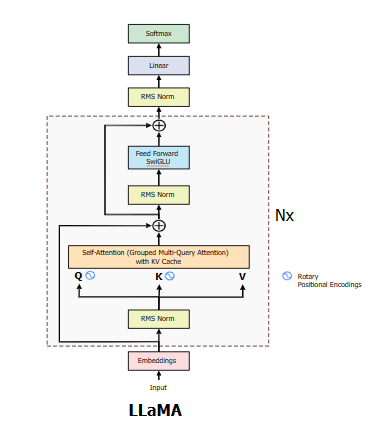
|
import json |
|
|
|
import torch |
|
import torch.nn.functional as F |
|
from flash_attn import flash_attn_with_kvcache |
|
|
|
from tokenizer import Tokenizer |
|
import collections |
|
import time |
|
|
|
device = 'cuda' |
|
model_name = './Llama3.2-3B' |
|
tokenizer_path = f'{model_name}/tokenizer.model' |
|
tokenizer = Tokenizer(model_path=tokenizer_path) |
|
|
|
model = torch.load(f'{model_name}/consolidated.00.pth', map_location=device, mmap=False, weights_only=True) |
|
|
|
with open(f'{model_name}/params.json', 'r') as f: |
|
config = json.load(f) |
|
|
|
head_dim = config['dim'] // config['n_heads'] # 4096 // 32 = 128 |
|
max_seq_len = 256 |
|
block_size = 256 |
|
|
|
stop_tokens = torch.tensor(list(tokenizer.stop_tokens), device=device) |
|
|
|
# Precompute freqs cis for rope |
|
zero_to_one_split_into_64_parts = torch.tensor(range(head_dim//2), device=device)/(head_dim//2) |
|
freqs = 1.0 / (torch.tensor(config['rope_theta'], device=device) ** zero_to_one_split_into_64_parts) |
|
freqs_for_each_token = torch.outer(torch.arange(max_seq_len, device=device), freqs) |
|
freqs_cis_max = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token) |
|
|
|
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor: |
|
# pair the last dimension into complex numbers |
|
complex = torch.view_as_complex(x.float().reshape(*x.shape[:-1], -1, 2)) |
|
# apply the rotary embedding, flatten back into reals. |
|
return torch.view_as_real(complex * freqs_cis.unsqueeze(2)).flatten(3).type_as(x) |
|
|
|
num_blocks = (max_seq_len // block_size) * 16 * config['n_layers'] |
|
k_cache = torch.randn(num_blocks, block_size, config['n_kv_heads'], head_dim, device=device, dtype=torch.bfloat16) |
|
v_cache = torch.randn(num_blocks, block_size, config['n_kv_heads'], head_dim, device=device, dtype=torch.bfloat16) |
|
kv_block_free = collections.deque(reversed(range(0, num_blocks, config['n_layers']))) |
|
|
|
# Generate next token i.e. do one forward pass of llama |
|
def forward(tokens, pos, block_table, n=1): |
|
bsz, T = tokens.shape |
|
final_embedding = F.embedding(tokens, weight=model['tok_embeddings.weight']) |
|
|
|
for layer in range(config['n_layers']): |
|
layer_embedding_norm = F.rms_norm( |
|
final_embedding, |
|
normalized_shape=final_embedding.shape[-1:], |
|
weight=model[f'layers.{layer}.attention_norm.weight'], |
|
eps=config['norm_eps'], |
|
) |
|
|
|
q = (layer_embedding_norm @ model[f'layers.{layer}.attention.wq.weight'].T).view(bsz, T, config['n_heads'], head_dim) |
|
k = (layer_embedding_norm @ model[f'layers.{layer}.attention.wk.weight'].T).view(bsz, T, config['n_kv_heads'], head_dim) |
|
v = (layer_embedding_norm @ model[f'layers.{layer}.attention.wv.weight'].T).view(bsz, T, config['n_kv_heads'], head_dim) |
|
|
|
freqs = freqs_cis_max[pos + torch.arange(n, device=device).repeat(bsz, 1)] |
|
q, k = apply_rotary_emb(q, freqs), apply_rotary_emb(k, freqs) |
|
|
|
stacked_qkv_attention = flash_attn_with_kvcache( |
|
q=q, |
|
k=k, |
|
v=v, |
|
k_cache=k_cache, |
|
v_cache=v_cache, |
|
cache_seqlens=pos[:, 0], |
|
block_table=block_table + layer, |
|
causal=True, |
|
).view(bsz, T, config['dim']) |
|
|
|
embedding_after_edit = final_embedding + torch.matmul(stacked_qkv_attention, model[f'layers.{layer}.attention.wo.weight'].T) |
|
embedding_after_edit_normalized = F.rms_norm( |
|
embedding_after_edit, |
|
normalized_shape=embedding_after_edit.shape[-1:], |
|
weight=model[f'layers.{layer}.ffn_norm.weight'], |
|
eps=config['norm_eps'], |
|
) |
|
w1, w2, w3 = model[f'layers.{layer}.feed_forward.w1.weight'], model[f'layers.{layer}.feed_forward.w2.weight'], model[f'layers.{layer}.feed_forward.w3.weight'] |
|
feed_forward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T)) * torch.matmul(embedding_after_edit_normalized, w3.T), w2.T) |
|
final_embedding = embedding_after_edit + feed_forward |
|
|
|
return torch.argmax(torch.matmul(F.rms_norm( |
|
final_embedding, |
|
normalized_shape=final_embedding.shape[-1:], |
|
weight=model['norm.weight'], |
|
eps=config['norm_eps'], |
|
), model['output.weight'].T), dim=-1)[:, -n:] |
|
|
|
completion_requests = [ |
|
tokenizer.encode("Do you know the muffin", bos=True, eos=False), |
|
tokenizer.encode("def levenshtein(a, b):\n", bos=True, eos=False), |
|
tokenizer.encode("The definition of surrepetitious is", bos=True, eos=False), |
|
tokenizer.encode("function crossEntropy(x, y) {\n", bos=True, eos=False), |
|
] |
|
|
|
t0 = time.time() |
|
token_count = 0 |
|
|
|
tokens = torch.zeros(len(completion_requests), max_seq_len, dtype=torch.long, device=device) |
|
kv_block_table = -torch.ones(len(completion_requests), (max_seq_len + block_size - 1) // block_size, dtype=torch.int32, device=device) |
|
prediction_pos = torch.zeros(len(completion_requests), 1, dtype=torch.int64, device=device) |
|
for i, t in enumerate(completion_requests): |
|
tokens[i, :len(t)] = torch.tensor(t, dtype=torch.long, device=device) |
|
for j in range(0, len(t), block_size): |
|
kv_block_table[i, j // block_size] = kv_block_free.pop() |
|
prediction_pos[i, 0] = len(t) |
|
prefill = max(len(t) for t in completion_requests) |
|
|
|
while tokens.shape[0] > 0: |
|
if prefill: |
|
output = forward(tokens[:, :prefill], torch.zeros(len(completion_requests), 1, device=device, dtype=torch.int32), kv_block_table, n=prefill) |
|
tokens.scatter_(1, prediction_pos, output) |
|
else: |
|
output = forward(tokens.gather(1, prediction_pos - 1), prediction_pos.type(dtype=torch.int32) - 1, kv_block_table) |
|
tokens.scatter_(1, prediction_pos, output) |
|
prediction_pos += 1 |
|
|
|
eos_reached = torch.any(torch.isin(output, stop_tokens), dim=-1) | (prediction_pos.squeeze(-1) >= max_seq_len) |
|
token_count += tokens.shape[0] |
|
|
|
for i in range(tokens.shape[0]): |
|
if eos_reached[i]: |
|
print(tokenizer.decode(tokens[i, :prediction_pos[i, 0]].tolist())) |
|
kv_block_free.extend(block for block in kv_block_table.unique() if block != -1) |
|
elif kv_block_table[i, prediction_pos[i, 0] // block_size] == -1: |
|
# we need to allocate a new block for the next prediction |
|
kv_block_table[i, prediction_pos[i, 0] // block_size] = kv_block_free.pop() |
|
|
|
tokens = tokens[~eos_reached, :] |
|
kv_block_table = kv_block_table[~eos_reached, :] |
|
prediction_pos = prediction_pos[~eos_reached, :] |
|
|
|
prefill = None |
|
|
|
dt = time.time() - t0 |
|
print(f'Time taken: {dt:.2f}s ({(token_count / dt):.2f} tokens/s)') |