| Framework | Image | Video | C/C++ | Python |
|---|---|---|---|---|
 OpenCV OpenCV |
✅ | ✅ | ✅ | ✅ |
| ✅ | ✅ | |||
| ✅ | ✅ |
| Library | Basic Transforms | Keypoints | Bounding Boxes | Segmentation |
|---|---|---|---|---|
| Torchvision | ✅ | |||
| imgaug | ✅ | ✅ | ✅ | ✅ |
| albumentations | ✅ | ✅ | ✅ | ✅ |
| Framework | Creator | Python | C/C++ | R | Java | Javascript |
|---|---|---|---|---|---|---|
| ✅ | ✅ | |||||
| ✅ | ✅ | ✅ | ✅ | |||
| UC Berkeley | ✅ | ✅ | ||||
| Joseph Redmon | ✅ | |||||
| Apache | ✅ | ✅ | ✅ | ✅ |
PyTorch is a Python package that provides * Tensor computation (like NumPy) with strong GPU acceleration * Deep neural networks built on a tape-based autograd system
- 🏠 Main page: https://pytorch.org/
GitHub: https://github.com/pytorch/pytorch
PyPI: https://pypi.org/project/torch
]
- 📘 Docs: https://pytorch.org/docs/stable/index.html
- Docker:


TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
- 🏠 Main page: https://www.tensorflow.org/?hl=es-419
- 📘 Docs: https://www.tensorflow.org/api_docs
- Docker:


Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license.
- 🏠 Main page: https://caffe.berkeleyvision.org/
- 📘 Docs: https://caffe.berkeleyvision.org/tutorial/
- Docker:


Darknet is an open source neural network framework written in C and CUDA. It is fast, easy to install, and supports CPU and GPU computation.
- 🏠 Main page: https://pjreddie.com/darknet/
- 📘 Docs: https://pjreddie.com/darknet/install/
- Docker:



A truly open source deep learning framework suited for flexible research prototyping and production.
-
🏠 Main page: https://mxnet.apache.org/versions/1.9.0/
-
Docker:


| Framework | Creator | ||||
|---|---|---|---|---|---|
| ✅ | |||||
| CILVR | ✅ | ||||
| ✅ | |||||
| DMLC | ✅ | ✅ | |||
| ✅ | |||||
 MMCV MMCV |
OpenMMLab | ✅ |
- 🏠 Main page: https://pytorch.org/vision/stable/index.html
- 📘 Docs: https://pytorch.org/vision/stable/index.html
- 💾 Datasets: https://pytorch.org/vision/stable/datasets.html
- 🐒 Model zoo: https://pytorch.org/vision/stable/models.html

- 🏠 Main page: https://www.pytorchlightning.ai/
- 📘 Docs: https://pytorch-lightning.readthedocs.io/en/stable/

- 🏠 Main page: https://keras.io/
- 📘 Docs: https://keras.io/api/
- 💾 Datasets: https://keras.io/api/datasets/
- 🐒 Model zoo: https://keras.io/api/applications/

- 🏠 Main page: https://cv.gluon.ai/
- 📘 Docs: https://cv.gluon.ai/install.html
- 💾 Datasets: https://cv.gluon.ai/api/data.datasets.html
- 🐒 Model zoo: https://cv.gluon.ai/model_zoo/index.html

- 🏠 Main page: https://mediapipe.dev/
- 📘 Docs: https://google.github.io/mediapipe/getting_started/python
- 🐒 Model zoo: https://google.github.io/mediapipe/solutions/solutions

- 🏠 Main page: https://github.com/facebookresearch/detectron
- 📘 Docs: https://detectron2.readthedocs.io/en/latest/tutorials/getting_started.html
- 💾 Datasets: https://detectron2.readthedocs.io/en/latest/tutorials/builtin_datasets.html
- 🐒 Model zoo: https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md

- 🏠 Main page: https://openmmlab.com/
- MMCV: https://pypi.org/project/mmcv
- MMClassification: https://pypi.org/project/mmcls
- MMDetection: https://pypi.org/project/mmdet
- MMSegmentation: https://pypi.org/project/mmsegmentation
- MMPose: https://pypi.org/project/mmpose
- MMCV: https://pypi.org/project/mmcv
- 📘 Docs: https://mmcv.readthedocs.io/en/latest/

Image classification refers to the task of extracting information classes from a multiband raster image.

| Family | Network | Year | #P (M) | * Acc@1 |
|---|---|---|---|---|
| AlexNet | AlexNet | Apr-2014 | 61 | 56.522 |
| VGG | VGG-11 (BN) | Sep-2014 | 133 | 70.370 |
| VGG | VGG-13 (BN) | Sep-2014 | 133 | 71.586 |
| VGG | VGG-16 (BN) | Sep-2014 | 138 | 73.360 |
| VGG | VGG-19 (BN) | Sep-2014 | 144 | 74.218 |
| GoogLeNet | GoogLeNet | 2014 | 13 | 69.778 |
| ResNet | ResNet-18 | 2015 | 12 | 69.758 |
| ResNet | ResNet-34 | 2015 | 22 | 73.314 |
| ResNet | ResNet-50 | 2015 | 26 | 76.130 |
| ResNet | ResNet-50 | 2015 | 45 | 77.374 |
| ResNet | ResNet-101 | 2015 | 50 | 78.312 |
| InceptionV3 | Inception-V3 | 2015 | 27 | 77.294 |
| SqueezeNet | SqueezeNet 1.0 | 2016 | 1 | 58.092 |
| SqueezeNet | SqueezeNet 1.1 | 2016 | 1 | 58.178 |
| DenseNet | DenseNet-121 | 2016 | 8 | 74.434 |
| DenseNet | DenseNet-126 | 2016 | 29 | 75.600 |
| DenseNet | DenseNet-169 | 2016 | 14 | 75.600 |
| DenseNet | DenseNet-201 | 2016 | 20 | 76.896 |
| DarknetV1 | Darknet-19 | 2016 | ? | 72.9 |
| Darknet | Darknet-53 | 2016 | ? | 77.2 |
| Wide ResNet | Wide ResNet-50-2 | 2017 | 69 | 78.468 |
| Wide ResNet | Wide ResNet-101-2 | 2017 | 127 | 78.848 |
| MobileNet | MobileNet-v2 | 2018 | 4 | 71.878 |
| MobileNet | MobileNet-v3-small | 2018 | 3 | 67.668 |
| MobileNet | MobileNet-v3-large | 2018 | 5 | 74.042 |
| MNASNet | MNASNet 0-5 | 2018 | 2 | 67.734 |
| MNASNet | MNASNet 0-75 | 2018 | 3 | ?? |
| MNASNet | MNASNet 1-0 | 2018 | 4 | 73.456 |
| MNASNet | MNASNet 1-3 | 2018 | 6 | ?? |
| EfficientNet | EfficientNet B0 | 2019 | 5 | 77.692 |
| EfficientNet | EfficientNet B1 | 2019 | 8 | 78.642 |
| EfficientNet | EfficientNet B2 | 2019 | 9 | 80.608 |
| EfficientNet | EfficientNet B3 | 2019 | 12 | 82.008 |
| EfficientNet | EfficientNet B4 | 2019 | 19 | 83.384 |
| EfficientNet | EfficientNet B5 | 2019 | 30 | 83.444 |
| EfficientNet | EfficientNet B6 | 2019 | 43 | 84.008 |
| EfficientNet | EfficientNet B6 | 2019 | 66 | 84.122 |
| Swin | Swin-S | 2021 | 49 | 83.21 |
| Swin | Swin-B | 2021 | 87 | 85.16 |
| Swin | Swin-L | 2021 | 196 | 86.24 |
| ViT | ViT-L/14 | 2020 | 307 | 87.46 |
| ViT | ViT-H/14 | 2020 | 632 | 88.55 |
- Acc@1: Top-1 Accuracy on ImageNet at 224x224 resolution
Object detection refers to identifying the location of one or more objects in an image with its bounding box.
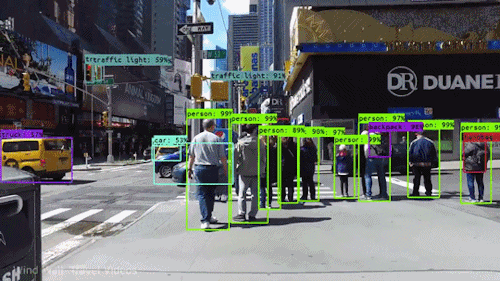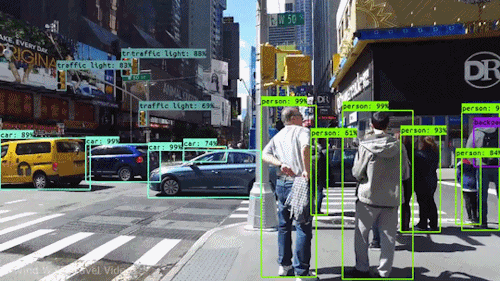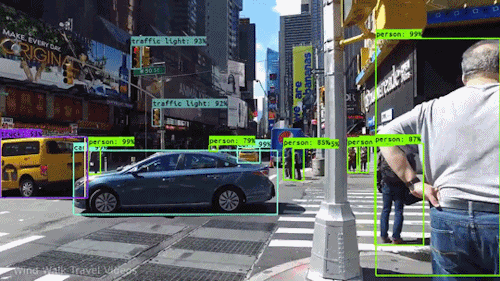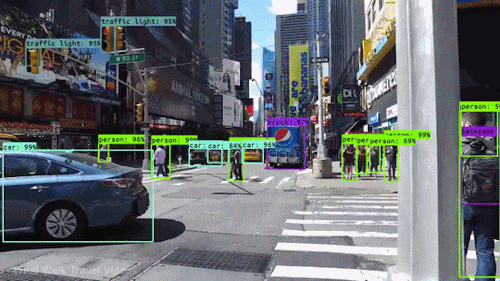
| Model | Paper | Published |
|---|---|---|
| R-CNN | Rich feature hierarchies for accurate object detection and semantic segmentation | Oct-2013 |
| Fast R-CNN | Fast R-CNN | Sep-2015 |
| Faster R-CNN | Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | Jan-2016 |
| YOLOv1 | You Only Look Once: Unified, Real-Time Object Detection | Jun-2015 |
| YOLOv2 | YOLO9000: Better, Faster, Stronger | Dec-2016 |
| SSD | SSD: Single Shot MultiBox Detector | Dec-2015 |
| YOLOv3 | YOLOv3: An Incremental Improvement | Apr-2018 |
| RetinaNet | Focal Loss for Dense Object Detection | Feb-2018 |
| MaskRCNN | Mask R-CNN | Mar-2017 |
| Cascade R-CNN | Cascade R-CNN: Delving into High Quality Object Detection | Dec-2017 |
| DETR | End-to-End Object Detection with Transformers | May-2020 |
| Family | Network | Backbone | Year | * AP |
|---|---|---|---|---|
| R-CNN | R-CNN | ?? | 2013 | - |
| Fast R-CNN | Fast R-CNN | VGG16 | 2015 | 19.7 |
| Faster R-CNN | Faster R-CNN | VGG16 | 2016 | 21.9 |
| YOLOv1 | YOLO V1 | * GoogLeNet | 2015 | - |
| YOLOv2 | YOLO V2 | Darknet-19 | 2016 | 21.6 |
| SSD | SSD300 | VGG16 | 2016 | 23.2 |
| SSD | SSD500 | VGG16 | 2016 | 26.8 |
| Cascade R-CNN | Cascade-R-CNN-100 | ResNet-101 | 2017 | 42.8 |
| YOLOv3 | YOLO V3 | Darknet-53 | 2018 | 33.0 |
| RetinaNet | RetinaNet-ResNet-101 | ResNet-101-FPN | 2017 | 39.1 |
| RetinaNet | RetinaNet-ResNeXt-101 | ResNeXt-101-FPN | 2017 | 40.8 |
| MaskRCNN | MaskRCNN R-101-FPN | ResNet-101-FP | 2018 | 40.8 |
| MaskRCNN | MaskRCNN X-101-64x4d-FPN | ResNeXt-101-64x4d | 2018 | 42.7 |
| DETR | DETR-DC5 | ResNet-50 + DC | 2020 | 43.3 |
| DETR | DETR-DC5-R101 | ResNet-101 + DC | 2020 | 44.9 |
- AP: AP[.5:.05:0.95] on COCO test-dev
Image Segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects

| Family | Backbone | Year | * mIoU |
|---|---|---|---|
| UNet | UNet-S5-D16 | 2016 | 69.10 |
| FCN | ResNet-18-D8 | 2017 | 71.11 |
| FCN | ResNet-50-D8 | 2017 | 73.61 |
| FCN | ResNet-101-D8 | 2017 | 76.80 |
| DeepLabV3 | ResNet-50-D8 | 2017 | 77.85 |
| PSPNet | ResNet-101-D8 | 2016 | 78.34 |
| UPerNet | ResNet-50 | 2018 | 78.19 |
| UPerNet | ResNet-101 | 2018 | 79.40 |
| DANet | ResNet-50-D8 | 2018 | 79.34 |
| DANet | ResNet-101-D8 | 2018 | 80.41 |
- mIoU: Mean IoU on CityScapes at 512x1024 resolution
Landmark/Keypoint Extraction is the process of determining spatial key-points of an object in an image (e.g: Pose keypoints)

- Cascade
- Heatmap methods
- Top-down heatmap
- Bottom-up heatmap
- Multi-Scale High-Resolution Networks
Papers:
| Model | Paper | Published |
|---|---|---|
| Deep Pose | DeepPose: Human Pose Estimation via Deep Neural Networks | Dec-2013 |
| CPM | Convolutional Pose Machines | Jan-2016 |
| RSN | Learning Delicate Local Representations for Multi-Person Pose Estimation | Mar-2020 |
| HRNet | Deep High-Resolution Representation Learning for Visual Recognition | Aug-2019 |
| Family | Method | Backbone | Year | * AP |
|---|---|---|---|---|
| Deep Pose | Cascade | Resnet-50 | 2014 | 52.6 |
| Deep Pose | Cascade | Resnet-101 | 2014 | 56.0 |
| Deep Pose | Cascade | Resnet-152 | 2014 | 58.3 |
| CPM | Top-down heatmap | ? | 2016 | 62.3 |
| ResnetV1 | Top-down Heatmap | ResnetV1D-50 | 2019 | 72.2 |
| ResnetV1 | Top-down Heatmap | ResnetV1D-100 | 2019 | 73.1 |
| ResnetV1 | Top-down Heatmap | Resnet-152 | 2019 | 73.7 |
| VGG | Top-down Heatmap | VGG-16 | 2015 | 69.8 |
| Mobilenetv2 | Top-down Heatmap | MobileNetV2 | 2018 | 64.6 |
| RSN | Top-down Heatmap | ResNet-18 | 2020 | 70.4 |
| RSN | Top-down Heatmap | 3x ResNet-50 | 2020 | 75.0 |
| HRNet | Multi-Scale High-Resolution Networks | HRNet-w48 | 2019 | 75.6 |
- AP: Average precision on COCO-2017 at 256x192 resolution
- Siamese Networks
- Meta-Learning
| Paper | Backbone | R@1 | Published |
|---|---|---|---|
| Siamese Neural Networks for One-shot Image Recognition | Custom | Aug-2016 | |
| Hardness-Aware Deep Metric Learning | GoogLeNet | 43.6 | Mar-2019 |
| Local Similarity-Aware Deep Feature Embedding | GoogLeNet | 58.3 | Oct-2016 |
| Hard-Aware Deeply Cascaded Embedding | GoogLeNet | 60.7 | Nov-2016 |
| Sampling Matters in Deep Embedding Learning | ResNet-50 | 63.9 | Jun-2017 |
| SoftTriple Loss: Deep Metric Learning Without Triplet Sampling | GoogLeNet | 65.4 | Sep-2019 |
| Calibrated neighborhood aware confidence measure for deep metric learning | ?? | 74.9 | Jun-2020 |
| A Closer Look at Few-shot Classification | Conv4 | 60.5 | Jan-2020 |
| Negative Margin Matters: Understanding Margin in Few-shot Classification | ResNet-18 | 72.7 | Mar-2020 |
| Prototypical Networks for Few-shot Learning | GoogLeNet | 54.6 | Jun-2016 |
A large database of handwritten digits
- 🏠 Main page: http://yann.lecun.com/exdb/mnist/
- #Images: L-24x24
- Train: 60k
- Test: 10k
- Classes: (10) 0,1,2,3,4,5,6,7,8,9
- Tasks:
- Multi-class Image Classification
Labeled subsets of the 80 million tiny images dataset
- 🏠 Main page: https://www.cs.toronto.edu/~kriz/cifar.html
- #Images: RGB-32x32
- Train: 50k
- Test: 10k
- Classes: (10) airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck
- Tasks:
- Multi-class Image classification
Labeled subsets of the 80 million tiny images dataset
- 🏠 Main page: https://www.cs.toronto.edu/~kriz/cifar.html
- #Images: RGB-32x32
- Train: 50k
- Test: 10k
- Super-Classes: (100) aquatic mammals, fish, flowers, food containers, fruit and vegetables, household electrical devices, household furniture, insects, large carnivores, large man-made outdoor things, large natural outdoor scenes, large omnivores and herbivores, medium-sized mammals, non-insect invertebrates, people, reptiles, small mammals, trees, vehicles 1, vehicles 2
- Tasks:
- Multi-class Image classification
Pictures of objects belonging to 101 categories
- Dificulty: Mid
- 🏠 Main page: http://www.vision.caltech.edu/Image_Datasets/Caltech101/
- Images: RGB ~300x200
- Train: ?
- Test: ?
- Tasks:
- Multi-class Image classification
Large-scale face attributes dataset
- 🏠 Main page: http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- Images:
- Train: 200k
- Test: ??
- Tasks:
- Face Detection: Object detection
- Face attributes: Image classification
- KeyPoint Extraction: Landmark/Keypoint Extraction
- Identity: Metric Learning / Few-Shot Learning
- Classes:
- Face attributes (40): 5_o_Clock_Shadow, Arched_Eyebrows, Attractive, Bags_Under_Eyes, Bald, Bangs, Big_Lips, Big_Nose, Black_Hair, Blond_Hair, Blurry, Brown_Hair, Bushy_Eyebrows, Chubby, Double_Chin, Eyeglasses, Goatee, Gray_Hair, Heavy_Makeup, High_Cheekbones, Male, Mouth_Slightly_Open, Mustache, Narrow_Eyes, No_Beard, Oval_Face, Pale_Skin, Pointy_Nose, Receding_Hairline, Rosy_Cheeks, Sideburns, Smiling, Straight_Hair, Wavy_Hair, Wearing_Earrings, Wearing_Hat, Wearing_Lipstick, Wearing_Necklace, Wearing_Necktie, Young,
- Landmarks: (5)
- Left-eye, Right-eye, Nose, Left-Mouth, Right-Mouth
A face detection benchmark dataset with a high degree of variability in scale, pose and occlusion
- 🏠 Main page: http://shuoyang1213.me/WIDERFACE/index.html
- Images:
- All: 32k
- Train: 12k
- Val: 3k
- Test: 16k
- Tasks:
- Face Detection: Object detection
A database of face photographs designed for studying the problem of unconstrained face recognition
- 🏠 Main page: http://vis-www.cs.umass.edu/lfw/
- Images: 13k
- Tasks:
- Face identification: Metric Learning / Few-Shot Learning
- Face attributes: Image classification
- Classes:
- Face attributes (73): Male, Asian, White, Black, Baby, Child, Youth, Middle_Aged, Senior, Black_Hair, Blond_Hair, Brown_Hair, Bald, No_Eyewear, Eyeglasses, Sunglasses, Mustache, Smiling, Frowning, Chubby, Blurry, Harsh_Lighting, Flash, Soft_Lighting, Outdoor, Curly_Hair, Wavy_Hair, Straight_Hair, Receding_Hairline, Bangs, Sideburns, Fully_Visible_Forehead, Partially_Visible_Forehead, Obstructed_Forehead, Bushy_Eyebrows, Arched_Eyebrows, Narrow_Eyes, Eyes_Open, Big_Nose, Pointy_Nose, Big_Lips, Mouth_Closed, Mouth_Slightly_Open, Mouth_Wide_Open, Teeth_Not_Visible, No_Beard, Goatee, Round_Jaw, Double_Chin, Wearing_Hat, Oval_Face, Square_Face, Round_Face, Color_Photo, Posed_Photo, Attractive_Man, Attractive_Woman, Indian, Gray_Hair, Bags_Under_Eyes, Heavy_Makeup, Rosy_Cheeks, Shiny_Skin, Pale_Skin, 5_o'_Clock_Shadow, Strong_Nose-Mouth_Lines, Wearing_Lipstick, Flushed_Face, High_Cheekbones, Brown_Eyes, Wearing_Earrings, Wearing_Necktie, Wearing_Necklace
Large-scale face attributes dataset
- 🏠 Main page: http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- Images:
- Train: 200k
- Test: ??
- Tasks:
- FaceParts segmentation: Instance segmentation
- Classes: (17)
- Instance classes: skin, nose, left_eye, right_eye, left_eyebrow, right_eyebrow, left_ear, right_ear, mouth, lip, hair, hat, eyeglass, earring, necklace, neck, cloth.
An image database organized according to the WordNet hierarchy (currently only the nouns), in which each node of the hierarchy is depicted by hundreds and thousands of images
- 🏠 Main page: https://www.image-net.org/
- Images:
- Total: 14M
- ILSVRC 2012-2017 subset:
- Train: 1M
- Valid: 50k
- Test: 100k
- Classes:
- All: (21K)
- ILSVRC 2017: (1k)
- Tasks:
A large-scale object detection, segmentation, and captioning dataset.
- 🏠 Main page: https://cocodataset.org/#home
- Images
- Total: 330K
- Labeled: 200K
- Classes:
- Object Detection & Object segmentation: 80
- Key-point: 18
- Tasks:
- Object detection
- Object & Stuff Segmentation: Image Segmentation
- Person Key-point detection: Landmark/Keypoint Extraction
- Image Captioning
A large-scale dataset that contains a diverse set of stereo video sequences recorded in street scenes from 50 different cities, with high quality pixel-level annotations of 5000 frames in addition to a larger set of 20 000 weakly annotated frames
- 🏠 Main page: https://www.cityscapes-dataset.com/
- Images:
- Total: 25k
- Val:
- Clases
- Flat: road, sidewalk, parking, rail track
- Human: person, rider
- Vehicle: car, truck, bus, on rails, motorcycle, bicycle, caravan, trailer
- Construction: building, wall, fence, guard rail, bridge, tunnel
- Object: pole, pole group, traffic sign, traffic light nature vegetation, terrain
- Sky: sky
- Void: ground, dynamic, static
- Tasks:
- 🏠 Main page: http://host.robots.ox.ac.uk/pascal/VOC/
- Images:
- Total: 11.5k
- Object Detection: 11.5k
- Image Segmentation: 6.9k
- Classes:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
- Tasks:
An extended version of the CUB-200 dataset, with roughly double the number of images per class and new part location annotations
- 🏠 Main page: http://www.vision.caltech.edu/visipedia/CUB-200-2011.html
- Images:
- Total: 11k
- Labels: 312
- Tasks: