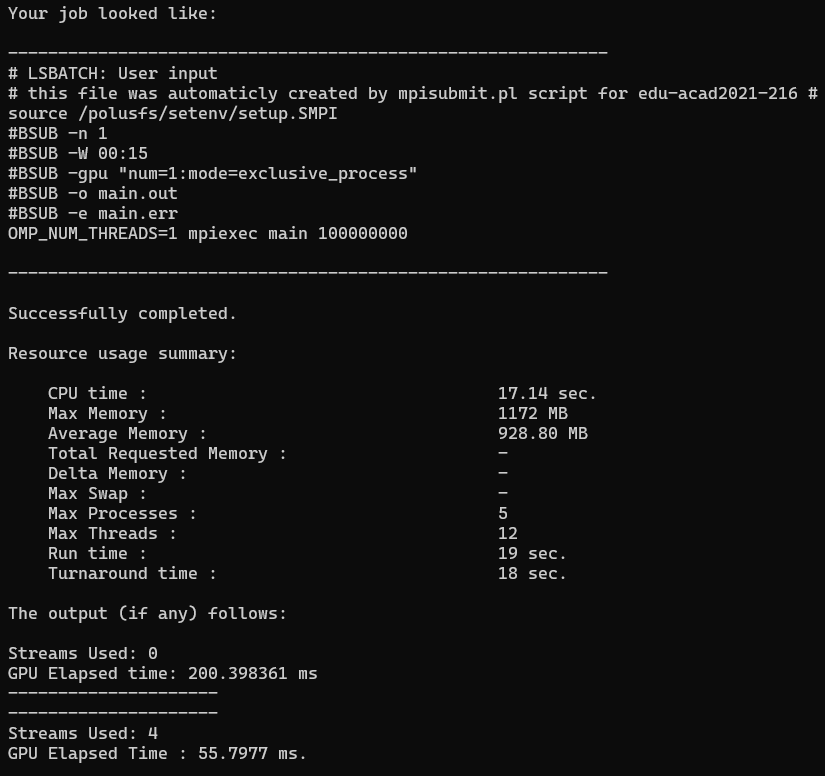
ЗАПУСК С 4 ПОТОКАМИ