-
-
Save HarshitRuwali/2e47e3182baa8aef58b34332a90f7fcf to your computer and use it in GitHub Desktop.
| #!/usr/bin/env python | |
| # -*- coding: utf-8 -*- | |
| import sys | |
| from datetime import datetime | |
| import requests | |
| from tqdm import tqdm | |
| import re | |
| def download(): | |
| url = input("Please enter the URL: ") | |
| x = re.match(r'^(https:)[/][/]www.([^/]+[.])*instagram.com', url) | |
| if x: | |
| request_image = requests.get(url) | |
| src = request_image.content.decode('utf-8') | |
| check_type = re.search(r'<meta name="medium" content=[\'"]?([^\'" >]+)', src) | |
| check_type_f = check_type.group() | |
| final = re.sub('<meta name="medium" content="', '', check_type_f) | |
| if final == "image": | |
| print("\nDownloading the image...") | |
| extract_image_link = re.search(r'meta property="og:image" content=[\'"]?([^\'" >]+)', src) | |
| image_link = extract_image_link.group() | |
| final = re.sub('meta property="og:image" content="', '', image_link) | |
| _response = requests.get(final).content | |
| file_size_request = requests.get(final, stream=True) | |
| file_size = int(file_size_request.headers['Content-Length']) | |
| block_size = 1024 | |
| filename = datetime.strftime(datetime.now(), '%Y-%m-%d-%H-%M-%S') | |
| t=tqdm(total=file_size, unit='B', unit_scale=True, desc=filename, ascii=True) | |
| with open(filename + '.jpg', 'wb') as f: | |
| for data in file_size_request.iter_content(block_size): | |
| t.update(len(data)) | |
| f.write(data) | |
| t.close() | |
| print("Image downloaded successfully") | |
| if final == 'video': | |
| print('downloading') | |
| extract_video_link = re.search(r'meta property="og:video" content=[\'"]?([^\'" >]+)', src) | |
| video_link = extract_video_link.group() | |
| final = re.sub('meta property="og:video" content="', '', video_link) | |
| _response = requests.get(final).content | |
| file_size_request = requests.get(final, stream=True) | |
| file_size = int(file_size_request.headers['Content-Length']) | |
| block_size = 1024 | |
| filename = datetime.strftime(datetime.now(), '%Y-%m-%d-%H-%M-%S') | |
| t=tqdm(total=file_size, unit='B', unit_scale=True, desc=filename, ascii=True) | |
| with open(filename + '.mp4', 'wb') as f: | |
| for data in file_size_request.iter_content(block_size): | |
| t.update(len(data)) | |
| f.write(data) | |
| t.close() | |
| print("Video downloaded successfully") | |
| while True: | |
| try: | |
| download() | |
| sys.exit() | |
| except (KeyboardInterrupt): | |
| print("Programme Interrupted") |
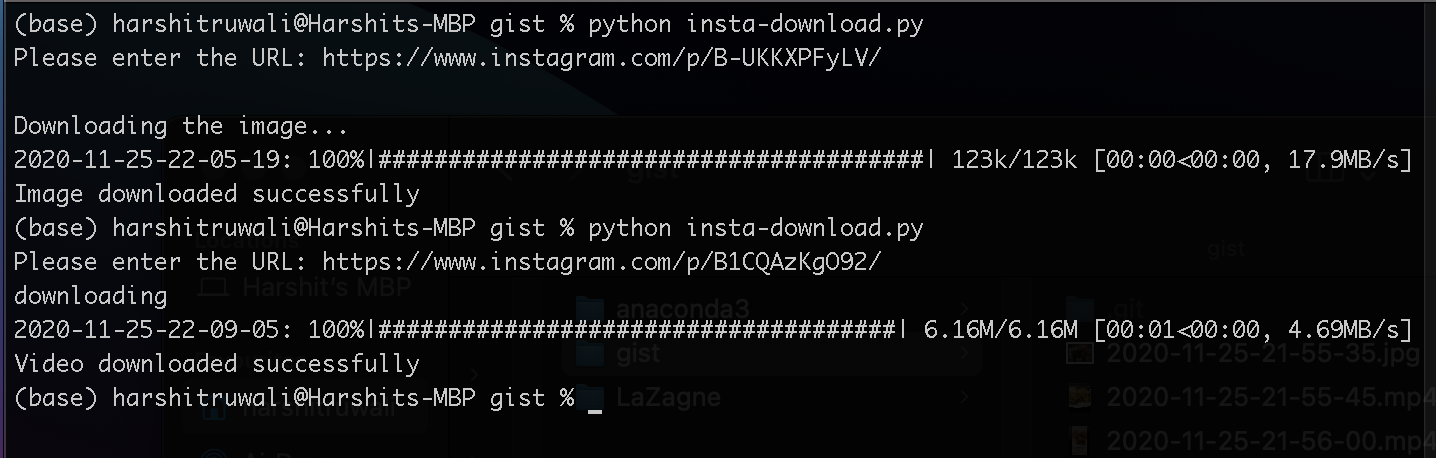
Kindly re-check. I am not getting any errors.
Here are the results for Image and Videos.
Please enter the URL: https://www.instagram.com/p/CH41AxsF1lk/
Traceback (most recent call last):
File "c:/Python/Projects/instaDDHarshitRuwali.py", line 59, in
download()
File "c:/Python/Projects/instaDDHarshitRuwali.py", line 16, in download
check_type_f = check_type.group()
AttributeError: 'NoneType' object has no attribute 'group'
i recently updated the chrome browser version to 87. is that problem?
No, updating the browser is not an issue. Its independent of that.
You are facing an issue with regex, so I suggest to give this StackOverflow question a look and tweak the code accordingly.
Btw, the image gets downloaded successfully.

i am using this code with posts links
for link in links:
if post in link and link not in post_links:
request_image = requests.get(link)
src = request_image.content.decode('utf-8')
check_type = re.search(
r'<meta name="medium" content=['"]?([^\'" >]+)', src)
check_type_f = check_type.group()
final = re.sub('<meta name="medium" content="', '', check_type_f)
if final == "video":
pass
else:
post_links.append(link)
if len(post_links) == 9: # count number of photo posts to be downloaded
for link in post_links:
print(link)
idx = post_links.index(link)+101
download_image_video(idx, link, account)
i am getting this error after 140 links...it works again after 2 days. again the same happend
Profile picture Downloading...
handy_hamper: 100%|###############################################################################################| 12.9k/12.9k [00:00<00:00, 800kB/s]
link loop started
loop link <a href= : https://www.instagram.com/p/CH2I7l5DOO_/
Unknown URL
loop link <a href= : https://www.instagram.com/p/CHEh77gjdWx/
Unknown URL
loop link <a href= : https://www.instagram.com/p/CHAK7wJnEzs/
Unknown URL
loop link <a href= : https://www.instagram.com/p/CHADKpeHY3I/
Unknown URL
I cannot say why you are getting this error. Everything is working fine on my end.
And btw there is a tool called InstaPy. Use that it will reduce you effort of getting every single link for images and stuff as you seems like to be downloading all the images from a single page.
check_type_f = check_type.group()
AttributeError: 'NoneType' object has no attribute 'group'
I getting this error