Seq2Seqといえば、TensorFlowでの実装が有名で、英語とフランス語の大規模コーパスを使ってやるものが、よくチューニングされており便利です
しかし、この翻訳のタスクに最適化されており、一般的なものと言い難い感じで任意のタスクに変換して利用する際に少々不便を感じていました。
(TensorFlowのものは、自分で改造するにしても人に説明する際も、ちょっと面倒)
今回、Kerasで実装して、ある程度、うまく動作することを確認しました
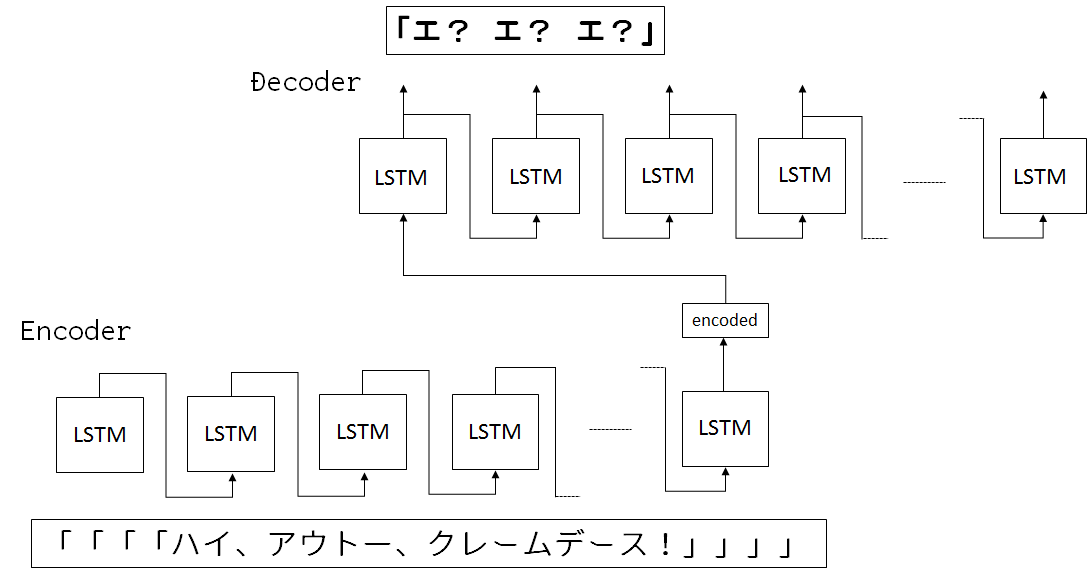
Seq2Seqは一般的に、Encoder-Decoderモデルと言われています。Encoderで次に続く単語をベクトル化して、Decoderでベクトル情報をもとに、予想を行います
このベクトル化は、今でも研究され続けており、Attention is All You Need[1]というものが発表されてました
中国人のデータサイエンティストから教えてもらったのですが、この論文は世界的に流行っているようです。
Attentionには様々な流儀があるのですが、Attentionがないモデルです
どこかのフォーラムで見たものです
softmax, tanh等の活性化関数を利用して、Encoderのベクトルを作ります
ここをCNNとかにしてもいいと思っており、色々やりがいがありそうですね

dot積を使って、softmaxやら、3つ以上のマトリックスを組み合わせてAttentionにしているのが、今回の[1]の論文の主要であったと理解しているのですが、 他の組み合わせも色々考えられるので、これからもState of the Artは更新され続けていくものだと認識しております
Kerasで実装するので、いくつか妥協した点があるのですが、自分で実装してみたのが、このネットワークです。(もっといいのが幾つかありそう)
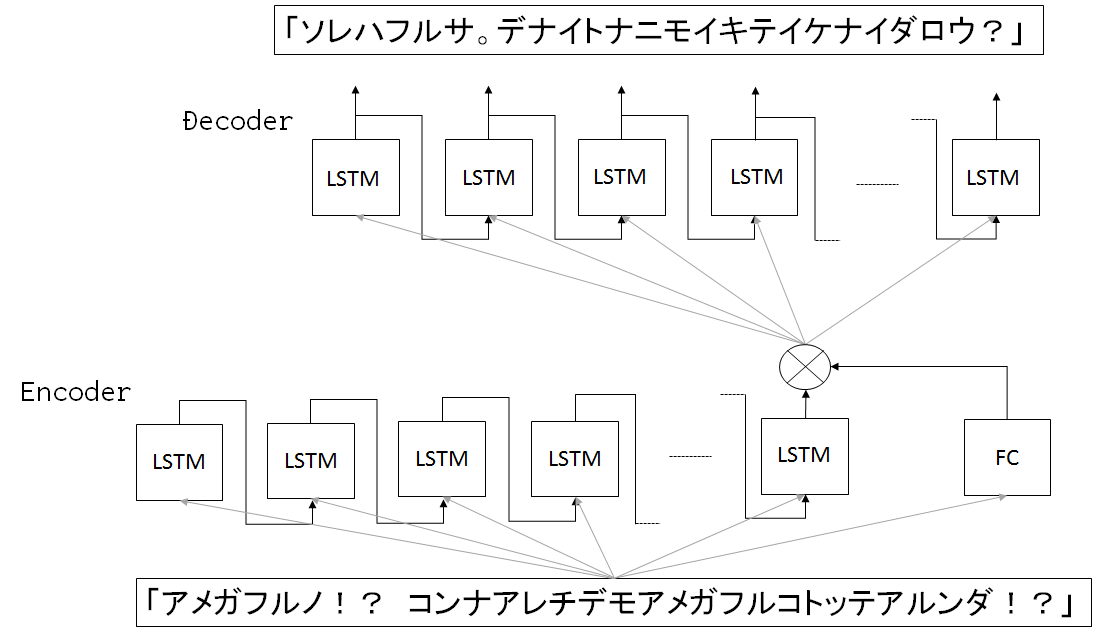
ネットワーク構成
コード
timesteps = 50
inputs = Input(shape=(timesteps, 128))
encoded = LSTM(512)(inputs)
inputs_a = Input(shape=(timesteps, 128))
a_vector = Dense(512, activation='softmax')(Flatten()(inputs))
# mul = merge([encoded, a_vector], mode='mul') # this for keras v1
mul = multiply([encoded, a_vector])
encoder = Model(inputs, mul)
x = RepeatVector(timesteps)(mul)
x = Bi(LSTM(512, return_sequences=True))(x)
decoded = TD(Dense(128, activation='softmax'))(x)
autoencoder = Model(inputs, decoded)
autoencoder.compile(optimizer=Adam(), loss='categorical_crossentropy')実行時にepochごとに、Optimizerをごちゃごちゃ切り替えるロジックを入れたのですが、挙動が単独のOptimizerを使うのと異なるので、何か影響があるのかもしれません
この前ダウンロードしたノクターンノベルズのデータセットを使って、学習を行いました ノクターンノベルズなどの小説では、対話文が多く入っており、会話文を学習させやすいです
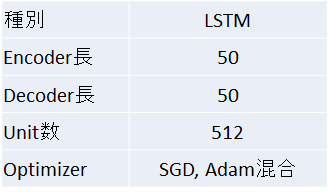
50万会話のコーパスを使い、図3のモデルで学習させました
なお、文字は簡単化のため、全てカタカナで表現して、Char Levelであてていくものです
学習したデータセットに対する予測性能は十分でした
Input:「コンナワスレモノ、アリ?」 -> Output:「トシニ、サンカイアルゾ」
Input:「オカアサン?」 -> Output: 「・・・・・・カゾクナノダカラコマッタトキハタスケルノガアタリマエデショウ。キニシナイノ」
Input:「ワタシガサリゲナクキイテミルワ」 -> Output: 「タノムヨ。カアサン」このように、コーパスが作品特有の文脈を持ってしまっているので、翻訳タスク以上に難しい印象があります
未知の単語を入力すると、もっとも有り得そうな解答が返ってきます
Input:「ウフフ」 -> Output:「アアー…」
Input:「ワタシハダイスキ」 -> Output:「ソレハ・・・・ムツカシイ」
Input:「ダイジョウブカ?」 -> Output:「オニイチャーン……」こういったタスクがうまくいく背景には中心極限定理が背景としてあるので、データセットのボリュームがあることが必要になってきます
$ python3 minimal.lstm.py --train非常に計算が重いので、途中から再開できます
$ python3 minimal.lstm.py --train --resume予想はこのように行います
$ python3 minimal.lstm.py --predict任意のデータセットで学習を行いたい場合は、データセットを差し替えていただければできると思います