-
-
Save jvelezmagic/f3653cc2ddab1c91e86751c8b423a1b6 to your computer and use it in GitHub Desktop.
| """QA Chatbot streaming using FastAPI, LangChain Expression Language , OpenAI, and Chroma. | |
| Features | |
| -------- | |
| - Persistent Chat Memory: | |
| Stores chat history in a local file. | |
| - Persistent Vector Store: | |
| Stores document embeddings in a local vector store. | |
| - Standalone Question Generation: | |
| Rephrases follow-up questions to standalone questions in their original language. | |
| - Document Retrieval: | |
| Searches and retrieves relevant documents based on user queries. | |
| - Context-Aware Responses: | |
| Generates responses based on a combined context from relevant documents. | |
| - Streaming Responses: | |
| Streams responses in real time either as plain text or as Server-Sent Events (SSE). | |
| SSE also sends the relevant documents as context. | |
| Next Steps | |
| ---------- | |
| - Add a proper exception handling mechanism during the streaming process. | |
| - Add pruning to the conversation buffer memory to prevent it from growing too large. | |
| - Combine documents using a more sophisticated method than simply concatenating them. | |
| Usage | |
| ----- | |
| 1. Install dependencies: | |
| ```bash | |
| pip install fastapi==0.99.1 uvicorn==0.23.2 python-dotenv==1.0.0 chromadb==0.4.5 tiktoken==0.4.0 langchain==0.0.257 openai==0.27.8 | |
| ``` | |
| or | |
| ```bash | |
| poetry install | |
| ``` | |
| 2. Run the server: | |
| ```bash | |
| uvicorn main:app --reload | |
| ``` | |
| 3. curl the server: | |
| With plain text: | |
| ```bash | |
| curl --no-buffer -X 'POST' \ | |
| 'http://localhost:8000/chat' \ | |
| -H 'accept: text/plain' \ | |
| -H 'Content-Type: application/json' \ | |
| -d '{ | |
| "session_id": "session_1", | |
| "message": "who'\''s playing in the river?" | |
| }' | |
| ``` | |
| With SSE: | |
| ```bash | |
| curl --no-buffer -X 'POST' \ | |
| 'http://localhost:8000/chat/sse/' \ | |
| -H 'accept: text/event-stream' \ | |
| -H 'Content-Type: application/json' \ | |
| -d '{ | |
| "session_id": "session_2", | |
| "message": "who'\''s playing in the garden?" | |
| }' | |
| Cheers! | |
| @jvelezmagic""" | |
| import os | |
| from functools import lru_cache | |
| from typing import AsyncGenerator, Literal | |
| from fastapi import Depends, FastAPI | |
| from fastapi.responses import StreamingResponse | |
| from langchain.chat_models import ChatOpenAI | |
| from langchain.embeddings import OpenAIEmbeddings | |
| from langchain.memory import ConversationBufferMemory, FileChatMessageHistory | |
| from langchain.prompts import PromptTemplate | |
| from langchain.schema import BaseChatMessageHistory, Document, format_document | |
| from langchain.schema.output_parser import StrOutputParser | |
| from langchain.vectorstores import Chroma | |
| from pydantic import BaseModel, BaseSettings | |
| class Settings(BaseSettings): | |
| openai_api_key: str | |
| class Config: # type: ignore | |
| env_file = ".env" | |
| env_file_encoding = "utf-8" | |
| class ChatRequest(BaseModel): | |
| session_id: str | |
| message: str | |
| class ChatSSEResponse(BaseModel): | |
| type: Literal["context", "start", "streaming", "end", "error"] | |
| value: str | list[Document] | |
| @lru_cache() | |
| def get_settings() -> Settings: | |
| return Settings() # type: ignore | |
| @lru_cache() | |
| def get_vectorstore() -> Chroma: | |
| settings = get_settings() | |
| embeddings = OpenAIEmbeddings(openai_api_key=settings.openai_api_key) # type: ignore | |
| vectorstore = Chroma( | |
| collection_name="chroma", | |
| embedding_function=embeddings, | |
| persist_directory="chroma", | |
| ) | |
| return vectorstore | |
| def combine_documents( | |
| docs: list[Document], | |
| document_prompt: PromptTemplate = PromptTemplate.from_template("{page_content}"), | |
| document_separator: str = "\n\n", | |
| ) -> str: | |
| doc_strings = [format_document(doc, document_prompt) for doc in docs] | |
| return document_separator.join(doc_strings) | |
| app = FastAPI( | |
| title="QA Chatbot Streaming using FastAPI, LangChain Expression Language , OpenAI, and Chroma", | |
| version="0.1.0", | |
| ) | |
| @app.on_event("startup") | |
| async def startup_event() -> None: | |
| vectorstore = get_vectorstore() | |
| is_collection_empty: bool = vectorstore._collection.count() == 0 # type: ignore | |
| if is_collection_empty: | |
| vectorstore.add_texts( # type: ignore | |
| texts=[ | |
| "Cats are playing in the garden.", | |
| "Dogs are playing in the river.", | |
| "Dogs and cats are mortal enemies, but they often play together.", | |
| ] | |
| ) | |
| if not os.path.exists("message_store"): | |
| os.mkdir("message_store") | |
| async def generate_standalone_question( | |
| chat_history: str, question: str, settings: Settings | |
| ) -> str: | |
| prompt = PromptTemplate.from_template( | |
| template="""Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. | |
| Chat History: | |
| {chat_history} | |
| Follow Up Input: {question} | |
| Standalone question:""" | |
| ) | |
| llm = ChatOpenAI(temperature=0, openai_api_key=settings.openai_api_key) | |
| chain = prompt | llm | StrOutputParser() # type: ignore | |
| return await chain.ainvoke( # type: ignore | |
| { | |
| "chat_history": chat_history, | |
| "question": question, | |
| } | |
| ) | |
| async def search_relevant_documents(query: str, k: int = 5) -> list[Document]: | |
| vectorstore = get_vectorstore() | |
| retriever = vectorstore.as_retriever() | |
| return await retriever.aget_relevant_documents(query=query, k=k) | |
| async def generate_response( | |
| context: str, chat_memory: BaseChatMessageHistory, message: str, settings: Settings | |
| ) -> AsyncGenerator[str, None]: | |
| prompt = PromptTemplate.from_template( | |
| """Answer the question based only on the following context: | |
| {context} | |
| Question: {question}""" | |
| ) | |
| llm = ChatOpenAI(temperature=0, openai_api_key=settings.openai_api_key) | |
| chain = prompt | llm # type: ignore | |
| response = "" | |
| async for token in chain.astream({"context": context, "question": message}): # type: ignore | |
| yield token.content | |
| response += token.content | |
| chat_memory.add_user_message(message=message) | |
| chat_memory.add_ai_message(message=response) | |
| async def generate_sse_response( | |
| context: list[Document], | |
| chat_memory: BaseChatMessageHistory, | |
| message: str, | |
| settings: Settings, | |
| ) -> AsyncGenerator[str, ChatSSEResponse]: | |
| prompt = PromptTemplate.from_template( | |
| """Answer the question based only on the following context: | |
| {context} | |
| Question: {question}""" | |
| ) | |
| llm = ChatOpenAI(temperature=0, openai_api_key=settings.openai_api_key) | |
| chain = prompt | llm # type: ignore | |
| response = "" | |
| yield ChatSSEResponse(type="context", value=context).json() | |
| try: | |
| yield ChatSSEResponse(type="start", value="").json() | |
| async for token in chain.astream({"context": context, "question": message}): # type: ignore | |
| yield ChatSSEResponse(type="streaming", value=token.content).json() | |
| response += token.content | |
| yield ChatSSEResponse(type="end", value="").json() | |
| chat_memory.add_user_message(message=message) | |
| chat_memory.add_ai_message(message=response) | |
| except Exception as e: # TODO: Add proper exception handling | |
| yield ChatSSEResponse(type="error", value=str(e)).json() | |
| @app.post("/chat") | |
| async def chat( | |
| request: ChatRequest, settings: Settings = Depends(get_settings) | |
| ) -> StreamingResponse: | |
| memory_key = f"./message_store/{request.session_id}.json" | |
| chat_memory = FileChatMessageHistory(file_path=memory_key) | |
| memory = ConversationBufferMemory(chat_memory=chat_memory, return_messages=False) | |
| standalone_question = await generate_standalone_question( | |
| chat_history=memory.buffer, question=request.message, settings=settings | |
| ) | |
| relevant_documents = await search_relevant_documents(query=standalone_question) | |
| combined_documents = combine_documents(relevant_documents) | |
| return StreamingResponse( | |
| generate_response( | |
| context=combined_documents, | |
| chat_memory=chat_memory, | |
| message=request.message, | |
| settings=settings, | |
| ), | |
| media_type="text/plain", | |
| ) | |
| @app.post("/chat/sse/") | |
| async def chat_sse( | |
| request: ChatRequest, settings: Settings = Depends(get_settings) | |
| ) -> StreamingResponse: | |
| memory_key = f"./message_store/{request.session_id}.json" | |
| chat_memory = FileChatMessageHistory(file_path=memory_key) | |
| memory = ConversationBufferMemory(chat_memory=chat_memory, return_messages=False) | |
| standalone_question = await generate_standalone_question( | |
| chat_history=memory.buffer, question=request.message, settings=settings | |
| ) | |
| relevant_documents = await search_relevant_documents(query=standalone_question, k=2) | |
| return StreamingResponse( | |
| generate_sse_response( | |
| context=relevant_documents, | |
| chat_memory=chat_memory, | |
| message=request.message, | |
| settings=settings, | |
| ), | |
| media_type="text/event-stream", | |
| ) |
| [tool.poetry] | |
| name = "langchain-language-expression-streaming-fastapi" | |
| version = "0.1.0" | |
| description = "" | |
| authors = ["Jesús Vélez Santiago"] | |
| packages = [{include = "app"}] | |
| [tool.poetry.dependencies] | |
| python = "^3.10" | |
| langchain = "^0.0.257" | |
| openai = "^0.27.8" | |
| fastapi = "0.99.1" | |
| uvicorn = "^0.23.2" | |
| python-dotenv = "^1.0.0" | |
| chromadb = "^0.4.5" | |
| tiktoken = "^0.4.0" | |
| [tool.poetry.group.dev.dependencies] | |
| black = "^23.7.0" | |
| [build-system] | |
| requires = ["poetry-core"] | |
| build-backend = "poetry.core.masonry.api" |
If anybody is getting the response as one big chunk on an nginx server but everything streams when running locally, you might try to add the X-Accel-Buffering: no header to the StreamingResponse
return StreamingResponse(
generate_sse_response(...),
media_type="text/event-stream",
headers={"X-Accel-Buffering": "no"}
)@jvelezmagic Many thanks for this! I'm facing a problem on the "/chat/sse" endpoint. Postman is not giving any data back, the connection is established, but closed in a few sec (see attached screenshot). BTW the "/chat " endpoints works on postman ... Appreciate your prompt response. UPDATE: Would be great if you can help with how to stream the results from fastAPI endpoint to python or javascript to get the full content. Cheers!
Postman doesn't stream the results back ... I recommend using curl. For example:
curl -N -X POST -H "Accept: text/event-stream" -H "Content-Type: application/json" -d '{"conversation_id": "123", "message": "What are the cats doing?" }' http://localhost:8000/chat/sse
I try to use this with a ConversationChain. It would not work. Any help with this? I simple added a ConversationChain in the generate_sse_response, any suggestiongs?
Just fond out how to do this.
from typing import AsyncGenerator, Literal
from pydantic import BaseModel
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import BaseChatMessageHistory, Document
from langchain.schema.output_parser import StrOutputParser
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnableMap
from langchain.prompts import ChatPromptTemplate
from langchain.chains import OpenAIModerationChain
from config import Settings
class ChatRequest(BaseModel):
session_id: str
message: str
class ChatSSEResponse(BaseModel):
type: Literal["context", "start", "streaming", "end", "error"]
value: str | list[Document]
async def generate_standalone_question(
chat_history: str,
question: str,
settings: Settings) -> str:
"""
Generate question from the previous chats and the user prompt or question
to get a stand alone question.
:param chat_history: History of chats
:param question: Question user wants to answer
:param settings: Settings basemodel for openai keys
:return: String of standalone question
"""
prompt = PromptTemplate.from_template(
template="""Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:""",
input=[]
)
llm = ChatOpenAI(temperature=0, openai_api_key=settings.openai_api_key)
chain = prompt | llm | StrOutputParser() # type: ignore
return await chain.ainvoke( # type: ignore
{
"chat_history": chat_history,
"question": question,
}
)
async def generate_sse_response(
memory: ConversationBufferMemory,
chat_memory: BaseChatMessageHistory,
message: str,
settings: Settings,
prompt_template: ChatPromptTemplate,
moderator_model: OpenAIModerationChain) -> AsyncGenerator[str, ChatSSEResponse]:
"""
Function to generate the response using Server Sent Events(SSE)
TODO: Generate good exception handling
TODO: Adding the moderator to add a safeguard againt violations, hate speech and violent content
:param context: List of all relevant documents with respect to user question to model
:param chat_memory: Memory of previous conversations
:param settings: Settings basemodel for openai keys
:param prompt_template: The chat prompt template feed to the AI, with System messages and human messages
:return: List of AsyncGenerator containing str and ChatSSEResponse
"""
llm = ChatOpenAI(temperature=0, openai_api_key=settings.openai_api_key)
# first get the memory then expand the memory
# https://python.langchain.com/docs/guides/expression_language/cookbook
chain = RunnableMap({
"input": lambda x: x["input"],
"memory": memory.load_memory_variables
}) | {
"input": lambda x: x["input"],
"history": lambda x: x["memory"]["history"]
} | prompt_template | llm
response = ""
try:
yield ChatSSEResponse(type="start", value="").json()
# type: ignore
async for token in chain.astream({"input": message}):
yield ChatSSEResponse(type="streaming", value=token.content).json()
response += token.content
yield ChatSSEResponse(type="end", value="").json()
chat_memory.add_user_message(message=message)
chat_memory.add_ai_message(message=response)
except Exception as e: # TODO: Add proper exception handling
yield ChatSSEResponse(type="error", value=str(e)).json()If you get TypeError: unsupported operand type(s) for |: 'type' and 'types.GenericAlias' in line value: str | list[Document], you should replace it with value: Union[str, list[Document]].
Hi, If you want an MVP (Minimal Working Example), this is what I've extracted from the script.
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from pydantic import BaseModel
from typing import AsyncGenerator
class ChatRequest(BaseModel):
session_id: str
message: str
app = FastAPI(
title="QA Chatbot Streaming using FastAPI, LangChain Expression Language , OpenAI, and Chroma",
version="0.1.0",
)
async def generate_response(
context: str,
message: str,
) -> AsyncGenerator[str, None]:
prompt = PromptTemplate.from_template(
"""Answer the question based only on the following context:
{context}
Question: {question}"""
)
llm = ChatOpenAI(
temperature=0,
openai_api_key=YOUR_OPENAI_KEY,
)
chain = prompt | llm # type: ignore
response = ""
async for token in chain.astream({"context": context, "question": message}): # type: ignore
yield token.content
response += token.content
@app.post("/chat")
async def chat(
request: ChatRequest,
) -> StreamingResponse:
return StreamingResponse(
generate_response(
context="",
message=request.message,
),
media_type="text/plain",
)Great content! I am struggling to make this work with AgentExecutor. Output never come as streamed token. Any ideas how to make the LCEL implementation of AgentExecutor to stream?
agent_executor = AgentExecutor(agent=agent_chain, memory=memory, verbose=True, tools=tool_list,return_intermediate_steps=False)
async for token in agent_executor .astream({"input ": "Hello"}):
yield token.content
response += token.content
@jvelezmagic Many thanks for this!
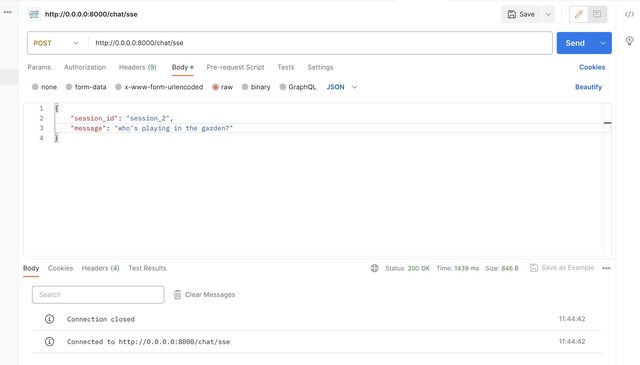
I'm facing a problem on the "/chat/sse" endpoint.
Postman is not giving any data back, the connection is established, but closed in a few sec (see attached screenshot).
BTW the "/chat " endpoints works on postman.
Appreciate your prompt response.
UPDATE: Would be great if you can help with how to stream the results from fastAPI endpoint to python or javascript to get the full content. Cheers!