-
Star
(162)
You must be signed in to star a gist -
Fork
(47)
You must be signed in to fork a gist
-
-
Save cbaziotis/7ef97ccf71cbc14366835198c09809d2 to your computer and use it in GitHub Desktop.
| def dot_product(x, kernel): | |
| """ | |
| Wrapper for dot product operation, in order to be compatible with both | |
| Theano and Tensorflow | |
| Args: | |
| x (): input | |
| kernel (): weights | |
| Returns: | |
| """ | |
| if K.backend() == 'tensorflow': | |
| return K.squeeze(K.dot(x, K.expand_dims(kernel)), axis=-1) | |
| else: | |
| return K.dot(x, kernel) | |
| class AttentionWithContext(Layer): | |
| """ | |
| Attention operation, with a context/query vector, for temporal data. | |
| Supports Masking. | |
| Follows the work of Yang et al. [https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf] | |
| "Hierarchical Attention Networks for Document Classification" | |
| by using a context vector to assist the attention | |
| # Input shape | |
| 3D tensor with shape: `(samples, steps, features)`. | |
| # Output shape | |
| 2D tensor with shape: `(samples, features)`. | |
| How to use: | |
| Just put it on top of an RNN Layer (GRU/LSTM/SimpleRNN) with return_sequences=True. | |
| The dimensions are inferred based on the output shape of the RNN. | |
| Note: The layer has been tested with Keras 2.0.6 | |
| Example: | |
| model.add(LSTM(64, return_sequences=True)) | |
| model.add(AttentionWithContext()) | |
| # next add a Dense layer (for classification/regression) or whatever... | |
| """ | |
| def __init__(self, | |
| W_regularizer=None, u_regularizer=None, b_regularizer=None, | |
| W_constraint=None, u_constraint=None, b_constraint=None, | |
| bias=True, **kwargs): | |
| self.supports_masking = True | |
| self.init = initializers.get('glorot_uniform') | |
| self.W_regularizer = regularizers.get(W_regularizer) | |
| self.u_regularizer = regularizers.get(u_regularizer) | |
| self.b_regularizer = regularizers.get(b_regularizer) | |
| self.W_constraint = constraints.get(W_constraint) | |
| self.u_constraint = constraints.get(u_constraint) | |
| self.b_constraint = constraints.get(b_constraint) | |
| self.bias = bias | |
| super(AttentionWithContext, self).__init__(**kwargs) | |
| def build(self, input_shape): | |
| assert len(input_shape) == 3 | |
| self.W = self.add_weight((input_shape[-1], input_shape[-1],), | |
| initializer=self.init, | |
| name='{}_W'.format(self.name), | |
| regularizer=self.W_regularizer, | |
| constraint=self.W_constraint) | |
| if self.bias: | |
| self.b = self.add_weight((input_shape[-1],), | |
| initializer='zero', | |
| name='{}_b'.format(self.name), | |
| regularizer=self.b_regularizer, | |
| constraint=self.b_constraint) | |
| self.u = self.add_weight((input_shape[-1],), | |
| initializer=self.init, | |
| name='{}_u'.format(self.name), | |
| regularizer=self.u_regularizer, | |
| constraint=self.u_constraint) | |
| super(AttentionWithContext, self).build(input_shape) | |
| def compute_mask(self, input, input_mask=None): | |
| # do not pass the mask to the next layers | |
| return None | |
| def call(self, x, mask=None): | |
| uit = dot_product(x, self.W) | |
| if self.bias: | |
| uit += self.b | |
| uit = K.tanh(uit) | |
| ait = K.dot(uit, self.u) | |
| a = K.exp(ait) | |
| # apply mask after the exp. will be re-normalized next | |
| if mask is not None: | |
| # Cast the mask to floatX to avoid float64 upcasting in theano | |
| a *= K.cast(mask, K.floatx()) | |
| # in some cases especially in the early stages of training the sum may be almost zero | |
| # and this results in NaN's. A workaround is to add a very small positive number ε to the sum. | |
| # a /= K.cast(K.sum(a, axis=1, keepdims=True), K.floatx()) | |
| a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx()) | |
| a = K.expand_dims(a) | |
| weighted_input = x * a | |
| return K.sum(weighted_input, axis=1) | |
| def compute_output_shape(self, input_shape): | |
| return input_shape[0], input_shape[-1] |
Will this work for images?
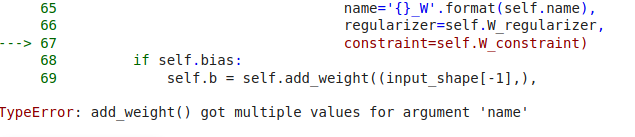
I am getting this error. Can anyone please help me resolve it.
CODE:
model.add(Bidirectional(LSTM(lstm_output_size, dropout_W=0.2,dropout_U=0.2, return_sequences=True)))
model.add(Bidirectional(LSTM(lstm_output_size, dropout_W=0.2,dropout_U=0.2, return_sequences=True)))
model.add(AttentionWithContext())
model.add(Dense(numclasses, activation='softmax'))
@cbaziotis
Thanks a lot for the code. I have a question about using mask. Could you please explain how to define and use a mask here? If I have already used a Masking layer before LSTM, e.g., x = Masking(mask_value=0.)(x), should I still use mask here? If so, how can I define the mask? I am using masking value as 0 in the masking layer for LSTM, then the LSTM layer knows which timesteps should be ignored. However, the LSTM features will not be zeros and might be arbitrary, how to define the mask for the attention layer then? Should we use the same mask as that for LSTM? Thank you very much.
@LuisPB7 I combine the context and key into a whole tensor as an input, then split them in the Attention class. But that needs some modification in the Attention codes (stuff like tensor calculation, input/output shape).