Last active
October 9, 2019 00:50
-
-
Save gordol/d8fe8ec223fc5a42da6a59931de3274f to your computer and use it in GitHub Desktop.
Example code that flattens an arbitrarily nested array of integers into a flat array of integers.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/usr/bin/env python3 | |
| import unittest | |
| def flattenIntArray(arr): | |
| '''Yield flattened elements from input array''' | |
| for element in arr: | |
| try: | |
| yield from flattenIntArray(element) | |
| except TypeError: | |
| yield element | |
| class TestFlattener(unittest.TestCase): | |
| def setUp(self): | |
| self.example_input = [[1, 2, [3]], 4] | |
| self.example_output = [1, 2, 3, 4] | |
| def testExampleTransform(self): | |
| self.assertEqual( | |
| list(flattenIntArray(self.example_input)), | |
| self.example_output, | |
| 'The given example did not evaluate as expected.' | |
| ) | |
| def testDeepTransform(self): | |
| self.assertEqual( | |
| list(flattenIntArray([0, [1, 2, 3], 4, [5, 6, 7], [8, [9, [10, [11]]]]] * 100)), | |
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] * 100, | |
| 'The deep tranform did not evaluate as expected.' | |
| ) | |
| def testReallyDeepTransform(self): | |
| self.assertEqual( | |
| list(flattenIntArray([0, [1, 2, 3], 4, [5, 6, 7], [8, [9, [10, [11]]]]] * 1000 * 1000)), | |
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] * 1000 * 1000, | |
| 'The really deep tranform did not evaluate as expected.' | |
| ) | |
| if __name__ == "__main__": | |
| unittest.main() |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
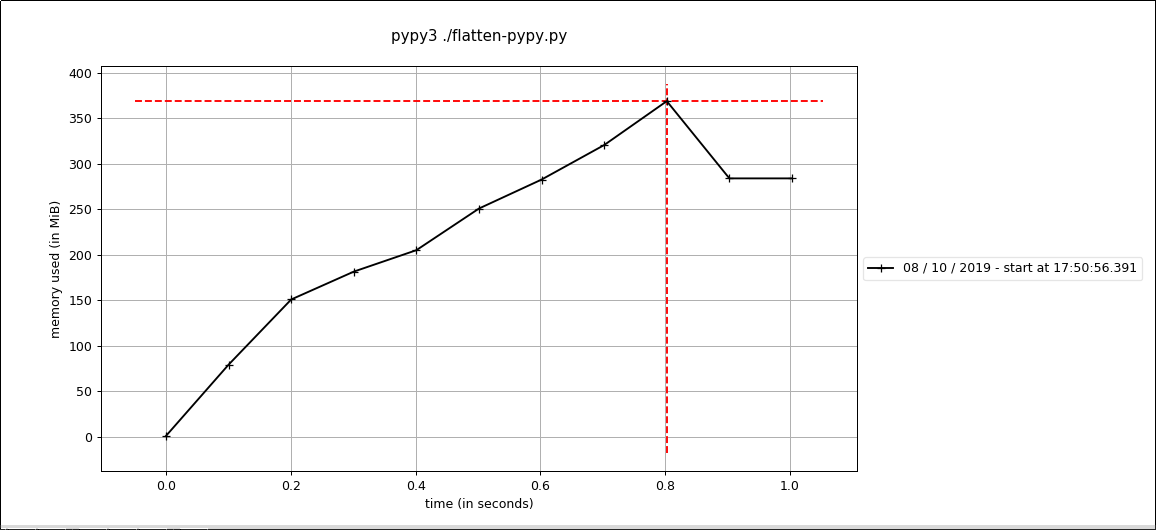
Here's a profile of the tests running under native cpython:
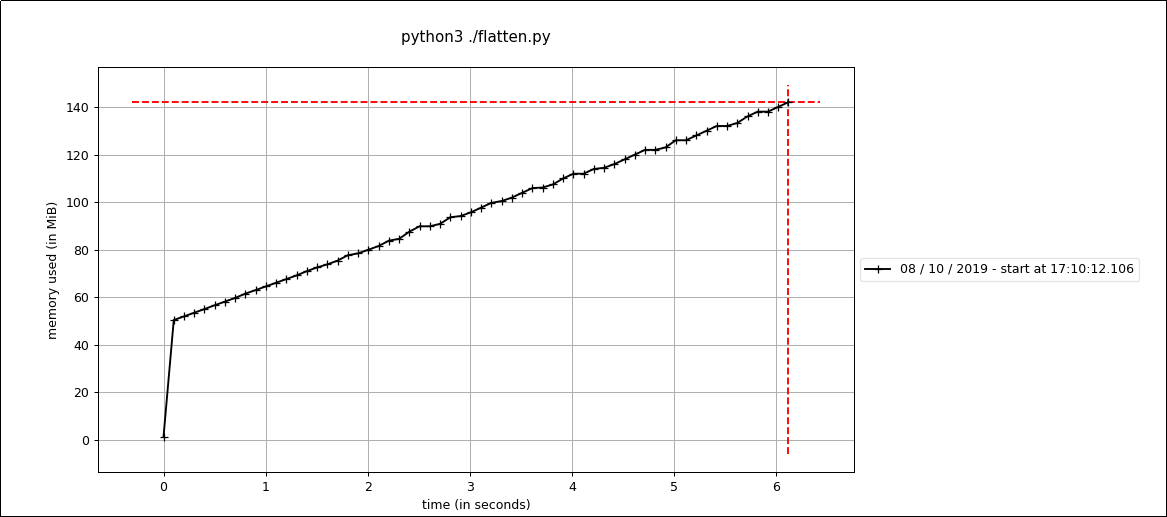
And here's a profile of the tests running under pypy (JIT):
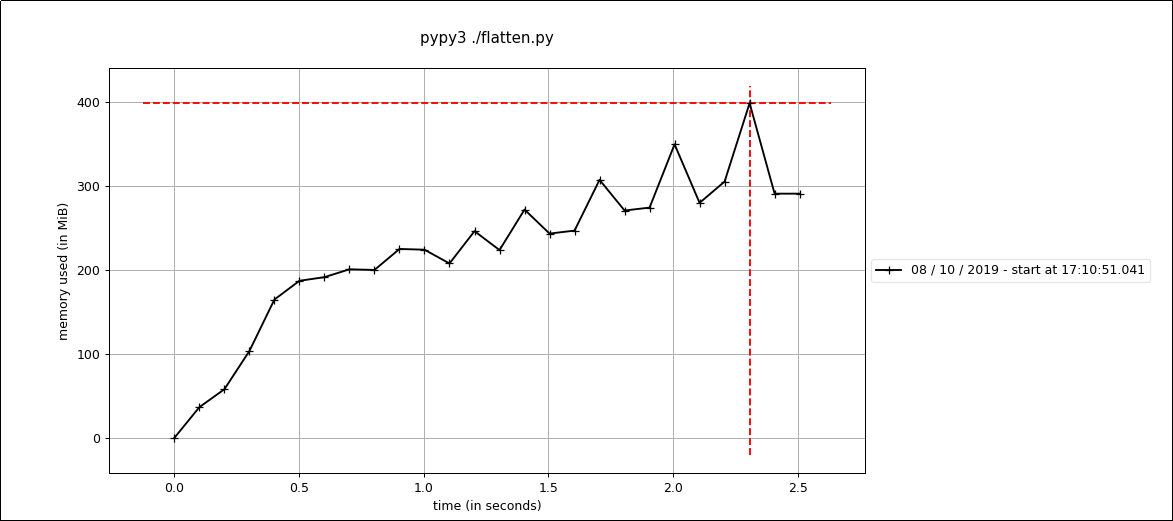
There are trade-offs to consider, execution time for a very large nested array may be shorter under PyPy, but the memory usage is increased.
We can also optimize this to run better under pypy by not using generators, by changing the flattenIntArray method as follows:
In native code, this runs ever so slightly faster, but memory usage is increased:
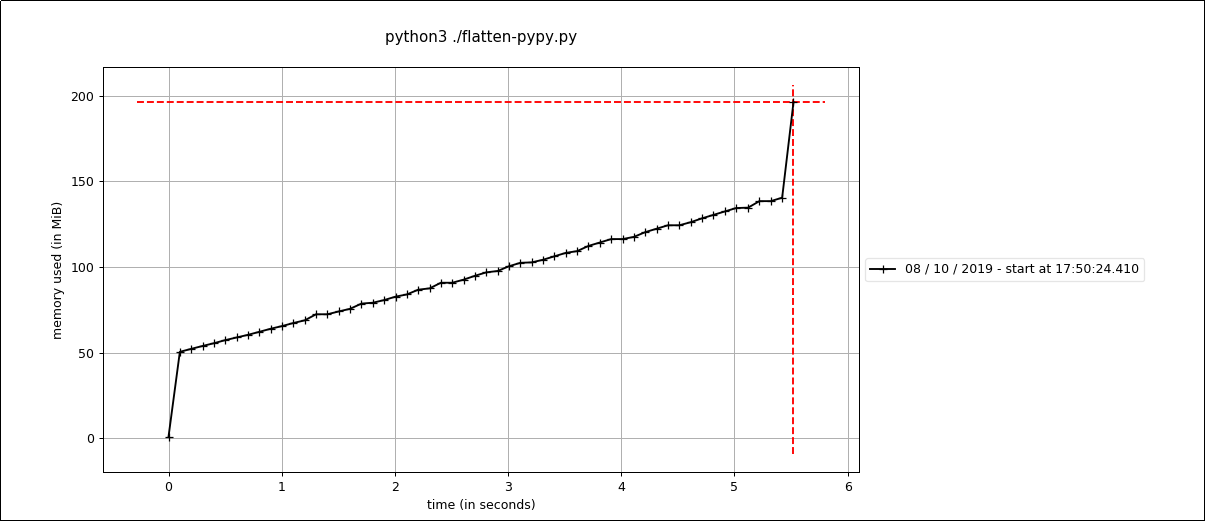
However, when running this revised method under PyPy, it runs almost twice as fast when not using a generator, and uses less memory than the generator variant in pypy: