Blog 2020/6/11
<- previous | index | next ->
Over the past few years, I've written a number of regex-based lexers and recursive-descent parsers, following the technique described in Gary Bernhardt's A Compiler from Scratch (free and well worth your time -- go watch it now!).
I've realized that writing this code is really just a mechanical process. This means we can write a program to write these lexers and parsers for us!
(Yes, I know, this is not a new idea :)
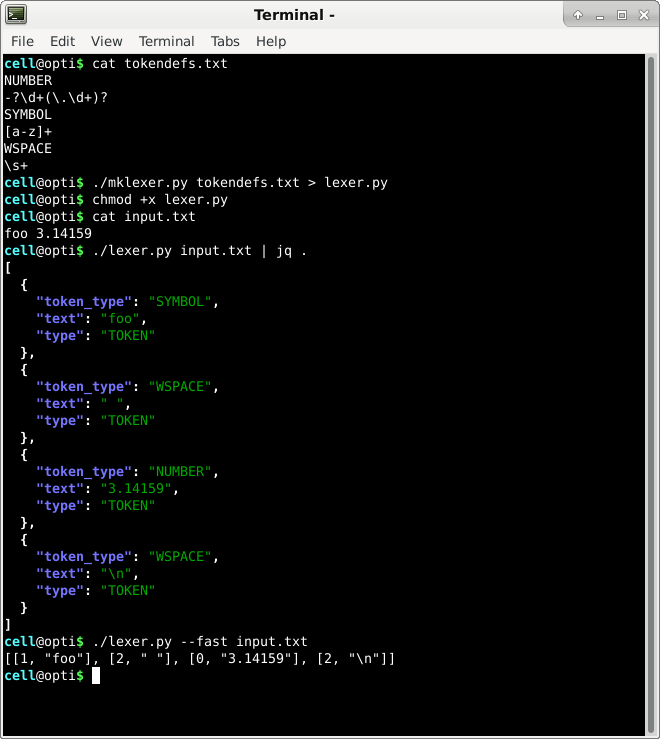
mklexer.py is a program which generates Python code which implements a regex-based lexer,
according to a token definitions file.
The generated lexer will output tokens in a standardized JSON format.
- Reap the benefits of a declarative approach
- Generate code which is easily understood and easy to hack on
- Reduce time spent on boilerplate
- Lexer performance
The format of the token definitions file is a series of pairs of lines:
- a line naming the token type (in ALLCAPS),
- followed by a line defining the regex which regonizes that type of token.
For example, here is a token definitions file which tokenizes a trivial S-expression syntax:
tokendefs.txt:
OPAREN
\(
CPAREN
\)
NUMBER
-?\d+(\.\d+)?
SYMBOL
[a-z]+
WSPACE
\s+
Here's an example of the sort of input which we expect this lexer to tokenize:
(define fibonacci
(lambda (n)
(if (lessthan n 2)
n
(sum (fibonacci (sum n -1)) (fibonacci (sum n -2))))))The generated lexer will spit out the tokens in JSON.
The JSON will conform the following format:
- The top-level JSON structure will be an array (of tokens)
- Each token will be a JSON object (dictionary)
- Each token will contain the following keys:
type, with valueTOKENtoken_type, with a value which is one of the ALLCAPS token typestext, with a value which is the text matched by the regex.
For example, if we use the above tokendefs.txt to tokenize the following input:
(define pi 3.14159)We should get the following JSON output:
[
{
"type": "TOKEN",
"token_type": "OPAREN",
"text": "("
},
{
"type": "TOKEN",
"token_type": "SYMBOL",
"text": "define"
},
{
"type": "TOKEN",
"token_type": "WSPACE",
"text": " "
},
{
"type": "TOKEN",
"token_type": "SYMBOL",
"text": "pi"
},
{
"type": "TOKEN",
"token_type": "WSPACE",
"text": " "
},
{
"type": "TOKEN",
"token_type": "NUMBER",
"text": "3.14159"
},
{
"type": "TOKEN",
"token_type": "CPAREN",
"text": ")"
}
]The generated lexer also supports an array-based "fast" token format.
Each token is array consisting of two elements:
- A numeric index into the list of token types
- The token text
For our same (define pi 3.14159) example, the "fast" output looks like this:
./lexer.py input2.txt --fast
[[0, "("], [3, "define"], [4, " "], [3, "pi"], [4, " "], [2, "3.14159"], [1, ")"], [4, "\n"]]
$ ./mklexer.py --help
mklexer.py: generate a Python lexer based on a token definitions file.
Display help:
mklexer.py -h
mklexer.py --help
Generate a lexer using tokendefs.txt:
mklexer.py tokendefs.txt > lexer.py
chmod +x lexer.py
tokendefs.txt consists of pairs of TOKENTYPE and <regex> lines.
Example tokendefs.txt:
NUMBER
-?\d+(\.\d+)?
SYMBOL
[a-zA-Z_][a-zA-Z0-9_-]*
Use the lexer on input.txt, producing the standard JSON token format:
./lexer.py input.txt | jq .
Two example tokens in standard JSON format:
{'type': 'TOKEN', 'token_type': 'NUMBER', 'text': '3.14159'}
{'type': 'TOKEN', 'token_type': 'SYMBOL', 'text': 'fibonacci'}
Use the lexer on input.txt, producing "fast" array-based JSON tokens:
./lexer.py --fast input.txt | jq .
"fast" tokens are [<token type index>, <matched text>] pairs.
The same example tokens, but in 'fast' JSON format:
[0, '3.14159']
[1, 'fibonacci']