Hi Derek!
Here are my answers between your questions:
>> First off I was wondering, how much benefit did you see from averaging the fine tuned models weights over the moving window of lowest validation loss?
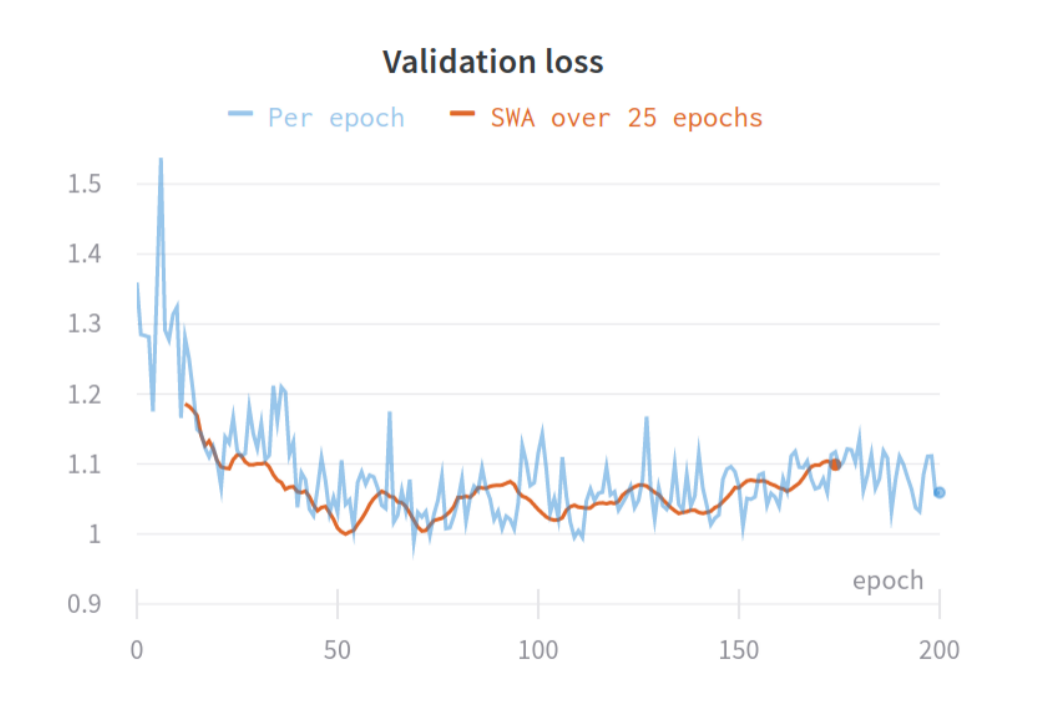
I saw small improvements for every experiment (AUC +/- 0.01 to 0.07). I really believe averaging weights is important if you have a small validation set. A small set will result in a noisy validation loss / metric curve and thus be hard to choose the right checkpoint to evaluate on the test set. Here is an example from an experiment with a very small validation set (not from this paper):