- openai에서 공개한 chatgpt api는 최대 요청 가능 텍스트의 길이가 정해져 있음 (max_token: 4096토큰: 약 3000 단어)
- 그런데 chatpdf.com 등의 서비스를 보면, 대용량의 pdf문서를 입력한 상태에서 내용을 요약해주는 모습을 볼 수 있음
- max_token 제한을 어떻게 우회한 것인지 찾아보기 시작
- text embedding 을 통해 ChatGPT에게 질문 할 때, 관련 컨텍스트를 같이 보내준다는 것을 알게 됨
- chatgpt에 제공할 수 있는 컨텍스트가 사실상 무제한으로 늘어난다는 사실을 알게 되었음
- 사내 풍부한 컨텐츠를 바탕으로 chatbot 서비스를 만들 수 있을 것 같다는 생각을 함
링크의 글을 간략하게 요약한 내용
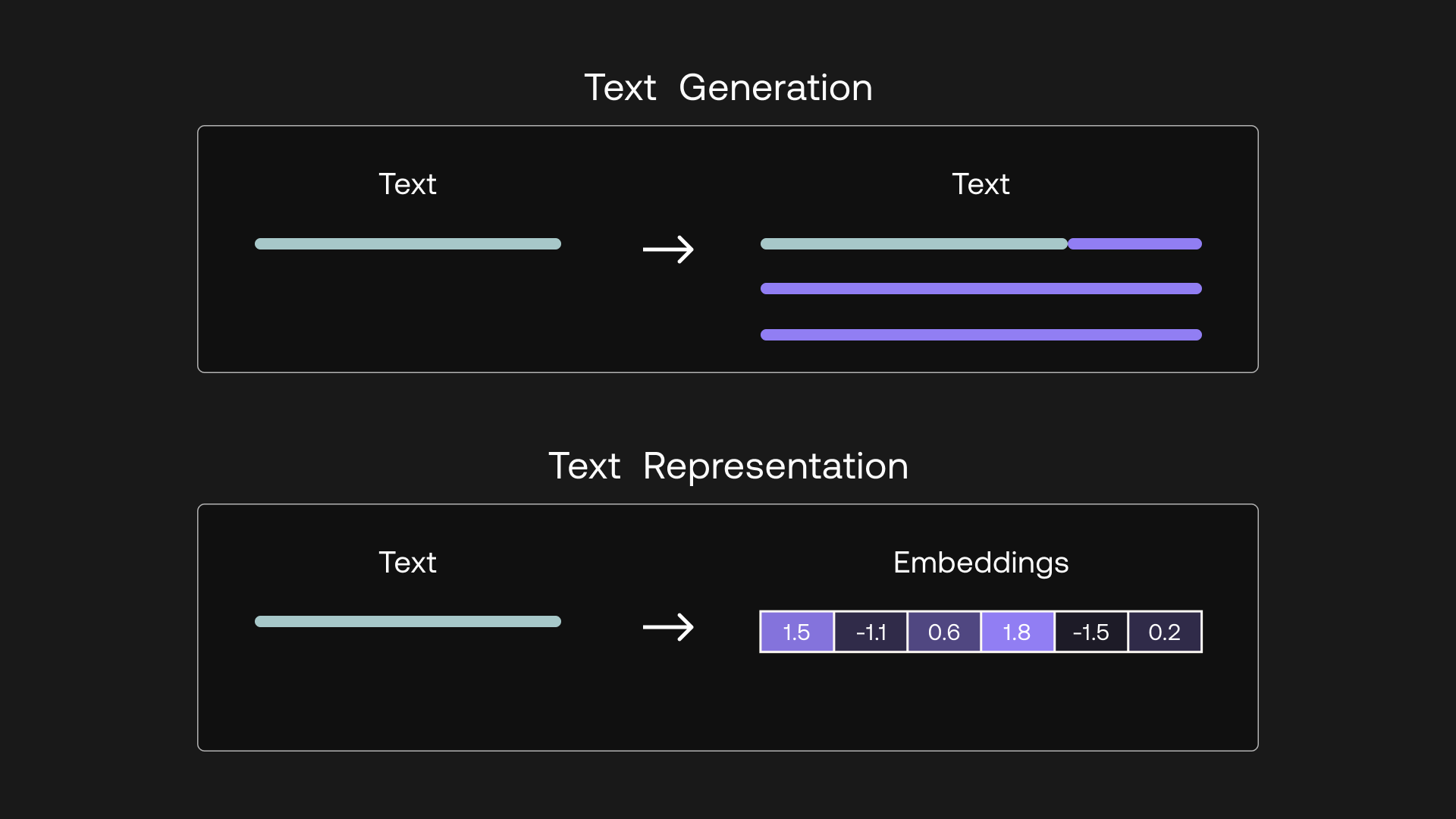
모델이 클수록 차원수가 더 많고, 각 차원은 텍스트에 대한 하나의 추가 정보를 저장. 차원 수가 증가할수록 표현력 + 정밀도가 증가
예시: "show me boston ground transport"라는 텍스트를 2048차원으로 아래와 같이 임베딩 할 수 있음
[0.20641953, 0.35582256, 0.6058123, -0.058944624, 0.8949609, 1.2956009, 1.2408538, -0.89241934, -0.56218493, -0.5521631, -0.11521566, 0.9081634, 1.662983, -0.9293592, -2.3170912, 1.177852, 0.35577637, ... ]
2048개의 차원을 표현할 수 없기 때문에 극단적으로 차원을 압축시켜서 이해하기 쉽게 만든다면 아래와 같이 표현할 수 있음
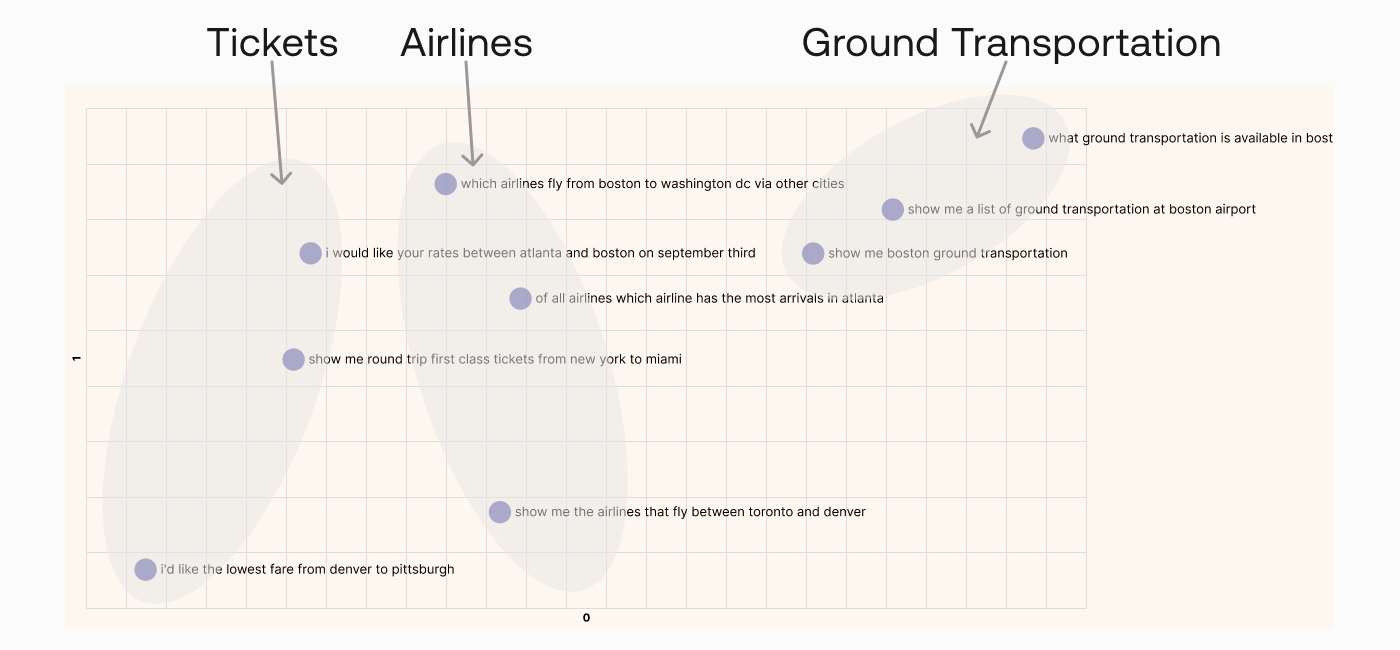
티켓에 대한 문의, 항공편에 대한 문의, 지상 교통편에 대한 문의 질문들을 2차원 좌표상에 위치시키면, 비슷한 질문들이 어떤 분포를 이뤄 위치한다는 것을 알 수 있음.
이를 바탕으로 어떤 질문이 추가적으로 들어왔을 때, 좌표 평면상 어떤 위치에 있는지를 파악한다면 그 질문이 다른 어떤 질문들과의 유사성을 갖고 있는지 파악할 수 있을 것임.
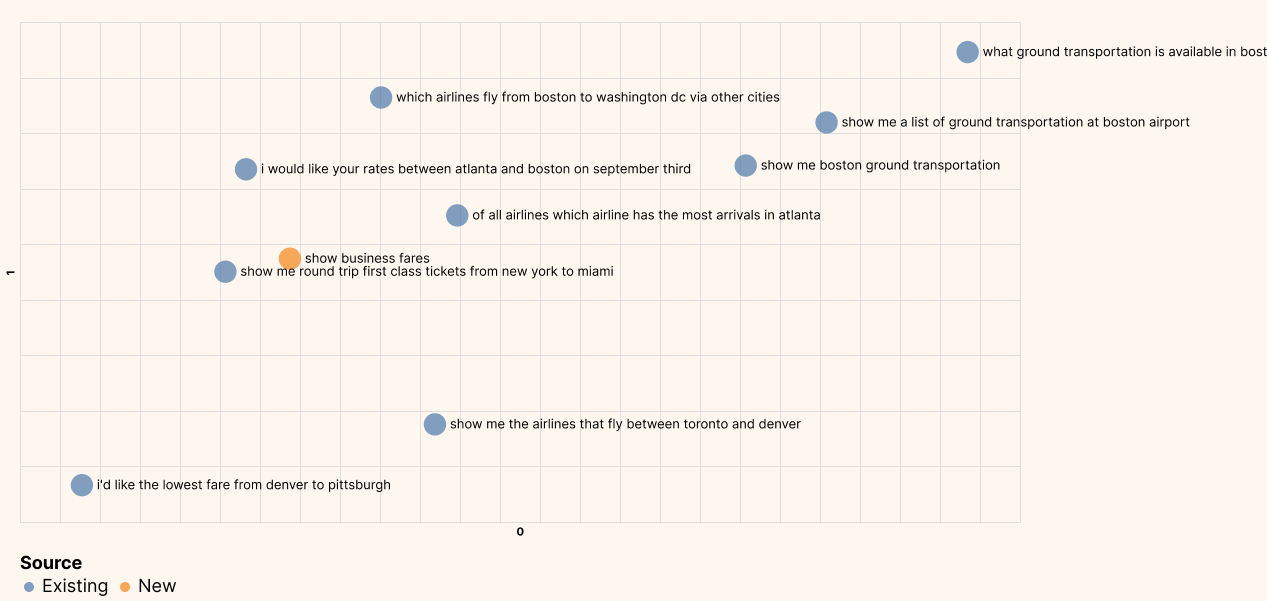
예를 들어 비즈니스 요금을 보여달라는 문의에 대해 유사한 다른 질문들을 뽑아내면, 질문에 좌석(class)이 라는 단어가 포함되어 있지 않음에도 일등석 좌석에 대한 문의를 가져옴. 그리고 유사한 질문에는 business라는 워딩도 없음.
New inquiry:
show business fares
Most similar FAQs:
Similarity: 0.52; show me round trip first class tickets from new york to miami
Similarity: 0.43; i'd like the lowest fare from denver to pittsburgh
Similarity: 0.39; show me a list of ground transportation at boston airport
즉 의미론적으로 유사한 텍스트들을 임베딩을 통해 추출할 수 있다는 의미.
새 질문의 위치가 일등석 요금 질문에 대한 위치와 가장 가깝다는 것을 볼 수 있음.

- 어학당 페이지 url 에서 html 문서 기반의 자료를 가져온다.
- 텍스트를 일정 크기로 자른다.
텍스트를 자를 분량 테스트 필요 - chatgpt에게 해당 자료가 무슨 어학당의 자료인지 대략적으로 설명해주고, 어학당을 잘 모르는 사람한테 설명할 수 있도록 친절하고 자세하게 정리해달라고 한다.
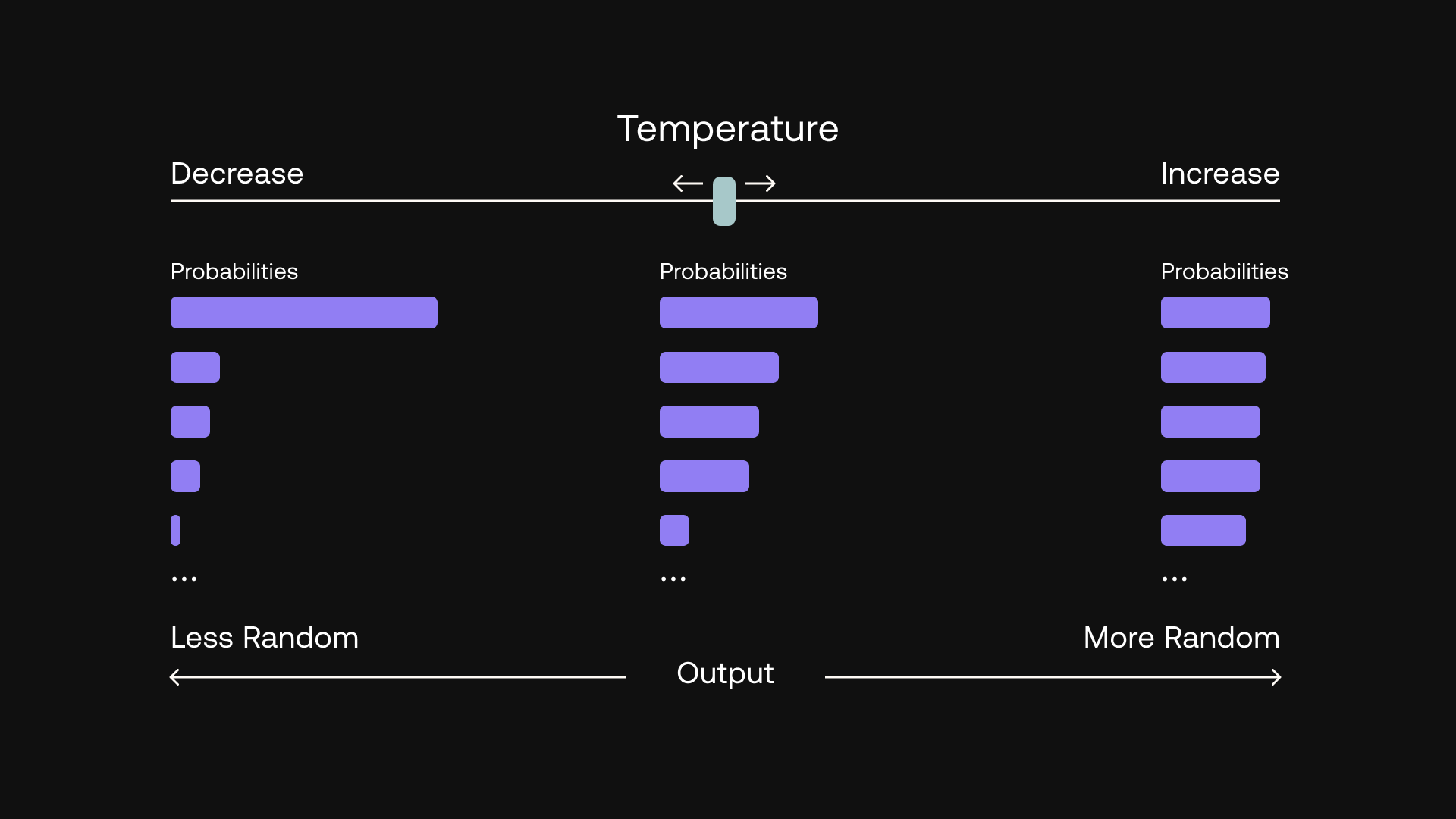
정리 요청 프롬프트 테스트 필요, temperature, top_p 값 변경하며 테스트 필요 - 정리한 내용을 바탕으로 docs를 만든다.
- 만들어진 docs를 임베딩해서 벡터 스토어에 넣는다.
- 질문 -> 질문에 대한 임베딩
질문 키워드 / chatgpt에게 요청하는 사전 프롬프트를 분리하는 방식으로 개선 가능할 것으로 보임 - 임베딩한 결과로 db에서 docs 조회 (연관성이 있는 텍스트를 함께 첨부해서 전송)
- docs를 싣고 openai api 호출
temperature, top_p 값 변경하며 테스트 필요 - 결과 반환
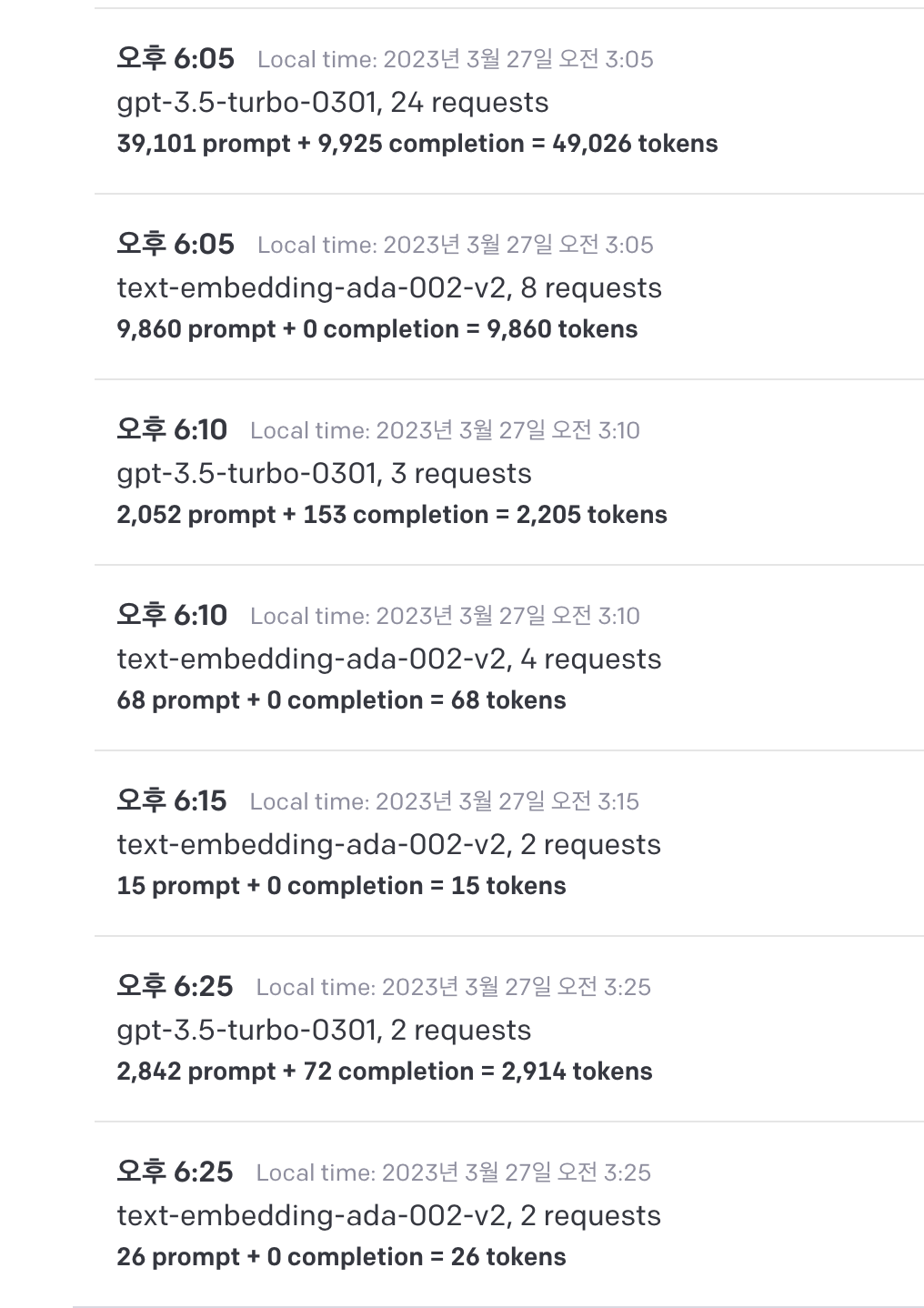
- gpt3.5-turbo 약 50,000 토큰
- text-embedding-ada-002 약 10,000 토큰
50,000/1000 * 0.002$ = 0.1$ 10,000/1000 * 0.0004$ = 0.004$
총 0.104$ = 약 135원
- gpt3.5-turbo 약 2~3,000 토큰
- text-embedding-ada-002 약 100 토큰 이내(입력 양에 따라 다름)
3,000/1000 * 0.002$ = 0.006$ 100/1000 * 0.0004$ = 0.00004$
총 약 0.006004$ = 약 8원
- docs를 싣고 openai api 호출
요 프로세스에서 docs를 덜 들고 가면 됨