Pipeline orchestration in DELVE CRMint for StrideGaming PLTV model
The aim of current project to provide fully automated PLTV predictions process to DCM API. As the main tool for that, we chosen DELVE CRMint under Google Cloud Composer, which no-ops fully manageable solution in the google cloud. It provides schedule, e-mail notifications and monitor pipelines that span across google cloud.
CRMint instance: https://delve-internal-crm-v1.appspot.com/
CRMint pipeline: https://delve-internal-crm-v1.appspot.com/pipelines/14
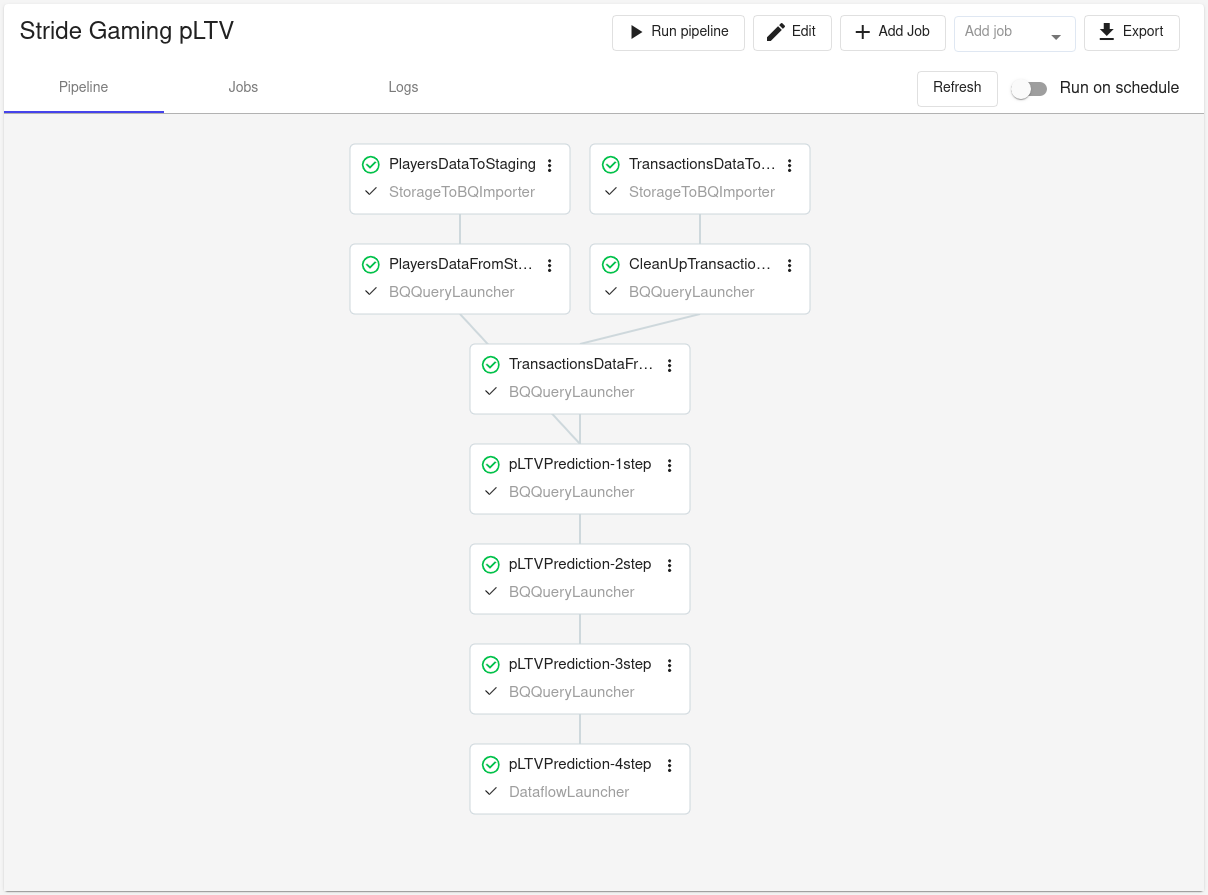
In DELVE CRMint instance where was created a pipeline called Stride Gaming pLTV, that includes the following jobs:
-
PlayersDataToStaging(Unload of players stat on player level. The aim is to unload actual data from the google storage bucket (gs://cirrus1-bucket-elt/Upload) to "staging" BQ table (project-cirrus-1.phase_2_maryia.players_stg) on daily basis. Loading data into the google storage bucket is under SG Data Engineering team responsibility. Loading files into the BQ table is under that job responsibility. In job parameters where used the next pattern gs://cirrus1-bucket-elt/Upload/player_stats_$(date+"%Y_%m_%d")* to load only actual data for current date. On each run job is overwriting BQ table with the new data) -
PlayersDataFromStgToTarget(Copies data from "staging" BQ table (project-cirrus-1.phase_2_maryia.players_stg) to "players" BQ table (project-cirrus-1.phase_2_maryia.players) with casting "LastLogindatetime" column to date type and renaming it to "LastLogindate" and adding a timestamp column of inserting time named "timestamp_inserted". Runs directly after the PlayersDataToStaging job if it was successful) -
TransactionsDataToStaging(Unload of transactional players data. The aim is to unload actual data from the google storage bucket (gs://cirrus1-bucket-elt/TransactionalDaily) to "staging" BQ table (project-cirrus-1.phase_2_maryia.trans_balance_stg) on daily basis. Loading data into the google storage bucket is under SG Data Engineering team responsibility as well. Loading files into the BQ table is under that job responsibility. In job parameters where used the next pattern gs://cirrus1-bucket-elt/TransactionalDaily/Fact_Balance_$(date+"%Y_%m_%d")* to load only actual data for current date. On each run job is overwriting BQ table with the new data) -
CleanUpTransactionsTarget(Removes all records with previous date in the "trans_balance" BQ table (project-cirrus-1.phase_2_maryia.trans_balance) by "DateKey" column. Runs directly after the TransactionsDataToStaging job if it was successful) -
TransactionsDataFromStgToTarget(Copies data from "staging" BQ table (project-cirrus-1.phase_2_maryia.trans_balance_stg) to "trans_balance" BQ table (project-cirrus-1.phase_2_maryia.trans_balance) with adding a timestamp column of inserting time named "timestamp_inserted". Runs directly after the CleanUpTransactionsTarget job if it was successful) -
pLTVPrediction-1step(TODO. Runs directly after the PlayersDataFromStgToTarget and TransactionsDataFromStgToTarget jobs if they were successful) -
pLTVPrediction-2step(Copies data from "ltv_players_features" BQ table (project-cirrus-1.phase_2_maryia.ltv_players_features) with the last process_id filter to "ltv_players_features_df" BQ table (project-cirrus-1.phase_2_maryia.ltv_players_features_df). On each run job is overwriting BQ table with the new data. Runs directly after the pLTVPrediction-1step job if it was successful) -
pLTVPrediction-3step(Copies data from "ltv_players_features_df" BQ table (project-cirrus-1.phase_2_maryia.ltv_players_features_df) with One Hot Encoding of the specified columns to "ltv_players_features_preproc" BQ table (project-cirrus-1.phase_2_maryia.ltv_players_features_preproc). On each run job is overwriting BQ table with the new data. Runs directly after the pLTVPrediction-2step job if it was successful) -
pLTVPrediction-4step(Runs a DataFlow template located in the google storage bucket (gs://project-cirrus-1-df/templates/predict_pipeline). Runs directly after the pLTVPrediction-3step job if it was successful. DataFlow template reads data from "ltv_players_features_preproc" BQ table (project-cirrus-1.phase_2_maryia.ltv_players_features_preproc), loads prediction model from the google storage bucket (gs://ltvml/scikitlearn/), does ETL players features processing, LTV prediction and loads prediction to target "ltv_players_predict" BQ table (project-cirrus-1.phase_2_maryia.ltv_players_predict))
Pipeline scheduled for execution on 10:00 AM UTC time and runs each job consistently or parallel (see the picture above). If any job fail you will receive an email notification with details for further investigations. Email and scheduling can be configured on the pipeline setting page: https://delve-internal-crm-v1.appspot.com/pipelines/14/edit
You can run any of the job in the pipeline manually in the web UI, just make sure all of the dependencies (like google storage) are exists.