-
-
Save ForeverZer0/a2cd292bd2f3b5e114956c00bb6e872b to your computer and use it in GitHub Desktop.
| using System; | |
| using System.IO; | |
| using System.IO.Compression; | |
| using System.Text; | |
| namespace TarExample | |
| { | |
| public class Tar | |
| { | |
| /// <summary> | |
| /// Extracts a <i>.tar.gz</i> archive to the specified directory. | |
| /// </summary> | |
| /// <param name="filename">The <i>.tar.gz</i> to decompress and extract.</param> | |
| /// <param name="outputDir">Output directory to write the files.</param> | |
| public static void ExtractTarGz(string filename, string outputDir) | |
| { | |
| using (var stream = File.OpenRead(filename)) | |
| ExtractTarGz(stream, outputDir); | |
| } | |
| /// <summary> | |
| /// Extracts a <i>.tar.gz</i> archive stream to the specified directory. | |
| /// </summary> | |
| /// <param name="stream">The <i>.tar.gz</i> to decompress and extract.</param> | |
| /// <param name="outputDir">Output directory to write the files.</param> | |
| public static void ExtractTarGz(Stream stream, string outputDir) | |
| { | |
| // A GZipStream is not seekable, so copy it first to a MemoryStream | |
| using (var gzip = new GZipStream(stream, CompressionMode.Decompress)) | |
| { | |
| const int chunk = 4096; | |
| using (var memStr = new MemoryStream()) | |
| { | |
| int read; | |
| var buffer = new byte[chunk]; | |
| do | |
| { | |
| read = gzip.Read(buffer, 0, chunk); | |
| memStr.Write(buffer, 0, read); | |
| } while (read == chunk); | |
| memStr.Seek(0, SeekOrigin.Begin); | |
| ExtractTar(memStr, outputDir); | |
| } | |
| } | |
| } | |
| /// <summary> | |
| /// Extractes a <c>tar</c> archive to the specified directory. | |
| /// </summary> | |
| /// <param name="filename">The <i>.tar</i> to extract.</param> | |
| /// <param name="outputDir">Output directory to write the files.</param> | |
| public static void ExtractTar(string filename, string outputDir) | |
| { | |
| using (var stream = File.OpenRead(filename)) | |
| ExtractTar(stream, outputDir); | |
| } | |
| /// <summary> | |
| /// Extractes a <c>tar</c> archive to the specified directory. | |
| /// </summary> | |
| /// <param name="stream">The <i>.tar</i> to extract.</param> | |
| /// <param name="outputDir">Output directory to write the files.</param> | |
| public static void ExtractTar(Stream stream, string outputDir) | |
| { | |
| var buffer = new byte[100]; | |
| while (true) | |
| { | |
| stream.Read(buffer, 0, 100); | |
| var name = Encoding.ASCII.GetString(buffer).Trim('\0'); | |
| if (String.IsNullOrWhiteSpace(name)) | |
| break; | |
| stream.Seek(24, SeekOrigin.Current); | |
| stream.Read(buffer, 0, 12); | |
| var size = Convert.ToInt64(Encoding.UTF8.GetString(buffer, 0, 12).Trim('\0').Trim(), 8); | |
| stream.Seek(376L, SeekOrigin.Current); | |
| var output = Path.Combine(outputDir, name); | |
| if (!Directory.Exists(Path.GetDirectoryName(output))) | |
| Directory.CreateDirectory(Path.GetDirectoryName(output)); | |
| if (!name.Equals("./", StringComparison.InvariantCulture)) | |
| { | |
| using (var str = File.Open(output, FileMode.OpenOrCreate, FileAccess.Write)) | |
| { | |
| var buf = new byte[size]; | |
| stream.Read(buf, 0, buf.Length); | |
| str.Write(buf, 0, buf.Length); | |
| } | |
| } | |
| var pos = stream.Position; | |
| var offset = 512 - (pos % 512); | |
| if (offset == 512) | |
| offset = 0; | |
| stream.Seek(offset, SeekOrigin.Current); | |
| } | |
| } | |
| } | |
| } | |
| /* | |
| This software is available under 2 licenses -- choose whichever you prefer. | |
| ------------------------------------------------------------------------------ | |
| ALTERNATIVE A - MIT License | |
| Copyright (c) 2017 Sean Barrett | |
| Permission is hereby granted, free of charge, to any person obtaining a copy of | |
| this software and associated documentation files (the "Software"), to deal in | |
| the Software without restriction, including without limitation the rights to | |
| use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies | |
| of the Software, and to permit persons to whom the Software is furnished to do | |
| so, subject to the following conditions: | |
| The above copyright notice and this permission notice shall be included in all | |
| copies or substantial portions of the Software. | |
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | |
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, | |
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE | |
| AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER | |
| LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, | |
| OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE | |
| SOFTWARE. | |
| ------------------------------------------------------------------------------ | |
| ALTERNATIVE B - Public Domain (www.unlicense.org) | |
| This is free and unencumbered software released into the public domain. | |
| Anyone is free to copy, modify, publish, use, compile, sell, or distribute this | |
| software, either in source code form or as a compiled binary, for any purpose, | |
| commercial or non-commercial, and by any means. | |
| In jurisdictions that recognize copyright laws, the author or authors of this | |
| software dedicate any and all copyright interest in the software to the public | |
| domain. We make this dedication for the benefit of the public at large and to | |
| the detriment of our heirs and successors. We intend this dedication to be an | |
| overt act of relinquishment in perpetuity of all present and future rights to | |
| this software under copyright law. | |
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | |
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, | |
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE | |
| AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN | |
| ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION | |
| WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | |
| */ |
getting exception in line 40 when trying to decompress large files of 100MB
40 memStr.Write(buffer, 0, read);
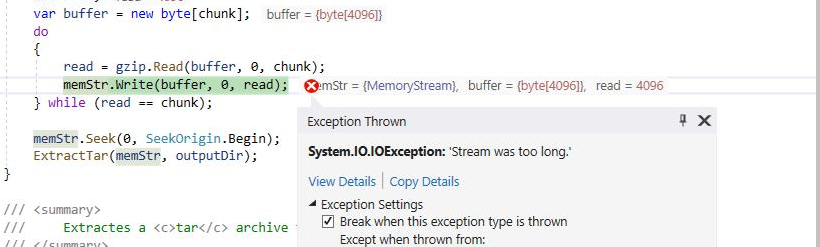

issue fixed https://gist.github.com/Su-s/438be493ae692318c73e30367cbc5c2a
ExtractTar use memory blocks for reading and writing. My tests showed 45% performance.
const int chunk = 2 * 1024 * 1024; //2MB var fbuf = new byte[chunk];
using (var str = File.Open(output, FileMode.OpenOrCreate, FileAccess.Write)) { int fbalance = size; int fread, fcount; while (true) { fcount = (fbuf.Length <= fbalance) ? fbuf.Length : fbalance; fread = stream.Read(fbuf, 0, fcount); if (fread <= 0) break; str.Write(fbuf, 0, fread); fbalance -= fread; } }
Excellent, just what I was looking for. I have wrapped this into a PowerShell function:
https://github.com/TheDotSource/Expand-TarBall/blob/main/Expand-TarBall.ps1
If you are using .NET 6 you should replace:
do
{
read = gzip.Read(buffer, 0, chunk);
memStr.Write(buffer, 0, read);
} while (read == chunk);
with the following code:
while ((read = gzip.Read(buffer, 0, buffer.Length)) > 0)
{
memStr.Write(buffer, 0, read);
}
This small code changes avoids writing a memory stream with only a few bytes in it and an endless loop in the ExtractTar method
Thanks for the inital snipped it really works great without using any dependencies
What license would you put this code under?
What license would you put this code under?
@voltagex I added choice of MIT or Public Domain, whichever you prefer. If neither of them suit your needs, I would have no problem with any exceptions. Free free to use/modify/sell the code as you see fit in any open/closed source project, commercial or otherwise, I don't require any credit.
If you are using .NET 6 you should replace:
do { read = gzip.Read(buffer, 0, chunk); memStr.Write(buffer, 0, read); } while (read == chunk);with the following code:
while ((read = gzip.Read(buffer, 0, buffer.Length)) > 0) { memStr.Write(buffer, 0, read); }This small code changes avoids writing a memory stream with only a few bytes in it and an endless loop in the ExtractTar method Thanks for the inital snipped it really works great without using any dependencies
Thanks for this comment! This resolved my issue which proved very hard to debug.
I forked the snippet and made some style refactos and "modernizations" along with the fixes mentioned in the comments. This version works great on .NET 6
need this class i.e. GZipStream.cs which they used inside this file
need this class i.e. GZipStream.cs which they used inside this file
It's System.IO.Compression.GZipStream. If you don't have it, you should update your .net version.
System.IO.Compression.GZipStream It is one of the features that is introduced in .NET 7 https://devblogs.microsoft.com/dotnet/announcing-dotnet-7/ The above example should work with .NET 6 if you replace this: https://gist.github.com/ForeverZer0/a2cd292bd2f3b5e114956c00bb6e872b?permalink_comment_id=4071264#gistcomment-4071264 and with older versions (.NET Core 3) without that replacement
I found an edge case where this code crashes. We encountered a case where the name in the 512 byte header of a file was longer than 100 characters (bytes). These cases were handled for us by the use of a "fake file" called ././@LongLink with a typeTag of 'L'. This fake file's data contains the full filename that is larger than 100 bytes. So we need to read this first and temporarily hold onto it as we are about to read the ACTUAL real file in the next iteration. The real file's name is truncated to 100 characters but we will just skip those and use the full name we just read last iteration instead. This solved our problems. I updated my own forked gist with the fix here: https://gist.github.com/Matheos96/da8990030dfe3e27b0a48722042d9c0b
getting exception in line 40 when trying to decompress large files of 100MB
40 memStr.Write(buffer, 0, read);