| title | Learn Accessibility | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | Learn Accessibility | ||||||||||
| seo |
|
||||||||||
| template | docs |
Created
June 17, 2022 04:06
-
-
Save bgoonz/2ae2ed84072bb28ae4d87a5f22c62b10 to your computer and use it in GitHub Desktop.
blog-docs
| title | Apendix | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | resources | ||||||||||
| seo |
|
||||||||||
| template | docs |
This appendix is a non-exhaustive list of new syntactic features and methods that were added to JavaScript in ES6. These features are the most commonly used and most helpful.
While this appendix doesn't cover ES6 classes, we go over the basics while learning about components in the book. In addition, this appendix doesn't include descriptions of some larger new features like promises and generators. If you'd like more info on those or on any topic below, we encourage you to reference the Mozilla Developer Network's website (MDN).
If you've worked with ES5 JavaScript before, you're likely used to seeing variables declared with var:
ar myVariable = 5;
Both the const and let statements also declare variables. They were introduced in ES6.
Use const in cases where a variable is never re-assigned. Using const makes this clear to whoever is reading your code. It refers to the "constant" state of the variable in the context it is defined within.
If the variable will be re-assigned, use let.
We encourage the use of const and let instead of var. In addition to the restriction introduced by const, both const and let are block scoped as opposed to function scoped. This scoping can help avoid unexpected bugs.
There are three ways to write arrow function bodies. For the examples below, let's say we have an array of city objects:
onst cities = [
{ name: 'Cairo', pop: 7764700 },
{ name: 'Lagos', pop: 8029200 },
];
If we write an arrow function that spans multiple lines, we must use braces to delimit the function body like this:
const formattedPopulations = cities.map((city) => {
const popMM = (city.pop / 1000000).toFixed(2);
return popMM + ' million';
});
console.log(formattedPopulations);
Note that we must also explicitly specify a return for the function.
However, if we write a function body that is only a single line (or single expression) we can use parentheses to delimit it:
const formattedPopulations2 = cities.map((city) => (
(city.pop / 1000000).toFixed(2) + ' million'
));
Notably, we don't use return as it's implied.
Furthermore, if your function body is terse you can write it like so:
const pops = cities.map(city => city.pop);
console.log(pops);
The terseness of arrow functions is one of two reasons that we use them. Compare the one-liner above to this:
const popsNoArrow = cities.map(function(city) { return city.pop });
Of greater benefit, though, is how arrow functions bind the this object.
The traditional JavaScript function declaration syntax (function () {}) will bind this in anonymous functions to the global object. To illustrate the confusion this causes, consider the following example:
unction printSong() {
console.log("Oops - The Global Object");
}
const jukebox = {
songs: [
{
title: "Wanna Be Startin' Somethin'",
artist: "Michael Jackson",
},
{
title: "Superstar",
artist: "Madonna",
},
],
printSong: function (song) {
console.log(song.title + " - " + song.artist);
},
printSongs: function () {
this.songs.forEach(function(song) {
this.printSong(song);
});
},
}
jukebox.printSongs();
The method printSongs() iterates over this.songs with forEach(). In this context, this is bound to the object (jukebox) as expected. However, the anonymous function passed to forEach() binds its internal this to the global object. As such, this.printSong(song) calls the function declared at the top of the example, not the method on jukebox.
JavaScript developers have traditionally used workarounds for this behavior, but arrow functions solve the problem by capturing the this value of the enclosing context. Using an arrow function for printSongs() has the expected result:
printSongs: function () {
this.songs.forEach((song) => {
this.printSong(song);
});
},
}
jukebox.printSongs();
For this reason, throughout the book we use arrow functions for all anonymous functions.
ES6 formally supports modules using the import/export syntax.
Named exports
Inside any file, you can use export to specify a variable the module should expose. Here's an example of a file that exports two functions:
export const sayHi = () => (console.log('Hi!'));
export const sayBye = () => (console.log('Bye!'));
const saySomething = () => (console.log('Something!'));
Now, anywhere we wanted to use these functions we could use import. We need to specify which functions we want to import. A common way of doing this is using ES6's destructuring assignment syntax to list them out like this:
import { sayHi, sayBye } from './greetings';
sayHi();
sayBye();
Importantly, the function that was not exported (saySomething) is unavailable outside of the module.
Also note that we supply a relative path to from, indicating that the ES6 module is a local file as opposed to an npm package.
Instead of inserting an export before each variable you'd like to export, you can use this syntax to list off all the exposed variables in one area:
const sayHi = () => (console.log('Hi!'));
const sayBye = () => (console.log('Bye!'));
const saySomething = () => (console.log('Something!'));
export { sayHi, sayBye };
We can also specify that we'd like to import all of a module's functionality underneath a given namespace with the import * as <Namespace> syntax:
import * as Greetings from './greetings';
Greetings.sayHi();
Greetings.sayBye();
Greetings.saySomething();
Default export
The other type of export is a default export. A module can only contain one default export:
const sayHi = () => (console.log('Hi!'));
const sayBye = () => (console.log('Bye!'));
const saySomething = () => (console.log('Something!'));
const Greetings = { sayHi, sayBye };
export default Greetings;
This is a common pattern for libraries. It means you can easily import the library wholesale without specifying what individual functions you want:
import Greetings from './greetings';
Greetings.sayHi();
Greetings.sayBye();
It's not uncommon for a module to use a mix of both named exports and default exports. For instance, with react-dom, you can import ReactDOM (a default export) like this:
import ReactDOM from 'react-dom';
ReactDOM.render(
);
Or, if you're only going to use the render() function, you can import the named render() function like this:
import { render } from 'react-dom';
render(
);
To achieve this flexibility, the export implementation for react-dom looks something like this:
export const render = (component, target) => {
};
const ReactDOM = {
render,
};
export default ReactDOM;
If you want to play around with the module syntax, check out the folder code/webpack/es6-modules.
For more reading on ES6 modules, see this article from Mozilla: "ES6 in Depth: Modules".
We use Object.assign() often throughout the book. We use it in areas where we want to create a modified version of an existing object.
Object.assign() accepts any number of objects as arguments. When the function receives two arguments, it copies the properties of the second object onto the first, like so:
onst coffee = { };
const noCream = { cream: false };
const noMilk = { milk: false };
Object.assign(coffee, noCream);
It is idiomatic to pass in three arguments to Object.assign(). The first argument is a new JavaScript object, the one that Object.assign() will ultimately return. The second is the object whose properties we'd like to build off of. The last is the changes we'd like to apply:
const coffeeWithMilk = Object.assign({}, coffee, { milk: true });
Object.assign() is a handy method for working with "immutable" JavaScript objects.
In ES5 JavaScript, you'd interpolate variables into strings like this:
var greeting = 'Hello, ' + user + '! It is ' + degF + ' degrees outside.';
With ES6 template literals, we can create the same string like this:
const greeting = `Hello, ${user}! It is ${degF} degrees outside.`;
In arrays, the ellipsis ... operator will expand the array that follows into the parent array. The spread operator enables us to succinctly construct new arrays as a composite of existing arrays.
Here is an example:
onst a = [ 1, 2, 3 ];
const b = [ 4, 5, 6 ];
const c = [ ...a, ...b, 7, 8, 9 ];
console.log(c);
Notice how this is different than if we wrote:
const d = [ a, b, 7, 8, 9 ];
console.log(d);
In ES5, all objects were required to have explicit key and value declarations:
const explicit = {
getState: getState,
dispatch: dispatch,
};
In ES6, you can use this terser syntax whenever the property name and variable name are the same:
const implicit = {
getState,
dispatch,
};
Lots of open source libraries use this syntax, so it's good to be familiar with it. But whether you use it in your own code is a matter of stylistic preference.
With ES6, you can specify a default value for an argument in the case that it is undefined when the function is called.
This:
unction divide(a, b) {
const divisor = typeof b === 'undefined' ? 1 : b;
return a / divisor;
}
Can be written as this:
function divide(a, b = 1) {
return a / b;
}
In both cases, using the function looks like this:
divide(14, 2);
divide(14, undefined);
divide(14);
Whenever the argument b in the example above is undefined, the default argument is used. Note that null will not use the default argument:
divide(14, null);
In ES5, extracting and assigning multiple elements from an array looked like this:
ar fruits = [ 'apples', 'bananas', 'oranges' ];
var fruit1 = fruits[0];
var fruit2 = fruits[1];
In ES6, we can use the destructuring syntax to accomplish the same task like this:
const [ veg1, veg2 ] = [ 'asparagus', 'broccoli', 'onion' ];
console.log(veg1);
console.log(veg2);
The variables in the array on the left are "matched" and assigned to the corresponding elements in the array on the right. Note that 'onion' is ignored and has no variable bound to it.
We can do something similar for extracting object properties into variables:
const smoothie = {
fats: [ 'avocado', 'peanut butter', 'greek yogurt' ],
liquids: [ 'almond milk' ],
greens: [ 'spinach' ],
fruits: [ 'blueberry', 'banana' ],
};
const { liquids, fruits } = smoothie;
console.log(liquids);
console.log(fruits);
We can use these same principles to bind arguments inside a function to properties of an object supplied as an argument:
const containsSpinach = ({ greens }) => {
if (greens.find(g => g === 'spinach')) {
return true;
} else {
return false;
}
};
containsSpinach(smoothie);
We do this often with functional React components:
const IngredientList = ({ ingredients, onClick }) => (
<ul className='IngredientList'>
{
ingredients.map(i => (
<li
key={i.id}
onClick={() => onClick(i.id)}
className='item'
>
{i.name}
</li>
))
}
</ul>
)
Here, we use destructuring to extract the props into variables (ingredients and onClick) that we then use inside the component's function body.
| title | Archive | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | more tools that I have created or collaborated on. | ||||||||||
| seo |
|
||||||||||
| template | docs |
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://resourcerepo2.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://drive.google.com/embeddedfolderview?id=1DHyQsPLziqSUODclplhnNX1eknzbZrL8#list" style="width:100%; height:600px; border:0;"> </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://archive.org/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://lambda-resources.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://bgoonz.github.io/bass-station/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://web-dev-interview-prep-quiz-website.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe class="<iframe " src="https://random-static-html-deploys.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe class="<iframe " src="https://thealgorithms.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe class="<iframe " src="https://markdown-templates-42.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe class="<iframe " src="https://bgoonz.github.io/everything-curl/index.html" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://devtools42.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://ternary42.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://githtmlpreview.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://fourm-builder-gui.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://codepen.io/bgoonz/embed/zYwLVmb?default-tab=html%2Cresult" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" src="https://web-dev-resource-hub.netlify.app/" height="1000px" width="1200px" scrolling="yes" frameborder="no" loading="lazy" allowtransparency="true" allowfullscreen="true" clipboard-write; allowfullscreen> </iframe>
| title | Bash Commands That Save Me Time and Frustration | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | Bash Commands That Save Me Time and Frustration | ||||||||
| seo |
|
||||||||
| template | docs |
Here's a list of bash commands that stand between me and insanity.
bgoonz/bash-commands-walkthroughThis article will be accompanied by the following > github repository > which will contain all the commands listed as well as folders that demonstrate before and after usage!
to accompany the medium article I am writing. Contribute to bgoonz/bash-commands-walkthrough development by creating an…github.com
The readme for this git repo will provide a much more condensed list… whereas this article will break up the commands with explanations… images & links!
I will include the code examples as both github gists (for proper syntax highlighting) and as code snippets adjacent to said gists so that they can easily be copied and pasted… or … if you're like me for instance; and like to use an extension to grab the markdown content of a page… the code will be included rather than just a link to the gist!
On the command line, it's important to know the directory we are currently working on. For that, we can use pwd command.
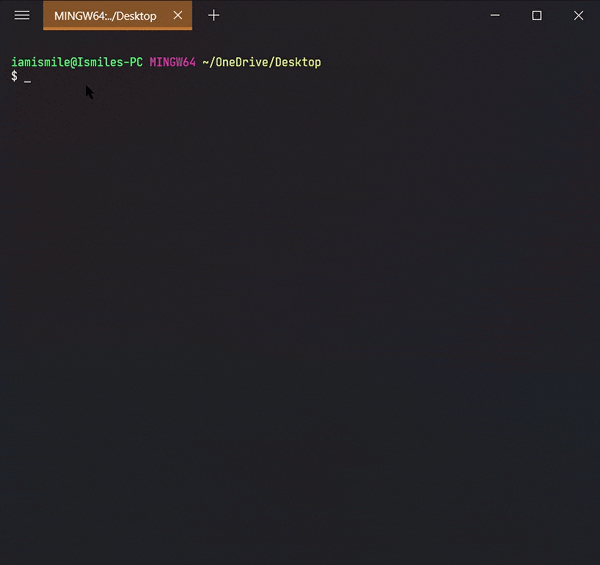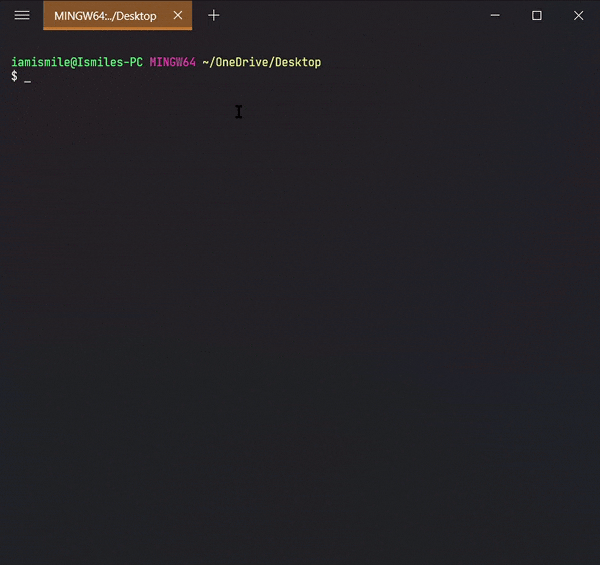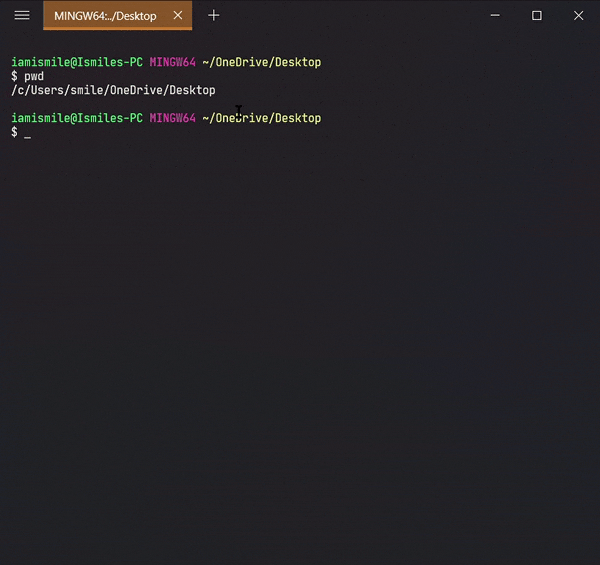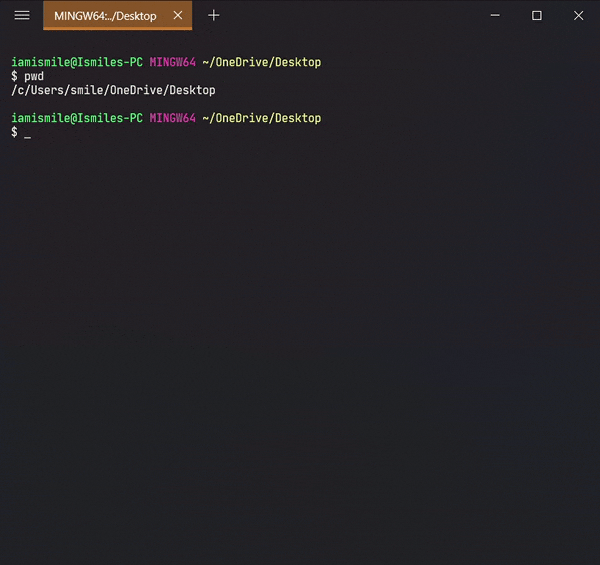
To see the list of files and directories in the current directory use ls command in your CLI.
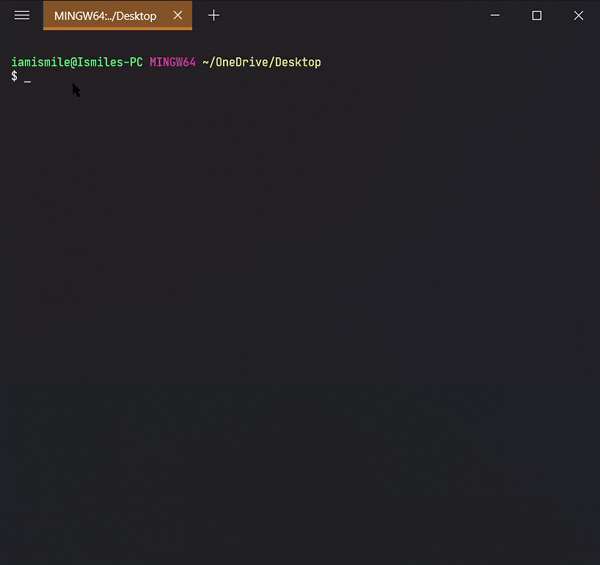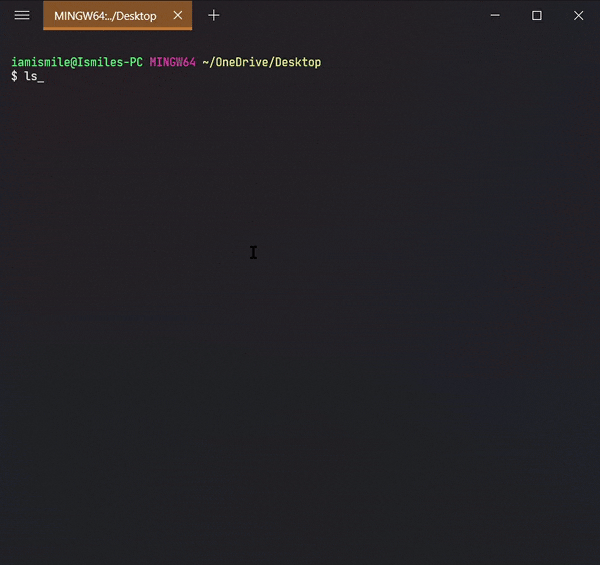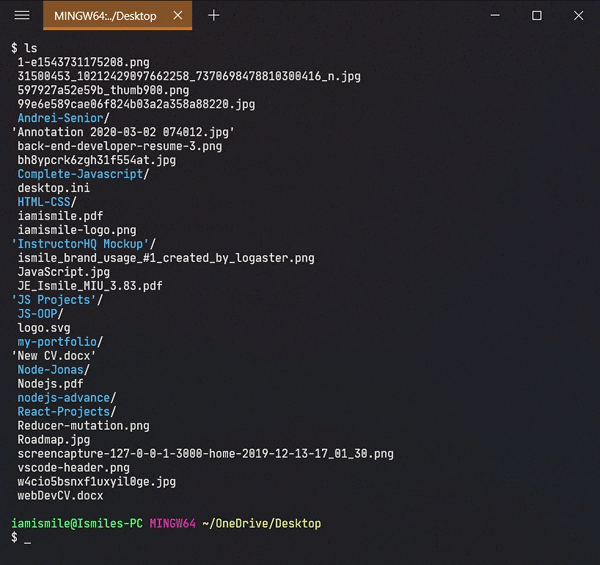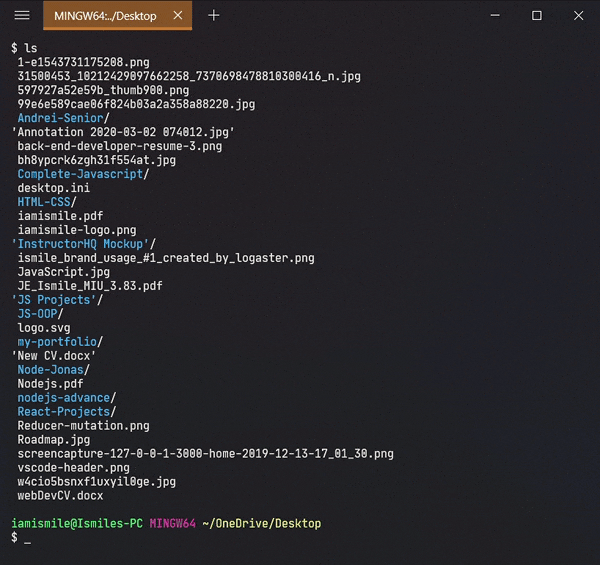
- To show the contents of a directory pass the directory name to the
lscommand i.e.ls directory_name. - Some useful
lscommand options:-
OptionDescriptionls -alist all files including hidden file starting with '.'ls -llist with the long formatls -lalist long format including hidden files
We can create a new folder using the mkdir command. To use it type mkdir folder_name.
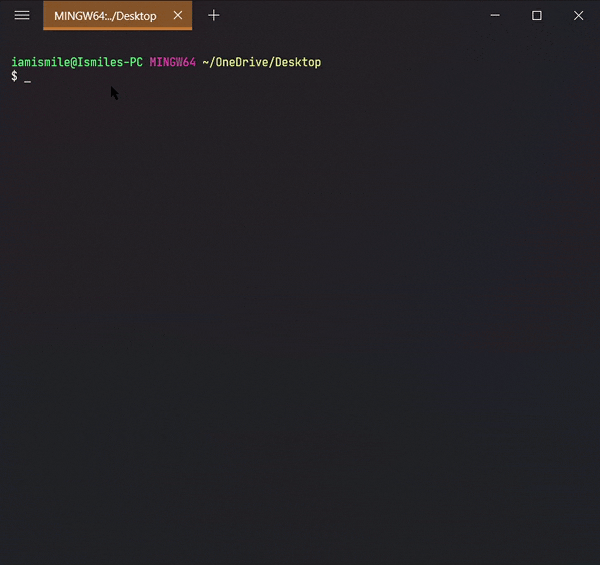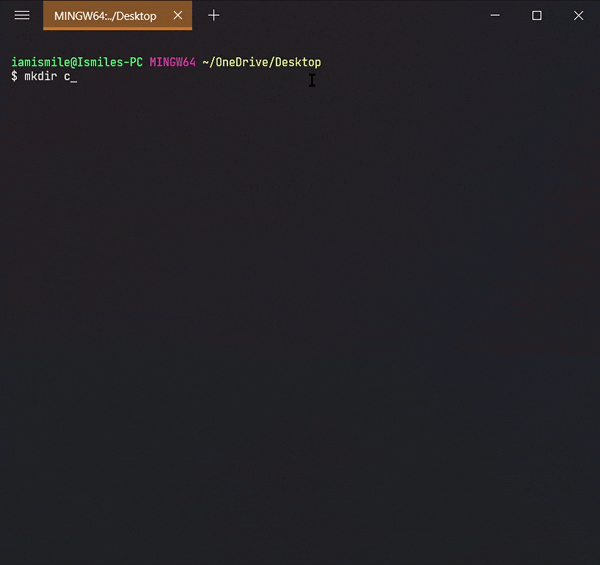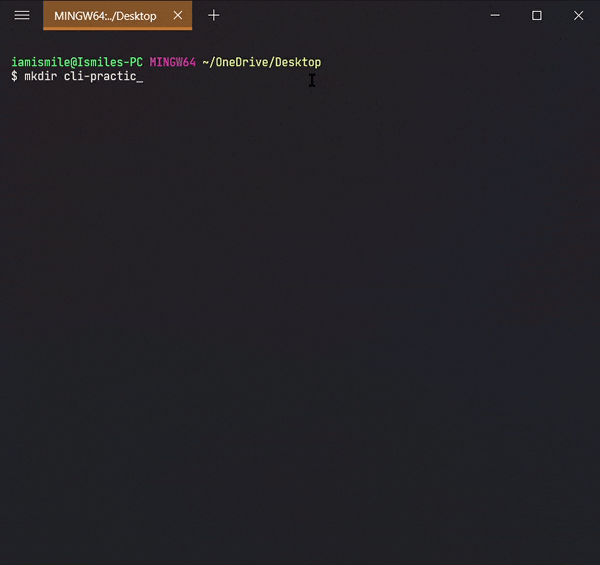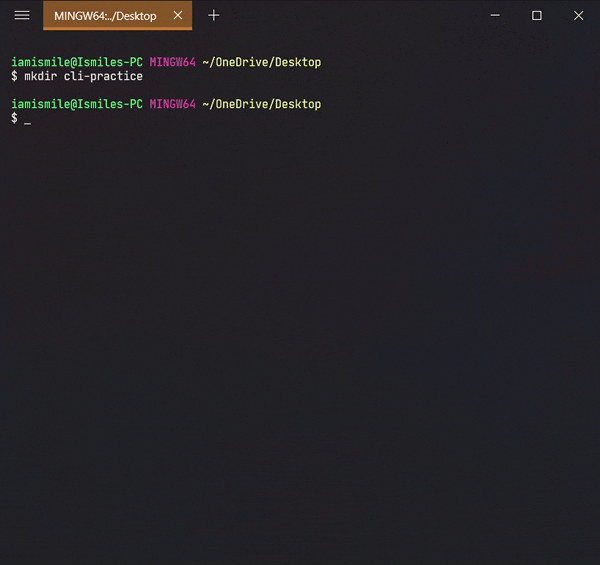
I created a cli-practice directory in my working directory i.e. Desktop directory.
It's used to change directory or to move other directories. To use it type cd directory_name.
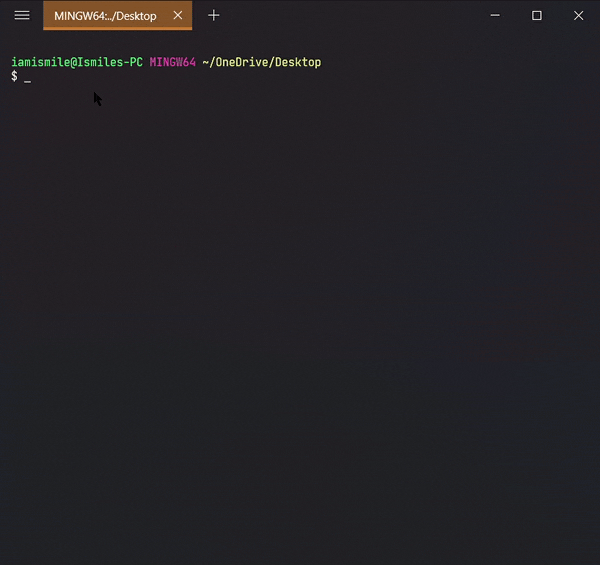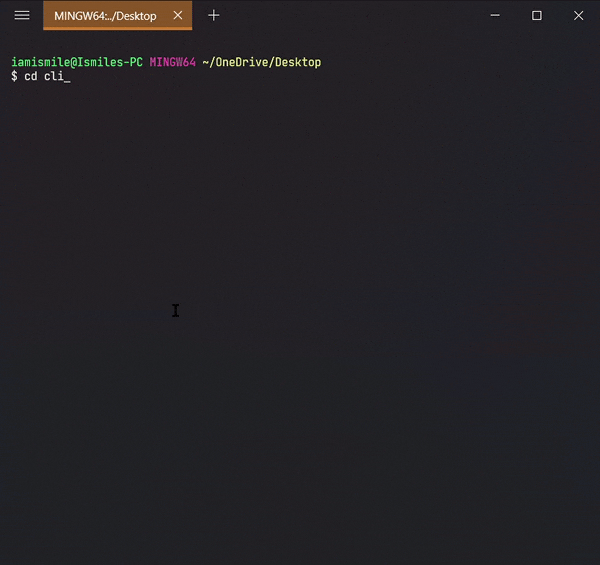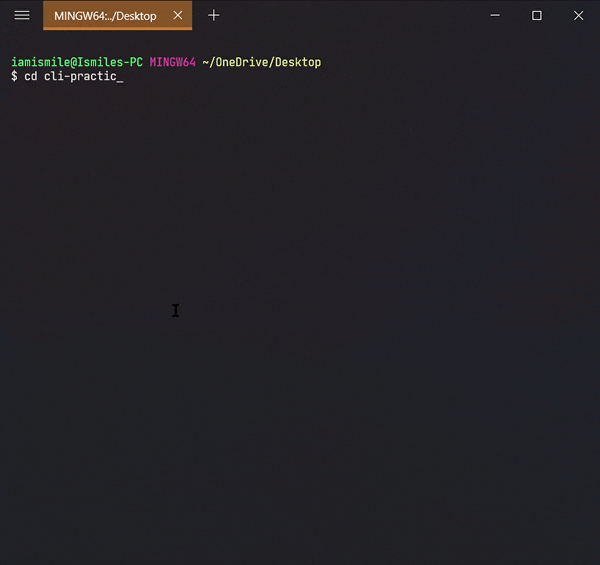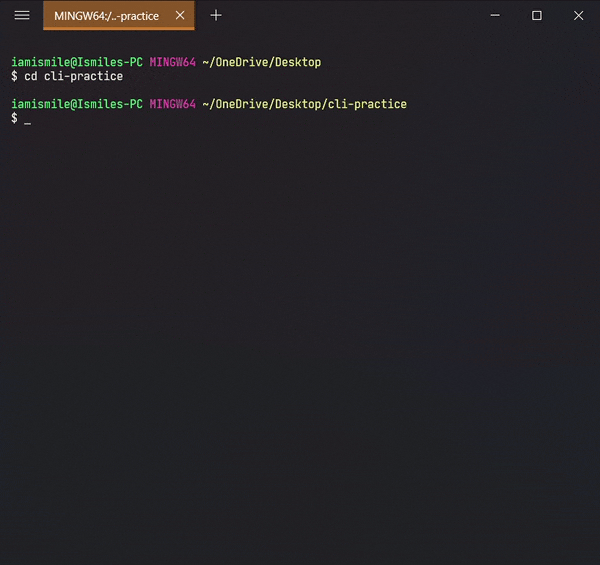
Changed my directory to the cli-practice directory. And the rest of the tutorial I'm gonna work within this directory.
We have seen cd command to change directory but if we want to move back or want to move to the parent directory we can use a special symbol .. after cd command, like cd ..
We can create an empty file by typing touch file_name. It's going to create a new file in the current directory (the directory you are currently in) with your provided name.
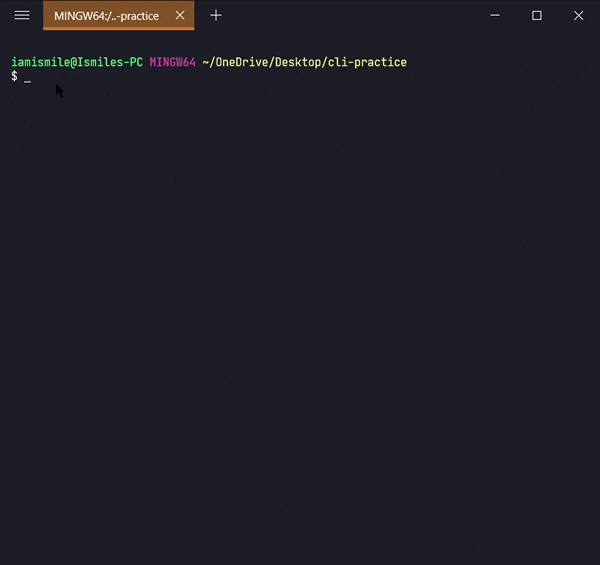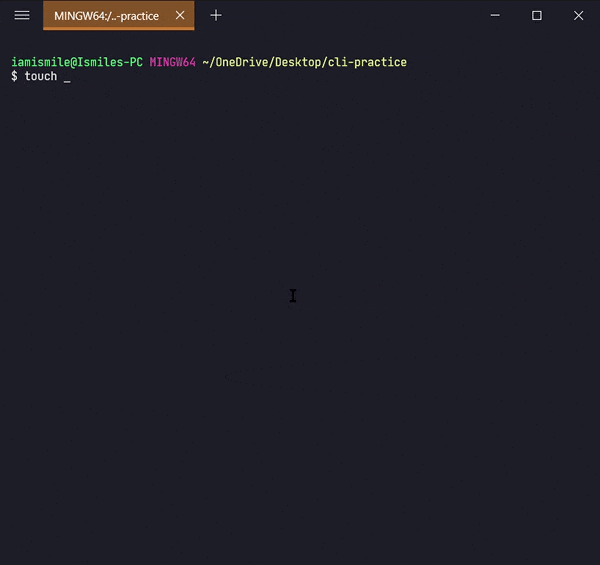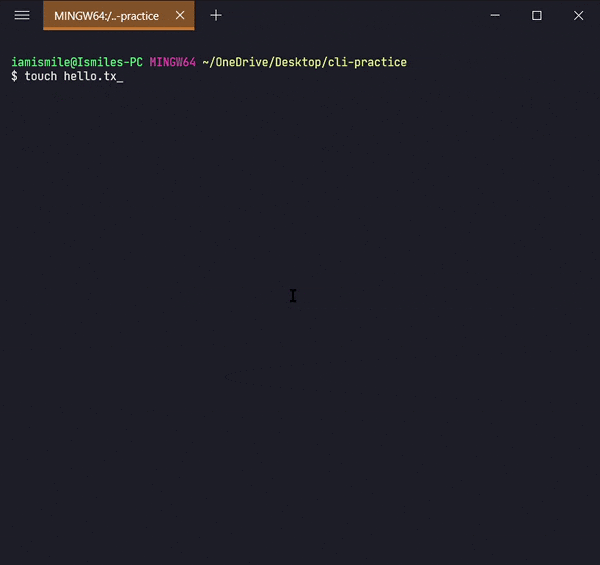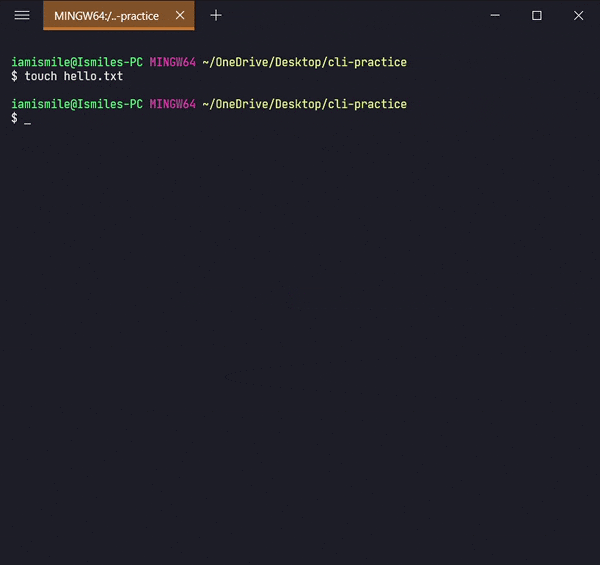
Now open your hello.txt file in your text editor and write Hello Everyone! into your hello.txt file and save it.
We can display the content of a file using the cat command. To use it type cat file_name.
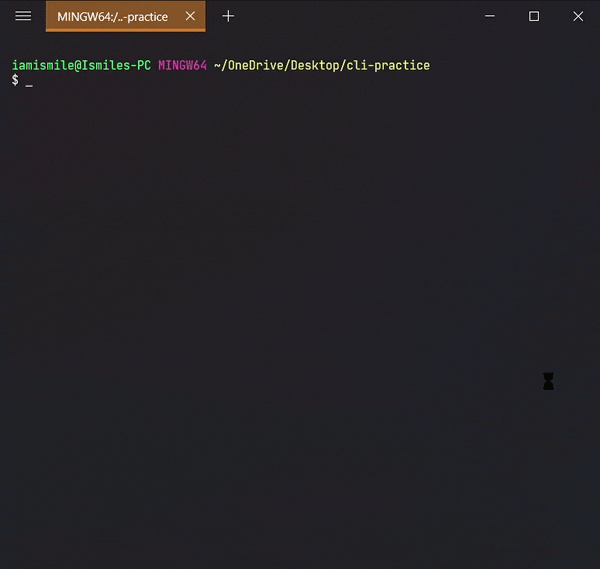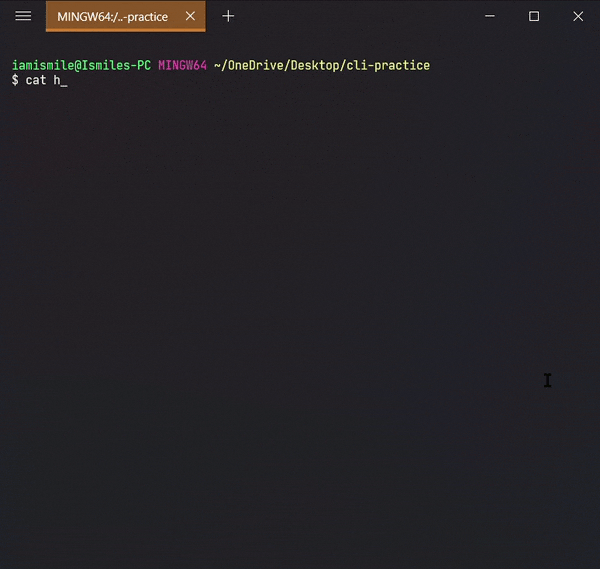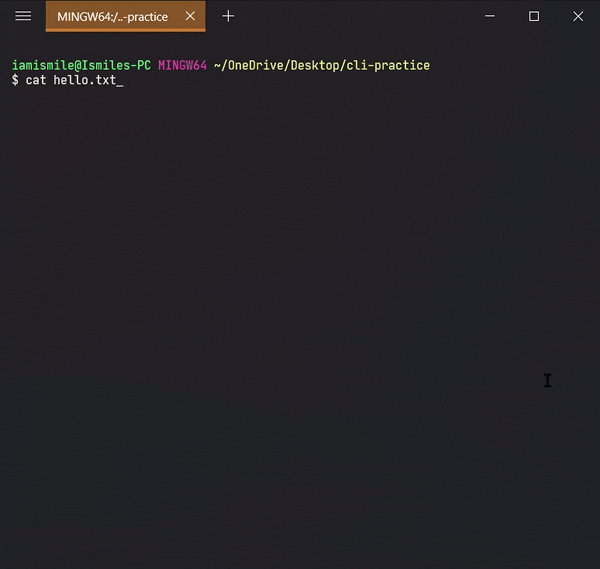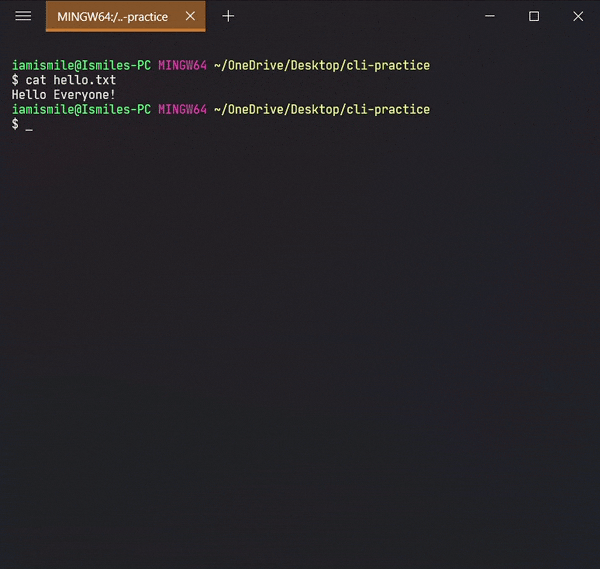
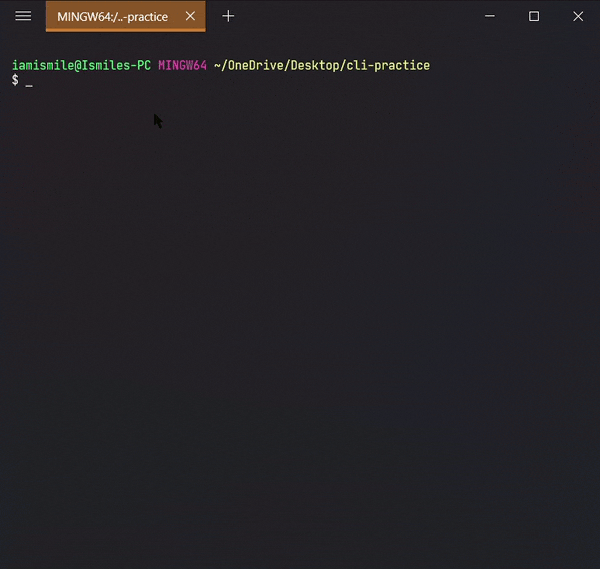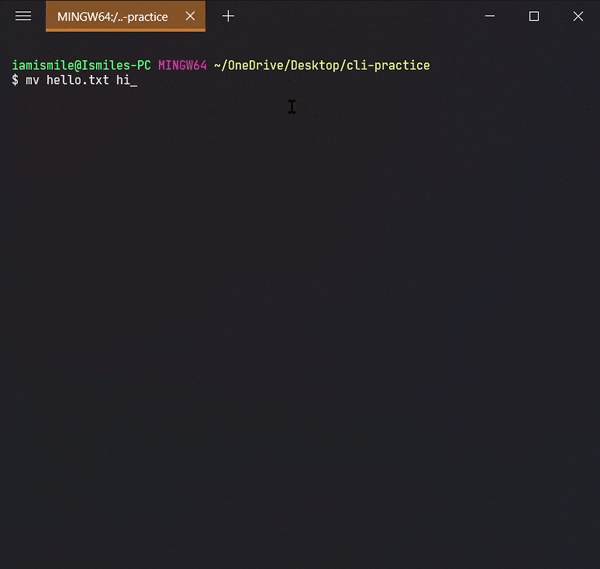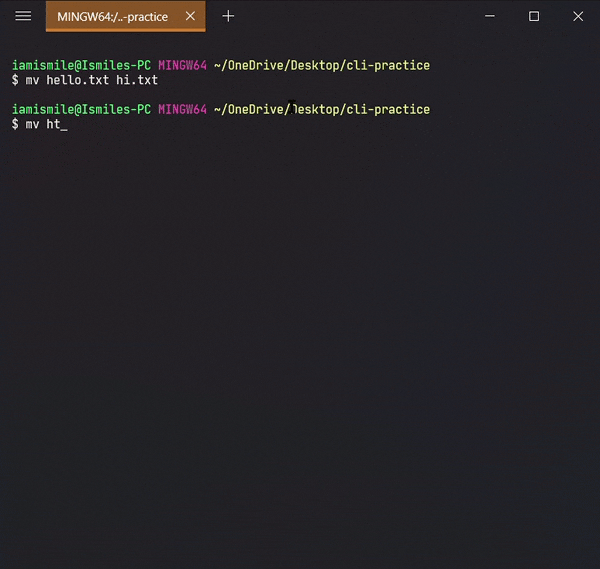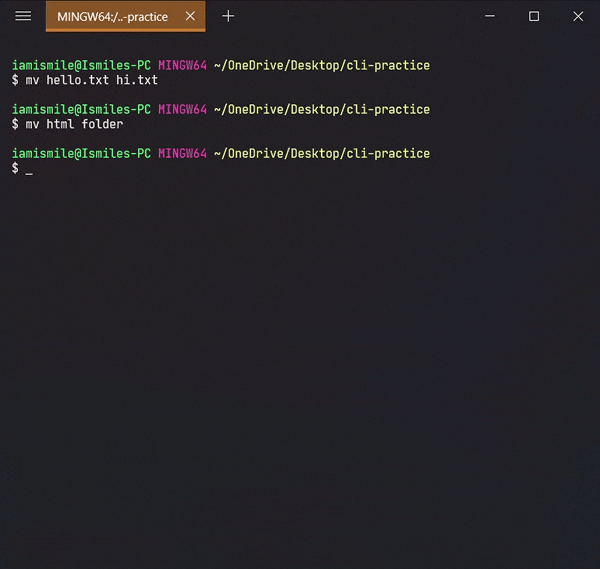
To move a file and directory, we use mv command.
By typing mv file_to_move destination_directory, you can move a file to the specified directory.
By entering mv directory_to_move destination_directory, you can move all the files and directories under that directory.
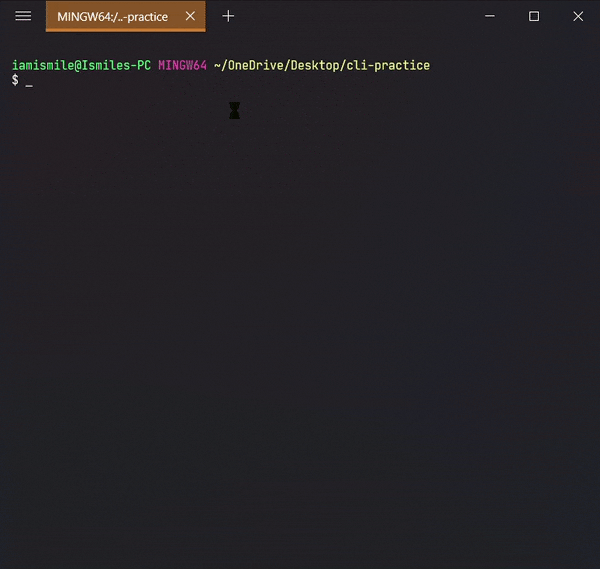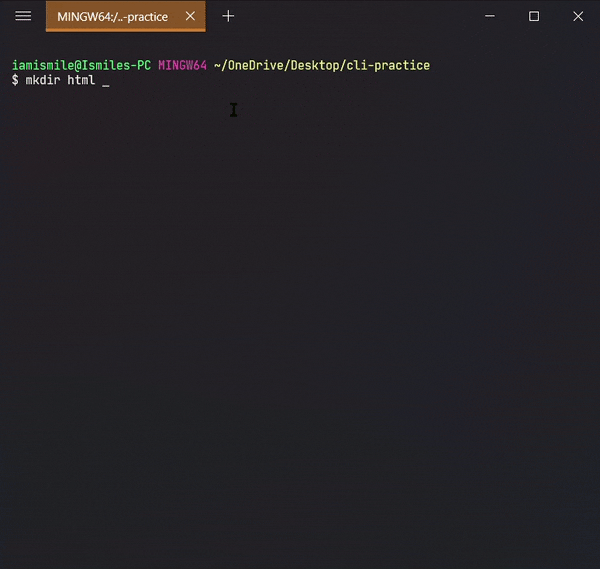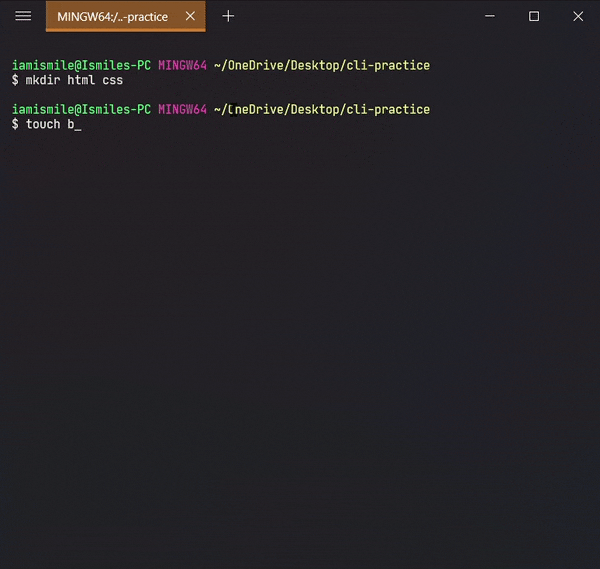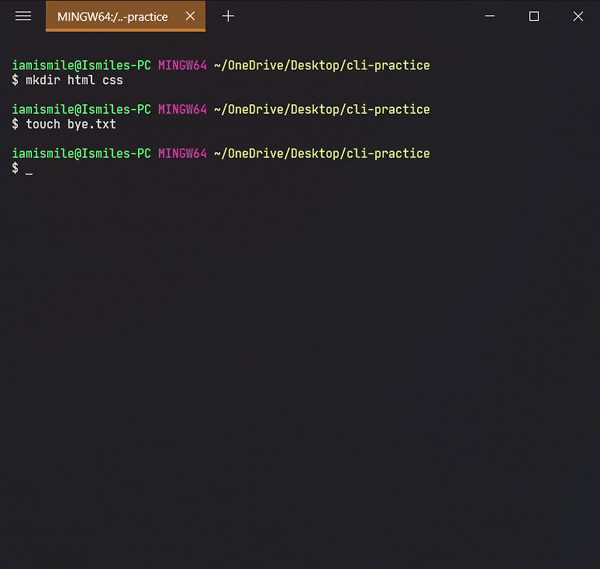
Before using this command, we are going to create two more directories and another txt file in our cli-practice directory.
mkdir html css touch bye.txt
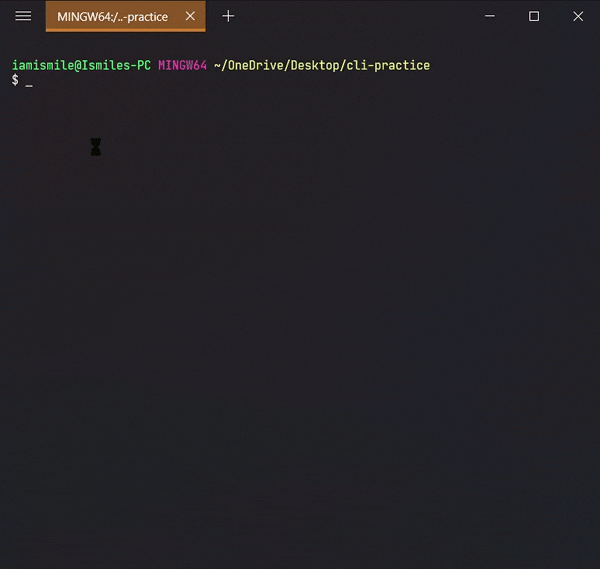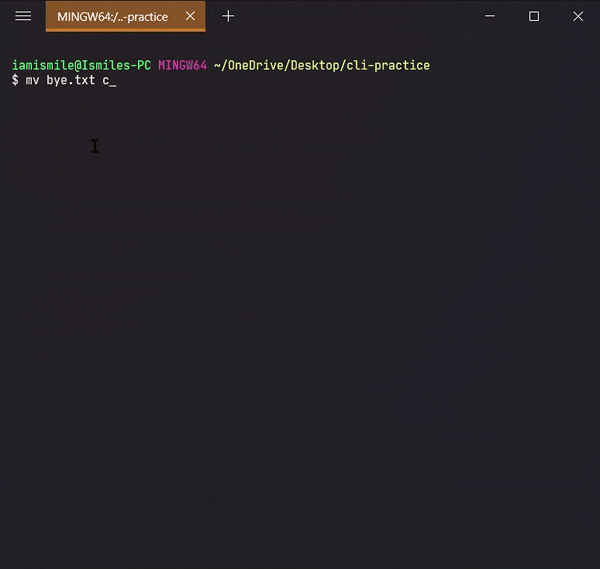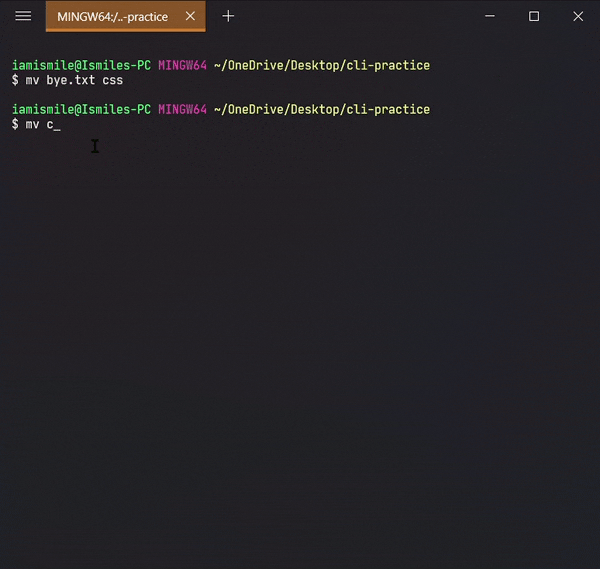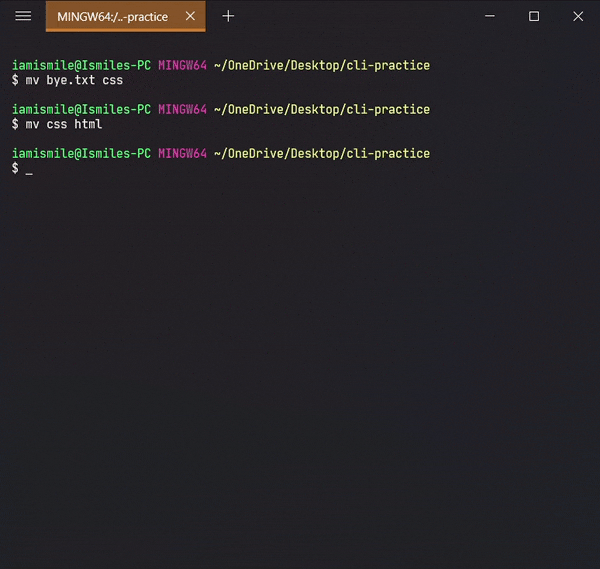
mv command can also be used to rename a file and a directory.
You can rename a file by typing mv old_file_name new_file_name & also rename a directory by typing mv old_directory_name new_directory_name.
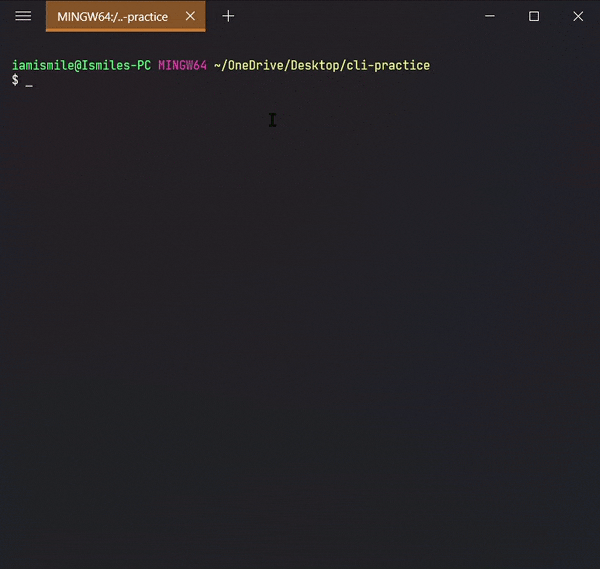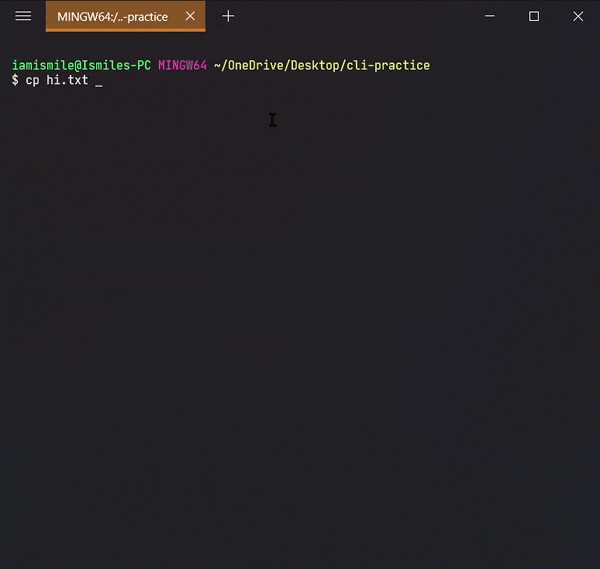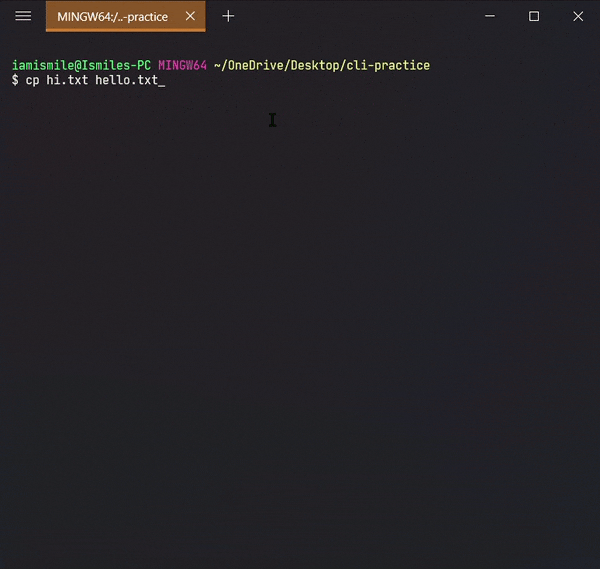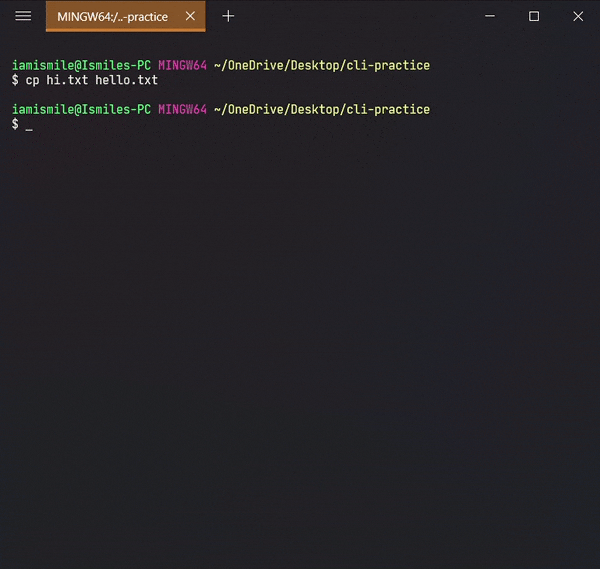
To do this, we use the cp command.
- You can copy a file by entering
cp file_to_copy new_file_name.
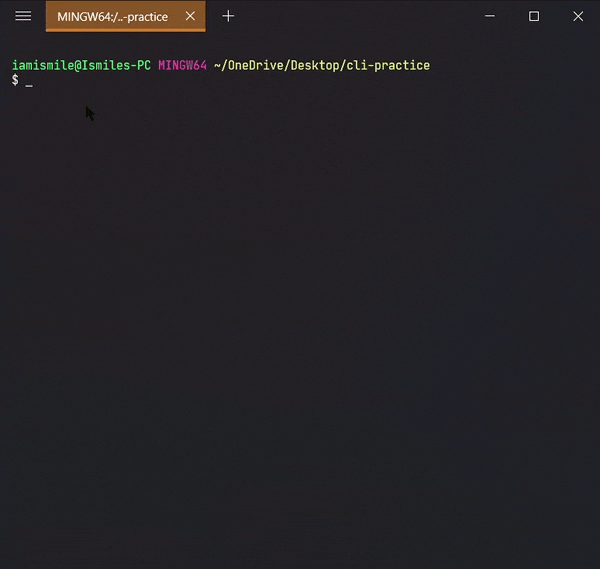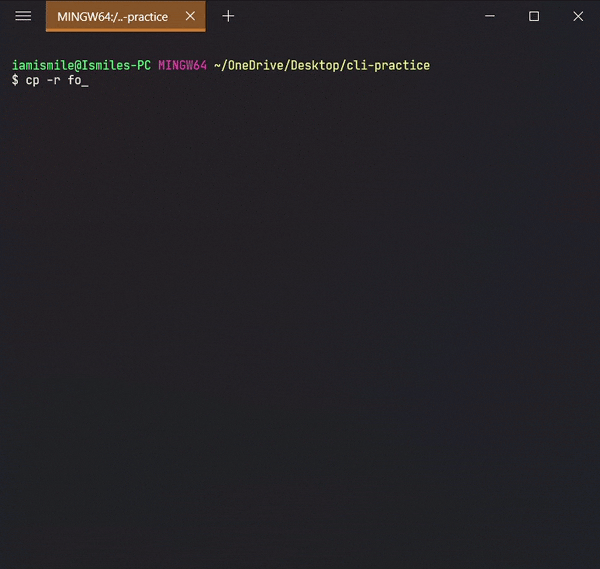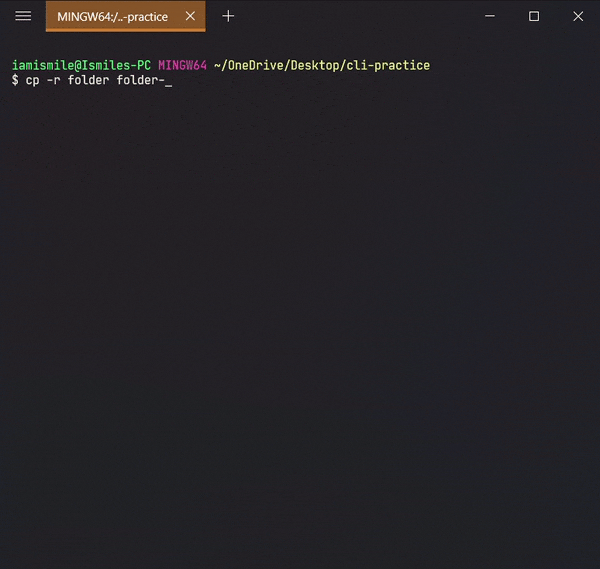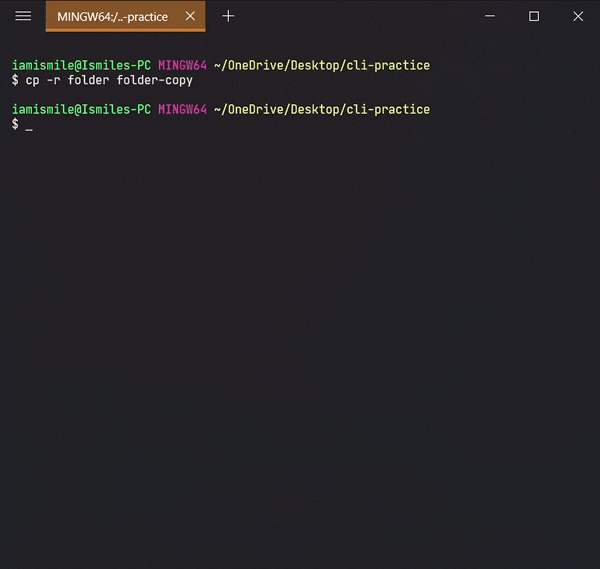
- You can also copy a directory by adding the
-roption, likecp -r directory_to_copy new_directory_name.
The -r option for "recursive" means that it will copy all of the files including the files inside of subfolders.
To do this, we use the rm command.
- To remove a file, you can use the command like
rm file_to_remove.
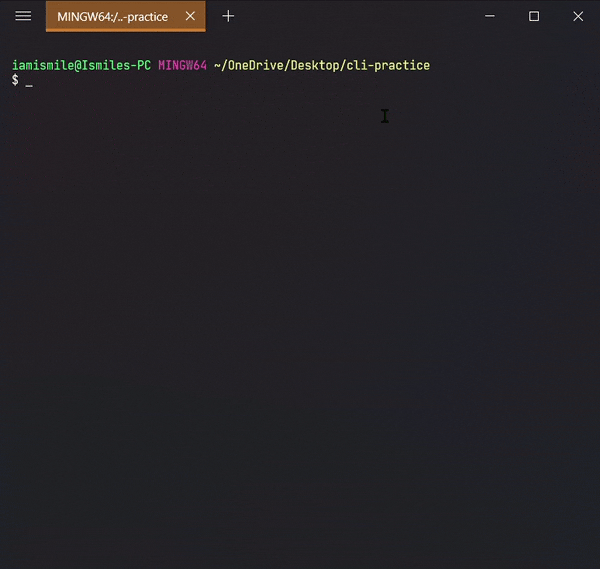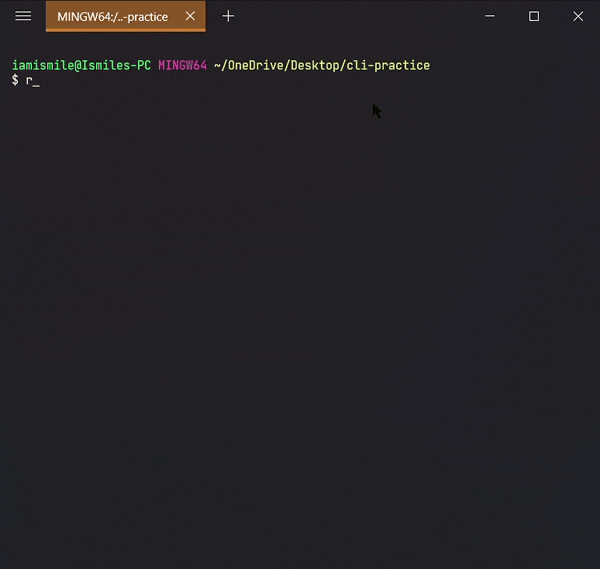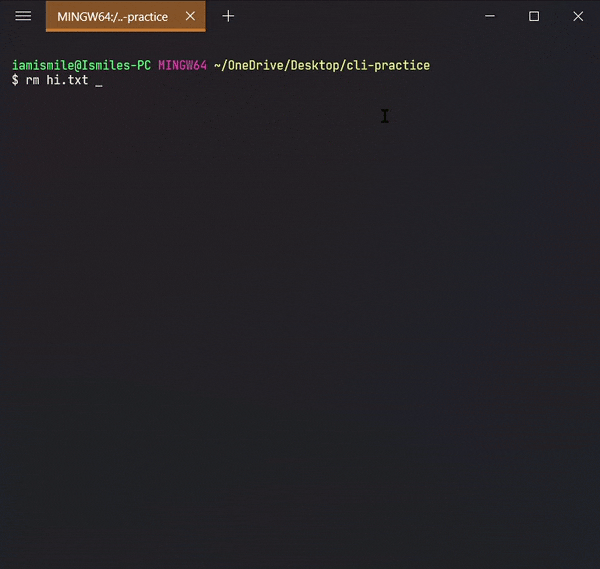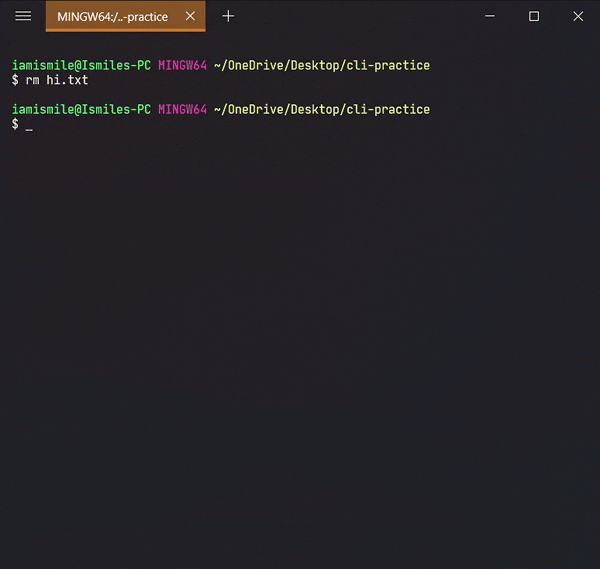
- To remove a directory, use the command like
rm -r directory_to_remove.
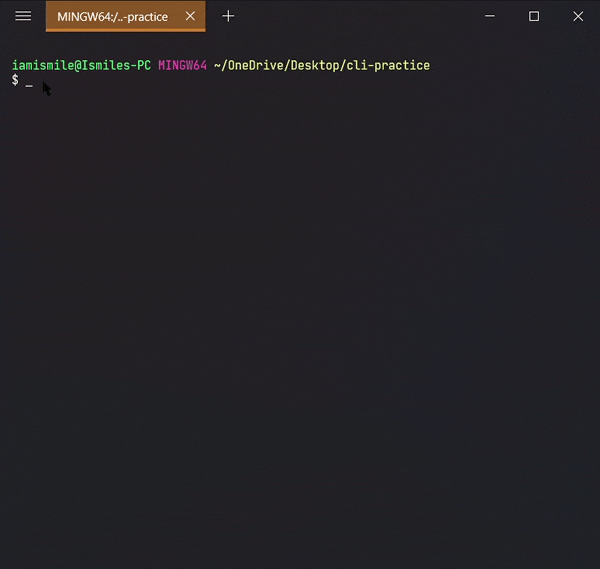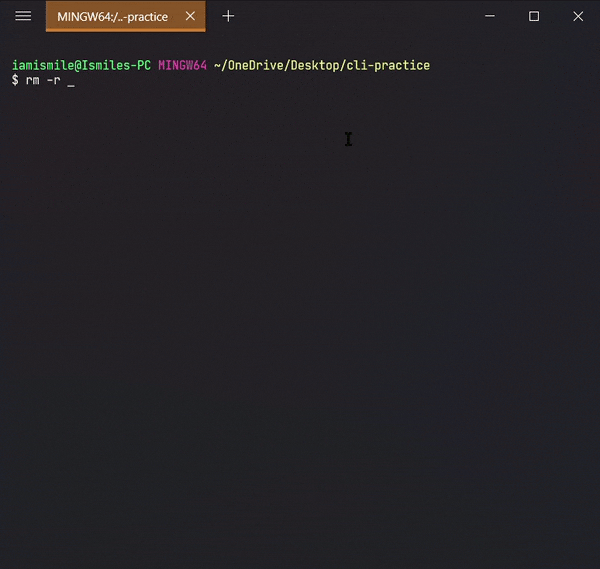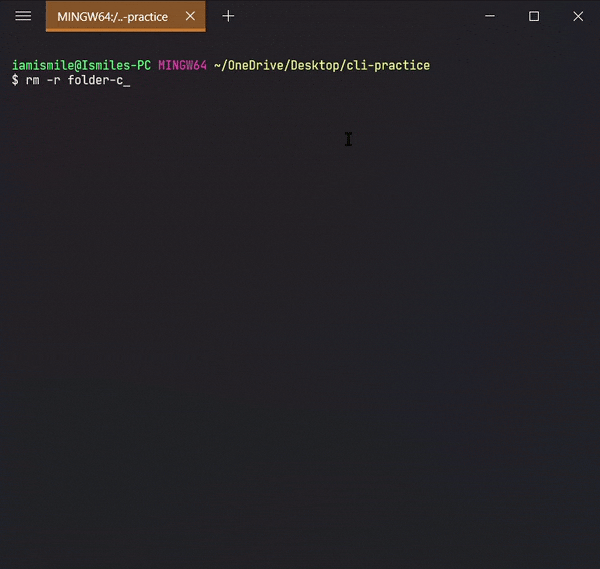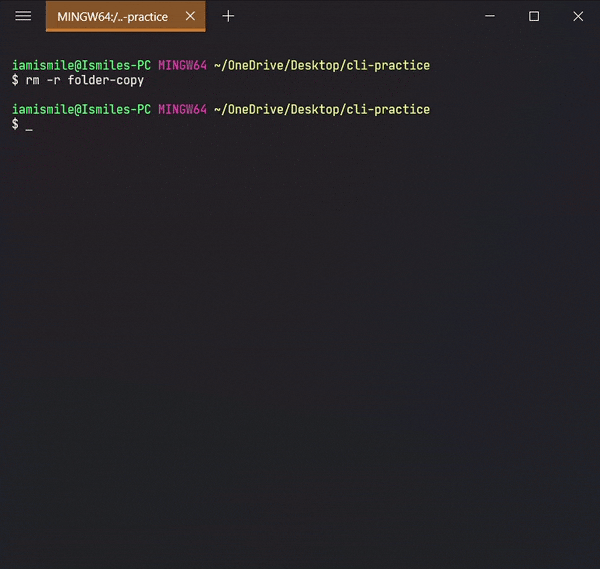
Clear command is used to clear the terminal screen.
The Home directory is represented by ~. The Home directory refers to the base directory for the user. If we want to move to the Home directory we can use cd ~ command. Or we can only use cd command.
here is a folde r containing the before and after… I had to change folder names slightly due to a limit on the length of file-paths in a github repo.
find . -name "*.zip" | while read filename; do unzip -o -d "`dirname "$filename"`" "$filename"; done;
find . -name "*.zip" -type f -print -delete
npm i -g recursive-install
npm-recursive-install
find . -empty -type f -print -delete #Remove empty files
# -------------------------------------------------------
find . -empty -type d -print -delete #Remove empty folders
# -------------------------------------------------------
# This will remove .git folders... .gitmodule files as well as .gitattributes and .gitignore files.
find . \( -name ".git" -o -name ".gitignore" -o -name ".gitmodules" -o -name ".gitattributes" \) -exec rm -rf -- {} +
# -------------------------------------------------------
# This will remove the filenames you see listed below that just take up space if a repo has been downloaded for use exclusively in your personal file system (in which case the following files just take up space)# Disclaimer... you should not use this command in a repo that you intend to use with your work as it removes files that attribute the work to their original creators!
find . \( -name "*SECURITY.txt" -o -name "*RELEASE.txt" -o -name "*CHANGELOG.txt" -o -name "*LICENSE.txt" -o -name "*CONTRIBUTING.txt" -name "*HISTORY.md" -o -name "*LICENSE" -o -name "*SECURITY.md" -o -name "*RELEASE.md" -o -name "*CHANGELOG.md" -o -name "*LICENSE.md" -o -name "*CODE_OF_CONDUCT.md" -o -name "\*CONTRIBUTING.md" \) -exec rm -rf -- {} +
The following output from my bash shell corresponds to the directory:
bgoonz/bash-commands-walkthroughDeployment github-pages Navigation Big O notation is the language we use for talking about how long an algorithm takes…github.com bgoonz/DS-ALGO-OFFICIAL
Deployment github-pages Navigation Big O notation is the language we use for talking about how long an algorithm takes…github.com
…..below is the terminal output for the following commands:
pwd
/mnt/c/Users/bryan/Downloads/bash-commands/steps/3-clean-up-fluf/DS-ALGO-OFFICIAL-master
After printing the working directory for good measure:
find . -empty -type f -print -delete
The above command deletes empty files recursively starting from the directory in which it was run:
./CONTENT/DS-n-Algos/File-System/file-utilities/node_modules/line-reader/test/data/empty_file.txt
./CONTENT/DS-n-Algos/_Extra-Practice/free-code-camp/nodejs/http-collect.js
./CONTENT/Resources/Comments/node_modules/mime/.npmignore
./markdown/tree2.md
./node_modules/loadashes6/lodash/README.md
./node_modules/loadashes6/lodash/release.md
./node_modules/web-dev-utils/Markdown-Templates/Markdown-Templates-master/filled-out-readme.md
|01:33:16|bryan@LAPTOP-9LGJ3JGS:[DS-ALGO-OFFICIAL-master] DS-ALGO-OFFICIAL-master_exitstatus:0[╗___________o>
The command seen below deletes empty folders recursively starting from the directory in which it was run:
find . -empty -type d -print -delete
The resulting directories….
|01:33:16|bryan@LAPTOP-9LGJ3JGS:[DS-ALGO-OFFICIAL-master] DS-ALGO-OFFICIAL-master_exitstatus:0[╗___________o>
find . -empty -type d -print -delete
./.git/branches
./.git/objects/info
./.git/refs/tags
|01:33:31|bryan@LAPTOP-9LGJ3JGS:[DS-ALGO-OFFICIAL-master] DS-ALGO-OFFICIAL-master_exitstatus:0[╗___________o>
The command seen below deletes .git folders as well as .gitignore, .gitattributes, .gitmodule files
find . \( -name ".git" -o -name ".gitignore" -o -name ".gitmodules" -o -name ".gitattributes" \) -exec rm -rf -- {} +
The command seen below deletes most SECURITY, RELEASE, CHANGELOG, LICENSE, CONTRIBUTING, & HISTORY files that take up pointless space in repo's you wish to keep exclusively for your own reference.
!!!Use with caution as this command removes the attribution of the work from it's original authors!!!!!

#!/bin/sh
# find ./ | grep -i "\.*$" >files
find ./ | sed -E -e 's/([^ ]+[ ]+){8}//' | grep -i "\.*$">files
listing="files"
out=""
html="index.html"
out="basename $out.html"
html="index.html"
cmd() {
echo ' <!DOCTYPE html>'
echo '<html>'
echo '<head>'
echo ' <meta http-equiv="Content-Type" content="text/html">'
echo ' <meta name="Author" content="Bryan Guner">'
echo '<link rel="stylesheet" href="./assets/prism.css">'
echo ' <link rel="stylesheet" href="./assets/style.css">'
echo ' <script async defer src="./assets/prism.js">
</script>' echo " <title> directory </title>" echo "" echo '<style>' echo ' a {' echo ' color: black;' echo ' }' echo '' echo ' li {' echo ' border: 1px solid black !important;' echo ' font-size: 20px;' echo ' letter-spacing: 0px;' echo ' font-weight: 700;' echo ' line-height: 16px;' echo ' text-decoration: none !important;' echo ' text-transform: uppercase;' echo ' background: #194ccdaf !important;' echo ' color: black !important;' echo ' border: none;' echo ' cursor: pointer;' echo ' justify-content: center;' echo ' padding: 30px 60px;' echo ' height: 48px;' echo ' text-align: center;' echo ' white-space: normal;' echo ' border-radius: 10px;' echo ' min-width: 45em;' echo ' padding: 1.2em 1em 0;' echo ' box-shadow: 0 0 5px;' echo ' margin: 1em;' echo ' display: grid;' echo ' -webkit-border-radius: 10px;' echo ' -moz-border-radius: 10px;' echo ' -ms-border-radius: 10px;' echo ' -o-border-radius: 10px;' echo ' }' echo ' </style>' echo '' echo '' echo "" # continue with the HTML stuff echo "" echo "" echo "
- "
awk '{print "
- <a href=""$1"">",$1," "}' $listing # awk '{print "
- "}; # {print " ",$1," "}' \ $listing echo "" echo "
I will use this copy of my Data Structures Practice Site to demonstrate the result:
side-projects-42/DS-Bash-Examples-DeployDeployment github-pages Navigation Big O notation is the language we use for talking about how long an algorithm takes…github.com
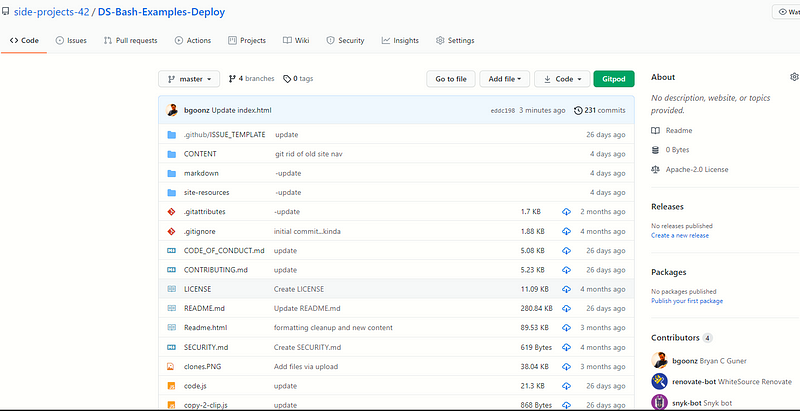
index.htmlhere is a link to and photo of the resulting html file:
CONTENT/DS-n-Algos/quirky-meninsky-4181b5.netlify.app
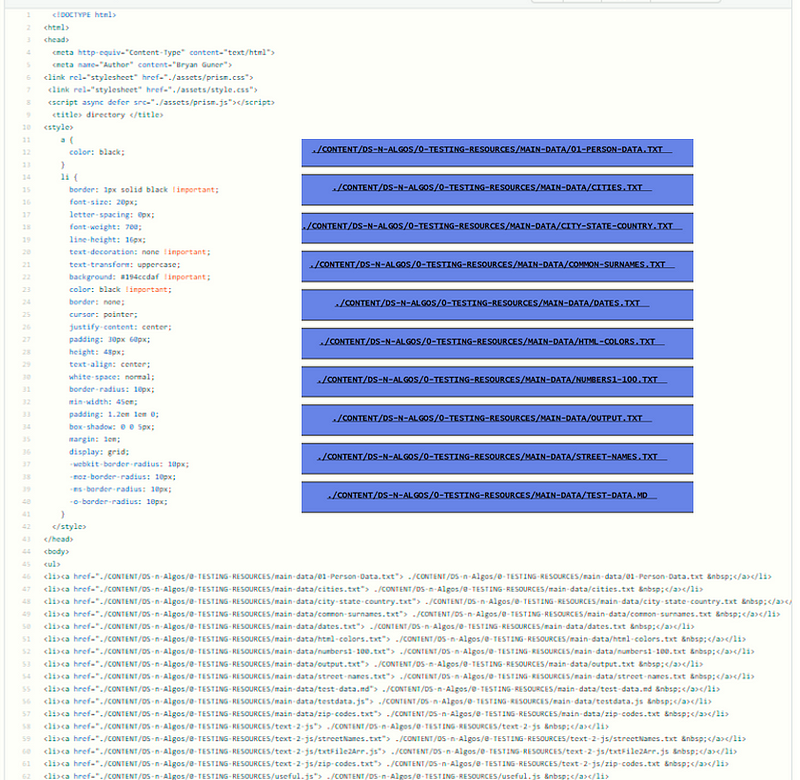
wget -r -A.pdf https://overapi.com/gitwget --wait=2 --level=inf --limit-rate=20K --recursive --page-requisites --user-agent=Mozilla --no-parent --convert-links --adjust-extension --no-clobber -e robots=off
The result is stored in this directory:
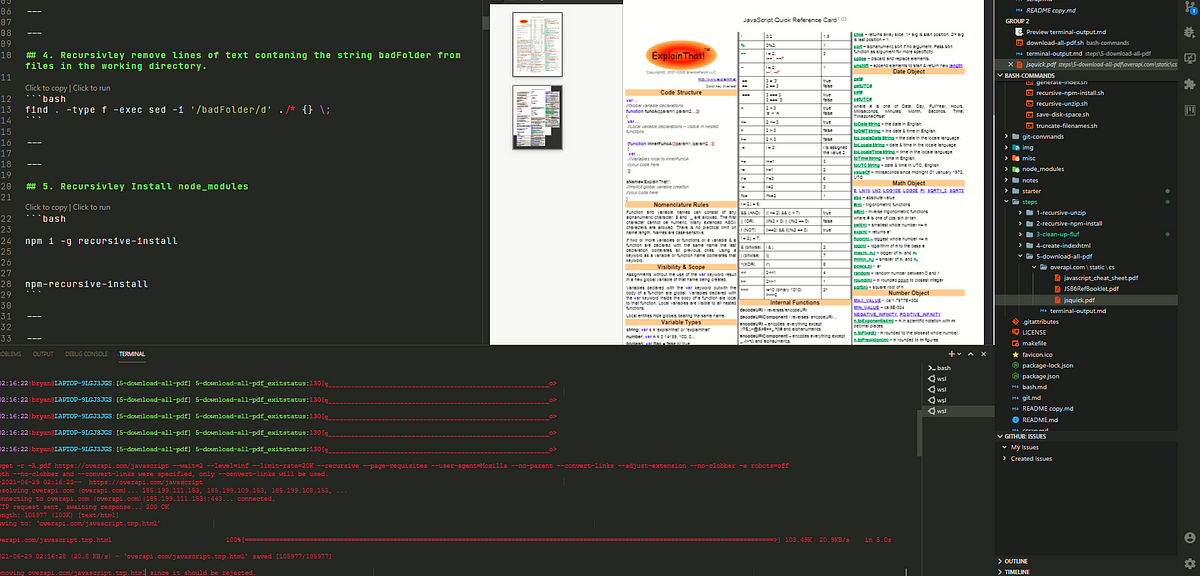
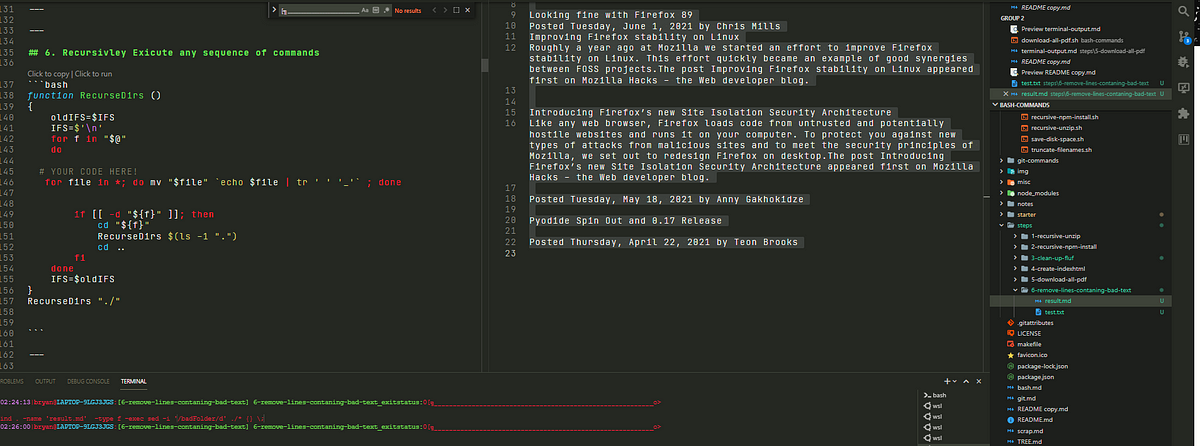
6.)Recursively remove lines of text containing the string badFolder from files in the working directory.
find . -type f -exec sed -i '/badFolder/d' ./* {} \;
# OR
find . -name 'result.md' -type f -exec sed -i '/badFolder/d' ./* {} \;
As an example I will run this command on a file containing the text:
Hacks Blog
Read more at hacks.mozilla.org
badFolder
badFolder Implementing Private Fields for JavaScript
When implementing a language feature for JavaScript, an implementer must make decisions about how the language in the specification maps to the implementation. Private fields is an example of where the specification language and implementation reality diverge, at least in SpiderMonkey- the JavaScript engine which powers Firefox. To understand more, I'll explain what private fields are, a couple of models for thinking about them, and explain why our implementation diverges from the specification language.The post Implementing Private Fields for JavaScript appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, June 8, 2021 by Matthew Gaudet
Looking fine with Firefox 89
Firefox 89 has smartened up and brings with it a slimmed-down, slightly more minimalist interface.badFolder Along with this new look, we get some great styling features including a force-colours feature for media queries and better control over how fonts are displayed. The long-awaited top-level await keyword for JavaScript modules is now enabled, as well as the PerformanceEventTiming interface, which is another addition to the performance suite of APIs: 89 really has been working out!The post Looking fine with Firefox 89 appeared first on Mozilla Hacks - the Web developer blog.
badFolder
Posted Tuesday, June 1, 2021 by Chris Mills
badFolder
Improving Firefox stability on Linux
Roughly a year ago at Mozilla we started an effort to improve Firefox stability on Linux. This effort quickly became an example of good synergies between FOSS projects.The post Improving Firefox stability on Linux appeared first on Mozilla Hacks - the Web developer blog.
Posted Wednesday, May 19, 2021 by Gabriele Svelto badFolder
Introducing Firefox's new Site Isolation Security Architecture
Like any web browser, Firefox loads code from untrusted and potentially hostile websites and runs it on your computer. To protect you against new types of attacks from malicious sites and to meet the security principles of Mozilla, we set out to redesign Firefox on desktop.The post Introducing Firefox's new Site Isolation Security Architecture appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, May 18, 2021 by Anny Gakhokidze
Pyodide Spin Out and 0.17 Release
We are happy to announce that Pyodide has become an independent and community-driven project. We are also pleased to announce the 0.17 release for Pyodide with many new features and improvements. Pyodide consists of the CPython 3.8 interpreter compiled to WebAssembly which allows Python to run in the browser.The post Pyodide Spin Out and 0.17 Release appeared first on Mozilla Hacks - the Web developer blog. badFolder
Posted Thursday, April 22, 2021 by Teon Brooks
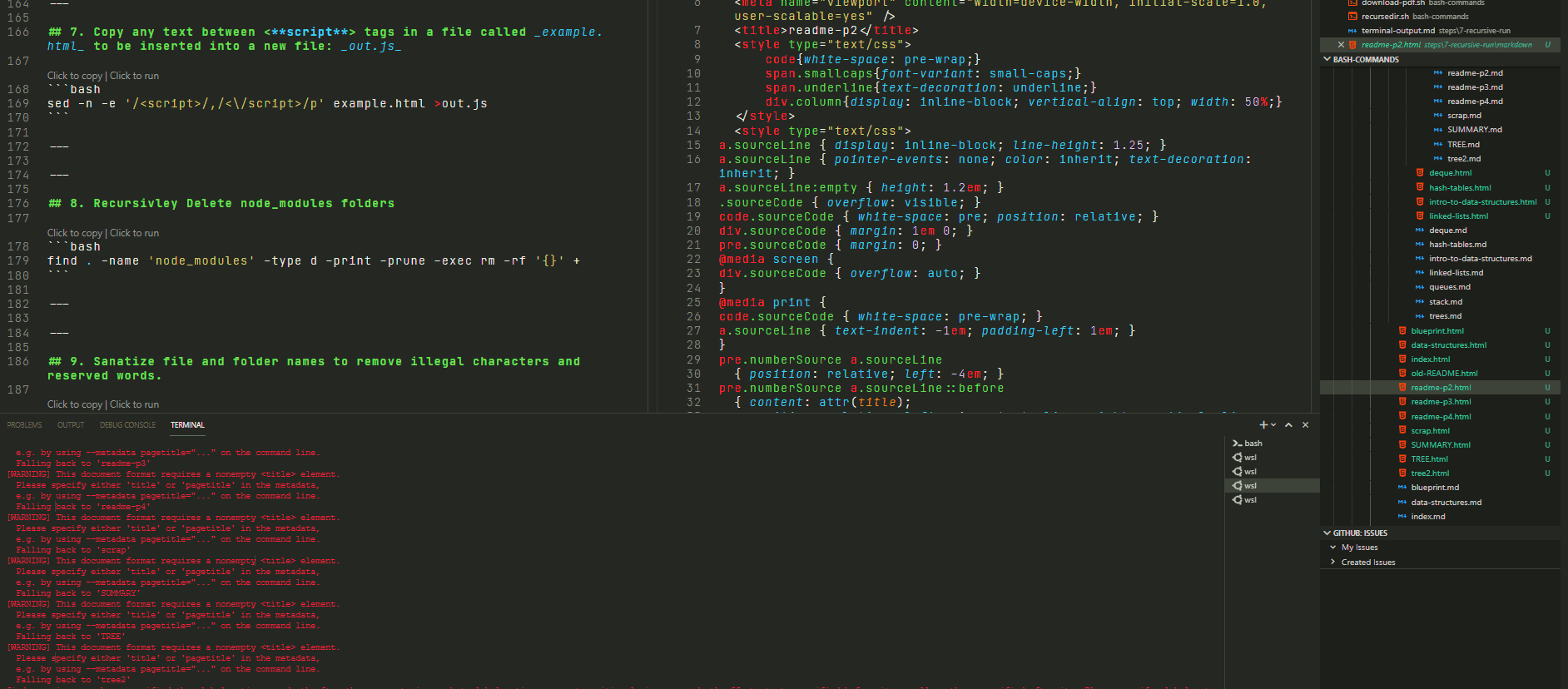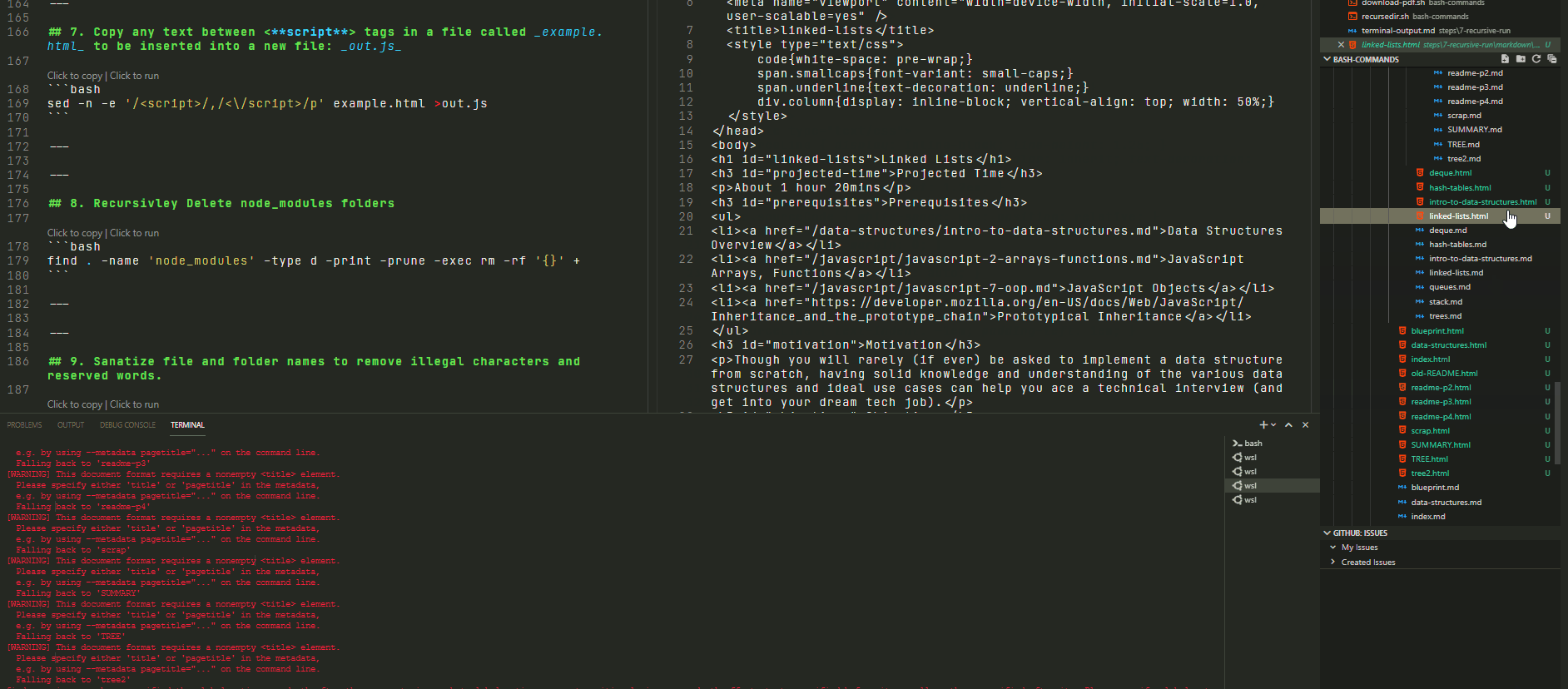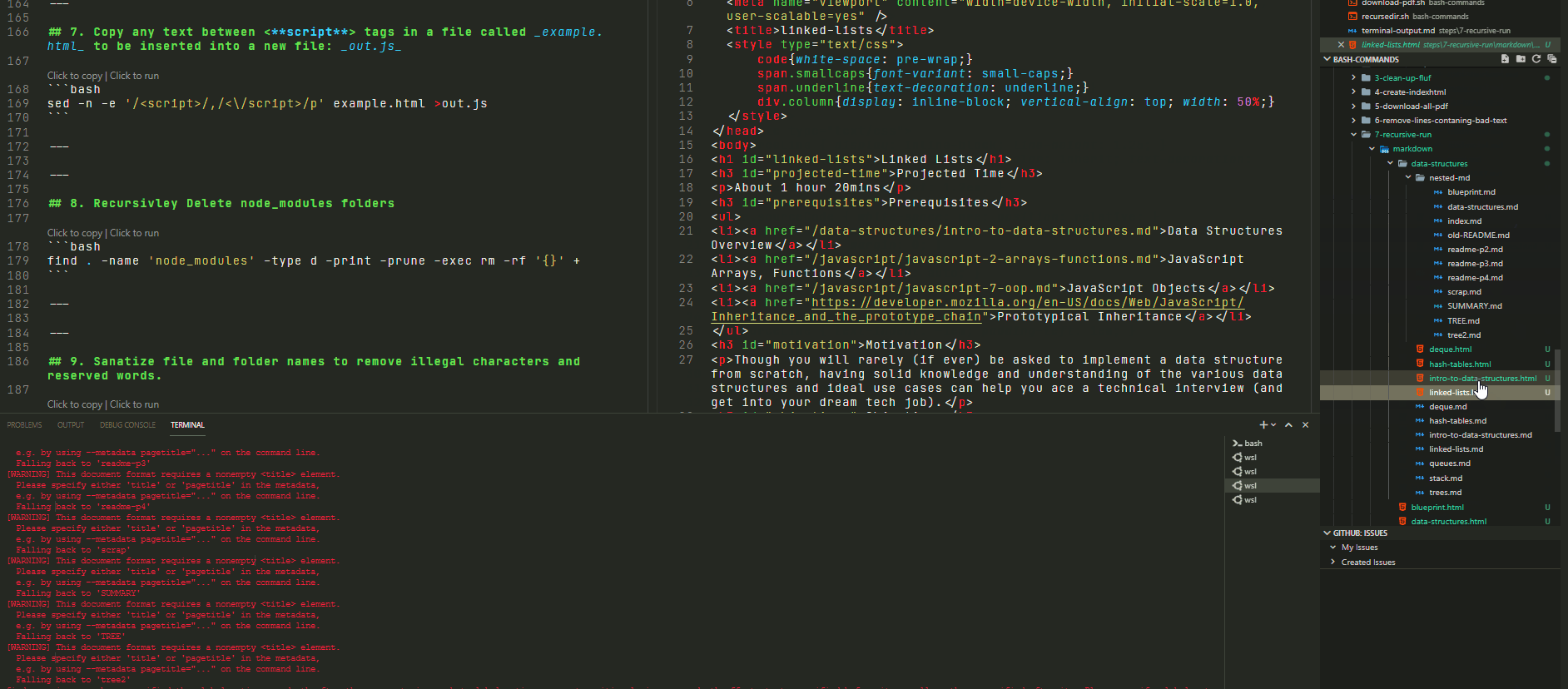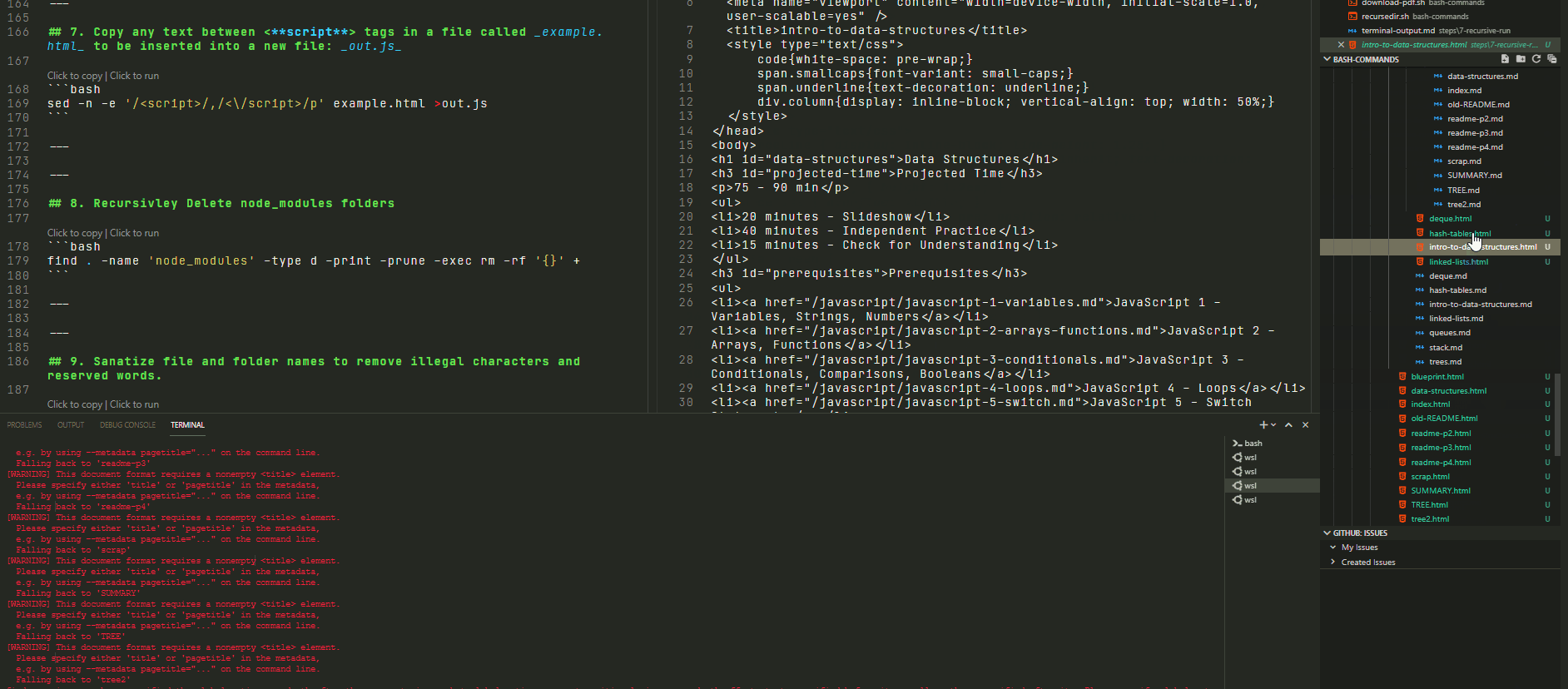
I modified the command slightly to apply only to files called 'result.md':
The result is :
Hacks Blog
Read more at hacks.mozilla.org
When implementing a language feature for JavaScript, an implementer must make decisions about how the language in the specification maps to the implementation. Private fields is an example of where the specification language and implementation reality diverge, at least in SpiderMonkey- the JavaScript engine which powers Firefox. To understand more, I'll explain what private fields are, a couple of models for thinking about them, and explain why our implementation diverges from the specification language.The post Implementing Private Fields for JavaScript appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, June 8, 2021 by Matthew Gaudet
Looking fine with Firefox 89
Posted Tuesday, June 1, 2021 by Chris Mills
Improving Firefox stability on Linux
Roughly a year ago at Mozilla we started an effort to improve Firefox stability on Linux. This effort quickly became an example of good synergies between FOSS projects.The post Improving Firefox stability on Linux appeared first on Mozilla Hacks - the Web developer blog.
Introducing Firefox's new Site Isolation Security Architecture
Like any web browser, Firefox loads code from untrusted and potentially hostile websites and runs it on your computer. To protect you against new types of attacks from malicious sites and to meet the security principles of Mozilla, we set out to redesign Firefox on desktop.The post Introducing Firefox's new Site Isolation Security Architecture appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, May 18, 2021 by Anny Gakhokidze
Pyodide Spin Out and 0.17 Release
Posted Thursday, April 22, 2021 by Teon Brooks
the test.txt and result.md files can be found here:
bgoonz/bash-commands-walkthroughto accompany the medium article I am writing. Contribute to bgoonz/bash-commands-walkthrough development by creating an…github.com
Here I have modified the command I wish to run recursively to account for the fact that the 'find' command already works recursively, by appending the -maxdepth 1 flag…
I am essentially removing the recursive action of the find command…
That way, if the command affects the more deeply nested folders we know the outer RecurseDirs function we are using to run the find/pandoc line once in every subfolder of the working directory… is working properly!
The results of said operation can be found in the following directory
🢃 Below 🢃
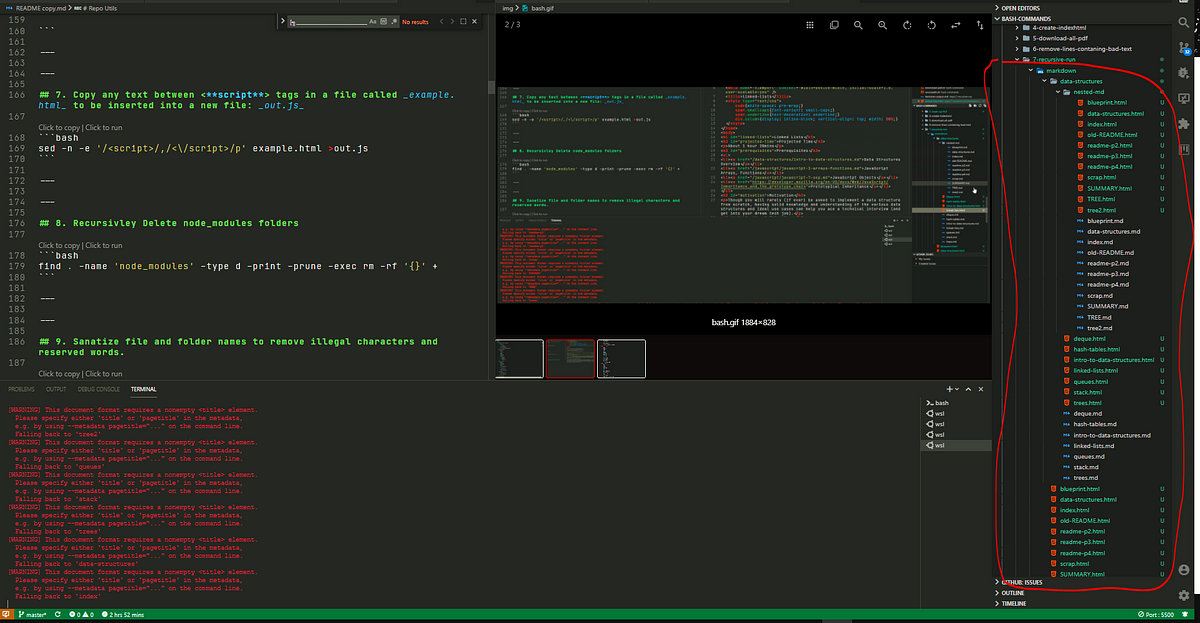
If you want to run any bash script recursively all you have to do is substitue out line #9 with the command you want to run once in every sub-folder.
function RecurseDirs ()
{
oldIFS=$IFS
IFS=$'\n'
for f in "$@"
do
#Replace the line below with your own command!
#find ./ -iname "*.md" -maxdepth 1 -type f -exec sh -c 'pandoc --standalone "${0}" -o "${0%.md}.html"' {} \;
#####################################################
# YOUR CODE BELOW!
#####################################################
if [[ -d "${f}" ]]; then
cd "${f}"
RecurseDirs $(ls -1 ".")
cd ..
fi
done
IFS=$oldIFS
}
RecurseDirs "./"
Here are some of the other commands I will cover in greater detail… at a later time:
9. Copy any text between <script> tags in a file called example.html to be inserted into a new file: out.js
sed -n -e '/<script>/,/<\/script>/p' example.html >out.js
find . -name 'node_modules' -type d -print -prune -exec rm -rf '{}' +
sanitize() {
shopt -s extglob;
filename=$(basename "$1")
directory=$(dirname "$1")
filename_clean=$(echo "$filename" | sed -e 's/[\\/:\*\?"<>\|\x01-\x1F\x7F]//g' -e 's/^\(nul\|prn\|con\|lpt[0-9]\|com[0-9]\|aux\)\(\.\|$\)//i' -e 's/^\.*$//' -e 's/^$/NONAME/')
if (test "$filename" != "$filename_clean")
then
mv -v "$1" "$directory/$filename_clean"
fi
}
export -f sanitize
sanitize_dir() {
find "$1" -depth -exec bash -c 'sanitize "$0"' {} \;
}
sanitize_dir '/path/to/somewhere'
sudo -u postgres psql
for f in * ; do
mv "$f" "$f.html"
doneecho "<form>
<input type="button" value="Go back!" onclick="history.back()">
</form>
</body>
#!/bin/bash
link="#insert url here#"
#links were a set of strings with just the index of the video as the variable
num=3
#first video was numbered 3 - weird.
ext=".mp4"
while [ $num -le 66 ]
do
wget $link$num$ext -P ~/Downloads/
num=$(($num+1))
done
sudo apt install rename
rename 's/\.txt$/.doc/' *.txt
find . -name "*.\.js\.download" -exec rename 's/\.js\.download$/.js/' '{}' +
find . -name '*.md' | cpio -pdm './../outputFolder'
Web-Dev-Hub
Memoization, Tabulation, and Sorting Algorithms by Example Why is looking at runtime not a reliable method of…bgoonz-blog.netlify.app Medium
Continued!!!medium.com
By Bryan Guner on June 29, 2021.
August 31, 2021.
Notes: Issue when renaming file without numbers collides with existing file name...
find . -name "* *" -type d | rename 's/ /_/g'
find . -name "* *" -type f | rename 's/ /_/g'```console
find $dir -type f | sed 's|\(.*/\)[^A-Z]*\([A-Z].*\)|mv \"&\" \"\1\2\"|' | sh
find $dir -type d | sed 's|\(.*/\)[^A-Z]*\([A-Z].*\)|mv \"&\" \"\1\2\"|' | sh
for i in *.html; do mv "$i" "${i%-*}.html"; done
for i in *.*; do mv "$i" "${i%-*}.${i##*.}"; done
---
### Description: combine the contents of every file in the contaning directory.
>Notes: this includes the contents of the file it's self...
###### code:
```js
//
//APPEND-DIR.js
const fs = require('fs');
let cat = require('child_process')
.execSync('cat *')
.toString('UTF-8');
fs.writeFile('output.md', cat, err => {
if (err) throw err;
});
Notes: ==> sudo apt install wget
wget --limit-rate=200k --no-clobber --convert-links --random-wait -r -p -E -e robots=off -U mozilla https://bootcamp42.gitbook.io/python/
Description: recursively removes git related folders as well as internal use files / attributions in addition to empty folders
Notes: To clear up clutter in repositories that only get used on your local machine.
find . -empty -type d -print -delete
find . \( -name ".git" -o -name ".gitignore" -o -name ".gitmodules" -o -name ".gitattributes" \) -exec rm -rf -- {} +
find . \( -name "*SECURITY.txt" -o -name "*RELEASE.txt" -o -name "*CHANGELOG.txt" -o -name "*LICENSE.txt" -o -name "*CONTRIBUTING.txt" -name "*HISTORY.md" -o -name "*LICENSE" -o -name "*SECURITY.md" -o -name "*RELEASE.md" -o -name "*CHANGELOG.md" -o -name "*LICENSE.md" -o -name "*CODE_OF_CONDUCT.md" -o -name "*CONTRIBUTING.md" \) -exec rm -rf -- {} +
Notes:
CNTX={users|orgs}; NAME={username|orgname}; PAGE=1
curl "https://api.github.com/$CNTX/$NAME/repos?page=$PAGE&per_page=100" |
grep -e 'git_url*' |
cut -d \" -f 4 |
xargs -L1 git cloneCNTX={users}; NAME={bgoonz}; PAGE=1
curl "https://api.github.com/$CNTX/$NAME/repos?page=$PAGE&per_page=200"?branch=master |
grep -e 'git_url*' |
cut -d \" -f 4 |
xargs -L1 git clone
CNTX={organizations}; NAME={TheAlgorithms}; PAGE=1
curl "https://api.github.com/$CNTX/$NAME/repos?page=$PAGE&per_page=200"?branch=master |
grep -e 'git_url*' |
cut -d \" -f 4 |
xargs -L1 git clone
git pull
git init
git add .
git commit -m"update"
git push -u origin mastergit init
git add .
git commit -m"update"
git push -u origin maingit init
git add .
git commit -m"update"
git push -u origin bryan-gunergit init
git add .
git commit -m"update"
git push -u origin gh-pagesgit init
git add .
git commit -m"update"
git push -u origin previewNotes:
find . -name "*.zip" | while read filename; do unzip -o -d "`dirname "$filename"`" "$filename"; done;
find . -name "*.zip" -type f -print -delete
Notes:
git stash
git pull
git stash pop
Notes:
sudo npm i prettier -g
prettier --write .
Notes:
find ./ -iname "*.md" -type f -exec sh -c 'pandoc --standalone "${0}" -o "${0%.md}.html"' {} \;
find ./ -iname "*.html" -type f -exec sh -c 'pandoc --wrap=none --from html --to markdown_strict "${0}" -o "${0%.html}.md"' {} \;
find ./ -iname "*.docx" -type f -exec sh -c 'pandoc "${0}" -o "${0%.docx}.md"' {} \;
Notes:
sudo apt install tree
sudo apt install pandoc -y
sudo apt install rename -y
sudo apt install black -y
sudo apt install wget -y
npm i lebab -g
npm i prettier -g
npm i npm-recursive-install -g
black .
prettier --write .
npm-recursive-installNotes:
npm i @bgoonz11/repoutils
Notes:
tree -d -I 'node_modules'
tree -I 'node_modules'
tree -f -I 'node_modules' >TREE.md
tree -f -L 2 >README.md
tree -f -I 'node_modules' >listing-path.md
tree -f -I 'node_modules' -d >TREE.md
tree -f >README.md
Notes:
find . -type f -exec rename 's/string1/string2/g' {} +
find . -type d -exec rename 's/-master//g' {} +
find . -type f -exec rename 's/\.download//g' {} +
find . -type d -exec rename 's/-main//g' {} +
rename 's/\.js\.download$/.js/' *.js\.download
rename 's/\.html\.markdown$/.md/' *.html\.markdown
find . -type d -exec rename 's/es6//g' {} +
Notes:
#!/bin/bash
for file in *.md.md
do
mv "${file}" "${file%.md}"
done
#!/bin/bash
for file in *.html.html
do
mv "${file}" "${file%.html}"
done#!/bin/bash
for file in *.html.png
do
mv "${file}" "${file%.png}"
done
for file in *.jpg.jpg
do
mv "${file}" "${file%.png}"
done
Notes:
for d in ./*; do mv $d ${d:0:12}; done
Notes: this includes the contents of the file it's self...
//
//APPEND-DIR.js
const fs = require('fs');
let cat = require('child_process').execSync('cat *').toString('UTF-8');
fs.writeFile('output.md', cat, (err) => {
if (err) throw err;
});Notes: Can be re-purposed to find and replace any set of strings in file or folder names.
find . -name "* *" -type f | rename 's/_//g'
find . -name "* *" -type d | rename 's/#/_/g'
Notes:
find . -name '.bin' -type d -prune -exec rm -rf '{}' +
find . -name '*.html' -type d -prune -exec rm -rf '{}' +
find . -name 'nav-index' -type d -prune -exec rm -rf '{}' +
find . -name 'node-gyp' -type d -prune -exec rm -rf '{}' +
find . -name 'deleteme.txt' -type f -prune -exec rm -rf '{}' +
find . -name 'right.html' -type f -prune -exec rm -rf '{}' +
find . -name 'left.html' -type f -prune -exec rm -rf '{}' +
Notes: Remove lines not containing
'.js'
sudo sed -i '/\.js/!d' ./*scrap2.md
sudo sed -i '/githubusercontent/d' ./*sandbox.md
sudo sed -i '/githubusercontent/d' ./*scrap2.md
sudo sed -i '/github\.com/d' ./*out.md
sudo sed -i '/author/d' ./*
Notes: //...syntax of uniq...// $uniq [OPTION] [INPUT[OUTPUT]] The syntax of this is quite easy to understand. Here, INPUT refers to the input file in which repeated lines need to be filtered out and if INPUT isn't specified then uniq reads from the standard input. OUTPUT refers to the output file in which you can store the filtered output generated by uniq command and as in case of INPUT if OUTPUT isn't specified then uniq writes to the standard output.
Now, let's understand the use of this with the help of an example. Suppose you have a text file named kt.txt which contains repeated lines that needs to be omitted. This can simply be done with uniq.
sudo apt install uniq
uniq -u input.txt output.txt
Notes:
sudo sed -i '/githubusercontent/d' ./*sandbox.md
sudo sed -i '/githubusercontent/d' ./*scrap2.md
sudo sed -i '/github\.com/d' ./*out.md
---
title: add_days
tags: date,intermediate
firstSeen: 2020-10-28T16:19:04+02:00
lastUpdated: 2020-10-28T16:19:04+02:00
---
sudo sed -i '/title:/d' ./*output.md
sudo sed -i '/firstSeen/d' ./*output.md
sudo sed -i '/lastUpdated/d' ./*output.md
sudo sed -i '/tags:/d' ./*output.md
sudo sed -i '/badstring/d' ./*
sudo sed -i '/stargazers/d' ./repo.txt
sudo sed -i '/node_modules/d' ./index.html
sudo sed -i '/right\.html/d' ./index.html
sudo sed -i '/right\.html/d' ./right.html
Notes:
#!/bin/bash
TSTAMP=`date '+%Y%m%d-%H%M%S'`
zip -r $1.$TSTAMP.zip $1 -x "**.git/*" -x "**node_modules/*" `shift; echo $@;`
printf "\nCreated: $1.$TSTAMP.zip\n"
# usage:
# - zipdir thedir
# - zip thedir -x "**anotherexcludedsubdir/*" (important the double quotes to prevent glob expansion)
# if in windows/git-bash, add 'zip' command this way:
# https://stackoverflow.com/a/55749636/1482990
Notes:
find . | xargs grep -l www.redhat.com | awk '{print "rm "$1}' > doit.sh
vi doit.sh // check for murphy and his law
source doit.sh
Notes:
#!/bin/sh
# find ./ | grep -i "\.*$" >files
find ./ | sed -E -e 's/([^ ]+[ ]+){8}//' | grep -i "\.*$">files
listing="files"
out=""
html="sitemap.html"
out="basename $out.html"
html="sitemap.html"
cmd() {
echo ' <!DOCTYPE html>'
echo '<html>'
echo '<head>'
echo ' <meta http-equiv="Content-Type" content="text/html">'
echo ' <meta name="Author" content="Bryan Guner">'
echo '<link rel="stylesheet" href="./assets/prism.css">'
echo ' <link rel="stylesheet" href="./assets/style.css">'
echo ' <script async defer src="./assets/prism.js">
</script>'
echo " <title> directory </title>"
echo '<link rel="stylesheet" href="https://cdn.jsdelivr.net/gh/bgoonz/GIT-CDN-FILES/mdn-article.css">'
echo '<link rel="stylesheet" href="https://cdn.jsdelivr.net/gh/bgoonz/GIT-CDN-FILES/markdown-to-html-style.css">'
echo ""
echo '<style>'
echo ' a {'
echo ' color: black;'
echo ' }'
echo ''
echo ' li {'
echo ' border: 1px solid black !important;'
echo ' font-size: 20px;'
echo ' letter-spacing: 0px;'
echo ' font-weight: 700;'
echo ' line-height: 16px;'
echo ' text-decoration: none !important;'
echo ' text-transform: uppercase;'
echo ' background: #194ccdaf !important;'
echo ' color: black !important;'
echo ' border: none;'
echo ' cursor: pointer;'
echo ' justify-content: center;'
echo ' padding: 30px 60px;'
echo ' height: 48px;'
echo ' text-align: center;'
echo ' white-space: normal;'
echo ' border-radius: 10px;'
echo ' min-width: 45em;'
echo ' padding: 1.2em 1em 0;'
echo ' box-shadow: 0 0 5px;'
echo ' margin: 1em;'
echo ' display: grid;'
echo ' -webkit-border-radius: 10px;'
echo ' -moz-border-radius: 10px;'
echo ' -ms-border-radius: 10px;'
echo ' -o-border-radius: 10px;'
echo ' }'
echo ' </style>'
echo '</head>'
echo '<body>'
echo ""
# continue with the HTML stuff
echo ""
echo ""
echo "<ul>"
awk '{print "<li>
<a href=\""$1"\">",$1," </a>
</li>"}' $listing
# awk '{print "<li>"};
# {print " <a href=\""$1"\">",$1,"</a>
</li> "}' \ $listing
echo ""
echo "</ul>"
echo "</body>"
echo "</html>"
}
cmd $listing --sort=extension >>$html
Description: Creates an index.html file that contains all the files in the working directory or any of it's sub folders as iframes instead of anchor tags.
Notes: Useful Follow up Code:
#!/bin/sh
# find ./ | grep -i "\.*$" >files
find ./ | sed -E -e 's/([^ ]+[ ]+){8}//' | grep -i "\.*$">files
listing="files"
out=""
html="index.html"
out="basename $out.html"
html="index.html"
cmd() {
echo ' <!DOCTYPE html>'
echo '<html>'
echo '<head>'
echo ' <meta http-equiv="Content-Type" content="text/html">'
echo ' <meta name="Author" content="Bryan Guner">'
echo '<link rel="stylesheet" href="./assets/prism.css">'
echo ' <link rel="stylesheet" href="./assets/style.css">'
echo ' <script async defer src="./assets/prism.js">
</script>'
echo " <title> directory </title>"
echo ""
echo '<style>'
echo ' a {'
echo ' color: black;'
echo ' }'
echo ''
echo ' li {'
echo ' border: 1px solid black !important;'
echo ' font-size: 20px;'
echo ' letter-spacing: 0px;'
echo ' font-weight: 700;'
echo ' line-height: 16px;'
echo ' text-decoration: none !important;'
echo ' text-transform: uppercase;'
echo ' background: #194ccdaf !important;'
echo ' color: black !important;'
echo ' border: none;'
echo ' cursor: pointer;'
echo ' justify-content: center;'
echo ' padding: 30px 60px;'
echo ' height: 48px;'
echo ' text-align: center;'
echo ' white-space: normal;'
echo ' border-radius: 10px;'
echo ' min-width: 45em;'
echo ' padding: 1.2em 1em 0;'
echo ' box-shadow: 0 0 5px;'
echo ' margin: 1em;'
echo ' display: grid;'
echo ' -webkit-border-radius: 10px;'
echo ' -moz-border-radius: 10px;'
echo ' -ms-border-radius: 10px;'
echo ' -o-border-radius: 10px;'
echo ' }'
echo ' </style>'
echo '</head>'
echo '<body>'
echo ""
# continue with the HTML stuff
echo ""
echo ""
echo "<ul>"
awk '{print "<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" style="resize:both; overflow:scroll;" src=\""$1"\">","</iframe>
<br>"}' $listing
# awk '{print "<li>"};
# {print " <a href=\""$1"\">",$1,"</a>
</li> "}' \ $listing
echo ""
echo "</ul>"
echo "</body>"
echo "</html>"
}
cmd $listing --sort=extension >>$html
Notes:
git filter-branch --index-filter 'git rm -r --cached --ignore-unmatch assets/_index.html' HEAD
Important: If you have any local changes, they will be lost. With or without --hard option, any local commits that haven't been pushed will be lost.[*] If you have any files that are not tracked by Git (e.g. uploaded user content), these files will not be affected.
Notes: First, run a fetch to update all origin/ refs to latest:
git fetch --all
# Backup your current branch:
git branch backup-master
# Then, you have two options:
git reset --hard origin/master
# OR If you are on some other branch:
git reset --hard origin/<branch_name>
# Explanation:
# git fetch downloads the latest from remote without trying to merge or rebase anything.
# Then the git reset resets the master branch to what you just fetched. The --hard option changes all the files in your working tree to match the files in origin/master
git fetch --all
git reset --hard origin/master
Notes:
Delete the relevant section from the .gitmodules file. Stage the .gitmodules changes git add .gitmodules Delete the relevant section from .git/config. Run git rm --cached path_to_submodule (no trailing slash). Run rm -rf .git/modules/path_to_submodule (no trailing slash). Commit git commit -m "Removed submodule " Delete the now untracked submodule files rm -rf path_to_submodule
git submodule deinitNotes:
sudo apt install wget
wget -q -O - https://api.github.com/users/bgoonz/gists | grep raw_url | awk -F\" '{print $4}' | xargs -n3 wget
wget -q -O - https://api.github.com/users/amitness/gists | grep raw_url | awk -F\" '{print $4}' | xargs -n3 wget
wget -q -O - https://api.github.com/users/drodsou/gists | grep raw_url | awk -F\" '{print $4}' | xargs -n1 wget
wget -q -O - https://api.github.com/users/thomasmb/gists | grep raw_url | awk -F\" '{print $4}' | xargs -n1 wget
Notes:
git remote remove origin
Notes:
git clone --bare --branch=master --single-branch https://github.com/bgoonz/My-Web-Dev-Archive.git
Notes:
git reset --hard master@{"10 minutes ago"}
Notes:
# Safe:
lebab --replace ./ --transform arrow
lebab --replace ./ --transform arrow-return
lebab --replace ./ --transform for-of
lebab --replace ./ --transform for-each
lebab --replace ./ --transform arg-rest
lebab --replace ./ --transform arg-spread
lebab --replace ./ --transform obj-method
lebab --replace ./ --transform obj-shorthand
lebab --replace ./ --transform multi-var
# ALL:
lebab --replace ./ --transform obj-method
lebab --replace ./ --transform class
lebab --replace ./ --transform arrow
lebab --replace ./ --transform let
lebab --replace ./ --transform arg-spread
lebab --replace ./ --transform arg-rest
lebab --replace ./ --transform for-each
lebab --replace ./ --transform for-of
lebab --replace ./ --transform commonjs
lebab --replace ./ --transform exponent
lebab --replace ./ --transform multi-var
lebab --replace ./ --transform template
lebab --replace ./ --transform default-param
lebab --replace ./ --transform destruct-param
lebab --replace ./ --transform includes
lebab --replace ./ --transform obj-method
lebab --replace ./ --transform class
lebab --replace ./ --transform arrow
lebab --replace ./ --transform arg-spread
lebab --replace ./ --transform arg-rest
lebab --replace ./ --transform for-each
lebab --replace ./ --transform for-of
lebab --replace ./ --transform commonjs
lebab --replace ./ --transform exponent
lebab --replace ./ --transform multi-var
lebab --replace ./ --transform template
lebab --replace ./ --transform default-param
lebab --replace ./ --transform destruct-param
lebab --replace ./ --transform includes
Notes:
wsl.exe --shutdown
Get-Service LxssManager | Restart-Service
Notes:
npm i mediumexporter -g
mediumexporter https://medium.com/codex/fundamental-data-structures-in-javascript-8f9f709c15b4 >ds.md
Notes:
find . -size +75M -a -print -a -exec rm -f {} \;
find . -size +98M -a -print -a -exec rm -f {} \;
Notes:
wget -r -A.pdf https://overapi.com/git
Notes:
killall -s KILL node
Description: In the example below I am using this command to remove the string "-master" from all file names in the working directory and all of it's sub directories.
find <mydir> -type f -exec sed -i 's/<string1>/<string2>/g' {} +
find . -type f -exec rename 's/-master//g' {} +
Notes: The same could be done for folder names by changing the -type f flag (for file) to a -type d flag (for directory)
find <mydir> -type d -exec sed -i 's/<string1>/<string2>/g' {} +
find . -type d -exec rename 's/-master//g' {} +
Notes: need to run
sudo apt install renameto use this command
find . -name "* *" -type d | rename 's/ /_/g'
find . -name "* *" -type f | rename 's/ /_/g'Notes:
for i in */; do zip -r "${i%/}.zip" "$i"; done
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
Notes:
PARAM (
[string] $ZipFilesPath = "./",
[string] $UnzipPath = "./RESULT"
)
$Shell = New-Object -com Shell.Application
$Location = $Shell.NameSpace($UnzipPath)
$ZipFiles = Get-Childitem $ZipFilesPath -Recurse -Include *.ZIP
$progress = 1
foreach ($ZipFile in $ZipFiles) {
Write-Progress -Activity "Unzipping to $($UnzipPath)" -PercentComplete (($progress / ($ZipFiles.Count + 1)) * 100) -CurrentOperation $ZipFile.FullName -Status "File $($Progress) of $($ZipFiles.Count)"
$ZipFolder = $Shell.NameSpace($ZipFile.fullname)
$Location.Copyhere($ZipFolder.items(), 1040) # 1040 - No msgboxes to the user - https://msdn.microsoft.com/library/bb787866%28VS.85%29.aspx
$progress++
}
Notes:
sudo apt --purge remove zsh
Notes:
ln -s "$(pwd)" ~/NameOfLink
ln -s "$(pwd)" ~/Downloads
Notes:
npx @appnest/readme generate
Notes:
sudo -u postgres psqlNotes:
https://www.youtube.com/channel/UC1HDa0wWnIKUf-b4yY9JecQ?sub_confirmation=1
https://repl.it/@bgoonz/Data-Structures-Algos-Codebase?lite=true&referrer=https%3A%2F%2Fbryanguner.medium.com
https://repl.it/@bgoonz/node-db1-project?lite=true&referrer=https%3A%2F%2Fbryanguner.medium.com
https://repl.it/@bgoonz/interview-prac?lite=true&referrer=https%3A%2F%2Fbryanguner.medium.com
https://repl.it/@bgoonz/Database-Prac?lite=true&referrer=https%3A%2F%2Fbryanguner.medium.com
Notes:
find . -name *right.html -type f -exec sed -i 's/target="_parent"//g' {} +
find . -name *right.html -type f -exec sed -i 's/target="_parent"//g' {} +
Notes:
#!/bin/bash
# SHORTCUTS and HISTORY
CTRL+A # move to beginning of line
CTRL+B # moves backward one character
CTRL+C # halts the current command
CTRL+D # deletes one character backward or logs out of current session, similar to exit
CTRL+E # moves to end of line
CTRL+F # moves forward one character
CTRL+G # aborts the current editing command and ring the terminal bell
CTRL+H # deletes one character under cursor (same as DELETE)
CTRL+J # same as RETURN
CTRL+K # deletes (kill) forward to end of line
CTRL+L # clears screen and redisplay the line
CTRL+M # same as RETURN
CTRL+N # next line in command history
CTRL+O # same as RETURN, then displays next line in history file
CTRL+P # previous line in command history
CTRL+Q # resumes suspended shell output
CTRL+R # searches backward
CTRL+S # searches forward or suspends shell output
CTRL+T # transposes two characters
CTRL+U # kills backward from point to the beginning of line
CTRL+V # makes the next character typed verbatim
CTRL+W # kills the word behind the cursor
CTRL+X # lists the possible filename completions of the current word
CTRL+Y # retrieves (yank) last item killed
CTRL+Z # stops the current command, resume with fg in the foreground or bg in the background
ALT+B # moves backward one word
ALT+D # deletes next word
ALT+F # moves forward one word
ALT+H # deletes one character backward
ALT+T # transposes two words
ALT+. # pastes last word from the last command. Pressing it repeatedly traverses through command history.
ALT+U # capitalizes every character from the current cursor position to the end of the word
ALT+L # uncapitalizes every character from the current cursor position to the end of the word
ALT+C # capitalizes the letter under the cursor. The cursor then moves to the end of the word.
ALT+R # reverts any changes to a command you've pulled from your history if you've edited it.
ALT+? # list possible completions to what is typed
ALT+^ # expand line to most recent match from history
CTRL+X then ( # start recording a keyboard macro
CTRL+X then ) # finish recording keyboard macro
CTRL+X then E # recall last recorded keyboard macro
CTRL+X then CTRL+E # invoke text editor (specified by $EDITOR) on current command line then execute resultes as shell commands
BACKSPACE # deletes one character backward
DELETE # deletes one character under cursor
history # shows command line history
!! # repeats the last command
!<n> # refers to command line 'n'
!<string> # refers to command starting with 'string'
exit # logs out of current session
# BASH BASICS
env # displays all environment variables
echo $SHELL # displays the shell you're using
echo $BASH_VERSION # displays bash version
bash # if you want to use bash (type exit to go back to your previously opened shell)
whereis bash # locates the binary, source and manual-page for a command
which bash # finds out which program is executed as 'bash' (default: /bin/bash, can change across environments)
clear # clears content on window (hide displayed lines)
# FILE COMMANDS
ls # lists your files in current directory, ls <dir> to print files in a specific directory
ls -l # lists your files in 'long format', which contains the exact size of the file, who owns the file and who has the right to look at it, and when it was last modified
ls -a # lists all files in 'long format', including hidden files (name beginning with '.')
ln -s <filename> <link> # creates symbolic link to file
readlink <filename> # shows where a symbolic links points to
tree # show directories and subdirectories in easilly readable file tree
mc # terminal file explorer (alternative to ncdu)
touch <filename> # creates or updates (edit) your file
mktemp -t <filename> # make a temp file in /tmp/ which is deleted at next boot (-d to make directory)
cat <filename> # prints file raw content (will not be interpreted)
any_command > <filename> # '>' is used to perform redirections, it will set any_command's stdout to file instead of "real stdout" (generally /dev/stdout)
more <filename> # shows the first part of a file (move with space and type q to quit)
head <filename> # outputs the first lines of file (default: 10 lines)
tail <filename> # outputs the last lines of file (useful with -f option) (default: 10 lines)
vim <filename> # opens a file in VIM (VI iMproved) text editor, will create it if it doesn't exist
mv <filename1> <dest> # moves a file to destination, behavior will change based on 'dest' type (dir: file is placed into dir; file: file will replace dest (tip: useful for renaming))
cp <filename1> <dest> # copies a file
rm <filename> # removes a file
find . -name <name> <type> # searches for a file or a directory in the current directory and all its sub-directories by its name
diff <filename1> <filename2> # compares files, and shows where they differ
wc <filename> # tells you how many lines, words and characters there are in a file. Use -lwc (lines, word, character) to ouput only 1 of those informations
sort <filename> # sorts the contents of a text file line by line in alphabetical order, use -n for numeric sort and -r for reversing order.
sort -t -k <filename> # sorts the contents on specific sort key field starting from 1, using the field separator t.
rev # reverse string characters (hello becomes olleh)
chmod -options <filename> # lets you change the read, write, and execute permissions on your files (more infos: SUID, GUID)
gzip <filename> # compresses files using gzip algorithm
gunzip <filename> # uncompresses files compressed by gzip
gzcat <filename> # lets you look at gzipped file without actually having to gunzip it
lpr <filename> # prints the file
lpq # checks out the printer queue
lprm <jobnumber> # removes something from the printer queue
genscript # converts plain text files into postscript for printing and gives you some options for formatting
dvips <filename> # prints .dvi files (i.e. files produced by LaTeX)
grep <pattern> <filenames> # looks for the string in the files
grep -r <pattern> <dir> # search recursively for pattern in directory
head -n file_name | tail +n # Print nth line from file.
head -y lines.txt | tail +x # want to display all the lines from x to y. This includes the xth and yth lines.
# DIRECTORY COMMANDS
mkdir <dirname> # makes a new directory
rmdir <dirname> # remove an empty directory
rmdir -rf <dirname> # remove a non-empty directory
mv <dir1> <dir2> # rename a directory from <dir1> to <dir2>
cd # changes to home
cd .. # changes to the parent directory
cd <dirname> # changes directory
cp -r <dir1> <dir2> # copy <dir1> into <dir2> including sub-directories
pwd # tells you where you currently are
cd ~ # changes to home.
cd - # changes to previous working directory
# SSH, SYSTEM INFO & NETWORK COMMANDS
ssh user@host # connects to host as user
ssh -p <port> user@host # connects to host on specified port as user
ssh-copy-id user@host # adds your ssh key to host for user to enable a keyed or passwordless login
whoami # returns your username
passwd # lets you change your password
quota -v # shows what your disk quota is
date # shows the current date and time
cal # shows the month's calendar
uptime # shows current uptime
w # displays whois online
finger <user> # displays information about user
uname -a # shows kernel information
man <command> # shows the manual for specified command
df # shows disk usage
du <filename> # shows the disk usage of the files and directories in filename (du -s give only a total)
last <yourUsername> # lists your last logins
ps -u yourusername # lists your processes
kill <PID> # kills the processes with the ID you gave
killall <processname> # kill all processes with the name
top # displays your currently active processes
lsof # lists open files
bg # lists stopped or background jobs ; resume a stopped job in the background
fg # brings the most recent job in the foreground
fg <job> # brings job to the foreground
ping <host> # pings host and outputs results
whois <domain> # gets whois information for domain
dig <domain> # gets DNS information for domain
dig -x <host> # reverses lookup host
wget <file> # downloads file
time <command> # report time consumed by command execution
# VARIABLES
varname=value # defines a variable
varname=value command # defines a variable to be in the environment of a particular subprocess
echo $varname # checks a variable's value
echo $$ # prints process ID of the current shell
echo $! # prints process ID of the most recently invoked background job
echo $? # displays the exit status of the last command
read <varname> # reads a string from the input and assigns it to a variable
read -p "prompt" <varname> # same as above but outputs a prompt to ask user for value
column -t <filename> # display info in pretty columns (often used with pipe)
let <varname> = <equation> # performs mathematical calculation using operators like +, -, *, /, %
export VARNAME=value # defines an environment variable (will be available in subprocesses)
array[0]=valA # how to define an array
array[1]=valB
array[2]=valC
array=([2]=valC [0]=valA [1]=valB) # another way
array=(valA valB valC) # and another
${array[i]} # displays array's value for this index. If no index is supplied, array element 0 is assumed
${#array[i]} # to find out the length of any element in the array
${#array[@]} # to find out how many values there are in the array
declare -a # the variables are treated as arrays
declare -f # uses function names only
declare -F # displays function names without definitions
declare -i # the variables are treated as integers
declare -r # makes the variables read-only
declare -x # marks the variables for export via the environment
${varname:-word} # if varname exists and isn't null, return its value; otherwise return word
${varname:word} # if varname exists and isn't null, return its value; otherwise return word
${varname:=word} # if varname exists and isn't null, return its value; otherwise set it word and then return its value
${varname:?message} # if varname exists and isn't null, return its value; otherwise print varname, followed by message and abort the current command or script
${varname:+word} # if varname exists and isn't null, return word; otherwise return null
${varname:offset:length} # performs substring expansion. It returns the substring of $varname starting at offset and up to length characters
${variable#pattern} # if the pattern matches the beginning of the variable's value, delete the shortest part that matches and return the rest
${variable##pattern} # if the pattern matches the beginning of the variable's value, delete the longest part that matches and return the rest
${variable%pattern} # if the pattern matches the end of the variable's value, delete the shortest part that matches and return the rest
${variable%%pattern} # if the pattern matches the end of the variable's value, delete the longest part that matches and return the rest
${variable/pattern/string} # the longest match to pattern in variable is replaced by string. Only the first match is replaced
${variable//pattern/string} # the longest match to pattern in variable is replaced by string. All matches are replaced
${#varname} # returns the length of the value of the variable as a character string
*(patternlist) # matches zero or more occurrences of the given patterns
+(patternlist) # matches one or more occurrences of the given patterns
?(patternlist) # matches zero or one occurrence of the given patterns
@(patternlist) # matches exactly one of the given patterns
!(patternlist) # matches anything except one of the given patterns
$(UNIX command) # command substitution: runs the command and returns standard output
# FUNCTIONS
# The function refers to passed arguments by position (as if they were positional parameters), that is, $1, $2, and so forth.
# $@ is equal to "$1" "$2"... "$N", where N is the number of positional parameters. $# holds the number of positional parameters.
function functname() {
shell commands
}
unset -f functname # deletes a function definition
declare -f # displays all defined functions in your login session
# FLOW CONTROLS
statement1 && statement2 # and operator
statement1 || statement2 # or operator
-a # and operator inside a test conditional expression
-o # or operator inside a test conditional expression
# STRINGS
str1 == str2 # str1 matches str2
str1 != str2 # str1 does not match str2
str1 < str2 # str1 is less than str2 (alphabetically)
str1 > str2 # str1 is greater than str2 (alphabetically)
str1 \> str2 # str1 is sorted after str2
str1 \< str2 # str1 is sorted before str2
-n str1 # str1 is not null (has length greater than 0)
-z str1 # str1 is null (has length 0)
# FILES
-a file # file exists or its compilation is successful
-d file # file exists and is a directory
-e file # file exists; same -a
-f file # file exists and is a regular file (i.e., not a directory or other special type of file)
-r file # you have read permission
-s file # file exists and is not empty
-w file # your have write permission
-x file # you have execute permission on file, or directory search permission if it is a directory
-N file # file was modified since it was last read
-O file # you own file
-G file # file's group ID matches yours (or one of yours, if you are in multiple groups)
file1 -nt file2 # file1 is newer than file2
file1 -ot file2 # file1 is older than file2
# NUMBERS
-lt # less than
-le # less than or equal
-eq # equal
-ge # greater than or equal
-gt # greater than
-ne # not equal
if condition
then
statements
[elif condition
then statements...]
[else
statements]
fi
for x in {1..10}
do
statements
done
for name [in list]
do
statements that can use $name
done
for (( initialisation ; ending condition ; update ))
do
statements...
done
case expression in
pattern1 )
statements ;;
pattern2 )
statements ;;
esac
select name [in list]
do
statements that can use $name
done
while condition; do
statements
done
until condition; do
statements
done
# COMMAND-LINE PROCESSING CYCLE
# The default order for command lookup is functions, followed by built-ins, with scripts and executables last.
# There are three built-ins that you can use to override this order: `command`, `builtin` and `enable`.
command # removes alias and function lookup. Only built-ins and commands found in the search path are executed
builtin # looks up only built-in commands, ignoring functions and commands found in PATH
enable # enables and disables shell built-ins
eval # takes arguments and run them through the command-line processing steps all over again
# INPUT/OUTPUT REDIRECTORS
cmd1|cmd2 # pipe; takes standard output of cmd1 as standard input to cmd2
< file # takes standard input from file
> file # directs standard output to file
>> file # directs standard output to file; append to file if it already exists
>|file # forces standard output to file even if noclobber is set
n>|file # forces output to file from file descriptor n even if noclobber is set
<> file # uses file as both standard input and standard output
n<>file # uses file as both input and output for file descriptor n
n>file # directs file descriptor n to file
n<file # takes file descriptor n from file
n>>file # directs file description n to file; append to file if it already exists
n>& # duplicates standard output to file descriptor n
n<& # duplicates standard input from file descriptor n
n>&m # file descriptor n is made to be a copy of the output file descriptor
n<&m # file descriptor n is made to be a copy of the input file descriptor
&>file # directs standard output and standard error to file
<&- # closes the standard input
>&- # closes the standard output
n>&- # closes the ouput from file descriptor n
n<&- # closes the input from file descripor n
|tee <file># output command to both terminal and a file (-a to append to file)
# PROCESS HANDLING
# To suspend a job, type CTRL+Z while it is running. You can also suspend a job with CTRL+Y.
# This is slightly different from CTRL+Z in that the process is only stopped when it attempts to read input from terminal.
# Of course, to interrupt a job, type CTRL+C.
myCommand & # runs job in the background and prompts back the shell
jobs # lists all jobs (use with -l to see associated PID)
fg # brings a background job into the foreground
fg %+ # brings most recently invoked background job
fg %- # brings second most recently invoked background job
fg %N # brings job number N
fg %string # brings job whose command begins with string
fg %?string # brings job whose command contains string
kill -l # returns a list of all signals on the system, by name and number
kill PID # terminates process with specified PID
kill -s SIGKILL 4500 # sends a signal to force or terminate the process
kill -15 913 # Ending PID 913 process with signal 15 (TERM)
kill %1 # Where %1 is the number of job as read from 'jobs' command.
ps # prints a line of information about the current running login shell and any processes running under it
ps -a # selects all processes with a tty except session leaders
trap cmd sig1 sig2 # executes a command when a signal is received by the script
trap "" sig1 sig2 # ignores that signals
trap - sig1 sig2 # resets the action taken when the signal is received to the default
disown <PID|JID> # removes the process from the list of jobs
wait # waits until all background jobs have finished
sleep <number> # wait # of seconds before continuing
pv # display progress bar for data handling commands. often used with pipe like |pv
yes # give yes response everytime an input is requested from script/process
# TIPS & TRICKS
# set an alias
cd; nano .bash_profile
> alias gentlenode='ssh admin@gentlenode.com -p 3404' # add your alias in .bash_profile
# to quickly go to a specific directory
cd; nano .bashrc
> shopt -s cdable_vars
> export websites="/Users/mac/Documents/websites"
source .bashrc
cd $websites
# DEBUGGING SHELL PROGRAMS
bash -n scriptname # don't run commands; check for syntax errors only
set -o noexec # alternative (set option in script)
bash -v scriptname # echo commands before running them
set -o verbose # alternative (set option in script)
bash -x scriptname # echo commands after command-line processing
set -o xtrace # alternative (set option in script)
trap 'echo $varname' EXIT # useful when you want to print out the values of variables at the point that your script exits
function errtrap {
es=$?
echo "ERROR line $1: Command exited with status $es."
}
trap 'errtrap $LINENO' ERR # is run whenever a command in the surrounding script or function exits with non-zero status
function dbgtrap {
echo "badvar is $badvar"
}
trap dbgtrap DEBUG # causes the trap code to be executed before every statement in a function or script
# ...section of code in which the problem occurs...
trap - DEBUG # turn off the DEBUG trap
function returntrap {
echo "A return occurred"
}
trap returntrap RETURN # is executed each time a shell function or a script executed with the . or source commands finishes executing
# COLORS AND BACKGROUNDS
# note: \e or \x1B also work instead of \033
# Reset
Color_Off='\033[0m' # Text Reset
# Regular Colors
Black='\033[0;30m' # Black
Red='\033[0;31m' # Red
Green='\033[0;32m' # Green
Yellow='\033[0;33m' # Yellow
Blue='\033[0;34m' # Blue
Purple='\033[0;35m' # Purple
Cyan='\033[0;36m' # Cyan
White='\033[0;97m' # White
# Additional colors
LGrey='\033[0;37m' # Ligth Gray
DGrey='\033[0;90m' # Dark Gray
LRed='\033[0;91m' # Ligth Red
LGreen='\033[0;92m' # Ligth Green
LYellow='\033[0;93m'# Ligth Yellow
LBlue='\033[0;94m' # Ligth Blue
LPurple='\033[0;95m'# Light Purple
LCyan='\033[0;96m' # Ligth Cyan
# Bold
BBlack='\033[1;30m' # Black
BRed='\033[1;31m' # Red
BGreen='\033[1;32m' # Green
BYellow='\033[1;33m'# Yellow
BBlue='\033[1;34m' # Blue
BPurple='\033[1;35m'# Purple
BCyan='\033[1;36m' # Cyan
BWhite='\033[1;37m' # White
# Underline
UBlack='\033[4;30m' # Black
URed='\033[4;31m' # Red
UGreen='\033[4;32m' # Green
UYellow='\033[4;33m'# Yellow
UBlue='\033[4;34m' # Blue
UPurple='\033[4;35m'# Purple
UCyan='\033[4;36m' # Cyan
UWhite='\033[4;37m' # White
# Background
On_Black='\033[40m' # Black
On_Red='\033[41m' # Red
On_Green='\033[42m' # Green
On_Yellow='\033[43m'# Yellow
On_Blue='\033[44m' # Blue
On_Purple='\033[45m'# Purple
On_Cyan='\033[46m' # Cyan
On_White='\033[47m' # White
# Example of usage
echo -e "${Green}This is GREEN text${Color_Off} and normal text"
echo -e "${Red}${On_White}This is Red test on White background${Color_Off}"
# option -e is mandatory, it enable interpretation of backslash escapes
printf "${Red} This is red \n"
| title | Learn Css | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | Learn Css | ||||||||||
| seo |
|
||||||||||
| template | docs |
CSS Selectors
CSS Selector: Applies styles to a specific DOM element(s), there are various types:Type Selectors: Matches by node name.Class Selectors: Matches by class name.ID Selectors: Matches by ID name.Universal Selectors: Selects all HTML elements on a page.Attribute Selectors: Matches elements based on the prescence or value of a given attribute. (i.e. a[title] will match all a elements with a title attribute)
/* Type selector */
div {
background-color: #000000;
}/* Class selector */
.active {
color: #ffffff;
}/* ID selector */
#list-1 {
border: 1px solid gray;
}/* Universal selector */
* {
padding: 10px;
}/* Attribute selector */
a[title] {
font-size: 2em;
}
Class Selectors
- Used to select all elements of a certain class denoted with a
.[class name] - You can assign multiple classes to a DOM element by separating them with a space.
Compound Class Selectors
- To get around accidentally selecting elements with multiple classes beyond what we want to grab we can chain dots.
- TO use a compound class selector just append the classes together when referencing them in the CSS.
<div class="box yellow">
- i.e. .box.yellow will select only the first element.
- KEEP IN MIND that if you do include a space it will make the selector into a descendant selector.
h1#heading,
h2.subheading {
font-style: italic;
}
- When we want to target all
h1tags with the id ofheading.
CSS Combinators
- CSS Combinators are used to combine other selectors into more complex or targeted selectors — they are very powerful!
- Be careful not to use too many of them as they will make your CSS far too complex.
Descendant Selectors- Separated by a space.
- Selects all descendants of a parent container.
Direct Child Selectors- Indicated with a
>. - Different from descendants because it only affects the direct children of an element.
.menu > .is-active { background-color: #ffe0b2; }<body> <div class="menu"> <div class="is-active">Belka</div> <div> <div class="is-active">Strelka</div> </div> </div> </body> <div class="is-active"> Laika </div> </body>- Belka would be the only element selected.
Adjacent Sibling Selectors- Uses the
+symbol. - Used for elements that directly follow one another and who both have the same parent.
h1 + h2 { font-style: italic; } <h1>Big header</h1> <h2>This one is styled because it is directly adjacent to the H1</h2> <h2>This one is NOT styled because there is no H1 right before it</h2>
Pseudo-Classes
Pseudo-Class: Specifies a special state of the seleted element(s) and does not refer to any elements or attributes contained in the DOM.- Format is a
Selector:Pseudo-Class NameorA:B a:hover { font-family: "Roboto Condensed", sans-serif; color: #4fc3f7; text-decoration: none; border-bottom: 2px solid #4fc3f7; }- Some common pseudo-classes that are frequently used are:
active: 'push down', when ele are activated.checked: applies to things like radio buttons or checkbox inputs.disabled: any disabled element.first-child: first element in a group of children/siblings.focus: elements that have current focus.hover: elements that have cursor hovering over it.invalid: any form elements in an invalid state from client-side form validation.last-child: last element in a group of children/siblings.not(selector): elements that do not match the provided selector.required: form elements that are required.valid: form elements in a valid state.visited: anchor tags of whih the user has already been to the URL that the href points to.
Pseudo-Selectors
- Used to create pseudo-elements as children of the elements to which the property applies.
::after::before
<style>
p::before {
background-color: lightblue;
border-right: 4px solid violet;
content: ":-) ";
margin-right: 4px;
padding-left: 4px;
}
</style>
<p>This is the first paragraph</p>
<p>This is the second paragraph</p>
<p>This is the third paragraph</p>
- Will add some blue smiley faces before the p tag elements.
CSS Rules
CSS Rule: Collection of single or compound selectors, a curly brace, zero or more propertiesCSS Rule Specificity: Sometimes CSS rules will contain multiple elements and may have overlapping properties rules for those same elements - there is an algorithm in CSS that calculates which rule takes precedence.The Four Number Calculation: listed in increasing order of importance.
Who has the most IDs? If no one, continue.
Who has the most classes? If no one, continue.
Who has the most tags? If no one, continue.
Last Read in the browser wins.

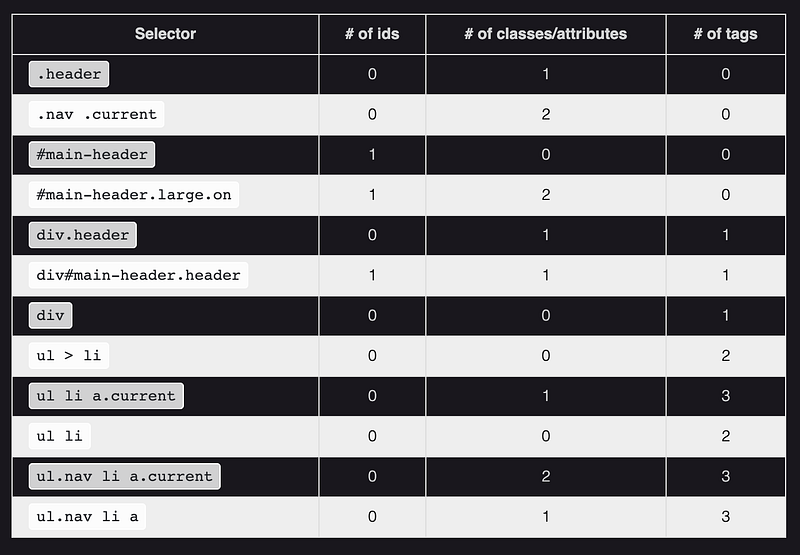


- Coming back to our example where all the CSS Rules have tied, the last step 4 wins out so our element will have a
purple border.
Typography
font-family: change the font.

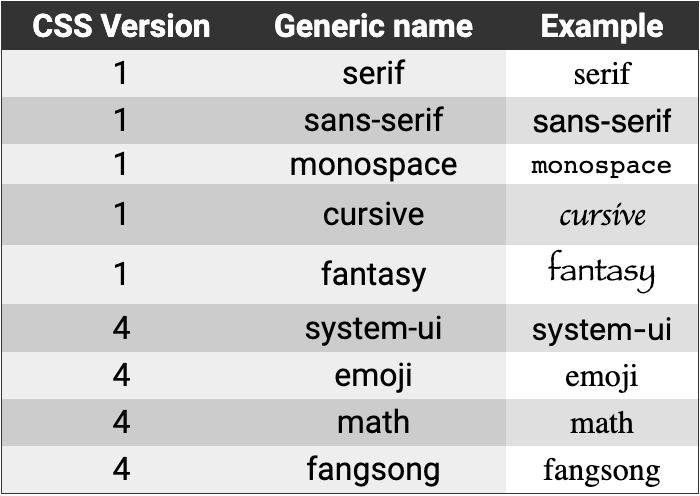
Background-Images
- You can use the background-image property to set a background image for an element.
Colors
- You can set colors in CSS in three popular ways: by name, by hexadecimal RGB value, and by their decimal RGB value.
- rgba() is used to make an rbg value more transparent, the
ais used to specify thealpha channel. - Color : Property used to change the color of text.
- Background-Color : Property to change the backgrounf color of an element.
Borders
- Borders take three values: The width of the border, the style (i.e. solid, dotted, dashed), color of the border.
Shadows
- There are two kinds of shadows in CSS:
box shadowsandtext shadows. - Box refers to HTML elements.
- Text refers to text.
- Shadows take values such as, the horizontal & vertical offsets of the shadow, the blur radius of the shadow, the spread radius, and of course the colors.
Box Model : A concept that basically boils down that every DOM element has a box around it.
Imagine a gift, inside is the gift, wrapped in foam all around (padding), and the giftbox outside of it (border) and then a wrapping paper on the giftbox (margin).- For items that are using block as it's display, the browser will follow these rules to layout the element: - The box fills 100% of the available container space. - Every new box takes on a new line/row. - Width and Height properties are respected. - Padding, Margin, and Border will push other elements away from the box. - Certain elements have block as their default display, such as: divs, headers, and paragraphs.- For items that are using inline as it's display, the browser will follow these rules to layout the element: - Each box appears in a single line until it fills up the space. - Width and height are not respected. - Padding, Margin, and Border are applied but they do not push other elements away from the box. - Certain elements have inline as their default display, such as: span tags, anchors, and images.
Standard Box Model vs Border-Box- As per the standard Box Model, the width and height pertains to the content of the box and excludes any additional padding, borders, and margins.
This bothered many programmers so they created the border box to include the calculation of the entire box's height and width.
Inline-Block- Inline-block uses the best features of both block and inline. - Elements still get laid out left to right. - Layout takes into account specified width and height.
Padding- Padding applies padding to every side of a box. It is shorthand for four padding properties in this order: padding-top, padding-right, padding-bottom, padding-left (clockwise!)
Border- Border applies a border on all sides of an element. It takes three values in this order: border-width, border-style, border-color. - All three properties can be broken down in the four sides clockwise: top, right, bottom, left.
Margin- Margin sets margins on every side of an element. It takes four values in this order: margin-top, margin-right, margin-bottom, margin-left. - You can use margin: 0 auto to center an element.
- The
positionproperty allows us to set the position of elements on a page and is an integral part of creatnig a Web page layout. - It accepts five values:
static,relative,absolute,fixed,sticky. - Every property (minus
static) is used with:top,right,bottom, andleftto position an element on a page.
Static Positioning
- The default position value of page elements.
- Most likely will not use static that much.
Relative Positioning
- Remains in it's original position in the page flow.
- It is positioned RELATIVE to the it's ORIGINAL PLACE on the page flow.
- Creates a stacking context : overlapping elements whose order can be set by the z-index property.
#pink-box {
background-color: #ff69b4;
bottom: 0;
left: -20px;
position: relative;
right: 0;
top: 0;
}


- Absolute elements are removed from the normal page flow and other elements around it act like it's not there. (how we can easily achieve some layering)
- Here are some examples to illustration absolute positioning:
.container {
background-color: #2b2d2f;
position: relative;
}#pink-box {
position: absolute;
top: 60px;
}


.container {
background-color: #2b2d2f;
position: relative;
}#pink-box {
position: absolute;
top: 60px;
}#blue-box {
position: absolute;
}


.container {
background-color: #2b2d2f;
position: relative;
}#pink-box {
background-color: #ff69b4;
bottom: 60px;
position: absolute;
}


.container {
background-color: #2b2d2f;
}#pink-box {
background-color: #ff69b4;
bottom: 60px;
position: absolute;
}


Fixed Positioning
- Another positioning that removes it's element from the page flow, and automatically positions it's parent as the HTML doc itself.
- Fixed also uses top, right, bottom, and left.
- Useful for things like nav bars or other features we want to keep visible as the user scrolls.
Sticky Positioning
- Remains in it's original position in the page flow, and it is positioned relative to it's closest block-level ancestor and any scrolling ancestors.
- Behaves like a relatively positioned element until the point at which you would normally scroll past it's viewport — then it sticks!
- It is positioned with top, right, bottom, and left.
- A good example are headers in a scrollable list.


- Flexbox is a CSS module that provides a convenient way for us to display items inside a flexible container so that the layout is responsive.
- Float was used back in the day to display position of elements in a container.
- A very inconvenient aspect of float is the need to clear the float.
- To 'clear' a float we need to set up a ghost div to properly align — this is already sounds so inefficient.
Using Flexbox
- Flexbox automatically resizes a container element to fit the viewport size without needing to use breakpoints.
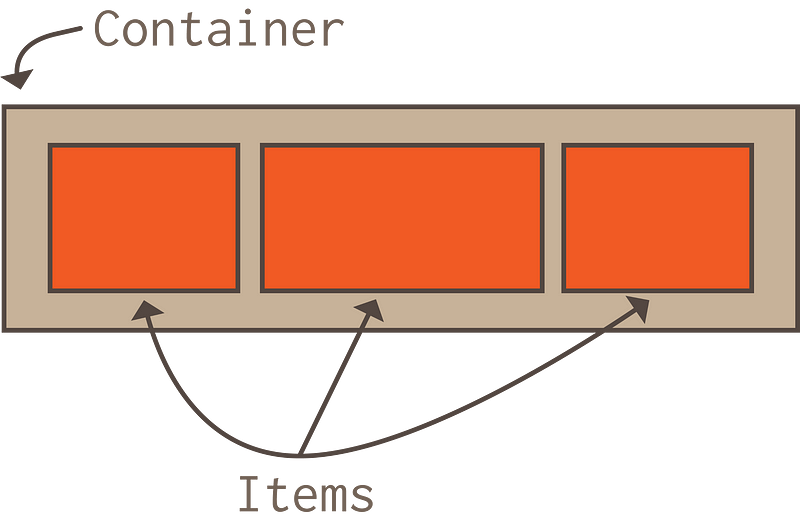
.container {
display: flex; /*sets display to use flex*/
flex-wrap: wrap; /*bc flex tries to fit everything into one line, use wrap to have the elements wrap to the next line*/
flex-direction: row; /*lets us create either rows or columns*/
}
flex-flowcan be used to combine wrap and direction.justify-contentused to define the alignment of flex items along the main axis.align-itemsused to define the alignment on the Y-axis.align-contentredistributes extra space on the cross axis.- By default, flex items will appear in the order they are added to the DOM, but we can use the
orderproperty to change that. - Some other properties we can use on flex items are:
flex-grow: dictates amount of avail. space the item should take up.flex-shrink: defines the ability for a flex item to shrink.flex-basis: Default size of an element before the remaining space is distributed.flex: shorthand for grow, shrink and basis.align-self: Overrides default alignment in the container.
- CSS Grid is a 2d layout system that let's use create a grid with columns and rows purely using Vanilla CSS. (flex is one dimensional)
Bootstrap vs CSS Grid
- Bootstrap was a front-end library commonly used to create grid layouts but now CSS grid provides greater flexibility and control.
- Grid applies style to a parent container and it's child elements.
.grid-container {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: auto;
grid-template-areas:
"header header header"
"main . sidebar"
"footer footer footer"; grid-column-gap: 20px;
grid-row-gap: 30px;
justify-items: stretch;
align-items: stretch;
justify-content: stretch;
align-content: stretch;
}.item-1 {
grid-area: header;
}
.item-2 {
grid-area: main;
}
.item-3 {
grid-area: sidebar;
}
.item-4 {
grid-area: footer;
}
- Columns and Rows can be defined with: pixels, percentages, auto, named grid lines, using
repeat, fractions. Grid Template Areasgives us a handy way to map out and visualize areas of the grid layout.- Combine areas with templates to define how much space an area should take up.
Grid Gapscan be used to create 'gutters' between grid item.s- The way we have defined our grid with
grid-templatesandareasare considered explicit. - We can also
implicitlydefine grids.
.grid-container {
display: grid;
grid-template-columns: 100px 100px 100px 100px;
grid-template-rows: 50px 50px 50px;
grid-auto-columns: 100px;
grid-auto-rows: 50px;
}
- Any grid items that aren't explicity placed are automatically placed or re-flowed
Spanning Columns & Rows
- We can use the following properties to take up a specified num of cols and rows.
grid-column-startgrid-column-endgrid-row-startgrid-row-end- All four properties can take any of the following values: the line number, span #, span name, auto.
.item-1 {
grid-row-start: row2-start; /* Item starts at row line named "row2-start" */
grid-row-end: 5; /* Item ends at row line 5 */
grid-column-start: 1; /* Item starts at column line 1 */
grid-column-end: three; /* Item ends at column line named "three" */
}.item-2 {
grid-row-start: 1; /* Item starts at row line 1 */
grid-row-end: span 2; /* Item spans two rows and ends at row line 3 */
grid-column-start: 3; /* Item starts at column line 3 */
grid-column-end: span col5-start; /* Item spans and ends at line named "col5-start" */
}
Grid Areas
- We use the grid areas in conjunction with grid-container property to define sections of the layout.
- We can then assign named sections to individual element's css rules.
Justify & Align Self
- Justify items and Align Items can be used to align all grid items at once.
- Justify Self is used to align self on the row.
- It can take four values: start, end, center, stretch.
- Align Self is used to align self on the column.
- It can take four values: start, end, center, stretch.
CSS Hover Effect and Handling
Overflow
css .btn { background-color: #00bfff; color: #ffffff; border-radius: 10px; padding: 1.5rem; }
.btn--active:hover { cursor: pointer; transform: translateY(-0.25rem);
/* Moves our button up/down on the Y axis */ }
The Pseudo Class Selector hover activates when the cursor goes over the selected element.
Content Overflow- You can apply an overflow content property to an element if it's inner contents are spilling over.
There are three members in the overflow family: — overflow-x : Apply horizontally. - overflow-y : Apply vertically. - overflow : Apply both directions.
- Transitions provide a way to control animation speed when changing CSS properties.
- Implicit Transitions : Animations that involve transitioning between two states.
Defining Transitions
transition-property: specifies the name of the CSS property to apply the transition.transition-duration: during of the transition.transition-delay: time before the transition should start.
Examples :
#delay {
font-size: 14px;
transition-property: font-size;
transition-duration: 4s;
transition-delay: 2s;
}#delay:hover {
font-size: 36px;
}


.box {
border-style: solid;
border-width: 1px;
display: block;
width: 100px;
height: 100px;
background-color: #0000ff;
transition: width 2s, height 2s, background-color 2s, transform 2s;
}.box:hover {
background-color: #ffcccc;
width: 200px;
height: 200px;
transform: rotate(180deg);
}


- BEM was created as a guideline to solve the issue of loose standards around CSS naming conventions.
- BEM stands for
block,element,modifier. - Block
- A standalone entity that is meaningful on it's own.
- Can be nested and interact with one another.
- Holistic entities without DOM rep can be blocks.
- May consist latin letters, digits, and dashes.
- Any DOM node can be a block if it accepts a class name.
- Element
- Part of a block and has no standalone meaning.
- Any element that is semantically tied to a block.
- May consist latin letters, digits, and dashes.
- Formed by using two underscores after it's block name.
- Any DOM node within a block can be an element.
- Element classes should be used independently.
- Modifier
- A flag on blocks or elements. Use them to change appearance, behavior or state.
- Extra class name to add onto blocks or elements.
- Add mods only to the elements they modify.
- Modifier names may consist of Latin letters, digits, dashes and underscores.
- Written with two dashes.
BEM Example
<form class="form form--theme-xmas form--simple">
<input class="form__input" type="text" />
<input class="form__submit form__submit--disabled" type="submit" />
</form>/* block selector */
.form {
}/* block modifier selector */
.form--theme-xmas {
}/* block modifier selector */
.form--simple {
}/* element selector */
.form__input {
}/* element selector */
.form__submit {
}/* element modifier selector */
.form__submit--disabled {
}
Web Developer, Electrical Engineer JavaScript | CSS | Bootstrap | Python | React | Node.js | Express | Sequelize…github.com
Or Checkout my personal Resource Site:
a/A-Student-ResourcesEdit descriptiongoofy-euclid-1cd736.netlify.app
By Bryan Guner on March 6, 2021.
| title | Git Reference | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | Git Reference | ||||||||
| seo |
|
||||||||
| template | docs |
Git is a distributed version control and source code management system.
It does this through a series of snapshots of your project, and it works with those snapshots to provide you with functionality to version and manage your source code.
Version control is a system that records changes to a file(s), over time.
- Centralized version control focuses on synchronizing, tracking, and backing
- up files.
- Distributed version control focuses on sharing changes. Every change has a unique id.
- Distributed systems have no defined structure. You could easily have a SVN style, centralized system, with git.
- Can work offline.
- Collaborating with others is easy!
- Branching is easy!
- Branching is fast!
- Merging is easy!
- Git is fast.
- Git is flexible.
A set of files, directories, historical records, commits, and heads. Imagine it as a source code data structure, with the attribute that each source code "element" gives you access to its revision history, among other things.
A git repository is comprised of the .git directory & working tree.
The .git directory contains all the configurations, logs, branches, HEAD, and more. Detailed List.
This is basically the directories and files in your repository. It is often referred to as your working directory.
The Index is the staging area in git. It's basically a layer that separates your working tree from the Git repository. This gives developers more power over what gets sent to the Git repository.
A git commit is a snapshot of a set of changes, or manipulations to your Working Tree. For example, if you added 5 files, and removed 2 others, these changes will be contained in a commit (or snapshot). This commit can then be pushed to other repositories, or not!
A branch is essentially a pointer to the last commit you made. As you go on committing, this pointer will automatically update to point to the latest commit.
A tag is a mark on specific point in history. Typically people use this functionality to mark release points (v1.0, and so on).
HEAD is a pointer that points to the current branch. A repository only has 1 active HEAD. head is a pointer that points to any commit. A repository can have any number of heads.
- Modified - Changes have been made to a file but file has not been committed
- to Git Database yet
- Staged - Marks a modified file to go into your next commit snapshot
- Committed - Files have been committed to the Git Database
Create an empty Git repository. The Git repository's settings, stored information, and more is stored in a directory (a folder) named ".git".
$ git initTo configure settings. Whether it be for the repository, the system itself,
or global configurations ( global config file is ~/.gitconfig ).
# Print & Set Some Basic Config Variables (Global)
git config --global user.email "bryan.guner@gmail.com"
git config --global user.name "bryan"To give you quick access to an extremely detailed guide of each command. Or to just give you a quick reminder of some semantics.
# Quickly check available commands
$ git help
# Check all available commands
$ git help -a
# Command specific help - user manual
# git help <command_here>
$ git help add
$ git help commit
$ git help init
# or git <command_here> --help
$ git add --help
$ git commit --help
$ git init --helpTo intentionally untrack file(s) & folder(s) from git. Typically meant for private & temp files which would otherwise be shared in the repository.
$ echo "temp/" >> .gitignore
$ echo "private_key" >> .gitignoreTo show differences between the index file (basically your working copy/repo) and the current HEAD commit.
# Will display the branch, untracked files, changes and other differences
$ git status
# To learn other "tid bits" about git status
$ git help statusTo add files to the staging area/index. If you do not git add new files to
the staging area/index, they will not be included in commits!
# add a file in your current working directory
$ git add HelloWorld.java
# add a file in a nested dir
$ git add /path/to/file/HelloWorld.c
# Regular Expression support!
$ git add ./*.java
# You can also add everything in your working directory to the staging area.
$ git add -AThis only adds a file to the staging area/index, it doesn't commit it to the working directory/repo.
Manage your branches. You can view, edit, create, delete branches using this command.
# list existing branches & remotes
$ git branch -a
# create a new branch
$ git branch myNewBranch
# delete a branch
$ git branch -d myBranch
# rename a branch
# git branch -m <oldname> <newname>
$ git branch -m myBranchName myNewBranchName
# edit a branch's description
$ git branch myBranchName --edit-descriptionManage your tags
# List tags
$ git tag
# Create a annotated tag
# The -m specifies a tagging message, which is stored with the tag.
# If you don't specify a message for an annotated tag,
# Git launches your editor so you can type it in.
$ git tag -a v2.0 -m 'my version 2.0'
# Show info about tag
# That shows the tagger information, the date the commit was tagged,
# and the annotation message before showing the commit information.
$ git show v2.0
# Push a single tag to remote
$ git push origin v2.0
# Push a lot of tags to remote
$ git push origin --tagsUpdates all files in the working tree to match the version in the index, or specified tree.
# Checkout a repo - defaults to master branch
$ git checkout
# Checkout a specified branch
$ git checkout branchName
# Create a new branch & switch to it
# equivalent to "git branch <name>; git checkout <name>"
$ git checkout -b newBranchClones, or copies, an existing repository into a new directory. It also adds remote-tracking branches for each branch in the cloned repo, which allows you to push to a remote branch.
# Clone learnxinyminutes-docs
$ git clone https://github.com/adambard/learnxinyminutes-docs.git
# shallow clone - faster cloning that pulls only latest snapshot
$ git clone --depth 1 https://github.com/adambard/learnxinyminutes-docs.git
# clone only a specific branch
$ git clone -b master-cn https://github.com/adambard/learnxinyminutes-docs.git --single-branchStores the current contents of the index in a new "commit." This commit contains the changes made and a message created by the user.
# commit with a message
$ git commit -m "Added multiplyNumbers() function to HelloWorld.c"
# signed commit with a message (user.signingkey must have been set
# with your GPG key e.g. git config --global user.signingkey 5173AAD5)
$ git commit -S -m "signed commit message"
# automatically stage modified or deleted files, except new files, and then commit
$ git commit -a -m "Modified foo.php and removed bar.php"
# change last commit (this deletes previous commit with a fresh commit)
$ git commit --amend -m "Correct message"Shows differences between a file in the working directory, index and commits.
# Show difference between your working dir and the index
$ git diff
# Show differences between the index and the most recent commit.
$ git diff --cached
# Show differences between your working dir and the most recent commit
$ git diff HEADAllows you to quickly search a repository.
Optional Configurations:
# Thanks to Travis Jeffery for these
# Set line numbers to be shown in grep search results
$ git config --global grep.lineNumber true
# Make search results more readable, including grouping
$ git config --global alias.g "grep --break --heading --line-number"# Search for "variableName" in all java files
$ git grep 'variableName' -- '*.java'
# Search for a line that contains "arrayListName" and, "add" or "remove"
$ git grep -e 'arrayListName' --and \( -e add -e remove \)Google is your friend; for more examples Git Grep Ninja
Display commits to the repository.
# Show all commits
$ git log
# Show only commit message & ref
$ git log --oneline
# Show merge commits only
$ git log --merges
# Show all commits represented by an ASCII graph
$ git log --graph"Merge" in changes from external commits into the current branch.
# Merge the specified branch into the current.
$ git merge branchName
# Always generate a merge commit when merging
$ git merge --no-ff branchNameRename or move a file
# Renaming a file
$ git mv HelloWorld.c HelloNewWorld.c
# Moving a file
$ git mv HelloWorld.c ./new/path/HelloWorld.c
# Force rename or move
# "existingFile" already exists in the directory, will be overwritten
$ git mv -f myFile existingFilePulls from a repository and merges it with another branch.
# Update your local repo, by merging in new changes
# from the remote "origin" and "master" branch.
# git pull <remote> <branch>
$ git pull origin master
# By default, git pull will update your current branch
# by merging in new changes from its remote-tracking branch
$ git pull
# Merge in changes from remote branch and rebase
# branch commits onto your local repo, like: "git fetch <remote> <branch>, git
# rebase <remote>/<branch>"
$ git pull origin master --rebasePush and merge changes from a branch to a remote & branch.
# Push and merge changes from a local repo to a
# remote named "origin" and "master" branch.
# git push <remote> <branch>
$ git push origin master
# By default, git push will push and merge changes from
# the current branch to its remote-tracking branch
$ git push
# To link up current local branch with a remote branch, add -u flag:
$ git push -u origin master
# Now, anytime you want to push from that same local branch, use shortcut:
$ git pushStashing takes the dirty state of your working directory and saves it on a stack of unfinished changes that you can reapply at any time.
Let's say you've been doing some work in your git repo, but you want to pull
from the remote. Since you have dirty (uncommitted) changes to some files, you
are not able to run git pull. Instead, you can run git stash to save your
changes onto a stack!
$ git stash
Saved working directory and index state \
"WIP on master: 049d078 added the index file"
HEAD is now at 049d078 added the index file
(To restore them type "git stash apply")Now you can pull!
git pull...changes apply...
Now check that everything is OK
$ git status
# On branch master
nothing to commit, working directory cleanYou can see what "hunks" you've stashed so far using git stash list.
Since the "hunks" are stored in a Last-In-First-Out stack, our most recent
change will be at top.
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051 Revert "added file_size"
stash@{2}: WIP on master: 21d80a5 added number to logNow let's apply our dirty changes back by popping them off the stack.
$ git stash pop
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: index.html
# modified: lib/simplegit.rb
#git stash apply does the same thing
Now you're ready to get back to work on your stuff!
Take all changes that were committed on one branch, and replay them onto another branch. Do not rebase commits that you have pushed to a public repo.
# Rebase experimentBranch onto master
# git rebase <basebranch> <topicbranch>
$ git rebase master experimentBranchReset the current HEAD to the specified state. This allows you to undo merges, pulls, commits, adds, and more. It's a great command but also dangerous if you don't know what you are doing.
# Reset the staging area, to match the latest commit (leaves dir unchanged)
$ git reset
# Reset the staging area, to match the latest commit, and overwrite working dir
$ git reset --hard
# Moves the current branch tip to the specified commit (leaves dir unchanged)
# all changes still exist in the directory.
$ git reset 31f2bb1
# Moves the current branch tip backward to the specified commit
# and makes the working dir match (deletes uncommitted changes and all commits
# after the specified commit).
$ git reset --hard 31f2bb1Reflog will list most of the git commands you have done for a given time period, default 90 days.
This give you the chance to reverse any git commands that have gone wrong (for instance, if a rebase has broken your application).
You can do this:
git reflogto list all of the git commands for the rebase
38b323f HEAD@{0}: rebase -i (finish): returning to refs/heads/feature/add_git_reflog
38b323f HEAD@{1}: rebase -i (pick): Clarify inc/dec operators
4fff859 HEAD@{2}: rebase -i (pick): Update java.html.markdown
34ed963 HEAD@{3}: rebase -i (pick): [yaml/en] Add more resources (#1666)
ed8ddf2 HEAD@{4}: rebase -i (pick): pythonstatcomp spanish translation (#1748)
2e6c386 HEAD@{5}: rebase -i (start): checkout 02fb96d
- Select where to reset to, in our case its
2e6c386, orHEAD@{5} - 'git reset --hard HEAD@{5}' this will reset your repo to that head
- You can start the rebase again or leave it alone.
Revert can be used to undo a commit. It should not be confused with reset which restores the state of a project to a previous point. Revert will add a new commit which is the inverse of the specified commit, thus reverting it.
# Revert a specified commit
$ git revert <commit>The opposite of git add, git rm removes files from the current working tree.
# remove HelloWorld.c
$ git rm HelloWorld.c
# Remove a file from a nested dir
$ git rm /pather/to/the/file/HelloWorld.c
git checkoutgit resetgit restoregit switch
I'll throw in one more, the misnamed git revert, as well.
All you need are git checkout, git reset, and git revert. These commands have been in Git all along.
But git checkout has, in effect, two modes of operation. One mode is "safe": it won't accidentally destroy any unsaved work. The other mode is "unsafe": if you use it, and it tells Git to wipe out some unsaved file, Git assumes that (a) you knew it meant that and (b) you really did mean to wipe out your unsaved file, so Git immediately wipes out your unsaved file.
This is not very friendly, so the Git folks finally---after years of users griping---split git checkout into two new commands. This leads us to:
git restore is new, having first come into existence in August 2019, in Git 2.23. git reset is very old, having been in Git all along, dating back to before 2005. Both commands have the ability to destroy unsaved work.
The git switch command is also new, introduced along with git restore in Git 2.23. It implements the "safe half" of git checkout; git restore implements the "unsafe half".
This is the most complicated part, and to really understand it, we need to know the following items:
-
Git is really all about commits. Commits get stored in the Git repository. The
git pushandgit fetchcommands transfer commits---whole commits, as an all-or-nothing deal^1^---to the other Git. You either have all of a commit, or you don't have it. Other commands, such asgit mergeorgit rebase, all work with local commits. Thepullcommand runsfetch(to get commits) followed by a second command to work with the commits once they're local. -
New commits add to the repository. You almost never remove a commit from the repository. Only one of the five commands listed here---checkout, reset, restore, revert, and switch---is capable of removing commits.^2^
-
Each commit is numbered by its hash ID, which is unique to that one particular commit. It's actually computed from what's in the commit, which is how Git makes these numbers work across all Gits eveywhere. This means that what is in the commit is frozen for all time: if you change anything, what you get is a new commit with a new number, and the old commit is still there, with its same old number.
-
Each commit stores two things: a snapshot, and metadata. The metadata include the hash ID(s) of some previous commit(s). This makes commits form backwards-looking chains.
-
A branch name holds the hash ID of one commit. This makes the branch name find that commit, which in turn means two things:
- that particular commit is the tip commit of that branch; and
- all commits leading up to and including that tip commit are on that branch.
-
We're also going to talk about Git's index in a moment, and your working tree. They're separate from these but worth mentioning early, especially since the index has three names: Git sometimes calls it the index, sometimes calls it the staging area, and sometimes---rarely these days---calls it the cache. All three names refer to the same thing.
Everything up through the branch name is, I think, best understood via pictures (at least for most people). If we draw a series of commits, with newer commits towards the right, using o for each commit and omitting some commits for space or whatever, we get something like this:
o--o---o <-- feature-top
/\
o--o--o--o--...--o---o--o <-- main
\ /
o--o--...--o--o <-- feature-hull
which, as you can see, is a boat repository. 😀 There are three branches. The mainline branch holds every commit, including all the commits on the top row and bottom (hull) row. The feature-top branch holds the top three commits and also the three commits along the main line to the left, but not any of the commits on the bottom row. All the connectors between commits are---well, should be but I don't have a good enough font---one-way arrows, pointing left, or down-and-left, or up-and-left.
These "arrows", or one way connections from commit to commit, are technically arcs, or one-way edges, in a directed graph. This directed graph is one without cycles, making it a Directed Acyclic Graph or DAG, which has a bunch of properties that are useful to Git.
If you're just using Git to store files inside commits, all you really care about are the round o nodes or vertices (again two words for the same thing), each of which acts to store your files, but you should at least be vaguely aware of how they are arranged. It matters, especially because of merges. Merge commits are those with two outgoing arcs, pointing backwards to two of what Git calls parent commits. The child commit is the one "later": just as human parents are always older than their children, Git parent commits are older than their children.
We need one more thing, though: Where do new commits come from? We noted that what's in a commit---both the snapshot, holding all the files, and the metadata, holding the rest of the information Git keeps about a commit---is all read-only. Your files are not only frozen, they're also transformed, and the transformed data are then de-duplicated, so that even though every commit has a full snapshot of every file, the repository itself stays relatively slim. But this means that the files in a commit can only be read by Git, and nothing---not even Git itself---can write to them. They get saved once, and are de-duplicated from then on. The commits act as archives, almost like tar or rar or winzip or whatever.
To work with a Git repository, then, we have to have Git extract the files. This takes the files out of some commit, turning those special archive-formatted things into regular, usable files. Note that Git may well be able to store files that your computer literally can't store: a classic example is a file named aux.h, for some C program, on a Windows machine. We won't go into all the details, but it is theoretically possible to still get work done with this repository, which was probably built on a Linux system, even if you're on a Windows system where you can't work with the aux.h file directly.
Anyway, assuming there are no nasty little surprises like aux.h, you would just run git checkout or git switch to get some commit out of Git. This will fill in your working tree, populating it from the files stored in the tip commit of some branch. The tip commit is, again, the last commit on that branch, as found by the branch name. Your git checkout or git switch selected that commit to be the current commit, by selecting that branch name to be the current branch. You now have all the files from that commit, in an area where you can see them and work on them: your working tree.
Note that the files in your working tree are not actually in Git itself. They were just extracted from Git. This matters a lot, because when git checkout extracts the files from Git, it actually puts each file in two places. One of those places is the ordinary everyday file you see and work on / with. The other place Git puts each file is into Git's index.
As I mentioned a moment ago, the index has three names: index, staging area, and cache. All refer to the same thing: the place Git sticks these "copies" of each file. Each one is actually pre-de-duplicated, so the word "copy" is slightly wrong, but---unlike much of the rest of its innards---Git actually does a really good job of hiding the de-duplication aspect. Unless you start getting into internal commands like git ls-files and git update-index, you don't need to know about this part, and can just think of the index as holding a copy of the file, ready to go into the next commit.
What this all means for you as someone just using Git is that the index / staging-area acts as your proposed next commit. When you run git commit, Git is going to package up these copies of the file as the ones to be archived in the snapshot. The copies you have in your working tree are yours; the index / staging-area copies are Git's, ready to go. So, if you change your copies and want the changed copy to be what goes in the next snapshot, you must tell Git: Update the Git copy, in the Git index / staging-area. You do this with git add.^3^ The git add command means make the proposed-next-commit copy match the working-tree copy. It's the add command that does the updating: this is when Git compresses and de-duplicates the file and makes it ready for archiving, not at git commit time.^4^
Then, assuming you have some series of commits ending with the one with hash-N:
[hash1] <-[hash2] ... <-[hashN] <--branch
you run git commit, give it any metadata it needs (a commit log message), and you get an N+1'th commit:
[hash1] <-[hash2] ... <-[hashN] <-[hashN+1] <--branch
Git automatically updates the branch name to point to the new commit, which has therefore been added to the branch.
Let's look at each of the various commands now:
-
git checkout: this is a large and complicated command.We already saw this one, or at least, half of this one. We used it to pick out a branch name, and therefore a particular commit. This kind of checkout first looks at our current commit, index, and working tree. It makes sure that we have committed all our modified files, or---this part gets a bit complicated---that if we haven't committed all our modified files, switching to that other branch is "safe". If it's not safe,
git checkouttells you that you can't switch due to having modified files. If it is safe,git checkoutwill switch; if you didn't mean to switch, you can just switch back. (See also Checkout another branch when there are uncommitted changes on the current branch)But
git checkouthas an unsafe half. Suppose you have modified some file in your working tree, such asREADME.mdoraux.hor whatever. You now look back at what you changed and think: No, that's a bad idea. I should get rid of this change. I'd like the file back exactly as it was before.To get this---to wipe out your changes to, say,
README.md---you can run:
git checkout -- README.md
The `--` part here is optional. It's a good idea to use it, because it tells Git that the part that comes after `--` is a _file name_, not a _branch name_.
Suppose you have a _branch_ named `hello` _and_ a _file_ named `hello`. What does:
git checkout hello
mean? Are we asking Git to clobber the _file_ `hello` to remove the changes we made, or are we asking Git to check out the _branch_ `hello`? To make this unambiguous, you have to write either:
git checkout -- hello (clobber the file)
or:
git checkout hello -- (get the branch)
This case, where there are branches and files or directories with the same name, is a particularly insidious one. It has bitten real users. It's _why_ `git switch` exists now. The `git switch` command _never means clobber my files_. It only means _do the safe kind of `git checkout`._
(The `git checkout` command has been smartened up too, so that if you have the new commands and you run the "bad" kind of ambiguous `git checkout`, Git will just complain at you and do nothing at all. Either use the smarter split-up commands, or add the `--` at the right place to pick which kind of operation you want.)
More precisely, _this kind_ of `git checkout`, ideally spelled `git checkout -- *paths*`, is a request for Git to copy files from Git's index to your working tree. This means _clobber my files_. You can also run `git checkout *tree-ish* -- *paths*`, where you add a commit hash ID^5^ to the command. This tells Git to copy the files from that commit, first to Git's index, and then on to your working tree. This, too, means _clobber my files:_ the difference is where Git gets the copies of the files it's extracting.
If you ran `git add` on some file and thus copied it into Git's index, you need `git checkout HEAD -- *file*` to get it back from the current commit. The copy that's in Git's _index_ is the one you `git add`-ed. So these two forms of `git checkout`, with a commit hash ID (or the name `HEAD`), the optional `--`, and the file name, are the unsafe _clobber my files_ forms.
-
git reset: this is also a large and complicated command.There are, depending on how you count, up to about five or six different forms of
git reset. We'll concentrate on a smaller subset here.-
git reset [ --hard | --mixed | --soft ] [ *commit* ]Here, we're asking Git to do several things. First, if we give a
commitargument, such asHEADorHEAD~3or some such, we've picked a particular commit that Git should reset to. This is the kind of command that will remove commits by ejecting them off the end of the branch. Of all the commands listed here, this is the only one that removes any commits. One other command---git commit --amend---has the effect of ejecting the last commit while putting on a new replacement, but that one is limited to ejecting one commit.Let's show this as a drawing. Suppose we have:
-
...--E--F--G--H <-- branch
That is, this branch, named `branch`, ends with four commits whose hash IDs we'll call `E`, `F`, `G`, and `H` in that order. The name `branch` currently stores the hash ID of the last of these commits, `H`. If we use `git reset --hard HEAD~3`, we're telling Git to eject the _last three commits_. The result is:
F--G--H ???
/
...--E <-- branch
The name `branch` now selects commit `E`, not commit `H`. If we did not write down (on paper, on a whiteboard, in a file) the hash IDs of the last three commits, they've just become somewhat hard to find. Git does gives a way to find them again, for a while, but mostly they just seem to be _gone_.
The `HEAD~3` part of this command is how we chose to drop the last three commits. It's part of a whole sub-topic in Git, documented in [the gitrevisions manual](https://git-scm.com/docs/gitrevisions), on ways to name specific commits. The reset command just needs the hash ID of an actual commit, or anything equivalent, and `HEAD~3` means _go back three first-parent steps_, which in this case gets us from commit `H` back to commit `E`.
The `--hard` part of the `git reset` is how we tell Git what to do with (a) its index and (b) our working tree files. We have three choices here:
- `--soft` tells Git: _leave both alone_. Git will move the _branch name_ without touching the index or our working tree. If you run `git commit` now, whatever is (still) in the index is what goes into the _new_ commit. If the index matches the snapshot in commit `H`, this gets you a new commit whose _snapshot_ is `H`, but whose _parent_ is `E`, as if commits `F` through `H` had all been collapsed into a single new commit. People usually call this _squashing_.
- `--mixed` tells Git: _reset your index, but leave my working tree alone_. Git will move the branch name, then _replace every file that is in the index with the one from the newly selected commit_. But Git will leave all your _working tree_ files alone. This means that as far as Git is concerned, you can start `git add`ing files to make a new commit. Your new commit won't match `H` unless you `git add` _everything_, so this means you could, for instance, build a new intermediate commit, sort of like `E+F` or something, if you wanted.
- `--hard` tells Git: _reset your index **and** my working tree._ Git will move the branch name, replace all the files in its index, and replace all the files in your working tree, all as one big thing. It's now as if you never made those three commits at all. You no longer have the files from `F`, or `G`, or `H`: you have the files from commit `E`.
Note that if you leave out the _`commit`_ part of this kind of (hard/soft/mixed) `reset`, Git will use `HEAD`. Since `HEAD` names the _current commit_ (as selected by the current branch name), this leaves the branch name itself unchanged: it still selects the same commit as before. So this is only useful with `--mixed` or `--hard`, because `git reset --soft`, with no commit hash ID, means _don't move the branch name, don't change Git's index, and don't touch my working tree_. Those are the three things this kind of `git reset` can do---move the branch name, change what's in Git's index, and change what's in your working tree---and you just ruled all three out. Git is OK with doing nothing, but why bother?
- `git reset [ *tree-ish* ] -- *path*`
This is the other kind of `git reset` we'll care about here. It's a bit like a mixed reset, in that it means _clobber some of the index copies of files_, but here you specify _which files to clobber_. It's also a bit _unlike_ a mixed reset, because this kind of `git reset` will never move the branch name.
Instead, you pick which files you want copied from somewhere. The _somewhere_ is the _`tree-ish`_ you give; if you don't give one, the _somewhere_ is `HEAD`, i.e., the current commit. This can only restore files in the _proposed next commit_ to the form they have in _some existing commit_. By defaulting to the _current_ existing commit, this kind of `git reset -- *path*` has the effect of undoing a `git add -- *path*`.^6^
There are several other forms of `git reset`. To see what they all mean, consult [the documentation](https://git-scm.com/docs/git-reset).
-
git restore: this got split off fromgit checkout.Basically, this does the same thing as the various forms of
git checkoutandgit resetthat clobber files (in your working tree and/or in Git's index). It's smarter than the oldgit checkout-and-clobber-my-work variant, in that you get to choose where the files come from and where they go, all in the one command line.To do what you used to do with
git checkout -- *file*, you just rungit restore --staged --worktree -- *file*. (You can leave out the--part, as withgit checkout, in most cases, but it's just generally wise to get in the habit of using it. Likegit add, this command is designed such that only files named-whateverare actually problematic.)To do what you used to do with
git reset -- *file*, you just rungit restore --staged -- *file*. That is, you tellgit restoreto copy fromHEADto staging area / index, which is howgit resetoperates.Note that you can copy a file from some existing commit, to Git's index, without touching your working tree copy of that file:
git restore --source *commit* --staged -- *file*does that. You can't do that at all with the oldgit checkoutbut you can do that with the oldgit reset, asgit reset *commit* -- *file*. And, you can copy a file from some existing commit, to your working tree, without touching the staged copy:git restore --source *commit* --worktree -- *file*does that. The overlapping part (restore and reset) exists becausegit restoreis new, and this kind of restore makes sense; probably, ideally, we should always usegit restorehere, instead of using the oldgit resetway of doing things, but Git tries to maintain backwards compatibility.The new ability---to copy from any arbitrary source, to your working tree, without touching Git's index / staging-area copy---is just that: new. You couldn't do it before. (You could run
git show *commit*:*path* > *path*, before, but that falls outside our five commands to examine.) -
git switch: this just does the "safe half" ofgit checkout. That's really all you need to know. Usinggit switch, without--force, Git won't overwrite your unsaved work, even if you make a typo or whatever. The oldgit checkoutcommand could overwrite unsaved work: if your typo turns a branch name into a file name, for instance, well, oops. -
git revert(I added this for completeness): this makes a new commit. The point of the new commit is to back out what someone did in some existing commit. You therefore need to name the existing commit that revert should back out. This command probably should have been namedgit backout.If you back out the most recent commit, this does revert to the second-most-recent snapshot:
...--G--H <-- branch
becomes:
...--G--H--Ħ <-- branch
where commit `Ħ` (H-bar) "undoes" commit `H` and therefore leaves us with the same _files_ as commit `G`. But we don't have to undo the _most recent_ commit. We could take:
...--E--F--G--H <-- branch
and add a commit `Ǝ` that undoes `E` to get:
...--E--F--G--H--Ǝ <-- branch
which may not match the source snapshot of any previous commit!
-
[Learn Git Branching - the most visual and interactive way to learn Git on the web](http://learngitbranch
-
[Udemy Git Tutorial: A Comprehensive Guide](https://blog
-
[Git Immersion - A Guided tour that walks through the fundamentals of git
-
[git-scm - Video Tutorials](http://g
-
[git-scm - Documentation](http://git-scm.com/d
-
The New Boston tutorial to Git covering basic commands and workflow
| title | Git Repo List | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | lorem-ipsum | ||||||||||
| seo |
|
||||||||||
| template | docs |
===➤(_CLICK TO SEE MORE_)➤
- https://github.com/bgoonz/03-fetch-data
- https://github.com/bgoonz/a-whole-bunch-o-gatsby-templates
- https://github.com/bgoonz/activity-box
- https://github.com/bgoonz/All-Undergrad-Archive
- https://github.com/bgoonz/alternate-blog-theme
- https://github.com/bgoonz/anki-cards
- https://github.com/bgoonz/ask-me-anything
- https://github.com/bgoonz/atlassian-templates
- https://github.com/bgoonz/Authentication-Notes
- https://github.com/bgoonz/bash-commands-walkthrough
- https://github.com/bgoonz/bash-config-backup
- https://github.com/bgoonz/bash-shell-utility-functions
- https://github.com/bgoonz/bass-station
- https://github.com/bgoonz/bgoonz
- https://github.com/bgoonz/BGOONZBLOG2.0STABLE
- https://github.com/bgoonz/BGOONZ_BLOG_2.0
- https://github.com/bgoonz/Binary-Search
- https://github.com/bgoonz/blog-2.o-versions
- https://github.com/bgoonz/blog-templates
- https://github.com/bgoonz/blog-w-comments
- https://github.com/bgoonz/Blog2.0-August-Super-Stable
- https://github.com/bgoonz/bootstrap-sidebar-template
- https://github.com/bgoonz/callbacks
- https://github.com/bgoonz/Comments
- https://github.com/bgoonz/commercejs-nextjs-demo-store
- https://github.com/bgoonz/Common-npm-Readme-Compilation
- https://github.com/bgoonz/Comparing-Web-Development-Bootcamps-2021
- https://github.com/bgoonz/Connect-Four-Final-Version
- https://github.com/bgoonz/convert-folder-contents-2-website
- https://github.com/bgoonz/Copy-2-Clipboard-jQuery
- https://github.com/bgoonz/Data-Structures-Algos-Codebase
- https://github.com/bgoonz/DATA_STRUC_PYTHON_NOTES
- https://github.com/bgoonz/design-home-page-with-routes-bq5v7k
- https://github.com/bgoonz/docs-collection
- https://github.com/bgoonz/Documentation-site-react
- https://github.com/bgoonz/DS-ALGO-OFFICIAL
- https://github.com/bgoonz/DS-AND-ALGO-Notes-P2
- https://github.com/bgoonz/ecommerce-interactive
- https://github.com/bgoonz/embedable-repl-and-integrated-code-space-playground
- https://github.com/bgoonz/excel2html-table
- https://github.com/bgoonz/Exploring-Promises
- https://github.com/bgoonz/express-API-template
- https://github.com/bgoonz/Express-basic-server-template
- https://github.com/bgoonz/express-knex-postgres-boilerplate
- https://github.com/bgoonz/EXPRESS-NOTES
- https://github.com/bgoonz/fast-fourier-transform-
- https://github.com/bgoonz/form-builder-vanilla-js
- https://github.com/bgoonz/Front-End-Frameworks-Practice
- https://github.com/bgoonz/full-stack-react-redux
- https://github.com/bgoonz/Full-Text-Search
- https://github.com/bgoonz/Games
- https://github.com/bgoonz/gatsby-netlify-cms-norwex
- https://github.com/bgoonz/gatsby-react-portfolio
- https://github.com/bgoonz/GIT-CDN-FILES
- https://github.com/bgoonz/GIT-HTML-PREVIEW-TOOL
- https://github.com/bgoonz/gitbook
- https://github.com/bgoonz/github-readme-stats
- https://github.com/bgoonz/github-reference-repo
- https://github.com/bgoonz/GoalsTracker
- https://github.com/bgoonz/graphql-experimentation
- https://github.com/bgoonz/https*__mihirbeg.com*
- https://github.com/bgoonz/iframe-showcase
- https://github.com/bgoonz/Image-Archive-Traning-Data
- https://github.com/bgoonz/Independent-Blog-Entries
- https://github.com/bgoonz/INTERVIEW-PREP-COMPLETE
- https://github.com/bgoonz/JAMSTACK-TEMPLATES
- https://github.com/bgoonz/Javascript-Best-Practices_--Tools
- https://github.com/bgoonz/jsanimate
- https://github.com/bgoonz/Jupyter-Notebooks
- https://github.com/bgoonz/Lambda
- https://github.com/bgoonz/Lambda-Resource-Static-Assets
- https://github.com/bgoonz/learning-nextjs
- https://github.com/bgoonz/Learning-Redux
- https://github.com/bgoonz/Links-Shortcut-Site
- https://github.com/bgoonz/live-examples
- https://github.com/bgoonz/live-form
- https://github.com/bgoonz/loadash-es6-refactor
- https://github.com/bgoonz/markdown-css
- https://github.com/bgoonz/Markdown-Templates
- https://github.com/bgoonz/meditation-app
- https://github.com/bgoonz/MihirBegMusicLab
- https://github.com/bgoonz/MihirBegMusicV3
- https://github.com/bgoonz/Mihir_Beg_Final
- https://github.com/bgoonz/mini-project-showcase
- https://github.com/bgoonz/Music-Theory-n-Web-Synth-Keyboard
- https://github.com/bgoonz/my-gists
- https://github.com/bgoonz/My-Medium-Blog
- https://github.com/bgoonz/nextjs-netlify-blog-template
- https://github.com/bgoonz/norwex-coff-ecom
- https://github.com/bgoonz/old-c-and-cpp-repos-from-undergrad
- https://github.com/bgoonz/old-code-from-undergrad
- https://github.com/bgoonz/picture-man-bob-v2
- https://github.com/bgoonz/Project-Showcase
- https://github.com/bgoonz/promises-with-async-and-await
- https://github.com/bgoonz/psql-practice
- https://github.com/bgoonz/python-playground-embed
- https://github.com/bgoonz/python-practice-notes
- https://github.com/bgoonz/python-scripts
- https://github.com/bgoonz/PYTHON_PRAC
- https://github.com/bgoonz/random-list-of-embedable-content
- https://hub.com/bgoonz/random-static-html-page-deploy
- https://hub.com/bgoonz/React-movie-app
- https://hub.com/bgoonz/react-redux-medium-clone
- https://hub.com/bgoonz/react-redux-notes-v5
- https://hub.com/bgoonz/react-redux-registration-login-example
- https://hub.com/bgoonz/React_Notes_V3
- https://hub.com/bgoonz/Recursion-Practice-Website
- https://hub.com/bgoonz/Regex-and-Express-JS
- https://hub.com/bgoonz/repo-utils
- https://hub.com/bgoonz/resume-cv-portfolio-samples
- https://hub.com/bgoonz/Revamped-Automatic-Guitar-Effect-Triggering
- https://hub.com/bgoonz/scope-closure-context
- https://hub.com/bgoonz/Shell-Script-Practice
- https://hub.com/bgoonz/site-analysis
- https://hub.com/bgoonz/sorting-algorithms
- https://hub.com/bgoonz/sorting-algos
- https://hub.com/bgoonz/sqlite3-nodejs-demo
- https://hub.com/bgoonz/stalk-photos-web-assets
- https://hub.com/bgoonz/Standalone-Metranome
- https://hub.com/bgoonz/Star-wars-API-Promise-take2
- https://hub.com/bgoonz/Static-Study-Site
- https://hub.com/bgoonz/styling-templates
- https://hub.com/bgoonz/supertemp
- https://hub.com/bgoonz/Ternary-converter
- https://hub.com/bgoonz/TetrisJS
- https://hub.com/bgoonz/TexTools
- https://hub.com/bgoonz/The-Algorithms
- https://hub.com/bgoonz/TRASH
- https://hub.com/bgoonz/Triggered-Guitar-Effects-Platform
- https://hub.com/bgoonz/Useful-Snippets-js
- https://hub.com/bgoonz/UsefulResourceRepo2.0
- https://hub.com/bgoonz/vscode-customized-config
- https://hub.com/bgoonz/vscode-Extension-readmes
- https://hub.com/bgoonz/web-crawler-node
- https://hub.com/bgoonz/web-dev-interview-prep-quiz-website
- https://hub.com/bgoonz/web-dev-notes-resource-site
- https://hub.com/bgoonz/web-dev-setup-checker
- https://hub.com/bgoonz/WEB-DEV-TOOLS-HUB
- https://hub.com/bgoonz/web-dev-utils-package
- https://hub.com/bgoonz/WebAudioDaw
- https://hub.com/bgoonz/website
| title | lorem-ipsum | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | lorem-ipsum | ||||||||
| seo |
|
||||||||
| template | docs |
- Glossary
- HTTP Errors
- Infrastructure
- Navigation
A 404 is a Standard Response Code meaning that the Glossary("Server", "server") cannot find the requested resource.
- '502'
- Bad Gateway
- Glossary
- HTTP Errors
- Infrastructure
- Navigation
An Glossary("HTTP") error code meaning "Bad Gateway".
A Glossary("Server", "server") can act as a gateway or proxy (go-between) between a client (like your Web browser) and another, upstream server. When you request to access a Glossary("URL"), the gateway server can relay your request to the upstream server. "502" means that the upstream server has returned an invalid response.
Normally the upstream server is not down (i.e. furnishes no response to the gateway/proxy), but does not understand the same data-exchange protocol as the gateway/proxy. Internet Glossary("Protocol", "protocols") are quite explicit, and so a 502 usually means that one or both machines were incorrectly or incompletely programmed.
- Abstraction
- Coding
- CodingScripting
- Glossary
- Programming Language
Abstraction in Glossary("computer programming") is a way to reduce complexity and allow efficient design and implementation in complex software systems. It hides the technical complexity of systems behind simpler Glossary("API", "APIs").
- Helps the user to avoid writing low level code.
- Avoids code duplication and increases reusability.
- Can change internal implementation of class independently without affecting the user.
- Helps to increase security of an application or program as only important details are provided to the user.
//
class ImplementAbstraction {
// method to set values of internal members
set(x, y) {
this.a = x;
this.b = y;
}
display() {
console.log('a = ' + this.a);
console.log('b = ' + this.b);
}
}
const obj = new ImplementAbstraction();
obj.set(10, 20);
obj.display();
// a = 10
// b = 20- interwiki("wikipedia", "Abstraction (computer science)", "Abstraction") on Wikipedia
- Glossary
- Input
- accent
An accent is a typically bright color that contrasts with the more utilitarian background and foreground colors within a color scheme. These are present in the visual style of many platforms (though not all).
On the web, an accent is sometimes used in HTMLElement("input") elements for the active portion of the control, for instance the background of a checked checkbox.
You can set the color of the accent for a given element by setting the element's CSS cssxref("accent-color") property to the appropriate cssxref("<color>") value.
- AOM
- Accessibility
- DOM
- Glossary
- Reference
The accessibility tree contains Glossary("accessibility")-related information for most HTML elements.
Browsers convert markup into an internal representation called the DOM tree. The DOM tree contains objects representing all the markup's elements, attributes, and text nodes. Browsers then create an accessibility tree based on the DOM tree, which is used by platform-specific Accessibility APIs to provide a representation that can be understood by assistive technologies, such as screen readers.
There are four things in an accessibility tree object:
- name
-
- : How can we refer to this thing? For instance, a link with the text "Read more" will have "Read more" as its name (find more on how names are computed in the [Accessible Name and Description Com
- description
-
- : How do we describe this thing, if we want to provide more description beyond the name? The description of a table could explain what kind of information the table contains.
- role
- : What kind of thing is it? For example, is it a button, a nav bar, or a list of items?
- state
- : Does it have a state? Examples include checked or unchecked for checkboxes, and collapsed or expanded for the
<summary>element.
- : Does it have a state? Examples include checked or unchecked for checkboxes, and collapsed or expanded for the
Additionally, the accessibility tree often contains information on what can be done with an element: a link can be followed, a text input can be typed into, etc.
While still in draft form within the Web Incubator Community Group, the Accessibility Object Model (AOM) intends to incubate APIs that make it easier to express accessibility semantics and potentially allow read access to the computed accessibility tree.
-
- Glossary("Accessibility")
- Glossary("ARIA")
- Accessibility
- Glossary
Web Accessibility (A11Y) refers to best practices for keeping a website usable despite physical and technical restrictions. Web accessibility is formally defined and discussed at the Glossary("W3C") through the Glossary("WAI","Web Accessibility Initiative") (WAI).
- Accessibility resources at MDN
- Interwiki("wikipedia", "Web accessibility") on Wikipedia
- Learn accessibility on MDN
- Web Accessibility In Mind
- The ARIA documentation on MDN
- The Web Accessibility Initiative homepage
- The WAI-ARIA recommendation
Flash is an obsolete technology developed by Adobe for viewing expressive web applications, multimedia content, and streaming media.
As of 2021, Flash is no longer supported by Adobe or any major web browsers.
- Adobe Flash end-of-life announcement
- Saying goodbye to Flash in Chrome
- Firefox Roadmap for Flash End-of-Life
- Microsoft Windows Flash Player removal
- Accessibility
- Glossary
The advance measure of a glyph is its advance width or advance height, whichever is in the inline axis of the element.
This term is used in the definition of a number of CSS cssxref("<length>") units.
For example, ch is the advance measure of the "0" character in the given typeface.
For a horizontal inline axis, this will be the width of the character.
- cssxref("<length>")
- AJAX
- CodingScripting
- Glossary
- Infrastructure
- l10n:priority
Ajax, which initially stood for Asynchronous Glossary("JavaScript") And Glossary("XML"), is a programming practice of building complex, dynamic webpages using a technology known as Glossary("XHR(XMLHttpRequest)","XMLHttpRequest"_).
Ajax allows you to update parts of the Glossary("DOM") of an Glossary("HTML") page without the need for a full page refresh. Ajax also lets you work asynchronously, meaning your code continues to run while the targeted part of your web page is trying to reload (compared to synchronously, which blocks your code from running until that part of your page is done reloading).
With interactive websites and modern web standards, Ajax is gradually being replaced by functions within JavaScript frameworks and the official domxref("Fetch API") Standard.
-
interwiki("wikipedia", "AJAX") on Wikipedia
-
- Glossary("XHR(XMLHttpRequest)","XMLHttpRequest"_)
-
DOMxRef("XMLHttpRequest")
-
DOMxRef("Fetch API")
- CodingScripting
- Glossary
An algorithm is a self-contained series of instructions to perform a function.
In other words, an algorithm is a means of describing a way to solve a problem so that it can be solved repeatedly, by humans or machines. Computer scientists compare the efficiency of algorithms through the concept of "Algorithmic Complexity" or "Big O" notation.
For example:
- A cooking recipe is a simple algorithm for humans.
- A sorting algorithm is often used in computer programming to explain a machine how to sort data.
Common algorithms are Pathfinding algorithms such as the Traveling Salesman Problem, Tree Traversal algorithms and so on.
There are also Machine Learning algorithms such as Linear Regression, Logistic Regression, Decision Tree, Random Forest, Support Vector Machine, Recurrent Neural Network (RNN), Long Short Term Memory (LSTM) Neural Network, Convolutional Neural Network (CNN), Deep Convolutional Neural Network and so on.
- Interwiki("wikipedia", "Algorithm", "Algorithm") on Wikipedia
- Explanations of sorting algorithms
- Explanations of algorithmic complexity
- Alignment container
- CSS
- Glossary
- alignment
The alignment container is the rectangle that the alignment subject is aligned within. This is defined by the layout mode; it is usually the alignment subject's containing block, and assumes the writing mode of the box establishing the containing block.
- Alignment subject
- CSS
- Glossary
- alignment
In CSS Box Alignment the alignment subject is the thing (or things) being aligned by the property.
For cssxref("justify-self") and cssxref("align-self"), the alignment subject is the margin box of the box the property is set on, using the writing mode of that box.
For cssxref("justify-content") and cssxref("align-content"), the writing mode of the box is also used. The definition of the alignment subject depends on the layout mode being used.
- Block containers (including table cells)
-
- : The entire content of the block as a single unit.
- Multicol containers
- : The column boxes, with any spacing inserted between column boxes added to the relevant column gaps.
- Flex containers
- : For cssxref("justify-content"), the flex items in each flex line. For cssxref("align-content"), the flex lines. Note, this only has an effect on multi-line flex containers.
- Grid containers
- : The grid tracks in the appropriate axis, with any spacing inserted between tracks added to the relevant gutters. Collapsed gutters are treated as a single opportunity for space insertion.
- Alpha
- Alpha Channel
- Drawing
- Glossary
- Graphics
- Translucency
- Translucent
- Transparency
- Transparent
- WebGL
- WebXR
- channel
- color
- pixel
Colors are represented in digital form as a collection of numbers, each representing the strength or intensity level of a given component of the color. Each of these components is called a channel. In a typical image file, the color channels describe how much red, green, and blue are used to make up the final color. To represent a color through which the background can be seen to some extent, a fourth channel is added to the color: the alpha channel. The alpha channel specifies how opaque the color is.
For example, the color #8921F2 (also described as rgb(137, 33, 242) or hsl(270, 89%, 54)) is a nice shade of purple. Below you see a small box of that color in the top-left corner and a box of the same color but with an alpha channel set at 0.5 (50% opacity). The two boxes are drawn on top of a paragraph of text.

As you can see, the color without an alpha channel completely blocks the background text, while the box with the alpha channel leaves it visible through the purple background color.
- CodingScripting
- Glossary
- Infrastructure
An API (Application Programming Interface) is a set of features and rules that exist inside a software program (the application) enabling interaction with it through software - as opposed to a human user interface. The API can be seen as a simple contract (the interface) between the application offering it and other items, such as third party software or hardware.
In Web development, an API is generally a set of code features (e.g. glossary("method","methods"), Glossary("property","properties"), events, and Glossary("URL","URLs")) that a developer can use in their apps for interacting with components of a user's web browser, or other software/hardware on the user's computer, or third party websites and services.
For example:
- The getUserMedia API can be used to grab audio and video from a user's webcam, which can then be used in any way the developer likes, for example, recording video and audio, broadcasting it to another user in a conference call, or capturing image stills from the video.
- The Geolocation API can be used to retrieve location information from whatever service the user has available on their device (e.g. GPS), which can then be used in conjunction with the Google Maps APIs to for example plot the user's location on a custom map and show them what tourist attractions are in their area.
- The Twitter APIs can be used to retrieve data from a user's twitter accounts, for example, to display their latest tweets on a web page.
- The Web Animations API can be used to animate parts of a web page — for example, to make images move around or rotate.
- Interwiki("wikipedia", "API", "API") on Wikipedia
- Web API reference
- Glossary
- Navigation
- WebMechanics
Safari is a Glossary("Browser","Web browser") developed by Apple and bundled with both macOS and iOS. It's based on the open source WebKit engine.
- Interwiki("wikipedia", "Safari (web browser)", "Safari") on Wikipedia
- Safari on apple.com
- The WebKit project
- WebKit nightly build
- Reporting a bug for Safari
- CodingScripting
- Glossary
An application context is a top-level browsing context that has a manifest applied to it.
If an application context is created as a result of the user agent being asked to navigate to a deep link, the user agent must immediately navigate to the deep link with replacement enabled. Otherwise, when the application context is created, the user agent must immediately navigate to the start URL with replacement enabled.
Please note that the start URL is not necessarily the value of the start_url member: the user or user agent could have changed it when the application was added to home-screen or otherwise bookmarked.
- CodingScripting
- Glossary
- JavaScript
An argument is a glossary("value") (Glossary("primitive") or Glossary("object")) passed as input to a Glossary("function").
- Interwiki("wikipedia", "Parameter(computerprogramming)", "Difference between Parameter and Argument") on Wikipedia
- The jsxref("Functions/arguments","arguments") object in glossary("JavaScript")
- Accessibility
- Glossary
ARIA (Accessible Rich _glossary("Internet") Applications*) is a _Glossary("W3C"*) specification for adding semantics and other metadata to Glossary("HTML") to cater to users of assistive technology.
For example, you could add the attribute role="alert" to a HTMLElement("p") glossary("tag") to notify a sight-challenged user that the information is important and time-sensitive (which you might otherwise convey through text color).
- Glossary
- Infrastructure
.arpa (address and routing parameter area) is a glossary("TLD","top-level domain") used for Internet infrastructure purposes, especially reverse DNS lookup (i.e., find the glossary('domain name') for a given glossary("IP address")).
- Official website
- Interwiki("wikipedia", ".arpa") on Wikipedia
- Glossary
- Infrastructure
The ARPANET (Advanced Research Projects Agency NETwork) was an early computer network, constructed in 1969 as a robust medium to transmit sensitive military data and to connect leading research groups throughout the United States. ARPANET first ran NCP (Network Control Protocol) and subsequently the first version of the Internet protocol or glossary("TCP")/glossary("IPv4","IP") suite, making ARPANET a prominent part of the nascent glossary("Internet"). ARPANET was closed in early 1990.
- Interwiki("wikipedia", "ARPANET") on Wikipedia
- Array
- CodingScripting
- Glossary
- JavaScript
- programming
An array is an ordered collection of data (either Glossary("primitive") or Glossary("object") depending upon the language). Arrays are used to store multiple values in a single variable. This is compared to a variable that can store only one value.
Each item in an array has a number attached to it, called a numeric index, that allows you to access it. In JavaScript, arrays start at index zero and can be manipulated with various Glossary("Method", "methods").
What an array in JavaScript looks like:
//
let myArray = [1, 2, 3, 4];
let catNamesArray = ['Jacqueline', 'Sophia', 'Autumn'];
//Arrays in JavaScript can hold different types of data, as shown above.- Interwiki("wikipedia", "Array data structure", "Array") on Wikipedia
- JavaScript jsxref("Array") on MDN
- Glossary
- Infrastructure
ASCII (American Standard Code for Information Interchange) is one of the most popular coding method used by computers for converting letters, numbers, punctuation and control codes into digital form. Since 2007, Glossary("UTF-8") superseded it on the Web.
Interwiki("wikipedia", "ASCII") on Wikipedia
- Glossary
- Web
- WebMechanics
- asynchronous
The term asynchronous refers to two or more objects or events not existing or happening at the same time (or multiple related things happening without waiting for the previous one to complete). In computing, the word "asynchronous" is used in two major contexts.
-
Networking and communications
-
: Asynchronous communication is a method of exchanging messages between two or more parties in which each party receives and processes messages whenever it's convenient or possible to do so, rather than doing so immediately upon receipt. Additionally, messages may be sent without waiting for acknowledgement, with the understanding that if a problem occurs, the recipient will request corrections or otherwise handle the situation.
For humans, e-mail is an asynchronous communication method; the sender sends an email and the recipient will read and reply to the message when it's convenient to do so, rather than doing so at once. And both sides can continue to send and receive messages whenever they wish, instead of having to schedule them around each other.
When software communicates asynchronously, a program may make a request for information from another piece of software (such as a server), and continue to do other things while waiting for a reply. For example, the AJAX (Asynchronous JavaScript and Glossary("XML")) programming technique—now usually "Ajax", even though Glossary("JSON") is usually used rather than XML in modern applications—is a mechanism that requests relatively small amounts of data from the server using Glossary("HTTP"), with the result being returned when available rather than immediately.
-
-
Software design
-
: Asynchronous software design expands upon the concept by building code that allows a program to ask that a task be performed alongside the original task (or tasks), without stopping to wait for the task to complete. When the secondary task is completed, the original task is notified using an agreed-upon mechanism so that it knows the work is done, and that the result, if any, is available.
There are a number of programming techniques for implementing asynchronous software. See the article Asynchronous JavaScript for an introduction to them.
-
- Fetching data from the server (Learning Area)
- glossary("Synchronous")
- ATAG
- Accessibility
- Authoring Tool Accessibility Guidelines
- Glossary
ATAG (Authoring Tool glossary("Accessibility") Guidelines) is a Glossary("W3C") recommendation for building accessible-authoring tools that produce accessible contents.
- ATAG as part of the Web Accessibility Initiative on WikiPedia
- Authoring Tool Accessibility Guidelines (ATAG) Overview
- The ATAG 2.0 recommendation
- CodingScripting
- Glossary
- HTML
An attribute extends an HTML or XML Glossary("element"), changing its behavior or providing metadata.
An attribute always has the form name="value" (the attribute's identifier followed by its associated value).
You may see attributes without the equals sign or a value. That is a shorthand for providing the empty string in HTML, or the attribute's name in XML.
<input required />
<!-- is the same as… -->
<input required="" />
<!-- or -->
<input required="required" />Attributes may be reflected into a particular property of the specific interface. It means that the value of the attribute can be read by accessing the property, and can be modified by setting the property to a different value.
For example, the placeholder below is reflected into domxref("HTMLInputElement.placeholder").
Considering the following HTML:
<input placeholder="Original placeholder" />We can check the reflection between domxref("HTMLInputElement.placeholder") and the attribute using:
//
let input = document.getElementsByTagName('input')[0];
let attr = input.getAttributeNode('placeholder');
console.log(attr.value);
console.log(input.placeholder); //Returns the same value as `attr.value`and
//
let input2 = document.getElementsByTagName('input')[0];
let attr2 = input.getAttributeNode('placeholder');
console.log(attr2.value); // Returns `Original placeholder`
input2.placeholder = 'Modified placeholder'; // Also change the value of the reflected attribute.
console.log(attr2.value); // Returns `Modified placeholder`- HTML attribute reference
- Information about HTML's global attributes
- Audio
- Glossary
- Media
- Multimedia
- Video
The term media (more accurately, multimedia) refers to audio, video, or combined audio-visual material such as music, recorded speech, movies, TV shows, or any other form of content that is presented over a period of time.
More broadly, media may include still images such as photographs or other still images.
Media content can be recorded, played back, presented, and at times interacted with in various ways.
- interwiki("wikipedia", "Multimedia") on Wikipedia
- Web media technologies: a guide to all the ways media can be used in web content
- Multimedia and Embedding in the MDN learning area
- HTMLElement("audio") and HTMLElement("video") elements, used to present media in Glossary("HTML") documents
- Glossary
- Infrastructure
Bandwidth is the measure of how much information can pass through a data connection in a given amount of time. It is usually measured in multiples of bits-per-second (bps), for example megabits-per-second (Mbps) or gigabits-per-second (Gbps).
- Interwiki("wikipedia", "Bandwidth") on Wikipedia
- Advanced
- Base64
- JavaScript
- Typed Arrays
- URI
- URL
- Unicode Problem
- atob()
- btoa()
Base64 is a group of similar binary-to-text encoding schemes that represent binary data in an ASCII string format by translating it into a radix-64 representation. The term Base64 originates from a specific MIME content transfer encoding.
Base64 encoding schemes are commonly used when there is a need to encode binary data that needs to be stored and transferred over media that are designed to deal with ASCII. This is to ensure that the data remain intact without modification during transport. Base64 is commonly used in a number of applications including email via MIME, and storing complex data in XML.
One common application of Base64 encoding on the web is to encode binary data so it can be included in a data: URL.
In JavaScript there are two functions respectively for decoding and encoding Base64 strings:
btoa(): creates a Base64-encoded ASCII string from a "string" of binary data ("btoa" should be read as "binary to ASCII").atob(): decodes a Base64-encoded string("atob" should be read as "ASCII to binary").
The algorithm used by atob() and btoa() is specified in RFC 4648, section 4.
Note that btoa() expects to be passed binary data, and will throw an exception if the given string contains any characters whose UTF-16 representation occupies more than one byte. For more details, see the documentation for btoa().
Each Base64 digit represents exactly 6 bits of data. So, three 8-bits bytes of the input string/binary file (3×8 bits = 24 bits) can be represented by four 6-bit Base64 digits (4×6 = 24 bits).
This means that the Base64 version of a string or file will be at least 133% the size of its source (a ~33% increase). The increase may be larger if the encoded data is small. For example, the string "a" with length === 1 gets encoded to "YQ==" with length === 4 — a 300% increase.
Since DOMStrings are 16-bit-encoded strings, in most browsers calling window.btoa on a Unicode string will cause a Character Out Of Range exception if a character exceeds the range of a 8-bit ASCII-encoded character. There are two possible methods to solve this problem:
- the first one is to escape the whole string and then encode it;
- the second one is to convert the UTF-16
DOMStringto an UTF-8 array of characters and then encode it.
Here are the two possible methods.
//
function utf8_to_b64(str) {
return window.btoa(unescape(encodeURIComponent(str)));
}
function b64_to_utf8(str) {
return decodeURIComponent(escape(window.atob(str)));
}
// Usage:
utf8_to_b64('✓ à la mode'); // "4pyTIMOgIGxhIG1vZGU="
b64_to_utf8('4pyTIMOgIGxhIG1vZGU='); // "✓ à la mode"This solution has been proposed by Johan Sundström.
Another possible solution without utilizing the now deprecated 'unescape' and 'escape' functions.
//
function b64EncodeUnicode(str) {
return btoa(
encodeURIComponent(str).replace(/%([0-9A-F]{2})/g, function (match, p1) {
return String.fromCharCode('0x' + p1);
})
);
}
b64EncodeUnicode('✓ à la mode'); // "4pyTIMOgIGxhIG1vZGU="Note: The following code is also useful to get an ArrayBuffer from a Base64 string and/or viceversa (see below).
//
'use strict';
/*\
|*|
|*| Base64 / binary data / UTF-8 strings utilities
|*|
|*| https://developer.mozilla.org/en-US/docs/Web/JavaScript/Base64_encoding_and_decoding
|*|
\*/
/* Array of bytes to Base64 string decoding */
function b64ToUint6(nChr) {
return nChr > 64 && nChr < 91
? nChr - 65
: nChr > 96 && nChr < 123
? nChr - 71
: nChr > 47 && nChr < 58
? nChr + 4
: nChr === 43
? 62
: nChr === 47
? 63
: 0;
}
function base64DecToArr(sBase64, nBlocksSize) {
var sB64Enc = sBase64.replace(/[^A-Za-z0-9\+\/]/g, ''),
nInLen = sB64Enc.length,
nOutLen = nBlocksSize ? Math.ceil(((nInLen * 3 + 1) >> 2) / nBlocksSize) * nBlocksSize : (nInLen * 3 + 1) >> 2,
taBytes = new Uint8Array(nOutLen);
for (var nMod3, nMod4, nUint24 = 0, nOutIdx = 0, nInIdx = 0; nInIdx < nInLen; nInIdx++) {
nMod4 = nInIdx & 3;
nUint24 |= b64ToUint6(sB64Enc.charCodeAt(nInIdx)) << (6 * (3 - nMod4));
if (nMod4 === 3 || nInLen - nInIdx === 1) {
for (nMod3 = 0; nMod3 < 3 && nOutIdx < nOutLen; nMod3++, nOutIdx++) {
taBytes[nOutIdx] = (nUint24 >>> ((16 >>> nMod3) & 24)) & 255;
}
nUint24 = 0;
}
}
return taBytes;
}
/* Base64 string to array encoding */
function uint6ToB64(nUint6) {
return nUint6 < 26 ? nUint6 + 65 : nUint6 < 52 ? nUint6 + 71 : nUint6 < 62 ? nUint6 - 4 : nUint6 === 62 ? 43 : nUint6 === 63 ? 47 : 65;
}
function base64EncArr(aBytes) {
var nMod3 = 2,
sB64Enc = '';
for (var nLen = aBytes.length, nUint24 = 0, nIdx = 0; nIdx < nLen; nIdx++) {
nMod3 = nIdx % 3;
if (nIdx > 0 && ((nIdx * 4) / 3) % 76 === 0) {
sB64Enc += '\r\n';
}
nUint24 |= aBytes[nIdx] << ((16 >>> nMod3) & 24);
if (nMod3 === 2 || aBytes.length - nIdx === 1) {
sB64Enc += String.fromCodePoint(
uint6ToB64((nUint24 >>> 18) & 63),
uint6ToB64((nUint24 >>> 12) & 63),
uint6ToB64((nUint24 >>> 6) & 63),
uint6ToB64(nUint24 & 63)
);
nUint24 = 0;
}
}
return sB64Enc.substr(0, sB64Enc.length - 2 + nMod3) + (nMod3 === 2 ? '' : nMod3 === 1 ? '=' : '==');
}
/* UTF-8 array to DOMString and vice versa */
function UTF8ArrToStr(aBytes) {
var sView = '';
for (var nPart, nLen = aBytes.length, nIdx = 0; nIdx < nLen; nIdx++) {
nPart = aBytes[nIdx];
sView += String.fromCodePoint(
nPart > 251 && nPart < 254 && nIdx + 5 < nLen /* six bytes */
? /* (nPart - 252 << 30) may be not so safe in ECMAScript! So...: */
(nPart - 252) * 1073741824 +
((aBytes[++nIdx] - 128) << 24) +
((aBytes[++nIdx] - 128) << 18) +
((aBytes[++nIdx] - 128) << 12) +
((aBytes[++nIdx] - 128) << 6) +
aBytes[++nIdx] -
128
: nPart > 247 && nPart < 252 && nIdx + 4 < nLen /* five bytes */
? ((nPart - 248) << 24) + ((aBytes[++nIdx] - 128) << 18) + ((aBytes[++nIdx] - 128) << 12) + ((aBytes[++nIdx] - 128) << 6) + aBytes[++nIdx] - 128
: nPart > 239 && nPart < 248 && nIdx + 3 < nLen /* four bytes */
? ((nPart - 240) << 18) + ((aBytes[++nIdx] - 128) << 12) + ((aBytes[++nIdx] - 128) << 6) + aBytes[++nIdx] - 128
: nPart > 223 && nPart < 240 && nIdx + 2 < nLen /* three bytes */
? ((nPart - 224) << 12) + ((aBytes[++nIdx] - 128) << 6) + aBytes[++nIdx] - 128
: nPart > 191 && nPart < 224 && nIdx + 1 < nLen /* two bytes */
? ((nPart - 192) << 6) + aBytes[++nIdx] - 128
: /* nPart < 127 ? */ /* one byte */
nPart
);
}
return sView;
}
function strToUTF8Arr(sDOMStr) {
var aBytes,
nChr,
nStrLen = sDOMStr.length,
nArrLen = 0;
/* mapping... */
for (var nMapIdx = 0; nMapIdx < nStrLen; nMapIdx++) {
nChr = sDOMStr.codePointAt(nMapIdx);
if (nChr > 65536) {
nMapIdx++;
}
nArrLen += nChr < 0x80 ? 1 : nChr < 0x800 ? 2 : nChr < 0x10000 ? 3 : nChr < 0x200000 ? 4 : nChr < 0x4000000 ? 5 : 6;
}
aBytes = new Uint8Array(nArrLen);
/* transcription... */
for (var nIdx = 0, nChrIdx = 0; nIdx < nArrLen; nChrIdx++) {
nChr = sDOMStr.codePointAt(nChrIdx);
if (nChr < 128) {
/* one byte */
aBytes[nIdx++] = nChr;
} else if (nChr < 0x800) {
/* two bytes */
aBytes[nIdx++] = 192 + (nChr >>> 6);
aBytes[nIdx++] = 128 + (nChr & 63);
} else if (nChr < 0x10000) {
/* three bytes */
aBytes[nIdx++] = 224 + (nChr >>> 12);
aBytes[nIdx++] = 128 + ((nChr >>> 6) & 63);
aBytes[nIdx++] = 128 + (nChr & 63);
} else if (nChr < 0x200000) {
/* four bytes */
aBytes[nIdx++] = 240 + (nChr >>> 18);
aBytes[nIdx++] = 128 + ((nChr >>> 12) & 63);
aBytes[nIdx++] = 128 + ((nChr >>> 6) & 63);
aBytes[nIdx++] = 128 + (nChr & 63);
nChrIdx++;
} else if (nChr < 0x4000000) {
/* five bytes */
aBytes[nIdx++] = 248 + (nChr >>> 24);
aBytes[nIdx++] = 128 + ((nChr >>> 18) & 63);
aBytes[nIdx++] = 128 + ((nChr >>> 12) & 63);
aBytes[nIdx++] = 128 + ((nChr >>> 6) & 63);
aBytes[nIdx++] = 128 + (nChr & 63);
nChrIdx++;
} /* if (nChr <= 0x7fffffff) */ else {
/* six bytes */
aBytes[nIdx++] = 252 + (nChr >>> 30);
aBytes[nIdx++] = 128 + ((nChr >>> 24) & 63);
aBytes[nIdx++] = 128 + ((nChr >>> 18) & 63);
aBytes[nIdx++] = 128 + ((nChr >>> 12) & 63);
aBytes[nIdx++] = 128 + ((nChr >>> 6) & 63);
aBytes[nIdx++] = 128 + (nChr & 63);
nChrIdx++;
}
}
return aBytes;
}//
/* Tests */
var sMyInput = 'Base 64 \u2014 Mozilla Developer Network';
var aMyUTF8Input = strToUTF8Arr(sMyInput);
var sMyBase64 = base64EncArr(aMyUTF8Input);
alert(sMyBase64);
var aMyUTF8Output = base64DecToArr(sMyBase64);
var sMyOutput = UTF8ArrToStr(aMyUTF8Output);
alert(sMyOutput);These function let us to create also uint8Arrays or arrayBuffers from Base64-encoded strings:
//
// "Base 64 \u2014 Mozilla Developer Network"
var myArray = base64DecToArr('QmFzZSA2NCDigJQgTW96aWxsYSBEZXZlbG9wZXIgTmV0d29yaw==');
// "Base 64 \u2014 Mozilla Developer Network"
var myBuffer = base64DecToArr('QmFzZSA2NCDigJQgTW96aWxsYSBEZXZlbG9wZXIgTmV0d29yaw==').buffer;
alert(myBuffer.byteLength);Note: The function
base64DecToArr(sBase64[, nBlocksSize])returns anuint8Arrayof bytes. If your aim is to build a buffer of 16-bit / 32-bit / 64-bit raw data, use thenBlocksSizeargument, which is the number of bytes of which theuint8Array.buffer.bytesLengthproperty must result a multiple (1or omitted for ASCII, binary strings or UTF-8-encoded strings,2for UTF-16 strings,4for UTF-32 strings).
- CSS
- Glossary
- SVG
- alignment
- typography
The baseline is a term used in European and West Asian typography meaning an imaginary line upon which the characters of a font rest.
The descenders of characters like g and p extend below this line. Glossary("glyph", "Glyphs") with rounded lower and upper extents like C or 3 slightly extend below it.
East Asian scripts have no baseline. Their glyphs are placed in a square box without ascenders or descenders.
- Baseline on Wikipedia
- CSS Box Alignment on MDN
- Beacon
- Glossary
- Reference
- Web Performance
A web beacon is a small object, such as a 1 pixel gif, embedded in markup, used to communicate information back to the web server or to 3rd party servers. Beacons are generally included to provide information about the user for statistical purposes. Beacons are often included within third party scripts for collecting user data, performance metrics and error reporting.
There is a W3C Draft Beacon Specification to standardize the beacon as an interface to asynchronously transfer HTTP data from User Agent to a web server prior to page load without negative performance impact.
- Accessibility
- Glossary
BiDi (BiDirectional) refers to a document containing both right-to-left and left-to-right text. Even when both directionalities occur in the same paragraph, the text in each language must appear in its proper directionality.
- Interwiki("wikipedia", "Bi-directional text") on Wikipedia
- BigInt
- Glossary
- JavaScript
- Reference
- arbitrary precision format
In Glossary("JavaScript"), BigInt is a numeric data type that can represent integers in the arbitrary precision format. In other programming languages different numeric types can exist, for examples: Integers, Floats, Doubles, or Bignums.
- Interwiki("wikipedia", "Data type#Numeric_types", "Numeric types") on Wikipedia
- The JavaScript type:
BigInt - The JavaScript global object jsxref("BigInt")
- Glossary
- Infrastructure
- Layout
- Rendering engine
Blink is an open-source browser layout engine developed by Google as part of Chromium (and therefore part of glossary("Google Chrome", "Chrome") as well). Specifically, Blink began as a fork of the WebCore library in glossary("WebKit"), which handles layout, rendering, and glossary("DOM"), but now stands on its own as a separate glossary("rendering engine").
-
Blink project home page
-
Blink on Wikipedia
-
FAQ on Blink
-
- glossary("Google Chrome")
- glossary("Gecko")
- glossary("Trident")
- glossary("WebKit")
- glossary("Rendering engine")
- Block cipher mode of operation
- Cryptography
- Glossary
- Security
A block cipher mode of operation, usually just called a "mode" in context, specifies how a block cipher should be used to encrypt or decrypt messages that are longer than the block size.
Most symmetric-key algorithms currently in use are block ciphers: this means that they encrypt data a block at a time. The size of each block is fixed and determined by the algorithm: for example AES uses 16-byte blocks. Block ciphers are always used with a mode, which specifies how to securely encrypt messages that are longer than the block size. For example, AES is a cipher, while CTR, CBC, and GCM are all modes. Using an inappropriate mode, or using a mode incorrectly, can completely undermine the security provided by the underlying cipher.
- Disambiguation
- Glossary
The term block can have several meanings depending on the context. It may refer to:
_GlossaryDisambiguation}}
- Boolean
- CodingScripting
- Glossary
- JavaScript
- Programming Languages
- data types
In computer science, a Boolean is a logical data type that can have only the values
trueorfalse.
For example, in JavaScript, Boolean conditionals are often used to decide which sections of code to execute (such as in if statements) or repeat (such as in for loops).
Below is some JavaScript pseudocode (it's not truly executable code) demonstrating this concept.
//
/* JavaScript if statement */
if (boolean conditional) {
// code to execute if the conditional is true
}
if (boolean conditional) {
console.log("boolean conditional resolved to true");
} else {
console.log("boolean conditional resolved to false");
}
/* JavaScript for loop */
for (control variable; boolean conditional; counter) {
// code to execute repeatedly if the conditional is true
}
for (var i=0; i < 4; i++) {
console.log("I print only when the boolean conditional is true");
}The Boolean value is named after English mathematician interwiki("wikipedia", "George Boole"), who pioneered the field of mathematical logic.
- Interwiki("wikipedia", "Boolean data type", "Boolean") on Wikipedia
- The JavaScript global object: jsxref("Boolean")
- JavaScript data types and data structures
- B2G
- Boot2Gecko
- Firefox OS
- Glossary
- Infrastructure
- Intro
Boot2Gecko (B2G) is the engineering codename for glossary("Firefox OS") and refers to builds that haven't yet received official Firefox OS branding. (Firefox OS was also often called Boot2Gecko before the project had an official name.)
- Bootstrap
- CSS
- Glossary
- Intro
- framework
Bootstrap is a free, open source Glossary("HTML"), CSS, and Glossary("JavaScript") framework for quickly building responsive websites.
Initially, Bootstrap was called Twitter Blueprint and was developed by a team working at Twitter. It supports responsive design and features predefined design templates that you can use out of the box, or customize for your needs with your code. You don't need to worry about compatibility with other browsers either, as Bootstrap is compatible with all modern browsers and newer versions of glossary("Microsoft Internet Explorer", "Internet Explorer").
- interwiki("wikipedia", "Bootstrap (front-end framework)", "Bootstrap") on Wikipedia
- Download Bootstrap
- Get started with the latest version
- Bounding Box
- CodingScripting
- Design
- Glossary
The bounding box of an element is the smallest possible rectangle (aligned with the axes of that element's user coordinate system) that entirely encloses it and its descendants.
- Accessibility
- Glossary
- Navigation
- Search
- Site map
- breadcrumb
A breadcrumb, or breadcrumb trail, is a navigational aid that is typically placed between a site's header and the main content, displaying either a hierarchy of the current page in relation to the site's structure, from top level to current page, or a list of the links the user followed to get to the current page, in the order visited.
A location breadcrumb for this document might look something like this:
Breadcrumb trails enable users to be aware of their location within a website. This type of navigation, if done correctly, helps users know where they are in a site and how they got there. They can also help a user get back to where they were before and can reduce the number of clicks needed to get to a higher-level page.
- Brotli
- Glossary
- Reference
- Web Performance
- compression
Brotli is a general-purpose lossless compression algorithm.
It compresses data using a combination of a modern variant of the LZ77 algorithm, Huffman coding, and second-order context modeling, providing a compression ratio comparable to the best currently available general-purpose compression methods. Brotli provides better compression ratios than glossary("GZip_compression", "gzip") and deflate speeds are comparable, but brotli compressing is a slower process than Gzip compression, so gzip may be a better option for the compression of non-glossary("Cache", "cacheable") content.
Brotli is compatible with most modern browsers, but you may want to consider a fallback.
- brotli.org
- Brotli Github repository
- interwiki("wikipedia", "Brotli") on Wikipedia
- Brotli on Caniuse
- Glossary
- Navigation
A Web browser or browser is a program that retrieves and displays pages from the Glossary("World Wide Web","Web"), and lets users access further pages through Glossary("hyperlink","hyperlinks"). A browser is the most familiar type of Glossary("user agent").
-
Interwiki("wikipedia", "Web browser") on Wikipedia
-
Glossary("user agent") (Glossary)
-
HTTPHeader("User-agent") (HTTP Header)
-
Download a browser
- Glossary
A browsing context is the environment in which a browser displays a domxref("Document"). In modern browsers, it usually is a tab, but can be a window or even only parts of a page, like a frame or an iframe.
Each browsing context has a specific origin, the origin of the active document and a history that memorize all the displayed documents, in order.
Communication between browsing context is severely constrained. Between browsing context of the same origin, a domxref("BroadcastChannel") can be opened and used.
- See glossary("origin")
- Buffer
- CodingScripting
- Glossary
- NeedsContent
A buffer is a storage in physical memory used to temporarily store data while it is being transferred from one place to another.
- Data buffer on Wikipedia
- Bézier curve
- Glossary
- Graphics
- Reference
A Bézier curve (pronounced [bezje]) is a mathematically described curve used in computer graphics and animation. In Glossary("vector image", "vector images"), they are used to model smooth curves that can be scaled indefinitely.
The curve is defined by a set of control points with a minimum of two. Web related graphics and animations use Cubic Béziers, which are curves with four control points P0, P1, P2, and P3.
To draw the curve, two imaginary lines are drawn, one from P0 to P1 and the other from P1 to P2. The end points of the lines are then steadily moved to the next point. A third imaginary line is drawn with its starting point moving steadily on the first helper line and the end point on the second helper line. On this imaginary line a point is drawn from its starting point moving steadily to its end point. The curve this point describes is the Bézier curve. Here's an animated illustration demonstrating the creation of the curve:

- Bézier curve on Wikipedia
- Cubic Bézier timing functions in CSS
- SVGAttr("keySplines") SVG attribute
- Glossary
- WebMechanics
A cacheable response is an HTTP response that can be cached, that is stored to be retrieved and used later, saving a new request to the server. Not all HTTP responses can be cached, these are the following constraints for an HTTP response to be cached:
- The method used in the request is itself cacheable, that is either a HTTPMethod("GET") or a HTTPMethod("HEAD") method. A response to a HTTPMethod("POST") or HTTPMethod("PATCH") request can also be cached if freshness is indicated and the HTTPHeader("Content-Location") header is set, but this is rarely implemented. (For example, Firefox does not support it per https://bugzilla.mozilla.org/show_bug.cgi?id=109553.) Other methods, like HTTPMethod("PUT") or HTTPMethod("DELETE") are not cacheable and their result cannot be cached.
- The status code of the response is known by the application caching, and it is considered cacheable. The following status code are cacheable: HTTPStatus("200"), HTTPStatus("203"), HTTPStatus("204"), HTTPStatus("206"), HTTPStatus("300"), HTTPStatus("301"), HTTPStatus("404"), HTTPStatus("405"), HTTPStatus("410"), HTTPStatus("414"), and HTTPStatus("501").
- There are specific headers in the response, like HTTPHeader("Cache-Control"), that prevents caching.
Note that some non-cacheable requests/responses to a specific URI may invalidate previously cached responses on the same URI. For example, a HTTPMethod("PUT") to pageX.html will invalidate all cached HTTPMethod("GET") or HTTPMethod("HEAD") requests to the same URI.
When both, the method of the request and the status of the response, are cacheable, the response to the request can be cached:
GET /pageX.html HTTP/1.1
(…)
200 OK
(…)
A HTTPMethod("PUT") request cannot be cached. Moreover, it invalidates cached data for request to the same URI done via HTTPMethod("HEAD") or HTTPMethod("GET"):
PUT /pageX.html HTTP/1.1
(…)
200 OK
(…)
A specific HTTPHeader("Cache-Control") header in the response can prevent caching:
GET /pageX.html HTTP/1.1
(…)
200 OK
Cache-Control: no-cache
(…)
- Definition of cacheable in the HTTP specification.
- Description of common cacheable methods: HTTPMethod("GET"), HTTPMethod("HEAD")
- Description of common non-cacheable methods: HTTPMethod("PUT"), HTTPMethod("DELETE"), often HTTPMethod("POST")
- Glossary
- HTTP
A cache (web cache or HTTP cache) is a component that stores HTTP responses temporarily so that it can be used for subsequent HTTP requests as long as it meets certain conditions.
- interwiki("wikipedia", "Web cache") on Wikipedia
- CalDAV
- Glossary
- Infrastructure
CalDAV (Calendaring extensions to Glossary("WebDAV")) is a glossary("protocol") standardized by the Glossary("IETF") and used to remotely access calendar data from a glossary("server").
- Interwiki("wikipedia", "CalDAV") on Wikipedia
- RFC 4791: Calendaring extensions to WebDAV (CalDAV)
- RFC 6638: Scheduling Extensions to CalDAV
- Call Stack
- CodingScripting
- Glossary
- JavaScript
A call stack is a mechanism for an interpreter (like the JavaScript interpreter in a web browser) to keep track of its place in a script that calls multiple glossary("function","functions") — what function is currently being run and what functions are called from within that function, etc.
- When a script calls a function, the interpreter adds it to the call stack and then starts carrying out the function.
- Any functions that are called by that function are added to the call stack further up, and run where their calls are reached.
- When the current function is finished, the interpreter takes it off the stack and resumes execution where it left off in the last code listing.
- If the stack takes up more space than it had assigned to it, it results in a "stack overflow" error.
//
function greeting() {
// [1] Some code here
sayHi();
// [2] Some code here
}
function sayHi() {
return 'Hi!';
}
// Invoke the `greeting` function
greeting();
// [3] Some code hereThe code above would be executed like this:
-
Ignore all functions, until it reaches the
greeting()function invocation. -
Add the
greeting()function to the call stack list.Note: Call stack list: - greeting
-
Execute all lines of code inside the
greeting()function. -
Get to the
sayHi()function invocation. -
Add the
sayHi()function to the call stack list.Note: Call stack list: - sayHi - greeting
-
Execute all lines of code inside the
sayHi()function, until reaches its end. -
Return execution to the line that invoked
sayHi()and continue executing the rest of thegreeting()function. -
Delete the
sayHi()function from our call stack list.Note: Call stack list: - greeting
-
When everything inside the
greeting()function has been executed, return to its invoking line to continue executing the rest of the JS code. -
Delete the
greeting()function from the call stack list.Note: Call stack list: EMPTY
In summary, then, we start with an empty Call Stack. Whenever we invoke a function, it is automatically added to the Call Stack. Once the function has executed all of its code, it is automatically removed from the Call Stack. Ultimately, the Stack is empty again.
-
Interwiki("wikipedia", "Call stack") on Wikipedia
-
- Glossary("Call stack")
- Glossary("Function")
- Callback
- Callback function
- CodingScripting
- Glossary
A callback function is a function passed into another function as an argument, which is then invoked inside the outer function to complete some kind of routine or action.
Here is a quick example:
//
function greeting(name) {
alert('Hello ' + name);
}
function processUserInput(callback) {
var name = prompt('Please enter your name.');
callback(name);
}
processUserInput(greeting);The above example is a glossary("synchronous") callback, as it is executed immediately.
Note, however, that callbacks are often used to continue code execution after an glossary("asynchronous") operation has completed — these are called asynchronous callbacks. A good example is the callback functions executed inside a .then() block chained onto the end of a promise after that promise fulfills or rejects. This structure is used in many modern web APIs, such as fetch().
- interwiki("wikipedia", "Callback(computerprogramming)", "Callback") on Wikipedia
- Canonical order
- CodingScripting
- Glossary
In CSS, canonical order is used to refer to the order in which separate values need to be specified (or Glossary("parse", "parsed")) or are to be Glossary("serialization", "serialized") as part of a CSS property value. It is defined by the formal Glossary("syntax") of the property and normally refers to the order in which longhand values should be specified as part of a single shorthand value.
For example, cssxref("background") shorthand property values are made up of several background-* longhand properties. The canonical order of those longhand values is defined as
- cssxref("background-image")
- cssxref("background-position")
- cssxref("background-size")
- cssxref("background-repeat")
- cssxref("background-attachment")
- cssxref("background-origin")
- cssxref("background-clip")
- cssxref("background-color")
Furthermore, its syntax defines, that if a value for the cssxref("background-size") is given, it must be specified after the value for the cssxref("background-position"), separated by a slash. Other values may appear in any order.
- What does "canonical order" mean with respect to CSS properties? on Stack Overflow provides useful further discussion.
- The description of the formal syntax used for CSS values on MDN
- CodingScripting
- Glossary
- Graphics
- HTML
- JavaScript
The canvas element is part of HTML5 and allows for dynamic, scriptable rendering of 2D and 3D shapes and bitmap images.
It is a low level, procedural model that updates a bitmap and does not have a built-in scene graph. It provides an empty graphic zone on which specific Glossary("JavaScript") Glossary("API","APIs") can draw (such as Canvas 2D or Glossary("WebGL")).
- Interwiki("wikipedia", "Canvas element", "Canvas") on Wikipedia
- The Canvas tutorial on MDN
- The HTML HTMLElement("canvas") element on MDN
- The Canvas general documentation on MDN
- domxref("CanvasRenderingContext2D"): The canvas 2D drawing API
- The Canvas 2D API specification
- Card sorting
- Design
- Glossary
Card sorting is a simple technique used in glossary("Information architecture") whereby people involved in the design of a website (or other type of product) are invited to write down the content / services / features they feel the product should contain, and then organize those features into categories or groupings. This can be used for example to work out what should go on each page of a website. The name comes from the fact that often card sorting is carried out by literally writing the items to sort onto cards, and then arranging the cards into piles.
- interwiki("wikipedia", "Card_sorting", "Card sorting") on Wikipedia
- CardDAV
- Glossary
- Infrastructure
CardDAV (vCard Extension to Glossary("WebDAV")) is a glossary("protocol") standardized by the Glossary("IETF") and used to remote-access or share contact information over a glossary("server").
- Interwiki("wikipedia", "CardDAV") on Wikipedia
- RFC 6352: vCard Extensions to Web Distributed Authoring and Versioning (WebDAV)
- Cursor
- Glossary
- Input
- caret
- insertion point
- text cursor
- text entry
- text input
- text insertion point
A caret (sometimes called a "text cursor") is an indicator displayed on the screen to indicate where text input will be inserted.
Most user interfaces represent the caret using a thin vertical line or a character-sized box that flashes, but this can vary. This point in the text is called the insertion point. The word "caret" differentiates the text insertion point from the mouse cursor.
On the web, a caret is used to represent the insertion point in HTMLElement("input") and HTMLElement("textarea") elements, as well as any elements whose htmlattrxref("contenteditable") attribute is set, thereby allowing the contents of the element to be edited by the user.
- interwiki("wikipedia", "Caret navigation") on Wikipedia
You can set the color of the caret for a given element's editable content by setting the element's CSS cssxref("caret-color") property to the appropriate cssxref("<color>") value.
These elements provide text entry fields or boxes and therefore make use of the caret.
<input type="text"><input type="password"><input type="search"><input type="date">,<input type="time">,<input type="datetime">, and<input type="datetime-local"><input type="number">,<input type="range"><input type="email">,<input type="tel">, and<input type="url">- HTMLElement("textarea")
- Any element with its htmlattrxref("contenteditable") attribute set
- Glossary
- Infrastructure
A CDN (Content Delivery Network) is a group of servers spread out over many locations. These servers store duplicate copies of data so that servers can fulfill data requests based on which servers are closest to the respective end-users. CDNs make for fast service less affected by high traffic.
CDNs are used widely for delivering stylesheets and Javascript files (static assets) of libraries like Bootstrap, jQuery etc. Using CDN for those library files is preferable for a number of reasons:
- Serving libraries' static assets over CDN lowers the request burden on an organization's own servers.
- Most CDNs have servers all over the globe, so CDN servers may be geographically nearer to your users than your own servers. Geographical distance affects latency proportionally.
- CDNs are already configured with proper cache settings. Using a CDN saves further configuration for static assets on your own servers.
- Cryptography
- Glossary
- Security
A certificate authority (CA) is an organization that Glossary("Signature/Security", "signs") Glossary("Digital certificate", "digital certificates") and their associated Glossary("Key", "public keys"), thereby asserting that the contained information and keys are correct.
For a website digital certificate, this information minimally includes the name of the organization that requested the digital certificate (e.g., Mozilla Corporation), the site that it is for (e.g., mozilla.org), and the certificate authority.
Certificate authorities are the part of the Internet public key infrastructure that allows browsers to verify website identity and securely connect over SSL (and HTTPS).
Note: Web browsers come preloaded with a list of "root certificates". The browser can use these to reliably check that the website certificate was signed by a certificate authority that "chains back" to the root certificate (i.e. was trusted by the owner of the root certificate or an intermediate CA). Ultimately this process relies on every CA performing adequate identity checks before signing a certificate!
- Certificate authority on Wikipedia
- Public key infrastructure on Wikipedia
- Mozilla Included CA Certificate List
- Apps
- B2G
- Firefox OS
- Glossary
- Security
- Trustworthy
Certified means that an application, content or data transmission has successfully undergone evaluation by professionals with expertise in the relevant field, thereby indicating completeness, security and trustworthiness.
For details on certification in glossary("Cryptography"), please refer to glossary("Digital Certificate").
- Interwiki("wikipedia", "Professional_certification(computertechnology)#Information_systems_security", "Certification") on Wikipedia
- Security
In security protocols, a challenge is some data sent to the client by the server in order to generate a different response each time. Challenge-response protocols are one way to fight against replay attacks where an attacker listens to the previous messages and resends them at a later time to get the same credentials as the original message.
The HTTP authentication protocol is challenge-response based, though the "Basic" protocol isn't using a real challenge (the realm is always the same).
- Challenge-response authentication on Wikipedia.
- Composing
- Glossary
An encoding defines a mapping between bytes and text. A sequence of bytes allows for different textual interpretations. By specifying a particular encoding (such as UTF-8), we specify how the sequence of bytes is to be interpreted.
For example, in HTML we normally declare a character encoding of UTF-8, using the following line:
<meta charset="utf-8" />This ensures that you can use characters from just about any human language in your HTML document, and they will display reliably.
- Character encoding on W3C
- Interwiki("wikipedia", "Character encoding") on Wikipedia
- Glossary
- character encoding
- character set
A character set is an encoding system to let computers know how to recognize Glossary("Character"), including letters, numbers, punctuation marks, and whitespace.
In earlier times, countries developed their own character sets due to their different languages used, such as Kanji JIS codes (e.g. Shift-JIS, EUC-JP, etc.) for Japanese, Big5 for traditional Chinese, and KOI8-R for Russian. However, Glossary("Unicode") gradually became most acceptable character set for its universal language support.
If a character set is used incorrectly (For example, Unicode for an article encoded in Big5), you may see nothing but broken characters, which are called Interwiki("wikipedia", "Mojibake").
-
Interwiki("wikipedia", "Character encoding") (Wikipedia)
-
Interwiki("wikipedia", "Mojibake") (Wikipedia)
-
- Glossary("Character")
- Glossary("Unicode")
- CodingScripting
- Glossary
- strings
A character is either a symbol (letters, numbers, punctuation) or non-printing "control" (e.g., carriage return or soft hyphen). glossary("UTF-8") is the most common character set and includes the graphemes of the most popular human languages.
- interwiki("wikipedia", "Character (computing)") on Wikipedia
- interwiki("wikipedia", "Character encoding") on Wikipedia
- interwiki("wikipedia", "ASCII") on Wikipedia
- interwiki("wikipedia", "UTF-8") on Wikipedia
- interwiki("wikipedia", "Unicode") on Wikipedia
- Browser
- Chrome
- Glossary
- WebMechanics
In a browser, the chrome is any visible aspect of a browser aside from the webpages themselves (e.g., toolbars, menu bar, tabs). This is not to be confused with the glossary("Google Chrome") browser.
- Glossary
- Security
CIA (Confidentiality, Integrity, Availability) (also called the CIA triad or AIC triad) is a model that guides an organization's policies for information security.
- Interwiki("wikipedia", "Information_security#Key_concepts", "CIA") on Wikipedia
- Cryptography
- Glossary
- Security
A cipher suite is a combination of a key exchange algorithm, authentication method, bulk encryption Glossary("cipher"), and message authentication code.
In a Glossary("cryptosystem") like Glossary("TLS"), the client and server must agree on a cipher suite before they can begin communicating securely. A typical cipher suite looks like ECDHE_RSA_WITH_AES_128_GCM_SHA256 or ECDHE-RSA-AES128-GCM-SHA256, indicating:
- ECDHE (elliptic curve Diffie-Hellman ephemeral) for key exchange
- RSA for authentication
- AES-128 as the cipher, with Galois/Counter Mode (GCM) as the block cipher mode of operation
- SHA-256 as the hash-based message authentication code (HMAC)
- Cryptography
- Glossary
- Privacy
- Security
In glossary("cryptography"), a cipher is an algorithm that can glossary("encryption", "encode") glossary("Plaintext") to make it unreadable, and to glossary("decryption", "decode") it back.
Ciphers were common long before the information age (e.g., substitution ciphers, transposition ciphers, and permutation ciphers), but none of them were cryptographically secure except for the one-time pad.
Modern ciphers are designed to withstand glossary("attack", "attacks") discovered by a glossary("cryptanalysis", "cryptanalyst"). There is no guarantee that all attack methods have been discovered, but each algorithm is judged against known classes of attacks.
Ciphers operate two ways, either as block ciphers on successive blocks, or buffers, of data, or as stream ciphers on a continuous data flow (often of sound or video).
They also are classified according to how their glossary("key", "keys") are handled:
- symmetric key algorithms use the same key to encode and decode a message. The key also must be sent securely if the message is to stay confidential.
- asymmetric key algorithms use a different key for encryption and decryption.
-
Interwiki("wikipedia", "Cipher") on Wikipedia
-
- Glossary("Block cipher mode of operation")
- Glossary("Cipher")
- Glossary("Ciphertext")
- Glossary("Cipher suite")
- Glossary("Cryptanalysis")
- Glossary("Cryptography")
- Glossary("Decryption")
- Glossary("Encryption")
- Glossary("Key")
- Glossary("Plaintext")
- Glossary("Public-key cryptography")
- Glossary("Symmetric-key cryptography")
- Cryptography
- Glossary
- Privacy
- Security
In glossary("cryptography"), a ciphertext is a scrambled message that conveys information but is not legible unless glossary("decryption","decrypted") with the right glossary("cipher") and the right secret (usually a glossary("key")), reproducing the original glossary("Plaintext"). A ciphertext's security, and therefore the secrecy of the contained information, depends on using a secure cipher and keeping the key secret.
- Interwiki("wikipedia", "Ciphertext") on Wikipedia
- CodingScripting
- Glossary
In glossary("OOP","object-oriented programming"), a class defines an glossary("object","object's") characteristics. Class is a template definition of an object's glossary("property","properties") and glossary("method","methods"), the "blueprint" from which other more specific instances of the object are drawn.
- Class-based vs. prototype-based programming languages (like JavaScript)
- Using functions as classes in JavaScript
- Class-based programming on Wikipedia
- Object-oriented programming on Wikipedia
- Clickjacking
- Interface-based attack
- Glossary
- Security
- vulnerability
- exploit
Clickjacking is an interface-based attack that tricks website users into unwittingly clicking on malicious links. In clickjacking, the attackers embed their malicious links into buttons or legitimate pages in a website. In an infected glossary("Site"), whenever a user clicks on a legitimate link, the attacker gets the confidential information of that user, which ultimately compromises the user's privacy on the Internet.
Clickjacking can be prevented by implementing a Content Security Policy (frame-ancestors) and implementing Set-Cookie attributes.
- Web security: clickjacking protection
- Clickjacking on Wikipedia
- Clickjacking on OWASP
- CodingScripting
- Glossary
The binding which defines the glossary("scope") of execution. In glossary("JavaScript"), glossary("function","functions") create a closure context.
- Interwiki("wikipedia", "Closure%28computerprogramming%29", "Closure") on Wikipedia
- Closure on MDN
- CMS
- Composing
- Content management system
- Glossary
A CMS (Content Management System) is software that allows users to publish, organize, change, or remove various kinds of content, not only text but also embedded images, video, audio, and interactive code.
- Interwiki("wikipedia", "Content management system") on Wikipedia
- Glossary
A code point is a number assigned to represent an abstract character in a system for representing text (such as Unicode). In Unicode, a code point is expressed in the form "U+1234" where "1234" is the assigned number. For example, the character "A" is assigned a code point of U+0041.
Character encoding forms, such as UTF-8 and UTF-16, determine how a Unicode code point should be encoded as a sequence of bytes. Different encoding forms may encode the same code point as different byte sequences: for example, the Cyrillic character "Ф", whose code point is U+0424, is encoded as 0xd0a4 in UTF-8 and as 0x0424 in UTF-16.
- Glossary
- Reference
- Web Performance
- code splitting
- latency
Code splitting is the splitting of code into various bundles or components which can then be loaded on demand or in parallel.
As an application grows in complexity or is maintained, CSS and JavaScripts files or bundles grow in byte size, especially as the number and size of included third-party libraries increases. To prevent the requirement of downloading ginormous files, scripts can be split into multiple smaller files. Then features required at page load can be downloaded immediately with additional scripts being lazy loaded after the page or application is interactive, thus improving performance. While the total amount of code is the same (and perhaps even a few bytes larger), the amount of code needed during initial load can be reduced.
Code splitting is a feature supported by bundlers like Webpack and Browserify which can create multiple bundles that can be dynamically loaded at runtime.
- Bundling
- Lazy loading
- HTTP/2
- Tree shaking
- Glossary
A code unit is the basic component used by a character encoding system (such as UTF-8 or UTF-16). A character encoding system uses one or more code units to encode a Unicode Glossary("code point").
In UTF-16 (the encoding system used for JavaScript strings) code units are 16-bit values. This means that operations such as indexing into a string or getting the length of a string operate on these 16-bit units. These units do not always map 1-1 onto what we might consider characters.
For example, sometimes characters with diacritics such as accents are represented using two Unicode code points:
//
const myString = 'ñ';
myString.length;
// 2Also, since not all of the code points defined by Unicode fit into 16 bits, many Unicode code points are encoded as a pair of UTF-16 code units, which is called a surrogate pair:
//
const face = '🥵';
face.length;
// 2The jsxref("String/codePointAt", "codePointAt()") method of the JavaScript jsxref("String") object enables you to retrieve the Unicode code point from its encoded form:
//
const face = '🥵';
face.codePointAt(0);
// 129397- Glossary
- WebMechanics
A codec (a blend word derived from "**coder-dec**oder") is a program, algorithm, or device that encodes or decodes a data stream. A given codec knows how to handle a specific encoding or compression technology.
- Interwiki("wikipedia", "Codec") on Wikipedia
- Web video codec guide
- Web audio codec guide
- Guide to media types and formats on the web
- CodingScripting
- Glossary
- JavaScript
The compile time is the time from when the program is first loaded until the program is Glossary("parse","parsed").
- Interwiki("wikipedia", "Compile time") on Wikipedia
- CodingScripting
- Glossary
Compiling is the process of transforming a computer program written in a given Glossary("computer programming", "language") into a set of instructions in another format or language. A compiler is a computer program to execute that task.
Typically, a compiler transforms code written in a higher-level language such as C++ or Rust or Java into executable (runnable) code — so-called binary code or machine code. WebAssembly, for example, is a form of executable binary code that can be compiled from code written in C++, Rust, C#, Go, Swift, and several other languages and that can then be run on any web page, in any browser.
Most compilers perform either ahead-of-time (AOT) compilation or just-in-time (JIT) compilation.
The GNU gcc compiler is one well-known example of an AOT compiler. AOT compilers are typically invoked from the command line in a shell environment (from within a terminal or console) or within an Glossary("IDE").
JIT compilers are typically not invoked directly but are instead built into software runtimes internally, for the purpose of improving performance. For example, all major browsers now use JavaScript engines that have built-in JIT compilers.
Compilers may also translate among higher-level languages — for example, from TypeScript to Glossary("JavaScript") — in which case, they are often sometimes referred to as transpilers.
- Compiling from C/C++ to WebAssembly
- Compiling from Rust to WebAssembly
- Wikipedia: Interwiki("wikipedia", "Compiler")
- CodingScripting
- Computer Programming
- Programming Language
- programming
Computer programming is a process of composing and organizing a collection of instructions. These tell a computer/software program what to do in a language which the computer understands. These instructions come in the form of many different languages such as C++, Java, JavaScript, HTML, Python, Ruby, and Rust.
Using an appropriate language, you can program/create all sorts of software. For example, a program that helps scientists with complex calculations, a database that stores huge amounts of data, a web site that allows people to download music, or animation software that allows people to create animated movies.
- Interwiki("wikipedia", "Computer programming") on Wikipedia
- List of Programming Languages: Wikipedia
- Beginner
- CodingScripting
- Glossary
A condition is a set of rules that can interrupt normal code execution or change it, depending on whether the condition is completed or not.
An instruction or a set of instructions is executed if a specific condition is fulfilled. Otherwise, another instruction is executed. It is also possible to repeat the execution of an instruction, or set of instructions, while a condition is not yet fulfilled.
- interwiki("wikipedia", "Exception_handling#Condition_systems", "Condition") on Wikipedia
- Control flow on MDN
- Making decisions in your code — conditionals
- Control flow and error handling in JavaScript on MDN
- CodingScripting
- Constant
- Glossary
A constant is a value that the programmer cannot change, for example numbers (1, 2, 42). With glossary("variable","variables"), on the other hand, the programmer can assign a new glossary("value") to a variable name already in use.
Like variables, some constants are bound to identifiers. For example, the identifier pi could be bound to the value 3.14... .
- Interwiki("wikipedia", "Constant(computerprogramming)", "Constant") on Wikipedia
- CodingScripting
- Glossary
A constructor belongs to a particular class glossary("object") that is instantiated. The constructor initializes this object and can provide access to its private information. The concept of a constructor can be applied to most glossary("OOP","object-oriented programming") languages. Essentially, a constructor in glossary("JavaScript") is usually declared at the instance of a glossary("class").
//
// This is a generic default constructor class Default
function Default() {
}
// This is an overloaded constructor class Overloaded
// with parameter arguments
function Overloaded(arg1, arg2, ..., argN){
}To call the constructor of the class in JavaScript, use a new operator to assign a new glossary("object reference") to a glossary("variable").
//
function Default() {}
// A new reference of a Default object assigned to a
// local variable defaultReference
var defaultReference = new Default();- Interwiki("wikipedia", "Constructor%28object-orientedprogramming%29", "Constructor") on Wikipedia
- The constructor in object oriented programming for JavaScript on MDN
- New operator in JavaScript on MDN
- Glossary
- Media
Continuous media is data where there is a timing relationship between source and destination. The most common examples of continuous media are audio and motion video. Continuous media can be real-time (interactive), where there is a "tight" timing relationship between source and sink, or streaming (playback), where the relationship is less strict.
CSS can be used in a variety of contexts, including print media. And some CSS, particularly those that are used for layout, behave differently depending on the context they are in.
Continuous Media, therefore, identifies a context where the content is not broken up. It flows continuously. Web content displayed on a screen is continuous media, as is spoken content.
- CodingScripting
- Glossary
- JavaScript
The control flow is the order in which the computer executes statements in a script.
Code is run in order from the first line in the file to the last line, unless the computer runs across the (extremely frequent) structures that change the control flow, such as conditionals and loops.
For example, imagine a script used to validate user data from a webpage form. The script submits validated data, but if the user, say, leaves a required field empty, the script prompts them to fill it in. To do this, the script uses a Glossary("Conditional", "conditional") structure or if...else, so that different code executes depending on whether the form is complete or not:
if (field==empty) {
promptUser();
} else {
submitForm();
}
A typical script in glossary("JavaScript") or glossary("PHP") (and the like) includes many control structures, including conditionals, Glossary("Loop", "loops") and Glossary("Function", "functions"). Parts of a script may also be set to execute when Glossary("Event", "events") occur.
For example, the above excerpt might be inside a function that runs when the user clicks the Submit button for the form. The function could also include a loop, which iterates through all of the fields in the form, checking each one in turn. Looking back at the code in the if and else sections, the lines promptUser and submitForm could also be calls to other functions in the script. As you can see, control structures can dictate complex flows of processing even with only a few lines of code.
Control flow means that when you read a script, you must not only read from start to finish but also look at program structure and how it affects order of execution.
- Interwiki("wikipedia", "Control flow") on Wikipedia
- JavaScript Reference - Control flow on MDN
- Statements (Control flow) on MDN
- Glossary
- WebMechanics
A cookie is a small piece of information left on a visitor's computer by a website, via a web browser.
Cookies are used to personalize a user's web experience with a website. It may contain the user's preferences or inputs when accessing that website. A user can customize their web browser to accept, reject, or delete cookies.
Cookies can be set and modified at the server level using the Set-Cookie HTTP header, or with JavaScript using document.cookie.
- HTTP cookie on Wikipedia
- Glossary
- OpenPractices
- Remixing
- Sharing
Copyleft is a term, usually referring to a license, used to indicate that such license requires that redistribution of said work is subject to the same license as the original. Examples of copyleft licenses are the GNU Glossary("GPL") (for software) and the Creative Commons SA (Share Alike) licenses (for works of art).
- Interwiki("wikipedia", "Copyleft") on Wikipedia
- CORS
- Fetch
A CORS-safelisted request header is one of the following HTTP headers:
- HTTPHeader("Accept"),
- HTTPHeader("Accept-Language"),
- HTTPHeader("Content-Language"),
- HTTPHeader("Content-Type").
When containing only these headers (and values that meet the additional requirements laid out below), a requests doesn't need to send a glossary("preflight request") in the context of CORS.
You can safelist more headers using the HTTPHeader("Access-Control-Allow-Headers") header and also list the above headers there to circumvent the following additional restrictions:
CORS-safelisted headers must also fulfill the following requirements in order to be a CORS-safelisted request header:
- For HTTPHeader("Accept-Language") and HTTPHeader("Content-Language"): can only have values consisting of
0-9,A-Z,a-z, space or*,-.;=. - For HTTPHeader("Accept") and HTTPHeader("Content-Type"): can't contain a CORS-unsafe request header byte:
0x00-0x1F(except for0x09 (HT), which is allowed),"():<>?@[\]{}, and0x7F (DEL). - For HTTPHeader("Content-Type"): needs to have a MIME type of its parsed value (ignoring parameters) of either
application/x-www-form-urlencoded,multipart/form-data, ortext/plain. - For any header: the value's length can't be greater than 128.
- Glossary("CORS-safelisted response header")
- Glossary("Forbidden header name")
- Glossary("Request header")
- CORS
- Fetch
- Glossary
- HTTP
A CORS-safelisted response header is an HTTP header in a CORS response that it is considered safe to expose to client scripts. Only safelisted response headers are made available to web pages.
By default, the safelist includes the following response headers:
- HTTPHeader("Cache-Control")
- HTTPHeader("Content-Language")
- HTTPHeader("Content-Length")
- HTTPHeader("Content-Type")
- HTTPHeader("Expires")
- HTTPHeader("Last-Modified")
- HTTPHeader("Pragma")
Additional headers can be added to the safelist using HTTPHeader("Access-Control-Expose-Headers").
Note: HTTPHeader("Content-Length") was not part of the original set of safelisted response headers [ref]
You can extend the list of CORS-safelisted response headers by using the HTTPHeader("Access-Control-Expose-Headers") header:
Access-Control-Expose-Headers: X-Custom-Header, Content-Encoding
-
HTTPHeader("Access-Control-Expose-Headers")
-
- Glossary("CORS")
- Glossary("CORS-safelisted_request_header", "CORS-safelisted request header")
- Glossary("Forbidden header name")
- Glossary("Request header")
- Glossary
- Infrastructure
- Security
CORS (Cross-Origin Resource Sharing) is a system, consisting of transmitting Glossary("HTTP_header", "HTTP headers"), that determines whether browsers block frontend JavaScript code from accessing responses for cross-origin requests.
The same-origin security policy forbids cross-origin access to resources. But CORS gives web servers the ability to say they want to opt into allowing cross-origin access to their resources.
- Cross-Origin Resource Sharing (CORS) on MDN
- Interwiki("wikipedia", "Cross-origin resource sharing") on Wikipedia
- Fetch specification
- HTTPHeader("Access-Control-Allow-Origin")
-
- : Indicates whether the response can be shared.
- HTTPHeader("Access-Control-Allow-Credentials")
-
- : Indicates whether or not the response to the request can be exposed when the credentials flag is true.
- HTTPHeader("Access-Control-Allow-Headers")
-
- : Used in response to a preflight request to indicate which HTTP headers can be used when making the actual reques
- HTTPHeader("Access-Control-Allow-Methods")
-
- : Specifies the method or methods allowed when accessing the resource in response to a preflight request.
- HTTPHeader("Access-Control-Expose-Headers")
- : Indicates which headers can be exposed as part of the response by listing their names.
- HTTPHeader("Access-Control-Max-Age")
- : Indicates how long the results of a preflight request can be cached.
- HTTPHeader("Access-Control-Request-Headers")
- : Used when issuing a preflight request to let the server know which HTTP headers will be used when the actual request is made.
- HTTPHeader("Access-Control-Request-Method")
- : Used when issuing a preflight request to let the server know which HTTP method will be used when the actual request is made.
- HTTPHeader("Origin")
- : Indicates where a fetch originates from.
- Browser
- Crawler
- Glossary
- Infrastructure
A web crawler is a program, often called a bot or robot, which systematically browses the glossary("World Wide Web","Web") to collect data from webpages. Typically search engines (e.g. Google, Bing, etc.) use crawlers to build indexes.
- Interwiki("wikipedia", "Web crawler") on Wikipedia
- Glossary("Search engine") (Glossary)
- CR
- CRLF
- Glossary
- Infrastructure
- LF
- carriage return
- line feed
CR and LF are control characters or bytecode that can be used to mark a line break in a text file.
- CR = Carriage Return (
\r,0x0Din hexadecimal, 13 in decimal) — moves the cursor to the beginning of the line without advancing to the next line. - LF = Line Feed (
\n,0x0Ain hexadecimal, 10 in decimal) — moves the cursor down to the next line without returning to the beginning of the line.
A CR immediately followed by a LF (CRLF, \r\n, or 0x0D0A) moves the cursor down to the next line and then to the beginning of the line.
- interwiki("wikipedia", "Newline#In_programming_languages", "Newline") on Wikipedia
- interwiki("wikipedia", "Carriage_return#Computers", "Carriage return") on Wikipedia
- Cross Site Scripting
- DOM
- Glossary
- Security
- XSS
- exploit
Cross-site scripting (XSS) is a security exploit which allows an attacker to inject into a website malicious client-side code. This code is executed by the victims and lets the attackers bypass access controls and impersonate users. According to the Open Web Application Security Project, XSS was the seventh most common Web app vulnerability in 2017.
These attacks succeed if the Web app does not employ enough validation or encoding. The user's browser cannot detect the malicious script is untrustworthy, and so gives it access to any cookies, session tokens, or other sensitive site-specific information, or lets the malicious script rewrite the glossary("HTML") content.
- Cross-site scripting (XSS)
- Interwiki("wikipedia", "Cross-site scripting") on Wikipedia
- Cross-site scripting on OWASP
- Another article about Cross-site scripting
- XSS Attack - Exploit & Protection
- CSS
- Glossary
- cross axis
- flexbox
The cross axis in glossary("flexbox") runs perpendicular to the glossary("main axis"), therefore if your cssxref("flex-direction") is either
roworrow-reversethen the cross axis runs down the columns.

If your main axis is column or column-reverse then the cross axis runs along the rows.

Alignment of items on the cross axis is achieved with the align-items property on the flex container or align-self property on individual items. In the case of a multi-line flex container, with additional space on the cross axis, you can use align-content to control the spacing of the rows.
- cssxref("align-content")
- cssxref("align-items")
- cssxref("align-self")
- cssxref("flex-wrap")
- cssxref("flex-direction")
- cssxref("flex")
- cssxref("flex-basis")
- cssxref("flex-flow")
- cssxref("flex-grow")
- cssxref("flex-shrink")
- cssxref("justify-content")
- cssxref("order")
-
CSS Flexbox Guide: Basic Concepts of Flexbox
-
CSS Flexbox Guide: Aligning items in a flex container
-
CSS Flexbox Guide: Mastering wrapping of flex items
-
- Glossary("Flex")
- Glossary("Flex Container")
- Glossary("Flex Item")
- Glossary("Grid")
- Glossary
- Infrastructure
CRUD (Create, Read, Update, Delete) is an acronym for ways one can operate on stored data. It is a mnemonic for the four basic functions of persistent storage. CRUD typically refers to operations performed in a database or datastore, but it can also apply to higher level functions of an application such as soft deletes where data is not actually deleted but marked as deleted via a status.
- Interwiki("wikipedia", "CRUD") on Wikipedia
- Cryptography
- Glossary
- Privacy
- Security
Cryptanalysis is the branch of glossary("cryptography") that studies how to break codes and cryptosystems. Cryptanalysis creates techniques to break glossary("cipher","ciphers"), in particular by methods more efficient than a brute-force search. In addition to traditional methods like frequency analysis and index of coincidence, cryptanalysis includes more recent methods, like linear cryptanalysis or differential cryptanalysis, that can break more advanced ciphers.
- Interwiki("wikipedia", "Cryptanalysis") on Wikipedia
- Cryptography
- Glossary
- Security
A cryptographic hash function, also sometimes called a digest function, is a glossary("cryptography", "cryptographic") primitive transforming a message of arbitrary size into a message of fixed size, called a glossary("digest"). Cryptographic hash functions are used for authentication, Glossary("digital signature", "digital signatures"), and Glossary("HMAC", "message authentication codes").
To be used for cryptography, a hash function must have these qualities:
- quick to compute (because they are generated frequently)
- not invertible (each digest could come from a very large number of messages, and only brute-force can generate a message that leads to a given digest)
- tamper-resistant (any change to a message leads to a different digest)
- collision-resistant (it should be impossible to find two different messages that produce the same digest)
Cryptographic hash functions such as MD5 and SHA-1 are considered broken, as attacks have been found that significantly reduce their collision resistance.
-
interwiki("wikipedia", "Cryptographic hash function", "Cryptographic hash function") on Wikipedia
-
- Glossary("Symmetric-key cryptography")
- Cryptography
- Glossary
- Privacy
- Security
Cryptography, or cryptology, is the science that studies how to encode and transmit messages securely. Cryptography designs and studies algorithms used to encode and decode messages in an insecure environment, and their applications.
More than just data confidentiality, cryptography also tackles identification, authentication, non-repudiation, and data integrity. Therefore it also studies usage of cryptographic methods in context, cryptosystems.
-
Interwiki("wikipedia", "Cryptography") on Wikipedia
-
- Glossary("Block cipher mode of operation")
- Glossary("Cipher")
- Glossary("Ciphertext")
- Glossary("Cipher suite")
- Glossary("Cryptanalysis")
- Glossary("Cryptography")
- Glossary("Decryption")
- Glossary("Encryption")
- Glossary("Key")
- Glossary("Plaintext")
- Glossary("Public-key cryptography")
- Glossary("Symmetric-key cryptography")
- Glossary
- HTTP
- Infrastructure
A CSP (Content Security Policy) is used to detect and mitigate certain types of website related attacks like Glossary("Cross-site_scripting"), clickjacking and data injections.
The implementation is based on an Glossary("HTTP") header called HTTPHeader("Content-Security-Policy").
- Glossary
- Security
CSRF (Cross-Site Request Forgery) is an attack that impersonates a trusted user and sends a website unwanted commands.
This can be done, for example, by including malicious parameters in a glossary("URL") behind a link that purports to go somewhere else:
<img src="https://www.example.com/index.php?action=delete&id=123" />For users who have modification permissions on https://www.example.com, the <img> element executes action on https://www.example.com without their noticing, even if the element is not at https://www.example.com.
There are many ways to prevent CSRF, such as implementing glossary("REST", "RESTful API"), adding secure tokens, etc.
- Interwiki("wikipedia", "Cross-site request forgery") on Wikipedia
- Prevention measures
- CSS
- CSS Pixel
- Glossary
- height
- length
- pixel
- size
- unit
- width
The term CSS pixel is synonymous with the CSS unit of absolute length px — which is normatively defined as being exactly 1/96th of 1 inch.
- CSS Length Explained on the MDN Hacks Blog
- CSS
- Glossary
A CSS preprocessor is a program that lets you generate Glossary("CSS") from the preprocessor's own unique Glossary("syntax").
There are many CSS preprocessors to choose from, however most CSS preprocessors will add some features that don't exist in pure CSS, such as mixin, nesting selector, inheritance selector, and so on. These features make the CSS structure more readable and easier to maintain.
To use a CSS preprocessor, you must install a CSS compiler on your web Glossary("server"); Or use the CSS preprocessor to compile on the development environment, and then upload compiled CSS file to the web server.
-
A few of most popular CSS preprocessors:
-
- Glossary("CSS")
- CSS
- CSS Selector
- CodingScripting
- Glossary
- HTML
- Selector
A CSS selector is the part of a CSS rule that describes what elements in a document the rule will match. The matching elements will have the rule's specified style applied to them.
Consider this CSS:
p {
color: green;
}
div.warning {
width: 100%;
border: 2px solid yellow;
color: white;
background-color: darkred;
padding: 0.8em 0.8em 0.6em;
}
#customized {
font: 16px Lucida Grande, Arial, Helvetica, sans-serif;
}The selectors here are "p" (which applies the color green to the text inside any HTMLElement("p") element), "div.warning" (which makes any HTMLElement("div") element with the Glossary("CSS class", "class") "warning" look like a warning box), and "#customized", which sets the base font of the element with the ID "customized" to 16-pixel tall Lucida Grande or one of a few fallback fonts.
We can then apply this CSS to some HTML, such as:
<p>This is happy text.</p>
<div class="warning">Be careful! There are wizards present, and they are quick to anger!</div>
<div id="customized">
<p>This is happy text.</p>
<div class="warning">Be careful! There are wizards present, and they are quick to anger!</div>
</div>The resulting page content is styled like this:
EmbedLiveSample("Example", 640, 240)
-
Learn more about CSS selectors in our introduction to CSS.
-
Basic selectors
- Type selectors
elementname - Class selectors
.classname - ID selectors
#idname - Universal selectors
* ns|* *|* - Attribute selectors
[attr=value] - State selectors
a:active, a:visited
- Type selectors
-
Grouping selectors
- Selector list
A, B
- Selector list
-
Combinators
- Adjacent sibling selectors
A + B - General sibling selectors
A ~ B - Child selectors
A > B - Descendant selectors
A B
- Adjacent sibling selectors
-
Pseudo
- CSS
- Glossary
- Intro
- Media
In the context of Glossary("CSS") (Cascading Style Sheets), the term media refers to the destination to which the document is to be drawn by the Glossary("rendering engine").
Typically, this is a screen—but it may also be a printer, Braille display, or another type of device.
CSS offers several features that allow you to tweak your document's styles—or even offer different styles—according to the media type (such as screen or print, to name two) or media capabilities (such as width, resolution, or other values) of the viewer's device.
- Using media queries
- Media queries
- cssxref("@media") at-rule: Conditionally apply part of a stylesheet, based on the result of a media query.
- domxref("Window.matchMedia()"): Test the viewing device against a media query
- CSS
- CSSOM
- DOM
- Glossary
The CSS Object Model (CSSOM) is a set of APIs for reading and modifying a document's style-related (CSS) information. In other words, similar to the way in which the DOM enables a document's structure and content to be read and modified from JavaScript, the CSSOM allows the document's styling to be read and modified from JavaScript.
- CodingScripting
- Data structure
- Glossary
Data structure is a particular way of organizing data so that it can be used efficiently.
- interwiki("wikipedia", "Data_structure", "Data structure") on Wikipedia
- Database
- Glossary
- Sql
A database is a storing system that collects organized data, to make some works easier like searching, structure, and extend.
In web development, most databases use the relational database management system (RDBMS) to organize data and programming in glossary("SQL"). Some databases, however, don't follow the former mechanism to organized data, which called NoSQL.
Some famous server-side RDBMS are MySQL(or MariaDB which is a fork of it), SQL Server, and Oracle Database. On the other hand, some famous NoSQL examples are MongoDB, Cassandra, and Redis.
Browsers also have their own database system called glossary("IndexedDB").
-
Interwiki("wikipedia", "Database") on Wikipedia
-
Glossary
- Glossary("IndexedDB")
- Glossary("SQL")
- Cryptography
- Glossary
- Privacy
- Security
In glossary("cryptography"), decryption is the conversion of glossary("ciphertext") into glossary("Plaintext").
Decryption is a cryptographic primitive: it transforms a ciphertext message into plaintext using a cryptographic algorithm called a glossary("cipher"). Like encryption, decryption in modern ciphers is performed using a specific algorithm and a secret, called the glossary("key"). Since the algorithm is often public, the key must stay secret if the encryption stays secure.

Decryption is the reverse of glossary("encryption") and if the key stays secret, decryption without knowing the specific secret, decryption is mathematically hard to perform. How hard depends on the security of the cryptographic algorithm chosen and evolves with the progress of glossary("cryptanalysis").
- Delta
- Glossary
- difference
- value
The term delta refers to the difference between two values or states.
The name originates from the Greek letter Δ (delta), which is equivalent to the letter D in the Roman alphabet. Delta refers to the use of the letter Δ as a shorthand for difference.
The term delta is commonly used when communicating changes in speed, position, or acceleration of a physical or virtual object. It's also used when describing changes in the volume or frequency of sound waves.
For example, when describing how far an object on the screen moves left-to-right, one might use the term delta x or Δx.
Likewise, given the new value of X and its old value, you might compute the delta like this:
//
let deltaX = newX - oldX;More commonly, you receive the delta and use it to update a saved previous condition:
//
let newX = oldX + deltaX;- Mouse wheel events (domxref("WheelEvent") offer the amount the wheel moved since the last event in its domxref("WheelEvent.deltaX", "deltaX"), domxref("WheelEvent.deltaY", "deltaY"), and domxref("WheelEvent.deltaZ", "deltaZ") properties, for example.
- Attack
- Denial of Service
- Glossary
- Intro
- Security
See DoS attack for more information.
- CSS
- CodingScripting
- Glossary
- NeedsContent
A CSS descriptor defines the characteristics of an cssxref("at-rule"). At-rules may have one or multiple descriptors. Each descriptor has:
- A name
- A value, which holds the component values
- An "!important" flag, which in its default state is unset
- Deserialization
- Deserialize
- Glossary
- JavaScript
The process whereby a lower-level format (e.g. that has been transferred over a network, or stored in a data store) is translated into a readable object or other data structure.
In Glossary("JavaScript"), for example, you can deserialize a Glossary("JSON") Glossary("string") to an object by calling the Glossary("function") jsxref("JSON.parse()").
- Serialization on Wikipedia
- CodingScripting
- Developer Tools
- Glossary
Developer tools (or "development tools" or short "DevTools") are programs that allow a developer to create, test and debug software.
Current browsers provide integrated developer tools, which allow to inspect a website. They let users inspect and debug the page's Glossary("HTML"), Glossary("CSS"), and Glossary("JavaScript"), allow to inspect the network traffic it causes, make it possible to measure it's performance, and much more.
- interwiki("wikipedia", "Web development tools", "Web development tools") on Wikipedia
- Firefox Developer Tools on MDN
- Firebug (former developer tool for Firefox)
- Chrome DevTools on chrome.com
- Safari Web Inspector on apple.com
- Edge Dev Tools on microsoft.com
- CodingScripting
- DHTML
- Glossary
- HTML
DHTML (Dynamic glossary("HTML")) refers to the code behind interactive webpages that need no plugins like Glossary("Adobe Flash","Flash") or Glossary("Java"). DHTML aggregates the combined functionality of Glossary("HTML"), Glossary("CSS"), the Glossary("DOM"), and Glossary("JavaScript").
- interwiki("wikipedia", "Dynamic HTML", "DHTML") on Wikipedia
- Cryptography
- Glossary
- Privacy
- Security
A digest is a small value generated by a glossary("cryptographic hash function", "hash function") from a whole message. Ideally, a digest is quick to calculate, irreversible, and unpredictable, and therefore indicates whether someone has tampered with a given message.
A digest can be used to perform several tasks:
- in non-cryptographic applications (e.g., the index of hash tables, or a fingerprint used to detect duplicate data or to uniquely identify files)
- verify message integrity (a tampered message will have a different hash)
- store passwords so that they can't be retrieved, but can still be checked (To do this securely, you also need to salt the password.)
- generate pseudo-random numbers
- generate glossary("key","keys")
It is critical to choose the proper hash function for your use case to avoid collisions and predictability.
- See glossary("Cryptographic hash function")
- interwiki("wikipedia", "Cryptographic_hash_function", "Hash function") on Wikipedia
- Cryptography
- Glossary
- Security
A digital certificate is a data file that binds a publicly known Glossary("Key", "cryptographic key") to an organization.
A digital certificate contains information about an organization, such as the common name (e.g., mozilla.org), the organization unit (e.g., Mozilla Corporation), and the location (e.g., Mountain View). Digital certificates are most commonly signed by a Glossary("certificate authority"), attesting to the certificate's authenticity.
- interwiki("wikipedia", "Public_key_certificate", "Digital certificate ") on Wikipedia
- Attack
- DDoS
- Denial of Service
- Glossary
- Intro
- Security
A Distributed Denial-of-Service (DDoS) is an attack in which many compromised systems are made to attack a single target, in order to swamp server resources and block legitimate users.
Normally many persons, using many bots, attack high-profile Web glossary("server","servers") like banks or credit-card payment gateways. DDoS concerns computer networks and CPU resource management.
In a typical DDoS attack, the assailant begins by exploiting a vulnerability in one computer system and making it the DDoS master. The attack master, also known as the botmaster, identifies and infects other vulnerable systems with malware. Eventually, the assailant instructs the controlled machines to launch an attack against a specified target.
There are two types of DDoS attacks: a network-centric attack (which overloads a service by using up bandwidth) and an application-layer attack (which overloads a service or database with application calls). The overflow of data to the target causes saturation in the target machine so that it cannot respond or responds very slowly to legitimate traffic (hence the name "denial of service"). The infected computers' owners normally don't know that their computers have been compromised, and they also suffer loss of service.
A computer under an intruder's control is called a zombie or bot. A network of co-infected computers is known as a botnet or a zombie army. Both Kaspersky Labs and Symantec have identified botnets -- not spam, viruses, or worms -- as the biggest threat to Internet security.
The United States Computer Emergency Readiness Team (US-CERT) defines symptoms of denial-of-service attacks to include:
- Unusually slow network performance (opening files or accessing websites)
- Unavailability of a particular website
- Inability to access any website
- Dramatic increase in the number of spam emails received—(this type of DoS attack is considered an email bomb)
- Disconnection of a wireless or wired internet connection
- Longterm denial of access to the Web or any internet services
- interwiki("wikipedia", "Denial-of-service_attack", "Denial-of-service attack") on Wikipedia
- Glossary
- Networking
- Security
A DMZ (DeMilitarized Zone) is a way to provide an insulated secure interface between an internal network (corporate or private) and the outside untrusted world — usually the Internet.
It exposes only certain defined endpoints, while denying access to the internal network from Glossary('node/networking', 'external nodes').
- Interwiki("wikipedia", "DMZ (computing)", "DMZ") on Wikipedia
- DNS
- Domain Name System
- Glossary
- Infrastructure
DNS (Domain Name System) is a hierarchical and decentralized naming system for Internet connected resources. DNS maintains a list of Glossary("domain name","domain names") along with the resources, such as IP addresses, that are associated with them.
The most prominent function of DNS is the translation of human-friendly domain names (such as mozilla.org) to a numeric Glossary("IP address") (such as 151.106.5.172); this process of mapping a domain name to the appropriate IP address is known as a DNS lookup. By contrast, a reverse DNS lookup (rDNS) is used to determine the domain name associated with an IP address.
- Understanding domain names
- Interwiki("wikipedia", "Domain_Name_System", "Domain Name System") on Wikipedia
- Browser
- CodingScripting
- DOCTYPE
- Glossary
- HTML
- Intro
In Glossary("HTML"), the doctype is the required "
<!DOCTYPE html>" preamble found at the top of all documents. Its sole purpose is to prevent a Glossary("browser") from switching into so-called "quirks mode" when rendering a document; that is, the "<!DOCTYPE html>" doctype ensures that the browser makes a best-effort attempt at following the relevant specifications, rather than using a different rendering mode that is incompatible with some specifications.
- Definition of the DOCTYPE in the HTML specification
- Quirks Mode and Standards Mode
- Document.doctype, a JavaScript method that returns the doctype
- CSP
- Directive
- Document
- Glossary
- HTTP
- Security
Glossary("CSP") document directives are used in a HTTPHeader("Content-Security-Policy") header and govern the properties of a document or worker environment to which a policy applies.
Document directives don't fall back to the CSP("default-src") directive.
See Document directives for a complete list.
-
- Glossary("CSP")
- Glossary("Reporting directive")
- Glossary("Fetch directive")
- Glossary("Navigation directive")
-
Reference
- https://www.w3.org/TR/CSP/#directives-document
- HTTPHeader("Content-Security-Policy/upgrade-insecure-requests", "upgrade-insecure-requests")
- HTTPHeader("Content-Security-Policy/block-all-mixed-content", "block-all-mixed-content")
- HTTPHeader("Content-Security-Policy/require-sri-for", "require-sri-for") _Deprecated_Inline}}
- HTTPHeader("Content-Security-Policy")
- CodingScripting
- Glossary
- JavaScript
When the JavaScript global environment is a window or an iframe, it is called a document environment. A global environment is an environment that doesn't have an outer environment.
- document environment in the HTML specification
- Domain Name
- Glossary
- Protocol
- WebMechanics
A domain name is a website's address on the Glossary("Internet"). Domain names are used in Glossary("URL","URLs") to identify to which server belong a specific webpage. The domain name consists of a hierarchical sequence of names (labels) separated by periods (dots) and ending with an glossary("TLD","extension").
- interwiki("wikipedia", "Domain_name", "Domain name") on Wikipedia
- Understanding domain names
- DNS
- Glossary
- HTTP
- Reference
- Web Performance
- latency
Browsers limit the number of active connections for each domain. To enable concurrent downloads of assets exceeding that limit, domain sharding splits content across multiple subdomains. When multiple domains are used to serve multiple assets, browsers are able to download more resources simultaneously, resulting in a faster page load time and improved user experience.
The problem with domain sharding, in terms of performance, is the cost of extra DNS lookups for each domain and the overhead of establishing each TCP connection.
The initial response from an HTTP request is generally an HTML file listing other resources such as JavaScript, CSS, images and other media files that need to be downloaded. As browsers limit the number of active connections per domain, serving all the required resources from a single domain could be slow as assets need to be downloaded sequentially. With domain sharding, the required downloads are served from more than one domain, enabling the browser to simultaneously download needed resources. Multiple domains, however, is an anti-pattern, as DNS lookups slow initial load times.
HTTP2 supports unlimited concurrent requests making domain sharding an obsolete requirement when HTTP/2 is enabled.
- Browser
- Domain
- Glossary
- Infrastructure
- Networking
A domain is an authority within the internet that controls its own resources. Its "domain name" is a way to address this authority as part of the hierarchy in a Glossary("URL") - usually the most memorable part of it, for instance a brand name.
A fully qualified domain name (FQDN) contains all necessary parts to look up this authority by name unambiguously using the Glossary("DNS") system of the internet.
For example, in "developer.mozilla.org":
- "org" is called a interwiki("wikipedia", "Top-level_domain", "top-level domain"). They are registered as an internet standard by the interwiki("wikipedia", "Internet_Assigned_Numbers_Authority", "IANA") . Here, "org" means "organization" which is defined in a top-level domain registry.
- "mozilla" is the domain. If you like to own a domain you have to register it with one of the many interwiki("wikipedia", "Domain_name_registrar", "registrars") who are allowed to do so with a top-level domain registry.
- "developer" is a "sub-domain", something you as the owner of a domain may define yourself. Many owners choose to have a subdomain "www" to point to their Glossary("World_Wide_Web") resource, but that's not required (and has even fallen somewhat out of favor).
- interwiki("wikipedia", "Domain_name", "Domain Name") on Wikipedia
- CodingScripting
- Glossary
In graph theory, node A dominates node B if every path from the root node to B passes through A.
This concept is important for Glossary("garbage collection") because it means that B is only reachable through A. So if the garbage collector found A to be unreachable and eligible for reclaiming, than B would also be unreachable and eligible for reclaiming. So objects that A dominates contribute to the retained size of A: that is, the total amount of memory that could be freed if A itself were freed.
- interwiki("wikipedia", "Dominator (graph theory)", "Dominator") on Wikipedia
- Dominators
- Garbage collection
- CodingScripting
- DOM
- Glossary
The DOM (Document Object Model) is an glossary("API") that represents and interacts with any glossary("HTML") or glossary("XML") document. The DOM is a document model loaded in the glossary("browser") and representing the document as a node tree, where each node represents part of the document (e.g. an Glossary("element"), text string, or comment).
The DOM is one of the most-used Glossary("API")s on the glossary("World Wide Web","Web") because it allows code running in a browser to access and interact with every node in the document. Nodes can be created, moved and changed. Event listeners can be added to nodes and triggered on occurrence of a given event.
DOM was not originally specified—it came about when browsers began implementing Glossary("JavaScript"). This legacy DOM is sometimes called DOM 0. Today, the WHATWG maintains the DOM Living Standard.
-
interwiki("wikipedia", "Document_Object_Model", "The Document Object Model") on Wikipedia
-
- Glossary("API")
- Glossary("HTML")
- Glossary("XML")
- Glossary("World Wide Web")
- Glossary
- Security
DoS (Denial of Service) is a network attack that prevents legitimate use of glossary("server") resources by flooding the server with requests.
There are also Distributed Denial of Service (DDoS) Attacks in which a multitude of servers are used to exhaust the computing capacity of an attacked computer.
DoS attacks are more of a category than a particular kind of attack. Here is a non-exhaustive list of DoS attack types:
- bandwidth attack
- service request flood
- SYN flooding attack
- ICMP flood attack
- peer-to-peer attack
- permanent DoS attack
- application level flood attack
- interwiki("wikipedia", "Denial-of-service_attack", "Denial-of-service attack") on Wikipedia
- Denial-of-service on OWASP
- Glossary("Distributed Denial of Service","DDoS")
- DTLS
- Intro
Datagram Transport Layer Security (DTLS) is a protocol used to secure datagram-based communications. It's based on the stream-focused Transport Layer Security (Glossary("TLS")), providing a similar level of security. As a datagram protocol, DTLS doesn't guarantee the order of message delivery, or even that messages will be delivered at all. However, DTLS gains the benefits of datagram protocols, too; in particular, the lower overhead and reduced latency.
These features are especially useful for one of the most common areas in which DTLS comes into play: Glossary("WebRTC"). All of the WebRTC related protocols are required to encrypt their communications using DTLS; this includes Glossary("SCTP"), Glossary("RTP", "SRTP"), and Glossary("STUN").
-
Interwiki("wikipedia", "Datagram Transport Layer Security") on Wikipedia
-
Specifications:
- RFC(6347, "Datagram Transport Layer Security Version 1.2")
- Datagram Transport Layer Security Protocol Version 1.3 draft specification
-
Related specification
- RFC(5763, "Framework for Establishing a Secure Real-time Transport Protocol (SRTP) Security Context Using DTLS")
- RFC(5764, "DTLS Extension to Establish Keys for the Secure Real-time Transport Protocol (SRTP)")
- RFC(6083, "DTLS for Stream Control Transmission Protocol (SCTP)")
- RFC(8261, "Datagram Transport Layer Security (DTLS) Encapsulation of SCTP Packets")
- RFC(7350, "Datagram Transport Layer Security (DTLS) as Transport for Session Traversal Utilities for NAT (STUN)")
- RFC(7925, "TLS / DTLS Profiles for the Internet of Things")
- DTMF
- Glossary
- WebRTC
Dual-Tone Multi-Frequency (DTMF) signaling is a system by which audible tones are used to represent buttons being pressed on a keypad. Frequently referred to in the United States as "touch tone" (after the Touch-Tone trademark used when the transition from pulse dialing to DTMF began), DTMF makes it possible to signal the digits 0-9 as well as the letters "A" through "D" and the symbols "#" and "*". Few telephone keypads include the letters, which are typically used for control signaling by the telephone network.
Computers may make use of DTMF when dialing a modem, or when sending commands to a menu system for teleconferencing or other purposes.
- interwiki("wikipedia", "Dual-tone multi-frequency signaling") on Wikipedia
- interwiki("wikipedia", "Pulse dialing") on Wikipedia
- CodingScripting
- Glossary
- ProgrammingLanguage
Dynamically-typed languages are those (like glossary("JavaScript")) where the interpreter assigns glossary("variable","variables") a glossary("type") at runtime based on the variable's glossary("value") at the time.
- JavaScript data types and data structures
- interwiki("wikipedia", "Type_system#DYNAMIC", "Type system") on Wikipedia
- Glossary
- Stub
- WebMechanics
Ecma International (formally European Computer Manufacturers Association) is a non-profit organization that develops standards in computer hardware, communications, and programming languages.
On the web it is famous for being the organization which maintain the ECMA-262 specification (aka. Glossary("ECMAScript")) which is the core specification for the Glossary("JavaScript") language.
- interwiki("wikipedia", "Ecma_International", "Ecma International") on Wikipedia
- The Ecma International web site
- Glossary
- WebMechanics
ECMAScript is a scripting language specification on which glossary("JavaScript") is based. Ecma International is in charge of standardizing ECMAScript.
- Interwiki("wikipedia", "ECMAScript") on Wikipedia
- ECMAScript
- Glossary
- Navigator
- Network Information API
- NetworkInformation
- Performance
- Reference
- Web Performance
- connect
- effective connection type
- effectiveType
Effective connection type (ECT) refers to the measured network performance, returning a cellular connection type, like 3G, even if the actual connection is tethered broadband or WiFi, based on the time between the browser requesting a page and effective type of the connection.
The values of 'slow-2g', '2g', '3g', and '4g' are determined using observed round-trip times and downlink values.
| ECT | Minimum RTT | Maximum downlink | Explanation |
|---|---|---|---|
slow-2g |
2000ms | 50 Kbps | The network is suited for small transfers only such as text-only pages. |
2g |
1400ms | 70 Kbps | The network is suited for transfers of small images. |
3g |
270ms | 700 Kbps | The network is suited for transfers of large assets such as high resolution images, audio, and SD video. |
4g |
0ms | ∞ | The network is suited for HD video, real-time video, etc. |
effectiveType is a property of the Network Information API, exposed to JavaScript via the navigator.connection object. To see your effective connection type, open the console of the developer tools of a supporting browser and enter the following:
//
navigator.connection.effectiveType;- Network Information API
- domxref('NetworkInformation')
- domxref('NetworkInformation.effectiveType')
- HTTPHeader("ECT")
- CodingScripting
- Glossary
- HTML
An element is a part of a webpage. In glossary("XML") and glossary("HTML"), an element may contain a data item or a chunk of text or an image, or perhaps nothing. A typical element includes an opening tag with some glossary("attribute", "attributes"), enclosed text content, and a closing tag.

- Getting started with HTML
- Defining custom elements
- The domxref("Element") interface, representing an element in the DOM.
- CodingScripting
- Glossary
- Intermediate
An empty element is an Glossary("element") from HTML, SVG, or MathML that cannot have any child nodes (i.e., nested elements or text nodes).
The HTML, SVG, and MathML specifications define very precisely what each element can contain. Many combinations have no semantic meaning, for example an HTMLElement("audio") element nested inside an HTMLElement("hr") element.
In HTML, using a closing tag on an empty element is usually invalid. For example, <input type="text"> </input> is invalid HTML.
The empty elements in HTML are as follows:
- HTMLElement("area")
- HTMLElement("base")
- HTMLElement("br")
- HTMLElement("col")
- HTMLElement("embed")
- HTMLElement("hr")
- HTMLElement("img")
- HTMLElement("input")
- HTMLElement("keygen")(HTML 5.2 Draft removed)
- HTMLElement("link")
- HTMLElement("meta")
- HTMLElement("param")
- HTMLElement("source")
- HTMLElement("track")
- HTMLElement("wbr")
- CodingScripting
- Glossary
Encapsulation is the packing of data and glossary("function","functions") into one component (for example, a glossary("class")) and then controlling access to that component to make a "blackbox" out of the glossary("object"). Because of this, a user of that class only needs to know its interface (that is, the data and functions exposed outside the class), not the hidden implementation.
- Encapsulation on Wikipedia
- Cryptography
- Glossary
- Privacy
- Security
In glossary("cryptography"), encryption is the conversion of glossary("plaintext") into a coded text or glossary("ciphertext"). A ciphertext is intended to be unreadable by unauthorized readers.
Encryption is a cryptographic primitive: it transforms a plaintext message into a ciphertext using a cryptographic algorithm called a glossary("cipher"). Encryption in modern ciphers is performed using a specific algorithm and a secret, called the glossary("key"). Since the algorithm is often public, the key must stay secret if the encryption stays secure.

Without knowing the secret, the reverse operation, glossary("decryption"), is mathematically hard to perform. How hard depends on the security of the cryptographic algorithm chosen and evolves with the progress of glossary("cryptanalysis").
- Coding
- CodingScripting
- Glossary
Endian and endianness (or "byte-order") describe how computers organize the bytes that make up numbers.
Each memory storage location has an index or address. Every byte can store an 8-bit number (i.e. between 0x00 and 0xff), so you must reserve more than one byte to store a larger number. By far the most common ordering of multiple bytes in one number is the little-endian, which is used on all Intel processors. Little-endian means storing bytes in order of least-to-most-significant (where the least significant byte takes the first or lowest address), comparable to a common European way of writing dates (e.g., 31 December 2050).
Naturally, big-endian is the opposite order, comparable to an ISO date (2050-12-31). Big-endian is also often called "network byte order", because Internet standards usually require data to be stored big-endian, starting at the standard UNIX socket level and going all the way up to standardized Web binary data structures. Also, older Mac computers using 68000-series and PowerPC microprocessors formerly used big-endian.
Examples with the number 0x12345678 (i.e. 305 419 896 in decimal):
- little-endian:
0x78 0x56 0x34 0x12 - big-endian:
0x12 0x34 0x56 0x78 - mixed-endian (historic and very rare):
0x34 0x12 0x78 0x56
- jsxref("ArrayBuffer")
- jsxref("DataView")
- Typed Arrays
- Interwiki("wikipedia", "Endianness") (Wikipedia)
- Glossary("Data structure") (Glossary)
- CodingScripting
- Glossary
- NeedsContent
The glossary("JavaScript") engine is an interpreter that parses and executes a JavaScript program.
- Interwiki("wikipedia", "JavaScript engine") on Wikipedia
- Glossary
- WebMechanics
Warning: The current HTTP/1.1 specification no longer refers to entities, entity headers or entity-body. Some of the fields are now referred to as glossary("Representation header") fields.
An entity header is an glossary("HTTP_header", "HTTP header") that describes the payload of an HTTP message (i.e. metadata about the message body). Entity headers include: HTTPHeader("Content-Length"), HTTPHeader("Content-Language"), HTTPHeader("Content-Encoding"), HTTPHeader("Content-Type"), HTTPHeader("Expires"), etc. Entity headers may be present in both HTTP request and response messages.
In the following example, HTTPHeader("Content-Length") is an entity header, while HTTPHeader("Host") and HTTPHeader("User-Agent") are requests headers:
POST /myform.html HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Content-Length: 128
- Glossary("Representation header")
- CodingScripting
- Composing
- Glossary
- HTML
An glossary("HTML") entity is a piece of text ("string") that begins with an ampersand (
&) and ends with a semicolon (;) . Entities are frequently used to display reserved characters (which would otherwise be interpreted as HTML code), and invisible characters (like non-breaking spaces). You can also use them in place of other characters that are difficult to type with a standard keyboard.
Note: Many characters have memorable entities. For example, the entity for the copyright symbol (
©) is©. For less memorable characters, such as—or—, you can use a reference chart or decoder tool.
Some special characters are reserved for use in HTML, meaning that your browser will parse them as HTML code. For example, if you use the less-than (<) sign, the browser interprets any text that follows as a Glossary('tag').
To display these characters as text, replace them with their corresponding character entities, as shown in the following table.
| Character | Entity | Note |
|---|---|---|
| & | & |
Interpreted as the beginning of an entity or character reference. |
| < | < |
Interpreted as the beginning of a Glossary('tag') |
| > | > |
Interpreted as the ending of a Glossary('tag') |
| " | " |
Interpreted as the beginning and end of an Glossary('attribute')'s value. |
- CodingScripting
- Glossary
Events are assets generated by DOM elements, which can be manipulated by a Javascript code.
- Event documentation on MDN
- Official website
- Interwiki("wikipedia", "DOM Events") on Wikipedia
- Beginner
- CodingScripting
- Glossary
An exception is a condition that interrupts normal code execution. In JavaScript glossary("syntax error", "syntax errors") are a very common source of exceptions.
- Interwiki("wikipedia", "Exception handling") on Wikipedia
- EXIF
- Image
The Exchangeable Image File Format (EXIF) is a standard that specifies how metadata about a multimedia file can be embedded within the file. For example, an image might contain EXIF data describing the: pixel width, height, and density, shutter speed, aperture, ISO settings, capture date, etc.
- EXIF (Wikipedia)
- CIPA Standards, including "CIPA DC-008-Translation-2019 Exchangeable image file format for digital still cameras : Exif Version 2.32"
- CodingScripting
- JavaScript
- Reference
- expando
Expando properties are properties added to glossary("DOM") nodes with glossary("JavaScript"), where those properties are not part of the glossary("object","object's") DOM specification:
//
window.document.foo = 5; // foo is an expandoThe term may also be applied to properties added to objects without respecting the object's original intent, such as non-numeric named properties added to an glossary("Array").
- CSS
- Glossary
- alignment
In CSS Box Alignment, a fallback alignment is specified in order to deal with cases where the requested alignment cannot be fulfilled. For example, if you specify
justify-content: space-betweenthere must be more than one alignment subject. If there is not, the fallback alignment is used. This is specified per alignment method, as detailed below.
- First baseline
-
- :
start
- :
- Last baseline
-
- :
safe end
- :
- Baseline
-
- :
start
- :
- Space-between
- :
flex-start(start)
- :
- Space-around
- :
center
- :
- Space-evenly
- :
center
- :
- Stretch
- :
flex-start(start)
- :
- CodingScripting
- Glossary
- JavaScript
A falsy (sometimes written falsey) value is a value that is considered false when encountered in a Glossary("Boolean") context.
Glossary("JavaScript") uses Glossary("Type_Conversion", "type conversion") to coerce any value to a Boolean in contexts that require it, such as Glossary("Conditional", "conditionals") and Glossary("Loop", "loops").
The following table provides a complete list of JavaScript falsy values:
| Value | Description |
|---|---|
false |
The keyword false. |
0 |
The jsxref("Number") zero (so, also 0.0, etc., and 0x0). |
-0 |
The jsxref("Number") negative zero (so, also -0.0, etc., and -0x0). |
0n |
The jsxref("BigInt") zero (so, also 0x0n). Note that there is no jsxref("BigInt") negative zero — the negation of 0n is 0n. |
"", '', `` |
Empty string value. |
| Glossary("null") | null — the absence of any value. |
| Glossary("undefined") | undefined — the primitive value. |
| Glossary("NaN") | NaN — not a number. |
| domxref("document.all") | Objects are falsy if and only if they have the [[IsHTMLDDA]] internal slot.That slot only exists in domxref("document.all") and cannot be set using JavaScript. |
Examples of falsy values in JavaScript (which are coerced to false in Boolean contexts, and thus bypass the if block):
//
if (false)
if (null)
if (undefined)
if (0)
if (-0)
if (0n)
if (NaN)
if ("")If the first object is falsy, it returns that object
//
false && 'dog';
// ↪ false
0 && 'dog';
// ↪ 0- Glossary("Truthy")
- Glossary("Type_coercion", "Coercion")
- Glossary("Boolean")
- Glossary
- Intro
- favicon
- user agent
A favicon (favorite icon) is a tiny icon included along with a website, which is displayed in places like the browser's address bar, page tabs and bookmarks menu.
Note, however, that most modern browsers replaced the favicon from the address bar by an image indicating whether or not the website is using Glossary("https","HTTPS").
Usually, a favicon is 16 x 16 pixels in size and stored in the Glossary("GIF"), Glossary("PNG"), or ICO file format.
They are used to improve user experience and enforce brand consistency. When a familiar icon is seen in the browser's address bar, for example, it helps users know they are in the right place.
-
interwiki("wikipedia", "Favicon", "Favicon") on Wikipedia
-
Tools
- CSP
- HTTP
- Security
Glossary("CSP") fetch directives are used in a HTTPHeader("Content-Security-Policy") header and control locations from which certain resource types may be loaded. For instance, CSP("script-src") allows developers to allow trusted sources of script to execute on a page, while CSP("font-src") controls the sources of web fonts.
All fetch directives fall back to CSP("default-src"). That means, if a fetch directive is absent in the CSP header, the user agent will look for the default-src directive.
See Fetch directives for a complete list.
-
- Glossary("CSP")
- Glossary("Reporting directive")
- Glossary("Document directive")
- Glossary("Navigation directive")
-
Reference
- https://www.w3.org/TR/CSP/#directives-fetch
- HTTPHeader("Content-Security-Policy/upgrade-insecure-requests", "upgrade-insecure-requests")
- HTTPHeader("Content-Security-Policy/block-all-mixed-content", "block-all-mixed-content")
- HTTPHeader("Content-Security-Policy/require-sri-for", "require-sri-for") _Deprecated_Inline}}
- HTTPHeader("Content-Security-Policy")
- Fetch Metadata Request Headers
- Glossary
A fetch metadata request header is an Glossary("Request header", "HTTP request header") that provides additional information about the context from which the request originated. This allows the server to make decisions about whether a request should be allowed based on where the request came from and how the resource will be used.
With this information a server can implement a Glossary("resource isolation policy"), allowing external sites to request only those resources that are intended for sharing, and that are used appropriately. This approach can help mitigate common cross-site web vulnerabilities such as Glossary("CSRF"), Cross-site Script Inclusion('XSSI'), timing attacks, and cross-origin information leaks.
These headers are prefixed with Sec-, and hence have Glossary("Forbidden header name", "forbidden header names"). As such, they cannot be modified from JavaScript.
The fetch metadata request headers are:
- HTTPHeader("Sec-Fetch-Site")
- HTTPHeader("Sec-Fetch-Mode")
- HTTPHeader("Sec-Fetch-User")
- HTTPHeader("Sec-Fetch-Dest")
-
Protect your resources from web attacks with Fetch Metadata (web.dev)
-
Fetch Metadata Request Headers playground (secmetadata.appspot.com)
-
- Glossary("Representation header")
- Glossary("HTTP_header","HTTP header")
- Glossary("Response header")
- Glossary("Request header")
- B2G
- Boot2Gecko
- Firefox OS
- Glossary
- Infrastructure
- Intro
Firefox OS is a discontinued open source mobile operating system developed by Mozilla. See interwiki("wikipedia", "Firefox OS") for more details.
- DDoS
- Firewall
- Glossary
- Security
- computer network
A firewall is a system that filters network traffic. It can either let it pass or block it, according to some specified rules. For example, it can block incoming connections aimed at a certain port or outgoing connections to a certain IP address.
Firewalls can be as simple as a single piece of software, or more complex, like a dedicated machine whose only function is to act as a firewall.
- Interwiki("wikipedia", "Firewall (computing)") on Wikipedia
- CodingScripting
- Glossary
- JavaScript
A programming language is said to have First-class functions when functions in that language are treated like any other variable. For example, in such a language, a function can be passed as an argument to other functions, can be returned by another function and can be assigned as a value to a variable.
//
const foo = function () {
console.log('foobar');
};
foo(); // Invoke it using the variable
// foobarWe assigned an Anonymous Function in a glossary("Variable"), then we used that variable to invoke the function by adding parentheses () at the end.
Note: Even if your function was named, you can use the variable name to invoke it. Naming it will be helpful when debugging your code. But it won't affect the way we invoke it.
//
function sayHello() {
return 'Hello, ';
}
function greeting(helloMessage, name) {
console.log(helloMessage() + name);
}
// Pass `sayHello` as an argument to `greeting` function
greeting(sayHello, 'JavaScript!');
// Hello, JavaScript!We are passing our sayHello() function as an argument to the greeting() function, this explains how we are treating the function as a value.
Note: The function that we pass as an argument to another function, is called a glossary("Callback function").
sayHellois a Callback function.
//
function sayHello() {
return function () {
console.log('Hello!');
};
}In this example; We need to return a function from another function - We can return a function because we treated function in JavaScript as a value.
Note: A function that returns a function is called a Higher-Order Function.
Back to our example; Now, we need to invoke sayHello function and its returned Anonymous Function. To do so, we have two ways:
//
const sayHello = function () {
return function () {
console.log('Hello!');
};
};
const myFunc = sayHello();
myFunc();
// Hello!This way, it returns the Hello! message.
Note: You have to use another variable. If you invoked
sayHellodirectly, it would return the function itself without invoking its returned function.
//
function sayHello() {
return function () {
console.log('Hello!');
};
}
sayHello()();
// Hello!We are using double parentheses ()() to invoke the returned function as well.
-
Interwiki("wikipedia", "First-class_function", "First-class functions") on Wikipedia
-
- glossary("Callback function")
- glossary("Function")
- glossary("Variable")
- Glossary
- Performance
- Reference
- Web Performance
First Contentful Paint (FCP) is when the browser renders the first bit of content from the DOM, providing the first feedback to the user that the page is actually loading. The question "Is it happening?" is "yes" when the first contentful paint completes.
The First Contentful Paint time stamp is when the browser first rendered any text, image (including background images), non-white canvas or SVG. This excludes any content of iframes, but includes text with pending webfonts. This is the first time users could start consuming page content.
- Glossary
- Lighthouse
- Performance
- Web Performance
First CPU Idle measures when a page is minimally interactive, or when the window is quiet enough to handle user input. It is a non-standard Google web performance metric. Generally, it occurs when most, but not necessarily all visible UI elements are interactive, and the user interface responds, on average, to most user input within 50ms. It is also known as First interactive.
- Glossary
- Reference
- Web Performance
First input delay (FID) measures the time from when a user first interacts with your site (i.e. when they click a link, tap on a button, or use a custom, JavaScript-powered control) to the time when the browser is actually able to respond to that interaction.
It is the length of time, in milliseconds, between the first user interaction on a web page and the browser's response to that interaction. Scrolling and zooming are not included in this metric.
The time between when content is painted to the page and when all the functionality becomes responsive to human interaction often varies based on the size and complexity of the JavaScript needing to be downloaded, parsed, and executed on the main thread, and on the device speed or lack thereof (think low end mobile devices). The longer the delay, the worse the user experience. Reducing site initialization time and eliminating long tasks can help eliminate first input delays.
- Glossary
- Lighthouse
- Web Performance
_draft}}
First Interactive, also known as first CPU idle, is a non-standard web performance metric that measures when the user's window is quiet enough to handle user input, or what is termed as minimally interactive.
Minimally interactive is defined as when some, but not necessarily all, UI elements on the page have loaded and are interactive, and, on average, respond to user input in a reasonable amount of time.
First interactive is a variation of Time to Interactive, which is split into First Interactive and Consistently Interactive. These metrics have been proposed by the Web Incubator Community Group and are already being used in various tools. This metric has been called First CPU Idle since Lighthouse 3.0
- Glossary
- Reference
- Web Performance
First Meaningful Paint (FMP) is the paint after which the biggest above-the-fold layout change has happened and web fonts have loaded. It is when the answer to "Is it useful?" becomes "yes", upon first meaningful paint completion.
- Beginner
- Glossary
- Performance
- Web Performance
First Paint, part of the Paint Timing API, is the time between navigation and when the browser renders the first pixels to the screen, rendering anything that is visually different from what was on the screen prior to navigation. It answers the question "Is it happening?"
- CSS
- Glossary
- flex container
- flexbox
A glossary("flexbox") layout is defined using the
flexorinline-flexvalues of thedisplayproperty on the parent item. This element then becomes a flex container, and each one of its children becomes a glossary("flex item").
A value of flex causes the element to become a block level flex container, and inline-flex an inline level flex container. These values create a flex formatting context for the element, which is similar to a block formatting context in that floats will not intrude into the container, and the margins on the container will not collapse with those of the items.
- cssxref("align-content")
- cssxref("align-items")
- cssxref("flex")
- cssxref("flex-direction")
- cssxref("flex-flow")
- cssxref("flex-wrap")
- cssxref("justify-content")
- CSS Flexbox Guide: Basic Concepts of Flexbox
- CSS Flexbox Guide: Aligning items in a flex container
- CSS Flexbox Guide: Mastering wrapping of flex items
- Firefox Developer Tools > How to: CSS Flexbox Inspector: Examine Flexbox layouts
- CSS
- Glossary
- flex item
- flexbox
The direct children of a glossary("Flex Container") (elements with
display: flexordisplay: inline-flexset on them) become flex items.
Continuous runs of text inside flex containers will also become flex items.
- cssxref("align-self")
- cssxref("flex-basis")
- cssxref("flex-grow")
- cssxref("flex-shrink")
- cssxref("order")
- CSS Flexbox Guide: Basic Concepts of Flexbox
- CSS Flexbox Guide: Ordering flex items
- CSS Flexbox Guide: Controlling Ratios of flex items along the main axis
- CSS
- Glossary
- Intro
- flexbox
Flexbox is the commonly-used name for the CSS Flexible Box Layout Module, a layout model for displaying items in a single dimension — as a row or as a column.
In the specification, Flexbox is described as a layout model for user interface design. The key feature of Flexbox is the fact that items in a flex layout can grow and shrink. Space can be assigned to the items themselves, or distributed between or around the items.
Flexbox also enables alignment of items on the main or cross axis, thus providing a high level of control over the size and alignment of a group of items.
- cssxref("align-content")
- cssxref("align-items")
- cssxref("align-self")
- cssxref("flex")
- cssxref("flex-basis")
- cssxref("flex-direction")
- cssxref("flex-flow")
- cssxref("flex-grow")
- cssxref("flex-shrink")
- cssxref("flex-wrap")
- cssxref("justify-content")
- cssxref("order")
- CSS Flexible Box Layout Module Level 1 Specification
- CSS Flexbox Guide: Basic Concepts of Flexbox
- CSS Flexbox Guide: Relationship of flexbox to other layout methods
- CSS Flexbox Guide: Aligning items in a flex container
- CSS Flexbox Guide: Ordering flex items
- CSS Flexbox Guide: Controlling Ratios of flex items along the main axis
- CSS Flexbox Guide: Mastering wrapping of flex items
- CSS Flexbox Guide: Typical use cases of flexbox
- CSS
- Flex
- Glossary
- flexbox
flexis a new value added to the CSS cssxref("display") property. Along withinline-flexit causes the element that it applies to in order to become a glossary("flex container"), and the element's children to each become a glossary("flex item"). The items then participate in flex layout, and all of the properties defined in the CSS Flexible Box Layout Module may be applied.
The flex property is a shorthand for the flexbox properties flex-grow, flex-shrink and flex-basis.
In addition <flex> can refer to a flexible length in CSS Grid Layout.
- cssxref("align-content")
- cssxref("align-items")
- cssxref("align-self")
- cssxref("flex")
- cssxref("flex-basis")
- cssxref("flex-direction")
- cssxref("flex-flow")
- cssxref("flex-grow")
- cssxref("flex-shrink")
- cssxref("flex-wrap")
- cssxref("justify-content")
- cssxref("order")
- CSS Flexible Box Layout Module Level 1 Specification
- CSS Flexbox Guide: Basic Concepts of Flexbox
- CSS Flexbox Guide: Relationship of flexbox to other layout methods
- CSS Flexbox Guide: Aligning items in a flex container
- CSS Flexbox Guide: Ordering flex items
- CSS Flexbox Guide: Controlling Ratios of flex items along the main axis
- CSS Flexbox Guide: Mastering wrapping of flex items
- CSS Flexbox Guide: Typical use cases of flexbox
- Fetch
- Glossary
- HTTP
- Headers
- forbidden
A forbidden header name is the name of any HTTP header that cannot be modified programmatically; specifically, an HTTP request header name (in contrast with a Glossary("Forbidden response header name")).
Modifying such headers is forbidden because the user agent retains full control over them. Names starting with Sec- are reserved for creating new headers safe from glossary("API","APIs") using Fetch that grant developers control over headers, such as domxref("XMLHttpRequest").
Forbidden header names start with Proxy- or Sec-, or are one of the following names:
Accept-CharsetAccept-EncodingAccess-Control-Request-HeadersAccess-Control-Request-MethodConnectionContent-LengthCookieCookie2DateDNTExpectFeature-PolicyHostKeep-AliveOriginProxy-Sec-RefererTETrailerTransfer-EncodingUpgradeVia
Note: The
User-Agentheader is no longer forbidden, as per spec — see forbidden header name list (this was implemented in Firefox 43) — it can now be set in a Fetch Headers object, or via XHR setRequestHeader(). However, Chrome will silently drop the header from Fetch requests (see Chromium bug 571722).
Glossary("Forbidden response header name") (Glossary)
- Glossary
- HTTP
- Response
- forbidden
A forbidden response header name is an HTTP header name (either `
Set-Cookie` or `Set-Cookie2`) that cannot be modified programmatically.
- Fork
- Glossary
- Tools
- git
A fork is a copy of an existing software project at some point to add someone's own modifications to the project.
Basically, if the license of the original software allows, you can copy the code to develop your own version of it, with your own additions, which will be a "fork".
Forks are often seen in free and open source software development. This is now a more popular term thanks to contribution model using Git (and/or the GitHub platform).
-
interwiki("wikipedia", "Fork(softwaredevelopment)","Fork") on Wikipedia
-
How to fork a GitHub repo (fork as in a Git context)
-
Glossary("Fork") (Glossary)
-
Various "well-known" forks
{kind=link}
- Animation
- Glossary
- Web Performance
- requestAnimationFrame
A frame rate is the speed at which the browser is able to recalculate, layout and paint content to the display. The frames per second, or fps, is how many frames can be repainted in one second. The goal frame rate for in web site computer graphics is 60fps.
Movies generally have a frame rate of 24 fps. They are able to have fewer frames per second because the illusion of life is created with motion blurs. When moving on a computer screen there are no motion blurs (unless you are animating an image sprite with motion blurs).
- Interwiki("wikipedia", "Frame rate") (Wikipedia)
- glossary("FPS") (Glossary)
- CSS
- CSS Fragmentation Specification
- Glossary
- fragmentainer
A fragmentainer is defined in the CSS Fragmentation Specification as follows:
A box—such as a page box, column box, or region—that contains a portion (or all) of a fragmented flow. Fragmentainers can be pre-defined, or generated as needed. When breakable content would overflow a fragmentainer in the block dimension, it breaks into the next container in its fragmentation context instead.
Fragmented contexts are found in CSS Paged Media, where the fragmentainer would be the box which defines a page. In Multiple-column Layout the fragmentainer is the column box created when columns are defined on a multicol container. In CSS Regions each Region is a fragmentainer.
- CodingScripting
- FTP
- Glossary
- Protocol
FTP (File Transfer Protocol) is an insecure glossary("protocol") for transferring files from one glossary("host") to another over the Internet.
For many years it was the defacto standard way of transferring files, but as it is inherently insecure, it is no longer supported by many hosting accounts. Instead you should use SFTP (a secure, encrypted version of FTP) or another secure method for transferring files like Rsync over SSH.
- Beginner's guide to uploading files via FTP
- interwiki("wikipedia", "File Transfer Protocol", "FTP") on Wikipedia
- FTU
- Firefox OS
- First time use
- Gaia
- Glossary
- Infrastructure
- Intro
FTU (First Time Use) is the app that loads when you run a newly-installed version of glossary("Gecko") on a glossary("Firefox OS") device.
You can use FTU to set many important options (e.g. timezone, WiFi details, default language, importing contacts), or take the "Phone Tour" to find out more about your device.
- CodingScripting
- Glossary
- IIFE
- Immediately Invoked Function Expressions (IIFE)
- Intro
- JavaScript
A function is a code snippet that can be called by other code or by itself, or a Glossary("variable") that refers to the function. When a function is called, Glossary("Argument", "arguments") are passed to the function as input, and the function can optionally return a value. A function in glossary("JavaScript") is also an glossary("object").
A function name is an Glossary("identifier") included as part of a function declaration or function expression. The function name's Glossary("scope") depends on whether the function name is a declaration or expression.
An anonymous function is a function without a function name. Only function expressions can be anonymous, function declarations must have a name:
//
// When used as a function expression
(function () {});
// or using the ECMAScript 2015 arrow notation
() => {};The following terms are not used in the ECMAScript language specification, they're jargon used to refer to different types of functions.
A named function is a function with a function name:
//
// Function declaration
function foo() {}
// Named function expression
(function bar() {});
// or using the ECMAScript 2015 arrow notation
const foo = () => {};An inner function is a function inside another function (square in this case). An outer function is a function containing a function (addSquares in this case):
//
function addSquares(a, b) {
function square(x) {
return x * x;
}
return square(a) + square(b);
}
//Using ECMAScript 2015 arrow notation
const addSquares = (a, b) => {
const square = (x) => x * x;
return square(a) + square(b);
};A recursive function is a function that calls itself. See Glossary("Recursion", "recursion").
//
function loop(x) {
if (x >= 10) return;
loop(x + 1);
}
//Using ECMAScript 2015 arrow notation
const loop = (x) => {
if (x >= 10) return;
loop(x + 1);
};An Immediately Invoked Function Expressions (glossary("IIFE")) is a function that is called directly after the function is loaded into the browser's compiler. The way to identify an IIFE is by locating the extra left and right parenthesis at the end of the function's definition.
//
// Declared functions can't be called immediately this way
// Error (https://en.wikipedia.org/wiki/Immediately-invoked_function_expression)
/*
function foo() {
console.log('Hello Foo');
}();
*/
// Function expressions, named or anonymous, can be called immediately
(function foo() {
console.log('Hello Foo');
})();
(function food() {
console.log('Hello Food');
})();
(() => console.log('hello world'))();If you'd like to know more about IIFEs, check out the following page on Wikipedia : Immediately Invoked Function Expression
- Firefox
- Fuzzing
- Mozilla
- QA
- Security
- Testing
Fuzzing is a technique for testing software using automated tools to provide invalid or unexpected input to a program or function in a program, then checking the results to see if the program crashes or otherwise acts inappropriately. This is an important way to ensure that software is stable, reliable, and secure, and we use fuzzing a lot at Mozilla.
- Jesse's blog posts about fuzzing
- Wikipedia: Fuzz testing
- fuzzdb
- jsfuzz - coverage guided javascript fuzzer
- CodingScripting
- Glossary
Garbage collection is a term used in Glossary("computer programming") to describe the process of finding and deleting Glossary("object", "objects") which are no longer being Glossary("object reference", "referenced") by other objects.
In other words, garbage collection is the process of removing any objects which are not being used by any other objects. Often abbreviated "GC," garbage collection is a fundamental component of the memory management system used by Glossary("JavaScript").
- interwiki("wikipedia", "Memory management") on Wikipedia
- interwiki("wikipedia", "Garbage collection (computer science)") on Wikipedia
- Garbage collection in the MDN JavaScript guide.
- Memory management in JavaScript
- Firefox OS
- Gecko
- Glossary
- Infrastructure
- Intro
- Mozilla
Gecko is the layout engine developed by the Mozilla Project and used in many apps/devices, including glossary("Mozilla Firefox","Firefox") and glossary("Firefox OS").
Web glossary("browser","browsers") need software called a layout engine to interpret glossary("HTML"), glossary("CSS"), glossary("JavaScript"), and embedded content (like images) and draw everything to your screen. Besides this, Gecko makes sure associated glossary("API","APIs") work well on every operating system Gecko supports, and that appropriate APIs are exposed only to relevant support targets. This means that Gecko includes, among other things, a networking stack, graphics stack, layout engine, a JavaScript virtual machine, and porting layers.
Since all Firefox OS apps are Web apps, Firefox OS uses Gecko as its app runtime as well.
- interwiki("wikipedia", "Gecko (software)", "Gecko") on Wikipedia
- Glossary
- WebMechanics
General header is an outdated term used to refer to an glossary('HTTP_header', 'HTTP header') that can be used in both request and response messages, but which doesn't apply to the content itself (a header that applied to the content was called an glossary("entity header")). Depending on the context they are used in, general headers might either be glossary("Response header", "response") or glossary("request header", "request headers") (e.g. HTTPheader("Cache-Control")).
Note: Current versions of the HTTP/1.1 specification do not specifically categorize headers as "general headers". These are now simply refered to as glossary("Response header", "response") or glossary("request header", "request headers") depending on context.
- Composing
- Glossary
GIF (Graphics Interchange Format) is an image format that uses lossless compression and can be used for animations. A GIF uses up to 8 bits per pixel and a maximum of 256 colors from the 24-bit color space.
- Interwiki("wikipedia", "GIF") on Wikipedia
- Collaborating
- Glossary
Git is a free, open-source, distributed Source Code Management (Glossary("SCM", "SCM", 1)) system. It facilitates handling code bases with distributed development teams. What sets it apart from previous SCM systems is the ability to do common operations (branching, committing, etc.) on your local development machine, without having to change the master repository or even having write access to it.
- Official website with documentation
- GitHub, a Git-based graphical project host
- CodingScripting
- Glossary
- NeedsContent
A global object is an glossary("object") that always exists in the glossary("global scope").
In JavaScript, there's always a global object defined. In a web browser, when scripts create global variables defined with the var keyword, they're created as members of the global object. (In Glossary("Node.js") this is not the case.) The global object's Glossary("interface") depends on the execution context in which the script is running. For example:
- In a web browser, any code which the script doesn't specifically start up as a background task has a domxref("Window") as its global object. This is the vast majority of JavaScript code on the Web.
- Code running in a domxref("Worker") has a domxref("WorkerGlobalScope") object as its global object.
- Scripts running under Glossary("Node.js") have an object called
globalas their global object.
Note: Unlike jsxref("Statements/var", "var"), the statements jsxref("Statements/let", "let") and jsxref("Statements/const", "const") do not create properties of the global object.
The window object is the Global Object in the Browser. Any Global Variables or Functions can be accessed as properties of the window object.
//
var foo = 'foobar';
foo === window.foo; // Returns: trueAfter defining a Global Variable foo, we can access its value directly from the window object, by using the variable name foo as a property name of the Global Object window.foo.
The global variable foo was stored in the window object, like this:
//
foo: 'foobar';//
function greeting() {
console.log('Hi!');
}
window.greeting(); // It is the same as the normal invoking: greeting();The example above explains how Global Functions are stored as properties in the window object. We created a Global Function called greeting, then invoked it using the window object.
The global function greeting was stored in the window object, like this:
//
greeting: function greeting() {
console.log('Hi!');
}-
- glossary("global scope")
- glossary("object")
-
domxref("Window")
-
domxref("WorkerGlobalScope")
- CodingScripting
- Glossary
- NeedsContent
In a programming environment, the global scope is the glossary("scope") that contains, and is visible in, all other scopes.
In client-side JavaScript, the global scope is generally the web page inside which all the code is being executed.
- Introduction to variable scope in JavaScript
- interwiki("wikipedia", "Scope (computer science)", "Scope") on Wikipedia
- CodingScripting
- Glossary
A global variable is a glossary("variable") that is declared in the glossary("global scope") in other words, a variable that is visible from all other scopes.
In JavaScript it is a glossary("property") of the glossary("global object").
- Interwiki("wikipedia", "Global variable") on Wikipedia
- Glossary
- SVG
- typography
A glyph is a term used in typography for the visual representation of one or more Glossary("character", "characters").
The fonts used by a website contain different sets of glyphs, which represent the characters of the font.
- Glyph on Wikipedia
- Glyph, character and grapheme on Quora
- Browser
- Chrome canary
- Chrome stable
- Chromium
- Glossary
- WebMechanics
- google chrome
Google Chrome is a free Web glossary("browser") developed by Google. It's based on the Chromium open source project. Some key differences are described on the Chromium wiki. Chrome supports its own layout called glossary("Blink"). Note that the iOS version of Chrome uses that platform's WebView, not Blink.
- interwiki("wikipedia", "Google Chrome", "Google Chrome") on Wikipedia
Use one of these links if you're an everyday user.
If you want to try the latest Chrome features, install one of the pre-stable builds. Google pushes updates frequently and has designed the distributions to run side-by-side with the stable version. Visit the Chrome Releases Blog to learn what's new.
- GPL
- Glossary
- License
- OpenPractices
- Remixing
- Sharing
The (GNU) GPL (General Public License) is a Glossary("copyleft") free software license published by the Free Software Foundation. Users of a GPL-licensed program are granted the freedom to use it, read the source code, modify it and redistribute the changes they made, provided they redistribute the program (modified or unmodified) under the same license.
- FAQ on GNU licenses
- GNU GPL on Wikipedia
- GPL License text
- Glossary
- Graphics
- Infrastructure
The GPU (Graphics Processing Unit) is a computer component similar to the CPU (Central Processing Unit). It specializes in the drawing of graphics (both 2D and 3D) on your monitor.
- Design
- Glossary
- graceful degradation
Graceful degradation is a design philosophy that centers around trying to build a modern web site/application that will work in the newest browsers, but falls back to an experience that while not as good still delivers essential content and functionality in older browsers.
Glossary("Polyfill","Polyfills") can be used to build in missing features with JavaScript, but acceptable alternatives to features like styling and layout should be provided where possible, for example by using the CSS cascade, or HTML fallback behavior. Some good examples can be found in Handling common HTML and CSS problems.
It is a useful technique that allows Web developers to focus on developing the best possible websites, given that those websites are accessed by multiple unknown user-agents. Glossary("Progressive enhancement") is related but different — often seen as going in the opposite direction to graceful degradation. In reality both approaches are valid and can often complement one another.
-
Interwiki("wikipedia", "Graceful degradation") on Wikipedia
-
- Glossary("Graceful degradation")
- Glossary("Polyfill")
- Glossary("Progressive enhancement")
- CSS
- CSS Grids
- Reference
A grid area is one or more glossary("grid cell", "grid cells") that make up a rectangular area on the grid. Grid areas are created when you place an item using line-based placement or when defining areas using named grid areas.

Grid areas must be rectangular in nature; it is not possible to create, for example, a T- or L-shaped grid area.
In the example below I have a grid container with two grid items. I have named these with the cssxref("grid-area") property and then laid them out on the grid using cssxref("grid-template-areas"). This creates two grid areas, one covering four grid cells, the other two.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}.wrapper {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: 100px 100px;
grid-template-areas:
'a a b'
'a a b';
}
.item1 {
grid-area: a;
}
.item2 {
grid-area: b;
}<div class="wrapper">
<div class="item1">Item</div>
<div class="item2">Item</div>
</div>_ EmbedLiveSample('Example', '300', '280') }}
- cssxref("grid-template-columns")
- cssxref("grid-template-rows")
- cssxref("grid-auto-rows")
- cssxref("grid-auto-columns")
- cssxref("grid-template-areas")
- cssxref("grid-area")
- CSS Grid Layout Guide: Basic concepts of grid layout
- CSS Grid Layout Guide: Grid template areas
- Definition of Grid Areas in the CSS Grid Layout specification
- CSS
- CSS Grids
CSS Grid Layout is a two-dimensional layout method enabling the laying out of content in rows and columns. Therefore in any grid we have two axes. The block or column axis, and the inline or row axis.
It is along these axes that items can be aligned and justified using the properties defined in the Box Alignment specification.
In CSS the block or column axis is the axis used when laying out blocks of text. If you have two paragraphs and are working in a right to left, top to bottom language they lay out one below the other, on the block axis.

The inline or row axis runs across the Block Axis and is the direction along which regular text flows. These are our rows in CSS Grid Layout.

The physical direction of these axes can change according to the writing mode of the document.
- CSS Grid Layout Guide: Basic concepts of grid layout
- CSS Grid Layout Guide: Box alignment in Grid Layout
- CSS Grid Layout Guide: Grids, logical values and writing modes
- CSS Grids
In a CSS Grid Layout, a grid cell is the smallest unit you can have on your CSS grid. It is the space between four intersecting glossary("grid lines") and conceptually much like a table cell.

If you do not place items using one of the grid placement methods, direct children of the grid container will be placed one into each individual grid cell by the auto-placement algorithm. Additional row or column glossary("grid tracks", "tracks") will be created to create enough cells to hold all items.
In the example we have created a three column track grid. The five items are placed into grid cells working along an initial row of three grid cells, then creating a new row for the remaining two.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}.wrapper {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-auto-rows: 100px;
}<div class="wrapper">
<div>One</div>
<div>Two</div>
<div>Three</div>
<div>Four</div>
<div>Five</div>
</div>_ EmbedLiveSample('Example', '300', '280') }}
- cssxref("grid-template-columns")
- cssxref("grid-template-rows")
- cssxref("grid-auto-rows")
- cssxref("grid-auto-columns")
- CSS Grid Layout Guide: Basic concepts of grid layout
- Definition of Grid Cells in the CSS Grid Layout specification
- CSS
- CodingScripting
A grid column is a vertical track in a CSS Grid Layout, and is the space between two vertical grid lines. It is defined by the cssxref("grid-template-columns") property or in the shorthand cssxref("grid") or cssxref("grid-template") properties.
In addition, columns may be created in the implicit grid when items are placed outside of columns created in the explicit grid. These columns will be auto-sized by default, or can have a size specified with the cssxref("grid-auto-columns") property.
When working with alignment in CSS Grid Layout, the axis down which columns run is known as the block, or column, axis.
- cssxref("grid-template-columns")
- cssxref("grid-auto-columns")
- cssxref("grid")
- cssxref("grid-template")
- CSS Grid Layout Guide: Basic concepts of grid layout
- CSS
- Glossary
- grid
Using the value
gridorinline-gridon an element turns it into a grid container using CSS Grid Layout, and any direct children of this element become grid items.
When an element becomes a grid container it establishes a grid formatting context. The direct children can now lay themselves out on any explicit grid defined using cssxref("grid-template-columns") and cssxref("grid-template-rows"), or on the implicit grid created when an item is placed outside of the explicit grid.
- cssxref("grid-template-columns")
- cssxref("grid-template-rows")
- cssxref("grid-auto-columns")
- cssxref("grid-auto-rows")
- cssxref("grid")
- cssxref("grid-template")
- CSS Grid Layout guide: Basic concepts of grid layout
- CSS Grids
Grid lines are created when you define glossary("Grid tracks", "tracks") in the explicit grid using CSS Grid Layout.
In the following example there is a grid with three column tracks and two row tracks. This gives us 4 column lines and 3 row lines.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: repeat(3, 100px);
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}<div class="wrapper">
<div>One</div>
<div>Two</div>
<div>Three</div>
<div>Four</div>
<div>Five</div>
</div>.wrapper {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: 100px 100px;
}_ EmbedLiveSample('Example', '500', '250') }}
Lines can be addressed using their line number. In a left-to-right language such as English, column line 1 will be on the left of the grid, row line 1 on the top. Lines numbers respect the writing mode of the document and so in a right-to-left language for example, column line 1 will be on the right of the grid. The image below shows the line numbers of the grid, assuming the language is left-to-right.

Lines are also created in the implicit grid when implicit tracks are created to hold content positioned outside of the explicit grid, however these lines cannot be addressed by a number.
Having created a grid, you can place items onto the grid by line number. In the following example the item is positioned from column line 1 to column line 3, and from row line 1 to row line 3.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: repeat(3, 100px);
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}<div class="wrapper">
<div class="item">Item</div>
</div>.wrapper {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: 100px 100px;
}
.item {
grid-column-start: 1;
grid-column-end: 3;
grid-row-start: 1;
grid-row-end: 3;
}_ EmbedLiveSample('Placing_items_onto_the_grid_by_line_number', '500', '250') }}
The lines created in the explicit grid can be named, by adding the name in square brackets before or after the track sizing information. When placing an item, you can then use these names instead of the line number, as demonstrated below.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: repeat(3, 100px);
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}<div class="wrapper">
<div class="item">Item</div>
</div>.wrapper {
display: grid;
grid-template-columns: [col1-start] 1fr [col2-start] 1fr [col3-start] 1fr [cols-end];
grid-template-rows: [row1-start] 100px [row2-start] 100px [rows-end];
}
.item {
grid-column-start: col1-start;
grid-column-end: col3-start;
grid-row-start: row1-start;
grid-row-end: rows-end;
}_ EmbedLiveSample('Naming_lines', '500', '250') }}
- cssxref("grid-template-columns")
- cssxref("grid-template-rows")
- cssxref("grid-column-start")
- cssxref("grid-column-end")
- cssxref("grid-column")
- cssxref("grid-row-start")
- cssxref("grid-row-end")
- cssxref("grid-row")
- CSS Grid Layout Guide: Basic concepts of grid layout
- CSS Grid Layout Guide: Line-based placement with CSS Grid
- CSS Grid Layout Guide: Layout using named grid lines
- CSS Grid Layout Guide: CSS Grids, Logical Values and Writing Modes
- Definition of Grid Lines in the CSS Grid Layout specification
- CSS Grids
A grid row is a horizontal track in a CSS Grid Layout, that is the space between two horizontal grid lines. It is defined by the cssxref("grid-template-rows") property or in the shorthand cssxref("grid") or cssxref("grid-template") properties.
In addition, rows may be created in the implicit grid when items are placed outside of rows created in the explicit grid. These rows will be auto sized by default, or can have a size specified with the cssxref("grid-auto-rows") property.
When working with alignment in CSS Grid Layout, the axis along which rows run is known as the inline, or row, axis.
- cssxref("grid-template-rows")
- cssxref("grid-auto-rows")
- cssxref("grid")
- cssxref("grid-template")
- CSS Grid Layout Guide: Basic concepts of grid layout
- CSS Grids
A grid track is the space between two adjacent glossary("grid lines"). They are defined in the explicit grid by using the cssxref("grid-template-columns") and cssxref("grid-template-rows") properties or the shorthand cssxref("grid") or cssxref("grid-template") properties. Tracks are also created in the implicit grid by positioning a grid item outside of the tracks created in the explicit grid.
The image below shows the first row track on a grid.

When defining grid tracks using cssxref("grid-template-columns") and cssxref("grid-template-rows") you may use any length unit, and also the flex unit, fr which indicates a portion of the available space in the grid container.
The example below demonstrates a grid with three column tracks, one of 200 pixels, the second of 1fr, the third of 3fr. Once the 200 pixels has been subtracted from the space available in the grid container, the remaining space is divided by 4. One part is given to column 2, 3 parts to column 3.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}.wrapper {
display: grid;
grid-template-columns: 200px 1fr 3fr;
}<div class="wrapper">
<div>One</div>
<div>Two</div>
<div>Three</div>
<div>Four</div>
<div>Five</div>
</div>_ EmbedLiveSample('Example', '500', '230') }}
Tracks created in the implicit grid are auto-sized by default, however you can define a size for these tracks using the cssxref("grid-auto-rows") and cssxref("grid-auto-columns") properties.
-
Definition of Grid Tracks in the CSS Grid Layout specification
-
Property reference
- cssxref("grid-template-columns")
- cssxref("grid-template-rows")
- cssxref("grid")
- cssxref("grid-template")
- CSS
- CSS Grid
- Glossary
A CSS grid is defined using the
gridvalue of the cssxref("display") property; you can define columns and rows on your grid using the cssxref("grid-template-rows") and cssxref("grid-template-columns") properties.
The grid that you define using these properties is described as an explicit grid.
If you place content outside of this explicit grid, or if you are relying on auto-placement and the grid algorithm needs to create additional row or column glossary("grid tracks", "tracks") to hold glossary("grid item", "grid items"), then extra tracks will be created in the implicit grid. The implicit grid is the grid created automatically due to content being added outside of the tracks defined.
In the example below I have created an explicit grid of three columns and two rows. The third row on the grid is an implicit grid row track, formed due to their being more than the six items which fill the explicit tracks.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #ffd8a8;
padding: 1em;
color: #d9480f;
}.wrapper {
display: grid;
grid-template-columns: 1fr 1fr 1fr;
grid-template-rows: 100px 100px;
}<div class="wrapper">
<div>One</div>
<div>Two</div>
<div>Three</div>
<div>Four</div>
<div>Five</div>
<div>Six</div>
<div>Seven</div>
<div>Eight</div>
</div>_ EmbedLiveSample('Example', '500', '330') }}
-
Property reference:
- cssxref("grid-template-columns")
- cssxref("grid-template-rows")
- cssxref("grid")
- cssxref("grid-template")
- API
- CodingScripting
- Glossary
- guard
Guard is a feature of domxref("Headers") objects (as defined in the domxref("Fetch_API","Fetch spec"), which affects whether methods such as domxref("Headers.set","set()") and domxref("Headers.append","append()") can change the header's contents. For example,
immutableguard means that headers can't be changed. For more information, read Fetch basic concepts: guard.
- CSS Grids
Gutters or alleys are spacing between content tracks. These can be created in CSS Grid Layout using the cssxref("column-gap"), cssxref("row-gap"), or cssxref("gap") properties.
In the example below we have a three-column and two-row track grid, with 20-pixel gaps between column tracks and 20px-gaps between row tracks.
* {
box-sizing: border-box;
}
.wrapper {
border: 2px solid #f76707;
border-radius: 5px;
background-color: #fff4e6;
}
.wrapper > div {
border: 2px solid #ffa94d;
border-radius: 5px;
background-color: #fff8f8;
padding: 1em;
color: #d9480f;
}.wrapper {
display: grid;
grid-template-columns: repeat(3, 1.2fr);
grid-auto-rows: 45%;
grid-column-gap: 20px;
grid-row-gap: 20px;
}<div class="wrapper">
<div>One</div>
<div>Two</div>
<div>Three</div>
<div>Four</div>
<div>Five</div>
</div>_ EmbedLiveSample('Example', '300', '280') }}
In terms of grid sizing, gaps act as if they were a regular grid track however nothing can be placed into the gap. The gap acts as if the grid line at that location has gained extra size, so any grid item placed after that line begins at the end of the gap.
The grid-gap properties are not the only thing that can cause tracks to space out. Margins, padding or the use of the space distribution properties in Box Alignment can all contribute to the visible gap - therefore the grid-gap properties should not be seen as equal to "the gutter size" unless you know that your design has not introduced any additional space with one of these methods.
- cssxref("column-gap")
- cssxref("row-gap")
- cssxref("gap")
- CSS Grid Layout Guide: Basic concepts of grid layout
- Definition of gutters in the CSS Grid Layout specification
- Glossary
- compression
- gzip
gzip is a file format used for file compression and decompression. It is based on the Deflate algorithm that allows files to be made smaller in size which allows for faster network transfers. gzip is commonly supported by web servers and modern browsers, meaning that servers can automatically compress files with gzip before sending them, and browsers can uncompress files upon receiving them.
- CodingScripting
- Cryptography
- Glossary
- Hash
The hash function takes a variable-length message input and produces a fixed-length hash output. It is commonly in the form of a 128-bit "fingerprint" or "message digest". Hashes are very useful for glossary("cryptography") — they insure the integrity of transmitted data, and provide the basis for glossary("HMAC"), which enables message authentication.
- Interwiki("wikipedia", "Hash function") on Wikipedia
- CodingScripting
- Glossary
- HTML
- head
- metadata
The Head is the part of an glossary("HTML") document that contains glossary("metadata") about that document, such as author, description, and links to glossary("CSS") or glossary("JavaScript") files that should be applied to the HTML.
- htmlelement("head") element reference on MDN
- The HTML <head> on the MDN Learning Area
- CodingScripting
- Glossary
A high-level programming language has a significant abstraction from the details of computer operation. It is designed to be easily understood by humans and for this reason they must be translated by another software. Unlike low-level programming languages, it may use natural language elements, or may automate (or even entirely hide) significant areas of computing systems, making the process of developing simpler and more understandable relative to a lower-level language. The amount of abstraction provided defines how "high-level" a programming language is.
The idea of a language automatically translatable into machine code, but nearer to human logic, was introduced in computer science in the 1950s, especially thanks to the work of John Backus (IBM), to whom it owes the first high-level language to have been widely circulated: Fortran. For this innovation Backus received the Turing prize.
- Cryptography
- Glossary
- Hash
- Security
Hash-based message authentication code(HMAC) is a protocol used for Glossary("cryptography", "cryptographically") authenticating messages.
It can use any kind of Glossary("Cryptographic hash function", "cryptographic functions"), and its strength depends on the underlying function (SHA1 or MD5 for instance), and the chosen secret key. With such a combination, the HMAC verification Glossary("Algorithm", "algorithm") is then known with a compound name such as HMAC-SHA1.
HMAC is used to ensure both integrity and authentication.
- Interwiki("wikipedia", "Hash-based message authentication code", "HMAC") on Wikipedia
- RFC 2104 on IETF
- CodingScripting
- Glossary
- JavaScript
JavaScript Hoisting refers to the process whereby the interpreter appears to move the declaration of functions, variables or classes to the top of their scope, prior to execution of the code.
Hoisting allows functions to be safely used in code before they are declared.
Variable and class declarations are also hoisted, so they too can be referenced before they are declared. Note that doing so can lead to unexpected errors, and is not generally recommended.
Note: The term hoisting is not used in any normative specification prose prior to ECMAScript® 2015 Language Specification. Hoisting was thought up as a general way of thinking about how execution contexts (specifically the creation and execution phases) work in JavaScript.
One of the advantages of hoisting is that it lets you use a function before you declare it in your code.
//
catName('Tiger');
function catName(name) {
console.log("My cat's name is " + name);
}
/*
The result of the code above is: "My cat's name is Tiger"
*/Without hoisting you would have to write the same code like this:
//
function catName(name) {
console.log("My cat's name is " + name);
}
catName('Tiger');
/*
The result of the code above is the same: "My cat's name is Tiger"
*/Hoisting works with variables too, so you can use a variable in code before it is declared and/or initialized.
However JavaScript only hoists declarations, not initializations! This means that initialization doesn't happen until the associated line of code is executed, even if the variable was originally initialized then declared, or declared and initialized in the same line.
Until that point in the execution is reached the variable has its default initialization (undefined for a variable declared using var, otherwise uninitialized).
Note: Conceptually variable hoisting is often presented as the interpreter "splitting variable declaration and initialization, and moving (just) the declarations to the top of the code".
Below are some examples showing what can happen if you use a variable before it is declared.
Here we declare then initialize the value of a var after using it.
The default initialization of the var is undefined.
//
console.log(num); // Returns 'undefined' from hoisted var declaration (not 6)
var num; // Declaration
num = 6; // Initialization
console.log(num); // Returns 6 after the line with initialization is executed.The same thing happens if we declare and initialize the variable in the same line.
//
console.log(num); // Returns 'undefined' from hoisted var declaration (not 6)
var num = 6; // Initialization and declaration.
console.log(num); // Returns 6 after the line with initialization is executed.If we forget the declaration altogether (and only initialize the value) the variable isn't hoisted.
Trying to read the variable before it is initialized results in ReferenceError exception.
//
console.log(num); // Throws ReferenceError exception - the interpreter doesn't know about `num`.
num = 6; // InitializationNote however that initialization also causes declaration (if not already declared). The code snippet below will work, because even though it isn't hoisted, the variable is initialized and effectively declared before it is used.
//
a = 'Cran'; // Initialize a
b = 'berry'; // Initialize b
console.log(a + '' + b); // 'Cranberry'Variables declared with let and const are also hoisted but, unlike var, are not initialized with a default value.
An exception will be thrown if a variable declared with let or const is read before it is initialized.
//
console.log(num); // Throws ReferenceError exception as the variable value is uninitialized
let num = 6; // InitializationNote that it is the order in which code is executed that matters, not the order in which it is written in the source file. The code will succeed provided the line that initializes the variable is executed before any line that reads it.
For information and examples see let > temporal dead zone.
Classes defined using a class declaration are hoisted, which means that JavaScript has a reference to the class.
However the class is not initialized by default, so any code that uses it before the line in which it is initialized is executed will throw a ReferenceError.
Function expressions and class expressions are not hoisted.
The expressions evaluate to a function or class (respectively), which are typically assigned to a variable. In this case the variable declaration is hoisted and the expression is its initialization. Therefore the expressions are not evaluated until the relevant line is executed.
varstatement — MDNletstatement — MDNconststatement — MDNfunctionstatement — MDN
- Glossary
- Intermediate
- Web
- WebMechanics
A host is a device connected to the glossary("Internet") (or a local network). Some hosts called glossary("server","servers") offer additional services like serving webpages or storing files and emails.
The host doesn't need to be a hardware instance. It can be generated by virtual machines. The host generated by virtual machines is called "Virtual hosting".
- interwiki("wikipedia", "Host (network)", "Host") on Wikipedia
- Glossary
- WebMechanics
A hotlink (also known as an inline link) is an object (typically an image) directly linked to from another site. For example, an image hosted on site1.com is shown directly on site2.com.
The practice is often frowned upon as it can cause unwanted bandwidth usage on the website hosting the linked-to object, and copyright concerns — it is considered stealing when it is done without permission.
- Interwiki("wikipedia", "Inline linking", "Hotlink") on Wikipedia
- glossary("Hyperlink") (Glossary)
- CSS
- CSS API
- Glossary
- Houdini
- Reference
Houdini is a set of low level APIs that give developers the power to extend CSS, providing the ability to hook into the styling and layout process of a browser's rendering engine. Houdini gives developers access to the CSS Object Model (CSSOM), enabling developers to write code the browser can parse as CSS.
The benefit of Houdini is that developers can create CSS features without waiting for web standards specifications to define them and without waiting for every browser to fully implement the features.
While many of the features Houdini enables can be created with JavaScript, interacting directly with the CSSOM before JavaScript is enabled provides for faster parse times. Browsers create the CSSOM — including layout, paint, and composite processes — before applying any style updates found in scripts: layout, paint, and composite processes are repeated for updated JavaScript styles to be implemented. Houdini code doesn't wait for that first rendering cycle to be complete. Rather, it is included in that first cycle, creating renderable, understandable styles.
- Glossary
- Security
HTTP Public Key Pinning (HPKP) is a security feature that tells a web client to associate a specific cryptographic public key with a certain web server to decrease the risk of Glossary("MITM") attacks with forged certificates.
- HTTPHeader("Public-Key-Pins")
- HTTPHeader("Public-Key-Pins-Report-Only")
- RFC 7469
- Wikipedia: HTTP Public Key Pinning
- HTTP
- Security
HTTP Strict Transport Security lets a web site inform the browser that it should never load the site using HTTP and should automatically convert all attempts to access the site using HTTP to HTTPS requests instead. It consists in one HTTP header, HTTPHeader("Strict-Transport-Security"), sent by the server with the resource.
In other words, it tells the browser that changing the protocol from HTTP to HTTPS in a URL works (and is more secure) and asks the browser to do it for every request.
- HTTPHeader("Strict-Transport-Security")
- OWASP Article: HTTP Strict Transport Security
- Wikipedia: interwiki("wikipedia", "HTTP Strict Transport Security")
- CodingScripting
- Glossary
- HTML
- HTML5
- Markup
The term HTML5 is essentially a buzzword that refers to a set of modern web technologies. This includes the Glossary("HTML") Living Standard, along with glossary("JavaScript") glossary("API","APIs") to enhance storage, multimedia, and hardware access.
You may sometimes hear about "new HTML5 elements", or find HTML5 described as a new version of HTML. HTML5 was the successor to previous HTML versions and introduced new elements and capabilities to the language on top of the previous version, HTML 4.01, as well as improving or removing some existing functionality. However, as a Living Standard HTML now has no version. The up-to-date specification can be found at html.spec.whatwg.org/.
Any modern site should use the HTML doctype — this will ensure that you are using the latest version of HTML.
Note: Until 2019, the glossary("W3C") published a competing HTML5 standard with version numbers. Since 28 May 2019, the WHATWG Living Standard was announced by the W3C as the sole version of HTML.
- CodingScripting
- Glossary
- HTML
- l10n:priority
HTML (HyperText Markup Language) is a descriptive language that specifies webpage structure.
In 1990, as part of his vision of the Glossary("World Wide Web","Web"), Tim Berners-Lee defined the concept of Glossary("hypertext"), which Berners-Lee formalized the following year through a markup mainly based on Glossary("SGML"). The Glossary("IETF") began formally specifying HTML in 1993, and after several drafts released version 2.0 in 1995. In 1994 Berners-Lee founded the Glossary("W3C") to develop the Web. In 1996, the W3C took over the HTML work and published the HTML 3.2 recommendation a year later. HTML 4.0 was released in 1999 and became an Glossary("ISO") standard in 2000.
At that time, the W3C nearly abandoned HTML in favor of Glossary("XHTML"), prompting the founding of an independent group called Glossary("WHATWG") in 2004. Thanks to WHATWG, work on Glossary("HTML5") continued: the two organizations released the first draft in 2008 and the final standard in 2014.
An HTML file is normally saved with an .htm or .html extension, served by a Glossary("Server","web server"), and can be rendered by any Glossary("Browser","Web browser").
- interwiki("wikipedia", "HTML", "HTML") on Wikipedia
- Our HTML tutorial
- The web course on codecademy.com
- The HTML documentation on MDN
- The HTML specification
- Glossary
- HTTP
- Infrastructure
- Reference
- Web Performance
- l10n:priority
HTTP/2 is a major revision of the HTTP network protocol.
The primary goals for HTTP/2 are to reduce glossary("latency") by enabling full request and response multiplexing, minimize protocol overhead via efficient compression of HTTP header fields, and add support for request prioritization and server push.
HTTP/2 does not modify the application semantics of HTTP in any way. All the core concepts found in HTTP 1.1, such as HTTP methods, status codes, URIs, and header fields, remain in place. Instead, HTTP/2 modifies how the data is formatted (framed) and transported between the client and server, both of which manage the entire process, and hides application complexity within the new framing layer. As a result, all existing applications can be delivered without modification.
-
interwiki("wikipedia", "HTTP/2", "HTTP/2") on Wikipedia
-
- glossary("HTTP")
- glossary("Latency")
- HTTP
- Intro
- NeedsContent
HTTP/3 is the upcoming major revision of the HTTP network protocol, succeeding glossary("HTTP 2", "HTTP/2").
The major point of HTTP/3 is that it uses a new glossary("UDP") protocol named QUIC, instead of glossary("TCP").
-
interwiki("wikipedia", "HTTP/3", "HTTP/3") on Wikipedia
-
- glossary("HTTP")
- glossary("HTTP 2")
- glossary("Latency")
- Glossary
- HTTP Header
- WebMechanics
An HTTP header is a field of an HTTP request or response that passes additional context and metadata about the request or response. For example, a request message can use headers to indicate it's preferred media formats, while a response can use header to indicate the media format of the returned body. Headers are case-insensitive, begin at the start of a line and are immediately followed by a
':'and a header-dependent value. The value finishes at the next CRLF or at the end of the message.
The HTTP and Fetch specifications refer to a number of header categories, including:
- Glossary("Request header"): Headers containing more information about the resource to be fetched or about the client itself.
- Glossary("Response header"): Headers with additional information about the response, like its location or about the server itself (name, version, …).
- Glossary("Representation header"): metadata about the resource in the message body (e.g. encoding, media type, etc.).
- Glossary("Fetch metadata request header"): Headers with metadata about the resource in the message body (e.g. encoding, media type, etc.).
A basic request with one header:
GET /example.http HTTP/1.1
Host: example.com
Redirects have mandatory headers (HTTPHeader("Location")):
302 Found
Location: /NewPage.html
A typical set of headers:
304 Not Modified
Access-Control-Allow-Origin: *
Age: 2318192
Cache-Control: public, max-age=315360000
Connection: keep-alive
Date: Mon, 18 Jul 2016 16:06:00 GMT
Server: Apache
Vary: Accept-Encoding
Via: 1.1 3dc30c7222755f86e824b93feb8b5b8c.cloudfront.net (CloudFront)
X-Amz-Cf-Id: TOl0FEm6uI4fgLdrKJx0Vao5hpkKGZULYN2TWD2gAWLtr7vlNjTvZw==
X-Backend-Server: developer6.webapp.scl3.mozilla.com
X-Cache: Hit from cloudfront
X-Cache-Info: cached
Note: Older versions of the specification referred to:
- Glossary("General header"): Headers applying to both requests and responses but with no relation to the data eventually transmitted in the body.
- Glossary("Entity header"): Headers containing more information about the body of the entity, like its content length or its MIME-type (this is a superset of what are now referred to as the Representation metadata headers)
-
Syntax of headers in the HTTP specification
-
- Glossary("HTTP header")
- Glossary("Request header")
- Glossary("Response header")
- Glossary("Representation header")
- Glossary("Fetch metadata request header")
- Glossary("Forbidden header name")
- Glossary("Forbidden response header name")
- Glossary("CORS-safelisted request header")
- Glossary("CORS-safelisted response header")
- Glossary
- WebMechanics
An HTTP method is safe if it doesn't alter the state of the server. In other words, a method is safe if it leads to a read-only operation. Several common HTTP methods are safe: HTTPMethod("GET"), HTTPMethod("HEAD"), or HTTPMethod("OPTIONS"). All safe methods are also glossary("idempotent"), but not all idempotent methods are safe. For example, HTTPMethod("PUT") and HTTPMethod("DELETE") are both idempotent but unsafe.
Even if safe methods have a read-only semantic, servers can alter their state: e.g. they can log or keep statistics. What is important here is that by calling a safe method, the client doesn't request any server change itself, and therefore won't create an unnecessary load or burden for the server. Browsers can call safe methods without fearing to cause any harm to the server; this allows them to perform activities like pre-fetching without risk. Web crawlers also rely on calling safe methods.
Safe methods don't need to serve static files only; a server can generate an answer to a safe method on-the-fly, as long as the generating script guarantees safety: it should not trigger external effects, like triggering an order in an e-commerce Web site.
It is the responsibility of the application on the server to implement the safe semantic correctly, the webserver itself, being Apache, Nginx or IIS, can't enforce it by itself. In particular, an application should not allow HTTPMethod("GET") requests to alter its state.
A call to a safe method, not changing the state of the server:
GET /pageX.html HTTP/1.1
A call to a non-safe method, that may change the state of the server:
POST /pageX.html HTTP/1.1
A call to an idempotent but non-safe method:
DELETE /idX/delete HTTP/1.1
- Definition of safe in the HTTP specification.
- Description of common safe methods: HTTPMethod("GET"), HTTPMethod("HEAD"), HTTPMethod("OPTIONS")
- Description of common unsafe methods: HTTPMethod("PUT"), HTTPMethod("DELETE"), HTTPMethod("POST")
- Glossary
- HTTPS
- HTTPS RR
- Infrastructure
- Security
HTTPS RR (HTTPS Resource Records) are a type of DNS record that delivers configuration information and parameters for how to access a service via Glossary("HTTPS").
An HTTPS RR can be used to optimize the process of connecting to a service using HTTPS. Further, the presence of an HTTPS RR signals that all useful Glossary("HTTP") resources on the origin are reachable over HTTPS, which in turn means that a browser can safely upgrade connections to the domain from HTTP to HTTPS.
- Service binding and parameter specification via the DNS (DNS SVCB and HTTPS RRs) (Draft IETF specification: draft-ietf-dnsop-svcb-https-00)
- Strict Transport Security vs. HTTPS Resource Records: the showdown (Emily M. Stark blog)
- glossary("SSL")
- glossary("TLS")
- Glossary
- HTTPS
- Infrastructure
- Security
HTTPS (HyperText Transfer Protocol Secure) is an encrypted version of the Glossary("HTTP") protocol. It uses Glossary("SSL") or Glossary("TLS") to encrypt all communication between a client and a server. This secure connection allows clients to safely exchange sensitive data with a server, such as when performing banking activities or online shopping.
-
Interwiki("wikipedia", "HTTPS") on Wikipedia
-
- glossary("HTTP")
- glossary("SSL")
- glossary("TLS")
- CodingScripting
- Glossary
- HTML
- Navigation
Hyperlinks connect webpages or data items to one another. In HTML, HTMLElement("a") elements define hyperlinks from a spot on a webpage (like a text string or image) to another spot on some other webpage (or even on the same page).
- interwiki("wikipedia", "Hyperlink", "Hyperlink") on Wikipedia
- The Hyperlink guide on MDN
- Links in HTML Documents - W3C
- HTML5 a - hyperlink - W3C
<a>on MDN<link>on MDN
- Glossary
- Web
- WebMechanics
Hypertext is text that contains links to other texts, as opposed to a single linear flow like in a novel.
The term was coined by Ted Nelson around 1965.
- interwiki("wikipedia", "Hypertext", "Hypertext") on Wikipedia
- Beginner
- Credibility
- Glossary
- Internationalization
- OpenPractices
- i18n
i18n (from "internationalization", a 20-letter word) is the best practice that enables products or services to be readily adapted to any target culture.
Internationalization is the design and development of a product, application or document content that enables easy localization for target audiences that vary in culture, region, or language. (The Glossary("W3C") definition)
Among other things, i18n requires support for multiple
- character sets (usually via Unicode)
- units of measure (currency, °C/°F, km/miles, etc.)
- time and date formats
- keyboard layouts
- text directions
- interwiki("wikipedia", "Internationalization and localization", "i18n") on Wikipedia
- i18n on W3C
- i18n on gala-global.org
- i18n material on i18nguy.com
- Glossary
- Infrastructure
IANA (Internet Assigned Numbers Authority) is a subsidiary of glossary("ICANN") charged with recording and/or assigning glossary("domain name","domain names"), glossary("IP address","IP addresses"), and other names and numbers used by Internet glossary("protocol","protocols").
- Official website
- interwiki("wikipedia", "Internet Assigned Numbers Authority", "IANA") on Wikipedia
- Glossary
- Infrastructure
ICANN (Internet Corporation for Assigned Names and Numbers) is an international nonprofit that maintains the glossary("DNS","domain name system") and the record of glossary("IP address","IP addresses").
- Official website
- interwiki("wikipedia", "ICANN", "ICANN") on Wikipedia
- CodingScripting
- Glossary
- Networking
- Protocols
- WebRTC
ICE (Interactive Connectivity Establishment) is a framework used by glossary("WebRTC") (among other technologies) for connecting two peers, regardless of network topology (usually for audio and video chat). This protocol lets two peers find and establish a connection with one another even though they may both be using Network Address Translator (glossary("NAT")) to share a global IP address with other devices on their respective local networks.
The framework algorithm looks for the lowest-latency path for connecting the two peers, trying these options in order:
- Direct UDP connection (In this case—and only this case—a glossary("STUN") server is used to find the network-facing address of a peer)
- Direct TCP connection, via the HTTP port
- Direct TCP connection, via the HTTPS port
- Indirect connection via a relay/glossary("TURN") server (if a direct connection fails, e.g., if one peer is behind a firewall that blocks NAT traversal)
- WebRTC, the principal web-related protocol which uses ICE
- WebRTC protocols
- rfc("5245"), the IETF specification for ICE
- domxref("RTCIceCandidate"), the interface representing a ICE candidate
- CodingScripting
- Glossary
An Integrated Development Environment (IDE) or Interactive Development environment is a software application that provides comprehensive facilities to computer programmers for software development. An IDE normally consists of a source code editor, build automation tools and a debugger.
- interwiki("wikipedia", "Integrated_development_environment", "IDE") on Wikipedia
- Glossary
- WebMechanics
An HTTP method is idempotent if an identical request can be made once or several times in a row with the same effect while leaving the server in the same state. In other words, an idempotent method should not have any side-effects (except for keeping statistics). Implemented correctly, the HTTPMethod("GET"), HTTPMethod("HEAD"), HTTPMethod("PUT"), and HTTPMethod("DELETE") methods are idempotent, but not the HTTPMethod("POST") method. All glossary("Safe/HTTP", "safe") methods are also idempotent.
To be idempotent, only the actual back-end state of the server is considered, the status code returned by each request may differ: the first call of a HTTPMethod("DELETE") will likely return a HTTPStatus("200"), while successive ones will likely return a HTTPStatus("404"). Another implication of HTTPMethod("DELETE") being idempotent is that developers should not implement RESTful APIs with a delete last entry functionality using the DELETE method.
Note that the idempotence of a method is not guaranteed by the server and some applications may incorrectly break the idempotence constraint.
GET /pageX HTTP/1.1 is idempotent. Called several times in a row, the client gets the same results:
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
POST /add_row HTTP/1.1 is not idempotent; if it is called several times, it adds several rows:
POST /add_row HTTP/1.1
POST /add_row HTTP/1.1 -> Adds a 2nd row
POST /add_row HTTP/1.1 -> Adds a 3rd row
DELETE /idX/delete HTTP/1.1 is idempotent, even if the returned status code may change between requests:
DELETE /idX/delete HTTP/1.1 -> Returns 200 if idX exists
DELETE /idX/delete HTTP/1.1 -> Returns 404 as it just got deleted
DELETE /idX/delete HTTP/1.1 -> Returns 404
- Definition of idempotent in the HTTP specification.
- Description of common idempotent methods: HTTPMethod("GET"), HTTPMethod("HEAD"), HTTPMethod("PUT"), HTTPMethod("DELETE"), HTTPMethod("OPTIONS"), HTTPMethod("TRACE")
- Description of common non-idempotent methods: HTTPMethod("POST"),HTTPMethod("PATCH"), HTTPMethod("CONNECT")
- Beginner
- CodingScripting
- Glossary
- Sharing
An identifier is a sequence of characters in the code that identifies a glossary("variable"), glossary("function"), or glossary("property").
In glossary("JavaScript"), identifiers are case-sensitive and can contain glossary("Unicode") letters, $, _, and digits (0-9), but may not start with a digit.
An identifier differs from a string in that a glossary("string") is data, while an identifier is part of the code. In JavaScript, there is no way to convert identifiers to strings, but sometimes it is possible to parse strings into identifiers.
-
interwiki("wikipedia", "Identifier#In_computer_science", "Identifier") on Wikipedia
-
- glossary("Identifier")
- glossary("Scope")
- glossary("string")
- glossary("Unicode")
- CodingScripting
- Glossary
- IDL
- Interface description language
An IDL (Interface Description Language) is a generic language used to specified objects' interfaces apart from any specific programming language.
In HTML, most attributes have two faces: the content attribute and the IDL attribute.
The content attribute is the attribute as you set it from the content (the HTML code) and you can set it or get it via domxref("element.setAttribute()") or domxref("element.getAttribute()"). The content attribute is always a string even when the expected value should be an integer. For example, to set an HTMLElement("input") element's maxlength to 42 using the content attribute, you have to call setAttribute("maxlength", "42") on that element.
The IDL attribute is also known as a JavaScript property. These are the attributes you can read or set using JavaScript properties like element.foo. The IDL attribute is always going to use (but might transform) the underlying content attribute to return a value when you get it and is going to save something in the content attribute when you set it. In other words, the IDL attributes, in essence, reflect the content attributes.
Most of the time, IDL attributes will return their values as they are really used. For example, the default type for HTMLElement("input") elements is "text", so if you set input.type="foobar", the <input> element will be of type text (in the appearance and the behavior) but the "type" content attribute's value will be "foobar". However, the type IDL attribute will return the string "text".
IDL attributes are not always strings; for example, input.maxlength is a number (a signed long). When using IDL attributes, you read or set values of the desired type, so input.maxlength is always going to return a number and when you set input.maxlength, it wants a number. If you pass another type, it is automatically converted to a number as specified by the standard JavaScript rules for type conversion.
IDL attributes can reflect other types such as unsigned long, URLs, booleans, etc. Unfortunately, there are no clear rules and the way IDL attributes behave in conjunction with their corresponding content attributes depends on the attribute. Most of the time, it will follow the rules laid out in the specification, but sometimes it doesn't. HTML specifications try to make this as developer-friendly as possible, but for various reasons (mostly historical), some attributes behave oddly (select.size, for example) and you should read the specifications to understand how exactly they behave.
- interwiki("wikipedia", "Interface description language", "IDL") on Wikipedia
- HTML attribute reference
- Interface Definition Language
- Glossary
- IETF
- Infrastructure
- Internet
The Internet Engineering Task Force (IETF) is a worldwide organization that drafts glossary('specification','specifications') governing the mechanisms behind the glossary("Internet"), especially the glossary("TCP")/glossary("IPv6","IP") or Internet glossary("Protocol") Suite.
The IETF is open, run by volunteers, and sponsored by the Internet Society.
- CodingScripting
- DesignPattern
- Functions
- Glossary
- JavaScript
An IIFE (Immediately Invoked Function Expression) is a glossary("JavaScript") glossary("function") that runs as soon as it is defined. The name IIFE is promoted by Ben Alman in his blog.
//
(function () {
statements;
})();It is a design pattern which is also known as a glossary("Self-Executing Anonymous Function") and contains two major parts:
- The first is the anonymous function with lexical scope enclosed within the jsxref("Operators/Grouping", "Grouping Operator")
(). This prevents accessing variables within the IIFE idiom as well as polluting the global scope. - The second part creates the immediately invoked function expression
()through which the JavaScript engine will directly interpret the function.
Because our application could include many functions and global variables from different source files, it's important to limit the number of global variables. If we have some initiation code that we don't need to use again, we could use the IIFE pattern. As we will not reuse the code again, using IIFE in this case is better than using a function declaration or a function expression.
//
(function () {
// some initiation code
let firstVariable;
let secondVariable;
})();
// firstVariable and secondVariable will be discarded after the function is executed.We would also use IIFE to create private and public variables and methods. For a more sophisticated use of the module pattern and other use of IIFE, you could see the book Learning JavaScript Design Patterns by Addy Osmani.
//
const makeWithdraw = (balance) =>
(function (copyBalance) {
let balance = copyBalance; // This variable is private
let doBadThings = function () {
console.log('I will do bad things with your money');
};
doBadThings();
return {
withdraw: function (amount) {
if (balance >= amount) {
balance -= amount;
return balance;
} else {
return 'Insufficient money';
}
}
};
})(balance);
const firstAccount = makeWithdraw(100); // "I will do bad things with your money"
console.log(firstAccount.balance); // undefined
console.log(firstAccount.withdraw(20)); // 80
console.log(firstAccount.withdraw(30)); // 50
console.log(firstAccount.doBadThings); // undefined; this method is private
const secondAccount = makeWithdraw(20); // "I will do bad things with your money"
console.log(secondAccount.withdraw(30)); // "Insufficient money"
console.log(secondAccount.withdraw(20)); // 0We could see the following use of IIFE in some old code, before the introduction of the statements let and const in ES6 and the block scope. With the statement var, we have only function scopes and the global scope. Suppose we want to create 2 buttons with the texts Button 0 and Button 1 and we click them, we would like them to alert 0 and 1. The following code doesn't work:
//
for (var i = 0; i < 2; i++) {
const button = document.createElement('button');
button.innerText = 'Button ' + i;
button.onclick = function () {
alert(i);
};
document.body.appendChild(button);
}
console.log(i); // 2When clicked, both Button 0 and Button 1 alert 2 because i is global,
with the last value 2. To fix this problem before ES6, we could use the IIFE pattern:
//
for (var i = 0; i < 2; i++) {
const button = document.createElement('button');
button.innerText = 'Button ' + i;
button.onclick = (function (copyOfI) {
return function () {
alert(copyOfI);
};
})(i);
document.body.appendChild(button);
}
console.log(i); // 2When clicked, Buttons 0 and 1 alert 0 and 1.
The variable i is globally defined.
Using the statement let, we could simply do:
//
for (let i = 0; i < 2; i++) {
const button = document.createElement('button');
button.innerText = 'Button ' + i;
button.onclick = function () {
alert(i);
};
document.body.appendChild(button);
}
console.log(i); // Uncaught ReferenceError: i is not defined.When clicked, these buttons alert 0 and 1.
-
Quick example (at the end of the "Functions" section, right before "Custom objects")
-
interwiki("wikipedia", "Immediately-invoked function expression", "IIFE") (Wikipedia)
-
- Glossary("Function")
- Glossary("Self-Executing Anonymous Function")
- Beginner
- Glossary
- Infrastructure
- MailNews
IMAP (Internet Message Access Protocol) is a Glossary("protocol") used to retrieve and store emails. More recent than Glossary("POP"), IMAP allows folders and rules on the server.
Unlike POP3, IMAP allows multiple simultaneous connections to one mailbox. Clients accessing a mailbox can receive information about state changes made from other clients. IMAP also provides a mode for clients to stay connected and receive information on demand.
Mark Crispin initially developed IMAP in 1986 as Interim Mail Access Protocol. IMAP4 revision 1 is the current version, defined by RFC 3501.
- RFC(3501)
- Glossary("POP")
- interwiki("wikipedia", "Internet Message Access Protocol", "IMAP") on Wikipedia
- CodingScripting
- Glossary
An immutable glossary("object") is one whose content cannot be changed. An object can be immutable for various reasons, for example:
- To improve performance (no planning for the object's future changes)
- To reduce memory use (make glossary("object reference","object references") instead of cloning the whole object)
- Thread-safety (multiple threads can reference the same object without interfering with one other)
- interwiki("wikipedia", "Immutable object", "Immutable") on Wikipedia
- Beginner
- Definitions
- Dictionary
- Glossary
- Index
- Landing
- Terminology
Web technologies contain long lists of jargon and abbreviations that are used in documentation and coding. This glossary provides definitions of words and abbreviations you need to know to successfully understand and build for the web.
Glossary terms can be selected from the sidebar (or listed below on mobile devices and other narrow width screens).
Note: This glossary is a never-ending work in progress. You can help improve it by writing new entries or by making the existing ones better.
LearnBox({"title":"Learn a new word ..."})
- MDN Web Docs Glossary _ListSubpagesForSidebar("/en-us/docs/Glossary", 1_)
- API
- CodingScripting
- Database
- Glossary
- Sql
IndexedDB is a Web glossary("API") for storing large data structures within browsers and indexing them for high-performance searching. Like an glossary("SQL")-based RDBMS, IndexedDB is a transactional database system. However, it uses glossary("JavaScript") objects rather than fixed columns tables to store data.
- The domxref('IndexedDB_API','IndexedDB API','',1) on MDN
- The W3C specification for IndexedDB
- Glossary
- Index
- MDN Meta
- Navigation
Index("/en-US/docs/Glossary")
- Design
- Glossary
- information architecture
Information architecture, as applied to web design and development, is the practice of organizing the information / content / functionality of a web site so that it presents the best user experience it can, with information and services being easily usable and findable.
- interwiki("wikipedia", "Information_architecture", "Information architecture") on Wikipedia
- CodingScripting
- Glossary
- Inheritance
- Programming Language
Inheritance is a major feature of glossary("OOP","object-oriented programming"). Data abstraction can be carried up several levels, that is, glossary("class","classes") can have superclasses and subclasses.
As an app developer, you can choose which of the superclass's glossary("attribute","attributes") and glossary("method","methods") to keep and add your own, making class definition very flexible. Some languages let a class inherit from more than one parent (multiple inheritance).
- Glossary
An input method editor (IME) is a program that provides a specialized user interface for text input. Input method editors are used in many situations:
- to enter Chinese, Japanese, or Korean text using a Latin keyboard
- to enter Latin text using a numeric keypad
- to enter text on a touch screen using handwriting recognition
-
Interwiki("wikipedia", "Input method")
-
- Glossary("I18N")
- Beginner
- CodingScripting
- Glossary
- JavaScript
- NeedsExample
- OOP
An glossary("object") created by a glossary("constructor") is an instance of that constructor.
- interwiki("wikipedia", "Instance (computer science)", "Instance") on Wikipedia
- Glossary
- Internationalization
- Reference
Internationalization, often shortened to "i18n", is the adapting of a web site or web application to different languages, regional differences, and technical requirements for different regions and countries. Internationalization is the process of architecting your web application so that it can be quickly and easily adapted to various languages and regions without much engineering effort when new languages and regions are supported. Also so that a user can browse features to translate or localize the application to access all the content without breaking the layout.
Internationalization includes support for multiple character sets (usually via Unicode), units of measure (currency, °C/°F, km/miles, etc.), date and time formats, keyboard layouts, and layout and text directions.
- Beginner
- Glossary
- Guide
- Intro
- NeedsContent
- Tutorial
- Web
- WebMechanics
The Internet is a worldwide network of networks that uses the Internet protocol suite (also named glossary("TCP")/glossary("IPv6","IP") from its two most important glossary("protocol","protocols")).
- How the Internet works (introduction for beginners)
- CSS
- Glossary
- Intrinsic size
In CSS, the intrinsic size of an element is the size it would be based on its content, if no external factors were applied to it. For example, inline elements are sized intrinsically:
width,height, and vertical margin and padding have no impact, though horizontal margin and padding do.
How intrinsic sizes are calculated is defined in the CSS Intrinsic and Extrinsic Sizing Specification.
Intrinsic sizing takes into account the min-content and max-content size of an element. For text the min-content size would be if the text wrapped as small as it can in the inline direction without causing an overflow, doing as much soft-wrapping as possible. For a box containing a string of text, the min-content size would be defined by the longest word. The keyword value of min-content for the cssxref("width") property will size an element according to the min-content size.
The max-content size is the opposite — in the case of text, this would have the text display as wide as possible, doing no soft-wrapping, even if an overflow was caused. The keyword value max-content exposes this behavior.
For images the intrinsic size has the same meaning — it is the size that an image would be displayed if no CSS was applied to change the rendering. By default images are assumed to have a "1x" pixel density (1 device pixel = 1 CSS pixel) and so the intrinsic size is simply the pixel height and width. The intrinsic image size and resolution can be explicitly specified in the Glossary("EXIF") data. The intrinsic pixel density may also be set for images using the htmlattrxref("srcset", "img") attribute (note that if both mechanisms are used, the srcset value is applied "over" the EXIF value).
- Beginner
- Glossary
- Infrastructure
- Web
An IP address is a number assigned to every device connected to a network that uses the Internet protocol.
"IP address" typically still refers to 32-bit IPv4 addresses until IPv6 is deployed more broadly.
- interwiki("wikipedia", "IP address", "IP address") on Wikipedia
- Glossary
- IPv4
- Infrastructure
- Internet Protocol
- Protocol
IPv4 is the fourth version of the communication Glossary("protocol") underlying the glossary("Internet") and the first version to be widely deployed.
First formalized in 1981, IPv4 traces its roots to the initial development work for ARPAnet. IPv4 is a connectionless protocol to be used on packet-switched Link layer networks (ethernet). glossary("IPv6") is gradually replacing IPv4 owing to IPv4's security problems and the limitations of its address field. (Version number 5 was assigned in 1979 to the experimental Internet Stream Protocol, which however has never been called IPv5.)
interwiki("wikipedia", "IPv4", "IPv4") on Wikipedia
- Glossary
- IPv6
- Infrastructure
- Intermediate
- Web
- WebMechanics
IPv6 is the current version of the communication glossary("protocol") underlying the glossary("Internet"). Slowly IPv6 is replacing Glossary("IPv4"), among other reasons because IPv6 allows for many different Glossary("IP address","IP addresses").
- interwiki("wikipedia", "IPv6", "IPv6") on Wikipedia
- Glossary
- Infrastructure
- Internet Relay Chat
- Open Protocol
- irc
IRC (Internet Relay Chat) is a worldwide chat system requiring an Internet connection and an IRC client, which sends and receives messages via the IRC server.
Designed in the late 1980s by Jarrko Oikarinen, IRC uses glossary("TCP") and is an open protocol. The IRC server broadcasts messages to everyone connected to one of many IRC channels (each with their own ID).
- Glossary
- ISO
- Infrastructure
- Web Standards
- web specifications
ISO (International Organization for Standardization) is a global association that develops uniform criteria coordinating the companies in each major industry.
- Glossary
- ISP
- Internet Service Provider
- Web
- WebMechanics
An ISP (Internet Service Provider) sells Internet access, and sometimes email, web hosting, and voice over IP, either by a dial-up connection over a phone line (formerly more common), or through a broadband connection such as a cable modem or DSL service.
- How the Internet works (explanation for beginners)
- interwiki("wikipedia", "Internet service provider", "Internet service provider") on Wikipedia
- Glossary
- ITU
- Standardization
- organization
The International Telecommunication Union (ITU) is the organization authorized by the United Nations to establish standards and rules for telecommunication, including telegraph, radio, telephony and the internet.
From defining rules for ensuring transmissions get to where they need to go to and creating the "SOS" alert signal used in Morse code, the ITU has long played a key role in how we use technology to exchange information and ideas.
In the Internet Age, the ITU's role of establishing standards for video and audio data formats used for streaming, teleconferencing, and other purposes. For example, the ITU and the Moving Picture Experts Group (MPEG) worked together to develop and publish, as well as to maintain, the various MPEG specifications, such as MPEG-2 (ITU H.262), AVC (ITU H.264), and HEVC (ITU H.265).
- Beginner
- CodingScripting
- Glossary
- Performance
- Web Performance
- CodingScripting
- Glossary
- Java
- Programming Language
Java is a glossary("Compile", "compiled"), glossary("OOP", "object-oriented"), highly portable Glossary("computer programming", "programming") language.
Java is statically typed and features a similar syntax to C. It comes with a large library of readily usable functions, the Java Software Development Kit (SDK).
Programs are glossary("Compile", "compiled") only once ahead of time into a proprietary byte code and package format that runs inside the Java Virtual Machine (JVM). The JVM is available across many platforms, which allows Java programs to run almost everywhere without the need to be compiled or packaged again. This makes it a preferred language in many large enterprises with heterogenous landscapes, but may be perceived "heavy".
- interwiki("wikipedia", "Java (programming language)", "Java") on Wikipedia
- CodingScripting
- Glossary
- JavaScript
- l10n:priority
JavaScript (or "JS") is a programming language used most often for dynamic client-side scripts on webpages, but it is also often used on the Glossary("Server","server")-side, using a runtime such as Node.js.
JavaScript should not be confused with the interwiki("wikipedia", "Java(programminglanguage)", "Java programming language"). Although "Java" and "JavaScript" are trademarks (or registered trademarks) of Oracle in the U.S. and other countries, the two programming languages are significantly different in their syntax, semantics, and use cases.
JavaScript is primarily used in the browser, enabling developers to manipulate webpage content through the Glossary("DOM"), manipulate data with Glossary("AJAX") and Glossary("IndexedDB"), draw graphics with Glossary("canvas"), interact with the device running the browser through various Glossary("API","APIs"), and more. JavaScript is one of the world's most commonly-used languages, owing to the recent growth and performance improvement of Glossary("API","APIs") available in browsers.
Conceived as a server-side language by Brendan Eich (then employed by the Netscape Corporation), JavaScript soon came to Netscape Navigator 2.0 in September 1995. JavaScript enjoyed immediate success and glossary("Microsoft Internet Explorer", "Internet Explorer 3.0") introduced JavaScript support under the name JScript in August 1996.
In November 1996, Netscape began working with ECMA International to make JavaScript an industry standard. Since then, the standardized JavaScript is called ECMAScript and specified under ECMA-262, whose latest (eleventh, ES2020) edition is available as of June 2020.
Recently, JavaScript's popularity has expanded even further through the successful Node.js platform—the most popular cross-platform JavaScript runtime environment outside the browser. Node.js - built using Chrome's V8 JavaScript Engine - allows developers to use JavaScript as a scripting language to automate things on a computer and build fully functional Glossary("HTTP") and Glossary("WebSockets") servers.
- interwiki("wikipedia", "JavaScript", "JavaScript") on Wikipedia
- The Link("/en-US/docs/Web/JavaScript/Guide") on MDN
- The "javascripting" workshop on NodeSchool
- The JavaScript course on codecademy.com
- The latest ECMAScript standard
- The Link("/en-US/docs/Web/JavaScript/reference") on MDN
- The Eloquent JavaScript book
- Beginner
- Composing
- Glossary
- Images
- JPEG
JPEG (Joint Photographic Experts Group) is a commonly used method of lossy compression for digital images.
JPEG compression is composed of three compression techniques applied in successive layers, including chrominance subsampling, discrete cosine transformation and quantization, and run-length Delta & Huffman encoding. Chroma subsampling involves implementing less resolution for chroma information than for luma information, taking advantage of the human visual system's lower acuity for color differences than for luminance. A discrete cosine transform expresses a finite sequence of data points in terms of a sum of cosine functions oscillating at different frequencies.
- Interwiki("wikipedia", "JPEG") on Wikipedia
- Glossary
- JQuery
- JavaScript
jQuery is a Glossary("JavaScript") Glossary("Library") that focuses on simplifying Glossary("DOM") manipulation, Glossary("AJAX") calls, and Glossary("Event") handling.
jQuery uses a format, $(selector).action() to assign an element(s) to an event. To explain it in detail, $(selector) will call jQuery to select selector element(s), and assign it to an event Glossary("API") called .action().
//
$(document).ready(function () {
alert('Hello World!');
$('#blackBox').hide();
});The above code carries out the same function as the following code:
//
window.onload = function () {
alert('Hello World!');
document.getElementById('blackBox').style.display = 'none';
};Or:
//
window.addEventListener('load', () => {
alert('Hello World!');
document.getElementById('blackBox').style.display = 'none';
});- Interwiki("wikipedia", "jQuery") on Wikipedia
- jQuery Official Website
- Official API reference documentation
- CodingScripting
- Glossary
- Intro
- JSON
- l10n:priority
JavaScript Object Notation (JSON) is a data-interchange format. Although not a strict subset, JSON closely resembles a subset of Glossary("JavaScript") syntax. Though many programming languages support JSON, it is especially useful for JavaScript-based apps, including websites and browser extensions.
JSON can represent numbers, booleans, strings, null, arrays (ordered sequences of values), and objects (string-value mappings) made up of these values (or of other arrays and objects). JSON does not natively represent more complex data types like functions, regular expressions, dates, and so on. (Date objects by default serialize to a string containing the date in ISO format, so the information isn't completely lost.) If you need JSON to represent additional data types, transform values as they are serialized or before they are deserialized.
- interwiki("wikipedia", "JSON", "JSON") on Wikipedia
- Link("/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON") on MDN
- Cryptography
- Glossary
- Security
A key is a piece of information used by a Glossary("cipher") for Glossary("encryption") and/or Glossary("decryption").
Encrypted messages should remain secure even if everything about the Glossary("cryptosystem"), except for the key, is public knowledge.
In Glossary("symmetric-key cryptography"), the same key is used for both encryption and decryption. In Glossary("public-key cryptography"), there exists a pair of related keys known as the public key and private key. The public key is freely available, whereas the private key is kept secret. The public key is able to encrypt messages that only the corresponding private key is able to decrypt, and vice versa.
-
Kerckhoffs's principle on Wikipedia
-
- Glossary("Block cipher mode of operation")
- Glossary("Cipher")
- Glossary("Ciphertext")
- Glossary("Cipher suite")
- Glossary("Cryptanalysis")
- Glossary("Cryptography")
- Glossary("Decryption")
- Glossary("Encryption")
- Glossary("Key")
- Glossary("Plaintext")
- Glossary("Public-key cryptography")
- Glossary("Symmetric-key cryptography")
- Glossary
- Keyword
- Search
- keyword search
A keyword is a word or phrase that describes content. Online keywords are used as queries for search engines or as words identifying content on websites.
When you use a search engine, you use keywords to specify what you are looking for, and the search engine returns relevant webpages. For more accurate results, try more specific keywords, such as "Blue Mustang GTO" instead of "Mustang". Webpages also use keywords in a meta tag (in the htmlelement("head") section) to describe page content, so search engines can better identify and organize webpages.
- interwiki("wikipedia", "Keyword_research", "Keyword") on Wikipedia
- Glossary
- Khronos
The Khronos Group is an open, non-profit, member-driven consortium of over 150 industry-leading companies. Their purpose is to create advanced, royalty-free interoperability standards for 3D graphics, augmented and virtual reality, parallel programming, vision acceleration, and machine learning.
The organization maintains standards such as Glossary("OpenGL") and the domxref("WebGL API").
- interwiki("wikipedia", "Khronos_Group", "The Khronos Group") on Wikipedia
- The Khronos Group web site
- Audio
- Glossary
- Media
- Networking
- Reference
- Video
- Web Performance
- latency
Latency is the network time it takes for a requested resource to reach its destination. Low latency is good, meaning there is little or no delay. High latency is bad, meaning it takes a long time for the requested resource to reach its destination.
Latency can be a factor in any kind of data flow, but is most commonly discussed in terms of network latency (the time it takes for a packet of data to travel from source to destination) and media codec latency (the time it takes for the source data to be encoded or decoded and reach the consumer of the resulting data).
- CodingScripting
- Glossary
- Layout
- layout viewport
- viewport
The layout viewport is the viewport into which the browser draws a web page. Essentially, it represents what is available to be seen, while the Glossary("visual viewport") represents what is currently visible on the user's display device.
This becomes important, for example, on mobile devices, where a pinching gesture can usually be used to zoom in and out on a site's contents. The rendered document doesn't change in any way, so the layout viewport remains the same as the user adjusts the zoom level. Instead, the visual viewport is updated to indicate the area of the page that they can see.
- Visual Viewport API
- Interwiki("wikipedia", "Viewport") on Wikipedia
- A tale of two viewports (Quirksmode)
- Glossary("Viewport") in the MDN Glossary
- Glossary("Visual viewport") in the MDN Glossary
- Glossary
- Lazy loading
- Reference
- Web Performance
Lazy loading is a strategy that delays the loading of some assets (e.g., images) until they are needed by the user based on the user's activity and navigation pattern; typically, these assets are only loaded when they are scrolled into view.
If correctly implemented, this delay in asset loading is seamless to the user experience and might help improve initial load performance, including time to interactive, as fewer assets are required for the page to start working.
- Glossary
- License
- OpenPractices
- Remixing
- Sharing
LGPL (GNU Lesser General Public License) is a free software license published by the Free Software Foundation. The LGPL provides a more permissive alternative for the strictly Glossary("copyleft") Glossary("GPL"). While any derivative work using a GPL-licensed program must be released under the same terms (free to use, share, study, and modify), the LGPL only requires the LGPL-licensed component of the derivative program to continue using the LGPL, not the whole program. LGPL is usually used to license shared components such as libraries (
.dll,.so,.jar, etc.).
- interwiki("wikipedia", "GNU Lesser General Public License", "GNU LGPL") on Wikipedia
- LGPL License text on gnu.org
- CSS
- Design
- Glossary
A ligature is a joining of two characters into one shape. For example, in French "œ" is a ligature of "oe".
You can implement ligatures in your webpage with cssxref("font-variant-ligatures").
- interwiki("wikipedia", "Typographic ligature", "Ligature") on Wikipedia
- Literal
- JavaScript
- Glossary
Literals represent values in JavaScript. These are fixed values—not variables—that you literally provide in your script.
- Array literals
- Boolean literals
- Floating-point literals
- Numeric literals
- Object literals
- RegExp literals
- String literals
A string literal is zero or more characters enclosed in double (") or single quotation marks ('). A string must be delimited by quotation marks of the same type (that is, either both single quotation marks, or both double quotation marks).
The following are examples of string literals:
//
'foo';
'bar';
'1234';
'one line \n new line';
"John's cat";An object literal is a list of zero or more pairs of property names and associated values of an object, enclosed in curly braces ({}).
The following is an example of an object literal. The first element of the car object defines a property, myCar, and assigns to it a new string, "Toyota"; the second element, the getCar property, is immediately assigned the result of invoking the function carTypes('Honda'); the third element, the special property, uses an existing variable (sales).
//
var sales = 'BMW';
function carTypes(name) {
if (name == 'Honda') {
return name;
} else {
return "Sorry, we don't sell " + name + '.';
}
}
var car = { myCar: 'Toyota', getCar: carTypes('Honda'), special: sales };
console.log(car.myCar); // Toyota
console.log(car.getCar); // Honda
console.log(car.special); // BMW- interwiki("wikipedia", "Literal (computer programming)", "Literal") on Wikipedia
- CodingScripting
- Glossary
- NeedsContent
Local scope is a characteristic of glossary("variable","variables") that makes them local (i.e., the variable name is only bound to its glossary("value") within a scope which is not the glossary("global scope")).
- interwiki("wikipedia", "Scope (computer science)", "Scope") on Wikipedia
- CodingScripting
- Glossary
- NeedsContent
A glossary("variable") whose name is bound to its glossary("value") only within a Glossary("local scope").
//
var global = 5; //is a global variable
function fun() {
var local = 10; //is a local variable
}- interwiki("wikipedia", "Local variable", "Local variable") on Wikipedia
- Composing
- Glossary
- Locale
Locale is a set of language- or country-based preferences for a user interface.
A program draws its locale settings from the language of the host system. Among other things, locales represent paper format, currency, date format, and numbers according to the protocols in the given region.
- interwiki("wikipedia", "Locale", "Locale") on Wikipedia
- Collaborating
- Glossary
- Intro
- Localization
- WebMechanics
Localization (l10n) is the process of adapting a software user interface to a specific culture.
The following are common factors to consider:
- language
- unit of measure (e.g., kilometers in Europe, miles in U.S.)
- text direction (e.g., European languages are left-to-right, Arabic right-to-left)
- capitalization in Latin script (e.g., English uses capitals for weekdays, Spanish uses lowercase)
- adaptation of idioms (e.g., "raining cats and dogs" makes no sense when translated literally)
- use of register (e.g., in Japanese respectful speech differs exceptionally from casual speech)
- number format (e.g., 10 000,00 in Germany vs. 10,000.00 in the U.S.)
- date format
- currency
- cultural references
- paper size
- color psychology
- compliance with local laws
- local holidays
- personal names
- interwiki("wikipedia", "Language localisation", "Localization") on Wikipedia
- Glossary
- Long Tasks API
- Reference
- Web Performance
A long task is a task that takes more than 50ms to complete.
It is an uninterrupted period where the main UI thread is busy for 50 ms or longer. Common examples include long running event handlers, expensive reflows and other re-renders, and work the browser does between different turns of the event loop that exceeds 50 ms.
- CodingScripting
- Glossary
- control flow
- programming
A loop is a sequence of instructions that is continually repeated until a certain condition is met in Glossary("computer programming"). An example would be the process of getting an item of data and changing it, and then making sure some Glossary("conditional", "condition") is checked such as, if a counter has reached a prescribed number.
for (statement 1; statement 2; statement 3){
execute code block
}
- Statement 1 is executed once before the code block is run.
- Statement 2 defines the condition needed to execute the code block.
- Statement 3 is executed every time the code block is run.
//
for (var i = 0; i < 10; i++) {
console.log(i);
}
//This loop will print numbers 0-9, will stop when condition is met (i = 10)For the above example, the syntax is as follows:
- Statement 1 sets the variable for the loop (var i = 0).
- Statement 2 sets the loop condition (i < 10).
- Statement 3 increases the value of i (i++) each time the code block is run.
while (condition){
execute code block
}
- The code block will continue to loop as long as the condition is true.
//
var i = 0;
while (i < 5) {
console.log(i);
i++;
}
//This loop will print number 0-4, will stop when condition becomes false (i >=5)For the above example, the syntax is as follows:
- The code block will continue to run as long as the variable (i) is less than 5.
-
interwiki("wikipedia", "Control_flow#Loops","Control flow") on Wikipedia
-
- Glossary("Loop")
- Beginner
- Composing
- Glossary
- Images
- Web Performance
- compression
- lossless
Lossless compression is a class of data compression algorithms that allows the original data to be perfectly reconstructed from the compressed data. Lossless compression methods are reversible. Examples of lossless compression include glossary("GZIP"), glossary("Brotli"), WebP, and glossary("PNG"),
glossary("Lossy compression"), on the other hand, uses inexact approximations by discarding some data from the original file, making it an irreversible compression method.
-
- glossary("GZIP")
- glossary("Brotli")
- glossary("PNG")
- glossary("Lossy compression")
- Beginner
- Composing
- Glossary
- Images
- JPEG
- Lossy
- Web Performance
- compression
Lossy compression, or irreversible compression, is a data-compression method that uses inexact approximations and partial-data discarding to represent content. In simpler terms: lossy compression causes data from the initial file to be lost, possibly causing degradation in quality. The process of such compression is irreversible; once lossy compression of the content has been performed, the content cannot be restored to its original state. Therefore, content that has undergone lossy compression should generally not be further edited.
Lossy compression is widely used in image formats.

Although there is no obvious difference quality between the two images above, the size of the second image has been significantly reduced, using lossy compression.
- Composing
- Glossary
- Localization
LTR (Left To Right) is a Glossary("locale") property indicating that text is written from left to right. For example, the
en-USlocale (for US English) specifies left-to-right.
Most Western languages, as well as many others around the world, are written LTR.
The opposite of LTR, Glossary("RTL") (Right To Left) is used in other common languages, including Arabic (ar) and Hebrew (he).
-
- Glossary("locale")
- Glossary("LTR")
- Glossary("RTL")
-
- htmlattrxref("dir")
- htmlattrxref("lang")
-
- cssxref(":dir")
- cssxref("direction")
- cssxref("unicode-bidi")
- cssxref("writing-mode")
- CSS
- Glossary
- Main axis
- flexbox
The main axis in glossary("flexbox") is defined by the direction set by the cssxref("flex-direction") property. There are four possible values for
flex-direction. These are:
rowrow-reversecolumncolumn-reverse
Should you choose row or row-reverse then your main axis will run along the row in the inline direction.

Choose column or column-reverse and your main axis will run top to bottom of the page in the block direction.

On the main axis you can control the sizing of flex items by adding any available space to the items themselves, by way of flex properties on the items. Or, you can control the space between and around items by using the justify-content property.
- cssxref("flex-basis")
- cssxref("flex-direction")
- cssxref("flex-grow")
- cssxref("flex-shrink")
- cssxref("justify-content")
- cssxref("flex")
- CSS Flexbox Guide: Basic Concepts of Flexbox
- CSS Flexbox Guide: Aligning items in a flex container
- CSS Flexbox Guide: Controlling Ratios of flex items along the main axis
- Glossary
- Reference
- Web Performance
The main thread is where a browser processes user events and paints. By default, the browser uses a single thread to run all the JavaScript in your page, as well as to perform layout, reflows, and garbage collection. This means that long-running JavaScript functions can block the thread, leading to an unresponsive page and a bad user experience.
Unless intentionally using a web worker, such as a service worker, JavaScript runs on the main thread, so it's easy for a script to cause delays in event processing or painting. The less work required of the main thread, the more that thread can respond to user events, paint, and generally be responsive to the user.
-
- Glossary("Thread")
- Glossary
- Intro
- Markup
- NeedsContent
A markup language is one that is designed for defining and presenting text. glossary("HTML") (HyperText Markup Language), is an example of a markup language.
- Presentational Markup:
-
- : Used by traditional word processing system with WYSIWYG (what you see it is what you get); this is hidden from human authors, users and editors.
- Procedural Markup:
- : Combined with text to provide instructions on text processing to programs. This text is visibly manipulated by the author.
- Descriptive Markup:
- : Labels sections of documents as to how the program should handle them. For example, the HTML HTMLElement("td") defines a cell in a HTML table.
-
- Glossary("HTML")
- Glossary("XHTML")
- Glossary("XML")
- Glossary("SVG")
- CodingScripting
- Glossary
- MathML
- Mathematical Markup Language
- XML
MathML (an glossary("XML") application) is an open standard for representing mathematical expressions in webpages. In 1998 the W3C first recommended MathML for representing mathematical expressions in the glossary("browser"). MathML has other applications also including scientific content and voice synthesis.
- interwiki("wikipedia", "MathML", "MathML") on Wikipedia
- MathML
- Authoring MathML
- spec("http://www.w3.org/Math/whatIsMathML.html", "MathML", "REC")
- Disambiguation
- Glossary
The term media is an overloaded one when talking about the web; it takes on different meanings depending on the context.
_GlossaryDisambiguation}}
- interwiki("wikipedia", "Media") on Wikipedia
- CodingScripting
- Glossary
- HTML
- metadata
Metadata is — in its very simplest definition — data that describes data. For example, an glossary("HTML") document is data, but HTML can also contain metadata in its htmlelement("head") element that describes the document — for example who wrote it, and its summary.
- interwiki("wikipedia", "metadata", "metadata") on Wikipedia
- The htmlelement("meta") element on MDN
- CodingScripting
- Glossary
- JavaScript
A method is a glossary("function") which is a glossary("property") of an glossary("object"). There are two kind of methods: Instance Methods which are built-in tasks performed by an object instance, or _Glossary("static method", "Static Methods")_ which are tasks that are called directly on an object constructor.
Note: In JavaScript functions themselves are objects, so, in that context, a method is actually an glossary("object reference") to a function.
-
InterWiki("wikipedia","Method (computer programming)") in Wikipedia
-
Defining a method in JavaScript (comparison of the traditional syntax and the new shorthand)
-
- Glossary("function")
- Glossary("object")
- Glossary("property")
- Glossary("static method")
- Browser
- Glossary
- Infrastructure
Microsoft Edge is a free-of-cost graphical glossary("World Wide Web", "Web") Glossary("browser") bundled with Windows 10 and developed by Microsoft since 2014. Initially known as Spartan, Edge replaced the longstanding browser glossary("Microsoft Internet Explorer","Internet Explorer").
-
- Glossary("Google Chrome")
- Glossary("Microsoft Edge")
- Glossary("Microsoft Internet Explorer")
- Glossary("Mozilla Firefox")
- Glossary("Netscape Navigator")
- Glossary("Opera Browser")
- Browser
- Glossary
- Internet Explorer
- Microsoft
- Microsoft Internet Explorer
- Navigation
- Web Browser
- Windows
- Windows Operating System
Internet Explorer (or IE) is a free graphical glossary("browser") maintained by Microsoft for legacy enterprise uses. glossary("Microsoft Edge") is currently the default Windows browser.
Microsoft first bundled IE with Windows in 1995 as part of the package called "Microsoft Plus!". By around 2002, Internet Explorer had become the most used browser in the world, but has since lost ground to Chrome, Firefox, Edge, and Safari.
IE has gone through many releases and currently stands at version 11.0.12, with desktop, mobile, and Xbox Console versions available. Formerly available on Mac and UNIX, Microsoft discontinued those versions in 2003 and 2001 respectively.
- interwiki("wikipedia", "Internet Explorer", "Internet Explorer") on Wikipedia
- interwiki("wikipedia", "History of Internet Explorer", "History of Internet Explorer") on Wikipedia
- interwiki("wikipedia", "Internet Explorer versions", "Internet Explorer versions") on Wikipedia
- http://windows.microsoft.com/en-us/internet-explorer/download-ie
- http://windows.microsoft.com/en-us/windows7/getting-started-with-internet-explorer-9
- http://windows.microsoft.com/en-us/internet-explorer/internet-explorer-help
- http://windows.microsoft.com/en-us/internet-explorer/make-ie-default-browser#ie=ie-11
- http://windows.microsoft.com/en-us/internet-explorer/products/ie-8/system-requirements
- http://windows.microsoft.com/en-us/internet-explorer/products/ie-9/system-requirements
- http://support.microsoft.com/kb/969393
- CodingScripting
- Glossary
Middleware is a (loosely defined) term for any software or service that enables the parts of a system to communicate and manage data. It is the software that handles communication between components and input/output, so developers can focus on the specific purpose of their application.
In server-side web application frameworks, the term is often more specifically used to refer to pre-built software components that can be added to the framework's request/response processing pipeline, to handle tasks such as database access.
- Interwiki("wikipedia", "Middleware(distributedapplications)", "Middleware(distributedapplications)") on Wikipedia
- Interwiki("wikipedia", "Middleware", "Middleware") on Wikipedia
- Glossary
- WebMechanics
A MIME type (now properly called "media type", but also sometimes "content type") is a string sent along with a file indicating the type of the file (describing the content format, for example, a sound file might be labeled
audio/ogg, or an image fileimage/png).
It serves the same purpose as filename extensions traditionally do on Windows. The name originates from the glossary("mime","MIME") standard originally used in E-Mail.
- interwiki("wikipedia", "Internet media type", "Internet media type") on Wikipedia
- List of MIME types
- Properly Configuring Server MIME Types
- Details information about the usage of MIME Types in a Web context.
- Incomplete list of MIME types
- MediaRecorder.mimeType
- Beginner
- Glossary
- Infrastructure
- MIME
MIME "Multipurpose internet mail extensions" is a standard to describe documents in other forms beside ASCII text, e.g. audio, video and images. Initially used for E-Mail attachments, it has become the de facto standard to define types of documents anywhere.
See also MIME-Type
- MIME on Wikipedia
- Glossary
- Performance
- Reference
- Web Performance
Minification is the process of removing unnecessary or redundant data without affecting how a resource is processed by the browser.
Minification can include the removal of code comments, white space, and unused code, as well as the shortening of variable and function names. Minification is used to improve web performance by reducing file size. It is generally an automated step that occurs at build time.
As minification makes code less legible to humans, developer tools have 'prettification' features that can add white space back into the code to make it a bit more legible.
- Glossary
- Security
A manipulator-in-the-middle attack (MitM) intercepts a communication between two systems. For example, a Wi-Fi router can be compromised.
Comparing this to physical mail: If you're writing letters to each other, the mail carrier can intercept each letter you mail. They open it, read it, eventually modify it, and then repackage the letter and only then send it to whom you intended to sent the letter for. The original recipient would then mail you a letter back, and the mail carrier would again open the letter, read it, eventually modify it, repackage it, and give it to you. You wouldn't know there's a manipulator in the middle in your communication channel - the mail carrier is invisible to you and to your recipient.
In physical mail and in online communication, MITM attacks are tough to defend. A few tips:
- Don't just ignore certificate warnings. You could be connecting to a phishing server or an imposter server.
- Sensitive sites without HTTPS encryption on public Wi-Fi networks aren't trustworthy.
- Check for HTTPS in your address bar and ensure encryption is in-place before logging in.
- OWASP: Manipulator-in-the-middle attack
- PortSwigger: Latest manipulator-in-the-middle attacks news
- Wikipedia: Man-in-the-middle attack
- The HTTPHeader("Public-Key-Pins") header (Glossary("HPKP")) can significantly decrease the risk of MITM by instructing browsers to require an allowlisted certificate for all subsequent connections to that website.
- CodingScripting
- Glossary
- Method
- Mixin
- Property
A mixin is a Glossary("class") (interface, in WebAPI spec terms) in which some or all of its Glossary("method", "methods") and/or Glossary("property", "properties") are unimplemented, requiring that another Glossary("class") or Glossary("interface") provide the missing implementations.
The new class or interface then includes both the properties and methods from the mixin as well as those it defines itself. All of the methods and properties are used exactly the same regardless of whether they're implemented in the mixin or the interface or class that implements the mixin.
The advantage of mixins is that they can be used to simplify the design of APIs in which multiple interfaces need to include the same methods and properties.
For example, the WindowOrWorkerGlobalScope mixin is used to provide methods and properties that need to be available on both the domxref("Window") and domxref("WorkerGlobalScope") interfaces. The mixin is implemented by both of those interfaces.
- Mixin on Wikipedia
- Design
- Glossary
- Layout
- Layout mobile
Mobile first, a form of Glossary("progressive enhancement"), is a web-development and web-design approach that focuses on prioritizing design and development for mobile screen sizes over design and development for desktop screen sizes. The rationale behind the mobile-first approach is to provide users with good user experiences at all screen sizes—by starting with creating a user experience that works well on small screens, and then building on top of that to further enrich the user experience as the screen size increases. The mobile-first approach contrasts with the older approach of designing for desktop screen sizes first, and then only later adding some support for small screen sizes.
- Infrastructure
- Navigation
A modem ("modulator-demodulator") is a device that converts digital information to analog signals and vice-versa, for sending data through networks.
Different kinds are used for different networks: DSL modems for telephone wires, WiFi modems for short-range wireless radio signals, 3G modems for cellular data towers, and so on.
Modems are different from Glossary("Router","routers"), but many companies sell modems combined with routers.
- Interwiki("wikipedia", "Modem") on Wikipedia
- CodingScripting
- Glossary
The term Modularity refers to the degree to which a system's components may be separated and recombined, it is also division of a software package into logical units. The advantage of a modular system is that one can reason the parts independently
- Interwiki("wikipedia", "Modularity") on Wikipedia
- Browser
- Firefox
- Glossary
- Infrastructure
- Mozilla
- Mozilla Firefox
Mozilla Firefox is a free open-source Glossary("browser") whose development is overseen by the Mozilla Corporation. Firefox runs on Windows, OS X, Linux, and Android.
First released in November 2004, Firefox is completely customizable with themes, plug-ins, and add-ons. Firefox uses glossary("Gecko") to render webpages, and implements both current and upcoming glossary("world wide web", "Web") standards.
- CodingScripting
- Glossary
- NeedsContent
Mutable is a type of variable that can be changed. In glossary("JavaScript"), only Glossary("Object","objects") and Glossary("Array","arrays") are mutable, not Glossary("primitive", "primitive values").
(You can make a variable name point to a new value, but the previous value is still held in memory. Hence the need for garbage collection.)
A mutable object is an object whose state can be modified after it is created.
Immutables are the objects whose state cannot be changed once the object is created.
Strings and Numbers are Immutable. Lets understand this with an example:
var immutableString = "Hello";
// In the above code, a new object with string value is created.
immutableString = immutableString + "World";
// We are now appending "World" to the existing value.
On appending the "immutableString" with a string value, following events occur:
- Existing value of "immutableString" is retrieved
- "World" is appended to the existing value of "immutableString"
- The resultant value is then allocated to a new block of memory
- "immutableString" object now points to the newly created memory space
- Previously created memory space is now available for garbage collection.
- Interwiki("wikipedia", "Immutable object") on Wikipedia
- Glossary
- Infrastructure
- Intro
- MVC
- Model View Controller
MVC (Model-View-Controller) is a pattern in software design commonly used to implement user interfaces, data, and controlling logic. It emphasizes a separation between the software's business logic and display. This "separation of concerns" provides for a better division of labor and improved maintenance. Some other design patterns are based on MVC, such as MVVM (Model-View-Viewmodel), MVP (Model-View-Presenter), and MVW (Model-View-Whatever).
The three parts of the MVC software-design pattern can be described as follows:
- Model: Manages data and business logic.
- View: Handles layout and display.
- Controller: Routes commands to the model and view parts.
Imagine a simple shopping list app. All we want is a list of the name, quantity and price of each item we need to buy this week. Below we'll describe how we could implement some of this functionality using MVC.

The model defines what data the app should contain. If the state of this data changes, then the model will usually notify the view (so the display can change as needed) and sometimes the controller (if different logic is needed to control the updated view).
Going back to our shopping list app, the model would specify what data the list items should contain — item, price, etc. — and what list items are already present.
The view defines how the app's data should be displayed.
In our shopping list app, the view would define how the list is presented to the user, and receive the data to display from the model.
The controller contains logic that updates the model and/or view in response to input from the users of the app.
So for example, our shopping list could have input forms and buttons that allow us to add or delete items. These actions require the model to be updated, so the input is sent to the controller, which then manipulates the model as appropriate, which then sends updated data to the view.
You might however also want to just update the view to display the data in a different format, e.g., change the item order to alphabetical, or lowest to highest price. In this case the controller could handle this directly without needing to update the model.
As a web developer, this pattern will probably be quite familiar even if you've never consciously used it before. Your data model is probably contained in some kind of database (be it a traditional server-side database like MySQL, or a client-side solution such as IndexedDB [en-US].) Your app's controlling code is probably written in HTML/JavaScript, and your user interface is probably written using HTML/CSS/whatever else you like. This sounds very much like MVC, but MVC makes these components follow a more rigid pattern.
In the early days of the Web, MVC architecture was mostly implemented on the server-side, with the client requesting updates via forms or links, and receiving updated views back to display in the browser. However, these days, more of the logic is pushed to the client with the advent of client-side data stores, and XMLHttpRequest allowing partial page updates as required.
Web frameworks such as AngularJS and Ember.js all implement an MVC architecture, albeit in slightly different ways.
- interwiki("wikipedia", "Model-view-controller") on Wikipedia
- CodingScripting
- Glossary
- Operating System
Namespace is a context for identifiers, a logical grouping of names used in a program. Within the same context and same scope, an identifier must uniquely identify an entity.
In an operating system a directory is a namespace. Each file or subdirectory has a unique name, but one file may use the same name multiple times.
- Interwiki("wikipedia", "Namespace") on Wikipedia
- CodingScripting
- Computing
- Glossary
- NaN
NaN (Not a Number) is a numeric Glossary("Type", "data type") that means an undefined value or value that cannot be represented, especially results of floating-point calculations.
For example, NaNs can represent infinity, result of division by zero, missing value, or the square root of a negative (which is imaginary, whereas a floating-point number is real).
Practically speaking, if I divide two variables in a glossary("JavaScript") program, the result may be NaN, which is predefined in JavaScript as "undefined". Hence this division may break the program. Now, if this computation was a small part of a much larger algorithm, it would be really painful to figure out where the error actually occurs. Fortunately, since the result will be NaN and I know my divisor may turn out to be 0, I can set up testing conditions that prevent any such computations in the first place or notify me of where they happen.
- Interwiki("wikipedia", "NaN") on Wikipedia
- NaN in JavaScript
- Beginner
- Glossary
- Infrastructure
- WebMechanics
- WebRTC
NAT (Network Address Translation) is a technique for letting multiple computers share an IP address. NAT assigns unique addresses to each computer on the local network and adjusts incoming/outgoing network traffic to send data to the right place.
- WebRTC protocols
- interwiki("wikipedia", "NAT") on Wikipedia
- CodingScripting
- Glossary
A native application has been compiled to run on the hardware/software environment that comprises the targeted architecture.
An example of a native Android app would be a mobile application written in Java using the Android toolchain.
On the other hand, a Web App that runs inside a browser is not native — it is run in the web browser, which sits on top of the native environment, not the native environment itself.
- Interwiki("wikipedia", "Native (computing)") on Wikipedia
- CSP
- HTTP
- Security
Glossary("CSP") navigation directives are used in a HTTPHeader("Content-Security-Policy") header and govern to which location a user can navigate to or submit a form to, for example.
Navigation directives don't fall back to the CSP("default-src") directive.
See Navigation directives for a complete list.
-
Other kinds of directives:
- Glossary("Fetch directive")
- Glossary("Document directive")
- Glossary("Reporting directive")
block-all-mixed-contentupgrade-insecure-requestsrequire-sri-fortrusted-types
-
HTTPHeader("Content-Security-Policy")
- Browser
- Glossary
- Navigation
- Netscape
- Netscape Navigator
Netscape Navigator or Netscape was a leading glossary("browser") in the 1990s. Netscape was based on Mosaic and the Netscape team was led by Marc Andreessen, a programmer who also wrote code for Mosaic.
Netscape helped make the glossary("World Wide Web","Web") graphical rather than a text-only experience. Many browsing features became standard after Netscape introduced them. Netscape could display a webpage while loading, used JavaScript for forms and interactive content, and stored session information in cookies. Despite Netscape's technical advantages and initial dominance, by the late 1990s glossary("Microsoft Internet Explorer", "Internet Explorer") swiftly overtook Netscape in market share.
- Interwiki("wikipedia", "Netscape Navigator") on Wikipedia
- Glossary
- RUM
- Reference
- Synthetic monitoring
- Web Performance
Network throttling is an intentional slowing down of internet speed. In web performance, network throttling, or network condition emulation, it is used to emulate low bandwidth conditions experienced by likely a large segment of a site's target user base.
It's important not to overlook network conditions users experience on mobile. The internet speeds for developers creating web applications in a corporate office building on a powerful computer are generally very fast. As a developer, tech writer, or designer, this is likely your experience. The network speeds of a mobile user accessing that web application, possibly while traveling or in a remote area with poor data plan coverage, will likely be very slow, if they are able to get online at all. Network throttling enables a developer to emulate an experience of a user. Most browser developer tools, such as the browser inspector, provide a function to emulate different network conditions. By emulating your user's experience via network throttling, you can more readily identify and fix load time issues.
Browser developer tools generally have network throttling options, to allow you to test your app under slow network conditions. Firefox's developer tools for example have a drop-down menu available in both the Network Monitor and Responsive Design Mode containing network speed options (e.g. wifi, good 3G, 2G...)
- Glossary
- Infrastructure
In networking, a node is a connection point in the network. In physical networks, a node is usually a device, like a computer or a router.
- Interwiki("wikipedia", "Node (networking)", "Node") on Wikipedia
- Glossary
- Infrastructure
NNTP (Network News Transfer Protocol) is a Glossary("protocol") used to transfer Glossary("Usenet") messages from client to server or between servers.
- Interwiki("wikipedia", "Network_News_Transfer_Protocol", "NNTP") at Wikipedia
- From the IETF: RFC 3977 about NNTP (2006)
- Glossary
- Infrastructure
- JavaScript
- node.js
Node.js is a cross-platform Glossary("JavaScript") runtime environment that allows developers to build server-side and network applications with JavaScript.
npm is bundled with Node.js. It runs on the command line as the command npm. It is a package manager that downloads packages into a node_modules folder. You call the downloaded packages through const libraryModule = require("libraryname").
- Interwiki("Wikipedia", "Node.js") on Wikipedia
- Node.js website
- API reference documentation
- Tutorials
- npm Documentation
- Disambiguation
- Glossary
The term node can have several meanings depending on the context. It may refer to:
_GlossaryDisambiguation}}
Another use of the word is when talking about Glossary("Node.js")
- Glossary
- Infrastructure
- Specification
- Standardization
Software Glossary("specification", "specifications") often contains information marked as non-normative or informative, which means that those are provided there for the purpose of helping the readers to understand the specification better or to show an example or a best practice, and not needed to be followed as a rule. Sections that contain official part of the specification that must be followed are often marked as Glossary("normative", "normative").
- Description of normative and informative content in WHATWG wiki
- Glossary
- Infrastructure
- Specification
- Standardization
Normative is a word commonly used in software Glossary("specification", "specifications") to denote sections that are standardized and must be followed as a rule. Specifications might also contain sections that are marked as _Glossary("non-normative")_ or _informative_, which means those are provided there for the purpose of helping the reader understand the specifications better or to showcase an example or best practice, which need not be followed as a rule.
- Description of normative and informative content in WHATWG wiki
- CodingScripting
- Glossary
In computer science, a
nullvalue represents a reference that points, generally intentionally, to a nonexistent or invalid glossary("object") or address. The meaning of a null reference varies among language implementations.
In Glossary("JavaScript"), null is marked as one of the Glossary("Primitive", "primitive values"), because its behavior is seemingly primitive.
But in certain cases, null is not as "primitive" as it first seems! Every Object is derived from null value, and therefore typeof operator returns object for it:
//
typeof null === 'object'; // true-
The JavaScript global object: jsxref("null")
-
Interwiki("wikipedia", "Null pointer") on Wikipedia
-
- Glossary("JavaScript")
- Glossary("string")
- Glossary("number")
- Glossary("bigint")
- Glossary("boolean")
- Glossary("null")
- Glossary("undefined")
- Glossary("symbol")
- Glossary
- JavaScript
- 'Null'
- Primitive
- undefined
In JavaScript, a nullish value is the value which is either JSxRef("null") or JSxRef("undefined"). Nullish values are always falsy.
- CodingScripting
- Glossary
- JavaScript
In Glossary("JavaScript"), Number is a numeric data type in the double-precision 64-bit floating point format (IEEE 754). In other programming languages different numeric types exist; for example, Integers, Floats, Doubles, or Bignums.
-
Interwiki("wikipedia", "Data type#Numeric_types", "Numeric types") on Wikipedia
-
The JavaScript type:
Number -
The JavaScript global object jsxref("Number")
-
- Glossary("JavaScript")
- Glossary("Primitive")
- CodingScripting
- Glossary
A link to an glossary("object"). Object references can be used exactly like the linked objects.
The concept of object references becomes clear when assigning the same object to more than one glossary("property"). Rather than holding a copy of the object, each assigned property holds object references that link to the same object, so that when the object changes all properties referring to the object reflect the change.
- Interwiki("wikipedia", "Reference (computer science)") on Wikipedia
- CodingScripting
- Glossary
- Intro
- Object
In JavaScript, objects can be seen as a collection of properties. With the object literal syntax, a limited set of properties are initialized; then properties can be added and removed. Property values can be values of any type, including other objects, which enables building complex data structures. Properties are identified using key values. A key value is either a Glossary("String", "String value") or a Glossary("Symbol", "Symbol value").
There are two types of object properties: The data property and the accessor property.
Note: It's important to recognize it's accessor property — not accessor method. We can give a JavaScript object class-like accessors by using a function as a value — but that doesn't make the object a class.
- Detailed explanation of JavaScript objects in the JavaScript data types and data structures article
- jsxref("Object") in the JavaScript reference
- Beginner
- CodingScripting
- Glossary
OOP (Object-Oriented Programming) is an approach in programming in which data is encapsulated within glossary("object","objects") and the object itself is operated on, rather than its component parts.
glossary("JavaScript") is heavily object-oriented. It follows a prototype-based model (as opposed to class-based).
- Interwiki("wikipedia", "Object-oriented programming") on Wikipedia
- Introduction to object-oriented JavaScript
- CodingScripting
- Glossary
- OpenGL
OpenGL (Open Graphics Library) is a cross-language, multi-platform application programming interface (API) for rendering 2D and 3D vector graphics. The API is typically used to interact with a graphics processing unit (GPU), to achieve hardware-accelerated rendering.
- Interwiki("wikipedia", "OpenGL") on Wikipedia
- OpenGL
- Glossary
- Security
OpenSSL is an open-source implementation of glossary("SSL") and glossary("TLS").
- Interwiki("wikipedia", "OpenSSL") on Wikipedia
- Official website
- Browser
- Glossary
- Navigation
- Opera
- Opera Browser
Opera is the fifth most used web glossary("browser"), publicly released in 1996 and initially running on Windows only. Opera uses glossary("Blink") as its layout engine since 2013 (before that, glossary("Presto")). Opera also exists in mobile and tablet versions.
- Interwiki("wikipedia", "Opera Browser") on Wikipedia
- Opera browser web site
- CodingScripting
- Glossary
An operand is the part of an instruction representing the data manipulated by the glossary("operator"). For example, when you add two numbers, the numbers are the operand and "+" is the operator.
- Interwiki("wikipedia", "Operand") on Wikipedia
- CodingScripting
- Glossary
Reserved syntax consisting of punctuation or alphanumeric characters that carries out built-in functionality. For example, in JavaScript the addition operator ("+") adds numbers together and concatenates strings, whereas the "not" operator ("!") negates an expression — for example making a
truestatement returnfalse.
- Interwiki("wikipedia", "Operator (computer programming)") on Wikipedia
- JavaScript operators
- Glossary
- Security
- WebMechanics
- origin
Web content's origin is defined by the scheme (protocol), hostname (domain), and port of the Glossary("URL") used to access it. Two objects have the same origin only when the scheme, hostname, and port all match.
Some operations are restricted to same-origin content, and this restriction can be lifted using Glossary("CORS").
These are same origin because they have the same scheme (http) and hostname (example.com), and the different file path does not matter:
http://example.com/app1/index.htmlhttp://example.com/app2/index.html
These are same origin because a server delivers HTTP content through port 80 by default:
http://Example.com:80http://example.com
These are not same origin because they use different schemes:
http://example.com/app1https://example.com/app2
These are not same origin because they use different hostnames:
http://example.comhttp://www.example.comhttp://myapp.example.com
These are not same origin because they use different ports:
http://example.comhttp://example.com:8080
- Same-origin policy
- Glossary("Site")
- HTML specification: origin
- Glossary
- Infrastructure
- Intro
- OTA
- Over the air
- updates
Over The Air (OTA) refers to automatic updating of software on connected devices from a central server. All device owners receiving a given set of updates are on the same "channel", and each device often can access several channels (e.g. for production or engineering builds).
- Interwiki("wikipedia", "Over-the-air programming") on Wikipedia
- Glossary
- Security
OWASP (Open Web Application Security Project) is a non-profit organization and worldwide network that works for security in Free Software, especially on the Web.
- Glossary
- Infrastructure
- Networking
- P2P
P2P (Peer-to-peer) is a computer networking architecture in which all participating nodes (peers) have equal privileges and share the workload. P2P differs from a client-server network architecture, where multiple client nodes connect to centralized servers for services. P2P is commonly found in Blockchain Applications.
- P2P on Wikipedia
- CodingScripting
- Glossary
A Proxy Auto-Configuration file (PAC file) is a file which contains a function,
FindProxyForURL(), which is used by the browser to determine whether requests (including HTTP, HTTPS, and FTP) should go directly to the destination or if they need to be forwarded through a web proxy server.
//
function FindProxyForURL(url, host) {
/* ... */
}
ret = FindProxyForURL(url, host);See Proxy Auto-Configuration (PAC) file for details about how these are used and how to create new ones.
- PAC on Wikipedia
- Proxy Auto-Configuration file on MDN
- Glossary
- Network packet
- Packet
- Reference
- TCP
- Web Performance
- payload
A packet, or network packet, is a formatted chunk of data sent over a network. The main components of a network packet are the user data and control information. The user data is known as the payload. The control information is the information for delivering the payload. It consists of network addresses for the source and destination, sequencing information, and error detection codes and is generally found in packet headers and footer.
A hop occurs when a packet is passed from one network to the next network. It is a field that is decreases by one each time a packet goes through, once it reaches 0 it has failed and the packet is discarded.
Over time the number packets can cause traversing within closed circuits, the number of packets circulating would build up and then ultimately lead to the networking in failing.
Error detection and correction are codes that are used to detect and apply corrections to the errors that occur when data is transmitted to the receiver. There are two types of error corrections backward and forward error correction. Backward error correction is when the receiver requests the sender to retransmit the entire data unit. Forward error correction is when the receiver uses the error-correcting code which automatically corrects the errors
At the transmitter, the calculation is performed before the packet is sent. When received at the destination, the checksum is recalculated, and compared with the one in the packet.
This field indicates which packet should have higher priority over the others. The high priority queue is emptied more quickly than lower priority queues when the network is congested.
When routing network packets it requires two network addresses the source address of the sending host, and the destination address of the receiving host.
Payload is the data that is carried on behalf of an application. It is usually of variable length, up to a maximum that is set by the network protocol and sometimes the equipment on the route.
- https://en.wikipedia.org/wiki/Network_packet
- https://en.m.wikipedia.org/wiki/Hop_(networking)
- https://www.techradar.com/news/computing/how-error-detection-and-correction-works-1080736
- Glossary
- Timings
- Web Performance
- metrics
- page load time
Page load time is the time it takes for a page to load, measured from navigation start to the start of the load event.
//
let time = performance.timing;
let pageloadtime = time.loadEventStart - time.navigationStart;While page load time 'sounds' like the perfect web performance metric, it isn't. Load times can vary greatly between users depending on device capabilities, network conditions, and, to a lesser extent, distance from the server. The development environment, where page load time is measured, is likely an optimal experience, not reflective of your users' reality. In addition, web performance isn't just about when the load event happens. It's also about perceived performance, responsiveness, jank and jitter.
- Navigation and resource timing
- domxref("PerformanceNavigationTiming")
- domxref("PerformanceResourceTiming"),
- Glossary
- Security
- Web Performance
- page prediction
Page Prediction is a browser feature or script which, when enabled, tells the browser to download resources the user is likely to visit before the user requests the content. Page prediction improves performance by enabling almost instant loading of predicted content. However, page prediction may also download content a user does not seek.
Some web applications include a prediction feature completing search text and address bar URLs based on browsing history and related searches. For example, as the user types in the address bar, the browser might send the current text in the address bar to the search engine before the user submits the request.
Although browser page prediction and prediction services enable faster page loads, they consume additional bandwidth. Also, pre-loaded websites and embedded content can set and read their cookies as if they were visited even if they weren't.
- CodingScripting
- Glossary
- JavaScript
A parameter is a named variable passed into a Glossary("function"). Parameter variables are used to import Glossary("argument","arguments") into functions.
For example:
//
function example(parameter) {
console.log(parameter); // Output = foo
}
const argument = 'foo';
example(argument);Note the difference between parameters and arguments:
- Function parameters are the names listed in the function's definition.
- Function Glossary("argument","arguments") are the real values passed to the function.
- Parameters are initialized to the values of the arguments supplied.
Two kinds of parameters:
- input parameters
-
- : the most common kind; they pass values into functions. Depending on programming language, input parameters can be passed several ways (e.g., call-by-value, call-by-address, call-by-reference).
- output/return parameters
- : primarily return multiple values from a function, but not recommended since they cause confusion
- CodingScripting
- Glossary
- NeedsContent
The glossary("object") to which a given glossary("property") or glossary("method") belongs.
- Browser
- CSS
- CodingScripting
- Glossary
- HTML
- JavaScript
- Web Performance
Parsing means analyzing and converting a program into an internal format that a runtime environment can actually run, for example the glossary("JavaScript") engine inside browsers.
When the browser encounters CSS styles, it parses the text into the CSS Object Model (or glossary('CSSOM')), a data structure it then uses for styling layouts and painting. The browser then creates a render tree from both these structures to be able to paint the content to the screen. JavaScript is also downloaded, parsed, and then execute.
JavaScript parsing is done during glossary("compile time") or whenever the glossary("parser") is invoked, such as during a call to a method.
- Parse on Wikipedia
- CodingScripting
- Glossary
A parser is the module of a compiler or interpreter that glossary("parse","parses") a source code file.
More generally, it's a piece of software that parses text and transforms its content to another representation.
- Parser on Wikipedia
- HTTP
- HTTP Header
The HTTP message payload body is the information ("payload") part of the data that is sent in the HTTP Message Body (if any), prior to HTTPHeader("Transfer-Encoding","transfer encoding") being applied. If transfer encoding is not used, the payload body and message body are the same thing!
For example, in this response the message body contains only the payload body: "Mozilla Developer Network":
HTTP/1.1 200 OK
Content-Type: text/plain
Mozilla Developer Network
By contrast, the below response uses transfer encoding to encode the payload body into chunks. The payload body (information) sent is still "Mozilla Developer Network", but the message body includes additional data to separate the chunks:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
7\r\n
Mozilla\r\n
9\r\n
Developer\r\n
7\r\n
Network\r\n
0\r\n
\r\n
For more information see RFC 7230, section 3.3: Message Body and RFC 7230, section 3.3.1: Transfer-Encoding.
- Glossary
- Payload header
- Headers
- WebMechanics
A payload header is an Glossary("HTTP_header", "HTTP header") that describes the payload information related to safe transport and reconstruction of the original resource Glossary("Representation header", "representation"), from one or more messages. This includes information like the length of the message payload, which part of the resource is carried in this payload (for a multi-part message), any encoding applied for transport, message integrity checks, etc.
Payload headers may be present in both HTTP request and response messages (i.e. in any message that is carrying payload data).
The payload headers include: HTTPHeader("Content-Length"), HTTPHeader("Content-Range"), HTTPHeader("Trailer"), and HTTPHeader("Transfer-Encoding").
-
- HTTPHeader("Content-Length")
- HTTPHeader("Content-Range")
- HTTPHeader("Trailer")
- HTTPHeader("Transfer-Encoding")
- Glossary("Representation header")
- Composing
- Glossary
- Portable Document Format
PDF (Portable Document Format) is a file format used to share documentation without depending on any particular software implementation, hardware platform, or operating system. PDF provides a digital image of a printed document, and keeps the same appearance when printed.
- Interwiki("wikipedia", "Portable Document Format", "PDF") on Wikipedia
- Glossary
- Perceived Performance
- Reference
- Web Performance
Perceived performance is a measure of how fast, responsive, and reliable a website feels to its users. The perception of how well a site is performing can have more impact on the user experience that the actual load and response times.
- Glossary
- WebMechanics
Percent-encoding is a mechanism to encode 8-bit characters that have specific meaning in the context of Glossary("URL", "URLs"). It is sometimes called URL encoding. The encoding consists of substitution: A '%' followed by the hexadecimal representation of the ASCII value of the replace character.
Special characters needing encoding are: ':', '/', '?', '#', '[', ']', '@', '!', '$', '&', "'", '(', ')', '*', '+', ',', ';', '=', as well as '%' itself. Other characters don't need to be encoded, though they could.
| Character | Encoding |
|---|---|
':' |
%3A |
'/' |
%2F |
'?' |
%3F |
'#' |
%23 |
'[' |
%5B |
']' |
%5D |
'@' |
%40 |
'!' |
%21 |
'$' |
%24 |
'&' |
%26 |
"'" |
%27 |
'(' |
%28 |
')' |
%29 |
'*' |
%2A |
'+' |
%2B |
',' |
%2C |
';' |
%3B |
'=' |
%3D |
'%' |
%25 |
' ' |
%20 or + |
Depending on the context, the character ' ' is translated to a '+' (like in the percent-encoding version used in an application/x-www-form-urlencoded message), or in '%20' like on URLs.
- Definition of percent-encoding in Wikipedia.
- RFC(3986), section 2.1, where this encoding is defined.
- Beginner
- CodingScripting
- Glossary
- Infrastructure
- Intro
- PHP
PHP (a recursive initialism for PHP: Hypertext Preprocessor) is an open-source server-side scripting language that can be embedded into HTML to build web applications and dynamic websites.
// start of PHP code
<?php
// PHP code goes here
?>
// end of PHP code<?php
echo "Hello World!";
?><?php
// variables
$nome='Danilo';
$sobrenome='Santos';
$pais='Brasil';
$email='danilocarsan@gmailcom';
// printing the variables
echo $nome;
echo $sobrenome;
echo $pais;
echo $email;
?>-
Interwiki("wikipedia", "PHP") on Wikipedia
-
PHP on Wikibooks
-
- Glossary("Java")
- Glossary("JavaScript")
- Glossary("Python")
- Glossary("Ruby")
- Design
- Glossary
- Graphics
A pixel is the smallest building block of a graphical display like a computer screen.
Display resolution is expressed in the unit of pixels. eg: A "800 x 600" pixel resolution means that 800 pixels can be displayed in width and 600 pixels in height.
- Pixel on Wikipedia
- Cryptography
- Glossary
- Security
Placeholder names are commonly used in cryptography to indicate the participants in a conversation, without resorting to terminology such as "Party A," "eavesdropper," and "malicious attacker."
The most commonly used names are:
- Alice and Bob, two parties who want to send messages to each other, occasionally joined by Carol, a third participant
- Eve, a passive attacker who is eavesdropping on Alice and Bob's conversation
- Mallory, an active attacker ("man-in-the-middle") who is able to modify their conversation and replay old messages
- Cryptography
- Glossary
- Security
Plaintext refers to information that is being used as an input to an Glossary("encryption") Glossary("algorithm"), or to Glossary("ciphertext") that has been decrypted.
It is frequently used interchangeably with the term cleartext, which more loosely refers to any information, such as a text document, image, etc., that has not been encrypted and can be read by a human or computer without additional processing.
A browser plugin is a software component that users can install to handle content that the browser can't support natively. Browser plugins are usually written using the NPAPI (Netscape Plugin Application Programming Interface) architecture.
The most well-known and widely used plugin was the Adobe Flash player, which enabled browsers to run Glossary("Adobe Flash") content.
As browsers have become more powerful, plugins have become less useful. Plugins also have a history of causing security and performance problems for web users.
Between 2016 and 2021 browser vendors worked on a deprecation roadmap for plugins and in particular for Adobe Flash, and today plugins are no longer supported by any major browsers.
Plugins should not be confused with browser extensions, which unlike plugins are distributed as source code rather than binaries, and which are still supported by browsers, notably using the Glossary("WebExtensions") system.
- Beginner
- Composing
- Glossary
- Infrastructure
- PNG
PNG (Portable Network Graphics) is a graphics file format that supports lossless data compression.
- PNG on Wikipedia
- Browser Support
- CodingScripting
- Glossary
- JavaScript
- polyfill
A polyfill is a piece of code (usually JavaScript on the Web) used to provide modern functionality on older browsers that do not natively support it.
For example, a polyfill could be used to mimic the functionality of a cssxref("text-shadow") in IE7 using proprietary IE filters, or mimic rem units or media queries by using JavaScript to dynamically adjust the styling as appropriate, or whatever else you require.
The reason why polyfills are not used exclusively is for better functionality and better performance. Native implementations of APIs can do more and are faster than polyfills. For example, the Object.create polyfill only contains the functionalities that are possible in a non-native implementation of Object.create.
Other times, polyfills are used to address issues where browsers implement the same features in different ways. The polyfill uses non-standard features in a certain browser to give JavaScript a standards-compliant way to access the feature. Although this reason for polyfilling is very rare today, it was especially prevalent back in the days of IE6 and Netscape where each browser implemented JavaScript very differently. The 1st version of JQuery was an early example of a polyfill. It was essentially a compilation of browser-specific workarounds to provide JavaScript developers with a single common API that worked in all browsers. At the time, JavaScript developers were having major problems trying to get their website to work across all devices because there was such a discrepancy between browsers that the website might have to be programmed radically differently and have a much different user interface based upon the user's browser. Thus, the JavaScript developer had access to only a very tiny handful of JavaScript APIs that worked more-or-less consistently across all browsers. Using a polyfill to handle browser-specific implementations is less common today because modern browsers mostly implement a broad set of APIs according to standard semantics.
- What is a polyfill? (article by Remy Sharp, the originator of the term)
- CodingScripting
- Glossary
Polymorphism is the presentation of one interface for multiple data types.
For example, integers, floats, and doubles are implicitly polymorphic: regardless of their different types, they can all be added, subtracted, multiplied, and so on.
In the case of glossary("OOP"), by making the glossary("class") responsible for its code as well as its own data, polymorphism can be achieved in that each class has its own glossary("function") that (once called) behaves properly for any glossary("object").
- Polymorphism on Wikipedia
- Beginner
- Glossary
- Infrastructure
POP3 (Post Office Protocol) is a very common glossary("protocol") for getting emails from a mail server over a glossary("TCP") connection. POP3 does not support folders, unlike the more recent Glossary("IMAP"), which is harder to implement because of its more complex structure.
Clients usually retrieve all messages and then delete them from the server, but POP3 does allow retaining a copy on the server. Nearly all email servers and clients currently support POP3.
-
Interwiki("wikipedia", "Post Office Protocol", "POP") on Wikipedia
-
RFC 1734 (Specification of POP3 authentication mechanism)
-
RFC 1939 (Specification of POP3)
-
RFC 2449 (Specification of POP3 extension mechanism)
-
- Glossary("IMAP")
- Glossary
- Intro
- Security
- computer network
- port
For a computer connected to a network with an Glossary("IP address"), a port is a communication endpoint. Ports are designated by numbers, and below 1024 each port is associated by default with a specific Glossary("protocol").
For example, the default port for the Glossary("HTTP") protocol is 80 and the default port for the HTTPS protocol is 443, so a Glossary("HTTP") server waits for requests on those ports. Each Internet protocol is associated with a default port: Glossary("SMTP") (25), Glossary("POP") (110), Glossary("IMAP") (143), Glossary("IRC") (194), and so on.
- Interwiki("wikipedia", "Port (computer networking)" , "Port") on Wikipedia
- Glossary
- Prefetch
- Reference
- Web Performance
Prefetching is when content is downloaded in the background, this is based on the assumption that the content will likely be requested, enabling the content to load instantly if and when the user requests it. The content is downloaded and cached for anticipated future use without the user making an explicit request for it.
Domain lookups can be slow, especially with network latency on mobile phones. They are most relevant when there are a plethora of links to external websites that may be clicked on, like search engine results, DNS prefetching resolves domain names in advance thereby speeding up load times by reducing the time associated with domain lookup at request time.
<link rel="dns-prefetch" href="https://example.com/">
Link prefetching is a performance optimization technique that works by assuming which links the user is likely to click, then downloading the content of those links. If the user decides to click on one of the links, then the page will be rendered instantly as the content has already been downloaded.
The prefetch hints are sent in HTTP headers:
Link: ; rel=dns-prefetch,
; as=script; rel=preload,
; rel=prerender,
; as=style; rel=preload
Browsers will prefetch content when the prefetch <link> tag directs it to, giving the developer control over what resources should be prefetched.
<link rel="prefetch" href="https://www.example.com/solutions" />
- defer
- async
- preload
- page prediction
- lazy loading
- CORS
- Glossary
- HTTP
- Preflight
- request
A CORS preflight request is a Glossary("CORS") request that checks to see if the CORS protocol is understood and a server is aware using specific methods and headers.
It is an HTTPMethod("OPTIONS") request, using three HTTP request headers: HTTPHeader("Access-Control-Request-Method"), HTTPHeader("Access-Control-Request-Headers"), and the HTTPHeader("Origin") header.
A preflight request is automatically issued by a browser and in normal cases, front-end developers don't need to craft such requests themselves. It appears when request is qualified as "to be preflighted" and omitted for simple requests.
For example, a client might be asking a server if it would allow a HTTPMethod("DELETE") request, before sending a DELETE request, by using a preflight request:
OPTIONS /resource/foo
Access-Control-Request-Method: DELETE
Access-Control-Request-Headers: origin, x-requested-with
Origin: https://foo.bar.org
If the server allows it, then it will respond to the preflight request with an HTTPHeader("Access-Control-Allow-Methods") response header, which lists DELETE:
HTTP/1.1 204 No Content
Connection: keep-alive
Access-Control-Allow-Origin: https://foo.bar.org
Access-Control-Allow-Methods: POST, GET, OPTIONS, DELETE
Access-Control-Max-Age: 86400
The preflight response can be optionally cached for the requests created in the same Glossary("URL") using HTTPHeader("Access-Control-Max-Age") header like in the above example.
- Glossary("CORS")
- HTTPMethod("OPTIONS")
- Glossary
- Prefetch
- Security
- Web Performance
- prerender
With prerendering, the content is prefetched and then rendered in the background by the browser as if the content had been rendered into an invisible separate tab. When the user navigates to the prerendered content, the current content is replaced by the prerendered content instantly.
<link rel="prerender" href="https://example.com/content/to/prerender" />- Glossary
- Infrastructure
Presto was the proprietary browser layout engine used to power the Glossary("Opera browser") until version 15. Since then, the Opera browser is based on Chromium, which uses the Glossary('Blink') layout engine.
- Presto layout engine on Wikipedia
- CodingScripting
- Glossary
- JavaScript
In Glossary("JavaScript"), a primitive (primitive value, primitive data type) is data that is not an Glossary("object") and has no glossary("method","methods"). There are 7 primitive data types: Glossary("string"), Glossary("number"), Glossary("bigint"), Glossary("boolean"), Glossary("undefined"), Glossary("symbol"), and Glossary("null").
Most of the time, a primitive value is represented directly at the lowest level of the language implementation.
All primitives are immutable, i.e., they cannot be altered. It is important not to confuse a primitive itself with a variable assigned a primitive value. The variable may be reassigned a new value, but the existing value can not be changed in the ways that objects, arrays, and functions can be altered.
This example will help you understand that primitive values are immutable.
//
// Using a string method doesn't mutate the string
var bar = 'baz';
console.log(bar); // baz
bar.toUpperCase();
console.log(bar); // baz
// Using an array method mutates the array
var foo = [];
console.log(foo); // []
foo.push('plugh');
console.log(foo); // ["plugh"]
// Assignment gives the primitive a new (not a mutated) value
bar = bar.toUpperCase(); // BAZA primitive can be replaced, but it can't be directly altered.
Except for null and undefined, all primitive values have object equivalents that wrap around the primitive values:
- jsxref("String") for the string primitive.
- jsxref("Number") for the number primitive.
- jsxref("BigInt") for the bigint primitive.
- jsxref("Boolean") for the boolean primitive.
- jsxref("Symbol") for the symbol primitive.
The wrapper's valueOf() method returns the primitive value.
-
Interwiki("wikipedia", "Primitive data type") (Wikipedia)
-
- Glossary("JavaScript")
- Glossary("string")
- Glossary("number")
- Glossary("bigint")
- Glossary("boolean")
- Glossary("null")
- Glossary("undefined")
- Glossary("symbol")
- privileged
Privileged code - Javascript code of your extension. For example, code in content scripts.
Non-privileged - Javascript on web-page.
- Glossary
- Security
Users are said to be privileged when they are granted additional rights to a system, or given ultimate access to content in a higher priority level when compared to normal users.
- Interwiki("wikipedia", "Privilege (computing)") on Wikipedia
- Information Security Tutorial
- Accessibility
- Design
- Glossary
Progressive enhancement is a design philosophy that provides a baseline of essential content and functionality to as many users as possible, while delivering the best possible experience only to users of the most modern browsers that can run all the required code.
The word progressive in progressive enhancement means creating a design that achieves a simpler-but-still-usable experience for users of older browsers and devices with limited capabilities, while at the same time being a design that progresses the user experience up to a more-compelling, fully-featured experience for users of newer browsers and devices with richer capabilities.
Feature detection is generally used to determine whether browsers can handle more modern functionality, while polyfills are often used to add missing features with JavaScript.
Special notice should be taken of accessibility. Acceptable alternatives should be provided where possible.
Progressive enhancement is a useful technique that allows web developers to focus on developing the best possible websites while making those websites work on multiple unknown user agents. Glossary("Graceful degradation") is related but is not the same thing and is often seen as going in the opposite direction to progressive enhancement. In reality both approaches are valid and can often complement one another.
- Interwiki("wikipedia", "Progressive enhancement") at Wikipedia
- What is Progressive Enhancement, and why it matters at freeCodeCamp
- Progressive Enhancement reading list 2021 at QuirksMode
- Understanding Progressive Enhancement by Aaron Gustafson; a 2008 A List Apart article which first "placed progressive enhancement at the forefront of web developer thinking"
- Inclusive Web Design For the Future with Progressive Enhancement (related article) by Steve Champeon and Nick Finck; a 2003 SXSW presentation cited by Aaron Gustafson as "unveiling a blueprint for a new way of approaching web development", and naming it "progressive enhancement"
- Composing
- Glossary
- Progressive web apps
Progressive web apps is a term used to describe the modern state of web app development. This involves taking standard web sites/apps that enjoy all the best parts of the Web — such as discoverability via search engines, being linkable via Glossary("URL")s, and working across multiple form factors — and supercharging them with modern APIs (such as Service Workers and Push) and features that confer other benefits more commonly attributed to native apps.
These features include being installable, working offline, and being easy to sync with and re-engage the user from the server.
- The App Center on MDN
- Progressive web apps on Google Developers
- Glossary
- Promise
- Promises
- asynchronous
A jsxref("Promise") is an Glossary("object") that's returned by a Glossary("function") that has not yet completed its work. The promise literally represents a promise made by the function that it will eventually return a result through the promise object.
When the called function finishes its work Glossary("asynchronous", "asynchronously"), a function on the promise object called a resolution (or fulfillment, or completion) handler is called to let the original caller know that the task is complete.
- interwiki("wikipedia", "Futures and promises")
- jsxref("Promise") in the JavaScript Reference.
- Using promises
- Disambiguation
- Glossary
The term property can have several meanings depending on the context. It may refer to:
_GlossaryDisambiguation}}
- Glossary
- Infrastructure
- Protocols
A protocol is a system of rules that define how data is exchanged within or between computers. Communications between devices require that the devices agree on the format of the data that is being exchanged. The set of rules that defines a format is called a protocol.
-
Interwiki("wikipedia", "Communications protocol") on Wikipedia
-
Glossary:
- glossary("TCP")
- glossary("Packet")
- CodingScripting
- Glossary
Prototype-based programming is a style of Glossary("OOP", "object-oriented programming") in which Glossary('Class', 'classes') are not explicitly defined, but rather derived by adding properties and methods to an instance of another class or, less frequently, adding them to an empty object.
In simple words: this type of style allows the creation of an Glossary('Object', 'object') without first defining its Glossary('Class', 'class').
- Interwiki("wikipedia", "Prototype-based programming", "Prototype-based programming") on Wikipedia
- Apps
- Composing
- Glossary
A prototype is a model that displays the appearance and behavior of an application or product early in the development lifecycle.
See Inheritance and the prototype chain
- Interwiki("wikipedia", "Software Prototyping") on Wikipedia
- Glossary
- Proxy
- Server
A proxy server is an intermediate program or computer used when navigating through different networks of the Internet. They facilitate access to content on the World Wide Web. A proxy intercepts requests and serves back responses; it may forward the requests, or not (for example in the case of a cache), and it may modify it (for example changing its headers, at the boundary between two networks).
A proxy can be on the user's local computer, or anywhere between the user's computer and a destination server on the Internet. In general there are two main types of proxy servers:
- A forward proxy that handles requests from and to anywhere on the Internet.
- A reverse proxy taking requests from the Internet and forwarding them to servers in an internal network.
- Proxy servers and tunneling
- Proxy server on Wikipedia
- CSS
- CodingScripting
- Glossary
- Selector
In CSS, a pseudo-class selector targets elements depending on their state rather than on information from the document tree. For example, the selector
a_ cssxref(":visited") }} applies styles only to links that the user has already followed.
- CSS
- CodingScripting
- Glossary
In CSS, a pseudo-element selector applies styles to parts of your document content in scenarios where there isn't a specific HTML element to select. For example, rather than putting the first letter of each paragraph in its own element, you can style them all with
p_ Cssxref("::first-letter") }}.
- CodingScripting
- Glossary
- Pseudocode
Pseudocode refers to code-like syntax that is generally used to indicate to humans how some code syntax works, or illustrate the design of an item of code architecture. It won't work if you try to run it as code.
- interwiki("wikipedia", "Pseudocode", "Pseudocode") on Wikipedia.
- Cryptography
- Glossary
- Public-key cryptography
- Security
Public-key cryptography — or asymmetric cryptography — is a cryptographic system in which keys come in pairs. The transformation performed by one of the keys can only be undone with the other key. One key (the private key) is kept secret while the other is made public.
When used for digital signatures, the private key is used to sign and the public key to verify. This means that anyone can verify a signature, but only the owner of the corresponding private key could have generated it.
When used for encryption, the public key is used to encrypt and the private key is used to decrypt. This gives public-key encryption systems an advantage over symmetric encryption systems in that the encryption key can be made public. Anyone could encrypt a message to the owner of the private key, but only the owner of the private key could decrypt it. However, they are typically much slower than symmetric algorithms and the size of message they can encrypt is proportional to the size of the key, so they do not scale well for long messages.
As a result, it's common for an encryption system to use a symmetric algorithm to encrypt the message, then a public-key system to encrypt the symmetric key. This arrangement can confer the benefits of both systems.
Commonly used public-key cryptosystems are RSA (for both signing and encryption), DSA (for signing) and Diffie-Hellman (for key agreement).
-
- Glossary("Symmetric-key cryptography")
- CodingScripting
- Glossary
- Language
- Python
- programming
Python is a high level general-purpose programming language. It uses a multi-paradigm approach, meaning it supports procedural, object-oriented, and some functional programming constructs.
It was created by Guido van Rossum as a successor to another language (called ABC) between 1985 and 1990, and is currently used on a large array of domains like web development, desktop applications, data science, DevOps, and automation/productivity.
Python is developed under an OSI-approved open source license, making it freely usable and distributable, even for commercial use. Python's license is administered by the Python Software Foundation.
-
interwiki('wikipedia','Python (programming language)','Python') on Wikipedia
-
- Glossary("Java")
- Glossary("JavaScript")
- Glossary("PHP")
- Glossary("Python")
- Glossary("Ruby")
- Glossary
- WebMechanics
Quality values, or q-values and q-factors, are used to describe the order of priority of values in a comma-separated list. It is a special syntax allowed in some HTTP headers and in HTML.
The importance of a value is marked by the suffix ';q=' immediately followed by a value between 0 and 1 included, with up to three decimal digits, the highest value denoting the highest priority. When not present, the default value is 1.
The following syntax
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
indicates the order of priority:
| Value | Priority |
|---|---|
text/html and application/xhtml+xml |
1.0 |
application/xml |
0.9 |
*/* |
0.8 |
If there is no priority defined for the first two values, the order in the list is irrelevant. Nevertheless, with the same quality, more specific values have priority over less specific ones:
text/html;q=0.8,text/*;q=0.8,*/*;q=0.8
| Value | Priority |
|---|---|
text/html |
0.8 (but totally specified) |
text/* |
0.8 (partially specified) |
*/* |
0.8 (not specified) |
Some syntax, like the one of HTTPHeader("Accept"), allow additional specifiers like text/html;level=1. These increase the specificity of the value. Their use is extremely rare.
Starting with Firefox 18, the quality factor values are clamped to 2 decimal places. They used to be clamped to only 1 decimal place in earlier versions (bug(672448)).
- HTTP headers using q-values in their syntax: HTTPHeader("Accept"), HTTPHeader("Accept-Language"), HTTPHeader("TE").
- Header field definitions.
- Definition
- Glossary
- Orientation
- Quaternion
- WebXR
- rotation
A quaternion is the quotient of two 3D vectors and is used in 3D graphics and in accelerometer-based sensors to represent orientation or rotational data.
While mathematical quaternions are more involved than this, the unit quaternions (or rotational quaternions) used to represent rotation while using WebGL or WebXR, for example, are represented using the same syntax as a 3D point. As such, the type domxref("DOMPoint") (or domxref("DOMPointReadOnly")) is used to store quaternions.
- interwiki("wikipedia", "Quaternions and spatial rotation") on Wikipedia
- interwiki("wikipedia", "Quaternion") on Wikipedia
- domxref("XRRigidTransform.orientation") in the WebXR Device API reference
- Glossary
- HTTP
- QUIC
- Reference
- Web Performance
Quick UDP Internet Connection, or QUIC, is an experimental multiplexed transport protocol implemented on UDP. It was developed by Google as a way to experiment with ways to improve TCP and web application delivery.
As TCP is built into the kernel of many operating systems being able to experiment with changes, test them and implement modifications is an extremely slow process. The creation of QUIC allows developers to conduct experiments and try new things faster.
QUIC was designed to support the semantics of HTTP/2. It provides multiplexing, flow control, security and congestion control.
Key features of QUIC include:
- Reduction in connection establishment time.
- Improved congestion control.
- Multiplexing without head-of-line blocking.
- Forward error correction.
- Connection migration.
There is limited browser and server support for QUIC today.
- Glossary
- RAIL
- Timings
- Web Performance
RAIL, an acronym for Response, Animation, Idle, and Load, is a performance model originated by the Google Chrome team in 2015, focused on user experience and performance within the browser. The performance mantra of RAIL is "Focus on the user; the end goal isn't to make your site perform fast on any specific device, it's to make users happy." There are 4 stages of interaction: page load, idle, response to input, and scrolling and animation. In acronym order, the main tenets are:
- Response
-
- : Respond to users immediately, acknowledging any user input in 100ms or less.
- Animation
-
- : When animating, render each frame in under 16ms, aiming for consistency and avoiding jank.
- Idle
- : When using the main JavaScript thread, work in chunks for less than 50ms to free up the thread for user interactions.
- Load
- : Deliver interactive content in less than 1 second.
- CUR
- Documents
- Glossary
- ICO
- JPEG
- PNG
- gif
- raster image
A raster image is an image file defined as a grid of pixels. They're also referred to as bitmaps. Common raster image formats on the Web are JPEG, PNG, GIF, and ICO.
Raster image files usually contain one set of dimensions, but the ICO and CUR formats, used for favicons and CSS cursor images, can contain multiple sizes.
- glossary("Vector images")
- CodingScripting
- Glossary
- Infrastructure
- OpenPractices
- WebMechanics
RDF (Resource Description Framework) is a language developed by W3C for representing information on the World Wide Web, such as Webpages. RDF provides a standard way of encoding resource information so that it can be exchanged in a fully automated way between applications.
- Interwiki("wikipedia", "Resource Description Framework") on Wikipedia
- Glossary
- RUM
- Reference
- Web Performance
Real User Monitoring or RUM measures the performance of a page from real users' machines. Generally, a third party script injects a script on each page to measure and report page load data for every request made. This technique monitors an application's actual user interactions. In RUM, the third party script collects performance metrics from the real users' browsers. RUM helps identify how an application is being used, including the geographic distribution of users and the impact of that distribution on the end user experience.
- CodingScripting
- Glossary
The act of a function calling itself, recursion is used to solve problems that contain smaller sub-problems. A recursive function can receive two inputs: a base case (ends recursion) or a recursive case (resumes recursion).
The following Python code defines a function that takes a number, prints it, and then calls itself again with the number's value -1. It keeps going until the number is equal to 0, in which case it stops.
//
def recurse(x):
if x > 0:
print(x)
recurse(x - 1)
recurse(10)The output will look like this:
10 9 8 7 6 5 4 3 2 1
- Interwiki("wikipedia", "Recursion (computer science)") on Wikipedia
- More details about recursion in JavaScript
- CodingScripting
- Glossary
- NeedsContent
In the context of glossary("object","objects"), this is an glossary("object reference"). On MDN, we could be talking about the glossary("JavaScript") reference itself.
In computing, a reference is a value that indirectly accesses data to retrieve a variable or a record in a computer's memory or other storage device.
- Interwiki("wikipedia", "Reference (computer science)") on Wikipedia
- Glossary
- WebMechanics
Reflow happens when a glossary("browser") must process and draw part or all of a webpage again, such as after an update on an interactive site.
- CodingScripting
- Glossary
- Regular Expression
Regular expressions (or regex) are rules that govern which sequences of characters come up in a search.
Regular expressions are implemented in various languages, but the best-known implementation is the Perl Implementation, which has given rise to its own ecosystem of implementations called PCRE (Perl Compatible Regular Expression). On the Web, glossary("JavaScript") provides another regex implementation through the jsxref("RegExp") object.
- Interwiki("wikipedia", "Regular expressions") on Wikipedia
- Interactive tutorial
- Visualized Regular Expression
- Writing regular expressions in JavaScript
- Glossary
- Infrastructure
- Rendering engine
- Web browser engine
A rendering engine is software that draws text and images on the screen. The engine draws structured text from a document (often glossary("HTML")), and formats it properly based on the given style declarations (often given in glossary("CSS")). Examples of layout engines: glossary("Blink"), glossary("Gecko"), EdgeHTML, glossary("WebKit").
- Interwiki("wikipedia", "Web browser engine") on Wikipedia
- Venkatraman.R - Behind Browsers (Part 1, Basics)
- Glossary
- Infrastructure
- Intro
- Repo
- Repository
In a revision control system like Glossary("Git") or Glossary("SVN"), a repo (i.e. "repository") is a place that hosts an application's code source, together with various metadata.
- Repository on Wikipedia
- CSP
- HTTP
- Policy
- Reporting
- Security
- Violation
Glossary("CSP") reporting directives are used in a HTTPHeader("Content-Security-Policy") header and control the reporting process of CSP violations.
See Reporting directives for a complete list.
-
- Glossary("CSP")
- Glossary("Fetch directive")
- Glossary("Document directive")
- Glossary("Navigation directive")
-
Reference
- https://www.w3.org/TR/CSP/#directives-reporting
- HTTPHeader("Content-Security-Policy/upgrade-insecure-requests", "upgrade-insecure-requests")
- HTTPHeader("Content-Security-Policy/block-all-mixed-content", "block-all-mixed-content")
- HTTPHeader("Content-Security-Policy/require-sri-for", "require-sri-for") _deprecated_inline}}
- HTTPHeader("Content-Security-Policy")
- Glossary
- WebMechanics
A representation header is an glossary("HTTP_header", "HTTP header") that describes the particular representation of the resource sent in an HTTP message body.
Representations are different forms of a particular resource. For example, the same data might be formatted as a particular media type such as XML or JSON, localised to a particular written language or geographical region, and/or compressed or otherwise encoded for transmission. The underlying resource is the same in each case, but its representation is different.
Clients specify the formats that they prefer to be sent during content negotiation (using Accept-* headers), and the representation headers tell the client the format of the selected representation they actually received.
Representation headers may be present in both HTTP request and response messages.
If sent as a response to a HEAD request, they describe the body content that would be selected if the resource was actually requested.
Representation headers include: HTTPHeader("Content-Type"), HTTPHeader("Content-Encoding"), HTTPHeader("Content-Language"), and HTTPHeader("Content-Location").
- RFC 7231, section 3: Representations
- List of all HTTP headers
- Glossary("Payload header")
- glossary("Entity header")
- HTTPHeader("Digest")/ HTTPHeader("Want-Digest")
- Glossary
- WebMechanics
A request header is an glossary("HTTP header") that can be used in an HTTP request to provide information about the request context, so that the server can tailor the response. For example, the HTTPHeader("Accept", "Accept-*") headers indicate the allowed and preferred formats of the response. Other headers can be used to supply authentication credentials (e.g. HTTPHeader("Authorization")), to control caching, or to get information about the user agent or referrer, etc.
Not all headers that can appear in a request are referred to as request headers by the specification. For example, the HTTPHeader("Content-Type") header is referred to as a glossary("representation header").
In addition, CORS defines a subset of request headers as glossary('simple header', 'simple headers'), request headers that are always considered authorized and are not explicitly listed in responses to glossary("preflight request", "preflight") requests.
The HTTP message below shows a few request headers after a HTTPMethod("GET") request:
GET /home.html HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/testpage.html
Connection: keep-alive
Upgrade-Insecure-Requests: 1
If-Modified-Since: Mon, 18 Jul 2016 02:36:04 GMT
If-None-Match: "c561c68d0ba92bbeb8b0fff2a9199f722e3a621a"
Cache-Control: max-age=0- Glossary
- Timings
- Web Performance
Diagnosing performance issues requires performance data at the granularity of the resource. The Resource Timing API is a JavaScript API that is able to capture timing information for each individual resource that is fetched when a page is loaded.
- Glossary
- WebMechanics
A response header is an glossary("HTTP header") that can be used in an HTTP response and that doesn't relate to the content of the message. Response headers, like HTTPHeader("Age"), HTTPHeader("Location") or HTTPHeader("Server") are used to give a more detailed context of the response.
Not all headers appearing in a response are categorized as response headers by the specification. For example, the HTTPHeader("Content-Type") header is a glossary("representation header") indicating the original type of data in the body of the response message (prior to the encoding in the HTTPHeader("Content-Encoding") representation header being applied). However, "conversationally" all headers are usually referred to as response headers in a response message.
The following shows a few response and representation headers after a HTTPMethod("GET") request.
200 OK
Access-Control-Allow-Origin: *
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Mon, 18 Jul 2016 16:06:00 GMT
Etag: "c561c68d0ba92bbeb8b0f612a9199f722e3a621a"
Keep-Alive: timeout=5, max=997
Last-Modified: Mon, 18 Jul 2016 02:36:04 GMT
Server: Apache
Set-Cookie: mykey=myvalue; expires=Mon, 17-Jul-2017 16:06:00 GMT; Max-Age=31449600; Path=/; secure
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
X-Backend-Server: developer2.webapp.scl3.mozilla.com
X-Cache-Info: not cacheable; meta data too large
X-kuma-revision: 1085259
x-frame-options: DENY
-
- Glossary("Representation header")
- Glossary("HTTP header")
- Glossary("Response header")
- Glossary("Fetch metadata response header")
- Glossary("Request header")
- Accessibility
- Design
- Glossary
- Responsive web design
Responsive Web Design (RWD) is a Web development concept focusing on making sites look and behave optimally on all personal computing devices, from desktop to mobile.
- Architecture
- Beginner
- Glossary
- HTTP
- Rest
- WebMechanics
REST (Representational State Transfer) refers to a group of software architecture design constraints that bring about efficient, reliable and scalable distributed systems.
The basic idea of REST is that a resource, e.g. a document, is transferred via well-recognized, language-agnostic, and reliably standardized client/server interactions. Services are deemed RESTful when they adhere to these constraints.
HTTP APIs in general are sometimes colloquially referred to as RESTful APIs, RESTful services, or REST services, although they don't necessarily adhere to all REST constraints. Beginners can assume a REST API means an HTTP service that can be called using standard web libraries and tools.
- restapitutorial.com
- restcookbook.com
- Interwiki("wikipedia", "Representational_state_transfer", "REST") on Wikipedia
- REST Architecture
- Beginner
- CSS
- Design
- Guide
Red Green Blue (RGB) is a color model that represents colors as mixtures of three underlying components (or channels), namely, red, green, and blue. Each color is described by a sequence of three numbers (typically between 0.0 and 1.0, or between 0 and 255) that represent the different intensities (or contributions) of red, green, and blue, in determining the final color.
There are many ways to describe the RGB components of a color. In Glossary("CSS") they can be represented as a single 24-bit integer in hexadecimal notation (for example, #``add8e6 is light blue), or in functional notation as three separate 8-bit integers (for example, rgb(46, 139, 87) is sea green). In Glossary("OpenGL"), Glossary("WebGL"), and Glossary("GLSL") the red-green-blue components are fractions (floating-point numbers between 0.0 and 1.0), although in the actual color buffer they are typically stored as 8-bit integers. Graphically, a color can be represented as a point in a three-dimensional grid or cube, where each dimension (or axis) corresponds to a different channel.
- B2G
- Firefox OS
- Glossary
- Infrastructure
- Intro
- Mobile
- Telephony
RIL (Radio Interface Layer) is a mobile operating system component which communicates between the device's software and the device's phone, radio, or modem hardware.
- Interwiki("wikipedia", "Radio Interface Layer") on Wikipedia
- CodingScripting
- Glossary
A PRNG (pseudorandom number generator) is an algorithm that outputs numbers in a complex, seemingly unpredictable pattern. Truly random numbers (say, from a radioactive source) are utterly unpredictable, whereas all algorithms are predictable, and a PRNG returns the same numbers when passed the same starting parameters or seed.
PRNGs can be used for a variety of applications, such as games.
A cryptographically secure PRNG is a PRNG with certain extra properties making it suitable for use in cryptography. These include:
- that it's computationally unfeasible for an attacker (without knowledge of the seed) to predict its output
- that if an attacker can work out its current state, this should not enable the attacker to work out previously emitted numbers.
Most PRNGs are not cryptographically secure.
- Interwiki("wikipedia", "Pseudorandom number generator") on Wikipedia
- jsxref("Math.random()"), a built-in JavaScript PRNG function. Note that this is not a cryptographically secure PRNG.
- domxref("Crypto.getRandomValues()"): this is intended to provide cryptographically secure numbers.
- Glossary
- Infrastructure
Robots.txt is a file which is usually placed in the root of any website. It decides whether Glossary("crawler", "crawlers") are permitted or forbidden access to the web site.
For example, the site admin can forbid crawlers to visit a certain folder (and all the files therein contained) or to crawl a specific file, usually to prevent those files being indexed by other search engines.
- Interwiki("wikipedia", "Robots.txt") on Wikipedia
- https://developers.google.com/search/reference/robots_txt
- Standard specification draft: https://datatracker.ietf.org/doc/html/draft-rep-wg-topic
- https://www.robotstxt.org/
- Beginner
- Glossary
- Performance
- Resource
- Round Trip Time
- Web Performance
Round Trip Time (RTT) is the length time it takes for a data packet to be sent to a destination plus the time it takes for an acknowledgment of that packet to be received back at the origin. The RTT between a network and server can be determined by using the
pingcommand.
$ ping example.com
PING example.com (216.58.194.174): 56 data bytes
64 bytes from 216.58.194.174: icmp_seq=0 ttl=55 time=25.050 ms
64 bytes from 216.58.194.174: icmp_seq=1 ttl=55 time=23.781 ms
64 bytes from 216.58.194.174: icmp_seq=2 ttl=55 time=24.287 ms
64 bytes from 216.58.194.174: icmp_seq=3 ttl=55 time=34.904 ms
64 bytes from 216.58.194.174: icmp_seq=4 ttl=55 time=26.119 ms
--- google.com ping statistics ---
5 packets transmitted, 5 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 23.781/26.828/34.904/4.114 msIn the above example, the average round trip time is shown on the final line as 26.8ms.
- Intro
There are three definitions for routers on the web:
- For the network layer, the router is a networking device that decides data Glossary('Packet')s directions. They are distributed by retailers allowing user interaction to the internet.
- For a _Glossary('SPA', 'Single-page application' _) in the application layer, a router is a library that decides what web page is presented by a given Glossary('URL'). This middleware module is used for all URL functions, as these are given a path to a file that is rendered to open the next page.
- In the implementation of an Glossary('API') in a service layer, a router is a software component that parses a request and directs or routes the request to various handlers within a program. The router code usually accepts a response from the handler and facilitates its return to the requester.
For network layer context:
- Interwiki("wikipedia", "Router (computing)") on Wikipedia
For SPA in application layer context, most of the popular SPA frameworks has its routing library:
- Glossary
- OpenPractices
- RSS
- Sharing
- WebMechanics
RSS (Really Simple Syndication) refers to several XML document formats designed for publishing site updates. When you subscribe to a website's RSS feed, the website sends information and updates to your RSS reader in an RSS document called a feed, so you don't need to check all your favorite websites manually.
- Interwiki("wikipedia", "RSS") on Wikipedia
- Latest specification
Rsync is an open-source file synchronizing tool that provides incremental file transfer It can be used over insecure and secure transports (like SSH). It is available on most Unix-based systems (such as macOS and Linux) and Windows. There are also GUI-based tools that use rsync, for example, Acrosync.
A basic command looks like this:
rsync [-options] SOURCE user@x.x.x.x:DESTINATION-optionsis a dash followed by one or more letters, for example-vfor verbose error messages, and-bto make backups. See the full list of options at the rsync man page. (Search for "Options summary.")SOURCEis the path to the local file or directory that you want to copy or synchronizeuser@is the credentials of the user on the remote server you want to copy files over to.x.x.x.xis the IP address of the remote server.DESTINATIONis the path to the location you want to copy your directory or files to on the remote server.
You can also make a connection over SSH using the -e option as shown:
rsync [-options] -e "ssh [SSH DETAILS GO HERE]" SOURCE user@x.x.x.x:DESTINATIONThere are numerous examples on the Internet, including those at the official website, and at the Wikipedia entry for rsync.
- Glossary
- Media
- Networking
- Protocol
- RTCP
- control
The RTP Control Protocol (RTCP) is a partner to the Glossary("RTP") protocol. RTCP is used to provide control and statistical information about an RTP media streaming session.
This lets control and statistics packets be separated logically and functionally from the media streaming while using the underlying packet delivery layer to transmit the RTCP signals as well as the RTP and media contents.
RTCP periodically transmits control packets to all of an RTP session's participants, using the same mechanism that is being used to transmit the data packets. That underlying protocol handles the multiplexing of the data and control packets and may use separate network ports for each type of packet.
- Introduction to the Real-time Transport Protocol
- interwiki("wikipedia", "RTP Control Protocol")
- RFC(3550, 6, "RFC 3550 Section 6")
- Composing
- Format
- Glossary
- RTF
- Rich Text Format
RTF (Rich Text Format) is a plain-text-based file format with support for formatting instructions (like bold or italic).
Three programmers in the Microsoft Word team created RTF in the 1980s, and Microsoft continued to develop the format until 2008. However, many word-processing programs can still read and write RTF.
- Interwiki("wikipedia", "Rich Text Format") on Wikipedia
- final specification from Microsoft
- Composing
- Glossary
- Localization
RTL (Right To Left) is a Glossary("locale") property indicating that text is written from right to left.
For example, the he locale (for Hebrew) specifies right-to-left. Arabic (ar) is another common language written RTL.
The opposite of RTL, LTR (Left To Right) is used in other languages, including English (en, en-US, en-GB, etc.), Spanish (es), and French (fr).
-
- Glossary("Localization")
- Glossary("LTR", "LTR (Left to Right)")
- Glossary("RTL", "RTL (Right to Left)")
- Glossary
- Network
- Protocol
- RTP
The Real-time Transport Protocol (RTP) is a network protocol which described how to transmit various media (audio, video) from one endpoint to another in a real-time fashion. RTP is suitable for video-streaming application, telephony over glossary("IP") like Skype and conference technologies.
The secure version of RTP, SRTP, is used by WebRTC, and uses encryption and authentication to minimize the risk of denial-of-service attacks and security breaches.
RTP is rarely used alone; instead, it is used in conjunction with other protocols like glossary("RTSP") and glossary("SDP").
- Introduction to the Real-time Transport Protocol
- Interwiki("wikipedia", "Real-time_Transport_Protocol","RTP") on Wikipedia
- RFC(3550) (one of the documents that specify precisely how the protocol works)
- Glossary
- Real-time streaming protocol
- Reference
- rtsp
Real-time streaming protocol (RTSP) is a network protocol that controls how the streaming of a media should occur between a glossary("server") and a glossary("client"). Basically, RTSP is the protocol that describes what happens when you click "Pause"/"Play" when streaming a video. If your computer were a remote control and the streaming server a television, RTSP would describe how the instruction of the remote control affects the TV.
-
Interwiki("wikipedia", "Real_Time_Streaming_Protocol","RTSP") on Wikipedia
-
RFC 7826 (one of the documents that specifies precisely how the protocol works)
-
- Glossary("RTSP")
- CodingScripting
- Glossary
- Ruby
Ruby is an open-source programming language. In a glossary("world wide web","Web") context, Ruby is often used server-side with the Ruby On Rails (ROR) framework to produce websites/apps.
Ruby is also a method for annotating east Asian text in HTML documents to provide pronunciation information; see the HTMLElement("ruby") element.
- Ruby on Wikipedia
- Ruby's official web site
- Ruby On Rails' official web site
- Glossary
- Disambiguation
The term safe can have several meanings depending on the context. It may refer to:
_GlossaryDisambiguation}}
- Glossary
- Same-origin policy
- origin
The same-origin policy is a critical security mechanism that restricts how a document or script loaded from one Glossary("origin") can interact with a resource from another origin.
It helps isolate potentially malicious documents, reducing possible attack vectors.
-
- Glossary("CORS")
- Glossary("origin")
- CodingScripting
- Glossary
- SCM
SCM (Source Control Management) is a system for managing source code. Usually it refers to the use of software to handle versioning of source files. A programmer can modify source code files without being afraid of editing out useful stuff, because a SCM keeps track of how the source code has changed and who made the changes.
Some SCM systems include CVS, SVN, GIT.
- Interwiki("wikipedia", "Revision control") on Wikipedia
- CodingScripting
- Glossary
- JavaScript
The current context of execution. The context in which glossary("value","values") and expressions are "visible" or can be referenced. If a glossary("variable") or other expression is not "in the current scope," then it is unavailable for use. Scopes can also be layered in a hierarchy, so that child scopes have access to parent scopes, but not vice versa.
A glossary("function") serves as a closure in glossary("JavaScript"), and thus creates a scope, so that (for example) a variable defined exclusively within the function cannot be accessed from outside the function or within other functions. For instance, the following is invalid:
//
function exampleFunction() {
var x = 'declared inside function'; // x can only be used in exampleFunction
console.log('Inside function');
console.log(x);
}
console.log(x); // Causes errorHowever, the following code is valid due to the variable being declared outside the function, making it global:
//
var x = 'declared outside function';
exampleFunction();
function exampleFunction() {
console.log('Inside function');
console.log(x);
}
console.log('Outside function');
console.log(x);- Interwiki("wikipedia", "Scope (computer science)") on Wikipedia
- Accessibility
- Glossary
- Screen reader
- Voice Over
- Voiceover
Screen readers are software applications that attempt to convey what is seen on a screen display in a non-visual way, usually as text to speech, but also into braille or sound icons. Screen readers are essential to people who are blind, as well as useful to people who are visually impaired, illiterate, or have a learning disability. There are some browser extension screen readers, but most screen readers operate system-wide for all user applications, not just the browser.
In terms of web accessibility, most user agents provide an accessibility object model and screen readers interact with dedicated accessibility APIs, using various operating system features and employing hooking techniques.
macOS comes with VoiceOver, a built-in screen reader. To access VoiceOver, go to System Preferences > Accessibility > VoiceOver. You can also toggle VoiceOver on and off with fn+command + F5. VoiceOver both reads aloud and displays content. The content read aloud is displayed in a dark grey box.
Desktop/laptop screen reader users navigate websites with a keyboard or other non-pointing device. The best way to emulate use is to do the same.
Just like keyboard navigation without VoiceOver, you can navigate through interactive elements using the tab key and the arrow keys:
- Next interactive element: Tab
- Previous interactive element: Shift + Tab
- Next radio button in a same named-group: right or down arrow
- Previous radio button in a same named-group: left or up arrow
Navigating through the content of a page is done with the tab key and a series of other keys along with Control + Option keys
- Next heading: Control + Option + H
- Next list: Control + Option + X
- Next graphic: Control + Option + G
- Next table: Control + Option + T
- Down an HTML hierarchical order Control + Option + right arrow
- Previous heading: Shift + Control + Option + H
- Previous list: Shift + Control + Option + X
- Previous graphic: Shift + Control + Option + G
- Previous table: Shift + Control + Option + T
- Up an HTML hierarchical order: Control + Option + left arrow
- Glossary
- HTML
- HTML Content Categories
- scripts
In an Glossary("HTML") document, script-supporting elements are those elements that don't directly contribute to the appearance or layout of the page; instead, they're either scripts or contain information that's only used by scripts.
These elements may be important, but do not affect the displayed page unless the page's scripts explicitly cause them to do so.
There are only two script-supporting elements: HTMLElement("script") and HTMLElement("template").
SectionOnPage("/en-US/docs/Web/HTML/Kinds_of_HTML_content", "Script-supporting elements")
- CodingScripting
- Glossary
- JavaScript
In glossary("JavaScript"), a block is a collection of related glossary("statement","statements") enclosed in braces ("{}"). For example, you can put a block of statements after an jsxref("Statements/if...else","if (condition)") block, indicating that the interpreter should run the code inside the block if the condition is true, or skip the whole block if the condition is false.
- Glossary
- scroll container
A scroll container is created by applying
overflow: scrollto a container, oroverflow: autowhen there is enough content to cause overflow.
The scroll container allows the user to scroll through parts of the overflow region that would otherwise be clipped and hidden from view. The visible part of the scroll container is referred to as the glossary("Scrollport", "scrollport").
-
- glossary("Scroll container")
- glossary("Scrollport")
-
Related CSS Properties:
- cssxref("overflow")
- Glossary
- scrollport
The scrollport is the visual viewport of a glossary("Scroll container", "scroll container") in a document. A scroll container is created by applying
overflow: scrollto a container, oroverflow: autowhen there is enough content to cause overflow. The scrollport coincides with the padding box of that container and represents the content that can be seen as the box is scrolled.
-
- glossary("Scroll container")
- glossary("Scrollport")
-
Related CSS Properties:
- cssxref("overflow")
- Glossary
- Infrastructure
- SCTP
- WebRTC
SCTP (Stream Control Transmission glossary("Protocol")) is an Glossary("IETF") standard for a transport protocol which enables the reliable, in-order transmission of messages while offering congestion control, multi-homing, and other features to improve reliability and stability of the connection. It's used for sending traditional telephone calls over the Internet, but is also used for Glossary("WebRTC") data.
- RFC(4960, "Stream Control Transmission Protocol")
- Interwiki("wikipedia", "Stream Control Transmission Protocol") on Wikipedia
- Advanced
- Collaborating
- Glossary
- Infrastructure
- Protocol
- WebRTC
SDP (Session Description glossary("Protocol")) is the standard describing a Glossary("P2P","peer-to-peer") connection. SDP contains the Glossary("codec"), source address, and timing information of audio and video.
Here is a typical SDP message:
v=0
o=alice 2890844526 2890844526 IN IP4 host.anywhere.com
s=
c=IN IP4 host.anywhere.com
t=0 0
m=audio 49170 RTP/AVP 0
a=rtpmap:0 PCMU/8000
m=video 51372 RTP/AVP 31
a=rtpmap:31 H261/90000
m=video 53000 RTP/AVP 32
a=rtpmap:32 MPV/90000
SDP is never used alone, but by protocols like Glossary("RTP") and Glossary("RTSP"). SDP is also as component of Glossary("WebRTC"), which uses SDP as a way of describing a session.
- WebRTC protocols
- Interwiki("wikipedia", "Session Description Protocol") on Wikipedia
- Definition
- Glossary
- Indexing
- Search Engine
- Searching
- Web Crawling
- WebMechanics
- World Wide Web
- details
A search engine is a software system that collects information from the Glossary("World Wide Web") and presents it to users who are looking for specific information.
A search engine conducts the following processes:
- Web crawling: Searching web sites by navigating Glossary("Hyperlink", "Hyperlinks") on web pages, both within a site, and from one site to another. A web site owner can exclude areas of the site from being accessed by a search engine's web crawler (or spider), by defining "robot exclusion" information in a file named
robots.txt. - Indexing: Associating keywords and other information with specific web pages that have been crawled. This enables users to find relevant pages as quickly as possible.
- Searching: Looking for relevant web pages based on queries consisting of key words and other commands to the search engine. The search engine finds the URLs of pages that match the query, and ranks them based on their relevance. It then presents results to the user in order of the ranking.
The most popular search engine is Google. Other top search engines include Yahoo!, Bing, Baidu, and AOL.
- Web search engine on Wikipedia
- Search engine on Webopedia
- How Internet search engines work on How Stuff Works
- Glossary
- Infrastructure
A Second Level Domain (Glossary("SLD")) is the part of the domain name that is located right before a Top Level Domain (Glossary("TLD")).
For example, in mozilla.org the SLD is mozilla and the TLD is org.
A domain name is not limited to a TLD and an SLD. Additional subdomains can be created in order to provide additional information about various functions of a server or to delimit areas under the same domain. For example, www is a commonly used subdomain to indicate the domain points to a web server.
As another example, in developer.mozilla.org, the developer subdomain is used to specify that the subdomain contains the developer section of the Mozilla website.
-
Interwiki("wikipedia", "Second-level domain", "SLD") (Wikipedia)
-
- Glossary("DNS")
- Glossary("Domain")
- Glossary("Domain name")
- Glossary("TLD")
- Glossary
- Security
- Secure contexts
A secure context is a
WindoworWorkerin which certain minimum standards of authentication and confidentiality are met. Many Web APIs and features are only accessible in secure contexts, reducing the opportunity for misuse by malicious code.
For more information see: Web > Security > Secure Contexts.
- Cryptography
- Glossary
- Privacy
- Security
A signature, or digital signature, is a glossary("protocol") showing that a message is authentic.
From the glossary("hash") of a given message, the signing process first generates a digital signature linked to the signing entity, using the entity's private glossary("key").
On receiving the message, the verification process
- authenticates the sender - uses the sender's public key to glossary("decryption","decrypt") the signature and recover the hash, which can only be created with the sender's private key, and
- checks message integrity - compares the hash with a newly calculated one from the received document (the two hashes will differ if the document has been tampered with)
The system fails if the private key is compromised or the recipient is deceitfully given the wrong public key.
- Interwiki("wikipedia", "Digital signature") on Wikipedia
- See glossary("digest"), glossary("encryption")
- Glossary
A glossary("JavaScript") glossary("function") that runs as soon as it is defined. Also known as an glossary("IIFE") (Immediately Invoked Function Expression).
See the IIFE glossary page linked above for more information.
- CodingScripting
- Glossary
- HTML
- semantics
In programming, Semantics refers to the meaning of a piece of code — for example "what effect does running that line of JavaScript have?", or "what purpose or role does that HTML element have" (rather than "what does it look like?".)
In JavaScript, consider a function that takes a string parameter, and returns an htmlelement("li") element with that string as its textContent. Would you need to look at the code to understand what the function did if it was called build('Peach'), or createLiWithContent('Peach')?
In CSS, consider styling a list with li elements representing different types of fruits. Would you know what part of the DOM is being selected with div > ul > li, or .fruits__item?
In HTML, for example, the htmlelement("h1") element is a semantic element, which gives the text it wraps around the role (or meaning) of "a top level heading on your page."
<h1>This is a top level heading</h1>By default, most browser's user agent stylesheet will style an htmlelement("h1") with a large font size to make it look like a heading (although you could style it to look like anything you wanted).
On the other hand, you could make any element look like a top level heading. Consider the following:
<span style="font-size: 32px; margin: 21px 0;">Is this a top level heading?</span>This will render it to look like a top level heading, but it has no semantic value, so it will not get any extra benefits as described above. It is therefore a good idea to use the right HTML element for the right job.
HTML should be coded to represent the data that will be populated and not based on its default presentation styling. Presentation (how it should look), is the sole responsibility of CSS.
Some of the benefits from writing semantic markup are as follows:
- Search engines will consider its contents as important keywords to influence the page's search rankings (see glossary("SEO"))
- Screen readers can use it as a signpost to help visually impaired users navigate a page
- Finding blocks of meaningful code is significantly easier than searching through endless
divs with or without semantic or namespaced classes - Suggests to the developer the type of data that will be populated
- Semantic naming mirrors proper custom element/component naming
When approaching which markup to use, ask yourself, "What element(s) best describe/represent the data that I'm going to populate?" For example, is it a list of data?; ordered, unordered?; is it an article with sections and an aside of related information?; does it list out definitions?; is it a figure or image that needs a caption?; should it have a header and a footer in addition to the global site-wide header and footer?; etc.
These are some of the roughly 100 semantic elements available:
- htmlelement("article")
- htmlelement("aside")
- htmlelement("details")
- htmlelement("figcaption")
- htmlelement("figure")
- htmlelement("footer")
- htmlelement("header")
- htmlelement("main")
- htmlelement("mark")
- htmlelement("nav")
- htmlelement("section")
- htmlelement("summary")
- htmlelement("time")
-
HTML element reference on MDN
-
interwiki("wikipedia", "Semantics#Computer_science", "The meaning of semantics in computer science") on Wikipedia
-
- Glossary("SEO")
-
Semantic elements in HTML:
- htmlelement("article")
- htmlelement("aside")
- htmlelement("details")
- htmlelement("figcaption")
- htmlelement("figure")
- htmlelement("footer")
- htmlelement("header")
- htmlelement("main")
- htmlelement("mark")
- htmlelement("nav")
- htmlelement("section")
- htmlelement("summary")
- htmlelement("time")
- Glossary
- Intro
- SEO
- Search
- WebMechanic
SEO (Search Engine Optimization) is the process of making a website more visible in search results, also termed improving search rankings.
Search engines Glossary("Crawler", "crawl") the web, following links from page to page, and index the content found. When you search, the search engine displays the indexed content. Crawlers follow rules. If you follow those rules closely when doing SEO for a website, you give the site the best chances of showing up among the first results, increasing traffic and possibly revenue (for ecommerce and ads).
Search engines give some guidelines for SEO, but big search engines keep result ranking as a trade secret. SEO combines official search engine guidelines, empirical knowledge, and theoretical knowledge from science papers or patents.
SEO methods fall into three broad classes:
- technical
-
- : Tag the content using semantic Glossary("HTML"). When exploring the website, crawlers should only find the content you want indexed.
- copywriting
- : Write content using your visitors' vocabulary. Use text as well as images so that crawlers can understand the subject.
- popularity
- : You get most traffic when other established sites link to your site.
- Interwiki("wikipedia", "SEO") on Wikipedia
- Google Search Central
- CodingScripting
- Glossary
- JavaScript
- Serialization
The process whereby an object or data structure is translated into a format suitable for transferral over a network, or storage (e.g. in an array buffer or file format).
In Glossary("JavaScript"), for example, you can serialize an object to a Glossary("JSON") Glossary("string") by calling the Glossary("function") jsxref("JSON.stringify()").
Glossary("CSS") values are serialized by calling the function domxref("CSSStyleDeclaration.getPropertyValue()").
- Serialization on Wikipedia
- Glossary
- Reference
- Server Timing
- Web Performance
The Server Timing specification enables the server to communicate performance metrics from the request-response cycle to the user agent, and utilizes a JavaScript interface to allow applications to collect, process, and act on these metrics to optimize application delivery.
- Glossary
- Infrastructure
- Networking
- Protocol
- Server
A server is a software or hardware offering a service to a user, usually referred to as client. A hardware server is a shared computer on a network, usually powerful and housed in a data center. A software server (often running on a hardware server) is a program that provides services to client programs or a glossary("UI","user interface") to human clients.
Services are provided generally over local area networks or wide area networks such as the internet. A client program and server program traditionally connect by passing messages encoded using a glossary("protocol") over an glossary("API").
For example:
- An Internet-connected Web server is sending a glossary("HTML") file to your browser software so that you can read this page
- Local area network server for file, name, mail, print, and fax
- Minicomputers, mainframes, and super computers at data centers
- Introduction to servers
- Interwiki("wikipedia", "Server (computing)") on Wikipedia
- Glossary
- Security
- session hijacking
Session hijacking occurs when an attacker takes over a valid session between two computers. The attacker steals a valid session ID in order to break into the system and snoop data.
Most authentication occurs only at the start of a glossary("TCP") session. In TCP session hijacking, an attacker gains access by taking over a TCP session between two machines in mid session.

- no account lockout for invalid session IDs
- weak session-ID generation algorithm
- insecure handling
- indefinite session expiration time
- short session IDs
- transmission in plain text
- Sniff, that is perform a man-in-the-middle (MITM) attack, place yourself between victim and server.
- Monitor packets flowing between server and user.
- Break the victim machine's connection.
- Take control of the session.
- Inject new packets to the server using the Victim's Session ID.
- create a secure communication channel with SSH (secure shell)
- pass authentication cookies over HTTPS connection
- implement logout functionality so the user can end the session
- generate the session ID after successful login
- pass encrypted data between the users and the web server
- use a string or long random number as a session key
- Interwiki("wikipedia", "Session hijacking") on Wikipedia
- CodingScripting
- Composing
- Glossary
- SGML
The Standard Generalized Markup Language (SGML) is an Glossary("ISO") specification for defining declarative markup languages.
On the web, Glossary("HTML") 4, Glossary("XHTML"), and Glossary("XML") are popular SGML-based languages. It is worth noting that since its fifth edition, HTML is no longer SGML-based and has its own parsing rules.
- Interwiki("wikipedia", "SGML") on Wikipedia
- Introduction to SGML
- DOM
- Glossary
- Shadow Tree
- shadow dom
A shadow tree is a tree of DOM Glossary("node", "nodes") whose topmost node is a shadow root; that is, the topmost node within a shadow DOM. A shadow tree is a hidden set of standard DOM nodes which is attached to a standard DOM node that serves as a host. The hidden nodes are not directly visible using regular DOM functionality, but require the use of a special Shadow DOM API to access.
Nodes within the shadow tree are not affected by anything applied outside the shadow tree, and vice versa. This provides a way to encapsulate implementation details, which is especially useful for custom elements and other advanced design paradigms.
- Using shadow DOM
- domxref("Element.shadowRoot") and domxref("Element.attachShadow()")
- domxref("ShadowRoot")
- HTMLElement("slot")
- CodingScripting
- Glossary
A shim is a piece of code used to correct the behavior of code that already exists, usually by adding new API that works around the problem. This differs from a Glossary("polyfill"), which implements a new API that is not supported by the stock browser as shipped.
- Interwiki("wikipedia", "Shim (computing)", "Shim") on Wikipedia
- Disambiguation
- Glossary
The term signature can have several meanings depending on the context. It may refer to:
_GlossaryDisambiguation}}
- Interwiki("wikipedia", "Signature(disambiguation)", "Signature"_) on Wikipedia
- CodingScripting
- Glossary
- JavaScript
SIMD (pronounced "sim-dee") is short for Single Instruction/Multiple Data which is one Interwiki("wikipedia","Flynn%27s_taxonomy","classification of computer architectures"). SIMD allows one same operation to be performed on multiple data points resulting in data level parallelism and thus performance gains — for example, for 3D graphics and video processing, physics simulations or cryptography, and other domains.
See also Glossary("SISD") for a sequential architecture with no parallelism in either the instructions or the data sets.
-
Interwiki("wikipedia", "SIMD") on Wikipedia
-
- Glossary("SIMD")
- Glossary("SISD")
- CORS
- Glossary
- HTTP
- Infrastructure
Old term for Glossary("CORS-safelisted request header").
- CORS
- Glossary
- HTTP
Old term for Glossary("CORS-safelisted response header").
- CodingScripting
- Glossary
SISD is short for Single Instruction/Single Data which is one Interwiki("wikipedia","Flynn%27s_taxonomy","classification of computer architectures"). In SISD architecture, a single processor executes a single instruction and operates on a single data point in memory.
See also Glossary("SIMD") for a parallel architecture that allows one same operation to be performed on multiple data points.
- Interwiki("wikipedia", "SISD") on Wikipedia
- Accessibility
- Glossary
- Search
- Site map
A site map or sitemap is a list of pages of a web site.
Structured listings of a site's page help with search engine optimization, providing a link for web crawlers such as search engines to follow. Site maps also help users with site navigation by providing an overview of a site's content in a single glance.
- Glossary
- Security
- WebMechanics
The site of a piece of web content is determined by the registrable domain of the host within the origin. This is computed by consulting a Public Suffix List to find the portion of the host which is counted as the public suffix (e.g.
com,orgorco.uk).
The concept of a site is used in SameSite cookies, as well as a web application's Cross-Origin Resource Policy.
These are the same site because the registrable domain of mozilla.org is the same (different host and files path don't matter):
https://developer.mozilla.org/en-US/docs/https://support.mozilla.org/en-US/
These are the same site because scheme and port are not relevant:
http://example.com:8080https://example.com
These are not same site because the registrable domain of the two URLs differs:
https://developer.mozilla.org/en-US/docs/https://example.com
- What is a URL
- Glossary("Origin")
- Same-origin policy
- Glossary
- Infrastructure
An SLD (Second Level Domain) is the part of the domain name that is located right before a Top Level Domain (Glossary("TLD")). For example, in
mozilla.orgthe SLD ismozillaand the TLD isorg.
See Second Level Domain for more information.
- CodingScripting
- Glossary
- JavaScript
- Sloppy
Glossary("ECMAScript") 5 and later let scripts opt in to a new strict mode, which alters the semantics of JavaScript in several ways to improve its resiliency and which make it easier to understand what's going on when there are problems.
The normal, non-strict mode of JavaScript is sometimes referred to as sloppy mode. This isn't an official designation, but you are likely to come across it if you spend time doing serious JavaScript code.
- "Strict Mode" in chapter 7 ("JavaScript Syntax") in the book Speaking JavaScript.
- Community
- Glossary
- Intermediate
- MDN
- URL
- Web
A Slug is the unique identifying part of a web address, typically at the end of the URL. In the context of MDN, it is the portion of the URL following "<locale>/docs/".
- Composing
- Glossary
- Intro
- QA
- Testing
A smoke test consists of functional or unit tests of critical software functionality. Smoke testing comes before further, in-depth testing.
Smoke testing answers questions like
- "Does the program start up correctly?"
- "Do the main control buttons function?"
- "Can you save a simple blank new test user account?"
If this basic functionality fails, there is no point investing time in more detailed QA work at this stage.
- Interwiki("wikipedia", "Smoke testing (software)") on Wikipedia
- Engineers
- Glossary
- Motion Picture
- Movies
- SMPTE
- Specifications
- Television
- standards
The Society of Motion Picture and Television Engineers (SMPTE) is the professional association of engineers and scientists that develop and define standards and technologies used to create, broadcast, store, and present entertainment media.
For example, SMPTE defines the standards used for digital cinema used by modern digital movie theaters.
- Beginner
- Collaboration
- Glossary
- Infrastructure
- Sharing
SMTP (Simple Mail Transfer Protocol) is a glossary("protocol") used to send a new email. Like glossary("POP") and glossary("NNTP"), it is a Glossary("state machine")-driven protocol.
The protocol is relatively straightforward. Primary complications include supporting various authentication mechanisms (GSSAPI, CRAM-MD5, NTLM, MSN, AUTH LOGIN, AUTH PLAIN, etc.), handling error responses, and falling back when authentication mechanisms fail (e.g., the server claims to support a mechanism, but doesn't).
-
Interwiki("wikipedia", "SMTP") (Wikipedia)
-
- glossary("NNTP")
- glossary("POP")
- glossary("protocol")
- Glossary("state machine")
- Glossary
- snap positions
A scroll container may set snap positions — points that the scrollport will stop moving at after a scrolling operation is completed. This allows a scrolling experience that gives the effect of paging through content rather than needing to drag content into view.
Defining Snap positions on the scroll container was introduced in the CSS Scroll Snap specification.
- Glossary
- Infrastructure
- SOAP
- WebMechanics
SOAP (Simple Object Access Protocol) is a glossary('protocol') for transmitting data in glossary('XML') format.
- Interwiki("wikipedia", "SOAP") on Wikipedia
- Specification
- Glossary
- SPA
- single-page app
An SPA (Single-page application) is a web app implementation that loads only a single web document, and then updates the body content of that single document via JavaScript APIs such as domxref("XMLHttpRequest") and Fetch when different content is to be shown.
This therefore allows users to use websites without loading whole new pages from the server, which can result in performance gains and a more dynamic experience, with some tradeoff disadvantages such as SEO, more effort required to maintain state, implement navigation, and do meaningful performance monitoring.
-
Interwiki("wikipedia", "Single-page application") (Wikipedia)
-
- Glossary("API")
- Glossary("AJAX")
- Glossary("JavaScript")
-
Popular SPA frameworks:
- Glossary
- OpenPractices
- Standardization
A specification is a document that lays out in detail what functionality or attributes a product must include before delivery. In the context of describing the Web, the term "specification" (often shortened to "spec") generally means a document describing a language, technology, or Glossary("API") which makes up the complete set of open Web technologies.
- Interwiki("wikipedia", "Specification") on Wikipedia
- Advanced
- HTML
- HTML5
- NeedsUpdate
- Web Development
- Web Performance
Traditionally in browsers the HTML parser ran on the main thread and was blocked after a
</script>tag until the script has been retrieved from the network and executed. Some HTML parser, such as Firefox since Firefox 4, support speculative parsing off of the main thread. It parses ahead while scripts are being downloaded and executed. The HTML parser starts speculative loads for scripts, style sheets and images it finds ahead in the stream and runs the HTML tree construction algorithm speculatively. The upside is that when a speculation succeeds, there's no need to reparse the part of the incoming file that was already scanned for scripts, style sheets and images. The downside is that there's more work lost when the speculation fails.
This document helps you avoid the kind of things that make speculation fail and slow down the loading of your page.
To make speculative loads of linked scripts, style sheets and images successful, avoid domxref('document.write'). If you use a <base> element to override the base URI of your page, put the element in the non-scripted part of the document. Don't add it via document.write() or domxref('document.createElement').
Speculative tree building fails when document.write() changes the tree builder state such that the speculative state after the </script> tag no longer holds when all the content inserted by document.write() has been parsed. However, only unusual uses of document.write() cause trouble. Here are the things to avoid:
- Don't write unbalanced trees.
<script>document.write("<div>");</script>is bad. `<script>document.write("
` is bad.
- Don't finish your writing with a carriage return. `<script>document.write("Hello World!\r");</script>` is bad. `<script>document.write("Hello World!\n");</script>` is OK.
- Don't format part of a table. `
<script>document.write("");</script>
| Hello World! |
- Glossary
- Performance
- Reference
- Web Performance
Speed Index (SI) is a page load performance metric that shows you how quickly the contents of a page are visibly populated. It is the average time at which visible parts of the page are displayed. Expressed in milliseconds, and dependent on the size of the viewport, the lower the score, the better.

The calculation calculates what percent of the page is visually complete at every 100ms interval until the page is visually complete. The overall score, the above the fold metric, is a sum of the individual 10 times per second intervals of the percent of the screen that is not-visually complete**.**
- Glossary
- Security
- Sql
- Sql Injection
- Webapp
SQL injection takes advantage of Web apps that fail to validate user input. Hackers can maliciously pass SQL commands through the Web app for execution by a backend database.
SQL injection can gain unauthorized access to a database or to retrieve information directly from the database. Many data breaches are due to SQL injection.
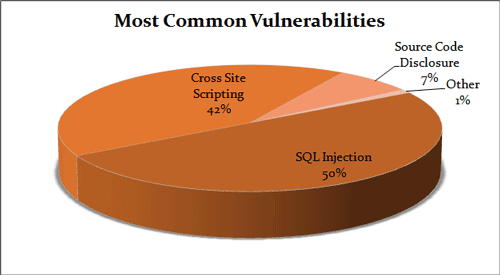

After entering username and password, behind the GUI the SQL queries work as follows:
"SELECT Count(*) FROM Users WHERE Username=' " + txt.User.Text+" ' AND Password=' "+ txt.Password.Text+" ' ";Now suppose User enters the User## Term: admin and Password: passwd123, so after clicking on the Log in button, SQL query will run as follows:
"SELECT Count(*) FROM Users WHERE Username=' admin ' AND Password=' passwd123 ' ";If the credentials are correct, then the user is allowed to log in, so it's a very simple (and therefore insecure) mechanism. Hackers use this insecurity to gain unauthorized access.
Hackers use a simple string called a Magical String, for example:
User## Term: admin
Password: anything 'or'1'='1
After clicking on the login button, the SQL query will work as follows:
"SELECT Count(*) FROM Users WHERE Username=' admin ' AND Password=' anything 'or'1'='1 ' ";Just take a closer look at the above query's password section.
Password=' anything 'or'1'='1 '
The password is not 'anything', hence password=anything results in FALSE, but '1'='1' is a TRUE statement and hence returns a TRUE value. Finally, due to the OR operator, the value ( FALSE OR TRUE ) is TRUE, so authentication bypasses successfully. Just due to a simple string (Magical String) the entire database is compromised.
Before executing the queries for the user credentials, make some changes like the following:
$id = $_GET['id']
(1) $id = Stripslashes($id)
(2) $id = mysql_real_escape_String($id)So due to (1) each single quote (') in the input string is replaced with double quotes ("), and due to (2) before every (') it adds (/). The revised magical string fails to bypass the authentication, and your database stays secure.
- Interwiki("wikipedia", "SQL injection") on Wikipedia
- Explanation of SQL injection on OWASP (Open Web Application Security Project)
- CodingScripting
- Database
- Glossary
- Sql
SQL (Structured Query Language) is a descriptive computer language designed for updating, retrieving, and calculating data in table-based databases.
- Interwiki("wikipedia", "SQL") on Wikipedia
- Learn SQL on sqlzoo.net
- Tutorials Point
- CSP
- Security
Subresource Integrity (SRI) is a security feature that enables browsers to verify that files they fetch (for example, from a Glossary("CDN")) are delivered without unexpected manipulation. It works by allowing you to provide a cryptographic hash that a fetched file must match.
- Subresource Integrity
- HTTPHeader("Content-Security-Policy"): CSP("require-sri-for")
- Glossary
- SSL
- Security
- TLS
- Web Performance
Secure Sockets Layer, or SSL, was the old standard security technology for creating an encrypted network link between a server and client, ensuring all data passed is private and secure. The current version of SSL is version 3.0, released by Netscape in 1996, and has been superseded by the Glossary("TLS", "Transport Layer Security (TLS)") protocol.
-
Interwiki("wikipedia", "Transport Layer Security") (Wikipedia)
-
- Glossary("HTTPS")
- Glossary("TLS")
- CSS
- CodingScripting
- Glossary
Stacking context refers to how elements on a webpage appear to sit on top of other elements, just as you can arrange index cards on your desk to lie side-by-side or overlap each other.
- CodingScripting
- Finite
- Glossary
- Input
- Mealy
- Moore
- State Machine
- Turing Machine
A state machine is a mathematical abstraction used to design algorithms. A state machine reads a set of inputs and changes to a different state based on those inputs.
A state is a description of the status of a system waiting to execute a transition. A transition is a set of actions to execute when a condition is fulfilled or an event received. In a state diagram, circles represent each possible state and arrows represent transitions between states.
Looking at the final state, you can discern something about the series of inputs leading to that state.
There are two types of basic state machines:
- deterministic finite state machine
-
- : This kind allows only one possible transition for any allowed input. This is like the "if" Glossary("statement") in that
if x == true then doThis else doThatis not possible. The computer must perform one of the two options.
- : This kind allows only one possible transition for any allowed input. This is like the "if" Glossary("statement") in that
- non-deterministic finite state machine
- : Given some state, an input can lead to more than one different state.
Figure 1: Deterministic Finite State Machine

In Figure 1, the state begins in State 1; the state changes to State 2 given input 'X', or to State 3 given input 'Y'.
Figure 2: Non-Deterministic Finite State Machine

In Figure 2, given input 'X', the state can persist or change to State 2.
Note that any Glossary("regular expression") can be represented by a state machine.
- Interwiki("wikipedia", "Finite-state machine") on Wikipedia
- Interwiki("wikipedia", "UML state machine") on Wikipedia
- Interwiki("wikipedia", "Moore machine") on Wikipedia
- Interwiki("wikipedia", "Mealy machine") on Wikipedia
- Beginner
- CodingScripting
- Glossary
In a computer programming language, a statement is a line of code commanding a task. Every program consists of a sequence of statements.
- Interwiki("wikipedia", "Statement (computer science)") on Wikipedia
- JavaScript statements and declarations
- CodingScripting
- Glossary
- JavaScript
- Method
- Static
- Static Method
A static method (or static function) is a Glossary("method") defined as a member of an Glossary("object") but is accessible directly from an API object's constructor, rather than from an object instance created via the constructor.
In a Web API, a static method is one which is defined by an interface but can be called without instantiating an object of that type first.
Methods called on object instances are called instance methods.
In the Notifications API, the domxref("Notification.requestPermission()") method is called on the actual domxref("Notification") constructor itself — it is a static method:
//
let promise = Notification.requestPermission();The domxref("Notification.close()") method on the other hand, is an instance method — it is called on an specific notification object instance to close the system notification it represents:
//
let myNotification = new Notification('This is my notification');
myNotification.close();-
Static Method on Techopedia
-
- Glossary("Object")
- Glossary("Method")
- CodingScripting
- Glossary
- Type
A statically-typed language is a language (such as Java, C, or C++) where variable types are known at compile time. In most of these languages, types must be expressly indicated by the programmer; in other cases (such as OCaml), type inference allows the programmer to not indicate their variable types.
- Interwiki("wikipedia", "Type system") on Wikipedia
- Glossary
- JavaScript
- Reference
JavaScript's strict mode is a way to opt in to a restricted variant of JavaScript, thereby implicitly opting-out of "Glossary("Sloppy_mode", "sloppy mode")". Strict mode isn't just a subset: it intentionally has different semantics from normal code.
Strict mode for an entire script is invoked by including the statement "use strict"; before any other statements.
-
- Glossary("Sloppy mode")
- CodingScripting
- Glossary
- Stringifier
An Glossary("object", "object's") stringifier is any Glossary("attribute") or Glossary("method") that is defined to provide a textual representation of the object for use in situations where a Glossary("string") is expected.
- Stringifiers in Information contained in a WebIDL file
- Beginner
- CodingScripting
- Glossary
- String
In any computer programming language, a string is a sequence of Glossary("character","characters") used to represent text.
In Glossary("JavaScript"), a String is one of the Glossary("Primitive", "primitive values") and the jsxref("String") object is a Glossary("wrapper") around a String primitive.
- Interwiki("wikipedia", "String (computer science)") on Wikipedia
- JavaScript data types and data structures
- Glossary
- Infrastructure
- STUN
- WebMechanics
- WebRTC
STUN (Session Traversal Utilities for NAT) is an auxiliary protocol for transmitting data around a glossary("NAT") (Network Address Translator). STUN returns the glossary("IP address"), glossary("port"), and connectivity status of a networked computer behind a NAT.
- Interwiki("wikipedia", "STUN") on Wikipedia
- WebRTC protocols
- CSS
- Glossary
- Style
- Style Origin
- origin
In Glossary("CSS"), there are three categories of sources for style changes. These categories are called style origins. They are the user agent origin, user origin, and the author origin.
- User-agent origin
-
- : The user agent origin is the style origin comprised of the default styles used by the user's web browser. If no other styles are applied to content, the user agent origin's styles are used while rendering elements.
- User origin
- Author origin
- : The author origin is the style origin which contains all of the styles which are part of the document, whether embedded within the Glossary("HTML") or loaded from an external stylesheet file.
The style origins are used to determine where to stop rolling back (or backtracking through) the cascade of styles that have been applied to an element when removing styles, such as when using the cssxref("unset") or cssxref("revert") keywords.
- Glossary
- StyleSheet
A stylesheet is a set of CSS rules used to control the layout and design of a webpage or document. Internal stylesheets are placed inside a htmlelement("style") element inside the htmlelement("head") of a web document, and external stylesheets are placed inside a separate
.cssfile, which is applied to a document by referencing the file inside a htmlelement("link") element in the document's head.
External stylesheets are generally preferred because they allow you to control the styling of multiple pages from a single place, rather than having to repeat the CSS across each page.
- CSS first steps
- Stylesheets on Wikipedia
- Beginner
- CodingScripting
- Glossary
- Graphics
- SVG
- l10n:priority
Scalable Vector Graphics (SVG) is a 2D vector image format based on an Glossary("XML") syntax.
The Glossary("W3C") began work on SVG in the late 1990s, but SVG only became popular when Glossary("Microsoft Internet Explorer", "Internet Explorer") 9 came out with SVG support. All major Glossary("browser","browsers") now support SVG.
As a vector image format, SVG graphics can scale infinitely, making them invaluable in Glossary("responsive web design", "responsive design"), since you can create interface elements and graphics that scale to any screen size. SVG also provides a useful set of tools, such as clipping, masking, filters, and animations.
- Interwiki("wikipedia", "SVG") on Wikipedia
- W3.org's SVG Primer
- SVG documentation on MDN
- Latest SVG specification
- Collaborating
- Glossary
Apache Subversion (SVN) is a free source control management (Glossary("SCM")) system. It allows developers to keep a history of text and code modifications. Although SVN can also handle binary files, we do not recommend that you use it for such files.
- Interwiki("wikipedia", "Apache Subversion") on Wikipedia
- Official website
- Data Type
- ECMAScript 2015
- Glossary
- JavaScript
- Sharing
- Symbol
In Glossary("JavaScript"), Symbol is a Glossary("Primitive", "primitive value").
A value having the data type Symbol can be referred to as a "Symbol value". In a JavaScript runtime environment, a symbol value is created by invoking the function jsxref("Symbol"), which dynamically produces an anonymous, unique value. A symbol may be used as an object property.
Symbol can have an optional description, but for debugging purposes only.
A Symbol value represents a unique identifier. For example:
//
// Here are two symbols with the same description:
let Sym1 = Symbol('Sym');
let Sym2 = Symbol('Sym');
console.log(Sym1 === Sym2); // returns "false"
// Symbols are guaranteed to be unique.
// Even if we create many symbols with the same description,
// they are different values.Note: If you are familiar with Ruby (or another language) that also has a feature called "symbols", please don't be misled. JavaScript symbols are different.
Symbol type is a new feature in ECMAScript 2015. There is no ECMAScript 5 equivalent for Symbol.
In some programming languages, the symbol data type is referred to as an "atom."
Most values in JavaScript support implicit conversion to a string. For instance, we can alert almost any value, and it will work. Symbols are special. They don't auto-convert.
For example:
//
let Sym = Symbol('Sym');
alert(Sym); // TypeError: Cannot convert a Symbol value to a stringThat's a "language guard" against messing up, because strings and symbols are fundamentally different, and should not occasionally convert one into another.
If you really want to show a symbol, we need to call .toString() on it.
//
let Sym = Symbol('Sym');
alert(Sym.toString()); // Symbol(Sym), now it worksOr you can use the symbol.description property to get its description:
//
let _Sym = Symbol('Sym');
alert(_Sym.description); // SymThe jsxref("Symbol") class has constants for so-called well-known symbols. These symbols let you configure how JS treats an object, by using them as property keys.
Examples of well-known symbols are: jsxref("Symbol.iterator") for array-like objects, or jsxref("Symbol.search") for string objects.
They are listed in the specification in the Well-known symbols table:
Symbol.hasInstanceSymbol.isConcatSpreadableSymbol.iteratorSymbol.toPrimitive- …and so on.
There is a global symbol registry holding all available symbols. The methods that access the registry are jsxref("Symbol.for()") and jsxref("Symbol.keyFor()"); these mediate between the global symbol table (or "registry") and the run-time environment. The global symbol registry is mostly built by JavaScript's compiler infrastructure, and the global symbol registry's content is not available to JavaScript's run-time infrastructure, except through these reflective methods.
The method Symbol.for(tokenString) returns a symbol value from the registry, and Symbol.keyFor(symbolValue) returns a token string from the registry; each is the other's inverse, so the following is true:
//
Symbol.keyFor(Symbol.for('tokenString')) === 'tokenString'; // true-
Interwiki("wikipedia", "Symbol (programming)") on Wikipedia
-
jsxref("Symbol") in the MDN JS reference
-
jsxref("Object.getOwnPropertySymbols()")
-
- Glossary("JavaScript")
- Glossary("Primitive")
- Cryptography
- Glossary
- Security
- Symmetric-key cryptography
Symmetric-key cryptography is a term used for cryptographic algorithms that use the same key for encryption and for decryption. The key is usually called a "symmetric key" or a "secret key".
This is usually contrasted with Glossary("public-key cryptography"), in which keys are generated in pairs and the transformation made by one key can only be reversed using the other key.
Symmetric-key algorithms should be secure when used properly and are highly efficient, so they can be used to encrypt large amounts of data without having a negative effect on performance.
Most symmetric-key algorithms currently in use are block ciphers: this means that they encrypt data one block at a time. The size of each block is fixed and determined by the algorithm: for example Glossary("AES") uses 16-byte blocks. Block ciphers are always used with a _Glossary("Block cipher mode of operation", "mode")_, which specifies how to securely encrypt messages that are longer than the block size. For example, AES is a cipher, while CTR, CBC, and GCM are all modes. Using an inappropriate mode, or using a mode incorrectly, can completely undermine the security provided by the underlying cipher.
-
- Glossary("Block cipher mode of operation")
- Glossary("Cryptography")
- Glossary("Cryptographic hash function")
- Glossary("Symmetric-key cryptography")
- Glossary
- Web
- WebMechanics
Synchronous refers to real-time communication where each party receives (and if necessary, processes and replies to) messages instantly (or as near to instantly as possible).
A human example is the telephone — during a telephone call you tend to respond to another person immediately.
Many programming commands are also synchronous — for example when you type in a calculation, the environment will return the result to you instantly, unless you program it not to.
- glossary("Asynchronous")
- Synchronous and asynchronous requests using the XMLHttpRequest() glossary("API")
- CodingScripting
- Glossary
- JavaScript
An Glossary("exception") caused by the incorrect use of a pre-defined Glossary("syntax"). Syntax errors are detected while compiling or parsing source code.
For example, if you leave off a closing brace (}) when defining a Glossary("JavaScript") function, you trigger a syntax error. Browser development tools display Glossary("JavaScript") and Glossary("CSS") syntax errors in the console.
- Interwiki("wikipedia", "Syntax error") on Wikipedia
- jsxref("SyntaxError") JavaScript object
- CodingScripting
- Glossary
- Syntax
Syntax specifies the required combination and sequence of Glossary("character","characters") making up correctly structured code. Syntax generally includes grammar and the rules that apply to writing it, such as indentation requirements in Python.
Syntax varies from language to language (e.g., syntax is different in Glossary("HTML") and Glossary("JavaScript")). Although languages can share few similarities in terms of their syntaxes for example "operand operator operand" rule in javaScript and python. This does not mean the two languages share similarities with syntax.
Syntax applies both to programming languages (commands to the computer) and markup languages (document structure information) alike.
Syntax only governs ordering and structure; the instructions must also be meaningful, which is the province of Glossary("semantics").
Code must have correct syntax in order to Glossary("compile") correctly, otherwise a Glossary("syntax error") occurs. Even small errors, like a missing parenthesis, can stop source code from compiling successfully.
Frameworks are said to have a "clean" syntax if they produce simple, readable, concise results. If a codebase uses "a lot of syntax", it requires more characters to achieve the same functionality.
- Interwiki("wikipedia", "Syntax (programming languages)") on Wikipedia
- Glossary
- RUM
- Reference
- Synthetic monitoring
- Web Performance
Synthetic monitoring involves monitoring the performance of a page in a 'laboratory' environment, typically with automation tooling in an environment that is as consistent as possible.
With a consistent baseline, synthetic monitoring is good for measuring the effects of code changes on performance. However, it doesn't necessarily reflect what users are experiencing.
Synthetic Monitoring involves deploying scripts to simulate the path an end-user might take through a web application, reporting back the performance of the simulator experiences. Examples of popular synthetic monitoring tools include WebPageTest and Lighthouse. The traffic measured is not of your actual users, but rather synthetically generated traffic collecting data on page performance.
Unlike RUM, synthetic monitoring provides a narrow view of performance that doesn't account for user differences, making it useful in getting basic data about an application's performance and spot-checking performance in development environments. Combined with other tools, such as network throttling, can provide excellent insight into potential problem areas.
- Glossary
- CSS
- Tables
The Table Grid Box is a block level box which contains all of the table internal boxes, excluding the caption. The box which includes the caption is referred to as the Table Wrapper Box.
- Glossary
- CSS
- Tables
The Table Wrapper Box is the box generated around table grid boxes which accounts for the space needed for any caption displayed for the table. This box will become the containing block for absolutely positioned items where the table is the containing block.
- CodingScripting
- Glossary
- HTML
- Intro
In Glossary("HTML"), a tag is used for creating an Glossary("element").
The name of an HTML element is the name used in angle brackets such as <p> for paragraph. Note that the end tag's name is preceded by a slash character, </p>, and that in glossary("empty element", "empty elements"), the end tag is neither required nor allowed. If Glossary("attribute", "attributes") are not mentioned, default values are used in each case.
- Interwiki("wikipedia", "HTML element") on Wikipedia
- HTML elements syntax on glossary("WHATWG")
- Introduction to HTML
- Glossary
- Networking
- SSL
- Security
- TCP
- TCP handshake
- TLS
- Web Performance
glossary('Transmission Control Protocol (TCP)','TCP (Transmission Control Protocol)') uses a three-way handshake (aka TCP-handshake, three message handshake, and/or SYN-SYN-ACK) to set up a TCP/IP connection over an IP based network.
The three messages transmitted by TCP to negotiate and start a TCP session are nicknamed SYN, SYN-ACK, and ACK for SYNchronize, SYNchronize-ACKnowledgement, and ACKnowledge respectively. The three message mechanism is designed so that two computers that want to pass information back and forth to each other can negotiate the parameters of the connection before transmitting data such as HTTP browser requests.
The host, generally the browser, sends a TCP SYNchronize packet to the server. The server receives the SYN and sends back a SYNchronize-ACKnowledgement. The host receives the server's SYN-ACK and sends an ACKnowledge. The server receives ACK and the TCP socket connection is established.
This handshake step happens after a glossary('DNS', 'DNS lookup') and before the glossary('TLS') handshake, when creating a secure connection. The connection can be terminated independently by each side of the connection via a four-way handshake.
- Transport Layer Security (TLS) protocol
- Glossary("HTTPS")
- Interwiki("wikipedia", "Transport Layer Security") on Wikipedia
- Glossary
- Infrastructure
- Networking
- TCP
- Transmission Control Protocol
- Web Performance
- data
glossary('TCP') slow start helps buildup transmission speeds to the network's capabilities. It does this without initially knowing what those capabilities are and without creating congestion. glossary('TCP') slow start is an algorithm used to detect the available bandwidth for packet transmission, and balances the speed of a network connection. It prevents the appearance of network congestion whose capabilities are initially unknown, and slowly increases the volume of information diffused until the network's maximum capacity is found.
To implement TCP slow start, the congestion window (cwnd) sets an upper limit on the amount of data a source can transmit over the network before receiving an acknowledgment (ACK). The slow start threshold (ssthresh) determines the (de)activation of slow start. When a new connection is made, cwnd is initialized to one TCP data or acknowledgment packet, and waits for an acknowledgement, or ACK. When that ACK is received, the congestion window is incremented until the cwnd is greater than ssthresh. Slow start also terminates when congestion is experienced.
Congestion itself is a state that happens within a network layer when the message traffic is too busy it slows the network response time. The server sends data in TCP packets, the user's client then confirms delivery by returning acknowledgements, or ACKs. The connection has a limited capacity depending on hardware and network conditions. If the server sends too many packets too quickly, they will be dropped. Meaning, there will be no acknowledgement. The server registers this as missing ACKs. Congestion control algorithms use this flow of sent packets and ACKs to determine a send rate.
- Glossary
- Infrastructure
- Networking
- TCP
- Transmission Control Protocol
- data
TCP (Transmission Control Protocol) is an important network Glossary("protocol") that lets two hosts connect and exchange data streams. TCP guarantees the delivery of data and packets in the same order as they were sent. Vint Cerf and Bob Kahn, who were DARPA scientists at the time, designed TCP in the 1970s.
TCP's role is to ensure the packets are reliably delivered, error free. TCP has concurrence control, which means the initial requests start small, increasing in size to the levels of bandwidth the computers, servers, and network can support.
-
Interwiki("wikipedia", "Transmission Control Protocol") (Wikipedia)
-
- Glossary("IPv4")
- Glossary("IPv6")
- Glossary("Packet")
- Glossary
- Infrastructure
Telnet is a command line tool and an underlying TCP/IP protocol for accessing remote computers.
- interwiki('wikipedia','Telnet') on Wikipedia
- 3D
- Drawing
- Glossary
- Graphics
- Texel
- Texture
A Texel is a single-pixel within a texture map, which is an image that gets used (in whole or in part) as the image presented on a polygon's surface within a 3D rendered image. It is not to be confused with pixel which is the unit of screen space. This is one of the main differences between Texel's and pixels, pixels are image data. Texel components are made up of subjective data, therefore they can be an image as well as a depth map.
The process of mapping the appropriate Texel's to their corresponding points on a polygon is called texture mapping, which is a stage of the process of rendering a 3D image for display. Texture mapping is typically done prior to lighting the scene; however, in WebGL, lighting is performed as part of the texture mapping process.
Textures are characterised by collections of Texel's, as how images are characterised by collections of pixels. When texture mapping occurs the renderer maps Texel's to the appropriate pixels.
- interwiki("wikipedia", "Texel (graphics)") on Wikipedia
- Using textures in WebGL
- Lighting in WebGL
- Animating textures in WebGL
- Glossary
- Thread
- asynchronous
Thread in computer science is the execution of running multiple tasks or programs at the same time. Each unit capable of executing code is called a thread.
However, modern Glossary("JavaScript") offers ways to create additional threads, each executing independently while possibly communicating between one another. This is done using technologies such as web workers, which can be used to spin off a sub-program which runs concurrently with the main thread in a thread of its own. This allows slow, complex, or long-running tasks to be executed independently of the main thread, preserving the overall performance of the site or app—as well as that of the browser overall. This also allows individuals to take advantage of modern multi-core processors.
A special type of worker, called a service worker, can be created which can be left behind by a site—with the user's permission—to run even when the user isn't currently using that site. This is used to create sites capable of notifying the user when things happen while they're not actively engaged with a site. Such as notifying a user they have received new email even though they're not currently logged into their mail service.
Overall it can be observed these threads within our operating system are extremely helpful. They help minimize the context switching time, enables more efficient communication and allows further use of the multiprocessor architecture.
-
- Glossary("Main thread")
- Browser
- CodingScripting
- JavaScript
- Programming Language
- three.js
three.js is a Glossary("JavaScript")-based Glossary("WebGL") engine that can run GPU-powered games and other graphics-powered apps straight from the Glossary("browser"). The three.js library provides many features and Glossary("API","APIs") for drawing 3D scenes in your browser.
- Interwiki("wikipedia", "Three.js") on Wikipedia
- three.js official website
- Glossary
- Performance
- Reference
- Web Performance
Time to First Byte (TTFB) refers to the time between the browser requesting a page and when it receives the first byte of information from the server. This time includes DNS lookup and establishing the connection using a TCP handshake and SSL handshake if the request is made over https.
TTFB is the time it takes between the start of the request and the start of the response, in milliseconds:
TTFB = responseStart - navigationStart
- Glossary
- Performance
- Reference
- Web Performance
Time to Interactive (TTI) is a non-standardized web performance 'progress' metric defined as the point in time when the last Long Task finished and was followed by 5 seconds of network and main thread inactivity.
TTI, proposed by the Web Incubator Community Group in 2018, is intended to provide a metric that describes when a page or application contains useful content and the main thread is idle and free to respond to user interactions, including having event handlers registered.
TTI is derived by leveraging information from the domxref("Long Tasks API"). Although available in some performance monitoring tools, TTI is not a part of any official web specification at the time of writing.
- Definition of TTI from Web Incubator Community Group
- Time to Interactive — focusing on human-centric metrics by Radimir Bitsov
- Tracking TTI
- Glossary
- Web
- WebMechanics
A TLD (top-level domain) is the most generic Glossary("domain") in the Internet's hierarchical Glossary("DNS") (domain name system). A TLD is the final component of a Glossary("domain name"), for example, "org" in
developer.mozilla.org.
Glossary("ICANN") (Internet Corporation for Assigned Names and Numbers) designates organizations to manage each TLD. Depending on how strict an administrating organization might be, TLD often serves as a clue to the purpose, ownership, or nationality of a website.
Consider an example Internet address: https://developer.mozilla.org
Here org is the TLD; mozilla.org is the second-level domain name; and developer is a subdomain name. All together, these constitute a fully-qualified domain name; the addition of https:// makes this a complete URL.
Glossary("IANA") today distinguishes the following groups of top-level domains:
- country-code top-level domains (ccTLD)
-
- : Two-character domains established for countries or territories. Example: .us for United States.
- internationalized country code top-level domains (IDN ccTLD)
-
- : ccTLDs in non-Latin character sets (e.g., Arabic or Chinese).
- generic top-level domains (gTLD)
-
- : Top-level domains with three or more characters.
- unsponsored top-level domains
- : Domains that operate directly under policies established by ICANN processes for the global Internet community, for example "com" and "edu".
- sponsored top-level domains (sTLD)
- : These domains are proposed and sponsored by private organizations that decide whether an applicant is eligible to use the TLD, based on community theme concepts.
- infrastructure top-level domain
- : This group consists of one domain, the Glossary("ARPA", "Address and Routing Parameter Area") (ARPA).
- Interwiki("wikipedia", "TLD") on Wikipedia
- List of top-level domains
- Cryptography
- Glossary
- Infrastructure
- Security
- Web Performance
Transport Layer Security (TLS), formerly known as Glossary("SSL", "Secure Sockets Layer (SSL)"), is a Glossary("protocol") used by applications to communicate securely across a network, preventing tampering with and eavesdropping on email, web browsing, messaging, and other protocols. Both SSL and TLS are client / server protocols that ensure communication privacy by using cryptographic protocols to provide security over a network. When a server and client communicate using TLS, it ensures that no third party can eavesdrop or tamper with any message.
All modern browsers support the TLS protocol, requiring the server to provide a valid Glossary("Digital certificate", "digital certificate") confirming its identity in order to establish a secure connection. It is possible for both the client and server to mutually authenticate each other, if both parties provide their own individual digital certificates.
Note: TLS 1.0 and 1.1 support will be removed from all major browsers in early 2020; you'll need to make sure your web server supports TLS 1.2 or 1.3 going forward. From version 74 onwards, Firefox will return a Secure Connection Failed error when connecting to servers using the older TLS versions (bug(1606734)).
-
Interwiki("wikipedia", "Transport Layer Security") (Wikipedia)
-
RFC 5246 (The Transport Layer Security Protocol, Version 1.2)
-
- Glossary("HTTPS")
- Glossary("SSL")
- HTTP
- SSH
- Security
Trust On First Use (TOFU) is a security model in which a client needs to create a trust relationship with an unknown server. To do that, clients will look for identifiers (for example public keys) stored locally. If an identifier is found, the client can establish the connection. If no identifier is found, the client can prompt the user to determine if the client should trust the identifier.
TOFU is used in the SSH protocol, in HTTP Public Key Pinning (Glossary("HPKP")) where the browsers will accept the first public key returned by the server, and in HTTPHeader("Strict-Transport-Security") (Glossary("HSTS")) where a browser will obey the redirection rule.
- HTTP Public Key Pinning (Glossary("HPKP"))
- HTTPHeader("Public-Key-Pins")
- Wikipedia: TOFU
- Transferable
- Workers
Transferable objects are objects that own resources that can be transferred from one context to another, ensuring that the resources are only available in one context at a time. Following a transfer, the original object is no longer usable; it no longer points to the transferred resource, and any attempt to read or write the object will throw an exception.
Transferrable objects are commonly use to share resources that can only be safely exposed to a single JavaScript thread at a time. For example, an jsxref("ArrayBuffer") is a transferrable object that owns a block of memory. When such a buffer is transferred between threads, the associated memory resource is detached from the original buffer and attached to the buffer object created in the new thread. The buffer object in the original thread is no longer usable because it no longer owns a memory resource.
Transferring may also be used when creating deep copies of objects with domxref("structuredClone()"). Following the cloning operation, the transferred resources are moved rather than copied to the cloned object.
The mechanism used to transfer an object's resources depends on the object. For example, when an jsxref("ArrayBuffer") is transferred between threads, the memory resource that it points to is literally moved between contexts in a fast and efficient zero-copy operation. Other objects may be transferred by copying the associated resource and then deleting it from the old context.
Not all objects are transferable. A list of transferable objects is provided below.
The code below demonstrates how transferring works when sending a message from a main thread to a domxref("Web Workers API", "web worker thread","","true").
The jsxref("Uint8Array") is copied (duplicated) in the worker while its buffer is transferred.
After transfer any attempt to read or write uInt8Array from the main thread will throw, but you can still check the byteLength to confirm it is now zero.
//
// Create an 8MB "file" and fill it.
var uInt8Array = new Uint8Array(1024 * 1024 * 8); // 8MB
for (var i = 0; i < uInt8Array.length; ++i) {
uInt8Array[i] = i;
}
console.log(uInt8Array.byteLength); // 8388608
// Transfer the underlying buffer to a worker
worker.postMessage(uInt8Array, [uInt8Array.buffer]);
console.log(uInt8Array.byteLength); // 0Note: Typed arrays like jsxref("Int32Array") and jsxref("Uint8Array"), are serializable, but not transferable. However their underlying buffer is an jsxref("ArrayBuffer"), which is a transferable object. We could have sent
uInt8Array.bufferin the data parameter, but notuInt8Arrayin the transfer array.
The code below shows a domxref("structuredClone()") operation where the underlying buffer is copied from the original object to the clone.
//
const original = new Uint8Array(1024);
const clone = structuredClone(original);
console.log(original.byteLength); // 1024
console.log(clone.byteLength); // 1024
original[0] = 1;
console.log(clone[0]); // 0
// Transferring the Uint8Array would throw an exception as it is not a transferrable object
// const transferred = structuredClone(original, {transfer: [original]});
// We can transfer Uint8Array.buffer.
const transferred = structuredClone(original, { transfer: [original.buffer] });
console.log(transferred.byteLength); // 1024
console.log(transferred[0]); // 1
// After transferring Uint8Array.buffer cannot be used.
console.log(original.byteLength); // 0The items that can be transferred are:
- jsxref("ArrayBuffer")
- domxref("MessagePort")
- domxref("ReadableStream")
- domxref("WritableStream")
- domxref("TransformStream")
- domxref("AudioData")
- domxref("ImageBitmap")
- domxref("VideoFrame")
- domxref("OffscreenCanvas")
Note: Transferrable objects are marked up in Web IDL files with the attribute
Transferrable.
- Transferable Objects: Lightning Fast!
- Using Web Workers
- Transferable objects in the HTML specification
- domxref("DedicatedWorkerGlobalScope.postMessage()")
- Transient activation
- Glossary
- JavaScript
Transient activation (or "transient user activation") is a window state that indicates a user has recently pressed a button, moved a mouse, used a menu, or performed some other user interaction.
This state is sometimes used as a mechanism for ensuring that a web API can only function if triggered by user interaction. For example, scripts cannot arbitrarily launch a popup that requires transient activation —it must be triggered from a UI element's event handler.
Examples of APIs that require transient activation are:
- domxref("MediaDevices.selectAudioOutput()")
Note: Transient activation expires after a timeout (if not renewed by further interaction), and may also be "consumed" by some APIs.
- domxref("MediaDevices.selectAudioOutput()")
- HTML Living Standard > Transient activation
- JavaScript
- Modules
- Statement
- Web Performance
- export
- import
- tree shaking
Tree shaking is a term commonly used within a JavaScript context to describe the removal of dead code.
It relies on the import and export statements in ES2015 to detect if code modules are exported and imported for use between JavaScript files.
In modern JavaScript applications, we use module bundlers (e.g., webpack or Rollup) to automatically remove dead code when bundling multiple JavaScript files into single files. This is important for preparing code that is production ready, for example with clean structures and minimal file size.
- "Benefits of dead code elimination during bundling" in Axel Rauschmayer's book: "Exploring JS: Modules"
- Tree shaking implementation with webpack
- Browser
- Glossary
- Infrastructure
- Trident
Trident (or MSHTML) was a layout engine that powered Glossary("Microsoft Internet Explorer","Internet Explorer"). A Trident Glossary("fork") called EdgeHTML replaced Trident in Internet Explorer's successor, Glossary("Microsoft Edge","Edge").
- Trident layout engine on Wikipedia
- CodingScripting
- Glossary
- JavaScript
In Glossary("JavaScript"), a truthy value is a value that is considered
truewhen encountered in a Glossary("Boolean") context. All values are truthy unless they are defined as Glossary("Falsy", "falsy") (i.e., except forfalse,0,-0,0n,"",null,undefined, andNaN).
Glossary("JavaScript") uses Glossary("Type_Coercion", "type coercion") in Boolean contexts.
Examples of truthy values in JavaScript (which will be coerced to true in boolean contexts, and thus execute the if block):
//
if (true)
if ({})
if ([])
if (42)
if ("0")
if ("false")
if (new Date())
if (-42)
if (12n)
if (3.14)
if (-3.14)
if (Infinity)
if (-Infinity)If the first object is truthy, the logical AND operator returns the second operand:
//
true && "dog"
// returns "dog"
[] && "dog"
// returns "dog"- Glossary("Falsy")
- Glossary("Type_Coercion", "Type coercion")
- Glossary("Boolean")
- Caching
- Domain Name System
- Glossary
- Infrastructure
- Networking
- Performance
Time To Live (TTL) can refer to either the lifetime of a packet in a network, or the expiry time of cached data.
In networking, the TTL, embedded in the packet, is a usually defined as a number of hops or as an expiration timestamp after which the packet is dropped. It provides a way to avoids network congestion, but releasing packets after they roamed the network too long.
In the context of caching, TTL (as an unsigned 32-bit integer) being a part of the Glossary("Response header", "HTTP response header") or the Glossary("DNS") query, indicates the amount of time in seconds during which the resource can be cached by the requester.
- Glossary
- Infrastructure
- TURN
- WebMechanics
- WebRTC
TURN (Traversal Using Relays around NAT) is a Glossary('protocol') enabling a computer to receive and send data from behind a glossary("NAT", "Network Address Translator") (NAT) or firewall. TURN is used by Glossary("WebRTC") to allow any two devices on the Internet to enter a peer-to-peer connection.
- Interwiki("wikipedia", "TURN") on Wikipedia
- WebRTC protocols
- Specification
- Specification update for IPv6
- Coercion
- JavaScript
- Type coercion
Type coercion is the automatic or implicit conversion of values from one data type to another (such as strings to numbers). _Glossary("Type conversion")_ is similar to _type coercion_ because they both convert values from one data type to another with one key difference — type coercion is implicit whereas type conversion can be either implicit or explicit.
//
const value1 = '5';
const value2 = 9;
let sum = value1 + value2;
console.log(sum);In the above example, JavaScript has coerced the 9 from a number into a string and then concatenated the two values together, resulting in a string of 59. JavaScript had a choice between a string or a number and decided to use a string.
The compiler could have coerced the 5 into a number and returned a sum of 14, but it did not. To return this result, you'd have to explicitly convert the 5 to a number using the jsxref("Global_Objects/Number", "Number()") method:
//
sum = Number(value1) + value2;-
Interwiki("wikipedia", "Type conversion") (Wikipedia)
-
- Glossary("Type")
- Glossary("Type conversion")
- CodingScripting
- Glossary
- Type casting
- Type conversion
Type conversion (or typecasting) means transfer of data from one data type to another. Implicit conversion happens when the compiler automatically assigns data types, but the source code can also explicitly require a conversion to take place. For example, given the instruction
5+2.0, the floating point2.0is implicitly typecasted into an integer, but given the instructionNumber("0x11"), the string "0x11" is explicitly typecasted as the number 17.
-
Interwiki("wikipedia", "Type conversion") (Wikipedia)
-
- Glossary("Type")
- Glossary("Type coercion")
- CodingScripting
- Glossary
- JavaScript
Type is a characteristic of a glossary("value") affecting what kind of data it can store, and the structure that the data will adhere to. For example, a Glossary("boolean") Data Type can hold only a
trueorfalsevalue at any given time, whereas a Glossary("string") has the ability to hold a string or a sequence of characters, a Glossary("number") can hold numerical values of any kind, and so on.
A value's data type also affects the operations that are valid on that value. For example, a value of type number can be multiplied by another number, but not by a string - even if that string contains only a number, such as the string "2".
Types also provides us with useful knowledge about the comparison between different values. Comparison between structured types is not always an easy assumption, as even if the previous data structure is the same, there could be inherited structures inside of the Prototype Chain.
If you are unsure of the type of a value, you can use the typeof operator.
-
Interwiki("wikipedia", "Data type") on Wikipedia
-
- Glossary("JavaScript")
- Glossary("string")
- Glossary("number")
- Glossary("bigint")
- Glossary("boolean")
- Glossary("null")
- Glossary("undefined")
- Glossary("symbol")
- Glossary
- Infrastructure
- Networking
- Protocols
- UDP
UDP (User Datagram Protocol) is a long standing glossary("protocol") used together with glossary("IPv6","IP") for sending data when transmission speed and efficiency matter more than security and reliability.
UDP uses a simple connectionless communication model with a minimum of protocol mechanism. UDP provides checksums for data integrity, and port numbers for addressing different functions at the source and destination of the datagram. It has no handshaking dialogues, and thus exposes the user's program to any unreliability of the underlying network; There is no guarantee of delivery, ordering, or duplicate protection. If error-correction facilities are needed at the network interface level, an application may use the Transmission Control Protocol (TCP) or Stream Control Transmission Protocol (SCTP) which are designed for this purpose.
UDP is suitable for purposes where error checking and correction are either not necessary or are performed in the application; UDP avoids the overhead of such processing in the protocol stack. Time-sensitive applications often use UDP because dropping packets is preferable to waiting for packets delayed due to retransmission, which may not be an option in a real-time system.
- Interwiki("wikipedia", "User Datagram Protocol") on Wikipedia
- Specification
- Accessibility
- Design
- Glossary
User Interface (UI) is anything that facilitates the interaction between a user and a machine. In the world of computers, it can be anything from a keyboard, a joystick, a screen or a program. In case of computer software, it can be a command-line prompt, a webpage, a user input form, or the front-end of any application.
- interwiki("wikipedia", "User_interface", "User interface") on Wikipedia
- interwiki("wikipedia", "Front_end_development", "Front end development") on Wikipedia
- CodingScripting
- Glossary
- JavaScript
- NeedsContent
undefinedis a Glossary("primitive") value automatically assigned to glossary("variable", "variables") that have just been declared, or to formal Glossary("Argument","arguments") for which there are no actual arguments.
//
var x; //create a variable but assign it no value
console.log("x's value is", x); //logs "x's value is undefined"- Interwiki("wikipedia", "Undefined value") on Wikipedia
- JavaScript data types and data structures
- Infrastructure
Unicode is a standard Glossary("Character set","character set") that numbers and defines Glossary("Character","characters") from the world's different languages, writing systems, and symbols.
By assigning each character a number, programmers can create Glossary("Character encoding","character encodings"), to let computers store, process, and transmit any combination of languages in the same file or program.
Before Unicode, it was difficult and error-prone to mix languages in the same data. For example, one character set would store Japanese characters, and another would store the Arabic alphabet. If it was not clearly marked which parts of the data were in which character set, other programs and computers would display the text incorrectly, or damage it during processing. If you've ever seen text where characters like curly quotes ("") were replaced with gibberish like £, then you've seen this problem, known as Interwiki("wikipedia", "Mojibake").
The most common Unicode character encoding on the Web is Glossary("UTF-8"). Other encodings exist, like UTF-16 or the obsolete UCS-2, but UTF-8 is recommended.
- Interwiki("wikipedia", "Unicode") on Wikipedia
- The Unicode Standard: A Technical Introduction
- Glossary
- HTTP
- Search
- URI
- URL
A URI (Uniform Resource Identifier) is a string that refers to a resource.
The most common are Glossary("URL","URL")s, which identify the resource by giving its location on the Web. Glossary("URN","URN")s, by contrast, refer to a resource by a name, in a given namespace, such as the ISBN of a book.
- Interwiki("wikipedia", "URI") on Wikipedia
- RFC 3986 on URI
- Glossary
- Infrastructure
- l10n:priority
Uniform Resource Locator (URL) is a text string that specifies where a resource (such as a web page, image, or video) can be found on the Internet.
In the context of Glossary("HTTP"), URLs are called "Web address" or "link". Your glossary("browser") displays URLs in its address bar, for example: https://developer.mozilla.org Some browsers display only the part of a URL after the "//", that is, the Glossary("Domain name").
URLs can also be used for file transfer (Glossary("FTP")) , emails (Glossary("SMTP")), and other applications.
- Interwiki("wikipedia", "URL") on Wikipedia
- Understanding URLs and their structure
- The syntax of URLs is defined in the URL Living Standard
- Glossary
- Intro
- Navigation
- urn
URN (Uniform Resource Name) is a Glossary("URI") in a standard format, referring to a resource without specifying its location or whether it exists. This example comes from RFC3986:
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
- Interwiki("wikipedia", "URN") on Wikipedia
- Glossary
- WebMechanics
Usenet is an internet discussion system where each post is duplicated on many servers. The equivalent of Internet forums in its day, Usenet functioned like a bulletin board system.
- Interwiki("wikipedia", "Usenet") on Wikipedia
- Browser
- Glossary
- UA
- User-agent
- Web Browser
- WebMechanics
- agent
- user agent
- userAgent
A user agent is a computer program representing a person, for example, a Glossary("Browser","browser") in a Glossary("World Wide Web", "Web") context.
Besides a browser, a user agent could be a bot scraping webpages, a download manager, or another app accessing the Web. Along with each request they make to the server, browsers include a self-identifying HTTPHeader("User-Agent") Glossary("HTTP") header called a user agent (UA) string. This string often identifies the browser, its version number, and its host operating system.
Spam bots, download managers, and some browsers often send a fake UA string to announce themselves as a different client. This is known as user agent spoofing.
The user agent string can be accessed with Glossary("JavaScript") on the client side using the domxref("Navigator/userAgent", "NavigatorID.userAgent") property.
A typical user agent string looks like this: "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:35.0) Gecko/20100101 Firefox/35.0".
-
interwiki("wikipedia", "User agent") on Wikipedia
-
domxref("Navigator/userAgent", "NavigatorID.userAgent")
-
RFC(2616, "14.43"): The
User-Agentheader -
- Glossary("Browser")
-
HTTP Headers
- HTTPHeader("User-agent")
- CodingScripting
- Glossary
- HTML
- JavaScript
- Utf-8
UTF-8 (UCS Transformation Format 8) is the World Wide Web's most common Glossary("Character encoding", "character encoding"). Each character is represented by one to four bytes. UTF-8 is backward-compatible with Glossary("ASCII") and can represent any standard Unicode character.
The first 128 UTF-8 characters precisely match the first 128 ASCII characters (numbered 0-127), meaning that existing ASCII text is already valid UTF-8. All other characters use two to four bytes. Each byte has some bits reserved for encoding purposes. Since non-ASCII characters require more than one byte for storage, they run the risk of being corrupted if the bytes are separated and not recombined.
- Interwiki("wikipedia", "UTF-8") on Wikipedia
- FAQ about UTF-8 on Unicode website
- Glossary
- Infrastructure
A Universally Unique Identifier (UUID) is a label used to uniquely identify a resource among all other resources of that type.
Computer systems generate UUIDs locally using very large random numbers. In theory the IDs may not be globally unique, but the probability of duplicates is vanishingly small. If systems really need absolutely unique IDs then these might be allocated by a central authority.
UUIDs are 128-bit values that are canonically represented as a 36-character string in the format 123e4567-e89b-12d3-a456-426614174000 (5 hex strings separated by hyphens).
There are a number of versions that differ slightly in the way they are calculated; for example, the inclusion of temporal information.
The formal definition can be found in: RFC4122: A Universally Unique IDentifier (UUID) URN Namespace.
- Interwiki("wikipedia", "UUID") on Wikipedia
Crypto.randomUUID()
- Accessibility
- Composing
- Design
- Glossary
- Navigation
UX is an acronym that stands for User eXperience. It is the study of the interaction between users and a system. Its goal is to make a system easy to interact with from the user's point of view.
The system can be any kind of product or application that an end user is meant to interact with. UX studies undertaken on a web page for example can demonstrate whether it is easy for users to understand the page, navigate to different areas, and complete common tasks, and where such processes could have less friction.
- Interwiki("wikipedia", "User experience") on Wikipedia
- Beginner
- Glossary
- Security
A validator is a program that checks for syntax errors in code. Validators can be created for any format or language, but in our context we speak of tools that check Glossary("HTML"), Glossary("CSS"), and Glossary("XML").
- Interwiki("wikipedia", "Validator") on Wikipedia
- Short list of validators
- CodingScripting
- Glossary
- NeedsContent
In the context of data or an object Glossary("Wrapper", "wrapper") around that data, the value is the Glossary("Primitive","primitive value") that the object wrapper contains. In the context of a Glossary("Variable","variable") or Glossary("Property","property"), the value can be either a primitive or an Glossary("Object reference","object reference").
- Interwiki("wikipedia", "Primitive wrapper class") on Wikipedia
- CodingScripting
- Glossary
- JavaScript
A variable is a named reference to a Glossary("Value", "value"). That way an unpredictable value can be accessed through a predetermined name.
- Interwiki("wikipedia", "Variable (computer science)") on Wikipedia
- Declaring variables in JavaScript
varstatement in JavaScript
- CodingScripting
- Glossary
Browser vendors sometimes add prefixes to experimental or nonstandard CSS properties and JavaScript APIs, so developers can experiment with new ideas while—in theory—preventing their experiments from being relied upon and then breaking web developers' code during the standardization process. Developers should wait to include the unprefixed property until browser behavior is standardized.
Note: Browser vendors are working to stop using vendor prefixes for experimental features. Web developers have been using them on production Web sites, despite their experimental nature. This has made it more difficult for browser vendors to ensure compatibility and to work on new features; it's also been harmful to smaller browsers who wind up forced to add other browsers' prefixes in order to load popular web sites.
Lately, the trend is to add experimental features behind user-controlled flags or preferences, and to create smaller specifications which can reach a stable state much more quickly.
The major browsers use the following prefixes:
-webkit-(Chrome, Safari, newer versions of Opera, almost all iOS browsers including Firefox for iOS; basically, any WebKit based browser)-moz-(Firefox)-o-(old pre-WebKit versions of Opera)-ms-(Internet Explorer and Microsoft Edge)
Sample usage:
-webkit-transition: all 4s ease;
-moz-transition: all 4s ease;
-ms-transition: all 4s ease;
-o-transition: all 4s ease;
transition: all 4s ease;
Historically, vendors have also used prefixes for experimental APIs. If an entire interface is experimental, then the interface's name is prefixed (but not the properties or methods within). If an experimental property or method is added to a standardized interface, then the individual method or property is prefixed.
Prefixes for interface names are upper-cased:
WebKit(Chrome, Safari, newer versions of Opera, almost all iOS browsers (including Firefox for iOS); basically, any WebKit based browser)Moz(Firefox)O(Older, pre-WebKit, versions of Opera)MS(Internet Explorer and Microsoft Edge)
The prefixes for properties and methods are lower-case:
webkit(Chrome, Safari, newer versions of Opera, almost all iOS browsers (including Firefox for iOS); basically, any WebKit based browser)moz(Firefox)o(Old, pre-WebKit, versions of Opera)ms(Internet Explorer and Microsoft Edge)
Sample usage:
//
var requestAnimationFrame =
window.requestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.oRequestAnimationFrame ||
window.msRequestAnimationFrame;- Interwiki("wikipedia", "CSS_hack#Browser_prefixes", "Vendor prefix") on Wikipedia
- CodingScripting
- Glossary
- Layout
- viewport
A viewport represents a polygonal (normally rectangular) area in computer graphics that is currently being viewed. In web browser terms, it refers to the part of the document you're viewing which is currently visible in its window (or the screen, if the document is being viewed in full screen mode). Content outside the viewport is not visible onscreen until scrolled into view.
The portion of the viewport that is currently visible is called the Glossary("visual viewport"). This can be smaller than the layout viewport, such as when the user has pinched-zoomed. The Glossary("layout viewport") remains the same, but the visual viewport became smaller.
- Visual Viewport API
- Interwiki("wikipedia", "Viewport") on Wikipedia
- A tale of two viewports (Quirksmode)
- Glossary("Visual viewport") in the MDN Glossary
- Glossary("Layout viewport") in the MDN Glossary
- Glossary
- VisualViewport
- viewport
- visual viewport
The portion of the Glossary("viewport") that is currently visible is called the visual viewport. This can be smaller than the layout viewport, such as when the user has pinched-zoomed. The visual viewport is the visual portion of a screen excluding on-screen keyboards, areas outside of a pinch-zoom area, or any other on-screen artifact that doesn't scale with the dimensions of a page.
- Visual Viewport API
- Interwiki("wikipedia", "Viewport") on Wikipedia
- A tale of two viewports (Quirksmode)
- Glossary("Viewport") in the MDN Glossary
- Glossary("Layout viewport") in the MDN Glossary
- Glossary
- Infrastructure
- VoIP
VoIP (Voice over Internet Protocol) is a technology used to transmit voice messages over IP (Internet Protocol) networks. Common VoIP packages include Skype, Msn Messenger, Yahoo and many more. Everything transferred through VoIP is digital. It is also known as IP telephony, or broadband telephony. The main reason for using VoIP technology is because of cost.
VoIP allows you to make a call directly from a computer, a special VoIP phone, or a traditional phone connected to a special adapter. A high speed internet connection is required for VoIP. Usually, telephone calls over the Internet do not incur further charges beyond what the user is paying for Internet access, much in the same way that the user doesn't pay for sending individual emails over the Internet.
- Interwiki("wikipedia", "VoIP") on Wikipedia
- Community
- Consortium
- Glossary
- Intro
- W3C
- Web consortium
The World Wide Web Consortium (W3C) is an international body that maintains Glossary("World Wide Web", "Web-related") rules and frameworks.
It consists of over 350 member-organizations that jointly develop Web standards, run outreach programs, and maintain an open forum for talking about the Web. The W3C coordinates companies in the industry to make sure they implement the same W3C standards.
Each standard passes through four stages of maturity: Working Draft (WD), Candidate Recommendation (CR), Proposed Recommendation (PR), and W3C Recommendation (REC).
- W3C website
- Interwiki("wikipedia", "World Wide Web Consortium", "W3C") on Wikipedia
- Accessibility
- Glossary
WAI or Web Accessibility Initiative is an effort by the World Wide Web Consortium (W3C) to improve accessibility for people with various challenges, who may need a nonstandard Glossary("browser") or devices.
- WAI website
- Interwiki("wikipedia", "Web Accessibility Initiative") on Wikipedia
- Accessibility
- Glossary
- WCAG
- Web Guidelines
Web Content Accessibility Guidelines (WCAG) are a recommendation published by the Glossary("WAI","Web Accessibility Initiative") group at the Glossary("W3C"). They outline a set of guidelines for making content accessible primarily for people with disabilities but also for limited-resource devices such as mobile phones.
WCAG 2.0 which superseded WCAG 1.0 was published as a W3C Recommendation on 11 December 2008. It consists of 12 guidelines organized under 4 principles (perceivable, operable, understandable, and robust) and each guideline has testable success criteria.
WCAG uses three levels of conformance:
- Priority 1: Web developers must satisfy these requirements, otherwise it will be impossible for one or more groups to access the Web content. Conformance to this level is described as A.
- Priority 2: Web developers should satisfy these requirements, otherwise some groups will find it difficult to access the Web content. Conformance to this level is described as AA or Double-A.
- Priority 3: Web developers may satisfy these requirements, in order to make it easier for some groups to access the Web content. Conformance to this level is described as AAA or Triple-A.
- Interwiki("wikipedia", "Web Content Accessibility Guidelines", "WCAG") on Wikipedia
- Accessibility information on MDN
- The WCAG 2.0 recommendation at the W3C
- Glossary
- Perceived Performance
- Reference
- Web Performance
Web performance is the objective time from when a request for content is made until the requested content is displayed in the user's browser, objective render times, and the subjective user experience of load time and runtime.
Objectively, it is measurable time, in milliseconds, it takes for the web page or web application to be downloaded, painted in the user's web browser, and become responsive and interactive. It is the frames per second and times the main thread is not available for user interactions. Subjectively, it is the user's perception of whether the time it takes between the time the user requests the content and the time until the user feels the content requested is available and usable feels slow or fast.
- web server
- web-server
A web server is a piece of software that often runs on a hardware server offering service to a user, usually referred to as the client. A server, on the other hand, is a piece of hardware that lives in a room full of computers, commonly known as a data center.
- Introduction to servers
- Interwiki("wikipedia", "Server (computing)") on Wikipedia
- Glossary
- Infrastructure
- Web Standards
- standards
- web specifications
Web standards are rules established by international standards bodies and defining how the Glossary("World Wide Web", "Web") works (and sometimes controlling the Glossary("Internet") as well).
Several standards bodies are responsible for defining different aspects of the Web, and all the standards must coordinate to keep the Web maximally usable and accessible. Web standards also must evolve to improve the current status and adapt to new circumstances.
This non-exhaustive list gives you an idea of which standards websites and network systems must conform to:
- IETF (Internet Engineering Task Force): Internet standards (STD), which among other things govern set-up and use of Glossary("URI", "URIs"), Glossary("HTTP"), and Glossary("MIME")
- Glossary("W3C"): specifications for markup language (e.g., Glossary("HTML")), style definitions (i.e., Glossary("CSS")), Glossary("DOM"), Glossary("Accessibility", "accessibility")
- IANA (Internet Assigned Numbers Authority): name and number registries
- Ecma Intl.: scripting standards, most prominently for Glossary("JavaScript")
- Glossary("ISO") (International Organization for Standardization): standards governing a diverse array of aspects, including character encodings, website management, and user-interface design
- Interwiki("wikipedia", "Web standards") on Wikipedia
- Glossary
- Infrastructure
WebAssembly (abbr. Wasm) is an open Glossary("binary") programming format that can be run in modern web Glossary("Browser", "browsers") in order to gain performance and/or provide new features for web pages.
- interwiki('wikipedia','WebAssembly') on Wikipedia
- Official website
- WebAssembly on MDN
- Glossary
- Infrastructure
WebDAV (Web Distributed Authoring and Versioning) is an Glossary("HTTP") Extension that lets web developers update their content remotely from a client.
WebDAV is rarely used alone, but two extensions are very common: Glossary("CalDAV") (remote-access calendar) and Glossary("CardDAV") (remote-access address book).
WebDAV allows clients to
- add, delete, and retrieve webpage metadata (e.g. author or creation date)
- link pages of any media type to related pages
- create sets of documents and retrieve hierarchical list
- copy and move webpages
- lock a document from being edited by more than one person at a time
-
Interwiki("wikipedia", "WebDAV") on Wikipedia
-
Specifications:
- rfc(2518)
- rfc(3253)
- rfc(3744)
- CodingScripting
- Glossary
- NeedsContent
- WebExtensions
WebExtensions is a cross-browser system for developing browser extensions in Firefox. This system provides APIs, which to a large extent are supported across different browsers like Mozilla Firefox, Google Chrome, Opera Browser, Microsoft Edge, or Apple Safari.
- Browser extensions on MDN
- Advanced
- CodingScripting
- Glossary
- Web Graphics
- WebGL
WebGL (Web Graphics Library) is a Glossary("JavaScript") Glossary("API") that draws interactive 2D and 3D graphics.
The Khronos Group maintains WebGL, which is based on Glossary("OpenGL") ES 2.0.
You can invoke WebGL within the Glossary("HTML") HTMLElement("canvas") element, which provides a rendering surface.
All major Glossary("Browser","browsers") now support WebGL, but its availability depends also on external factors (e.g. GPU support).
- Interwiki("wikipedia", "WebGL") on Wikipedia
- Check for WebGL support
- WebGL on MDN
- Support table for WebGL
- CodingScripting
- Glossary
- WebIDL
WebIDL is the interface description language used to describe the Glossary("type", "data types"), Glossary("interface", "interfaces"), Glossary("method", "methods"), Glossary("property", "properties"), and other components which make up a Web application programming interface (Glossary("API")). It uses a somewhat stylized syntax which is independent of any specific programming language, so that the underlying code which is used to build each API can be written in whatever language is most appropriate, while still being possible to map the API's components to JavaScript-compatible constructs.
WebIDL is used in nearly every API Glossary("specification") for the Web, and due to its standard format and syntax, the programmers who create Web browsers can more easily ensure that their browsers are compatible with one another, regardless of how they choose to write the code to implement the API.
- Specification
- Information contained in a WebIDL file
- WebIDL bindings
- interwiki("wikipedia", "WebIDL")
- Browser
- Glossary
- Intro
- Web
- WebKit
- WebMechanics
WebKit is a framework that displays properly-formatted webpages based on their markup. Glossary("Apple Safari") depends on WebKit, and so do many mobile browsers (since WebKit is highly portable and customizable).
WebKit began life as a fork of KDE's KHTML and KJS libraries, but many individuals and companies have since contributed (including KDE, Apple, Google, and Nokia).
WebKit is an Apple trademark, and the framework is distributed under a BSD-form license. However, two important components fall under the Glossary("LGPL"): the WebCore rendering library and the JavaScriptCore engine.
- Interwiki("wikipedia", "WebKit") on Wikipedia
- WebKit CSS extensions
- Composing
- Glossary
- Infrastructure
- WebM
WebM is royalty-free and is an open web video format natively supported in Mozilla Firefox.
- WebM on Wikipedia
- Beginner
- Composing
- Glossary
- Infrastructure
- WebP
WebP is a lossless and lossy compression image format developed by Google.
- WebP on Wikipedia
- CodingScripting
- Glossary
- Infrastructure
- JavaScript
- P2P
- VoIP
- Web
- WebRTC
WebRTC (Web Real-Time Communication) is an Glossary("API") that can be used by video-chat, voice-calling, and P2P-file-sharing Web apps.
WebRTC consists mainly of these parts:
- domxref("MediaDevices.getUserMedia", "getUserMedia()")
-
- : Grants access to a device's camera and/or microphone, and can plug in their signals to a
- domxref("RTCPeerConnection")
- : An interface to configure video chat or voice calls.
- domxref("RTCDataChannel")
- : Provides a method to set up a Glossary("P2P", "peer-to-peer") data pathway between browsers.
- Interwiki("wikipedia", "WebRTC") on Wikipedia
- WebRTC API on MDN
- Browser support for WebRTC
- Connection
- Glossary
- Infrastructure
- Networking
- Protocols
- Web
- WebSocket
WebSocket is a Glossary("protocol") that allows for a persistent Glossary("TCP") connection between Glossary("Server", "server") and client so they can exchange data at any time.
Any client or server application can use WebSocket, but principally web Glossary("Browser", "browsers") and web servers. Through WebSocket, servers can pass data to a client without prior client request, allowing for dynamic content updates.
- Interwiki("wikipedia", "Websocket") on Wikipedia
- WebSocket reference on MDN
- Writing WebSocket client applications
- Writing WebSocket servers
- Audio
- CodingScripting
- Glossary
- Video
- Web
- WebVTT
WebVTT (Web Video Text Tracks) is a Glossary("W3C") specification for a file format marking up text track resources in combination with the HTML HTMLElement("track") element.
WebVTT files provide metadata that is time-aligned with audio or video content like captions or subtitles for video content, text video descriptions, chapters for content navigation, and more.
- Interwiki("wikipedia", "WebVTT") on Wikipedia
- WebVTT on MDN
- Specification
- Community
- DOM
- Glossary
- HTML
- HTML5
- WHATWG
- Web
- standards
The WHATWG (Web Hypertext Application Technology Working Group) is a community that maintains and develops web standards, including Glossary("DOM"), Fetch, and Glossary("HTML"). Employees of Apple, Mozilla, and Opera established WHATWG in 2004.
- Interwiki("wikipedia", "WHATWG") on Wikipedia
- WHATWG website
- Glossary
- Lexical Grammar
- whitespace
Whitespace refers to Glossary("Character", "characters") which are used to provide horizontal or vertical space between other characters. Whitespace is often used to separate tokens in Glossary("HTML"), Glossary("CSS"), Glossary("JavaScript"), and other computer languages.
Whitespace characters and their usage vary among languages.
The Infra Living Standard defines five characters as "ASCII whitespace": U+0009 TAB, U+000A LF, U+000C FF, U+000D CR, and U+0020 SPACE.
The ECMAScript Language Specification defines several Unicode codepoints as "white space": U+0009 CHARACTER TABULATION <TAB>, U+000B LINE TABULATION <VT>, U+000C FORM FEED <FF>, U+0020 SPACE <SP>, U+00A0 NO-BREAK SPACE <NBSP>, U+FEFF ZERO WIDTH NO-BREAK SPACE <ZWNBSP>, and any other Unicode "Space_Separator" code points <USP>.
-
interwiki("wikipedia", "Whitespace character") (Wikipedia)
-
cssxref("white-space")
-
Specifications
-
- Glossary("Character")
- Glossary
- Window
- WindowProxy
A
WindowProxyobject is a wrapper for aWindowobject. AWindowProxyobject exists in every browsing context. All operations performed on aWindowProxyobject will also be applied to the underlyingWindowobject it currently wraps. Therefore, interacting with aWindowProxyobject is almost identical to directly interacting with aWindowobject. When a browsing context is navigated, theWindowobject itsWindowProxywraps is changed.
- HTML specification: WindowProxy section
- Stack Overflow question: WindowProxy and Window objects?
- Glossary
- Infrastructure
- WWW
- World Wide Web
The World Wide Web—commonly referred to as WWW, W3, or the Web—is an interconnected system of public webpages accessible through the Glossary("Internet"). The Web is not the same as the Internet: the Web is one of many applications built on top of the Internet.
Tim Berners-Lee proposed the architecture of what became known as the World Wide Web. He created the first web Glossary("Server","server"), web Glossary("Browser","browser"), and webpage on his computer at the CERN physics research lab in 1990. In 1991, he announced his creation on the alt.hypertext newsgroup, marking the moment the Web was first made public.
The system we know today as "the Web" consists of several components:
- The Glossary("HTTP") protocol governs data transfer between a server and a client.
- To access a Web component, a client supplies a unique universal identifier, called a Glossary("URL") (uniform resource locator) or Glossary("URI") (uniform resource identifier) (formally called Universal Document Identifier (UDI)).
- Glossary("HTML") (hypertext markup language) is the most common format for publishing web documents.
Linking, or connecting resources through Glossary("Hyperlink","hyperlinks"), is a defining concept of the Web, aiding its identity as a collection of connected documents.
Soon after inventing the Web, Tim Berners-Lee founded the Glossary("W3C") (World Wide Web Consortium) to standardize and develop the Web further. This consortium consists of core Web interest groups, such as web browser developers, government entities, researchers, and universities. Its mission includes education and outreach.
- Learn the Web
- Interwiki("wikipedia", "World Wide Web") on Wikipedia
- The W3C website
- CodingScripting
- Glossary
- Wrapper
In programming languages such as JavaScript, a wrapper is a function that is intended to call one or more other functions, sometimes purely for convenience, and sometimes adapting them to do a slightly different task in the process.
For example, SDK Libraries for AWS are examples of wrappers.
-
Interwiki("wikipedia", "Wrapper function") (Wikipedia)
-
- Glossary("API")
- Glossary("Class")
- Glossary("Function")
- CodingScripting
- Glossary
- Deprecated
- XForms
XForms is a convention for building Web forms and processing form data in the glossary("XML") format.
Note: No major browser supports XForms any longer—we suggest using HTML5 forms instead.
- API
- Beginner
- CodingScripting
- Glossary
- XMLHttpRequest
domxref("XMLHttpRequest") (XHR) is a Glossary("JavaScript") Glossary("API") to create Glossary("AJAX") requests. Its methods provide the ability to send network requests between the Glossary("browser") and a Glossary("server").
- interwiki("wikipedia", "XMLHttpRequest") on Wikipedia
- Synchronous vs. Asynchronous Communications
- The domxref("XMLHttpRequest") object
- The documentation on MDN about how to use XMLHttpRequest
- CodingScripting
- Glossary
- XHTML
XHTML is a term that was historically used to describe HTML documents written to conform with Glossary("XML") syntax rules.
(Note that this has not been thoroughly tested for all circumstances and may not necessarily reflect the standard behavior completely.)
Note also that if you wish to allow xml:base, you will need the xml:base function, and the line beginning var href = ... should become:
//
var href = getXmlBaseLink(/* XLink sans xml:base */ xinclude.getAttribute('href'), /* Element to query from */ xinclude);//
function resolveXIncludes(docu) {
// http://www.w3.org/TR/xinclude/#xml-included-items
var xincludes = docu.getElementsByTagNameNS('http://www.w3.org/2001/XInclude', 'include');
if (xincludes) {
for (i = 0; i < xincludes.length; i++) {
var xinclude = xincludes[i];
var href = xinclude.getAttribute('href');
var parse = xinclude.getAttribute('parse');
var xpointer = xinclude.getAttribute('xpointer');
var encoding = xinclude.getAttribute('encoding'); // e.g., UTF-8 // "text/xml or application/xml or matches text/*+xml or application/*+xml" before encoding (then UTF-8)
var accept = xinclude.getAttribute('accept'); // header "Accept: "+x
var acceptLanguage = xinclude.getAttribute('accept-language'); // "Accept-Language: "+x
var xiFallback = xinclude.getElementsByTagNameNS('http://www.w3.org/2001/XInclude', 'fallback')[0]; // Only one such child is allowed
if (href === '' || href === null) {
// Points to same document if empty (null is equivalent to empty string)
href = null; // Set for uniformity in testing below
if (parse === 'xml' && xpointer === null) {
alert('There must be an XPointer attribute present if "href" is empty an parse is "xml"');
return false;
}
} else if (href.match(/#$/, '') || href.match(/^#/, '')) {
alert('Fragment identifiers are disallowed in an XInclude "href" attribute');
return false;
}
var j;
var xincludeParent = xinclude.parentNode;
try {
netscape.security.PrivilegeManager.enablePrivilege('UniversalXPConnect UniversalBrowserRead'); // Necessary with file:///-located files trying to reach external sites
if (href !== null) {
var response, responseType;
var request = new XMLHttpRequest();
request.open('GET', href, false);
request.setRequestHeader('If-Modified-Since', 'Thu, 1 Jan 1970 00:00:00 GMT');
request.setRequestHeader('Cache-Control', 'no-cache');
if (accept) {
request.setRequestHeader('Accept', accept);
}
if (acceptLanguage) {
request.setRequestHeader('Accept-Language', acceptLanguage);
}
switch (parse) {
case 'text':
// Priority should be on media type:
var contentType = request.getResponseHeader('Content-Type');
//text/xml; charset="utf-8" // Send to get headers first?
// Fix: We test for file extensions as well in case file:// doesn't return content type (as seems to be the case); can some other tool be used in FF (or IE) to detect encoding of local file? Probably just need BOM test since other encodings must be specified
var patternXML = /\.(svg|xml|xul|rdf|xhtml)$/;
if (
(contentType && contentType.match(/[text|application]\/(.*)\+?xml/)) ||
(href.indexOf('file://') === 0 && href.match(patternXML))
) {
/* Grab the response as text (see below for that routine) and then find encoding within*/
var encName = '([A-Za-z][A-Za-z0-9._-]*)';
var pattern = new RegExp('^<\\?xml\\s+.*encoding\\s*=\\s*([\'"])' + encName + '\\1.*\\?>'); // Check document if not?
// Let the request be processed below
} else {
if (encoding === '' || encoding === null) {
// Encoding has no effect on XML
encoding = 'utf-8';
}
request.overrideMimeType('text/plain; charset=' + encoding); //'x-user-defined'
}
responseType = 'responseText';
break;
case null:
case 'xml':
responseType = 'responseXML';
break;
default:
alert('XInclude element contains an invalid "parse" attribute value');
return false;
break;
}
request.send(null);
if ((request.status === 200 || request.status === 0) && request[responseType] !== null) {
response = request[responseType];
if (responseType === 'responseXML') {
// apply xpointer (only xpath1() subset is supported)
var responseNodes;
if (xpointer) {
var xpathResult = response.evaluate(xpointer, response, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
var a = [];
for (var k = 0; k < xpathResult.snapshotLength; k++) {
a[k] = xpathResult.snapshotItem(k);
}
responseNodes = a;
} else {
// Otherwise, the response must be a single well-formed document response
responseNodes = [response.documentElement]; // Put in array so can be treated the same way as the above
}
// PREPEND ANY NODE(S) (AS XML) THEN REMOVE XINCLUDE
for (j = 0; j < responseNodes.length; j++) {
xincludeParent.insertBefore(responseNodes[j], xinclude);
}
xincludeParent.removeChild(xinclude);
} else if (responseType === 'responseText') {
if (encName) {
var encodingType = response.match(pattern);
if (encodingType) {
encodingType = encodingType[2];
} else {
encodingType = 'utf-8';
}
// Need to make a whole new request apparently since cannot convert the encoding after receiving it (to know what the encoding was)
var request2 = new XMLHttpRequest();
request2.overrideMimeType('text/plain; charset=' + encodingType);
request2.open('GET', href, false);
request2.setRequestHeader('If-Modified-Since', 'Thu, 1 Jan 1970 00:00:00 GMT');
request2.setRequestHeader('Cache-Control', 'no-cache');
request2.send(null);
response = request2[responseType]; // Update the response for processing
}
// REPLACE XINCLUDE WITH THE RESPONSE AS TEXT
var textNode = docu.createTextNode(response);
xincludeParent.replaceChild(textNode, xinclude);
}
// replace xinclude in doc with response now (as plain text or XML)
}
}
} catch (e) {
// Use xi:fallback if XInclude retrieval above failed
var xiFallbackChildren = xiFallback.childNodes;
// PREPEND ANY NODE(S) THEN REMOVE XINCLUDE
for (j = 0; j < xiFallbackChildren.length; j++) {
xincludeParent.insertBefore(xiFallbackChildren[j], xinclude);
}
xincludeParent.removeChild(xinclude);
}
}
}
return docu;
}- CodingScripting
- Glossary
XLink is a W3C standard which is used to describe links between XML and XML or other documents. Some its behaviors are left to the implementation to determine how to handle.
Simple XLinks are "supported" in Firefox (at least in SVG and MathML), though they do not work as links if one loads a plain XML document with XLinks and attempts to click on the relevant points in the XML tree.
For those who may have found XLink 1.0 cumbersome for regular links, XLink 1.1 drops the need to specify xlink:type="simple" for simple links.
XLink is used in SVG, MathML, and other important standards.
- XML
- Code snippets:getAttributeNS - a wrapper for dealing with some browsers not supporting this DOM method
- CodingScripting
- Glossary
- XML
- l10n:priority
eXtensible Markup Language (XML) is a generic markup language specified by the W3C. The information technology (IT) industry uses many languages based on XML as data-description languages.
- CodingScripting
- Glossary
- XML
- XPath
XPath is a query language that can access sections and content in an glossary("XML") document.
- XPath documentation on MDN
- XPath specification
- Official website
- Interwiki("wikipedia", "XPath") on Wikipedia
- CodingScripting
- Glossary
- XML
- XQuery
XQuery is a computer language for updating, retrieving, and calculating data in glossary("XML") databases.
- Official website
- Interwiki("wikipedia", "XQuery") on Wikipedia
- CodingScripting
- Glossary
- XML
- XSLT
eXtensible Stylesheet Language Transformations (XSLT) is a declarative language used to convert Glossary("XML") documents into other XML documents, Glossary("HTML"), Glossary("PDF"), plain text, and so on.
XSLT has its own processor that accepts XML input, or any format convertible to an XQuery and XPath Data Model. The XSLT processor produces a new document based on the XML document and an XSLT stylesheet, making no changes to the original files in the process.
- Interwiki("wikipedia", "XSLT") on Wikipedia
- XSLT documentation on MDN
| title | Learn HTML | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | Learn HTML | ||||||||||
| seo |
|
||||||||||
| template | docs |
| title | HTML Elements | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | HTML Elements | ||||||||
| seo |
|
||||||||
| template | docs |
HTML Elements
- A
- B
- C
- D
- E
- F
- G H
](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/hr) 6. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/html) 8. I 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/i) 2. [<iframe>](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe) 3. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/img) 4. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input) 5. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/ins) 6. ~~
This is a searchable index. Enter search keywords:
~~ 9. J K 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/kbd) 2. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/keygen) 10. L 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/label) 2. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/legend) 3. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/li) 4. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/link) 5. ~~~~ 11. M 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/main) 2. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/map) 3. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/mark) 4. ~~[](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/marquee)~~ 5. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/menu) 6. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/menuitem) 7. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/meta) 8. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/meter) 12. N 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/nav) 2. ~~[](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/nobr)~~ 3. ~~[<noframes>](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/noframes)~~ 4. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/noscript) 13. O 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/object) 2. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/ol) 3. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/optgroup) 4. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/option) 5. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/output) 14. P 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/p) 2. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/param) 3. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/picture) 4. ~~[<plaintext>](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/plaintext)~~ 5. [
](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/pre) 6. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/progress) 15. Q 1. [](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/q) 16. R 1. [
| title | Docs | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||||
| excerpt | Documentation | ||||||||||
| seo |
|
||||||||||
| template | docs |
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" style="resize:both; overflow:scroll;" style="z-index:-1!important; overflow:scroll;resize:both;" src="https://devdecs42.herokuapp.com/" height="800px" width="1000px" scrolling="yes" frameborder="yes" loading="lazy" allowfullscreen="true" frameborder="0" > </iframe>
<iframe style="resize:both; overflow:scroll;" sandbox="allow-scripts" style="resize:both; overflow:scroll;" style="z-index:-1!important; overflow:scroll;resize:both;" src="https://bryan-guner.gitbook.io/my-docs/" height="800px" width="1000px" scrolling="yes" frameborder="yes" loading="lazy" allowfullscreen="true" frameborder="0" > </iframe>
- /job-hunt/
- /notes-template/
- /
- /showcase/
- /blog/
- /review/
- /blog/blog-archive/
- /blog/my-medium/
- /blog/blogwcomments/
- /blog/data-structures/
- /docs/gallery/
- /blog/python-for-js-dev/
- /blog/platform-docs/
- /docs/sitemap/
- /docs/about/me/
- /blog/python-resources/
- /docs/about/resume/
- /docs/
- /blog/web-scraping/
- /docs/about/
- /docs/articles/algo/
- /docs/articles/install/
- /docs/articles/
- /docs/articles/gallery/
- /docs/articles/intro/
- /docs/articles/basic-web-dev/
- /docs/articles/reading-files/
- /docs/articles/writing-files/
- /docs/audio/audio/
- /docs/content/projects/
- /docs/audio/terms/
- /docs/faq/
- /docs/community/
- /docs/articles/resources/
- /docs/content/
- /docs/docs/git-repos/
- /docs/content/trouble-shooting/
- /docs/articles/python/
- /docs/interact/clock/
- /docs/docs/python/
- /docs/interact/jupyter-notebooks/
- /docs/interact/
- /docs/faq/contact/
- /docs/quick-reference/docs/
- /docs/interact/other-sites/
- /docs/quick-reference/new-repo-instructions/
- /docs/quick-reference/Emmet/
- /docs/quick-reference/installation/
- /docs/quick-reference/vscode-themes/
- /docs/react/createReactApp/
- /docs/react/react2/
- /docs/quick-reference/
- /docs/react/
- /docs/tools/
- /docs/tools/notes-template/
- /docs/tools/more-tools/
- /docs/tools/plug-ins/
- /docs/articles/node/install/
- /docs/tools/vscode/
- /docs/articles/node/intro/
- /docs/articles/node/nodejs/
- /docs/articles/node/nodevsbrowser/
- /docs/articles/node/npm/
- /docs/articles/node/reading-files/
- /docs/articles/node/writing-files/
- /docs/react-in-depth/
- /docs/articles/article-compilation/
- /docs/medium/my-websites/
- /docs/medium/social/
- /docs/medium/medium-links/
- /docs/medium/
| title | Markdown | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | Markdown | ||||||||
| seo |
|
||||||||
| template | docs |
Markdown is a universal doc format that is easy to write and easy to add to a version control system.
- Open - Anyone can submit content, fix typos & update anything via pull requests
- Version control - Roll back & see the history of any given post
- No CMS lock in - We can easily port to any static site generator
- It's just simple - No user accounts to manage, no CMS software to upgrade, no plugins to install.
The basics of markdown can be found here & here. Super easy!
This is the code you need to align images to the left:
<img align="left" width="100" height="100" src="">
This is the code you need to align images to the right:
<img align="right" width="100" height="100" src="">
<p align="center">
<img width="460" height="300" src="http://www.fillmurray.com/460/300">
</p>
Collapsing large blocks of text can make your markdown much easier to digest
"Click to expand"
this is hidden block<details>
<summary>"Click to expand"</summary>
this is hidden
</details>
Collapsing large blocks of Markdown text
To make sure markdown is rendered correctly in the collapsed section...
- Put an empty line after the
<summary>block. - Insert your markdown syntax
- Put an empty line before the
</details>tag
<details>
<summary>To make sure markdown is rendered correctly in the collapsed section...</summary>
1. Put an **empty line** after the `<summary>` block.
2. *Insert your markdown syntax*
3. Put an **empty line** before the `</details>` tag
</details>
Website • Email Updates • Gitter • Forum • Meetups • Twitter • Facebook • Contact Us
[Website](http://www.serverless.com) • [Email Updates](http://eepurl.com/b8dv4P) • [Gitter](https://gitter.im/serverless/serverless) • [Forum](http://forum.serverless.com) • [Meetups](https://github.com/serverless-meetups/main) • [Twitter](https://twitter.com/goserverless) • [Facebook](https://www.facebook.com/serverless) • [Contact Us](mailto:hello@serverless.com)
I hate them so. Don't use badges.
For whatever reason the graphql syntax will nicely highlight file trees like below:
# Code & components for pages
./src/*
├─ src/assets - # Minified images, fonts, icon files
├─ src/components - # Individual smaller components
├─ src/fragments - # Larger chunks of a page composed of multiple components
├─ src/layouts - # Page layouts used for different types of pages composed of components and fragments
├─ src/page - # Custom pages or pages composed of layouts with hardcoded data components, fragments, & layouts
├─ src/pages/* - # Next.js file based routing
│ ├─ _app.js - # next.js app entry point
│ ├─ _document.js - # next.js document wrapper
│ ├─ global.css - # Global CSS styles
│ └─ Everything else... - # File based routing
└─ src/utils - # Utility functions used in various placesYAML front-matter is your friend. You can keep metadata in markdown files
title: Serverless Framework Documentation
description: "Great F'in docs!"
menuText: Docs
layout: Doc
Useful for rendering markdown in HTML/React
- Schedule Posts - Post scheduler for static sites
Show DEMO
Show DEMO
-
Monodraw - Flow charts for days
-
Kap - Make gifs
-
Stuck on WordPress? Try easy-markdown plugin
Serverless.com is comprised of 3 separate repositories
- https://github.com/serverless/blog
- https://github.com/serverless/serverless | Shoutout to Phenomic.io
- https://github.com/serverless/site
Why multiple repos?
- We wanted documentation about the framework to live in the serverless github repo for easy access
- We wanted our blog content to be easily portable to any static site generator separate from the implementation (site)
prebuildnpm script pulls the content together & processes them for site build
A single repo is easier to manage but harder for people to find/edit/PR content.
- Site structure
- Serverless build process
- Validation
- Editing Flow
- Github optimizations
- Link from top of each doc to live link on site
- use markdown magic =) to auto generate tables etc
- Hide yaml frontmatter from github folks
- consider linking everything to site
- Verb - Documentation generator for GitHub projects
- ACSII docs - Markdown alternative
| title | lorem-ipsum | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | lorem-ipsum | ||||||||
| seo |
|
||||||||
| template | docs |
-
Ableton | Berlin, Germany | Take-home programming task (discussed via Skype), then pair programming and debugging session on-site
-
Abstract | San Francisco, CA
-
Accenture | San Francisco, CA / Los Angeles, CA / New York, NY | Technical phone discussion with architec
-
Accredible | Cambridge, UK / San Francisco, CA / Remote | Take home project, then a pair-programming and discussion onsite / Skype round.
-
Acko | Mumbai, India | Phone interview, followed by a small take
-
Acumen | London, UK | Small take home test, and sit in on some sprint rit
-
Addstones | Paris, FR / Singapore, SG / Bucharest, RO / London, UK | Multiple interviews, discussio
-
Adnymics | Munich, DE | Take home project, then work with the team for a day
-
Adthena | London, UK | Takehome project and discussion on-site
-
AdWyze | Bangalore, India | Short takehome project + (for fulltime) onsite pairing
-
AeroFS | San Francisco, CA | Short takehome project + phone interview
-
Affinity | San Francisco, CA | Implementation of a children's game, then take-home project OR real-world
-
Ageno | Bielsko-Biala, Poland | Simple Magento Take-home project and discussion on the real world problems.
-
AgileMD | San Francisco, CA | Takehome project
-
Agoda | Bangkok, Thailand | Take-home project, then a discussion onsite ro
-
Agrilyst | New York, NY / Remote | Short takehome project & remote pairing
-
Airbrake | San Francisco, CA / Remote | Take-home project & pair on a problem similar to daily work
-
Aiwip | London, UK | Skype/phone interview followed by takehome project or worksample (or whiteboard)
-
Ajira | Chennai, India / Austin, TX | Take home project, then pair programming, technical discussions, cultural fit
-
Algolia | Paris, France / San Francisco, CA | Takehome project & Onsite discussions and presentation
-
all about apps GmbH | Vienna, Austria | 2-phase technical discussion & examination with department heads and management.
-
Allegro | Warsaw, Poland; Poznan, Poland; Torun, Poland; Wroclaw, Poland; Krakow, Poland | Take home, simple project. Series of 2 technical interviews (how to build things, how to solve specific, real world problem) and meeting with a team leader.
-
Alluvium | Brooklyn, NY | Take-home assignment, on-site review dovetailing into collaborative
-
AlphaSights | London, UK / New York, NY / Remote | Initial interview, pair programming then final ro
-
AMAGI | Makati, Philippines | 1) Review of your resume, portfolio, and/or GitHub profile; 2) 1 hour discussion (in-person or Skype) about your goals, experience, personal culture, and how to apply technical solutions
-
Analytical Flavor Systems | Manhattan, New York | Code sample or take-home project, both with discussion.
-
Apollo Agriculture | Nairobi, Kenya/Remote | Takehome project or Work
-
Applied | London, UK | Situational judgement tests focusing on real-world soft skills (online then in structured interview)
-
Arachnys | London, UK | Take home test, real world pair programming
-
Articulate | Remote | Take-home project & pair program on a problem similar to daily work
-
Artsy | New York, NY / London, UK / Berlin, Germany / Los Angeles, CA / Hong Kong, Hong Kong / Remote | Our process: 1) Informal chat 2) Application 3) Phone screen 4) In-p
-
ASI Data Science | London, UK | Project to work at home, general technical questions, pair programming with engineers
-
ASOS | London, UK | Take home or in-per
-
Ataccama | Prague, Czech Republic | Face to face interview (skype or onsite), coding task for
-
aTech Media | London, UK | Face to face interview, review of existing open source contributions or, if none are available, asked to write a library for something that i
-
Aura Frames | New York, NY / San Francisco, CA | Simplified real-world coding task on Coderpad.i
-
Aurora Solar | San Francisco, CA | Our process: 1) Initial phone call 2) 1 hour take home project in CoderP
-
Auth0 | Bellevue, WA / Buenos Aires, Argentina / Remote | Series of interviews, go
-
Auto1 | Berlin, DE | Series of Skype interviews which covers general technical questions, f
-
Automattic | Remote | short take-home real-world ta
-
AutoScout24 | Munich, Germany | Skype interview followed by home assignment from our day-to
-
Avant | Chicago, IL | Pair programming interviews.
-
Avarteq GmbH | Berlin, Germany / Saarbrücken, Germany | Technical interview w
-
Avocarrot | Athens, Greece | on-site real world problem discussion and pair programming
-
Axelerant | Remote | Take-home project, interviews with hr and engineering team.
-
Axiacore | Bogota, Colombia | We talk about on how is your process when solving problems.
-
Axios | Arlington, VA / New York, NY / San Francisco, CA / Remote | Take-home project, with discussion.
-
B12 | New York, NY | Take-home exercises and pair-programming w
-
B2W Digital | Rio de Janeiro, Brazil; São Paulo, Brazil | Time-boxed coding exercise at home, on-site pair programming with engineers and live software architecture challenges based on real situations.
-
Babylon Health iOS Team | London, UK | Take-home project, on-site presentation and discussion, design and product interview.
-
Backbase | Amsterdam, Netherlands; Cardiff, Wales; London, UK; Atlanta, GA | Takehome project, interviews
-
Badi | Barcelona, Spain | Phone Screen, Take-home project, then a discussion onsite round.
-
Badoo | London, UK | Take-home project, then a discussion onsite round.
-
Bakken & Bæck | Oslo, Norway; Amsterdam, Netherlands; Bonn, Germany | Skype interview followed by take-home assignment and a visit to one of our offices
-
Balabit | Budapest, Hungary | Take-home project (medium size, with restrictions, e.g. only stdlib may be used), then discussion on-site
-
Barracuda View Team | Chelmsford, MA / Remote | Phone screen, remote pair programming session, technical discussion interview, culture fit interview
-
Basecamp | Chicago, IL / Remote
-
Beam Dental | Columbus, OH | Phone Screen, Take Home Project, In-Person Pairing and
-
Belka | Trento, Italy; Munich, Germany | We give you a small task that you can do alone and then we evaluate your work with you
-
Bemind Interactive | Biella, Italy / Latina, Italy / Remote | Series of interviews, discussion about techn
-
Bendyworks | Madison, WI | Interviews and pair programming on personal projects
-
Betterment | New York, NY | Phone interview followed by on-site pair programming to simulate a Betterment feature build.
-
BetterPT | New York, NY | Initial phone interview, project using our tech stack, on-site code review/pair programming and "meet
-
Big Nerd Ranch | Atlanta, GA & Remote | Interviews and pair programming on an internal project or problem.
-
BioConnect | Toronto, Canada | Take-home assignment & discussion
-
bitExpert AG | Mannheim, Germany | Interview with experience based tec
-
Bits of Love | Bruges, Belgium | In-person interview to evaluate experience and moti
-
Blackdot Solutions | Cambridge, UK | Take-home project followed by on-site face-to-face walkthru of your code focusing on decisions/
-
Bleacher Report | San Francisco, CA, USA | Take-home project; on-site discussion about the project and meeting with di
-
Blendle | Utrecht, The Netherlands | Take-home pro
-
blogfoster | Berlin, Germany | Take-home project, discussion on-site
-
Blue Bottle Coffee | Oakland, CA | Technical Phone Screen, Take Home Challenge, Technical in-persons.
-
Bluesoft | São Paulo, Brazil | Takehome project and an interview to evaluate the candidate's previous experience.
-
Bocoup | Boston, MA / Remote | Pair programming with personal laptop on typical problem seen at work
-
Bolste | Phoenix, AZ | Conversational in-person interviews with team members and pair programming through real world problems
-
BookingSync | Remote | Small takehome project, interviews over skype with team members.
-
BoomTown | Charleston, SC / Atlanta, GA / Remote | Conversational in-person interviews with potential team members and managers that revolve around past experience and how that could be applied to future work
-
Bouvet | Bergen, Norway | Pair programming with senior engineers
-
brainn.co | São Paulo, BR | Zoom/On-site interview, take-home project and interview with a team leader.
-
BrainStation-23 | Dhaka, BD | A practical project followed by series of in-person interview sessions
-
Breather | Montreal, Canada | Series of interviews including a conversation about the candidate's experience and a technical discussion involving real world problems
-
BrightBytes | San Francisco, CA | Time-boxed coding exercise at home and on-site pair programming with engineers
-
BrightHR | Manchester, UK | Telephone conversation, coding exercise at home, on-site pairing with a cultural interview, meet the team.
-
brightwheel | San Francisco, CA | Take home exercise, and systems design.
-
Broad Institute's Data Sciences Platform | Cambridge, MA | Phone screen, small take home project, both a technical and non-technical discussion panel, and a panel following up on the take home project walking through the solution and making a modification to the original code
-
Bubblin Superbooks | Remote | View code, projects, libraries or any other open source story that you have been a part of, a small take-home project with real code occasionally.
-
Buffer | Remote | Interviews over video call, code walkthrough of real code focussing on decisions and reasoning, then a 45 day full time, fully paid contract project working on production code.
-
Bugcrowd | San Francisco, CA / Sydney, NSW | Take home exercise, half-day onsite walking through code, and pair programming.
-
Buhler Group | Prague, CZ | Interview with a couple of technical questions. No task needed. Depending on the team there is another round with the guys in the HQ via skype.
-
Bulb | London, UK | Phone screening, followed by a 2-4 hours take home task. If successful, on-site interview to discuss and extend with the reviewer and one other engineer, followed by 2x informal "Meet the team" interviews.
-
Busbud | Montreal, Canada | Phone screening, followed by a 2-4 hours take home assignment. If the challenge is a success, on-site or remote interview with team members, including someone who reviewed it, to talk about it and potential next steps if the challenge was a real life task.
-
Bustle | New York City, Ny / Remote | Half day pair programming on a task for production or one of our Open Source projects. We'll also buy you lunch with the team.
-
busuu | London, UK | Video call to show real code as first stage. In office pair programming, white board real world problem that we've encountered before, and history/experience discussion.
-
ButterCMS | Chicago, IL; Remote | Take home exercise and half-day of pair programming
-
ByBox | Remote | Phone interview followed by interview with devs (ideally in person but sometimes Skype) covering technical experience and coding exercise with real code.
-
CACI Rome | Rome, NY; Remote | Phone interview followed by in-person or Skype screen sharing interview with a coding exercise in either Java, web (Node.js + frontend), or both. Interview format is exclusive to the Rome, NY office and may not be shared by other regional CACI offices.
-
Cake Solutions | Manchester, UK; London, UK; New York, NY | Skype / Hangouts / phone call to explain the technical background, current position and set expectations about the salary, relocation, etc; if all good, what to expect next. Then take-home exercise for roughly 4 hours to demonstrate good thinking and ability to pick up new things, explain & document the solution, finishing with pair programming with senior developers (remote or in person); use the code as a talking point around the more difficult things after getting through the simple starter tasks.
-
Capgemini UK Java Team | London, UK; Woking, UK; Bristol, UK; Cardiff, Wales; Birmingham, UK; Manchester, UK; Leeds, UK; Rotherham, UK; Liverpool, UK; Newcastle, UK; Edinburgh, Scotland; Glasgow, Scotland | Technical telephone interview (30 minutes), take-home non-CompSci coding exercise (3-4 hours), face-to-face role-played consulting scenario involving a solution architecture and a delivery plan (two hours)
-
Caravelo | Barcelona, Spain | Take home project, then technical discussion about the code in-person or Skype and hang out with the team.
-
Cartegraph | Dubuque, IA / Remote | Phone screen, hiring manager interview, small take-home coding project, and team code review/interview
-
CARTO | Madrid, Spain | Phone screen, take-home project, team code review/interview, hiring manager interview
-
Casetext | San Francisco, CA | Submit code sample for review/discussion, contract for one full day (paid)
-
CASHLINK | Frankfurt, Germany | Skype/phone interview, take-home project
-
Causeway | United Kingdom, India | Skype or Telephonic discussion on approaches and experience in regards to solve projects related work, then face to face round to write small solutions to common problems in related field.
-
Centroida | Sofia, Bulgaria | Series of interviews, pair programming and take-home projects
-
Chain.Reaction | Budapest, Hungary | Partnership-fit discussion, code-review and trial days.
-
Chargify | San Antonio, TX / Remote | Take-home project & pair on a problem similar to daily work
-
Checkout 51 | Toronto, Canada | Phone conversation (15-20 minutes) followed by on-site pair programming and discussion focused on understanding decisions made during on-site work
-
Chesapeake Technology | Denver, CO / Santa Barbara, CA / Camarillo, CA / Dulles, VA / California, MD / Remote | Phone screen (30 minutes), take home at leisure question based on real development followed by in person review of solution and general technical questions with actual team and opportunity for you to ask questions and provide feedback ( 2-3 hours)
-
CircleCI | San Francisco, CA / Remote | Take-home project and discussion, followed by on-site interview that includes pair programming on actual CircleCI bugs/feature requests.
-
City of Boston's Analytics Team | Boston, MA | Take-home project and in-person or phone/Skype interviews
-
City of Philadelphia's Office of Open Data & Digital Transformation | Philadelphia, PA | Take-home project
-
Civis Analytics | Chicago, IL | Take-home project and discussion via Skype, followed by pair programming exercise
-
CJ Affiliate | Los Angeles, CA & Westlake Village, CA | Phone coding design exercise (no algorithms), followed by an on-site final interview that includes pair programming on a realistic object-oriented design problem
-
Clara Lending | San Francisco, CA | Phone conversation around technical background and experience, followed by take-home project, pair programming and discussion
-
Clerkie | San Francisco, CA | Phone conversation followed by take-home project
-
ClickMagick | Austin, TX / Remote | Phone conversations and examples of Free Software/Open Source work
-
Clippings | Sofia, Bulgaria | Video screening first, then send us code they've recently wrote, then technical interview. We could ask questions about the code they wrote at home.
-
Clockwork Consulting | Copenhagen, Denmark | Interviews, discussion of technical background and experiences.
-
Cloudistics | Reston, VA | Multiple interviews, discussion of technical background and experiences.
-
Clubhouse | New York, NY & Remote | Phone interview, followed by onsite discussions and pair programming
-
Cogent Labs | Tokyo, Japan | On-site or video call conversation around technical background and experience, followed by take-home project that resembles a problem Cogent Labs solves for. This project will serve as the base of discussion with the developers for the second interview.
-
Cognitect, Inc. | Remote | Phone interview followed by pair programming.
-
Cognitran | Essex, UK / Szczecin, Poland / Detroit, MI | Skype/phone interview followed by pair programming.
-
Collabora | Cambridge, UK / Montreal, Canada / Remote | On-site or video interview, discussion of technical experience and sometimes approach for tackling a hypothetical problem.
-
COMPEON | Duesseldorf, Germany | Phone interview, followed by onsite discussions and pair programming with our developers
-
Concordia Publishing House | St Louis, MO | Take-home project followed by discussion of it on-site with future teammates.
-
Contactlab | Milan, Italy | Recruiter interview, tech interview (technical background and experiences), both on-site.
-
Contentful | Berlin, Germany & SF, USA | Multiple interviews, discussion of technical background & live coding challenge (you can use the internet).
-
ContentSquare | Paris, France | Real-world challenges with open discussions.
-
Cookpad | Tokyo, Japan; Bristol, UK | Interviews, discussion of technical background and experiences, remotely pair with devs.
-
Coorp Academy | Paris, France | Technical interview as an open discussion
-
CoverHound, Inc. | San Francisco, CA | Open technical discussion, short on-site coding challenge.
-
Credit Kudos | London, UK | Take-home project and pair programming via Skype or on-site.
-
CrossBrowserTesting | Memphis, TN | Take home project that resembles a problem support engineers deal with on a daily basis. On-Site interviews in a comfortable environement with a focus on hiring talented people vs exact skill-sets.
-
Crowdstrike | Remote | Multiple interviews onsite or remote as appropriate followed by small take-home project.
-
Crownstone | Rotterdam, Netherlands | Technical interaction using previously created Github projects, followed by in-person interview with a focus on someone's professional ambition in the short and long term.
-
cube19 | London, UK | Take-home project, then an on-site discussion about the code and previous experience.
-
Cultivate | Edinburgh, UK | 30 minute pair-programming screening interview on a simple exercise (remote or in-person). Half day pair programming, with 3 or 4 different team members plus informal chat, typically on-site.
-
Culture Foundry | Austin, TX | Paid take-home project
-
CurrencyTransfer | London, UK & Remote | Take-home project
-
Dark Sky | Cambridge, MA | Phone interviews and a very short, real paid project
-
Data Theorem | Palo Alto, CA; Paris, Fr; Bangladesh, India | Phone interview, then a take home project and finally in-person interview.
-
Datalogue | Montreal, Canada | We Ask candidates to contribute meaningfully to an Open source project that reflects the stack they will be wor
-
DataMade | Chicago, IL | After submitting an application, selected applicants are moved on to a round of interviews and will be asked to submit a piece of code
-
Datascope | Chicago, IL | Take home exploratory data project with public data, dis
-
Datlinq | Rotterdam, Netherlands | Take-home project based on actual work on data done by the
-
DealTap | Toronto, Canada | Technical Interview, Solution Design, Take Home Assignment, then Culture fit interview with the team, and optional pa
-
Def Method | NYC, NY | Take home test, pair programming with dev on test and client work, receive offer same day as pairing interview
-
Deliveroo | London, UK & Remote | Short take-home project and pa
-
Dentolo | Berlin, Germany | Phone interview with the HR department, take-home project and technical inte
-
Deskbookers | Amsterdam, Netherlands | Phone screen, take-home project, on-site interview
-
DeSmart | Gdynia, Poland | Technical interview, take-home project and talk about y
-
Despark | Sofia, Bulgaria & Remote | Culture add interview, sample code review and paid pair programming with team member or take-home project.
-
Detroit Labs | Detroit, MI | Our technical interview starts with a take-home assignment that we will look at during the
-
DevMynd | Chicago, IL; San Francisco, CA | Take-home project, take-home project phone
-
DG-i | Cologne, Germany | Take-home project and/or discussion on-site about past experiences
-
DICE | Stockholm, Sweden | Take-home project and code review at the on-site
-
Digitally Imported | Denver, Colorado & Remote | Video meetings on past experience and high level tech questions, take-home project
-
Dollar Shave Club | Venice, California | Phone interview, take-home projects, on-site interview
-
door2door | Berlin, Germany | Take home challenge + on-site interview + trial day
-
DoorDash 🏃💨 | San Francisco, CA | Take home project + an on-site interview building of
-
Draft Fantasy | Tel Aviv, Israel | Talk about past experience and what the developer has actua
-
Drawbotics | Brussels, Belgium | Take-home project, bootcamp on-site
-
drchrono | Mountain View, CA | Hackerrank test (but not CS trivia, it's real product problems) & on-site/take-home project w/ presentation
-
Drivy | Paris, France | Phone screening followed by a take-home as
-
DroneDeploy | San Francisco, CA | Pair program on a problem similar to daily work
-
DroneSeed | Seattle, WA | Take home assignment of a real problem we've worked on, group code review in subsequent interview.
-
dubizzle | Dubai, UAE | Take home assignment, general technical questions, pair programming with engineers or tech leads
-
E-accent | Hilversum, Netherlands; Remote | Skype conversation, take-home assignment
-
Easy Taxi | São Paulo, Brazil | Take-home project, interview to evaluate the candidate's previous experience.
-
Eaze | San Francisco, CA | Take home project, on-site interview building off of the project
-
[eBay Kleinanzeigen](https://careers.ebayinc.com/join-our-team/start-your-search/find-jobs-by-lo
-
Echobind | Boston, MA; Remote | Meet the entire team, share examples of previous work and pair with one team member
-
Edenspiekermann | Amsterdam, Netherlands / Berlin, Germany / Los Angeles, CA / San Francisco, CA / Singapore, Sin
-
EF Education First | London, UK; Boston, MA | Short phone interview, take-home project, discussion of project and real world engineering
-
Eidu | Berlin, Germany | Take-home project, discussion of results with team, and test days with pair programming
-
El Passion | Warsaw, Poland | Take-home project, interview to 1)
-
Electric Pulp | Sioux Falls, SD, USA | Phone interviews with lead
-
Elements Interactive | Almere, The Netherlands & Barcelona, Spain | Take-home project & discussion via Skype or on-site
-
Ellucian | Reston, VA, USA | Discussion of real world problems (from resume,
-
elmah.io | Aarhus, Denmark / Remote | Discussion about code and looking at hobby projects (if
-
Elvie | London, England | Discussing real code, pairing and a paid day to see how you work with the team. No coding for free or time-restricted take-home projects, code challenges or abstract algorithm tests
-
eMarketer | New York, NY | Short phone interview, then come in and meet the team, check out our space, and have a discussion with team members about real-world problems
-
Emarsys | Budapest, Hungary | Take-home project (small, 1-2 days to solve), then discussion on-site
-
Endava | Belgrade, Serbia; Bucharest, Romania; Chisinau, Moldova; Cluj-Napoca, Romania; Iasi, Romania; Pitesti, Romania; Skopje, Macedonia; Sofia, Bulgaria; Frankfurt, Germany; Glasgow, Scotland; Hilversum, Netherlands; London, UK; Oxford, UK; Bogota, Colombia; Atlanta, GA; New Jersey, NJ; New York, NY | On-site discussion about previous experience and technical questions about the target technologies.
-
Engel & Völkers Technology | Hamburg, Germany | Remote technical interview with an Engineering Manager, followed by a practical coding challenge implemented in 5 hours, ending with a technical discussion with the team on the produced code either remotely or on-site based on geographical practicality.
-
Enhancv | Sofia, Bulgaria | Talk is cheap, show us your code: github profile or other project examples. Explain them in person / remotely. Discuss habits and interests to see if we have a culture fit.
-
Enigma | New York, NY | 2-part takehome project, followed by a pair programming exercise
-
Enki | London, UK | Skype/phone interview followed by takehome project
-
Ento.com | Melbourne, Australia | On-site interview to talk about your experiences and what you're looking for in your next role, followed by a take-home practical test relevant to the work you'll be undertaking at Ento.
-
Equal Experts | London, UK; Manchester, UK; New York, NY; Pune, India; Lisbon, Portugal; Calgary, Canada | Fizzbuzz test done at home followed by Pair Programming session at office and finally face to face technical and attitude interview.
-
Ericsson | Dublin, Ireland | Skype/phone interview followed by Face 2 Face interview, discussions and architecture questions followed by final small project on a problem similar to daily work.
-
eShares, Inc | San Francisco, CA; Palo Alto, CA; Seattle, WA; Rio de Janeiro, Brazil; London, UK; New York, NY | Phone call, practical technical screen, on site to meet the team & explore the company
-
Etix Everywhere | Luxembourg City, Luxembourg
-
EURA NOVA | Mont-Saint-Guibert, Belgium; Marseille, France; Tunis, Tunisia | attitude interview, unpaid take-home project, technical discussion with 1 or 2 technical employees (remote or face 2 face), face 2 face discussion with HR, partner, and technical staff to have a foretaste of the collaboration
-
Euro Payment Group | Frankfurt, Germany | Take-home project followed by face to face interview
-
Exoscale | Bern, Switzerland | Take-home project. Discussion and presentation. Then entire team meet.
-
F(x) | São Paulo, Brazil | Skype interview, Take-home project and onsite interview to evaluate the candidate
-
Falcon.io | Copenhagen, Denmark | Initial call/Skype culture interview. Take-home tech assignment (game) and code review. On-site Interview about your experience and meeting the team.
-
FATMAP | London, UK; Berlin, Germany; Vilnius, Lithuania | Skype discussion, Take-home project, Face to face
-
Fauna | San Francisco, CA / Remote | Take home project, then follow up with interviews on-site or remote. Interviews are both technical and non-technical. Technical interviews comprehend the scope of the home project.
-
Feather | Remote | Take-home challenge, portfolio discussion & team meeting
-
Findy | Tokyo, Japan | Tech interview + On-site discussion
-
FINE | Portland, OR | Small take-home challenge + follow-up discussion
-
Firemind | Maidstone, UK; London, UK; Remote | Small pre-interview challenge on github + discussion face to face in person or via video
-
Fitbot | Boulder, CO | Pairing & writing code with the founders for a few hours
-
Flatfox | Zurich, Switzerland | Informal conversation to check mutual fit, small (4h) take-home assignment, discussion in team
-
Fluidly | London, UK | Casual 30min phone call. ~1hr take home tech exercise (not pass or fail). 1 stage onsite interview - discussion about experience, 1 hour pair programming on the real code base, then your turn to interview us!
-
Food52 | New York, NY; Remote | Take-home project, discussion on-site or remote, interviews with both technical and non-technical staff
-
Fooji | Lexington, KY; Remote | Take-home project
-
Formidable Labs | Seattle, WA; London, UK; Remote | Take-home project, remote pair programming, discussion on-site or remote
-
Fortumo | Tallinn, Estonia; Tartu, Estonia | After a 30-min call you get a simplified version of a task that has recently been a challenge for the engineering team
-
Founders | Copenhagen, Denmark | Take Home project + Interviews
-
Foundry Interactive | Seattle, WA | On-site or remote discussion, paid trial project with pairing and code reviews
-
fournova | Remote | Take-home project, discussion via video call
-
FreeAgent | Edinburgh, UK | Take-home project, pair programming, discussion and interviews
-
Freeletics | Munich, Germany | Small real-world challenge, multiple interviews on-site/remote and social gathering with team.
-
Freetrade | London, England | Initial hangout with fizz buzz style question followed by an on-site real world coding question and systems design conversation.
-
FRIDAY | Berlin, Germany | Take-home real-world challenge, interview on-site or remote
-
Frontside | Austin, Texas | Phone interview with remote pairing session. Followed by in person pairing (paid for the day) and lunch with the team.
-
Funda | Amsterdam, The Netherlands | Take Home test + Discussion On-Site/Remote
-
FundApps | London, UK | Coffee with an Engineer; take-home kata; code review + on-site pair programming exercise.
-
Gamevy | London, UK; Bilbao, ES; Remote | Informal culture discussions, pair programming with our engineers
-
Garner | Toronto, Canada | step 1: online chat with hiring manager, step 2: at home assignment solving real-life problem, step
-
GatherContent | Remote | Culture-first interviews, pair programming and remote, informal technical discussions
-
GeneralUI | Seattle, WA | A short phone screen with questions regarding general knowledge related to the
-
Ginetta | Zurich, Switzerland; Braga, Portugal | Culture-first interviews, take home assignment that resembles a real-wor
-
GitHub | Remote; San Francisco, CA; Boulder, CO| Take-home exercise, code review and technical discussions.
-
GitPrime | Denver, CO; Remote | small short term real-world projec
-
Glints | Singapore, Singapore; Jakarta, Indonesia | Culture
-
GoCardless | London, UK | Project to work at home, general technical questions, pair programming with
-
GoDaddy | Sunnyvale, CA | Pair programming with senior engineers
-
GoJek | Bangalore, India; Jakarta, Indonesia; Singapore, SG; Bangkok, Thailand | Take-home exercise, Pair programming wit
-
Gower Street Analytics | Remote; London, UK | Initial telephone chat, then either a) work with us, fully p
-
Graffino | Sibiu, Romania | Take-home project, discussion on-site
-
Grafton Studio | Boston, MA | Take-home project, discussion on-site
-
Gramercy Tech | New York, NY | Pair programming & discussion on-site
-
grandcentrix | Cologne, Germany | Take-home project, discussion on-site
-
Grape | Vienna, Austria / Remote | Github or code samples -> Pair
-
Graphcool | Berlin, Germany | On-site pair programming of a small, isolated real world task
-
Graphicacy | Washington, DC | Phone interview; in-person or virtual interview depending on locat
-
Graphistry | Oakland, CA; San Francisco, CA; Remote | Engineering, culture, and product discussions, and for junior develop
-
Grok Interactive | San Antonio, TX | Take-home project with code r
-
Gruntwork | Remote | Paid, take-home
-
GTM Sportswear | Manhattan, KS / Remote | Remote pairing session, then a ta
-
Happy Team | Warsaw, Poland; Remote | General technical questions, takehome paid exercise with feedback/discussion during implementation
-
Happypie | Uppsala, Sweden | Takehome excercise with code review after, in-person int
-
Hash | Sao Paulo, Brazil | Take-home project and/or discussion (on-site or remote)
-
Hashrocket | Chicago, IL/Jacksonville Beach, FL | Remote pairing session,
-
Headspring | Austin, TX; Houston, TX; Monterrey, Mexico | Take-home situational questionnaire
-
Healthify | Remote & New York City, NY | Take-home project, discussion via Zoom, pair programmin
-
Heetch | Paris, France | Values-fit interview (via zoom.us), Take-home project with review, Team Discussions (via zoom.us), on-site day
-
HE:labs | Rio de Janeiro, Brazil & Remote | Take-home project and discussion via Skype.
-
HelloFresh | Berlin, Germany | Take-home project, discussion via Skype or on-site
-
Heptio | Seattle, WA; Remote | Take-home project, discussion on-site
-
Hill Holliday | Boston, MA | Take-home project on GitHub, in-person interview / culture fit interview
-
Hireology | Chicago, IL; Remote | Walk through personal/work projects and discuss experience
-
Hiventive | Pessac, France | Phone interview, home coding challenge, on-site interview with general programming questions, discussion of proposed solutions and personal experience.
-
HolidayPirates | Berlin, Germany | Take-home project, discussion via Skype or on-site
-
HoloBuilder | Aachen, Germany | Take-home project, discussion via Skype or on-site
-
Home Chef | Chicago, IL; Remote | Get-to-know-you meeting with the team, followed by a half-day collaborative coding session
-
HomeLight | San Francisco, CA; Scottsdale, AZ; Seattle, WA | Phone screen, take home that is close to production code, onsite with pair programming
-
HoxHunt | Helsinki, Finland | Take-home project, pair programming on-site
-
Human API | Redwood City, CA | Technical phone interview, then on-site pair programming and design discussion
-
I|O | Cape Town, South Africa
-
Icalia Labs | Monterrey, Mexico | Pair programming, cultural fit session
-
iConstituent | Washington, DC | Take-home project and code review in-person
-
Ideamotive | Warsaw, Poland & Remote | Take-home project, technical interview with developer
-
IDEO | San Francisco, CA; New York, NY; Chicago, IL; Cambridge, MA | Take home project that resembles a problem IDEO solves for, then pairing session in person or over video chat.
-
ImmobilienScout24 | Berlin, Germany | Take-home project, discussion on-site
-
Impraise | Amsterdam, The Netherlands | Take home test, real world pair programming
-
Incloud | Darmstadt, Germany | Technical interview with developers, followed by a full day on site with a practical project
-
Indellient | Oakville, Canada | Series of interviews both technical and non-technical
-
InfluxData | San Francisco, CA & Remote | Technical and non-technical interviews, pair programming, with prospective manager and multiple prospective teammates
-
InfoSum | Basingstoke, UK | On-site unsupervised exercise & discussion.
-
inKind Capital | Boulder, CO | Discussing real-world problems, pair programming, dinner & drinks with the team
-
Inmar | Winston-Salem, NC; Austin, TX & Remote | Take-home project and conversation-style interviews
-
Innoplexus | Pune, India; Frankfurt, Germany | Take-home projects and On-site pair programming assignment.
-
Instacart | San Francisco, CA | Take-home real world project, pair programming on-site
-
InstantPost | Bangaluru, India | Remote assignment followed by Technical and Team round interview
-
Integral. | Detroit, MI | Initial remote technical screen featuring test-driven development & pair programming, then on-site full day interview that involves pair programming on production code using test-driven development.
-
Intelipost | São Paulo, BR | Take-home project, on-site code review and presentation (skype available if needed), discussion involving real world problems and interviews with different teams
-
Intercom | San Francisco, CA; Chicago, IL; Dublin, Ireland | Real-world technical design and problem discussion, pair programming on-site
-
Interset | Ottawa, Canada | Discussion of technical background and past experience. Relevant take-home project for junior developers
-
Ithaka | Mumbai, India | Phone interview followed by a small development task. Finally a phone interview with CEO.
-
iTrellis | Seattle, WA | Phone screen, then a take-home project, then pairing (remote or on-site) with 3 developers on the take-home project.
-
iZettle | Stockholm, Sweden | Remote pair programming exercise, propose an architecture for an application and discuss about it in an informal format.
-
Jamasoftware | Portland, OR | Initial phone screen with hiring manager. In person pairing on project similar to day-to-day work with a separate cultural interview
-
Jamit Labs | Karlsruhe, Germany | Phone interview or on-site interview & take-home
-
Jiminny | Sofia, Bulgaria | Phone screen. Take-home exercise. Follow-up discussion.
-
Jitbit | Remote; London, UK; Tel-Aviv, Israel | Take-home real-world task
-
Jobtome | Stabio, Switzerland | Phone screen introduction with hiring manager. In site (or screen call) with Engineer Manager for a talk on skills and cultural fit.
-
Journal Tech | Los Angeles, CA | Mini take-home project, phone interview, discussion on-site
-
Journalism++ | Berlin, Germany | Apply through a relevant online challenge to show your technical skills and your capacity to investigate
-
JustWatch | Berlin, Germany | Take-Home project, discussion on-site
-
K Health | Tel Aviv, Israel | Phone screening to discuss technical background and past experience. Tak
-
Kahoot! | London, UK / Oslo, Norway | Phone screening to discuss technical background and pa
-
Kata.ai | Malang, Indonesia / Jakarta, Indonesia | Take-home assignment, then invited to discuss the assignment and interview.
-
Kayako | London, UK / Gurgaon, India | Take-home assignment, series of experienc
-
Kentik | San Francisco, CA | Phone screening to discuss technical background and past experience. Take-home ass
-
Keymetrics | Paris, France | Phone Interview, Take-home project based on our API, IRL meeting with the whole team
-
Kindred Group, Native Apps Team | Stockholm SE, London UK | On-site/Skype progra
-
Kinnek | New York, NY | Phone screen, on-site pairing session, take-home project
-
Kiwi.com | Brno, Czech Republic | Phone Interview, Take-home projects, On-site code review & interview
-
KNPLabs | Nantes, France | First step: screening call directly with the CEO, to discuss company
-
Koddi Inc. | Fort Worth, TX | Phone Interview(s), take-home project, on-site i
-
Kong | San Francisco, CA | Phone interview. Pairing and technical interviews.
-
Kongregate | Portland, OR | Phone screening. Take home project. On-site pairing and conversational technical interviews.
-
Korbit | Seoul, South Korea | Take home assignment followed by on-site code review and i
-
Lab.Coop | Budapest, Hungary | Partnership-fit discussion, code-review and trial days.
-
Landing.jobs | Lisbon, Portugal | Interviews (in-person or remote), Take home co
-
Lanetix | San Francisco, CA | [Our Hiring Process](https://engineering.lanetix.com/201
-
LateRooms | Manchester, UK | Telephone interview followed by coding problem at home. Suitable submissions proceed to an onsite interview.
-
Launch Academy | Boston, Philadelphia | Nontechnical phone screen, pair programming with team member, and potentially a "guest lecture" for our students
-
LaunchDarkly | Oakland, CA | Informational phone screen with Eng leadership, take home project, onsite interviews
-
Learningbank | Copenhagen, DK | Take home assignment, followed by on-site code review.
-
Legalstart.fr | Paris, France | Telephone interview followed by take-home challenges. Suitable applicants are asked to do further on-pair interviews on site.
-
Leverton | Berlin, Germany | Initial chat with the HR continued with 1-2 rounds chat with the team; followed by a technical test and finally a chat with the CTO/MD. Jobs page
-
Liberty Mutual | Seattle, WA; Boston, MA; Indianapolis, IN | Initial interview, discussion on-site, interview with peers
-
Librato | San Francisco, CA; Boston, MA; Austin, TX; Vancouver, Canada; Krakow, Poland | Take home coding project, conversational technical interviews on-site
-
Lightning Jar | San Antonio, Tx | Remote pairing session, Initial interview,discussion on-site
-
Lightricks | Jerusalem, Israel | Initial interview, Take home project, discussion on-site
-
LinkResearchTools | Vienna, Austria | Skype interview, mini take-home exercise, discussion on-site / personal interview
-
Listium | Melbourne, Australia | Design and code proof of concept features with the team
-
Litmus | Remote | General technical questions, take-home code challenge, discussion, on-site programming session, meet & greet with the team
-
LittleThings | New York, NY | Take home code challenge, Discussion
-
LoanZen | Bengaluru, India | Initial phone interview about experience, a solve-at-home project based on the kind of work we do at our company, on-site interview discussing the submitted solution and a general discussion with the whole team
-
Lob | San Francisco, CA | Initial phone screen followed by an on-site interview. Technical problems discussed during the interview are all simplified versions of problems we've had to solve in production. Our entire interview process and what we're looking for is described in our blog post How We Interview Engineers.
-
Locastic | Split, Croatia | Take-home code challenge, tehnical discussion & on-site programming session, meet & greet with the team
-
Locaweb | São Paulo, Brazil | Skype interview, take-home project and discussion on-site
-
LOGIBALL GmbH | Berlin, Hannover and Herne in Germany | Interviews and discussion
-
Logic Soft | Chennai, India | Phone discussion, F2F pair programming exercise + discussion
-
LonRes | London, United Kingdom | Quick introduction call with tech (Skype), coding task for ≈1 hour, face-to-face interview (or via Skype) and meeting with team members.
-
LookBookHQ | Toronto, Canada | On-site discussion, pair programming exercise
-
Loom | San Francisco, CA | Google Hangouts resume dive on past experience, take-home project OR architectural phone screen, on-site interviews (2 technical architecture related to work, 1 or 2 non-technical)
-
Lydia | Paris, FR | Mini take-home project, phone interview, discussion on-site
-
Lyft | San Francisco, CA | Pair programming on-site with your own personal laptop
-
Lyoness Austria GmbH | Graz, Austria | Take-Home project, discussion on-site
-
Made Tech | London, UK | Our hiring process
-
Magnetis | São Paulo, Brazil & Remote | Phone interview + take home assignment, followed by pair programming and informal meeting with the team.
-
Major League Soccer | New York, NY |
-
MakeMusic | Boulder, CO; Denver, CO | Phone screen, take home project, remote and on-site interviews for technical and cultural fit
-
MakeTime | Lexington, KY | Practical exercise and/or a pairing session on site
-
Mango Solutions | London (UK), Chippenham (UK) | Initial phone
-
Mapbox | San Francisco, CA; Washington, DC; Ayacucho, Peru; Bangalore, India; Berlin, Germany; Remote | Conversational interview
-
Mavenlink | San Francisco, CA; Irvine, CA; Salt Lake City, UT | On-site pairing with
-
Maxwell Health | Boston, MA | Take-home exercise or pairing session with team. Then conversational mee
-
Me & Company | Düsseldorf, Germany | You join us for one or two paid trial days to work on an assignment and to meet the team.
-
Media Pop | Singapore, Singapore | Take-home or unsupervised (onsite) real-world assignment
-
Meetrics | Berlin, Germany | Initial interview, take-home code challenge and review
-
Meltwater | Manchester, NH | Small take home exercise that will be presented to the team during
-
Mention | Paris, FR | Take-home small exercise followed up by on site meetings with your future
-
Mercatus | Toronto, Canada | Practical on-site project similar to dai
-
mfind | Warsaw, PL | Phone call about technical experience, Take-home project or technical test(depends on experience), Onsite interview with technical lead.
-
miDrive | London, UK | Phone screen, Take-home project / technical test, Onsite interview with senior and peer.
-
milch & zucker | Gießen, Germany | Interview with direct feedback, applicants providing working sample, code review (product code or personal code of applications)
-
Mimir | Indianapolis, Indiana | Take home interview, phone screen, in person interview where you decide how you wan
-
Minute Media | Tel-Aviv, Israel | Phone screening with engineer. On-site r
-
Mirumee | Wroclaw, Poland; Remote | Pair programming and code review using one of the is
-
Mixmax | San Francisco, CA | Takehome assignment purely based on their platform, followed by phone interview
-
MobileCashout | Barcelona, Spain; Valencia, Spain | Quick introduction video call with a tech (less than 10-15 minutes). On-site open source contribution to a project of candidates choosing, paired with a tech from the team. Interview and a short questionaire about
-
Mobilethinking | Geneva, Switzerland | 1 hour discussion about technical b
-
Mode | San Francisco, CA | Phone interview followed by onsite pair-architecting and discussion
-
MokaHR | Beijing, China | Take home project/challenge, then on-site pr
-
Moneytree Front-end Web Team | Tokyo, Japan | Pair programming exercise and social ga
-
Monzo | London, UK & Remote | Phone interview with another engineer. Take-home assignment. Call to debrief on take-home assignment. Half-day interview (on-site or Hangouts) with three c
-
Moteefe | London, UK & Remote | Interview with CTO. Take
-
Mutual Mobile | Austin, TX; Hyderabad, India | Technical discussion, code test based on actual work y
-
Mutual of Omaha | Omah
-
Mutually Human Software | MI, OH, WA | Collaborative problem analysis and design exercise, pairing exercise
-
Nanobox | Lehi, UT; Remote | A phone/video/person-to-person interview with a look at past projects (github, bitbucket, source code, etc.)
-
Native Instruments | Berlin, Germany | Takehome programming assignment and personal interviews with part of the hiring team.
-
Nearsoft Inc | Hermosillo, Mexico; Chihuahua, Mexico; Mexico City, Mexico | Takehome [logi
-
Nedap | Groenlo, Netherlands / Remote | A simple conversation, human
-
Neoteric | Gdańsk, Warsaw Poland; Remote | Face2
-
Netflix | Los Gatos, CA | Takehome exercise, series of r
-
Netguru | Warsaw, Poland; Remote | Takehome exercise & pair programming session
-
Netlandish | Los Angeles, CA; Remote | Takehome exercise, chat interview, video interview
-
Netlify | San Francisco, CA | Paid takehome project and online/onsite discussion
-
New Relic | San Francisco, CA | Takehome exercise &/ or pair programming session depending on the team
-
NewStore | Berlin, Germany; Hannover, Germany; Erfurt, Germany; Boston, MA | Telephone technical interview, code sample submission or takeaway coding exercise, on-site pair programming, design session (1/2 day)
-
NewVoiceMedia | Basingstoke, England; Wroclaw, Poland | Telephone interview, takeaway coding exercise, on-site pair programming, code review & technical discussion (1/2 day)
-
Nexcess.net | Southfield, MI | We mostly chat to get a feel on both ends if there's a good cultural fit. We ask questions to see what experience you have and how you think as a programmer. At some point we look at some of your code or have you work on some of ours (1 hour).
-
Nimbl3 | Bangkok, Thailand | Takehome exercise and specific role discussion
-
Niteoweb | Ljubljana, Slovenia | Join us for a week to see if we fit
-
Nitro | Dublin, Ireland; San Francisco, CA | Phone Call, Take Home Test, Hiring Manager Phone Interview followed by an onsite discussion
-
Noa | Berlin, Germany; San Francisco, CA | 1 technical chat, 2-3 cultural chats with colleagues from different departments in the team, if these work a pair programming exercise
-
NodeSource | Remote | A person-to-person walk through of a past project of yours
-
Nomoko,camera | Zurich, Switzerland | Three interrogations
-
Nord Software | Helsinki, Finland; Tampere, Finland; Stockholm, Sweden | Take-home exercise & interview with CEO and senior developer
-
NoRedInk | San Francisco, CA | Take-home exercise & pair programming session
-
NoviCap | Barcelona, Spain | Takehome exercise & discussion on-site
-
Novoda | London, UK; Liverpool, UK; Berlin, Germany; Barcelona, Spain; Remote | 2 x Pairing sessions & conversational interviews (public repo)
-
Novus Partners | New York, NY | Take-home exercise & on-site exercises (choice of laptop or whiteboard)
-
Nozbe | Remote | Take-home exercise & interview with the team
-
npm, Inc | Oakland, CA / Remote | No technical challenges. Just interview conversations.
-
Nubank | São Paulo, BR | Phone conversation, take-home exercise, code walkthrough, on-site code pairing.
-
numberly | Paris, France | Series of interviews, that go over technical background, past experiences and cultural knowledge
-
numer.ai | San Francisco, CA
-
Nutshell | Ann Arbor, MI, US | Email screen / take-home programming excercise (public repo)
-
Nyon | Amsterdam, The Netherlands | 1. Skype (or real life) interview 2. Take home exercise (3-4 hours) 3. Meet entire team and pair programming sessions
-
O'Reilly Media | Sebastopol, CA; Boston, MA; Remote | Phone conversation, take-home exercise or pair programming session, team interview, all via Google Hangout
-
Object Partners, Inc. | Minneapolis, MN; Omaha, NE | Phone interview to gauge mutual interest, followed by a slightly more in-depth technical round-table interview
-
Objective, Inc. | Salt Lake City, UT | Take-home programming exercise, then onsite friendly chat with team
-
OCTO Technology | Paris, France | HR interview to go over your experiences and cultural knowledge. Then more or less informal discussion with two future team members about architecture design, agile practices, take-home project, pair programming...
-
Olist | Curitiba, Brazil | Take-home project and remote or on-site interviews
-
Omada Health | San Francisco, CA | Take home exercise and/or pair programming session.
-
Onfido | London, UK; Lisbon, Portugal | Take-home exercise and on-site interview/discussion with potential team
-
Ontame.io | Copenhagen, Denmark | Take home exercise and specific role discussion
-
Opbeat | Copenhagen, Denmark | Pairing on a real-world problem
-
Openmind | Monza, Italy | On-site interviews
-
Optoro | Washington, DC | Take home exercise. Review your code onsite.
-
Ostmodern | London, UK | Take-home exercise & discussion on-site
-
Outbrain | NYC, Israel | Take-home exercise & discussion
-
Outlandish | London, UK | Take-home exercise, real-world pair programming session, friendly chat with team
-
Outlook iOS & Android | San Francisco, CA / New York, NY | Take-home project & online / onsite discussion
-
The Nerdery | Minneapolis, MN; Chicago, IL; Phoenix, AZ; Kansas City, KS | Take-home exercise
-
The Outline | New York, NY | Take-home exercise
-
PACE Telematics | Karlsruhe, Germany | Culture and mindset check, on-site meet and great, small code challenge to see development style and strategy
-
Paessler AG | Nuremberg, Germany | Pairing with different engineers on a real problem
-
Pagar.me | São Paulo, BR | Skype interview, on-site pairing task and-or real world problem solving process / presentat
-
Pager | New York, NY; Remote | Short phone interview, conversational interviews, take-home exercise & discussion
-
PagerDuty | San Francisco, CA / Toronto, Canada / Atlanta, GA | Zoom
-
Palatinate Tech | London, UK | Hangout/Skype/phone followed by (normally) on-site pairing task
-
Parabol | New York, NY; Los Angeles, CA; Remote | Culture check followed by compensated, open-source contribution skills evaluation
-
Pariveda Solutions | Dallas, TX / Houston, TX / Atlana, GA
-
PassFort | London, UK | Skype interview, and on-site pairing task
-
Paws | London, UK | Phone screening, take-home project, on-site pairing/discussion on your solution and meet the team.
-
Paybase | London, UK | Phone screening, Take home project, On-site interview for technical and culture fit, Open Q&A session with team
-
PayByPhone | Vancouver, Canada | Remote programming interview, on-site "meet the team"
-
Peaksware Companies (TrainingPeaks, TrainHeroic, MakeMusic) | Boulder, CO; Denver, CO | Phone screen, take home project, remote and on-si
-
PeerStreet | Los Angeles, CA | Phone, take home project & on-site to meet the team
-
Pento | Remote | Quick personal interview, take ho
-
Persgroep, de | Amsterdam, Netherlands | Tech interview (technical background and experienc
-
Pex | Los Angeles, CA; Remote | 3 sessions: brief phone conversation (30 min); take home assignment
-
Phoodster | Stockholm, Sweden | Take-home exercise + on-site discussion
-
Pillar Technology | Ann Arbor, MI; Columbus, OH; Des Moines, IA | Phone, take home exercise, in-person pairing se
-
Pilot | Remote | Two calls. Introduction one (30m) + verification of communication skills and remote work experien
-
Pivotal | San Francisco, CA; Los Angeles, CA; New York, NY; Boston, MA; Denver, CO; Atlanta, GA; Chicago, IL; Seattl
-
Platform.sh | Paris, International | Remote Interview, Wide-Ranging discussions on many diverse subjects. Remote interviews with team member
-
Platform45 | Johannesburg, South Africa; Cape Town, South Africa | On-site interv
-
Playlyfe | Bangalore, India | Short personal interview, on-site demonstration of programming in browser devtools followed by discussion about the problem
-
Pluralsight | Salt Lake City, UT; San Francisco, CA; Boston, MA; Orlando, FL | Takehome exercise & pair programming session
-
Pointman | Buffalo, NY | Takehome exercise + on-site discussion
-
Poki | Amsterdam, The Netherlands | Pair programming on-site w/ two engineers where we focus on teamwork, googling relevant documentation and fixing things together.
-
Polar | Toronto, Canada | Phone interview, followed by 1-2 onsite pair-programming interviews based on thei
-
Popstand | Los Angeles, CA | Build MVPs for startups
-
Popular Pays | Chicago, IL | Phone chat/coffee to determine what will be worked
-
Pragmateam | Sydney, Australia | Engineering Consultancy And Delivery - Takehome exerc
-
PremiumBeat | Montreal, Canada | Discussion and general, high level ques
-
Primary | New York, NY / Remote | Phone chat, take home exercise, pair prog
-
PromptWorks | Philadelphia, PA | Take-home project, pair programming, discussion on-site
-
Pusher | London, UK | Solve a real-world problem through a design session with our engineers
-
Pygmalios | Bratislava, Slovakia | Take-home project related to business and discussion with our engineers.
-
Quiet Light Communications | Rockford, IL, USA | Discussion, work samples and/or small freelance project
-
Quintype | Bengaluru, India / San Mateo, USA | Take home project, pair programming, discussion on-site
-
Quizizz | Bengaluru, India | Phone chat, real world assignment, discussion w/ developers, pair programming, discussion on-site
-
Ragnarson | Lodz, Poland; Remote | Take-home exercise & pair programming session
-
Railslove | Cologne, Germany | Have a coffee in our office, casual chat with us, pair programming on a real project
-
Raising IT | London, UK | Coffee with a team member, on-site pair programming and discussion
-
Rakuten | Tokyo, Japan | Discuss about relevant experience
-
Rapyuta Robotics | Bengaluru, India / Tokyo, Japan / Zurich, Switzerland | Take-home assignment related to our ongoing projects, series of technical / experience based interviews, candidate presentation
-
Rayfeed | Vancouver, Warsaw | Video-call interview followed by a take-home exercise
-
Razorpay | Bangalore, India | Phone screen, On-site pair programming, and ocassionally a take home project.
-
ReactiveOps | Remote | Start with a brief talk with CTO or VP of Engineering, take home coding challenge, then remote interviews with several people on the engineering team
-
Reaktor | New York, NY; Amsterdam, Netherlands; Helsinki, Finland; Tokyo, Japan | Discussion, work samples from previous projects (work or hobby), take-home exercise if needed for further info
-
Real HQ | Austin, TX / Chicago, IL / Remote | Phone/video interviews, a take-home coding exercise, and a remote pair programming session.
-
Realync | Chicago, IL / Carmel, IN / Remote | Quick phone interview, then a take home project and finally in person interview (open discussions instead of quizzes - anything technical are real-world problems).
-
Red Badger | London, UK | Phone & Skype interview, take home exercise, On-site interview
-
RedCarpet | New Delhi, India | Interview, work sample/take-home project and discussion/code reviews
-
Reflektive | San Francisco, CA; Bengaluru, India | A short take home project/assignment, followed by a couple of technical and non-technical discussions online and offline.
-
Relabe | San Juan, PR | First we screen for cultural fit then check for technical proficiency. 2-3 Interviews max in SJ
-
Rentify | London, UK | Phone call, take home real-world project, on-site pair programming, product discussion
-
RentoMojo | Bangalore, India | Short takehome project + phone interview
-
Resin.io | Remote | Take home real-world project and a couple of technical and non-technical discussions
-
ReSpark | London, UK | Phone conversation followed by on-site interview w/ task relevant to daily role.
-
RestaurantOps | Scottsdale, AZ | Take Home Project & pair programming session
-
Revlv | Manila, Philippines | Discussion about developer skills, previous projects and experiences.
-
Rex Software | Brisbane, Australia | Take home project, feedback + interview
-
Rizk.com | Ta' Xbiex, Malta | Take-home assignment, discussion w/ developers
-
Rockode | Bangalore, India | Real world assignment, group hack session, discussions
-
Rose Digital | New York, NY | Phone conversation followed by pair coding components that mirror day to day work, in person discussion about code, take home project if needed for more info
-
RubyGarage | Dnipro, UA | Take-home project, code review and discussion on-site
-
Runtastic | Linz, Austria; Vienna, Austria | Video call with recruiting staff, take home project, video call for code review, discussion, questions
-
Sahaj Software Solutions | Bangalore, India; Chennai, India; San Jose, CA | Take home code + Pairing + Discussion
-
Salesforce.org Tech & Products | Remote | Phone screen, hands-on programming test solving real-world problems, Google Hangouts video sessions wit
-
Salesloft | Atlanta, GA | Phone interview, take-home project, cultural-fit interview, technical interview where candidate modifies take-home project
-
Samsara | San Francisco, CA; Atlanta, GA; London, UK | Phone interview, onsite interview (technical challenges based on real problems we've faced at Sams
-
SC5 Online | Helsinki, Finland; Jyväskylä, Finland | Take-home assignment (intentionally short, takes at most an hour to complete), discussion and review assignments
-
Segment | San Francisco, CA; Vancouver, Canada | Phone interview, take-home assignment (small fun project),
-
Sensor Tower | San Francisco, CA | Phone call, on-site interview including discussion about projects/skills and a short real-worl
-
Sensu | Remote | Video call, choice of pairing session or take home programming assignment
-
Séntisis | Madrid, Spain; Mexico City, Mexico; Bogotá, Colombia; Santiago de Chile, Chile; Remote | Phone call, on-site/remote
-
SerpApi | Austin, TX / Remote | Skype core value and culture interview, review of contr
-
Sertis | Bangkok, Thailand | Technical & culture fit interview, take-home project, follow-up discussion
-
Setapp Sp. z o.o. | Poznan, Poland | Online/face-to-face discussion with developers about everyday programming dilemmas & reviewing your own code
-
Sharoo | Zurich, Switzerland; Remote | Soft skills interview, take home project, technical interview based on take home project.
-
Shogun | Remote | Discussion about software development and past experience, code samples, paid trial period.
-
Showmax | Beroun, Czechia; Prague, Czechia; Remote | Take home project, then a pair-programming and discussion onsite / Hangouts round.
-
ShuttleCloud | Chicago, IL / Madrid, Spain | Take-home project, then on-site code walk through and a real world problem discussion.
-
Signal AI | London, UK | Phone screen; take home code exercise; on-site code extension with pair programming and discussion
-
Simple | Portland, OR | Discussion about software development and archite
-
Simpli.fi | Fort Worth, TX, USA | Takehome code challenge and review
-
SimpliField | Lille, France | Interview with the C
-
Simply Business | London, UK / Remote | Three sta
-
Skyrise Pro | Chicago, IL | Take-home coding project, on-site interview including coding enhancements to the take-home project, offsite group activity
-
Slack | San Francisco, CA | Call with recruiter, 1 week take-home project, call with hiring manager, on-site interview co
-
Small Improvements | Berlin, Germany
-
Social Tables | Washington, DC | Chat about skills and past experiences + bring in a
-
SocialCops | New Delhi, India | A mini project (to be done within 8 days), followed by a discussion with the team you're applying to. T
-
Softwear | Amsterdam, Netherlands | Writing software for the fashion industry - remot
-
Sogilis | Grenoble, France | Discussion about interests,
-
Sourcegraph | San Francisco, CA & Remote | Tailored to the candidate, often consists of take-home
-
Splice | New York, NY; Remote | Call with recruiter, 4 hr take-home project, video interview w two en
-
Spreedly | Durham, NC | Take-home project related to business
-
Springer Nature (Asia) | Tokyo, Japan | Discussion & Pair programming session
-
Springer Nature Digital | Berlin, Germany; London, UK | Phone chat; take-home proje
-
SpronQ | Amsterdam, Netherlands | Takehome coding challenge
-
Square | San Francisco, CA | Pair programming in a work environment
-
Srijan Technologies | Delhi, India | General high level questions/discussion followed by Pair prog
-
Stardog Union | Washington, DC; Remote | Technical discussion and general interest conversations
-
Statflo | Toronto, Canada | Phone screening, take home project, on-sit
-
store2be | Berlin, Germany | Skype/on-site interview, take-home project
-
Storm | Seattle, WA; Remote | Phone/skype screen --> Take-home coding assignment --> on-site/skype interview loop to discuss assignment; meet-and
-
STYLABS | Mumbai, India | Phone Screen, Take-home project and discussion on-site
-
Subvertical (VerticalChange) | Remote | Phone screening, live pair programming & personal project code
-
Sulvo | New York, NY / Remote | Interview over video call for cultural fit first, if you pass we proceed with technical interview that doesn't include coding games or challenges
-
Superplayer | Porto Alegre, Brazil | Skype/On-site interview, take-home pro
-
SurveySparrow | Kochi, India | Skype interview, take home project and code review,
-
SVTi (Sveriges Television) | Stockholm, Sweden | On-site interview, take-home project, follow up interview where you walk through how you
-
SweetIQ | Montreal, Canada | Discussion and general, high level questions
-
Symphony Commerce | San Francisco, CA / Remote | Take-home project (phone), design discussion, review and criti
-
Symplicity | Arlington, VA | Take-home project and code review in-person
-
SysGarage | Buenos Aires, Argentina | Take-home project and real world pair programming
-
TableCheck | Tokyo, Japan | Show us your code! Brief Skype interview and take-home project or pairing for those without code.
-
Tailor Brands | Tel Aviv-Yafo, Israel | Discuss knowledge and interests, explore previous work experience, during the technical interview we discuss real-life problems.
-
tails.com | Richmond (London), UK | Live pair programming or take home project with review
-
Tanooki Labs | New York, NY | Paid half-day take home project with followup review and discussion
-
Tattoodo | Copenhagen, Denmark | Takehome exercise
-
Telus Digital | Toronto, Canada; Vancouver, Canada | Discuss knowledge and interest, explore previous work, pair with developers when possible, alternatively take home project.
-
Ten Thousand Coffees | Toronto, Canada | Take home project, then explain how you solved the project
-
Tes | Remote; London, UK | Remote pair programming session on React/Node kata with small takehome exercise as prep. Remote interview with senior engineers about previous experience, technical knowledge and interests.
-
Tesco PLC | London, United Kingdom | Pair programming and casual hypothetical system design discussion
-
Test Double | Remote | Initial conversation, Consulting interview, Technical interview, Pair programming, Takehome exercise.
-
Textio | Seattle, WA | Initial screen to discuss experience and interest in a role at Textio; then a take-home programming task is discussed during a 1-hour tech screen (on-site or remote); finally a larger take-home project, simulating real work, is discussed during an on-site presentation plus 1-1s; How we hire
-
The Book of Everyone | Barcelona, Spain | Quick interview, meet the team, pairing with developers on your own project
-
theScore | Toronto, Canada | Coding challenge & systems design challenge
-
Thinkmill | Sydney, Australia | Initial meet and greet interview with Thinkmillers from the relevant team, take home assignment followed by tech review on a followup interview.
-
Thinslices | Iasi, Romania | Takehome exercise & in person pair programming on a simple Kata.
-
thoughtbot | San Francisco, CA; London, UK | Our interview process
-
ThoughtWorks | San Francisco, CA | Interviews with ThoughtWorkers of diverse backgrounds and roles; take home assignment followed by in person pairing session.
-
Thread | London, UK | Take home test, real world architecture design, real world pair programming.
-
ThreatSpike Labs | London, UK | Take home computing and security related challenges to be completed over a week.
-
Tilde | Portland, OR | Pair programming sessions with each member of the team, working on problems similar to daily work.
-
Timbuktu | Cape Town, South Africa | On site interview and pair programming exercise
-
Titanium | Moldova, Chisinau | High level review of public activity on GitHub/BitBucket/Gitlab (if applicable) and screening via phone, On-site technical & Team fit interview, Formal "Meet the Team" meeting
-
Toggl | Remote / Tallinn, Estonia | Online test on basic programming skills, followed by interview (typically includes get-to-know questions and technical skill testing). Depending on the team, there may be a take-home or live coding assignment. Paid test week to work with the team on actual bugs/features.
-
Torii | Raanana, Israel | Take-home fun full-stack-app exercise followed by an on-site review
-
Toucan Toco | Paris, France | Pair-programming and TDD
-
Touché | Singapore, Singapore; Barcelona, Spain | Skype / Phone / on-site interview, take-home project, technical interview to discuss the project, team interview.
-
TrademarkVision | Brisbane, Australia | On site interview and quick take-home excercise
-
TrainHeroic | Boulder, CO; Denver, CO | Phone screen, take home project, remote and on-site interviews for technical and cultural fit
-
TrainingPeaks | Boulder, CO; Denver, CO | Phone screen, take home project, remote and on-site interviews for technical and cultural fit
-
TripStack | Toronto, Canada | Take-home assignment, followed up by a face to face code walk through
-
Trivago | Düsseldorf, Germany | Case Study, Skype Interview, On site Interview with some code review exercises
-
Trōv | Remote | Take-home project with followup interview from actual prospective teammates
-
Truefit | Pittsburgh, PA | Phone screen, Take-home project, In-person interview with the team that you would join
-
Truora | Bogotá, Colombia; Cali, Colombia; Remote | Take-home project, followed by phone interview with tech leads to discuss the project.
-
Truss | San Francisco, CA; Remote | Phone screen/ Take-home project that resembles a problem Truss has seen many times before / Followup interview about the project / Closing Interview, all interviews done remotely
-
Twistlock | Tel Aviv, Israel | Takehome
-
uberall | Berlin, Germany | 30-min coding on-site, then a trial day
-
uBiome | San Francisco, CA / Santiago, Chile | High level screening over the phone or on-site, take home project, code review and discussion
-
Ubots | Porto Alegre, Brazil | Skype/On-site interview, take-home project, technical interview
-
Unbounce | Vancouver, BC | Phone screen, take-home project, project discussion, technical interview
-
Unboxed | London, UK | Take home feature requests, pairing with developers to extend solution, team-fit interviews, chat with a director
-
Unearth | Seattle, WA | Take home project, team-fit interviews, technical discussion
-
Unito | Montreal, Canada | Team-fit interviews, technical discussion, take home project
-
Untappd | Wilmington, NC; New York, NY; Los Angeles, CA | Review portfolio - What projects have you worked on? + personality assessment, + interview
-
Updater | New York, NY | Begin-at-home assignment highly relevant to role, presented and discussed during on-site.
-
Uprise | Uppsala, Sweden | Take-home assignment, code review and discussion on-site
-
Urban Massage | London, UK | Project done at home, in-person walk through. Meeting the team is an integral part.
-
UserTesting | Atlanta, GA; San Francisco, CA; Mountain View, CA | Initial interview, pair programming, and offer
-
uSwitch | London, UK | Take-home project related to our business area, followed by pairing with developers to extend it
-
Valassis Digital | Seattle, WA; San Francisco, CA; Lansing, MI; Hamburg, Germany | Phone screen, on-site interview with group, paired whiteboard problem solving and discussion, take-home project and follow-up review
-
Valuemotive | Helsinki, Finland | Code examples from previous projects (work or hobby) or take-home exercise
-
Varsity Tutors | Remote | Take home assignment, presentation of assignment, live code review with team. Advanced / high-level chat with team based on skillset and role.
-
Vayu Technology | Sydney, Australia; Kathmandu, Nepal | Short interview, general programming questions and short take home challenge.
-
Venminder, Inc. | Elizabethtown, KY; Louisville, KY | Initial phone screen to explain position. If candida
-
Verve | London, UK | An intentionally short, take home exercise that mirrors real project work and incorporates code
-
Vingle | Seoul, Korea | Written interview, takehome project, in-person, conversational code review and interviews with e
-
virtual7 | Kalrsruhe, Germany | Phone interview and on-site interview based on personal experience.
-
Visma e-conomic | Copenhagen, Denmark | Take home assignment, assignment presentatio
-
Voltra Co. | Amsterdam, Netherlands / New York, NY / Remote | Show us your github account, tell us what you know. Let's pair on an OSS PR!
-
VSX | Dresden, Germany | On-site interview, home coding challenge, presentation/discussion o
-
VTEX | Rio de Janeiro, Brazil | Take-home project, Skype interview and then in-person talk.
-
VTS | New York City, New York | Technical Phone Screen, Pair programming on-
-
Waymark | Detroit, MI | Technical phone screen, take-home project, going over the project in person, follow up day in the office
-
Wealthsimple | Toronto, Canada | Pair programming on a
-
WeAreHive | London, UK | Just walk us through your best code or we give you a small real-world exercise to do at home.
-
Webantic | Manchester, UK | Basic TNA self-assessment and real-world problem-solving
-
Webflow | San Francisco, CA & Remote | Short take-home challenge, followed by a paid 3-5 day freelance contract project
-
Weebly | San Francisco, CA; Scottsdale, AZ; New York, NY | Phone screens (30 min to 1 hour) by a recruiter, an engineering manager (focused on your past experiences), an engineer (focused on system / db / api design). Followed by a paid 3 day onsite where you work on a project and then present it to a team of engineers.
-
Weedmaps | Irvine, CA; Denver, CO; Tucson, AZ; Madrid, Spain; Remote | Phone screen, Group interview, and possible code review
-
wemake.services | Remote | Short unpaid take-home challenge, code review, portfolio discussion
-
Weploy | Melbourne, Australia; Sydney, Australia | Phase 1: Face to face interview to get to know the candidate. Phase 2: Problem solving session that involves designing a solution to a real-world problem followed by 1/2 day of pairing with a senior dev on implementing the proposed solution.
-
WeTransfer | Amsterdam, Netherlands | Culture fit and fundamentals chat, skills interview - no whiteboarding! - and take-home project, communication and collaboration interview, meet with the VP of Engineering
-
Wheely | Moscow, Russia | Get to know each other in under 30 minutes on-site or via Skype, take-home challenge, on-site review and interview with the team.
-
Wildbit | Philadelphia, PA & Remote | Take-home project followed by interviews.
-
Wirecard Brasil | São Paulo, Brazil | Phone or on-site Cultural Fit interview, take-home coding challenge, code review and discussing in-person.
-
WorldGaming | Toronto, Canada | Technical Interview, Solution Design, Take Home Assignment, then Culture fit interview with the team
-
woumedia | Remote | Getting to know each other and aligning expectations. Talking about past experiences, projects you are proud of and latest challenges you faced. It's followed by a use case study from one of our current projects.
-
WyeWorks | Montevideo, Uruguay | Take-home project and discussion on-site
-
X-Team | Remote | A short, fun Node.js challenge, followed by a series of culture-based interview questions, followed by a creative mock project with tons of freedom on how to approach, and follow-up questions about the approach they chose to discuss the tradeoffs. Usually a 10-30 day paid training is rewarded to top candidates to prep them for remote communication skills needed to join a team.
-
XING | Hamburg, Germany | Take-home coding challenge, on-site review and short interviews with future team.
-
1000mercis group | Paris, France | Series of interviews, that go over technical background, past experiences and cultural knowledge
-
18F | Remote; Washington, DC; New York, NY; Chicago, IL; San Francisco, CA | take-home coding exercise (2-4 hours), technical and values-match interviews over video chat
-
3D Hubs | Amsterdam, The Netherlands | Take-home code challenge from o
-
500friends | San Francisco, CA; Remote | Take home challenge followed by onsite ex
-
500Tech | Tel Aviv, Israel | Pair programming on a laptop in w
-
8th Light | Chicago, IL; London, UK; Los Angeles, CA; New York, NY | Take home code challenge, discussion, pair programming session
-
Yhat | Brooklyn, NY | Demo something cool you built and walk us thru the code + design decisions
-
YLD | London, UK | Take home-code challenge, pair-programming session and discussion about past experi
-
Yodas | Binyamina, Israel | Coding tasks over github repository
-
Yoyo Wallet | London, UK | Take home code challenge, discussion of the code challenge, and general, high level questions
-
YunoJuno | London, UK | Code challenge based on a realistic feature request on a real open-source package created and used at YunoJuno; phone/video interview with members of the Product team to explore technical background, experiences, interests, cultural fit; on-site interview, usually with Product Manager and CTO
-
ZAP Group | São Paulo, Brazil | Takehome exercise, series of real-world interviews with engineers, HR, engineering managers and product managers on site.
-
Zencargo | London, UK | Initial interview with CTO, covering professional experience interests and expectations, followed by one technical interview focused on fundamentals and familiarity with best practices. A further short chat with co-founders to get to know each other - - either onsite or remote.
-
Zenefits (UI Team) | San Francisco, CA | One technical phone screen focused on JS fundamentals and/or one timeboxed take-home challenge. The onsite is a series of interviews designed to test your understanding of JS, HTML/CSS, design, etc.
-
Zerodha | Bengaluru, India | Technical call at the beginning and one take home programming task.
-
Zype | New York, NY & Remote | Skype/Video call with VP of Product and a take-home challenge.
| title | Node Docs | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 0 | ||||||||
| excerpt | Node Docs | ||||||||
| seo |
|
||||||||
| template | docs |
description: "REPL stands for Read-Evaluate-Print-Loop, and it's a great way to explore the Node.js features in a quick way"
The node command is the one we use to run our Node.js scripts:
node script.js
If we omit the filename, we use it in REPL mode:
node
Note: REPL also known as Read Evaluate Print Loop is a programming language environment (basically a console window) that takes single expression as user input and returns the result back to the console after execution.
If you try it now in your terminal, this is what happens:
❯ node
>
the command stays in idle mode and waits for us to enter something.
Tip: if you are unsure how to open your terminal, google "How to open terminal on <your-operating-system>".
The REPL is waiting for us to enter some JavaScript code, to be more precise.
Start simple and enter
> console.log('test')
test
undefined
>
The first value, test, is the output we told the console to print, then we get undefined which is the return value of running console.log().
We can now enter a new line of JavaScript.
The cool thing about the REPL is that it's interactive.
As you write your code, if you press the tab key the REPL will try to autocomplete what you wrote to match a variable you already defined or a predefined one.
Try entering the name of a JavaScript class, like Number, add a dot and press tab.
The REPL will print all the properties and methods you can access on that class:

You can inspect the globals you have access to by typing global. and pressing tab:

If after some code you type _, that is going to print the result of the last operation.
The REPL has some special commands, all starting with a dot .. They are
-
.help: shows the dot commands help -
.editor: enables editor mode, to write multiline JavaScript code with ease. Once you are in this mode, enter ctrl-D to run the c -
.break: when inputting a multi-line expression, entering the .break command -
.clear: resets the REPL context to an empty object and clears any multi-line expression currently being input. -
.load: loads a JavaScript file, relative to the current working directory -
.save: saves all you entered in the REPL session to a file (specify the filename) -
.exit: exits the repl (same as pressing ctrl-C two times)
The REPL knows when you are typing a multi-line statement without the need to invoke .editor.
For example if you start typing an iteration like this:
//
[1, 2, 3].forEach(num => {and you press enter, the REPL will go to a new line that starts with 3 dots, indicating you can now continue to work on that block.
//
... console.log(num)
... })If you type .break at the end of a line, the multiline mode will stop and the statement will not be executed.
description: 'How to accept arguments in a Node.js program passed from the command line'
You can pass any number of arguments when invoking a Node.js application using
node app.js
Arguments can be standalone or have a key and a value.
For example:
node app.js joe
or
node app.js name=joe
This changes how you will retrieve this value in the Node.js code.
The way you retrieve it is using the process object built into Node.js.
It exposes an argv property, which is an array that contains all the command line invocation arguments.
The first element is the full path of the node command.
The second element is the full path of the file being executed.
All the additional arguments are present from the third position going forward.
You can iterate over all the arguments (including the node path and the file path) using a loop:
//
process.argv.forEach((val, index) => {
console.log(`${index}: ${val}`);
});You can get only the additional arguments by creating a new array that excludes the first 2 params:
//
const args = process.argv.slice(2);If you have one argument without an index name, like this:
node app.js joe
you can access it using
//
const args = process.argv.slice(2);
args[0];In this case:
node app.js name=joe
args[0] is name=joe, and you need to
parse it. The best way to do so is by using the minimist library, which helps dealing with arguments:
//
const args = require('minimist')(process.argv.slice(2));
args['name']; //joeInstall the required minimist package using npm (lesson about the package manager comes later on).
npm install minimist
This time you need to use double dashes before each argument name:
node app.js --name=joe
description: 'How to print to the command line console using Node.js, from the basic console.log to more complex scenarios'
Node.js provides a console module which provides tons of very useful ways to interact with the command line.
It is basically the same as the console object you find in the browser.
The most basic and most used method is console.log(), which prints the string you pass to it to the console.
If you pass an object, it will render it as a string.
You can pass multiple variables to console.log, for example:
//
const x = 'x';
const y = 'y';
console.log(x, y);and Node.js will print both.
We can also format pretty phrases by passing variables and a format specifier.
For example:
//
console.log('My %s has %d years', 'cat', 2);-
%sformat a variable as a string -
%dformat a variable as a number -
%iformat a variable as its integer part only -
%oformat a variable as an object
Example:
//
console.log('%o', Number);console.clear() clears the console (the behavior might depend on the console used)
console.count() is a handy method.
Take this code:
<iframe title="Output to the command line using Node.js" src="https://stackblitz.com/edit/nodejs-dev-0002-01?index.js&zenmode=1&view=editor" alt="nodejs-dev-0002-01 on StackBlitz" style="height: 400px; width: 100%; border: 0;"> </iframe>What happens is that console.count() will count the number of times a string is printed, and print the count next to it:
You can just count apples and oranges:
//
const oranges = ['orange', 'orange'];
const apples = ['just one apple'];
oranges.forEach((fruit) => {
console.count(fruit);
});
apples.forEach((fruit) => {
console.count(fruit);
});The console.countReset() method resets counter used with console.count().
We will use the apples and orange example to demonstrate this.
//
const oranges = ['orange', 'orange'];
const apples = ['just one apple'];
oranges.forEach((fruit) => {
console.count(fruit);
});
apples.forEach((fruit) => {
console.count(fruit);
});
console.countReset('orange');
oranges.forEach((fruit) => {
console.count(fruit);
});Notice how the call to console.countReset('orange') resets the value counter to zero.
There might be cases where it's useful to print the call stack trace of a function, maybe to answer the question how did you reach that part of the code?
You can do so using console.trace():
//
const function2 = () => console.trace();
const function1 = () => function2();
function1();This will print the stack trace. This is what's printed if we try this in the Node.js REPL:
Trace
at function2 (repl:1:33)
at function1 (repl:1:25)
at repl:1:1
at ContextifyScript.Script.runInThisContext (vm.js:44:33)
at REPLServer.defaultEval (repl.js:239:29)
at bound (domain.js:301:14)
at REPLServer.runBound [as eval] (domain.js:314:12)
at REPLServer.onLine (repl.js:440:10)
at emitOne (events.js:120:20)
at REPLServer.emit (events.js:210:7)
You can easily calculate how much time a function takes to run, using time() and timeEnd()
//
const doSomething = () => console.log('test');
const measureDoingSomething = () => {
console.time('doSomething()');
//do something, and measure the time it takes
doSomething();
console.timeEnd('doSomething()');
};
measureDoingSomething();As we saw console.log is great for printing messages in the Console. This is what's called the standard output, or stdout.
console.error prints to the stderr stream.
It will not appear in the console, but it will appear in the error log.
You can color the output of your text in the console by using escape sequences. An escape sequence is a set of characters that identifies a color.
Example:
//
console.log('\x1b[33m%s\x1b[0m', 'hi!');You can try that in the Node.js REPL, and it will print hi! in yellow.
However, this is the low-level way to do this. The simplest way to go about coloring the console output is by using a library. Chalk is such a library, and in addition to coloring it also helps with other styling facilities, like making text bold, italic or underlined.
You install it with npm install chalk, then you can use it:
//
const chalk = require('chalk');
console.log(chalk.yellow('hi!'));Using chalk.yellow is much more convenient than trying to remember the escape codes, and the code is much more readable.
Check the project link posted above for more usage examples.
Progress is an awesome package to create a progress bar in the console. Install it using npm install progress
This snippet creates a 10-step progress bar, and every 100ms one step is completed. When the bar completes we clear the interval:
//
const ProgressBar = require('progress');
const bar = new ProgressBar(':bar', { total: 10 });
const timer = setInterval(() => {
bar.tick();
if (bar.complete) {
clearInterval(timer);
}
}, 100);description: 'How to make a Node.js CLI program interactive using the built-in readline Node.js module'
How to make a Node.js CLI program interactive?
Node.js since version 7 provides the readline module to perform exactly this: get input from a readable stream such as the process.stdin stream, which during the execution of a Node.js program is the terminal input, one line at a time.
//
const readline = require('readline').createInterface({
input: process.stdin,
output: process.stdout
});
readline.question(`What's your name?`, (name) => {
console.log(`Hi ${name}!`);
readline.close();
});This piece of code asks the username, and once the text is entered and the user presses enter, we send a greeting.
The question() method shows the first parameter (a question) and waits for the user input. It calls the callback function once enter is pressed.
In this callback function, we close the readline interface.
readline offers several other methods, and I'll let you check them out on the package documentation linked above.
If you need to require a password, it's best not to echo it back, but instead show a * symbol.
The simplest way is to use the readline-sync package which is very similar in terms of the API and handles this out of the box.
A more complete and abstract solution is provided by the Inquirer.js package.
You can install it using npm install inquirer, and then you can replicate the above code like this:
//
const inquirer = require('inquirer');
var questions = [
{
type: 'input',
name: 'name',
message: "What's your name?"
}
];
inquirer.prompt(questions).then((answers) => {
console.log(`Hi ${answers['name']}!`);
});Inquirer.js lets you do many things like asking multiple choices, having radio buttons, confirmations, and more.
It's worth knowing all the alternatives, especially the built-in ones provided by Node.js, but if you plan to take CLI input to the next level, Inquirer.js is an optimal choice.
description: 'How to use the module.exports API to expose data to other files in your application, or to other applications as well'
Node.js has a built-in module system.
A Node.js file can import functionality exposed by other Node.js files.
When you want to import something you use
//
const library = require('./library');to import the functionality exposed in the library.js file that resides in the current file folder.
In this file, functionality must be exposed before it can be imported by other files.
Any other object or variable defined in the file by default is private and not exposed to the outer world.
This is what the module.exports API offered by the module system allows us to do.
When you assign an object or a function as a new exports property, that is the thing that's being exposed, and as such, it can be imported in other parts of your app, or in other apps as well.
You can do so in 2 ways.
The first is to assign an object to module.exports, which is an object provided out of the box by the module system, and this will make your file export just that object:
//
// car.js
const car = {
brand: 'Ford',
model: 'Fiesta'
};
module.exports = car;//
// index.js
const car = require('./car');The second way is to add the exported object as a property of exports. This way allows you to export multiple objects, functions or data:
//
const car = {
brand: 'Ford',
model: 'Fiesta'
};
exports.car = car;or directly
//
exports.car = {
brand: 'Ford',
model: 'Fiesta'
};And in the other file, you'll use it by referencing a property of your import:
//
const items = require('./items');
const car = items.car;or
//
const car = require('./items').car;What's the difference between module.exports and exports?
The first exposes the object it points to.
The latter exposes the properties of the object it points to.
description: 'A quick guide to npm, the powerful package manager key to the success of Node.js. In January 2017 over 350000 packages were reported being listed in the npm registry, making it the biggest single language code repository on Earth, and you can be sure there is a package for (almost!) everything.'
npm is the standard package manager for Node.js.
In January 2017 over 350000 packages were reported being listed in the npm registry, making it the biggest single language code repository on Earth, and you can be sure there is a package for (almost!) everything.
It started as a way to download and manage dependencies of Node.js packages, but it has since become a tool used also in frontend JavaScript.
There are many things that npm does.
Yarn and pnpm are alternatives to npm cli. You can check them out as well.
npm manages downloads of dependencies of your project.
If a project has a package.json file, by running
npm install
it will install everything the project needs, in the node_modules folder, creating it if it's not existing already.
You can also install a specific package by running
npm install <package-name>
Furthermore, since npm 5, this command adds <package-name> to the package.json file dependencies. Before version 5, you needed to add the flag --save.
Often you'll see more flags added to this command:
-
--save-devinstalls and adds the entry to thepackage.jsonfile devDependencies -
--no-saveinstalls but does not add the entry to thepackage.jsonfile dependencies -
--save-optionalinstalls and adds the entry to thepackage.jsonfile optionalDependencies -
--no-optionalwill prevent optional dependencies from being installed
Shorthands of the flags can also be used:
-
-S: --save
-
-D: --save-dev
-
-O: --save-optional
The difference between devDependencies and dependencies is that the former contains development tools, like a testing library, while the latter is bundled with the app in production.
As for the optionalDependencies the difference is that build failure of the dependency will not cause installation to fail. But it is your program's responsibility to handle the lack of the dependency. Read more about optional dependencies.
Updating is also made easy, by running
npm update
npm will check all packages for a newer version that satisfies your versioning constraints.
You can specify a single package to update as well:
npm update <package-name>
In addition to plain downloads, npm also manages versioning, so you can specify any specific version of a package, or require a version higher or lower than what you need.
Many times you'll find that a library is only compatible with a major release of another library.
Or a bug in the latest release of a lib, still unfixed, is causing an issue.
Specifying an explicit version of a library also helps to keep everyone on the same exact version of a package, so that the whole team runs the same version until the package.json file is updated.
In all those cases, versioning helps a lot, and npm follows the semantic versioning (semver) standard.
The package.json file supports a format for specifying command line tasks that can be run by using
npm run <task-name>
For example:
//on
{
"scripts": {
"start-dev": "node lib/server-development",
"start": "node lib/server-production"
}
}It's very common to use this feature to run Webpack:
//on
{
"scripts": {
"watch": "webpack --watch --progress --colors --config webpack.conf.js",
"dev": "webpack --progress --colors --config webpack.conf.js",
"prod": "NODE_ENV=production webpack -p --config webpack.conf.js"
}
}So instead of typing those long commands, which are easy to forget or mistype, you can run
$ npm run watch
$ npm run dev
$ npm run prod
description: 'How to find out where npm installs the packages'
When you install a package using npm you can perform 2 types of installation:
- a local install
- a global install
By default, when you type an npm install command, like:
npm install lodash
the package is installed in the current file tree, under the node_modules subfolder.
As this happens, npm also adds the lodash entry in the dependencies property of the package.json file present in the current folder.
A global installation is performed using the -g flag:
npm install -g lodash
When this happens, npm won't install the package under the local folder, but instead, it will use a global location.
Where, exactly?
The npm root -g command will tell you where that exact location is on your machine.
On macOS or Linux this location could be /usr/local/lib/node_modules.
On Windows it could be C:\Users\YOU\AppData\Roaming\npm\node_modules
If you use nvm to manage Node.js versions, however, that location would differ.
I, for example, use nvm and my packages location was shown as /Users/joe/.nvm/versions/node/v8.9.0/lib/node_modules.
description: 'How to include and use in your code a package installed in your node_modules folder'
When you install a package into your node_modules folder using npm , or also globally, how do you use it in your Node.js code?
Say you install lodash, the popular JavaScript utility library, using
npm install lodash
This is going to install the package in the local node_modules folder.
To use it in your code, you just need to import it into your program using require:
//
const _ = require('lodash');What if your package is an executable?
In this case, it will put the executable file under the node_modules/.bin/ folder.
One easy way to demonstrate this is cowsay.
The cowsay package provides a command line program that can be executed to make a cow say something (and other animals as well 🦊).
When you install the package using npm install cowsay, it will install itself and a few dependencies in the node_modules folder:

There is a hidden .bin folder, which contains symbolic links to the cowsay binaries:

How do you execute those?
You can of course type ./node_modules/.bin/cowsay to run it, and it works, but npx, included in the recent versions of npm (since 5.2), is a much better option. You just run:
npx cowsay
and npx will find the package location.

description: 'The package.json file is a key element in lots of app codebases based on the Node.js ecosystem.'
If you work with JavaScript, or you've ever interacted with a JavaScript project, Node.js or a frontend project, you surely met the package.json file.
What's that for? What should you know about it, and what are some of the cool things you can do with it?
The package.json file is kind of a manifest for your project. It can do a lot of things, completely unrelated. It's a central repository of configuration for tools, for example. It's also where npm and yarn store the names and versions for all the installed packages.
Here's an example package.json file:
//on
{
}It's empty! There are no fixed requirements of what should be in a package.json file, for an application. The only requirement is that it respects the JSON format, otherwise it cannot be read by programs that try to access its properties programmatically.
If you're building a Node.js package that you want to distribute over npm things change radically, and you must have a set of properties that will help other people use it. We'll see more about this later on.
This is another package.json:
//on
{
"name": "test-project"
}It defines a name property, which tells the name of the app, or package, that's contained in the same folder where this file lives.
Here's a much more complex example, which was extracted from a sample Vue.js application:
//on
{
"name": "test-project",
"version": "1.0.0",
"description": "A Vue.js project",
"main": "src/main.js",
"private": true,
"scripts": {
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js",
"start": "npm run dev",
"unit": "jest --config test/unit/jest.conf.js --coverage",
"test": "npm run unit",
"lint": "eslint --ext .js,.vue src test/unit",
"build": "node build/build.js"
},
"dependencies": {
"vue": "^2.5.2"
},
"devDependencies": {
"autoprefixer": "^7.1.2",
"babel-core": "^6.22.1",
"babel-eslint": "^8.2.1",
"babel-helper-vue-jsx-merge-props": "^2.0.3",
"babel-jest": "^21.0.2",
"babel-loader": "^7.1.1",
"babel-plugin-dynamic-import-node": "^1.2.0",
"babel-plugin-syntax-jsx": "^6.18.0",
"babel-plugin-transform-es2015-modules-commonjs": "^6.26.0",
"babel-plugin-transform-runtime": "^6.22.0",
"babel-plugin-transform-vue-jsx": "^3.5.0",
"babel-preset-env": "^1.3.2",
"babel-preset-stage-2": "^6.22.0",
"chalk": "^2.0.1",
"copy-webpack-plugin": "^4.0.1",
"css-loader": "^0.28.0",
"eslint": "^4.15.0",
"eslint-config-airbnb-base": "^11.3.0",
"eslint-friendly-formatter": "^3.0.0",
"eslint-import-resolver-webpack": "^0.8.3",
"eslint-loader": "^1.7.1",
"eslint-plugin-import": "^2.7.0",
"eslint-plugin-vue": "^4.0.0",
"extract-text-webpack-plugin": "^3.0.0",
"file-loader": "^1.1.4",
"friendly-errors-webpack-plugin": "^1.6.1",
"html-webpack-plugin": "^2.30.1",
"jest": "^22.0.4",
"jest-serializer-vue": "^0.3.0",
"node-notifier": "^5.1.2",
"optimize-css-assets-webpack-plugin": "^3.2.0",
"ora": "^1.2.0",
"portfinder": "^1.0.13",
"postcss-import": "^11.0.0",
"postcss-loader": "^2.0.8",
"postcss-url": "^7.2.1",
"rimraf": "^2.6.0",
"semver": "^5.3.0",
"shelljs": "^0.7.6",
"uglifyjs-webpack-plugin": "^1.1.1",
"url-loader": "^0.5.8",
"vue-jest": "^1.0.2",
"vue-loader": "^13.3.0",
"vue-style-loader": "^3.0.1",
"vue-template-compiler": "^2.5.2",
"webpack": "^3.6.0",
"webpack-bundle-analyzer": "^2.9.0",
"webpack-dev-server": "^2.9.1",
"webpack-merge": "^4.1.0"
},
"engines": {
"node": ">= 6.0.0",
"npm": ">= 3.0.0"
},
"browserslist": ["> 1%", "last 2 versions", "not ie <= 8"]
}there are lots of things going on here:
-
versionindicates the current version -
namesets the application/package name -
descriptionis a brief description of the app/package -
mainsets the entry point for the application -
privateif set totrueprevents the app/package to be accidental -
scriptsdefines a set of node scripts you can run -
dependenciessets a list ofnpmpackages installed as dependencies -
devDependenciessets a list ofnpmpackages installed as development dependencies -
enginessets which versions of Node.js this package/app works on -
browserslistis used to tell which browsers (and their versions) you want to support
All those properties are used by either npm or other tools that we can use.
Most of those properties are only used on https://www.npmjs.com/, others by scripts that interact with your code, like npm or others.
Sets the package name.
Example:
//on
"name": "test-project"The name must be less than 214 characte
View raw
(Sorry about that, but we can’t show files that are this big right now.)
View raw
(Sorry about that, but we can’t show files that are this big right now.)
View raw
(Sorry about that, but we can’t show files that are this big right now.)
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment