trait Foo {}
fn bug() -> impl Foo<[(); |_: ()| {}]> {}
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import re | |
| def prime(n: int): | |
| return re.match(r"^(aa+?)\1+$", "a" * n) is None | |
| for i in range(2, 10000): | |
| if prime(i): | |
| print(i) |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #![allow(unused_imports)] | |
| #![allow(unused_macros)] | |
| use std::cmp::Reverse as R; | |
| use std::collections::*; | |
| use std::io::{stdin, BufWriter, Read, Write}; | |
| use std::mem; | |
| #[allow(unused_macros)] | |
| macro_rules! parse { | |
| ($it: ident ) => {}; |
tamuhey
/ rust_memory_reorder.rs
Created
September 5, 2020 16:07
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // Ref: https://preshing.com/20120515/memory-reordering-caught-in-the-act/ | |
| // Let's change `Relaxed` to `SeqCst` and see what changed | |
| use std::sync::atomic::AtomicUsize; | |
| use std::sync::atomic::Ordering::*; | |
| use std::thread::spawn; | |
| static X: AtomicUsize = AtomicUsize::new(0); | |
| static Y: AtomicUsize = AtomicUsize::new(0); | |
| use rand; | |
| use rand::Rng; |
tamuhey
/ tokenizations_post.md
Last active
July 27, 2024 14:46
How to calculate the alignment between BERT and spaCy tokens effectively and robustly
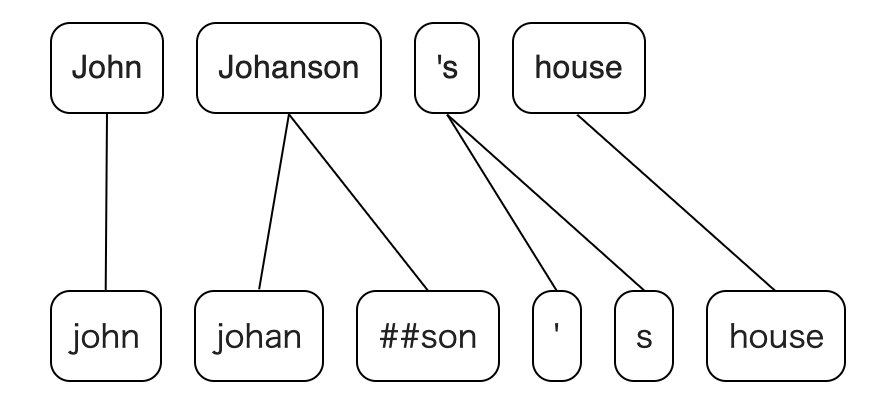
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| docker build -t test . <<EOF | |
| FROM busybox | |
| RUN mkdir /tmp/build/ | |
| # Add context to /tmp/build/ | |
| COPY . /tmp/build/ | |
| EOF | |
| docker run --rm -it test find /tmp/build |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| test |
言語処理をする際,mecabなどのトークナイザを使って分かち書きすることが多いと思います.本記事では,異なるトークナイザの出力(分かち書き)の対応を計算する方法とその実装(tokenizations)を紹介します. 例えば以下のような,sentencepieceとBERTの分かち書きの結果の対応を計算する,トークナイザの実装に依存しない方法を見ていきます.
# 分かち書き
(a) BERT : ['フ', '##ヘルト', '##ゥス', '##フルク', '条約', 'を', '締結']
(b) sentencepiece : ['▁', 'フ', 'ベル', 'トゥス', 'ブルク', '条約', 'を', '締結']
tamuhey
/ tokenizations.md
Last active
February 18, 2020 11:12
言語処理をする際,mecabなどのトークナイザを使ってテキストを分かち書きすることが多いと思います.本記事では,異なるトークナイザの出力(分かち書き)の対応を計算する方法とその実装(tokenizations)を紹介します. 例えば以下のような,sentencepieceとBERTの分かち書きの結果の対応を計算する,トークナイザの実装に依存しない一般的な方法を見ていきます.
# 分かち書き
(a) BERT : ['フ', '##ヘルト', '##ゥス', '##フルク', '条約', 'を', '締結']
(b) sentencepiece : ['▁', 'フ', 'ベル', 'トゥス', 'ブルク', '条約', 'を', '締結']
tamuhey
/ tokenizations.md
Created
February 18, 2020 11:03
https://github.com/tamuhey/tokenizations
言語処理をする際,mecabなどのトークナイザを使ってテキストを分かち書きすることが多いと思います.本記事では,異なるトークナイザの出力(分かち書き)の対応を計算する方法とその実装(tokenizations)を紹介します. 例えば,以下のようなsentencepieceとBERTの分かち書きの結果の対応を計算する,トークナイザの実装に依存しない一般的な方法を見ていきます.
# 分かち書き
(a) BERT : ['フ', '##ヘルト', '##ゥス', '##フルク', '条約', 'を', '締結']
(b) sentencepiece : ['▁', 'フ', 'ベル', 'トゥス', 'ブルク', '条約', 'を', '締結']
NewerOlder