Below you have some articles related about prompting and some papers
GPT can [tell bad jokes](https://zapier.com/blog/can-chatgpt-be-funny) and write accidentally hilarious poems about your life, but it can also help you do your job better. The catch: you need to help it do _its_ job better, too.At its most basic level, OpenAI's GPT-3 and GPT-4 predict text based on an input called a prompt. But to get the best results, you need to write a clear prompt with ample context. After tinkering with it for more hours than I'd like to admit, these are my tips for writing an effective GPT-3 or GPT-4 prompt.
There's very little chance that the first time you put your AI prompt in, it'll spit out exactly what you're looking for. You need to write, test, refine, test, and so on, until you consistently get an outcome you're happy with. I recommend testing your prompt in the OpenAI playground or with Zapier's OpenAI integration.
GPT vs. ChatGPT. GPT-3 and GPT-4 aren't the same as ChatGPT. ChatGPT, the conversation bot that you've been hanging out with on Friday nights, has more instructions built in from OpenAI. GPT-3 and GPT-4, on the other hand, are a more raw AI that can take instructions more openly from users. The tips here are for GPT-3 and GPT-4—but they can apply to your ChatGPT prompts, too.
As you're testing, you'll see a bunch of variables—things like model, temperature, maximum length, stop sequences, and more. It can be a lot to get the hang of, so to get started, I suggest playing with just two of them.
-
Temperature allows you to control how creative you want the AI to be (on a scale of 0 to 1). A lower score makes the bot less creative and more likely to say the same thing given the same prompt. A higher score gives the bot more flexibility and will cause it to write different responses each time you try the same prompt. The default of 0.7 is pretty good for most use cases.
-
Maximum length is a control of how long the combined prompt and response can be. If you notice the AI is stopping its response mid-sentence, it's likely because you've hit your max length, so increase it a bit and test again.
Help the bot help you. If you do each of the things listed below—and continue to refine your prompt—you should be able to get the output you want.
Just like humans, AI does better with context. Think about exactly what you want the AI to generate, and provide a prompt that's tailored specifically to that.
Here are a few examples of ways you can improve a prompt by adding more context:
Basic prompt: "Write about productivity."
Better prompt: "Write a blog post about the importance of productivity for small businesses."
By including the type of content ("blog") as well as some details on what specifically to cover in the blog post, the bot will be a lot more helpful.
Here's another example, this time with different types of details.
Basic prompt: "Write about how to house train a dog."
Better prompt: "As a professional dog trainer, write an email to a client who has a new 3-month-old Corgi about the activities they should do to house train their puppy."
In the better prompt, we ask the AI to take on a specific role ("dog trainer"), and we offer specific context around the age and type of dog. We also, like in the previous example, tell them what type of content we want ("email").
The AI can change the writing style of its output, too, so be sure to include context about that if it matters for your use case.
Basic prompt: "Write a poem about leaves falling."
Better prompt: "Write a poem in the style of Edgar Allan Poe about leaves falling."
This can be adapted to all sorts of business tasks (think: sales emails), too—e.g., "write a professional but friendly email" or "write a formal executive summary."
Let's say you want to write a speaker's introduction for yourself: how is the AI supposed to know about you? It's not that smart (yet). But you can give it the information it needs, so it can reference it directly. For example, you could copy your resume or LinkedIn profile and paste it at the top of your prompt like this:
Reid's resume: [paste full resume here]
Given the above information, write a witty speaker bio about Reid.
Another common use case is getting the AI to summarize an article for you. Here's an example of how you'd get OpenAI's GPT-3 to do that effectively.
[Paste the full text of the article here]
Summarize the content from the above article with 5 bullet points.
Remember that GPT-3 and GPT-4 only have access to things published prior to 2021, and they have no internet access. This means you shouldn't expect it to be up to date with recent events, and you can't give it a URL to read from. While it might appear to work sometimes, it's actually just using the text within the URL itself (as well as its memory of what's typically on that domain) to generate a response.
(The exception here is if you're using ChatGPT Plus and have turned on access to its built-in Bing web browser.)
Providing examples in the prompt can help the AI understand the type of response you're looking for (and gives it even more context).
For example, if you want the AI to reply to a user's question in a chat-based format, you might include a previous example conversation between the user and the agent. You'll want to end your prompt with "Agent:" to indicate where you want the AI to start typing. You can do so by using something like this:
You are an expert baker answering users' questions. Reply as agent.
Example conversation:
User: Hey can you help me with something
Agent: Sure! What do you need help with?
User: I want to bake a cake but don't know what temperature to set the oven to.
Agent: For most cakes, the oven should be preheated to 350°F (177°C).
Current conversation:
User: [Insert user's question]
Agent:
Examples can also be helpful for math, coding, parsing, and anything else where the specifics matter a lot. If you want to use OpenAI to format a piece of data for you, it'll be especially important to give it an example. Like this:
Example:
Input: 2020-08-01T15:30:00Z
Add 3 days and convert the following time stamp into MMM/DD/YYYY HH:MM:SS format
Output: Aug/04/2020 15:30:00
Input: 2020-07-11T12:18:03.934Z
Output:
Providing positive examples (those that you like) can help guide the AI to deliver similar results. But you can also tell it what to avoid by showing it negative examples—or even previous results it generated for you that you didn't like.
Basic prompt: Write an informal customer email for a non-tech audience about how to use Zapier Interfaces.
Better prompt: Write a customer email for a non-tech audience about how to use Zapier Interfaces. It should not be overly formal. This is a "bad" example of the type of copy you should avoid: [Insert bad example].
When crafting your GPT prompts, It's helpful to provide a word count for the response, so you don't get a 500-word answer when you're looking for a sentence (or vice versa). You might even use a range of acceptable lengths.
For example, if you want a 500-word response, you could provide a prompt like "Write a 500-750-word summary of this article." This gives the AI the flexibility to generate a response that's within the specified range. You can also use less precise terms like "short" or "long."
Basic prompt: "Summarize this article."
Better prompt: "Write a 500-word summary of this article."
GPT can output various code languages like Python and HTML as well as visual styles like charts and CSVs. Telling it the format of both your input and your desired output will help you get exactly what you need. For example:
Product Name,Quantity
Apple,1
Orange,2
Banana,1
Kiwi,1
Pineapple,2
Jackfruit,1
Apple,2
Orange,1
Banana,1
Using the above CSV, output a chart of the frequency each product appears in the text above.
It's easy to forget to define the input format (in this case, CSV), so be sure to double-check that you've done that.
Another example: perhaps you want to add the transcript of your latest podcast interview to your website but need it converted to HTML. The AI is great at doing this, but you need to tell it exactly what you need.
[Insert full text of an interview transcript]
Output the above interview in HTML.
Another effective strategy for creating powerful prompts is to have the AI do it for you. That's not a joke: you can ask GPT to craft the ideal prompt based on your specific needs—and then reuse it on itself.
The idea here is to use the AI model as a brainstorming tool, employing its knowledge base and pattern recognition capabilities to generate prompt ideas that you might not have considered.
To do this, you just need to frame your request as clearly and specifically as possible—and detail the parameters of your needs. For example, say you want GPT to help you understand error messages when something goes wrong on your computer.
Basic prompt: I'm looking to create a prompt that explains an error message.
Better prompt: I'm looking to create a prompt for error messages. I have a few needs: I need to understand the error, I need the main components of the error broken down, and I need to know what's happened sequentially leading up to the error, its possible root causes, and recommended next steps—and I need all this info formatted in bullet points.
GPT will take those requirements into consideration and return a prompt that you can then use on it—it's the circle of (artificial) life.
Sometimes it's just about finding the exact phrase that OpenAI will respond to. Here are a few phrases that folks have found work well with OpenAI to achieve certain outcomes.
"Let's think step by step"
This makes the AI think logically and can be specifically helpful with math problems.
"Thinking backwards"
This can help if the AI keeps arriving at inaccurate conclusions.
"In the style of [famous person]"
This will help match styles really well.
"As a [insert profession/role]"
This helps frame the bot's knowledge, so it knows what it knows—and what it doesn't.
"Explain this topic for [insert specific age group]"
Defining your audience and their level of understanding of a certain topic will help the bot respond in a way that's suitable for the target audience.
"For the [insert company/brand publication]"
This helps GPT understand which company you're writing or generating a response for, and can help it adjust its voice and tone accordingly.
GPT can respond from a designated point of view (e.g., market researcher or expert in solar technologies) or in a specific coding language without you having to repeat these instructions every time you interact with it.
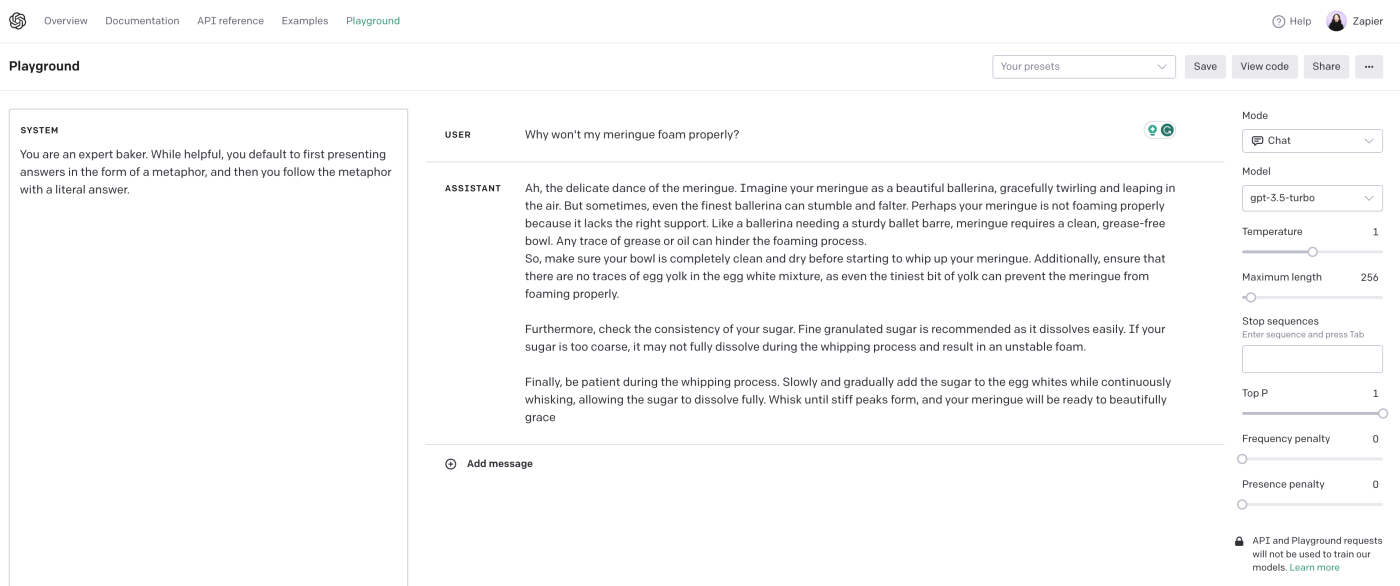
To do this, in the OpenAI playground, modify the System prompt from its default "You are a helpful assistant" to whatever you want GPT to be. For example:
You are an expert baker. While helpful, you default to first presenting answers in the form of a metaphor, and then you follow the metaphor with a literal answer.
By giving GPT a role, you're automatically adding persistent context to any future prompts you input.
If you're using ChatGPT, you can do something similar with custom instructions. Simply tell ChatGPT the reference material or instructions you want it to consider every time it generates a response, and you're set.
Now that you know how to write an effective prompt, it's time to put that skill to use in your workflows. With Zapier's OpenAI and ChatGPT integrations, you can automate your prompts, so they run whenever things happen in the apps you use most. That way, you can do things like automatically draft email responses, brainstorm content ideas, or create task lists. Here are a few pre-made workflows to get you started.
Slack + ChatGPT
More details
Ready to bring the power of ChatGPT to your Slack workspace? Use this Zap to create a reply bot that lets you have a conversation with ChatGPT right inside Slack when a prompt is posted in a particular channel. Now, your team can ask questions and get responses without having to leave Slack.
Dropbox + PDF.co + ChatGPT
More details
Whenever a new file is added to a Dropbox folder, PDF.co will convert it to a PDF automatically. Afterwards get the document summary with the help of ChatGPT.
Slack + ChatGPT + Notion
More details
This Zapier template automates the process of task creation in Notion's kanban board using ChatGPT and Slack reactions. When a user adds a specific reaction to a message in Slack, ChatGPT generates a task from the message and adds it to Notion. The template then adds the task to the designated kanban board, making it easy to track and manage. This template streamlines task management and saves valuable time for teams.
Gmail + OpenAI (GPT-3, DALL-E, Whisper)
More details
Whenever you receive a new customer email, create different email responses with OpenAI and save them automatically as Gmail drafts. This Zap lets you send your prospects and clients better-worded, faster email responses without any added clicks or keystrokes.
Zapier Chrome extension + OpenAI (GPT-3, DALL-E, Whisper) + Web Parser by Zapier
More details
Take control of your reading list with this AI automation. With this Zap, you can select an article right from your browser and automatically get a summary of the content from OpenAI. Catch up on industry news or create content for an email newsletter with just a few clicks.
Or you can use Zapier and GPT to build your own AI chatbot. Zapier's free AI chatbot builder uses the power of GPT to help you customize your own chatbot—no coding required.
Zapier is the leader in workflow automation—integrating with 6,000+ apps from partners like Google, Salesforce, and Microsoft. Use interfaces, data tables, and logic to build secure, automated systems for your business-critical workflows across your organization's technology stack. Learn more.
And here are some deeper dives into how you can automate your GPT-3 and GPT-4 prompts:
Want to build GPT-powered apps for your clients or coworkers? Zapier's new Interfaces product makes it easy to create dynamic web pages that trigger automated workflows.
This article was originally published in January 2023 and has also had contributions from Elena Alston and Jessica Lau. The most recent update was in August 2023.
Generative AI is finally coming into its own as a tool for research, learning, creativity and interaction. The key to a modern generative AI interface is the prompt: the request that users compose to query an AI system in an attempt to elicit a desirable response.But AI has its limits, and getting the right answer means asking the right question. AI systems lack the insight and intuition to actually understand users' needs and wants. Prompts require careful wording, proper formatting and clear details. Often, prompts should avoid much of the slang, metaphors and social nuance that humans take for granted in everyday conversation.
Getting the most from a generative AI system requires expertise in creating and manipulating prompts. Here are some ideas that can help users construct better prompts for AI interactions.
A prompt is a request made by a human to a generative AI system, often a large language model.
Many prompts are simply plain-language questions, such as "What was George Washington's middle name?" or "What time is sunset today in the city of Boston?" In other cases, a prompt can result in tangible outcomes, such as the command "Set the thermostat in the house to 72 degrees Fahrenheit" for a smart home system.
But prompts can also involve far more complicated and detailed requests. For example, a user might request a 2,000-word explanation of marketing strategies for new computer games, a report for a work project, or pieces of artwork and music on a specific topic.
Prompts can grow to dozens or even hundreds of words that detail the user's request, set formats and limits, and include guiding examples, among other parameters. The AI system's front-end interface parses the prompt into actionable tasks and parameters, then uses those extracted elements to access data and perform tasks that meet the user's request within the limits of the system's underlying models and data set.
At a glance, the idea of a prompt is easy to understand. For example, many users interact with online chatbots and other AI entities by asking and answering questions to resolve problems, place orders, request services or perform other simple business transactions.
However, complex prompts can easily become large, highly structured and exquisitely detailed requests that elicit very specific responses from the model. This high level of detail and precision often requires the extensive expertise provided by a type of AI professional called a prompt engineer.
A successful prompt engineer has the following characteristics:
- A working knowledge of the AI system's underlying model architecture.
- An understanding of the contents and limitations of the training data set.
- The ability to extend the data set and use new data to fine-tune the AI system.
- Detailed knowledge of the AI system's prompt interface mechanics, including formatting and parsing methodologies.
Ultimately, a prompt engineer is well versed in creating and refining effective prompts for complex and detailed AI requests. But regardless of your level of prompt engineering experience and knowledge, the following 10 tips can help you improve the quality and results of your AI prompts.
<iframe id="ytplayer-0" src="https://www.youtube.com/embed/Bq-ncjOGeVU?autoplay=0&modestbranding=1&rel=0&widget_referrer=https://www.techtarget.com/searchenterpriseai/tip/Prompt-engineering-tips-and-best-practices&enablejsapi=1&origin=https://www.techtarget.com" type="text/html" height="360" width="640" frameborder="0" data-gtm-yt-inspected-45516328_67="true" title="What is Prompt Engineering? (in about a minute)" data-gtm-yt-inspected-83="true" data-gtm-yt-inspected-88="true"></iframe>Any user can prompt an AI tool, but creating good prompts takes some knowledge and skill. The user must have a clear perspective of the answer or result they seek and possess a thorough understanding of the AI system, including the nuances of its interface and its limitations.
This is a broader challenge than it might initially seem. Keep the following guidelines in mind when creating prompts for generative AI tools.
Successful prompt engineering is largely a matter of knowing what questions to ask and how to ask them effectively. But this means nothing if the user doesn't know what they want in the first place.
Before a user ever interacts with an AI tool, it's important to define the goals for the interaction and develop a clear outline of the anticipated results beforehand. Plan it out: Decide what to achieve, what the audience should know and any associated actions that the system must perform.
AI systems can work with simple, direct requests using casual, plain-language sentences. But complex requests will benefit from detailed, carefully structured queries that adhere to a form or format that is consistent with the system's internal design.
This kind of knowledge is essential for prompt engineers. Form and format can differ for each model, and some tools, such as art generators, might have a preferred structure that involves using keywords in predictable locations. For example, the company Kajabi recommends a prompt format similar to the following for its conversational AI assistant, Ama:
"Act like" + "write a" + "define an objective" + "define your ideal format"
A sample prompt for a text project, such as a story or report, might resemble the following:
Act like a history professor who is writing an essay for a college class to provide a detailed background on the Spanish-American War using the style of Mark Twain.
AI is neither psychic nor telepathic. It's not your best buddy and it has not known you since elementary school; the system can only act based on what it can interpret from a given prompt.
Form clear, explicit and actionable requests. Understand the desired outcome, then work to describe the task that needs to be performed or articulate the question that needs to be answered.
For example, a simple question such as "What time is high tide?" is an ineffective prompt because it lacks essential detail. Tides vary by day and location, so the model would not have nearly enough information to provide a correct answer. A much clearer and more specific query would be "What times are high tides in Gloucester Harbor, Massachusetts, on August 31, 2023?"
Prompts might be subject to minimum and maximum character counts. Many AI interfaces don't impose a hard limit, but extremely long prompts can be difficult for AI systems to handle.
AI tools often struggle to parse long prompts due to the complexity involved in organizing and prioritizing the essential elements of a lengthy request. Recognize any word count limitations for a given AI and make the prompt only as long as it needs to be to convey all the required parameters.
Like any computer system, AI tools can be excruciatingly precise in their use of commands and language, including not knowing how to respond to unrecognized commands or language.
The most effective prompts use clear and direct wording. Avoid ambiguity, colorful language, metaphors and slang, all of which can produce unexpected and undesirable results.
However, ambiguity and other discouraged language can sometimes be employed with the deliberate goal of provoking unexpected or unpredictable results from a model. This can produce some interesting outputs, as the complexity of many AI systems renders their decision-making processes opaque to the user.
Generative AI is designed to create -- that's its purpose. Simple yes-or-no questions are limiting and will likely yield short and uninteresting output.
Posing open questions, in contrast, gives room for much more flexibility in output. For example, a simple prompt such as "Was the American Civil War about states' rights?" will likely lead to a similarly simple, brief response. However, a more open-ended prompt, such as "Describe the social, economic and political factors that led to the outbreak of the American Civil War," is far more likely to provoke a comprehensive and detailed answer.
A generative AI tool can frame its output to meet a wide array of goals and expectations, from short, generalized summaries to long, detailed explorations. To make use of this versatility, well-crafted prompts often include context that helps the AI system tailor its output to the user's intended audience.
For example, if a user simply asks an LLM to explain the three laws of thermodynamics, it's impossible to predict the length and detail of the output. But adding context can help ensure the output is suitable for the target reader. A prompt such as "Explain the three laws of thermodynamics for third-grade students" will produce a dramatically different level of length and detail compared with "Explain the three laws of thermodynamics for Ph.D.-level physicists."
Although generative AI is intended to be creative, it's often wise to include guardrails on factors such as output length. Context elements in prompts might include requesting a simplified and concise versus lengthy and detailed response, for example.
Keep in mind, however, that generative AI tools generally can't adhere to precise word or character limits. This is because natural language processing models such as GPT-3 are trained to predict words based on language patterns, not count. Thus, LLMs can usually follow approximate guidance such as "Provide a two- or three-sentence response," but they struggle to precisely quantify characters or words.
Long and complex prompts sometimes include ambiguous or contradictory terms. For example, a prompt that includes both the words detailed and summary might give the model conflicting information about expected level of detail and length of output. Prompt engineers take care to review the prompt formation and ensure all terms are consistent.
The most effective prompts use positive language and avoid negative language. A good rule of thumb is "Do say 'do,' and don't say 'don't.'" The logic here is simple: AI models are trained to perform specific tasks, so asking an AI system not to do something is meaningless unless there is a compelling reason to include an exception to a parameter.
Just as humans rely on punctuation to help parse text, AI prompts can also benefit from the judicious use of commas, quotation marks and line breaks to help the system parse and operate on a complex prompt.
Consider the simple elementary school grammar example of "Let's eat Grandma" versus "Let's eat, Grandma." Prompt engineers are thoroughly familiar with the formation and formatting of the AI systems they use, which often includes specific recommendations for punctuation.
The 10 tips covered above are primarily associated with LLMs, such as ChatGPT. However, a growing assortment of generative AI image platforms is emerging that can employ additional prompt elements or parameters in requests.
When working specifically with image generators such as Midjourney and Stable Diffusion, keep the following seven tips in mind:
- Describe the image. Offer some details about the scene -- perhaps a cityscape, field or forest -- as well as specific information about the subject. When describing people as subjects, be explicit about any relevant physical features, such as race, age and gender.
- Describe the mood. Include descriptions of actions, expressions and environments -- for example, "An old woman stands in the rain and cries by a wooded graveside."
- Describe the aesthetic. Define the overall style desired for the resulting image, such as watercolor, sculpture, digital art or oil painting. You can even describe techniques or artistic styles, such as impressionist, or an example artist, such as Monet.
- Describe the framing. Define how the scene and subject should be framed: dramatic, wide-angle, close-up and so on.
- Describe the lighting. Describe how the scene should be lit using terms such as morning, daylight, evening, darkness, firelight and flashlight. All these factors can affect light and shadow.
- Describe the coloring. Denote how the scene should use color with descriptors such as saturated or muted.
- Describe the level of realism. AI art renderings can range from abstract to cartoonish to photorealistic. Be sure to denote the desired level of realism for the resulting image.
Prompt formation and prompt engineering can be more of an art than a science. Subtle differences in prompt format, structure and content can have profound effects on AI responses. Even nuances in how AI models are trained can result in different outputs.
Along with tips to improve prompts, there are several common prompt engineering mistakes to avoid:
- Don't be afraid to test and revise. Prompts are never one-and-done efforts. AI systems such as art generators can require enormous attention to detail. Be prepared to make adjustments and take multiple attempts to build the ideal prompt.
- Don't look for short answers. Generative AI is designed to be creative, so form prompts that make the best use of the AI system's capabilities. Avoid prompts that look for short or one-word answers; generative AI is far more useful when prompts are open-ended.
- Don't stick to the default temperature. Many generative AI tools incorporate a "temperature" setting that, in simple terms, controls the AI's creativity. Based on your specific query, try adjusting the temperature parameters: higher to be more random and diverse, or lower to be narrower and more focused.
- Don't use the same sequence in each prompt. Prompts can be complex queries with many different elements. The order in which instructions and information are assembled into a prompt can affect the output by changing how the AI parses and interprets the prompt. Try switching up the structure of your prompts to elicit different responses.
- Don't take the same approach for every AI system. Because different models have different purposes and areas of expertise, posing the same prompt to different AI tools can produce significantly different results. Tailor your prompts to the unique strengths of the system you're working with. In some cases, additional training, such as introducing new data or more focused feedback, might be needed to refine the AI's responses.
- Don't forget that AI can be wrong. The classic IT axiom "garbage in, garbage out" applies perfectly to AI outputs. Model responses can be wrong, incomplete or simply made-up, a phenomenon often termed hallucination. Always fact-check AI output for inaccurate, misleading, biased, or plausible yet incorrect information.
Creating a detailed guide for crafting prompts, especially for AI applications or creative endeavors, is indeed a valuable resource. Let’s break down how we can expand on our initial outline and transform it into a comprehensive guide that can be shared widely, such as on a blog or GitHub Pages.
Step 1: Define the Scope and Objective
Before diving into the details, clearly define the scope of your guide. Are you focusing on prompts for AI text generation, image creation, or another specific application? Once the scope is clear, outline the objective of your guide. What will the reader learn or be able to do after reading it?
Step 2: Identify Your Audience
Understand who your guide is for. Is it aimed at beginners, intermediate users, or experts? Knowing your audience will help you tailor the content’s depth and complexity. For instance, beginners may need more background information and definitions, while experts might appreciate advanced tips and tricks.
Step 3: Create a Detailed Outline
Expand your initial outline into a more detailed structure. Here’s an example of what this could look like:
- Introduction to Prompts
- Definition and importance
- Types of prompts (text, image, code, etc.)
- Basics of Crafting Prompts
- Understanding the AI’s capabilities and limitations
- The role of specificity and clarity
- Examples of simple prompts and their outcomes
- Advanced Techniques
- Using prompts to guide AI creativity
- Adjusting tone and style
- Combining prompts for complex tasks
- Examples of advanced prompts and their outcomes
- Practical Applications
- Case studies or scenarios where prompts have been effectively used
- How to iterate on prompts based on outcomes
- Resources and Tools
- Software or platforms for testing prompts
- Communities and forums for feedback and ideas
- Conclusion and Next Steps
- Summary of key points
- Encouragement to practice and experiment
- How to share feedback and results with the community
Step 4: Write Detailed Content for Each Section
For each section in your outline, write content that is informative, engaging, and easy to follow. Include examples, screenshots, or diagrams where applicable to illustrate your points more clearly. When discussing advanced techniques or specific scenarios, provide real-world examples to demonstrate how your advice can be applied.
Step 5: Publish and Share Your Guide
Once your guide is written, choose a platform for sharing. For a text-based guide, a blog platform like WordPress or Medium can be ideal. If your guide includes code snippets or interactive elements, consider GitHub Pages. Ensure your guide is well-formatted, with a clear structure and navigation.
Step 6: Engage with Your Audience
After publishing your guide, share the link in communities where potential readers might be. This could include forums, social media groups, or Reddit. Be open to feedback and questions, and engage with your audience to refine and improve your guide based on their experiences.
See you later :ok_hand
[
](https://medium.com/@2twitme?source=post_page-----24d2ff4f6bca--------------------------------)[

Better prompts is all you need for better responses

The notion of a prompt is not new. This idea of offering a prompt permeates many disciplines: arts (to spur a writer or to speak spontaneously); science (to commence an experiment); criminal investigation (to offer or follow initial clues); computer programming (to take an initial step, given a specific context). All these are deliberative prompts as requests to elicit a desired respective response.
Interacting with large language models (LLMs) is no different. You engineer the best prompt to generate the best response. To get an LLM to generate a desired response has borne a novel discipline: prompt engineering–as “the process [and practice] of structuring text that can be interpreted and understood by a generative AI model.” [1]
In this article, we explore what is prompt engineering, what constitutes best techniques to engineer a well-structured prompt, and what prompt types steer an LLM to generate the desired response; contrastingly, what prompt types deter an LLM to generate a desired response.
Prompt engineering is not strictly an engineering discipline or precise science, supported by mathematical and scientific foundations; rather it’s a practice with a set of guidelines to craft precise, concise, creative wording of text to instruct an LLM to carry out a task. Another way to put it is that “prompt engineering is the art of communicating with a generative large language model.” [2]
To communicate with LLM with precise and task-specific instructions prompts, Bsharat et.al [3] present a comprehensive principled instructions and guidelines to improve the quality of prompts for LLMs. The study suggests that because LLMs exhibit an impressive ability and quality in understanding natural language and in carrying out tasks in various domains such as answering questions, mathematical reasoning, code generation, translation and summarization of tasks, etc., a principled approach to curate various prompt types and techniques immensely improves a generated response.
Take this simple example of a prompt before and after applying one of the principles of conciseness and precision in the prompt. The difference in the response suggests both readability and simplicity–and the desired target audience for the response.
Figure 1: An Illustration showing a general prompt on the left and a precise and specific prompte on the right.[4]
As you might infer from the above example that the more concise and precise your prompt, the better LLM comprehends the task at hand, and, hence, the better response it formulates.
Let’s examine some of the principles, techniques and types of prompt that offer better insight in how to carry out a task in various domains of natural language processing.
Bsharat et.al tabulate 26 ordered prompt principles, which can further be categorized into five distinct categories, as shown in Figure 2:
- Prompt Structure and Clarity: Integrate the intended audience in the prompt.
- Specificity and Information: Implement example-driven prompting (Use few-shot prompting)
- User Interaction and Engagement: Allow the model to ask precise details and requirements until it has enough information to provide the needed response
- Content and Language Style: Instruct the tone and style of response
- Complex Tasks and Coding Prompts: Break down complex tasks into a sequence of simpler steps as prompts.
Figure 2. : Prompt principle categories.
Equally, Elvis Saravia’s prompt engineering guide states that a prompt can contain many elements:
Instruction: describe a specific task you want a model to perform
Context: additional information or context that can guide’s a model’s response
Input Data: expressed as input or question for a model to respond to
Output and Style Format: the type or format of the output, for example, JSON, how many lines or paragraphs. Prompts are associated with roles, and roles inform an LLM who is interacting with it and what the interactive behavior ought to be. For example, a system prompt instructs an LLM to assume a role of an Assistant or Teacher.
A user takes a role of providing any of the above prompt elements in the prompt for the LLM to use to respond. Saravia, like the Bsharat et.al’s study, echoes that prompt engineering is an art of precise communication. That is, to obtain the best response, your prompt must be designed and crafted to be precise, simple, and specific. The more succinct and precise the better the response.
Also, OpenAI’s guide on prompt engineering imparts similar authoritative advice, with similar takeaways and demonstrable examples:
- Write clear instructions
- Provide reference text
- Split complex tasks into simpler subtasks
- Give the model time to “think”
Finally, Sahoo, Singh and Saha, et.al [5] offer a systematic survey of prompt engineering techniques, and offer a concise “overview of the evolution of prompting techniques, spanning from zero-shot prompting to the latest advancements.” They breakdown into distinct categories as shows in the figure below.
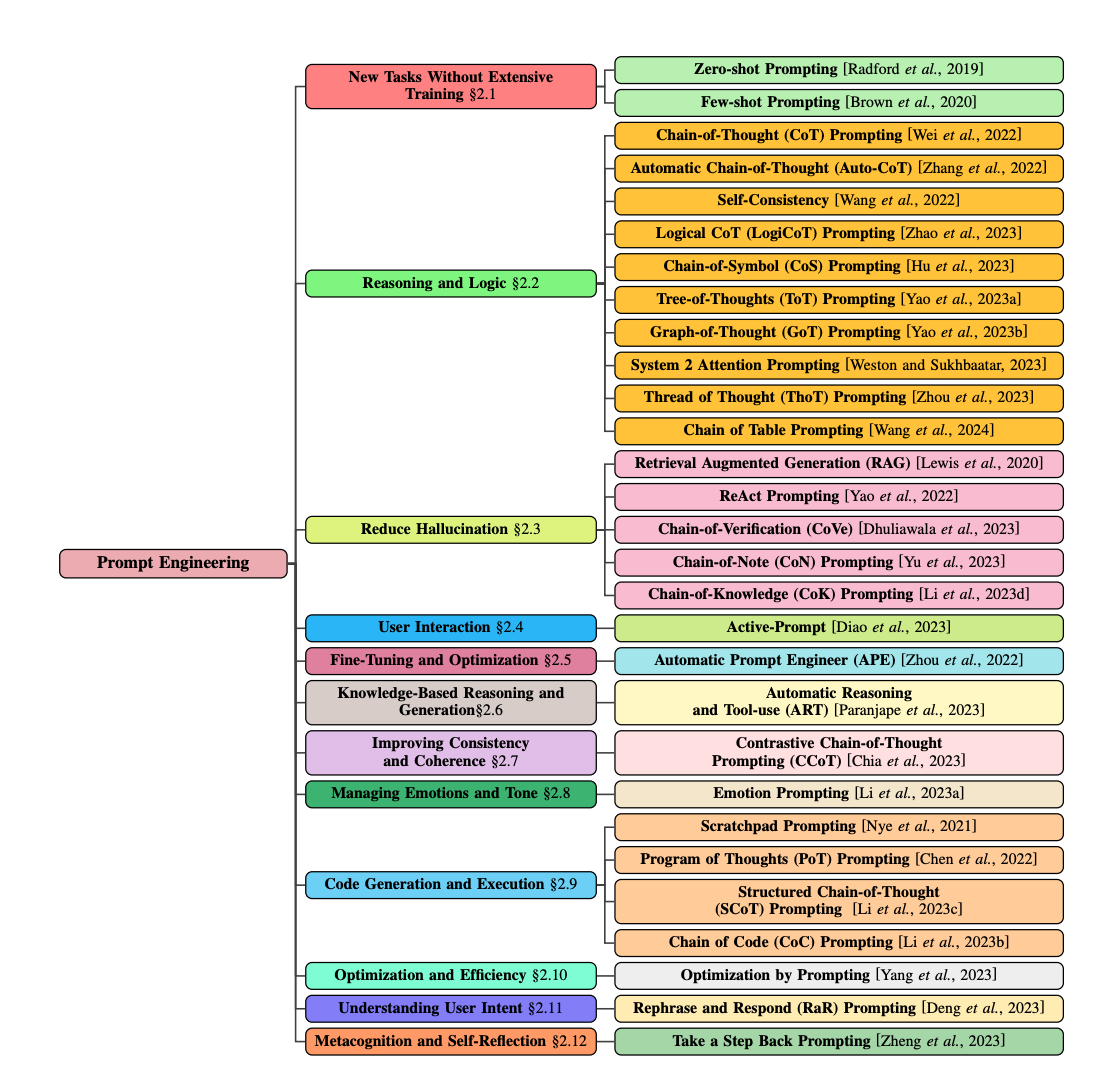
Figure 3. Taxonomy of prompt engineering techniques
But the CO-STAR prompt framework [6] goes a step further. It simplifies and crystalizes all these aforementioned guidelines and principles as a practical approach.
In her prompt engineering blog that won Singapore’s GPT-4 prompt engineering competition, Sheila Teo offers a practical strategy and worthy insights into how to obtain the best results from LLM by using the CO-STAR framework.
In short, Ms. Teo condenses and crystallizes Bsharat et.al (see Figure. 2) principles, along with other above principles, into six simple and digestible terms, as CO-STAR (Figure 4):
C: Context: Provide background and information on the task
O: Objective: Define the task that you want the LLM to perform
S: Style: Specify the writing style you want the LLM to use
T: Tone: Set the attitude and tone of the response
A: Audience: Identify who the response is for
R: Response: Provide the response format and style
Figure 4: The CO-STAR’s distinct and succinct five principles of a prompt guide
Here is a simple example of a CO-STAR prompt in a demonstrative notebook:
Figure 4 (a): An example prompt with CO-STAR framework
With this CO-STAR prompt, we get the following concise response from our LLM.
Figure 4(b): An example response with CO-STAR framework
You can view extensive examples in these two Colab notebooks:
Besides CO-STAR, other frameworks specific to ChatGPT have emerged, yet the core of crafting effective prompts remains remains the same: clarity, specificity, context, objective, task, action etc. [7]
So far we have explored best practices, guiding principles, and techniques, from an array of sources, on how to craft a concise prompt to interact with an LLM — all to generate the desired and accurate response. Prompts are linked to type of tasks, meaning the kind of task you wish the LLM perform equates to a type of prompt–and how you will craft it.
Saravia [8] analyzes various task-related prompts and advises on crafting effective prompts to accomplish these tasks. Generally, these tasks include:
- Text summarization
- Zero and few shot learning
- Information extractions
- Question answering
- Text and image classification
- Conversation
- Reasoning
- Code generation
I won’t elaborate on the explanation for brevity. But do explore prompt types through illustrative examples in the Colab notebooks below for insights on crafting effective prompts and obtaining accurate responses.

Figure 5. Example notebooks that explore type of prompts associated with type of tasks.
Note: All notebook examples have been tested using OpenAI APIs on GPT-4-turbo, Llama 2 series models, Mixtral series, Code Llama 70B (running on Anyscale Endpoints). To execute these examples, you must have accounts on OpenAI and Ansyscale Endpoints. These examples are derived from a subset of GenAI Cookbook GitHub Repository.
In this article, we covered what is prompt engineering, provided an array of authoritative guiding principles and techniques to curate and craft effective prompts to obtain the best response from LLMs. At the same time, the OpenAI guide also advised what prompts not to use.
Incorporating above principles, we discussed the CO-STAR prompt framework and provided a couple of examples on how to use this prompting framework.
Finally, we linked prompt types to common tasks for LLMs and offered a set of illustrative notebook examples for each type of task.
All the above serve a helpful first step into your journey into crafting and curating effective prompts for LLMs and obtaining the best response.
Read the next sequence of blogs on GenAI Cookbook series on LLMs:
- LLM Beyond its Core Capabilities as AI Assistants or Agents
- Crafting Intelligent User Experiences: A Deep Dive into OpenAI Assistants API
[1] https://en.wikipedia.org/wiki/Prompt_engineering
[2] ChatGPT, 2023
[3] https://arxiv.org/pdf/2312.16171.pdf
[4] https://arxiv.org/pdf/2312.16171.pdf
[5] https://arxiv.org/pdf/2402.07927.pdf
[7] https://www.linkedin.com/pulse/9-frameworks-master-chatgpt-prompt-engineering-edi-hezri-hairi/
[8] https://www.promptingguide.ai/introduction/examples
[9] https://platform.openai.com/docs/guides/prompt-engineering
[10] https://platform.openai.com/examples
[11] https://github.com/dmatrix/genai-cookbook/blob/main/README.m
Excerpt from M. C. Escher, Metamorphosis III (1968)
December 2020
Contents
- The central role of retrieval practice
- A recipe for chicken stock
- Factual knowledge
- Procedural knowledge
- Conceptual knowledge
- Open lists
- Salience prompts
- Prompt-writing, in practice
This guide and its embedded spaced repetition system were made possible by a crowd-funded research grant from my Patreon community. If you find my work interesting, you can become a member to get ongoing behind-the-scenes updates and early access to new work.
As a child, I had a goofy recurring daydream: maybe if I type just the right sequence of keys, the computer would beep a few times in sly recognition, then a hidden world would suddenly unlock before my eyes. I’d find myself with new powers which I could use to transcend my humdrum life.
Such fantasies probably came from playing too many video games. But the feelings I have when using spaced repetition systems are strikingly similar. At their best, these systems feel like magic.This guide assumes basic familiarity with spaced repetition systems. For an introduction, see Michael Nielsen, Augmenting Long-term Memory (2018), which is also the source of the phrase “makes memory a choice.” Memory ceases to be a haphazard phenomenon, something you hope happens: spaced repetition systems make memory a choice. Used well, they can accelerate learning, facilitate creative work, and more. But like in my childhood daydreams, these wonders unfold only when you press just the right sequence of keys, producing just the right incantation. That is, when you manage to write good prompts—the questions and answers you review during practice sessions.
Spaced repetition systems work only as well as the prompts you give them. And especially when new to these systems, you’re likely to give them mostly bad prompts. It often won’t even be clear which prompts are bad and why, much less how to improve them. My early experiments with spaced repetition systems felt much like my childhood daydreams: prodding a dusty old artifact, hoping it’ll suddenly spring to life and reveal its magic.
Happily, prompt-writing does not require arcane secrets. It’s possible to understand somewhat systematically what makes a given prompt effective or ineffective. From that basis, you can understand how to write good prompts. Now, there are many ways to use spaced repetition systems, and so there are many ways to write good prompts. This guide aims to help you create understanding in the context of an informational resource like an article or talk. By that I mean writing prompts not only to durably internalize the overt knowledge presented by the author, but also to produce and reinforce understandings of your own, understandings which you can carry into your life and creative work.
For readers who are new to spaced repetition, this guide will help you overcome common problems that often lead people to abandon these systems. In later sections, we’ll cover some unusual prompt-writing perspectives which may help more experienced readers deepen their practice.If you don’t have a spaced repetition system, I’d suggest downloading Anki and reading Michael’s aforementioned essay. Our discussion will focus on high-level principles, so you can follow along using any spaced repetition system you like. Let’s get started.
No matter the application, it’s helpful to remember that when you write a prompt in a spaced repetition system, you are giving your future self a recurring task. Prompt design is task design.
If a prompt “works,” it’s because performing that task changes you in some useful way. It’s worth trying to understand the mechanisms behind those changes, so you can design tasks which produce the kind of change you want.
The most common mechanism of change for spaced repetition learning tasks is called retrieval practice. In brief: when you attempt to recall some knowledge from memory, the act of retrieval tends to reinforce those memories.For more background, see Roediger and Karpicke, The Power of Testing Memory (2006). Gwern Branwen’s article on spaced repetition is a good popular overview. You’ll forget that knowledge more slowly. With a few retrievals strategically spaced over time, you can effectively halt forgetting. The physical mechanisms are not yet understood, but hundreds of cognitive scientists have explored this effect experimentally, reproducing the central findings across various subjects, knowledge types (factual, conceptual, procedural, motor), and testing modalities (multiple choice, short answer, oral examination).
The value of fluent recall isn’t just in memorizing facts. Many of these experiments tested students not with parroted memory questions but by asking them to make inferences, draw concept mapsSee e.g. Karpicke and Blunt, Retrieval Practice Produces More Learning than Elaborative Studying with Concept Mapping (2011); and Blunt and Karpicke, Learning With Retrieval-Based Concept Mapping (2014)., or answer open-ended questions. In these studies, improved recall translated into improved general understanding and problem-solving ability.
Retrieval is the key element which distinguishes this effective mode of practice from typical study habits. Simply reminding yourself of material (for instance by re-reading it) yields much weaker memory and problem-solving performance. The learning produced by retrieval is called the “testing effect” because it occurs when you explicitly test yourself, reaching within to recall some knowledge from the tangle of your mind. Such tests look like typical school exams, but in some sense they’re the opposite: retrieval practice is about testing your knowledge to produce learning, rather than to assess learning.
Spaced repetition systems are designed to facilitate this effect. If you want prompts to reinforce your understanding of some topic, you must learn to write prompts which collectively invoke retrieval practice of all the key details.
We’ll have to step outside the scientific literature to understand how to write good prompts: existing evidence stops well short of exact guidance. In lieu of that, I’ve distilled the advice in this guide from my personal experience writing thousands of prompts, grounded where possible in experimental evidence.
For more background on the mnemonic medium, see Matuschak and Nielsen, How can we develop transformative tools for thought? (2019).This guide is an example of what Michael Nielsen and I have called a mnemonic medium. It exemplifies its own advice through spaced repetition prompts interleaved directly into the text. If you’re reading this, you’ve probably already used a spaced repetition system. This guide’s system, Orbit, works similarly.If you have an existing spaced repetition practice, you may find it annoying to review prompts in two places. As Orbit matures, we’ll release import / export tools to solve this problem. But it has a deeper aspiration: by integrating expert-authored prompts into the reading experience, authors can write texts which readers can deeply internalize with relatively little effort. If you’re an author, then, this guide may help you learn how to write good prompts both for your personal practice and also for publications you write using Orbit. You can of course read this guide without answering the embedded prompts, but I hope you’ll give it a try.
These embedded prompts are part of an ongoing research project. The first experiment in the mnemonic medium was Quantum Country, a primer on quantum computation. Quantum Country is concrete and technical: definitions, notation, laws. By contrast, this guide mostly presents heuristics, mental models, and advice. The embedded prompts therefore play quite different roles in these two contexts. You may not need to memorize precise definitions here, but I believe the prompts will help you internalize the guide’s ideas and put them into action. On the other hand, this guide’s material may be too contingent and too personal to benefit from author-provided prompts. It’s an experiment, and I invite you to tell me about your experiences.
One important limitation is worth noting. This guide describes how to write prompts which produce and reinforce understandings of your own, going beyond what the author explicitly provides. Orbit doesn’t yet offer readers the ability to remix author-provided prompts or add their own. Future work will expand the system in that direction.
Writing good prompts feels surprisingly similar to translating written text. When translating prose into another language, you’re asking: which words, when read, would light a similar set of bulbs in readers’ minds? It’s not a rote operation. If the passage involves allusion, metaphor, or humor, you won’t translate literally. You’ll try to find words which recreate the experience of reading the original for a member of a foreign culture.
When writing spaced repetition prompts meant to invoke retrieval practice, you’re doing something similar to language translation. You’re asking: which tasks, when performed in aggregate, require lighting the bulbs which are activated when you have that idea “fully loaded” into your mind?
The retrieval practice mechanism implies some core properties of effective prompts. We’ll review them briefly here, and the rest of this guide will illustrate them through many examples.
These properties aren’t laws of nature. They’re more like rules you might learn in an English class. Good writers can (and should!) strategically break the rules of grammar to produce interesting effects. But you need to have enough experience to understand why doing something different makes sense in a given context.
Retrieval practice prompts should be focused. A question or answer involving too much detail will dull your concentration and stimulate incomplete retrievals, leaving some bulbs unlit. Unfocused questions also make it harder to check whether you remembered all parts of the answer and to note places where you differed. It’s usually best to focus on one detail at a time.
Retrieval practice prompts should be precise about what they’re asking for. Vague questions will elicit vague answers, which won’t reliably light the bulbs you’re targeting.
Retrieval practice prompts should produce consistent answers, lighting the same bulbs each time you perform the task. Otherwise, you may run afoul of an interference phenomenon called “retrieval-induced forgetting”This effect has been produced in many experiments but is not yet well understood. For an overview, see Murayama et al, Forgetting as a consequence of retrieval: a meta-analytic review of retrieval-induced forgetting (2014).: what you remember during practice is reinforced, but other related knowledge which you didn’t recall is actually inhibited. Now, there is a useful type of prompt which involves generating new answers with each repetition, but such prompts leverage a different theory of change. We’ll discuss them briefly later in this guide.
SuperMemo’s algorithms (also used by most other major systems) are tuned for 90% accuracy. Each review would likely have a larger impact on your memory if you targeted much lower accuracy numbers—see e.g. Carpenter et al, Using Spacing to Enhance Diverse Forms of Learning (2012). Higher accuracy targets trade efficiency for reliability.Retrieval practice prompts should be tractable. To avoid interference-driven churn and recurring annoyance in your review sessions, you should strive to write prompts which you can almost always answer correctly. This often means breaking the task down, or adding cues.
Retrieval practice prompts should be effortful. It’s important that the prompt actually involves retrieving the answer from memory. You shouldn’t be able to trivially infer the answer. Cues are helpful, as we’ll discuss later—just don’t “give the answer away.” In fact, effort appears to be an important factor in the effects of retrieval practice.For more on the notion that difficult retrievals have a greater impact than easier retrievals, see the discussion in Bjork and Bjork, A New Theory of Disuse and an Old Theory of Stimulus Fluctuation (1992). Pyc and Rawson, Testing the retrieval effort hypothesis: Does greater difficulty correctly recalling information lead to higher levels of memory? (2009) offers some focused experimental tests of this theory, which they coin the “retrieval effort hypothesis.” That’s one motivation for spacing reviews out over time: if it’s too easy to recall the answer, retrieval practice has little effect.
Achieving these properties is mostly about writing tightly-scoped questions. When a prompt’s scope is too broad, you’ll usually have problems: retrieval will often lack a focused target; you may produce imprecise or inconsistent answers; you may find the prompt intractable. But writing tightly-scoped questions is surprisingly difficult. You’ll need to break knowledge down into its discrete components so that you can build those pieces back up as prompts for retrieval practice. This decomposition also makes review more efficient. The schedule will rapidly remove easy material from regular practice while ensuring you frequently review the components you find most difficult.
Now imagine you’ve just read a long passage on a new topic. What, specifically, would have to be true for you to say you “know” it? To continue the translation metaphor, you must learn to “read” the language of knowledge—recognizing nouns and verbs, sentence structures, narrative arcs—so that you can write their analogues in the translated language. Some details are essential; some are trivial. And you can’t stop with what’s on the page: a good translator will notice allusions and draw connections of their own.
So we must learn two skills to write effective retrieval practice prompts: how to characterize exactly what knowledge we’ll reinforce, and how to ask questions which reinforce that knowledge.
Our discussion so far has been awfully abstract. We’ll continue by analyzing a concrete example: a recipe for chicken stock.
A recipe may seem like a fairly trivial target for prompt-writing, and in some sense that’s true. It’s a conveniently short and self-contained example. But in fact, my spaced repetition library contains hundreds of prompts capturing foundational recipes, techniques, and observations from the kitchen. This is itself an essential prompt-writing skill to build—noticing unusual but meaningful applications for prompts—so I’ll briefly describe my experience.
I’d cooked fairly seriously for about a decade before I began to use spaced repetition, and of course I naturally internalized many core techniques and ratios. Yet whenever I was making anything complex, I’d constantly pause to consult references, which made it difficult to move with creativity and ease. I rarely felt “flow” while cooking. My experiences felt surprisingly similar to my first few years learning to program, in which I encountered exactly the same problems. With years of full-time attention, I automatically internalized all the core knowledge I needed day-to-day as a programmer. I’m sure that I’d eventually do the same in the kitchen, but since cooking has only my part-time attention, the process might take a few more decades.
I started writing prompts about core cooking knowledge three years ago, and it’s qualitatively changed my life in the kitchen. These prompts have accelerated my development of a deeply satisfying ability: to show up at the market, choose what looks great in that moment, and improvise a complex meal with confidence. If the sunchokes look good, I know they’d pair beautifully with the mustard greens I see nearby, and I know what else I need to buy to prepare those vegetables as I imagine. When I get home, I already know how to execute the meal; I can move easily about the kitchen, not hesitating to look something up every few minutes. Despite what this guide’s lengthy discussion might suggest, these prompts don’t take me much time to write. Every week or two I’ll trip on something interesting and spend a few minutes writing prompts about it. That’s been enough to produce a huge impact.
At a decent restaurant, even simple foods often taste much better than most home cooks’ renditions. Sautéed vegetables seem richer; grains seem richer; sauces seem more luscious. One key reason for this is stock, a flavorful liquid building block. Restaurants often use stocks in situations where home cooks might use water: adding a bit of steam to sautéed vegetables, thinning a purée, simmering whole grains, etc. Stocks are also the base of many sauces, soups, and braises.
Stock is made by simmering flavorful ingredients in water. By varying the ingredients, we can produce different types of stock: chicken stock, vegetable stock, mushroom stock, pork stock, and so on. But unlike a typical broth, stock isn’t meant to have a distinctive flavor that can stand on its own. Instead, its job is to provide a versatile foundation for other preparations.
One of the most useful stocks is chicken stock. When used to prepare vegetables, chicken stock doesn’t make them taste like chicken: it makes them taste more savory and complete. It also adds a luxurious texture because it’s rich in gelatin from the chicken bones. Chicken stock takes only a few minutes of active time to make, and in a typical kitchen, it’s basically free: the primary ingredient is chicken bones, which you can naturally accumulate in your freezer if you cook chicken regularly.
- 2lbs (~1kg) chicken bones
- 2qt (~2L) water
- 1 onion, roughly chopped
- 2 carrots, roughly chopped
- 2 ribs of celery, roughly chopped
- 4 cloves garlic, smashed
- half a bunch of fresh parsley
- Combine all the ingredients in a large pot.
- Bring to a simmer on low heat (this will take about an hour). We use low heat to produce a bright, clean flavor: at higher temperatures, the stock will both taste and look duller.
- Lower heat to maintain a bare simmer for an hour and a half.
- Strain, wait until cool, then transfer to storage containers.
Chicken stock will keep for a week in the fridge or indefinitely in the freezer. There will be a cap of fat on the stock; skim that off before using the stock, and deploy the fat in place of oil or butter in any savory cooking situation.
This recipe can be scaled up or down to the quantity of chicken bones you have. The basic ratio is a pound of bones to a quart of water. The vegetables are flexible in choice and ratio.
For a more French flavor profile, replace the celery with leeks and add any/all of bay leaves, black peppercorns, and thyme. For a deeper flavor, roast the bones and vegetables first to make what’s called a “brown chicken stock” (the recipe above is for a “white chicken stock,” which is more delicate but also more versatile).
A few ideas for what you might do with your chicken stock:
- Cook barley, farro, couscous and other grains in it.
- Purée with roasted vegetables to make soup.
- Wilt hearty greens like kale, chard, or collards in oil, then add a bit of stock and cover to steam through.
- After roasting or pan-searing meat, deglaze the pan with stock to make a quick sauce.
To organize our efforts, it’s helpful to ask: what would it mean to “know” this material? I’d suggest that someone who “knows” this material should:
- know how to make and store chicken stock
- know what stock is and (at least shallowly) understand why and when it matters
- know the role and significance of chicken stock, specifically
- know some ways one might use chicken stock, both generally and with some specific examples
- know of a few common variations and when they might be used
Some of this knowledge is factual; some of it is procedural; some of it is conceptual. We’ll see strategies for dealing with each of these types of knowledge.
But understanding is inherently personal. Really “knowing” something often involves going beyond what’s on the page to connect it to your life, other ideas you’re exploring, and other activities you find meaningful. We’ll also look at how to write questions of that kind.
If you’re a vegetarian, I hope you can look past the discussion of bones: choosing this example involved many trade-offs.In this guide, we’ll imagine that you’re an interested home cook who’s never made stock before. Naturally, if you’re an experienced cook, you’d probably need only a few of these prompts. And of course, if you don’t cook at all, you’d write none of these prompts! Try to read the examples as demonstrations of how you might internalize a resource deeply without much prior fluency.
To demonstrate a wide array of principles, we’ll treat this material quite exhaustively. But it’s worth noting that in practice, you usually won’t study resources as systematically as this. You’ll jump around, focusing only on the parts which seem most valuable. You may return to a resource on a few occasions, writing more prompts as you understand what’s most relevant. That’s good! Exhaustiveness may seem righteous in a shallow sense, but an obsession with completionism will drain your gumption and waste attention which could be better spent elsewhere. We’ll return to this issue in greater depth later.
This guide aspires to demonstrate a wide variety of techniques, so I’ve deliberately analyzed the chicken stock recipe quite exhaustively. But in practice, if you were examining a recipe for the first time, I certainly wouldn’t recommend writing dozens of prompts at once like we’ve done here. If you try to analyze everything you read so comprehensively, you’re likely to waste time and burn yourself out.
Those issues aside, it’s hard to write good prompts on your first exposure to new ideas. You’re still developing a sense of which details are important and which are not—both objectively, and to you personally. You likely don’t know which elements will be particularly challenging to remember (and hence worth extra reinforcement). You may not understand the ideas well enough to write prompts which access their “essence”, or which capture subtle implications. And you may need to live with new ideas for a while before you can write prompts which connect them vibrantly with whatever really matters to you.
All this suggests an iterative approach.
Say you’re reading an article that seems interesting. Try setting yourself an accessible goal: on your first pass, aim to write a small number of prompts (say, 5-10) about whatever seems most important, meaningful, or useful.
I find that such goals change the way I read even casual texts. When first adopting spaced repetition practice, I felt like I “should” write prompts about everything. This made reading a chore. By contrast, it feels quite freeing to aim for just a few key prompts at a time.As Michael Nielsen notes, similar lightweight prompt-writing goals can enliven seminars, professional conversations, events, and so on. I read a notch more actively, noticing a tickle in the back of my mind: “Ooh, that’s a juicy bit! Let’s get that one!”
If the material is fairly simple, you may be able to write these prompts while you read. But for texts which are challenging or on an unfamiliar topic, it may be too disruptive to switch back and forth. In such cases it’s better to highlight or make note of the most important details. Then you can write prompts about your understanding of those details in a batch at the end or at a suitable stopping point. For these tougher topics, I find it’s best to focus initially on prompts about basic details you can build on: raw facts, terms, notation, etc.
Books are more complicated: there are many kinds of books and many ways to read them. This is true of articles, too, of course, but books amplify the variance. For one thing, you’re less likely to read a book linearly than an article. And, of course, they’re longer, so a handful of prompts will rarely suffice. The best prompt-writing approach will depend on how and why you’re reading the book, but in general, if I’m trying to internalize a non-fiction book, I’ll often begin by aiming to write a few key prompts on my first pass through a chapter or major section.
For many resources, one pass of prompt-writing is all that’s worth doing, at least initially. But if you have a rich text which you’re trying to internalize thoroughly, it’s often valuable to make multiple passes, even in the first reading session. That doesn’t necessarily mean doubling down on effort: just write another handful of apparently-useful prompts each time. For a vivid account of this process in mathematics, see Michael Nielsen, Using spaced repetition systems to see through a piece of mathematics (2019).With each iteration, you’ll likely find yourself able to understand (and write prompts for) increasingly complex details. You may notice your attention drawn to patterns, connections, and bigger-picture insights. Even better: you may begin to focus on your own observations and questions, rather than those of the author. But it’s also important to notice if you feel yourself becoming restless. There’s no deep virtue in writing a prompt about every detail. In fact, it’s much more important to remain responsive to your sense of curiosity and interest.
Piotr Wozniak, a pioneer of spaced repetition, has been developing a system he calls incremental reading which attempts to actively support this kind of iterative, incremental prompt writing.If you notice a feeling of duty or completionism, remind yourself that you can always write more prompts later. In fact, they’ll probably be better if you do: motivated by something meaningful, like a new connection or a gap in your understanding.
Let’s consider our chicken stock recipe again for a moment. If I were an aspiring cook who had never heard of stock before, I’d probably write a few prompts about what stock is and why it matters: those details seem useful beyond the scope of this single recipe, and they connect to happy dining experiences I’ve had. That’s probably all I’d do until I actually made a batch of stock for myself. At that point, I’d know which steps were obvious and which made me consult the recipe. If I found I wanted to make stock again, I’d write another batch of prompts to recall details like ingredient ratios and times. I’d try to notice places where I found myself straining, vaguely aware that I’d “read something about this” but unsure of the details. As I used my first batch of stock in subsequent dishes, I might then write prompts about those experiences. And so on.
While you’re drafting prose, a spell checker and grammar checker can help you avoid some simple classes of error. Such tools don’t yet exist for prompt-writing, so it’s helpful to collect simple tests which can serve a similar function.
False positives: How might you produce the correct answer without really knowing the information you intend to know?
Discourage pattern matching. If you write a long question with unusual words or cues, you might eventually memorize the shape of that question and learn its corresponding answer—not because you’re really thinking about the knowledge involved, but through a mechanical pattern association. Cloze deletions seem particularly susceptible to this problem, especially when created by copying and editing passages from texts. This is best avoided by keeping questions short and simple.
Avoid binary prompts. Questions which ask for a yes/no or this/that answer tend to require little effort and produce shallow understanding. I find I can often answer such questions without really understanding what they mean. Binary prompts are best rephrased as more open-ended prompts. For instance, the first of these can be improved by transforming it into the second:
Q. Does chicken stock typically make vegetable dishes taste like chicken?
A. No.
Q. How does chicken stock affects the flavor of vegetable dishes? (according to Andy’s recipe)
A. It makes them taste more “complete.”
Improving a binary prompt often involves connecting it to something else, like an example or an implication. The lenses in the conceptual knowledge section are useful for this.
False negatives: How might you know the information the prompt intends to capture but fail to produce the correct answer? Such failures are often caused by not including enough context.
It’s easy to accidentally write a question which has correct answers besides the one you intend. You must include enough context that reasonable alternative answers are clearly wrong, while not including so much context that you encourage pattern matching or dilute the question’s focus.
For example, if you’ve just read a recipe for making an omelette, it might feel natural to ask: “What’s the first step to cook an omelette?” The answer might seem obvious relative to the recipe you just read: step one is clearly “heat butter in pan”! But six months from now, when you come back to this question, there are many reasonable answers: whisk eggs; heat butter in a pan; mince mushrooms for filling; etc.
One solution is to give the question extremely precise context: “What’s the first step in the Bon Appetit Jun ’18 omelette recipe?” But this framing suggests the knowledge is much more provincial than it really is. When possible, general knowledge should be expressed generally, so long as you can avoid ambiguity. This may mean finding another angle on the question; for instance: “When making an omelette, how must the pan be prepared before you add the eggs?”
False negatives often feel like the worst nonsense from school exams: “Oh, yes, that answer is correct—but it’s not the one we were looking for. Try again?” Soren Bjornstad points out that a prompt which fails to exclude alternative correct answers requires that you also memorize “what the prompt is asking.”
It’s often tough to diagnose issues with prompts while you’re writing them. Problems may become apparent only upon review, and sometimes only once a prompt’s repetition interval has grown to many months. Prompt-writing involves long feedback loops. So just as it’s important to write prompts incrementally over time, it’s also important to revise prompts incrementally over time, as you notice problems and opportunities.
In your review sessions, be alert to feeling an internal “sigh” at a prompt. Often you’ll think: “oh, jeez, this prompt—I can never remember the answer.” Or “whenever this prompt comes up, I know the answer, but I don’t really understand what it means.” Listen for those reactions and use them to drive your revision. To avoid disrupting your review session, most spaced repetition systems allow you to flag a prompt as needing revision during a review. Then once your session is finished, you can view a list of flagged prompts and improve them.
The analogy to sentences is drawn from Matuschak and Nielsen, How can we develop transformative tools for thought? (2019).Learning to write good prompts is like learning to write good sentences. Each of these skills sometimes seems trivial, but each can be developed to a virtuosic level. And whether you’re writing prompts or writing sentences, revision is a holistic endeavor. When editing prose, you can sometimes focus your attention on a single sentence. But to fix an awkward line, you may find yourself merging several sentences together, modifying your narrative devices, or changing broad textual structures. I find a similar observation applies to editing spaced repetition prompts. A prompt can sometimes be improved in isolation, but as my understanding shifts I’ll often want to revise holistically—merge a few prompts here, reframe others there, split these into finer details. If you’ve attempted the exercises, you may notice that it’s easier to revise across question boundaries when composing multiple questions in the same text field. As an experiment, I’ve written almost all new prompts in 2020 as simple “Q. / A.” lines (like the examples in this guide) embedded in plaintext notes, using an old-fashioned text editor instead of a dedicated interface. I find I prefer this approach in most situations. In the future, I may release tools which allow others to write prompts in this way.Unfortunately, most spaced repetition interfaces treat each prompt as a sovereign unit, which makes this kind of high-level revision difficult. It’s as if you’re being asked to write a paper by submitting sentence one, then sentence two, and so on, revising only by submitting a request to edit a specific sentence number. Future systems may improve upon this limitation, but in the meantime, I’ve found I can revise prompts more effectively by simply keeping a holistic aspiration in mind.
In this guide, I’ve analyzed an example quite exhaustively to illustrate a wide array of principles, and I’ve advised you to write more prompts than might feel natural. So I’d like to close by offering a contrary admonition.
I believe the most important thing to “optimize” in spaced repetition practice is the emotional connection to your review sessions and their contents. It’s worth learning how to create prompts which effectively represent many different kinds of understanding, but a prompt isn’t worth reviewing just because it satisfies all the properties I’ve described here. If you find yourself reviewing something you don’t care about anymore, you should act. Sometimes upon reflection you’ll remember why you cared about the idea in the first place, and you can revise the prompt to cue that motivation. But most of the time the correct way to revise such prompts is to delete them.
Another way to approach this advice is to think about its reverse: what material should you write prompts about? When are these systems worth using? Many people feel paralyzed when getting started with spaced repetition, intrigued but unsure where it applies in their life. Others get started by trying to memorize trivia they feel they “should” know, like the names of all the U.S. presidents. Boredom and abandonment typically ensue. The best way to begin is to use these systems to help you do something that really matters to you—for example, as a lever to more deeply understand ideas connected to your core creative work. With time and experience, you’ll internalize the benefits and costs of spaced repetition, which may let you identify other useful applications (like I did with cooking). If you don’t see a way to use spaced repetition systems to help you do something that matters to you, then you probably shouldn’t bother using these systems at all.
These resources have been especially useful to me as I’ve developed an understanding of how to write good prompts:
- Piotr Wozniak’s Effective learning: Twenty rules of formulating knowledge and the more detailed Knowledge structuring and representation in learning based on active recall tackle the same topic as this guide from a different perspective.
- Michael Nielsen’s Augmenting Long-term Memory: a thorough review of how spaced repetition works and why you should care; more details on how to practically integrate prompt-writing into your reading practices, particularly when reading academic literature; notes on creative applications; and much more.
- Michael Nielsen’s Using spaced repetition systems to see through a piece of mathematics demonstrates how to iteratively deepen one’s understanding of a piece of mathematics, using spaced repetition prompts as a lever.
For more perspectives on this and related topics, see:
- Soren Bjornstad’s series on memory systems helpfully covers many practical topics in maintaining a prompt library, including some advice on prompt-writing.
- Nicky Case’s How To Remember Anything Forever-ish introduces spaced repetition and covers some prompt-writing techniques through delightful illustrations.
- How can we develop transformative tools for thought? (from Michael Nielsen and me) discusses the challenges of prompt-writing with particular focus on the “mnemonic medium,” which involves embedding prompts in narrative prose.
My thanks to Peter Hartree, Michael Nielsen, Ben Reinhardt, and Can Sar for helpful feedback on this guide; to the many attendees of the prompt-writing workshops I held while developing this guide; and to Gwern Branwen and Taylor Rogalski for helpful discussions on prompt-writing which informed this work. I’m particularly grateful to Michael Nielsen for years of conversations and collaborations around memory systems, which have shaped all aspects of how I think about the subject.
This guide (and Orbit, its embedded spaced repetition system) were made possible by a crowd-funded research grant from my Patreon community. If you find my work interesting, you can become a member to get ongoing behind-the-scenes updates and early access to new work.
This work is licensed under CC BY-NC 4.0, which means that you can copy, share, and build on this essay (with attribution), but not sell it.
In academic work, please cite this as:
Andy Matuschak, “How to write good prompts: using spaced repetition to create understanding”, https://andymatuschak.org/prompts, San Francisco (2020).
A range of [AI business tools](https://www.digitalocean.com/resources/article/ai-tools-in-business)—from Chat GPT to Claude 3—have become cornerstones of the AI revolution, weaving their way into everyday life and business operations. These advanced chatbots are used by individuals and professionals alike to perform various personal and professional tasks. According to [DigitalOcean’s bi-annual Currents survey](https://www.digitalocean.com/currents/november-2023#AI-ML), 45% of respondents acknowledged that AI and machine learning tools have made their job easier. However, there’s a catch: 43% of those surveyed also feel that the effectiveness of these tools is often over-hyped and exaggerated.This disparity in user satisfaction may be traced to one crucial factor: the art of prompt engineering or the lack thereof. Crafting the right prompt can mean the difference between an AI delivering a valuable output that streamlines your workflow and receiving an inadequate response that leaves you more frustrated than relieved, forcing you to tackle the task independently. As the AI revolution charges forward, the skill of prompt engineering has emerged as a distinct discipline; prompt engineer has become a lucrative and sought-after role within organizations.
This article delves into prompt engineering, providing best practices and a few examples to help your business extract maximum value from these large language models.
Prompt engineering is the craft of designing and refining inputs (prompts) to elicit the desired output from AI language models. It requires a blend of creativity, understanding of the model’s capabilities, and strategic structuring of the question or statement to guide the AI towards providing accurate, relevant, and useful responses. Prompt engineering improves communication between humans and machines, ensuring the resulting interaction is efficient and effective.
Prompt engineering is crucial because it influences the performance and utility of AI language models. The quality of the input determines the relevance and accuracy of the AI’s response, making prompt engineering a pivotal skill for anyone looking to harness the full potential of these powerful tools. Prompt engineering is not only for prompt engineers. By effectively communicating with AI, anyone can unlock insights, generate ideas, and solve problems more efficiently.
Here are several reasons why prompt engineering is important:
-
Improves accuracy: Well-crafted prompts lead to more precise answers, reducing the likelihood of misinterpretation or irrelevant responses from the AI.
-
Saves time: Prompt engineering streamlines interactions with the AI by getting the desired information in fewer attempts, saving valuable time for users.
-
Facilitates complex tasks: Complex tasks require complex understanding; good prompts translate intricate questions into a form that AI can process effectively.
-
Improves user experience: A user’s experience with an AI system can greatly improve when the prompts lead to clear, concise, and contextually appropriate answers.
-
Enables better outcomes: In areas such as coding, content creation, and data analysis, well-engineered prompts can lead to higher-quality outcomes by leveraging AI’s capabilities to the fullest.
-
Drives innovation: As we better understand how to communicate with AI, we can push the boundaries of what’s possible, leading to innovative applications and solutions.
Crafting effective prompts for AI can improve the quality and relevance of the responses you receive. This expertise requires a nuanced understanding of how AI interprets and processes natural language inputs. Ahead, we explore ten AI prompt engineering best practices to help you communicate with AI more effectively:
Specificity is key to obtaining the most accurate and relevant information from an AI when writing prompts. A specific prompt minimizes ambiguity, allowing the AI to understand the request’s context and nuance, preventing it from providing overly broad or unrelated responses. To achieve this, include as many relevant details as possible without overloading the AI with superfluous information. This balance ensures that the AI has just enough guidance to produce the specific outcome you’re aiming for.
When creating the best prompts for an AI, ask for the following specifics:
-
Detailed context: Provide the AI with enough background information to understand the scenario you’re inquiring about. This includes the subject matter, scope, and any relevant constraints.
-
Desired format: Clearly specify the format in which you want the information to be presented, whether it’s a list, a detailed report, bullet points, or a summary. Mention any structural preferences, such as headings, subheadings, or paragraph limits.
-
Output length: Detail how long you want the AI’s response, whether “3 paragraphs” or “250 words.”
-
Level of detail: Indicate the level of detail required for the response, from high-level overviews to in-depth analysis, to ensure the model’s output matches your informational needs.
-
Tone and style: Request the preferred tone and style, whether it’s formal, conversational, persuasive, or informational, to make sure the output aligns with your intended audience or purpose.
-
Examples and comparisons: Ask the AI to include examples, analogies, or comparisons to clarify complex concepts or make the information more relatable and easily understood.
💡 Prompt Example:
Please provide an outline for a comprehensive report that analyzes the current trends in social media marketing for technology companies, focusing on the developments from 2020 onward.
The outline should include an introduction, three main sections addressing different aspects of social media trends, and a conclusion summarizing the findings. Please suggest the types of graphs that could illustrate user engagement trends and list bullet points that summarize key marketing strategies in each section.
Incorporating examples into your prompts is a powerful technique to steer the AI’s responses in the desired direction. By providing examples as you write prompts, you set a precedent for the type of information or response you expect. This practice is particularly useful for complex tasks where the desired output might be ambiguous or for creative tasks with more than one correct answer.
When you supply the AI with examples, ensure they represent the quality and style of your desired result. This strategy clarifies your expectations and helps the AI model its responses after the examples provided, leading to more accurate and tailored outputs.
Here are some example types you could provide to an AI to help guide it toward generating the best response possible:
-
Sample texts: Share excerpts reflecting the style, tone, and content you want the AI to replicate.
-
Data formats: To guide the AI’s output, provide specific data structures, such as table layouts or spreadsheet formats.
-
Templates for documents: Offer templates to ensure the AI’s response follows a desired structure and format.
-
Code snippets: Provide code examples if you need help with programming tasks to ensure correct syntax and logic.
-
Graphs and charts examples: If you’re asking the AI to create similar graphics, share samples of visual data representation.
-
Marketing copy: If you’re crafting marketing content, present ad copy that aligns with your brand’s voice for the AI to mimic.
💡 Prompt Example:
Create a comparison table for two project management tools, Tool A and Tool B.
Include the following categories: Price, Key Features, User Reviews, and Support Options. For instance, under Key Features, list things like ‘Task Assignment’, ‘Time Tracking’, and ‘File Sharing’.
The format should mirror something like this:
| Feature | Tool A | Tool B |
|--------|-------|-------|
| Price | $X per user/month | $Y per user/month |
| Key Features | Task Assignment | File Sharing |
| User Reviews | X stars | Y stars |
| Support Options | 24/7 Live Chat, Email | Business Hours Phone, Email |
Please ensure the table is concise and suitable for inclusion in a business report.
Incorporating specific and relevant data into your prompts significantly enhances the quality of AI-generated responses, providing a solid foundation for the AI to understand the context and craft precise answers. Providing data that includes numerical values, dates, or categories, organized in a clear and structured way, allows for detailed analysis and decision-making. It’s essential to give context to the data and, when possible, to cite its source, lending credibility and clarity to the specific task, whether for quantitative analysis or comparisons.
To ensure the AI delivers the most relevant and insightful answers, always use updated and well-organized information, and if comparisons are needed, establish clear parameters. Supplying the AI with concrete, contextualized data transforms raw figures into intelligible and actionable insights. Data-driven prompts are particularly valuable in tasks requiring a deep dive into numbers, trends, or patterns, enabling the AI to generate outputs that can effectively inform business strategies or research conclusions.
💡 Prompt Example:
Please analyze the sales data from the first quarter of 2024 provided in the attached PDF document. I need a summary that identifies our best-selling product, the overall sales trend, and any notable patterns in customer purchases.
The PDF contains detailed monthly sales units for three products: Product A, Product B, and Product C. After reviewing the data, summarize your findings in a concise paragraph that is suitable for a business meeting. Highlight significant increases or decreases in sales and offer insights into potential factors driving these trends.
When engaging with AI, articulate the precise format and structure you expect in the response. Specify whether you require a detailed report, a summary, bullet points, or a narrative form to ensure the AI tailors its output to your needs.
Indicate any preferences such as tone, style, and the inclusion of certain elements like headings or subheadings. By clearly defining your desired output, you guide the AI to deliver information that aligns seamlessly with your intended use.
💡 Prompt Example:
Create a comprehensive overview of the key milestones in the history of software development. The output should be structured as a timeline with bullet points, each bullet including the year, the milestone event, and a brief description of its significance. Start from the 1980s. The tone should be educational. Please limit the overview to ten major milestones to maintain conciseness.
When constructing prompts for AI, it’s more effective to direct the system toward the desired action rather than detailing what it should avoid. This positive instruction approach reduces ambiguity and focuses the AI’s processing power on generating constructive outcomes.
Negative instructions often require the AI to interpret and invert them, increasing the cognitive load and potential for misunderstanding. By clearly stating the intended actions, you enable the AI to apply its capabilities directly to fulfilling the task at hand, improving the efficiency and accuracy of the response.
💡 Prompt Examples:
-
Avoid: "Don’t write too much detail. → Use Instead: “Please provide a concise summary.”
-
Avoid: “Avoid using technical jargon.” → Use Instead: “Use clear and simple language accessible to a general audience.”
-
Avoid: “Don’t give examples from before the year 2000.” → Use Instead: “Provide examples from the year 2000 onwards.”
Assigning a persona or a specific frame of reference to an AI model can significantly enhance the relevance and precision of its output. By doing so, you get more relevant responses, aligned with a particular perspective or expertise, ensuring that the information provided meets the unique requirements of your query.
This approach is especially beneficial in business contexts where domain-specific knowledge is pivotal, as it guides the AI to utilize a tone and terminology appropriate for the given scenario. The persona also helps set the right expectations and can make interactions with the AI more relatable and engaging for the end user.
💡 Prompt Example:
Imagine you are a seasoned marketing consultant. Please draft an email to a new startup client outlining three digital marketing strategies tailored for their upcoming product launch (see attached PDF for details).
Include key performance indicators (KPIs) for each strategy that will help track their campaign’s success. Ensure the tone is encouraging and professional, imparting confidence in your expertise.
Chain of thought prompting is a technique that elicits a more deliberate and explanatory response from an AI by specifically asking it to detail the reasoning behind its answer. By prompting the AI to articulate the steps it takes to reach a conclusion, users can better understand the logic employed and the reliability of the response.
This approach is particularly useful when tackling complex problems or when the reasoning process itself is as important as the answer. It ensures a deeper level of problem-solving and provides a learning opportunity for the user to see a modeled approach to reasoning.
💡 Prompt Example:
Imagine you are a software engineer tasked with optimizing this piece of software for performance:
[Insert code block]
Use the following chain of thought to guide your approach:
-
Performance profiling: Start with how you would profile the software to identify current performance bottlenecks.
-
Optimization techniques: Discuss the specific techniques you would consider to address the identified bottlenecks, such as algorithm optimization, code refactoring, or hardware acceleration.
-
Testing and validation: Describe your method for testing the optimized software to ensure that the changes have had the desired effect and have not introduced new issues.
-
Implementation strategy: Finally, outline how you would safely implement the optimized code into the production environment, ensuring minimal disruption.
Conclude with a summary of the key steps in the optimization process and how you would document and maintain the improvements over time.
When dealing with complex tasks, breaking them into simpler, more manageable components can make them more approachable for an AI. Using step by step instructions helps prevent the AI from becoming overwhelmed and ensures that each part of the task is handled with attention to detail.
Additionally, this approach allows for easier monitoring and adjustment of each step, facilitating better quality control throughout the process. By compartmentalizing tasks, the AI can also use its resources more efficiently, allocating the necessary attention where it’s most needed, resulting in a more effective problem-solving strategy.
💡 Prompt Example:
Avoid a single broad prompt:
- “Write a 1500-word article on the impact of AI on remote work.”
Try an initial prompt and follow-up prompts instead:
-
“Develop a detailed outline for a 1500-word article titled ‘Revolutionizing Remote Work: The Role of AI for Tech Professionals.’ The outline should include an engaging introduction, three main sections titled ‘Enhancing Productivity with AI Tools,’ ‘AI-Driven Communication Optimization,’ and ‘Advanced Project Management through AI,’ plus a conclusion that offers a perspective on future developments.”
-
“Compose a detailed introduction for the article ‘Revolutionizing Remote Work: The Role of AI for Tech Professionals.’ The introduction should be 150-200 words, setting the stage for how AI is changing the game for remote workers in the tech industry, and providing a hook that will entice tech professionals to continue reading.”
In crafting prompts for an AI, recognize the model’s limitations to set realistic expectations. Prompting AI to perform tasks it’s not designed for, such as interacting with external databases or providing real-time updates, will lead to ineffective and potentially misleading outputs called AI hallucinations.
Here are some known shortcomings of AI models:
-
Lack of real-time data processing, as the knowledge is up-to-date only until the last training cut-off.
-
Inability to access or retrieve personal data unless it has been shared during the interaction.
-
No direct interaction with external software, databases, or live web content.
-
Potential bias in the data, as AI models can inadvertently learn and replicate biases present in their training data.
-
Limited understanding of context can lead to less nuanced responses in complex or ambiguous situations.
-
The absence of personal experiences or emotions means the AI cannot form genuine, empathetic connections or offer personal anecdotes.
Prompt engineering is an emergent field that necessitates an experimental mindset. As you navigate this new territory, use an iterative process to test various prompts, paying careful attention to how slight modifications can significantly alter the AI’s responses. You’ll only learn how models respond by testing them.
While maintaining a commitment to AI privacy and ethical standards is key, don’t hesitate to explore diverse phrasings and structures to discover the most effective prompts. This trial-and-error process can yield better results and contribute to a broader understanding of how large language models interpret and act on different types of instructions.
For an in-depth understanding of AI advancements and practical applications, head to the Paperspace blog and delve into a wealth of knowledge tailored for novices and experts.
At DigitalOcean, we understand the unique needs and challenges of startups and small-to-midsize businesses. Experience our simple, predictable pricing and developer-friendly cloud computing tools like Droplets, Kubernetes, and App Platform.
% \pdfoutput=1 %\documentclass[11pt]{article}
% % \usepackage{acl}
% \usepackage{times} \usepackage{latexsym}
% \usepackage[T1]{fontenc} % % %
% \usepackage[utf8]{inputenc}
% % % \usepackage{microtype}
% \usepackage{graphicx} \usepackage{caption} \usepackage{subcaption} \usepackage{booktabs} \usepackage{colortbl}% \usepackage{multirow} \usepackage{bm} \usepackage[export]{adjustbox} % \usepackage{amsmath} \usepackage[normalem]{ulem} \usepackage{array}
%
% \usepackage{cleveref} \crefname{section}{\S}{\S\S} \Crefname{section}{\S}{\S\S} \crefformat{section}{\S#2#1#3} \crefname{figure}{Figure}{Figures} \crefname{alg}{Alg.}{Algs.} \crefname{thm}{Theorem}{Theorems} \crefname{line}{line}{lines} \crefname{appendix}{Appendix}{} \crefname{equation}{Eq.}{Eqs.} \crefname{defin}{Def.}{Defs.} \crefname{tab}{Table}{Tables} \crefname{prop}{Proposition}{Propositions} \crefname{cor}{Corollary}{} \crefname{observation}{Observation}{} \crefname{assumption}{Assumption}{} \crefname{hypothesis}{Hyp.}{Hypotheses}
% % \usepackage{todonotes} % \makeatletter \newcommand*\iftodonotes{\if@todonotes@disabled\expandafter@secondoftwo\else\expandafter@firstoftwo\fi} % \makeatother \newcommand{\noindentaftertodo}{\iftodonotes{\noindent}{}} % \newcommand{\fixme}[2][]{\todo[color=yellow,size=\scriptsize,fancyline,caption={},#1]{#2}} % \newcommand{\Fixme}[2][]{\fixme[inline,#1]{#2}\noindentaftertodo}
\newcommand{\note}[4][]{\todo[author=#2,color=#3,size=\scriptsize,fancyline,caption={},#1]{#4}} % \newcommand{\response}[1]{\vspace{3pt}\hrule\vspace{3pt}\textbf{#1:}}
\newcommand{\notewho}[3][]{\note[#1]{#2}{blue!40}{#3}} % \newcommand{\Notewho}[3][]{\notewho[inline,#1]{#2}{#3}\noindentaftertodo}
\newcommand{\marius}[2][]{\note[#1]{Marius}{orange!40}{#2}} \newcommand{\Marius}[2][]{\marius[inline,#1]{#2}\noindentaftertodo}
\newcommand{\ye}[2][]{\note[#1]{Yanai}{green!40}{#2}} \newcommand{\Yanai}[2][]{\ye[inline,#1]{#2}\noindentaftertodo}
\newcommand{\shauli}[2][]{\note[#1]{Shauli}{cyan!40}{#2}} \newcommand{\Shauli}[2][]{\shauli[inline,#1]{#2}\noindentaftertodo}
\newcommand{\tiago}[2][]{\note[#1]{tiago}{magenta!40}{#2}} \newcommand{\Tiago}[2][]{\tiago[inline,#1]{#2}\noindentaftertodo}
% \newcommand{\ia}{{(IA)\textsuperscript{3}}\xspace}
% \definecolor{tableau-blue}{RGB}{31, 119, 180} \definecolor{tableau-orange}{RGB}{255, 127, 14} \definecolor{tableau-green}{RGB}{44, 160, 44}
% \newcommand{\tiagosuggests}[2]{\textcolor{cyan}{#2}}
\newcommand{\mariussuggests}[2]{\textcolor{green}{#2}}
% % % % %
% % % % % % % % % \title{Few-shot Fine-tuning vs. In-context Learning:\ A Fair Comparison and Evaluation}
%
%
%
%
% % % % % % % % % % % % % % %
\author{Marius Mosbach\textsuperscript{1} , Tiago Pimentel\textsuperscript{2} , Shauli Ravfogel\textsuperscript{3} , Dietrich Klakow\textsuperscript{1} , Yanai Elazar\textsuperscript{4,5} \ \ % % % \textsuperscript{1}Saarland University, Saarland Informatics Campus, \textsuperscript{2}University of Cambridge, \ \textsuperscript{3}Bar-Ilan University, \textsuperscript{4}Allen Institute for Artificial Intelligence, \textsuperscript{5}University of Washington\ {\tt mmosbach@lsv.uni-saarland.de} }
\begin{document} \maketitle
%
\begin{abstract}
Few-shot fine-tuning and in-context learning are two alternative strategies for task adaptation of pre-trained language models. Recently, in-context learning has gained popularity over fine-tuning due to its simplicity and improved out-of-domain generalization, and because extensive evidence shows that fine-tuned models pick up on spurious correlations. Unfortunately, previous comparisons of the two approaches were done using models of different sizes. This raises the question of whether the observed weaker out-of-domain generalization of fine-tuned models is an inherent property of fine-tuning or a limitation of the experimental setup. In this paper, we compare the generalization of few-shot fine-tuning and in-context learning to challenge datasets, while controlling for the models used, the number of examples, and the number of parameters, ranging from 125M to 30B. Our results show that fine-tuned language models \emph{can} in fact generalize well out-of-domain. We find that both approaches generalize similarly; they exhibit large variation and depend on properties such as model size and the number of examples, highlighting that robust task adaptation remains a challenge. % \footnote{Code available at: \href{https://github.com/uds-lsv/llmft}{https://github.com/uds-lsv/llmft}.\looseness=-1 % }
\end{abstract}
% % % \section{Introduction} \label{sec:introduction} %
% \begin{figure}[t] \centering \resizebox{0.99\columnwidth}{!}{% \begin{tabular}{cc} \small{ICL -- 16 samples} & \small{FT -- 16 samples} \ \includegraphics[valign=m,width=1.5in]{figures/in-context/in-context_30B_16-shots_rte_gpt-3_teaser} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_in-domain_pattern-verbalizer-ft} \ % % % % \end{tabular} }% \caption{In-domain (RTE) and out-of-domain performance (HANS) for in-context learning (ICL) and fine-tuning (FT) with OPT models of various sizes. We fine-tune models using pattern-based fine-tuning. We report results using 10 different data seeds. When using 16 samples, ICL's performance with a 30B model is comparable to that of FT with smaller models (6.7B) and for most model sizes, FT outperforms ICL (see \Cref{tab:appendix-statistical-tests-in-domain-ood-rte} for significance tests). % \textcolor{red}{$\boldsymbol{-}$} in the x- and y-axes indicates majority class accuracy. } % \vspace{-7pt} \label{fig:teaser} \end{figure}
%
Adapting a pre-trained language model to a target task is of high practical importance to the natural language processing (NLP) community \citep[as seen in][\emph{inter alia}]{peters-etal-2018-deep,howard-ruder-2018-universal, devlin-etal-2019-bert, brown-etal-2020-language}. Among the commonly used \textit{task adaptation} strategies, two stand out: \textit{fine-tuning} (FT) and \textit{in-context learning} (ICL).\footnote{We describe both these strategies in further detail in Section \cref{sec:background}. In short, fine-tuning a model involves a supervised learning setup on a target dataset; while ICL involves prompting a model with a series of input--label pairs, without updating the model's parameters.}\looseness-1
Both approaches come with pros and cons: ICL reuses a single pre-trained model for various downstream tasks, allows specifying the desired behavior via natural language, and has recently shown impressive results on challenging reasoning tasks \citep{brown-etal-2020-language,wei2022chain,press2022measuring}. However, the model's context size limits the number of demonstrations that can be used. For instance, using 32 randomly selected examples from the RTE dataset \citep{dagan-etal-2006-rte} already exceeds the context size of OPT models \citep{zhang2022opt}.\footnote{While GPT-3 and OPT both have a context size of 2048 tokens, more recent models such as GPT-4 \citep{openai2023gpt4} -- which has been developed concurrently to this work -- support larger contexts of up to 8192 tokens.} % % % In addition, ICL is highly sensitive to the format and order of its inputs \citep{lu-etal-2022-fantastically, min-etal-2022-rethinking}. FT, on the other hand, typically results in a single specialized model per task,\footnote{Parameter-efficient FT methods (e.g. \citet{ben-zaken-etal-2022-bitfit, hu2022lora}) address this issue and allow to re-use most of the pre-trained weights across tasks.} and can be applied to training sets of arbitrary size. However, such models are sensitive to initialization \cite{dodge-etal-2020-fine} and can suffer from instability during training \citep{mosbach-etal-2021-on}.
For text classification tasks, where both strategies often lead to similar performance on in-domain data (when using the same amount of data), recent works have argued that ICL leads to better out-of-domain (OOD) generalization \citep{si2023prompting, awadalla-etal-2022-exploring}. However, these comparisons of generalization abilities were not conducted under equal conditions. Most studies compare the ICL abilities of large models \citep[e.g. GPT-3, 175B;][]{brown-etal-2020-language} to the FT abilities of much smaller models \citep[e.g. RoBERTa-large, 350M; ][]{liu-etal-2019-roberta}. % These comparisons raise the question of whether FT indeed leads to weaker OOD generalization than ICL, or whether this is just a byproduct of the experimental setup. In \cref{fig:teaser}, we show this is indeed the case: when given only 16 examples, fine-tuning a 6.7B parameters model already achieves similar results to ICL with a 30B model, and FT performance keeps improving with larger models.\footnote{\Cref{tab:appendix-statistical-tests-in-domain-ood-rte} presents significance tests for these results.} Moreover, we show in Section \ref{sec:closer-look-ft} that fine-tuning performance improves even further when training on more data.
In this paper, we compare ICL and FT on an \textbf{equal footing} (\cref{sec:approach}). We compare both strategies using the same model \citep[OPT;][]{zhang2022opt}, the same number of parameters (from 125M to 30B), and the same number of examples. Our results and analyses (\cref{sec:results}) show that both approaches often achieve comparable results. Both methods are unstable and can perform badly on in-domain and OOD data due to training instability, or prompt choice. We also find that both approaches improve as we increase model size, and that, for the models and datasets we consider, FT often generalizes even better than ICL. Notably, this is in contrast to prior work (\cref{sec:related-work}), highlighting the need for fair comparisons of task adaptation strategies. Based on our findings, we discuss the strengths and limitations of FT and ICL (\cref{sec:ft-icl-comparison}), which can inform when to use and how to get the most out of each method.\looseness=-1
% % % \section{Background} \label{sec:background} %
% \subsection{Fine-tuning} %
\textit{Pattern-based fine-tuning} (PBFT) is a recently proposed FT approach that uses the pre-trained language modeling head\footnote{In the case of encoder-only masked language models, such as BERT, this is usually an MLP layer. In the case of decoder-only models, such as OPT, this is a linear projection.} instead of a randomly initialized classifier (as used in standard fine-tuning; \citealt{howard-ruder-2018-universal, devlin-etal-2019-bert}), to obtain predictions \citep[\emph{inter alia}]{schick-schutze-2021-exploiting, gao-etal-2021-making}. Compared to vanilla FT, we have to specify an \textit{input pattern} (to cast the task as a language modeling problem) and define a \textit{verbalizer} \citep[which maps tokens in the pre-trained model's vocabulary to labels;][]{schick-etal-2020-automatically}. For example, a NLI pattern might look as follows: \texttt{{premise} Question: {hypothesis} Yes or No?}, and the verbalizer will use \texttt{Yes} and \texttt{No} as tokens. Given these inputs and targets, model parameters are fine-tuned as usual. % This method has been shown to be efficient for few-shot learning despite having no advantage over vanilla FT when the number of examples is large \cite{tam-etal-2021-improving,logan-iv-etal-2022-cutting}.
% \subsection{In-context learning} %
\textit{In-context learning} (ICL) is a task adaptation strategy that does not update the weights of the pre-trained model \cite{brown-etal-2020-language}; instead, ICL adapts a model to a task by conditioning it on a sequence of \textit{demonstrations}.
A demonstration typically refers to an input
% % % \vspace{-3pt} \section{A fair comparison of FT and ICL} \label{sec:approach} %
We perform a fair comparison of task adaptation via FT and ICL, focusing on in-domain and OOD generalization. We compare them in the few-shot setting using the same models. In the following paragraphs, we provide details about our setup.
% \paragraph{In-domain generalization} %
We measure in-domain generalization by measuring accuracy on the validation set of each dataset. This is a common practice in analysis works, and used in previous work \cite{utama-etal-2021-avoiding, bandel-etal-2022-lexical}.
% \paragraph{Out-of-domain generalization} %
We consider OOD generalization under \textit{covariate shift} \citep{hupkes-etal-2022-state-of}. Specifically, we focus on generalization to \emph{challenge datasets}, designed to test whether models adopt a particular heuristic, or make predictions based on spurious correlations during inference \citep{mccoy-etal-2019-right,elazar-etal-2021-back}.
% \paragraph{Models} %
We run all our experiments using 7 different OPT models \citep{zhang2022opt} ranging from 125 million to 30 billion parameters, all of which have been trained on the same data. This allows us to study the effect of model size on performance without the confound of using different training data.\footnote{OPT 30B is the largest model we were able to fit given our resources.}\looseness-1 %
% \paragraph{Tasks and datasets} %
We focus on two classification tasks in English: natural language inference (NLI) and paraphrase identification. For NLI, we use MNLI \citep{williams-etal-2018-broad} and RTE \citep{dagan-etal-2006-rte} as in-domain datasets, and evaluate OOD generalization on the lexical overlap subset of HANS \citep{mccoy-etal-2019-right}.\footnote{Due to similar trends on different HANS subsets in preliminary experiments, we focus on the lexical overlap subset.\looseness=-1} We binarize MNLI by removing the neutral examples\footnote{We compare this to merging the neutral and contradiction classes in \cref{appendix:additional-results-ft}, and obtain very similar results.} which allows us to better compare MNLI with RTE (which only has two labels). For paraphrase identification, we train on QQP \citep{qqp} and evaluate OOD generalization on PAWS-QQP \citep{zhang-etal-2019-paws}. Given the large size of the QQP validation set (more than 300k examples), we randomly select 1000 validation examples.
% \begin{figure*}[ht] \centering \begin{tabular}{lccc} & \hspace{4mm} \small{MNLI} & \hspace{4mm} \small{RTE} & \hspace{4mm} \small{QQP} \
\small{ICL} &
\includegraphics[valign=m,width=1.5in]{figures/in-context/in-context_all-models_16-shots_mnli_gpt-3_legend} &
\includegraphics[valign=m,width=1.5in]{figures/in-context/in-context_all-models_16-shots_rte_gpt-3} &
\includegraphics[valign=m,width=1.5in]{figures/in-context/in-context_all-models_16-shots_qqp_eval-harness.pdf} \\
\small{PBFT} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_16_best_out-of-domain_pattern-verbalizer-ft.pdf} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_out-of-domain_pattern-verbalizer-ft.pdf} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_qqp_16_best_out-of-domain_pattern-verbalizer-ft.pdf} \\
\end{tabular} \caption{ICL and FT results for OPT models of various sizes. For each approach, we use 16 examples and perform model selection according to OOD performance. We plot 10 runs per model size which differ only in the data seed. \textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates majority class accuracy. } \label{fig:results-summary} \end{figure*}
%
%
\begin{table*}
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} &
\bottomrule
\end{tabular}%
}
}
\caption{RTE}\label{tab:appendix-statistical-tests-in-domain-ood-rte}
\end{subtable}%
~~
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \\ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} & $-0.00$ & $\phantom{-}0.00$ & \cellcolor{blue!35}$\phantom{-}0.02$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.07$ \\
& \textbf{350M} & $-0.00$ & $\phantom{-}0.00$ & \cellcolor{blue!35}$\phantom{-}0.02$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.07$ \\
& \textbf{1.3B} & $-0.01$ & $-0.00$ & \cellcolor{blue!35}$\phantom{-}0.01$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.07$ \\
& \textbf{2.7B} & $-0.01$ & $-0.00$ & $\phantom{-}0.01$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.07$ \\
& \textbf{6.7B} & \cellcolor{red!15}$-0.01$ & $-0.01$ & $\phantom{-}0.01$ & $\phantom{-}0.00$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.06$ \\
& \textbf{13B} & \cellcolor{red!15}$-0.03$ & \cellcolor{red!15}$-0.03$ & $-0.02$ & $-0.02$ & \cellcolor{blue!35}$\phantom{-}0.07$ & \cellcolor{blue!35}$\phantom{-}0.08$ & $\phantom{-}0.04$ \\
& \textbf{30B} & \cellcolor{red!15}$-0.07$ & \cellcolor{red!15}$-0.07$ & $-0.05$ & \cellcolor{red!15}$-0.06$ & $\phantom{-}0.03$ & $\phantom{-}0.04$ & $\phantom{-}0.00$ \\
\bottomrule
\end{tabular}%
}
}
\caption{MNLI}\label{tab:appendix-statistical-tests-in-domain-ood-mnli}
\end{subtable}%
\caption{Difference between average \textbf{out-of-domain performance} of ICL and FT on RTE (a) and MNLI (b) across model sizes. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to in-domain performance. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference.\looseness-1
} \label{tab:appendix-statistical-tests-in-domain-ood}
\end{table*} %
% \paragraph{Few-shot setup} %
We follow the same procedure for both approaches.
We randomly sample
% \paragraph{FT setup} \label{sec:ft-setup} %
We perform few-shot PBFT using a minimal pattern \citep{logan-iv-etal-2022-cutting}, which simply adds a question mark at the end of every example.
For the NLI verbalizer, we use \texttt{Yes} and \texttt{No}, which we map to the task's labels \texttt{entailment} and \texttt{not-entailment} respectively. For QQP, we also use \texttt{Yes} and \texttt{No} and map them to \texttt{not-duplicate} and \texttt{duplicate}.\footnote{Preliminary experiments showed that \texttt{Yes} and \texttt{No} is a strong verbalizer for binary classification tasks. This is consistent with previous findings \citep{webson-pavlick-2022-prompt}.}
We follow the recommendations of \citet{mosbach-etal-2021-on} and fine-tune all models for 40 epochs using a learning rate of
% \paragraph{ICL setup} \label{sec:in-context-setup} %
Given OPT's fixed context size of 2048 tokens we are limited in the number of examples used for demonstration. Our main experiments focus on 16 demonstrations, but we also present additional experiments using 2 and 32 demonstrations in \Cref{appendix:additional-results}.\footnote{With the exception of RTE, where 32 examples do not fit OPT's context size}. We consider a prediction to be correct if the probability assigned to the verbalizer token of the ground-truth label is larger than the probability of the other verbalizer token. We use the same verbalizer tokens as for fine-tuning. %
% % % \section{Results} \label{sec:results} %
We present the results for in-domain and OOD model performance in \cref{fig:results-summary}, comparing both ICL and FT. We perform task adaptation using 16 examples for both strategies. For ICL, we provide additional results that demonstrate the importance of choosing the right pattern and number of demonstrations in \cref{appendix:additional-results-in-context}. For FT, we provide more details, ablations and discussion of various choices later in this section.\looseness=-1
% \paragraph{In-domain performance} %
For MNLI and RTE, both ICL and FT exhibit in-domain performance above the majority baseline for most model sizes. Focusing on ICL, MNLI and RTE in-domain performance improves as model size increases.
On MNLI the largest model (30B) obtains an average performance of
For FT, we similarly observe that in-domain performance increases with model size. Moreover, across all datasets and model sizes, FT with just 16 examples leads to similar in-domain performance as ICL (see \Cref{tab:appendix-statistical-tests-in-domain-in-domain,tab:appendix-statistical-tests-ood-in-domain} in \Cref{appendix:significance-tests} for statistical tests comparing in-domain performance of FT and ICL on RTE and MNLI). On QQP, we again observe no clear relationship between model size and performance. Only 10 out of 70 models perform better than the majority baseline.\looseness-1
% \begin{figure*}[ht] \centering \begin{tabular}{lccc} & \hspace{4mm} \small{Best in-domain} & \hspace{4mm} \small{Last checkpoint} & \hspace{4mm} \small{Best out-of-domain} \
\small{MNLI} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_16_best_in-domain_pattern-verbalizer-ft_legend} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_16_last_pattern-verbalizer-ft} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_16_best_out-of-domain_pattern-verbalizer-ft} \\
\small{RTE} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_in-domain_pattern-verbalizer-ft} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_last_pattern-verbalizer-ft} &
\includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_out-of-domain_pattern-verbalizer-ft} \\
\end{tabular} \caption{Comparing model selection strategies in FT. The first and second rows show results for MNLI and RTE respectively. We train on 16 examples and plot results for 10 runs for each model size. \textcolor{red}{$\boldsymbol{-}$} in the x- and y-axes indicates majority class accuracy. } \label{fig:ft-model-selection-mnli} \end{figure*} %
% \paragraph{Out-of-domain performance} %
Turning to OOD performance, we find that for MNLI and QQP most of the ICL models perform close to the majority baseline. On MNLI, only the largest model (30B) shows good OOD generalization for 4 out of 10 runs. On RTE, in-domain and OOD performance of the 30B model mostly overlap, which is consistent with the findings of \citet{si2023prompting}. In particular, when comparing the relationship between the in-domain and OOD performance of the 30B model to the smallest fine-tuned models (125M and 350M) one might conclude that ICL leads to better OOD performance; for FT on MNLI and RTE, indeed, the smallest models have poor OOD performance.
However, as model size increases, OOD performance increases as well, demonstrating that even in the challenging few-shot setting, fine-tuned models can generalize OOD. Focusing on the largest models (6.7B, 13B, and 30B) fine-tuned on MNLI, we find that for most runs, OOD performance is on par or even better than in-domain performance. On RTE, the trend is even stronger. Even with the 1.3B model, we observe good in-domain and OOD performance, and both improve as the models get larger. Notably, for many models, OOD performance is even better than in-domain performance.
In summary, \textbf{our comparison shows that fine-tuned language models can generalize OOD as well or even better than models adapted via ICL} (see statistical tests comparing them in \Cref{tab:appendix-statistical-tests-in-domain-ood}). This highlights the importance of comparing adaptation approaches using models of the same size.
% % \subsection{A closer look at FT generalization} \label{sec:closer-look-ft} %
Having established that few-shot FT can also lead to strong in-domain and OOD performance, we now focus on better understanding the individual choices that impact the in-domain and out-of-domain performance of FT. Given that on QQP, most models achieve close to majority accuracy, we focus on MNLI and RTE in the following and present results for QQP in \Cref{appendix:additional-results}.
% \paragraph{The role of model selection} %
Our FT results in \cref{fig:results-summary} show that many fine-tuned models lead to good out-of-domain generalization. But what is the role of model selection in identifying these checkpoints? To answer this question, we compare selecting the model (a) with the best in-domain performance, (b) at the end of fine-tuning, and (c) with the best out-of-domain performance. \cref{fig:ft-model-selection-mnli} shows the results when fine-tuning on 16 examples. Results for additional sample sizes are shown in \cref{fig:appendix-ft-model-selection-mnli,fig:appendix-ft-model-selection-rte,fig:appendix-ft-model-selection-qqp} in \cref{appendix:additional-results-ft}.
% \begin{figure*}[ht] \centering \resizebox{0.99\textwidth}{!}{% \begin{tabular}{lcccc} & \hspace{4mm} \small{16 samples} & \hspace{4mm} \small{32 samples} & \hspace{4mm} \small{64 samples} & \hspace{4mm} \small{128 samples} \ \small{MNLI} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_16_best_out-of-domain_pattern-verbalizer-ft_legend} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_32_best_out-of-domain_pattern-verbalizer-ft} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_64_best_out-of-domain_pattern-verbalizer-ft} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_mnli_128_best_out-of-domain_pattern-verbalizer-ft} \ \small{RTE} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_out-of-domain_pattern-verbalizer-ft} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_32_best_out-of-domain_pattern-verbalizer-ft} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_64_best_out-of-domain_pattern-verbalizer-ft} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_128_best_out-of-domain_pattern-verbalizer-ft} \ \end{tabular} }% \caption{ % Exploring the effect of increasing training examples on FT. % The first and second rows show results for MNLI and RTE respectively. We plot results for 10 runs for each model size and perform model selection according to out-of-domain performance. \textcolor{red}{$\boldsymbol{-}$} in the x- and y-axes indicates majority class accuracy. % % } \vspace{-10pt} \label{fig:ft-more-data-mnli} \end{figure*} %
Our results show that when performing model selection according to in-domain performance, only the largest models achieve good OOD performance. On the other hand, when performing model selection according to OOD performance, smaller models can also generalize well (e.g. for the 2.7B model on RTE, 7 out of 10 models have equal or even better OOD than in-domain performance), and this trend persists as model size increases. Interestingly, on RTE, we also observe models with a strong OOD performance when selecting the last checkpoint, which typically leads to poor OOD performance on MNLI.
% \paragraph{Training on more data} %
In contrast to ICL, where the maximum number of demonstrations is limited by the context size of a model, FT allows us to perform task adaptation using arbitrary amounts of data. Here, we analyze how the relationship between in-domain and OOD performance is impacted by training on more data. \cref{fig:ft-more-data-mnli} shows the results for MNLI and RTE, and results for QQP are provided in \cref{fig:appendix-ft-model-selection-qqp} in \cref{appendix:additional-results-ft}. For the smallest models, we find that while in-domain performance increases with more training data, OOD performance remains low, which is consistent with previous work \citep{utama-etal-2021-avoiding}. However, for larger models, OOD performance improves as the amount of training data increases and the same trend can be observed when performing model selection according to in-domain performance (see \cref{fig:appendix-ft-model-selection-mnli,fig:appendix-ft-model-selection-rte,fig:appendix-ft-model-selection-qqp} in \cref{appendix:additional-results-ft}).
% \paragraph{How much OOD data is needed?} %
In the experiments so far, we evaluated the models on the full evaluation set (unless mentioned otherwise). Further, we selected FT models based on this evaluation; choosing the best model according to its in-domain or OOD performance in this entire set. This setup is not realistic, since in such a scenario where large amounts of data are available for evaluation, it can be used more effectively for training \citep{zhu-etal-2023-weaker}. Hence, in this experiment, we quantify the ability to estimate a model's performance on OOD data using smaller evaluation sets. We fine-tune OPT 13B on MNLI using 128 examples using three different data seeds and plot the OOD generalization in \cref{fig:less-ood-data}. Our results show that using just 50 randomly selected examples is sufficient to distinguish checkpoints that generalize well from those that do not, which would allow us to select, with only these 50 examples, the best OOD checkpoint in a model's training run. This is also reflected in the Pearson correlation of the OOD performance during FT when evaluating it on all vs. 50 examples, which is very high:~$0.99$.
% \begin{figure}[t] \centering \begin{subfigure}[b]{0.85\columnwidth} \centering \includegraphics[width=\columnwidth]{figures/ft/facebook-opt-13b_out_of_domain_performance_difference} % \end{subfigure} \caption{Estimating OOD performance using less data. We compare OOD performance estimated using all vs. 50 examples when fine-tuning OPT 13B on RTE. Each color corresponds to a run with a different data seed. } \label{fig:less-ood-data} % \end{figure} %
% \begin{figure*}[ht] \centering \begin{tabular}{lccc} & \hspace{4mm} \small{Vanilla FT} & \hspace{4mm} \small{PBFT} & \hspace{4mm} \small{PBFT + LoRA} \ % % % % % & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_out-of-domain_vanilla-ft_legend.pdf} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_out-of-domain_pattern-verbalizer-ft.pdf} & \includegraphics[valign=m,width=1.5in]{figures/ft/all-models_rte_16_best_out-of-domain_pattern-verbalizer-ft-lora} \ \end{tabular} \caption{Comparing FT approaches on RTE. We use 16 examples and perform model selection according to out-of-domain performance. \textcolor{red}{$\boldsymbol{-}$} in the x- and y-axes indicates majority class accuracy. } \label{fig:ft-comparing-approaches-rte-128} % \end{figure*} %
% \subsection{Comparing fine-tuning approaches} %
Lastly, we investigate the importance of performing pattern-based FT instead of vanilla FT by fine-tuning a model with a randomly initialized classification head \citep{howard-ruder-2018-universal, devlin-etal-2019-bert}. Further, as an extra fine-tuning strategy, we also apply LoRA \citep{hu2022lora} -- a recently proposed approach for parameter-efficient fine-tuning -- on top of pattern-based FT for comparison. This makes adaptation via FT more similar to adaptation via ICL as it allows the re-use of a large fraction of the weights of a pre-trained language model across tasks.\footnote{We provide more details on both approaches in \cref{sec:appendix-ft-details}.} We fine-tune all models on 16 examples from RTE and present the results in \cref{fig:ft-comparing-approaches-rte-128}. For all FT approaches, we observe a clear improvement in both in-domain and OOD performance as models become larger. Compared to vanilla FT, pattern-based FT leads to better overall performance. When combined with LoRA, pattern-based FT leads to very similar performance as training all parameters. These results demonstrate the generality of our findings beyond a specific FT method.
% % % \subsection{Our findings generalize beyond OPT} \label{sec:pythia-results} %
% \begin{figure}[t] \centering \resizebox{0.99\columnwidth}{!}{% \begin{tabular}{cc} \small{ICL -- 16 samples} & \small{FT -- 16 samples} \ \includegraphics[valign=m,width=1.5in]{figures/in-context/pythia_16-shots_rte_gpt-3.pdf} & % \includegraphics[valign=m,width=1.5in]{figures/ft/pythia_rte_16_best_in-domain_pattern-verbalizer-ft.pdf} \
\end{tabular} }% \caption{ICL and FT results for Pythia models on RTE. We fine-tune models using PBFT. For each approach, we use 16 examples and perform model selection according to % in-domain performance. We plot 10 runs per model size which differ only in the data seed. \textcolor{red}{$\boldsymbol{-}$} in the x- and y-axes indicates majority class accuracy. } \label{fig:pythia-results} \end{figure} %
\noindent \Cref{fig:pythia-results} provides a comparison of ICL and FT using Pythia models\footnote{We use the non-deduped models.} of different sizes ranging from 410M to 12B parameters \citep{biderman2023pythia}. The corresponding significance tests for OOD performance are shown in \Cref{tab:appendix-statistical-tests-pythia-ood-ood} (significance tests for in-domain performance are in \Cref{sec:appendix-pythia}). Similar to OPT, all Pythia models have been trained on the same data, and in the same order. % % We fine-tune using PBFT and select models according to in-domain performance. The results for additional patterns, model selection strategies, and sample sizes are discussed in \Cref{sec:appendix-pythia}.
Similarly to OPT, we observe a clear effect of model size on both in-domain and OOD performance. For most model sizes, FT leads to significantly better OOD performance than ICL and both the in-domain and OOD performance of Pythia models improve drastically as we fine-tune on more data (see \Cref{fig:appendix-pythia}). This demonstrates the generality of our findings beyond a single model.\looseness-1
%
\begin{table}[t]
\centering
\resizebox{1.0\columnwidth}{!}{%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
\begin{tabular}{llccccc}
\toprule
%
%
&
%
& \multicolumn{5}{c}{\textbf{FT}} \ \cmidrule{3-7}
& & \textbf{410M} & \textbf{1.4B} & \textbf{2.8B} & \textbf{6.9B} & \textbf{12B}
\ \midrule
\multirow{5}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{410M} & \cellcolor{blue!35}$0.02$ & \cellcolor{blue!35}$0.06$ & \cellcolor{blue!35}$0.05$ & \cellcolor{blue!35}$0.09$ & \cellcolor{blue!35}$0.11$ \
& \textbf{1.4B} &
% % % \section{Discussion} \label{sec:discussion} %
Our findings in the previous section demonstrate that fine-tuned language models can generalize OOD too, highlighting the importance of comparing adaptation approaches fairly. In this section, we present further insights from our experiments and provide a high-level comparison of the pros and cons of adaptation via ICL and FT.\looseness-1
% \paragraph{What signal to learn from?} %
Both our ICL and FT results exhibit a large variance in both in-domain and OOD performance. Our results show different OOD behavior during FT when varying only the data seed. In addition, as previous work has shown, the choice of patterns and verbalizers impact both ICL and PBFT performance in unintuitive ways. For instance, \citet{webson-pavlick-2022-prompt} find that pattern-based fine-tuned models perform well even when using misleading patterns. Here, we find that ICL's generalization is heavily dependent on the choice of pattern and verbalizer. This shows the importance of the choice of training data and patterns for task adaptation.\looseness-1
% \paragraph{Advances in task adaptation} %
The success of ICL led to the development of new methods for improving on it further, such as calibration \citep{pmlr-v139-zhao21c}, and chain-of-thought prompting \citep{wei2022chain}. In this work, we focus on the `vanilla' version of ICL and the fine-tuning approach most similar to it -- pattern-based fine-tuning. Our results suggest that these two approaches are more similar than previously thought, as they achieve similar performance both in-domain and OOD. As such, new methods for ICL can also be applied to PBFT, and we expect them to achieve similar results.
% \paragraph{Analyzing the fine-tuning loss surface} %
Looking at the OOD generalization curves throughout fine-tuning (in \cref{fig:less-ood-data} and additional plots in \cref{sec:appendix-individual-ft-runs}), we observe that for some runs, OOD performance fluctuates heavily and models change their generalization `strategy' during FT. In \cref{fig:less-ood-data}, we can see that some fine-tuning runs undergo a dramatic change in OOD performance after 75 steps. We leave it to future work to further study this behavior and the relationship between the FT loss surface and OOD generalization \cite{shwartz-ziv2022pretrain, juneja2023linear}.\looseness=-1
% % % \section{Comparing FT and ICL} \label{sec:ft-icl-comparison} %
% \begin{table}[t] \centering \resizebox{1.\columnwidth}{!}{% \begin{tabular}{lll} \toprule \textbf{Feature} & \textbf{FT} & \textbf{ICL} \ \midrule \multirow{2}{}{Users} & Experts & Experts & \ & & Non-experts \ Interaction & Pre-defined & Textual \ Reusability & Medium & High \ % Applicability to & \multirow{2}{}{High} & \multirow{2}{}{Limited} \ low-resource languages & & \ % % \midrule Requires training & Yes & No \ % \multirow{2}{}{Inference time} & \multirow{2}{*}{$|$test example$|$} & $|$test example$|$ + \ & & $|$demonstrations$|$ \ $|$Demonstrations$|$ & Unlimited & $\leq$100 \ Variance & High & High \ \midrule SOTA & Yes & Yes \ Size scaling & Standard & Standard \ $|$Demonstrations$|$ scaling & Standard & Limited \ Invented & 2018 & 2020 \ Well understood & No & No \ \bottomrule \end{tabular} }% \caption{A high-level comparison between key features of fine-tuning and in-context learning.} \label{tab:comparison} \vspace{-0.1in} \end{table} %
\noindent This section examines the key features for task adaptation and compares FT and ICL. We summarize our findings in \Cref{tab:comparison}. We begin by discussing features related to user interaction, which can be found in the first part of the table. FT requires expertise in model training, whereas ICL only requires natural language, i.e., non-experts can use this approach more easily. ICL is also highly reusable as it does not modify the pre-trained model and hence, the same model can be used for many tasks; FT, however, is not as reusable (with the exception of parameter-efficient methods) and typically results in a specialized model per task. Unfortunately, despite its user-friendliness and reusability, ICL does not work out of the box for some tasks which require more sophisticated prompting \citep{wei2022chain}.\looseness-1
ICL requires large models to work in contrast to FT, which works well even with small models \citep{devlin-etal-2019-bert}. This hinders the applicability of ICL to models developed for low-resource languages, as training billion parameter-scale models requires huge amounts of training data, which are simply unavailable for many languages. As such, FT is still the dominating adaptation approach in this setting \citep[\emph{inter alia}]{pfeiffer-etal-2022-lifting, alabi-etal-2022-adapting}.\looseness=-1 % %
Next, we compare technical details regarding the training and inference of such approaches. While FT requires training (which when dealing with large models can become expensive), ICL does not. On the other hand, the inference time of fine-tuned models is much smaller than ICL, since it only includes the time that it takes to process the minimal pattern and the test instance. When using ICL, each test instance has to include all of the demonstrations as well, which increases the inference time. The fixed context size of the model also limits the number of demonstrations that can be used\footnote{Note that some methods allow an infinite context \cite[e.g.][]{press2022train, martins-etal-2022-former}. Most current successful LMs, however, have limited context sizes.}\looseness=-1, while FT allows for unlimited training examples. We show in this work that both methods can achieve strong performance on both in-domain and OOD datasets. Both approaches improve with model size, but FT benefits more from additional samples than ICL does, as was also shown in previous work \cite{min-etal-2022-rethinking}. %
Finally, we highlight that both methods are relatively recent: vanilla FT was invented in 2018 \cite{howard-ruder-2018-universal} and ICL in 2020 \cite{brown-etal-2020-language}.\footnote{PBFT was also invented in 2020 \citep{schick-schutze-2021-exploiting}.\looseness=-1} As such, these methods are still poorly understood, and more research is required on both approaches to better understand their strengths and weaknesses.\looseness=-1
% \section{Related work} \label{sec:related-work} %
\citet{brown-etal-2020-language} compare GPT-3's few-shot in-context learning performance with fine-tuned language models trained in the fully supervised setting, finding that both approaches lead to similar results in question answering. However, the fine-tuned models they compare ICL to are smaller models, making the task adaptation comparison unfair. For SuperGLUE, while using smaller models, they find that FT largely outperforms ICL. This is consistent with our findings. Even in the few-shot setting, fine-tuned language models can outperform ICL when comparing models of the same size. Recently, \citet{liu2022fewshot} compared parameter-efficient few-shot FT of T0 \citep{sanh-etal-2022-multitask} to ICL with GPT-3, finding that their parameter-efficient FT approach outperforms ICL. This is consistent with our findings; however, unlike our work, they only consider in-domain performance. %
Focusing on OOD performance, \citet{si2023prompting} investigate the generalization of GPT-3 along various axes, including generalization under covariate shift -- as we do. However, they compare models of different sizes, i.e., RoBERTa-large and GPT-3 (which has 500 times the number of parameters), and different training settings, i.e., fully supervised for FT vs. few-shot for ICL. They observe much better OOD performance for ICL than FT, concluding that ICL with GPT-3 is more robust than FT using BERT or RoBERTa. While this conclusion is valid, it holds for specific models, rather than the methods in general. We show how important it is to compare methods fairly. Based on our comparable results, fine-tuning language models results in similar or even better OOD generalization. Another work that compares the OOD generalization of different adaptation approaches is \citet{awadalla-etal-2022-exploring}. Unlike our choice of MNLI and RTE, they investigate the robustness of question answering models under various types of distribution shifts and find that ICL is more robust to distribution shifts than FT. Moreover, they argue that for FT, increasing model size does not have a strong impact on generalization. However, they don't scale beyond 1.5B parameters. Our findings suggest that the relationship between in-domain and OOD performance does depend on model size.
While we focus on the task adaptation of decoder-only models, \citet{utama-etal-2021-avoiding} investigate the OOD generalization of encoder-only models adapted via pattern-based few-shot FT. For MNLI and HANS, they find that these models adopt similar inference heuristics to those trained with vanilla FT and hence perform poorly OOD. They observe that models rely even more on heuristics when fine-tuned on more data. This is in contrast to our results where we find that pattern-based few-shot FT can lead to good OOD generalization, and OOD generalization improves as we train on more data. We attribute this to the fact that they experiment with a smaller model (RoBERTa-large; 350M).\footnote{This is also related to \citeposs{warstadt-etal-2020-learning} results, who show that better pre-trained models are less prone to rely on superficial (and potentially spurious) features for predictions.\looseness=-1} % Lastly, \citet{bandel-etal-2022-lexical} show that masked language models can generalize well on HANS if fine-tuned for a sufficient number of steps. While they focus on fine-tuning on the entire dataset, their findings provide additional evidence that fine-tuned language models can generalize well OOD.\looseness-1
% % % \section{Conclusion} \label{sec:conclusion} %
We perform a fair comparison between in-domain and OOD generalization of two alternative task adaptation strategies: Few-shot ICL and FT. We compare OPT models \cite{zhang2022opt} ranging from 125M to 30B parameters on three classification datasets across two tasks. We find that for both approaches, performance improves as models become larger. For the largest models we experiment with (OPT-30B), we find that FT outperforms ICL on both in-domain and OOD performance and even improves further as we train on more data. % However, our results also demonstrate that the performance of both FT and ICL exhibits high variance, highlighting that truly robust task adaptation remains an open challenge. We end by providing a high-level comparison between the two approaches, listing the benefits and limitations of each, and discussing some future directions.\looseness-1
% % % % \section{Limitations} \label{sec:limitations} %
In this work, we focus on a specific type of OOD generalization, namely, covariate shift \citep{hupkes-etal-2022-state-of}. Under this setup, we refer to OOD as the specific challenge datasets we use. As such, different conclusions might be reached by repeating the experiments and evaluating different datasets.
We focus specifically on OPT decoder-only models as the goal of our work is to compare the generalization of adaptation via fine-tuning vs. in-context learning using the same pre-trained model. % To the best of our knowledge, existing encoder-only models do not have strong in-context learning abilities. For encoder--decoder models such as T5, only recent variants such as Flan-T5 \citep{chung2022scaling} demonstrate the ability to respond well to instructions. However, these models require an additional supervised fine-tuning step on instruction data. This makes it challenging to attribute generalization abilities (or the lack thereof) to specific adaptation techniques (fine-tuning vs in-context learning). Hence, we focus on decoder-only models pre-trained exclusively with a language modeling objective.
Many recent papers that experiment with in-context learning use GPT-3. While fine-tuning GPT-3 is possible via an API, it is unclear what fine-tuning approach is used behind that API. Since this makes a fair comparison difficult, we chose not to experiment with GPT-3.
While similarly large models (e.g. OPT-175B) are publicly available, we do not have the computational resources to run such models. While we expect the trends we observe in this work to hold with larger models, we are not able to empirically test that. Moreover, we only experiment with English language models as, to the best of our knowledge, there are no publicly available models which are similar to OPT (decoder-only models of various sizes trained on the same data) for other languages.\looseness=-1
Finally, we only experiment with basic FT and ICL methods. However, for both approaches there exist more advanced techniques which we do not consider \citep[e.g. calibration;][]{pmlr-v139-zhao21c}. We note that such techniques can typically be applied for both adaptation approaches. Hence we expect an improvement for one method to improve the other as well.
% % % \section*{Acknowledgments} \label{sec:acknowledgments}
We are grateful to Vagrant Gautam for their valuable feedback and patience when proofreading our work. We also thank Badr Abdullah for his help with proofreading and feedback during early stages of this work. Marius Mosbach acknowledges funding from the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 232722074 – SFB 1102.
% % %
\bibliography{anthology,custom} \bibliographystyle{acl_natbib}
% % % \newpage \appendix
\onecolumn
%
% % % \section{Experimental details} \label{appendix:experimental-details}
We access all models via huggingface transformers \citep{wolf-etal-2020-transformers} and use its DeepSpeed \citep{deepspeed} integration for efficient distributed training and evaluation. %
\subsection{Hardware}
We run our experiments on 8x A100 GPUs with 80GB of memory.
\subsection{Label distribution}
Table \ref{tab:majority_baselines} shows the accuracy of the majority class label on each of the datasets. Note that MNLI (when merging the neutral and contradiction classes) and PAWS-QQP are highly unbalanced.
%
\begin{table}[h]
\centering
\resizebox{0.55\textwidth}{!}{%
\begin{tabular}{lc}
\toprule
\textbf{Dataset} & \textbf{Majority class} \ \midrule
MNLI (remove neutral) &
\subsection{In-context learning: Additional details} \label{sec:appendix:icl-details}
\paragraph{Patterns} We present the patterns used for ICL in Table \ref{tab:appendix-in-context-learning-patterns}. We obtain the \texttt{GPT-3} pattern from \citet{brown-etal-2020-language}. The \texttt{eval-harness} pattern is based on \citet{eval-harness}.
\begin{table*}[h] \centering \resizebox{1.0\textwidth}{!}{% \begin{tabular}{lllll} \toprule \textbf{Dataset(s)} & \textbf{Pattern} & \textbf{Text} & \textbf{Answer prefix} & \textbf{Target tokens} \ \midrule MNLI, RTE & \texttt{minimal} & {premise} {hypothesis} ? & -- & Yes, No \ MNLI, RTE& \texttt{gpt-3} & {premise} question: {hypothesis} Yes or No? & answer: & Yes, No \ MNLI, RTE & \texttt{eval-harness} & {premise} \textbackslash n Question: {hypothesis} True or False? & \textbackslash n Answer: & True, False\ \midrule QQP & \texttt{minimal} & {question 1} {question 2} ? & -- & Yes, No\ \multirow{2}{}{QQP} & \multirow{2}{}{\texttt{eval-harness}} & Question 1: {question 1} \textbackslash n Question 2:{question 2} & \multirow{2}{}{Answer:} & \multirow{2}{}{Yes, No} \ & & \textbackslash n Question: Do both questions ask the same thing? & \ \bottomrule \end{tabular} }% \caption{Patterns used for ICL. The minimal patterns are used for PBFT as well.} \label{tab:appendix-in-context-learning-patterns} \end{table*}
% \subsection{In-context learning: Comparison with previous work} \label{sec:appendix-icl-previous} %
\Cref{tab:icl-previous-work} compares our ICL results to results from previous work. On RTE and MNLI we achieve comparable performance to previous work. On QQP, our ICL results are much worse (and very close to the majority class classifier). We hypothesize that this is due to the difference in model size (GPT-3 with 175B parameters vs. OPT with 30B parameters) and hence focus on MNLI and RTE for most of our experiments.
%
\begin{table}[h]
\centering
\resizebox{0.55\textwidth}{!}{%
\begin{tabular}{llcc}
\toprule
\textbf{Model} & \textbf{Dataset} & \textbf{In-domain} & \textbf{Out-of-domain} \ \midrule
GPT-3 175B & MNLI &
% \subsection{Fine-tuning: Additional details} \label{sec:appendix-ft-details} %
\paragraph{Vanilla FT} Vanilla FT \citep{howard-ruder-2018-universal, devlin-etal-2019-bert} is one of the most commonly used task adaptation approaches for pre-trained language models. % % During FT we typically: (i) replace the model's language modeling head with a new randomly initialized classification head; (ii) update all model parameters, as well as the new head's, on the downstream task's training data.\footnote{We will refer to any FT approach that uses a randomly initialized classifier as vanilla FT.} % % When trained on entire datasets, fine-tuned language models dominate academic leaderboards, such as GLUE \cite{wang-etal-2018-glue} and SuperGLUE \cite{wang-etal-2019-superglue}. % However, despite their strong in-domain performance, fine-tuned language models tend to generalize poorly OOD, which is often attributed to adopting inference heuristics during FT \citep{mccoy-etal-2019-right,elazar-etal-2021-back}. %
\paragraph{Parameter-efficient FT} Parameter-efficient FT methods update only a small number of parameters relative to the total number of parameters of the pre-trained model \citep[\emph{inter alia}]{pmlr-v97-houlsby19a, ben-zaken-etal-2022-bitfit, hu2022lora}. % Such approaches can be applied to either vanilla or prompt-based FT and are appealing since they allow large parts of a model to be re-used across tasks. %
%
%
\begin{table}[ht]
\centering
\resizebox{0.55\textwidth}{!}{%
\begin{tabular}{ll}
\toprule
\textbf{Hyperparameter} & \textbf{Value} \ \midrule
Optimizer & AdamW \
Learning rate &
\label{tab:hyperparameters}
\end{table} %
\paragraph{Hyperparameters} Table \ref{tab:hyperparameters} provides an overview of all hyperparameters used during FT.
% % % % %
%
%
% %
%
% %
%
%
%
% % % % % % % % % % % % % % % % %
%
%
% % % % % % % % % % %
%
%
%
%
% % % % % % % % % % %
%
% % % \section{Additional results for OPT models}% \label{appendix:additional-results}
\subsection{Significance tests} \label{appendix:significance-tests}
\Cref{tab:appendix-statistical-tests-in-domain-in-domain,tab:appendix-statistical-tests-ood-in-domain,tab:appendix-statistical-tests-in-domain-ood,tab:appendix-statistical-tests-ood-ood} show the results of a Welch's t-test comparing the average in-domain and out-of-domain performance of ICL and PBFT on RTE and MNLI. We use 16 samples and 10 different seeds for each approach and consider a p-value of 0.05 to be statistically significant. For FT, we compare two different approaches of model selection: (1) based on in-domain performance and (2) based on out-of-domain performance (note that these are the same models as those shown in the first row of \cref{fig:teaser}).
For RTE, our results show that ICL outperforms FT only when comparing large models to smaller models. However, when comparing models of the same size, FT performs at least equally well to ICL, and in some cases even significantly better. For MNLI, for larger models (6.7B onwards) ICL outperforms FT in terms of in-domain performance. Looking at OOD performance, however, we again see that ICL only outperforms FT when comparing large models to much smaller models.
%
\begin{table*}
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.08$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.10$ \
& \textbf{350M} & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.08$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.10$ \
& \textbf{1.3B} & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.08$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.09$ \
& \textbf{2.7B} &
\bottomrule
\end{tabular}%
}
}
\caption{RTE}\label{tab:appendix-statistical-tests-in-domain-in-domain-rte}
\end{subtable}%
~~
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \\ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} & \cellcolor{blue!35}$\phantom{-}0.07$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.14$ & \cellcolor{blue!35}$\phantom{-}0.12$ & \cellcolor{blue!35}$\phantom{-}0.17$ & \cellcolor{blue!35}$\phantom{-}0.13$ \\
& \textbf{350M} & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.07$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.16$ & \cellcolor{blue!35}$\phantom{-}0.11$ \\
& \textbf{1.3B} & $-0.02$ & $-0.00$ & $\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.05$ & $\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.08$ & $\phantom{-}0.03$ \\
& \textbf{2.7B} & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.07$ & \cellcolor{blue!35}$\phantom{-}0.08$ & \cellcolor{blue!35}$\phantom{-}0.06$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.06$ \\
& \textbf{6.7B} & \cellcolor{red!15}$-0.06$ & \cellcolor{red!15}$-0.04$ & $-0.00$ & $\phantom{-}0.01$ & $-0.01$ & \cellcolor{blue!35}$\phantom{-}0.04$ & $-0.00$ \\
& \textbf{13B} & \cellcolor{red!15}$-0.13$ & \cellcolor{red!15}$-0.11$ & \cellcolor{red!15}$-0.07$ & \cellcolor{red!15}$-0.06$ & \cellcolor{red!15}$-0.08$ & $-0.03$ & \cellcolor{red!15}$-0.08$ \\
& \textbf{30B} & \cellcolor{red!15}$-0.11$ & \cellcolor{red!15}$-0.09$ & \cellcolor{red!15}$-0.05$ & \cellcolor{red!15}$-0.04$ & \cellcolor{red!15}$-0.06$ & $-0.01$ & \cellcolor{red!15}$-0.06$ \\
\bottomrule
\end{tabular}%
}
}
\caption{MNLI}\label{tab:appendix-statistical-tests-in-domain-in-domain-mnli}
\end{subtable}%
\caption{Difference between average \textbf{in-domain performance} of ICL and FT on RTE (a) and MNLI (b) across model sizes. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to \underline{in-domain performance}. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference between ICL and FT.\looseness-1
} \label{tab:appendix-statistical-tests-in-domain-in-domain}
\end{table*} %
% % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % % % %
% % % % % % % %
%
\begin{table*}
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} &
\bottomrule
\end{tabular}%
}
}
\caption{RTE}\label{tab:appendix-statistical-tests-ood-in-domain-rte}
\end{subtable}%
~~
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \\ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} & $\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.07$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.08$ \\
& \textbf{350M} & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.07$ & \cellcolor{blue!35}$\phantom{-}0.09$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.12$ & \cellcolor{blue!35}$\phantom{-}0.06$ \\
& \textbf{1.3B} & \cellcolor{red!15}$-0.07$ & \cellcolor{red!15}$-0.04$ & $-0.01$ & $\phantom{-}0.01$ & $-0.02$ & $\phantom{-}0.04$ & $-0.01$ \\
& \textbf{2.7B} & \cellcolor{red!15}$-0.03$ & $-0.01$ & $\phantom{-}0.02$ & $\phantom{-}0.04$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.07$ & $\phantom{-}0.02$ \\
& \textbf{6.7B} & \cellcolor{red!15}$-0.10$ & \cellcolor{red!15}$-0.08$ & \cellcolor{red!15}$-0.04$ & $-0.03$ & \cellcolor{red!15}$-0.06$ & $\phantom{-}0.00$ & \cellcolor{red!15}$-0.05$ \\
& \textbf{13B} & \cellcolor{red!15}$-0.17$ & \cellcolor{red!15}$-0.15$ & \cellcolor{red!15}$-0.11$ & \cellcolor{red!15}$-0.10$ & \cellcolor{red!15}$-0.13$ & \cellcolor{red!15}$-0.07$ & \cellcolor{red!15}$-0.12$ \\
& \textbf{30B} & \cellcolor{red!15}$-0.16$ & \cellcolor{red!15}$-0.13$ & \cellcolor{red!15}$-0.10$ & \cellcolor{red!15}$-0.08$ & \cellcolor{red!15}$-0.11$ & $-0.05$ & \cellcolor{red!15}$-0.10$ \\
\bottomrule
\end{tabular}%
}
}
\caption{MNLI}\label{tab:appendix-statistical-tests-ood-in-domain-mnli}
\end{subtable}%
\caption{Difference between average \textbf{in-domain performance} of ICL and FT on RTE (a) and MNLI (b) across model sizes. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to \underline{out-of-domain performance}. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference between ICL and FT.\looseness-1
} \label{tab:appendix-statistical-tests-ood-in-domain}
\end{table*} %
% % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % % %
%
\begin{table*}
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} & \cellcolor{blue!35}$\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.02$ & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.16$ & \cellcolor{blue!35}$\phantom{-}0.18$ & \cellcolor{blue!35}$\phantom{-}0.16$ \
& \textbf{350M} & \cellcolor{blue!35}$\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.02$ & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.16$ & \cellcolor{blue!35}$\phantom{-}0.18$ & \cellcolor{blue!35}$\phantom{-}0.16$ \
& \textbf{1.3B} &
\bottomrule
\end{tabular}%
}
}
\caption{RTE}\label{tab:appendix-statistical-tests-ood-ood-rte}
\end{subtable}%
~~
\begin{subtable}{.49\textwidth}\centering
{
\resizebox{1\textwidth}{!}{%
\begin{tabular}{llccccccc}
\toprule
%
%
&
%
& \multicolumn{7}{c}{\textbf{FT}} \\ \cmidrule{3-9}
& & \textbf{125M} & \textbf{350M} & \textbf{1.3B} & \textbf{2.7B} & \textbf{6.7B} & \textbf{13B} & \textbf{30B}
\\ \midrule
\multirow{7}{*}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{125M} & \cellcolor{blue!35}$\phantom{-}0.00$ & \cellcolor{blue!35}$\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.14$ & \cellcolor{blue!35}$\phantom{-}0.17$ \\
& \textbf{350M} & \cellcolor{blue!35}$\phantom{-}0.00$ & \cellcolor{blue!35}$\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.14$ & \cellcolor{blue!35}$\phantom{-}0.17$ \\
& \textbf{1.3B} & $\phantom{-}0.00$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.14$ & \cellcolor{blue!35}$\phantom{-}0.16$ \\
& \textbf{2.7B} & $\phantom{-}0.00$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.05$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.14$ & \cellcolor{blue!35}$\phantom{-}0.16$ \\
& \textbf{6.7B} & $-0.01$ & $-0.00$ & \cellcolor{blue!35}$\phantom{-}0.04$ & \cellcolor{blue!35}$\phantom{-}0.03$ & \cellcolor{blue!35}$\phantom{-}0.12$ & \cellcolor{blue!35}$\phantom{-}0.13$ & \cellcolor{blue!35}$\phantom{-}0.16$ \\
& \textbf{13B} & \cellcolor{red!15}$-0.03$ & \cellcolor{red!15}$-0.02$ & $\phantom{-}0.02$ & $\phantom{-}0.01$ & \cellcolor{blue!35}$\phantom{-}0.10$ & \cellcolor{blue!35}$\phantom{-}0.11$ & \cellcolor{blue!35}$\phantom{-}0.13$ \\
& \textbf{30B} & \cellcolor{red!15}$-0.06$ & \cellcolor{red!15}$-0.06$ & $-0.01$ & $-0.02$ & $\phantom{-}0.06$ & \cellcolor{blue!35}$\phantom{-}0.08$ & \cellcolor{blue!35}$\phantom{-}0.10$ \\
\bottomrule
\end{tabular}%
}
}
\caption{MNLI}\label{tab:appendix-statistical-tests-ood-ood-mnli}
\end{subtable}%
\caption{Difference between average \textbf{out-of-domain performance} of ICL and FT on RTE (a) and MNLI (b) across model sizes. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to \underline{out-of-domain performance}. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference between ICL and FT.\looseness-1
} \label{tab:appendix-statistical-tests-ood-ood}
\end{table*} %
% % % % % % % % % % % % % % % % % % % %
% % % % % % % %
\subsection{In-context learning} \label{appendix:additional-results-in-context}
Figures \ref{fig:in-context-model-selection-mnli}, \ref{fig:in-context-model-selection-rte}, and \ref{fig:in-context-model-selection-qqp} show ICL results on MNLI, RTE, and QQP for all OPT model sizes grouped by number of demonstrations and patterns. %
\paragraph{Sensitivity to pattern choice and number of examples}
On MNLI and RTE, we find that only the largest model benefits from the instructive \texttt{gpt-3} and \texttt{eval-harness} patterns. Moreover, on all datasets and for all patterns, models are sensitive to the number of demonstrations and do not necessarily improve with more demonstrations.
%
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_mnli_minimal_legend.pdf} \caption{2 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_mnli_gpt-3.pdf} \caption{2 samples -- \texttt{gpt-3}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_mnli_eval-harness.pdf} \caption{2 samples -- \texttt{eval-harness}} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_mnli_minimal.pdf} \caption{16 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_mnli_gpt-3.pdf} \caption{16 samples -- \texttt{gpt-3}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_mnli_eval-harness.pdf} \caption{16 samples -- \texttt{eval-harness}} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_32-shots_mnli_gpt-3.pdf} \caption{32 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_32-shots_mnli_gpt-3.pdf} \caption{32 samples -- \texttt{gpt-3}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_32-shots_mnli_eval-harness.pdf} \caption{32 samples -- \texttt{eval-harness}} \end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of ICL on MNLI} for OPT models of various sizes. Rows vary amount of training data. Columns vary input pattern.
Colors indicate model size. We run 10 models per setting varying only the data seed.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:in-context-model-selection-mnli}
\end{figure*} %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_rte_minimal_legend.pdf} \caption{2 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_rte_gpt-3.pdf} \caption{2 samples -- \texttt{gpt-3}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_rte_eval-harness.pdf} \caption{2 samples -- \texttt{eval-harness}} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_rte_minimal.pdf} \caption{16 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_rte_gpt-3.pdf} \caption{16 samples -- \texttt{gpt-3}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_rte_eval-harness.pdf} \caption{16 samples -- \texttt{eval-harness}} \end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of ICL on RTE} for OPT models of various sizes. Rows vary amount of training data. Columns vary input pattern.
Colors indicate model size. We run 10 models per setting varying only the data seed.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:in-context-model-selection-rte}
\end{figure*} %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_qqp_minimal_legend.pdf} \caption{2 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_2-shots_qqp_eval-harness.pdf} \caption{2 samples -- \texttt{eval-harness}} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_qqp_minimal.pdf} \caption{16 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_16-shots_qqp_eval-harness.pdf} \caption{16 samples -- \texttt{eval-harness}} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_32-shots_qqp_minimal.pdf} \caption{32 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/in-context_all-models_32-shots_qqp_eval-harness.pdf} \caption{32 samples -- \texttt{eval-harness}} \end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of ICL on QQP} for OPT models of various sizes. Rows vary amount of training data. Columns vary input pattern.
Colors indicate model size. We run 10 models per setting varying only the data seed.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:in-context-model-selection-qqp}
\end{figure*} %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
\subsection{Fine-tuning} \label{appendix:additional-results-ft}
% % % % % % % % % % % % % % %
% % % % % % % % % % % % % %
We provide all FT results in Figures \ref{fig:appendix-ft-model-selection-mnli}, \ref{fig:appendix-ft-model-selection-rte}, and \ref{fig:appendix-ft-model-selection-qqp}. When comparing results across rows, we see the impact of the number of training examples on the results. Comparing results across columns demonstrates the importance of model selection for in-domain and out-of-domain performance.
\Cref{fig:appendix-ft-mnli-original-16,fig:appendix-ft-mnli-original} show a comparison between two different ways of binarizing MNLI. For our main experiments, we remove the neutral class entirely. Merging it with the contradiction class instead leads to an even better relationship between in-domain and OOD performance.
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_16_best_in-domain_pattern-verbalizer-ft_legend.pdf} \caption{16 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_16_last_pattern-verbalizer-ft.pdf} \caption{16 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_16_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{16 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_32_best_in-domain_pattern-verbalizer-ft.pdf} \caption{32 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_32_last_pattern-verbalizer-ft.pdf} \caption{32 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_32_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{32 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_64_best_in-domain_pattern-verbalizer-ft.pdf} \caption{64 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_64_last_pattern-verbalizer-ft.pdf} \caption{64 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_64_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{64 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_128_best_in-domain_pattern-verbalizer-ft.pdf} \caption{128 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_128_last_pattern-verbalizer-ft.pdf} \caption{128 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_128_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{128 -- out-of-domain} \end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of PBFT on MNLI} for OPT models of various sizes. Rows vary amount of training data. Columns vary model selection strategy.
Colors indicate model size. We fine-tune 10 models per setting varying only the data seed.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:appendix-ft-model-selection-mnli}
\end{figure*} %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_16_best_in-domain_pattern-verbalizer-ft_legend.pdf} \caption{16 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_16_last_pattern-verbalizer-ft.pdf} \caption{16 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_16_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{16 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_32_best_in-domain_pattern-verbalizer-ft.pdf} \caption{32 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_32_last_pattern-verbalizer-ft.pdf} \caption{32 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_32_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{32 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_64_best_in-domain_pattern-verbalizer-ft.pdf} \caption{64 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_64_last_pattern-verbalizer-ft.pdf} \caption{64 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_64_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{64 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_128_best_in-domain_pattern-verbalizer-ft.pdf} \caption{128 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_128_last_pattern-verbalizer-ft.pdf} \caption{128 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_rte_128_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{128 -- out-of-domain} \end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of PBFT on RTE} for OPT models of various sizes. Rows vary amount of training data. Columns vary model selection strategy.
Colors indicate model size. We fine-tune 10 models per setting varying only the data seed.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:appendix-ft-model-selection-rte}
\end{figure*} %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_16_best_in-domain_pattern-verbalizer-ft_legend.pdf} \caption{16 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_16_last_pattern-verbalizer-ft.pdf} \caption{16 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_16_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{16 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_32_best_in-domain_pattern-verbalizer-ft.pdf} \caption{32 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_32_last_pattern-verbalizer-ft.pdf} \caption{32 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_32_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{32 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_64_best_in-domain_pattern-verbalizer-ft.pdf} \caption{64 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_64_last_pattern-verbalizer-ft.pdf} \caption{64 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_64_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{64 -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_128_best_in-domain_pattern-verbalizer-ft.pdf} \caption{128 -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_128_last_pattern-verbalizer-ft.pdf} \caption{128 -- last checkpoint} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_qqp_128_best_out-of-domain_pattern-verbalizer-ft.pdf} \caption{128 -- out-of-domain} \end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of PBFT on QQP} for OPT models of various sizes. Rows vary amount of training data. Columns vary model selection strategy.
Colors indicate model size. We fine-tune 10 models per setting varying only the data seed.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:appendix-ft-model-selection-qqp}
\end{figure*} %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli-original_16_best_in-domain_pattern-verbalizer-ft_legend} \caption{\textit{merge} -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli-original_16_last_pattern-verbalizer-ft} \caption{\textit{merge} -- last} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli-original_16_best_out-of-domain_pattern-verbalizer-ft} \caption{\textit{merge} -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_16_best_in-domain_pattern-verbalizer-ft} \caption{\textit{remove} -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering
\includegraphics[width=\textwidth]{figures/ft/all-models_mnli_16_last_pattern-verbalizer-ft}
\caption{\textit{remove} -- last}
\end{subfigure}
~
\begin{subfigure}[b]{0.31\textwidth}
\centering
\includegraphics[width=\textwidth]{figures/ft/all-models_mnli_16_best_out-of-domain_pattern-verbalizer-ft}
\caption{\textit{remove} -- out-of-domain}
\end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of PBFT on MNLI} for OPT models of various sizes when \textbf{merging} the neutral and contradiction classes \textbf{vs. removing} the neutral examples altogether.
We fine-tune on \textbf{16 examples} using 10 different seeds.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:appendix-ft-mnli-original-16}
\end{figure*} %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli-original_128_best_in-domain_pattern-verbalizer-ft_legend} \caption{\textit{merge} -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli-original_128_last_pattern-verbalizer-ft} \caption{\textit{merge} -- last} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli-original_128_best_out-of-domain_pattern-verbalizer-ft} \caption{\textit{merge} -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/all-models_mnli_128_best_in-domain_pattern-verbalizer-ft} \caption{\textit{remove} -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering
\includegraphics[width=\textwidth]{figures/ft/all-models_mnli_128_last_pattern-verbalizer-ft}
\caption{\textit{remove} -- last}
\end{subfigure}
~
\begin{subfigure}[b]{0.31\textwidth}
\centering
\includegraphics[width=\textwidth]{figures/ft/all-models_mnli_128_best_out-of-domain_pattern-verbalizer-ft}
\caption{\textit{remove} -- out-of-domain}
\end{subfigure}
\caption{\textbf{Relationship between in-domain and out-of-domain performance of PBFT on MNLI} for OPT models of various sizes when \textbf{merging} the neutral and contradiction classes \textbf{vs. removing} the neutral examples altogether.
We fine-tune on \textbf{128 examples} using 10 different seeds.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:appendix-ft-mnli-original}
\end{figure*} %
\section{Additional results for Pythia models} \label{sec:appendix-pythia}
\cref{fig:appendix-pythia} compares FT and ICL of % Pythia models ranging from 410M to 12B parameters \citep{biderman2023pythia}. Similar to OPT, the Pythia models differ only in their size and have all been trained on exactly the same data (even in the exact same order). We focus on RTE and report results using 16 examples. For ICL, we use three different patterns (\texttt{minimal}, \texttt{gpt-3}, \texttt{eval-harness}). For FT, we report results using 16 and 128 examples and three different model selection strategies (best in-domain, last checkpoint, best out-of-domain). Significance tests are provided in \Cref{tab:appendix-statistical-tests-pythia-ood-ood,tab:appendix-statistical-tests-pythia-in-domain-in-domain,tab:appendix-statistical-tests-pythia-in-domain-ood,tab:appendix-statistical-tests-pythia-ood-in-domain}.
%
%
% % % % % % % % % % % % % % % % % % % % % % % % % % % % %
% % % % % % % % % % % % % % % % % %
% % % % % % % % %
% % % % % %
%
For ICL, all models perform poorly when using the \texttt{minimal} pattern. With the \texttt{gpt-3} pattern, we can observe a clear impact of model size on in-domain and out-of-domain performance. On the other hand, with the \texttt{eval-harness} pattern, for Pythia models, only in-domain performance improves with model size.
For FT, when using 16 samples and selecting checkpoints according to out-of-domain performance, almost all checkpoints lead to better out-of-domain than in-domain performance. Moreover, almost all fine-tuned models perform significantly better OOD than models adapted via ICL. When fine-tuning with 128 examples, we can see a very clear effect of model size on both in-domain and out-of-domain performance. In particular, when selecting checkpoints according to out-of-domain performance, almost all models perform better out-of-domain than in-domain.
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/pythia_16-shots_rte_minimal.pdf} \caption{ICL 16 samples -- \texttt{minimal}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/pythia_16-shots_rte_gpt-3.pdf} \caption{ICL 16 samples -- \texttt{gpt-3}} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/in-context/pythia_16-shots_rte_eval-harness.pdf} \caption{ICL 16 samples -- \texttt{eval-harness}} \end{subfigure} \ \begin{subfigure}[b]{0.31\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/pythia_rte_16_best_in-domain_pattern-verbalizer-ft.pdf} \caption{FT 16 samples -- best in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.31\textwidth} \centering
\includegraphics[width=\textwidth]{figures/ft/pythia_rte_16_last_pattern-verbalizer-ft.pdf}
\caption{FT 16 samples -- last}
\end{subfigure}
~
\begin{subfigure}[b]{0.31\textwidth}
\centering
\includegraphics[width=\textwidth]{figures/ft/pythia_rte_16_best_out-of-domain_pattern-verbalizer-ft.pdf}
\caption{FT 16 samples -- best out-of-domain}
\end{subfigure}
\\
\begin{subfigure}[b]{0.31\textwidth}
\centering
\includegraphics[width=\textwidth]{figures/ft/pythia_rte_128_best_in-domain_pattern-verbalizer-ft.pdf}
\caption{FT 128 samples -- best in-domain}
\end{subfigure}
~
\begin{subfigure}[b]{0.31\textwidth}
\centering
\includegraphics[width=\textwidth]{figures/ft/pythia_rte_128_last_pattern-verbalizer-ft.pdf}
\caption{FT 128 samples -- last}
\end{subfigure}
~
\begin{subfigure}[b]{0.31\textwidth}
\centering
\includegraphics[width=\textwidth]{figures/ft/pythia_rte_128_best_out-of-domain_pattern-verbalizer-ft.pdf}
\caption{FT 128 samples -- best out-of-domain}
\end{subfigure}
\caption{\textbf{ICL and FT results for Pythia models of different size}. For ICL, we report results using 16 examples and three different patterns (\texttt{minimal}, \texttt{gpt-3}, \texttt{eval-harness}). For FT, we report results using 16 and 128 examples using three different model selection strategies (best in-domain, last checkpoint, best out-of-domain). In all cases, we show results for 10 different random seeds.
\textcolor{red}{$\boldsymbol{-}$} in the x- and y-axis indicates the performance of the majority class label.
}
\label{fig:appendix-pythia}
\end{figure*} %
% \begin{table*}[hp] \centering \resizebox{0.55\textwidth}{!}{% \begin{tabular}{llccccc} \toprule % % & % & \multicolumn{5}{c}{\textbf{FT}} \ \cmidrule{3-7} & & \textbf{410M} & \textbf{1.4B} & \textbf{2.8B} & \textbf{6.9B} & \textbf{12B} \ \midrule \multirow{5}{}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{410M} & \cellcolor{blue!35}$0.05$ & \cellcolor{blue!35}$0.06$ & \cellcolor{blue!35}$0.06$ & \cellcolor{blue!35}$0.09$ & \cellcolor{blue!35}$0.07$ \ & \textbf{1.4B} & \cellcolor{blue!35}$0.03$ & \cellcolor{blue!35}$0.04$ & \cellcolor{blue!35}$0.04$ & \cellcolor{blue!35}$0.07$ & \cellcolor{blue!35}$0.05$ \ & \textbf{2.8B} & $-0.02$ & $-0.00$ & $-0.01$ & $0.02$ & $0.01$ \ & \textbf{6.9B} & \cellcolor{red!15}$-0.03$ & \cellcolor{red!15}$-0.02$ & \cellcolor{red!15}$-0.02$ & $0.01$ & $-0.01$ \ & \textbf{12B} & \cellcolor{red!15}$-0.04$ & \cellcolor{red!15}$-0.03$ & \cellcolor{red!15}$-0.03$ & $-0.00$ & $-0.02$ \ \bottomrule \end{tabular}% } \caption{Difference between average \textbf{in-domain performance} of ICL and FT with Pythia models on RTE. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to \underline{in-domain performance}. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference between ICL and FT.\looseness-1 } \label{tab:appendix-statistical-tests-pythia-in-domain-in-domain} \end{table} %
% \begin{table*}[hp] \centering \resizebox{0.55\textwidth}{!}{% \begin{tabular}{llccccc} \toprule % % & % & \multicolumn{5}{c}{\textbf{FT}} \ \cmidrule{3-7} & & \textbf{410M} & \textbf{1.4B} & \textbf{2.8B} & \textbf{6.9B} & \textbf{12B} \ \midrule \multirow{5}{}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{410M} & $-0.00$ & \cellcolor{blue!35}$0.04$ & $0.02$ & \cellcolor{blue!35}$0.06$ & \cellcolor{blue!35}$0.06$ \ & \textbf{1.4B} & $-0.02$ & $0.02$ & $0.00$ & \cellcolor{blue!35}$0.04$ & \cellcolor{blue!35}$0.04$ \ & \textbf{2.8B} & \cellcolor{red!15}$-0.06$ & \cellcolor{red!15}$-0.03$ & \cellcolor{red!15}$-0.04$ & $-0.01$ & $-0.01$ \ & \textbf{6.9B} & \cellcolor{red!15}$-0.08$ & \cellcolor{red!15}$-0.04$ & \cellcolor{red!15}$-0.06$ & \cellcolor{red!15}$-0.02$ & \cellcolor{red!15}$-0.02$ \ & \textbf{12B} & \cellcolor{red!15}$-0.09$ & \cellcolor{red!15}$-0.05$ & \cellcolor{red!15}$-0.07$ & \cellcolor{red!15}$-0.03$ & \cellcolor{red!15}$-0.03$ \ \bottomrule \end{tabular}% } \caption{Difference between average \textbf{in-domain performance} of ICL and FT with Pythia models on RTE. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to \underline{out-of-domain performance}. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference between ICL and FT.\looseness-1 } \label{tab:appendix-statistical-tests-pythia-in-domain-ood} \end{table} %
% % % % % % % % % % % % % % % % % % % % % % % % %
% \begin{table*}[hp] \centering \resizebox{0.55\textwidth}{!}{% % % % % % % % % % % % % % % % % \begin{tabular}{llccccc} \toprule % % & % & \multicolumn{5}{c}{\textbf{FT}} \ \cmidrule{3-7} & & \textbf{410M} & \textbf{1.4B} & \textbf{2.8B} & \textbf{6.9B} & \textbf{12B} \ \midrule \multirow{5}{}{\rotatebox[origin=c]{90}{\textbf{ICL}}} & \textbf{410M} & \cellcolor{blue!35}$0.05$ & \cellcolor{blue!35}$0.08$ & \cellcolor{blue!35}$0.13$ & \cellcolor{blue!35}$0.15$ & \cellcolor{blue!35}$0.14$ \ & \textbf{1.4B} & \cellcolor{blue!35}$0.04$ & \cellcolor{blue!35}$0.07$ & \cellcolor{blue!35}$0.12$ & \cellcolor{blue!35}$0.14$ & \cellcolor{blue!35}$0.13$ \ & \textbf{2.8B} & $-0.00$ & \cellcolor{blue!35}$0.03$ & \cellcolor{blue!35}$0.08$ & \cellcolor{blue!35}$0.10$ & \cellcolor{blue!35}$0.09$ \ & \textbf{6.9B} & \cellcolor{blue!35}$0.04$ & \cellcolor{blue!35}$0.07$ & \cellcolor{blue!35}$0.12$ & \cellcolor{blue!35}$0.14$ & \cellcolor{blue!35}$0.13$ \ & \textbf{12B} & $0.00$ & \cellcolor{blue!35}$0.03$ & \cellcolor{blue!35}$0.08$ & \cellcolor{blue!35}$0.10$ & \cellcolor{blue!35}$0.09$ \ \bottomrule \end{tabular}% } \caption{Difference between average \textbf{out-of-domain performance} of ICL and FT with Pythia models on RTE. We use 16 examples and 10 random seeds for both approaches. For ICL, we use the \texttt{gpt-3} pattern. For FT, we use pattern-based fine-tuning (PBFT) and select checkpoints according to \underline{out-of-domain performance}. We perform a Welch's t-test and color cells according to whether: \textcolor{red!45}{ICL performs significantly better than FT}, \textcolor{blue!75}{FT performs significantly better than ICL}. For cells without color, there is no significant difference between ICL and FT.\looseness-1 } \label{tab:appendix-statistical-tests-pythia-ood-in-domain} \end{table} %
% % % \section{Analyzing individual OPT fine-tuning runs} \label{sec:appendix-individual-ft-runs}
Looking at the in-domain and out-of-domain performance for individual checkpoints does not reveal the generalization behavior of individual FT runs during training. In particular, this view does not tell us how stable the generalization of individual runs is during FT. Therefore, in Figures \ref{fig:appendix-individual-runs-mnli} and \ref{fig:appendix-individual-runs-rte} we visualize both in-domain and out-of-domain performance throughout FT on MNLI and RTE when using 128 examples. We observe that out-of-domain performance varies considerably across seeds and even during fine-tuning.
% % % % % % % % % % % % % %
% % % % % %
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-1.3b_mnli_128_pattern-verbalizer-ft_in-domain} \caption{1.3B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-1.3b_mnli_128_pattern-verbalizer-ft_out-of-domain} \caption{1.3B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-2.7b_mnli_128_pattern-verbalizer-ft_in-domain} \caption{2.7B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-2.7b_mnli_128_pattern-verbalizer-ft_out-of-domain} \caption{2.7B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-6.7b_mnli_128_pattern-verbalizer-ft_in-domain} \caption{6.7B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-6.7b_mnli_128_pattern-verbalizer-ft_out-of-domain} \caption{6.7B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-13b_mnli_128_pattern-verbalizer-ft_in-domain} \caption{13B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-13b_mnli_128_pattern-verbalizer-ft_out-of-domain} \caption{13B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-30B_mnli_128_pattern-verbalizer-ft_in-domain} \caption{30B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-30B_mnli_128_pattern-verbalizer-ft_out-of-domain} \caption{30B -- out-of-domain} \end{subfigure}
\caption{\textbf{Generalization throughout PBFT on MNLI for OPT models of various sizes.} We train on 128 examples. Colors denote different data seeds. First column shows in-domain, second column out-of-domain performance.
}
\label{fig:appendix-individual-runs-mnli}
\end{figure*}
%
% \begin{figure*}[h] \centering \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-1.3b_rte_128_pattern-verbalizer-ft_in-domain} \caption{1.3B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-1.3b_rte_128_pattern-verbalizer-ft_out-of-domain} \caption{1.3B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-2.7b_rte_128_pattern-verbalizer-ft_in-domain} \caption{2.7B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-2.7b_rte_128_pattern-verbalizer-ft_out-of-domain} \caption{2.7B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-6.7b_rte_128_pattern-verbalizer-ft_in-domain} \caption{6.7B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-6.7b_rte_128_pattern-verbalizer-ft_out-of-domain} \caption{6.7B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-13b_rte_128_pattern-verbalizer-ft_in-domain} \caption{13B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-13b_rte_128_pattern-verbalizer-ft_out-of-domain} \caption{13B -- out-of-domain} \end{subfigure} \ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-30B_rte_128_pattern-verbalizer-ft_in-domain} \caption{30B -- in-domain} \end{subfigure} ~ \begin{subfigure}[b]{0.35\textwidth} \centering \includegraphics[width=\textwidth]{figures/ft/facebook-opt-30B_rte_128_pattern-verbalizer-ft_out-of-domain} \caption{30B -- out-of-domain} \end{subfigure}
\caption{\textbf{Generalization throughout PBFT on RTE for OPT models of various sizes.} We train on 128 examples. Colors denote different data seeds. First column shows in-domain, second column out-of-domain performance.
}
\label{fig:appendix-individual-runs-rte}
\end{figure*}
%
\end{document}
</paper 1> <paper 2> \section{A Crash Introduction to RL: Online RL, Offline RL, and Inverse RL}
In this section, we will briefly introduce some basic concepts needed in our discussion later. We begin by highlighting the important intuitions behind the technique of Reinforcement Learning (RL), followed by a more technical formalism. Our goal is to ensure everyone, regardless of their background, can grasp the intricacies of RL and its impact on Large Language Models.
\subsection{Essential Concepts} In RL, an agent learns through interacting with an environment and receiving feedback in the form of rewards. The fundamental objective of RL is to find a policy, which is a mapping from states to actions, that maximizes the expected cumulative reward over time.
Here are several useful concepts:
\begin{itemize}
\item (\textbf{Environment} \includegraphics[height=1em]{figs/earth_asia.png}=\includegraphics[height=1em]{figs/gear.png}+\includegraphics[height=1em]{figs/scales.png}.) When we are talking about an \textit{Environment} \includegraphics[height=1em]{figs/earth_asia.png} we are talking about the \textit{dynamics model }\includegraphics[height=1em]{figs/gear.png} and the \textit{reward function} \includegraphics[height=1em]{figs/scales.png}.
\item (\textbf{Agent} \includegraphics[height=1em]{figs/robot_face.png}) An \textit{Agent} is the subject of a \textit{policy} that interacts with the environment. In a sequential decision-making problem, there can be multiple decision steps, and a smart policy will make its decision at every step by considering every piece of information it can collect till then. e.g., using recurrent networks to record histories in \cite{sun2021safe,ni2021recurrent}
\item (\textbf{Difficulties} \includegraphics[height=1em]{figs/exploding_head.png}) Why is it hard to learn? 1. the learning objective is non-differentiable, it engages the unknown environment. 2. the policy needs to trade off between exploring \textit{random} novel behaviors that potentially can be better than the current, yet as those are random behaviors, they are usually worse than the current --- you may imagine how hard it would be for the LLM generation tasks when there are 10k tokens (as action) to choose from ...
\item (\textbf{Learning} \includegraphics[height=1em]{figs/thinking_face.png}) The key insight behind the \textit{learning} step in RL is to increase the probability of executing the \textit{good} actions (which leads to a high cumulative future reward) and decrease the probability of executing \textit{bad} actions (which have a low cumulative future reward). An easy-to-follow approach can be performing supervised learning on a collected set of good actions. e.g., Using Supervised Learning to mimic successful trajectories as an alternative approach to RL\cite{sun2019policy,sun2020zeroth}.
\end{itemize}
\subsection{Technical Formumation}
RL can be formally represented using the Markov Decision Processes (MDPs), where decisions are made in discrete time steps, and each decision affects the state of the environment in the subsequent step.
\subsubsection{Markov Decision Processes}
Formally, we denote the MDP as
At each time step
The most obvious difficulty in the offline RL setting is such a setting prohibits exploration --- hence it hinders the improvement of policy learning to be improved over the demonstration data (though sometimes the learned policy can be better than the demonstration).
Another fundamental challenge is the \textit{distributional shift}: although offline RL learns from a static dataset, its evaluation is actually based on rolling out a policy in an environment --- this is different from the ordinary supervised learning settings where the training set and test set are sampled from the same distribution. In offline RL training, the state distribution is sampled from rolling out the behavior policy
To be more specific, assuming the decision dataset is collected from an optimal behavior policy $\pi_\beta^$, such that every decision $a^i_t$ is optimal. We denote the state-action pairs in the dataset as $(s_t, a^t)$, then the expected number of mistakes made by the learned policy $\pi$ based on such an expert decision dataset can be denoted as
\begin{equation}
\ell(\pi) = \mathbb{E}{p_\pi(\tau)} \left[ \sum_{t=0}^T \mathbbm{1}(\pi(s_t)\ne a^t) \right]
\end{equation}
Then we have the following theorems:
\begin{theorem}[Behavior Clone Error Bound. \citet{ross2011reduction}]
\label{theorem:1}
If $\pi$ is trained via empirical risk minimization on $s_t\sim p{\pi_\beta}(\tau)$ and optimal labels $a_t^
In order to alleviate the challenge of compounding error we discussed above, \textit{Imitation Learning} (IL) considers the setting where a dynamics model is available during learning.
\paragraph{Another Motivation of IL: Reward Design is Hard} The setup of IL is especially common for problems where reward engineering is hard. This is because although the “reward hypothesis” tells us whenever we can define a reward function for a task, it can be solved by RL, it does not consider whether this task can be efficiently solved. For instance, in playing Go or StarCraft, it's easy to define a reward function that returns
\paragraph{A Method for Reward Engineering} In a previous paper~\cite{sun2022exploit}, we show and illustrate why using a
To alleviate the challenge of reward engineering in RL tasks, IL is introduced to learn to use the dynamics model but without a pre-defined reward model. Consider those examples: (1) in learning humanoid robotics locomotion skills, it is hard to define an objective to let the robot “walk as a human” --- however, providing demonstration data to show how humans walk is much easier. (2) in autonomous driving, it is hard to define the objective of “driving safe and well” --- however, we should be able to provide human driving videos or control sequences as demonstrations of good and safe driving behaviors.
The objective of IL is to learn from a (decision) demonstration dataset, with access to a dynamics model --- such that the current policy can be rolled out in the real environment. Intuitively, with such a dynamics model, the optimization objective will no longer be
\begin{figure}[h!] \centering \includegraphics[width=0.6\linewidth]{figs/fig3.png} \caption{\small In Imitation Learning (IL), the agent learns from feedback from the decision dataset, but the observations are from a real dynamics model.} \label{fig:3_il} \end{figure}
There are many practical methods for implementing such a learning process, and the most famous work in the Deep-RL era is the GAIL~\citep{ho2016generative}, which conducts IL through adversarial learning: the policy is a \textit{generator} of behaviors, while a \textit{discriminator} then tries to identify whether a trajectory is generated by the behavior policy
For the theory results, we have the following theorem:
\begin{theorem}[DAgger Error Bound, \citet{ross2011reduction}]
\label{theorem:2}
If
\textbf{Takeaway:} Comparing Theorem \ref{theorem:1} and Theorem \ref{theorem:2}, we see that \textbf{having access to a \textit{dynamics model} \includegraphics[height=1em]{figs/gear.png} is essential in controlling the error bound.}
\subsubsection{Inverse Reinforcement Learning}
Inverse reinforcement learning (IRL) is actually just one of the many solutions to IL problems, with an emphasis on reward model learning. It first learns a reward model, and then uses such a reward model --- combined with the dynamics model --- to perform online RL. \begin{figure}[h!] \centering \includegraphics[width=0.85\linewidth]{figs/fig4.png} \caption{\small Inverse Reinforcement Learning (IRL) solves the IL tasks in two steps: (1). reward modeling that distills the knowledge of underlying learning objectives that the behavior policy seems to optimize from the offline decision demonstration dataset. (2). combining such a learned reward model and the accessible dynamics model, everything needed for an online RL algorithm is right there.} \label{fig:4_irl} \end{figure}
\textbf{Offline IL and Offline IRL:} What if both the reward model and dynamics model are not available? This situation is clearly more challenging. The demonstration dataset in such settings will be in the form of $\mathcal{D}{\mathrm{OIL}} = {(s^i_t,a^i_t,s^i{t+1})}$. Besides the behavior cloning method, there are several alternative approaches like the energy-based method SBIL~\cite{jarrett2020strictly}, and the latent space decomposition method ABC~\cite{sun2023accountable}. ABC can be regarded as an accountable counterpart of BC, therefore, it works in all settings where BC can be applied.
\subsubsection{Learning from Demonstrations} Another related but different topic is Learning from Demonstrations (LfD)\cite{schaal1996learning,hester2018deep,nair2018overcoming}, which leverages the demonstration dataset as a warm-start for RL. For instance, in the aforementioned tasks of Go or StarCraft, we can first use the demonstration dataset to perform behavior cloning (BC) and then use the learned BC policy as a warm start for RL. LfD also benefits the exploration of robotics control tasks where the reward can be extremely sparse, and defined as “whether the goal is achieved”. In a nutshell, LfD uses demonstrations to improve exploration in reward sparse tasks, and those demonstrations may not be optimal (e.g., non-expert players’ replay of StarCraft\cite{vinyals2019grandmaster}), LfD then returns to RL and a sparse reward function to further refine the policy learned from demonstration dataset.
\subsubsection{Comparison Between Different Settings} The table below summarizes the differences between RL, Offline-RL, IL, IRL, Offline-IRL, and LfD. \begin{table}[h] \fontsize{8}{10}\selectfont \centering \caption{\small Summarization of the differences between RL, Offline-RL, IL, IRL, Offline-IRL, and LfD.} \begin{tabular}{l|c|c|c|c|c} \toprule \textbf{Problem} & \textbf{External} & \textbf{External} & \textbf{Learned} & \textbf{(Near)-Expert} & \textbf{Example} \ \textbf{Settings} & \textbf{Dynamics} & \textbf{Reward} & \textbf{ Reward} & \textbf{Demonstration} & \textbf{Solvers} \ \textbf{} & \textbf{Model} & \textbf{Model} & \textbf{Model} & \textbf{} & \ \midrule RL & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/x.png} & PPO~\cite{schulman2017proximal}, TD3~\cite{fujimoto2018addressing},SAC~\cite{haarnoja2018soft}\ % \hline Offline-RL & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} or \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & BC, ABC~\cite{sun2023accountable}, CQL~\cite{kumar2020conservative}, WGCSL~\cite{yang2022rethinking} \ % \hline IL & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} or \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & BC, ABC~\cite{sun2023accountable}, GAIL~\cite{ho2016generative} \ % \hline IRL & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & BC, ABC~\cite{sun2023accountable}, T-REX~\cite{brown2019extrapolating} \ % \hline Offline-IRL & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & BC, ABC~\cite{sun2023accountable}, SBIL~\cite{jarrett2020strictly} \ % \hline LfD & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & \includegraphics[height=1em]{figs/x.png} & \includegraphics[height=1em]{figs/white_check_mark.png} & DQNfD~\cite{hester2018deep}, DDPGfD~\cite{nair2018overcoming}, AlphaStar~\cite{vinyals2019grandmaster} \ \bottomrule \end{tabular} \end{table} \section{RLHF: Solving the Problem of Offline RL with Online Inverse RL}
\subsection{LLM Alignment from Human Feedback}
In the task of LLM alignment from human feedback, LLMs are fine-tuned to better follow user instructions. In the seminal paper of OpenAI~\cite{ouyang2022training}, such an alignment includes two general parts: supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). Figure~\ref{fig:5_rlhf} below illustrates those concrete steps. The first part of SFT is relatively easy to follow and implement, yet the secret and insight behind RLHF are more intricate.
\begin{figure}[h!] \centering \includegraphics[width=0.9\linewidth]{figs/fig5.png} \caption{\small (From \citet{ouyang2022training}) There are 3 steps to align LLMs to human preference. Step 1: supervised fine-tuning of pre-trained LLM to follow instructions (generated by human demonstration data). Step 2: sample multiple responses for every query, and rank those responses according to human preference. Then a reward model can be learned to mimic the human preference. Step 3: Optimize the language model through RL to maximize the feedback from the reward model} \label{fig:5_rlhf} \end{figure}
\subsection{Aligning with Human Preference: the Online Nature and Offline Practice}
Ideally, the RLHF phase can be conducted with human-in-the-loop, as shown in Figure~\ref{fig:6_rlhf_online}. In such an online setting, Human provides feedback to every response of LLMs, and LLMs learn from the external reward model of human preference. In fact, OpenAI now should be able to conduct such a process by collecting user’s feedback on ChatGPT’s response. But usually, such an online setting is infeasible due to its high cost of keeping humans in the loop.
\begin{figure}[h!] \centering \includegraphics[width=0.66\linewidth]{figs/fig6.png} \caption{\small RLHF as an online RLproblem: Human preference is the underlying reward model, however, querying humans to provide feedback on every response is usually infeasible.} \label{fig:6_rlhf_online} \end{figure}
Practically, RLHF addresses such a difficulty by generating an \textit{offline alignment dataset} that contains different queries (i.e., states
Recall the problems of distributional shift and compounding error we discussed above in Offline RL, it seems RLHF must suffer from such problems. However, we show in the next section that RLHF can actually be solved as an \textbf{Online IL} problem, rather than an offline RL problem.
\subsection{RLHF: From Offline-RL to Online Imitation}
The essential observation we would highlight in RLHF is that \textbf{\textit{the dynamics model in response generation is known.}} Specifically, harking back to Figure 6, the actions are tokens generated by LLMs, and the responses (trajectories) are concatenations of those generated tokens. Given the auto-regression nature of LLMs’ generation process, given an initial query denoted as
Figure~\ref{fig:8_rlhf_onlineil} showcases why the LLM alignment task can be solved as an online IL in practice (c.f. Figure~\ref{fig:3_il}: pictorial illustration of IL) \begin{figure}[h!] \centering \includegraphics[width=0.4\linewidth]{figs/fig8.png} \caption{\small When aligning LLMs using an offline dataset, the dynamics model is a concatenation of the generated token and existing tokens, therefore, the offline RL problem can be solved by online IL.} \label{fig:8_rlhf_onlineil} \end{figure}
Practically, RLHF chooses to use the Inverse RL approach for the IL problem --- with the first step explicitly learning a reward model, and the second step conducting RL using such a reward model. Figure~\ref{fig:9_rlhf_onlineirl} illustrates the learning procedure.
\begin{figure}[h!] \centering \includegraphics[width=0.6\linewidth]{figs/fig9.png} \caption{\small RLHF is online IRL. The reward modeling step learns a reward function from the alignment dataset, and given such a reward model and the known transition dynamics (concatenation), online RL algorithms like PPO can then be applied.} \label{fig:9_rlhf_onlineirl} \end{figure}
\textbf{Takeaway:} When aligning LLMs with an \textit{\textbf{offline human-preference alignment dataset}}, RLHF uses an \textit{\textbf{online IRL}} approach. This is because the transition dynamics model is known. Leveraging such a property, \textbf{the compounding error and distributional shift problems of offline RL can be alleviated.}
\subsection{Challenges and Open Questions from an RL Perspective}
\subsubsection{Why is RLHF better than SFT?}
Given the discussions above, the reason RLHF can be better than SFT --- from an RL perspective --- is that RLHF leverages the fact that the dynamics model is known, and uses IL to solve the alignment problem. On the other hand, SFT corresponds to the behavior clone approach, which suffers from the problem of compounding error. \textbf{Therefore, as long as IL > BC, we have RLHF > SFT.}
\subsubsection{Is PPO the Only Solution?}
Recently, several works have proposed alternatives to RLHF, including DPO~\cite{rafailov2023direct} that directly optimizes the LLM using human-preference data without reward modeling, RRHF~\cite{yuan2023rrhf} and RAFT~\cite{dong2023raft} propose ranking-based sampling methods as alternatives to PPO to address the computational instability issue and high GPU memory demand of PPO.
So clearly, there is still a lot of space for future improvement over PPO. We would like to mention the following pros and cons (mostly based on empirical observations) of PPO: \begin{enumerate} \item PPO works well in large-scale discrete tasks~\cite{vinyals2019grandmaster}. The action space of LLM is far larger than normal RL problems. \item PPO has a faster wall-clock training time compared to off-policy methods like DQN~\cite{mnih2013playing}. PPO can be highly environment-parallelized. In fact, this is normally an implementation problem: in DQN a higher Update-to-Data (UTD) ratio~\cite{janner2019trust} is used: updates of networks in DQN are conducted every time step, but in PPO the updates of networks only happen at the end of an episode. e.g., after the entire response is generated. \item Aligning to human preference is a sparse reward problem. In the sense that only at the end of an episode will the agent receive a reward signal (provided by human feedback or the learned reward function). Such a setting is relevant to the multi-goal robotics control tasks~\cite{plappert2018multi} where the idea of Hindsight learning shines with the value-based methods~\cite{andrychowicz2017hindsight,sun2019policy} --- rather than policy-based methods like TRPO~\cite{schulman2015trust} and PPO. There are several attempts using the Hindsight relabeling trick for LLM fine-tuning~\cite{liu2023languages,zhang2023wisdom}. \item A fun fact is that policy-gradient and value-based methods are almost equivalent~\cite{schulman2017equivalence}. But in practice, the studies on LLM finetuning now mainly focus on the on-policy policy-based methods. The performance differences between policy-based methods and value-based methods can be mainly attributed to (1). on-policy/ off-policy data --- the staleness of the data they used for value and policy learning; and (2). whether using an aggressive and explicit or conservative and implicit policy learning --- while the policy-gradient methods like PPO and TRPO use a value function \textit{implicitly} for policy learning (i.e., use them as \textit{critics} to calculate policy gradient values that improve policy quality), the value-based methods like TD3 and SAC \textit{explicitly} turns the learned value function into policies (i.e., through either deterministic policy gradient DPG~\cite{silver2014deterministic} in TD3 or the Boltzmann policy~\cite{o2016combining} as in SAC/soft Q-learning~\cite{haarnoja2017reinforcement}.) \end{enumerate}
\subsubsection{What to Improve?}
\begin{enumerate}
\item \textbf{Credit Assignment:} The preference provided by humans is on a trajectory level. Hence the learned reward model can only compare responses on an entire level. Is there a way to assign credit to different tokens or part of tokens? A known fact in RL is dense reward problems are much easier to learn, though they do not necessarily outperform the sparse reward settings.\cite{plappert2018multi} (because of local minima, again, a reward engineering problem)
\item \textbf{Algorithmic Design:} RL algorithms are seldom designed in a way that assumes knowing the dynamics model. But in LLM alignment, the actions are actually generated in an auto-regressive manner. Is there a more efficient and stable RL algorithm that works better than PPO in such a \textit{series generation} setting? This is a sort of Auto-Regressive MDP.
\item \textbf{Prompting:} Is the prompting strategy optimized? Maybe the prompting strategy is not correct in getting the desired answer. Prompt optimization can definitely help improve the performance of LLMs. \textit{To address such a point, we introduce recent work on query-dependent prompt optimization\cite{sun2023offline} in the next section, which also links RL and LLM.}
\end{enumerate}
\section{Prompting with Offline IRL: Prompt Optimization is RL from AI Feedback}
\begin{figure}[h!] \centering \includegraphics[width=1.0\linewidth]{figs/motivating.png} \caption{\small (From \citet{sun2023offline}.) A motivating example (\href{https://chat.openai.com/share/0f2d11b1-322a-4c47-a877-ad6fbace8179}{left}, \href{https://chat.openai.com/share/15870a47-93c7-4b98-96c8-af0516c0c999}{right}). No prompt is perfect that works for all queries. The optimal prompt is query-dependent. Yet the seeking of such prompts is hindered by 2 challenges. Prompt-OIRL~\cite{sun2023offline} optimizes prompt during inference on a query-dependent level effectively and cost-efficiently.} \label{fig:10_prompt_motiv} \end{figure}
\subsection{The Query-Dependent Prompting Problem} Out of the many attempts, \textit{prompting} --- a natural language prefix or instruction that explains how to complete the task --- stands out as a lightweight promising solution for eliciting the capabilities of LLMs without model parameter tuning. While the advances in zero-shot prompting strategies highlight the potential for finding effective query-independent solutions, its reliance on manual crafting efforts and the vast search space over natural language intensifies the difficulty in discovering effective prompts. Moreover, as demonstrated in Figure~\ref{fig:10_prompt_motiv}, the optimal prompt is query dependent --- there is no perfect prompt that works for all queries.
\subsection{Prompt-OIRL: Prompt Evaluation and Optimization with Offline Inverse RL}
Prompt-OIRL is a novel approach grounded in offline inverse reinforcement learning, designed to reconcile effective and cost-efficient query-dependent prompt evaluation and optimization. This method leverages offline datasets from existing evaluations, utilizing Inverse-RL to craft a reward model tailored for offline, query-specific prompt evaluations. Prompt-OIRL offers several benefits: it forecasts prompt efficacy, minimizes costs, and explores the prompt space more effectively --- all at a query-dependent level. We validate our approach across various LLMs and arithmetic reasoning datasets, underscoring its viability as a formidable solution for query-dependent offline prompt evaluation and optimization.
\subsection{Potential Applications} While Prompt-OIRL primarily centers on arithmetic reasoning tasks, we wish to underscore the versatility of Prompt-OIRL's insights for broader applications, especially where there exists a prompting demonstration dataset accompanied by ratings of the prompted responses. As a hypothetical approach to dataset construction with human annotators incorporated into the process, consider this: human annotators could employ LLMs to accomplish specific tasks. They might offer multiple prompts as instructions for the task, and the ensuing LLM responses can then be graded based on proficiency in executing the given task. In fact, these annotators could be everyday LLM users keen on evaluating diverse responses. We earmark this intriguing concept for subsequent exploration.
</paper 2> <paper 3>
Prompt design and engineering has rapidly become essential for maximizing the potential of large language models. In this paper, we introduce core concepts, advanced techniques like Chain-of-Thought and Reflection, and the principles behind building LLM-based agents. Finally, we provide a survey of tools for prompt engineers.
A prompt in generative AI models is the textual input provided by users to guide the model’s output. This could range from simple questions to detailed descriptions or specific tasks. In the context of image generation models like DALLE-3, prompts are often descriptive, while in LLMs like GPT-4 or Gemini, they can vary from simple queries to complex problem statements.
Prompts generally consist of instructions, questions, input data, and examples. In practice, to elicit a desired response from an AI model, a prompt must contain either instructions or questions, with other elements being optional.
Basic prompts in LLMs can be as simple as asking a direct question or providing instructions for a specific task. Advanced prompts involve more complex structures, such as "chain of thought" prompting, where the model is guided to follow a logical reasoning process to arrive at an answer.
As mentioned above, a prompt is constructed by combining instructions, questions, input data, and examples. In order to obtain a result, either 1 or 2 must be present. Everything else is optional. Let’s see a few examples (all of them using ChatGPT-4).
Beyond asking a simple question, possibly the next level of sophistication in a prompt is to include some instructions on how the model should answer the question. Here I ask for advice on how to write a college essay, but also include instructions on the different aspects I am interested to hear about in the answer.
“How should I write my college admission essay? Give me suggestions about the different sections I should include, what tone I should use, and what expressions I should avoid.”
See output in Figure 1
Figure 1: Instructions + Question Prompt result example
Continuing with the previous example, it does not escape anyone that if you can ask a LLM for advice on how to write an essay, you can also directly ask it to write the essay itself.1
Let’s see what happens when we input some data about me and give some instructions:
“Given the following information about me, write a 4 paragraph college essay: I am originally from Barcelona, Spain. While my childhood had different traumatic events, such as the death of my father when I was only 6, I still think I had quite a happy childhood.. During my childhood, I changed schools very often, and attended all kinds of schools, from public schools to very religious private ones. One of the most “exotic” things I did during those years is to spend a full school year studying 6th grade in Twin Falls, Idaho, with my extended family.
I started working very early on. My first job, as an English teacher, was at age 13. After that, and throughout my studies, I worked as a teacher, waiter, and even construction worker.”
See output in Figure 2
Figure 2: Instructions + Input Prompt result example
You can also feed examples into a language model. In the example below I include some of the shows I like and don’t like to build a “cheap” recommender system. Note that while I added only a few shows, the length of this list is only limited by whatever token limit we might have in the LLM interface.
“Here are some examples of TV shows I really like: Breaking Bad, Peaky Blinders, The Bear. I did not like Ted Lasso. What other shows do you think I might like?”
See output in Figure 3
Figure 3: Question + Examples Prompt results example
Prompt engineering in generative AI models is a rapidly emerging discipline that shapes the interactions and outputs of these models. At its core, a prompt is the textual interface through which users communicate their desires to the model, be it a description for image generation in models like DALLE-3 or Midjourney, or a complex problem statement in Large Language Models (LLMs) like GPT-4 and Gemini. The prompt can range from simple questions to intricate tasks, encompassing instructions, questions, input data, and examples to guide the AI’s response.
The essence of prompt engineering lies in crafting the optimal prompt to achieve a specific goal with a generative model. This process is not only about instructing the model but also involves a deep understanding of the model’s capabilities and limitations, and the context within which it operates. In image generation models, for instance, a prompt might be a detailed description of the desired image, while in LLMs, it could be a complex query embedding various types of data.
Prompt engineering transcends the mere construction of prompts; it requires a blend of domain knowledge, understanding of the AI model, and a methodical approach to tailor prompts for different contexts. This might involve creating templates that can be programmatically modified based on a given dataset or context. For example, generating personalized responses based on user data might use a template that is dynamically filled with relevant information.
Furthermore, prompt engineering is an iterative and exploratory process, akin to traditional software engineering practices such as version control and regression testing. The rapid growth of this field suggests its potential to revolutionize certain aspects of machine learning, moving beyond traditional methods like feature or architecture engineering, especially in the context of large neural networks. On the other hand, traditional engineering practices such as version control and regression testing need to be adapted to this new paradigm just like they were adapted to other machine learning approaches [1].
This paper aims to delve into this burgeoning field, exploring both its foundational aspects and its advanced applications. We will focus on the applications of prompt engineering to LLM. However, most techniques can find applications in multimodal generative AI models too.
Large Language Models (LLMs), including those based on the Transformer architecture[2], have become pivotal in advancing natural language processing. These models, pre-trained on vast datasets to predict subsequent tokens, exhibit remarkable linguistic capabilities. However, despite their sophistication, LLMs are constrained by inherent limitations that affect their application and effectiveness.
-
•
Transient State: LLMs inherently lack persistent memory or state, necessitating additional software or systems for context retention and management.
-
•
Probabilistic Nature: The stochastic nature of LLMs introduces variability in responses, even to identical prompts, challenging consistency in applications. This means you might get slightly different answers each time, even with the same prompt.
-
•
Outdated Information: Reliance on pre-training data confines LLMs to historical knowledge, precluding real-time awareness or updates.
-
•
Content Fabrication: LLMs may generate plausible yet factually incorrect information, a phenomenon commonly referred to as "hallucination."
-
•
Resource Intensity: The substantial size of LLMs translates to significant computational and financial costs, impacting scalability and accessibility.
-
•
Domain Specificity: While inherently generalist, LLMs often require domain-specific data to excel in specialized tasks.
These limitations underscore the need for advanced prompt engineering and specialized techniques to enhance LLM utility and mitigate inherent constraints. Subsequent sections delve into sophisticated strategies and engineering innovations aimed at optimizing LLM performance within these bounds.
In chain of thought prompting, we explicitly encourage the model to be factual/correct by forcing it to follow a series of steps in its “reasoning”.
In the examples in figures 4 and 5, we use prompts of the form:
Original question?
Use this format:
Q: <repeat_question>
A: Lets think step by step. <give_reasoning> Therefore, the answer is <final_answer>.
Figure 4: Chain of thought prompting example
Figure 5: Chain of thought prompting example
One of the most important problems with generative models is that they are likely to hallucinate knowledge that is not factual or is wrong. You can improve factuality by having the model follow a set of reasoning steps as we saw in the previous subsection. And, you can also point the model in the right direction by prompting it to cite the right sources. (Note that we will later see that this approach has severe limitations since the citations themselves could be hallucinated or made up).
Are mRNA vaccines safe? Answer only using reliable sources and cite those sources.
See results in figure 6.
Figure 6: Getting factual sources
GPT based LLMs have a special message <|endofprompt|> that instructs the language model to interpret what comes after the code as a completion task. This enables us to explicitly separate some general instructions from e.g. the beginning of what you want the language model to write.
Write a poem describing a beautify day <|endofprompt|>. It was a beautiful winter day
Figure 7: Special tokens can sometimes be used in prompts
Note in the result in figure 7 how the paragraph continues from the last sentence in the “prompt”.
Language models do not always react well to nice, friendly language. If you REALLY want them to follow some instructions, you might want to use forceful language. Believe it or not, all caps and exclamation marks work! See example in figure 8
Figure 8: Don’t try to be nice to the AI
In example in figure 9 we get ChatGPT to create a “questionable” article. We then ask the model to correct it in 10.
Write a short article about how to find a job in tech. Include factually incorrect information.
Figure 9: It is possible to generate very questionable content with AI
Is there any factually incorrect information in this article: [COPY ARTICLE ABOVE HERE]
Figure 10: It is also possible to use the AI to correct questionable content!
LLMs do not have a strong sense of what is true or false, but they are pretty good at generating different opinions. This can be a great tool when brainstorming and understanding different possible points of views on a topic. We will see how this can be used in our favor in different ways by applying more advanced Prompt Engineering techniques in the next section. In the following example, we feed an article found online and ask ChatGPT to disagree with it. Note the use of tags and to guide the model. The result of this input can be seen in figure 11.
The text between <begin> and <end> is an example article.
<begin>
From personal assistants and recommender systems to self-driving cars and natural language processing, machine learning applications have demonstrated remarkable capabilities to enhance human decision-making, productivity and creativity in the last decade. However, machine learning is still far from reaching its full potential, and faces a number of challenges when it comes to algorithmic design and implementation. As the technology continues to advance and improve, here are some of the most exciting developments that could occur in the next decade.
-
Data integration: One of the key developments that is anticipated in machine learning is the integration of multiple modalities and domains of data, such as images, text and sensor data to create richer and more robust representations of complex phenomena. For example, imagine a machine learning system that can not only recognize faces, but also infer their emotions, intentions and personalities from their facial expressions and gestures. Such a system could have immense applications in fields like customer service, education and security. To achieve this level of multimodal and cross-domain understanding, machine learning models will need to leverage advances in deep learning, representation learning and self-supervised learning, as well as incorporate domain knowledge and common sense reasoning.
-
Democratization and accessibility: In the future, machine learning may become more readily available to a wider set of users, many of whom will not need extensive technical expertise to understand how to use it. Machine learning platforms may soon allow users to easily upload their data, select their objectives and customize their models, without writing any code or worrying about the underlying infrastructure. This could significantly lower the barriers to entry and adoption of machine learning, and empower users to solve their own problems and generate their own insights.
-
Human-centric approaches: As machine learning systems grow smarter, they are also likely to become more human-centric and socially-aware, not only performing tasks, but also interacting with and learning from humans in adaptive ways. For instance, a machine learning system may not only be able to diagnose diseases, but also communicate with patients, empathize with their concerns and provide personalized advice. Systems like these could enhance the quality and efficiency of healthcare, as well as improve the well-being and satisfaction of patients and providers
<end>
Given that example article, write a similar article that disagrees with it.
Figure 11: The AI is pretty good at creating different opinions
Language models themselves don’t keep track of state. However, applications such as ChatGPT implement the notion of “session” where the chatbot keeps track of state from one prompt to the next. This enables much more complex conversations to take place. Note that when using API calls this would involved keeping track of state on the application side.
In the example in 12, we make ChatGPT discuss worst-case time complexity of the bubble sort algorithm as if it were a rude Brooklyn taxi driver.
Figure 12: While LLMs don’t have memory in themselves, most applications like ChatGPT have added this functionality
One of the most useful abilities of LLMs is the fact that they can learn from what they are being fed in the prompt. This is the so-called zero-shot learning ability. The following example is taken from the appendix in "Teaching Algorithmic Reasoning via In-context Learning"[3] where the definition of parity of a list is fed in an example.
The following is an example of how to compute parity for a list
Q: What is the parity on the list a=[1, 1, 0, 1, 0]?
A: We initialize s=
a=[1, 1, 0, 1, 0]. The first element of a is 1 so b=1. s = s + b = 0 + 1 = 1. s=1.
a=[1, 0, 1, 0]. The first element of a is 1 so b=1. s = s + b = 1 + 1 = 0. s=0.
a=[0, 1, 0]. The first element of a is 0 so b=0. s = s + b = 0 + 0 = 0. s=0.
a=[1, 0]. The first element of a is 1 so b=1. s = s + b = 0 + 1 = 1. s=1.
a=[0]. The first element of a is 0 so b=0. s = s + b = 1 + 0 = 1. s=1.
a=[] is empty. Since the list a is empty and we have s=1, the parity is 1
Given that definition, what would be the parity of this other list b= [0, 1, 1, 0, 0, 0, 0, 0]
See results in figure 13.
Figure 13: Who said LLMs cannot learn?
It is worth keeping in mind that LLMs like GPT only read forward and are in fact completing text. This means that it is worth it to prompt them in the right order. It has been found that giving the instruction before the example helps. Furthermore, even the order the examples are given makes a difference (see Lu et. al[4]). Keep that in mind and experiment with different orders of prompt and examples.
Affordances are functions that are defined in the prompt and the model is explicitly instructed to use when responding. E.g. you can tell the model that whenever finding a mathematical expression it should call an explicit CALC() function and compute the numerical result before proceeding. It has been shown that using affordances can help in some cases.
In the previous section we introduced more complex examples of how to think about prompt design. However, those tips and tricks have more recently evolved into more tested and documented techniques that bring more "engineering" and less art to how to build a prompt. In this section we cover some of those advanced techniques that build upon what we discussed so far.
Building on the foundational concepts introduced earlier, the Chain of Thought (CoT) technique, as delineated in "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" by Google researchers[5], marks a significant leap in harnessing the reasoning capabilities of Large Language Models (LLMs). This technique capitalizes on the premise that, while LLMs excel at predicting sequences of tokens, their design does not inherently facilitate explicit reasoning processes.
Figure 14: Illustration of Chain of Thought Prompting versus Standard Prompting, adapted from [5]. This figure demonstrates how CoT prompting guides the model through a series of logical steps to arrive at a reasoned conclusion, contrasting with the direct approach of standard prompting.
CoT transforms the often implicit reasoning steps of LLMs into an explicit, guided sequence, thereby enhancing the model’s ability to produce outputs grounded in logical deduction, particularly in complex problem-solving contexts.
Figure 15: Comparison of Zero-shot and Manual Chain of Thought techniques as per [5]. This figure underscores the structured approach of Manual CoT in providing detailed reasoning pathways, as opposed to the more generalized guidance in Zero-shot CoT.
The methodology manifests predominantly in two variants:
-
Zero-Shot CoT: This approach prompts the LLM to unravel the problem iteratively, encouraging a step-by-step elucidation of its reasoning process.
-
Manual CoT: This more intricate variant necessitates the provision of explicit, stepwise reasoning examples as templates, thereby guiding the model more definitively towards reasoned outputs. Despite its efficacy, Manual CoT’s reliance on meticulously crafted examples poses scalability and maintenance challenges.
Although Manual CoT often outperforms its Zero-shot counterpart, its effectiveness hinges on the diversity and relevance of the provided examples. The labor-intensive and potentially error-prone process of crafting these examples paves the way for the exploration of Automatic CoT[6], which seeks to streamline and optimize the example generation process, thereby expanding the applicability and efficiency of CoT prompting in LLMs.
The Tree of Thought (ToT) prompting technique, as introduced in recent advancements[7], marks a significant evolution in the domain of Large Language Models (LLMs). Drawing inspiration from human cognitive processes, ToT facilitates a multi-faceted exploration of problem-solving pathways, akin to considering a spectrum of possible solutions before deducing the most plausible one. Consider a travel planning context: an LLM might branch out into flight options, train routes, and car rental scenarios, weighing the cost and feasibility of each, before suggesting the most optimal plan to the user.
Figure 16: Illustrative representation of the Tree of Thought methodology, showcasing the branching out into multiple reasoning pathways as adapted from [7]. Each branch symbolizes a distinct line of reasoning, enabling a comprehensive exploration of potential solutions.
Central to the ToT approach is the concept of "thought trees," where each branch embodies an alternative reasoning trajectory. This multiplicity allows the LLM to traverse through diverse hypotheses, mirroring the human approach to problem-solving by weighing various scenarios before reaching a consensus on the most likely outcome.
A pivotal component of ToT is the systematic evaluation of these reasoning branches. As the LLM unfolds different threads of thought, it concurrently assesses each for its logical consistency and pertinence to the task at hand. This dynamic analysis culminates in the selection of the most coherent and substantiated line of reasoning, thereby enhancing the decision-making prowess of the model.
ToT’s capability to navigate through complex and multifaceted problem spaces renders it particularly beneficial in scenarios where singular lines of reasoning fall short. By emulating a more human-like deliberation process, ToT significantly amplifies the model’s proficiency in tackling tasks imbued with ambiguity and intricacy.
In the realm of advanced prompt engineering, the integration of Tools, Connectors, and Skills significantly enhances the capabilities of Large Language Models (LLMs). These elements enable LLMs to interact with external data sources and perform specific tasks beyond their inherent capabilities, greatly expanding their functionality and application scope.
Tools in this context are external functions or services that LLMs can utilize. These tools extend the range of tasks an LLM can perform, from basic information retrieval to complex interactions with external databases or APIs.
Figure 17: An example of tool usage from Langchain library
Connectors act as interfaces between LLMs and external tools or services. They manage data exchange and communication, enabling effective utilization of external resources. The complexity of connectors can vary, accommodating a wide range of external interactions.
Skills refer to specialized functions that an LLM can execute. These encapsulated capabilities, such as text summarization or language translation, enhance the LLM’s ability to process and respond to prompts, even without direct access to external tools.
In the paper “Toolformer: Language Models Can Teach Themselves to Use Tools”[8], the authors go beyond simple tool usage by training an LLM to decide what tool to use when, and even what parameters the API needs. Tools include two different search engines, or a calculator. In the following examples, the LLM decides to call an external Q&A tool, a calculator, and a Wikipedia Search Engine More recently, researchers at Berkeley have trained a new LLM called Gorilla[9] that beats GPT-4 at the use of APIs, a specific but quite general tool.
Automatic Multi-step Reasoning and Tool-use (ART)[10] is a prompt engineering technique that combines automated chain of thought prompting with the use of external tools. ART represents a convergence of multiple prompt engineering strategies, enhancing the ability of Large Language Models (LLMs) to handle complex tasks that require both reasoning and interaction with external data sources or tools.
ART involves a systematic approach where, given a task and input, the system first identifies similar tasks from a task library. These tasks are then used as examples in the prompt, guiding the LLM on how to approach and execute the current task. This method is particularly effective when tasks require a combination of internal reasoning and external data processing or retrieval.
In the quest for accuracy and reliability in Large Language Model (LLM) outputs, the Self-Consistency approach emerges as a pivotal technique. This method, underpinned by ensemble-based strategies, involves prompting the LLM to produce multiple answers to the same question, with the coherence among these responses serving as a gauge for their credibility.
Figure 18: Illustrative diagram of the Self-Consistency approach, demonstrating the process of generating and evaluating multiple responses to ensure accuracy, adapted from [11]. This representation underscores the iterative nature of response generation and the subsequent analysis for consistency.
The essence of Self-Consistency lies in the assumption that the generation of similar responses to a singular prompt by an LLM increases the likelihood of those responses’ accuracy (see Figure 18). The implementation of this approach entails the LLM addressing a query multiple times, with each response undergoing scrutiny for consistency. The evaluation of consistency can be conducted through various lenses, including but not limited to, content overlap, semantic similarity assessments, and advanced metrics like BERT-scores or n-gram overlaps, offering a multifaceted view of response agreement. This enhances the reliability of LLMs in fact-checking tools, helping ensure only the most consistent and verifiable claims are presented to the user.
The utility of Self-Consistency spans numerous domains where factual precision is imperative. It holds particular promise in applications such as fact-checking and information verification, where the integrity of AI-generated content is paramount. By leveraging this technique, developers and users can significantly bolster the dependability of LLMs, ensuring their outputs are not only coherent but also factually sound, thereby enhancing their applicability in critical and information-sensitive tasks.
The concept of Reflection, as introduced in recent literature[12], marks a significant stride towards endowing Large Language Models (LLMs) with the capability for self-improvement. Central to Reflection is the LLM’s engagement in an introspective review of its outputs, a process akin to human self-editing, where the model assesses its initial responses for factual accuracy, logical consistency, and overall relevance.
This reflective process entails a structured self-evaluation where the LLM, following the generation of an initial response, is prompted to scrutinize its output critically. Through this introspection, the model identifies potential inaccuracies or inconsistencies, paving the way for the generation of revised responses that are more coherent and reliable.
For instance, an LLM might initially provide a response to a complex query. It is then prompted to evaluate this response against a set of predefined criteria, such as the verifiability of facts presented or the logical flow of arguments made. Should discrepancies or areas for enhancement be identified, the model embarks on an iterative process of refinement, potentially yielding a series of progressively improved outputs.
However, the implementation of Reflection is not without challenges. The accuracy of self-evaluation is contingent upon the LLM’s inherent understanding and its training on reflective tasks. Moreover, there exists the risk of the model reinforcing its own errors if it incorrectly assesses the quality of its responses.
Despite these challenges, the implications of Reflection for the development of LLMs are profound. By integrating self-evaluation and revision capabilities, LLMs can achieve greater autonomy in improving the quality of their outputs, making them more versatile and dependable tools in applications where precision and reliability are paramount.
Expert Prompting, as delineated in contemporary research[13], represents a novel paradigm in augmenting the utility of Large Language Models (LLMs) by endowing them with the capability to simulate expert-level responses across diverse domains. This method capitalizes on the LLM’s capacity to generate informed and nuanced answers by prompting it to embody the persona of experts in relevant fields.
A cornerstone of this approach is the multi-expert strategy, wherein the LLM is guided to consider and integrate insights from various expert perspectives. This not only enriches the depth and breadth of the response but also fosters a multidimensional understanding of complex issues, mirroring the collaborative deliberations among real-world experts. For instance, when addressing a medical inquiry, the LLM might be prompted to channel the insights of a clinician, a medical researcher, and a public health expert. These diverse perspectives are then adeptly woven together, leveraging sophisticated algorithms, to produce a response that encapsulates a comprehensive grasp of the query.
This synthesis of expert viewpoints not only augments the factual accuracy and depth of the LLM’s outputs but also mitigates the biases inherent in a singular perspective, presenting a balanced and well-considered response.
However, Expert Prompting is not devoid of challenges. Simulating the depth of real expert knowledge necessitates advanced prompt engineering and a nuanced understanding of the domains in question. Furthermore, the reconciliation of potentially divergent expert opinions into a coherent response poses an additional layer of complexity.
Despite these challenges, the potential applications of Expert Prompting are vast, spanning from intricate technical advice in engineering and science to nuanced analyses in legal and ethical deliberations. This approach heralds a significant advancement in the capabilities of LLMs, pushing the boundaries of their applicability and reliability in tasks demanding expert-level knowledge and reasoning.
Chains represent a transformative approach in leveraging Large Language Models (LLMs) for complex, multi-step tasks. This method, characterized by its sequential linkage of distinct components, each designed to perform a specialized function, facilitates the decomposition of intricate tasks into manageable segments. The essence of Chains lies in their ability to construct a cohesive workflow, where the output of one component seamlessly transitions into the input of the subsequent one, thereby enabling a sophisticated end-to-end processing capability.
Figure 19: Illustration of the PromptChainer interface, showcasing a visual representation of Chains and their components, as adapted from [14]. This interface exemplifies the modular nature of Chains, where each block signifies a step in the workflow, contributing to the overall task resolution.
In the realm of Chains, components might range from simple information retrieval modules to more complex reasoning or decision-making blocks. For instance, a Chain for a medical diagnosis task might begin with symptom collection, followed by differential diagnosis generation, and conclude with treatment recommendation.
The development and optimization of Chains, as explored in "PromptChainer: Chaining Large Language Model Prompts through Visual Programming"[14], present both challenges and innovative solutions. One significant challenge lies in the orchestration of these components to ensure fluidity and coherence in the workflow. PromptChainer (see figure 19) addresses this by offering a visual programming environment, enabling users to intuitively design and adjust Chains, thus mitigating complexities associated with traditional coding methods.
The application of Chains extends across various domains, from automated customer support systems, where Chains guide the interaction from initial query to resolution, to research, where they can streamline the literature review process.
While Chains offer a robust framework for tackling multifaceted tasks, potential limitations, such as the computational overhead associated with running multiple LLM components and the necessity for meticulous design to ensure the integrity of the workflow, warrant consideration.
Nonetheless, the strategic implementation of Chains, supported by tools like PromptChainer, heralds a new era of efficiency and capability in the use of LLMs, enabling them to address tasks of unprecedented complexity and scope.
Rails in advanced prompt engineering represent a strategic approach to directing the outputs of Large Language Models (LLMs) within predefined boundaries, ensuring their relevance, safety, and factual integrity. This method employs a structured set of rules or templates, commonly referred to as Canonical Forms, which serve as a scaffold for the model’s responses, ensuring they conform to specific standards or criteria.
Figure 20: Visualization of the Rails framework, illustrating the mechanism through which predefined guidelines shape and constrain LLM outputs, as exemplified in the Nemo Guardrails framework. This schematic representation highlights the different types of Rails and their roles in maintaining the quality and integrity of LLM responses.
Canonical Forms within the Rails framework act as modeling languages or templates that standardize the structure and delivery of natural language sentences, guiding the LLM in generating outputs that align with desired parameters (see figure 20). These are akin to standardized structures for language, guiding the LLM to conform to certain response patterns. The design and implementation of Rails can vary widely, tailored to the specific requirements of the application:
-
•
Topical Rails: Designed to keep the LLM focused on a specified subject or domain, preventing digression or the inclusion of irrelevant information.
-
•
Fact-Checking Rails: Aim to reduce the propagation of inaccuracies by guiding the LLM towards evidence-based responses and discouraging speculative or unverified claims.
-
•
Jailbreaking Rails: Established to deter the LLM from producing outputs that circumvent its operational constraints or ethical guidelines, safeguarding against misuse or harmful content generation.
In practice, Rails might be applied in various scenarios, from educational tools where Topical Rails ensure content relevance, to news aggregation services where Fact-Checking Rails uphold informational integrity. Jailbreaking Rails are crucial in interactive applications to prevent the model from engaging in undesirable behaviors.
While Rails offer a robust mechanism for enhancing the quality and appropriateness of LLM outputs, they also present challenges, such as the need for meticulous rule definition and the potential stifling of the model’s creative capabilities. Balancing these considerations is essential for leveraging Rails effectively, ensuring that LLMs deliver high-quality, reliable, and ethically sound responses.
Automatic Prompt Engineering (APE)[15] automates the intricate process of prompt creation. By harnessing the LLMs’ own capabilities for generating, evaluating, and refining prompts, APE aims to optimize the prompt design process, ensuring higher efficacy and relevance in eliciting desired responses.
Figure 21: Illustration of the APE process, showcasing the cyclic nature of prompt generation, evaluation, and refinement, as conceptualized in [15]. This diagram highlights the self-referential mechanism through which LLMs iteratively improve the quality of prompts, aligning them more closely with the intended task objectives.
The APE methodology (see figure 21) unfolds through a series of distinct yet interconnected steps:
-
•
Prompt Generation: Initially, the LLM produces a variety of prompts tailored to a specific task, leveraging its vast linguistic database and contextual understanding.
-
•
Prompt Scoring: Subsequently, these prompts undergo a rigorous evaluation phase, where they are scored against key metrics such as clarity, specificity, and their potential to drive the desired outcome, ensuring that only the most effective prompts are selected for refinement.
-
•
Refinement and Iteration: The refinement process involves tweaking and adjusting prompts based on their scores, with the aim of enhancing their alignment with the task requirements. This iterative process fosters continuous improvement in prompt quality.
By automating the prompt engineering process, APE not only alleviates the burden of manual prompt creation but also introduces a level of precision and adaptability previously unattainable. The ability to generate and iteratively refine prompts can significantly enhance the utility of LLMs across a spectrum of applications, from automated content generation to sophisticated conversational agents.
However, the deployment of APE is not without challenges. The need for substantial computational resources and the complexity of establishing effective scoring metrics are notable considerations. Moreover, the initial set-up may require a carefully curated set of seed prompts to guide the generation process effectively.
Despite these challenges, APE represents a significant leap forward in prompt engineering, offering a scalable and efficient solution to unlock the full potential of LLMs in diverse applications, thereby paving the way for more nuanced and contextually relevant interactions.
In addressing the constraints of pre-trained Large Language Models (LLMs), particularly their limitations in accessing real-time or domain-specific information, Retrieval Augmented Generation (RAG) emerges as a pivotal innovation. RAG extends LLMs by dynamically incorporating external knowledge, thereby enriching the model’s responses with up-to-date or specialized information not contained within its initial training data.
Figure 22: An example of integrating RAG with LLMs for a question answering application, showcasing the process of query extraction, information retrieval, and response synthesis [16].
Figure 23: Illustration of using a Knowledge Graph (KG) as a retrieval mechanism in conjunction with LLMs to enhance response generation with structured external knowledge [17].
RAG operates by formulating queries from input prompts and leveraging these queries to fetch pertinent information from diverse sources, such as search engines (see figure 22) or knowledge graphs(see figure 23). This retrieved content is seamlessly integrated into the LLM’s workflow, significantly augmenting its ability to generate informed and contextually relevant responses.
The advent of RAG has spurred the development of sophisticated prompting techniques designed to leverage its capabilities fully. Among these, Forward-looking Active Retrieval Augmented Generation (FLARE) stands out for its innovative approach to enhancing LLM performance.
FLARE iteratively enhances LLM outputs by predicting potential content and using these predictions to guide information retrieval. Unlike traditional RAG models, which typically perform a single retrieval step before generation, FLARE engages in a continuous, dynamic retrieval process, ensuring that each segment of the generated content is supported by the most relevant external information.
This process is characterized by an evaluation of confidence levels for each generated segment. When the confidence falls below a predefined threshold, FLARE prompts the LLM to use the content as a query for additional information retrieval, thereby refining the response with updated or more relevant data.
For a comprehensive understanding of RAG, FLARE, and related methodologies, readers are encouraged to consult the survey on retrieval augmented generation models, which provides an in-depth analysis of their evolution, applications, and impact on the field of LLMs [18].
The concept of AI agents, autonomous entities that perceive, decide, and act within their environments, has evolved significantly with the advent of Large Language Models (LLMs). LLM-based agents represent a specialized instantiation of augmented LLMs, designed to perform complex tasks autonomously, often surpassing simple response generation by incorporating decision-making and tool utilization capabilities.
Figure 24: Example block representation of an LLM-based agent, highlighting its components and their interaction in task execution.
LLM agents can access external tools and services, leveraging them to complete tasks, and making informed decisions based on contextual input and predefined goals. Such agents can, for instance, interact with APIs to fetch weather information or execute purchases, thereby acting on the external world as well as interpreting it.
The integration of LLMs into agent frameworks has led to the development of novel prompt engineering techniques, including Reasoning without Observation (ReWOO), Reason and Act (ReAct), and Dialog-Enabled Resolving Agents (DERA), each tailored to enhance the autonomous functionality of LLM-based agents.
ReWOO enables LLMs to construct reasoning plans without immediate access to external data, relying instead on a structured reasoning framework that can be executed once relevant data becomes available (see figure 25). This approach is particularly useful in scenarios where data retrieval is costly or uncertain, allowing LLMs to maintain efficiency and reliability.
Figure 25: Workflow of ReWOO, illustrating the meta-planning and execution phases in the reasoning process.
ReAct (see figure 26) enhances LLMs’ problem-solving capabilities by interleaving reasoning traces with actionable steps, facilitating a dynamic approach to task resolution where reasoning and action are closely integrated.
Figure 26: Comparison of ReAct with simpler prompting methods, highlighting its interleaved reasoning-action structure.
DERA (see figure 27) introduces a collaborative agent framework where multiple agents, each with specific roles, engage in dialogue to resolve queries and make decisions. This multi-agent approach enables handling complex queries with depth and nuance, closely mirroring human decision-making processes.
Figure 27: Conceptual representation of DERA, showcasing the interaction between different agent roles within a dialogue context.
The development of LLM-based agents and associated prompt engineering techniques represents a significant leap forward in AI, promising to enhance the autonomy, decision-making, and interactive capabilities of LLMs across a wide range of applications.
The proliferation of advanced prompt engineering techniques has catalyzed the development of an array of tools and frameworks, each designed to streamline the implementation and enhance the capabilities of these methodologies. These resources are pivotal in bridging the gap between theoretical approaches and practical applications, enabling researchers and practitioners to leverage prompt engineering more effectively.
Langchain has emerged as a cornerstone in the prompt engineering toolkit landscape, initially focusing on Chains but expanding to support a broader range of functionalities including Agents and web browsing capabilities. Its comprehensive suite of features makes it an invaluable resource for developing complex LLM applications.
Semantic Kernel, by Microsoft, offers a robust toolkit for skill development and planning, extending its utility to include chaining, indexing, and memory access. Its versatility in supporting multiple programming languages enhances its appeal to a wide user base.
The Guidance library, also from Microsoft, introduces a modern templating language tailored for prompt engineering, offering solutions that are aligned with the latest advancements in the field. Its focus on modern techniques makes it a go-to resource for cutting-edge prompt engineering applications.
Nemo Guardrails by NVidia is specifically designed to construct Rails, ensuring that LLMs operate within predefined guidelines, thereby enhancing the safety and reliability of LLM outputs.
LlamaIndex specializes in data management for LLM applications, providing essential tools for handling the influx of data that these models require, streamlining the data integration process.
From Intel, FastRAG extends the basic RAG approach with advanced implementations, aligning closely with the sophisticated techniques discussed in this guide, and offering optimized solutions for retrieval-augmented tasks.
Auto-GPT stands out for its focus on designing LLM agents, simplifying the development of complex AI agents with its user-friendly interface and comprehensive features. Similarly, AutoGen by Microsoft has gained traction for its capabilities in agent and multi-agent system design, further enriching the ecosystem of tools available for prompt engineering.
These tools and frameworks are instrumental in the ongoing evolution of prompt engineering, offering a range of solutions from foundational prompt management to the construction of intricate AI agents. As the field continues to expand, the development of new tools and the enhancement of existing ones will remain critical in unlocking the full potential of LLMs in a variety of applications.
Prompt design and engineering will only become more critical as LLMs and generative AI evolve. We discussed foundations and cutting-edge approaches such as Retrieval Augmented Generation (RAG) – essential tools for the next wave of intelligent applications. As prompt design and engineering rapidly progress, resources like this will offer a historical lens on early techniques. Remember, innovations like Automatic Prompt Engineering (APE) covered here could become standard practice in the years to come. Be part of shaping the trajectory of these exciting developments!
- [1] D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, and Michael Young. Machine learning: The high interest credit card of technical debt. In SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop), 2014.
- [2] Xavier Amatriain, Ananth Sankar, Jie Bing, Praveen Kumar Bodigutla, Timothy J. Hazen, and Michaeel Kazi. Transformer models: an introduction and catalog, 2023.
- [3] Hattie Zhou, Azade Nova, Hugo Larochelle, Aaron Courville, Behnam Neyshabur, and Hanie Sedghi. Teaching algorithmic reasoning via in-context learning, 2022.
- [4] Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity, 2022.
- [5] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc., 2022.
- [6] Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models, 2022.
- [7] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023.
- [8] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023.
- [9] Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023.
- [10] Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. Art: Automatic multi-step reasoning and tool-use for large language models, 2023.
- [11] Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models, 2023.
- [12] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023.
- [13] Sarah J. Zhang, Samuel Florin, Ariel N. Lee, Eamon Niknafs, Andrei Marginean, Annie Wang, Keith Tyser, Zad Chin, Yann Hicke, Nikhil Singh, Madeleine Udell, Yoon Kim, Tonio Buonassisi, Armando Solar-Lezama, and Iddo Drori. Exploring the mit mathematics and eecs curriculum using large language models, 2023.
- [14] Tongshuang Wu, Ellen Jiang, Aaron Donsbach, Jeff Gray, Alejandra Molina, Michael Terry, and Carrie J Cai. Promptchainer: Chaining large language model prompts through visual programming, 2022.
- [15] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers, 2023.
- [16] Amazon Web Services. Question answering using retrieval augmented generation with foundation models in amazon sagemaker jumpstart, Year of publication, e.g., 2023. Accessed: Date of access, e.g., December 5, 2023.
- [17] Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap. arXiv preprint arXiv:2306.08302, 2023.
- [18] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
</paper 3>
Below do you have official explanations and examples about differents techniques Techniques
Prompt Engineering helps to effectively design and improve prompts to get better results on different tasks with LLMs.
While the previous basic examples were fun, in this section we cover more advanced prompting engineering techniques that allow us to achieve more complex tasks and improve reliability and performance of LLMs.
Zero-shot PromptingFew-shot PromptingChain-of-Thought PromptingSelf-ConsistencyGenerate Knowledge PromptingPrompt ChainingTree of ThoughtsRetrieval Augmented GenerationAutomatic Reasoning and Tool-useAutomatic Prompt EngineerActive-PromptDirectional Stimulus PromptingProgram-Aided Language ModelsReActReflexionMultimodal CoTGraph Prompting
Examples of PromptsZero-shot Prompting Reflexion is a framework to reinforce language-based agents through linguistic feedback. According to Shinn et al. (2023) (opens in a new tab), "Reflexion is a new paradigm for ‘verbal‘ reinforcement that parameterizes a policy as an agent’s memory encoding paired with a choice of LLM parameters."
At a high level, Reflexion converts feedback (either free-form language or scalar) from the environment into linguistic feedback, also referred to as self-reflection, which is provided as context for an LLM agent in the next episode. This helps the agent rapidly and effectively learn from prior mistakes leading to performance improvements on many advanced tasks.
As shown in the figure above, Reflexion consists of three distinct models:
- An Actor: Generates text and actions based on the state observations. The Actor takes an action in an environment and receives an observation which results in a trajectory. Chain-of-Thought (CoT) (opens in a new tab) and ReAct (opens in a new tab) are used as Actor models. A memory component is also added to provide additional context to the agent.
- An Evaluator: Scores outputs produced by the Actor. Concretely, it takes as input a generated trajectory (also denoted as short-term memory) and outputs a reward score. Different reward functions are used depending on the task (LLMs and rule-based heuristics are used for decision-making tasks).
- Self-Reflection: Generates verbal reinforcement cues to assist the Actor in self-improvement. This role is achieved by an LLM and provides valuable feedback for future trials. To generate specific and relevant feedback, which is also stored in memory, the self-reflection model makes use of the reward signal, the current trajectory, and its persistent memory. These experiences (stored in long-term memory) are leveraged by the agent to rapidly improve decision-making.
In summary, the key steps of the Reflexion process are a) define a task, b) generate a trajectory, c) evaluate, d) perform reflection, and e) generate the next trajectory. The figure below demonstrates examples of how a Reflexion agent can learn to iteratively optimize its behavior to solve various tasks such as decision-making, programming, and reasoning. Reflexion extends the ReAct framework by introducing self-evaluation, self-reflection and memory components.
Experimental results demonstrate that Reflexion agents significantly improve performance on decision-making AlfWorld tasks, reasoning questions in HotPotQA, and Python programming tasks on HumanEval.
When evaluated on sequential decision-making (AlfWorld) tasks, ReAct + Reflexion significantly outperforms ReAct by completing 130/134 tasks using self-evaluation techniques of Heuristic and GPT for binary classification.
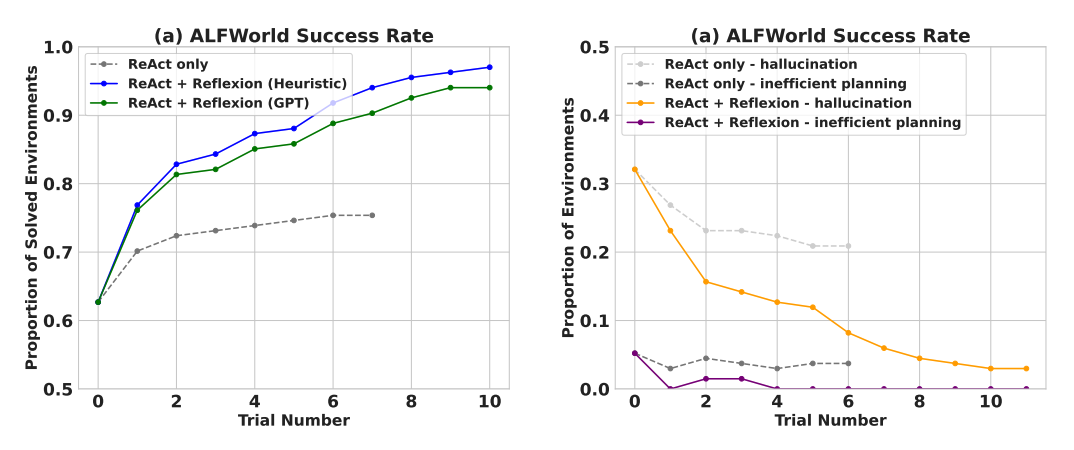
Reflexion significantly outperforms all baseline approaches over several learning steps. For reasoning only and when adding an episodic memory consisting of the most recent trajectory, Reflexion + CoT outperforms CoT only and CoT with episodic memory, respectively.
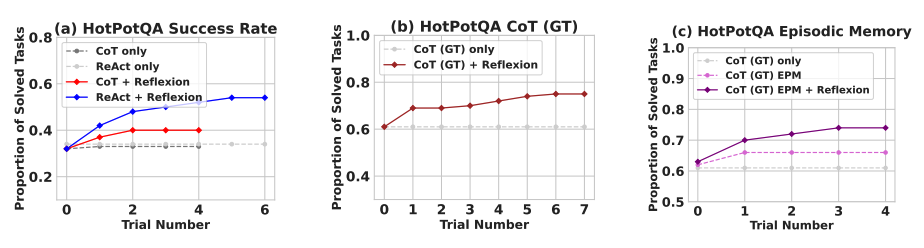
As summarized in the table below, Reflexion generally outperforms the previous state-of-the-art approaches on Python and Rust code writing on MBPP, HumanEval, and Leetcode Hard.

Reflexion is best suited for the following:
-
An agent needs to learn from trial and error: Reflexion is designed to help agents improve their performance by reflecting on past mistakes and incorporating that knowledge into future decisions. This makes it well-suited for tasks where the agent needs to learn through trial and error, such as decision-making, reasoning, and programming.
-
Traditional reinforcement learning methods are impractical: Traditional reinforcement learning (RL) methods often require extensive training data and expensive model fine-tuning. Reflexion offers a lightweight alternative that doesn't require fine-tuning the underlying language model, making it more efficient in terms of data and compute resources.
-
Nuanced feedback is required: Reflexion utilizes verbal feedback, which can be more nuanced and specific than scalar rewards used in traditional RL. This allows the agent to better understand its mistakes and make more targeted improvements in subsequent trials.
-
Interpretability and explicit memory are important: Reflexion provides a more interpretable and explicit form of episodic memory compared to traditional RL methods. The agent's self-reflections are stored in its memory, allowing for easier analysis and understanding of its learning process.
Reflexion is effective in the following tasks:
- Sequential decision-making: Reflexion agents improve their performance in AlfWorld tasks, which involve navigating through various environments and completing multi-step objectives.
- Reasoning: Reflexion improved the performance of agents on HotPotQA, a question-answering dataset that requires reasoning over multiple documents.
- Programming: Reflexion agents write better code on benchmarks like HumanEval and MBPP, achieving state-of-the-art results in some cases.
Here are some limitations of Reflexion:
- Reliance on self-evaluation capabilities: Reflexion relies on the agent's ability to accurately evaluate its performance and generate useful self-reflections. This can be challenging, especially for complex tasks but it's expected that Reflexion gets better over time as models keep improving in capabilities.
- Long-term memory constraints: Reflexion makes use of a sliding window with maximum capacity but for more complex tasks it may be advantageous to use advanced structures such as vector embedding or SQL databases.
- Code generation limitations: There are limitations to test-driven development in specifying accurate input-output mappings (e.g., non-deterministic generator function and function outputs influenced by hardware).
Figures source: Reflexion: Language Agents with Verbal Reinforcement Learning (opens in a new tab)
- Reflexion: Language Agents with Verbal Reinforcement Learning (opens in a new tab)
- Can LLMs Critique and Iterate on Their Own Outputs? (opens in a new tab) Li et al., (2023) (opens in a new tab) proposes a new prompting technique to better guide the LLM in generating the desired summary.
A tuneable policy LM is trained to generate the stimulus/hint. Seeing more use of RL to optimize LLMs.
The figure below shows how Directional Stimulus Prompting compares with standard prompting. The policy LM can be small and optimized to generate the hints that guide a black-box frozen LLM.

Image Source: Li et al., (2023) (opens in a new tab)
Full example coming soon!
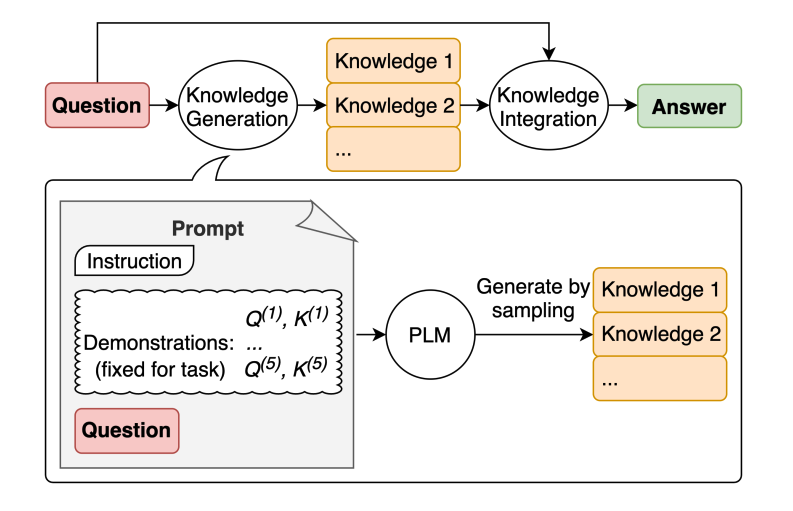
Image Source: Liu et al. 2022 (opens in a new tab)
LLMs continue to be improved and one popular technique includes the ability to incorporate knowledge or information to help the model make more accurate predictions.
Using a similar idea, can the model also be used to generate knowledge before making a prediction? That's what is attempted in the paper by Liu et al. 2022 (opens in a new tab) -- generate knowledge to be used as part of the prompt. In particular, how helpful is this for tasks such as commonsense reasoning?
Let's try a simple prompt:
Prompt:
Output:
This type of mistake reveals the limitations of LLMs to perform tasks that require more knowledge about the world. How do we improve this with knowledge generation?
First, we generate a few "knowledges":
Prompt:
Knowledge 1:
Knowledge 2:
We are using the prompt provided in the paper by Liu et al. 2022 (opens in a new tab).
The next step is to integrate the knowledge and get a prediction. I reformatted the question into QA format to guide the answer format.
Prompt:
Answer 1 (confidence very high):
Answer 2 (confidence is a lot lower):
Some really interesting things happened with this example. In the first answer, the model was very confident but in the second not so much. I simplified the process for demonstration purposes but there are a few more details to consider when arriving at the final answer. Check out the paper for more. Combining CoT prompting and tools in an interleaved manner has shown to be a strong and robust approach to address many tasks with LLMs. These approaches typically require hand-crafting task-specific demonstrations and carefully scripted interleaving of model generations with tool use. Paranjape et al., (2023) (opens in a new tab) propose a new framework that uses a frozen LLM to automatically generate intermediate reasoning steps as a program.
ART works as follows:
- given a new task, it select demonstrations of multi-step reasoning and tool use from a task library
- at test time, it pauses generation whenever external tools are called, and integrate their output before resuming generation
ART encourages the model to generalize from demonstrations to decompose a new task and use tools in appropriate places, in a zero-shot fashion. In addition, ART is extensible as it also enables humans to fix mistakes in the reasoning steps or add new tools by simply updating the task and tool libraries. The process is demonstrated below:
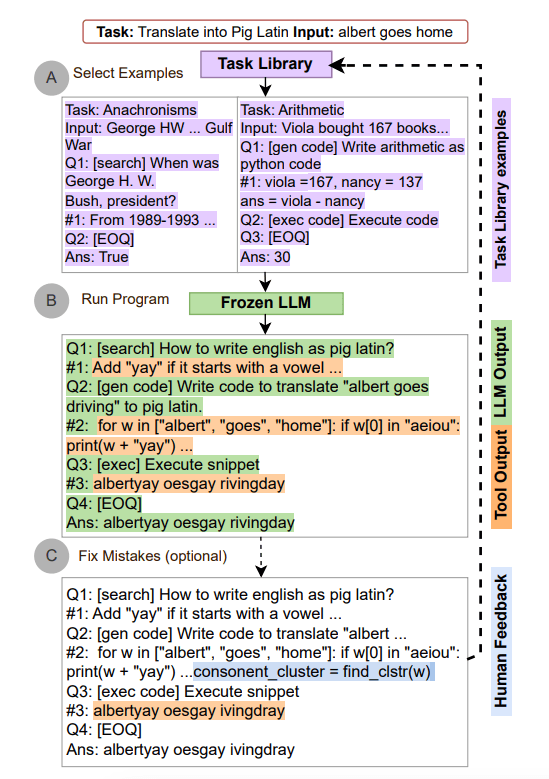
Image Source: Paranjape et al., (2023) (opens in a new tab)
ART substantially improves over few-shot prompting and automatic CoT on unseen tasks in the BigBench and MMLU benchmarks, and exceeds performance of hand-crafted CoT prompts when human feedback is incorporated.
Below is a table demonstrating ART's performance on BigBench and MMLU tasks:
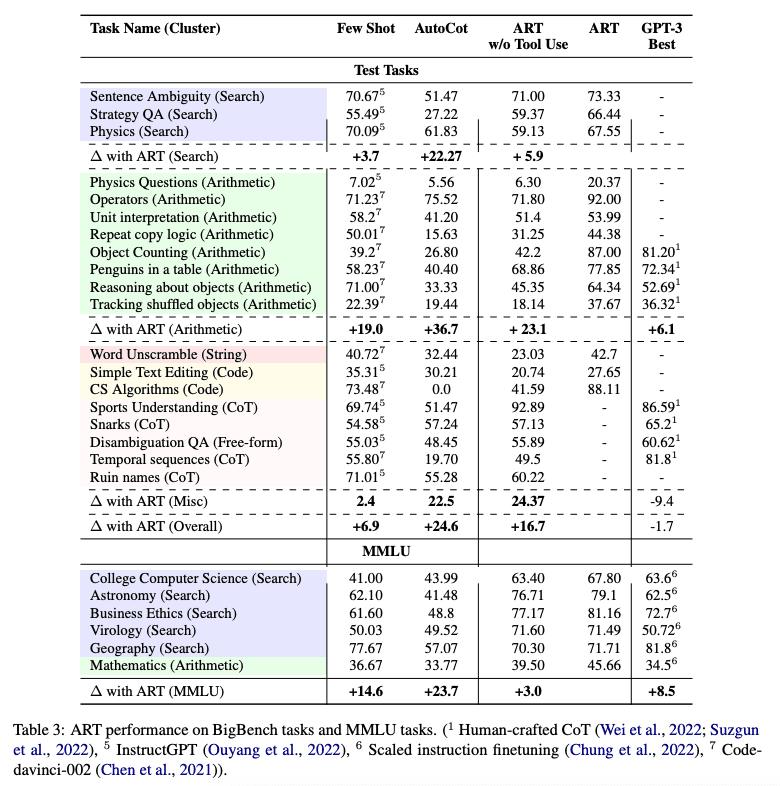
Image Source: Paranjape et al., (2023) (opens in a new tab) For complex tasks that require exploration or strategic lookahead, traditional or simple prompting techniques fall short. Yao et el. (2023) (opens in a new tab) and Long (2023) (opens in a new tab) recently proposed Tree of Thoughts (ToT), a framework that generalizes over chain-of-thought prompting and encourages exploration over thoughts that serve as intermediate steps for general problem solving with language models.
ToT maintains a tree of thoughts, where thoughts represent coherent language sequences that serve as intermediate steps toward solving a problem. This approach enables an LM to self-evaluate the progress through intermediate thoughts made towards solving a problem through a deliberate reasoning process. The LM's ability to generate and evaluate thoughts is then combined with search algorithms (e.g., breadth-first search and depth-first search) to enable systematic exploration of thoughts with lookahead and backtracking.
The ToT framework is illustrated below:
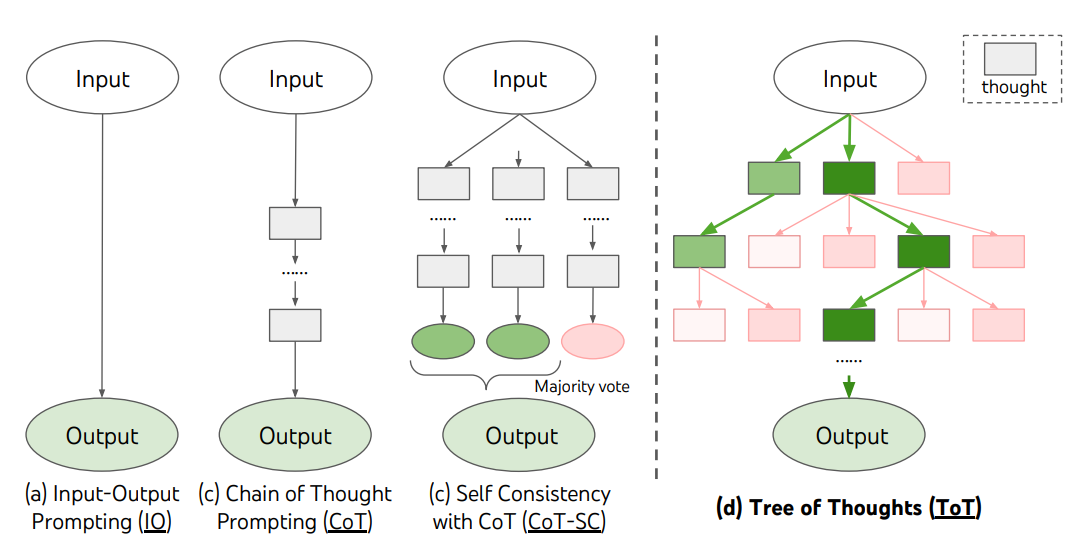
Image Source: Yao et el. (2023) (opens in a new tab)
When using ToT, different tasks requires defining the number of candidates and the number of thoughts/steps. For instance, as demonstrated in the paper, Game of 24 is used as a mathematical reasoning task which requires decomposing the thoughts into 3 steps, each involving an intermediate equation. At each step, the best b=5 candidates are kept.
To perform BFS in ToT for the Game of 24 task, the LM is prompted to evaluate each thought candidate as "sure/maybe/impossible" with regard to reaching 24. As stated by the authors, "the aim is to promote correct partial solutions that can be verdicted within few lookahead trials, and eliminate impossible partial solutions based on "too big/small" commonsense, and keep the rest "maybe"". Values are sampled 3 times for each thought. The process is illustrated below:
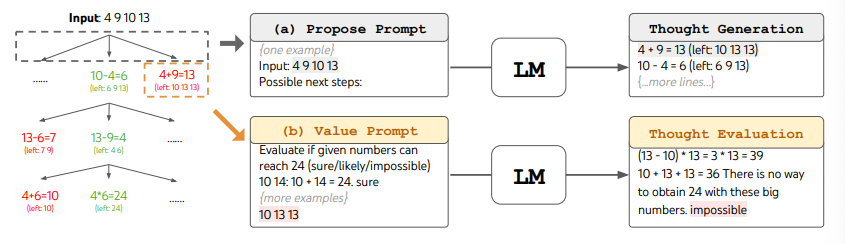
Image Source: Yao et el. (2023) (opens in a new tab)
From the results reported in the figure below, ToT substantially outperforms the other prompting methods:
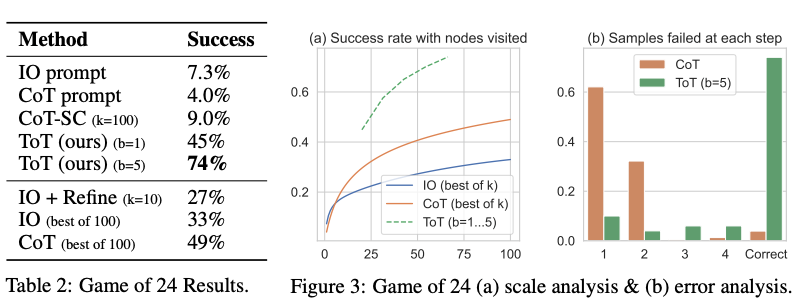
Image Source: Yao et el. (2023) (opens in a new tab)
Code available here (opens in a new tab) and here (opens in a new tab)
At a high level, the main ideas of Yao et el. (2023) (opens in a new tab) and Long (2023) (opens in a new tab) are similar. Both enhance LLM's capability for complex problem solving through tree search via a multi-round conversation. One of the main difference is that Yao et el. (2023) (opens in a new tab) leverages DFS/BFS/beam search, while the tree search strategy (i.e. when to backtrack and backtracking by how many levels, etc.) proposed in Long (2023) (opens in a new tab) is driven by a "ToT Controller" trained through reinforcement learning. DFS/BFS/Beam search are generic solution search strategies with no adaptation to specific problems. In comparison, a ToT Controller trained through RL might be able learn from new data set or through self-play (AlphaGo vs brute force search), and hence the RL-based ToT system can continue to evolve and learn new knowledge even with a fixed LLM.
Hulbert (2023) (opens in a new tab) has proposed Tree-of-Thought Prompting, which applies the main concept from ToT frameworks as a simple prompting technique, getting the LLM to evaluate intermediate thoughts in a single prompt. A sample ToT prompt is:
Sun (2023) (opens in a new tab) benchmarked the Tree-of-Thought Prompting with large-scale experiments, and introduce PanelGPT --- an idea of prompting with Panel discussions among LLMs. Techniques
Graph Prompting
Liu et al., 2023 (opens in a new tab) introduces GraphPrompt, a new prompting framework for graphs to improve performance on downstream tasks.
More coming soon!
Multimodal CoTApplications Zhang et al. (2023) (opens in a new tab) recently proposed a multimodal chain-of-thought prompting approach. Traditional CoT focuses on the language modality. In contrast, Multimodal CoT incorporates text and vision into a two-stage framework. The first step involves rationale generation based on multimodal information. This is followed by the second phase, answer inference, which leverages the informative generated rationales.
The multimodal CoT model (1B) outperforms GPT-3.5 on the ScienceQA benchmark.
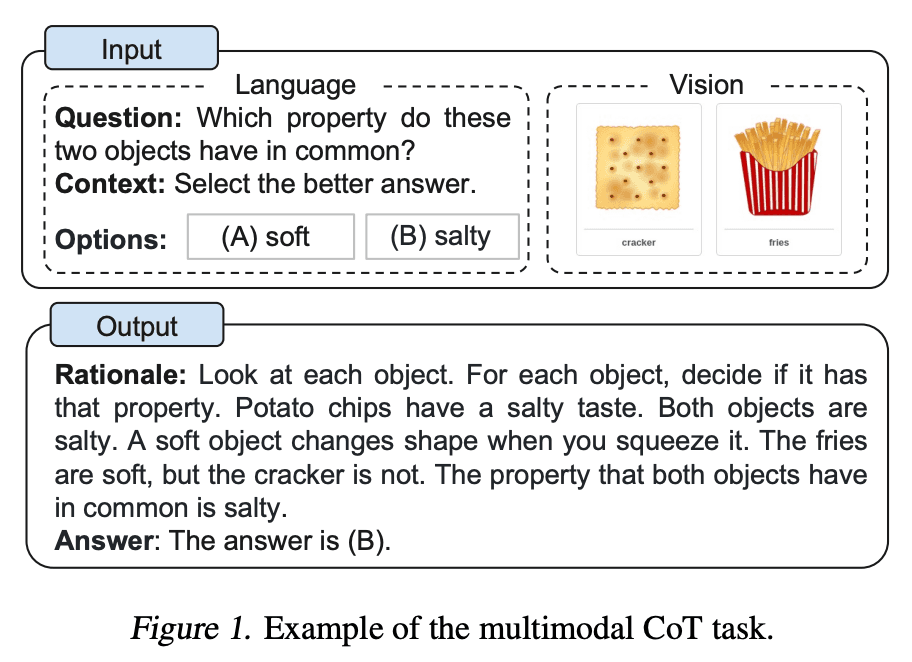
Image Source: Zhang et al. (2023) (opens in a new tab)
Further reading:
- Language Is Not All You Need: Aligning Perception with Language Models (opens in a new tab) (Feb 2023)
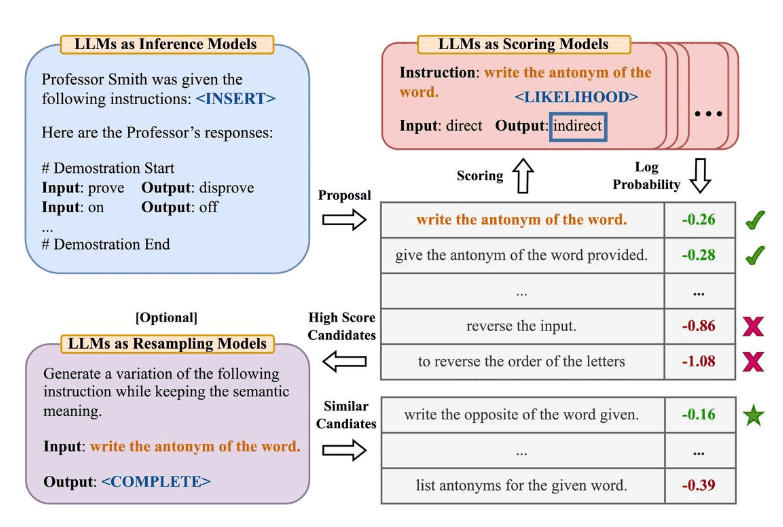
Image Source: Zhou et al., (2022) (opens in a new tab)
Zhou et al., (2022) (opens in a new tab) propose automatic prompt engineer (APE) a framework for automatic instruction generation and selection. The instruction generation problem is framed as natural language synthesis addressed as a black-box optimization problem using LLMs to generate and search over candidate solutions.
The first step involves a large language model (as an inference model) that is given output demonstrations to generate instruction candidates for a task. These candidate solutions will guide the search procedure. The instructions are executed using a target model, and then the most appropriate instruction is selected based on computed evaluation scores.
APE discovers a better zero-shot CoT prompt than the human engineered "Let's think step by step" prompt (Kojima et al., 2022 (opens in a new tab)).
The prompt "Let's work this out in a step by step way to be sure we have the right answer." elicits chain-of-thought reasoning and improves performance on the MultiArith and GSM8K benchmarks:

Image Source: Zhou et al., (2022) (opens in a new tab)
This paper touches on an important topic related to prompt engineering which is the idea of automatically optimizing prompts. While we don't go deep into this topic in this guide, here are a few key papers if you are interested in the topic:
- Prompt-OIRL (opens in a new tab) - proposes to use offline inverse reinforcement learning to generate query-dependent prompts.
- OPRO (opens in a new tab) - introduces the idea of using LLMs to optimize prompts: let LLMs "Take a deep breath" improves the performance on math problems.
- AutoPrompt (opens in a new tab) - proposes an approach to automatically create prompts for a diverse set of tasks based on gradient-guided search.
- Prefix Tuning (opens in a new tab) - a lightweight alternative to fine-tuning that prepends a trainable continuous prefix for NLG tasks.
- Prompt Tuning (opens in a new tab) - proposes a mechanism for learning soft prompts through backpropagation. Yao et al., 2022 (opens in a new tab) introduced a framework named ReAct where LLMs are used to generate both reasoning traces and task-specific actions in an interleaved manner.
Generating reasoning traces allow the model to induce, track, and update action plans, and even handle exceptions. The action step allows to interface with and gather information from external sources such as knowledge bases or environments.
The ReAct framework can allow LLMs to interact with external tools to retrieve additional information that leads to more reliable and factual responses.
Results show that ReAct can outperform several state-of-the-art baselines on language and decision-making tasks. ReAct also leads to improved human interpretability and trustworthiness of LLMs. Overall, the authors found that best approach uses ReAct combined with chain-of-thought (CoT) that allows use of both internal knowledge and external information obtained during reasoning.
ReAct is inspired by the synergies between "acting" and "reasoning" which allow humans to learn new tasks and make decisions or reasoning.
Chain-of-thought (CoT) prompting has shown the capabilities of LLMs to carry out reasoning traces to generate answers to questions involving arithmetic and commonsense reasoning, among other tasks (Wei et al., 2022) (opens in a new tab). But its lack of access to the external world or inability to update its knowledge can lead to issues like fact hallucination and error propagation.
ReAct is a general paradigm that combines reasoning and acting with LLMs. ReAct prompts LLMs to generate verbal reasoning traces and actions for a task. This allows the system to perform dynamic reasoning to create, maintain, and adjust plans for acting while also enabling interaction to external environments (e.g., Wikipedia) to incorporate additional information into the reasoning. The figure below shows an example of ReAct and the different steps involved to perform question answering.

Image Source: Yao et al., 2022 (opens in a new tab)
In the example above, we pass a prompt like the following question from HotpotQA (opens in a new tab):
Note that in-context examples are also added to the prompt but we exclude that here for simplicity. We can see that the model generates task solving trajectories (Thought, Act). Obs corresponds to observation from the environment that's being interacted with (e.g., Search engine). In essence, ReAct can retrieve information to support reasoning, while reasoning helps to target what to retrieve next.
To demonstrate how ReAct prompting works, let's follow an example from the paper.
The first step is to select cases from a training set (e.g., HotPotQA) and compose ReAct-format trajectories. These are used as few-shot exemplars in the prompts. The trajectories consist of multiple thought-action-observation steps as shown in the figure above. The free-form thoughts are used to achieve different tasks such as decomposing questions, extracting information, performing commonsense/arithmetic reasoning, guide search formulation, and synthesizing final answer.
Here is an example of what the ReAct prompt exemplars look like (obtained from the paper and shortened to one example for simplicity):
Note that different prompts setups are used for different types of tasks. For tasks where reasoning is of primary importance (e.g., HotpotQA), multiple thought-action-observation steps are used for the task-solving trajectory. For decision making tasks involving lots of action steps, thoughts are used sparsely.
The paper first evaluates ReAct on knowledge-intensive reasoning tasks such as question answering (HotPotQA) and fact verification (Fever (opens in a new tab)). PaLM-540B is used as the base model for prompting.
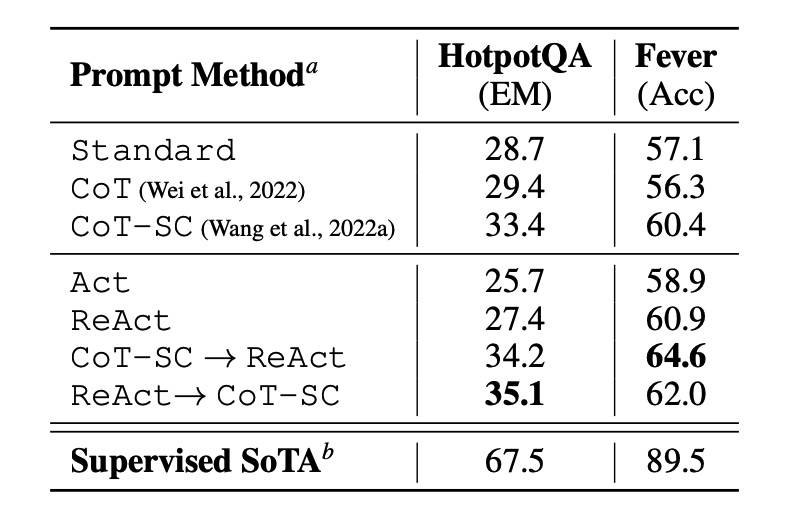
Image Source: Yao et al., 2022 (opens in a new tab)
The prompting results on HotPotQA and Fever using different prompting methods show that ReAct generally performs better than Act (involves acting only) on both tasks.
We can also observe that ReAct outperforms CoT on Fever and lags behind CoT on HotpotQA. A detailed error analysis is provided in the paper. In summary:
- CoT suffers from fact hallucination
- ReAct's structural constraint reduces its flexibility in formulating reasoning steps
- ReAct depends a lot on the information it's retrieving; non-informative search results derails the model reasoning and leads to difficulty in recovering and reformulating thoughts
Prompting methods that combine and support switching between ReAct and CoT+Self-Consistency generally outperform all the other prompting methods.
The paper also reports results demonstrating ReAct's performance on decision making tasks. ReAct is evaluated on two benchmarks called ALFWorld (opens in a new tab) (text-based game) and WebShop (opens in a new tab) (online shopping website environment). Both involve complex environments that require reasoning to act and explore effectively.
Note that the ReAct prompts are designed differently for these tasks while still keeping the same core idea of combining reasoning and acting. Below is an example for an ALFWorld problem involving ReAct prompting.
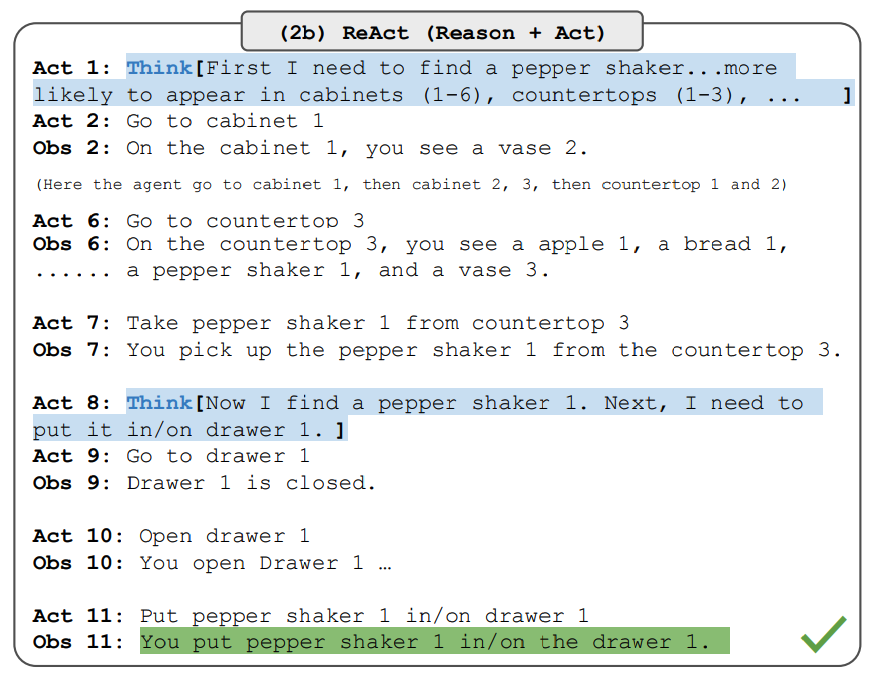
Image Source: Yao et al., 2022 (opens in a new tab)
ReAct outperforms Act on both ALFWorld and Webshop. Act, without any thoughts, fails to correctly decompose goals into subgoals. Reasoning seems to be advantageous in ReAct for these types of tasks but current prompting-based methods are still far from the performance of expert humans on these tasks.
Check out the paper for more detailed results.
Below is a high-level example of how the ReAct prompting approach works in practice. We will be using OpenAI for the LLM and LangChain (opens in a new tab) as it already has built-in functionality that leverages the ReAct framework to build agents that perform tasks by combining the power of LLMs and different tools.
First, let's install and import the necessary libraries:
Now we can configure the LLM, the tools we will use, and the agent that allows us to leverage the ReAct framework together with the LLM and tools. Note that we are using a search API for searching external information and LLM as a math tool.
Once that's configured, we can now run the agent with the desired query/prompt. Notice that here we are not expected to provide few-shot exemplars as explained in the paper.
The chain execution looks as follows:
The output we get is as follows:
We adapted the example from the LangChain documentation (opens in a new tab), so credit goes to them. We encourage the learner to explore different combination of tools and tasks.
You can find the notebook for this code here: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb (opens in a new tab) Gao et al., (2022) (opens in a new tab) presents a method that uses LLMs to read natural language problems and generate programs as the intermediate reasoning steps. Coined, program-aided language models (PAL), it differs from chain-of-thought prompting in that instead of using free-form text to obtain solution it offloads the solution step to a programmatic runtime such as a Python interpreter.

Image Source: Gao et al., (2022) (opens in a new tab)
Let's look at an example using LangChain and OpenAI GPT-3. We are interested to develop a simple application that's able to interpret the question being asked and provide an answer by leveraging the Python interpreter.
Specifically, we are interested to create a functionality that allows the use of the LLM to answer questions that require date understanding. We will provide the LLM a prompt that includes a few exemplars which are adopted from here (opens in a new tab).
These are the imports we need:
Let's first configure a few things:
Setup model instance:
Setup prompt + question:
This will output the following:
The contents of llm_out are a Python code snippet. Below, the exec command is used to execute this Python code snippet.
This will output the following: 02/27/1998
Chain-of-thought (CoT) methods rely on a fixed set of human-annotated exemplars. The problem with this is that the exemplars might not be the most effective examples for the different tasks. To address this, Diao et al., (2023) (opens in a new tab) recently proposed a new prompting approach called Active-Prompt to adapt LLMs to different task-specific example prompts (annotated with human-designed CoT reasoning).
Below is an illustration of the approach. The first step is to query the LLM with or without a few CoT examples. k possible answers are generated for a set of training questions. An uncertainty metric is calculated based on the k answers (disagreement used). The most uncertain questions are selected for annotation by humans. The new annotated exemplars are then used to infer each question.
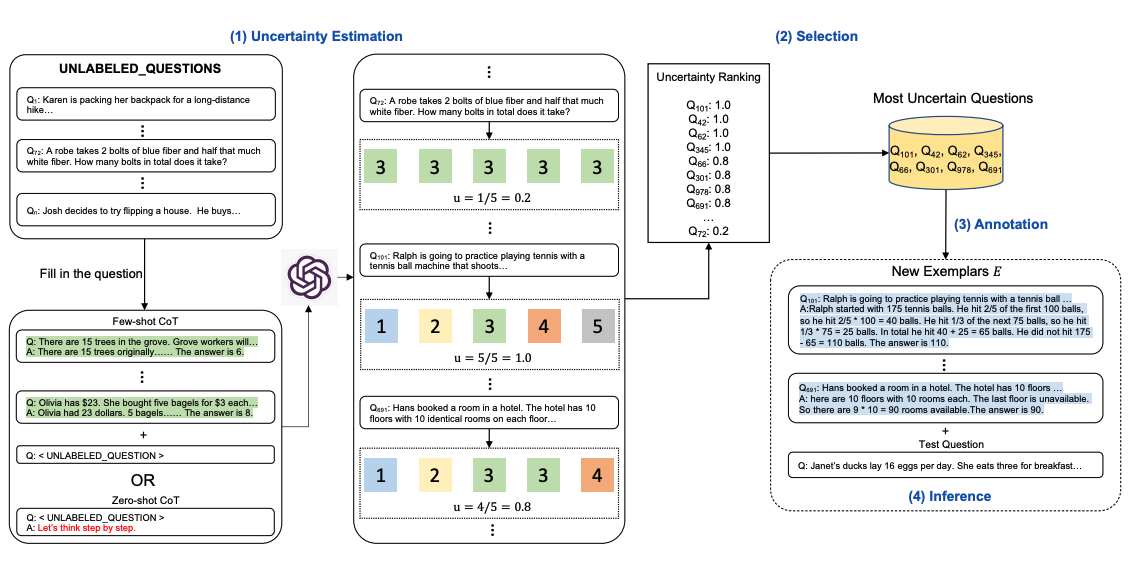
Image Source: Diao et al., (2023) (opens in a new tab) Large language models (LLMs) today, such as GPT-3.5 Turbo, GPT-4, and Claude 3, are tuned to follow instructions and are trained on large amounts of data. Large-scale training makes these models capable of performing some tasks in a "zero-shot" manner. Zero-shot prompting means that the prompt used to interact with the model won't contain examples or demonstrations. The zero-shot prompt directly instructs the model to perform a task without any additional examples to steer it.
We tried a few zero-shot examples in the previous section. Here is one of the examples (ie., text classification) we used:
Prompt:
Output:
Note that in the prompt above we didn't provide the model with any examples of text alongside their classifications, the LLM already understands "sentiment" -- that's the zero-shot capabilities at work.
Instruction tuning has been shown to improve zero-shot learning Wei et al. (2022) (opens in a new tab). Instruction tuning is essentially the concept of finetuning models on datasets described via instructions. Furthermore, RLHF (opens in a new tab) (reinforcement learning from human feedback) has been adopted to scale instruction tuning wherein the model is aligned to better fit human preferences. This recent development powers models like ChatGPT. We will discuss all these approaches and methods in upcoming sections.
When zero-shot doesn't work, it's recommended to provide demonstrations or examples in the prompt which leads to few-shot prompting. In the next section, we demonstrate few-shot prompting.
Last updated on April 17, 2024 Perhaps one of the more advanced techniques out there for prompt engineering is self-consistency. Proposed by Wang et al. (2022) (opens in a new tab), self-consistency aims "to replace the naive greedy decoding used in chain-of-thought prompting". The idea is to sample multiple, diverse reasoning paths through few-shot CoT, and use the generations to select the most consistent answer. This helps to boost the performance of CoT prompting on tasks involving arithmetic and commonsense reasoning.
Let's try the following example for arithmetic reasoning:
Prompt:
Output:
The output is wrong! How may we improve this with self-consistency? Let's try it out. We will use the few-shot exemplars from Wang et al. 2022 (Table 17):
Prompt:
Output 1:
Output 2:
Output 3:
Computing for the final answer involves a few steps (check out the paper for the details) but for the sake of simplicity, we can see that there is already a majority answer emerging so that would essentially become the final answer.
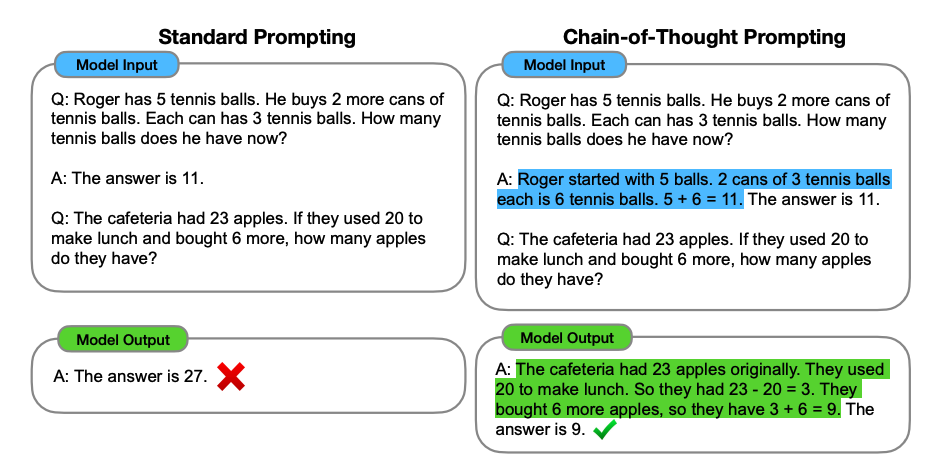
Image Source: Wei et al. (2022) (opens in a new tab)
Introduced in Wei et al. (2022) (opens in a new tab), chain-of-thought (CoT) prompting enables complex reasoning capabilities through intermediate reasoning steps. You can combine it with few-shot prompting to get better results on more complex tasks that require reasoning before responding.
Prompt:
Output:
Wow! We can see a perfect result when we provided the reasoning step. In fact, we can solve this task by providing even fewer examples, i.e., just one example seems enough:
Prompt:
Output:
Keep in mind that the authors claim that this is an emergent ability that arises with sufficiently large language models.

Image Source: Kojima et al. (2022) (opens in a new tab)
One recent idea that came out more recently is the idea of zero-shot CoT (opens in a new tab) (Kojima et al. 2022) that essentially involves adding "Let's think step by step" to the original prompt. Let's try a simple problem and see how the model performs:
Prompt:
Output:
The answer is incorrect! Now Let's try with the special prompt.
Prompt:
Output:
It's impressive that this simple prompt is effective at this task. This is particularly useful where you don't have too many examples to use in the prompt.
When applying chain-of-thought prompting with demonstrations, the process involves hand-crafting effective and diverse examples. This manual effort could lead to suboptimal solutions. Zhang et al. (2022) (opens in a new tab) propose an approach to eliminate manual efforts by leveraging LLMs with "Let's think step by step" prompt to generate reasoning chains for demonstrations one by one. This automatic process can still end up with mistakes in generated chains. To mitigate the effects of the mistakes, the diversity of demonstrations matter. This work proposes Auto-CoT, which samples questions with diversity and generates reasoning chains to construct the demonstrations.
Auto-CoT consists of two main stages:
- Stage 1): question clustering: partition questions of a given dataset into a few clusters
- Stage 2): demonstration sampling: select a representative question from each cluster and generate its reasoning chain using Zero-Shot-CoT with simple heuristics
The simple heuristics could be length of questions (e.g., 60 tokens) and number of steps in rationale (e.g., 5 reasoning steps). This encourages the model to use simple and accurate demonstrations.
The process is illustrated below:
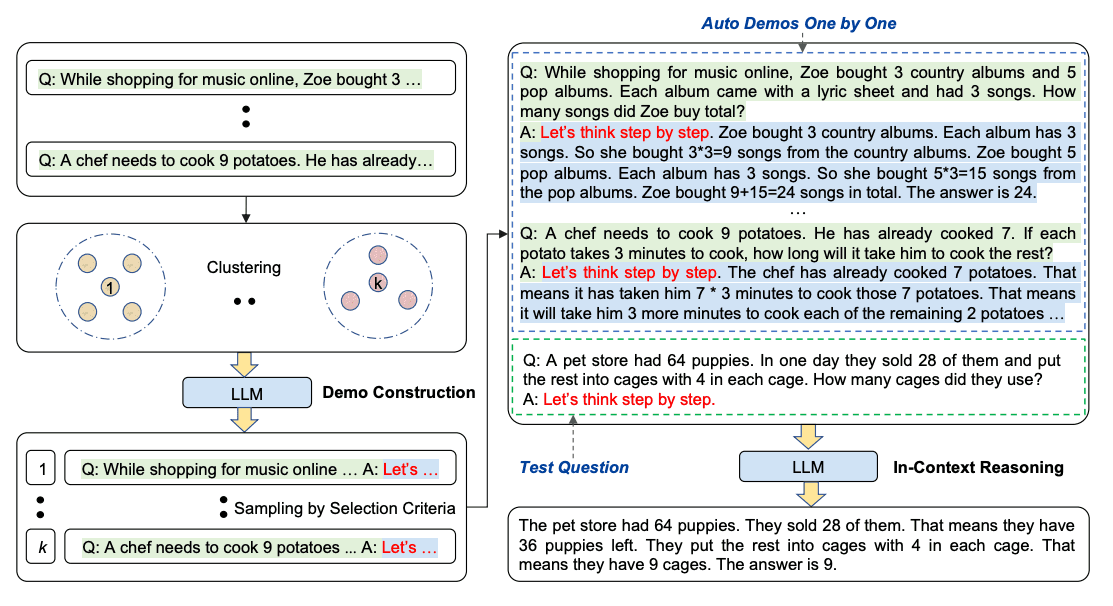
Image Source: Zhang et al. (2022) (opens in a new tab)
Code for Auto-CoT is available here (opens in a new tab). While large-language models demonstrate remarkable zero-shot capabilities, they still fall short on more complex tasks when using the zero-shot setting. Few-shot prompting can be used as a technique to enable in-context learning where we provide demonstrations in the prompt to steer the model to better performance. The demonstrations serve as conditioning for subsequent examples where we would like the model to generate a response.
According to Touvron et al. 2023 (opens in a new tab) few shot properties first appeared when models were scaled to a sufficient size (Kaplan et al., 2020) (opens in a new tab).
Let's demonstrate few-shot prompting via an example that was presented in Brown et al. 2020 (opens in a new tab). In the example, the task is to correctly use a new word in a sentence.
Prompt:
Output:
We can observe that the model has somehow learned how to perform the task by providing it with just one example (i.e., 1-shot). For more difficult tasks, we can experiment with increasing the demonstrations (e.g., 3-shot, 5-shot, 10-shot, etc.).
Following the findings from Min et al. (2022) (opens in a new tab), here are a few more tips about demonstrations/exemplars when doing few-shot:
- "the label space and the distribution of the input text specified by the demonstrations are both important (regardless of whether the labels are correct for individual inputs)"
- the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all.
- additional results show that selecting random labels from a true distribution of labels (instead of a uniform distribution) also helps.
Let's try out a few examples. Let's first try an example with random labels (meaning the labels Negative and Positive are randomly assigned to the inputs):
Prompt:
Output:
We still get the correct answer, even though the labels have been randomized. Note that we also kept the format, which helps too. In fact, with further experimentation, it seems the newer GPT models we are experimenting with are becoming more robust to even random formats. Example:
Prompt:
Output:
There is no consistency in the format above but the model still predicted the correct label. We have to conduct a more thorough analysis to confirm if this holds for different and more complex tasks, including different variations of prompts.
Standard few-shot prompting works well for many tasks but is still not a perfect technique, especially when dealing with more complex reasoning tasks. Let's demonstrate why this is the case. Do you recall the previous example where we provided the following task:
If we try this again, the model outputs the following:
This is not the correct response, which not only highlights the limitations of these systems but that there is a need for more advanced prompt engineering.
Let's try to add some examples to see if few-shot prompting improves the results.
Prompt:
Output:
That didn't work. It seems like few-shot prompting is not enough to get reliable responses for this type of reasoning problem. The example above provides basic information on the task. If you take a closer look, the type of task we have introduced involves a few more reasoning steps. In other words, it might help if we break the problem down into steps and demonstrate that to the model. More recently, chain-of-thought (CoT) prompting (opens in a new tab) has been popularized to address more complex arithmetic, commonsense, and symbolic reasoning tasks.
Overall, it seems that providing examples is useful for solving some tasks. When zero-shot prompting and few-shot prompting are not sufficient, it might mean that whatever was learned by the model isn't enough to do well at the task. From here it is recommended to start thinking about fine-tuning your models or experimenting with more advanced prompting techniques. Up next we talk about one of the popular prompting techniques called chain-of-thought prompting which has gained a lot of popularity.
To improve the reliability and performance of LLMs, one of the important prompt engineering techniques is to break tasks into its subtasks. Once those subtasks have been identified, the LLM is prompted with a subtask and then its response is used as input to another prompt. This is what's referred to as prompt chaining, where a task is split into subtasks with the idea to create a chain of prompt operations.
Prompt chaining is useful to accomplish complex tasks which an LLM might struggle to address if prompted with a very detailed prompt. In prompt chaining, chain prompts perform transformations or additional processes on the generated responses before reaching a final desired state.
Besides achieving better performance, prompt chaining helps to boost the transparency of your LLM application, increases controllability, and reliability. This means that you can debug problems with model responses much more easily and analyze and improve performance in the different stages that need improvement.
Prompt chaining is particularly useful when building LLM-powered conversational assistants and improving the personalization and user experience of your applications.
Prompt chaining can be used in different scenarios that could involve several operations or transformations. For instance, one common use case of LLMs involves answering questions about a large text document. It helps if you design two different prompts where the first prompt is responsible for extracting relevant quotes to answer a question and a second prompt takes as input the quotes and original document to answer a given question. In other words, you will be creating two different prompts to perform the task of answering a question given in a document.
The first prompt below extracts the relevant quotes from the document given the question. Note that for simplicity, we have added a placeholder for the document {{document}}. To test the prompt you can copy and paste an article from Wikipedia such as this page for prompt engineering (opens in a new tab). Due to larger context used for this task, we are using the gpt-4-1106-preview model from OpenAI. You can use the prompt with other long-context LLMs like Claude.
Prompt 1:
Here is a screenshot of the entire prompt including the question which is passed using the user role.
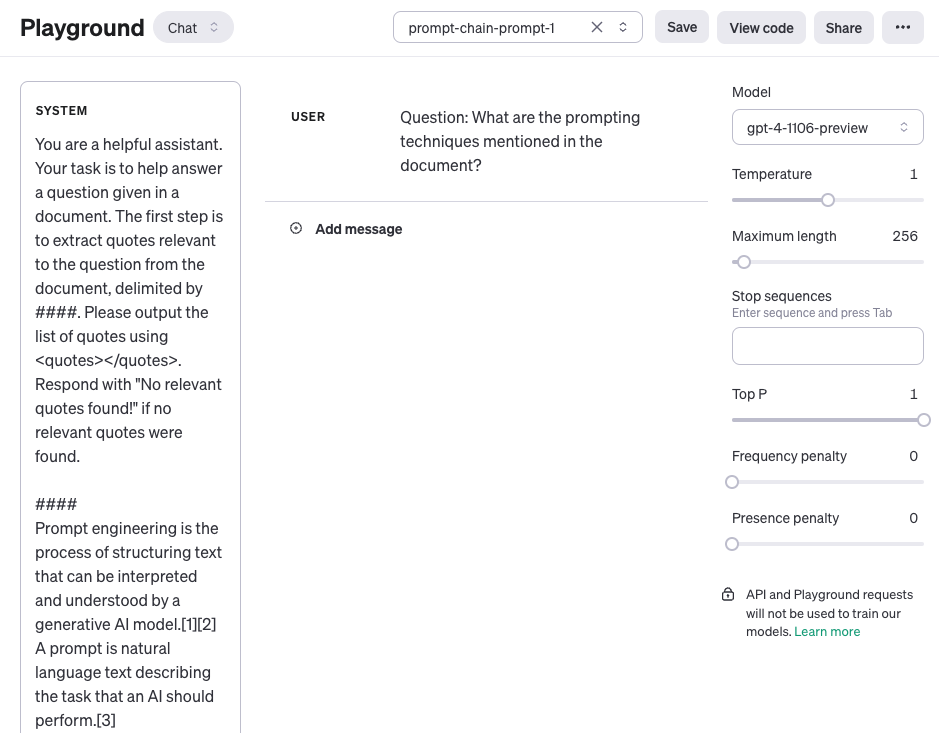
Output of Prompt 1:
The quotes that were returned in the first prompt can now be used as input to the second prompt below. Note that you can clean up the quotes a bit more, i.e., remove the citations. Those citations could be removed or utilized as part of another prompt in the chain but you can ignore this for now. The second prompt then takes the relevant quotes extracted by prompt 1 and prepares a helpful response to the question given in the document and those extracted quotes. The second prompt can be the following:
Prompt 2:
Output of Prompt 2:
As you can see, simplifying and creating prompt chains is a useful prompting approach where the responses need to undergo several operations or transformations. As an exercise, feel free to design a prompt that removes the citations (e.g., [27]) from the response before sending this as a final response to the user of your application.
You can also find more examples of prompt chaining in this documentation (opens in a new tab) that leverages the Claude LLM. Our example is inspired and adapted from their examples. General-purpose language models can be fine-tuned to achieve several common tasks such as sentiment analysis and named entity recognition. These tasks generally don't require additional background knowledge.
For more complex and knowledge-intensive tasks, it's possible to build a language model-based system that accesses external knowledge sources to complete tasks. This enables more factual consistency, improves reliability of the generated responses, and helps to mitigate the problem of "hallucination".
Meta AI researchers introduced a method called Retrieval Augmented Generation (RAG) (opens in a new tab) to address such knowledge-intensive tasks. RAG combines an information retrieval component with a text generator model. RAG can be fine-tuned and its internal knowledge can be modified in an efficient manner and without needing retraining of the entire model.
RAG takes an input and retrieves a set of relevant/supporting documents given a source (e.g., Wikipedia). The documents are concatenated as context with the original input prompt and fed to the text generator which produces the final output. This makes RAG adaptive for situations where facts could evolve over time. This is very useful as LLMs's parametric knowledge is static. RAG allows language models to bypass retraining, enabling access to the latest information for generating reliable outputs via retrieval-based generation.
Lewis et al., (2021) proposed a general-purpose fine-tuning recipe for RAG. A pre-trained seq2seq model is used as the parametric memory and a dense vector index of Wikipedia is used as non-parametric memory (accessed using a neural pre-trained retriever). Below is a overview of how the approach works:
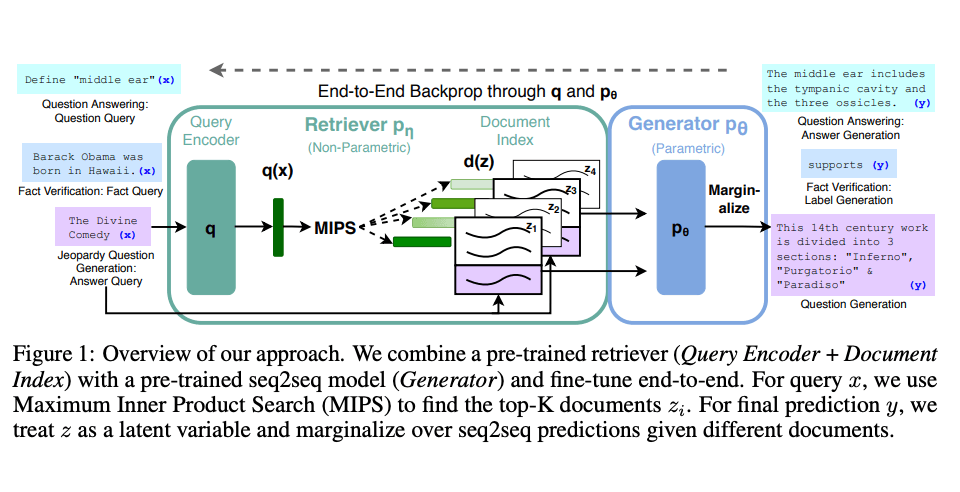
{kind=link}
Image Source: Lewis et el. (2021) (opens in a new tab)
RAG performs strong on several benchmarks such as Natural Questions (opens in a new tab), WebQuestions (opens in a new tab), and CuratedTrec. RAG generates responses that are more factual, specific, and diverse when tested on MS-MARCO and Jeopardy questions. RAG also improves results on FEVER fact verification.
This shows the potential of RAG as a viable option for enhancing outputs of language models in knowledge-intensive tasks.
More recently, these retriever-based approaches have become more popular and are combined with popular LLMs like ChatGPT to improve capabilities and factual consistency.
Below, we have prepared a notebook tutorial showcasing the use of open-source LLMs to build a RAG system for generating short and concise machine learning paper titles:
what a thread, so much prompt knowledge 🧠 here.. come share with God Tier Prompts! 🪄