__Due to the documentation being updated, the description may have errors. __
This library supports model fine tuning (fine tuning), DreamBooth, training LoRA and text inversion (Textual Inversion) (including XTI:P+ ) This document will explain their common learning data preparation methods and options, etc.
Please refer to the README of this warehouse in advance to prepare the environment.
Below this section explains.
-
Regarding the new form of preparing learning data (using settings files)
-
A brief explanation of the terms used in the study
-
Previously specified format (not using a setting file, but specifying from the command line)
-
Generate example images during learning
-
Common options commonly used in each script
-
Prepare the metadata of the fine tuning method: such as explanatory text (labeling), etc.
-
If executed only once, learning can take place (see documentation of individual scripts for details). You can always refer to it later if needed.
Prepare image files for training data in any folder (or multiple folders). Support .png, .jpg, .jpeg, .webp, .bmp format files. Usually no preprocessing such as resizing etc. is required.
But do not use extremely small images whose size is smaller than the training resolution (mentioned later), it is recommended to use super-resolution AI, etc. to enlarge beforehand. Also, be careful not to use very large images (approximately more than 3000 x 3000 pixels), as this may cause errors, it is recommended to scale down beforehand.
At training time, the image data to be used to train the model needs to be organized and assigned to the script. There are several ways to specify training data, depending on factors such as the amount of training data, training goals, and availability of instructions (image descriptions). Here are some of those methods (each name is not generic, but a custom definition for this repository). Information on regularizing images will be provided later.
-
DreamBooth, class + identifier method (regularized images can be used)
Associate the training target with a specific word (identifier) for training. No need to prepare instructions. For example, when you want to learn a specific character, it is convenient because there is no need to prepare instructions, but since all elements of the learning data are associated with identifiers, such as hairstyles, clothing, backgrounds, etc., there may be problems when generating clothing that cannot be changed. Condition.
-
DreamBooth, description method (regularized image can be used)
Prepare a text file recording each image caption for training. For example, by recording image details (such as character A in white clothes, character A in red clothes, etc.)
-
Fine-tuning method (regularized images cannot be used)
First collect the instructions into a metadata file. Features such as support for separating labels and descriptions and pre-caching latents to speed up training (these will be covered in another document). (Although it is called fine tuning method, it is not limited to fine tuning.) The combination of what you will learn and the canonical methods you can use is as follows.
| learning object or method | script | DB/class+identifier | DB/caption | fine tuning |
|---|---|---|---|---|
| fine tuning fine-tuning model | fine_tune.py |
x | x | o |
| DreamBooth training model | train_db.py |
o | o | x |
| LoRA | train_network.py |
o | o | o |
| Textual Inversion | train_textual_inversion.py |
o | o | o |
If you want to learn LoRA, Textual Inversion without preparing an introduction file, it is recommended to use DreamBooth class+identifier. The DreamBooth Captions method is even better if you are able to prepare it. If you have a large amount of training data and do not use regularized images, consider fine-tuning methods.
The same is true for DreamBooth, but the fine-tuning method cannot be used. For the fine-tuning method, only the fine-tuning method can be used.
Here, we only present typical patterns for each specified method. For more detailed specification methods, see Dataset Settings.
In this method, each image will be considered for training with the same caption as the class identifier (eg shs dog).
This way, each image is equivalent to being trained with a caption "classification label" (eg "shs dog").
To associate a learned goal with an identifier and a class belonging to that goal.
(Although there are many names, but for the time being, follow the original paper.)
Below is a brief description (see details).
class is the general category of learning objectives. For example, if you want to learn about a specific breed of dog, the class would be "dog". For anime characters, depending on the model, it could be "boy" or "girl", or "1boy" or "1girl".
The identifier is a word used to identify the learning object and learn it. Any word can be used, but according to the original paper, "rare words of 3 or fewer characters generated by the Tokenizer" are the best choices.
Using an identifier and a class, for example, "shs dog" can train the model to recognize and learn the desired object from the class.
In image generation, using "shs dog" will generate an image of the learned dog breed.
(As an identifier, some references I've used recently are "shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny" etc. Preferably words not included in Danbooru tags.)
Regularized images are images generated to prevent the aforementioned language drift, where entire categories are pulled as learning targets. Without regularized images, such as when learning a specific character in shs 1girl, even when generated with a simple 1girl cue, it will become more and more like that character. This is because 1girl includes information about the character in the title during training.
By simultaneously learning both target and regularized images, the classes remain invariant, and target images are only generated when identifiers are appended to the cues.
If you only want to use a specific character in LoRA or DreamBooth, you can do without the regularized image.
It also doesn't need to be used in Textual Inversion (if the token string to learn is not included in the header, nothing will be learned).
In general, it is common practice to use images generated using only the class names when training the target model as regularized images (e.g. 1girl). However, if the resulting image is of poor quality, try modifying the prompt or use an additional image downloaded from the web.
(Since regularized images are also trained, their quality affects the model.)
Usually, it is ideal to prepare hundreds of images (too few images will prevent class images from generalizing and learning their features).
If you want to use the resulting image, size it to fit the training resolution (more precisely, the bucket's resolution) usually.
Create a text file and change its extension to .toml. For example, you could describe it as follows:
(The part starting with # is a comment, so you can copy and paste it directly, or delete it, no problem.)
[general]
enable_bucket = true # Whether to use Aspect Ratio Bucketing
[[datasets]]
resolution = 512 # learning resolution
batch_size = 4 # batch size
[[datasets.subsets]]
image_dir = 'C:\hoge' # specify the folder containing the training images
class_tokens = 'hoge girl' # specify the identifier class
num_repeats = 10 # number of iterations for training images
# The following is only described when using regularized images. delete if not in use
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg' # specify the folder containing regularized images
class_tokens = 'girl' # specify category
num_repeats = 1 # The number of iterations of the regularized image, basically 1 is enoughBasically just change the following locations to learn.
-
Learning resolution
Specifying a number means square (512x512 if
512), or horizontal × vertical (512x768 if[512,768]) if two numbers separated by square brackets and commas are used. In the SD1.x series, the original learning resolution is 512. Specifying a larger resolution, such as[512,768]may reduce errors in portrait and landscape image generation. In the SD2.x 768 series, the resolution is768. -
Batch size
Specify how many data to learn at the same time. It depends on the GPU's VRAM size and learning resolution. Details will be described later. In addition, fine tuning/DreamBooth/LoRA, etc. will also affect the batch size, please check the description of each script.
-
Folder specification
Specifies the folder of images used for learning and regularized images (only if used). Specifies the folder containing image data.
-
Designation of identifier and class
Same as the example, as mentioned.
-
Number of iterations
It will be described later.
The number of repetitions is used to adjust the number of regularization images and training images. Since the number of regularized images is larger than the number of training images, training images need to be reused to achieve a one-to-one ratio for training.
Please specify the number of repetitions as "number of repetitions of training images × number of training images ≥ number of repetitions of regularized images × number of regularized images".
(The amount of data for 1 epoch (data once a week) is "number of repetitions of training images × number of training images". If the number of regularized images exceeds this value, the remaining regularized images will not be used .)
Please study according to the reference of each document.
In this way, each image will be learned by caption.
Please place a file with the same filename as the image and extension .caption (can be changed in settings) in the folder used for training images. Each file should have only one line. Encoded as UTF-8.
Same format as class+identifier. Captions can be appended to normalized images, but usually are not required.
Create a text file and change the extension to .toml. For example, recording can be performed as follows.
[general]
enable_bucket = true # Aspect Ratio Bucketing をうかNoか
[[datasets]]
resolution = 512 # learning resolution
batch_size = 4 # batch size
[[datasets.subsets]]
image_dir = 'C:\hoge' # specify the folder containing the training images
caption_extension = '.caption' # Override when using the subtitle file extension .txt
num_repeats = 10 # number of iterations for training images
# The following is only described when using regularized images. delete if not in use
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg' #Specify the folder containing the regularized image
class_tokens = 'girl' # class is specified
num_repeats = 1#
The number of iterations of the regularized image, basically 1 is enoughBasically, you can learn by just rewriting the following locations. Same as class+identifier method unless otherwise noted.
-
Learning resolution
-
Batch size
-
Folder specification
-
Title file extension
Any extension can be specified.
-
Number of repetitions
Please refer to each document to learn.
The incorporation of titles and tags into administrative documents is called metadata. It has the extension .json and the format is json. Since the creation method is longer, it is described at the end of this document.
Create a text file and set the extension to .toml. For example, it can be written as follows:
[general]
shuffle_caption = true
keep_tokens = 1
[[datasets]]
resolution = 512 # image resolution
batch_size = 4 # batch size
[[datasets.subsets]]
image_dir = 'C:\piyo' # specify the folder containing the training images
metadata_file = 'C:\piyo\piyo_md.json' # metadata file nameBasically, you can learn by just rewriting the following locations. Unless otherwise specified, it is the same as DreamBooth, the method of class + identifier.
-
Learn resolution
-
Batch size
-
Specify folder
-
Metadata file name
Specifies a metadata file created using the method described later.
Please refer to each document for learning.
Please refer to the details yourself as details are omitted and I don't fully understand them myself.
Refers to training a model and fine-tuning its performance. The exact meaning varies by usage, but in Stable Diffusion, fine-tuning in the narrow sense refers to training a model using images and captions. DreamBooth can be seen as a special approach to narrow fine-tuning. Fine-tuning in a broad sense includes LoRA, Textual Inversion, Hypernetworks, etc., including everything that trains the model.
Roughly speaking, each time a computation is performed on the training data is a step. Specifically, "pass the title of the training data to the current model, compare the resulting image with the image of the training data, change the model slightly so that it more closely resembles the training data" is a step.
The batch size specifies how much data to compute at each step. Batch calculations can improve speed. In general, the larger the batch size, the higher the accuracy.
"Batch size × number of steps" is the amount of data used for training. Therefore, it is recommended to reduce the number of steps to increase the batch size.
(However, for example, "batch size 1, steps 1600" and "batch size 4, steps 400" will not yield the same results. Often the latter will result in The model is underfitting. Try increasing the learning rate (e.g. 2e-6), setting the number of steps to 500, etc.)
The larger the batch size, the greater the GPU memory consumption. This will cause errors if you run out of memory, or will slow down training when you're on the edge. It is recommended to check the amount of memory used in Task Manager or the nvidia-smi command to adjust.
In addition, batch means "a piece of data".
The learning rate refers to the degree of change in each step. If you specify a large value, the learning speed will be faster, but there may be cases where the change is too large and the model crashes or does not reach the optimal state. If you specify a small value, the learning rate will be slower and may not be optimal.
In the process of fine tuning, DreamBooth, LoRA, etc., the learning rate will vary greatly, and will also be affected by factors such as training data, model to be trained, batch size and number of steps. It is recommended to start with a general value, observe the training status and adjust it gradually.
By default, the learning rate is fixed throughout training. But how the learning rate varies can be specified via the scheduler, so the results will vary.
Epoch refers to the situation where the training data is completely trained once (that is, the data is one week). If the number of repetitions is specified, after one week of repeated data, it is 1 epoch.
The number of steps in 1 epoch is usually "data volume ÷ batch size", but if you use Aspect Ratio Bucketing, it will increase slightly (because the data of different buckets cannot be in the same batch, the number of steps will increase).
The v1 of Stable Diffusion is trained at a resolution of 512*512, but it is also possible to train at other resolutions, such as 256*1024 and 384*640. This reduces the cropped parts and is expected to learn the relationship between images and captions more accurately.
Furthermore, since training can be performed at arbitrary resolutions, it is no longer necessary to unify the aspect ratio of the image data beforehand.
This setting is valid in configuration and can be toggled, but was enabled (set to true) in the configuration file example before this.
The learning resolution will be adjusted according to the resolution area provided by the parameters (that is, the memory usage), and the adjustment and creation will be made in the vertical and horizontal directions with a unit of 64 pixels (default value, which can be changed).
In machine learning, it is often desirable to have all inputs of the same size, but in practice it is only necessary to be uniform within the same batch. The bucketing that NovelAI refers to refers to pre-classifying the training data into each learning resolution according to the aspect ratio, and unifying the batch image size by using the images in each bucket to create batches.
Here's a way to do it via command line options instead of specifying a .toml file. There are three methods: DreamBooth class + identifier method, DreamBooth title method, and fine-tuning method.
Specify a folder name to specify the number of iterations. Also use the train_data_dir and reg_data_dir options.
Create a folder for storing training images. Additionally, create a directory with the following names.
<Number of Iterations>_<Identifier> <Category>
Don't forget the underscore _.
For example, if the data is repeated 20 times at a prompt named "sls frog", it would be "20_sls frog". As follows:

The method is very simple. In the image folder used for training, multiple folders need to be prepared. Each folder is named after "repeat_ ". Similarly, in the regularization image In the folder, multiple folders also need to be prepared, and each folder is named after "repeat times_".
For example, if you want to train "sls frog" and "cpc rabbit" at the same time, you should prepare the folder as follows.
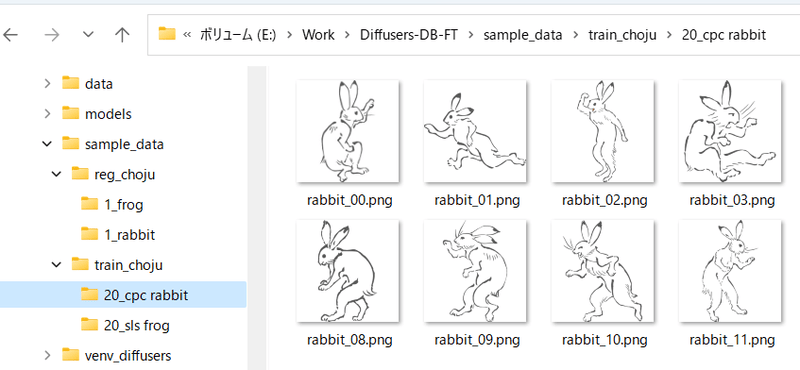
If a class contains multiple objects, it is possible to use only one folder of regularized images. For example, if you have a character A and a character B in the 1girl category, it can be handled as follows:
- train_girls
- 10_sls 1girl
- 10_cpc 1girl
- reg_girls
- 1_1girl
This is the process when using regularized images.
Create a folder to store the regularized images. Additionally, creates a directory called <repeat count>_<class>.
For example, with hint "frog" and without repeating data (only once):
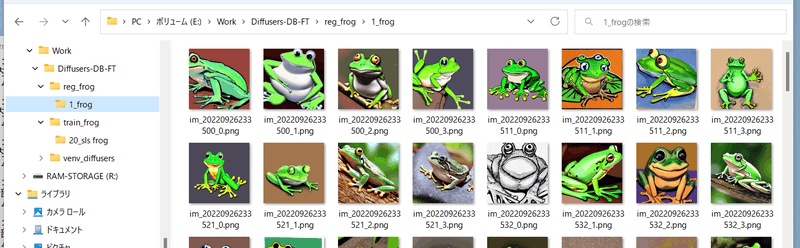
Step 3. Execute Learning
Execute each study script. Use the --train_data_dir option to specify the parent folder containing the training data folder (not the folder containing the images), use the --reg_data_dir option to specify the parent folder containing the regularized images (not the folder containing the images) .
In the folder containing the training images and the regularized images, place a file .caption (which can be changed using options) with the same filename as the images, and then load the captions from this file as hints for learning.
※ Folder names (identifier classes) are no longer used for training with these images.
The default caption file extension is .caption. This can be changed using the --caption_extension option of the learn script. Using the --shuffle_caption option will also shuffle the learned captions while learning for each comma-separated section.
Metadata is created in the same way as with configuration files. Use the in_json option to specify the metadata file.
Learning progress can be checked by using the model to generate images during training. Specify the following options as learning scripts.
-
--sample_every_n_steps/--sample_every_n_epochsSpecifies the number of steps or epochs to sample. Output samples for each of these numbers. If both are specified, the epoch number takes precedence.
-
--sample_promptsSpecifies a hints file for example output.
-
--sample_samplerSpecifies the sampler used to sample the output.
'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a'が选べます.
To output the samples, you need to prepare a text file containing the prompts in advance. Enter one hint per line.
# prompt 1
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy, bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
# prompt 2
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy, bad composition, poor, low effort --w 576 --h 832 --d 2 -- l 5.5 --s 40Lines starting with "#" are comments. You can specify options for the generated image using -- + lowercase letter, for example --n. you can use it:
--nnegates prompting to next option.--wspecifies the width of the generated image.--hspecifies the height of the generated image.--dspecifies the seed for generating images.--lspecifies the CFG scale of the resulting image.--sspecifies the number of steps in the build process.
Documentation updates may not keep up with script updates. In this case, use the --help option to check available options.
-
--v2/--v_parameterizationIf using Hugging Face's stable-diffusion-2-base or a fine-tuned model from it as the learning target model (for models instructed to use
v2-inference.yamlat inference time), the-v2option is used with stable -diffusion-2, 768-v-ema.ckpt and its fine-tuned model (for models that usev2-inference-v.yamlduring inference),--specify both -v2and--v_parameterizationoptions.The following points have changed significantly in Stable Diffusion 2.0.
- Use a tokenizer
- Which Text Encoder to use, which output layer to use (2.0 uses the penultimate layer)
- The output dimension of Text Encoder (768->1024)
- The structure of U-Net (the number of CrossAttention heads, etc.)
- v-parameterization (the sampling method seems to have changed)
Among them, 1-4 bases are used, and 1-5 non-bases are used (768-v). Use 1-4 for v2 selection and 5 for v_parameterization selection.
-
--pretrained_model_name_or_pathSpecifies the model from which to perform additional training. You can specify a stable diffusion checkpoint file (.ckpt or .safetensors), a model directory on the diffuser's local disk, or a diffuser model ID (eg "stabilityai/stable-diffusion-2").
-
--output_dirSpecifies the folder to save the model after training.
-
--output_nameSpecify the model filename without extension.
-
--dataset_configSpecifies a .toml file describing the configuration of the dataset.
-
--max_train_steps/--max_train_epochsSpecifies the number of steps or epochs to learn. If both are specified, the epoch number takes precedence.
-
--mixed_precision
Train with mixed precision to save memory. Specify something like --mixed_precision="fp16". Accuracy may be lower compared to no mixed precision (the default), but training requires significantly less GPU memory.
(You can also specify `bf16` after the RTX30 series, please cooperate with the acceleration settings you made when building the environment).
-
--gradient_checkpointingReduces the amount of GPU memory required for training by computing weights incrementally rather than all at once during training. Turning it off doesn't affect accuracy, but turning it on allows for larger batch sizes, so there is an effect there.
Also, turning it on usually slows things down, but can increase the batch size, so the total learning time might actually be faster.
-
--xformers/--mem_eff_attnWhen xformers option is specified, xformers CrossAttention is used. If xformers is not installed or an error occurs (depending on the environment, eg
mixed_precision="no"), specify themem_eff_attnoption instead of using the memory saving version of CrossAttention (xformers is slower than that). -
--save_precisionSpecifies the data precision when saving. Specifying float, fp16, or bf16 for the save_precision option will save the model in that format (doesn't work when saving in Diffusers format in DreamBooth, fine-tuning). Use it when you want to reduce the size of your model.
-
--save_every_n_epochs/--save_state/--resumeSpecifying a number for the save_every_n_epochs option saves the model during each epoch of training.If the save_state option is specified at the same time, the learning state, including the state of the optimizer, will be saved together. . The save destination will be a folder.
The learning state is output to a folder named "<output_name>-??????-state" (?????? is the epoch number) in the target folder. Please use it when studying for a long time.
Use the resume option to resume training from a saved training state. Specify the learning status folder (the status folder inside, not
output_dir).Note that due to the Accelerator specification, epoch numbers and global step numbers are not saved, even though they start at 1 when restored.
-
--save_model_as(DreamBooth, fine tuning only)You can choose the model save format from
ckpt, safetensors, diffusers, diffusers_safetensors. -
--save_model_as=safetensorsspecifies preference when reading stable diffusion format (ckpt or safe tensors) and saving in diffuser format, missing information is supplemented by removing v1.5 or v2.1 information from Hugging Face . -
--clip_skip2If specified, use the output of the second-to-last layer of the text encoder (CLIP). If 1 or option is omitted, the last layer is used.*SD2.0 uses the penultimate layer by default, please do not specify it when learning SD2.0.
2 is a good value if the model being trained was originally trained to use the second layer.
If you're using the last layer, the entire model is trained on that assumption. Therefore, if the second layer is used for training again, a certain amount of teacher data and longer learning time may be required to obtain the desired learning results.
-
--max_token_lengthThe default value is 75. You can extend the token length to learn by specifying "150" or "225". Specify when learning with long subtitles.
However, since the specification of token expansion during learning is slightly different from Automatic1111's web UI (division and other specifications), it is recommended to use 75 for learning if it is not necessary.
As with clip_skip, learning a different length than the model learns state may require a certain amount of teacher data and a longer learning time.
-
--persistent_data_loader_workersSpecifying it in a Windows environment can significantly reduce the delay between epochs.
-
--max_data_loader_n_workersSpecifies the number of processes for data loading. A large number of processes loads data faster and uses the GPU more efficiently, but consumes more main memory. The default is "
8orCPU concurrent execution thread number - 1, whichever is smaller", so if there is no space in the main memory or the GPU usage is above 90%, just look at those numbers and2or reduce it to about1. -
--logging_dir/--log_prefixOption to keep a study log. Specify the log saving destination folder in the logging_dir option. Save logs in TensorBoard format.
For example, if you specify --logging_dir=logs, a logs folder will be created in your working folder and the logs will be saved in the date/time folder. Also, if you specify the --log_prefix option, the specified string will be prepended to the date and time. Use "--logging_dir=logs --log_prefix=db_style1_" for identification.
To check the logs in TensorBoard, open another command prompt and type in your working folder:
tensorboard --logdir=logsI think tensorboard will be installed when the environment is built. If it is not installed, please install it with
pip install tensorboard. )Then open the browser to http://localhost:6006/ and you can see it.
-
--noise_offsetImplementation of this article: https://www.crosslabs.org//blog/diffusion-with-offset-noiseIt looks like it might produce better results for overall darker and lighter images. It also seems to work for LoRA learning. Specifying a value around 0.1 seems fine.
-
--debug_datasetBy adding this option, you can check what kind of image data and title will be learned before learning. Press Esc to exit and return to the command line. Press
Sto go to the next step (batch),Eto go to the next epoch.*Pictures are not displayed under Linux environment (including Colab).
-
--vaeIf you specify a stable diffusion checkpoint, a VAE checkpoint file, a diffusion model, or a VAE in the vae options (both can specify a local or hugging surface model ID), then that VAE is used for learning (latency while caching) or when learning Get latent in the process).
For DreamBooth and fine-tuning, the saved model will contain this VAE
-
--cache_latentsCache VAE output in main memory to reduce VRAM usage. Any enhancements other than flip_aug will not be available. Also, the overall learning rate is slightly faster.
-
--min_snr_gammaSpecifies the minimum SNR weighting strategy. Details are here see.
5is recommended in the paper.
-
--optimizer_type-- Specifies the optimizer type. You can specify- AdamW : torch.optim.AdamW
- same as in previous versions when no option was specified
- AdamW8bit : ditto
- Same as --use_8bit_adam specified in past releases
- Lion: https://github.com/lucidrains/lion-pytorch
- Same as --use_lion_optimizer specified in past versions
- SGDNesterov : torch.optim.SGD, nesterov=True
- SGDNesterov8bit : same argument as above
- DAdaptation : https://github.com/facebookresearch/dadaptation
- AdaFactor : Transformers AdaFactor
- any optimizer
-
--learning_rateSpecifies the learning rate. Appropriate learning rates depend on the learning script, so refer to each for an explanation.
-
--lr_scheduler/--lr_warmup_steps/--lr_scheduler_num_cycles/--lr_scheduler_powerA scheduler-related specification for the learning rate.
With the lr_scheduler option you can choose the learning rate scheduler from linear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup or any scheduler. The default value is constant.
With lr_warmup_steps you can specify the number of steps to warm up the scheduler (gradually change the learning rate).
lr_scheduler_num_cycles is the number of restarts in the cosine with restarts scheduler, and lr_scheduler_power is the polynomial power in the polynomial scheduler.
For details, do your own research.
To use any scheduler, specify the optional arguments with "--scheduler_args" as you would with any optimizer.
Use the --optimizer_args option to specify optimizer option arguments. Multiple values can be specified in the format key=value. Additionally, you can specify multiple values, separated by commas. For example, to specify parameters for the AdamW optimizer, --optimizer_args weight_decay=0.01 betas=.9,.999.
When specifying optional parameters, check the specifications of each optimizer. Some optimizers have a required parameter which is added automatically if omitted (eg SGDNesterov's momentum). Check the console output.
The D-Adaptation optimizer automatically adjusts the learning rate. The value specified by the learning rate option is not the learning rate itself, but the application rate of the learning rate determined by D-Adaptation, so 1.0 is usually specified. If you want the learning rate of Text Encoder to be half that of U-Net, please specify --text_encoder_lr=0.5 --unet_lr=1.0.
If relative_step=True is specified, the AdaFactor optimizer can automatically adjust the learning rate (if omitted, it will be added by default). When autotuning, the learning rate scheduler is forced to use adafactor_scheduler. Also, specifying scale_parameter and warmup_init seems good too.
Options for autotuning are something like --optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True".
Add the optional parameter relative_step=False if you do not want to automatically adjust the learning rate. In that case, it seems to be advisable to use constant_with_warmup for the learning rate scheduler instead of clipping the norm for gradients. So the parameters are like --optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0.
When using the torch.optim optimizer, only specify the class name (eg --optimizer_type=RMSprop), when using other modules' optimizers, specify "module name.class name". (e.g. --optimizer_type=bitsandbytes.optim.lamb.LAMB).
(Operation not confirmed internally via importlib only. Install package if needed.)
Prepare the image data you want to study as mentioned above, and put it in any folder.
For example, storing an image like this:
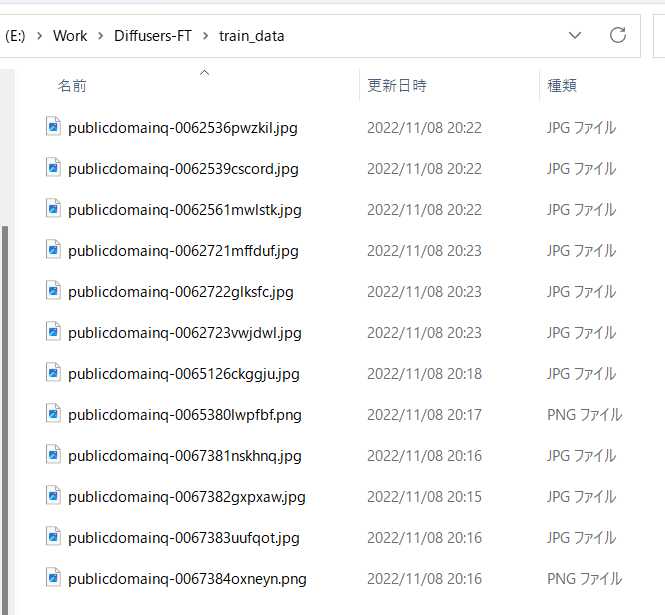
Skip if you just want to learn about labels without titles.
Also, when preparing subtitles manually, please prepare them in the same directory as the teacher data image, with the same file name, extension .caption, etc. Each file should be a text file with only one line.
The latest version no longer requires BLIP downloads, weight downloads and additional virtual environments. Works as is.
Run make_captions.py in the finetune folder.
python finetune\make_captions.py --batch_size <バッチサイズ> <teacherデータフォルダ>
If the batch size is 8 and the training data is placed in the parent folder train_data, it will be as follows
python finetune\make_captions.py --batch_size 8 ..\train_data
Caption files are created in the same directory as the teacher data images and have the same filename and extension .caption.
Increase or decrease batch_size according to the GPU's VRAM capacity. Bigger is faster (I think 12GB of VRAM can be a bit more). You can specify the maximum length of the title with the max_length option. The default value is 75. It may be longer if the model is trained with a token length of 225. You can change the caption extension with the caption_extension option. Defaults to .caption (.txt conflicts with DeepDanbooru described later). If there are multiple teacher data folders, it is executed for each folder.
Note that inference is stochastic, so the results will change each run. If you want to fix it, use the --seed option to specify a random number seed, eg --seed 42.
For other options, please refer to help with --help (it seems that there is no documentation to explain the meaning of the parameters, it depends on the source code).
By default, a caption file with a .caption extension is generated.
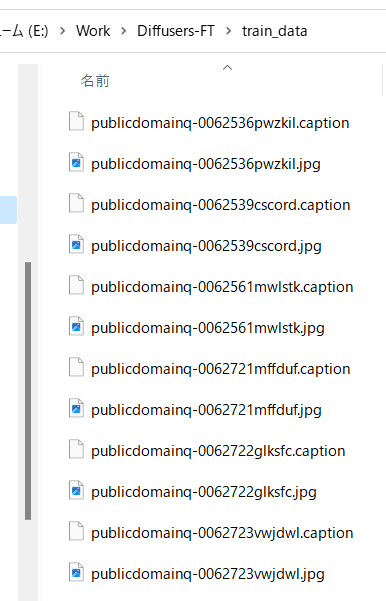
For example, the title is as follows:
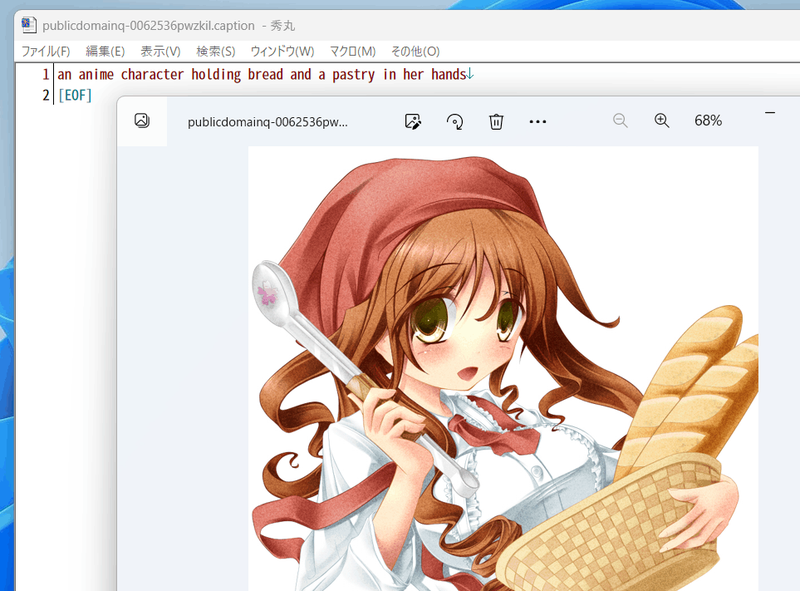
If you don't want to tag the danbooru tag itself, please continue to "Preprocessing of title and tag information".
Tagging was done using DeepDanbooru or WD14Tagger. WD14Tagger seems to be more accurate. If you want to use WD14Tagger for tagging, skip to the next chapter.
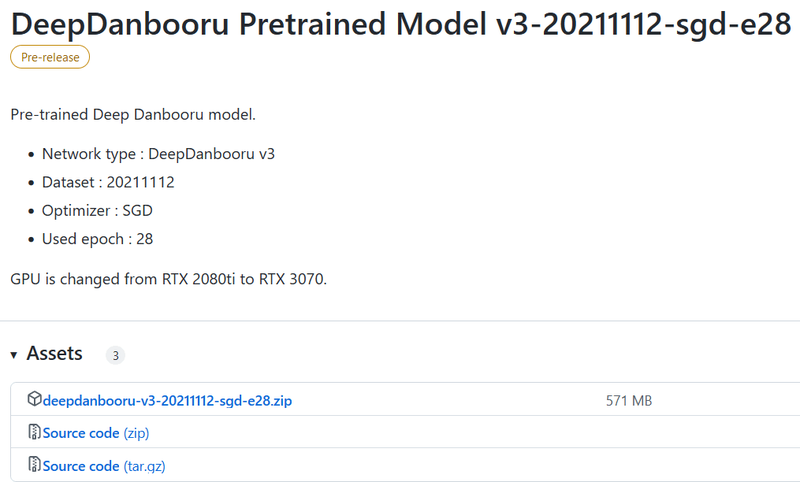
Clone DeepDanbooru https://github.com/KichangKim/DeepDanbooru into your working folder, or download and expand the zip. I unzipped it. Also, download deepdanbooru-v3-20211112-sgd-e28.zip from the assets of "DeepDanbooru pre-trained model v3-20211112-sgd-e28" on the DeepDanbooru release page https://github.com/KichangKim/DeepDanbooru/releases and unzip it Go to the DeepDanbooru folder.
Download it from below. Click to open the asset and download it from there.
Make a directory structure like this
 Install the necessary libraries for the Diffuser environment. Go into the DeepDanbooru folder and install it (I think it actually just adds tensorflow-io).
Install the necessary libraries for the Diffuser environment. Go into the DeepDanbooru folder and install it (I think it actually just adds tensorflow-io).
pip install -r requirements.txt
Next, install DeepDanbooru itself.
pip install .
This completes the preparation of the labeling environment.
Go to DeepDanbooru's folder and run deepdanbooru to label.
deepdanbooru evaluate <teacher folder> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
If you put the training data in the parent folder train_data as follows.
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
Create a marker file with the same file name and extension .txt in the same directory as the teacher data image. It's slow because it's processed one by one.
If there are multiple teacher data folders, it is executed for each folder.
It is generated as follows.
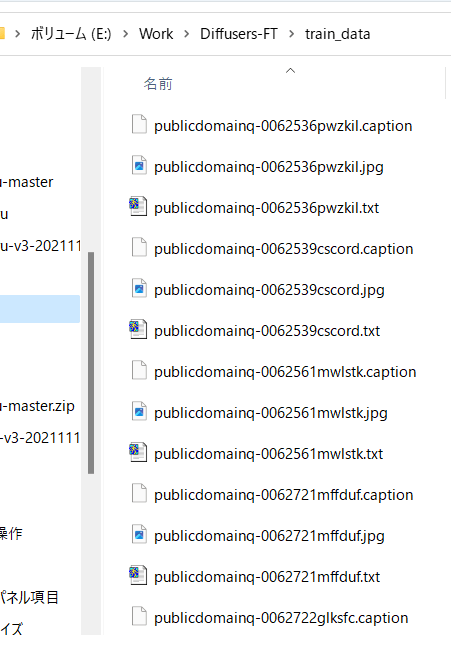
It will be marked as such (very informative...).
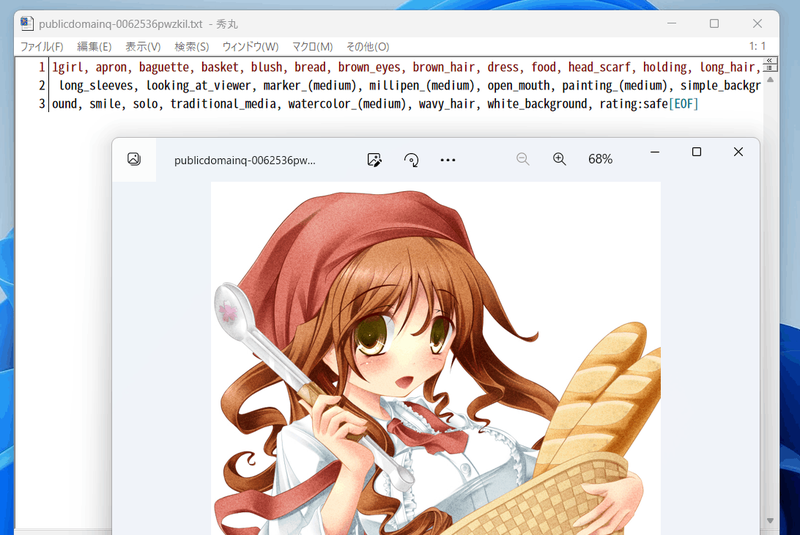
This process uses WD14Tagger instead of DeepDanbooru.
Use the tokenizer used in Mr. Automatic1111's WebUI. I refer to the information on this github page (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger).
The modules required for initial environment maintenance are already installed. Weights are automatically downloaded from Hugging Face.
Run the script for tagging.
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <teacherデータフォルダ>
If you put the training data in the parent folder train_data as follows
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
Model files will be automatically downloaded to wd14_tagger_model folder on first launch (folder can be changed in options). It will look like this.
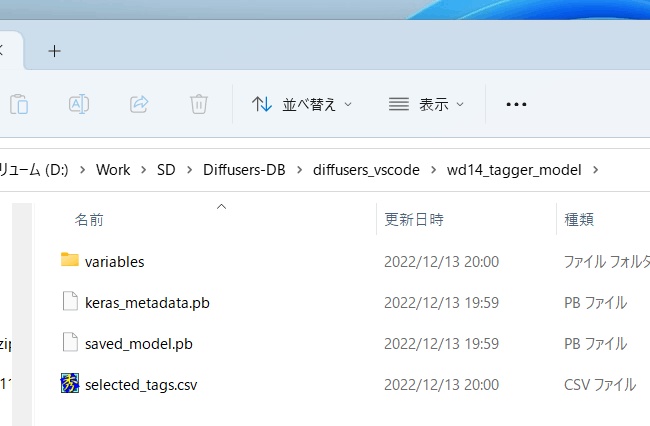
Create a marker file with the same file name and extension .txt in the same directory as the teacher data image.


With the thresh option, you can specify the confidence level of the determined label to attach the label to. The default is 0.35, the same as the WD14Tagger example. Lower values give more labels, but are less accurate.
Increase or decrease batch_size according to the GPU's VRAM capacity. Bigger is faster (I think 12GB of VRAM can be a bit more). You can change the caption file extension with the caption_extension option. The default is .txt.
You can use the model_dir option to specify the folder where the model is saved.
Also, if the force_download option is specified, the model will be re-downloaded even if there is a save destination folder.
If there are multiple teacher data folders, it is executed for each folder.
Combine subtitles and tags as metadata into a single file for easy handling from scripts.
To put subtitles into metadata, run the following command in your working folder (you don't need to run it if you don't use subtitles for study) (it's actually one line, and so on). Specify the --full_path option to store the full path to the image file in metadata. If this option is omitted, relative paths are logged, but a separate folder specification is required in the .toml file.
python merge_captions_to_metadata.py --full_path <teacher folder>
--in_json <metadata filename to read> <metadata filename>
The metadata file name is arbitrary. If the training data is train_data, the metadata file is not read, and the metadata file is meta_cap.json, it will be as follows.
python merge_captions_to_metadata.py --full_path train_data meta_cap.json
You can specify a caption extension with the caption_extension option.
If there are multiple teacher data folders, specify the full_path parameter and execute for each folder.
python merge_captions_to_metadata.py --full_path
train_data1 meta_cap1.json
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
train_data2 meta_cap2.json
If in_json is omitted, the target metadata file, if any, will be read from there and overwritten.
__* It is safe to override in_json options and write targets each time and write to a separate metadata file. __
Likewise, labels are collected in metadata (this is unnecessary if labels are not used for learning).
python merge_dd_tags_to_metadata.py --full_path <teacher folder>
--in_json <metadata filename to read> <metadata filename to write>
The same directory structure, when reading meta_cap.json and writing meta_cap_dd.json, will be like this.
python merge_dd_tags_to_metadata.py --full_path train_data --in_json meta_cap.json meta_cap_dd.json
If there are multiple teacher data folders, specify the full_path parameter and execute for each folder.
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
train_data1 meta_cap_dd1.json
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
train_data2 meta_cap_dd2.json
If in_json is omitted, the target metadata file, if any, will be read from there and overwritten. __※ It is safe to write to a separate metadata file by overriding the in_json option and write target each time. __
So far, the title and DeepDanbooru tags have been organized into metadata files. However, the title generated by automatic title has subtle issues such as differences in expression (※), while underlines and ratings may be included in the label (in the case of DeepDanbooru). Therefore, it is best to use your editor's replace function to clean up titles and tags.
※For example, if you want to learn girls in anime, the title may contain different expressions such as girl/girls/woman/women. Also, simply replacing "anime girl" with "girl" might be more appropriate.
We provide a script for cleanup, please edit the script according to your situation and use it.
(Teacher data folder does not need to be specified. All data in metadata will be cleaned up.)
python clean_captions_and_tags.py <metadata file name to read> <metadata file name to write>
Note that --in_json is not included. For example:
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
Preprocessing of titles and tags is now complete.
※ This step is not necessary. Even if this step is omitted, latents can be obtained during training. However, if you do something like random_crop or color_aug during training, you cannot prefetch latents (because the image will change each time). If you don't prefetch, you can use the metadata so far for training.
The potential representation of the image is obtained ahead of time and saved to disk. This speeds up the training process. At the same time, bucketing (classification of training data according to aspect ratio) is performed.
Please enter the following in your working folder.
python prepare_buckets_latents.py --full_path <teacher folder>
<metadata filename to read> <metadata filename to write>
<model name or checkpoint to fine-tune>
--batch_size <batch size>
--max_resolution <resolution width, height>
--mixed_precision <precision>
If you want to read metadata from meta_clean.json, and write it to meta_lat.json, using model model.ckpt, batch size 4, training resolution 512*512, precision no(float32), you should As follows.
python prepare_buckets_latents.py --full_path
train_data meta_clean.json meta_lat.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
In the teacher data folder, latents are saved in numpy npz format.
You can use the --min_bucket_reso option to specify the minimum resolution size and --max_bucket_reso to specify the maximum size. The default values are 256 and 1024 respectively. For example, if you specify a minimum size of 384, then resolutions of 2561024 or 320768 etc. will no longer be used. If you increase the resolution to something larger like 768*768, it is better to specify the max size as 1280 etc.
If the --flip_aug option is specified, data augmentation with left-right flipping is performed. While this can double the amount of data to fake, it can lead to unsuccessful training if the data is not left-right symmetric (e.g. character appearance, hairstyle, etc.).
For flipped images, latents are also fetched, and files named *_flip.npz are saved, which is a simple implementation. No specific options are required in fline_tune.py. If there is a file with _flip, it will be loaded randomly with and without flip.
Even with 12GB of VRAM, the batch size can be slightly increased. The resolution is specified in the form of "width, height", which must be a multiple of 64. The resolution directly affects the memory size during fine tuning. In 12GB VRAM, 512,512 seems to be the limit(*). If you have 16GB, you can bump that up to 512,704 or 512,768. Even with a resolution of 256, 256, etc., VRAM 8GB is hard to bear (because parameters, optimizers, etc. have nothing to do with resolution and require a certain amount of memory).
*It has been reported to use 12GB VRAM and a resolution of 640,640 in batch size 1 training.
Here is how the bucketing results are displayed.
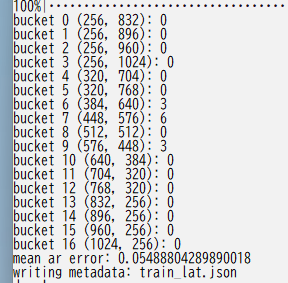
If you have multiple teacher data folders, specify the full_path parameter and execute for each folder
python prepare_buckets_latents.py --full_path
train_data1 meta_clean.json meta_lat1.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
python prepare_buckets_latents.py --full_path
train_data2 meta_lat1.json meta_lat2.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
It is possible to set the read source and write destination to be the same, but it is safer to set them separately.
__※ It is recommended to change the parameter every time and write it to another metadata file for security. __