Disclaimer: These questions and answers aren't at all mine. These were scavanged around in the web. I hope it helps.
-
Answer: Linux is the most commonly used operating system that is open source and free. For any computer, the operating system acts as the backbone, and it is most important software that is required for any computer.
Consists of 3 components which are:
- Kernel: Linux is a monolithic kernel that is free and open source software that is responsible for managing hardware resources for the users.
- System Library: System Library plays a vital role because application programs access Kernels feature using system library.
- System Utility: System Utility performs specific and individual level tasks.
-
Answer: Linux is a UNIX clone, the Kernel of which is created by Linus Torvalds. There are so many differences between Linux and UNIX operating system which are as follows:
-
Open Source Operating System:
-
Free of Cost:
-
Compatibility and Flexibility:
-
-
Answer: BASH stands for Bourne Again Shell. BASH is the UNIX shell for the GNU operating system. So, BASH is the command language interpreter that helps you to enter your input, and thus you can retrieve information. In a straightforward language, we can say that it is a program that will understand the data entered by the user and execute the command and gives output.
-
Answer: Cron is a scheduler that executes the commands at a regular interval as per the specific date and time defined. We have multiple users in Linux, and all the users can have their crontab separately. The crontabs files are saved at a particular location that is /var/spool/cron/crontabs.
There are six fields in the format for the crontab that is as below:
<Day_of_the_Month><Month_of_the_Year><Day_of_the_Week><command/program to execute>
-
Answer: CLI is an acronym for Command Line Interface. We have to provide the information to the computer so that it can perform the function accordingly. In Linux, CLI is the interface that provides the user an interface so that user can type the commands and it complete the tasks. CLI is very easy to use, but it should be typed very precisely.
-
Answer: When we have insufficient RAM space in the system and we need more RAM to process our applications then Linux allows an extra allocation of RAM in the physical hard disk which is called a swap space. It is used to hold current programs that are currently running in the system.
-
Answer: The root account resembles an administrator account and permits you to take full control of the framework. Here you can make and keep up client accounts, allocating distinctive accounts for each user. It is the default account that is created every time you install Linux.
-
Answer: LILO or Linux Loader is the default boot loader for Linux. It is independent of a specific file system and can boot operating system from hard disks. Various parameters such as root device can be set independently using LILO.
-
Answer: The GNU project was begun to make a working framework which will be free for clients. The clients would have the opportunity to run, share, circulate, study, change, and enhance or roll out new improvements to the product.
Nowadays the bit Linux is exceptionally normal. Outside the piece, every other piece of the Linux framework is GNU. It was taken under variant 2 of GNU and subsequently, the name Linux was named to GNU/Linux.
-
Answer: Any filename can have a most extreme of 255 characters. This farthest point does exclude the pathname, so accordingly the whole pathname and filename could very much surpass 255 characters.
-
If you back up a DC seven months old, you could encounter lingering objects that lead to inconsistent data. Backup files, as a general rule, shouldn't be over 180 days old
-
Bash Shell – Default shell in many Linux/Unix distribution. Has Features like
- Edit command history
- Shell functions and gives aliases to it
- Unlimited command history
- Array with unlimited size with index.
Tcsh/Csh Shell (Normally called C shell) – Tcsh is enhanced C shell,
- More of C like syntax
- Auto-completion of word and filename is programmable
- Spell check
- Job control
K Shell – It is called Korn Shell or Ksh.More than an interactive Shell, K shell is a complete, powerful, high-level programming language. It has features like
- Options and variables that give you more ways to customize your environment.
- Advanced security features
- Advanced regular expressions,- well-known utilities like grep and awk.
-
RAID (redundant array of independent disks; originally redundant array of inexpensive disks) is a way of storing the same data in different places on multiple hard disks to protect data in the case of a drive failure. However, not all RAID levels provide redundancy
RAID 0**:** This configuration has striping, but no redundancy of data. It offers the best performance, but no fault tolerance.
RAID 1: Also known as disk mirroring, this configuration consists of at least two drives that duplicate the storage of data. There is no striping. Read performance is improved since either disk can be read at the same time. Write performance is the same as for single disk storage.
RAID 5: This level is based on block-level striping with parity. The parity information is striped across each drive, allowing the array to function even if one drive were to fail. The array's architecture allows read and write operations to span multiple drives. This results in performance that is usually better than that of a single drive, but not as high as that of a RAID 0 array. RAID 5 requires at least three disks, but it is often recommended to use at least five disks for performance reasons.
RAID 10: Combining RAID 1 and RAID 0, this level is often referred to as RAID 10, which offers higher performance than RAID 1, but at a much higher cost. In RAID 1+0, the data is mirrored and the mirrors are striped.
-
A level 0 incremental backup, which is the base for subsequent incremental backups, copies all blocks containing data, backing the datafile up into a backup set just as a full backup would.
Incremental backup, only stores the data that has changed since some point in time (typically the previous backup)
-
Virtual memory is a memory management of an operating system (OS) that uses hardware and software to allow a computer to compensate for physical memory shortages by temporarily transferring data from random access memory (RAM) to disk storage. Virtual address increased using active memory in RAM and inactive memory in hard disk drives (HDDs) to form contiguous addresses that hold both the application and its data.
-
&puts the job in the background, that is, makes it block on attempting to read input, and makes the shell not wait for its completion.disownremoves the process from the shell's job control, but it still leaves it connected to the terminal. One of the results is that the shell won't send it aSIGHUP. Obviously, it can only be applied to background jobs, because you cannot enter it when a foreground job is running.
-
A sticky bit is a permission bit which is set on a file or folder, thereby permitting only the owner or root user of the file or folder to modify, rename or delete the concerned directory or file. No other user would be permitted to have these privileges on a file which has a sticky bit. In Unix-like systems, without the sticky bit on, any user can modify, rename or delete the directory or file regardless of the owner of the file or folder.
-
A file with an immutable attribute can not be:
- Modified
- Deleted
- Renamed
- No soft or hard link created by anyone including root user.
Only the root (superuser) or a process possessing the CAP_LINUX_IMMUTABLE capability can set or clear this attribute. Use the lsattr command to list file attributes on a Linux second extended file system that you set with the chattr command.
-
The simplest way to force fsck filesystem check on a root partition eg.
/dev/sda1is to create an empty file called
forcefsckin the partition's root directory.# touch /forcefsckThis empty file will temporarily override any other settings and force
fsckto check the filesystem on the next system reboot. Once the filesystem is checked theforcefsckfile will be removed thus next time you reboot your filesystem will NOT be checked again. -
A runlevel is one of the modes that a Unix-based operating system will run in. In Linux Kernel, there are 7 runlevels exists, starting from 0 to 6. The system can be booted into only one runlevel at a time. By default, a system boots either to runlevel 3 or to runlevel 5. Runlevel 3 is CLI, and 5 is GUI. The default runlevel is specified in /etc/inittab file in most Linux operating systems. Using runlevel, we can easily find out whether X is running, or network is operational, and so on. In this brief guide, we will talk about how to check the runlevel in Unix-like operating systems.
Here is the list of runlevels in Linux distributions,which were distributed with SysV init as default service manager.
- 0 – Halt
- 1 – Single-user text mode
- 2 – Not used (user-definable)
- 3 – Full multi-user text mode
- 4 – Not used (user-definable)
- 5 – Full multi-user graphical mode (with an X-based login screen)
- 6- Reboot
To find out the system runlevel, open your Terminal and run the following command:
$ runlevelSample output for the above command would be:
N 3 -
Now we create a user with a username techbrown. So start with the first step
[root@techbrown] # mkdir /home/techbrownCopy
It will create a home directory for user techbrown
[root@techbrown] # touch /var/spool/mail/techbrownCopy
This command will create a file in the mail directory so that all mail’s come to the user techbrown directly stores in this file.
Now we create an entry in passwd file so that the getty script will discover a information about the user.
[root@techbrown] # vim /etc/passwdCopy
Now it will show some users information which that are previously created. So now just make an entry in it as following or simple way just copy one of the entry from it. By using “yy(yank or copy)” and “p(paste)” and then edit it.
techbrown:x:501:501:Hello techbrown :/home/gopal:/bin/bash 1 :2 :3 :4 :5: 6 : 7Copy
:wq Here in “/etc/passwd“file you have to create 7 entries. Let’s discuss about it shortly. Username It indicates that the password is encrypted and stores in a shadow file User ID Group ID Comment Home directory of the User Last one shell prompt you can check it through “/etc/shells” file.
Now we are going to make entry in the shadow file which stores the information about an user with the encrypted password.
[root@techbrown] # vim /etc/shadowCopy
Now make entry in this file.
techbrown:! !:16244:0:99999:7: : : 1 :2 :3 :4:5 :6:7:8:9Copy
:wq! You will see 9 entries presently available in the /etc/shadow file so we will also discuss about that. Name of a user Password in encrypted The number of days since 1 January 1970 that the password last changed. The number of days permitted before the password can be changed. The number of days after which the password must be changed. The number of days before the password expires that the user is warned. The number of days after the password expires before the account is disabled. The number of days since 1 January 1970 after which the account is disabled. Reserved for the feature. but in above we didn’t edit that so just do the following step first go to the shell prompt and type following command
[root@techbrown] # grub-md5-crypt password:[type your password] retype password : [type above password again] $1$YgGpm1$hhDEbeY0mRpKccgyQsWQn0Copy
Now copy and paste this password in this section.
STEP-V(Create a file for mail address so that the mail come to that user will be shown in that file which is present in “/var/spool/mail/’username’”)
Now create a entry in the /etc/groups directory.
[root@techbrown] # vim /etc/groups techbrown :x : 501: 1 :2 : 3 :4Copy
:wq Here 1:2:3:4 as Username Password Group ID List of users, which are associated with the group.
[root@techbrown] # touch /var/spool/mail/techbrownCopy
This will create a mail box for the user for techbrown so that the mail generated for user techbrown comes to this file. Now use this command to login into user techbrown.
[root@techbrown ~]# su - techbrown -bash-4.1$Copy
[root@techbrown ~]#Copy
This shows the above error that is a bash error. Means to enter into the user, you should have some bash files into the home directory of the user. So do the following steps.
[root@techbrown ~]# cd /etc/skel/ [root@techbrown skel]# cp .bash* /home/techbrown [root@techbrown skel]# su - techbrown [techbrown@techbrown ~]$ [you are in user techbrown ] -
If you issue the ls -l command, you’ll see two numbers (separated by a comma) in the device file entries before the date of last modification, where the file length normally appears. These numbers are the major device number and minor device number for the particular device. The following listing shows a few devices as they appear on a typical system. Their major numbers are 1, 4, 7, and 10, while the minors are 1, 3, 5, 64, 65, and 129.
crw-rw-rw- 1 root root 1, 3 Feb 23 1999 null crw------- 1 root root 10, 1 Feb 23 1999 psaux crw------- 1 rubini tty 4, 1 Aug 16 22:22 tty1 crw-rw-rw- 1 root dialout 4, 64 Jun 30 11:19 ttyS0 crw-rw-rw- 1 root dialout 4, 65 Aug 16 00:00 ttyS1 crw------- 1 root sys 7, 1 Feb 23 1999 vcs1 crw------- 1 root sys 7, 129 Feb 23 1999 vcsa1 crw-rw-rw- 1 root root 1, 5 Feb 23 1999 zeroThe major number identifies the driver associated with the device. For example,
/dev/nulland/dev/zeroare both managed by driver 1, whereas virtual consoles and serial terminals are managed by driver 4;The minor number is used only by the driver specified by the major number; other parts of the kernel don’t use it, and merely pass it along to the driver. It is common for a driver to control several devices (as shown in the listing); the minor number provides a way for the driver to differentiate among them.
-
mknodwas originally used to create the character and block devices that populate/dev/. Nowadays software likeudevautomatically creates and removes device nodes on the virtual filesystem when the corresponding hardware is detected by the kernel, but originally/devwas just a directory in/that was populated during install. -
It's possible that a process has opened a large file which has since been deleted. You'll have to kill that process to free up the space. You may be able to identify the process by using lsof. On Linux deleted yet open files are known to lsof and marked as (deleted) in lsof's output.
You can check this with
sudo lsof +L1 -
Deleting the file won't free the space until you delete the processes that have open handles against that file.
-
On Linux, the
pscommand works by reading files in the proc filesystem The directory/proc/*PID*contains various files that provide information about process PID. The content of these files is generated on the fly by the kernel when a process reads them. -
What happens to a child process that dies and has no parent process to wait for it and what’s bad about this?
It becomes a Zombie process.
Zombie processes don’t use up any system resources. (Actually, each one uses a very tiny amount of system memory to store its process descriptor.) However, each zombie process retains its process ID (PID). Linux systems have a finite number of process IDs – 32767 by default on 32-bit systems. If zombies are accumulating at a very quick rate – for example, if improperly programmed server software is creating zombie processes under load — the entire pool of available PIDs will eventually become assigned to zombie processes, preventing other processes from launching.
-
In Linux a process can be in a number of states. It's easiest to observe it in tools like
psortop: it's usually in the column namedS. The documentation ofpsdescribes the possible values:PROCESS STATE CODES R running or runnable (on run queue) D uninterruptible sleep (usually IO) S interruptible sleep (waiting for an event to complete) Z defunct/zombie, terminated but not reaped by its parent T stopped, either by a job control signal or because it is being traced [...] -
Linux file types and ls command identifiers:
- - : regular file.
- d : directory.
- c : character device file.
- b : block device file.
- s : local socket file.
- p : named pipe.
- l : symbolic link.
-
What is the difference between a process and a thread? And parent and child processes after a fork system call?
A fork gives you a brand new process, which is a copy of the current process, with the same code segments. As the memory image changes (typically this is due to different behavior of the two processes) you get a separation of the memory images (Copy On Write), however the executable code remains the same. Tasks do not share memory unless they use some Inter Process Communication (IPC) primitive.
One process can have multiple threads, each executing in parallel within the same context of the process. Memory and other resources are shared among threads, therefore shared data must be accessed through some primitive and synchronization objects that allow you to avoid data corruption.
All the processes in operating system are created when a process executes the fork() system call except the startup process. The process that used the fork() system call is the parent process. In other words, a parent process is one that creates a child process. A parent process may have multiple child processes but a child process only one parent process.
On the success of a fork() system call, the PID of the child process is returned to the parent process and 0 is returned to the child process. On the failure of a fork() system call, -1 is returned to the parent process and a child process is not created.
A child process is a process created by a parent process in operating system using a fork() system call. A child process may also be called a subprocess or a subtask.
A child process is created as its parent process’s copy and inherits most of its attributes. If a child process has no parent process, it was created directly by the kernel.
If a child process exits or is interrupted, then a SIGCHLD signal is send to the parent process.
-
- fork starts a new process which is a copy of the one that calls it, while exec replaces the current process image with another (different) one.
- Both parent and child processes are executed simultaneously in case of fork() while Control never returns to the original program unless there is an exec() error.
-
nohupdisconnects the process from the terminal, redirects its output tonohup.outand shields it fromSIGHUP. One of the effects (the naming one) is that the process won't receive any sentSIGHUP. It is completely independent from job control and could in principle be used also for foreground jobs (although that's not very useful). -
$ cat /proc/scsi/scsi Host: scsi2 Channel: 00 Id: 00 Lun: 29 Vendor: EMC Model: SYMMETRIX
$ ls -ld /sys/block/sd*/device lrwxrwxrwx 1 root root 0 Oct 4 12:12 /sys/block/sdaz/device -> ../../devices/pci0000:20/0000:20:02.0/0000:27:00.0/host2/rport-2:0-0/target2:0:0/2:0:0:29 lrwxrwxrwx 1 root root 0 Oct 4 12:12 /sys/block/sdbi/device -> ../../devices/pci0000:20/0000:20:02.2/0000:24:00.0/host3/rport-3:0-0/target3:0:0/3:0:0:29
-
ulimitallows you to limit the resources that a process can use -
Object storage (also referred to as object-based storage) is a general term that refers to the way in which we organize and work with units of storage, called objects. Every object contains three things:
- The data itself. The data can be anything you want to store, from a family photo to a 400,000-page manual for assembling an aircraft.
- An expandable amount of metadata. The metadata is defined by whoever creates the object storage; it contains contextual information about what the data is, what it should be used for, its confidentiality, or anything else that is relevant to the way in which the data is used.
- A globally unique identifier. The identifier is an address given to the object in order for the object to be found over a distributed system. This way, it’s possible to find the data without having to know the physical location of the data (which could exist within different parts of a data center or different parts of the world).
With block storage, files are split into evenly sized blocks of data, each with its own address but with no additional information (metadata) to provide more context for what that block of data is. You’re likely to encounter block storage in the majority of enterprise workloads; it has a wide variety of uses (as seen by the rise in popularity of SAN arrays).
Object storage, by contrast, doesn’t split files up into raw blocks of data. There is no limit on the type or amount of metadata, which makes object storage powerful and customizable.
-
Explain Network Bonding and also explain the different types of Network bonding?
Answer: Network Bonding as the name implies that it is the process of bonding or joining two or more than two network interfaces to create one interface. It helps in improving the network throughput, bandwidth, redundancy, load balancing as in case any of the interfaces is down; the other one will continue to work. Several types of Network Bonding are available that are based on the kind of bonding method.
Below are the different bonding types in Linux:
- balance-rr or mode 0 – This is the default mode of network bonding that works on the round-robin policy that means from the first slave to the last, and it is used for fault tolerance and load balancing.
- active-backup or mode 1 – This type of network bonding works on the active-backup policy that means only one slave will be active and other will work just when another slave fails. This mode is also used for fault tolerance.
- **balance-xor or mode 2 –**This type of network bonding sets an exclusive or mode that means source MAC address is XOR’d with the destination address, and thus it provides fault tolerance and load balancing.
- **broadcast or mode 3 –**This mode sets a broadcast mode to provide fault tolerance, and it should be used for particular purposes. In this type of network bonding, all transmissions are sent to all slave interfaces.
- **802.3ad or mode 4 –**This mode will create the aggregation groups, and all the groups will share the same speed. For this, mode sets an IEEE 802.3ad dynamic link aggregation mode. It is done by particular switch support that supports IEEE 802.3ad dynamic link.
- **balance-tlb or mode 5 –**This mode sets a transmit load balancing mode for fault tolerance and load balancing and does not require any switch support.
- **balance-alb or mode 6 –**This mode sets an active load balancing to achieve fault tolerance and load balancing.
-
What is the similarity and difference between cron and anacron? Which one would you prefer to use?
Answer: Here we are going to discuss the similarity and the differences between cron and anacron. So, let’s start with the analogy:
Cron and Anacron are used to schedule the tasks in cron jobs. Both of these are the daemons that are used to schedule the execution of commands or tasks as per the information provided by the user.
Differences between cron and anacron:
- One of the main difference between cron and anacron jobs is that cron works on the system that are running continuously that means it is designed for the system that is running24*7. While anacron is used for the systems that are not running continuously.
- Other difference between the two is cron jobs can run every minute, but anacron jobs can be run only once a day.
- Any normal user can do the scheduling of cron jobs, but the scheduling of anacron jobs can be done by the superuser only.
- Cron should be used when you need to execute the job at a specific time as per the given time in cron, but anacron should be used in when there is no any restriction for the timing and can be executed at any time.
- If we think about which one is ideal for servers or desktops, then cron should be used for servers while anacron should be used for desktops or laptops.
-
What is the issue behind getting an error “filesystem is full” while there is space available when you check it through “df” command? How will you rectify this problem?
Answer: When all the inodes are consumed then even though you have free space, you will get the error that filesystem is full. So, to check whether there is space available, we have to use the command df –i. Sometimes, it may happen file system or storage unit contains the substantial number of small files, and each of the files takes 128 bytes of the inode structure then inode structure fills up, and we will not be able to copy any more file to the disk. So, to rectify the problem, you need to free the space in inode storage, and you will be able to save more files.
-
Where is password file located in Linux and how can you improve the security of password file?
Answer: This is an important question that is generally asked by the interviewers. User information along with the passwords in Linux is stored in/etc/passwd that is a compatible format. But this file is used to get the user information by several tools. Here, security is at risk. So, we have to make it secured.
To improve the security of the password file, instead of using a compatible format we can use shadow password format. So, in shadow password format, the password will be stored as single “x” character which is not the same file (/etc/passwd). This information is stored in another file instead with a file name /etc/shadow. So, to enhance the security, the file is made word readable and also, this file is readable only by the root user. Thus security risks are overcome to a great extent by using the shadow password format.
-
What is Key-based authentication? Explain.
Answer: There are various methods to enter into the servers. One of the ways to log in is using password-based authentication, but that is not secure. So, we need a method that is secured.
One of the ways to achieve the security is to use Key-based authentication. To use this type of authentication, we have to disable the password-based authentication. So, there is a procedure to set up this authentication which is as follows:
We have to get the SSH key pair using below command:
$ ssh-keygen -t rsaIt will generate the public/private rsa key pair.
Enter file where you want to save this generated key (/home/username/.ssh/id_rsa):
It will prompt you for the same location, i.e. ~/.ssh/id_rsa for the key pair. Press enter if you want to confirm the same location. Else, if you want to provide any other location, enter that and confirm the same.
Now copy ~/.ssh/id_rsa.pub into the ~/.ssh/authorized_keys that will be located where you have to connect.
Now, we have to provide the permissions to the file as per below command:
$ chmod 600 ~/.ssh/authorized_keys
Now try to sshthe machine you want to connect, and you will see that you are able to login to the machine without a password.
If you are confirmed that key-based authentication is working fine, disable the password-based authentication.
Go to the path /etc/ ssh/sshd_config
set the following property as no.
PasswordAuthentication no
-
Mention the steps to find out the memory usage by Linux.
Answer: You have to enter a command in the Linux shell called “Concatenate” to find out the memory usage by Linux.
Syntax: cat/proc/meminfo.
When you will enter this command then you will see a list of memory usage like Total Memory, Free Memory, Cache memory, and many other memory usages by Linux. Other commands used in Linux are:
- $ free –m // this is the simplest command where it will show the memory usage in MB.
- $ vmstat –s //this command gives a report on virtual memory statistics
- top // this command checks the usage of memory and cpu usage
- htop // similar like top command
-
What do you mean by an ext3 file system?
Answer: This is one of the top linux interview questions asked in the linux interview. It can be answered in the following manner. Ext3 file system is an upgraded version of ext2 and it also supports journaling. When an unclean shutdown is performed ext2 file system performs a check on the machine for errors which is a long process but it is not so in case of the ext3 file system.
In case of a hardware failure, an ext3 consistency check will occur without any pause. The time of the recovery of the file system is independent of the number of files. The time is dependent on the size of the journal which only takes a second which depends on the speed of the hardware.
-
What is the level of Security that Linux provides in comparison to other Operating Systems?
Answer: If an operating system is not secure then it is not successful. In comparison to other operating systems, Linux is the most secure operating system as it consists of Pluggable Authentication Modules. A secure layer is created between the authentication process and applications. It is because of PAM only by which an admin can give access to other users to log into the system. You can find the configuration of PAM applications in the “/etc/pam.d” or “/etc/pam.conf” directory.
-
What are soft links? Describe some of the features of soft links.
Answer: Soft Links or Symbolic Link or Symlink are special files which are used as a reference for another directory. Some features of softlinks are:
- They have a different INODE number with respect to source files or original files.
- If in case the original file is deleted then a soft link of that file is useless.
- We cannot update a soft link.
- Soft links are used to create links between directories.
- Soft links are independent of file system boundaries.
-
Explain INODE in Linux.
Answer: INODE is a structure which acts as an identity for all files and objects. Type a command in the shell “ls -i”. The numbers which are displayed at the adjacent of files and folders, these are INODE numbers which are assigned to each file that contains information about the file. The system uses this number to identify the file. Information like the size of the file, when the file was modified etc is contained in an INODE number.
The questions based on INODE is the most common linux interview question you may come across in your linux interview. So, read well and get enough knowledge even if you are not familiar with it and get ready with the answer.
-
What is the routing table in Linux?
Answer: The routing table is a method in which how all the networks and devices are interconnected with each other to efficiently establish communication with each other.
-
What is Puppet?
Answer: The Puppet is open source software which is used for software configuration management that runs on systems similar to that of UNIX. It is secure and scalable to use. It provides automation features in DevOps and Cloud environment.
-
What is automounting in Linux?
Answer: The automounting is a process of automatically mounting all the partitions on a hard disk on a Linux or Unix System while booting the system. fstab property can be used to automount the hard drives on Linux.
-
List the fields in /etc/passwd file.
Answer: The fields that are present in /etc/passwd file are Username, Password, User ID, Group ID, Comments, HomeDir and LoginShell. The /etc/passwd file has contents as below:
redhat:x:500:500:Redhat User:/home/redhat:/bin/bash
mssm:x:501:501:another user:/home/mssm:/bin/bash
– “x” in the password column indicates that the encrypted password is stored in /etc/shadow file.
-
Explain each system call used for process management in Linux.
Answer: This is the most popular Linux System Administration interview questions asked in an interview. The system calls that are used for process management are as follows:
Fork(): This is used to create a new process from an existing one.
Exec(): This is used to execute a new program.
Wait(): This is used to wait until the given process finishes the execution.
Exit(): This is used to exit from the process.
Getpid(): This helps in getting the unique process id of a particular process.
Getppid(): This helps in getting a parent process unique id.
Nice(): This is used to bias the existing property of the process.
-
Explain the steps to increase the size of the LVM partition.
Answer: The steps that need to be followed to increase the size of the LVM partition are as follows:
Run the below command: lvextend -L +500M /dev/.
Once this is done we can increase the size of the LVM partition by 500MB. A user can check the size of the partition by using ‘df -h’ command. The resizing can be done by resize2fs /dev/.
Let us move to the next Linux System Administration Interview Questions.
-
Which utility can be used to create the partition from a raw disk?
Answer: To create a partition from a raw disk the utility that is used is fdisk utility. To create a partition you can follow the below steps:
- Run this command: fdisk /dev/hd* (IDE) or /dev/sd* (SCSI).
- Type n to create a new partition.
- Once a partition is created then you can write the changes to this partition table. To write these changes type w.
-
. Explain the steps to create a new user and set a password for the user from a shell prompt in Linux.
Answer:
To create a new user account from shell prompt following steps are to be performed:
- Firstly login as a root user if you are not logged in as root use su – command.
- Enter the root password.
- The command to add a new user is useradd command and can be used in Linux. Use this command and then type the username you would like to create.
Eg: useradd sue
Once a user is created to set the password to follow below steps:
- To set a password for user sue type command: passwd sue.
- It will prompt the user to enter a new password.
- Once this is done it will also ask the user to retype password thereby setting up the password for the user.
-
What is a tunnel and how you can bypass a http proxy?
HTTP tunneling (ha outros tipos tipo SSH tunnel....) is the process in which communications are encapsulated by using HTTP protocol. An HTTP tunnel is often used for network locations which have restricted connectivity or are behind firewalls or proxy servers.
The server runs outside the protected network and acts as a special HTTP server. The client program is run on a computer inside the protected network. Whenever any network traffic is passed to the client, it repackages it as an HTTP request and relays it to the outside server, which extracts and executes the original network request for the client. The response to the request, which was sent to the server is repackaged as an HTTP response and relayed back to the client. Since all traffic is encapsulated inside normal GET and POST requests and responses, this approach works through most proxies and firewalls.
-
What is the difference between IDS and IPS?
An intrusion detection system (IDS) is a device or software application that monitors a network or systems for malicious activity or policy violations. Any malicious activity or violation is typically reported either to an administrator or collected centrally using a security information and event management (SIEM) system. A SIEM system combines outputs from multiple sources, and uses alarm filtering techniques to distinguish malicious activity from false alarms.
Intrusion prevention systems (IPS), also known as intrusion detection and prevention systems (IDPS), are network security appliances that monitor network or system activities for malicious activity. The main functions of intrusion prevention systems are to identify malicious activity, log information about this activity, report it and attempt to block or stop it
-
What shortcuts do you use on a regular basis?
-
What is the Linux Standard Base?
Linux Standard Base (LSB) is a joint project by several Linux distributions under the organizational structure of the Linux Foundation to standardize the software system structure, including the Filesystem Hierarchy Standard used in the Linux kernel.
-
What is an atomic operation?
Atomic operations in concurrent programming are program operations that run completely independently of any other processes. Atomic operations are used in many modern operating systems and parallel processing systems.
-
Your freshly configured http server is not running after a restart, what can you do?
Troubleshoot. Check if the service is running. Check for misconfigurations. Check the logs. etc. Check my own connection.
-
What kind of keys are in ~/.ssh/authorized_keys and what it is this file used for?
Authorized_keys File in SSH. The authorized_keys file in SSH specifies the SSH keys that can be used for logging into the user account for which the file is configured. It is a highly important configuration file, as it configures permanent access using SSH keys and needs proper management.
-
I've added my public ssh key into authorized_keys but I'm still getting a password prompt, what can be wrong?
Make sure the permissions on the ~/.ssh directory and its contents are proper. When I first set up my ssh key auth, I didn't have the ~/.ssh folder properly set up, and it yelled at me.
Your home directory ~, your ~/.ssh directory and the ~/.ssh/authorized_keys file on the remote machine must be writable only by you: rwx------ and rwxr-xr-x are fine, but rwxrwx--- is no good¹, even if you are the only user in your group (if you prefer numeric modes: 700 or 755, not 775). If ~/.ssh or authorized_keys is a symbolic link, the canonical path (with symbolic links expanded) is checked. Your ~/.ssh/authorized_keys file (on the remote machine) must be readable (at least 400), but you'll need it to be also writable (600) if you will add any more keys to it. Your private key file (on the local machine) must be readable and writable only by you: rw-------, i.e. 600. Also, if SELinux is set to enforcing, you may need to run restorecon -R -v ~/.ssh (see e.g. Ubuntu bug 965663 and Debian bug report #658675; this is patched in CentOS 6).
-
Did you ever create RPM's, DEB's or solaris pkg's?
-
What does
:(){ :|:& };:do on your system?This is called a fork bomb.
:()
means you are defining a function called:{:|: &}means run the function:and send its output to the:function again and run that in the background.The
;is a command separator, like&&.:runs the function the first time.Essentially you are creating a function that calls itself twice every call and doesn't have any way to terminate itself. It will keep doubling up until you run out of system resources.
-
How do you catch a Linux signal on a script?
trap sigusr1 USR1 # catch -USR1 signal -
Can you catch a SIGKILL?
You can't catch SIGKILL (and SIGSTOP ), so enabling your custom handler for SIGKILL is moot.
-
What's happening when the Linux kernel is starting the OOM killer and how does it choose which process to kill first?
-
Describe the linux boot process with as much detail as possible, starting from when the system is powered on and ending when you get a prompt.
-
What's a chroot jail?
A chroot jail is a way to isolate a process and its children from the rest of the system. It should only be used for processes that don't run as root, as root users can break out of the jail very easily.
-
When trying to umount a directory it says it's busy, how to find out which PID holds the directory?
open a terminal:
fuser -c /media/KINGSTON
It will output something like this:
/media/KINGSTON/: 3106c 11086
This will give you the pid of the processes using this volume. The extra character at the end of pid will give some extra info. ( c in 3106c)
c - the process is using the file as its current working directory m - the file is mapped with mmap o - the process is using it as an open file r - the file is the root directory of the process t - the process is accessing the file as a text file y - this file is the controlling terminal for the process
So to unmount just kill that pids and re-try the unmount
sudo kill -9 3106 11086 sudo umount /media/KINGSTON
-
What's LD_PRELOAD and when it's used?
If you set LD_PRELOAD to the path of a shared object, that file will be loaded before any other library (including the C runtime, libc.so). So to run ls with your special malloc() implementation, do this:
$ LD_PRELOAD=/path/to/my/malloc.so /bin/ls
-
You ran a binary and nothing happened. How would you debug this?
gdb debugger or check the return code
echo $? -
What are cgroups? Can you specify a scenario where you could use them?
cgroups (abbreviated from control groups) is a Linux kernel feature that limits, accounts for, and isolates the resource usage (CPU, memory, disk I/O, network, etc.) of a collection of processes.
-
How can you remove/delete a file with file-name consisting of only non-printable/non-type-able characters?
The file has a name, but it's made of non-printable characters. If you use ksh93, bash, zsh, mksh or FreeBSD sh, you can try to remove it by specifying its non-printable name. First ensure that the name is right with: ls -ld
$'\177' If it shows the right file, then use rm: rm $ '\177'Another (a bit more risky) approach is to use rm -i -- * . With the -i option rm requires confirmation before removing a file, so you can skip all files you want to keep but the one.
-
How can you increase or decrease the priority of a process in Linux?
nice -n 10 apt-get upgrade -
What are run-levels in Linux?
A runlevel is one of the modes that a Unix -based operating system will run in. Each runlevel has a certain number of services stopped or started, giving the user control over the behavior of the machine. Conventionally, seven runlevels exist, numbered from zero to six.
After the Linux kernel has booted, the init program reads the /etc/inittab file to determine the behavior for each runlevel. Unless the user specifies another value as a kernel boot parameter, the system will attempt to enter (start) the default runlevel.
Run Level Mode Action 0 Halt Shuts down system 1 Single-User Mode Does not configure network interfaces, start daemons, or allow non-root logins 2 Multi-User Mode Does not configure network interfaces or start daemons. 3 Multi-User Mode with Networking Starts the system normally. 4 Undefined Not used/User-definable 5 X11 As runlevel 3 + display manager(X) 6 Reboot Reboots the system
-
Explain the logical steps to increase the size of LVM partition?
Answer: Some logical steps need to be followed to increase the size of LVM partition. These are as follows:
- Run the command as per given format:
lvextend -L +500M /dev/<Name of the LVM Partition>Here, we are extending the size of LVM partition by 500MB.
- resize2fs /dev/
- You can check the size of partition using ‘df -h’ command
-
Using which utility you can create a partition from the raw disk?
Answer: To create the partition from the raw disk, you have to use fdisk utility.Below are the steps to create a partition from the raw disk:
Step 1: Run the below command:
fdisk /dev/hd* (IDE) or /dev/sd* (SCSI)Step 2: Type n to create a new partition
Step 3: Now partition has been created, and we have to write the changes to the partition table, so type w command to write the changes.
-
How do you create a new user account and set the password for a user from a shell prompt in Linux?
Answer: To create a new user account from a shell prompt follow the below steps:
- Log in as root user if you are not logged in as root using su – command.
- Enter the root user password
- The useradd command is used to create a new user in Linux. So, type command useradd and give the username you want to create as given below:
Useradd smith
- To set the password of the user smith type the command: passwd smith
- It will prompt for the new password. Enter the new password for user smith.
- It will ask to retype the password. So, retype the same password and password is set for the user.
-
What are the default port numbers used for SMTP, FTP,DNS, DHCP, SSH?
Answer:
Service Port SMTP 25 FTP 20 for data transfer and 21 for Connection established
DNS 53 DHCP 67/UDP(for DHCP server, 68/UDPfor DHCP client SSH 22
-
Explain all the fields in the/etc/passwd file?
Answer: /etc/passwd file contains the useful information for all the system users who log in. We have many fields in /etc/passwd file such as username, password, user ID, group ID, comment or user ID info, home directory, command /shell, etc. So, this file contains sensitive information regarding all the user accounts. There is a single line per user in this file. Colon (:) separates the fields in /etc/passwd. Below is the explanation of the fields.
- Username: First field is the username that contains the username which is 1 to 32 length characters.
- Password: This field does not show the actual password as the password is encrypted. Here, x character shows that password is encrypted that is located in /etc/shadow file.
- User ID (UID): All the users created in Linux is given a user ID whenever the user is created. UID 0 is fixed and reserved for the root user.
- Group ID (GID): This field specifies the name of the group to which the user belongs. The group information is also stored in a file /etc/group.
- User ID Info: Here you can add comments and you can add any extra information related to the users like full name, contact number, etc.
- Home directory: This field provides the path where the user is directed after the login. For example, /home/smith.
- Command/shell: This field provides the path of a command/shell and denotes that user has access to this shell i.e. /bin/bash.
-
How can an administrator know whether a user account is locked or not?
Answer: To check if the user account is locked or not just run this command in the shell:
passwd –S
Or search for the grep username in the location /etc/shadow file and it will show a symbol ‘!’ prefix to the encrypted field in the password box.
To just unlock the password type this command:
passwd –u
If there is a double exclamation mark then run this command two times:
usermod –U
-
What do you mean by SELinux?
Answer: SELinux is the abbreviation for Security Enhanced Linux. The access controls for the users can be controlled using SELinux. For example, the users can be stopped from running the scripts and accessing their own home directories. SELinux has the capability to support the access control and security policies. It basically operates on three different modes:
- **Enforcing –**to enforce its policies.
- **Permissive –**Polices want to apply but will be locked in case of violation.
- **Disabled –**SELinux will stay in disabled mode.
To check the status of SELinux, just type: #getenfore OR sestatus
-
Mention the run levels in Linux and steps to edit them.
Answer: Run levels are identified by numbers in Linux. The run levels determine what are the services that are currently in operation. There are seven different run levels in Linux:
- Halt System
- Single User Mode
- User Multi-Mode excluding NFS
- Full Multi-User mode
- Unused
- Multi-User mode (Graphical user mode)
- Reboot System
To change the edit level /etc/inittlab and edit the initdefault entry.
-
How can we create a local Yum repository in the location /media with the use of mounted Linux ISO image?
Answer: To create the local yum repository you have to create the files ending with extension .repo in the location /etc/yum.repos.d
Syntax: [root@localhost yum.repos.d]# cat local.repo
[local]
name=RHEL6.5
baseurl=file:///media
enabled=1
gpgcheck=1
gpgkey=file:///media/RPM-GPG-KEY-redhat-release
-
Mention the methods to check whether using Yum, the package is installed successfully or not.
Answer: There are several methods to check whether the package is installed or not. To understand, just see the below steps.
**Method 1 –**If the command is executed successfully then after running the yum command it will show ‘0’ on checking the exit status.
**Method 2-**You can run the rpm and –qa test.
**Method 3–**In the yum log, check if any entry is installed in the directory.
-
What is the difference between Hard Link and Soft Link?
Answer: A soft link(Symbolic Link) points to another file by name. As it just contains a name, that name does not actually have to exist or exist on a different file system. If you replace the file or change file content without changing a name, then the link still contains the same name and points to that file. A hard link points to the file by inode number. A file should actually exist in the same file system. A file will only be deleted from disk when the last link to its inode is removed.
-
A running process gets
EAGAIN: Resource temporarily unavailableon reading a socket. How can you close this bad socket/file descriptor without killing the process?get the file descriptor of the socket, debug the process and manually call close on the file descriptor.
On Linux systems:
- Find the offending process:
netstat -np - Find the socket file descriptor:
lsof -np $PID - Debug the process:
gdb -p $PID - Close the socket:
call close($FD) - Close the debugger:
quit - Profit.
From here.
- Find the offending process:
-
What do you control with swapiness?
The Linux kernel provides a tweakable setting that controls how often the swap file is used, called swappiness.
A swappiness setting of zero means that the disk will be avoided unless absolutely necessary (you run out of memory), while a swappiness setting of 100 means that programs will be swapped to disk almost instantly.
-
How do you change TCP stack buffers? How do you calculate it?
TCP Tuning http://www.linux-admins.net/2010/09/linux-tcp-tuning.html
-
What is Huge Tables? Why isn't it enabled by default? Why and when use it?
HugePages feature enables the Linux kernel to manage large pages of memory in addition to the standard 4KB (on x86 and x86_64) or 16KB (on IA64) page size. If you have a system with more than 16GB of memory running Oracle databases with a total System Global Area (SGA) larger than 8GB, you should enable the HugePages feature to improve database performance.
-
What is LUKS? How to use it?
LUKS is the standard for Linux hard disk encryption. By providing a standard on-disk-format, it does not only facilitate compatibility among distributions, but also provides secure management of multiple user passwords.
-
Answer: The most significant advantage of executing the running process in the background is that you can do any other task simultaneously while other processes are running in the background. So, more processes can be completed in the background while you are working on different processes. It can be achieved by adding a special character ‘&’ at the end of the command.
-
Answer: There are many differences between BASH and DOS that are as below:
- Out of these two commands, BASH is case sensitive while DOS is not case sensitive.
- In BASH ‘/’ acts the directory separator while in DOS ‘/’ acts as the command argument delimiter.
- In BASH ‘\’ is used as the escape character while in DOS ‘\’ acts as the directory separator.
- In BASH, there is a file convention used while in DOS, there is no any file convention used.
-
Answer: Linux machine can be made as a router so that multiple devices can share a single internet connection. For this, we have to use a feature called “IP Masquerade.” This functionality will help to connect multiple computers to connect to the Linux machine as well as internet. This functionality will also allow those internal computers to connect who do not have IP addresses.
-
If a volume group already exists and we need to extend the volume group to some extent. How will you achieve this?
Answer: Linux provide the facility to increase the size of a volume group even if it already exists. For this, we need to run a command.
First of all, we have to create a physical volume (/dev/sda1)
Size of the physical volume should be the size you want the size of the logical volume.
Now, run the below command:
vgextend VG1 /dev/sda1Here VG1 is the name of the volume group.
-
Answer: Finger Service acts as both the Web and FTP server. It is also known as Finger User Information Protocol which contains the information of the user that can be viewed by the clients. It allows a remote user to see the information about the admin such as login shell, login name and other confidential details. That is why, the finger service should be kept disabled when it’s not in use.
If it is not disabled, you have to modify and comment out the file “/etc/inetd.conf”.
-
Answer: You may generally come across this type of questions in Linux interview. Linux machine has the ability to turn it into a router with the help of IP Masquerade. You may have seen the servers found in commercial firewalls. IP Masquerade does the same function to one-to-many Network Address Translation servers. If the internal computers do not have the IP address then in this case, IP Masquerade can connect to the other internal computers which are connected to Linux box to access the internet.
Just follow these steps to enable IP Masquerade Linux:
- Connect your PC to LAN.
- This PC can be used as a default gateway for other systems for TCP/IP networking. You can use the same DNS on all other systems.
- Go in the Kernel and enable IP forwarding. You can also enable IP forwarding using the command: /etc/rc.d/rc.local file on rebooting the system.
- The last step is to run this command which sets up the rules to masquerade: /sbin/iptables
-
Answer: ACL is an acronym for Access Control List which is used to provide flexible permission mechanism for the file systems. We can enable ACL by following methods:
Type the code in the shell: /etc/fstab with a label=/home/ext3 acl
Now we have to remount this file system with the ACL partition: mount –t ext3 –o acl /dev/sda3/home
-
Answer: When the data is directed from one output to another output even when the output will serve the data as an input for another process, this is called redirection.
-
Answer: We can redirect a command from a file or to a file. It is usually done with the help of braces or parenthesis. When the command is grouped then redirection is done to the whole group.
The command is executed by the current shell when we use the braces () and in case we have to execute a command by a subshell then we use parenthesis {}.
-
Answer: Permissions are established for all files and directories. Permissions specify who can access a file or directory, and the types of access. All files and directories are owned by a user.
Permissions are controlled at three levels:
- Owner (called a user, or ‘u’)
- Group (‘g’)
- The rest users(called other, or ‘o’)
Level of access:
- Read – Filet can be viewed or copied.
- Write – File can be overwritten (e.g., using save as)
- Execute – File can be executed
To change permission – chmod < file(s)> is used. Here permissions can be specified different approaches. The parameter file(s) is one or more files (or directories). One approach to specify permissions is to describe the changes to be applied as a combination of u, g, o along with r, w, x. To add permission, use + and to remove permission, use –.
-
Answer: A process is a running program. Processes can be started from the GUI or the command line. Processes can also start other processes. Whenever a process runs, Linux keeps track of it through a process ID (PID). After booting, the first process is an initialization process called init. It is given a PID of 1. From that point on, each new process gets the next available PID.
A process can only be created by another process. We refer to the creating process as the parent and the created process as the child. The parent process spawns one or more child processes. The spawning of a process can be accomplished in one of several ways. Each requires a system call (function call) to the Linux kernel. These function calls are fork(), vfork(), clone(), wait(), and exec().
-
Answer: Linux Kernel is the component that manages the hardware resources for the user and that provides essential services and interact with the user commands. Linux Kernel is an open source software and free, and it is released under General Public License so we can edit it and it is legal.
-
Answer: We can build kernels by many different types, but 3 of the types of kernels are most commonly used: monolithic, microkernel and hybrid.
Microkernel: This type of kernel only manages CPU, memory, and IPC. This kind of kernel provides portability, small memory footprint and also security.
Monolithic Kernel: Linux is a monolithic kernel. So, this type of kernel provides file management, system server calls, also manages CPU, IPC as well as device drivers. It provides easier access to the process to communicate and as there is not any queue for processor time, so processes react faster.
Hybrid Kernel: In this type of kernels, programmers can select what they want to run in user mode and what in supervisor mode. So, this kernel provides more flexibility than any other kernel but it can have some latency problems.
-
Answer: There are six levels of a Linux Boot Sequence. These are as follows:
BIOS: Full form of BIOS is Basic Input or Output System that performs integrity checks and it will search and load and then it will execute the bootloader.
MBR: MBR means Master Boot Record. MBR contains the information regarding GRUB and executes and loads this bootloader.
GRUB: GRUB means Grand Unified Bootloader. In case, many kernel images are installed on your system then you can select which one you want to execute.
Kernel: Root file system is mounted by Kernel and executes the /sbin/init program.
Init: Init checks the file /etc/inittab and decides the run level. There are seven-run levels available from 0-6. It will identify the default init level and will load the program.
Runlevel programs: As per your default settings for the run level, the system will execute the programs.
-
Answer: Interrupts means the processor is transferred temporarily to another program or function. When that program is completed, the processor will be given back to that program to complete the task.
Interrupt handler is the function that the kernel runs for a specific interrupt. It is also called Interrupt Service Routine. Interrupts handlers are the function that matches a particular prototype and enables the kernel to pass the handler information accurately.
-
Answer: A page frame is a block of RAM that is used for virtual memory. It has its page frame number. The size of a page frame may vary from system to system, and it is in the power of 2 in bytes. Also, it is the smallest length block of memory in which an operating system maps memory pages.
-
Answer: To check the modules that are already installed inside the kernel, you have to run this code: lsmod. When the module has been built, now it is the stage to load it in the kernel. You can load it by the command “Insmod” or “Modprobe”.
Syntax: Insmod[filename][module-options] //module-options are command line arguments to kernel objects.
Insmod always accepts only one filename at a time.
Modprobe offers more features than Insmod like it can decide which module is to be loaded and is aware of the module dependencies.
-
Answer: When we run a program in userspace then we use “user virtual address” as we do not have any access to kernel virtual memory address. Normally when we are running our program in kernel mode then we use kernel address but in case we have to run our program in kernel mode and that program needs an interaction with a userspace then we will use “user virtual address” and be careful to first translate it to user virtual address.
-
Answer: We can debug a kernel code simply with the command printks. Else we can also use KDB and kernel probes. Other methods are:
- UML (User Mode Linux) – It is the best method for debugging but it does not support device drivers.
- KGDB (Kernel GNU Debugger)
- kdump tools which are used to dump kernel cores.
-
Answer: The questions based onDevice tree concept is commonly askedin a linux interview. Device tree is a data structure which is used to remove the repetitive codes in different boards. They are loaded in the memory with the help of bootloader to a binary file. Here the kernel is used to settle the structure of the device tree on the binary.
As much kernel is important in the linux as an operating system, the questions based on kernel are equally important in the linux interview. Device tree is an important concept in kernel so interviewer may ask this question to check your knowledge about it.
-
Answer: There are codes which are unnecessary and are not executed, we can find and disable them to make the processing faster in the project. The kernel comes with an editor known as “kernel’s configuration editor” by which we can remove and disable chunks of code that are not required.
There may be the codes for which the hardware is not present in the system and you have to make your system understand about what are your system’s requirements. Below are some guiding principles by which you can find the codes to be removed.
- **Hardware Networking Drivers:**Several of system-on-chips have Wi-Fi drivers, serial and other hardware that are not used, you can remove those drivers that are built on the kernel.
- **File Systems:**The system has the only requirement of few file systems but in the kernel you will find many file systems drivers that are not in use e.g. Devices which make use of flash file systems do not require ext2 or ext3 file system so they can be removed. Be cautious that do not remove the file systems that are essential or you may have the use of the systems in the future.
- **Debugging and Profiling:**All the systems which come under kernel hacking entry could be disabled if not in use.
-
Answer: The Kernel modules are the set of programs or code which can be loaded as per the requirement or demand which can be implemented without the process of rebooting the system. Each and every kernel is a module and is easily loadable. There will also be an automatic module handling.
-
What is the difference between “rm” and “rm –r”?
Answer: **“**rm” command is used to delete all the files while “rm –r” command is used to delete all the files in a directory and also in subdirectories.
For Example,
rm file.txt: It will delete the file with name file.txt
rm –r directory: It will remove directories and subdirectories and also their contents.
-
You run a bash script and you want to see its output on your terminal and save it to a file at the same time. How could you do it?
user@unknown:~$ sudo command -option | tee log.txt
-
Explain what echo "1" > /proc/sys/net/ipv4/ip_forward does.
Enable IP Forwarding on the fly
-
Explain the command and method to change the file permissions in Linux.
Answer: chmod command is used to change the permissions of a file. There are three parts to consider to set the file permissions.
- User (or Owner)
- Group
- Other
3 types of file permission that is given to a file.
- r – Reading permission
- w – Writing permission
- x – Execution permission
For example, chmod 751 filename
Then, three number 751 describes permissions given to the user, group and other in the order. Each number is the sum of the values,i.e. 4 for reading, 2 for write, 1 for execute.
Here 751 is the combination of (4+2+1), (4+0+1), (0+0+1).
So, chmod 751 filename will provide read, write and execute permission to the owner; read and execute permission to the group and only execute permission to the others.
-
How can we edit a file without opening in Linux?
Answer: sed command is used to edit a file without opening. sed is the acronym for StreamEditor. The “sed” command is used to modify or change the contents of a file
For example, we have a text file with below content
>cat file.txtWe want to replace the content of the file and we want to replace “sed” with “vi”. So, we will use below command for this.
>sed 's/sed/vi/' file.txtvi command is used to edit a file.
So, sed is replaced with vi in the text.
-
Explain grep command and its use.
Answer: grep command in Linux is used to search a specific pattern. Grep command will help you to explore the string in a file or multiple files.
The syntax for grep command:
grep ‘word’ filename
grep ‘word’ file1 file2 file3
command|grep‘string’
For example,
grep “smith” passwd
grep “smith” passwd shadow
netstat -an | grep8083
cat /etc/passwd | grep smith
-
Explain file content commands along with the description
Answer: There are many commands present in Linux which are used to look at the contents of the file.
head: to check the starting of a file.
tail: to check the ending of the file. It is the reverse of head command.
cat: used to view, create, concatenate the files.
rrep: used to find the specific pattern or string in a file.
more: used to display the text in the terminal window in pager form.
less: used to view the text in the backward direction and also provides single line movement.
-
Explain “cd” command in Linux.
Answer: In Linux, when a user needs to change the current directory then “cd” command is input in the shell.
Syntax: $cd
The purpose that can be fulfilled by the current command are –
- Redirect to a new directory from the current directory.
- Change a directory using absolute path and relative path.
The following commands are under the cd:
- cd ~: Redirect to home directory.
- cd-: Redirect to previous directory.
- cd/: Redirect to entire system directory.
-
Mention some of the networking commands in Linux.
Answer: If you connect a system to a network then you can easily troubleshoot the connection issues related to the system. Below are few of the networking commands used for configuration and troubleshooting.
- ifconfig(now is ip something)
- traceroute
- dig
- telnet
- nslookup
- netstat
-
Write the command to view an existing tar archive and how to extract it?
Answer: The command for viewing tar archive that is already existing: $ tar tvf archive_name.tar
The command to extract an existing tar archive: $ tar xvf archive_name.tar
The command for the creation of new tar archive: $ tar cvf archive_name.tar dirname/
You may be asked one or more command based interview questions in the linux interview. You should prepare yourself with as many commands as you can. There are several commands that are used for tar archive which are commonly asked in the linux interview, so don’t miss to cover this question while going for the linux interview.
-
Answer: This type of questions are most common in a Linux interview. Followings are the steps to make a USB bootable device –
- You have to write efidisk.img from RHEL 6 DVD images/ subdirectory
to USB dd if=efidisk.img of=/dev/usb (name of the usb device)
- Now you have to disable ping to avoid network /ICMP flood
- Now set the following in/etc/sysctl.conf : net.ipv4.icmp_echo_ignore_all =1
- Then “sysctl -p”
-
Answer: In case we want to create a new partition form a raw disk, you have to use a tool known as “fdisk utility”. The steps to create a raw disk are as follows:
- In case of IDE we use >>> fdisk/dev/hd and in case of SCSI we use >>> fdisk/dev/sd
- Then type n for creating a new partition.
- After the partition is created type ‘w’.
-
Answer: Manual pages are where an explanation of every command has stored. Manual pages for a specific command will have all information about that command and it can be called as ‘man eg: *‘man ls’.*Manual pages are categorized into different sets of user commands, system calls, library functions..etc.. A general layout of a manual page is –
NAME
The name of the command or function and simple explanation of it.
SYNOPSIS
For commands how to run it and parameters it takes. For functions, a list of the parameters it takes and which header file contains its definition.
DESCRIPTION
A detailed description of command or function we are searching for.
EXAMPLES
Some examples of usages.Most helpful section
SEE ALSO
This section will have a list of related commands or functions.
-
The top is the command used for this. This will give all information about each process running on a machine like –
- Process ID (PID)
- Owner of the process(USER)
- Priority of process(PR)
- Percentage of CPU (%CPU)
- Percentage of memory
- Total CPU time spends on the process.
- Command used to start a process.
The popular option used with top command
- top -u -> Process by a user.
- top – i -> exclude idle tasks
- top -p -> Show a particular process
-
Answer: Pipeline operator in Linux is used to redirect the output of one program or command to another program/command for further processing. Usually termed as redirection. Vertical bars,’|’ (“pipes” in common Unix verbiage) are used for this. For example, ls -l | grep key, will redirect the output of ls -l command to grep key command
-
Answer: A regular expression (regex) is a string that expresses a pattern used to match against other strings. The pattern will either match some portion of another string or not. There is a list of predefined metacharacters used in a regex.
- * Used to match the preceding character if it appears 0 or more times
- +Used to match the preceding character if it appears 1 or more times
- ? Used to match the preceding character if it appears 0 or 1 times
-
Answer: This is the popular Linux interview questions asked in an interview. Sed is a stream editor. A stream editor is a program that takes a stream of text and modifies it. With sed, you specify a regular expression which represents a pattern of what you want to replace. The generic form of a sed command is sed ‘s/pattern/replacement/’ filename.
-
Answer: The umask is a command which is often called as user file creation mask which is used to create file mask for the user that determines which file or directory permissions are available for the user based on the read or write or modify type.
-
Explain, in as much detail as you feel comfortable with, what is happening when you access Google.com
- You type maps.google.com into the address bar of your browser.
- The browser checks the cache for a DNS record to find the corresponding IP address of maps.google.com.
- If the requested URL is not in the cache, ISP’s DNS server initiates a DNS query to find the IP address of the server that hosts maps.google.com.
- Browser initiates a TCP connection with the server.
- The browser sends an HTTP request to the web server.
- The server handles the request and sends back a response.
- The server sends out an HTTP response.
- The browser displays the HTML content (for HTML responses which is the most common).
-
SSH port forwarding is a mechanism in SSH for tunneling application ports from the client machine to the server machine, or vice versa. It can be used for adding encryption to legacy applications, going through firewalls, and some system administrators and IT professionals use it for opening backdoors into the internal network from their home machines. It can also be abused by hackers and malware to open access from the Internet to the internal network.
-
Using netstat Command:
Netstat (network statistics) command is used to display information concerning network connections, routing tables, interface stats and beyond.
use it with grep command to find the process or service listening on a particular port in Linux as follows (specify the port).
$ netstat -ltnp | grep -w ':80'Check Port Using netstat Command
In the above command, the flags.
l– tells netstat to only show listening sockets.t– tells it to display tcp connections.n– instructs it show numerical addresses.p– enables showing of the process ID and the process name.grep -w– shows matching of exact string (:80).
-
Local forwarding is used to forward a port from the client machine to the server machine. Basically, the SSH client listens for connections on a configured port, and when it receives a connection, it tunnels the connection to an SSH server. The server connects to a configurated destination port, possibly on a different machine than the SSH server.
Typical uses for local port forwarding include:
- Tunneling sessions and file transfers through jump servers
- Connecting to a service on an internal network from the outside
- Connecting to a remote file share over the Internet
In OpenSSH, remote SSH port forwardings are specified using the
-Roption. For example:ssh -R 8080:localhost:80 public.example.comThis allows anyone on the remote server to connect to TCP port 8080 on the remote server. The connection will then be tunneled back to the client host, and the client then makes a TCP connection to port 80 on
localhost. Any other host name or IP address could be used instead oflocalhostto specify the host to connect to.This particular example would be useful for giving someone on the outside access to an internal web server.
-
The Domain Name System resolves the names of internet sites with their underlying IP addresses adding efficiency and even security in the process.
DNS is a directory of names that match with numbers. The numbers, in this case are IP addresses, which computers use to communicate with each other.
-
These are record types that are present inside a DNS server
DNS Resource Records (from: A, AAAA, CNAME, MX, NS, PTR, SOA, SRV, TXT
Zone DNS database is a collection of resource records and each of the records provides information about a specific object. A list of most common records is provided below:
- **Address Mapping records (A)**The record A specifies IP address (IPv4) for given host. A records are used for conversion of domain names to corresponding IP addresses. IP Version 6 Address records(AAAA)The record AAAA (also quad-A record) specifies IPv6 address for given host. So it works the same way as the A record and the difference is the type of IP address.
- Canonical Name records(CNAME) The CNAME record specifies a domain name that has to be queried in order to resolve the original DNS query. Therefore CNAME records are used for creating aliases of domain names. CNAME records are truly useful when we want to alias our domain to an external domain. In other cases we can remove CNAME records and replace them with A records and even decrease performance overhead
- Host Information records(HINFO) are used to acquire general information about a host. The record specifies type of CPU and OS. The HINFO record data provides the possibility to use operating system specific protocols when two hosts want to communicate. For security reasons the HINFO records are not typically used on public servers.
- **Integrated Services Digital Network records (ISDN)**The ISDN resource record specifies ISDN address for a host. An ISDN address is a telephone number that consists of a country code, a national destination code, a ISDN Subscriber number and, optionally, a ISDN sub address. The function of the record is only variation of the A resource record function.
- **Mail exchanger record (MX)**The MX resource record specifies a mail exchange server for a DNS domain name. The information is used by Simple Mail Transfer Protocol (SMTP) to route emails to proper hosts. Typically, there are more than one mail exchange server for a DNS domain and each of them have set priority.
- **Name Server records (NS)**The NS record specifies an authoritative name server for given host.
- **Reverse-lookup Pointer records (PTR)**As opposed to forward DNS resolution (A and AAAA DNS records), the PTR record is used to look up domain names based on an IP address
- Start of Authority records (SOA) The record specifies core information about a DNS zone, including the primary name server, the email of the domain administrator, the domain serial number, and several timers relating to refreshing the zone.
- Text records (TXT): The text record can hold arbitrary non-formatted text string. Typically, the record is used by [ender Policy Framework (SPF) to prevent fake emails to appear to be sent by you.
-
Split-Brain DNS, Split-Horizon DNS, or Split DNS are terms used to describe when two zones for the same domain are created, one to be used by the internal network, the other used by the external network (usually the Internet). I prefer the term "Split DNS" so we will just continue with that one.
A Split DNS infrastructure is used to direct internal hosts to an internal domain name server for name resolution and external hosts to an external domain name server for name resolution. This type of DNS configuration is very common in networks that have established an internal Active Directory domain name which is the same as the public external domain name. Let's begin by taking a look at an example where Split DNS is not used.
-
Stands for "Hypertext Transfer Protocol." HTTP is the protocol used to transfer data over the web. It is part of the Internet protocol suite and defines commands and services used for transmitting webpage data.
-
An HTTP Proxy serves two intermediary roles as an HTTP Client and an HTTP Server for security, management, and caching functionality. The HTTP Proxy routes HTTP Client requests from a Web browser to the Internet, while supporting the caching of Internet data.
Proxy server advantages include:
- Maintaining identity anonymity as a security precaution.
- Accelerating caching rates.
- Facilitating access to prohibited sites.
- Enforcing access policies on certain websites.
- Allowing a site to make external server requests.
- Avoiding security controls.
- Bypassing Internet filtering for access to prohibited content.
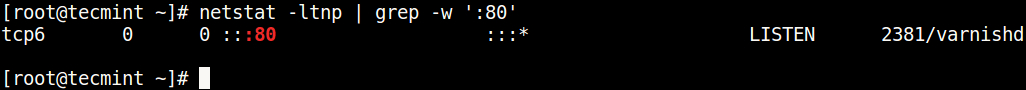
HTTP uses a server-client model.
When you access a website, your browser sends a request to the corresponding web server and it responds with an HTTP status code. If the URL is valid and the connection is granted, the server will send your browser the webpage and related files.
Some common HTTP status codes include:
- 200 - successful request (the webpage exists)
- 301 - moved permanently (often forwarded to a new URL)
- 401 - unauthorized request (authorization required)
- 403 - forbidden (access is not allowed to the page or directory)
- 500 - internal server error (often caused by an incorrect server configuration)
HTTP also defines commands such as GET and POST, which are used to handle form submissions on websites. The CONNECT command is used to facilitate a secure connection that is encrypted using SSL. Encrypted HTTP connections take place over HTTPS, an extension of HTTP designed for secure data transmissions.
-
What is SNMP and what is it used for?
SNMP (Simple Network Management Protocol is a widely used protocol for monitoring the health and welfare of network equipment (eg. routers), computer equipment and even devices like UPSs.
It is commonly used by network and system administrators to gather operational statistics(such as measuring network bandwidth traffic, cpu usage, or available hard drive space) as well as setting system parameters.
-
What is SMTP? Give the basic scenario of how a mail message is delivered via SMTP.
SMTP stands for Simple Transfer Email Protocol. Currently, the electronic mail (e-mail) standard for the Internet is SMTP. SMTP is the Application Level protocol that handles message services over [TCP/IP]. SMTP uses TCP Well Known Port25.
Simple Mail Transfer Protocol (SMTP) is based on end-to-end message delivery. An Simple Mail Transfer Protocol (SMTP) client contacts the destination host's Simple Mail Transfer Protocol (SMTP) server on well-known port 25, to deliver the mail. The client then waits for the server to send a 220 READY FOR MAIL message. Upon receipt of the 220 message, the client sends a HELO command. The server then responds with a "250 Requested mail action okay" message.
After this, the mail transaction will begin with a MAIL command that gives the sender identification as well as a FROM: field that contains the address to which errors should be reported.
After a successful MAIL command, the sender issues a series of RCPT commands that identify recipients of the mail message. The receiver will the acknowledge each RCPT command by sending 250 OK or by sending the error message 550 No such user here.
After all RCPT commands have been acknowledged, the sender issues a DATA command to inform the receiver that the sender is ready to transfer a complete mail message. The receiver responds with message 354 Start mail command with an ending sequence that the sender should use to terminate the message data. The termination sequence consists of 5 characters: carriage return, line feed, period, carriage return, and line feed (.).
The client now sends the data line by line, ending with the 5-character sequence . line, upon which the receiver will acknowledge with a 250 OK, or an appropriate error message if anything went wrong.
After the sending is completed, the client can follow any of these actions.
-
What is localhost and why would
ping localhostfail?In computer networking localhost is a hostname that means this computer. It is used to access the network services that are running on the host via the loopback network interface. Using the loopback interface bypasses any local network interface.
If ping localhost fail we should se if there is an interface configured with
lo0or any other interface with 127.0.0.1? Check the Rx packets/Tx packets count. Also, check to see if lo0 is configured in /etc/network/interfaces.output of 'ifconfig' lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:24 errors:0 dropped:0 overruns:0 frame:0 TX packets:24 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1440 (1.4 KB) TX bytes:1440 (1.4 KB) -
What is the similarity between "ping" & "traceroute" ? How is traceroute able to find the hops.
The main difference between the common Ping and Traceroute commands is that Ping is a quick and easy way to tell you if the destination server is online and estimates how long it takes to send and receive data to the destination. Traceroute tells you the exact route you take to reach the server from your computer (ISP) and how long each hop takes.
Traceroute makes use of a network mechanism called TTL, or "Time to Live" and Probing the Hops: Traceroute makes sure that each hop on the way to a destination device drops a packet, and sends back an ICMP error message.
-
What is the command used to show all open ports and/or socket connections on a machine?
ss -s # List currently established, closed, orphaned and waiting TCP sockets ss -l # display all open network ports ss -pl # to see process named using open socket: ss -lp | grep 4949 # Find out who is responsible for opening socket / port # 4949 using the ss command and grep command
-
Is 300.168.0.123 a valid IPv4 address?
A valid IP address must be in the form of xxx.xxx.xxx.xxx, where xxx is a number from 0-255 so no, this isn't a valid IPv4 address.
-
Which IP ranges/subnets are "private" or "non-routable" (RFC 1918)?
A private network is typically a network that uses private IP address space, following the RFC 1918]standard
The current IANA private internet (also called non-routable) addresses are:
Name IP address range number of addresses classful description largest CIDR block 24-bit block 10.0.0.0 – 10.255.255.255 16,777,216 single class A, 256 contiguous class Bs 10.0.0.0/8 20-bit block 172.16.0.0 – 172.31.255.255 1,048,576 16 contiguous class Bs 172.16.0.0/12 16-bit block 192.168.0.0 – 192.168.255.255 65,536 single class B, 256 contiguous class Cs 192.168.0.0/16 -
What is a VLAN?
A virtual LAN (VLAN) is any broadcast domain that is partitioned and isolated in a computer network at the data link layer. LAN is the abbreviation for local area network and in this context virtual refers to a physical object recreated and altered by additional logic. VLANs work by applying tags to network frames and handling these tags in networking systems – creating the appearance and functionality of network traffic that is physically on a single network but acts as if it is split between separate networks. In this way, VLANs can keep network applications separate despite being connected to the same physical network, and without requiring multiple sets of cabling and networking devices to be deployed.
-
What is ARP and what is it used for?
The Address Resolution Protocol (ARP) is a communication protocol used for discovering the link layer address, such as a MAC address, associated with a given internet layer address, typically an IPv4 address.This mapping is a critical function in the Internet protocol suite
-
What is the difference between TCP and UDP?
Both TCP and UDP are protocols used for sending bits of data — known as packets — over the Internet. They both build on top of the Internet protocol. In other words, whether you are sending a packet via TCP or UDP, that packet is sent to an IP address. These packets are treated similarly, as they are forwarded from your computer to intermediary routers and on to the destination.
TCP (Transmission Control Protocol) is connection oriented, whereas UDP (User Datagram Protocol) is connection-less. This means that TCP tracks all data sent, requiring acknowledgment for each octet (generally).
-
What is the purpose of a default gateway?
A default gateway serves as an access point or IP router that a networked computer uses to send information to a computer in another network or the internet. Default simply means that this gateway is used by default, unless an application specifies another gateway.
A default gateway lets devices in one network communicate with devices in another network. If your computer, for example, is requesting an internet web page, the request first runs through your default gateway before exiting the local network to reach the internet.
-
What are the layers of the OSI model?
The seven layers of function are provided by a combination of applications, operating systems, network card device drivers and networking hardware that enable a system to transmit a signal over a network Ethernet or fibber optic cable or through Wi-Fi or other wireless protocols
The seven Open Systems Interconnection layers are:
Layer 7: The application layer. This is the layer at which communication partners are identified -- Is there someone to talk to? -- network capacity is assessed -- Will the network let me talk to them right now? -- and where the data or application is presented in a visual form the user can understand. This layer is not the application itself, it is the set of services an application should be able to make use of directly, although some applications may perform application-layer functions.
Layer 6: The presentation layer.This layer is usually part of an operating system OS and converts incoming and outgoing data from one presentation [format to another -- for example, from clear text to encrypted text at one end and back to clear text at the other.
Layer 5: The session layer. This layer sets up, coordinates and terminates conversations. Its services include authentication and reconnection after an interruption. On the internet, Transmission Control Protocol TCP and User Datagram Protocol UDP provide these services for most applications.
Layer 4: The transport layer This layer manages packetization of data, then the delivery of the packets, including checking for errors in the data once it arrives. On the internet, TCP and UDP provide these services for most applications as well.
Layer 3: The network layer. This layer handles addressing and routing the data -- sending it in the right direction to the right destination on outgoing transmissions and receiving incoming transmissions at the packet level. IP is the network layer for the internet.
Layer 2: The data-link layer. This layer sets up links across the physical network, putting packets into network frames. This layer has two sub-layers: the logical link control layer and the media access control layer MAC. MAC layer types include Ethernet and 802.11 wireless specifications.
Layer 1: The physical layer. This layer conveys the bit stream across the network either electrically, mechanically or through radio waves. The physical layer covers a variety of devices and mediums, among them cabling, connectors, receivers, transceivers and repeaters.
-
Describe briefly the steps you need to take in order to create and install a valid certificate for the site https://foo.example.com.
E fala do Let's Encrypt https://letsencrypt.org/
-
Can you have several HTTPS virtual hosts sharing the same IP?
As many as you want. Just define virtual hosts and assign SSL certificates to them as needed.
-
What is a wildcard certificate?
A SSL Wildcard certificate is a single certificate with a wildcard character in the domain name field. This allows the certificate to secure multiple sub domain names (hosts) pertaining to the same base domain.
For example, a wildcard certificate for *.(domainname).com, could be used for www.(domainname).com, mail.(domainname).com, store.(domainname).com, in addition to any additional sub domain name in the (domainname).com.
-
What is command used to show the routing table on a Linux box?
ip route #or ip r -
A TCP connection on a network can be uniquely defined by 4 things. What are those things?
The TCP layer on either end maintains table entries corresponding to the 4-tuple (remote-ip-address, remote-port, source-ip-address, source-port). This 4-tuple uniquely identifies a connection.
-
When a client running a web browser connects to a web server, what is the source port and what is the destination port of the connection?
Source ports are randomly generated from the unregistered port range.
The source/destination port works similar to your IP. The port you send from, is the port the service will reply too. For instance; a website is simply a server listening for connections on port 80 (or 443).
When you attempt to load a website you generate a free port from the unregistered range and send the request from 192.168.1.1:45676 (Source port selected) your browser then sends the request to 200.20.20.20:80 (IP is an example) as the server is listening on this port.
Much like your IP, when the server replies to you it sets the destination IP AND port In the packets header to the source IP / Port it received the request on. This enables you to run multiple webpages at once.
If you had 4 webpages open, all sending and receiving on port 80, it would not know where the response traffic is meant to be directed. This is why the source port is used.
-
How do you add an IPv6 address to a specific interface?
Adding an IPv6 address is similar to the mechanism of "IP ALIAS" addresses in Linux IPv4 addressed interfaces.
Usage:
# /sbin/ip -6 addr add <ipv6address>/<prefixlength> dev <interface>Example:
# /sbin/ip -6 addr add 2001:0db8:0:f101::1/64 dev eth0 -
You have added an IPv4 and IPv6 address to interface eth0. A ping to the v4 address is working but a ping to the v6 address gives you the response
sendmsg: operation not permitted. What could be wrong?This means that your server is not allowed to send ICMP packets. Check firewall rules: $ ip6tables -P INPUT ACCEPT $ ip6tables -P OUTPUT ACCEPT $ ip6tables -P FORWARD ACCEPT
-
How many NTP servers would you configure in your local ntp.conf?
It is NOT recommended to use only two NTP servers.
If more than one NTP server is required, four NTP servers is the recommended minimum. Four servers protects against one incorrect timesource, or "falseticker".
-
What does the column 'reach' mean in
ntpq -poutput?The
whencolumn shows the time since the peer was last heard in seconds, while thereachcolumn shows the status of the reachability register (see RFC-1305) in octal. -
You need to upgrade kernel at 100-1000 servers, how you would do this?
Puppet ou https://www.quora.com/You-need-to-upgrade-kernel-at-100-1000-Linux-servers-how-you-would-do-this
-
How can you tell if the httpd package was already installed?
Try install it again? Or check it version httpd -v
-
How can you list the contents of a package?
dpkg -c (or --contents ) lists the contents of a .deb package file
-
How can you determine which package is better: openssh-server-5.3p1-118.1.el6_8.x86_64 or openssh-server-6.6p1-1.el6.x86_64 ?
Always more recent version, so second one.
-
What is SNAT and when should it be used?
Source NAT: Source Network Address Translation Destination NAT: Destination Network Address Translation
Use-Case for Source NAT: A local client behind Firewall or NAT device wanted to browse Internet.
Source NAT (SNAT) is the most common form of NAT. SNAT changes the source address of the packets passing through the Router. SNAT is typically used when an internal (private) host needs to initiate a session to an external (public) host; in this case, the device that is performing NAT changes the private IP address of the source host to some public IP address, as shown in the following figure. In “masquerade” NAT (a common type of SNAT), the source address of the outgoing packet is replaced with the primary IP address of the outbound interface. The destination address of return packets is automatically translated back to the IP address of the source host.
-
Explain how could you ssh login into a Linux system that DROPs all new incoming packets using a SSH tunnel.
https://unix.stackexchange.com/questions/46235/how-does-reverse-ssh-tunneling-work
-
How do you stop a DDoS attack?
netfilter iptables (soon to be replaced by nftables) is a user-space command line utility to configure kernel packet filtering rules developed by netfilter.
It’s the default firewall management utility on Linux systems – everyone working with Linux systems should be familiar with it or have at least heard of it.
iptables can be used to filter certain packets, block source or destination ports and IP addresses, forward packets via NAT and a lot of other things.
You can use it to block the ip or ip-ranges that are targetting your network.
You can also use commercial tools that do it for you like Cloudflare.
-
How can you see content of an ip packet?
# tcpdump -r /tmp/capture -A | grep '10.2.1.50'-Aoption totcpdumpgives the packet contents -
What is IPoAC (RFC 1149)?
IP over Avian Carriers (IPoAC) is a proposal to carry Internet Protocol (IP) traffic by birds such as homing pigeons.
-
What will happen when you bind port 0?
Asking to bind TCP on port 0 indicates a request to dynamically generate an unused port number. In other words, the port number you're actually listening on after that request is not zero.
-
What is the difference between a Hub and a switch?
A switch is used to connect various network segments. A network switch is a small hardware device that joins multiple computers together within one local area network (LAN). A Hub connects multiple Ethernet devices together, making them act as a single segment.
-
Nmap command
Nmap is used to discover hosts and services on a computer network by sending packets and analyzing the responses. Nmap provides a number of features for probing computer networks, including host discovery and service and operating system detection
-
What is the difference between these two commands?
myvar=helloexport myvar=hello. ###### What is bash quick substitution/caret replace(^x^y)?
https://stackoverflow.com/questions/2149482/caret-search-and-replace-in-bash-shell
It might be easier for you to remember the "line noise" version if you also think of
^string1^string2as already being equivalent to!!:s/string1/string2/. -
What is a tarpipe (or, how would you go about copying everything, including hardlinks and special files, from one server to another)?
tarpipe (or, how would you go about copying everything, including hardlinks and special files, from one server to another)
. ###### What is a shell?
Shell is an interface between the user and the kernel. Even though there can be only one kernel; a system can have many shell running simultaneously. So, whenever a user enters a command through the keyboard, the shell communicates with the kernel to execute it and then display the output to the user.
. ###### What are the different types of commonly used shells on a typical Linux system?
csh,ksh,bash,Bourne . The most commonly used and advanced shell used today is "Bash" .
. ###### What is the equivalent of a file shortcut that we have a window on a Linux system?**
Shortcuts are created using "links" on Linux. There are two types of links that can be used namely "soft link" and "hard link".
. ###### What is the difference between soft and hard links?
Soft links are link to the file name and can reside on different filesytem as well; however hard links are link to the inode of the file and have to be on the same filesytem as that of the file. Deleting the original file makes the soft link inactive (broken link) but does not affect the hard link (Hard link will still access a copy of the file)
-
How will you pass and access arguments to a script in Linux?
Arguments can be passed as: scriptName "Arg1" "Arg2"…."Argn" and can be accessed inside the script as $1 , $2 .. $n
. ###### What is the significance of $#?
$# shows the count of the arguments passed to the script.
-
What is the difference between
$* and $ @?$@ treats each quoted arguments as separate arguments but $ * will consider the entire set of positional parameters as a single string.8.Use sed command to replace the content of the file (emulate tac command)
Eg:
if cat fille
ABCD
EFGH
Then O/p should be
EFGH ABCD
sed '1! G; h;$!d' file1
Here G command appends to the pattern space,
h command copies pattern buffer to hold buffer
and d command deletes the current pattern space.
9. Given a file, replace all occurrence of word "ABC" with "DEF" from 5th line till end in only those lines that contains word "MNO"
sed –n '5,$p' file1|sed '/MNO/s/ABC/DEF/'
tr –s "(backslash)040" <file1|tr –s "(backslash)011"|tr "(backslash)040 (backslash)011" "(backslash)012" |uniq –c
where "(backslash)040" is octal equivalent of "space"
"(backslash)011" is an octal equivalent of "tab character" and
"(backslash)012" is an octal equivalent of the newline character.
-
How will you find the 99th line of a file using only tail and head command?
tail +99 file1|head -1
- Print the 10th line without using tail and head command.
sed –n '10p' file1
-
In my bash shell I want my prompt to be of format '$"Present working directory":"hostname"> and load a file containing a list of user-defined functions as soon as I log in, how will you automate this?
In bash shell, we can create ".profile" file which automatically gets invoked as soon as I log in and write the following syntax into it.
export PS1='$ `pwd`:`hostname`>' .File1
Here File1 is the file containing the user-defined functions and "." invokes this file in current shell.
-
"s" bit is called "set user id" (SUID) bit.
"s" bit on a file causes the process to have the privileges of the owner of the file during the instance of the program.
For example, executing "passwd" command to change current password causes the user to writes its new password to shadow file even though it has "root" as its owner.
We can create the directory giving read and execute access to everyone in the group and setting its sticky bit "t" on as follows:
mkdir direc1
chmod g+wx direc1
chmod +t direc1
-
How can you find out how long the system has been running?
We can find this by using the command "uptime".
-
How can any user find out all information about a specific user like his default shell, real-life name, default directory, when and how long he has been using the system?
finger "loginName" …where loginName is the login name of the user whose information is expected.
-
-
What is the difference between $ and $!?
$$ gives the process id of the currently executing process whereas $! Shows the process id of the process that recently went into the background.
-
What are zombie processes?
These are the processes which have died but whose exit status is still not picked by the parent process. These processes even if not functional still have its process id entry in the process table.
-
How will you copy a file from one machine to other?
We can use utilities like "ftp," "scp" or "rsync" to copy a file from one machine to other. E.g., Using ftp:
FTP hostname
>put file1
>bye
Above copies, file file1 from the local system to destination system whose hostname is specified.
-
I want to monitor a continuously updating log file, what command can be used to most efficiently achieve this?
We can use tail –f filename. This will cause only the default last 10 lines to be displayed on std o/p which continuously shows the updating part of the file.
-
I want to connect to a remote server and execute some commands, how can I achieve this?
We can use ssh to do this:
ssh username@serverIP -p sshport
Example: ssh root@122.52.251.171 -p 22
Once above command is executed, you will be asked to enter the password
-
I have 2 files and I want to print the records which are common to both.**
We can use "comm" command as follows:
comm -12 file1 file2 ... 12 will suppress the content which are
unique to 1st and 2nd file respectively.
-
Write a script to print the first 10 elements of Fibonacci series.
-
#!/bin/sh
a=1
b=1
echo $a
echo $b
for I in 1 2 3 4 5 6 7 8
do
c=a
b=$a
b=$(($a+$c))
echo $b
done
-
We can use isql utility that comes with open client driver as follows:
isql –S serverName –U username –P password
-
0 - Standard Input1 - Standard Output2 - Standard Error
-
I want to read all input to the command from file1 direct all output to file2 and error to file 3, how can I achieve this?
command <file1 1>file2 2>file3
"exec" overlays the newly forked process on the current process; so when I execute the command using exec, the command gets executed on the current shell without creating any new processes.
E.g., Executing "exec ls" on command prompt will execute ls and once ls exits, the process will shut down
awk 'END {print NR} fileName'
grep –c "ABC" file1
egrep is Extended grep that supports added grep features like "+" (1 or more occurrence of a previous character),"?"(0 or 1 occurrence of a previous character) and "|" (alternate matching)
-
/etc/shadow file has all the users listed.
awk –F ':' '{print $1} /etc/shadow'|uniq -u
Syntax in ksh:
Set –A arrayname= (element1 element2 ….. element)
In bash
A=(element1 element2 element3 …. elementn)
Syntax:
for iterator in (elements)
do
execute commands
done
-
du -s /home/user1 ....where user1 is the user for whom the total disk space needs to be found.
Syntax
If condition is successful
then
execute commands
else
execute commands
fi
-
What is the significance of $?
The command $? gives the exit status of the last command that was executed.
-
How do we delete all blank lines in a file?
-
sed '^ [(backslash)011(backslash)040]*$/d' file1
where (backslash)011 is an octal equivalent of space and
(backslash)040 is an octal equivalent of the tab
sed '100i\ABCDEF' file1
find . –mtime -2 –exec wc –l {} ;
-
How can I set the default rwx permission to all users on every file which is created in the current shell?
We can use:
umask 777
This will set default rwx permission for every file which is created for every user.
-
We can use "ps –p ProcessId"
Bootblock, super block, inode block and Datablock are found fundamental components of every file system on Linux.
This block contains a small program called "Master Boot record"(MBR) which loads the kernel during system boot up.
Super block contains all the information about the file system like the size of file system, block size used by its number of free data blocks and list of free inodes and data blocks.
This block contains the inode for every file of the file system along with all the file attributes except its name.
-
ip file1.zip file1|mailx –s "subject" Recipients email id
mail content
OF
. ###### How do we create command aliases in a shell?
alias Aliasname="Command whose alias is to be created".
-
"c " and "b" permission fields are generally associated with a device file. It specifies whether a file is a special character file or a block special file.
Shebang line at the top of each script determines the location of the engine which is to be used to execute the script.
-
Common TCP/IP Protocols and Ports
Protocol TCP/UDP Port Number Description File Transfer Protocol (FTP) (RFC 959) TCP 20/21 FTP is one of the most commonly used file transfer protocols on the Internet and within private networks. An FTP server can easily be set up with little networking knowledge and provides the ability to easily relocate files from one system to another. FTP control is handled on TCP port 21 and its data transfer can use TCP port 20 as well as dynamic ports depending on the specific configuration. Secure Shell (SSH) (RFC 4250-4256) TCP 22 SSH is the primary method used to manage network devices securely at the command level. It is typically used as a secure alternative to Telnet which does not support secure connections. Telnet (RFC 854) TCP 23 Telnet is the primary method used to manage network devices at the command level. Unlike SSH which provides a secure connection, Telnet does not, it simply provides a basic unsecured connection. Many lower level network devices support Telnet and not SSH as it required some additional processing. Caution should be used when connecting to a device using Telnet over a public network as the login credentials will be transmitted in the clear. Simple Mail Transfer Protocol (SMTP) (RFC 5321) TCP 25 SMTP is used for two primary functions, it is used to transfer mail (email) from source to destination between mail servers and it is used by end users to send email to a mail system. Domain Name System (DNS) (RFC 1034-1035) TCP/UDP 53 The DNS is used widely on the public internet and on private networks to translate domain names into IP addresses, typically for network routing. DNS is hieratical with main root servers that contain databases that list the managers of high level Top Level Domains (TLD) (such as .com). These different TLD managers then contain information for the second level domains that are typically used by individual users (for example, cisco.com). A DNS server can also be set up within a private network to private naming services between the hosts of the internal network without being part of the global system. Dynamic Host Configuration Protocol (DHCP) (RFC 2131) UDP 67/68 DHCP is used on networks that do not use static IP address assignment (almost all of them). A DHCP server can be set up by an administrator or engineer with a poll of addresses that are available for assignment. When a client device is turned on it can request an IP address from the local DHCP server, if there is an available address in the pool it can be assigned to the device. This assignment is not permanent and expires at a configurable interval; if an address renewal is not requested and the lease expires the address will be put back into the poll for assignment. Trivial File Transfer Protocol (TFTP) (RFC 1350) UDP 69 TFTP offers a method of file transfer without the session establishment requirements that FTP uses. Because TFTP uses UDP instead of TCP it has no way of ensuring the file has been properly transferred, the end device must be able to check the file to ensure proper transfer. TFTP is typically used by devices to upgrade software and firmware; this includes Cisco and other network vendors’ equipment. Hypertext Transfer Protocol (HTTP) (RFC 2616) TCP 80 HTTP is one of the most commonly used protocols on most networks. HTTP is the main protocol that is used by web browsers and is thus used by any client that uses files located on these servers. Post Office Protocol (POP) version 3 (RFC 1939) TCP 110 POP version 3 is one of the two main protocols used to retrieve mail from a server. POP was designed to be very simple by allowing a client to retrieve the complete contents of a server mailbox and then deleting the contents from the server. Network Time Protocol (NTP) (RFC 5905) UDP 123 One of the most overlooked protocols is NTP. NTP is used to synchronize the devices on the Internet. Even most modern operating systems support NTP as a basis for keeping an accurate clock. The use of NTP is vital on networking systems as it provides an ability to easily interrelate troubles from one device to another as the clocks are precisely accurate. NetBIOS (RFC 1001-1002) TCP/UDP 137/138/139 NetBIOS itself is not a protocol but is typically used in combination with IP with the NetBIOS over TCP/IP (NBT) protocol. NBT has long been the central protocol used to interconnect Microsoft Windows machines. Internet Message Access Protocol (IMAP) (RFC 3501) TCP 143 IMAP version3 is the second of the main protocols used to retrieve mail from a server. While POP has wider support, IMAP supports a wider array of remote mailbox operations which can be helpful to users. Simple Network Management Protocol (SNMP) (RFC 1901-1908, 3411-3418) TCP/UDP 161/162 SNMP is used by network administrators as a method of network management. SNMP has a number of different abilities including the ability to monitor, configure and control network devices. SNMP traps can also be configured on network devices to notify a central server when specific actions are occurring. Typically, these are configured to be used when an alerting condition is happening. In this situation, the device will send a trap to network management stating that an event has occurred and that the device should be looked at further for a source to the event. Border Gateway Protocol (BGP) (RFC 4271) TCP 179 BGP version 4 is widely used on the public internet and by Internet Service Providers (ISP) to maintain very large routing tables and traffic processing. BGP is one of the few protocols that have been designed to deal with the astronomically large routing tables that must exist on the public Internet. Lightweight Directory Access Protocol (LDAP) (RFC 4510) TCP/UDP 389 LDAP provides a mechanism of accessing and maintaining distributed directory information. LDAP is based on the ITU-T X.500 standard but has been simplified and altered to work over TCP/IP networks. Hypertext Transfer Protocol over SSL/TLS (HTTPS) (RFC 2818) TCP 443 HTTPS is used in conjunction with HTTP to provide the same services but doing it using a secure connection which is provided by either SSL or TLS. Lightweight Directory Access Protocol over TLS/SSL (LDAPS) (RFC 4513) TCP/UDP 636 Just like HTTPS, LDAPS provides the same function as LDAP but over a secure connection which is provided by either SSL or TLS. FTP over TLS/SSL (RFC 4217) TCP 989/990 Again, just like the previous two entries, FTP over TLS/SSL uses the FTP protocol which is then secured using either SSL or TLS. -
Bash cheat sheet
Example
#!/usr/bin/env bash NAME="John" echo "Hello $NAME!"Variables
NAME="John" echo $NAME echo "$NAME" echo "${NAME}!"String quotes
NAME="John" echo "Hi $NAME" #=> Hi John echo 'Hi $NAME' #=> Hi $NAMEShell execution
echo "I'm in $(pwd)" echo "I'm in `pwd`" # SameConditional execution
git commit && git push git commit || echo "Commit failed"Functions
get_name() { echo "John" } echo "You are $(get_name)"Conditionals
if [[ -z "$string" ]]; then echo "String is empty" elif [[ -n "$string" ]]; then echo "String is not empty" fiStrict mode
set -euo pipefail IFS=$'\n\t'Brace expansion
echo {A,B}.js{A,B}Same as A B{A,B}.jsSame as A.js B.js{1..5}Same as 1 2 3 4 5Parameter expansions
Basics
name="John" echo ${name} echo ${name/J/j} #=> "john" (substitution) echo ${name:0:2} #=> "Jo" (slicing) echo ${name::2} #=> "Jo" (slicing) echo ${name::-1} #=> "Joh" (slicing) echo ${name:(-1)} #=> "n" (slicing from right) echo ${name:(-2):1} #=> "h" (slicing from right) echo ${food:-Cake} #=> $food or "Cake"length=2 echo ${name:0:length} #=> "Jo"STR="/path/to/foo.cpp" echo ${STR%.cpp} # /path/to/foo echo ${STR%.cpp}.o # /path/to/foo.o echo ${STR##*.} # cpp (extension) echo ${STR##*/} # foo.cpp (basepath) echo ${STR#*/} # path/to/foo.cpp echo ${STR##*/} # foo.cpp echo ${STR/foo/bar} # /path/to/bar.cppSTR="Hello world" echo ${STR:6:5} # "world" echo ${STR:-5:5} # "world"SRC="/path/to/foo.cpp" BASE=${SRC##*/} #=> "foo.cpp" (basepath) DIR=${SRC%$BASE} #=> "/path/to/" (dirpath)Substitution
${FOO%suffix}Remove suffix ${FOO#prefix}Remove prefix ${FOO%%suffix}Remove long suffix ${FOO##prefix}Remove long prefix ${FOO/from/to}Replace first match ${FOO//from/to}Replace all ${FOO/%from/to}Replace suffix ${FOO/#from/to}Replace prefix Comments
# Single line comment: ' This is a multi line comment 'Substrings
${FOO:0:3}Substring (position, length) ${FOO:-3:3}Substring from the right Length
${#FOO}Length of $FOODefault values
${FOO:-val}$FOO, orvalif not set${FOO:=val}Set $FOOtovalif not set${FOO:+val}valif$FOOis set${FOO:?message}Show error message and exit if $FOOis not setThe
:is optional (eg,${FOO=word}works)Loops
Basic for loop
for i in /etc/rc.*; do echo $i doneC-like for loop
for ((i = 0 ; i < 100 ; i++)); do echo $i doneRanges
for i in {1..5}; do echo "Welcome $i" doneWith step size
for i in {5..50..5}; do echo "Welcome $i" doneReading lines
< file.txt | while read line; do echo $line doneForever
while true; do ··· doneFunctions
Defining functions
myfunc() { echo "hello $1" }# Same as above (alternate syntax) function myfunc() { echo "hello $1" }myfunc "John"Returning values
myfunc() { local myresult='some value' echo $myresult }result="$(myfunc)"Raising errors
myfunc() { return 1 }if myfunc; then echo "success" else echo "failure" fiArguments
$#Number of arguments $*All arguments $@All arguments, starting from first $1First argument Conditionals
Conditions
Note that
[[is actually a command/program that returns either0(true) or1(false). Any program that obeys the same logic (like all base utils, such asgrep(1)orping(1)) can be used as condition, see examples.[[ -z STRING ]]Empty string [[ -n STRING ]]Not empty string [[ STRING == STRING ]]Equal [[ STRING != STRING ]]Not Equal [[ NUM -eq NUM ]]Equal [[ NUM -ne NUM ]]Not equal [[ NUM -lt NUM ]]Less than [[ NUM -le NUM ]]Less than or equal [[ NUM -gt NUM ]]Greater than [[ NUM -ge NUM ]]Greater than or equal [[ STRING =~ STRING ]]Regexp (( NUM < NUM ))Numeric conditions [[ -o noclobber ]]If OPTIONNAME is enabled [[ ! EXPR ]]Not [[ X ]] && [[ Y ]]And `[[ X ]] File conditions
[[ -e FILE ]]Exists [[ -r FILE ]]Readable [[ -h FILE ]]Symlink [[ -d FILE ]]Directory [[ -w FILE ]]Writable [[ -s FILE ]]Size is > 0 bytes [[ -f FILE ]]File [[ -x FILE ]]Executable [[ FILE1 -nt FILE2 ]]1 is more recent than 2 [[ FILE1 -ot FILE2 ]]2 is more recent than 1 [[ FILE1 -ef FILE2 ]]Same files Example
if ping -c 1 google.com; then echo "It appears you have a working internet connection" fiif grep -q 'foo' ~/.bash_history; then echo "You appear to have typed 'foo' in the past" fi# String if [[ -z "$string" ]]; then echo "String is empty" elif [[ -n "$string" ]]; then echo "String is not empty" fi# Combinations if [[ X ]] && [[ Y ]]; then ... fi# Equal if [[ "$A" == "$B" ]]# Regex if [[ "A" =~ "." ]]if (( $a < $b )); then echo "$a is smaller than $b" fiif [[ -e "file.txt" ]]; then echo "file exists" fiArrays
Defining arrays
Fruits=('Apple' 'Banana' 'Orange')Fruits[0]="Apple" Fruits[1]="Banana" Fruits[2]="Orange"Working with arrays
echo ${Fruits[0]} # Element #0 echo ${Fruits[@]} # All elements, space-separated echo ${#Fruits[@]} # Number of elements echo ${#Fruits} # String length of the 1st element echo ${#Fruits[3]} # String length of the Nth element echo ${Fruits[@]:3:2} # Range (from position 3, length 2)Operations
Fruits=("${Fruits[@]}" "Watermelon") # Push Fruits+=('Watermelon') # Also Push Fruits=( ${Fruits[@]/Ap*/} ) # Remove by regex match unset Fruits[2] # Remove one item Fruits=("${Fruits[@]}") # Duplicate Fruits=("${Fruits[@]}" "${Veggies[@]}") # Concatenate lines=(`cat "logfile"`) # Read from fileIteration
for i in "${arrayName[@]}"; do echo $i doneDictionaries
Defining
declare -A soundssounds[dog]="bark" sounds[cow]="moo" sounds[bird]="tweet" sounds[wolf]="howl"Declares
soundas a Dictionary object (aka associative array).Working with dictionaries
echo ${sounds[dog]} # Dog's sound echo ${sounds[@]} # All values echo ${!sounds[@]} # All keys echo ${#sounds[@]} # Number of elements unset sounds[dog] # Delete dogIteration
Iterate over values
for val in "${sounds[@]}"; do echo $val doneIterate over keys
for key in "${!sounds[@]}"; do echo $key doneOptions
Options
set -o noclobber # Avoid overlay files (echo "hi" > foo) set -o errexit # Used to exit upon error, avoiding cascading errors set -o pipefail # Unveils hidden failures set -o nounset # Exposes unset variablesGlob options
set -o nullglob # Non-matching globs are removed ('*.foo' => '') set -o failglob # Non-matching globs throw errors set -o nocaseglob # Case insensitive globs set -o globdots # Wildcards match dotfiles ("*.sh" => ".foo.sh") set -o globstar # Allow ** for recursive matches ('lib/**/*.rb' => 'lib/a/b/c.rb')Set
GLOBIGNOREas a colon-separated list of patterns to be removed from glob matches.History
Commands
historyShow history shopt -s histverifyDon’t execute expanded result immediately Expansions
!$Expand last parameter of most recent command !*Expand all parameters of most recent command !-nExpand nth most recent command!nExpand nth command in history!<command>Expand most recent invocation of command <command>Operations
!!Execute last command again !!:s/<FROM>/<TO>/Replace first occurrence of <FROM>to<TO>in most recent command!!:gs/<FROM>/<TO>/Replace all occurrences of <FROM>to<TO>in most recent command!$:tExpand only basename from last parameter of most recent command !$:hExpand only directory from last parameter of most recent command !!and!$can be replaced with any valid expansion.Slices
!!:nExpand only nth token from most recent command (command is0; first argument is1)!^Expand first argument from most recent command !$Expand last token from most recent command !!:n-mExpand range of tokens from most recent command !!:n-$Expand nth token to last from most recent command!!can be replaced with any valid expansion i.e.!cat,!-2,!42, etc.Miscellaneous
Numeric calculations
$((a + 200)) # Add 200 to $a$((RANDOM%=200)) # Random number 0..200Subshells
(cd somedir; echo "I'm now in $PWD") pwd # still in first directoryRedirection
python hello.py > output.txt # stdout to (file) python hello.py >> output.txt # stdout to (file), append python hello.py 2> error.log # stderr to (file) python hello.py 2>&1 # stderr to stdout python hello.py 2>/dev/null # stderr to (null) python hello.py &>/dev/null # stdout and stderr to (null)python hello.py < foo.txt # feed foo.txt to stdin for pythonInspecting commands
command -V cd #=> "cd is a function/alias/whatever"Trap errors
trap 'echo Error at about $LINENO' ERRor
traperr() { echo "ERROR: ${BASH_SOURCE[1]} at about ${BASH_LINENO[0]}" } set -o errtrace trap traperr ERRCase/switch
case "$1" in start | up) vagrant up ;; *) echo "Usage: $0 {start|stop|ssh}" ;; esacSource relative
source "${0%/*}/../share/foo.sh"printf
printf "Hello %s, I'm %s" Sven Olga #=> "Hello Sven, I'm OlgaDirectory of script
DIR="${0%/*}"Getting options
while [[ "$1" =~ ^- && ! "$1" == "--" ]]; do case $1 in -V | --version ) echo $version exit ;; -s | --string ) shift; string=$1 ;; -f | --flag ) flag=1 ;; esac; shift; done if [[ "$1" == '--' ]]; then shift; fiHeredoc
cat <<END hello world ENDReading input
echo -n "Proceed? [y/n]: " read ans echo $ansread -n 1 ans # Just one characterSpecial variables
$?Exit status of last task $!PID of last background task $$PID of shell Go to previous directory
pwd # /home/user/foo cd bar/ pwd # /home/user/foo/bar cd - pwd # /home/user/foo
File Commands
| Command | Description |
|---|---|
| ls | directory listing |
| ls -al | formated listing with hidden files |
| cd dir | change directory to dir |
| cd | change to home |
| pwd | show current directory |
| mkdir dir | create directory dir |
| rm file | delete file |
| rm -r dir | delete directory dir |
| rm -f file | force remove file |
| rm -rf dir | force remove directory dir |
| cp file1 file2 | copy file1 to file2 |
| cp -r dir1 dir2 | copy dir1 to dir2; create dir2 if it doesn't exist |
| mv file1 file2 | rename or move file1 to file2 if file is an existing directory, moves file1 to sirectory file2 |
| ln -s file link | create symbolic link to file |
| touch file | create or update file |
| cat > file | places standard input into file |
| more file | output the contents of file |
| head file | output the first 10 lines of file |
| tail file | output the last 10 lines of file |
| tail -f file | output the contents of file as it grows starting with the last 10 lines |
System Info
| Command | Description |
|---|---|
| date | show the current date and time |
| cal | show this month's calendar |
| uptime | show current uptime |
| w | display who is online |
| whoami | who you are logged in as |
| finger user | display info about user |
| uname -a | show kernel info |
| cat /proc/cpuinfo | cpu info |
| cat /proc/meminfo | memory info |
| man command | show the manual for command |
| df | show disk usage |
| du | show directory space usage |
| free | show memory and swap usage |
| whereis app | show possible locations of app |
| which app | show which app will be run by default |
File permissions commands
| Command | Description |
|---|---|
| chmod octal file | change the permissions of file to octal, which can be found separately for user, group, and world by adding: 4 – read (r), 2- write(w), execute (x) |
| chmod 777 | read, write execute for all |
| chmod 755 | rwx for owner, rx for group and world |
Process management commands
| Command | Description |
|---|---|
| ps | display currently active processes |
| top | display all running processes |
| kill pid | kill process id pid |
| killall proc | kill al processes named proc |
| bg | lists stopped or background jobs; resume a stopped job in the background |
| fg | brings the most recent job to the foreground |
| fg n | brings job n to the foreground |
SSH commands
| Command | Description |
|---|---|
| ssh user@host | connect to host as user |
| ssh -p port user@host | connect to host on port as user |
| ssh-copy-id user@host | add your key to host for user to enable a keyed passwordless login |
Searching Commands
| Command | Description |
|---|---|
| grep pattern files | search for pattern in files |
| greo -r pattern dir | search recursively for pattern in dir |
| command | grep pattern | search for pattern in the output of command |
| locate file | find all instances of file |
Compression commands:
| Command | Description |
|---|---|
| tar cf file.tar files | created a tar named file.tar containing files |
| tar xf file.tar | extract the files from file.tar |
| tar czf file.tar.gz files | create a tar with Gzip compression |
| tar xzf file.tar.gz | extract a tar using Gzip |
| tar cjf file.tar.bz2 | create a tar with Bzip2 compression |
| tar xjf file.tar.bz2 | extract a tar using Bzip2 |
| gzip file | compresses file and renames it to file.gz |
| gzip -d file.gz | decompresses file.gz back to file |
Networking commands
| Command | Description |
|---|---|
| ping host | ping host and output results |
| whois domain | get whois information for domain |
| dig domain | get DNS information for domain |
| dig -x host | reverse lookup host |
| wget file | download file |
| wget -c file | continue a stopped download |
| Nmap Scan TypeOptionstarget. | scan a host |
| ifconfig | |
| traceroute domain/ip | traceroute prints the route packets take to network host. |
| telnet host | talk to “hosts” at the given port number. By default, the telnet port is port 23. |
| netstat –r | Print routing tables. |
| route add | Used for setting a static (non-dynamic by hand route) route path in the route tables |
| nslookup domain | Makes queries to the DNS server to translate IP to a name, or vice versa. |
Installation Commands
| Command | Description |
|---|---|
| make ./configure make install |
Install from source |
| dpkg -i pkg.deb | install a package (Debian) |
| rpm -Uvh pkg.rpm | install a package(RPM) |
Shortcuts
| Command | Description |
|---|---|
| Ctrl+C | halts the current command |
| Ctrl+Z | stops the current command, resume with fg in the foreground or bg in the background |
| Ctrl+D | log out of current session, similar to exit |
| Ctrl+W | erases one word in the current line |
| Ctrl+U | erases the whole line |
| Ctrl+R | type to bring up a recent command |
| !! | repeats the last command |
| exit | log out of current session |