└── arbitrum-docs └── how-arbitrum-works ├── 01-a-gentle-introduction.mdx ├── 02-transaction-lifecycle.mdx ├── 03-sequencer.mdx ├── 04-geth-at-the-core.mdx ├── 05-separating-execution-from-proving.mdx ├── 06-optimistic-rollup.mdx ├── 07-interactive-fraud-proofs.mdx ├── 08-anytrust-protocol.mdx ├── 09-gas-fees.mdx ├── 10-l1-to-l2-messaging.mdx ├── 11-l2-to-l1-messaging.mdx ├── bold ├── bold-economics-of-disputes.mdx ├── gentle-introduction.mdx ├── partials │ └── _bold-public-preview-banner-partial.mdx └── public-preview-expectations.mdx └── timeboost └── gentle-introduction.mdx
1 | --- 2 | title: 'A gentle introduction' 3 | description: 'Learn the fundamentals of Nitro, Arbitrum stack.' 4 | author: dzgoldman 5 | sme: dzgoldman 6 | user_story: As a current or prospective Arbitrum user, I need learn more about Nitros design. 7 | content_type: get-started 8 | --- 9 | 10 | import ImageWithCaption from '@site/src/components/ImageCaptions/'; 11 | 12 | This document is a deep-dive explanation of Arbitrum Nitro’s design and the rationale for it. This isn’t API documentation, nor is it a guided tour of the code--look elsewhere for those. “Inside Arbitrum Nitro” is for people who want to understand Nitro's design. 13 | 14 | The body of this document will describe Arbitrum Rollup, the primary use case of the Nitro technology and the one used on the Arbitrum One chain. There is a variant use case, called AnyTrust, which is used by the Arbitrum Nova chain. 15 | 16 | ## Why use Arbitrum? Why use Nitro? 17 | 18 | Arbitrum is an L2 scaling solution for Ethereum, offering a unique combination of benefits: 19 | 20 | - Trustless security: security rooted in Ethereum, with any one 21 | party able to ensure correct Layer 2 results 22 | - Compatibility with Ethereum: able to run unmodified EVM contracts and unmodified Ethereum transactions 23 | - Scalability: moving contracts’ computation and storage off of the main Ethereum chain, allowing much higher throughput 24 | - Minimum cost: designed and engineered to minimize the L1 gas footprint of the system, minimizing per-Transaction cost. 25 | 26 | Some other Layer 2 systems provide some of these features, but to our knowledge no other system offers the same combination of features at the same cost. 27 | 28 | Nitro is a major upgrade to Arbitrum including: 29 | 30 | - Advanced Calldata Compression, which further drives down transaction costs on Arbitrum by reducing the amount of data posted to L1. 31 | - Separate Contexts For Common Execution and Fault Proving, increasing the performance of L1 nodes, and thus offering lower fees. 32 | - Ethereum L1 Gas Compatibility, bringing pricing and accounting for EVM operations perfectly in line with Ethereum. 33 | - Additional L1 Interoperability, including tighter synchronization with L1 Block numbers, and full support for all Ethereum L1 precompiles. 34 | - Safe Retryables, eliminating the failure mode where a Retryable Ticket fails to get created. 35 | - Geth Tracing, for even broader debugging support. 36 | - And many, many more changes. 37 | 38 | ## The Big Picture 39 | 40 | At the most basic level, an Arbitrum chain works like this: 41 | 42 | <ImageWithCaption 43 | caption="Original napkin sketch drawn by Arbitrum co-founder Ed Felten" 44 | src="https://lh4.googleusercontent.com/qwf_aYyB1AfX9s-_PQysOmPNtWB164_qA6isj3NhkDnmcro6J75f6MC2_AjlN60lpSkSw6DtZwNfrt13F3E_G8jdvjeWHX8EophDA2oUM0mEpPVeTlMbsjUCMmztEM0WvDpyWZ6R" 45 | /> 46 | 47 | Users and contracts put messages into the inbox. The chain reads the messages one at a time, and processes each one. This updates the state of the chain and produces some outputs. 48 | 49 | If you want an Arbitrum chain to process a transaction for you, you need to put that transaction into the chain’s inbox. Then the chain will see your transaction, execute it, and produce some outputs: a transaction receipt, and any withdrawals that your transaction initiated. 50 | 51 | Execution is deterministic -- which means that the chain’s behavior is uniquely determined by the contents of its inbox. Because of this, the result of your transaction is knowable as soon as your transaction has been put in the inbox. Any Arbitrum node will be able to tell you the result. (And you can run an Arbitrum node yourself if you want.) 52 | 53 | All of the technical detail in this document is connected to this diagram. To get from this diagram to a full description of Arbitrum, we’ll need to answer questions like these: 54 | 55 | - Who keeps track of the inbox, Chain state, and outputs? 56 | - How does Arbitrum make sure that the chain state and outputs are correct? 57 | - How can Ethereum users and contracts interact with Arbitrum? 58 | - How does Arbitrum support Ethereum-compatible contracts and transactions? 59 | - How are ETH and tokens transferred into and out of Arbitrum chains, and how are they managed while on the chain? 60 | - How can I run my own Arbitrum node or Validator? 61 | 62 | ## Nitro's Design: The Four Big Ideas 63 | 64 | The essence of Nitro, and its key innovations, lie in four big ideas. We'll list them here with a very quick summary of each, then we'll unpack them in more detail in later sections. 65 | 66 | Big Idea: Sequencing, Followed by Deterministic Execution: Nitro processes transactions with a two-phase strategy. First, the transactions are organized into a single ordered sequence, and Nitro commits to that sequence. Then the transactions are processed, in that sequence, by a deterministic State Transition Function. 67 | 68 | Big Idea: Geth at the Core: Nitro supports Ethereum's data structures, formats, and virtual machine by compiling in the core code of the popular go-ethereum ("Geth") Ethereum node software. Using Geth as a library in this way ensures a very high degree of compatibility with Ethereum. 69 | 70 | Big Idea: Separate Execution from Proving: Nitro takes the same source code and compiles it twice, once to native code for execution in a Nitro node, optimized for speed, and again to WASM for use in proving, optimized for portability and security. 71 | 72 | Big Idea: Optimistic Rollup with Interactive Fraud Proofs: Nitro settles transactions to the Layer 1 Ethereum chain using an optimistic rollup protocol, including the interactive fraud proofs pioneered by Arbitrum. 73 | 74 | Now that we have covered the foundational concepts, the big picture, and the four big ideas of Arbitrum Nitro, we will begin a journey following a transaction through the Arbitrum protocol. In the next section, the transaction lifecycle begins. 75 |
1 | ---
2 | title: Sequencing, Followed by Deterministic Execution
3 | description: 'Learn the fundamentals of the Arbitrum Transaction Lifecycle, sequencing, and deterministic execution.'
4 | author: pete-vielhaber
5 | sme: gmehta2
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about the transaction lifecycle.
7 | content_type: get-started
8 | ---
9 |
10 | This section explores the various methods users can employ to submit transactions for inclusion on the Arbitrum chain. We discuss the different pathways available—sending transactions to the Sequencer or bypassing it by submitting transactions through the Delayed Inbox contract on the Parent chain. By outlining these options, we aim to clarify how users can interact with the network, detail the processes involved in each method, and identify the modules responsible for handling these transactions. This overview will enhance your understanding of the initial steps in Arbitrum ecosystem's Transaction lifecycle and prepare you for a detailed exploration of transaction inclusion mechanisms in the subsequent sections.
11 |
12 | The first subsection, Submitting Transactions to the Sequencer, presents four different methods users can utilize to send their transactions to the sequencer: via Public RPC, Third-Party RPC, Arbitrum Nodes, and the Sequencer Endpoint. Transactions sent through the first three pathways will route through our Load Balancer before reaching the sequencer. In contrast, the Sequencer Endpoint allows transactions to bypass the Load Balancer and be sent directly to the sequencer.
13 |
14 | The second subsection, Bypassing the Sequencer, describes an alternative method where users can include their transactions on the Arbitrum chain without relying on the sequencer. By sending transactions directly to the delayed inbox contract on the parent chain (Layer 1), users gain additional flexibility, ensuring that their transactions can be processed even if the sequencer is unavailable or if they prefer not to use it.
15 |
16 | This diagram illustrates the various pathways for submitting transactions to the Arbitrum chain. It highlights the options for sending transactions through the sequencer or bypassing it and using the delayed inbox contract on the parent chain.
17 |
18 | ## Submitting transactions to the Sequencer
19 |
20 | This section outlines the different methods for users to submit transactions to the sequencer on the Arbitrum chain. There are four primary ways to do this: Public RPC, Third-Party RPCs, Arbitrum Nodes, and the Sequencer Endpoint. We will explore these methods in detail, explaining when to choose one over the other and how to use each to effectively submit transactions to the Arbitrum sequencer.
21 |
22 | ### 1. Public RPC
23 |
24 | Arbitrum provides public RPCs for its main chains: Arbitrum One, Arbitrum Nova, and Arbitrum Sepolia. Due to their rate-limited nature, these RPC endpoints are suitable for less resource-intensive operations. Public RPCs can be an accessible option for general use cases and light interactions with the network.
25 |
26 | For more details on the specific RPC endpoints for each chain, please see this section of the documentation.
27 |
28 | ### 2. Third-Party RPC
29 |
30 | Users also have the option to interact with Arbitrum's public chains using third-party node providers. These providers are often the same popular ones used for Ethereum, making them reliable choices for resource-intensive operations. We recommend using these third-party providers when performance and scalability are critical.
31 |
32 | You can find a list of supported third-party providers here.
33 |
34 | ### 3. Arbitrum Nodes
35 |
36 | Another approach for sending transactions to the sequencer is through self-hosted Arbitrum nodes. Running a node gives you direct control over your transactions, which go to the sequencer via the Sequencer Feed.
37 |
38 | Please see the Arbitrum Node documentation to learn more about setting up and running a node.
39 |
40 | ### 4. Sequencer Endpoint
41 |
42 | The Sequencer Endpoint is the most direct method for users looking to minimize delays in their transactions reaching the sequencer. Unlike standard RPC URLs, the Sequencer Endpoint supports only eth_sendRawTransaction and eth_sendRawTransactionConditional calls, bypassing the load balancer entirely. This endpoint makes it an optimal choice for users who require the quickest transaction processing time.
43 |
44 | The diagram below shows different ways to submit transactions to the sequencer:
45 |
46 |  47 |
48 | ## Bypassing the Sequencer
49 |
50 | This section delves into an alternative method for submitting transactions to the Arbitrum chain, bypassing the sequencer. This page focuses on how users can send their transactions directly to the delayed inbox contract on the parent chain rather than through the sequencer. This method offers two distinct paths a transaction can take, with each route interacting with the network differently to achieve transaction inclusion. This approach provides users with greater flexibility and ensures that transactions can still be processed if the sequencer is unavailable or if users choose not to depend on it. This section highlights these alternative submission mechanisms and underscores the robustness and decentralization features inherent in the Arbitrum network.
51 |
52 | In Diagram 3, we demonstrate how users can submit their transactions using the delayed inbox contract to bypass the sequencer. As illustrated in the diagram, there are two possible paths for transaction handling. When a transaction is submitted to the delayed inbox, the sequencer may automatically pick it up, include it as an ordered transaction, and send it to the sequencer feed. However, if the sequencer does not process the transaction within 24 hours, users have the reliable option to call the
47 |
48 | ## Bypassing the Sequencer
49 |
50 | This section delves into an alternative method for submitting transactions to the Arbitrum chain, bypassing the sequencer. This page focuses on how users can send their transactions directly to the delayed inbox contract on the parent chain rather than through the sequencer. This method offers two distinct paths a transaction can take, with each route interacting with the network differently to achieve transaction inclusion. This approach provides users with greater flexibility and ensures that transactions can still be processed if the sequencer is unavailable or if users choose not to depend on it. This section highlights these alternative submission mechanisms and underscores the robustness and decentralization features inherent in the Arbitrum network.
51 |
52 | In Diagram 3, we demonstrate how users can submit their transactions using the delayed inbox contract to bypass the sequencer. As illustrated in the diagram, there are two possible paths for transaction handling. When a transaction is submitted to the delayed inbox, the sequencer may automatically pick it up, include it as an ordered transaction, and send it to the sequencer feed. However, if the sequencer does not process the transaction within 24 hours, users have the reliable option to call the forceInclude function on the sequencer inbox contract. This action ensures that the sequencer to picks up the transaction and includes it in the ordered transaction list, providing users with a sense of security about their transactions.
53 |
54 |  55 |
56 | To send a transaction to the delayed inbox instead of submitting it to the sequencer, users can construct their transaction and then call the
55 |
56 | To send a transaction to the delayed inbox instead of submitting it to the sequencer, users can construct their transaction and then call the sendL2Message function, passing the data of the serialized signed transaction as an argument. This function allows users to send a generic L2 message to the chain, suitable for any message that does not require L1 validation.
57 |
58 | If the sequencer is not back online within 24 hours or decides to censor the transaction, users can invoke the forceInclusion function on the SequencerInbox contract. This action ensures their transaction is included on the chain, bypassing the sequencer's role.
59 |
60 | Additionally, the Arbitrum SDK provides the InboxTools class, which simplifies the process of submitting transactions to the delayed inbox. Users can utilize the sendChildSignedTx method to send the transaction and the forceInclude method to ensure its inclusion. The SDK also offers helper methods like signChildTx to assist with signing the transaction during the creation of the serialized signed transaction hex string, streamlining the entire process.
61 |
1 | ---
2 | title: The Sequencer and Censorship Resistance
3 | description: 'Learn the fundamentals of the Arbitrum Sequencer.'
4 | author: pete-vielhaber
5 | sme: gmehta2
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about the Sequencer.
7 | content_type: get-started
8 | ---
9 |
10 | The Sequencer is a pivotal component of the Arbitrum network and is responsible for efficiently ordering and processing transactions. It plays a crucial role in providing users with fast Transaction confirmations while maintaining the security and integrity of the Blockchain. In Arbitrum, the Sequencer orders incoming transactions and manages the batching, compression, and posting of transaction data to Parent chain, optimizing costs and performance.
11 |
12 |  13 |
14 | In this section, we will explore the operation of the Sequencer in detail. The topics covered include:
15 |
16 | - Sequencing and Broadcasting (Sequencer Feed): An overview of the real-time transaction feed provided by the Sequencer, which allows nodes to receive instant updates on the transaction sequence.
17 | - Batch-Posting: How the Sequencer groups transactions into batches, compresses them to reduce data size and sends them to the Sequencer Inbox Contract on the parent chain. This section also delves into the L1 pricing model and how it affects transaction costs.
18 | - Batching
19 | - Compression
20 | - Submitting to the Sequencer Inbox Contract
21 | - Finality: Understanding how transaction finality is achieved in Arbitrum through both soft and hard finality mechanisms, ensuring that transactions are confirmed securely and reliably. (not as a sequencer task)
22 |
23 | By examining these aspects, you will understand the Sequencer's role within the Arbitrum ecosystem, including how it enhances transaction throughput, reduces latency, and maintains a fair and decentralized network.
24 |
25 | ## Sequencing and Broadcasting
26 |
27 | The Sequencer Feed is a critical component of the Arbitrum network's Nitro architecture. It enables real-time dissemination of transaction data as they are accepted and ordered by the Sequencer. It allows users and nodes to receive immediate updates on transaction sequencing, facilitating rapid transaction confirmations and enhancing the network's overall responsiveness.
28 |
29 | ### How the Sequencer Publishes the Sequence
30 |
31 | The Sequencer communicates the transaction sequence through two primary channels:
32 |
33 | 1. Real-Time Sequencer Feed: A live broadcast that publishes transactions instantly as they are sequenced. Nodes and clients subscribed to this feed receive immediate notifications, allowing them to process transactions without delay.
34 | 2. Batches Posted on the Parent Chain: At regular intervals, the Sequencer aggregates transactions and posts them to the parent chain for finality. (Refer to the Batch-Posting section for detailed information on this process.)
35 |
36 |
13 |
14 | In this section, we will explore the operation of the Sequencer in detail. The topics covered include:
15 |
16 | - Sequencing and Broadcasting (Sequencer Feed): An overview of the real-time transaction feed provided by the Sequencer, which allows nodes to receive instant updates on the transaction sequence.
17 | - Batch-Posting: How the Sequencer groups transactions into batches, compresses them to reduce data size and sends them to the Sequencer Inbox Contract on the parent chain. This section also delves into the L1 pricing model and how it affects transaction costs.
18 | - Batching
19 | - Compression
20 | - Submitting to the Sequencer Inbox Contract
21 | - Finality: Understanding how transaction finality is achieved in Arbitrum through both soft and hard finality mechanisms, ensuring that transactions are confirmed securely and reliably. (not as a sequencer task)
22 |
23 | By examining these aspects, you will understand the Sequencer's role within the Arbitrum ecosystem, including how it enhances transaction throughput, reduces latency, and maintains a fair and decentralized network.
24 |
25 | ## Sequencing and Broadcasting
26 |
27 | The Sequencer Feed is a critical component of the Arbitrum network's Nitro architecture. It enables real-time dissemination of transaction data as they are accepted and ordered by the Sequencer. It allows users and nodes to receive immediate updates on transaction sequencing, facilitating rapid transaction confirmations and enhancing the network's overall responsiveness.
28 |
29 | ### How the Sequencer Publishes the Sequence
30 |
31 | The Sequencer communicates the transaction sequence through two primary channels:
32 |
33 | 1. Real-Time Sequencer Feed: A live broadcast that publishes transactions instantly as they are sequenced. Nodes and clients subscribed to this feed receive immediate notifications, allowing them to process transactions without delay.
34 | 2. Batches Posted on the Parent Chain: At regular intervals, the Sequencer aggregates transactions and posts them to the parent chain for finality. (Refer to the Batch-Posting section for detailed information on this process.)
35 |
36 |  37 |
38 | ### Real-Time Sequencer Feed
39 |
40 | The real-time feed represents the Sequencer's commitment to process transactions in a specific order. By subscribing to this feed, nodes and clients can:
41 |
42 | - Receive Immediate Notifications: Obtain instant information about newly sequenced transactions and their ordering.
43 | - Process Transactions Promptly: Utilize the sequenced transactions to update the state locally, enabling rapid application responses and user interactions.
44 | - Benefit from Soft Finality: Gain provisional assurance about transaction acceptance and ordering before the parent chain reaches finality.
45 |
46 | This mechanism is particularly valuable for applications requiring low latency and high throughput, such as decentralized exchanges or real-time gaming platforms.
47 |
48 | ### Soft Finality and Trust Model
49 |
50 | "Soft finality" refers to the preliminary Confirmation of transactions based on the Sequencer's real-time feed. Key aspects include:
51 |
52 | - Dependence on Sequencer Integrity: The feed's accuracy and reliability depend on the Sequencer operating honestly and without significant downtime.
53 | - Immediate User Feedback: Users can act on transaction confirmations swiftly, improving the user experience.
54 | - Eventual Consistency with the Parent Chain: While the real-time feed provides quick updates, ultimate security, and finality are established once transactions are posted to and finalized on the parent chain. (See the Finality section for an in-depth discussion.)
55 |
56 | Understanding this trust model is essential. While we expect the Sequencer to behave correctly, users and developers should know that soft finality depends on this assumption. In scenarios where absolute certainty is required, parties may wait for transactions to achieve finality on the parent chain.
57 |
58 | ### Role of the Sequencer Feed in the Network
59 |
60 | The Sequencer Feed serves several vital functions within the Arbitrum ecosystem:
61 |
62 | - State Synchronization: Nodes use the feed to stay synchronized with the latest state of the network, ensuring consistency across the decentralized platform.
63 | - Application Development: Developers can build applications that respond instantly to network events, enabling features like live updates, instant notifications, and real-time analytics.
64 | - Ecosystem Transparency: The feed promotes transparency and trust within the community by providing visibility into transaction sequencing and network activity.
65 |
66 | ### Considerations and Limitations
67 |
68 | While the Sequencer Feed offers significant advantages, consider the following:
69 |
70 | - Reliance on Sequencer Availability: The effectiveness of the real-time feed depends on the Sequencer's uptime and responsiveness. Network issues or Sequencer downtime can delay transaction visibility.
71 | - Provisional Nature of Soft Finality: Until transactions reach finality on the parent chain, there is a small risk that the provisional ordering provided by the feed could change in exceptional circumstances.
72 | - Security Implications: For high-stakes transactions where security is paramount (e.g., centralized exchange deposits and withdrawals), users may prefer to wait for parent chain confirmation despite the longer latency.
73 |
74 | Developers and users should design their applications and interactions with these factors in mind, choosing the appropriate balance between speed and certainty based on their requirements.
75 |
76 | ### Delayed Messages on the Sequencer Feed
77 |
78 | As illustrated in the diagram, the Sequencer feed not only sends Child chain transactions posted directly to the Sequencer but also incorporates parent chain-submitted child chain transactions. These include L2 messages submitted on L1 and retryable transactions. The Sequencer agent monitors the finalized messages submitted to the parent chain's Delayed Inbox Contract. Once finalized, it processes them as incoming messages to the feed, ensuring they are added as ordered transactions.
79 |
80 | It is important to note that the Nitro node can be configured to add delayed inbox transactions immediately after their submission to the parent chain, even before finalization. However, this approach introduces a risk of child chain reorganization if the transaction fails to finalize on the parent chain. To mitigate this risk, on Arbitrum One and Nova, the Sequencer only includes these transactions in the feed once they are finalized on the Ethereum chain.
81 |
82 | You can also explore how the feed sends incoming messages via WebSocket and learn how to extract message data from the feed on this page: Read Sequencer Feed.
83 |
84 | ## Batch-Posting
85 |
86 | Batch-Posting is a fundamental process in the operation of the Sequencer within the Arbitrum network. It involves collecting multiple child chain transactions, organizing them into batches, compressing the data to reduce size, and sending these batches to the Sequencer Inbox Contract on parent chain. This mechanism is crucial for ensuring that transactions are securely recorded on the parent chain blockchain while optimizing for cost and performance.
87 |
88 | In this section, we will explore the Batch-Posting process in detail, covering the following topics:
89 |
90 | - Batching: How the Sequencer groups incoming transactions into batches for efficient processing and posting.
91 | - Compression: The methods used to compress transaction data, minimizing the amount of data that needs to be posted on parent chain and thereby reducing costs.
92 | - Sending to Sequencer Inbox Contract: The procedure for submitting compressed batches to the Sequencer Inbox Contract on parent chain, ensuring secure and reliable recording of transactions.
93 |
94 | Understanding Batch-Posting is essential for grasping how Arbitrum achieves scalability and cost-efficiency without compromising security. By delving into these subtopics, you'll gain insight into the Sequencer's role in optimizing transaction throughput and minimizing fees, as well as the innovative solutions implemented to address the challenges of Layer 1 data pricing.
95 |
96 | ## Batching and compression
97 |
98 | The Sequencer in Arbitrum is critical in collecting and organizing child chain transactions before posting them to the parent chain. The batching process is designed to optimize for both cost efficiency and timely transaction inclusion.
99 |
100 |
37 |
38 | ### Real-Time Sequencer Feed
39 |
40 | The real-time feed represents the Sequencer's commitment to process transactions in a specific order. By subscribing to this feed, nodes and clients can:
41 |
42 | - Receive Immediate Notifications: Obtain instant information about newly sequenced transactions and their ordering.
43 | - Process Transactions Promptly: Utilize the sequenced transactions to update the state locally, enabling rapid application responses and user interactions.
44 | - Benefit from Soft Finality: Gain provisional assurance about transaction acceptance and ordering before the parent chain reaches finality.
45 |
46 | This mechanism is particularly valuable for applications requiring low latency and high throughput, such as decentralized exchanges or real-time gaming platforms.
47 |
48 | ### Soft Finality and Trust Model
49 |
50 | "Soft finality" refers to the preliminary Confirmation of transactions based on the Sequencer's real-time feed. Key aspects include:
51 |
52 | - Dependence on Sequencer Integrity: The feed's accuracy and reliability depend on the Sequencer operating honestly and without significant downtime.
53 | - Immediate User Feedback: Users can act on transaction confirmations swiftly, improving the user experience.
54 | - Eventual Consistency with the Parent Chain: While the real-time feed provides quick updates, ultimate security, and finality are established once transactions are posted to and finalized on the parent chain. (See the Finality section for an in-depth discussion.)
55 |
56 | Understanding this trust model is essential. While we expect the Sequencer to behave correctly, users and developers should know that soft finality depends on this assumption. In scenarios where absolute certainty is required, parties may wait for transactions to achieve finality on the parent chain.
57 |
58 | ### Role of the Sequencer Feed in the Network
59 |
60 | The Sequencer Feed serves several vital functions within the Arbitrum ecosystem:
61 |
62 | - State Synchronization: Nodes use the feed to stay synchronized with the latest state of the network, ensuring consistency across the decentralized platform.
63 | - Application Development: Developers can build applications that respond instantly to network events, enabling features like live updates, instant notifications, and real-time analytics.
64 | - Ecosystem Transparency: The feed promotes transparency and trust within the community by providing visibility into transaction sequencing and network activity.
65 |
66 | ### Considerations and Limitations
67 |
68 | While the Sequencer Feed offers significant advantages, consider the following:
69 |
70 | - Reliance on Sequencer Availability: The effectiveness of the real-time feed depends on the Sequencer's uptime and responsiveness. Network issues or Sequencer downtime can delay transaction visibility.
71 | - Provisional Nature of Soft Finality: Until transactions reach finality on the parent chain, there is a small risk that the provisional ordering provided by the feed could change in exceptional circumstances.
72 | - Security Implications: For high-stakes transactions where security is paramount (e.g., centralized exchange deposits and withdrawals), users may prefer to wait for parent chain confirmation despite the longer latency.
73 |
74 | Developers and users should design their applications and interactions with these factors in mind, choosing the appropriate balance between speed and certainty based on their requirements.
75 |
76 | ### Delayed Messages on the Sequencer Feed
77 |
78 | As illustrated in the diagram, the Sequencer feed not only sends Child chain transactions posted directly to the Sequencer but also incorporates parent chain-submitted child chain transactions. These include L2 messages submitted on L1 and retryable transactions. The Sequencer agent monitors the finalized messages submitted to the parent chain's Delayed Inbox Contract. Once finalized, it processes them as incoming messages to the feed, ensuring they are added as ordered transactions.
79 |
80 | It is important to note that the Nitro node can be configured to add delayed inbox transactions immediately after their submission to the parent chain, even before finalization. However, this approach introduces a risk of child chain reorganization if the transaction fails to finalize on the parent chain. To mitigate this risk, on Arbitrum One and Nova, the Sequencer only includes these transactions in the feed once they are finalized on the Ethereum chain.
81 |
82 | You can also explore how the feed sends incoming messages via WebSocket and learn how to extract message data from the feed on this page: Read Sequencer Feed.
83 |
84 | ## Batch-Posting
85 |
86 | Batch-Posting is a fundamental process in the operation of the Sequencer within the Arbitrum network. It involves collecting multiple child chain transactions, organizing them into batches, compressing the data to reduce size, and sending these batches to the Sequencer Inbox Contract on parent chain. This mechanism is crucial for ensuring that transactions are securely recorded on the parent chain blockchain while optimizing for cost and performance.
87 |
88 | In this section, we will explore the Batch-Posting process in detail, covering the following topics:
89 |
90 | - Batching: How the Sequencer groups incoming transactions into batches for efficient processing and posting.
91 | - Compression: The methods used to compress transaction data, minimizing the amount of data that needs to be posted on parent chain and thereby reducing costs.
92 | - Sending to Sequencer Inbox Contract: The procedure for submitting compressed batches to the Sequencer Inbox Contract on parent chain, ensuring secure and reliable recording of transactions.
93 |
94 | Understanding Batch-Posting is essential for grasping how Arbitrum achieves scalability and cost-efficiency without compromising security. By delving into these subtopics, you'll gain insight into the Sequencer's role in optimizing transaction throughput and minimizing fees, as well as the innovative solutions implemented to address the challenges of Layer 1 data pricing.
95 |
96 | ## Batching and compression
97 |
98 | The Sequencer in Arbitrum is critical in collecting and organizing child chain transactions before posting them to the parent chain. The batching process is designed to optimize for both cost efficiency and timely transaction inclusion.
99 |
100 |  101 |
102 | Transaction Collection and Ordering:
103 |
104 | - Continuous Reception: The Sequencer continuously receives transactions submitted by users.
105 | - Ordering: Transactions are ordered based on the sequence in which they are received, maintaining a deterministic transaction order.
106 | - Buffering: Received transactions are temporarily stored in a buffer awaiting batch formation.
107 |
108 | Batch Formation Criteria:
109 |
110 | - Size Thresholds: Batch formation occurs when accumulated transactions reach a predefined size limit. This limit ensures that the fixed costs of posting data to the parent chain are amortized over more transaction, improving cost efficiency.
111 | - Time Constraints: The Sequencer also monitors the time elapsed since the last posted batch to prevent undue delays. Upon reaching the maximum time threshold, the Sequencer will create a batch with the transactions collected so far, even if the batch doesn't meet the size threshold.
112 |
113 | Batch Creation Process:
114 |
115 | - Aggregation: Once the batch formation criteria ( the size or time threshold) are satisfied, the Sequencer aggregates the buffered transactions into a single batch.
116 | - Metadata Inclusion: The batch includes the necessary metadata of all transactions.
117 | - Preparation for Compression: Batch preparation for the compression stage begins, where techniques will minimize the data size before posting to parent chain.
118 |
119 | This batching mechanism allows the Sequencer to efficiently manage transactions by balancing the need for cost-effective parent chain posting with the requirement for prompt transaction processing. By strategically grouping transactions into batches based on size and time criteria, the Sequencer reduces per-transaction costs and enhances the overall scalability of the Arbitrum network.
120 |
121 | ### Compression
122 |
123 | The Sequencer employs compression when forming transaction batches to optimize the data and cost of batches posted to the parent chain. Arbitrum uses the Brotli compression algorithm due to its high compression ratio and efficiency, crucial for reducing parent chain posting costs.
124 |
125 |
101 |
102 | Transaction Collection and Ordering:
103 |
104 | - Continuous Reception: The Sequencer continuously receives transactions submitted by users.
105 | - Ordering: Transactions are ordered based on the sequence in which they are received, maintaining a deterministic transaction order.
106 | - Buffering: Received transactions are temporarily stored in a buffer awaiting batch formation.
107 |
108 | Batch Formation Criteria:
109 |
110 | - Size Thresholds: Batch formation occurs when accumulated transactions reach a predefined size limit. This limit ensures that the fixed costs of posting data to the parent chain are amortized over more transaction, improving cost efficiency.
111 | - Time Constraints: The Sequencer also monitors the time elapsed since the last posted batch to prevent undue delays. Upon reaching the maximum time threshold, the Sequencer will create a batch with the transactions collected so far, even if the batch doesn't meet the size threshold.
112 |
113 | Batch Creation Process:
114 |
115 | - Aggregation: Once the batch formation criteria ( the size or time threshold) are satisfied, the Sequencer aggregates the buffered transactions into a single batch.
116 | - Metadata Inclusion: The batch includes the necessary metadata of all transactions.
117 | - Preparation for Compression: Batch preparation for the compression stage begins, where techniques will minimize the data size before posting to parent chain.
118 |
119 | This batching mechanism allows the Sequencer to efficiently manage transactions by balancing the need for cost-effective parent chain posting with the requirement for prompt transaction processing. By strategically grouping transactions into batches based on size and time criteria, the Sequencer reduces per-transaction costs and enhances the overall scalability of the Arbitrum network.
120 |
121 | ### Compression
122 |
123 | The Sequencer employs compression when forming transaction batches to optimize the data and cost of batches posted to the parent chain. Arbitrum uses the Brotli compression algorithm due to its high compression ratio and efficiency, crucial for reducing parent chain posting costs.
124 |
125 |  126 |
127 | ### Compression level in the Brotli algorithm
128 |
129 | Brotli’s compression algorithm includes a parameter: compression level, which ranges from 0 to 11. This parameter allows you to balance two key factors:
130 |
131 | - Compression Efficiency: Higher levels result in greater size reduction.
132 | - Computational Cost: Higher levels require more processing power and time.
133 |
134 | As the compression level increases, you achieve better compression ratios at the expense of longer compression times.
135 |
136 | ### Dynamic compression level setting
137 |
138 | The compression level on Arbitrum is dynamically adjusted based on the current backlog of batches waiting to be posted to parent chain by Sequencer. In scenarios where multiple batches are queued in the buffer, the compression level can be dynamically adjusted to improve throughput. When the buffer becomes overloaded with overdue batches, the compression level decreases.
139 |
140 | This tradeoff prioritizes speed over compression efficiency, enabling faster processing and transmitting pending batches. Doing so, clears the buffer more quickly, ensuring smoother overall system performance.
141 |
142 | Now that transactions are batched and compressed, they can be passed to batch-poster to be sent to the parent chain.
143 |
144 | ## Submitting to the Sequencer Inbox Contract
145 |
146 | After batching and compressing transactions, the Sequencer posts these batches to the parent chain to ensure security and finality. This process involves the Batch Poster, an Externally Owned Account (EOA) controlled by the Sequencer. The Batch Poster is responsible for submitting the compressed transaction batches to the Sequencer Inbox Contract on parent chain.
147 |
148 | There are two primary methods the Sequencer uses to send batches to the parent chain, depending on whether the chain supports EIP-4844 (Proto-Danksharding) and the current network conditions:
149 |
150 |
126 |
127 | ### Compression level in the Brotli algorithm
128 |
129 | Brotli’s compression algorithm includes a parameter: compression level, which ranges from 0 to 11. This parameter allows you to balance two key factors:
130 |
131 | - Compression Efficiency: Higher levels result in greater size reduction.
132 | - Computational Cost: Higher levels require more processing power and time.
133 |
134 | As the compression level increases, you achieve better compression ratios at the expense of longer compression times.
135 |
136 | ### Dynamic compression level setting
137 |
138 | The compression level on Arbitrum is dynamically adjusted based on the current backlog of batches waiting to be posted to parent chain by Sequencer. In scenarios where multiple batches are queued in the buffer, the compression level can be dynamically adjusted to improve throughput. When the buffer becomes overloaded with overdue batches, the compression level decreases.
139 |
140 | This tradeoff prioritizes speed over compression efficiency, enabling faster processing and transmitting pending batches. Doing so, clears the buffer more quickly, ensuring smoother overall system performance.
141 |
142 | Now that transactions are batched and compressed, they can be passed to batch-poster to be sent to the parent chain.
143 |
144 | ## Submitting to the Sequencer Inbox Contract
145 |
146 | After batching and compressing transactions, the Sequencer posts these batches to the parent chain to ensure security and finality. This process involves the Batch Poster, an Externally Owned Account (EOA) controlled by the Sequencer. The Batch Poster is responsible for submitting the compressed transaction batches to the Sequencer Inbox Contract on parent chain.
147 |
148 | There are two primary methods the Sequencer uses to send batches to the parent chain, depending on whether the chain supports EIP-4844 (Proto-Danksharding) and the current network conditions:
149 |
150 |  151 |
152 | ### 1. Using Blobs with
151 |
152 | ### 1. Using Blobs with addSequencerL2BatchFromBlobs
153 |
154 | - Default Approach: When the parent chain supports EIP-4844, the Sequencer utilizes blob transactions to post batches efficiently.
155 | - Method: The Batch Poster calls the addSequencerL2BatchFromBlobs function of the Sequencer Inbox Contract.
156 | - Process:
157 | - Batch data gets included as blobs—large binary data structures optimized for scalability.
158 | - The transaction includes metadata about the batch but does not include the batch data itself in the calldata.
159 | - Benefits:
160 | - Cost Efficiency: Blobs allow cheaper data inclusion than calldata, reducing gas costs.
161 | - Scalability: Leveraging blobs enhances the network's ability to handle large volumes of transactions.
162 |
163 | ### 2. Using Calldata with addSequencerL2Batch
164 |
165 | - Alternative Approach: If the Blob Base Fee is significantly high or the blob space is constrained during batch posting, the Sequencer may opt to use calldata.
166 | - Method: The Batch Poster calls the addSequencerL2Batch function of the Sequencer Inbox Contract.
167 | - Process:
168 | - The compressed batch transactions are included directly in the transaction's calldata.
169 | - Considerations:
170 | - Cost Evaluation: The Sequencer dynamically assesses whether using calldata is more cost-effective than blobs based on current gas prices and blob fees.
171 | - Compatibility: If the parent chain does not support EIP-4844, this method is the default and only option for batch posting.
172 |
173 | :::note
174 | The Sequencer continuously monitors network conditions to choose the most economical method for batch posting, ensuring optimal operation under varying circumstances.
175 | :::
176 |
177 | ### Authority and Finality
178 |
179 | - Exclusive Access: Only the Sequencer can call these methods on the Sequencer Inbox Contract. This exclusivity ensures that no other party can directly include messages.
180 | - Soft-Confirmation Receipts: The Sequencer's unique ability to immediately process and include transactions allows it to provide users with instant, "soft-confirmation" receipts,
181 | - Parent chain Finality: Once batches post, the transactions achieve parent-chain-level finality, secured by Parent chain’s consensus mechanism.
182 |
183 | By efficiently sending compressed transaction batches to the Sequencer Inbox Contract using the most cost-effective method available, the Sequencer ensures transactions are securely recorded on parent chain. This process maintains the integrity and reliability of the network, providing users with fast and secure transaction processing.
184 |
185 | ## Finality
186 |
187 | Finality in blockchain systems refers to the point at which a transaction becomes irreversible and permanently included in the blockchain's ledger. In the context of Arbitrum's Nitro architecture, understanding finality is crucial for developers and users to make informed decisions about transaction confirmations, security guarantees, and application design.
188 |
189 | Arbitrum offers two levels of finality:
190 |
191 | 1. Soft Finality: Provided by the Sequencer's real-time feed, offering immediate but provisional transaction confirmations.
192 | 2. Hard Finality: Occurs when transactions are included in batches posted to and finalized on the parent chain, providing strong security assurances.
193 |
194 | This section explores the concepts of soft and hard finality, their implications, trust considerations, and guidance for utilizing them effectively within the Arbitrum network.
195 |
196 | ### Soft Finality
197 |
198 | Soft finality refers to the preliminary confirmation of transactions based on the Sequencer's real-time feed. Key characteristics include:
199 |
200 | - Immediate Confirmation: Transactions are confirmed almost instantly as they are accepted and ordered by the Sequencer.
201 | - Provisional Assurance: The confirmations are provisional and rely on the Sequencer's integrity and availability.
202 | - High Performance: Enables applications to offer rapid responses and real-time interactions, enhancing user experience.
203 |
204 | Advantages of Soft Finality:
205 |
206 | - Low Latency: Users receive immediate feedback on transaction status.
207 | - Optimized for Speed: Ideal for applications where responsiveness is critical.
208 | - Improved User Experience: Reduces waiting times and uncertainty.
209 |
210 | Limitations of Soft Finality:
211 |
212 | - Trust Dependency: Relies on the Sequencer's honesty and ability to maintain uptime..
213 | - Potential for Reordering: In rare cases, if the Sequencer acts maliciously or encounters issues, the provisional ordering could change.
214 | - Not Suitable for High-Value Transactions: For transactions requiring strong security guarantees, soft finality may not suffice.
215 |
216 | ### Hard Finality
217 |
218 | Hard finality occurs when batched transactions get posted to the parent chain. Key characteristics include:
219 |
220 | - Strong Security Guarantees: When included in blocks on the parent chain, transactions inherit the parent chain's security assurances.
221 | - Irreversibility: Once finalized, transactions are immutable and cannot be altered or reversed.
222 | - Data Availability: All transaction data is recorded on-chain, ensuring transparency and verifiability.
223 |
224 | Advantages of Hard Finality:
225 |
226 | - Maximum Security: Protected by the robustness of the parent chain's consensus mechanism.
227 | - Trust Minimization: This does not require trust in the Sequencer; security comes from the underlying blockchain.
228 | - Suitable for High-Value Transactions: Ideal for scenarios where security and immutability are paramount.
229 |
230 | Limitations of Hard Finality:
231 |
232 | - Higher Latency: Achieving hard finality takes longer due to the time required for the parent chain to process and finalize batches.
233 | - Cost Considerations: Posting batches to the parent chain incurs fees, which may affect transaction costs.
234 |
235 | ### Trust Considerations
236 |
237 | Understanding the trust assumptions associated with each level of finality is essential:
238 |
239 | - Soft Finality Trust Model:
240 | - Reliance on the Sequencer: Users must trust that the Sequencer operates honestly, sequences transactions correctly, and remains available.
241 | - Risk of Misbehavior: If the Sequencer acts maliciously, it could reorder or censor certain transactions before they achieve hard finality.
242 | - Hard Finality Trust Model:
243 | - Reliance on the Parent Chain: Security is based on the consensus and integrity of the parent chain.
244 | - Reduced Trust in Sequencer: Even if the Sequencer misbehaves, transactions included in posted batches are secured once finalized on the parent chain.
245 |
246 | ### Application Implications
247 |
248 | Developers and users should consider the appropriate level of finality based on their specific use cases:
249 |
250 | - When to Rely on Soft Finality:
251 | - Low-Risk Transactions: For transactions where the potential impact of reordering or delays is minimal.
252 | - User Experience Priority: Applications where responsiveness and immediacy enhance user engagement, such as gaming or social platforms.
253 | - Frequent Transactions: Scenarios involving a high volume of small transactions where waiting for hard finality is impractical.
254 | - When to Require Hard Finality:
255 | - High-Value Transactions: Financial transfers, large trades, or any transaction where security is critical.
256 | - Regulatory Compliance: Situations requiring strict adherence to security standards and auditable records.
257 | - Centralized Exchanges (CeXs): For deposit and withdrawal operations where certainty of transaction finality is mandatory.
258 |
259 | ### Decentralized Fair Sequencing
260 |
261 | Arbitrum’s long-term vision includes transitioning from a centralized Sequencer to a decentralized, fair sequencing model. In this framework, a committee of servers (or validators) collectively determines transaction ordering, ensuring fairness, reducing the influence of any single party, and making it more resistant to manipulation. By requiring a supermajority consensus, this approach distributes sequencing power among multiple honest participants, mitigates the risks of front-running or censorship, and aligns with the broader blockchain principles of enhanced security, transparency, and decentralization.
262 |
1 | ---
2 | title: Geth at the core
3 | description: Learn the fundamentals of Geth and ArbOS.
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about Geth and ArbOS.
7 | content_type: get-started
8 | ---
9 |
10 | The second key design idea in Nitro is "Geth at the core." Here "geth" refers to go-ethereum, the most common node software for Ethereum. As its name would suggest, go-ethereum is written in the Go programming language, as is almost all of Nitro.
11 |
12 |  13 |
14 | The software that makes up a Nitro node can be thought of as built in three main layers, which are shown above:
15 |
16 | - The base layer is the core of geth--the parts of Geth that emulate the execution of EVM contracts and maintain the data structures that make up the Ethereum state. Nitro compiles in this code as a library, with a few minor modifications to add necessary hooks.
17 | - The middle layer, which we call ArbOS, is custom software that provides additional functions associated with Layer 2 functionality, such as decompressing and parsing the Sequencer's data batches, accounting for Layer 1 gas costs and collecting fees to reimburse for them, and supporting cross-chain Bridge functionalities such as deposits of Ether and tokens from L1 and withdrawals of the same back to L1. We'll dig in to the details of ArbOS below.
18 | - The top layer consists of node software, mostly drawn from geth. This handles connections and incoming RPC requests from clients and provides the other top-level functionality required to operate an Ethereum-compatible Blockchain node.
19 |
20 | Because the top and bottom layers rely heavily on code from geth, this structure has been dubbed a "geth sandwich." Strictly speaking, Geth plays the role of the bread in the sandwich, and ArbOS is the filling, but this sandwich is named for the bread.
21 |
22 | The State Transition Function consists of the bottom Geth layer, and a portion of the middle ArbOS layer. In particular, the STF is a designated function in the source code, and implicitly includes all of the code called by that function. The STF takes as input the bytes of a Transaction received in the inbox, and has access to a modifiable copy of the Ethereum state tree. Executing the STF may modify the state, and at the end will emit the header of a new block (in Ethereum's block header format) which will be appended to the Nitro chain.
23 |
24 | The rest of this section will be a deep dive into Geth and ArbOS. If deep technical knowledge does not suit you, skip to the next section Separating Execution from Proving.
25 |
26 | ## Geth
27 |
28 | Nitro makes minimal modifications to Geth in hopes of not violating its assumptions. This section will explore the relationship between Geth and ArbOS, which consists of a series of hooks, interface implementations, and strategic re-appropriations of Geth's basic types.
29 |
30 | We store ArbOS's state at an address inside a Geth
13 |
14 | The software that makes up a Nitro node can be thought of as built in three main layers, which are shown above:
15 |
16 | - The base layer is the core of geth--the parts of Geth that emulate the execution of EVM contracts and maintain the data structures that make up the Ethereum state. Nitro compiles in this code as a library, with a few minor modifications to add necessary hooks.
17 | - The middle layer, which we call ArbOS, is custom software that provides additional functions associated with Layer 2 functionality, such as decompressing and parsing the Sequencer's data batches, accounting for Layer 1 gas costs and collecting fees to reimburse for them, and supporting cross-chain Bridge functionalities such as deposits of Ether and tokens from L1 and withdrawals of the same back to L1. We'll dig in to the details of ArbOS below.
18 | - The top layer consists of node software, mostly drawn from geth. This handles connections and incoming RPC requests from clients and provides the other top-level functionality required to operate an Ethereum-compatible Blockchain node.
19 |
20 | Because the top and bottom layers rely heavily on code from geth, this structure has been dubbed a "geth sandwich." Strictly speaking, Geth plays the role of the bread in the sandwich, and ArbOS is the filling, but this sandwich is named for the bread.
21 |
22 | The State Transition Function consists of the bottom Geth layer, and a portion of the middle ArbOS layer. In particular, the STF is a designated function in the source code, and implicitly includes all of the code called by that function. The STF takes as input the bytes of a Transaction received in the inbox, and has access to a modifiable copy of the Ethereum state tree. Executing the STF may modify the state, and at the end will emit the header of a new block (in Ethereum's block header format) which will be appended to the Nitro chain.
23 |
24 | The rest of this section will be a deep dive into Geth and ArbOS. If deep technical knowledge does not suit you, skip to the next section Separating Execution from Proving.
25 |
26 | ## Geth
27 |
28 | Nitro makes minimal modifications to Geth in hopes of not violating its assumptions. This section will explore the relationship between Geth and ArbOS, which consists of a series of hooks, interface implementations, and strategic re-appropriations of Geth's basic types.
29 |
30 | We store ArbOS's state at an address inside a Geth statedb. In doing so, ArbOS inherits the statedb's statefulness and lifetime properties. For example, a transaction's direct state changes to ArbOS are discarded upon a revert.
31 |
32 | 0xA4B05FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
33 | The fictional account representing ArbOS
34 |
35 | :::info
36 |
37 | Please note any links on this page may be referencing old releases of Nitro or our fork of Geth. While we try to keep this up to date and most of this should be stable, please check against latest releases for Nitro and Geth for most recent changes.
38 |
39 | :::
40 |
41 | ### Hooks
42 |
43 | Arbitrum uses various hooks to modify Geth's behavior when processing
44 | transactions. Each provides an opportunity for ArbOS to update its state and make decisions about the
45 | transaction during its lifetime. Transactions are applied using Geth's [ApplyTransaction][applytransaction_link]
46 | function.
47 |
48 | Below is [ApplyTransaction][applytransaction_link]'s callgraph, with additional info on where the various Arbitrum-specific hooks are inserted. Click on any to go to their section. By default, these hooks do nothing so as to leave Geth's default behavior unchanged, but for chains configured with EnableArbOS set to true, ReadyEVMForL2 installs the alternative L2 hooks.
49 |
50 | - core.ApplyTransaction ⮕ core.applyTransaction ⮕ core.ApplyMessage
51 | - core.NewStateTransition
52 | - ReadyEVMForL2
53 | - core.TransitionDb
54 | - StartTxHook
55 | - core.transitionDbImpl
56 | - if IsArbitrum() remove tip
57 | - GasChargingHook
58 | - evm.Call
59 | - core.vm.EVMInterpreter.Run
60 | - PushCaller
61 | - PopCaller
62 | - core.StateTransition.refundGas
63 | - ForceRefundGas
64 | - NonrefundableGas
65 | - EndTxHook
66 | - added return parameter: transactionResult
67 |
68 | What follows is an overview of each hook, in chronological order.
69 |
70 | #### [ReadyEVMForL2][readyevmforl2_link]{#ReadyEVMForL2}
71 |
72 | A call to [ReadyEVMForL2][readyevmforl2_link] installs the other transaction-specific hooks into each Geth [EVM][evm_link] right before it performs a state transition. Without this call, the state transition will instead use the default [DefaultTxProcessor][defaulttxprocessor_link] and get exactly the same results as vanilla Geth. A [TxProcessor][txprocessor_link] object is what carries these hooks and the associated Arbitrum-specific state during the transaction's lifetime.
73 |
74 | #### [StartTxHook][starttxhook_link]{#StartTxHook}
75 |
76 | The [StartTxHook][starttxhook_link] is called by Geth before a transaction starts executing. This allows ArbOS to handle two Arbitrum-specific transaction types.
77 |
78 | If the transaction is ArbitrumDepositTx, ArbOS adds balance to the destination account. This is safe because the L1 bridge submits such a transaction only after collecting the same amount of funds on L1.
79 |
80 | If the transaction is an ArbitrumSubmitRetryableTx, ArbOS creates a retryable based on the transaction's fields. If the transaction includes sufficient gas, ArbOS schedules a retry of the new retryable.
81 |
82 | The hook returns true for both of these transaction types, signifying that the state transition is complete.
83 |
84 | #### [GasChargingHook][gascharginghook_link]
85 |
86 | This fallible hook ensures the user has enough funds to pay their poster's L1 calldata costs. If not, the transaction is reverted and the [EVM][evm_link] does not start. In the common case that the user can pay, the amount paid for calldata is set aside for later reimbursement of the poster. All other fees go to the network account, as they represent the transaction's burden on validators and nodes more generally.
87 |
88 | If the user attempts to purchase compute gas in excess of ArbOS's per-block gas limit, the difference is [set aside][difference_set_aside_link] and [refunded later][refunded_later_link] via ForceRefundGas so that only the gas limit is used. Note that the limit observed may not be the same as that seen [at the start of the block][that_seen_link] if ArbOS's larger gas pool falls below the [MaxPerBlockGasLimit][max_perblock_limit_link] while processing the block's previous transactions.
89 |
90 | [difference_set_aside_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L407
91 | [refunded_later_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/state_transition.go#L419
92 | [that_seen_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/block_processor.go#L176
93 | [max_perblock_limit_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/l2pricing/l2pricing.go#L86
94 |
95 | #### [PushCaller][pushcaller_link]{#PushCaller}
96 |
97 | These hooks track the callers within the EVM callstack, pushing and popping as calls are made and complete. This provides ArbSys with info about the callstack, which it uses to implement the methods WasMyCallersAddressAliased and MyCallersAddressWithoutAliasing.
98 |
99 | #### [L1BlockHash][l1blockhash_link]
100 |
101 | In Arbitrum, the BlockHash and Number operations return data that relies on underlying L1 blocks instead of L2 blocks, to accommodate the normal use-case of these opcodes, which often assume Ethereum-like time passes between different blocks. The L1BlockHash and L1BlockNumber hooks have the required data for these operations.
102 |
103 | #### [ForceRefundGas][forcerefundgas_link]{#ForceRefundGas}
104 |
105 | This hook allows ArbOS to add additional refunds to the user's tx. This is currently only used to refund any compute gas purchased in excess of ArbOS's per-block gas limit during the GasChargingHook.
106 |
107 | #### [NonrefundableGas][nonrefundablegas_link]{#NonrefundableGas}
108 |
109 | Because poster costs come at the expense of L1 aggregators and not the network more broadly, the amounts paid for L1 calldata should not be refunded. This hook provides Geth access to the equivalent amount of L2 gas the poster's cost equals, ensuring this amount is not reimbursed for network-incentivized behaviors like freeing storage slots.
110 |
111 | #### [EndTxHook][endtxhook_link]{#EndTxHook}
112 |
113 | The [EndTxHook][endtxhook_link] is called after the [EVM][evm_link] has returned a transaction's result, allowing one last opportunity for ArbOS to intervene before the state transition is finalized. Final gas amounts are known at this point, enabling ArbOS to credit the network and poster each's share of the user's gas expenditures as well as adjust the pools. The hook returns from the [TxProcessor][txprocessor_link] a final time, in effect discarding its state as the system moves on to the next transaction where the hook's contents will be set afresh.
114 |
115 | [applytransaction_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/state_processor.go#L152
116 | [evm_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/vm/evm.go#L101
117 | [defaulttxprocessor_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/vm/evm_arbitrum.go#L42
118 | [txprocessor_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L38
119 | [starttxhook_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L100
120 | [readyevmforl2_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbstate/geth-hook.go#L47
121 | [gascharginghook_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L354
122 | [pushcaller_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L76
123 | [popcaller_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L80
124 | [forcerefundgas_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L425
125 | [nonrefundablegas_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L418
126 | [endtxhook_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L429
127 | [l1blockhash_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L617
128 | [l1blocknumber_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/tx_processor.go#L600
129 |
130 | ### Interfaces and components
131 |
132 | #### [APIBackend][apibackend_link]
133 |
134 | APIBackend implements the [ethapi.Backend][ethapi.backend_link] interface, which allows simple integration of the Arbitrum chain to existing Geth API. Most calls are answered using the Backend member.
135 |
136 | [apibackend_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/apibackend.go#L34
137 | [ethapi.backend_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/internal/ethapi/backend.go#L42
138 |
139 | #### [Backend][backend_link]
140 |
141 | This struct was created as an Arbitrum equivalent to the [Ethereum][ethereum_link] struct. It is mostly glue logic, including a pointer to the ArbInterface interface.
142 |
143 | [backend_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/backend.go#L15
144 | [ethereum_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/eth/backend.go#L68
145 |
146 | #### [ArbInterface][arbinterface_link]
147 |
148 | This interface is the main interaction-point between geth-standard APIs and the Arbitrum chain. Geth APIs mostly either check status by working on the Blockchain struct retrieved from the [Blockchain][blockchain_link] call, or send transactions to Arbitrum using the [PublishTransactions][publishtransactions_link] call.
149 |
150 | [arbinterface_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/arbos_interface.go#L10
151 | [blockchain_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/arbos_interface.go#L12
152 | [publishtransactions_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/arbos_interface.go#L11
153 |
154 | #### [RecordingKV][recordingkv_link]
155 |
156 | RecordingKV is a read-only key-value store, which retrieves values from an internal trie database. All values accessed by a RecordingKV are also recorded internally. This is used to record all preimages accessed during block creation, which will be needed to prove execution of this particular block.
157 | A [RecordingChainContext][recordingchaincontext_link] should also be used, to record which block headers the block execution reads (another option would be to always assume the last 256 block headers were accessed).
158 | The process is simplified using two functions: [PrepareRecording][preparerecording_link] creates a stateDB and chaincontext objects, running block creation process using these objects records the required preimages, and [PreimagesFromRecording][preimagesfromrecording_link] function extracts the preimages recorded.
159 |
160 | [recordingkv_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/recordingdb.go#L22
161 | [recordingchaincontext_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/recordingdb.go#L123
162 | [preparerecording_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/recordingdb.go#L152
163 | [preimagesfromrecording_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/arbitrum/recordingdb.go#L174
164 |
165 | ### Transaction Types
166 |
167 | Nitro Geth includes a few L2-specific transaction types. Click on any to jump to their section.
168 |
169 | | Tx Type | Represents | Last Hook Reached | Source |
170 | | :------------------------------------------------ | :----------------------------------------------------------------------- | :------------------------- | ------ |
171 | | [ArbitrumUnsignedTx][arbtxunsigned] | An L1 to L2 message | [EndTxHook][he] | Bridge |
172 | | [ArbitrumContractTx][arbtxcontract] | A nonce-less L1 to L2 message | [EndTxHook][he] | Bridge |
173 | | [ArbitrumDepositTx][arbtxdeposit] | A user deposit | [StartTxHook][hs] | Bridge |
174 | | [ArbitrumSubmitRetryableTx][arbtxsubmit] | Creating a retryable | [StartTxHook][hs] | Bridge |
175 | | [ArbitrumRetryTx][arbtxretry] | A Retryable Redeem attempt | [EndTxHook][he] | L2 |
176 | | [ArbitrumInternalTx][arbtxinternal] | ArbOS state update | [StartTxHook][hs] | ArbOS |
177 |
178 | [arbtxunsigned]: #ArbitrumUnsignedTx
179 | [arbtxcontract]: #ArbitrumContractTx
180 | [arbtxsubmit]: #ArbitrumSubmitRetryableTx
181 | [arbtxretry]: #ArbitrumRetryTx
182 | [arbtxdeposit]: #ArbitrumDepositTx
183 | [arbtxinternal]: #ArbitrumInternalTx
184 | [hs]: #StartTxHook
185 | [he]: #EndTxHook
186 |
187 | The following reference documents each type.
188 |
189 | #### [ArbitrumUnsignedTx][arbitrumunsignedtx_link]{#ArbitrumUnsignedTx}
190 |
191 | Provides a mechanism for a user on L1 to message a contract on L2. This uses the bridge for authentication rather than requiring the user's signature. Note, the user's acting address will be remapped on L2 to distinguish them from a normal L2 caller.
192 |
193 | #### [ArbitrumContractTx][arbitrumcontracttx_link]{#ArbitrumContractTx}
194 |
195 | These are like an [ArbitrumUnsignedTx][arbitrumunsignedtx_link] but are intended for smart contracts. These use the bridge's unique, sequential nonce rather than requiring the caller specify their own. An L1 contract may still use an [ArbitrumUnsignedTx][arbitrumunsignedtx_link], but doing so may necessitate tracking the nonce in L1 state.
196 |
197 | #### [ArbitrumDepositTx][arbitrumdeposittx_link]{#ArbitrumDepositTx}
198 |
199 | Represents a user deposit from L1 to L2. This increases the user's balance by the amount deposited on L1.
200 |
201 | #### [ArbitrumSubmitRetryableTx][arbitrumsubmitretryabletx_link]{#ArbitrumSubmitRetryableTx}
202 |
203 | Represents a retryable submission and may schedule an ArbitrumRetryTx if provided enough gas. Please see the retryables documentation for more info.
204 |
205 | #### [ArbitrumRetryTx][arbitrumretrytx_link]{#ArbitrumRetryTx}
206 |
207 | These are scheduled by calls to the redeem method of the ArbRetryableTx precompile and via retryable auto-redemption. Please see the retryables documentation for more info.
208 |
209 | #### [ArbitrumInternalTx][arbitruminternaltx_link]{#ArbitrumInternalTx}
210 |
211 | Because tracing support requires ArbOS's state-changes happen inside a transaction, ArbOS may create a transaction of this type to update its state in-between user-generated transactions. Such a transaction has a [Type][internaltype_link] field signifying the state it will update, though currently this is just future-proofing as there's only one value it may have. Below are the internal transaction types.
212 |
213 | ##### [InternalTxStartBlock][arbinternaltxstartblock_link]
214 |
215 | Updates the L1 block number and L1 base fee. This transaction [is generated][block_generated_link] whenever a new block is created. They are [guaranteed to be the first][block_first_link] in their L2 Block.
216 |
217 | [arbitrumunsignedtx_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/arb_types.go#L43
218 | [arbitrumcontracttx_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/arb_types.go#L104
219 | [arbitrumsubmitretryabletx_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/arb_types.go#L232
220 | [arbitrumretrytx_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/arb_types.go#L161
221 | [arbitrumdeposittx_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/arb_types.go#L338
222 | [arbitruminternaltx_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/internal_tx.go
223 | [internaltype_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/arb_types.go#L387
224 | [arbinternaltxstartblock_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/internal_tx.go#L22
225 | [block_generated_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/block_processor.go#L181
226 | [block_first_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/block_processor.go#L182
227 |
228 | ### Transaction Run Modes and Underlying Transactions
229 |
230 | A [geth message][geth_message_link] may be processed for various purposes. For example, a message may be used to estimate the gas of a contract call, whereas another may perform the corresponding state transition. Nitro Geth denotes the intent behind a message by means of its [TxRunMode][txrunmode_link], [which it sets][set_run_mode_link] before processing it. ArbOS uses this info to make decisions about the transaction the message ultimately constructs.
231 |
232 | A message [derived from a transaction][asmessage_link] will carry that transaction in a field accessible via its [UnderlyingTransaction][underlying_link] method. While this is related to the way a given message is used, they are not one-to-one. The table below shows the various run modes and whether each could have an underlying transaction.
233 |
234 | | Run Mode | Scope | Carries an Underlying Tx? |
235 | | :--------------------------------------- | :---------------------- | :----------------------------------------------------------------------------------------------------------- |
236 | | [MessageCommitMode][mc0] | state transition | always |
237 | | [MessageGasEstimationMode][mc1] | gas estimation | when created via NodeInterface or when scheduled |
238 | | [MessageEthcallMode][mc2] | eth_calls | never |
239 |
240 | [mc0]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L654
241 | [mc1]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L655
242 | [mc2]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L656
243 | [geth_message_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L634
244 | [txrunmode_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L701
245 | [set_run_mode_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/internal/ethapi/api.go#L955
246 | [asmessage_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L676
247 | [underlying_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/types/transaction.go#L700
248 |
249 | ### Arbitrum Chain Parameters
250 |
251 | Nitro's Geth may be configured with the following [l2-specific chain parameters][chain_params_link]. These allow the rollup creator to customize their rollup at genesis.
252 |
253 | #### EnableArbos
254 |
255 | Introduces ArbOS, converting what would otherwise be a vanilla L1 chain into an L2 Arbitrum rollup.
256 |
257 | #### AllowDebugPrecompiles
258 |
259 | Allows access to debug precompiles. Not enabled for Arbitrum One. When false, calls to debug precompiles will always revert.
260 |
261 | #### DataAvailabilityCommittee
262 |
263 | Currently does nothing besides indicate that the rollup will access a data availability service for preimage resolution in the future. This is not enabled for Arbitrum One, which is a strict state-function of its L1 inbox messages.
264 |
265 | [chain_params_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/params/config_arbitrum.go#L25
266 |
267 | ### Miscellaneous Geth Changes
268 |
269 | #### ABI Gas Margin
270 |
271 | Vanilla Geth's abi library submits txes with the exact estimate the node returns, employing no padding. This means a transaction may revert should another arriving just before even slightly change the transaction's codepath. To account for this, we've added a GasMargin field to bind.TransactOpts that [pads estimates][pad_estimates_link] by the number of basis points set.
272 |
273 | #### Conservation of L2 ETH
274 |
275 | The total amount of L2 ether in the system should not change except in controlled cases, such as when bridging. As a safety precaution, ArbOS checks Geth's [balance delta][conservation_link] each time a block is created, [alerting or panicking][alert_link] should conservation be violated.
276 |
277 | #### MixDigest and ExtraData
278 |
279 | To aid with [Outbox proof construction][proof_link], the root hash and leaf count of ArbOS's [send merkle accumulator][merkle_link] are stored in the MixDigest and ExtraData fields of each L2 block. The yellow paper specifies that the ExtraData field may be no larger than 32 bytes, so we use the first 8 bytes of the MixDigest, which has no meaning in a system without miners/stakers, to store the send count.
280 |
281 | #### Retryable Support
282 |
283 | Retryables are mostly implemented in ArbOS. Some modifications were required in Geth to support them.
284 |
285 | - Added ScheduledTxes field to ExecutionResult. This lists transactions scheduled during the execution. To enable using this field, we also pass the ExecutionResult to callers of ApplyTransaction.
286 | - Added gasEstimation param to DoCall. When enabled, DoCall will also also executing any retryable activated by the original call. This allows estimating gas to enable retryables.
287 |
288 | #### Added accessors
289 |
290 | Added [UnderlyingTransaction][underlyingtransaction_link] to Message interface
291 | Added GetCurrentTxLogs to StateDB
292 | We created the AdvancedPrecompile interface, which executes and charges gas with the same function call. This is used by Arbitrum's precompiles, and also wraps Geth's standard precompiles.
293 |
294 | #### WASM build support
295 |
296 | The WASM Arbitrum executable does not support file operations. We created fileutil.go to wrap fileutil calls, stubbing them out when building WASM. fake_leveldb.go is a similar WASM-mock for leveldb. These are not required for the WASM block-replayer.
297 |
298 | #### Types
299 |
300 | Arbitrum introduces a new signer, and multiple new transaction types.
301 |
302 | #### ReorgToOldBlock
303 |
304 | Geth natively only allows reorgs to a fork of the currently-known network. In nitro, reorgs can sometimes be detected before computing the forked block. We added the ReorgToOldBlock function to support reorging to a block that's an ancestor of current head.
305 |
306 | #### Genesis block creation
307 |
308 | Genesis block in nitro is not necessarily block #0. Nitro supports importing blocks that take place before genesis. We split out [WriteHeadBlock][writeheadblock_link] from genesis.Commit and use it to commit non-zero genesis blocks.
309 |
310 | [pad_estimates_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/accounts/abi/bind/base.go#L355
311 | [conservation_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/state/statedb.go#L42
312 | [alert_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/block_processor.go#L424
313 | [proof_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/system_tests/outbox_test.go#L26
314 | [merkle_link]: https://github.com/OffchainLabs/nitro/blob/8e786ec6d1ac3862be85e0c9b5ac79cbd883791c/arbos/merkleAccumulator/merkleAccumulator.go#L13
315 | [underlyingtransaction_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/state_transition.go#L69
316 | [writeheadblock_link]: https://github.com/OffchainLabs/go-ethereum/blob/7503143fd13f73e46a966ea2c42a058af96f7fcf/core/genesis.go#L415
317 |
318 | ## ArbOS
319 |
320 | ArbOS is the Layer 2 EVM hypervisor that facilitates the execution environment of L2 Arbitrum. ArbOS is a trusted "system glue" component that runs at Layer 2 as part of the State Transition Function, it accounts for and manages network resources, produces blocks from incoming messages, cross-chain messaging, and operates its instrumented instance of Geth for Smart Contract execution.
321 |
322 | In Arbitrum, much of the work that would otherwise have to be done expensively at Layer 1 is instead done by ArbOS, trustlessly performing these functions at the speed and low cost of Layer 2.
323 |
324 | Supporting these functions in Layer 2 trusted software, rather than building them in to the L1-enforced rules of the architecture as Ethereum does, offers significant advantages in cost because these operations can benefit from the lower cost of computation and storage at Layer 2, instead of having to manage those resources as part of a Layer 1 contract. Having a trusted operating system at Layer 2 also has significant advantages in flexibility, because Layer 2 code is easier to evolve, or to customize for a particular chain, than a Layer-1 enforced architecture would be.
325 |
326 | ### Precompiles
327 |
328 | ArbOS provides L2-specific precompiles with methods smart contracts can call the same way they can solidity functions. Visit the precompiles conceptual page for more information about how these work, and the precompiles reference page for a full reference of the precompiles available in Arbitrum chains.
329 |
330 | A precompile consists of a solidity interface in [contracts/src/precompiles/][nitro_precompiles_dir] and a corresponding Golang implementation in [precompiles/][precompiles_dir]. Using Geth's ABI generator, [solgen/gen.go][gen_file] generates [solgen/go/precompilesgen/precompilesgen.go][precompilesgen_link], which collects the ABI data of the precompiles. The [runtime installer][installer_link] uses this generated file to check the type safety of each precompile's implementer.
331 |
332 | [The installer][installer_link] uses runtime reflection to ensure each implementer has all the right methods and signatures. This includes restricting access to stateful objects like the EVM and statedb based on the declared purity. Additionally, the installer verifies and populates event function pointers to provide each precompile the ability to emit logs and know their gas costs. Additional configuration like restricting a precompile's methods to only be callable by chain owners is possible by adding precompile wrappers like [ownerOnly][owneronly_link] and [debugOnly][debugonly_link] to their [installation entry][installation_link].
333 |
334 | The calling, dispatching, and recording of precompile methods are done via runtime reflection as well. This avoids any human error manually parsing and writing bytes could introduce, and uses Geth's stable APIs for [packing and unpacking][packing_link] values.
335 |
336 | Each time a transaction calls a method of an L2-specific precompile, a [call context][call_context_link] is created to track and record the gas burnt. For convenience, it also provides access to the public fields of the underlying [TxProcessor][txprocessor_link]. Because sub-transactions could revert without updates to this struct, the [TxProcessor][txprocessor_link] only makes public that which is safe, such as the amount of L1 calldata paid by the top level transaction.
337 |
338 | [nitro_precompiles_dir]: https://github.com/OffchainLabs/nitro-contracts/tree/main/src/precompiles
339 | [precompiles_dir]: https://github.com/OffchainLabs/nitro/tree/master/precompiles
340 | [installer_link]: https://github.com/OffchainLabs/nitro/blob/bc6b52daf7232af2ca2fec3f54a5b546f1196c45/precompiles/precompile.go#L379
341 | [installation_link]: https://github.com/OffchainLabs/nitro/blob/bc6b52daf7232af2ca2fec3f54a5b546f1196c45/precompiles/precompile.go#L403
342 | [gen_file]: https://github.com/OffchainLabs/nitro/blob/master/solgen/gen.go
343 | [owneronly_link]: https://github.com/OffchainLabs/nitro/blob/f11ba39cf91ee1fe1b5f6b67e8386e5efd147667/precompiles/wrapper.go#L58
344 | [debugonly_link]: https://github.com/OffchainLabs/nitro/blob/f11ba39cf91ee1fe1b5f6b67e8386e5efd147667/precompiles/wrapper.go#L23
345 | [precompilesgen_link]: https://github.com/OffchainLabs/nitro/blob/f11ba39cf91ee1fe1b5f6b67e8386e5efd147667/solgen/gen.go#L55
346 | [packing_link]: https://github.com/OffchainLabs/nitro/blob/bc6b52daf7232af2ca2fec3f54a5b546f1196c45/precompiles/precompile.go#L438
347 | [call_context_link]: https://github.com/OffchainLabs/nitro/blob/f11ba39cf91ee1fe1b5f6b67e8386e5efd147667/precompiles/context.go#L26
348 |
349 | ### Messages
350 |
351 | An [L1IncomingMessage][l1incomingmessage_link] represents an incoming sequencer message. A message includes one or more user transactions depending on load, and is made into a [unique L2 block][produceblockadvanced_link]. The L2 block may include additional system transactions added in while processing the message's user transactions, but ultimately the relationship is still bijective: for every [L1IncomingMessage][l1incomingmessage_link] there is an L2 block with a unique L2 block hash, and for every L2 block after chain initialization there was an [L1IncomingMessage][l1incomingmessage_link] that made it. A sequencer Batch may contain more than one [L1IncomingMessage][l1incomingmessage_link].
352 |
353 | [l1incomingmessage_link]: https://github.com/OffchainLabs/nitro/blob/4ac7e9268e9885a025e0060c9ec30f9612f9e651/arbos/incomingmessage.go#L54
354 | [produceblockadvanced_link]: https://github.com/OffchainLabs/nitro/blob/4ac7e9268e9885a025e0060c9ec30f9612f9e651/arbos/block_processor.go#L118
355 |
356 | ### Retryables
357 |
358 | A Retryable is a special message type for creating atomic L1 to L2 messages; for details, see L1 To L2 Messaging.
359 |
360 | ### ArbOS State
361 |
362 | ArbOS's state is viewed and modified via [ArbosState][arbosstate_link] objects, which provide convenient abstractions for working with the underlying data of its [backingStorage][backingstorage_link]. The backing storage's [keyed subspace strategy][subspace_link] makes possible [ArbosState][arbosstate_link]'s convenient getters and setters, minimizing the need to directly work with the specific keys and values of the underlying storage's [stateDB][statedb_link].
363 |
364 | Because two [ArbosState][arbosstate_link] objects with the same [backingStorage][backingstorage_link] contain and mutate the same underlying state, different [ArbosState][arbosstate_link] objects can provide different views of ArbOS's contents. [Burner][burner_link] objects, which track gas usage while working with the [ArbosState][arbosstate_link], provide the internal mechanism for doing so. Some are read-only, causing transactions to revert with vm.ErrWriteProtection upon a mutating request. Others demand the caller have elevated privileges. While yet others dynamically charge users when doing stateful work. For safety the kind of view is chosen when [OpenArbosState()][openarbosstate_link] creates the object and may never change.
365 |
366 | Much of ArbOS's state exists to facilitate its precompiles. The parts that aren't are detailed below.
367 |
368 | [arbosstate_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/arbosState/arbosstate.go#L36
369 | [backingstorage_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/storage/storage.go#L51
370 | [statedb_link]: https://github.com/OffchainLabs/go-ethereum/blob/0ba62aab54fd7d6f1570a235f4e3a877db9b2bd0/core/state/statedb.go#L66
371 | [subspace_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/storage/storage.go#L21
372 | [openarbosstate_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/arbosState/arbosstate.go#L57
373 | [burner_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/burn/burn.go#L11
374 |
375 | #### [arbosVersion][arbosversion_link], [upgradeVersion][upgradeversion_link] and [upgradeTimestamp][upgradetimestamp_link]
376 |
377 | ArbOS upgrades are scheduled to happen [when finalizing the first block][finalizeblock_link] after the [upgradeTimestamp][upgradetimestamp_link].
378 |
379 | [arbosversion_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/arbosState/arbosstate.go#L37
380 | [upgradeversion_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/arbosState/arbosstate.go#L38
381 | [upgradetimestamp_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/arbosState/arbosstate.go#L39
382 | [finalizeblock_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/block_processor.go#L350
383 |
384 | #### [blockhashes][blockhashes_link]
385 |
386 | This component maintains the last 256 L1 block hashes in a circular buffer. This allows the [TxProcessor][txprocessor_link] to implement the BLOCKHASH and NUMBER opcodes as well as support precompile methods that involve the outbox. To avoid changing ArbOS state outside of a transaction, blocks made from messages with a new L1 block number update this info during an [InternalTxUpdateL1BlockNumber][internaltxupdatel1blocknumber_link] [ArbitrumInternalTx][arbitruminternaltx_link] that is included as the first transaction in the block.
387 |
388 | [blockhashes_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/blockhash/blockhash.go#L15
389 | [internaltxupdatel1blocknumber_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/internal_tx.go#L24
390 | [arbitruminternaltx_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/block_processor.go#L116
391 | [txprocessor_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/tx_processor.go#L33
392 |
393 | #### [l1PricingState][l1pricingstate_link]
394 |
395 | In addition to supporting the ArbAggregator precompile, the L1 pricing state provides tools for determining the L1 component of a transaction's gas costs. This part of the state tracks both the total amount of funds collected from transactions in L1 gas fees, as well as the funds spent by batch posters to post data batches on L1.
396 |
397 | Based on this information, ArbOS maintains an L1 data fee, also tracked as part of this state, which determines how much transactions will be charged for L1 fees. ArbOS dynamically adjusts this value so that fees collected are approximately equal to batch posting costs, over time.
398 |
399 | [l1pricingstate_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/l1pricing/l1pricing.go#L16
400 |
401 | #### [l2PricingState][l2pricingstate_link]
402 |
403 | The L2 pricing state tracks L2 resource usage to determine a reasonable L2 gas price. This process considers a variety of factors, including user demand, the state of Geth, and the computational Speed Limit. The primary mechanism for doing so consists of a pair of pools, one larger than the other, that drain as L2-specific resources are consumed and filled as time passes. L1-specific resources like L1 calldata are not tracked by the pools, as they have little bearing on the actual work done by the network actors that the speed limit is meant to keep stable and synced.
404 |
405 | While much of this state is accessible through the ArbGasInfo and ArbOwner precompiles, most changes are automatic and happen during [block production][block_production_link] and the transaction hooks. Each of an incoming message's transactions removes from the pool the L2 component of the gas it uses, and afterward the message's timestamp [informs the pricing mechanism][notify_pricer_link] of the time that's passed as ArbOS [finalizes the block][finalizeblock_link].
406 |
407 | ArbOS's larger gas pool [determines][maintain_limit_link] the per-block gas limit, setting a dynamic [upper limit][per_block_limit_link] on the amount of compute gas an L2 block may have. This limit is always enforced, though for the [first transaction][first_transaction_link] it's done in the GasChargingHook to avoid sharp decreases in the L1 gas price from over-inflating the compute component purchased to above the gas limit. This improves UX by allowing the first transaction to succeed rather than requiring a resubmission. Because the first transaction lowers the amount of space left in the block, subsequent transactions do not employ this strategy and may fail from such compute-component inflation. This is acceptable because such transactions are only present in cases where the system is under heavy load and the result is that the user's transaction is dropped without charges since the state transition fails early. Those trusting the sequencer can rely on the transaction being automatically resubmitted in such a scenario.
408 |
409 | The reason we need a per-block gas limit is that Arbitrator WAVM execution is much slower than native transaction execution. This means that there can only be so much gas -- which roughly translates to wall-clock time -- in an L2 block. It also provides an opportunity for ArbOS to limit the size of blocks should demand continue to surge even as the price rises.
410 |
411 | ArbOS's per-block gas limit is distinct from Geth's block limit, which ArbOS [sets sufficiently high][geth_pool_set_link] so as to never run out. This is safe since Geth's block limit exists to constrain the amount of work done per block, which ArbOS already does via its own per-block gas limit. Though it'll never run out, a block's transactions use the [same Geth gas pool][same_geth_pool_link] to maintain the invariant that the pool decreases monotonically after each tx. Block headers [use the Geth block limit][use_geth_pool_link] for internal consistency and to ensure gas estimation works. These are both distinct from the [gasLeft][per_block_limit_link] variable, which ephemerally exists outside of global state to both keep L2 blocks from exceeding ArbOS's per-block gas limit and to [deduct space][deduct_space_link] in situations where the state transition failed or [used negligible amounts][negligible_amounts_link] of compute gas. ArbOS does not need to persist [gasLeft][per_block_limit_link] because it is its pool that induces a revert and because transactions use the Geth block limit during EVM execution.
412 |
413 | [l2pricingstate_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/l2pricing/l2pricing.go#L14
414 | [block_production_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/block_processor.go#L77
415 | [notify_pricer_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/block_processor.go#L336
416 | [maintain_limit_link]: https://github.com/OffchainLabs/nitro/blob/2ba6d1aa45abcc46c28f3d4f560691ce5a396af8/arbos/l2pricing/pools.go#L98
417 | [per_block_limit_link]: https://github.com/OffchainLabs/nitro/blob/2ba6d1aa45abcc46c28f3d4f560691ce5a396af8/arbos/block_processor.go#L146
418 | [first_transaction_link]: https://github.com/OffchainLabs/nitro/blob/2ba6d1aa45abcc46c28f3d4f560691ce5a396af8/arbos/block_processor.go#L237
419 | [geth_pool_set_link]: https://github.com/OffchainLabs/nitro/blob/2ba6d1aa45abcc46c28f3d4f560691ce5a396af8/arbos/block_processor.go#L166
420 | [same_geth_pool_link]: https://github.com/OffchainLabs/nitro/blob/2ba6d1aa45abcc46c28f3d4f560691ce5a396af8/arbos/block_processor.go#L199
421 | [use_geth_pool_link]: https://github.com/OffchainLabs/nitro/blob/2ba6d1aa45abcc46c28f3d4f560691ce5a396af8/arbos/block_processor.go#L67
422 | [deduct_space_link]: https://github.com/OffchainLabs/nitro/blob/faf55a1da8afcabb1f3c406b291e721bfde71a05/arbos/block_processor.go#L272
423 | [negligible_amounts_link]: https://github.com/OffchainLabs/nitro/blob/faf55a1da8afcabb1f3c406b291e721bfde71a05/arbos/block_processor.go#L328
424 |
1 | ---
2 | title: Separating Execution from Proving
3 | description: 'Learn the fundamentals of Arbitrum Rollup protocol.'
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about the Arbitrum Rollup protocol.
7 | content_type: get-started
8 | ---
9 |
10 | One of the challenges in designing a practical Rollup system is the tension between wanting the system to perform well in ordinary execution versus being able to reliably prove the results of execution. Nitro resolves this tension by using the same source code for both execution and proving, but compiling it to different targets for the two cases.
11 |
12 | When compiling the Nitro node software for execution, the ordinary Go compiler is used, producing native code for the target architecture, which of course will be different for different node deployments. (The node software is distributed in source code form and as a Docker image containing a compiled binary.)
13 |
14 | Separately, for proving, the portion of the code that is the State Transition Function is compiled by the Go compiler to WebAssembly (WASM), which is a typed, portable machine code format. The wasm code then goes through a simple transformation into a format we call WAVM, which is detailed below. If there is a dispute about the correct result of computing the STF, it is resolved with reference to the WAVM code.
15 |
16 | ## WAVM
17 |
18 | The Wasm format has many features that make it a good vehicle for fraud proofs—it is portable, structured, well-specified, and has reasonably good tools and support. However, it needs a few modifications to do the job completely. Nitro uses a slightly modified version of Wasm, which we call WAVM. A simple transformation stage turns the Wasm code produced by the Go compiler into WAVM code suitable for proving.
19 |
20 | WAVM differs from wasm in three main ways. First, WAVM removes some wasm features that the Go compiler does not generate; the transformation phase verifies that these features are not present.
21 |
22 | Second, WAVM restricts a few features of wasm. For example, WAVM does not contain floating-point instructions, so the transformer replaces floating-point instructions with calls to the Berkeley SoftFloat library. (We use software floating-point to reduce the risk of floating-point incompatibilities between architectures. The core Nitro functions never use floating-point, but the Go runtime does use some floating-point operations.) WAVM does not contain nested control flow, so the transformer flattens control flow constructs, turning control flow instructions into jumps. Some wasm instructions take a variable amount of time to execute, which we avoid in WAVM by transforming them into constructs using fixed-cost instructions. These transformations simplify proving.
23 |
24 | Third, WAVM adds a few opcodes to enable interaction with the Blockchain environment. For example, new instructions allow the WAVM code to read and write the chain's global state, to get the next message from the chain's inbox, or to signal a successful end to execute the State Transition Function.
25 |
26 | ## ReadPreImage and the Hash Oracle Trick
27 |
28 | The most interesting new instruction is ReadPreImage which takes as input a hash H and an offset I, and returns the word of data at offset I in the preimage of H (and the number of bytes written, which is zero if I is at or after the end of the preimage). Of course, it is not feasible in general to produce a preimage from an arbitrary hash. For safety, the ReadPreImage instruction can only be used in a context where the preimage is publicly known, and where the size of the preimage is known to be less than a fixed upper bound of about 110 kbytes.
29 |
30 | (In this context, "publicly known" information is information that can be derived or recovered efficiently by any honest party, assuming that the full history of the L1 Ethereum chain is available. For convenience, a hash preimage can also be supplied by a third party such as a public server, and the correctness of the supplied value is easily verified.)
31 |
32 | As an example, the state of a Nitro chain is maintained in Ethereum's state tree format, which is organized as a Merkle tree. Nodes of the tree are stored in a database, indexed by the Merkle hash of the node. In Nitro, the state tree is kept outside of the State Transition Function's storage, with the STF only knowing the root hash of the tree. Given the hash of a tree node, the STF can recover the tree node's contents by using ReadPreImage, relying on the fact that the full contents of the tree are publicly known and that nodes in the Ethereum state tree will always be smaller than the upper bound on preimage size. In this manner, the STF is able to arbitrarily read and write to the state tree, despite only storing its root hash.
33 |
34 | The only other use of ReadPreImage is to fetch the contents of recent L2 Block headers, given the header hash. This is safe because the block headers are publicly known and have bounded size.
35 |
36 | This "hash oracle trick" of storing the Merkle hash of a data structure, and relying on protocol participants to store the full structure and thereby support fetch-by-hash of the contents, goes back to the original Arbitrum design.
37 |
1 | ---
2 | title: Optimistic Rollup
3 | description: Learn the fundamentals of Arbitrum's optimistic rollup.
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about Arbitrum's Optimistic Rollup protocol.
7 | content_type: get-started
8 | ---
9 |
10 | Arbitrum is an optimistic rollup. Let’s unpack that term.
11 |
12 | Rollup
13 |
14 | Arbitrum is a Rollup, which means that the inputs to the chain -- the messages that are put into the inbox -- are all recorded on the Ethereum chain as calldata. Because of this, everyone has the information they would need to determine the current correct state of the chain -- they have the full history of the inbox, and the results are uniquely determined by the inbox history, so they can reconstruct the state of the chain based only on public information, if needed.
15 |
16 | This also allows anyone to be a full participant in the Arbitrum protocol, to run an Arbitrum node or participate as a Validator. Nothing about the history or state of the chain is a secret.
17 |
18 | Optimistic
19 |
20 | Arbitrum is optimistic, which means that Arbitrum advances the state of its chain by letting any party (a “validator”) post on Layer 1 a rollup block that that party claims is correct, and then giving everyone else a chance to Challenge that claim. If the Challenge Period (6.4 days) passes and nobody has challenged the claimed rollup block, Arbitrum confirms the rollup block as correct. If someone challenges the claim during the challenge period, then Arbitrum uses an efficient dispute resolution protocol (detailed below) to identify which party is lying. The liar will forfeit a deposit, and the truth-teller will take part of that deposit as a reward for their efforts (some of the deposit is burned, guaranteeing that the liar is punished even if there's some collusion going on).
21 |
22 | Because a party who tries to cheat will lose a deposit, attempts to cheat should be very rare, and the normal case will be a single party posting a correct rollup block, and nobody challenging it.
23 |
24 | ## Resolving disputes using interactive fraud proofs
25 |
26 | Among optimistic rollups, the most important design decision is how to resolve disputes. Suppose Alice claims that the chain will produce a certain result, and Bob disagrees. How will the protocol decide which version to accept?
27 |
28 | There are basically two choices: interactive proving, or re-executing transactions. Arbitrum uses interactive proving, which we believe is more efficient and more flexible. Much of the design of Arbitrum follows from this fact.
29 |
30 | ### Interactive proving
31 |
32 | The idea of interactive proving is that Alice and Bob will engage in a back-and-forth protocol, refereed by an L1 contract, to resolve their dispute with minimal work required from any L1 contract.
33 |
34 | Arbitrum's approach is based on Dissection of the dispute. If Alice's claim covers N steps of execution, she posts two claims of size N/2 which combine to yield her initial N-step claim, then Bob picks one of Alice's N/2-step claims to challenge. Now the size of the dispute has been cut in half. This process continues, cutting the dispute in half at each stage, until they are disagreeing about a single step of execution. Note that so far the L1 referee hasn't had to think about execution "on the merits". It is only once the dispute is narrowed down to a single step that the L1 referee needs to resolve the dispute by looking at what the instruction actually does and whether Alice's claim about it is correct.
35 |
36 | The key principle behind interactive proving is that if Alice and Bob are in a dispute, Alice and Bob should do as much off-chain work as possible needed to resolve their dispute, rather than putting that work onto an L1 contract.
37 |
38 | ### Re-executing transactions
39 |
40 | The alternative to interactive proving would be to have a rollup block contain a claimed machine state hash after every individual Transaction. Then in case of a dispute, the L1 referee would emulate the execution of an entire transaction, to see whether the outcome matches Alice's claim.
41 |
42 | ### Why interactive proving is better
43 |
44 | We believe strongly that interactive proving is the superior approach, for the following reasons.
45 |
46 | More efficient in the optimistic case: Because interactive proving can resolve disputes that are larger than one transaction, it can allow a rollup block to contain only a single claim about the end state of the chain after all of the execution covered by the block. By contrast, reexecution requires posting a state claim for each transaction within the rollup block. With hundred or thousands of transactions per rollup block, this is a substantial difference in L1 footprint -- and L1 footprint is the main component of cost.
47 |
48 | More efficient in the pessimistic case: In case of a dispute, interactive proving requires the L1 referee contract only to check that Alice and Bob's actions "have the right shape", for example, that Alice has divided her N-step claim into two claims half as large. (The referee doesn't need to evaluate the correctness of Alice's claims--Bob does that, off-chain.) Only one instruction needs to be reexecuted. By contrast, reexecution requires the L1 referee to emulate the execution of an entire transaction.
49 |
50 | Higher per-tx gas limit: Interactive proving can escape from Ethereum's tight per-transaction gas limit. The gas limit isn't infinite, for obvious reasons, but it can be larger than on Ethereum. As far as Ethereum is concerned, the only downside of a gas-heavy Arbitrum transaction is that it may require an interactive Fraud proof with slightly more steps (and only if indeed it is fraudulent). By contrast, reexecution must impose a lower gas limit than Ethereum, because it must be possible to emulate execution of the transaction (which is more expensive than executing it directly) within a single Ethereum transaction.
51 |
52 | More implementation flexibility: Interactive proving allows more flexibility in implementation. All that is necessary is the ability to verify a one-step proof on Ethereum. By contrast, reexecution approaches are tethered to limitations of the EVM.
53 |
54 | ### Interactive proving drives the design of Arbitrum
55 |
56 | Much of the design of Arbitrum is driven by the opportunities opened up by interactive proving. If you're reading about some feature of Arbitrum, and you're wondering why it exists, two good questions to ask are: "How does this support interactive proving?" and "How does this take advantage of interactive proving?" The answers to most "why" questions about Arbitrum relate to interactive proving.
57 |
58 | ## Arbitrum Rollup Protocol
59 |
60 | Before diving into the Rollup protocol, there are two things we need to cover.
61 |
62 | First, if you’re an Arbitrum user or developer, you don’t need to understand the Rollup protocol. You don’t ever need to think about it unless you want to. Your relationship with it can be like a train passenger’s relationship with the train’s engine: you know it exists, and you rely on it to keep working, but you don’t spend your time monitoring it or studying its internals.
63 |
64 | You’re welcome to study, observe, and even participate in the Rollup protocol, but you don’t need to, and most people won’t. So if you’re a typical train passenger who just wants to read or talk to your neighbor, you can skip right to the next section of this document. If not, read on!
65 |
66 | The second thing to understand about the Rollup protocol is that the protocol doesn’t decide the results of transactions, it only confirms the results. The results are uniquely determined by the sequence of messages in the chain’s inbox. So once your transaction message is in the chain’s inbox, its result is knowable, and Arbitrum nodes will report that your transaction has been completed. The role of the Rollup protocol is to confirm transaction results that, as far as Arbitrum users are concerned, have already occurred. (This is why Arbitrum users can effectively ignore the Rollup protocol.)
67 |
68 | You might wonder why we need the Rollup protocol. If everyone knows the results of transactions already, why bother confirming them? The Rollup protocol exists for two reasons. First, somebody might lie about a result, and we need a definitive, Trustless way to tell who is lying. Second, Ethereum doesn’t know the results. The whole point of a Layer 2 scaling system is to run transactions without Ethereum needing to do all of the work--and indeed, Arbitrum can go fast enough that Ethereum couldn’t hope to monitor every Arbitrum transaction. However, once the result is confirmed, Ethereum knows about it and can rely on it, enabling operations on Ethereum, such as processing withdrawals of funds from Nitro back to L1.
69 |
70 | With those preliminaries behind us, let’s jump into the details of the Rollup protocol.
71 |
72 | The parties who participate in the protocol are called validators. Some validators will choose to be bonders--they will place an ETH deposit which they’ll be able to recover if they’re not caught cheating. In the common case, it's expected that only one validator will be bonded, since as long as it's bonded on the current outcome, and there are no conflicting claims, there's no need for other parties to bond/take any action. The protocol allows for these roles to be permissionless in principle; currently on Arbitrum One, validators/bonders are allowlisted (see "State of Progressive Decentralization"). "Watchtower validators," who monitor the chain but don't take any on-chain actions, can be run permissionlessly (see "validators" below).
73 |
74 | The key security property of the Rollup protocol is that any one honest validator can force the correct execution of the chain to be confirmed. This means that the execution of an Arbitrum chain is as trustless as Ethereum. You, and you alone (or someone you hire), can force your transactions to be processed correctly. And that is true, no matter how many malicious people are trying to stop you.
75 |
76 | ### The Rollup Chain
77 |
78 | The Rollup protocol tracks a chain of Rollup blocks---we'll call these "RBlocks" for clarity. They're not the same as Layer 1 Ethereum blocks, and also not the same as Layer 2 Nitro blocks. You can think of the RBlocks as forming a separate chain, which the Arbitrum Rollup Protocol manages and oversees.
79 |
80 | Validators can propose RBlocks. New RBlocks will be unresolved at first. Eventually, every RBlock will be resolved, by being either confirmed or rejected. The confirmed RBlocks make up the confirmed history of the chain.
81 |
82 | :::note
83 |
84 | Validators and proposers serve different roles. Validators validate transactions to the State Transition Function (STF) and Chain state, whereas proposers can also assert and challenge the chain state.
85 |
86 | :::
87 |
88 | Each RBlock contains:
89 |
90 | - the RBlock number
91 | - the predecessor RBlock number: RBlock number of the last RBlock before this one that is (claimed to be) correct
92 | - the number of L2 blocks that have been created in the chain's history
93 | - the number of inbox messages that have been consumed in the chain’s history
94 | - a hash of the outputs produced over the chain’s history.
95 |
96 | Except for the RBlock number, the contents of the RBlock are all just claims by the RBlock's proposer. Arbitrum doesn’t know at first whether any of these fields are correct. If all of these fields are correct, the protocol should eventually confirm the RBlock. If one or more of these fields are incorrect, the protocol should eventually reject the RBlock.
97 |
98 | An RBlock is implicitly claiming that its predecessor RBlock is correct. This implies, transitively, that an RBlock implicitly claims the correctness of a complete history of the chain: a sequence of ancestor RBlocks that reaches all the way back to the birth of the chain.
99 |
100 | An RBlock is also implicitly claiming that its older siblings (older RBlocks with the same predecessor), if there are any, are incorrect. If two RBlocks are siblings, and the older sibling is correct, then the younger sibling is considered incorrect, even if everything else in the younger sibling is true.
101 |
102 | The RBlock is assigned a deadline, which says how long other validators have to respond to it. If you’re a validator, and you agree that an RBlock is correct, you don’t need to do anything. If you disagree with an RBlock, you can post another RBlock with a different result, and you’ll probably end up in a challenge against the first RBlock's bonder. (More on challenges below.)
103 |
104 | In the normal case, the rollup chain will look like this:
105 |
106 | mermaid 107 | graph RL 108 | f["First unresolved block"] 109 | l["Latest confirmed block"] 110 | 111 | 98-->97-->96-->95 112 | f-.-95 113 | 114 | 95-->94 115 | l-.-94 116 | 117 | 94-->93-->92-->91-->90-->x[...] 118 | 119 | subgraph Legend 120 | direction RL 121 | Confirmed 122 | Unconfirmed 123 | end 124 | 125 | classDef confirmed fill:#47b860,stroke:#37914c,stroke-width:2px,color:#fff 126 | class 94,93,92,91,90,x,Confirmed confirmed 127 | 128 | 129 | classDef unconfirmed fill:#2aa1f0,stroke:#1c86ca,stroke-width:2px,color:#fff 130 | class 98,97,96,95,Unconfirmed unconfirmed 131 | 132 | classDef note fill:#F1F5F6,stroke:#dbdede,stroke-width:1px,color:#000 133 | class l,f note 134 |
135 |
136 | On the left, representing an earlier part of the chain’s history, we have confirmed RBlocks. These have been fully accepted and recorded by the Layer 1 contracts that manage the chain. The newest of the confirmed RBlocks, RBlock 94, is called the “latest confirmed RBlock.” On the right, we see a set of newer proposed RBlocks. The protocol can’t yet confirm or reject them, because their deadlines haven’t run out yet. The oldest RBlock whose fate has yet to be determined, RBlock 95, is called the “first unresolved RBlock.”
137 |
138 | Notice that a proposed RBlock can build on an earlier proposed RBlock. This allows validators to continue proposing RBlocks without needing to wait for the protocol to confirm the previous one. Normally, all of the proposed RBlocks will be valid, so they will all eventually be accepted.
139 |
140 | Here’s another example of what the chain state might look like, if several validators are being malicious. It’s a contrived example, designed to illustrate a variety of cases that can come up in the protocol, all smashed into a single scenario.
141 |
142 | mermaid 143 | graph RL 144 | subgraph Legend 145 | direction RL 146 | Confirmed 147 | Rejected 148 | Unconfirmed 149 | end 150 | 151 | f["First unresolved block"] 152 | l["Latest confirmed block"] 153 | 154 | 155 | l-.-103 156 | f-.-106 157 | 158 | 108-->107-->106-->103 159 | 111-->104 160 | 101-->100 161 | 105-->104-->103 162 | 110-->109-->103-->102-->100-->x[...] 163 | 164 | classDef confirmed fill:#47b860,stroke:#37914c,stroke-width:2px,color:#fff 165 | class 100,102,103,x,Confirmed confirmed 166 | 167 | classDef rejected fill:#fdaa07,stroke:#fd8607,stroke-width:2px,color:#fff 168 | class 101,104,105,Rejected rejected 169 | 170 | classDef unconfirmed fill:#2aa1f0,stroke:#1c86ca,stroke-width:2px,color:#fff 171 | class 106,107,108,109,110,111,Unconfirmed unconfirmed 172 | 173 | classDef note fill:#F1F5F6,stroke:#dbdede,stroke-width:1px,color:#000 174 | class l,f note 175 | 176 |
177 |
178 | There’s a lot going on here, so let’s unpack it.
179 |
180 | - RBlock 100 has been confirmed.
181 | - RBlock 101 claimed to be a correct successor to RBlock 100, but 101 was rejected (hence it is orange).
182 | - RBlock 102 was eventually confirmed as the correct successor to 100.
183 | - RBlock 103 was confirmed and is now the latest confirmed RBlock.
184 | - RBlock 104 was proposed as a successor to RBlock 103, and 105 was proposed as a successor to 104. 104 was rejected as incorrect, and as a consequence 105 was rejected because its predecessor was rejected.
185 | - RBlock 106 is unresolved. It claims to be a correct successor to RBlock 103 but the protocol hasn’t yet decided whether to confirm or reject it. It is the first unresolved RBlock.
186 | - RBlocks 107 and 108 claim to chain from 106. They are also unresolved. If 106 is rejected, they will be automatically rejected too.
187 | - RBlock 109 disagrees with RBlock 106, because they both claim the same predecessor. At least one of them will eventually be rejected, but the protocol hasn’t yet resolved them.
188 | - RBlock 110 claims to follow 109. It is unresolved. If 109 is rejected, 110 will be automatically rejected too.
189 | - RBlock 111 claims to follow 104. 111 will inevitably be rejected because its predecessor has already been rejected. But it hasn’t been rejected yet, because the protocol resolves RBlocks in RBlock number order, so the protocol will have to resolve 106 through 110, in order, before it can resolve 111. After 110 has been resolved, 111 can be rejected immediately.
190 |
191 | Again: this sort of thing is very unlikely in practice. In this diagram, at least four parties must have bonded on wrong RBlocks, and when the dust settles at least four parties will have lost their bonds. The protocol handles these cases correctly, of course, but they’re rare corner cases. This diagram is designed to illustrate the variety of situations that are possible in principle, and how the protocol would deal with them.
192 |
193 | ### Staking
194 |
195 | At any given time, some validators will be bonders, and some will not. Bonders deposit funds that are held by the Arbitrum Layer 1 contracts and will be confiscated if the bonder loses a challenge. Nitro chains accept bonds in ETH.
196 |
197 | A single bond can cover a chain of RBlocks. Every bonder is bonded on the latest confirmed RBlock; and if you’re bonded on an RBlock, you can also bond on one successor of that RBlock. So you might be bonded on a sequence of RBlocks that represent a single coherent claim about the correct history of the chain. A single bond suffices to commit you to that sequence of RBlocks.
198 |
199 | In order to create a new RBlock, you must be a bonder, and you must already be bonded on the predecessor of the new RBlock you’re creating. The bond requirement for RBlock creation ensures that anyone who creates a new RBlock has something to lose if that RBlock is eventually rejected.
200 |
201 | The protocol keeps track of the current required bond amount. Normally this will equal the base bond amount, which is a parameter of the Nitro chain. But if the chain has been slow to make progress lately, the required bond will increase, as described in more detail below.
202 |
203 | The rules for staking are as follows:
204 |
205 | - If you’re not bonded, you can bond on the latest confirmed RBlock. When doing this, you deposit the current minimum bond amount.
206 | - If you’re bonded on an RBlock, you can also add your bond to any one successor of that RBlock. (The protocol tracks the maximum RBlock number you’re bonded on, and lets you add your bond to any successor of that RBlock, updating your maximum to that successor.) This doesn’t require you to place a new bond.
207 | - A special case of adding your bond to a successor RBlock is when you create a new RBlock as a successor to an RBlock you’re already bonded on.
208 | - If you’re bonded only on the latest confirmed RBlock (and possibly earlier RBlocks), you or anyone else can ask to have your bond refunded. Your bonded funds will be returned to you, and you will no longer be a bonder.
209 | - If you lose a challenge, your bond is removed from all RBlocks and you forfeit your bonded funds.
210 |
211 | Notice that once you are bonded on an RBlock, there is no way to unbond. You are committed to that RBlock. Eventually one of two things will happen: that RBlock will be confirmed, or you will lose your bond. The only way to get your bond back is to wait until all of the RBlocks you are bonded on are confirmed.
212 |
213 | #### Setting the current minimum bond amount
214 |
215 | One detail we deferred earlier is how the current minimum bond amount is set. Normally, this is just equal to the base bond amount, which is a parameter of the Nitro chain. However, if the chain has been slow to make progress in confirming RBlocks, the bond requirement will escalate temporarily. Specifically, the base bond amount is multiplied by a factor that is exponential in the time since the deadline of the first unresolved RBlock passed. This ensures that if malicious parties are placing false bonds to try to delay progress (despite the fact that they’re losing those bonds), the bond requirement goes up so that the cost of such a delay attack increases exponentially. As RBlock resolution starts advancing again, the bond requirement will go back down.
216 |
217 | ### Rules for Confirming or Rejecting RBlocks
218 |
219 | The rules for resolving RBlocks are fairly simple.
220 |
221 | The first unresolved RBlock can be confirmed if:
222 |
223 | - the RBlock's predecessor is the latest confirmed RBlock, and
224 | - the RBlock's deadline has passed, and
225 | - there is at least one bonder, and
226 | - All bonders are bonded to the RBlock.
227 |
228 | The first unresolved RBlock can be rejected if:
229 |
230 | - the RBlock's predecessor has been rejected, or
231 | - all of the following are true:
232 | - the RBlock's deadline has passed, and
233 | - there is at least one bonder, and
234 | - no bonder is bonded on the RBlock.
235 |
236 | A consequence of these rules is that once the first unresolved RBlock's deadline has passed (and assuming there is at least one bonder bonded on something other than the latest confirmed RBlock), the only way the RBlock can be unresolvable is if at least one bonder is bonded on it and at least one bonder is bonded on a different RBlock with the same predecessor. If this happens, the two bonders are disagreeing about which RBlock is correct. It’s time for a challenge, to resolve the disagreement.
237 |
238 | ## Delays
239 |
240 | Even if the Assertion Tree has multiple conflicting RBlocks and, say, multiple disputes are in progress, validators can continue making assertions; honest validators will simply build on the one valid RBlock (intuitively: an assertion is also an implicit claim of the validity of all of its parent-assertions.) Likewise, users can continue transacting on L2, since transactions continue to be posted in the chain's inbox.
241 |
242 | The only delay that users experience during a dispute is of their L2 to L1 messages (i.e., "their withdrawals"). Note that a "delay attacker" who seeks to grief the system by deliberately causing such delays will find this attack quite costly, since each bit of delay-time gained requires the attacker lose another stake.
243 |
244 | ## Validators
245 |
246 | Arbitrum full nodes normally "live at Layer 2" which means that they don’t worry about the rollup protocol but simply treat their Arbitrum chain as a mechanism that feeds inbox messages to the State Transition Function to evolve the Layer 2 chain and produce outputs.
247 |
248 | Some Arbitrum nodes will choose to act as validators. This means that they watch the progress of the rollup protocol and participate in that protocol to advance the state of the chain securely.
249 |
250 | Not all nodes will choose to do this. Because the Rollup protocol doesn’t decide what the chain will do but merely confirms the correct behavior that is fully determined by the inbox messages, a node can ignore the rollup protocol and simply compute for itself the correct behavior.
251 |
252 | Offchain Labs provides open source validator software, including
253 | a pre-built Docker image.
254 |
255 | Every validator can choose their own approach, but we expect validators to follow three common strategies:
256 |
257 | - The active validator strategy tries to advance the state of the chain by proposing new RBlocks. An Active Validator is always bonded, because creating an RBlock requires being bonded. A chain really only needs one honest active validator; any more is an inefficient use of resources. For the Arbitrum One chain, Offchain Labs runs an active validator.
258 | - The defensive validator strategy watches the rollup protocol operate. If only correct RBlocks are proposed, this strategy doesn't bond. But if an incorrect RBlock is proposed, this strategy intervenes by posting a correct RBlock or staking on a correct RBlock that another party has posted. This strategy avoids staking when things are going well, but if someone is dishonest it bonds in order to defend the correct outcome.
259 | - The watchtower validator strategy never bonds. It simply watches the Rollup protocol, and if an incorrect RBlock is proposed, it raises the alarm (by whatever means it chooses) so that others can intervene. This strategy assumes that other parties who are willing to bond will be willing to intervene in order to take some of the dishonest proposer’s bond and that that can happen before the dishonest RBlock’s deadline expires. (In practice, this will allow several days for a response.)
260 |
261 | Under normal conditions, validators using the defensive and watchtower strategies won’t do anything except observe. A malicious actor who is considering whether to try cheating won’t be able to tell how many defensive and watchtower validators are operating incognito. Perhaps some defensive validators will announce themselves, but others probably won’t, so a would-be attacker will always have to worry that defenders are waiting to emerge.
262 |
263 | The underlying protocol supports permissionless validation, i.e.,--anyone can do it. Currently on Arbitrum One, validators that require bond (i.e., active and defensive validators) are whitelisted; see "State of Progressive Decentralization".
264 |
265 | Who will be validators? Anyone will be able to do it, but most people will choose not to. In practice we expect people to validate a chain for several reasons.
266 |
267 | - Validators could be paid for their work, by the party that created the chain or someone else. A chain could be configured such that a portion of the funds from user transaction fees are paid directly to validators.
268 | - Parties who have significant assets at bond on a chain, such as dApp developers, exchanges, power-users, and liquidity providers, may choose to validate in order to protect their investment.
269 | - Anyone who chooses to validate can do so. Some users will probably choose to validate in order to protect their own interests or just to be good citizens. But ordinary users don’t need to validate, and we expect that the vast majority of users won’t.
270 |
1 | ---
2 | title: 'Challenges: Interactive Fraud Proofs'
3 | description: Learn the fundamentals of Arbitrum's Interactive Fraud Proofs and challenges.
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about Interactive Fraud Proofs and challenges.
7 | content_type: get-started
8 | ---
9 |
10 | Suppose the rollup chain looks like this:
11 |
12 | 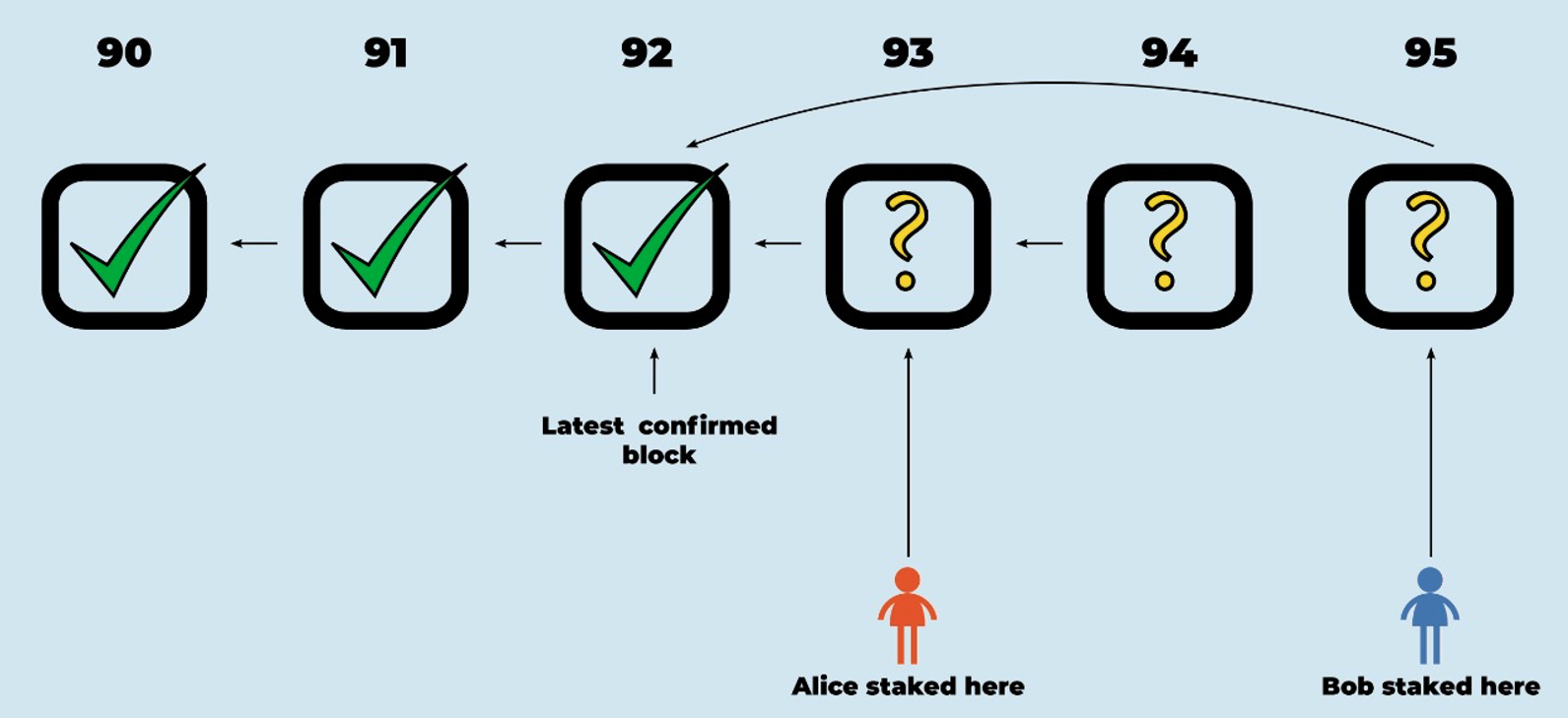
ChallengeManager and will walk through the arbitration of a challenge game in great detail. The ChallengeManager plays the role of the arbiter of challenge games. Here's a diagram of the challenge state machine:
73 |
74 |
75 |
76 | ### Block challenge
77 |
78 | The challenge begins by bisecting over global states (including block hashes).
79 | Before actual machine execution is disputed, the dispute is narrowed down to an individual block.
80 | Once the challenge has been bisected down to an individual block,
81 | challengeExecution can be called by the current responder.
82 | This operates similarly to a bisection in that the responder must provide a competing global state and machine state,
83 | but it uses that information to transition to the execution challenge phase.
84 |
85 | ### Execution challenge
86 |
87 | Once narrowed down to an individual block, the actual machine execution can be bisected.
88 | Once the execution has been bisected down to an individual step,
89 | oneStepProveExecution can be called by the current responder.
90 | The current responder must provide proof data to execute a step of the machine.
91 | If executing that step ends in a different state than was previously asserted,
92 | the current responder wins the challenge.
93 |
94 | ### General bisection protocol
95 |
96 | Note: the term bisection in this document is used for clarity but refers to a dissection of any degree.
97 |
98 | The ChallengeLib helper library contains a hashChallengeState method which hashes a list of segment hashes,
99 | a start position, and a total segments length, which generates the ChallengeLib.Challenge's challengeStateHash.
100 | This is enough information to infer the position of each segment hash.
101 | The challenge "degree" refers to the number of segment hashes minus one.
102 | The distance (in steps) between one segment and the next is floor(segmentsLength / degree), except for the
103 | last pair of segments, where segmentsLength % degree is added to the normal distance, so that
104 | the total distance is segmentsLength.
105 |
106 | A challenge begins with only two segments (a degree of one), which is the asserter's initial assertion.
107 | Then, the bisection game begins on the challenger's turn.
108 | In each round of the game, the current responder must choose an adjacent pair of segments to challenge.
109 | By doing so, they are disputing their opponent's claim that starting with the first segment and executing
110 | for the specified distance (number of steps) will result in the second segment. At this point the two parties
111 | agree on the correctness of the first segment but disagree about the correctness of the second segment.
112 | The responder must provide a bisection with a start segment equal to the first segment, but an end segment
113 | different from the second segment.
114 | In doing so, they break the challenge down into smaller distances, and it becomes their opponent's turn.
115 | Each bisection must have degree min(40, numStepsInChallengedSegment), ensuring the challenge makes progress.
116 |
117 | In addition, a segment with a length of only one step cannot be bisected.
118 | What happens there is specific to the phase of the challenge, as either a challengeExecution or oneStepProveExecution.
119 |
120 | Note that unlike in a traditional bisection protocol, where one party proposes segments and the other decides which to challenge,
121 | this protocol is symmetric in that both players take turns deciding where to challenge and proposing bisections
122 | when challenging.
123 |
124 | ### Winning the challenge
125 |
126 | Note that for the time being, winning the challenge isn't instant.
127 | Instead, it simply makes the current responder the winner's opponent,
128 | and sets the state hash to 0. In that state the party does not have any
129 | valid moves, so it will eventually lose by timeout.
130 | This is done as a precaution, so that if a challenge is resolved incorrectly,
131 | there is time to diagnose and fix the error with a contract upgrade.
132 |
133 | ## One Step Proof Assumptions
134 |
135 | The One Step Proof (OSP) implementation makes certain assumptions about the cases that can arise
136 | in a correct execution. This documents those assumptions about what's being executed.
137 |
138 | If a case is "unreachable", that is, the case is assumed to never arise in correct execution,
139 | then the OSP can implement any instruction semantics in that case.
140 |
141 | - In a challenge between malicious parties, any case can arise. The challenge protocol must do
142 | something safe in every case. But the instruction semantics can be weird in such cases because
143 | if both parties to a challenge are malicious, the protocol doesn't care who wins the challenge.
144 | - In a challenge with one honest party, the honest party will never need to one-step prove an
145 | unreachable case. The honest party will only assert correct executions, so it will only have to
146 | prove reachable cases.
147 | - In a challenge with one honest party, the dishonest party could assert an execution that transitions
148 | into an unreachable case, but such an execution must include an invalid execution of a reachable case
149 | earlier in the assertion. Because a challenge involving an honest party will eventually require an OSP
150 | over the first instruction where the parties disagree, the eventual OSP will be over the earlier point
151 | of divergence, and not over the later execution from an unreachable case.
152 |
153 | In general, some unreachable cases will be detectable by the OSP checker and some will not. For safety, the
154 | detectable unreachable cases should be defined by transition the machine into an error state, allowing
155 | governance to eventually push an upgrade to recover from the error. An undetectable unreachable case, if
156 | such a case were reached in correct execution, could lead to a security failure.
157 |
158 | The following assumptions, together, must prevent an unreachable case from arising in correct execution.
159 |
160 | ### The WAVM code is generated by Arbitrator from valid WASM
161 |
162 | WAVM is the name of the custom instruction set similar to WASM used for proving.
163 | Arbitrator transpiles WASM code into WAVM.
164 | It also invokes wasm-validate from wabt
165 | (the WebAssembly Binary Toolkit) to ensure the input WASM is valid.
166 | WAVM produced otherwise may not be executable, as it may try to close a non-existent block,
167 | mismatch types, or do any other number of invalid things which are prevented by WASM validation.
168 |
169 | WAVM code generated from by Arbitrator from valid WASM is assumed to never encounter an unreachable case.
170 |
171 | ### Inbox messages must not be too large
172 |
173 | The current method of inbox hashing requires the full inbox message be available for proving.
174 | That message must not be too large as to prevent it from being supplied for proving,
175 | which is enforced by the inboxes.
176 |
177 | The current length limit is 117,964 bytes, which is 90% of the
178 | max transaction size Geth will accept,
179 | leaving 13,108 bytes for other proving data.
180 |
181 | ### Requested preimages must be known and not too large
182 |
183 | WAVM has an opcode which resolves the preimage of a Keccak-256 hash.
184 | This can only be executed if the preimage is already known to all nodes,
185 | and can only be proven if the preimage isn't too long. Violations of this assumption are
186 | undetectable by the OSP checker.
187 |
188 | The current length limit is 117,964 bytes for the reasons mentioned above.
189 | Here's a list of which preimages may be requested by Nitro, and why they're known to all parties,
190 | and not too large:
191 |
192 | #### Block headers
193 |
194 | Nitro may request up to the last 256 L2 Block headers.
195 | The last block header is required to determine the current state,
196 | and blocks before it are required to implement the BLOCKHASH evm instruction.
197 |
198 | This is safe as previous block headers are a fixed size, and are known to all nodes.
199 |
200 | #### State trie access
201 |
202 | To resolve state, Nitro traverses the state trie by resolving preimages.
203 |
204 | This is safe as validators retain archive state of unconfirmed blocks,
205 | each trie branch is of a fixed size,
206 | and the only variable sized entry in the trie is contract code,
207 | which is limited by EIP-170 to about 24KB.
208 |
209 | ## WASM to WAVM
210 |
211 | Not all WASM instructions are 1:1 with WAVM opcodes.
212 | This document lists those which are not, and explains how they're expressed in WAVM.
213 | Many of the WAVM representations use opcodes not in WASM,
214 | which are documented in wavm-custom-opcodes.
215 |
216 | ### block and loop
217 |
218 | In WASM, a block contains instructions.
219 | Branch instructions exit a fixed number of blocks, jumping to their destination.
220 | A normal block's destination is the end of the block, whereas a loop's destination is the start of the loop.
221 |
222 | In WAVM, instructions are flat.
223 | At transpilation time, any branch instructions are replaced with jumps to the corresponding block's destination.
224 | This means that WAVM interpreters don't need to track blocks, and thus block instructions are unnecessary.
225 |
226 | ### if and else
227 |
228 | These are translated to a block with an ArbitraryJumpIf as follows:
229 |
230 | 231 | begin block with endpoint end 232 | conditional jump to else 233 | [instructions inside if statement] 234 | branch 235 | else: [instructions inside else statement] 236 | end 237 |
238 |
239 | ### br and br_if
240 |
241 | br and br_if are translated into ArbitraryJump and ArbitraryJumpIf respectively.
242 | The jump locations can be known at transpilation time, making blocks obsolete.
243 |
244 | ### br_table
245 |
246 | br_table is translated to a check for each possible branch in the table,
247 | and then if none of the checks hit, a branch of the default level.
248 |
249 | Each of the non-default branches has a conditional jump to a section afterwards,
250 | containing a drop for the selector, and then a jump to the target branch.
251 |
252 | ### local.tee
253 |
254 | local.tee is translated to a WAVM Dup and then a LocalSet.
255 |
256 | ### return
257 |
258 | To translate a return, the number of return values must be known from the function signature.
259 | A WAVM MoveFromStackToInternal is added for each return value.
260 | Then, a loop checks IsStackBoundary (which implicitly pops a value) until it's true and the stack boundary has been popped.
261 | Next, a MoveFromInternalToStack is added for each return value to put the return values back on the stack.
262 | Finally, a WAVM Return is added, returning control flow to the caller.
263 |
264 | ### Floating point instructions
265 |
266 | A floating point library module must be present to translate floating point instructions.
267 | They are translated by bitcasting f32 and f64 arguments to i32s and i64s,
268 | then a cross module call to the floating point library,
269 | and finally bitcasts of any return values from i32s and i64s to f32s and f64s.
270 |
271 | ## WAVM Custom opcodes not in WASM
272 |
273 | In addition to the MVP WASM specification,
274 | WAVM implements the multi value and sign extension ops WASM proposals.
275 |
276 | WAVM also implements the following unique opcodes,
277 | which are not part of WASM nor any WASM proposal.
278 |
279 | ### Invariants
280 |
281 | Many of these opcodes have implicit invariants about what's on the stack,
282 | e.g. "Pops an i32 from the stack" assumes that the top of the stack has an i32.
283 | If these conditions are not satisfied, execution is generally not possible.
284 | These invariants are maintained by WASM validation and Arbitrator codegen. (See One Step Proof Assumptions.)
285 |
286 | ### Codegen internal
287 |
288 | These are generated when breaking down a WASM instruction that does many things into many WAVM instructions which each do one thing.
289 | For instance, a WASM local.tee is implemented in WAVM with dup and then local.set, the former of which doesn't exist in WASM.
290 |
291 | Other times, these opcodes help out an existing WASM opcode by splitting out functionality.
292 | For instance, the WAVM return opcode by itself does not clean up the stack,
293 | but its WASM->WAVM codegen includes a loop that utilizes IsStackBoundary to perform the stack cleanup
294 | specified for WASM's return.
295 |
296 | | Opcode | Name | Description |
297 | | ------ | ----------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
298 | | 0x8000 | EndBlock | Pops an item from the block stack. |
299 | | 0x8001 | EndBlockIf | Peeks the top value on the stack, assumed an i32. If non-zero, pops an item from the block stack. |
300 | | 0x8002 | InitFrame | Pops a caller module index i32, then a caller module internals offset i32, and finally a return InternalRef from the stack. Creates a stack frame with the popped info and the locals merkle root in proving argument data. |
301 | | 0x8003 | ArbitraryJumpIf | Pops an i32 from the stack. If non-zero, jumps to the program counter in the argument data. |
302 | | 0x8004 | PushStackBoundary | Pushes a stack boundary to the stack. |
303 | | 0x8005 | MoveFromStackToInternal | Pops an item from the stack and pushes it to the internal stack. |
304 | | 0x8006 | MoveFromInternalToStack | Pops an item from the internal stack and pushes it to the stack. |
305 | | 0x8007 | IsStackBoundary | Pops an item from the stack. If a stack boundary, pushes an i32 with value 1. Otherwise, pushes an i32 with value 0. |
306 | | 0x8008 | Dup | Peeks an item from the stack and pushes another copy of that item to the stack. |
307 |
308 | The above opcodes eliminate the need for the following WASM opcodes (which are transpiled into other WAVM opcodes):
309 |
310 | - loop
311 | - if/else
312 | - br_table
313 | - local.tee
314 |
315 | ### Linking
316 |
317 | This is only generated to link modules together.
318 | Each import is replaced with a local function consisting primarily of this opcode,
319 | which handles the actual work needed to change modules.
320 |
321 | | Opcode | Name | Description |
322 | | ------ | --------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
323 | | 0x8009 | CrossModuleCall | Pushes the current program counter, module number, and module's internals offset to the stack. Then splits its argument data into the lower 32 bits being a function index, and the upper 32 bits being a module index, and jumps to the beginning of that function. |
324 |
325 | ### Host calls
326 |
327 | These are only used in the implementation of "host calls".
328 | Each of these has an equivalent host call method, which can be invoked from libraries.
329 | The exception is CallerModuleInternalCall,
330 | which is used for the implementation of all of the wavm_caller_* host calls.
331 | Those calls are documented in wavm-modules.mdx.
332 |
333 | For these instruction descriptions, all pointers and offsets are represented as WASM i32s.
334 |
335 | | Opcode | Name | Description |
336 | | ------ | ------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
337 | | 0x800A | CallerModuleInternalCall | Pushes the current program counter, module number, and module's internals offset (all i32s) to the stack. Then, it retrieves the caller module internals offset from the current stack frame. If 0, errors, otherwise, jumps to the caller module at function (internals offset + opcode argument data) and instruction 0. |
338 | | 0x8010 | GetGlobalStateBytes32 | Pops a pointer and then an index from the stack. If the index is greater than or equal to the number of global state bytes32s, errors. If the pointer mod 32 is not zero, errors. If the pointer + 32 is outside the programs memory, errors. Otherwise, writes the global state bytes32 value of the specified index to the specified pointer in memory. |
339 | | 0x8011 | SetGlobalStateBytes32 | Pops a pointer and then an index from the stack. If the index is greater than or equal to the number of global state bytes32s, errors. If the pointer mod 32 is not zero, errors. If the pointer + 32 is outside the programs memory, errors. Otherwise, reads a bytes32 from the specified pointer in memory and sets the global state bytes32 value of the specified index to it. |
340 | | 0x8012 | GetGlobalStateU64 | Pops a pointer and then an index from the stack. If the index is greater than or equal to the number of global state u64s, errors. If the pointer mod 32 is not zero, errors. If the pointer + 8 is outside the programs memory, errors. Otherwise, writes the global state u32 value of the specified index to the specified pointer in memory. |
341 | | 0x8013 | SetGlobalStateU64 | Pops a pointer and then an index from the stack. If the index is greater than or equal to the number of global state u64s, errors. If the pointer mod 32 is not zero, errors. If the pointer + 8 is outside the programs memory, errors. Otherwise, reads a u64 from the specified pointer in memory and sets the global state u64 value of the specified index to it. |
342 | | 0x8020 | ReadPreImage | Pops an offset and then a pointer from the stack. If the pointer mod 32 is not zero, errors. If the pointer + 32 is outside the programs memory, errors. Reads a 32 byte Keccak-256 hash from the specified pointer in memory. Writes up to 32 bytes of the preimage to that hash, beginning with the offset byte of the preimage. If offset is greater than or equal to the number of bytes in the preimage, writes nothing. Pushes the number of bytes written to the stack as an i32. |
343 | | 0x8021 | ReadInboxMessage | Pops an offset, then a pointer, and then an i64 message number from the stack. If the pointer mod 32 is not zero, errors. If the pointer + 32 is outside the programs memory, errors. Attempts to read an inbox message from the inbox identifier contained in the argument data (0 for the Sequencer inbox, 1 for the Delayed Inbox) at the specified message number. If this exceeds the machine's inbox limit, enters the "too far" state. Otherwise, writes up to 32 bytes of the specified inbox message, beginning with the offset byte of the message. If offset is greater than or equal to the number of bytes in the preimage, writes nothing. Pushes the number of bytes written to the stack as an i32. |
344 | | 0x8022 | HaltAndSetFinished | Sets the machine status to finished, halting execution and marking it as a success. |
345 |
346 | ## WAVM Floating point implementation
347 |
348 | Implementing correct, consistent, and deterministic floating point operations directly in WAVM
349 | (meaning both a Rust Arbitrator implementation and Solidity OSP implementation)
350 | would be an extremely tricky endeavor.
351 | WASM specifies floating point operations as being compliant to IEEE 754-2019,
352 | which is not deterministic, and full of edge cases.
353 |
354 | Instead, floating point operations (apart from trivial bit-casts like i32 <-> f32)
355 | are implemented using the C Berkeley SoftFloat-3e library running inside WAVM.
356 | Arbitrator links other WAVM guests against this,
357 | by replacing float point operations with cross module calls to the library.
358 |
359 | Berkeley SoftFloat does not implement all necessary floating point operations, however.
360 | Most importantly, it does not provide a min function, despite IEEE 754-2019 specifying one.
361 | The implementation of these operations,
362 | along with the export of convenient APIs for WASM opcode implementations,
363 | are contained in bindings32.c for 32 bit integers and bindings64.c for 64 bit integers.
364 |
365 | This ensures that floating point operations are deterministic and consistent between Arbitrator and the OSP,
366 | as they are implemented exclusively using operations already known to be deterministic and consistent.
367 | However, it does not ensure that the floating point operations are perfectly compliant to the WASM specification.
368 | Go uses floating points in its JS<->Go WASM interface,
369 | and floating points may be used outside core state transition code for imprecise computations,
370 | but the former is well exercised as used in Nitro,
371 | and the latter generally doesn't rely on details like the minimum of NaN and infinity.
372 |
373 | ### Known divergences from the WASM specification
374 |
375 | Floating point to integer truncation will saturate on overflow, instead of erroring.
376 | This is generally safer, because on x86, overflowing simply produces an undefined result.
377 | A WASM proposal exists to add new opcodes which are defined to saturate, but it's not widely adopted.
378 |
379 | ## WAVM Modules
380 |
381 | WASM natively has a notion of modules.
382 | Normally, in WASM, a module is the entire program.
383 | A .wasm file represents one module, and generally they aren't combined.
384 | An exception to this is C compiled via Clang, where wasm files are also used as object files,
385 | but its linking scheme is not supported in other languages.
386 |
387 | In WAVM this is extended to make the executing program composed of multiple modules.
388 | These may call each other, and library modules may write to their caller's memory to return results.
389 |
390 | ### The entrypoint module
391 |
392 | The entrypoint module is where execution begins.
393 | It calls modules' start functions if specified,
394 | and then calls the main module's main function, which is language specific.
395 | For Go it sets argv to ["js"] to match the JS environment, and calls run.
396 | For Rust it calls main with no arguments.
397 |
398 | ### Library exports
399 |
400 | Libraries may export functions with the name pattern module__name,
401 | which future libraries or the main module can import as "module" "name".
402 |
403 | For instance, this is used for wasi-stub to provide functions rust imports according
404 | to the WebAssembly System Interface.
405 |
406 | ### Floating point operations
407 |
408 | To provide floating point operations for future libraries,
409 | the soft float library exports functions which perform floating point ops.
410 | These have the same name as the WASM instruction names, except . is replaced with _.
411 | Their type signature is also the same, except all f32s and f64s are bitcasted to i32s and i64s.
412 |
413 | Future modules can implicitly use these by using WASM floating point operations,
414 | which are replaced at the WASM->WAVM level with bitcasts and cross module calls to these functions.
415 |
416 | ### WAVM guest calls
417 |
418 | Libraries may call the main module's exports via "env" "wavm_guest_call__*".
419 |
420 | For instance, go-stub calls Go's resume function when queueing async events
421 | via wavm_guest_call_resume(), and then retrieves the new stack pointer with
422 | wavm_guest_call_getsp().
423 |
424 | ### Caller module internals call
425 |
426 | Every stack frame retains its caller module and its caller module's "internals offset",
427 | which is the first internal function index.
428 | WAVM appends 4 "internal" functions to each module, which perform a memory load or store of 1 or 4 bytes.
429 |
430 | Via wavm_caller_{load,store}{8,32}, a library may access its caller's memory,
431 | which is implemented by calling these internal functions of the caller's module.
432 | Only libraries can access their caller's memory; the main module cannot.
433 |
434 | For instance, this is used to read arguments from and write return values to the Go stack,
435 | when Go calls into go-stub.
436 |
1 | ---
2 | title: AnyTrust Protocol
3 | description: 'Learn the fundamentals of the Arbitrum AnyTrust protocol.'
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about AnyTrust.
7 | content_type: get-started
8 | ---
9 |
10 | AnyTrust is a variant of Arbitrum Nitro technology that lowers costs by accepting a mild trust assumption.
11 |
12 | The Arbitrum protocol requires that all Arbitrum nodes, including validators (nodes that verify correctness of the chain and are prepared to stake on correct results), have access to the data of every L2 Transaction in the Arbitrum chain's inbox. An Arbitrum rollup provides data access by posting the data (in batched, compressed form) on L1 Ethereum as calldata. The Ethereum gas to pay for this is the largest component of cost in Arbitrum.
13 |
14 | AnyTrust relies instead on an external Data Availability Committee (hereafter, "the Committee") to store data and provide it on demand. The Committee has N members, of which AnyTrust assumes at least two are honest. This means that if N - 1 Committee members promise to provide access to some data, at least one of the promising parties must be honest. Since there are two honest members, and only one failed to make the promise, it follows that at least one of the promisers must be honest — and that honest member will provide data when it is needed to ensure the chain can properly function.
15 |
16 | ## Keysets
17 |
18 | A Keyset specifies the BLS public keys of Committee members and the number of signatures required for a Data Availability Certificate to be valid. Keysets make Committee membership changes possible and provide Committee members the ability to change their keys.
19 |
20 | A Keyset contains:
21 |
22 | - the number of Committee members, and
23 | - for each Committee member, a BLS public key, and
24 | - the number of Committee signatures required.
25 |
26 | Keysets are identified by their hashes.
27 |
28 | An L1 KeysetManager contract maintains a list of currently valid Keysets. The L2 chain's Owner can add or remove Keysets from this list. When a Keyset becomes valid, the KeysetManager contract emits an L1 Ethereum event containing the Keyset's hash and full contents. This allows the contents to be recovered later by anyone, given only the Keyset hash.
29 |
30 | Although the API does not limit the number of Keysets that can be valid at the same time, normally only one Keyset will be valid.
31 |
32 | ## Data Availability Certificates
33 |
34 | A central concept in AnyTrust is the Data Availability Certificate (hereafter, a "DACert"). A DACert contains:
35 |
36 | - the hash of a data block, and
37 | - an expiration time, and
38 | - proof that N-1 Committee members have signed the (hash, expiration time) pair, consisting of
39 | - the hash of the Keyset used in signing, and
40 | - a bitmap saying which Committee members signed, and
41 | - a BLS aggregated signature (over the BLS12-381 curve) proving that those parties signed.
42 |
43 | Because of the 2-of-N trust assumption, a DACert constitutes proof that the block's data (i.e., the preimage of the hash in the DACert) will be available from at least one honest Committee member, at least until the expiration time.
44 |
45 | In ordinary (non-AnyTrust) Nitro, the Arbitrum Sequencer posts data blocks on the L1 chain as calldata. The hashes of the data blocks are committed by the L1 Inbox contract, allowing the data to be reliably read by L2 code.
46 |
47 | AnyTrust gives the sequencer two ways to post a data block on L1: it can post the full data as above, or it can post a DACert proving availability of the data. The L1 inbox contract will reject any DACert that uses an invalid Keyset; the other aspects of DACert validity are checked by L2 code.
48 |
49 | The L2 code that reads data from the inbox reads a full-data block as in ordinary Nitro. If it sees a DACert instead, it checks the validity of the DACert, with reference to the Keyset specified by the DACert (which is known to be valid because the L1 Inbox verified that). The L2 code verifies that
50 |
51 | - the number of signers is at least the number required by the Keyset, and
52 | - the aggregated signature is valid for the claimed signers, and
53 | - the expiration time is at least two weeks after the current L2 timestamp.
54 |
55 | If the DACert is invalid, the L2 code discards the DACert and moves on to the next data block. If the DACert is valid, the L2 code reads the data block, which is guaranteed to be available because the DACert is valid.
56 |
57 | ## Data Availability Servers
58 |
59 | Committee members run Data Availability Server (DAS) software. The DAS exposes two APIs:
60 |
61 | - The Sequencer API, which is meant to be called only by the Arbitrum chain's Sequencer, is a JSON-RPC interface allowing the Sequencer to submit data blocks to the DAS for storage. Deployments will typically block access to this API from callers other than the Sequencer.
62 | - The REST API, which is meant to be available to the world, is a RESTful HTTP(S) based protocol that allows data blocks to be fetched by hash. This API is fully cacheable, and deployments may use a caching proxy or CDN to increase scale and protect against DoS attacks.
63 |
64 | Only Committee members have reason to support the Sequencer API. We expect others to run the REST API, and that is helpful. (More on that below.)
65 |
66 | The DAS software, based on configuration options, can store its data in local files, or in a Badger database, or on Amazon S3, or redundantly across multiple backing stores. The software also supports optional caching in memory (using Bigcache) or in a Redis instance.
67 |
68 | ## Sequencer-Committee Interaction
69 |
70 | When the Arbitrum sequencer produces a data Batch that it wants to post using the Committee, it sends the batch's data, along with an expiration time (normally three weeks in the future) via RPC to all Committee members in parallel. Each Committee member stores the data in its backing store, indexed by the data's hash. Then the member signs the (hash, expiration time) pair using its BLS key, and returns the signature with a success indicator to the sequencer.
71 |
72 | Once the Sequencer has collected enough signatures, it can aggregate the signatures and create a valid DACert for the (hash, expiration time) pair. The Sequencer then posts that DACert to the L1 inbox contract, making it available to the AnyTrust chain software at L2.
73 |
74 | If the Sequencer fails to collect enough signatures within a few minutes, it will abandon the attempt to use the Committee, and will "fall back to rollup" by posting the full data directly to the L1 chain, as it would do in a non-AnyTrust chain. The L2 software can understand both data posting formats (via DACert or via full data) and will handle each one correctly.
75 |
1 | ---
2 | title: Gas and Fees
3 | description: 'Learn the fundamentals of how to calculate fees on Arbitrum.'
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about gas/fee calculations on Arbitrum.
7 | content_type: get-started
8 | ---
9 |
10 | Gas is used by Arbitrum to track the cost of execution on a Nitro chain. It works the same as Ethereum gas, in the sense that every EVM instruction costs the same amount of gas that it would on Ethereum.
11 |
12 | There are two parties a user pays when submitting a tx:
13 |
14 | - the poster, if reimbursable, for L1 resources such as the L1 calldata needed to post the tx
15 | - the network fee account for L2 resources, which include the computation, storage, and other burdens L2 nodes must bear to service the tx
16 |
17 | The L1 component is the product of the Transaction's estimated contribution to its Batch's size — computed using Brotli on the transaction by itself — and the L2's view of the L1 data price, a value which dynamically adjusts over time to ensure the batch-poster is ultimately fairly compensated.
18 |
19 | The L2 component consists of the traditional fees Geth would pay to stakers in a vanilla L1 chain, such as the computation and storage charges applying the State Transition Function entails. ArbOS charges additional fees for executing its L2-specific precompiles, whose fees are dynamically priced according to the specific resources used while executing the call.
20 |
21 | The following sections will detail how to calculate L1 and L2 fees. If you do not need precise calculations or a technical understanding, skip to the next section, L1 to L2 messaging.
22 |
23 | ## L1 gas pricing
24 |
25 | ArbOS dynamically prices L1 gas, with the price adjusting to ensure that the amount collected in L1 gas fees is as close as possible to the costs that must be covered, over time.
26 |
27 | ### L1 costs
28 |
29 | There are two types of L1 costs: batch posting costs, and rewards.
30 |
31 | Batch posting costs reflect the actual cost a batch poster pays to post batch data on L1. Whenever a batch is posted, the L1 contract that records the batch will send a special "batch posting report" message to L2 ArbOS, reporting who paid for the batch and what the L1 basefee was at the time. This message is placed in the chain's Delayed Inbox, so it will be delivered to L2 ArbOS after some delay.
32 |
33 | When a batch posting report message arrives at L2, ArbOS computes the cost of the referenced batch by multiplying the reported basefee by the batch's data cost. (ArbOS retrieves the batch's data from its inbox state, and computes the L1 gas that the batch would have used by counting the number of zero bytes and non-zero bytes in the batch.) The resulting cost is recorded by the pricer as funds due to the party who is reported to have submitted the batch.
34 |
35 | The second type of L1 cost is an optional (per chain) per-unit reward for handling transaction calldata. In general the reward might be paid to the Sequencer, or to members of the Data Availability Committee in an AnyTrust chain, or to anyone else who incurs per-calldata-byte costs on behalf of the chain. The reward is a fixed number of wei per data unit, and is paid to a single address.
36 |
37 | The L1 pricer keeps track of the funds due to the reward address, based on the number of data units handled so far. This amount is updated whenever a batch posting report arrives at L2.
38 |
39 | ### L1 calldata fees
40 |
41 | L1 calldata fees exist because the Sequencer, or the batch poster which posts the Sequencer's transaction batches on Ethereum, incurs costs in L1 gas to post transactions on Ethereum as calldata. Funds collected in L1 calldata fees are credited to the batch poster to cover its costs.
42 |
43 | Every transaction that comes in through the Sequencer will pay an L1 calldata fee. Transactions that come in through the delayed inbox do not pay this fee because they don't add to batch posting costs--but these transactions pay gas fees to Ethereum when they are put into the delayed inbox.
44 |
45 | The L1 pricing algorithm assigns an L1 calldata fee to each Sequencer transaction. First, it computes the transaction's size, which is an estimate of how many bytes the transaction will add to the compressed batch it is in; the formula for this includes an estimate of how compressible the transaction is. Second, it multiplies the computed size estimate by the current price per estimated byte, to determine the transaction's L1 calldata wei, in wei. Finally, it divides this cost by the current L2 basefee to translate the fee into L2 gas units. The result is reported as the "poster fee" for the transaction.
46 |
47 | The price per estimated byte is set by a dynamic algorithm that compares the total L1 calldata fees collected to the total fees actually paid by batch posters, and tries to bring the two as close to equality as possible. If the batch posters' costs have been less than fee receipts, the price will increase, and if batch poster costs have exceeded fee receipts, the price will decrease.
48 |
49 | ### L1 fee collection
50 |
51 | A transaction is charged for L1 gas if and only if it arrived as part of a sequencer batch. This means that someone would have paid for L1 gas to post the transaction on the L1 chain.
52 |
53 | The estimated cost of posting a transaction on L1 is the product of the transaction's estimated size, and the current L1 Gas Basefee. This estimated cost is divided by the current L2 gas basefee to obtain the amount of L2 gas that corresponds to the L1 operation (more information about this can be found in [this article][two_dimensional_fees_medium_article_link]).
54 |
55 | The estimated size is measured in L1 gas and is calculated as follows: first, compress the transaction's data using the brotli-zero algorithm, then multiply the size of the result by 16. (16 is because L1 charges 16 gas per byte. L1 charges less for bytes that are zero, but that doesn't make sense here.) Brotli-zero is used in order to reward users for posting transactions that are compressible. Ideally we would like to reward for posting transactions that contribute to the compressibility (using the brotli compressor) of the entire batch, but that is a difficult notion to define and in any case would be too expensive to compute at L2. Brotli-zero is an approximation that is cheap enough to compute.
56 |
57 | L1 gas fee funds that are collected from transactions are transferred to a special [L1PricerFundsPool][l1pricerfundspool_link] account, so that account's balance represents the amount of funds that have been collected and are available to pay for costs.
58 |
59 | The L1 pricer also records the total number of "data units" (the sum of the estimated sizes, after multiplying by 16) that have been received.
60 |
61 | [l1pricerfundspool_link]: https://github.com/OffchainLabs/nitro/blob/3f4939df1990320310e7f39e8abb32d5c4d8045f/arbos/l1pricing/l1pricing.go#L46
62 | [two_dimensional_fees_medium_article_link]: https://medium.com/offchainlabs/understanding-arbitrum-2-dimensional-fees-fd1d582596c9
63 |
64 | ## L2 gas pricing
65 |
66 | The L2 gas price on a given Arbitrum chain has a set floor, which can be queried via ArbGasInfo's getMinimumGasPrice method (currently @arbOneGasFloorGwei@ gwei on Arbitrum One and @novaGasFloorGwei@ gwei on Nova).
67 |
68 | ### Estimating L2 Gas
69 |
70 | Calling an Arbitrum Node's eth_estimateGas RPC gives a value sufficient to cover the full transaction fee at the given L2 gas price; i.e., the value returned from eth_estimateGas multiplied by the L2 gas price tells you how much total Ether is required for the transaction to succeed. Note that this means that for a given operation, the value returned by eth_estimateGas will change over time (as the L1 calldata price fluctuates.) (See 2-D fees and How to estimate gas in Arbitrum for more.)
71 |
72 | ### L2 gas fees
73 |
74 | L2 gas fees work very similarly to gas on Ethereum. A transaction uses some amount of gas, and this is multiplied by the current basefee to get the L2 gas fee charged to the transaction.
75 |
76 | The L2 basefee is set by a version of the "exponential mechanism" which has been widely discussed in the Ethereum community, and which has been shown equivalent to Ethereum's EIP-1559 gas pricing mechanism.
77 |
78 | The algorithm compares gas usage against a parameter called the speed limit which is the target amount of gas per second that the chain can handle sustainably over time. (Currently the Speed Limit on Arbitrum One is @arbOneGasSpeedLimitGasPerSec@ gas per second.) The algorithm tracks a gas backlog. Whenever a transaction consumes gas, that gas is added to the backlog. Whenever the clock ticks one second, the speed limit is subtracted from the backlog; but the backlog can never go below zero.
79 |
80 | Intuitively, if the backlog grows, the algorithm should increase the gas price, to slow gas usage, because usage is above the sustainable level. If the backlog shrinks, the price should decrease again because usage has been below the below the sustainable limit so more gas usage can be welcomed.
81 |
82 | To make this more precise, the basefee is an exponential function of the backlog, F = exp(-a(B-b)), where a and b are suitably chosen constants: a controls how rapidly the price escalates with backlog, and b allows a small backlog before the basefee escalation begins.
83 |
84 | ### L2 Tips
85 |
86 | The sequencer prioritizes transactions on a first-come first-served basis. Because tips do not make sense in this model, they are ignored. Arbitrum users always just pay the basefee regardless of the tip they choose.
87 |
88 | ### Gas Estimating Retryables
89 |
90 | When a transaction schedules another, the subsequent transaction's execution [will be included][estimation_inclusion_link] when estimating gas via the node's RPC. A transaction's gas estimate, then, can only be found if all the transactions succeed at a given gas limit. This is especially important when working with retryables and scheduling redeem attempts.
91 |
92 | Because a call to redeem donates all of the call's gas, doing multiple requires limiting the amount of gas provided to each subcall. Otherwise the first will take all of the gas and force the second to necessarily fail irrespective of the estimation's gas limit.
93 |
94 | Gas estimation for Retryable submissions is possible via the NodeInterface and similarly requires the auto-redeem attempt to succeed.
95 |
96 | [estimation_inclusion_link]: https://github.com/OffchainLabs/go-ethereum/blob/d52739e6d54f2ea06146fdc44947af3488b89082/internal/ethapi/api.go#L999
97 |
98 | ### The Speed Limit
99 |
100 | The security of Nitro chains depends on the assumption that when one Validator creates an RBlock, other validators will check it, and respond with a correct RBlock and a Challenge if it is wrong. This requires that the other validators have the time and resources to check each RBlock quickly enough to issue a timely challenge. The Arbitrum protocol takes this into account in setting deadlines for RBlocks.
101 |
102 | This sets an effective speed limit on execution of a Nitro chain: in the long run the chain cannot make progress faster than a validator can emulate its execution. If RBlocks are published at a rate faster than the speed limit, their deadlines will get farther and farther in the future. Due to the limit, enforced by the rollup protocol contracts, on how far in the future a deadline can be, this will eventually cause new RBlocks to be slowed down, thereby enforcing the effective speed limit.
103 |
104 | Being able to set the speed limit accurately depends on being able to estimate the time required to validate an RBlock, with some accuracy. Any uncertainty in estimating validation time will force us to set the speed limit lower, to be safe. And we do not want to set the speed limit lower, so we try to enable accurate estimation.
105 |
106 | ## Total fee and gas estimation
107 |
108 | The total fee charged to a transaction is the L2 basefee, multiplied by the sum of the L2 gas used plus the L1 calldata charge. As on Ethereum, a transaction will fail if it fails to supply enough gas, or if it specifies a basefee limit that is below the current basefee. Ethereum also allows a "tip" but Nitro ignores this field and never collects any tips.
109 |
110 | ### Allocating funds and paying what is owed
111 |
112 | When a batch posting report is processed at L2, the pricer allocates some of the collected funds to pay for costs incurred. To allocate funds, the pricer considers three timestamps:
113 |
114 | - currentTime is the current time, when the batch posting report message arrives at L2
115 | - updateTime is the time at which the reported batch was submitted (which will typically be around 20 minutes before currentTime)
116 | - lastUpdateTime is the time at which the previous reported batch was submitted
117 |
118 | The pricer computes an allocation fraction F = (updateTime-lastUpdateTime) / (currentTime-lastUpdateTime) and allocates a fraction F of funds in the L1PricerFundsPool to the current report. The intuition is that the pricer knows how many funds have been collected between lastUpdateTime and currentTime, and we want to figure out how many of those funds to allocate to the interval between lastUpdateTime and updateTime. The given formula is the correct allocation, if we assume that funds arrived at a uniform rate during the interval between lastUpdateTime and currentTime. The pricer similarly allocates a portion of the total data units to the current report.
119 |
120 | Now the pricer pays out the allocated funds to cover the rewards due and the amounts due to batch posters, reducing the balance due to each party as a result. If the allocated funds aren't sufficient to cover everything that is due, some amount due will remain. If all of the amount due can be covered with the allocated funds, any remaining allocated funds are returned to the L1PricerFundsPool.
121 |
122 | ### Getting L1 fee info
123 |
124 | The L1 gas basefee can be queried via ArbGasInfo.getL1BaseFeeEstimate. To estimate the L1 fee a transaction will use, the NodeInterface.gasEstimateComponents() or NodeInterface.gasEstimateL1Component() method can be used.
125 |
126 | Arbitrum transaction receipts include a gasUsedForL1 field, showing the amount of gas used on L1 in units of L2 gas.
127 |
128 | ### Adjusting the L1 gas basefee
129 |
130 | After allocating funds and paying what is owed, the L1 Pricer adjusts the L1 Gas Basefee. The goal of this process is to find a value that will cause the amount collected to equal the amount owed over time.
131 |
132 | The algorithm first computes the surplus (funds in the L1PricerFundsPool, minus total funds due), which might be negative. If the surplus is positive, the L1 Gas Basefee is reduced, so that the amount collected over a fixed future interval will be reduced by exactly the surplus. If the surplus is negative, the Basefee is increased so that the shortfall will be eliminated over the same fixed future interval.
133 |
134 | A second term is added to the L1 Gas Basefee, based on the derivative of the surplus (surplus at present, minus the surplus after the previous batch posting report was processed). This term, which is multiplied by a smoothing factor to reduce fluctuations, will reduce the Basefee if the surplus is increasing, and increase the Basefee if the surplus is shrinking.
135 |
1 | ---
2 | title: L1 to L2 messaging
3 | description: 'Learn the fundamentals of L1 to L2 messaging on Arbitrum.'
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about messaging between L1 and L2 within Arbitrum.
7 | content_type: get-started
8 | ---
9 |
10 | import { AddressAliasHelper } from '@site/src/components/AddressAliasHelper';
11 |
12 | In the Transaction Lifecycle section, we covered how users interact with L2 contracts. They submit transactions by putting messages into the chain’s inbox or having a full node Sequencer or aggregator do so on their behalf.
13 |
14 | L1 and L2 chains run asynchronously from each other, so it is not possible to make a cross-chain call that produces a result within the same Transaction as the caller. Instead, cross-chain calls must be asynchronous, meaning that the caller submits the call at some point in time, and the call runs later. Consequently, a cross-chain contract-to-contract call can never produce a result available to the calling contract (except for acknowledgment of a successful call submitted for later execution).
15 |
16 | In this section, we will discuss how contracts interact between L1 and L2, how an L1 contract is called an L2 contract, and vice versa.
17 |
18 | ## Retryable Tickets
19 |
20 | Retryable tickets are Arbitrum's canonical method for creating L1 to L2 messages, i.e., L1 transactions that initiate a message to be executed on L2. A retryable can be submitted for a fixed cost (dependent only on its calldata size) paid at L1; its submission on L1 is separable / asynchronous with its execution on L2. Retryables provide atomicity between the cross chain operations; if the L1 transaction to request submission succeeds (i.e. does not revert) then the execution of the Retryable on L2 has a strong guarantee to ultimately succeed as well.
21 |
22 | ## Retryable Tickets Lifecycle
23 |
24 | Here we walk through the different stages of the lifecycle of a Retryable Ticket; (1) submission, (2) auto-redemption, and (3) manual redemption.
25 |
26 | ### Submission
27 |
28 | 1. Creating a retryable ticket is initiated with a call (direct or internal) to the createRetryableTicket function of the inbox contract. A ticket is guaranteed to be created if this call succeeds. Here, we describe parameters that need to be carefully set. Note that, this function forces the sender to provide a reasonable amount of funds (at least enough to submitting, and attempting to executing the ticket), but that doesn't guarantee a successful auto-redemption.
29 |
30 | | Parameter | Description |
31 | | :------------------------------------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
32 | | l1CallValue (also referred to as deposit) | Not a real function parameter, it is rather the callValue that is sent along with the transaction |
33 | | address to | The destination L2 address |
34 | | uint256 l2CallValue | The callvalue for retryable L2 message that is supplied within the deposit (l1CallValue) |
35 | | uint256 maxSubmissionCost | The maximum amount of ETH to be paid for submitting the ticket. This amount is (1) supplied within the deposit (l1CallValue) to be later deducted from sender's L2 balance and is (2) directly proportional to the size of the retryable’s data and L1 basefee |
36 | | address excessFeeRefundAddress | The unused gas cost and submssion cost will deposit to this address, formula is: (gasLimit x maxFeePerGas - execution cost) + (maxSubmission - (autoredeem ? 0 : submission cost)). (Note: excess deposit will transfer to the alias address of the Parent chain tx's msg.sender rather than this address) |
37 | | address callValueRefundAddress | The L2 address to which the l2CallValue is credited if the ticket times out or gets cancelled (this is also called the beneficiary, who's got a critical permission to cancel the ticket) |
38 | | uint256 gasLimit | Maximum amount of gas used to cover L2 execution of the ticket |
39 | | uint256 maxFeePerGas | The gas price bid for L2 execution of the ticket that is supplied within the deposit (l1CallValue) |
40 | | bytes calldata data | The calldata to the destination L2 address |
41 |
42 | 2. Sender's deposit must be enough to make the L1 submission succeed and for the L2 execution to be attempted. If provided correctly, a new ticket with a unique TicketID is created and added to retryable buffer. Also, funds (submissionCost + l2CallValue) are deducted from the sender and placed into the escrow for later use in redeeming the ticket.
43 |
44 | 3. Ticket creation causes the ArbRetryableTx precompile to emit a TicketCreated event containing the TicketID on L2.
45 |
46 |  47 |
48 | ### Automatic Redemption
49 |
50 | 4. It is very important to note that the submission of a ticket on L1 is separable / asynchronous from its execution on L2, i.e., a successful L1 ticket creation does not guarantee a successful redemption. Once the ticket is successfully created, the two following conditions are checked: (1) if the user's L2 balance is greater than (or equal to)
47 |
48 | ### Automatic Redemption
49 |
50 | 4. It is very important to note that the submission of a ticket on L1 is separable / asynchronous from its execution on L2, i.e., a successful L1 ticket creation does not guarantee a successful redemption. Once the ticket is successfully created, the two following conditions are checked: (1) if the user's L2 balance is greater than (or equal to) maxFeePerGas * gasLimit and (2) if the maxFeePerGas (provided by the user in the ticket submission process) is greater than (or equal to) the l2Basefee. If these conditions are both met, ticket's submission is followed by an attempt to execute it on L2 (i.e., an auto-redeem using the supplied gas, as if the redeem method of the ArbRetryableTx precompile had been called). Depending on how much gas the sender has provided in step 1, ticket's redemption can either (1) immediately succeed or (2) fail. We explain both situations here:
51 |
52 | - If the ticket is successfully auto-redeemed, it will execute with the sender, destination, callvalue, and calldata of the original submission. The submission fee is refunded to the user on L2 (excessFeeRefundAddress). Note that to ensure successful auto-redeem of the ticket, one could use the Arbitrum SDK which provides a convenience function that returns the desired gas parameters when sending L1-L2 messages.
53 |
54 | - If a redeem is not done at submission or the submission's initial redeem fails (for example, because the L2 gas price has increased unexpectedly), the submission fee is collected on L2 to cover the resources required to temporarily keep the ticket in memory for a fixed period (one week), and only in this case, a manual redemption of the ticket is required (see next section).
55 |
56 |  57 |
58 | ### Manual Redemption
59 |
60 | 5. At this point, anyone can attempt to manually redeem the ticket again by calling ArbRetryableTx's
57 |
58 | ### Manual Redemption
59 |
60 | 5. At this point, anyone can attempt to manually redeem the ticket again by calling ArbRetryableTx's redeem precompile method, which donates the call's gas to the next attempt. Note that the amount of gas is NOT limited by the original gasLimit set during the ticket creation. ArbOS will [enqueue the redeem][enqueue_link], which is its own special ArbitrumRetryTx type, to its list of redeems that ArbOS [guarantees to exhaust][exhaust_link] before moving on to the next non-redeem transaction in the block its forming. In this manner redeems are scheduled to happen as soon as possible, and will always be in the same block as the tx that scheduled it. Note that the redeem attempt's gas comes from the call to redeem, so there's no chance the block's gas limit is reached before execution.
61 |
62 | 6. If the fixed period (one week) elapses without a successful redeem, the ticket expires and will be [automatically discarded][discard_link], unless some party has paid a fee to [keep the ticket alive][renew_link] for another full period. A ticket can live indefinitely as long as it is renewed each time before it expires.
63 |
64 | [enqueue_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/block_processor.go#L245
65 | [exhaust_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/block_processor.go#L135
66 | [discard_link]: https://github.com/OffchainLabs/nitro/blob/fa36a0f138b8a7e684194f9840315d80c390f324/arbos/retryables/retryable.go#L262
67 | [renew_link]: https://github.com/OffchainLabs/nitro-contracts/blob/a68783436b5105a64f54efe5fbd55174704a7618/src/precompiles/ArbRetryableTx.sol#L41
68 |
69 |  70 |
71 | :::caution Avoid Losing Funds!
72 |
73 | If a ticket expires after 7 days without being redeemed or re-scheduled to a future date, any message and value (other than the escrowed
70 |
71 | :::caution Avoid Losing Funds!
72 |
73 | If a ticket expires after 7 days without being redeemed or re-scheduled to a future date, any message and value (other than the escrowed callvalue) it carries could be lost without possibility of being recovered.
74 |
75 | :::
76 |
77 | On success, the To address receives the escrowed callvalue, and any unused gas is returned to ArbOS's gas pools. On failure, the callvalue is returned to the escrow for the future redeem attempt. In either case, the network fee was paid during the scheduling tx, so no fees are charged and no refunds are made.
78 |
79 | Note that during redemption of a ticket, attempts to cancel the same ticket, or to schedule another redeem of the same ticket, will revert. In this manner retryable tickets are not self-modifying.
80 |
81 | If a ticket with a callvalue is eventually discarded (cancelled or expired), having never successfully run, the escrowed callvalue will be paid out to a callValueRefundAddress account that was specified in the initial submission (step 1).
82 |
83 | :::note Important Notes:
84 |
85 | If a redeem is not done at submission or the submission's initial redeem fails, anyone can attempt to redeem the retryable again by calling ArbRetryableTx's redeem precompile method, which donates the call's gas to the next attempt. ArbOS will [enqueue the redeem][enqueue_link], which is its own special ArbitrumRetryTx type, to its list of redeems that ArbOS [guarantees to exhaust][exhaust_link] before moving on to the next non-redeem transaction in the block its forming. In this manner redeems are scheduled to happen as soon as possible, and will always be in the same block as the transaction that scheduled it. Note that the redeem attempt's gas comes from the call to redeem, so there's no chance the block's gas limit is reached before execution.
86 |
87 | - One can redeem live tickets using the [Arbitrum Retryables Transaction Panel][retryable_dashboard_link]
88 | - The calldata of a ticket is saved on L2 until it is redeemed or expired
89 | - Redeeming cost of a ticket will not increase over time, it only depends on the current gas price and gas required for execution
90 |
91 | :::
92 |
93 | [retryable_dashboard_link]: https://retryable-dashboard.arbitrum.io/tx
94 |
95 | ### Receipts
96 |
97 | In the lifecycle of a retryable ticket, two types of L2 transaction receipts will be emitted:
98 |
99 | - Ticket Creation Receipt: This receipt indicates that a ticket was successfully created; any successful L1 call to the Inbox's createRetryableTicket method is guaranteed to create a ticket. The ticket creation receipt includes a TicketCreated event (from ArbRetryableTx), which includes a ticketId field. This ticketId is computable via RLP encoding and hashing the transaction; see calculateSubmitRetryableId.
100 | - Redeem Attempt: A redeem attempt receipt represents the result of an attempted L2 execution of a ticket, i.e, success / failure of that specific redeem attempt. It includes a RedeemScheduled event from ArbRetryableTx, with a ticketId field. At most, one successful redeem attempt can ever exist for a given ticket; if, e.g., the auto-redeem upon initial creation succeeds, only the receipt from the auto-redeem will ever get emitted for that ticket. If the auto-redeem fails (or was never attempted — i.e., the provided L2 gas limit * L2 gas price = 0), each initial attempt will emit a redeem attempt receipt until one succeeds.
101 |
102 | ### Alternative "unsafe" Retryable Ticket Creation
103 |
104 | The Inbox.createRetryableTicket convenience method includes sanity checks to help minimize the risk of user error: the method will ensure that enough funds are provided directly from L1 to cover the current cost of ticket creation. It also will convert the provided callValueRefundAddress and excessFeeRefundAddress to their Address Alias (see below) if either is a contract (determined by if the address has code during the call), providing a path for the L1 contract to recover funds. A power-user may bypass these sanity-check measures via the Inbox's unsafeCreateRetryableTicket method; as the method's name desperately attempts to warn you, it should only be accessed by a user who truly knows what they're doing.
105 |
106 | ## Eth deposits
107 |
108 | A special message type exists for simple Eth deposits; i.e., sending Eth from L1 to L2. Eth can be deposited via a call to the Inbox's depositEth method. If the L1 caller is EOA, the Eth will be deposited to the same EOA address on L2; the L1 caller is a contract, the funds will deposited to the contract's aliased address (see below).
109 |
110 | Note that depositing Eth via depositEth into a contract on L2 will not trigger the contract's fallback function.
111 |
112 | In principle, retryable tickets can alternatively be used to deposit Ether; this could be preferable to the special eth-deposit message type if, e.g., more flexibility for the destination address is needed, or if one wants to trigger the fallback function on the L2 side.
113 |
114 | ## Transacting via the Delayed Inbox
115 |
116 | While retryables and Eth deposits must be submitted through the Delayed Inbox, in principle, any message can be included this way; this is a necessary recourse to ensure the Arbitrum chain preserves censorship resistance even if the Sequencer misbehaves (see The Sequencer and Censorship Resistance). However, under ordinary/happy circumstances, the expectation/recommendation is that clients use the delayed inbox only for Retryables and Eth deposits, and transact via the Sequencer for all other messages.
117 |
118 | ### Address Aliasing
119 |
120 | Unsigned messages submitted via the Delayed Inbox get their sender's addressed "aliased": when these messages are executed on L2, the sender's address —i.e., that which is returned by msg.sender — will not simply be the L1 address that sent the message; rather it will be the address's "L2 Alias." An address's L2 alias is its value increased by the hex value 0x1111000000000000000000000000000000001111:
121 |
122 | sol 123 | L2_Alias = L1_Contract_Address + 0x1111000000000000000000000000000000001111 124 |
125 |
126 | :::tip Try it out
127 |
128 |
129 |
130 | :::
131 |
132 | The Arbitrum protocol's usage of L2 Aliases for L1-to-L2 messages prevents cross-chain exploits that would otherwise be possible if we simply reused the same L1 addresses as the L2 sender; i.e., tricking an L2 contract that expects a call from a given contract address by sending retryable ticket from the expected contract address on L1.
133 |
134 | If for some reason you need to compute the L1 address from an L2 alias on chain, you can use our AddressAliasHelper library:
135 |
136 | sol 137 | modifier onlyFromMyL1Contract() override { 138 | require(AddressAliasHelper.undoL1ToL2Alias(msg.sender) == myL1ContractAddress, "ONLY_COUNTERPART_CONTRACT"); 139 | _; 140 | } 141 |
142 |
143 | ### Signed Messages
144 |
145 | The delayed inbox can also accept messages that include a signature. In this case, the message will execute with the msg.sender address equal to the address that produced the included signature (i.e., not its alias). Intuitively, the signature proves that the sender address is not a contract, and thus is safe from cross-chain exploit concerns described above. Thus, it can safely execute from signer's address, similar to a transaction included in a Sequencer's Batch. For these messages, the address of the L1 sender is effectively ignored at L2.
146 |
147 | These signed messages submitted through the delayed inbox can be used to execute messages that bypass the Sequencer and require EOA authorization at L2, e.g., force-including an Ether withdrawal (see "withdraw eth tutorial").
148 |
1 | ---
2 | title: L2 to L1 messaging
3 | description: 'Learn the fundamentals of L2 to L1 messaging on Arbitrum.'
4 | author: pete-vielhaber
5 | sme: TucksonDev
6 | user_story: As a current or prospective Arbitrum user, I need to learn more about messaging between L2 and L1 on Arbitrum.
7 | content_type: get-started
8 | ---
9 |
10 | Arbitrum's Outbox system
11 | allows for arbitrary L2 to L1 contract calls; i.e., messages initiated from L2 which eventually
12 | resolve in execution on L1. L2-to-L1 messages (aka "outgoing" messages) bear many things in common
13 | with Arbitrum's L1-to-L2 messages (Retryables), "in
14 | reverse" though with a few differences.
15 |
16 | ### Protocol Flow
17 |
18 | Part of the L2 state of an Arbitrum chain — and consequently, part of what's asserted in every RBlock — is a Merkle root of all L2-to-L1 messages in the chain's history. Upon an asserted RBlock being confirmed (typically ~1 week after its asserted), this Merkle root is posted on L1 in the Outbox contract. The Outbox contract then lets users execute their messages — validating Merkle proofs of inclusion, and tracking which L2 to L1 messages have already been spent.
19 |
20 | ### Client Flow
21 |
22 | From a Client perspective, an L2 to L1 message begins with a call to the L2 ArbSys precompile contract's sendTxToL1 method. Once the message is included in an Assertion (typically within ~1 hour) and the assertion is confirmed (typically about ~ 1 week), any client can execute the message. To do this, the client first retrieves the proof data via a call to the Arbitrum chain's "virtual"/precompile-esque** NodeInterface contract's constructOutboxProof method. The data returned can then be used in the Outbox's executeTransaction method to perform the L1 execution.
23 |
24 | ### Protocol Design Details
25 |
26 | An important feature in the design of the Outbox system is that calls to confirmNode have constant overhead. Requiring that confirmNode only update the constant-sized outgoing message root hash, and that users themselves carry out the final step of execution, achieves this goal; i.e., no matter the number of outgoing messages in the root, or the gas cost of executing them on L1, the cost of confirming nodes remains constant; this ensures that the RBlock Confirmation processed can't be griefed.
27 |
28 | Unlike Retryables, which have an option to provide Ether for automatic L2 execution, outgoing messages can't provide in-protocol automatic L1 execution, for the simple reason that Ethereum itself doesn't offer scheduled execution affordances. However, application-layer contracts that interact with the Outbox could in principle be built to provide somewhat-analogous "execution market" functionality for outsourcing the final L1 execution step.
29 |
30 | Another difference between outgoing messages and Retryables is that Retryables have a limited lifetime before which they must be redeemed (or have their lifetime explicitly extended), whereas L2 to L1 messages are stored in L1 state, and thus persist permanently / have no deadline before which they must be executed.
31 | The week long delay period before outgoing messages can be executed is inherent and fundamental to the nature of Arbitrum Rollup, or any Optimistic Rollup style L2; the moment a Transaction is published on-chain, any observer can anticipate its result; however, for Ethereum itself to accept its result, the protocol must give time for Arbitrum validators to detect and prove fault if need-be. For a protocol overview, see Inside Arbitrum
32 |
33 | ** We refer to NodeInterface as a "virtual" contract; its methods are accessible via calls 0x00000000000000000000000000000000000000C8, but it doesn't really live on chain. It isn't really a precompile, but behaves a lot like a precompile that can't receive calls from other contracts. This is a cute trick that let's us provide Arbitrum-specific data without having to implement a custom RPC.
34 |
1 | ---
2 | title: 'Economics of Disputes in Arbitrum BoLD'
3 | sidebar_label: 'Economics of Disputes'
4 | description: 'An in-depth explanation on BoLD economic mechanisms.'
5 | user_story: 'As a user or researcher of the Arbitrum product suite, I want to understand BoLD economics mechanisms.'
6 | content_type: concept
7 | author: leeederek
8 | target_audience: 'Developers, users and researchers interested in the Arbitrum product suite.'
9 | sme: leeederek
10 | ---
11 |
12 | The following document explains the economics and denial-of-service protection mechanisms built into Arbitrum BoLD. It covers trade-offs Arbitrum has to make to enable permissionless validation, explaining the key problems in an accessible way.
13 |
14 | ## Background
15 |
16 | Arbitrum One is currently one of the most widely used Ethereum scaling solutions, with ~$14bn USD in total-value-locked at the time of writing. Not only do its scaling properties, such as its 250ms block times, make it popular, but so do its security properties and approach to decentralization. Currently, Arbitrum One is governed by the Arbitrum DAO, one of the most active and robust on-chain organizations.
17 |
18 | However, Arbitrum technology has not yet achieved its full promise of being fully decentralized. Currently, withdrawals from Arbitrum One back to Ethereum are verified by a permissioned list of validators. These validators can still challenge invalid withdrawals, but the system prevents anyone outside this list from holding them accountable. This permissioned list of validators limits Arbitrum One and Arbitrum Nova to being categorized as a Stage 1 Rollup on the L2Beat website, meaning it still has training wheels preventing it from reaching its full potential.
19 |
20 | The rollup technology powering Arbitrum One is called "optimistic" because claims about its state settled to and confirmed on Ethereum after a period of approximately seven days. During those 7 days, the claimed states can be disputed. To make an analogy, a check can be cashed immediately but can be taken to court to dispute if there is a problem within a specific time frame. Because Arbitrum's state is deterministic, a validator that is running a node and following the chain will always know if a posted claim is invalid. A key decentralization property allows anyone who knows the correct claim to challenge invalid claims and win the challenge. This preserves the accurate history of Arbitrum settling to Ethereum and protects the integrity of users' funds and withdrawals using a "single honest party" property. As long as there is a single entity following the chain and willing to dispute a claim, Arbitrum's security guarantees are maintained.
21 |
22 | Today, Arbitrum One's security properties are defined by the size of its permissioned set of validators. Validators could collude or finalize/confirm an incorrect state, and users have no recourse aside from the Arbitrum One security council stepping in. Elevating Arbitrum One's decentralization requires a different approach.
23 |
24 | In the Fall of 2023, Offchain Labs announced Arbitrum BoLD, a new dispute resolution protocol built from the ground up that will bring Arbitrum chains to the next level of decentralization. BoLD, which is an acryonym for Bounded Liquidity Delay, allows permissionless validation of Arbitrum chains. This means that chain owners can remove the list of permissioned validators for their chains to allow anyone to challenge invalid claims made about Arbitrum states on their parent chain and win.
25 |
26 | In this document, we'll explore the economics and trade-offs enabling permissionless validation.
27 |
28 | ## Settling Arbitrum states to Ethereum
29 |
30 | We frequently state that "Arbitrum chains settles their states to a parent chain", and we'll elaborate on what that means. All Arbitrum One transactions can be recreated by reading data from Ethereum L1, as compressed batches of all L2 transactions are frequently posted to Ethereum. Once a batched transaction is included in a finalized block on Ethereum, its history will never be reverted on Arbitrum One. Ethereum, however, does not know if a batch posted to it refers to a correct version of Arbitrum One's history. To verify batch integrity, there is a separate process that confirms batch correctness on Ethereum: it is called the "assertion."
31 |
32 | For Arbitrum One specifically, approximately every hour, entities known as validators check the correctness of batches by following the Arbitrum chain. Validators then post something called an "assertion", which attests to the validity of a batch, saying, "I have verified this batch". As Ethereum does not know what is correct on Arbitrum One, it allows about seven days for anyone to dispute one of these assertions. Currently, there is a permissioned list of validators who can post assertions and challenge assertion for all Arbitrum chains. Arbitrum BoLD will enable any chain owner, such as the ArbitrumDAO, to remove this permissioned list. Note that validators who opt to posting assertions are otherwise known as a "assertion proposers".
33 |
34 | ### Withdrawing assets back to Ethereum from Arbitrum
35 |
36 | Users of Arbitrum One that have bridged assets from Ethereum can withdraw said assets at any time. However, for this withdrawal to be fully executed, its corresponding claim must match a confirmed assertion on Ethereum. For instance, if Alice starts a withdrawal transaction on Arbitrum One, it gets posted in a batch on Ethereum. Then, a validator will post an assertion about that batch on Ethereum an hour later. The assertion has a seven-day window in which anyone can dispute it. If this assertion isn't disputed within that time frame, it gets confirmed. After that window passes, Alice will receive her withdrawn assets on Ethereum and is free to use them as she pleases.
37 |
38 | "Settling states" and having a seven-day dispute window is crucial to ensuring assets can be withdrawn safely. Allowing anyone to dispute invalid claims and win keeps withdrawals protected by strong security guarantees without needing to trust a group of validators. This "permissionless validation" separates Optimistic Rollups from side chains.
39 |
40 | ### The dispute period
41 |
42 | The reason there is a dispute window for assertions about Arbitrum One on Ethereum is because Ethereum itself has no knowledge about what is correct on Arbitrum One. The two blockchains are different domains with different states. Ethereum, however, can be used as a neutral referee for parties to dispute claims about Arbitrum One. The dispute period is seven days because it is seen as the maximum period of time an adversary could delay Ethereum before social intervention, originally proposed by Vitalik Buterin. This window gives enough time for parties to catch invalid claims and challenge them accordingly.
43 |
44 | ### Dispute resolution times
45 |
46 | An actual dispute occurs if a party disagrees with an assertion on Ethereum and posts an assertion they know to be correct as a counter-claim. This creates a "fork" in the chain of assertions, requiring a resolution process. We'll get into the high-level details of how disputes are resolved later in this document.
47 |
48 | Once an actual dispute is ongoing, it will also take time to resolve, as, once again, Ethereum has no knowledge of the correctness of Arbitrum One states. Ethereum must then give sufficient time for parties to submit their proofs and declare a winner. The new Arbitrum BoLD protocol guarantees that a dispute will be resolved within seven days so long as an honest party is present to defend against invalid claims.
49 |
50 | As assertions have a dispute window of seven days, and disputes require an additional seven days to resolve, a dispute made at the last second would delay assertion confirmation to a maximum of 14 days, or two weeks. BoLD is the only dispute protocol we are aware of that guarantees this bound.
51 |
52 | ### The cost of delaying withdrawals
53 |
54 | Delaying withdrawals incurs opportunity costs and impacts user experience for users who want to withdraw their assets. In the happy case of no disputes, withdrawals already have a baked-in, seven-day delay. A dispute adds seven days to that delay. The problem is that disputes delay all pending withdrawals from Arbitrum One back to Ethereum, not just a single claim. As such, disputing a claim must have a cost for the initiator proportional to the opportunity cost they impose on Arbitrum users.
55 |
56 | #### Requiring a bond to become a validator
57 |
58 | By default, all Arbitrum nodes act as validators, monitoring the chain to verify assertions posted to the parent chain and flagging any invalid assertions. On Arbitrum One, running a validator, known as a “watchtower” node, is permissionless and requires no additional cost other than the infrastructure for the node.
59 |
60 | Another type of validator, called a "proposer," performs additional tasks on top of their regular duties as a regular validator. Proposers compute Arbitrum states and propose assertions to the parent chain. To prevent abuse and delays in withdrawals, proposers must make a security deposit or "bond" to gain the privilege of proposing assertions. This bond can be withdrawn once their latest assertion is confirmed, ending their responsibilities as a proposer.
61 |
62 | Arbitrum BoLD allows validators to become proposers and challengers without permission. Proposers must bond ETH to propose state assertions to the parent chain. Only one proposer is needed for chain progress, allowing most validators to simply verify assertions. In case of disputes over state assertions, BoLD enables anyone to put up a "challenge bond" of ETH to dispute invalid assertions, acting as a challenger in defense of an Arbitrum chain.
63 |
64 | #### Pricing bonds
65 |
66 | Ensuring assertions are frequently posted is a requirement for Arbitrum, but at the same time, it should not be a privilege that is easily obtained, which is why the pricing of this "security deposit" is based on opportunity cost.
67 |
68 | To be highly conservative, in a "bank run"-like scenario, the Arbitrum One bridge contains approximately $3.4B USD worth of assets at the time of writing on Oct 23rd, 2024. Assuming funds could earn a 5% APY if invested elsewhere, the opportunity cost of 1 extra week of delay is approximately $3.27M USD. Given this scenario, we recommend a bond for assertion posters to be greater than $3.7M USD.
69 |
70 | Honest proposers can always withdraw their bond once their assertions are confirmed. However, adversaries stand to lose the entirety of their bond if they propose invalid assertions. A large bond size drastically improves the economic security of the system based on these two axes by making the cost to propose high and by guaranteeing that malicious actors will lose their entire bond when they are proven wrong by the protocol.
71 |
72 | Given that participation in BoLD is permissionless, we recommend that the size of bonds required to participate be high enough to disincentivize malicious actors from attacking Arbitrum One and to mitigate against spam (that would otherwise delay confirmations up to 1 challenge period). High bonding values do not harm decentralization because (1) trustless bonding (or staking) pools can be deployed permissionlessly to open challenges and post assertions, and (2) any number of honest parties of unknown identities can emerge to bond their funds to the correct assertion and participate in the defense of Arbitrum at any time within a challenge. As with the current dispute resolution protocol, there are no protocol level incentives for parties who opt in to participate in validating Arbitrum One with BoLD.
73 |
74 | While both of these bonds can be any ERC20 token and be set to any size, we recommend the use of the WETH ERC20 token & the following bond sizes for Arbitrum One:
75 |
76 | - Assertion bonds: 3600 ETH - required from validators to bond their funds to an assertion in the eventual hopes of having that assertion be confirmed by the rollup protocol. This is a one-time bond required to be able to start posting assertions. This bond can be withdrawn once a validator’s assertion is confirmed and can alternatively be put together via a trustless bonding pool.
77 | - Challenge-bonds, per level: 555/79 ETH - required from validators to open challenges against an assertion observed on the parent chain (Ethereum, in the case for Arbitrum One), for each level. Note that “level” corresponds to the level of granularity over which the interactive dissection game gets played, starting at the block level, moving on to a range of WASM execution steps, and then finally to the level of a single step of execution.
78 |
79 | These values were carefully calculated to optimize for the resource ratio (explained later) and gas costs in the event of an attack, as explained in BoLD whitepaper. This effectively means that an entity that has already put up a bond to propose an assertion does not need to put up a separate assertion bond to challenge an invalid state assertion that they observe. To be explicitly clear, the validator would still require 555 ETH and 79 ETH for ongoing challenges. These additional challenge bond amounts are needed to participate in the interactive dispute game (back and forth) and narrows down the disagreement to a single step of execution that is then proven on Ethereum. The 555 ETH and 79 ETH challenge bonds can be put together via a trustless bonding pool, and do not all have to be put up by the validator that opened the challenge. These bonds can be refunded at the end of a challenge and can also alternatively be put together by the community using a trustless bonding pool.
80 |
81 | #### Centralization concerns
82 |
83 | Requiring a high bond to post assertions about Arbitrum seems centralizing, as we are replacing an allowlist of validators with a system that requires substantial funds to participate. However, BoLD ships with a trustless bonding pool for assertion posting. That is, any group of honest parties can pool funds into a simple contract that will post an assertion to Ethereum without needing to trust each other. We believe that making it easy to pool the funds to become an assertion poster without needing trust to dispute invalid claims does not affect the safety or decentralization of BoLD.
84 |
85 | We claim optimizing for the unhappy case is more important than the happy case. As there only needs to be one honest assertion poster, we believe it falls into the security budget of the chain to set a high bond fee in order to become a proposer. It should be expensive to delay Arbitrum One withdrawals, and it should also have a high barrier to entry to perform a key responsibility. As long as disputes can be made in a trustless manner, and trustless pools are available in production, we claim the security properties of assertion posting hold equally.
86 |
87 | ## Resolving disputes
88 |
89 | One of the core properties BoLD achieves is providing a fixed upper bound for dispute resolution times. This section will discuss the constraints required to achieve this from first principles.
90 |
91 | ### Dispute game overview
92 |
93 | Every game between adversarial parties needs a referee: a neutral party that can enforce the rules to declare a fair winner. Arbitrum BoLD relies on Ethereum as its referee because of its properties as the most decentralized, censorship-resistant smart contract chain in the world.
94 |
95 | When a dispute happens about Arbitrum One assertions on Ethereum, there is a protocol for resolving them. At its core, a dispute is about the blockhash of an Arbitrum One block at a given height. Ethereum does not know which claim is correct and, instead, relies on a dispute game to be played out. The game involves different parties making claims with proof to eventually narrow down their disagreement to a single step of execution within the execution of a block, called a one-step proof (OSP). Ethereum can then verify this OSP by itself and, as the neutral referee, declare a winner.
96 |
97 | The "rules" of the dispute involve parties making claims with proof to reach the single point of disagreement. Parties "narrow down" their claims via moves called bisections. After a party has made a bisection, there is nothing else left to do until another party comes in and counters it. The core of the system is that an honest party winning a one-step proof leaves the malicious party with no other moves to make. Once the honest party has accumulated enough time without being countered, it is declared the winner.
98 |
99 | Compared to other dispute protocols, however, BoLD is not a dispute between two specific Ethereum addresses, such as Alice and Bob. Instead, it is a dispute between an absolute, correct history vs. an incorrect one. Claims in BoLD are not attached to a particular address or validator but instead to Merkle commitments of an Arbitrum chain's history. If Alice and Charlie are both honest, and Bob is malicious, Alice and Charlie can play the game as part of a single "team". If Alice goes offline in the middle of a dispute-game, Charlie can continue resolving the game on behalf of the honest team because Charlie and Alice claim and make moves on the correct history. This is why we say BoLD enables "trustless cooperation," as there is no need for communication between honest parties. We believe committing a set of chain history hashes instead of a specific hash at a moment in time is crucial for securing dispute protocols.
100 |
101 | ### Spamming the dispute game
102 |
103 | BoLD is a dispute-game in which the party that has accumulated seven days "not-countered" wins. That is, parties are incentivized to counter any new claims as soon as they appear to "block" their rivals from increasing their timers. For honest parties, responding to claims may sometimes require offchain computational work and, therefore, resources such as CPUs. However, malicious parties can make claims that are eventually found to be junk while making honest parties do actual work.
104 |
105 | Because malicious parties can submit incorrect claims that make honest parties do work, there has to be an economic cost associated with making moves in the dispute-game. Said differently, we need a way to prevent spam attacks in dispute games.
106 |
107 | #### The cost of moves
108 |
109 | When pricing the bonds required to make claims within disputes, we consider the marginal costs that the honest party incurs for each claim a malicious party makes. The BoLD research paper includes information such as the number of adversary moves multiplied by the gas cost of making bisections and claims and some estimates of the offchain computational costs. We deem this the marginal cost of a party in a dispute.
110 |
111 | With BoLD, the space of disagreements between parties is of max size 2^69. As such, the dispute game has to be played at different levels of granularity to make it computationally feasible.
112 |
113 | Let's use an analogy: say we have two one-meter sticks that seem identical, and we want to determine where they differ. They appear identical at the centimeter level, so we need to go down to the millimeter level, then the micrometer level, and then figure out where they differ at the nanometer level.
114 |
115 | This is what BoLD does over the space of disputes. Parties play the same game at different levels of granularity. At the centimeter level, each centimeter could trigger a millimeter dispute, and each millimeter dispute could have many micrometer disputes, etc. This dispute pattern could be abused unless spam is discouraged.
116 |
117 | #### Preventing spam
118 |
119 | Since Ethereum knows nothing about which claims are honest or malicious until a one-step proof is provided, how can the protocol detect and discourage spam? A key insight is that honest parties only need to make one honest claim. Honest parties will never spam and create thousands of conflicting claims with themselves. Given this, we can put a price tag on making moves by looking at something called the "resource ratio" between honest and malicious parties, as defined in the BoLD research paper.
120 |
121 | This ratio is computed as gas plus staking (or bonding) marginal costs of the adversary to the honest party. This means that certain values input into the equations can lead to different ratios. For instance, we can say the adversary has to pay 10x the marginal costs of the honest party. However, aiming to increase this ratio significantly by plugging in different values leads to higher costs for all parties.
122 |
123 | #### Dispute mini-bonds
124 |
125 | We require parties to lock up some capital called a "mini-bond" when making big claims in a dispute. These bonds are not needed when making bisection moves but are critical for posting an initial claim. Pricing these mini-bonds helps achieve a high resource ratio of dishonest parties to honest parties.
126 |
127 | It is clear that if we can multiply the cost to the malicious party by some multiplier of the honest party, we will get significant security benefits. For instance, imagine if a 1 billion dollar attack can be defended by simply pooling together 10 million dollars. Is it possible to achieve such a ratio?
128 |
129 | Let's explore the limitations of making the cost to malicious parties higher than the honest parties'.
130 |
131 | If we aim to have a constant resource ratio > 1, we have to do the following: if the adversary makes N stakes at any level, they can force the honest party to make N stakes at the next level down, where the adversary can choose not to place any stakes at all. Regarding resource ratio, to make the adversary always pay 10x in staking, we need to make the bond amount at one level 10x more than the next. As there are multiple levels, the equations for the bond size include an exponential factor on the desired constant resource ratio > 1.
132 |
133 | Below, we plot the bond size vs. the resource ratio of malicious to honest costs. The source for these equations can be found in the research paper and is represented in this calculator.
134 |
135 | If we desire a constant resource ratio of malicious to honest costs > 1, the required bond size in ETH increases as a polynomial at a particular challenge level.
136 |
137 | #### Trade-offs
138 |
139 | Having a 1000x resource ratio would be nice in theory, but it would, unfortunately, require a bond of 1M ETH ($2.56B USD at time of writing) to open a challenge in the first place, which is unreasonable. Instead, we can explore a more feasible ratio.
140 |
141 | The resource ratio will drive the price of disputes claims, impacting both honest and malicious parties. However, claims can always be made through a trustless pool. Honest parties can pool together funds to participate in disputes.
142 |
143 | #### The sweet spot
144 |
145 | So, now that we've established that a higher resource ratio is better but comes with some trade-offs, what is the sweet spot?
146 |
147 | We propose a resource of ratio of 6.46 for Arbitrum One. While odd, this resource ratio was calculated taking the initial "bond" to become a proposer (mentioned earlier) and a worst case scenario of 500 gwei/gas on L1 for posting assertions and making sub-challenge moves (i.e. if an attack were to happen, the malicious actor could choose to perform their attack during a period of elevated gas prices). Again, we should emphasize that the ratio of malicious to honest cost should be high to sufficiently deter attacks. Under our current assumptions (500gwei/gas) and proposed parameters (bond sizes, etc) for every $6.46 spent by malicious parties attacking, only $1 is needed to defend it successfully in BoLD. Here's a direct link to the calculations where the X-axis is L1 gas costs in gwei and the Y-axis is the resource ratio.
148 |
149 | Unfortunately, there is no "one size fits all" framework for choosing the resource ratio for your chain. Therefore, we recommend teams learn and understand the benefits and trade-offs of operating BoLD in a permissionless format - including performing the same type of economic risk analyses we have performed for Arbitrum One.
150 |
151 | ## Thinking about incentives
152 |
153 | Although we have made claims with hard numbers about how to price disputes and withdrawal delays in Arbitrum BoLD, we also took a step back and considered the theoretical assumptions we were making. Arbitrum One is a complex protocol used by many groups of people with different incentives. The research team at Offchain Labs has spent considerable effort studying the game theory of validators in Optimistic Rollup. Honest parties represent everyone with funds onchain, and they have a significant amount to gain by winning the challenge - as they can prevent the loss of their assets rather than losing them.
154 |
155 | A more complex model is proposed, which considers all parties staking and their associated costs paper "Incentive Schemes for Rollup Validators". The paper examines the incentives needed to get parties to check whether assertions are correct. It finds that there is no pure strategy, Nash equilibrium, and only a mixed equilibrium if there is no incentive for honest validators. However, the research showed a pure strategy equilibrium can be reached if honest parties are incentivized to check results. The problem of honest validators' "free riding" and not checking is well-documented as the verifier's dilemma. We believe future iterations of BOLD could include "attention challenges" that reward honest validators for also doing their job.
156 |
157 | ### Service fee for “Active” proposers
158 |
159 | For Arbitrum BoLD's initial launch, we believe that chain owners should pay a service fee to active, top-level proposers as a way of removing the disincentive for participation by honest parties who bond their own capital and propose assertions for Arbitrum One. The fee should be denominated in ETH and should correlate to the annualized income that Ethereum mainnet validators receive, over the same time period. At the time of writing, the estimated annual income for Ethereum mainnet validators is approximately 3% to 4% of their stake (based on CoinDesk Indices Composite Ether Staking Rate (CESR) benchmark and Rated.Network).
160 |
161 | This service fee can be paid out upon an active proposer’s top-level assertion being confirmed on Ethereum and will be calculated using the duration of time that the proposer was considered active by the protocol. The procedure that calculates this will be handled off-chain, using a procedure that will be published at a later date. BoLD makes it permissionless for any validator to become a proposer and also introduces a way to pay a service fee to honest parties for locking up capital to do so. Validators are not considered active proposers until they successfully propose an assertion with a bond.
162 |
163 | In order to become an active proposer for an Arbitrum chain, post-BoLD, a validator has to propose a state assertion to its parent chain. For Arbitrum One and Nova, the state assertion is posted onto L1 Ethereum. If they do not have an active bond on L1, they then need to attach a bond to their assertion in order to successfully post the assertion. Subsequent assertions posted by the same address will simply move the already-supplied bond to their latest proposed assertion. Meanwhile, if an entity, say Bob, has posted a successor assertion to one previously made by another entity, Alice, then Bob would be considered by the protocol to be the current active proposer. Alice would no longer be considered by the protocol as the active proposer and once Alice’s assertion is confirmed, then Alice gets her assertion bond refunded. There can only be 1 “active” proposer at any point in time.
164 |
165 | For Arbitrum One specifically, all eligible entities who wish to be paid this service fee from the Arbitrum Foundation must undergo the Arbitrum Foundation’s KYC process as no AIP "may be in violation of applicable laws, in particular sanctions-related regulations". This is also written in the ArbitrumDAO's Constitution.
166 |
167 | ### Rewards and Reimbursements for Defenders
168 |
169 | The service fee described above is meant to incentivize or reimburse an honest, active proposer for locking up their capital to propose assertions and advance the chain. Similarly, in the event of an attack, a bounty is proposed to be paid out to honest defenders using confiscated funds from malicious actors (in the event of a challenge).
170 |
171 | For Arbitrum One specifically, 1% (called the “defender’s bounty”) of the confiscated funds from a malicious actor is to be rewarded to honest parties who deposit a challenge bond and post assertions as part of a sub-challenge, proportional to the amount that a defender has put up to defend a correct state assertion during the challenge. This bounty applies for all challenges (block challenges, sub challenges and one step challenges). Note that any gas costs spent by honest parties to defend Arbitrum One during a challenge is 100% refundable by the Arbitrum Foundation. In this model, honest defenders and proposers of Arbitrum One are incentivized to participate while malicious actors stand to lose everything they spent attacking Arbitrum One. We believe chain owners who are interested in adopting BoLD for their own chain should follow a similar approach, described above for Arbitrum One, to incentivize challenge participation (but not necessarily assertion proposing).
172 |
173 | In this design, defenders are only eligible for the defender's bounty if they deposit a challenge bond (for Arbitrum One, this is either 555 or 79 ETH, depending on the level), posted to an on-chain assertion as part of a sub-challenge (i.e., not the top-level assertion), and have had their on-chain sub-challenge assertion get confirmed by the protocol. For Arbitrum One, the calculation for the defender's bounty is conducted off-chain by the Arbitrum Foundation, and payment will be made via an ArbitrumDAO governance vote (since confiscated funds go to an ArbitrumDAO-controlled address). Honest parties are not automatically rewarded with all the funds seized from malicious actors to avoid creating a situation where honest parties wastefully compete to be the first ones to make each honest move in the interactive fraud-proof game. Additionally, BoLD resolves disputes by determining which top-level assertion is correct, without necessarily being able to classify every move as “honest” or “malicious” as part of the interactive fraud-proof game without off-chain knowledge.
174 |
175 | Once all of a validator’s proposed assertions are confirmed, a validator can withdraw their bond in full. Additionally, the protocol will automatically handle refunds of challenge bonds for honest parties and confiscation of bonds from malicious parties in the event of a challenge. In other words, bonds put up by honest parties will always be returned and bonds put up by malicious parties will always be confiscated. For Arbitrum One specifically, L1 gas costs for honest parties defending a challenge will be reimbursed by the Arbitrum Foundation using a procedure that will be published at a later date. The chain owner could therefore consider the cost of incentivizing or lending the assets to a single honest proposer in the happy case as the security budget of the chain.
176 |
177 | For Arbitrum One specifically, all eligible entities who wish to be paid the defender's bounty from the ArbitrumDAO must undergo the Arbitrum Foundation’s KYC process as no AIP "may be in violation of applicable laws, in particular sanctions-related regulations". This is also written in the ArbitrumDAO's Constitution.
178 |
179 | ## Conclusion
180 |
181 | This page summarizes the rationale behind choosing bond sizes and the cost of spam prevention in Optimistic Rollup dispute protocols. We recommend that bond sizes be high enough to discourage challenges from being opened, as malicious parties will always stand to lose when playing the game. As Arbitrum BoLD does not tie disputes to specific addresses, honest parties can have trustless cooperation to resolve disputes if desired. We posit that making the cost of the malicious parties 10x that of the honest party leads to nice economic properties that help us reason about how to price bonds. Finally, we look at a high-level game theory discussion of Optimistic Rollups and argue that solving the verifier's dilemma by incentives to honest validators is an important addition to work towards.
182 |
183 | The topic of further improvements and new economic and incentive models for BoLD are valuable and we believe it deserves the full focus and attention of the community in future proposals and discussions. Details around additional or new proposed economic or incentive models for BoLD will need continued research and development work, but the deployment of BoLD as-is represents a substantial improvement to the security of Arbitrum even without economic-related concerns resolved.
184 |
1 | :::caution ALPHA RELEASE, PUBLIC PREVIEW DOCS
2 |
3 | The BoLD dispute protocol is currently deployed on a public testnet (that posts assertions to Ethereum Sepolia) and is tagged as an alpha release. The code has been audited by Trail of Bits and in a public audit competition with Code4rena, but should not be used in production scenarios. Please note that the public testnet is intended for Arbitrum users and researchers to test and experiment with the BoLD dispute protocol for the purposes of education and hardening the protocol via the surfacing of bugs. The public testnet may be paused, and its parameters may be updated at any time in response to scenarios that impact the network and its ability to fulfill its function as a working, reliable test environment. This documentation is currently in public preview.
4 |
5 | To provide feedback, click the Request an update button at the top of this document, join the Arbitrum Discord, or reach out to our team directly by completing this form.
6 |
7 | :::
8 |
1 | ---
2 | title: 'Public preview: What to expect'
3 | sidebar_label: 'Public preview'
4 | description: 'BoLD is currently tagged as an alpha release supported by public preview documentation. This concept document explains what this means, and what to expect.'
5 | author: symbolpunk
6 | sidebar_position: 10
7 | ---
8 |
9 | BoLD, Arbitrum's new dispute protocol, is currently tagged as an alpha release supported by public preview documentation. This concept document explains what "public preview" means, what to expect from public preview capabilities, and how to engage with our team as you tinker.
10 |
11 | ### How products are developed at Offchain Labs
12 |
13 | Offchain Labs builds products in a way that aligns loosely with the spirit of "building in public". We like to release things early and often so that we can capture feedback and iterate in service of your needs, as empirically as possible.
14 |
15 | To do this, some of our product offerings are documented with public preview disclaimers that look like this:
16 |
17 | This banner's purpose is to set expectations while inviting readers like you to express your needs so that we can incorporate them into the way that we iterate on product.
18 |
19 | ### What to expect when using public preview offerings
20 |
21 | As you tinker and provide feedback, we'll be listening. Sometimes, we'll learn something non-obvious that will result in a significant change. More commonly, you'll experience incremental improvements to the developer experience as the offering grows out of its public preview status, towards stable status.
22 |
23 | Public preview offerings are evolving rapidly, so don't expect the degree of release notes discipline that you'd expect from a stable offering. Keep your eyes open for notifications regarding patch, minor, and major changes, along with corresponding relnotes that highlight breaking changes and new capabilities.
24 |
25 | ### How to provide feedback
26 |
27 | Our product team primarily uses three feedback channels while iterating on public preview capabilities:
28 |
29 | 1. Docs: Click on the Request an update button located in the top-right corner of any document to provide feedback on the docs and/or developer experience. This will lead you to a prefilled Github issue that members of our product team periodically review.
30 | 2. Discord: Join the Arbitrum Discord to engage with members of the Arbitrum community and product team.
31 | 3. Google form: Complete this form to ask for support.
32 |
33 | ### What to expect when providing feedback
34 |
35 | Our ability to respond to feedback is determined by our ever-evolving capacity and priorities. We can't guarantee responses to all feedback submissions, but our small-but-mighty team is listening, and we'll try our best to acknowledge and respond to your feedback. No guarantees though!
36 |
37 | PS, our small-but-mighty team is hiring.
38 |
39 | ### Thank you!
40 |
41 | Thanks for helping us build things that meet your needs! We're excited to engage with OGs and newcomers alike; please don't hesitate to reach out.
42 |
1 | ---
2 | title: 'A gentle Introduction: Timeboost'
3 | sidebar_label: 'A gentle introduction'
4 | description: 'Learn how Timeboost works and how it can benefit your Arbitrum-based project.'
5 | author: leeederek
6 | sme: leeederek
7 | user_story: As a current or prospective Arbitrum user, I want to understand how Timeboost works and how to use it.
8 | content_type: gentle-introduction
9 | ---
10 |
11 | import ImageWithCaption from '@site/src/components/ImageCaptions/';
12 |
13 | This introduction will walk you through Arbitrum Timeboost: a novel transaction ordering policy for Arbitrum chains that allows chain owners to capture the Maximal Extractable Value (MEV) on their chain and reduce spam, all while preserving fast block times and protecting users from harmful types of MEV, such as sandwich attacks and front-running.
14 |
15 | Timeboost is the culmination of over a year of research and development by the team at Offchain Labs and will soon be available for any Arbitrum chain, including Arbitrum One and Arbitrum Nova (should the Arbitrum DAO choose to adopt it). Like all features and upgrades to the Arbitrum technology stack, Timeboost will be rolled out on Arbitrum Sepolia first for testing, and chain owners will have the option of adopting Timeboost at any time or customizing Timeboost in any way they choose.
16 |
17 | ### In a nutshell
18 |
19 | - The current "First-Come, First-Serve (FCFS)" ordering policy has many benefits, including a great UX and protection from harmful types of MEV. However, nearly all MEV on the chain is extracted by searchers who invest wastefully in hardware and spamming to win latency races (which negatively strains the network and leads to congestion). Timeboost is a new transaction ordering policy that preserves many of the great benefits of FCFS while unlocking a path for chain owners to capture some of the available MEV on their network and introducing an auction to reduce latency, racing, and, ultimately, spam.
20 | - Timeboost introduces a few new components to an Arbitrum chain’s infrastructure: a sealed-bid second-price auction and a new "express lane" at an Arbitrum chain’s sequencer. Valid transactions submitted to the express lane will be sequenced immediately with no delay, while all other transactions submitted to the chain’s sequencer will experience a nominal delay (default: 200ms). The auction winner is granted the sole right to control the express lane for pre-defined, temporary intervals. The default block time for Arbitrum chains will continue to be industry-leading at 250ms, even with Timeboost enabled. What will change with Timeboost is that some transactions not in the express lane will be delayed to the next block.
21 | - Timeboost is an optional feature for Arbitrum chains aimed at two types of groups of entities: (1) chain owners and their ecosystems and (2) sophisticated on-chain actors and searchers. Chain owners can use Timeboost to capture additional revenue from the MEV their chain generates already, and sophisticated on-chain actors and searchers will spend their resources on buying rights for the express lane (instead of spending those resources on winning latency races, which otherwise leads to spam and congestion on the network).
22 | - Timeboost will work with both centralized and decentralized sequencer setups. The specification for a centralized sequencer is public (here) and the proposal before the Arbitrum DAO allows us to deliver Timeboost to market sooner, rather than waiting until the design with a decentralized sequencer set up and its implementation are complete.
23 |
24 | ## Why do Arbitrum chains need Timeboost?
25 |
26 | Today, Arbitrum chains order incoming transactions on a "First-Come, First-Serve (FCFS)" basis. This ordering policy was chosen as the default for Arbitrum chains because it is simple to understand and implement, enables fast block times (starting at 250ms and down to 100ms if desired), and protects users from harmful types of MEV like front-running & sandwich attacks.
27 |
28 | However, there are a few downsides to an FCFS ordering policy. Under FCFS, searchers are incentivized to participate in and try to win latency races through investments in off-chain hardware. This means that for searchers on Arbitrum chains, generating a profit from arbitrage and liquidation opportunities involves a lot of spam, placing stress on chain infrastructure and contributing to congestion. Additionally, all of the captured MEV on an Arbitrum chain today under FCFS goes to searchers - returning none of the available MEV to the chain owner or the applications on the chain.
29 |
30 | Timeboost retains most FCFS benefits while addressing FCFS limitations.
31 |
32 | #### Timeboost preserves the great UX that Arbitrum chains are known for
33 |
34 | - The default block time for Arbitrum chains will continue to be industry-leading at 250ms, even after Timeboost. What will change with Timeboost is that some transactions not in the express lane will be delayed to the next block.
35 |
36 | #### With Timeboost, Arbitrum chains will continue to protect users from harmful types of MEV
37 |
38 | - Timeboost only grants the auction winner a temporary time advantage - not the power to view or reorder incoming transactions or be the first in every block. Furthermore, the transactions mempool will continue to be private, which means users with Timeboost enabled will continue to be protected from harmful MEV-like front-running and sandwich attacks.
39 |
40 | #### Timeboost unlocks a new value accrual path for chain owners
41 |
42 | - Chain owners may use Timeboost to capture a portion of the available MEV on their chain that would have otherwise gone entirely to searchers. There are many flavors of this, too - including custom gas tokens and/or redistribution of these proceeds back to the applications and users on the chain.
43 |
44 | #### Timeboost may help reduce spam and congestion on a network
45 |
46 | - By introducing the ability to “purchase a time advantage” through the Timeboost auction, it is expected that rational, profit-seeking actors will spend on auctions instead of investing in hardware or infrastructure to win latency races. This diversion of resources by these actors is expected to reduce FCFS MEV-driven spam on the network.
47 |
48 | ## What is Timeboost, and how does it work?
49 |
50 | Timeboost is a transaction ordering policy. It's a set of rules that the sequencer of an Arbitrum chain is trusted to follow when ordering transactions submitted by users. In the near future, multiple sequencers will be able to enforce those rules with decentralized Timeboost.
51 |
52 | For Arbitrum chains, the sequencer’s sole job is to take arriving, valid transactions from users, place them into an order dictated by the transaction ordering policy, and then publish the final sequence to a real-time feed and in compressed batches to the chain’s data availability layer. The current transaction ordering policy is FCFS, and Timeboost is a modified FCFS ordering policy.
53 |
54 | Timeboost is implemented using three separate components that work together:
55 |
56 | - A special “express lane” which allows valid transactions to be sequenced as soon as the sequencer receives them for a given round.
57 | - An off-chain auction to determine the controller of the express lane for a given round. This auction is managed by an autonomous auctioneer.
58 | - An auction contract deployed on the target chain to serve as the canonical source of truth for the auction results and handling of auction proceeds.
59 |
60 | To start, the default duration of a round is 60 seconds. Transactions not in the express lane will be subject to a default 200-millisecond artificial delay to their arrival timestamp before their transaction is sequenced, which means that some non-express lane transactions may get delayed to the next block. It’s important to note that the default Arbitrum block time will remain at 250 milliseconds (which can be adjusted to 100 milliseconds if desired). Let’s dive into how each of these components works.
61 |
62 | ### The express lane
63 |
64 |  65 | The express lane is implemented using a special endpoint on the sequencer, formally titled
65 | The express lane is implemented using a special endpoint on the sequencer, formally titled timeboost_sendExpressLaneTransaction. This endpoint is special because transactions submitted to it will be sequenced immediately by the sequencer, hence the name, express lane. The sequencer will only accept valid transaction payloads to this endpoint if they are correctly signed by the current round’s express lane controller. Other transactions can still be submitted to the sequencer as normal, but these will be considered non-express lane transactions and will, therefore, have their arrival timestamp delayed by 200 milliseconds. It is important to note that transactions from both the express and non-express lanes are eventually sequenced into a single, ordered stream of transactions for node operators to produce an assertion and later post the data to a data availability layer. The express lane controller does not:
66 |
67 | - Have the right to re-order transactions.
68 | - Have a guarantee that their transactions will always be first at the “top-of-the-block.”
69 | - Guarantee a profit at all.
70 |
71 | The value of the express lane will be the sum of how much MEV the express lane controller predicts they can extract during the upcoming round (i.e., MEV opportunity estimates made before the auction closes) plus the amount of MEV extracted by the express lane controller while they are in control (that they otherwise did not predict). Understanding how the value of the express lane is determined can be useful for chain owners when adjusting to the artificial delay and the time before the auction closes.
72 |
73 | ### The Timeboost auction
74 |
75 | Control of the express lane in each round (default: 60 seconds) is determined by a per-round auction, which is a sealed-bid, second-price auction. This auction is held to determine the express lane controller for the next round. In other words, the express lane controller was determined at any point in time in the previous auction round. Bids for the auction can be made with any ERC20 token, in any amount, and be collected by any address - at the full discretion of the chain owner.
76 |
77 |  78 |
79 | The auction for a round has a closing time that is
78 |
79 | The auction for a round has a closing time that is auctionClosingSeconds (default: 15) seconds before the beginning of the round. This means that, in the default parameters, parties have 45 seconds to submit bids before the auction will no longer accept bids. In the 15 seconds between when bids are no longer accepted and when the new round begins, the autonomous auctioneer will verify all bids, determine the winner, and make a call to the on-chain auction contract to formally resolve the auction.
80 |
81 | ### Auction contract
82 |
83 | Before placing a bid in the auction, a party must deposit funds into the Auction Contract. Deposits can be made, or funds can be added to an existing deposit at any time. These deposits are fully withdrawable, with some nominal delay (2 rounds, or 2 minutes by default), so as not to impact the outcome of an existing round. There is no minimum deposit amount, but there is a starting minimum bid of 0.001 ETH (default amount and token) called the "minimum reserve price". The minimum reserve price is set by the chain owner and can be updated at any time up to 30 seconds (default) before the start of the next round to ensure the auction participants will always know the reserve price at least 30 seconds before they must submit their bids. A reserve price can also be set by the chain owner (or by an address designated by the chain owner) as a way to raise the minimum bid as the Auction Contract enforces that the reserve price is never less than the minimum reserve price.
84 |
85 |  86 |
87 | Once the autonomous auctioneer determines an auction winner, the auction contract will deduct the second-highest bid amount from the account of the highest bidder and transfer those funds to a
86 |
87 | Once the autonomous auctioneer determines an auction winner, the auction contract will deduct the second-highest bid amount from the account of the highest bidder and transfer those funds to a beneficiary account designated by the chain owner by default. The expressLaneControllerAddress specified in the highest bid will become the express lane controller for the round.
88 |
89 | The auction contract also has functions that enable the express lane controller to update the address they wish to use for the express lane, which allows unique express lane control reselling use cases.
90 |
91 | ### Default parameters
92 |
93 | Below are a few of the default Timeboost parameters mentioned earlier. All these parameters and more are configurable by the chain owner.
94 |
95 | | Parameter name | Description | Recommended default value |
96 | | ----------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------ |
97 | | roundDurationSeconds | Duration of time that the sequencer will honor the express lane privileges for transactions signed by the current round’s express lane controller. | 60 seconds |
98 | | auctionClosingSeconds | Time before the start of the next round. The autonomous auctioneer will not accept bids during this time interval. | 15 seconds |
99 | | beneficiary | Address where proceeds from the Timeboost auction are sent to when flushBeneficiaryBalance() gets called on the auction contract. | An address controlled by the chain's owner |
100 | | _biddingToken | Address of the token used to make bids in the Timeboost auction. It can be any ERC20 token (assuming the token address chosen does not have fee-on-transfer, rebasing, transfer hooks, or otherwise non-standard ERC20 logic). | WETH |
101 | | nonExpressDelayMsec | The artificial delay applied to the arrival timestamp of non-express lane transactions before the non-express lane transactions are sequenced. | 0.2 seconds, or 200 milliseconds |
102 | | reservePrice | The minimum bid amount accepted by the auction contract for Timeboost auctions, denominated in _biddingToken. | None |
103 | | _minReservePrice | A value that must be equal to or below the reservePrice to act as a "floor minimum" for Timeboost bids. Enforced by the auction contract. | 0.001 WETH |
104 |
105 | ## Who is Timeboost for, and how do I use it?
106 |
107 | Timeboost is an optional addition to an Arbitrum chain’s infrastructure, meaning that enabling Timeboost is at the discretion of the chain owner and that an Arbitrum chain can fully function normally without Timeboost.
108 |
109 | When enabled, Timeboost is meant to serve different groups of parties with varying degrees of impact and benefits. Let’s go through them below:
110 |
111 | #### For regular users:
112 |
113 | Timeboost will have a minimal impact. Non-express lane transactions will be delayed by a nominal 200ms, which means to the average user, their transactions will take approximately 450ms to be sequenced and included into a block (up from approximately 200ms). All users will remain protected from harmful MEV activity, such as sandwich attacks and front-running, through the continued use of a private mempool.
114 |
115 | #### For chain owners:
116 |
117 | Timeboost represents a unique way to accrue value to their token and generate revenue for the chain. Explicitly, chain owners can set up their Timeboost auction to collect bid proceeds in the same token used for gas on their network and then choose what to do with these proceeds afterward.
118 |
119 | #### For searchers/arbitrageurs:
120 |
121 | Timeboost adds a unique twist to your existing or prospective MEV strategies that may become more profitable than before. For instance, purchasing the time advantage offered by Timeboost’s auction may end up costing less than the costs to invest in hardware and win latency races. Another example is the potential new business model of reselling express lane rights to other parties in time slots or on a granular, per-transaction basis.
122 |
123 | ### Special note on Timeboost for chain owners
124 |
125 | As with many new features and upgrades to Arbitrum Nitro, Timeboost is an optional feature that chain owners may choose to deploy and customize however they see fit. Deploying and enabling/disabling Timeboost on a live Arbitrum chain will not halt or impact the chain but will instead influence the chain's transaction ordering policy. An Arbitrum chain will, by default, fall back to FCFS if Timeboost is deployed but disabled or if there is no express lane controller for a given round.
126 |
127 | It is recommended that Arbitrum teams holistically assess the applicability and use cases of Timeboost for their chain before deploying and enabling Timeboost. This is because some Arbitrum chains may not have that much MEV (e.g., arbitrage) to begin with. Furthermore, we recommend that Arbitrum chains start with the default parameters recommended by Offchain Labs and closely monitor the results and impacts on your chain’s ecosystem over time before considering adjusting any of the parameters.
128 |
129 | ### Wen mainnet?
130 |
131 | Timeboost’s auction contract has completed a third-party audit and is rapidly approaching production readiness. Specifically for Arbitrum One and Arbitrum Nova, a temperature check vote on Snapshot has already passed and the AIP will move towards an on-chain Tally vote next hopefully before the end of Q1 2025.
132 |
133 | In the meantime, please read the following resources to learn more about Timeboost:
134 |
135 | - Arbitrum DAO Forum Post on Timeboost
136 | - Timeboost FAQ
137 | - Debunking common misconceptions about Timeboost
138 | - Technical specification for Timeboost with a centralized sequencer
139 | - Engineering design of Timeboost with a centralized sequencer
140 | - Implementation of Timeboost with a centralized sequencer
141 | - Technical specification for Timeboost with a decentralized sequencer
142 | - Audit report for Timeboost auction contracts
143 |