Blog 2020/8/21
<- previous | index | next ->
Let's learn how to implement a hash table in C! (See also part 1, 2, 3 and 4).
Let's take a look at the importance of the hash function by comparing "terrible hash" to DJB2 and SDBM
size_t djb2Hash(void* datap, size_t length) {
size_t hash = 5381;
uint8_t* cursorp = datap;
for (size_t i=0; i < length; cursorp++, i++) {
hash = ((hash << 5) + hash) ^ (*cursorp);
}
return hash;
}size_t sdbmHash(void* datap, size_t length) {
size_t hash = 0;
uint8_t* cursorp = datap;
for (size_t i=0; i < length; cursorp++, i++) {
hash = (*cursorp) + (hash << 6) + (hash << 16) - hash;
}
return hash;
}To analyze the performance of these hash functions,
we'll add all of the words (about 100,000) in /usr/share/dict/words as keys in a hash table,
then look at a histogram of slot list lengths.
We'll use a function pointer so that we can easily pass in different hashing functions.
HashTable* hashTheDictionary(size_t (*hashFuncp)(void*, size_t)) {
// open the dictionary file
int fd = open("/usr/share/dict/words", O_RDONLY);
assert(fd != -1);
// get the size of the file
struct stat statbuf;
int err = fstat(fd, &statbuf);
assert(err == 0);
off_t fsize = statbuf.st_size;
// read the file into memory.
char* fbuff = (char*)malloc(fsize);
assert(fbuff != NULL);
ssize_t bytesRead = read(fd, fbuff, fsize);
assert(bytesRead == fsize);
HashTable* htp = HashTableMake(1);
char* valuep = "common value";
char* cursorp = fbuff;
char* endp = fbuff + fsize;
char* keyp = cursorp;
while (cursorp != endp) {
if (*cursorp == '\n') {
*cursorp = '\0';
size_t keyLength = cursorp - keyp;
if (keyLength > 0) {
size_t keyHash = hashFuncp(keyp, keyLength);
HashTableSet(htp, keyp, keyLength, keyHash, valuep);
}
cursorp++;
keyp = cursorp;
continue;
} else {
cursorp++;
continue;
}
}
return htp;
}void analyzeHashTable(HashTable* htp) {
#define LENGTHS_LEN (1000)
size_t score = 0;
size_t lengths[LENGTHS_LEN] = {0};
for (size_t i=0; i < htp->capacity; i++) {
HTSlot* slotp = htp->slotspp[i];
size_t chainLength = 0;
while (slotp != NULL) {
if (slotp->valuep != NULL) {
chainLength++;
}
slotp = slotp->nextp;
continue;
}
lengths[chainLength]++;
score += (chainLength * chainLength);
continue;
}
printf("Chain lengths histogram:\n");
printf("length occurrences\n");
printf("------ -----------\n");
for (size_t i=0; i < LENGTHS_LEN; i++) {
if (lengths[i] == 0) {
continue;
}
if (i < 10) {
printf(" ");
} else if (i < 100) {
printf(" ");
} else if (i < 1000) {
printf(" ");
} else if (i < 10000) {
printf(" ");
} else if (i < 100000) {
printf(" ");
}
printf("%zu %zu\n", i, lengths[i]);
}
printf("population: %zu, slots: %zu, empty slots: %zu, score: %zu\n",
htp->population, htp->capacity, lengths[0], score
);
}int main(int argc, char** argv) {
HashTable* htp;
printf("\ndjb2 hash\n");
htp = hashTheDictionary(djb2Hash);
analyzeHashTable(htp);
printf("\nsdbm hash\n");
htp = hashTheDictionary(sdbmHash);
analyzeHashTable(htp);
printf("\nterrible hash\n");
htp = hashTheDictionary(terribleHash);
analyzeHashTable(htp);
return 0;
}What we are looking for is a "short tail". The ideal hash function would give us an even distribution of hash values. That is, if we had N slots and N keys, all of our slot lists would be length 1.
Practically, some slots will be empty and others will be length > 1.
First, let's take a look at "terrible hash":
terrible hash
Chain lengths histogram:
length occurrences
------ -----------
0 63741
1 206
2 95
3 67
4 55
5 35
6 36
7 28
8 28
9 32
10 20
11 20
12 13
13 22
14 14
15 12
(...many rows elided...)
82 8
83 10
84 12
85 7
86 11
87 6
88 8
89 2
90 6
91 5
(...many rows elided...)
266 1
267 1
268 2
269 2
272 2
274 1
279 1
283 1
288 2
298 1
population: 102401, slots: 65536, empty slots: 63741, score: 13240151
Oof! This is truly terrible! 97% of the slots are unused, and one of the slots has a chain which is 298 elements long!!!
This hash produces a long tail, which is the opposite of what we want!
Now let's compare that to DJB2 and SDBM.
DJB2 hash
Chain lengths histogram:
length occurrences
------ -----------
0 13809
1 21547
2 16591
3 8633
4 3484
5 1096
6 292
7 69
8 13
9 2
population: 102401, slots: 65536, empty slots: 13809, score: 263639
SDBM hash
Chain lengths histogram:
length occurrences
------ -----------
0 13778
1 21522
2 16539
3 8841
4 3447
5 1056
6 275
7 66
8 11
10 1
population: 102401, slots: 65536, empty slots: 13778, score: 262737
Visually:
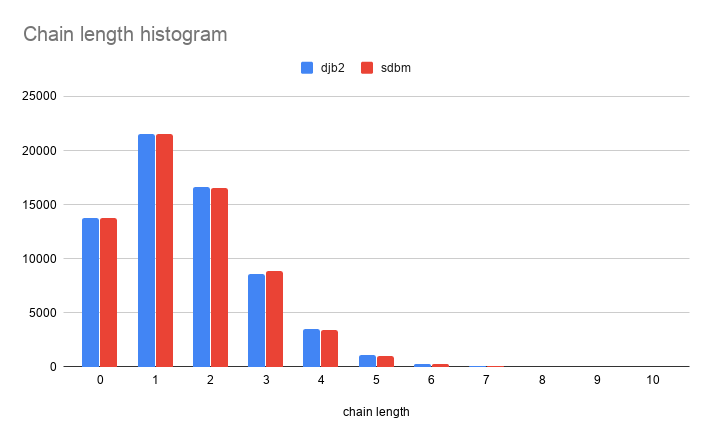
DBJ2 and SDBM are remarkably similar in distribution!
Now let's compare DJB2 to "terrible hash" :)
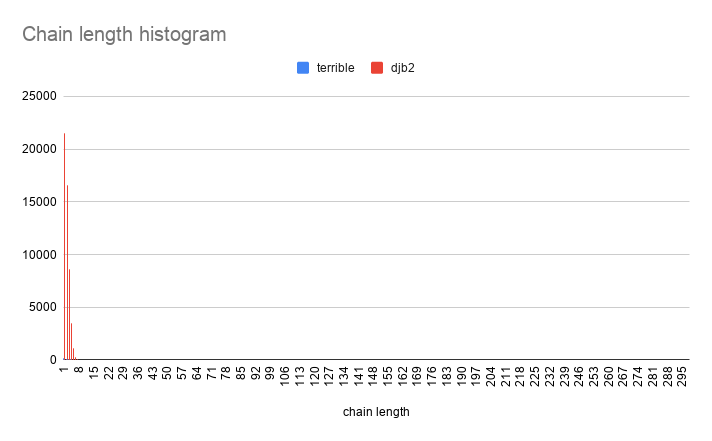
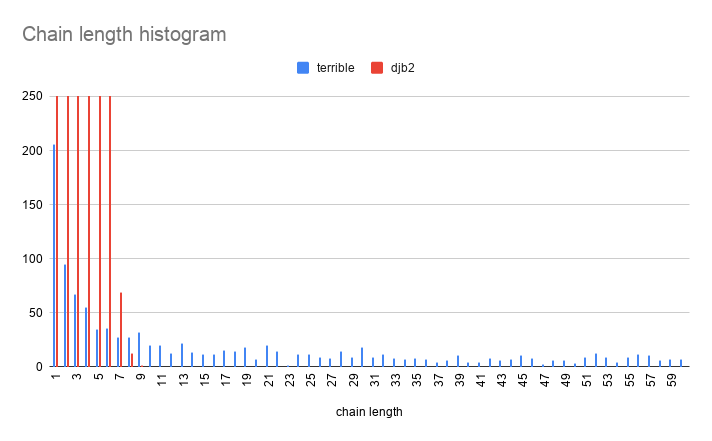
The difference in performance is so severe that they can't really be compared on the same graph! Let's zoom in:
In part 6, we'll take a look at using prime numbers for our slot array sizes.