Created
April 5, 2023 03:07
-
-
Save CookieLau/b077489c0df1fd3b1724855b682f61fb to your computer and use it in GitHub Desktop.
If you would like to process CIFAR dataset like the ImageNet-1K, i.e. split the train and test dataset and every category as an individual subdirectory, try this gist!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import cv2 | |
| import numpy as np | |
| import pickle | |
| import os | |
| import shutil | |
| from torchvision import datasets | |
| # %% | |
| def unpickle(file): | |
| with open(file, 'rb') as fo: | |
| dict = pickle.load(fo, encoding='bytes') | |
| return dict | |
| def cifar10(): | |
| _ = datasets.CIFAR10(root='./data', train=True, download=True) | |
| root = os.getcwd() | |
| os.chdir("./data/cifar-10-batches-py") | |
| def process(filenames, folder_name): | |
| os.makedirs(folder_name, exist_ok=True) | |
| # make directory for each class | |
| meta = unpickle('batches.meta') | |
| label_names = meta[b'label_names'] | |
| for label in label_names: | |
| os.makedirs(folder_name + "/" + label.decode('utf-8'), exist_ok=True) | |
| for index, batch in enumerate(filenames): | |
| data = unpickle(batch) | |
| images = data[b'data'] | |
| size = images.shape[0] | |
| images = images.reshape(size, 3, 32, 32).transpose(0,2,3,1).astype("uint8") | |
| label = data[b'labels'] | |
| # resize dataset to 224x224 | |
| images224 = np.zeros((size, 224, 224, 3), dtype=np.uint8) | |
| for i in range(size): | |
| images224[i] = cv2.cvtColor((cv2.resize(images[i], (224, 224), interpolation=cv2.INTER_CUBIC)), cv2.COLOR_BGR2RGB) | |
| # save images to each directory | |
| for i in range(size): | |
| cv2.imwrite(folder_name + "/" + label_names[label[i]].decode('utf-8') + '/batch_' + str(index) + "_" + str(i) + '.jpg', images224[i]) | |
| process(['data_batch_1', 'data_batch_2', 'data_batch_3', 'data_batch_4', 'data_batch_5'], "train") | |
| process(['test_batch'], "test") | |
| os.chdir(root) | |
| # %% | |
| def cifar100(): | |
| ## download training dataset | |
| _ = datasets.CIFAR100(root='./data', train=False, download=True) | |
| root = os.getcwd() | |
| os.chdir("./data/cifar-100-python") | |
| os.rename("test", "test.pkl") | |
| os.rename("train", "train.pkl") | |
| os.rename("meta", "meta.pkl") | |
| def process(pkl_file, folder_name): | |
| images = pkl_file[b'data'] | |
| size = images.shape[0] | |
| # %% | |
| images = images.reshape(size, 3, 32, 32).transpose(0,2,3,1).astype("uint8") | |
| # %% | |
| # resize dataset to 224x224 | |
| images224 = np.zeros((size, 224, 224, 3), dtype=np.uint8) | |
| for i in range(size): | |
| images224[i] = cv2.cvtColor((cv2.resize(images[i], (224, 224), interpolation=cv2.INTER_CUBIC)), cv2.COLOR_BGR2RGB) | |
| os.makedirs(folder_name, exist_ok=True) | |
| # save dataset to jpeg files | |
| for i in range(size): | |
| cv2.imwrite(folder_name + '/' + str(i) + '.jpg', images224[i]) | |
| # %% | |
| # save the 224x224 images into each class folder | |
| # create a folder for each class | |
| labels = pkl_file[b'fine_labels'] | |
| class_names = unpickle("meta.pkl")[b'fine_label_names'] | |
| for i in range(100): | |
| # os.makedirs("train/" + class_names[i].decode("utf-8")) | |
| os.makedirs(folder_name + "/" + class_names[i].decode("utf-8"), exist_ok=True) | |
| for i in range(size): | |
| shutil.move(folder_name + "/" + str(i) + ".jpg", folder_name + "/" + class_names[labels[i]].decode("utf-8") + "/" + str(i) + ".png") | |
| process(unpickle("train.pkl"), "train") | |
| process(unpickle("test.pkl"), "test") | |
| os.chdir(root) | |
| # %% | |
| if __name__ == "__main__": | |
| cifar10() | |
| cifar100() |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
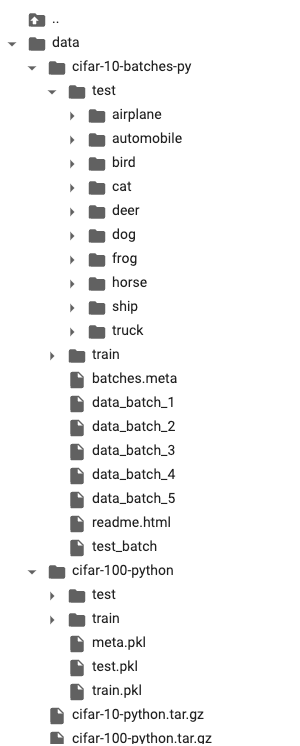
The final directory tree looks like this: