Last active
June 10, 2022 13:40
-
-
Save fauxneticien/8712db9f1a81ccc9e8eef19180fb059e to your computer and use it in GitHub Desktop.
Try to replicate fine-tuning wav2vec 2.0 with 10 minutes of Librispeech data
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| apt-get install -y tmux | |
| pip install transformers==4.19.2 datasets jiwer wandb bitsandbytes-cuda113 | |
| wget https://huggingface.co/facebook/wav2vec2-large-960h/raw/main/vocab.json |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # -*- coding: utf-8 -*- | |
| """LibriSpeech-10mins.ipynb | |
| Automatically generated by Colaboratory. | |
| Original file is located at | |
| https://colab.research.google.com/drive/1UK5YxGVrg-dGUbw_BTnymtAK7jJXYN1L | |
| # Replicating 10-minute fine-tuning results from wav2vec 2.0 paper | |
| We can see from Table 9 in the supplemental materials for the original wav2vec 2.0 paper [1] that the authors report being able to fine-tune the pre-trained wav2vec 2.0 model with just 10 minutes of data, achieving a word error rate of 43.5 on the Librispeech clean test set without a language model. | |
| Let's see whether this result can be replicated, based on the reported hyper-parameters... | |
| 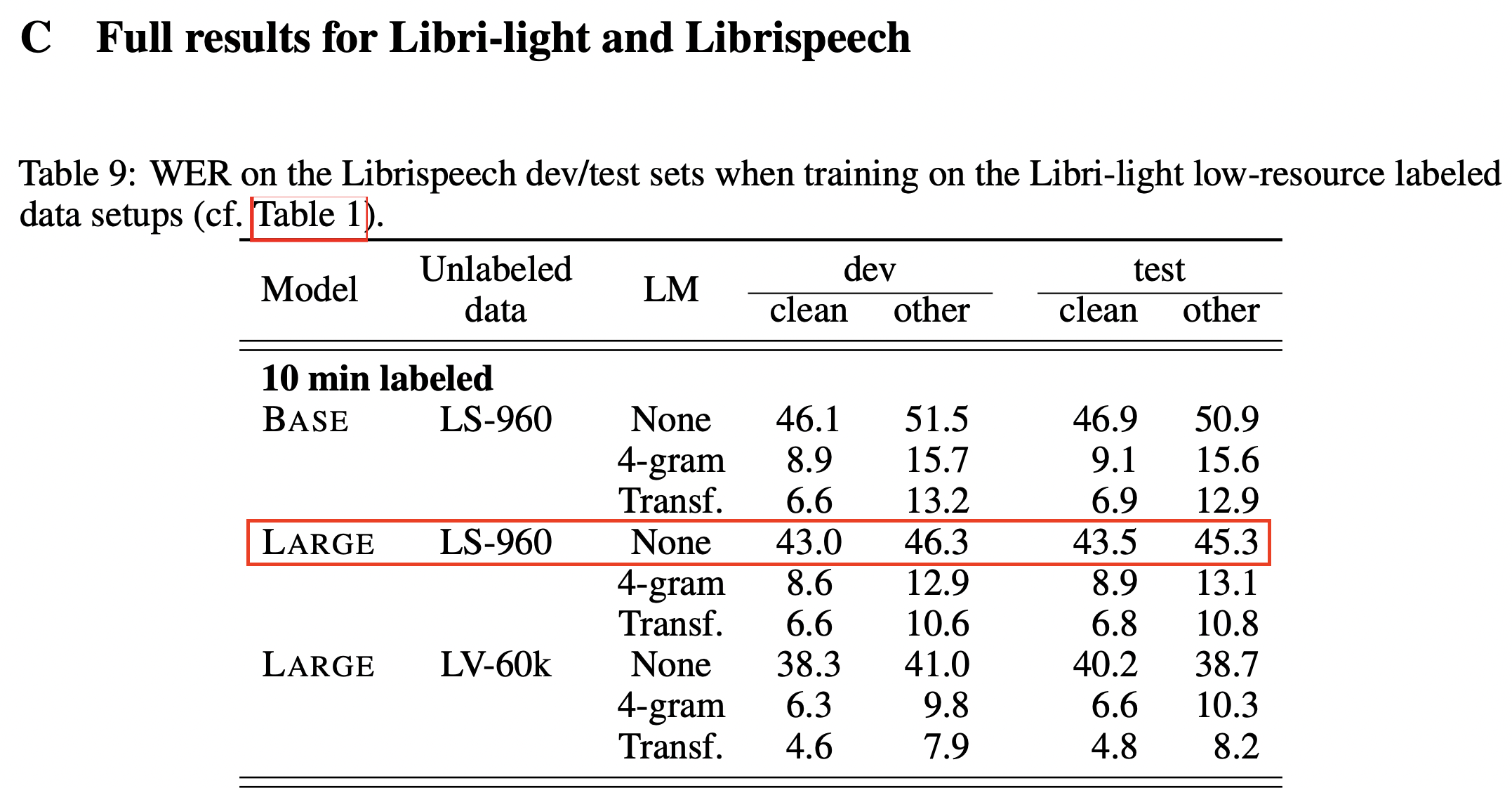 | |
| Sources: | |
| - [1]: https://proceedings.neurips.cc/paper/2020/file/92d1e1eb1cd6f9fba3227870bb6d7f07-Supplemental.pdf | |
| - [2]: https://proceedings.neurips.cc/paper/2020/file/92d1e1eb1cd6f9fba3227870bb6d7f07-Paper.pdf | |
| # Setup | |
| ## Install packages | |
| """ | |
| # Commented out IPython magic to ensure Python compatibility. | |
| # %%capture | |
| # !pip install transformers==4.19.2 datasets jiwer wandb bitsandbytes-cuda113 | |
| # | |
| """## Get data | |
| ### Sample 10 mins (= 48 items) of data from the 100-hour training set | |
| "Ten minutes of labeled data corresponds to just 48 recordings with an average length of 12.5 seconds." [2, p. 5] | |
| """ | |
| import torch | |
| import numpy as np | |
| import pandas as pd | |
| import transformers as hft | |
| import datasets as hfds | |
| from dataclasses import dataclass | |
| from typing import Dict, List, Union | |
| import wandb | |
| wandb_run_name="Initial attempt with parameters from paper" | |
| wandb.init(project="w2v2-10min-replication", entity="fauxneticien", name=wandb_run_name) | |
| print("Loading train dataset ...") | |
| train_set = hfds.load_dataset("librispeech_asr", "clean", split="train.100", streaming=True) | |
| # Use list() to download the data | |
| train_set = list(train_set.shuffle(seed=10).take(48)) | |
| # Convert back to a dataset object | |
| # HF Trainer class does not yet work with a streaming dataset of unknown length | |
| train_set = hfds.Dataset.from_pandas(pd.DataFrame(train_set)) | |
| # Check duration of training data in minutes | |
| # sum([ len(u['audio']['array'])/u['audio']['sampling_rate'] for u in train_set ]) / 60 | |
| """### Use standard test-clean dataset for evaluation""" | |
| print("Loading test dataset ...") | |
| test_set = hfds.load_dataset("librispeech_asr", "clean", split="test", streaming=True) | |
| test_set = hfds.Dataset.from_pandas(pd.DataFrame(list(test_set))) | |
| """## Fine-tuning | |
| ### Processor | |
| """ | |
| # Re-use the vocab.json from the fine-tuned model instead of re-deriving it from the train/test data | |
| # !wget https://huggingface.co/facebook/wav2vec2-large-960h/raw/main/vocab.json | |
| processor = hft.Wav2Vec2Processor( | |
| tokenizer=hft.Wav2Vec2CTCTokenizer("vocab.json"), | |
| feature_extractor=hft.Wav2Vec2FeatureExtractor(return_attention_mask=True) | |
| ) | |
| """### Model | |
|  | |
| """ | |
| model = hft.Wav2Vec2ForCTC.from_pretrained( | |
| pretrained_model_name_or_path = "facebook/wav2vec2-large", | |
| mask_time_prob=0.075, | |
| # Assuming authors are using 'channel' to mean the feature axis (vs. time axis) | |
| mask_feature_prob=0.008, | |
| pad_token_id=processor.tokenizer.pad_token_id | |
| ) | |
| model.freeze_feature_encoder() | |
| """#### Create trainer callback for gradually unfreezing layers | |
| Adapted from https://discuss.huggingface.co/t/gradual-layer-freezing/3381/4 | |
| """ | |
| class FreezingCallback(hft.TrainerCallback): | |
| def __init__(self, transformer_unfreeze_step): | |
| self.transformer_unfreeze_step = transformer_unfreeze_step | |
| def on_train_begin(self, args, state, control, **kwargs): | |
| print("Freezing transformer layers ...") | |
| for param in model.wav2vec2.parameters(): | |
| param.requires_grad = False | |
| def on_step_begin(self, args, state, control, **kwargs): | |
| if state.global_step == self.transformer_unfreeze_step: | |
| print("Unfreezing transformer layers ...") | |
| for param in model.wav2vec2.parameters(): | |
| param.requires_grad = True | |
| # Make sure feature extractor stays frozen | |
| model.wav2vec2.feature_extractor._freeze_parameters() | |
| """### Data pre-processors""" | |
| def to_inputs_and_labels(batch, processor=processor): | |
| batch["input_values"] = processor(batch["audio"]["array"], sampling_rate=16000).input_values[0] | |
| with processor.as_target_processor(): | |
| batch["labels"] = processor(batch["text"]).input_ids | |
| return batch | |
| train_set = train_set.map(to_inputs_and_labels, remove_columns=['file', 'audio', 'text', 'id', 'speaker_id', 'chapter_id']) | |
| test_set = test_set.map(to_inputs_and_labels, remove_columns=['file', 'audio', 'text', 'id', 'speaker_id', 'chapter_id']) | |
| @dataclass | |
| class DataCollatorCTCWithPadding: | |
| processor: hft.Wav2Vec2Processor | |
| padding: Union[bool, str] = True | |
| def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]: | |
| # split inputs and labels since they have to be of different lenghts and need | |
| # different padding methods | |
| input_features = [{"input_values": feature["input_values"]} for feature in features] | |
| label_features = [{"input_ids": feature["labels"]} for feature in features] | |
| batch = self.processor.pad( | |
| input_features, | |
| padding=self.padding, | |
| return_tensors="pt", | |
| ) | |
| with self.processor.as_target_processor(): | |
| labels_batch = self.processor.pad( | |
| label_features, | |
| padding=self.padding, | |
| return_tensors="pt", | |
| ) | |
| # replace padding with -100 to ignore loss correctly | |
| labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100) | |
| batch["labels"] = labels | |
| return batch | |
| """### Evaluation metrics""" | |
| wer_metric = hfds.load_metric("wer") | |
| cer_metric = hfds.load_metric("cer") | |
| def compute_metrics(pred): | |
| pred_logits = pred.predictions | |
| pred_ids = np.argmax(pred_logits, axis=-1) | |
| pred_str = processor.batch_decode(pred_ids) | |
| # Replace data collator padding with tokenizer's padding | |
| pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id | |
| # Retrieve labels as characters, e.g. 'hello', from label_ids, e.g. [5, 3, 10, 10, 2] (where 5 = 'h') | |
| label_str = processor.tokenizer.batch_decode(pred.label_ids, group_tokens=False) | |
| scoring_df = pd.DataFrame({"pred_str" : pred_str, "label_str" : label_str}) | |
| wandb.log({ "classifier_out": wandb.Table(scoring_df) }) | |
| print(scoring_df) | |
| wer = wer_metric.compute(predictions=pred_str, references=label_str) | |
| cer = cer_metric.compute(predictions=pred_str, references=label_str) | |
| return {"wer": wer, "cer": cer} | |
| """### Training hyperparameters | |
| There isn't much detail on the 10-minute fine-tuning set up. The hyperparameters reported in the main paper presumably relates to the fine-tuning for the whole Librispeech dataset, given batch size for example is reported as "1.28m samples". | |
| """ | |
| # Adapted from https://discuss.huggingface.co/t/weights-biases-supporting-wave2vec2-finetuning/4839/4 | |
| # Flat - Linear Learning Rate Schedule from Wav2Vec2 paper | |
| # Sharing Trainer code for the same learning rate schedule as the paper, 10% warmup, 40% flat, 50% linear decay | |
| def get_flat_linear_schedule_with_warmup(optimizer, num_warmup_steps:int, num_training_steps:int, last_epoch:int =-1): | |
| def lr_lambda(current_step): | |
| constant_steps = int(num_training_steps * 0.4) | |
| warmup_steps = int(num_training_steps * 0.1) | |
| if current_step < warmup_steps: | |
| return float(current_step) / float(max(1, warmup_steps)) | |
| elif current_step < warmup_steps+constant_steps: | |
| return 1 | |
| else: | |
| return max( | |
| 0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - (warmup_steps+constant_steps))) | |
| ) | |
| return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch) | |
| def get_flat_cheduler(name = None, optimizer = None, num_warmup_steps = None, num_training_steps = None): | |
| return get_flat_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps) | |
| class FlatTrainer(hft.Trainer): | |
| def __init__(self, *args, **kwargs): | |
| super().__init__(*args, **kwargs) | |
| def create_flat_scheduler(self, num_training_steps: int): | |
| self.lr_scheduler = get_flat_cheduler(optimizer = self.optimizer, | |
| num_training_steps=num_training_steps) | |
| def create_optimizer_and_scheduler(self, num_training_steps): | |
| self.create_optimizer() | |
| self.create_flat_scheduler(num_training_steps) | |
| training_args = hft.TrainingArguments( | |
| output_dir=".", | |
| group_by_length=True, | |
| per_device_train_batch_size=2, | |
| per_device_eval_batch_size=2, | |
| gradient_accumulation_steps=4, | |
| evaluation_strategy="steps", | |
| fp16=True, | |
| seed=4892, | |
| # total optim steps: "12k updates" (see Table 6 above) | |
| max_steps=12_000, | |
| save_steps=400, | |
| eval_steps=400, | |
| logging_steps=100, | |
| # unclear what the learning rate for fine-tuning with 10 mins is, try 1e-4 | |
| learning_rate=1e-4, | |
| warmup_steps=1200, | |
| # Tested with transformers 4.19.2 (should have 'adamw_bnb_8bit') | |
| optim="adamw_bnb_8bit", | |
| metric_for_best_model="wer", | |
| save_total_limit=1, | |
| load_best_model_at_end = True, | |
| greater_is_better=False, | |
| dataloader_num_workers=2, | |
| report_to="wandb", | |
| run_name=wandb_run_name | |
| ) | |
| trainer = FlatTrainer( | |
| model=model, | |
| data_collator=DataCollatorCTCWithPadding(processor=processor, padding=True), | |
| args=training_args, | |
| compute_metrics=compute_metrics, | |
| train_dataset=train_set, | |
| eval_dataset=test_set, | |
| tokenizer=processor.feature_extractor | |
| # callbacks=[ FreezingCallback(transformer_unfreeze_step=10000) ] | |
| ) | |
| """# Training""" | |
| trainer.train() |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment