Last active
May 28, 2018 01:54
-
-
Save imjakedaniels/c20677e11953e12d57d249f1d9a3440f to your computer and use it in GitHub Desktop.
Graph top words from a search query
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ```{r} | |
| library(rtweet) | |
| library(twitteR) | |
| library(tidyverse) | |
| library(tidytext) | |
| library(httpuv) | |
| data(stop_words) | |
| ``` | |
| ```{r} | |
| #insert your own tokens | |
| appname <- "xxxxx" | |
| key <- "xxxxx" | |
| secret <- "xxxxxx" | |
| twitter_token <- create_token( | |
| app = appname, | |
| consumer_key = key, | |
| consumer_secret = secret) | |
| ``` | |
| ```{r} | |
| #top words scraper | |
| #top_tweets[1] is the search term, include quotes | |
| #top_tweets[2] is number of results | |
| #top_tweets[3] is number of recent tweets, 18,000 | |
| #top_tweets[4] is basic colour scheme (default black) | |
| #add any junk terms to the word list in custom_stop_words | |
| top_words <- function(keyword, topn, total, visual = "black"){ | |
| tweet_data <- search_tweets(keyword, n = total, include_rts = F, type = "recent", retryonratelimit = T) | |
| custom_stop_words <- bind_rows(data_frame(word = c(gsub("#", "", keyword),"t.co", "https", "rt", "amp"), | |
| lexicon = c("custom")), stop_words) | |
| my_title <- paste("Online Discussion about", keyword) | |
| my_subtitle <- paste("based on", total, "recent tweets") | |
| tweet_data %>% | |
| unnest_tokens(word, text) %>% | |
| anti_join(custom_stop_words) %>% | |
| count(word, sort = T) %>% | |
| head(topn) %>% | |
| ggplot(aes(x = reorder(word, n), y = n, fill = "blue")) + | |
| geom_bar(show.legend = F, stat = "identity", width = 0.8) + | |
| scale_fill_manual(values = visual) + | |
| labs(title = my_title, subtitle = my_subtitle, y = "Number of Mentions", x = NULL) + | |
| coord_flip() + | |
| theme_classic() + | |
| theme(plot.title=element_text(family='', face='bold', colour = visual, size=16)) | |
| } | |
| ``` | |
| ```{r} | |
| #example | |
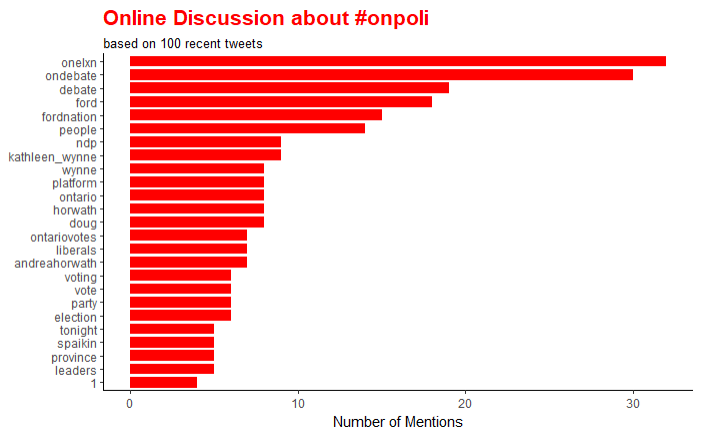
| top_words("#onpoli", 25, 1000, "red") | |
| ``` | |
| ```{r} | |
| #timeline scraper | |
| timeline_tweets <- function(keyword, topn, total, visual = "black"){ | |
| tweet_data <- get_timeline(keyword, n = total) | |
| custom_stop_words <- bind_rows(data_frame(word = c(gsub("#", "", keyword),"t.co", "https", "rt", "amp"), | |
| lexicon = c("custom")), stop_words) | |
| my_title <- paste0("Most frequent word usage by @", keyword) | |
| my_subtitle <- paste("based on", total, "recent tweets") | |
| tweet_data %>% | |
| unnest_tokens(word, text) %>% | |
| anti_join(custom_stop_words) %>% | |
| count(word, sort = T) %>% | |
| head(topn) %>% | |
| ggplot(aes(x = reorder(word, n), y = n, fill = "blue")) + | |
| geom_bar(show.legend = F, stat = "identity", width = 0.8) + | |
| scale_fill_manual(values = visual) + | |
| labs(title = my_title, subtitle = my_subtitle, y = "Number of Mentions", x = NULL) + | |
| coord_flip() + | |
| theme_classic() + | |
| theme(plot.title=element_text(family='', face='bold', colour = visual, size=16)) | |
| } | |
| ``` | |
| ```{r} | |
| timeline_tweets("Kathleen_Wynne", 15, 500, "red") | |
| timeline_tweets("AndreaHorwath", 15, 500, "orange") | |
| timeline_tweets("fordnation", 15, 500, "blue") | |
| ``` | |
| ```{r} | |
| #keywords of conversation | |
| wynne <- "@kathleen_wynne OR kathleen wynne OR wynne OR @OntLiberal" | |
| ford <- "@fordnation OR doug ford OR @OntarioPCParty)" | |
| horvath <- "@andreaHorwath OR andrea horwath OR horwath OR @OntarioNDP" | |
| conversation <- function(keyword, topn, total, visual = "black"){ | |
| tweet_data <- search_tweets(keyword, n = total, type = "recent", include_rts = F, retryonratelimit = TRUE) | |
| custom_stop_words <- bind_rows(data_frame(word = c(gsub("#", "", keyword), "t.co", "https", "rt", "amp"), | |
| lexicon = c("custom")), stop_words) | |
| my_title <- paste("Online Discussion Surrounding", keyword) | |
| my_subtitle <- paste("based on", total, "recent tweets") | |
| tweet_data %>% | |
| unnest_tokens(word, text) %>% | |
| anti_join(custom_stop_words) %>% | |
| count(word, sort = T) %>% | |
| head(topn) %>% | |
| ggplot(aes(x = reorder(word, n), y = n, fill = "blue")) + | |
| geom_bar(show.legend = F, stat = "identity", width = 0.8) + | |
| scale_fill_manual(values = visual) + | |
| labs(title = my_title, subtitle = my_subtitle, y = "Number of Mentions", x = NULL) + | |
| coord_flip() + | |
| theme_classic() + | |
| theme(plot.title=element_text(family='', face='bold', colour = visual, size=16)) | |
| } | |
| ``` | |
| ```{r} | |
| conversation(wynne, 25, 1000, "red") | |
| conversation(ford, 25, 1000, "blue") | |
| conversation(horvath, 25, 1000, "orange") | |
| ``` | |
| ```{r} | |
| #bigrams of conversation | |
| wynne <- "@kathleen_wynne OR kathleen wynne OR wynne OR @OntLiberal" | |
| ford <- "@fordnation OR doug ford OR @OntarioPCParty)" | |
| horvath <- "@andreaHorwath OR andrea horwath OR horwath OR @OntarioNDP" | |
| conversation2 <- function(keyword, total, visual = "black"){ | |
| tweet_data <- search_tweets(keyword, n = total, type = "recent", include_rts = F, retryonratelimit = TRUE) | |
| custom_stop_words <- bind_rows(data_frame(bigram = c("https t.co", "of the", "for the", "and the", "to be", "to the", "in the", "is a", "is the"), | |
| lexicon = c("custom")), stop_words) | |
| my_title <- paste("Bigrams on Discussion Surrounding", keyword) | |
| my_subtitle <- paste("based on", total, "recent tweets") | |
| tweet_data %>% | |
| unnest_tokens(bigram, text, token = "ngrams", n = 2, collapse = F) %>% | |
| anti_join(custom_stop_words) %>% | |
| count(bigram, sort = T) %>% | |
| head(15) %>% | |
| ggplot(aes(x = reorder(bigram, n), y = n, fill = "blue")) + | |
| geom_bar(show.legend = F, stat = "identity", width = 0.8) + | |
| scale_fill_manual(values = visual) + | |
| labs(title = my_title, subtitle = my_subtitle, y = "Number of Mentions", x = NULL) + | |
| coord_flip() + | |
| theme_classic() + | |
| theme(plot.title=element_text(family='', face='bold', colour = visual, size=16)) | |
| } | |
| ``` | |
| ```{r} | |
| conversation2(wynne, 1000, "red") | |
| conversation2(ford, 1000, "blue") | |
| conversation2(horvath, 1000, "orange") | |
| ``` |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Updated ggplot visuals and cleaned some consistencies with alignment.
Planning to remove any twitter handles from conversation by str_replace anything with @