libicu-dev (PyICU dependency)
brew reinstall pkg-config icu4c| #!/usr/bin/env python | |
| import re | |
| import os | |
| def srcrepl(match): | |
| "Return the file contents with paths replaced" | |
| absolutePath = "http://www.example.com/" #update the URL to be prefixed here. | |
| print "<" + match.group(1) + match.group(2) + "=" + "\"" + absolutePath + match.group(3) + match.group(4) + "\"" + ">" | |
| return "<" + match.group(1) + match.group(2) + "=" + "\"" + absolutePath + match.group(3) + match.group(4) + "\"" + ">" | |
| # |
| """ | |
| Learning Task: | |
| Given a sequence, predict a label based on the first value of the sequence | |
| Explanation of stateful LSTM and setup: | |
| http://philipperemy.github.io/keras-stateful-lstm/ | |
| Exmple: | |
| given a sequence [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], predict 1 | |
| given a sequence [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], predict 0 |
| # In development of this script I had four goals: | |
| # 1) Operate on a string fragment of HTML and assume it could be poorly formed (ie - might not parse well with lxml, etc.) | |
| # 2) Ability to call the function with base_url since it would be used in the processing of multiple sites and HTML fragments | |
| # from them | |
| # 3) Desire to use urlparse.urljoin to insure that the resulting absolute url was well formed | |
| # 4) Even if the HTML fragment contains absolute URLs I could pass it through this routine without issue | |
| # Starting with https://gist.github.com/sprintingdev/8843526 I found that certain | |
| # relative URLs would, when made absolute, were not always well formed. Often there | |
| # could be multiple slashes in the URL path. To combat this urlparse.urljoin was introduced. |
brew reinstall pkg-config icu4c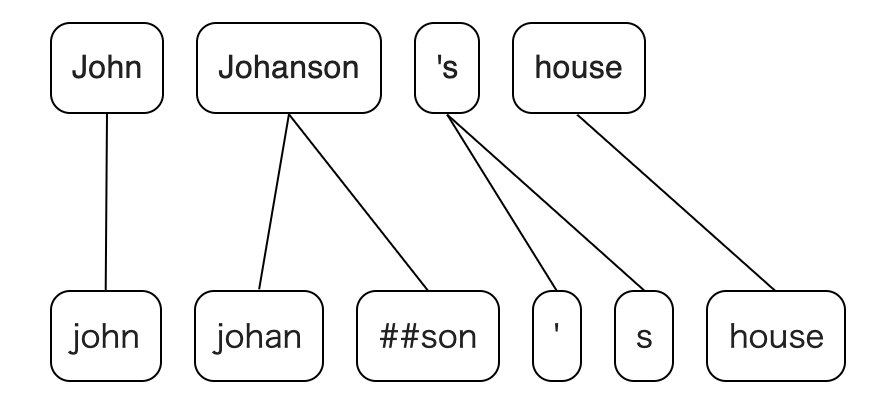
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links: