- Allosaurus is a pretrained universal phone recognizer: https://github.com/xinjli/allosaurus
- It has been trained on English, Japanese, Mandarin, Tagalog, Turkish, Vietnamese, German, Spanish, Amharic, Italian and Russian
- We test this off-the-shelf version on some Kaytetye data. The data are citation form headwords recorded by a female native speaker of Kaytetye in a music studio for a multimedia dictionary.
- For 2,360 headwords, we have ~2 repetitions per
word(e.g.palpalpe), and two transcriptions (t_1,t_2) by two independent human transcribers. - In the table below
int_t_distis the inter-transcriber string distance andmin_a_distis the minimum string distance between theallosaurustranscription and the human transcriptions.
| word | rep | t_1 | t_2 | allosaurus | int_t_dist | min_a_dist |
|---|---|---|---|---|---|---|
| kwake | 2 | kwakə | kwakə | kwakə | 0 | 0 |
| etelepwenke | 1 | itələpunk | itələpunk | itələpunk | 0 | 0 |
| itanperre | 1 | itanpəɾə | itanpəɾə | ətaɳpəɾə | 0 | 2 |
| palpalpe | 2 | paɭpaɭpə | palpalp | palʲpal | 3 | 2 |
| mwanyeme | 1 | mutɲəmə | muɲim | mwan | 3 | 4 |
| mwanyeme | 2 | muɲəmə | muɲim | mwanam | 2 | 4 |
| ngkwerengke | 1 | ŋkuɺəŋk | ŋkwuɺəŋk | pulan | 1 | 6 |
| ngkwerengke | 2 | ŋkuɺəŋk | ŋkwuɺəŋk | puɻaŋk | 1 | 4 |
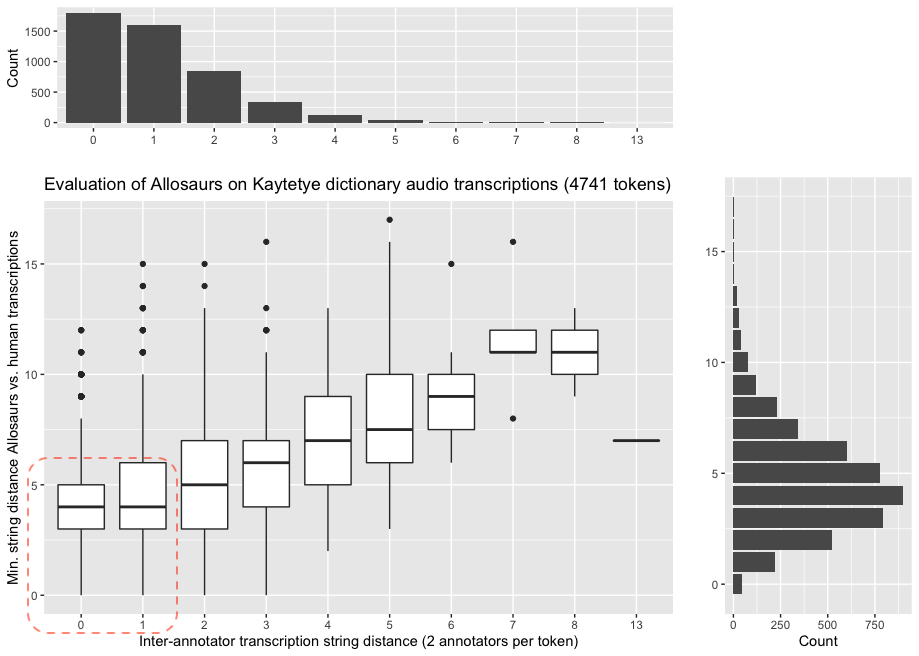
- The figure below shows the comparison between
int_t_dist(x-axis) andmin_a_dist(y-axis) for 4741 tokens (2360 types). Overall, human transcribers generally agree with each other (most human transcriptions are0or1). - The median allosaurus transcription is at least 4 characters off from the human transcriptions.
- One way to extend Allosaurus for Australian languages might be to include a Dravidian language in the training data.
- Many have noted superficial similarities in the phonological systems between Dravidian languages of South India (e.g. Tamil) and the Pama-Nyungan languages of Australia (e.g. Kaytetye).
- 5-6 places of articulation, for both stops [p t̪ t t (c) k] and nasals [m n̪ n ɳ (ɲ) ŋ]
- No voicing contrast [p, b] ∈ /p/
-
He et al. (2020) have recently released a "Crowdsourced high-quality Tamil multi-speaker speech data set": http://www.openslr.org/65/ with 50 speakers (25F) and ~8 hours of audio (~4F)
-
Each .wav file has an acommpanying transcript in Tamil script, e.g. for
tag_09162_01279273055.wav:- அவர்களின் படங்களின் டீஸருக்கு கிடைக்கும் வரவேற்பு அபிரிதமாக உள்ளது
-
Epitran, the grapheme-to-phoneme conversion tool, already has a Tamil script conversion function:
>>> import epitran >>> epi = epitran.Epitran('tam-Taml') >>> print(epi.transliterate(u'அவர்களின் படங்களின் டீஸருக்கு கிடைக்கும் வரவேற்பு அபிரிதமாக உள்ளது')) aʋaɾkaɭin paʈaŋkaɭin ʈiːsaɾukku kiʈajkkum ʋaɾaʋeːrpu apiɾit̪amaːka uɭɭat̪u -
Allovera https://github.com/dmort27/allovera the tool for phoneme-to-allophone mappings used by Allosaurus does not yet have a Tamil mapping, though the JSON format looks relatively straightforward:
{
"iso": "eng",
"glottocodes": ["nort3312"],
"primary src": "Ladefoged:1999-american",
"secondary srcs": [],
"epitran": "eng-Latn",
"mappings": [
{
"phone": "pʰ",
"phoneme": "p",
"environment": "word initially; in onset of stressed syllables"
},
{
"phone": "p",
"phoneme": "p",
"environment": "elsewhere"
},
...
-
So the current task is to create a draft phoneme-to-allophone mapping from a reference grammar and check it with a linguist who is familiar with Tamil phonology.
-
At the same time, I will need to find out how to train Allosaurus (the Git repo only seems to provide the pre-trained model).