Last active
December 11, 2017 03:02
-
-
Save Lerbytech/93cb6e8e2b62481860e0212932a5c0fc to your computer and use it in GitHub Desktop.
Хромов, программа 5 - Разбиение файлов.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // | |
| // 5 | |
| #include<stdio.h> | |
| #include<stdlib.h> | |
| #include<string.h> | |
| int main(int argc, char *argv[]) | |
| { | |
| //in_file.txt -n 10 -b base_ | |
| // Check | |
| if (argc != 6) | |
| { | |
| printf("ERROR! wrong number of arguments!"); | |
| } | |
| int is_key_n = 0; | |
| int is_key_b = 0; | |
| int is_key_s = 0; | |
| for (int i = 0; i < argc; i++) | |
| { | |
| if (strcmp(argv[i], "-n") == 0) is_key_n++; | |
| if (strcmp(argv[i], "-b") == 0) is_key_b++; | |
| if (strcmp(argv[i], "-s") == 0) is_key_s++; | |
| } | |
| if (is_key_n != 0 && is_key_s != 0) { | |
| printf("ERROR! -s and -n are in input"); return 0; | |
| } | |
| if (is_key_n == 0 && is_key_s == 0) | |
| { | |
| printf("ERROR! -s and -n are not found"); | |
| return 0; | |
| } | |
| if (is_key_n > 1 || is_key_s > 1) | |
| { | |
| printf("ERROR! too many -s or -n"); | |
| return 0; | |
| } | |
| if (is_key_b != 1) | |
| { | |
| printf("ERROR! -b not found or something else"); | |
| return 0; | |
| } | |
| //--- | |
| //vars | |
| char input_filename[100]; | |
| char out_filename[100]; | |
| char digit_buffer[12]; | |
| char base[50]; | |
| FILE *IN_ptrFile; // IN | |
| FILE *OUT_ptrFile; //OUT | |
| //------ | |
| strcpy(input_filename, argv[1]); | |
| strcpy(base, argv[ argc - 1 ]); | |
| fopen_s(&IN_ptrFile, input_filename, "rb"); | |
| // length | |
| fseek(IN_ptrFile, 0, SEEK_END); | |
| long lSize = ftell(IN_ptrFile); | |
| fseek(IN_ptrFile, 0, SEEK_SET); | |
| //bufsize calculate | |
| long bufSize; | |
| int N; | |
| if (is_key_n) | |
| { | |
| for (int i = 0; i < argc; i++) | |
| if (strcmp(argv[i], "-n") == 0) | |
| { | |
| N = atoi(argv[i + 1]); | |
| bufSize = lSize / N; | |
| break; | |
| } | |
| } | |
| else | |
| { | |
| for (int i = 0; i < argc; i++) | |
| if (strcmp(argv[i], "-s") == 0) | |
| { | |
| bufSize = atoi(argv[i + 1]); | |
| N = lSize / bufSize; | |
| break; | |
| } | |
| } | |
| char *buffer = (char*)malloc(sizeof(char) * bufSize); | |
| // PROCESS | |
| //------------- | |
| for (int i = 0; i < N; i++) | |
| { | |
| strcpy(out_filename, base); // filename1 = base; | |
| sprintf_s(digit_buffer, "%d", i); // 2 -> "2" | |
| strcat(out_filename, digit_buffer); | |
| strcat(out_filename, ext); | |
| fopen_s(&OUT_ptrFile, out_filename, "wb"); | |
| fread(buffer, 1, bufSize, IN_ptrFile); | |
| fwrite(buffer, 1, bufSize, OUT_ptrFile); | |
| fclose(OUT_ptrFile); | |
| fseek(IN_ptrFile, bufSize, SEEK_CUR); | |
| } | |
| long finalSize = lSize - bufSize * N; | |
| buffer = (char*)malloc(finalSize); | |
| if (finalSize > 0) | |
| { | |
| strcpy(out_filename, base); | |
| sprintf_s(digit_buffer, "%d", N + 1); | |
| strcat(out_filename, digit_buffer); | |
| strcat(out_filename, ext); | |
| fopen_s(&OUT_ptrFile, out_filename, "wb"); | |
| fread(buffer, 1, finalSize, IN_ptrFile); | |
| fwrite(buffer, 1, finalSize, OUT_ptrFile); | |
| fclose(OUT_ptrFile); | |
| } | |
| free(buffer); | |
| fclose(IN_ptrFile); | |
| printf("FINISHED!\n"); | |
| return 0; | |
| } |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Содержание
1. Условие (по Хромову)
Написать программу для разбиения исходного файла на фрагменты заданной длины или на заданное количество фрагментов одинаковой длины (за исключением последнего файла, в котором будет содержаться остаток исходного файла). При запуске программа должна получать из командной строки следующие параметры:
-s 1024, здесь значение 1024 приведено для примера, оно может быть произвольным и задает размер в байтах одного фрагмента, на которые нужно разбить исходный файл.-n 100, здесь значение 100 приведено для примера, оно может быть произвольным и задает количество фрагментов одинаковой длины, на которые нужно разбить исходный файл.-b base, здесь base имя "основы" для имен файлов с фрагментами, то есть эти файлы будут иметь имена base_1.txt, base_2.txt и т. д.Программа должна проверять корректность данных, введенных пользователем в командной строке, выводить сообщение об ошибке и завершать работу, если данные некорректны.
Параметры
-sи-nявляются взаимоисключающими, допускается наличие в командной строке только одного из них.Примеры запуска программы:
split file_ini.txt -s 2048 -b nameФайл file_ini.txt должен быть разбит на части длиной 2048 байтов, которые будут называться name_1.txt, name_2.txt и т. д.
split myfile.dat -n 200 -b baseФайл myfile.dat должен быть разбит на 200 равных частей, которые будут называться base_1.txt, base_2.txt и т. д.
Для успешной работы программы под операционными системами семейства MS WINDOWS, необходимо открывать файлы для чтения и записи в "двоичном режиме", т. е. использовать в качестве второго аргумента функции fopen "rb" или "wb".
2. Условие (упрощенно)
Само условие: Программа разбивает файл на множество других. Пользователь указывает либо количество конечных файлов, либо их размер.
Программу необходимо запускать не через среду разработки, а и из командной строки.
Немножко(нет) объяснений: В условии выше упоминаются: командная строка, параметры и общие требования к программе. Разберем подробнее.
Раньше вы запускали программу прямо из CodeBlocks либо Visual Studio. Появлялось окно, куда выводился результат и куда вводилось что-либо если того требовало условие задачи. В данной лабе впервые требуется сделать так, чтобы её можно было вызывать из командной строки. Командная строка - это отдельная программа, которая встроена в операционную систему (на Unix-подобных системах её так же называют терминалом или консолью).
Это может звучать сложно, но вы увидите что заводится подобное очень легко - нужно лишь исправить функцию main и вписать нужную логику в начале программы. Просто запомните: нет никакой разницы вводите ли вы параметры работы программы в командной строке или в самой вашей программе.
Чем отличается командная строка от CodeBlocks (и почему так сложно всё?)
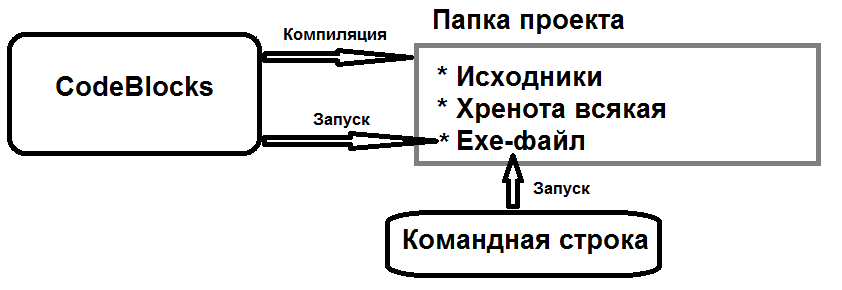
Прежде чем читать дальше, запомните одну вещь: программы могут вызывать другие программы. Когда вы включаете Excel или кликаете на иконку браузера, то программа отвечающая за рабочий стол вызывает ту программу, на которую указывает иконка. Операционную систему можно рассматривать как сложную совокупность программ которая может управлять другими программами. Так, командная строка Windows является очень мощным инструментом, встроенным в операционную систему. Она специально заточена под управление ОС - воспринимает команды вводимые пользователем и выполняет их. Львиную долю манипуляций с компьютером можно выполнять через неё (и у опытных спецов это выходит много быстрее, чем через графический интерфейс).
CodeBlocks же - это IDE, то есть интегрированная среда разработки. IDE можно представить как продвинутый текстовый редактор, совмещенный с полезными инструментами: компилятор, дебаггеры, различные профилировщики, навигацией по коду и тому подобное.
Приведем пример для понимания. CodeBlocks при запуске компиляции вызывает отдельную программу. Однако её можно было бы вызвать и вручную из командной строки:
gcc hromov5.c -o filesplitterСтрочка выше вызывает компилятор GCC и передает ему параметры:
hromov5.c- название файла с функцией main иfilesplitter- название исполняемого файла (.exe) который получим на выходе. Ключ-oуправляет настройками компилятора. В нашей лабе ближайшей аналогией ему будут ключи-n,-sи-bДля каждого созданного проекта IDE создает папку и складирует в неё исходные файлы с вашим кодом, множество своих служебных файлов и, главное, откомпилированную программу в виде исполняемого файла с расширением .exe.
Когда вы жмете кнопку "скомпилировать" (имеет рисунок шестеренки в codeblocks) IDE берет все текстовые (и иные) файлы вашей программы с исходными кодами и скармливает их компилятору. Компилятор формально является отдельной программой, которая вызывается IDE. Компилятор принимает команды от IDE, отрабатывает и создает в папке проекта исполняемый файл. Затем IDE вызывает этот файл и перед вами появляется окно программы, куда вы можете что-либо ввести. Если вы не будете перекомпилировать ваш проект, то при запуске программы IDE будет вызывать созданный ранее .exe файл. Если же перекомпилируете, то он будет переписан.
Созданный исполняемый файл можно вызывать и вручную. Просто кликните на него вне IDE и готово (так что если захотите однажды написать что-нибудь для себя знайте - не обязательно для запуска пользоваться CodeBlocks и прочим).
Существует альтернативный способ запуска вашей программы - через командную строку. Командная строка принимает имя файла, дополнительные параметры его работы, если таковые нужны, и вызывает .exe файл, передавая ему пользовательский ввод. Ниже приведена схема для лучшего понимания:
Таким образом, в данной лабораторной работе от вас просят написать программу так, чтобы ей можно было пользоваться вне CodeBlocks, а именно - через интерфейс командной строки.
3. Запуск программы с параметрами и командная строка
Ознакомимся поближе с командной строкой. Варианты вызова:
Должно появиться такое окно:
Обратите внимание на подчеркнутый красным текст. Он может отличаться от того, что будет видно на вашем компьютере, но по умолчанию должна быть папка:
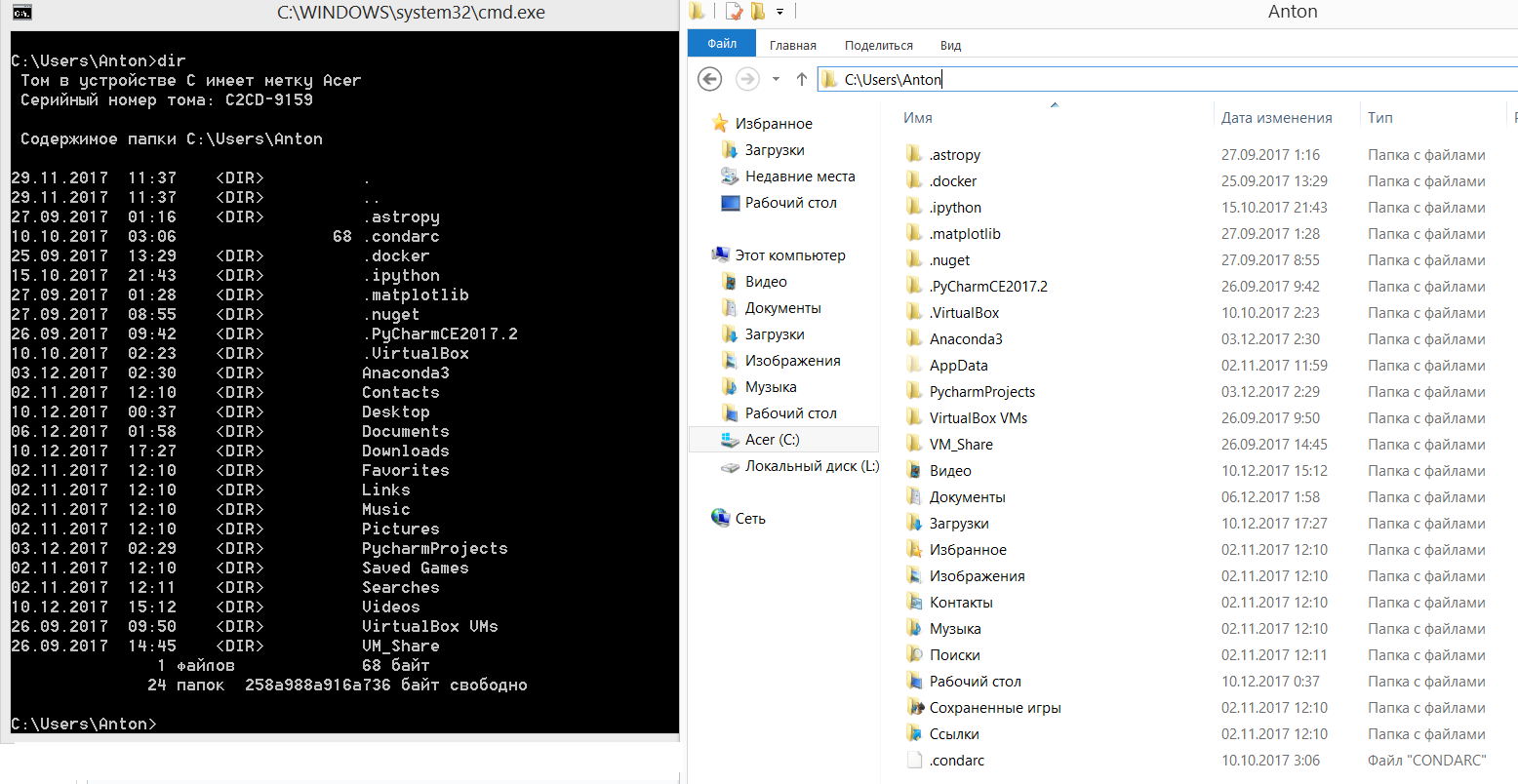
C:\Users\<название вашей учетной записи>. В силу некоторых причин, командная строка запускается "из определенной папки", то есть она видит файлы только из той папки которая сейчас для неё является активной. Между папками можно переходить (для этого есть командаcd), по умолчанию командная строка запускается из папки пользователя. Эта папка называется "рабочей директорией". Механика ничем не отличается от проводника Windows.Название рабочей директории дополняется значком
>, после которого вы можете вводить команды. Это приглашение пользователя к вводу.Покажем пример работы в командной строке и чуть лучше ознакомим вас с ней чтобы вы не пугались. Команда
dirвыводит содержимое текущей директории:Вы можете сопоставить названия файлов выведенных в командной строке с содержимым папки справа и увидеть что всё совпадает. Командная строка может использоваться для навигации по файловой системе компьютера и работе с ней.
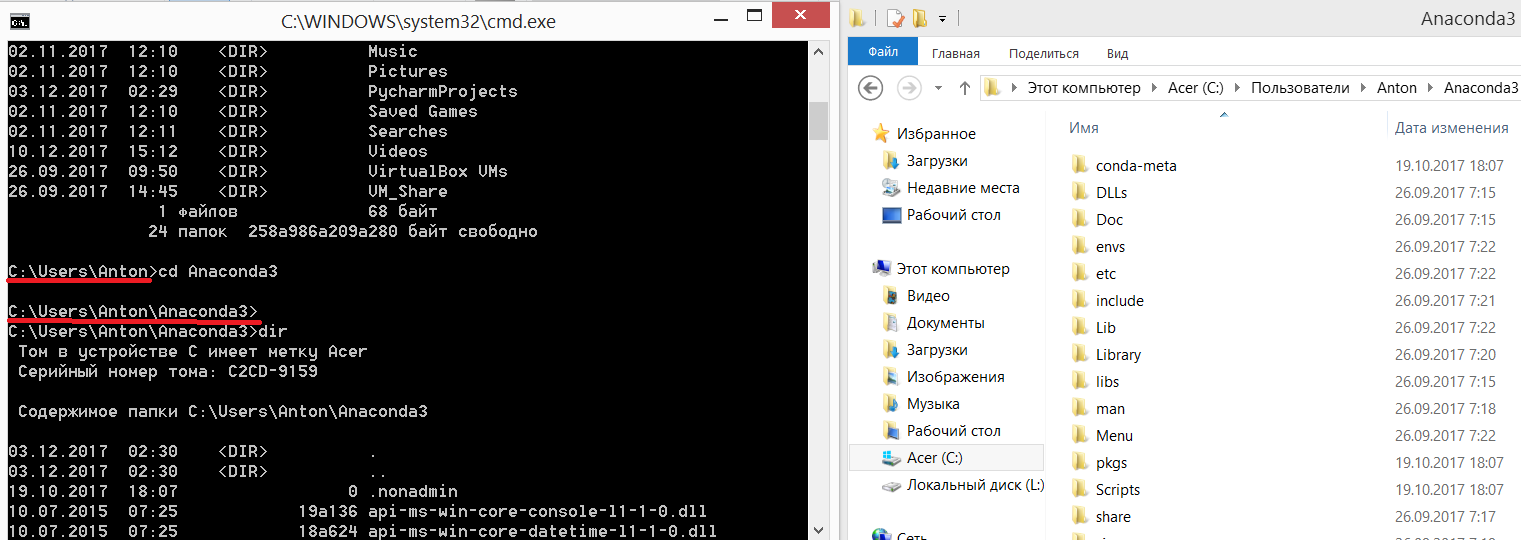
Перейдем в папку Anaconda3, для чего введём:
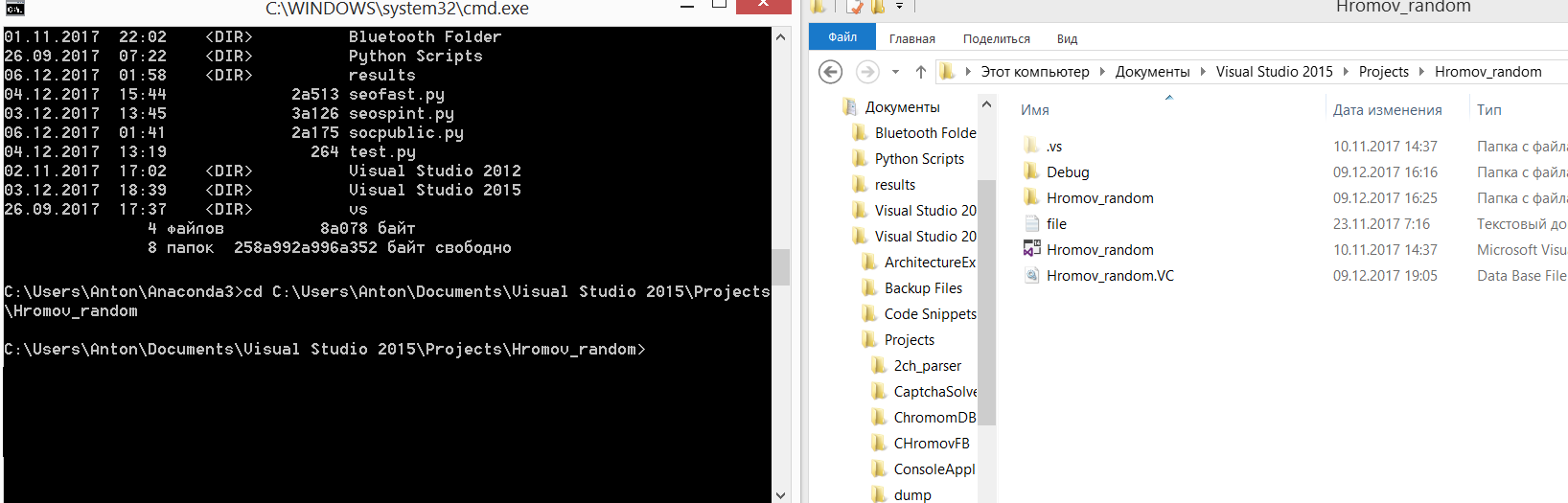
cd Anaconda3. Как можете видеть, название рабочей директории изменилось. Снова отобразим содержимое папки и сопоставим с проводником Windows:Через командную строку можно напрямую перейти в любую папку на компьютере. Перейдем сразу в папку нашей лабы:
У командной строки есть свой набор встроенных команд. К ним относятся и команды
dirиcdиз примеров выше. Если первое слово не находится в этом списке, то командная строка ищет в текущей рабочей директории исполняемый файл с совпадающим названием. Если он будет найден, то командная строка вызовет данную программу и передаст ей на вход набор введенных параметров. Если же подходящего файла нет, то будет выдана ошибка command not found, так как перебирать все файлы в компьютере в потугах найти подходящий файл долго, дорого и глупо.Из этих условий следует, что либо командную строку необходимо вызывать сразу из нужной папки (как именно будет показано позже), либо следует передавать полные пути к исполняемому файлу
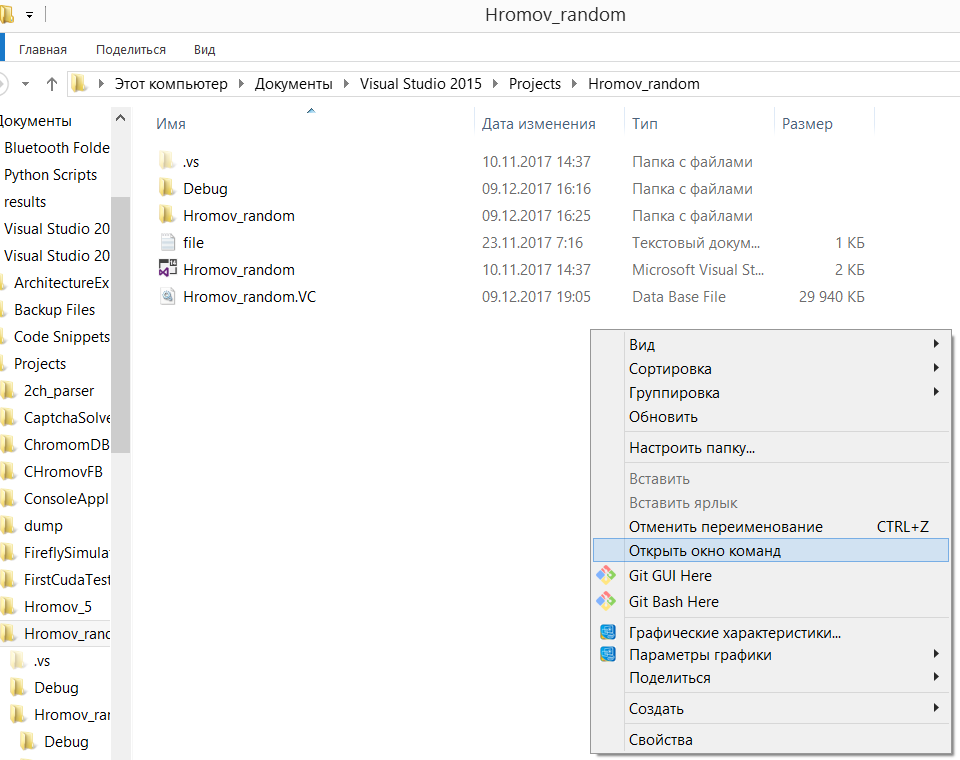
C:\Users\Admin\Documents\Visual Studio 2015\Projects\Hromov_random\Debug\filesplitter.exe(командная строка сама разберется с адресом файла представленного в таком виде). Для нашей лабы аналогично вам придется передавать полные пути и к остальным файлам. Очевидно что было бы проще не вводить полный путь. Для этого нужно либо через командуcdсменить рабочую директорию, либо сразу запустить командную строку из нужной папки.Для запуска из нужной папки перейдите в проводнике в нужную директорию, зажмите shift и кликните правой кнопкой мыши по свободному пространству. В выпадающем списке выберите "открыть окно команд"
Теперь когда вы в совершенстве освоили командную строку, разберемся как она распознает команды пользователя и как они передаются в вашу программу.
У командной строки есть своя логика работы и взаимодействия с пользователем. Когда вы вводите команду, она разбивается на отдельные слова по пробелам. Общепринято первым словом писать название выполняемой команды, а всё остальное рассматривается как её аргументы. Можете рассматривать командную строку как калькулятор, который принимает массив слов, где первое слово - это название функции F которую нужно посчитать, а остальное - её аргументы х1, х2 и т.д.
Программа на языке Cи должна содержать функцию main. На функцию main распространяются все те же требования, что и для любой другой функции на языке Си. Следовательно, функция main может принимать аргументы, в таком случае перепишем её как:
int main(int argc, char* argv[]).Такой предикат является общепринятым и отступать от него нежелательно. (но если решите поставить эксперименты обязательно расскажите мне о результатах). Приведенная строка — заголовок главной функции
main(), в скобочках объявлены параметрыargсиargv. При запуске через командную строку, введенная пользователем команда будет преобразована и передана через эти параметрыargcиargv[].Параметр
argcимеет тип данных int, и содержит количество параметров, передаваемых в функцию main.argcвсегда не меньше 1, даже когда мы не передаем никакой информации, так как первым параметром считается имя функции. Параметрargv[]это массив указателей на строки так как через командную строку можно передать только данные строкового типа.По условию лабораторной работы пользователь может ввести такую команду:
filesplitter file_ini.txt -s 2048 -b nameКомандная строка получив ввод разобьет его на отдельные слова. Получится массив из 6 слов. Затем она попытается найти встроенную команду совпадающую с первым словом. Когда ожидаемо ничего не выйдет, будет предпринята попытка найти файл исполняемый файл filesplitter.exe в текущей рабочей директории. Если он присутствует, то будет вызвана данная программа и ей на вход переданы значения
argcравный 6 иargvв виде массива строк{ 'filesplitter", "file_ini.txt" "-s" "2048" "-b" "name" }.На этапе передачи параметров вызываемой программе filesplitter роль командной строки будет исполнена. Так как мы работаем в оконном режиме, то filesplitter.exe откроется в отдельном окне и результаты работы (если таковые нужно выводить) будут выведены в нём же. Вся логика обработки команд введенных пользователем прописывается в самой вызываемой программе и командную строку не колышет как это будет реализовано. Её задача сводится лишь к превращению строки в набор
argc//argvи поиск и вызов нужной программы.В завершение рассмотрим понятие ключей. Мы рассмотрели командную строку по аналогии с калькулятором. Общепринято называть слова начинающиеся с знака тире ключами. Ключи рассматриваются как опции программы, от выбора и настроек которых зависит порядок работы программы. Следующее после ключа слово обычно является аргументом ключа. В редких случаях после ключа требуется ввести несколько слов. В таких случаях лучше почитать документацию на программу. В нашей лабе ключ
-nозначает, что исходный файл следует разбивать по количеству файлов, а аргумент200указывает их количество. Ответственность за грамотную реализацию лежит на вас как на авторах программы. Замечу, что хорошая программа всегда проверяет правильность набора ключей и уведомляет об этом пользователя в понятным для него образом, а так же индиффирентна к порядку следования ключей.4. Общая логика работы программы
Необходимо разбить исходный файл на множество файлов. Разбиение производится либо по количеству байт, либо по количеству символов. Программа должна успешно работать как с текстовыми, так и с бинарными файлами.
Процитируем Википедию:
Если требуется разбить файл на N файлов, то необходимо вычислить размер каждого файла. Если же требуется разбить файл на множество файлов заданного размера, то полезно, но не обязательно, знать количество конечных файлов. Необходимость работы с бинарными файлами наравне с текстовыми ставит нас перед дилеммой: либо писать отдельные функции для работы с текстовыми и бинарными файлами, либо писать универсальный алгоритм для обоих видов файлов. Вызвано это следующими причинами.
Для представления символов в текстовых файлах используется таблица ASCII. Для чтения текстовых файлов обычно используют методы, работающие с ними как с строками:
fgetsиfputsили группуfprintfиfscanf. Однако, данные функции не являются удобными по ряду причинам.Функция
fgetsвоспринимает последовательность символов как строку до тех пор, пока не встретит нуль-символ. По таблице ASCII значение нуль-символа равно 0. Бинарный файл как последовательность байт может содержать сколько угодно нулей, так как его устройство соответствует иным правилам в отличие от текстовых файлов. Так же, символ конца текстового файла может быть в середине потока бинарного файла, так как для него[потока] он не будет иметь смысла символаEOF. Альтернативным вариантом являютсяfprintf/fscanf. Они предоставляют возможности форматированного чтения файлов, но есть нюанс: если файл разбивается побайтово, то функция приобретает такой вид:fscanf(input_file, "%с", symbol);В таком виде технически она ничем не отличается от
fgetc, так как та тоже считывает только по одному символу за раз. Выходит, что для переноса информации из одного файла в другой мы вынуждены совершить множество операций копирования, каждая из которых переносит лишь один байт.Для чтения бинарных файлов используются функции
freadиfwrite, способные сразу работать с блоками данных произвольного размера. Данные функции позволяют копировать информацию из файла в файл как побайтово, так поблочно. При этом, размер блока можно указать равным размеру конечного файла: мы за один шаг скопируем всё, что нужно из исходного файла и перенесем это в конечный файл. Если же рассматривать текстовый файл как последовательность байт, то разница между бинарными файлами и текстовыми в рамках нашей задачи размывается.Следовательно, для решения ранее упомянутой дилеммы мы имеем выбор между написанием отдельных функций для посимвольного разбиения текстовых файлов и поблочного бинарных, либо можем написать универсальный алгоритм если рассматривать текстовые файлы как бинарные. Очевидно, что второе проще.
По условию задачи, пользователь вводит либо количество конечных файлов, либо их размеры. Размер конечного файла очевидным образом совпадает с размером блока который переносится из одного файла в другой. Для количества файлов ситуация несколько отличается. Однако мы можем найти длину исходного файла, поделить её на желаемое количество конечных файлов и найдем размер конечного файла, он же - размер блока. То есть, операция разбиения файла на N файлов является частным случаем разбиения исходного файла на файлы фиксированного размера. Впрочем, если найти кол-во конечных файлов, то мы упростим себе жизнь и при генерации их названий.
Из приведенных выше соображения опишем общие шаги работы программы:
argcиargv[]), проверить его на корректность.5. Работа с файлами
Файл в языке Си рассматривается как неструктурированная последовательность байтов. С этой точки зрения в языке программирования C файлом может быть как собственно файл на жестком диске, так и принтер, дисплей и другие подключаемые устройства ввода-вывода.
Как правило, взаимодействие между приложением и файлами производится посредством обмена блоков байт фиксированной длины (обычно длина представляет степень двойки - 256 или 512 байт). При чтении из файла данные помещаются в буфер операционной системы, а затем побайтно передаются приложению. При записи в файл данные накапливаются в буфере, а при заполнении буфера записываются на диск в виде единого блока байт.
Буферы представляют участки памяти, поэтому передача данных между приложением и буфером происходит довольно быстро в отличие от взаимодействия с физическими устройствами типа принтера. Файл вместе с предоставляемыми средствами буферизации представляет поток.
Язык программирования Си содержит необходимый функционал для работы с файлами и устройствами ввода-вывода. Для применения его применения в программе необходимо подключить заголовочный файл stdio.h.
Чтобы работать с потоком, его необходимо открыть. Для открытия потока применяется функция
fopen(), которая имеет следующий прототип:FILE * fopen(имя_файла, режим_открытия);Первый параметр представляет имя открываемого файла, а второй задает режим открытия, от которого зависит, как файл может быть обработан.
Функция возвращает указатель на структуру, которая имеет тип
FILE, определенный в том же файле stdio.h. Этот указатель идентифицирует поток в программе и через него мы сможем обращаться к открытому файлу.При открытии поток связывается со структурой
Режимы открытия
Каждый режим задается в виде набора символов. В частности, мы можем использовать следующие режимы:
Режимы позволяют разграничить доступ к файлу и открыть его только для чтения или только для записи или совместить оба варианта. Кроме того, на уровне режимов происходит разделение файлов на текстовые и бинарные. И программа будет обрабатывать файлы определенным образом, в зависимости какой режим будет выбран - для текстовых или бинарных файлов. Неправильно заданный режим может привести к некорректной интерпретации файла.
Закрытие файла
После завершения работы с файлом его следует закрыть. Для этого применяется функция
fclose():int fclose(указатель_на_поток);Единственный параметр функции представляет ранее полученный при открытии файла указатель на структуру
FILE, связанный с файлом.Функция возвращает число: 0 - в случае успешного выполнения и встроенное значение EOF в случае ошибки.
Например, откроем и закроем файл "C:\data.txt":
В процессе открытия или создания файла мы можем столкнуться с рядом ошибок, например, при открытии в режиме чтения не окажется подобного файла, недостаточно памяти и т.д. И в случае возникновения ошибки функция fopen() возвращает значение NULL. Мы можем обработать возникновение ошибки с помощью проверки результата функции:
Так как дальнейшие действия в программе в случае ошибки при открытии файла смысла не имеют, то с помощью вызова
exit(0)завершаем работу приложения.И если при попытке открытия файла по указанному пути его не окажется, то консоль выведет следующую ошибку:
fread (char *ptr, size_t size, size_t count, FILE *stream )Функция
fread()считываетcountобъектов — каждый объект поsizeсимволов в длину — из потока, указанногоstream, и помещает их в символьный массив, указанный вbuf. Указатель позиции в файле продвигается вперед на количество считанных символов.Если поток открыт для текстовых операций, то возврат каретки и последовательности перевода строки автоматически транслируются в символы новых строк. Но так как мы работаем с бинарными, то это неважно.
size_t fwrite(const void *buf, size_t size, size_t count, FILE *stream)Аналогично: функция
fwrite()записываетcountобъектов — каждый объект поsizeсимволов в длину — в поток, указанныйstream, из символьного массива, указанногоbuf. Указатель позиции в файле продвигается вперед на количество записанных символов.В общем случае, аргументы
sizeиcountперемножаются чтобы получить общее количество байтов что необходимо считать или записать из или в файл. Для нашего случая побайтового чтения размер элемента равен 1 байту, а число элементов - размеру блока в байтах.Проблема работы с
freadв том, что указатель на позицию потока не перемещается после выполнения операции считывания. Это основное отличие отfscanf/fgetc/fgets. Решается это принудительным применением командыfseek.Команда
fseekперемещает указатель файлового потока на определенную позицию. Функция имеет следующий вид:fseek (FILE *stream, long offset, int origin)Функция
fseek()устанавливает указатель положения в файле, связанном с потокомstream, в соответствии со значениямиoffsetиorigin. Аргументoffset— это выраженный в байтах сдвиг от позиции, определяемойorigin, до новой позиции. Для аргументовoriginобъявлены следующие макросы: SEEK_SET для начала файла, SEEK_CUR для текущей позиции, SEEK_END - для конца файла. Их значения соответствуют 0, 1 и 2.Для понимания представьте, что значения макросов следующие: SEEK_SET = 0, SEEK_CUR = <текущее положение потока>, SEEK_END = <конец потока, он же конец файла>. Тогда
fseek()аналогичен следующему выражению: stream = SEEK_*** + offset, где SEEK_*** - любой из макросов.Всё вместе собирается в следующий пример - откроем файл, прочитаем в нем 20 байт, отступим 10, снова прочитаем 20 и закроем его:
Вспомним общую логику работы программы:
argcиargv[]), проверить его на корректность.Рассмотрим пункт 1. Из задания следует, что параметры
-sи-nявляются взаимоисключающими, допускается наличие в командной строке только одного из них. Должен присутствовать параметр-b. Программа так же должна быть безразлична к порядку введения ключей. Будем считать, что после каждого ключа обязательно следует значение параметра (в условии это не прописано, но давайте немного упростим себе жизнь). Опишем наши проверки:argvравна 6.-n,-sи-b. Каждый ключ может быть не более чем в одном экземпляре, причем ключи -nи-s` являются взаимоисключающими. Объявим переменные счётчики количества повторов каждого параметра и пропишем логику проверки этих значений. Допустимые наборы значений: 0,1,1 или 1,0,1. Так как мы хотим выводить пользователю указание как именно он ошибся, то нам придется написать больше условий.Пройдемся по всему списку аргументов и найдем кол-во параметров.
Теперь введём проверки. Пропишем их так, чтобы было понятно как именно пользователь ошибся.
Например, можно ввести оба параметра
-nи-sИли их вообще может не быть
Можно ввести по ошибке дважды
Или ошибиться с ключем
-bВ целом, мы рассмотрели основные случаи ошибок. Теперь когда первая проверка пройдена, вытащим нужные для работы значения из пользовательского ввода.
Для работы нам понадобятся следующие переменные:
Что хранится в
argcи ячейкахargv?Строка
split file_ini.txt -s 2048 -b nameиз командной строки будет преобразована в массивargvиз 6 элементов (argcочевидно равно 6)Значения
argv:argv[0]splitargv[1]file_ini.txtargv[2]-sargv[3]2048argv[4]-bargv[5]nameПолучим название входного файла:
Ранее мы обсуждали
квантовой-волновой дуализмсхожесть текстовых и бинарных файлов и решили, что будем писать универсальный код. Так же мы рассмотрели опции-nи-sи поняли, что-nявляется частным случаем-s. Для алгоритма нам нужно найти размер исходного файла. Для этого используем волшебную функциюfseek. Формально, файловый поток показывает текущую позицию в исходном файле. Если мы переместить указатель потока в конец файла и найти расстояние между ним и началом файла, то это расстояние и будет размером. С помощьюfseekперенесем указатель в конец файла и найдем расстояние с помощью функцииftell. Вообще, она возвращает текущую позицию указателя в потоке, но для бинарных файлов эта позиция равна количеству байт от начала потока, то есть от начала файла. Мы работаем с бинарными файлами, так что "дайте две!". Единственный нюанс - функция возвращает значения типа long вместо int, но так даже правильнее: размер файла может превышать максимальное значение, что хранится в int. Для этого достаточен файл в ~1.9Гб. Довольно мало, согласитесь) Типlongспасёт наси отца русской демократии. В конце остается лишь перемотать поток обратно: поставим значение указателя в начало файла.Почему мы ищем размер файла так, а не иначе? Ведь можно было бы воспользоваться методами операционной системы. Метод
fseekиftellэто лучшее что есть не потому, что они отлично решают проблему, а потому, что остальное - ещё хуже. Подробнее здесь и здесьСледующий шаг: найти кол-во конечных файлов и размер каждого конечного файла. Методика подсчета зависит от опции: либо
-sлибо-n. Следующее слово после ключа является значением параметра. Оно представлено в текстовом виде, придется преобразовать в число с помощьюatoi. Так как по условию порядок параметров не важен, то найдем снова параметр с помощью цикла. Ранее мы убедились что все ключи стоят верно, так что искать можно в лоб:Обратите внимание что деление - целочисленное.
Для работы fread и fwrite нужен буффер. Мы нашли его размер, объявим переменную и выделим под неё память:
char *buffer = (char*)malloc(sizeof(char) * bufSize);Наконец-то переходим к основной задаче - разбиению файла.
Процедура следующая: в цикле
Определенные проблемы может вызвать составление названия исходящего файла. По идее оно следующее: <префикс> + <номер_файла_в_виде_строки> + ".txt"
В названии файла ничего нет - скопируем туда base. При пересоздании файла мы должны и перезаписать название out_filename, strcpy отлично подходит.
strcpy(out_filename, base);Для хранения строкового представления числа мы раньше объявили
digit_buffer. Функцияsprintf- это аналогprintfкоторый выводит значение не на экран, а в другую текстовую переменную.sprintf_s(digit_buffer, "%d", i);Остается добавить к названию файла это число и расширение:
strcat(out_filename, digit_buffer);strcat(out_filename, ".txt");И, наконец-то, сам кусок работы с файлами. Функция
fopenоткрывает файл на запись. Если его не существует, то файл будет создан. Если уже существует файл с таким названием, то он будет перезаписан.fopen_s(&OUT_ptrFile, out_filename, "wb");Считаем блок и сразу запишем его в исходящий файл (ну а что с ним ещё делать помимо этого?)
fread(buffer, 1, bufSize, IN_ptrFile);fwrite(buffer, 1, bufSize, OUT_ptrFile);Исходящий файл больше не нужен - можно закрыть
fclose(OUT_ptrFile);Переместим указатель в исходном файле на размер буфера вправо, чтобы считывать на следующей итерации новый кусок.
fseek(IN_ptrFile, bufSize, SEEK_CUR);Всё! На этом основной блок программы закончен. Нам остается лишь обработать остаток файла если таковой будет. Ранее мы высчитали количество исходящих файлов N. Их суммарный размер меньше либо равен размеру исходного файла.
Найдем разницу.
long finalSize = lSize - bufSize * N;Эта разница меньше, чем bufSize и, следовательно, меньше чем размера буфера. Нам нужно пересчитать размер
buffer:buffer = (char*)malloc(finalSize);Теперь мы можем повторить процедуру и скинуть в конечный файл оставшийся кусок:
В конце остается лишь прибраться за собой: очистим буффер и закроем входящий файл:
free(buffer);fclose(IN_ptrFile);Дополнительно можно вывести в консоль сообщение пользователю:
printf("FINISHED!\n");7. Вызов
Пара замечаний как это всё дело запускать.
Вариантов два:
Для CodeBlocks проследуйте в Project -> Set programs arguments, далее аналогично.
Теперь при запуске IDE вызываемому исполняемому файлу автоматически будут передаваться пользовательские аргументы, то есть IDE будет имитировать ввод из командной строки. В случае затруднений с CodeBlocks гуглите по запросам "CodeBlocks run with arguments"
Если ваша программа не может найти входящий файл, то сделайте следующее: в самом начале функции main создайте левый файл.
Этот код создает файл с названием TEMPFILE_FINDME.txt. Теперь вам нужно найти в папке проекта этот файл и поместить входящие файлы в содержащую временный файл папку. Исходящие файлы будут сохраняться в эту же папку.
Не забудьте удалить временный файл и сам временный код.