On a single-threaded CPU, we execute a program containing n functions. Each function has a unique ID between 0 and n-1.
Function calls are stored in a call stack: when a function call starts, its ID is pushed onto the stack, and when a function call ends, its ID is popped off the stack. The function whose ID is at the top of the stack is the current function being executed. Each time a function starts or ends, we write a log with the ID, whether it started or ended, and the timestamp.
You are given a list logs, where logs[i] represents the ith log message formatted as a string "{function_id}:{"start" | "end"}:{timestamp}". For example, "0:start:3" means a function call with function ID 0 started at the beginning of timestamp 3, and "1:end:2" means a function call with function ID 1 ended at the end of timestamp 2. Note that a function can be called multiple times, possibly recursively.
A function's exclusive time is the sum of execution times for all function calls in the program. For example, if a function is called twice, one call executing for 2 time units and another call executing for 1 time unit, the exclusive time is 2 + 1 = 3.
Return the exclusive time of each function in an array, where the value at the ith index represents the exclusive time for the function with ID i.
Example 1
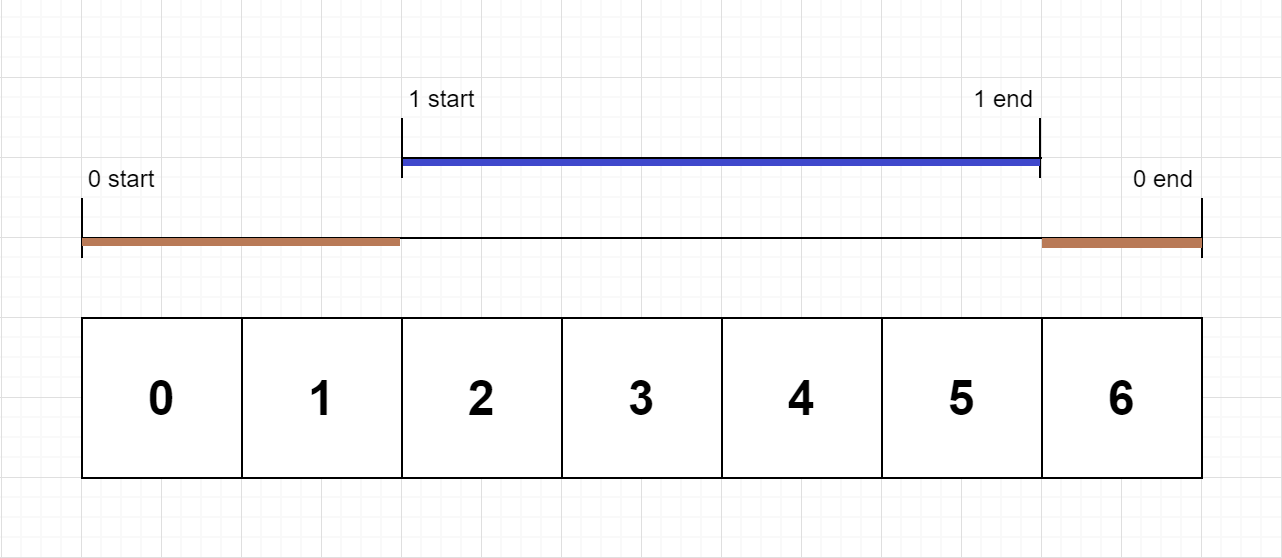
Input: n = 2, logs = ["0:start:0","1:start:2","1:end:5","0:end:6"] Output: [3,4] Explanation: Function 0 starts at the beginning of time 0, then it executes 2 for units of time and reaches the end of time 1. Function 1 starts at the beginning of time 2, executes for 4 units of time, and ends at the end of time 5. Function 0 resumes execution at the beginning of time 6 and executes for 1 unit of time. So function 0 spends 2 + 1 = 3 units of total time executing, and function 1 spends 4 units of total time executing.
Example 2
Input: n = 1, logs = ["0:start:0","0:start:2","0:end:5","0:start:6","0:end:6","0:end:7"] Output: [8] Explanation: Function 0 starts at the beginning of time 0, executes for 2 units of time, and recursively calls itself. Function 0 (recursive call) starts at the beginning of time 2 and executes for 4 units of time. Function 0 (initial call) resumes execution then immediately calls itself again. Function 0 (2nd recursive call) starts at the beginning of time 6 and executes for 1 unit of time. Function 0 (initial call) resumes execution at the beginning of time 7 and executes for 1 unit of time. So function 0 spends 2 + 4 + 1 + 1 = 8 units of total time executing.
Example 2
Input: n = 2, logs = ["0:start:0","0:start:2","0:end:5","1:start:6","1:end:6","0:end:7"] Output: [7,1] Explanation: Function 0 starts at the beginning of time 0, executes for 2 units of time, and recursively calls itself. Function 0 (recursive call) starts at the beginning of time 2 and executes for 4 units of time. Function 0 (initial call) resumes execution then immediately calls function 1. Function 1 starts at the beginning of time 6, executes 1 unit of time, and ends at the end of time 6. Function 0 resumes execution at the beginning of time 6 and executes for 2 units of time. So function 0 spends 2 + 4 + 1 = 7 units of total time executing, and function 1 spends 1 unit of total time executing.
Constraints:
1 <= n <= 1001 <= logs.length <= 5000 <= function_id < n0 <= timestamp <= 109- No two start events will happen at the same timestamp.
- No two end events will happen at the same timestamp.
- Each function has an
"end"log for each"start"log.
- First of all, this is a medium-level question. So it's a bit trickier to find the solution than the last note, which is fairly straight-forward. However, if you can find the solution without too much effort, you should give yourself some credits, because you are doing a pretty good job with stack problems!
- So our goal this time is to convert this problem to a easy level question and let's find out how.
- One thing I always try to remember is that based on the "behavior" of the problem, a proper data structure will get you very close to a (near) optimal solution.
- So let's anaylze what behavior this problem shows us.
- Let's look at example 1, so it looks like "function
0starts at time0, function1starts at time2, function1ends at time5, and function0ends at time6". - This is almost like telling us we should use stack. Why?
- First, it's about function calls in function calls, so "stack-y", lol!
- Second, there's this typical "cancellation" operation. So when a function call ends, it kinda "cancels" itself, meaning, we can record its current running time, and don't have to care about it anymore. (We do need to add the exclusive time to this function if we find that it's called again, but that's a different story.)
- So we should be pretty convinced that a stack will help us for this one. So let's see.
- If we meet a "start" event, we enqueue this event. What information do we need? At least we need to record the timestamp, so we know when this event happened.
- If we meet an "end" event, we know it's time to calculate the exclusive time. From the event
"function_id:end:timestamp", we know the function id, the event end timestamp. And we can pop the top of the stack, we know it is the start timestamp for the same function id (think about it why?), so we can simply subtract the end and start timestamp to get the exclusive time. - However, this is just a very simple case. It's like the function
1in Example 1. But it won't work for function0, right? - Because function
1takes up the cpu before end of function0, we cannot simply subtract the end and start event timestamp to get the exclusive time. So what's missing? - It's not too hard to find out that, the missing piece is that a function's execution time is
"its running interval (end timestamp - start timestamp)"-"time duration taken by other functions". So if we can figure out the time taken by other functions, we can solve it easily. - So again, if we look at the Example
1, we can see that the "time taken by function1" is exactly "the end timestamp - start timestamp of function1". Ah, that makes sense, lol. - Basically, when we meet the end event and pop the start event, we need to pass the information of "time taken by current function" to the previous function, so when we calculate the exclusive time for the previous function, we know how much time we need to subtract. And this works perfectly for more than 1 nested levels too, because the idea is the same.
- So we need to record the information "time taken by other functions" in the stack too. That's why we need to record the "timestamp" and "time take by others" in the code. The code should make more sense now.
- Also we need to record exclusive time for each function, we can just use an array to record the exclusive times for all functions since the indices are from
0-n-1. And we already know recording into or accessing of an array is very efficient (O(1)). So, sweet! - Thanks for reading, let me know if you have any questions.
const exclusiveTime = function(n, logs) {
const ans = new Array(n).fill(0);
const stack = []; // [start/end timestamp, timeTakenByOthers]
for (const log of logs) {
const [funcId, dir, timestamp ] = log.split(':');
if (dir == 'start') {
stack.push([timestamp, 0]);
} else if (dir == 'end') {
// now timestamp is the endTime timestamp, because
// the function runs in a FILO manner
const [startTime, timeTakenByOthers] = stack.pop();
// get run time for current funcId
const funcRunTime = timestamp - startTime + 1;
ans[funcId] += funcRunTime - timeTakenByOthers;
// if stack is not empty, meaning we have func running
// meaning we only recorded its start time, but not end time
// update its time taken by other function
// this time will be populated to previous function if
// the functions calls are nested
if (stack.length) {
stack[stack.length-1][1] += funcRunTime;
}
}
}
return ans;
};