Created
May 13, 2022 18:54
-
-
Save alexhallam/a827ba19c9b215075a17d1b7e5afbe16 to your computer and use it in GitHub Desktop.
PyTorch Learning
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import torch | |
| import torch.nn as nn | |
| import numpy as np | |
| from sklearn import datasets | |
| import matplotlib.pyplot as plt | |
| from torch.distributions.normal import Normal | |
| from torch.distributions.uniform import Uniform | |
| from pprint import pprint | |
| # 0) Prepare data | |
| X_numpy, y_numpy = datasets.make_regression(n_samples=100, n_features=1, noise=20, random_state=4) | |
| # cast to float Tensor | |
| X = torch.from_numpy(X_numpy.astype(np.float32)) | |
| y = torch.from_numpy(y_numpy.astype(np.float32)) | |
| y = y.view(y.shape[0], 1) | |
| n_samples, n_features = X.shape | |
| # 1) Model | |
| # Linear model f = wx + b | |
| input_size = n_features | |
| output_size = n_features | |
| model = nn.Linear(input_size, output_size) | |
| # 2) Loss and optimizer | |
| learning_rate = 0.01 | |
| criterion = nn.MSELoss() | |
| print(list(model.parameters())) | |
| optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) | |
| # 3) Training loop | |
| num_epochs = 100 | |
| for epoch in range(num_epochs): | |
| # Forward pass and loss | |
| y_predicted = model(X) | |
| loss = criterion(y_predicted, y) | |
| # Backward pass and update | |
| loss.backward() | |
| optimizer.step() | |
| # zero grad before new step | |
| optimizer.zero_grad() | |
| if (epoch+1) % 10 == 0: | |
| print(f'epoch: {epoch+1}, loss = {loss.item():.4f}') | |
| # Plot | |
| predicted = model(X).detach().numpy().flatten() | |
| bias = model.bias.detach().numpy() | |
| weight = model.weight.detach().numpy() | |
| se = y_numpy-predicted | |
| #pprint(list(zip(y_numpy, predicted, se))) | |
| sigma = np.std(y_numpy-predicted, ddof=1) | |
| mu_vec = (weight*X_numpy).flatten() | |
| n_samples = 250 | |
| def norm_dist_sample(mu): | |
| rnorm_sampler = Normal(loc = mu, scale = sigma) | |
| rnorm = rnorm_sampler.sample((n_samples,)) | |
| #print(f"\nmu: {mu}\nsigma: {sigma}") | |
| return rnorm | |
| X_explode = torch.tensor(X_numpy).tile((n_samples,)).flatten() | |
| dist = torch.cat(list(map(norm_dist_sample, mu_vec))) | |
| X_ex_np = X_explode.numpy() | |
| dist_np = dist.numpy() | |
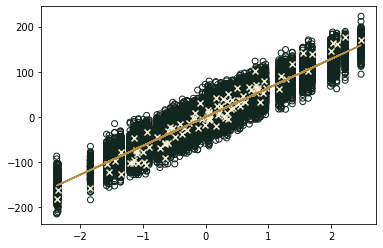
| plt.plot(X_numpy, predicted, '#B68D40') | |
| plt.scatter(X_ex_np, dist_np, fc='none', ec='#122620',marker='o') | |
| plt.scatter(X_numpy, y_numpy, fc='#F4EBD0', ec = '#F4EBD0',marker='x') | |
| plt.show() |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Regression with pytorch then generate probabilistic values for each point around the fit.