git clone [email protected]:YOUR-USERNAME/YOUR-FORKED-REPO.git
cd into/cloned/fork-repo
git remote add upstream git://github.com/ORIGINAL-DEV-USERNAME/REPO-YOU-FORKED-FROM.git
git fetch upstream
git clone [email protected]:YOUR-USERNAME/YOUR-FORKED-REPO.git
cd into/cloned/fork-repo
git remote add upstream git://github.com/ORIGINAL-DEV-USERNAME/REPO-YOU-FORKED-FROM.git
git fetch upstream
create different ssh key according the article Mac Set-Up Git
$ ssh-keygen -t rsa -C "[email protected]"
| Originall From: Posted 2015-05-29 http://ubwg.net/b/full-list-of-ffmpeg-flags-and-options | |
| This is the complete list that’s outputted by ffmpeg when running ffmpeg -h full. | |
| usage: ffmpeg [options] [[infile options] -i infile]… {[outfile options] outfile}… | |
| Getting help: | |
| -h — print basic options | |
| -h long — print more options | |
| -h full — print all options (including all format and codec specific options, very long) |
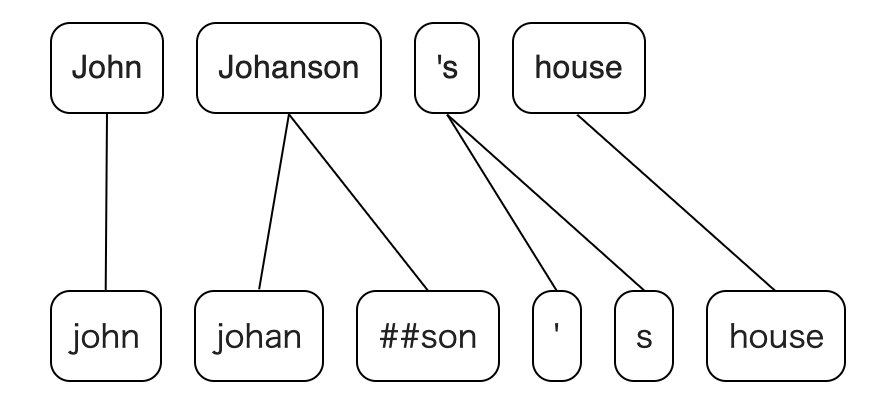
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links:
| """ | |
| The code below combines approaches published by both @eugene-yh and @jinyongyoo on Github. | |
| Thanks for the contributions guys! | |
| """ | |
| import torch | |
| import peft |