TensorFlow là một framework để triển khai mô hình học sâu. Các bản cập nhật gần đây cho phiên bản 2.0 cung cấp một số cải tiến, bao gồm những thay đổi quan trọng đối với eager execution. Google Cloud Function cung cấp cách thức thuận tiện, có thể mở rộng trong cơ sở hạ tầng Google Cloud.
Nội dung notebook bao gồm:
- Cách cài đặt và triển khai Google Cloud Function
- Cách lưu trữ mô hình
- Làm thế nào để sử dụng Cloud Functions API endpoint
Google Cloud Platform (GCP) cung cấp nhiều cách để triển khai trong điện toán đám mây. Hãy để so sánh các phương pháp sau đây để triển khai mô hình:
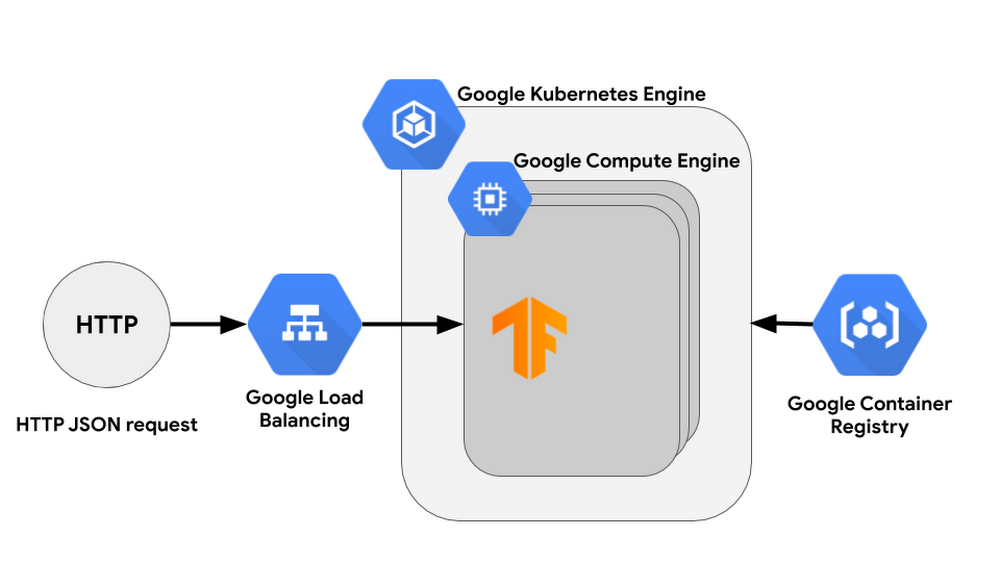
TensorFlow Serving
Thông thường, bạn có thể sử dụng một cụm (cluster) làm inference cho mô hình. Trong trường hợp này, TF serving sẽ là một cách tuyệt vời để tổ chức inference trên một hoặc nhiều máy ảo (VMs), tất cả những gì bạn cần làm là thêm một bộ cân bằng tải (load balancer) trên đầu cụm. Bạn có thể sử dụng các sản phẩm sau để triển khai phân phát TF trong Nền tảng AI:
Cách tiếp cận này có những ưu điểm sau:
- Thời gian đáp ứng tuyệt vời vì mô hình sẽ được tải trong bộ nhớ
- Chi phí cho mỗi lần chạy sẽ giảm đáng kể khi bạn có nhiều request
AI Platform Predictions
Nền tảng AI cung cấp một cách dễ dàng để triển khai các mô hình đã được huấn luyện (pre-trained) thông qua AI Platform Predictions. Điều này có nhiều lợi thế inference khi so sánh với phương pháp cụm:
- Cơ sở hạ tầng dễ mở rộng
- Không cần quản lý cơ sở hạ tầng
- Lưu trữ riêng cho mô hình, rất thuận tiện để theo dõi các phiên bản của mô hình và để so sánh hiệu năng của chúng
Cloud Functions
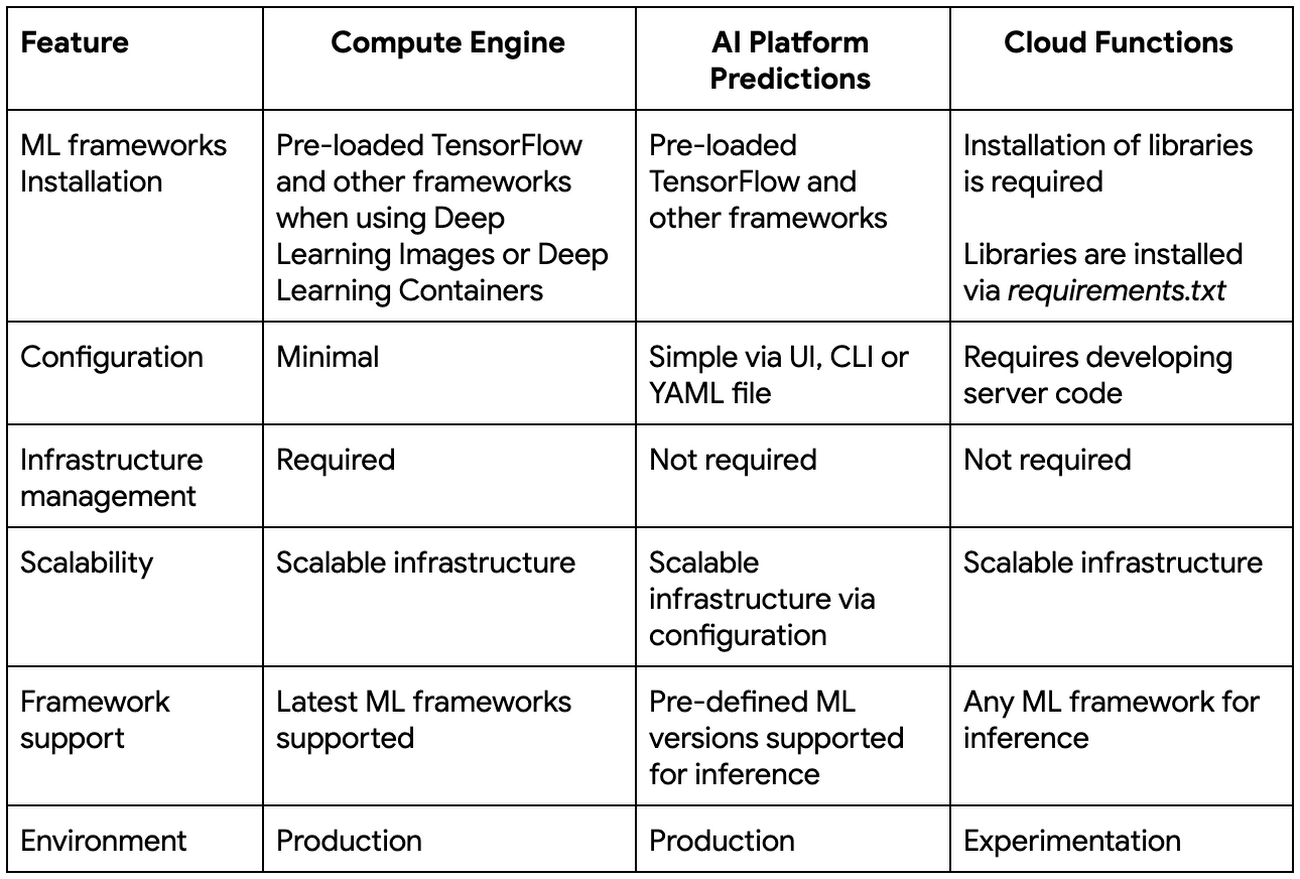
Khi so sánh Deep Learning VM images và AI Platform Predictions, phương pháp serverless cung cấp các ưu điểm sau:
- Code dễ cài đặt và triển khai
- Khả năng mở rộng tuyệt vời, cho phép bạn mở rộng từ 0 đến 10k gần như ngay lập tức
- Cấu trúc chi phí cho phép bạn chỉ trả tiền cho các lần chạy, nghĩa là bạn không phải trả tiền cho các máy chủ nhàn rỗi.
- Khả năng sử dụng các phiên bản tùy chỉnh của các framework như Tensorflow 2.0 hay PyTorch
So sánh trong bảng sau:
Nhược điểm sẽ là trong trường hợp mô hình quá lớn, khởi động có thể mất một thời gian và sẽ rất khó để đạt được hiệu năng thời gian thực. Ngoài ra, chúng ta cần lưu ý rằng cơ sở hạ tầng không có máy chủ (serverless) là giá của một cá nhân sử dụng sẽ giảm khi bạn không có một số lượng lớn request. Vì vậy, trong trường hợp này, có thể rẻ hơn khi sử dụng TF serving.

Mặt khác, Cloud Functions có thanh toán trên 100ms mà không có khoảng thời gian tối thiểu. Điều này có nghĩa là Cloud Functions rất tốt cho các công việc ngắn, không nhất quán nhưng nếu bạn cần xử lý một chuỗi công việc dài, nhất quán, Compute Engine có thể là lựa chọn tốt hơn.
Hệ thống của chúng ta sẽ khá đơn giản. Chúng ta sẽ huấn luyện mô hình ở máy tính cá nhân và sau đó tải nó lên Google Cloud. Cloud Functions sẽ được gọi thông qua API và sẽ tải xuống mô hình và ảnh test từ Cloud Storage.
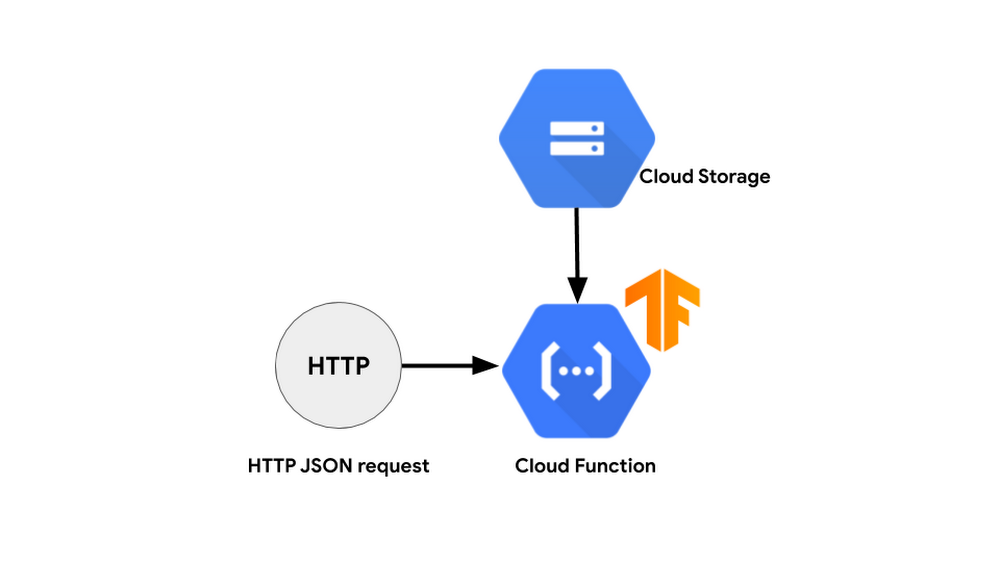
Có một số điều cần xem xét khi bạn thiết kế một hệ thống serverless:
Thứ nhất, ghi nhớ sự khác biệt giữa cold invocation. Khi chức năng cần thời gian để tải xuống và khởi tạo một mô hình và để warm invocation, khi chức năng sử dụng cached model. Việc tăng warm invocation không giúp tăng tốc độ sử lí. Cách khắc phục có thể sử dụng cơ chế pub/sub để normalize việc load do đó nó sẽ được sử lí bởi warm containers.
Thứ hai, bạn có thể sử dụng batching để tối ưu chi phí và tăng tốc độ sử lí. Bởi một mô hình có thể chạy dưới dạng batch thay vì chạy trong mỗi image. Batching cho phép bạn giảm sự khác biệt giữa cold và warm cải thiện tốc độ tổng thể.
Cuối cùng, bạn có thể lưu một phần mô hình của mình như một phần của thư viện. Bạn cũng có thể thử chia mô hình thành các lớp và xâu chuỗi chúng lại với nhau trên các chức năng riêng biệt. Trong trường hợp này, mỗi chức năng sẽ gửi một tầng kích hoạt (activity layer) trung gian xuống chuỗi và không có chức năng nào cần phải tải xuống mô hình.
Ta sử dụng bài toán MNIST fashion với TensorFlow 2.0 làm ví dụ:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
EPOCHS = 10
mnist = tf.keras.datasets.mnist
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension e.g. (60000, 28, 28) => (60000, 28, 28, 1)
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
class CustomModel(Model):
def __init__(self):
super(CustomModel, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
model = CustomModel()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
@tf.function
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Save the weights
model.save_weights('fashion_mnist_weights')
Sau quá trình huấn luyện tạo ra các tệp sau:
fashion_mnist_weights_new.index
fashion_mnist_weights.data-00000-of-00001
Chúng ta sẽ cần lưu trữ mô hình riêng biệt với code vì có giới hạn về kích thước tệp cục bộ trên Cloud Functions. Bạn có thể tải chúng lên Cloud Storage cùng với test image.
Một trong những ưu điểm chính của Cloud Function là bạn không phải tạo gói thư viện thủ công. Bạn chỉ có thể sử dụng tệp requirements.txt như trong python và liệt kê tất cả các thư viện được sử dụng như dưới đây. Ngoài ra, hãy nhớ để mô hình là một biến toàn cục để nó sẽ được lưu trữ và sử dụng lại trong warm invocations của Cloud Functions.
# requirements.txt
tensorflow==2.0
google-cloud-storage==1.16.1
Pillow==6.0.0
Triển khai mô hình với Cloud Functions:
import numpy
import tensorflow
from google.cloud import storage
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
from PIL import Image
# We keep model as global variable so we don't have to reload it in case of warm invocations
model = None
class CustomModel(Model):
def __init__(self):
super(CustomModel, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
def download_blob(bucket_name, source_blob_name, destination_file_name):
"""Downloads a blob from the bucket."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob(source_blob_name)
blob.download_to_filename(destination_file_name)
print('Blob {} downloaded to {}.'.format(
source_blob_name,
destination_file_name))
def handler(request):
global model
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Model load which only happens during cold starts
if model is None:
download_blob('<your_bucket_name>', 'tensorflow/fashion_mnist_weights.index', '/tmp/fashion_mnist_weights.index')
download_blob('<your_bucket_name>', 'tensorflow/fashion_mnist_weights.data-00000-of-00001', '/tmp/fashion_mnist_weights.data-00000-of-00001')
model = CustomModel()
model.load_weights('/tmp/fashion_mnist_weights')
download_blob('<your_bucket_name>', 'tensorflow/test.png', '/tmp/test.png')
image = numpy.array(Image.open('/tmp/test.png'))
input_np = (numpy.array(Image.open('/tmp/test.png'))/255)[numpy.newaxis,:,:,numpy.newaxis]
predictions = model.call(input_np)
print(predictions)
print("Image is "+class_names[numpy.argmax(predictions)])
return class_names[numpy.argmax(predictions)]
Bạn có thể dễ dàng triển khai và chạy Cloud Function bằng gcloud.
git clone https://github.com/ryfeus/gcf-packs
cd gcf-packs/tensorflow2.0/example/
gcloud functions deploy handler --runtime python37 --trigger-http --memory 2048
gcloud functions call handler
response:
executionId: omx2o2y27sm9
result: Trouser
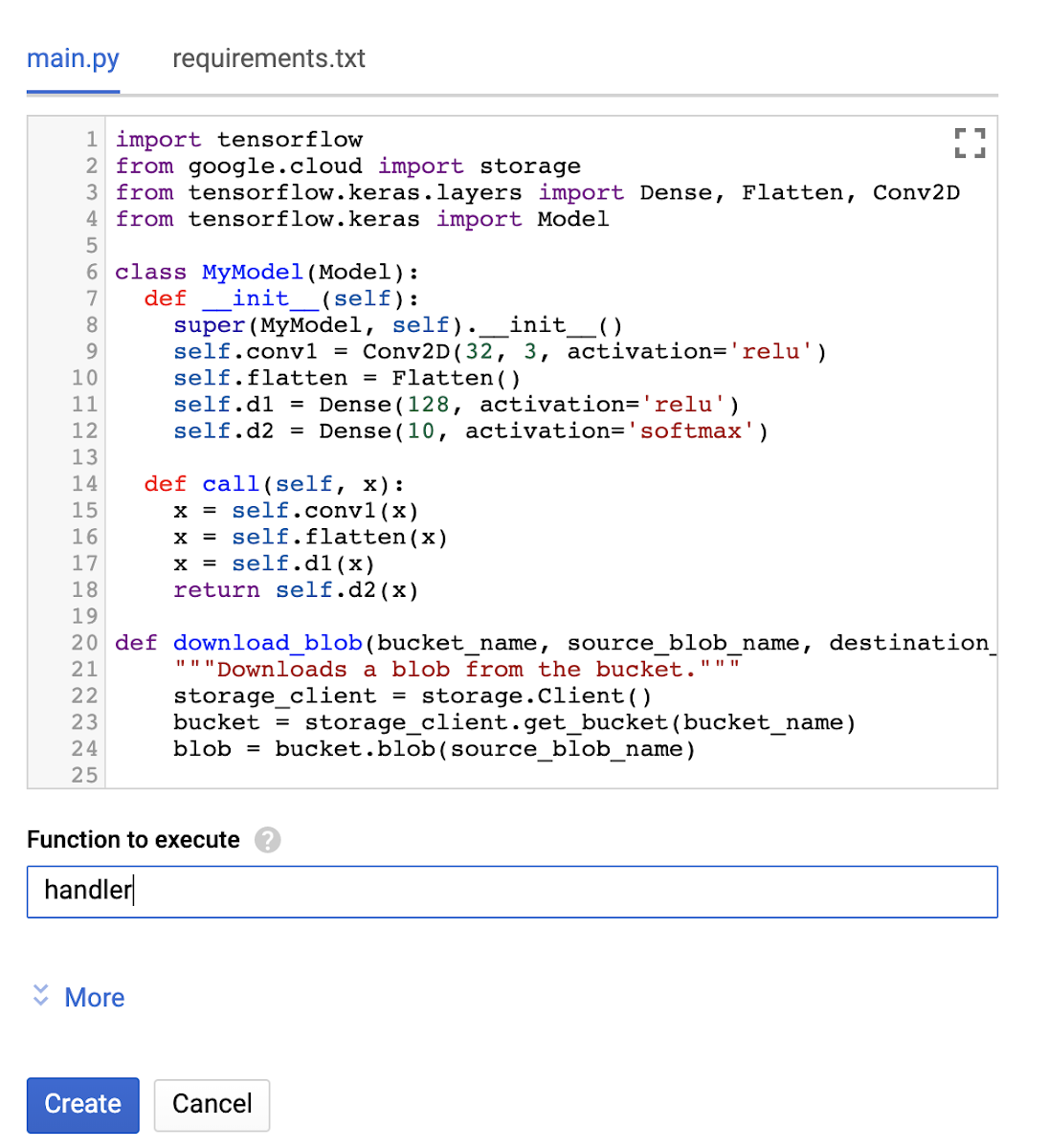
Đầu tiên, hãy để bắt đầu từ bảng điều khiển Cloud Function. Để tạo một Cloud Function mới, hãy chọn nút "Create function". Trong cửa sổ "Create function", hãy đặt tên chức năng là tensorflow2demo, bộ nhớ được phân bổ (2 GB trong trường hợp của chúng tôi để có hiệu năng tốt nhất), trigger là HTTP và runtime trên python 3.7
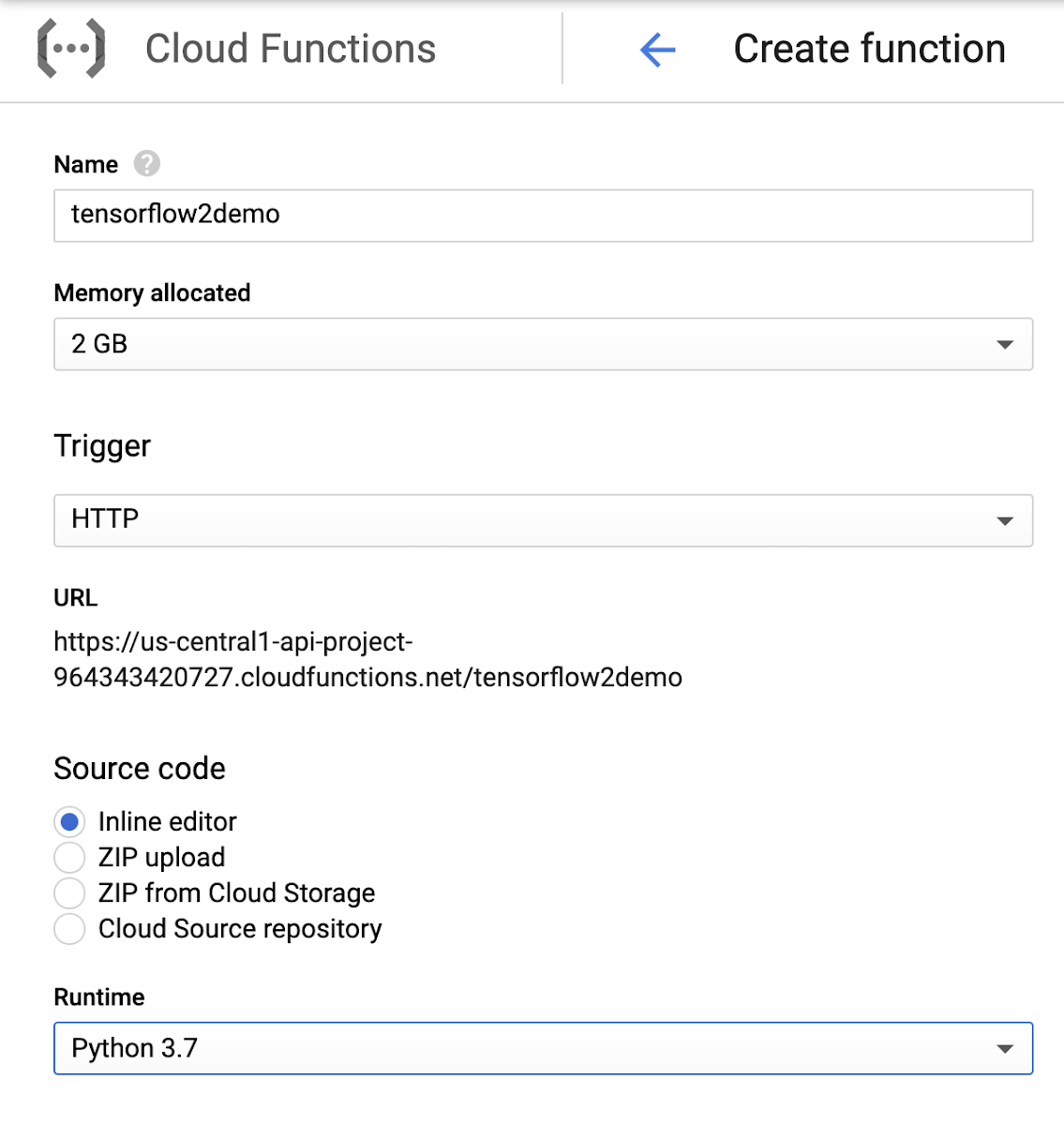
Tiếp theo, các tệp main.py và requirements.txt. Bạn chỉ có thể sao chép mã tại repo. Cuối cùng, hãy nhấn nút "Create" và khởi tạo chức năng.
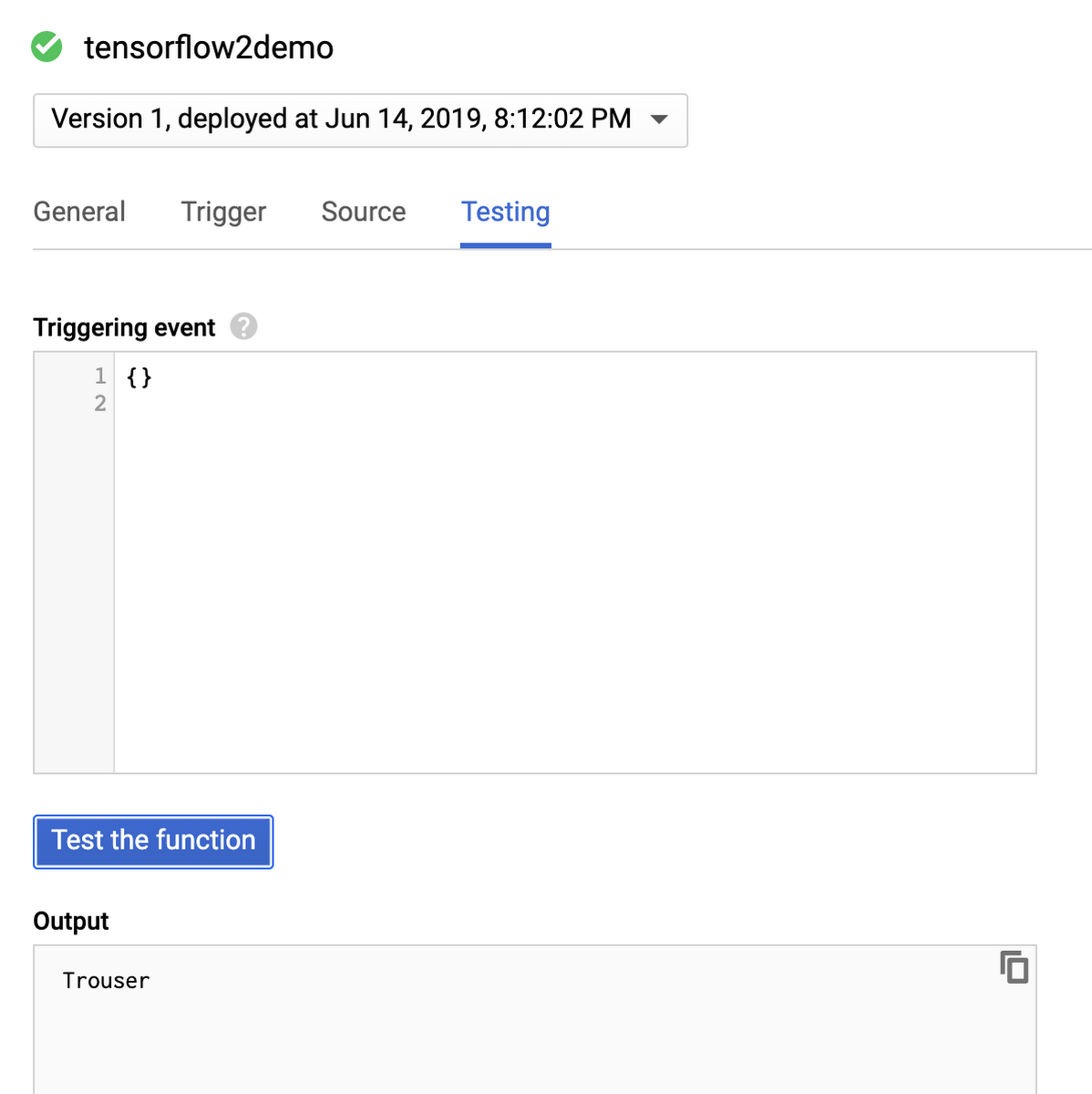
Sau khi chức năng được triển khai, bạn có thể kiểm tra nó trong phần Testing trên dashboard. Bạn cũng có thể tùy chỉnh các sự kiện đến và xem đầu ra cũng như logs.
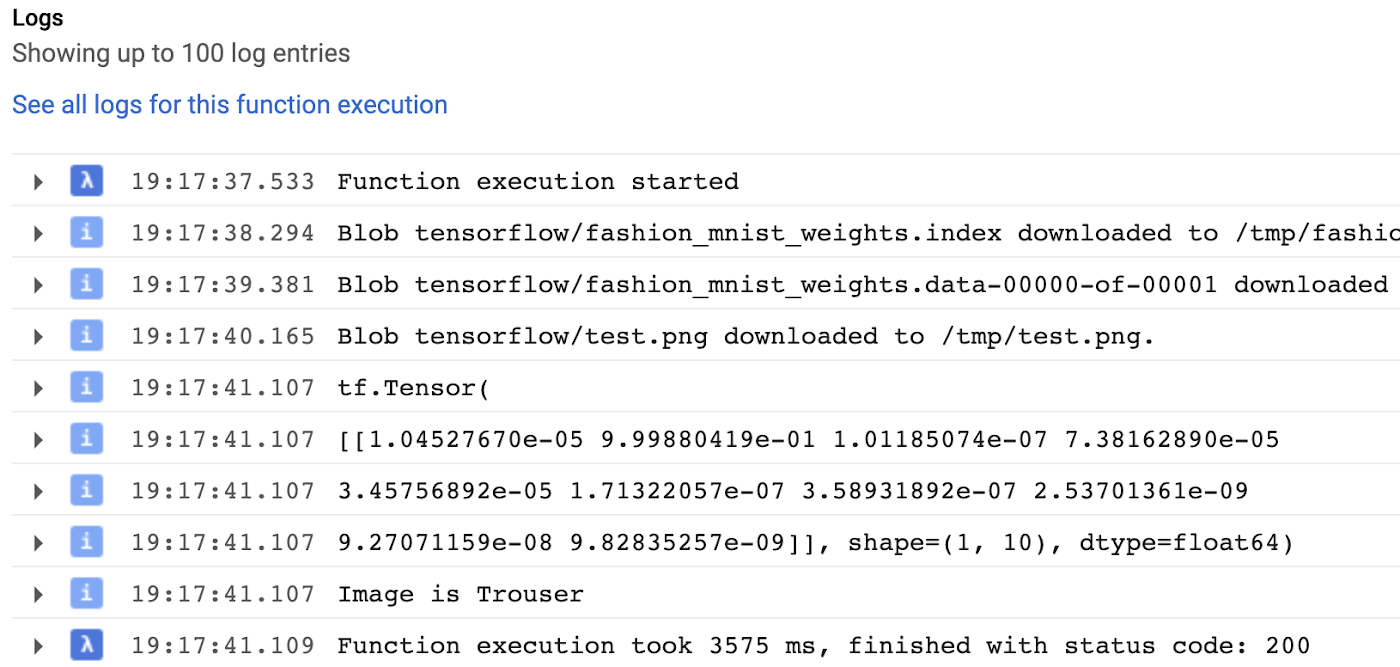
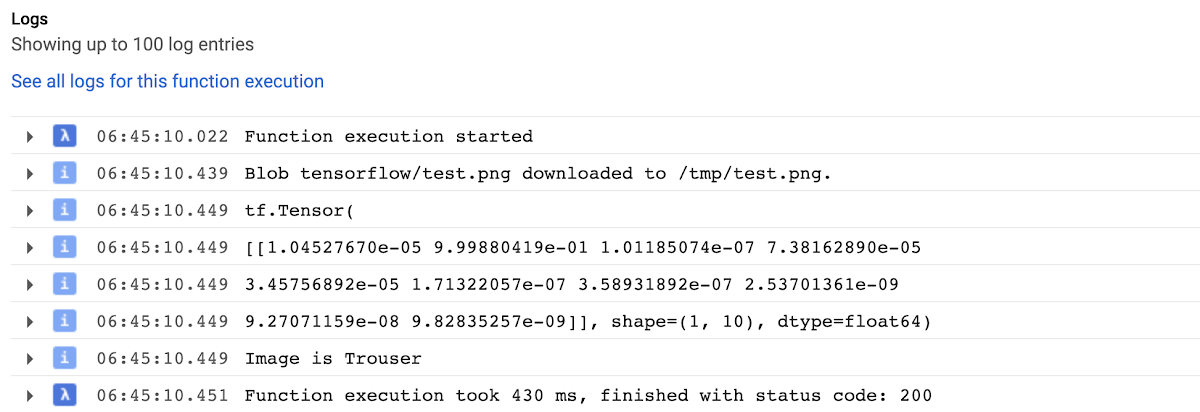
Như bạn có thể thấy, mô hình đã phân loại thành công hình ảnh là quần. Nếu chúng ta chạy các chức năng một lần nữa, chúng ta sẽ thấy rằng nó sẽ chạy nhanh hơn rất nhiều bởi vì chúng ta đã lưu mô hình vào bộ đệm.
{kind=link}