Hi Derek!
Here are my answers between your questions:
>> First off I was wondering, how much benefit did you see from averaging the fine tuned models weights over the moving window of lowest validation loss?
I saw small improvements for every experiment (AUC +/- 0.01 to 0.07). I really believe averaging weights is important if you have a small validation set. A small set will result in a noisy validation loss / metric curve and thus be hard to choose the right checkpoint to evaluate on the test set. Here is an example from an experiment with a very small validation set (not from this paper):
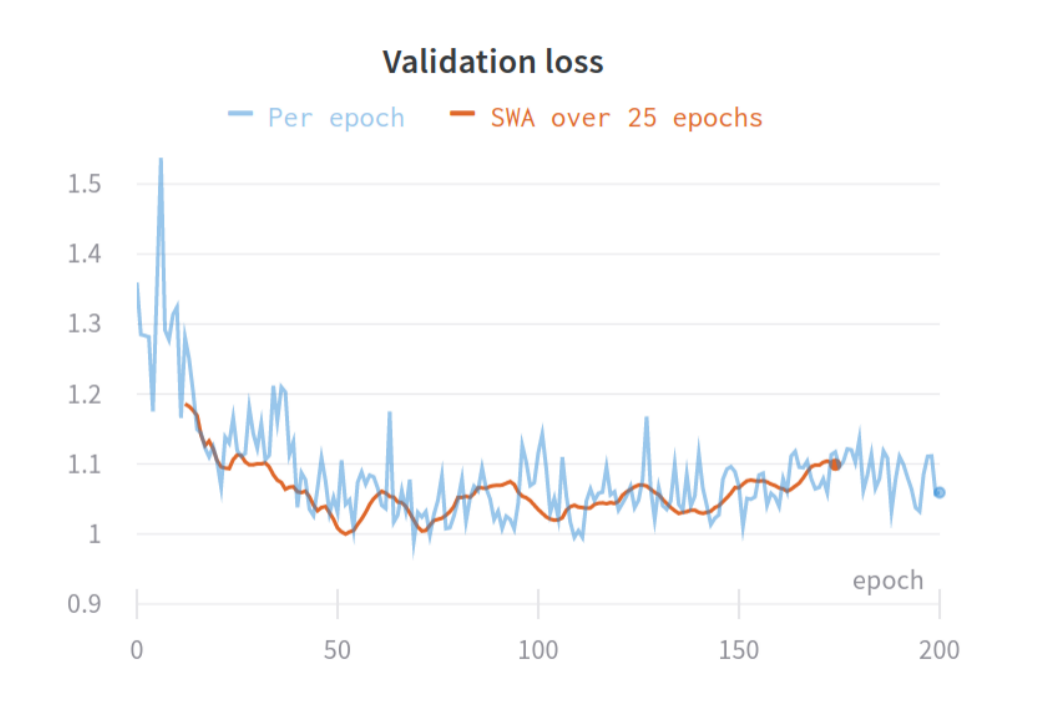
You see two loss curves; one original (blue) and one with an averaging window of 25 networks. It looks a bit like it's just a moving average of the loss curve, but this is incorrect! It's actually the loss of the weight-averaged model for a 'window' of 25 epochs.
>>Did you perform any quantitative analysis between the streaming and MIL approaches for localizing the tumor regions? I'm always curious how the numbers compare to particular heatmap visuals.
No we didn't, MIL probably performs better since it's a patch-based solution (and such can determine tumor per patch). The visualisations of streaming are saliency maps from which we know have quite some noise. We are currently working on using streaming on certain networks with localising properties. Also the research to improve saliency maps and there localising properties is very much on-going. There are better methods than the SmoothGrad we use in this paper.
>>Did the false positives and negatives for both models show the same types of errors in the Olympus test set or any new error patterns?
Yes, we saw a new error pattern for MIL. We noticed a lot of false negatives for MIL. I believe this is because the MIL network benefits less from augmentations (and thus generalizes less to different data) since it only really learns from one augmented patch per image. I think it would be possibly to improve this for MIL, e.g., slowly increase augmentation strength during training.
>>Sorry for the barrage of questions, you have very interesting papers :)
Thank you!