Last active
September 29, 2021 20:40
-
-
Save AxoyTO/c44df93da6744dfc4b96664cf6089123 to your computer and use it in GitHub Desktop.
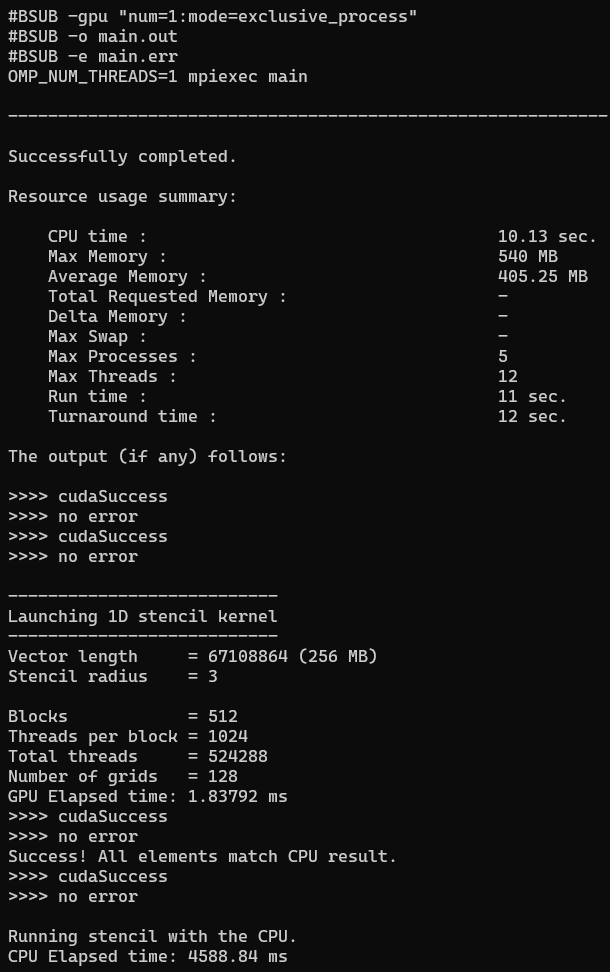
CUDA Stencil_1D (TASK_08)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // UCSC CMPE220 Advanced Parallel Processing | |
| // Prof. Heiner Leitz | |
| // Author: Marcelo Siero. | |
| // Modified from code by:: Andreas Goetz ([email protected]) | |
| // CUDA program to perform 1D stencil operation in parallel on the GPU | |
| // | |
| // /* FIXME */ COMMENTS ThAT REQUIRE ATTENTION | |
| #include <cuda.h> | |
| #include <device_launch_parameters.h> | |
| #include <cuda_device_runtime_api.h> | |
| #include <stdio.h> | |
| #include <chrono> | |
| #include <iostream> | |
| // define vector length, stencil radius, | |
| #define INPUTSIZE 64l | |
| #define N (1024 * 1024 * INPUTSIZE) | |
| #define RADIUS 3 | |
| #define GRIDSIZE 512 | |
| #define BLOCKSIZE 1024 | |
| int gridSize = GRIDSIZE; | |
| int blockSize = BLOCKSIZE; | |
| float milliseconds = 0; | |
| void cudaErrorCheck() { | |
| cudaError_t error = cudaGetLastError(); | |
| const char* errorName = cudaGetErrorName(error); | |
| std::string s0(errorName); | |
| std::cout << ">>>> " << s0 << std::endl; | |
| const char* errorDescription = cudaGetErrorString(error); | |
| std::string s1(errorDescription); | |
| std::cout << ">>>> " << s1 << std::endl; | |
| } | |
| void start_timer(cudaEvent_t* start) { | |
| // FIXME: ADD TIMING CODE, HERE, USE GLOBAL VARIABLES AS NEEDED. | |
| cudaEventCreate(start); | |
| cudaEventRecord(*start); | |
| } | |
| float stop_timer(cudaEvent_t* start, cudaEvent_t* stop) { | |
| // FIXME: ADD TIMING CODE, HERE, USE GLOBAL VARIABLES AS NEEDED. | |
| cudaEventCreate(stop); | |
| cudaEventRecord(*stop); | |
| cudaEventSynchronize(*stop); | |
| cudaEventElapsedTime(&milliseconds, *start, *stop); | |
| return (milliseconds); | |
| } | |
| cudaDeviceProp prop; | |
| int device; | |
| void getDeviceProperties() { | |
| /* | |
| FIXME: Implement this function so as to acquire and print the following | |
| device properties: | |
| Major and minor CUDA capability, total device global memory, | |
| size of shared memory per block, number of registers per block, | |
| warp size, max number of threads per block, number of multi-prccessors | |
| (SMs) per device, Maximum number of threads per block dimension (x,y,z), | |
| Maximumum number of blocks per grid dimension (x,y,z). | |
| These properties can be useful to dynamically optimize programs. For | |
| instance the number of SMs can be useful as a heuristic to determine | |
| how many is a good number of blocks to use. The total device global | |
| memory might be important to know just how much data to operate on at | |
| once. | |
| */ | |
| } | |
| void newline() { | |
| std::cout << std::endl; | |
| }; | |
| void printThreadSizes() { | |
| int noOfThreads = gridSize * blockSize; | |
| printf("Blocks = %d\n", gridSize); // no. of blocks to launch. | |
| printf("Threads per block = %d\n", blockSize); // no. of threads to launch. | |
| printf("Total threads = %d\n", noOfThreads); | |
| printf("Number of grids = %d\n", (N + noOfThreads - 1) / noOfThreads); | |
| } | |
| /* | |
| ------------------------------------------------------- | |
| CUDA device function that performs 1D stencil operation | |
| ------------------------------------------------------- | |
| */ | |
| __global__ void stencil_1D(int* in, int* out, long dim) { | |
| __shared__ int temp[BLOCKSIZE + 2 * RADIUS]; | |
| long gindex = threadIdx.x + blockDim.x * blockIdx.x; | |
| int stride = gridDim.x * blockDim.x; | |
| int tid = threadIdx.x; | |
| int lindex = threadIdx.x + RADIUS; | |
| // Go through all data | |
| // Step all threads in a block to avoid synchronization problem | |
| while (gindex < dim + blockDim.x) { /* FIXME PART 2 - MODIFY PROGRAM TO USE | |
| SHARED MEMORY. */ | |
| if (gindex < dim) { | |
| temp[lindex] = in[gindex]; | |
| } else { | |
| temp[lindex] = 0; | |
| } | |
| if (tid < RADIUS) { | |
| if (gindex < RADIUS) { | |
| temp[lindex - RADIUS] = 0; | |
| } else { | |
| temp[lindex - RADIUS] = in[gindex - RADIUS]; | |
| } | |
| if (gindex + BLOCKSIZE >= dim) { | |
| temp[lindex + BLOCKSIZE] = 0; | |
| } else { | |
| temp[lindex + BLOCKSIZE] = in[gindex + BLOCKSIZE]; | |
| } | |
| } | |
| __syncthreads(); | |
| // Apply the stencil | |
| int result = 0; | |
| for (int offset = -RADIUS; offset <= RADIUS; offset++) { | |
| if (lindex + offset < dim && lindex + offset > -1) | |
| result += temp[lindex + offset]; | |
| } | |
| // Store the result | |
| if (gindex < dim) | |
| out[gindex] = result; | |
| // Update global index and quit if we are done | |
| gindex += stride; | |
| __syncthreads(); | |
| } | |
| } | |
| #define True 1 | |
| #define False 0 | |
| void checkResults( | |
| int* h_in, | |
| int* h_out, | |
| int DoCheck = | |
| True) { /* | |
| DO NOT CHANGE THIS CODE. | |
| CPU calculates the stencil from data in *h_in | |
| if DoCheck is True (default) it compares it with *h_out | |
| to check the operation of this code. | |
| If DoCheck is set to False, it can be used to time the CPU. | |
| */ | |
| int i, j, ij, result, err; | |
| err = 0; | |
| for (i = 0; i < N; i++) { // major index. | |
| result = 0; | |
| for (j = -RADIUS; j <= RADIUS; j++) { | |
| ij = i + j; | |
| if (ij >= 0 && ij < N) | |
| result += h_in[ij]; | |
| } | |
| if (DoCheck) { // print out some errors for debugging purposes. | |
| if (h_out[i] != result) { // count errors. | |
| err++; | |
| if (err < 8) { // help debug | |
| printf("h_out[%d]=%d should be %d\n", i, h_out[i], result); | |
| }; | |
| } | |
| } else { // for timing purposes. | |
| h_out[i] = result; | |
| } | |
| } | |
| if (DoCheck) { // report results. | |
| if (err != 0) { | |
| printf("Error, %d elements do not match!\n", err); | |
| } else { | |
| printf("Success! All elements match CPU result.\n"); | |
| } | |
| } | |
| } | |
| /* | |
| ------------ | |
| main program | |
| ------------ | |
| */ | |
| int main(void) { | |
| int *h_in, *h_out; | |
| int *d_in, *d_out; | |
| long size = N * sizeof(int); | |
| int i; | |
| cudaEvent_t start, stop; | |
| // allocate host memory | |
| h_in = new int[N]; | |
| h_out = new int[N]; | |
| // getDeviceProperties(); | |
| // initialize vector | |
| for (i = 0; i < N; i++) { | |
| // h_in[i] = i+1; | |
| h_in[i] = 1; | |
| } | |
| // allocate device memory | |
| cudaMalloc((void**)&d_in, size); | |
| cudaMalloc((void**)&d_out, size); | |
| cudaErrorCheck(); | |
| // copy input data to device | |
| cudaMemcpy(d_in, h_in, size, cudaMemcpyHostToDevice); | |
| cudaErrorCheck(); | |
| // Apply stencil by launching a sufficient number of blocks | |
| printf("\n---------------------------\n"); | |
| printf("Launching 1D stencil kernel\n"); | |
| printf("---------------------------\n"); | |
| printf("Vector length = %ld (%ld MB)\n", N, N * 4 / 1024 / 1024); | |
| printf("Stencil radius = %d\n", RADIUS); | |
| //---------------------------------------------------------- | |
| // CODE TO RUN AND TIME THE STENCIL KERNEL. | |
| //---------------------------------------------------------- | |
| newline(); | |
| printThreadSizes(); | |
| start_timer(&start); | |
| stencil_1D<<<gridSize, blockSize>>>(d_in, d_out, N); | |
| std::cout << "GPU Elapsed time: " << stop_timer(&start, &stop) << " ms" | |
| << std::endl; | |
| // copy results back to host | |
| cudaMemcpy(h_out, d_out, size, cudaMemcpyDeviceToHost); | |
| cudaErrorCheck(); | |
| checkResults(h_in, h_out); | |
| //---------------------------------------------------------- | |
| // deallocate device memory | |
| cudaFree(d_in); | |
| cudaFree(d_out); | |
| cudaErrorCheck(); | |
| //===================================================== | |
| // Evaluate total time of execution with just the CPU. | |
| //===================================================== | |
| newline(); | |
| std::cout << "Running stencil with the CPU.\n"; | |
| start_timer(&start); | |
| // Use checkResults to time CPU version of the stencil with False flag. | |
| checkResults(h_in, h_out, False); | |
| std::cout << "CPU Elapsed time: " << stop_timer(&start, &stop) << " ms" | |
| << std::endl; | |
| //===================================================== | |
| // deallocate host memory | |
| free(h_in); | |
| free(h_out); | |
| return 0; | |
| } |
Author
AxoyTO
commented
Sep 29, 2021
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment