You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Whether you're preparing for a System Design Interview or you simply want to understand how systems work beneath the surface, we hope this repository will help you achieve that.
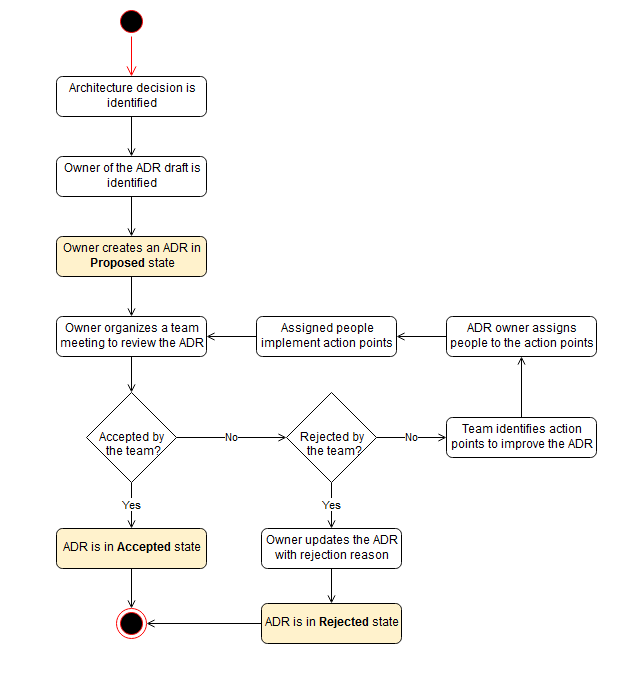
Analyze the existing ADR content and identify gaps in Context, Decision, and Consequences sections
Enrich the Context section with technical background, business drivers, and current state analysis
Enhance the Decision section with rationale, alternatives considered, and implementation approach
Expand the Consequences section with positive outcomes, negative outcomes, risks, and mitigation strategies
Review and refine the enriched ADR for completeness and clarity
Roo: ADR status
Based on the standard ADR (Architectural Decision Record) format and common practices in software architecture documentation, the typical status values available for Architectural Decision Records are:
Standard ADR Status Values
Proposed - The decision has been suggested but not yet accepted
Accepted - The decision has been approved and is currently in effect
Deprecated - The decision is no longer recommended but may still be in use
Superseded - The decision has been replaced by a newer decision (usually references the new ADR)
Rejected - The decision was considered but ultimately not accepted
Additional Status Values (Sometimes Used)
Draft - The ADR is still being written or refined
Pending - Awaiting review or approval
Amended - The decision has been modified from its original form
Status Workflow
The typical lifecycle follows this pattern:
graph LR
A[Draft/Proposed] --> B[Accepted]
A --> C[Rejected]
B --> D[Deprecated]
B --> E[Superseded]
B --> F[Amended]
Loading
These status values help track the evolution of architectural decisions over time and maintain a clear history of why certain choices were made or changed. The specific status values used in your project may vary based on your team's conventions, but these are the most commonly adopted standards based on the ADR format popularized by Michael Nygard.
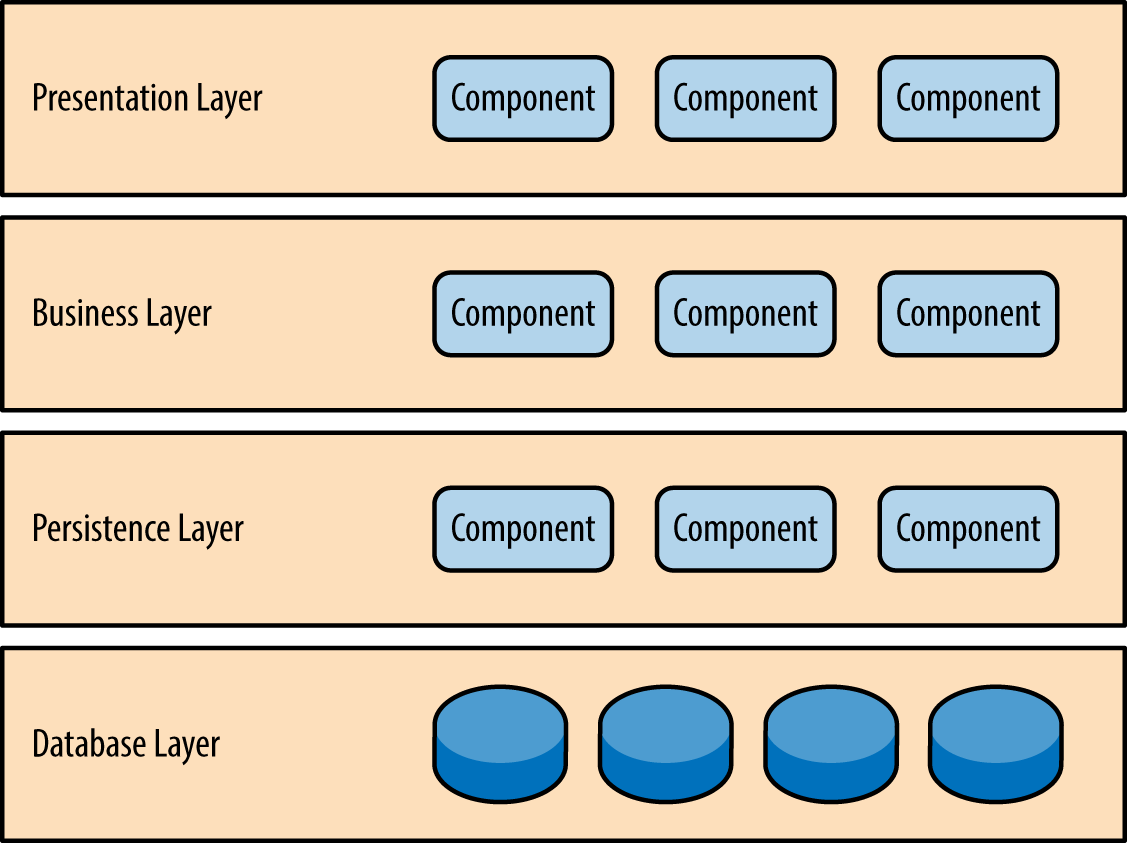
This classification has seven major elements. They are: platform and management, education and reference, home and entertainment, content and communication, operations and professional, product manufacturing and service delivery, and line of business.
Platform and management —Desktop and network infrastructure and management software that allows users to control the computer operating environment, hardware components and peripherals and infrastructure services and security.[4]
Education and reference —Educational software that does not contain resources, such as training or help files for a specific application.[4]
Home and entertainment —Applications designed primarily for use in or for the home, or for entertainment.[4]
Content and communications —Common applications for productivity, content creation, and communications. These typically include office productivity suites, multimedia players, file viewers, Web browsers, and collaboration tools.[4]
Operations and professional —Applications designed for business uses such as enterprise resource management, customer relations management, supply chain and manufacturing tasks, application development, information management and access, and tasks performed by both business and technical equipment.[4]
Product manufacturing and service delivery —Help users create products or deliver services in specific industries. Categories in this section are used by the North American Industry Classification System (NAICS).
Mermaid is a Markdown-inspired tool that renders text into diagrams. For example, Mermaid can render flow charts, sequence diagrams, pie charts and more. For more information, see the Mermaid documentation.
To create a Mermaid diagram, add Mermaid syntax inside a fenced code block with the mermaid language identifier. For more information about creating code blocks, see "Creating and highlighting code blocks."
graph TD
A[Christmas] -->|Get money| B(Go shopping)
B --> C{Let me think}
C -->|One| D[Laptop]
C -->|Two| E[iPhone]
C -->|Three| F[fa:fa-car Car]
Loading
Sequence diagram
sequenceDiagram
Alice->>+John: Hello John, how are you?
Alice->>+John: John, can you hear me?
John-->>-Alice: Hi Alice, I can hear you!
John-->>-Alice: I feel great!
Loading
class diagram
classDiagram
Animal <|-- Duck
Animal <|-- Fish
Animal <|-- Zebra
Animal : +int age
Animal : +String gender
Animal: +isMammal()
Animal: +mate()
class Duck{
+String beakColor
+swim()
+quack()
}
class Fish{
-int sizeInFeet
-canEat()
}
class Zebra{
+bool is_wild
+run()
}
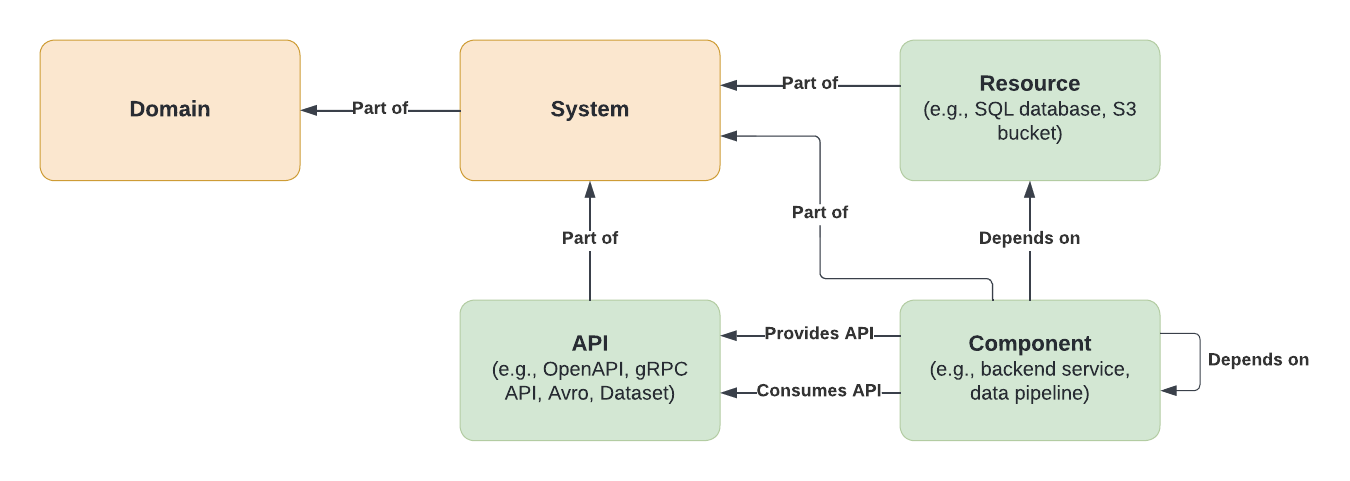
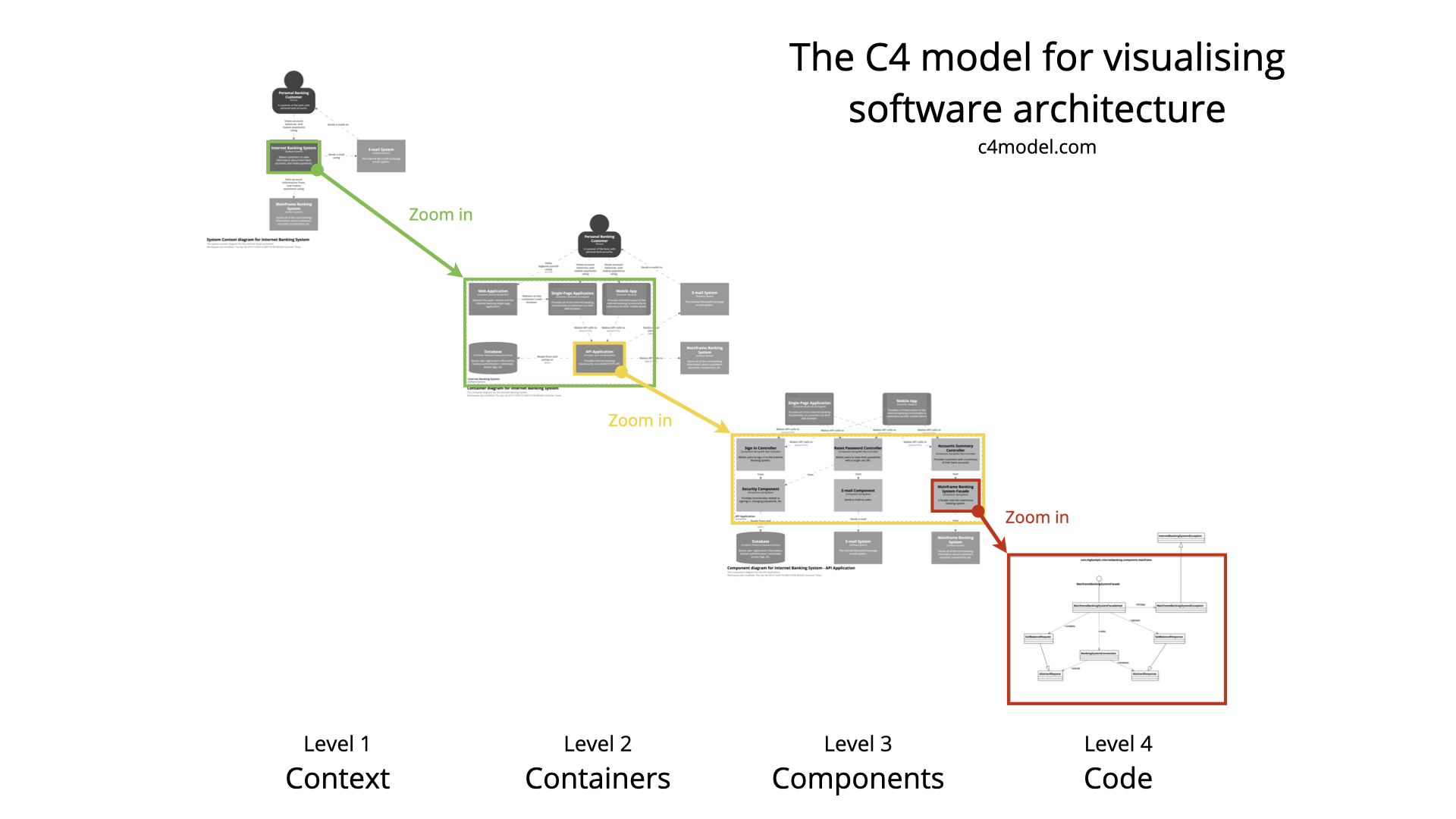
The C4 model is an "abstraction-first" approach to diagramming software architecture, based upon abstractions that reflect how software architects and developers think about and build software. The small set of abstractions and diagram types makes the C4 model easy to learn and use.
diagrams at this level of detail, especially when you can obtain them on demand from most IDEs.
Level 1, a system context diagram, shows the software system you are building and how it fits into the world in terms of the people who use it and the other software systems it interacts with. Here is an example of a system context diagram that describes an Internet banking system that you may be building:
Personal customers of the bank use the Internet banking system to view information about their bank accounts and to make payments. The Internet banking system uses the bank's existing mainframe banking system to do this, and uses the bank's existing e-mail system to send e-mail to customers. Colour coding in the diagram indicates which software systems already exist (the grey boxes) and those to be built (blue).
Level 2: Container diagram
Level 2, a container diagram, zooms into the software system, and shows the containers (applications, data stores, microservices, etc.) that make up that software system. Technology decisions are also a key part of this diagram. Below is a sample container diagram for the Internet banking system. It shows that the Internet banking system (the dashed box) is made up of five containers: a server-side web application, a client-side single-page application, a mobile app, a server-side API application, and a database.
The web application is a Java/Spring MVC web application that simply serves static content (HTML, CSS, and JavaScript), including the content that makes up the single-page application. The single-page application is an Angular application that runs in the customer's web browser, providing all of the Internet banking features. Alternatively, customers can use the cross-platform Xamarin mobile app to access a subset of the Internet banking functionality. Both the single-page application and mobile app use a JSON/HTTPS API, which another Java/Spring MVC application running on the server side provides. The API application gets user information from the database (a relational-database schema). The API application also communicates with the existing mainframe banking system, using a proprietary XML/HTTPS interface, to get information about bank accounts or make transactions. The API application also uses the existing e-mail system if it needs to send e-mail to customers.
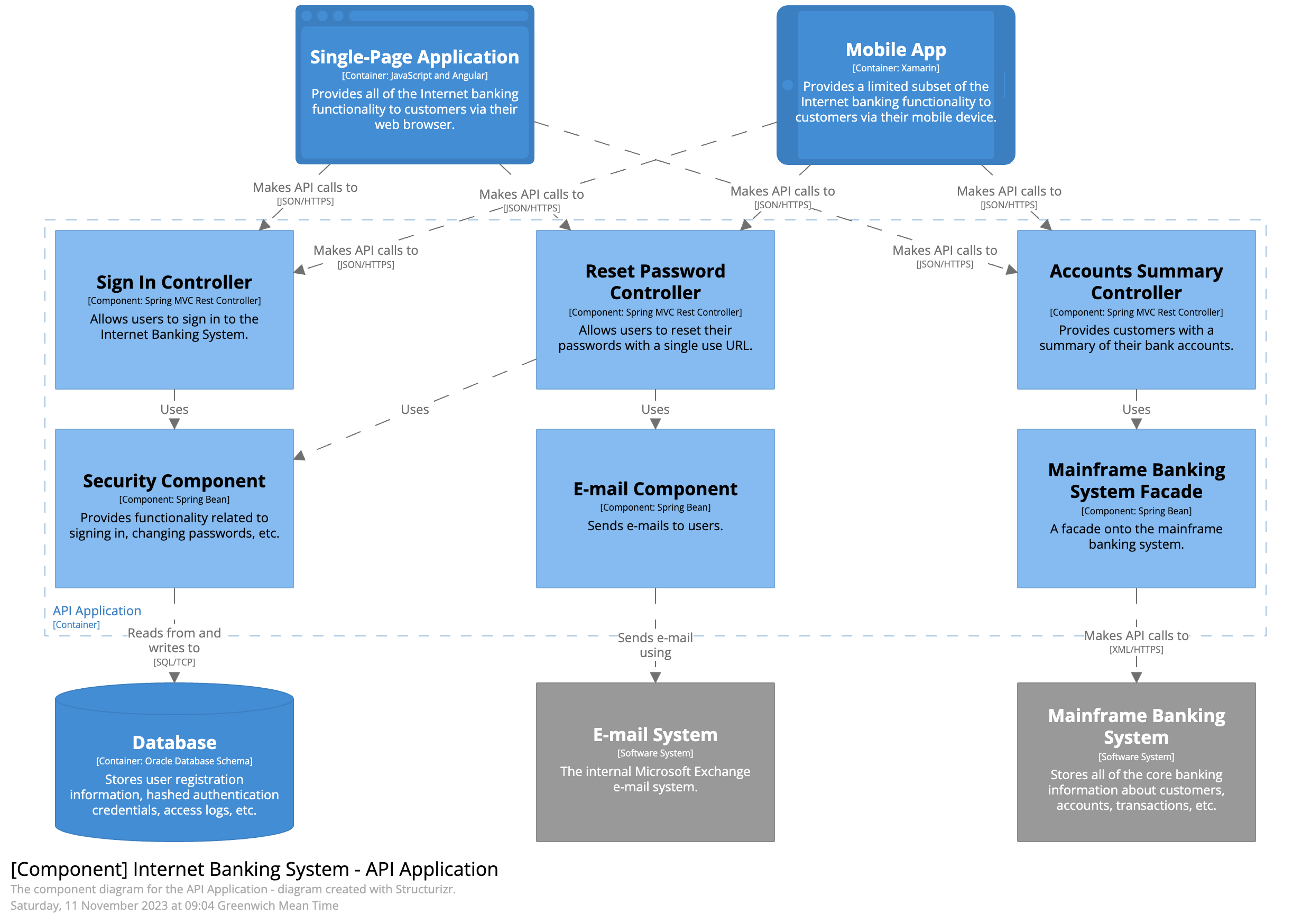
Level 3: Component diagram
Level 3, a component diagram, zooms into an individual container to show the components inside it. These components should map to real abstractions (e.g., a grouping of code) in your codebase. Here is a sample component diagram for the fictional Internet banking system that shows some (rather than all) of the components within the API application.
Two Spring MVC Rest Controllers provide access points for the JSON/HTTPS API, with each controller subsequently using other components to access data from the database and mainframe banking system.
Level 4: Code
Finally, if you really want or need to, you can zoom into an individual component to show how that component is implemented. This is a sample (and partial) UML class diagram for the fictional Internet banking system that, showing the code elements (interfaces and classes) that make up the MainframeBankingSystemFacade component.
It shows that the component is made up of a number of classes, with the implementation details directly reflecting the code. I wouldn't necessarily recommend creating
Structurizr is a web-based rendering tool designed to help software development teams create software architecture diagrams and documentation. It can render diagrams that are interactive, animatable, and embeddable. Structurizr can also publish Markdown/AsciiDoc documentation and architecture decision records (ADRs). Structurizr is available in a number of versions.
In Structurizr, each ADR has an ID, title, date and status (e.g. Proposed, Accepted, Superseded, etc), along with unstructured content written using Markdown or AsciiDoc. ADRs can either be created manually, or imported from tools like adr-tools.
In addition to the usual Markdown/AsciiDoc syntax for including images, you can embed live versions of the C4 model diagrams from your workspace into your documentation.
views {
systemContext financialRiskSystem "Context" "An example System Context diagram for the Financial Risk System architecture kata." {
include *
autoLayout
}
You can now click through the decisions, and press the Space key to open the quick navigation feature. Click the little graph button underneath the heading, and the visualisation will open.
Salt is a subproject included in PlantUML that may help you to design graphical interface or Website Wireframe or Page Schematic or Screen Blueprint.
The goal of this tool is to discuss about simple and sample windows.
You can use the archimate keyword to define an element. Stereotype can optionally specify an additional icon. Some colors (Business, Application, Motivation, Strategy, Technology, Physical, Implementation) are also available.
Once you agree that 100% is the wrong number, how do you determine the right number? And what are you measuring, anyway? Here, service level indicators come into play: an SLI is an indicator of the level of service that you are providing.
While many numbers can function as an SLI, we generally recommend treating the SLI as the ratio of two numbers: the number of good events divided by the total number of events. For example:
Number of successful HTTP requests / total HTTP requests (success rate)
Number of gRPC calls that completed successfully in < 100 ms / total gRPC requests
Number of search results that used the entire corpus / total number of search results, including those that degraded gracefully
Number of “stock check count” requests from product searches that used stock data fresher than 10 minutes / total number of stock check requests
Number of “good user minutes” according to some extended list of criteria for that metric / total number of user minutes
Types of components
The easiest way to get started with setting SLIs is to abstract your system into a few common types of components. You can then use our list of suggested SLIs for each component to choose the ones most relevant to your service:
Request-driven
The user creates some type of event and expects a response. For example, this could be an HTTP service where the user interacts with a browser or an API for a mobile application.
Pipeline
A system that takes records as input, mutates them, and places the output somewhere else. This might be a simple process that runs on a single instance in real time, or a multistage batch process that takes many hours. Examples include:
A system that periodically reads data from a relational database and writes it into a distributed hash table for optimized serving
A video processing service that converts video from one format to another
A system that reads in log files from many sources to generate reports
A monitoring system that pulls metrics from remote servers and generates time series and alerts
Storage
A system that accepts data (e.g., bytes, records, files, videos) and makes it available to be retrieved at a later date.
Simple laws for building cost-aware, sustainable, and modern architectures.
LAW I. Make Cost a Non-functional Requirement
When designing, developing, and operating systems, consider cost implications early and continuously in order to balance features, time-to-market, and efficiency.
LAW II. Systems that Last Align Cost to Business
Architect systems that align with the business model's profit levers to achieve economies of scale as revenue permits. Unrestrained growth without profitability erodes value.
LAW III. Architecting is a Series of Trade-offs
Every design decision comes with trade-offs. It's crucial to regularly re-evaluate technical and business trade-offs, and invest in resources aligned to business needs.
LAW IV. Unobserved Systems Lead to Unknown Costs
Though monitoring systems require upfront investment, they enable organizations to pinpoint wasteful practices, streamline workflows, and strategically allocate resources to priorities.
LAW V. Cost Aware Architectures Implement Cost Controls
With robust monitoring in place, you can take action in areas where you have identified opportunities for improvement. By implementing granular controls, you can optimize for both cost and user experience.
LAW VI. Cost Optimization is Incremental
The pursuit of cost efficiency is an ongoing journey. Monitor your systems to understand patterns and trim inefficiencies. Continual optimization requires revisiting systems to find further improvements.
LAW VII. Unchallenged Success Leads to Assumptions
Continuously question what's worked in the past. Revisit methods and tools despite previous successes. As Grace Hopper famously stated, one of the most dangerous phrases in English is: "we've always done it this way".
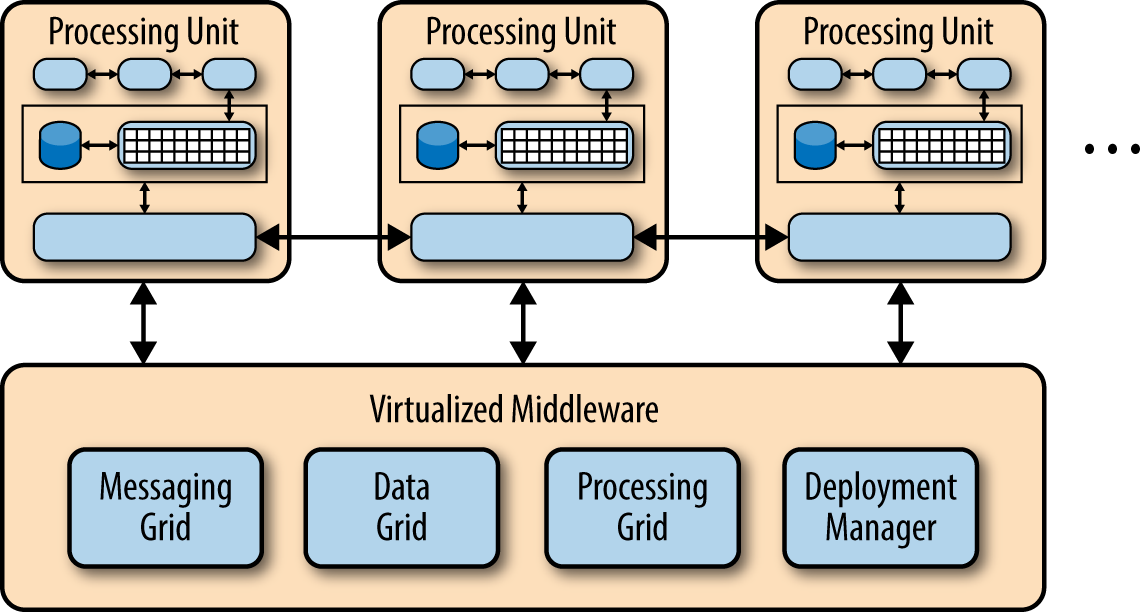
Scalability refers to the systems' ability to perform and operate as the number of users or requests increases. It is achievable with horizontal or vertical scaling of the machine or attaching AutoScalingGroup capabilities. Here are three areas to consider when architecting scalability into your system:
Traffic pattern: Understand the system's traffic pattern. It's not cost-efficient to spawn as many machines as possible due to underutilization. Here are three sample patterns:
Diurnal: Traffic increases in the morning and decreases in the evening for a particular region.
Global/regional: Heavy usage of the application in a particular region.
Thundering herd: Many users request resources, but only a few machines are available to serve the burst of traffic. This could occur during peak times or in densely populated areas.
Elasticity: This relates to the ability to quickly spawn a few machines to handle the burst of traffic and gracefully shrink when the demand is reduced.
Latency: This is the system's ability to serve a request as quickly as possible. This also includes optimizing the algorithms and using edge computing to replicate the system near users to reduce the round-trip time of a request.
Availability
Availability is measured as a percentage of uptime and defines the proportion of time that a system is functional and working. Availability is affected by system errors, infrastructure problems, malicious attacks, and system load. Things to consider include:
Deployment stamps: Deploy multiple independent copies of application components, including data stores.
Geodes: Deploy backend services into a set of geographical nodes, each of which can service any client request in any region.
Extensibility
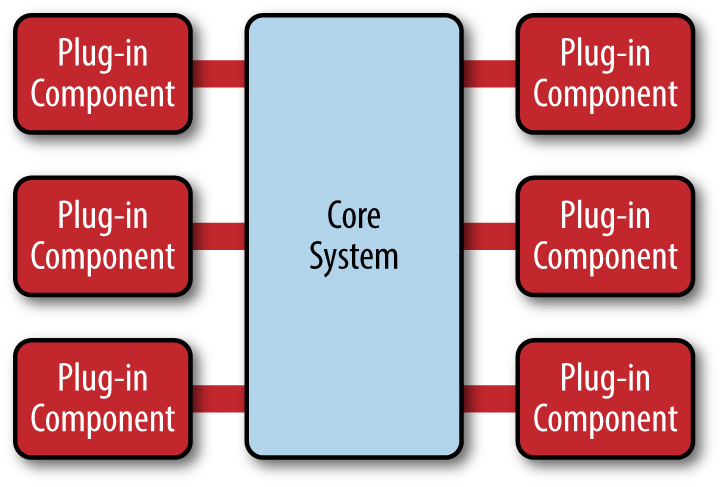
Extensibility measures the ability to extend a system and the effort required to implement the extension. The extension can occur by adding new functionality or modifying existing functionality. The principle provides enhancements without impairing current system functions. When architecting extensibility, consider:
Modularity and reusability: Reusability, together with extensibility, allows technology to be transferred to another project with less development and maintenance time, as well as enhanced reliability and consistency.
Pluggability: This is the ability to easily plug in other components, for example with microkernel architecture.
Consistency
Consistency guarantees that every read returns the most recent write. This means that after an operation executes, the data is consistent across all the nodes, and thus all clients see the same data at the same time, no matter which node they connect to. Consistency improves the data's freshness.
Resiliency
A system can gracefully handle and recover from accidental and malicious failures. Detecting failures and recovering quickly and efficiently is necessary to maintain resiliency. The primary factor to consider when architecting for resiliency is:
Recoverability: This is the preparatory processes and functionality that enable services to return to an initial functioning state after an unintended change. Unintended changes include soft or hard deletion or misconfiguration of applications.
Disaster recovery: Disaster recovery (DR) consists of best practices designed to prevent or minimize data loss and business disruption resulting from catastrophic events—everything from equipment failures and localized power outages to cyberattacks, civil emergencies, criminal or military attacks, and natural disasters.
Following are some DR design patterns you might implement to build resiliency into your architecture:
Bulkhead: This pattern isolates elements of an application into pools so that if one fails, the others will continue to function.
Circuit breaker: This pattern handles faults that might take a variable amount of time to fix when connecting to a remote service or resource.
Leader election: This pattern coordinates the actions performed by a collection of collaborating task instances in a distributed application by electing one instance as the leader that assumes responsibility for managing the other instances.
Usability
Usability is a system's capacity to enable users to perform tasks safely, effectively, and efficiently while enjoying the experience. It is the degree to which specified consumers can use software to achieve quantified objectives with effectiveness, efficiency, and satisfaction in a quantified context of use. Related factors include:
Accessibility: Make the software available to people with the broadest range of characteristics and capabilities, including users with deafness, blindness, colorblindness, and more.
Learnability: Make the software easy for users to learn.
API contract: Internal teams need to understand the API contracts to help them plug into any system.
Observability
Observability is the ability to collect data about program execution, modules' internal states, and communication between components. To improve observability, use various logging and tracing techniques and tools, including the following:
Logging: There are different types of logs generated within each request, such as event logs, transaction logs, message logs, and server logs.
Alerts and monitoring: Prepare monitoring dashboards, create service-level indicators (SLIs), and set up critical alerts.
Tiered levels of support: Set up on-call support processes for Level 1 and Level 2 support. L1 support includes interacting with customers. L2 support manages the tickets escalated by L1 and helps troubleshoot. L3 is the last line of support and usually comprises a development team that addresses the technical issues.
Security
Security is the degree to which the software protects information and data so that people, other products, or systems have data access appropriate to their types and levels of authorization. This family of characteristics includes the following five attributes:
Confidentiality: Data is accessible only to those authorized to have access.
Integrity: The software prevents unauthorized access to or modification of software or information.
Nonrepudiation: Prove whether actions or events have taken place.
Accountability: Trace user actions.
Authenticity: Prove the user's identity.
Additional security requirements include:
Auditability: Audit trails track system activity so that when a security breach occurs, you can determine the mechanism and extent of the breach. Storing audit trails remotely, where they can only be appended, can keep intruders from covering their tracks.
Legality: This involves adherence to laws or other industry requirements.
Compliance: Adherence to data protection laws like GDPR, CCPA, SOC2, PIPL, or FedRamp
Privacy: Ability to hide transactions from internal company employees, such as encrypting transactions so that even database administrators and network architects cannot see them
Authentication: Security requirements ensure users are who they say they are.
Authorization: Security requirements ensure users can access only certain functions within the application (by use case, subsystem, web page, business rule, field level, and so forth).
Durability
Durability relates to software's serviceability and ability to meet users' needs for a relatively long time. Things to consider include:
Replication: Share information to ensure consistency between redundant resources to improve reliability, fault-tolerance, or accessibility.
Fault tolerance: This enables a system to continue operating correctly in the event of one or more faults within some of its components.
Archivability: This manages whether the data needs to be archived or deleted after a period of time. For example, customer accounts will be deleted after three months or marked as obsolete and archived in a secondary database for future access.
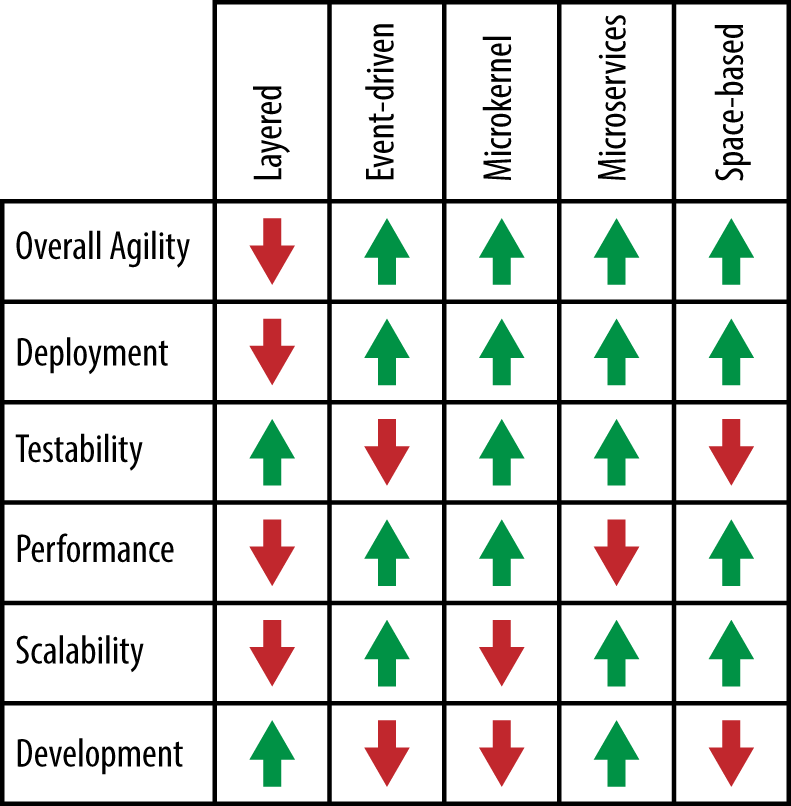
Agility
Agile is a software method that enables a team to respond to changes quickly. Software development is all about modification, so agility is a key NFR. Key factors include:
Maintainability: How easy is it to apply changes and enhance the system? Maintainability represents the degree to which developers can effectively and efficiently modify the software to improve, correct, or adapt it to changes in the environment and requirements.
Testability: How easily can developers and others test the software?
Ease of development: Can developers modify the software without introducing defects or degrading existing product quality?
Deployability: This is the time it takes to get code into production.
Installability: How easy is system installation on all necessary platforms?
Upgradeability: How quick and easy is it to upgrade from a previous version of an application or solution to a newer version on servers and clients?
Portability: Does the system need to run on more than one platform?
Configurability: How easily can end users change aspects of the software's configuration (through usable interfaces)?
Compatibility: How well can a product, system, or component exchange information with other products, designs, or members and perform its required functions while sharing the same hardware or software environment?
20190321 DEV308.Twelve-Factor (12 Factor) App Methodology and Modern Applications, EN, [video], ★★★
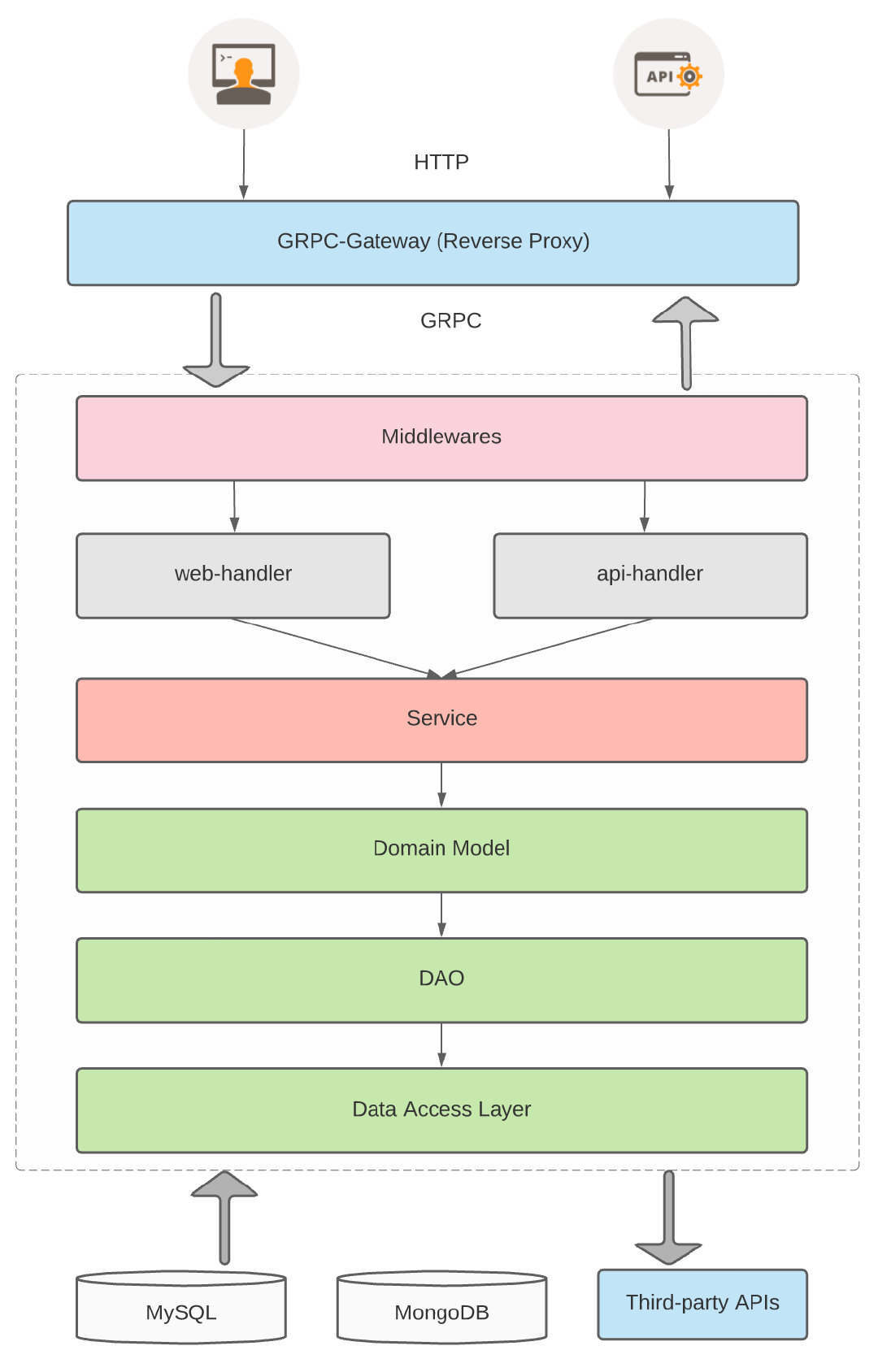
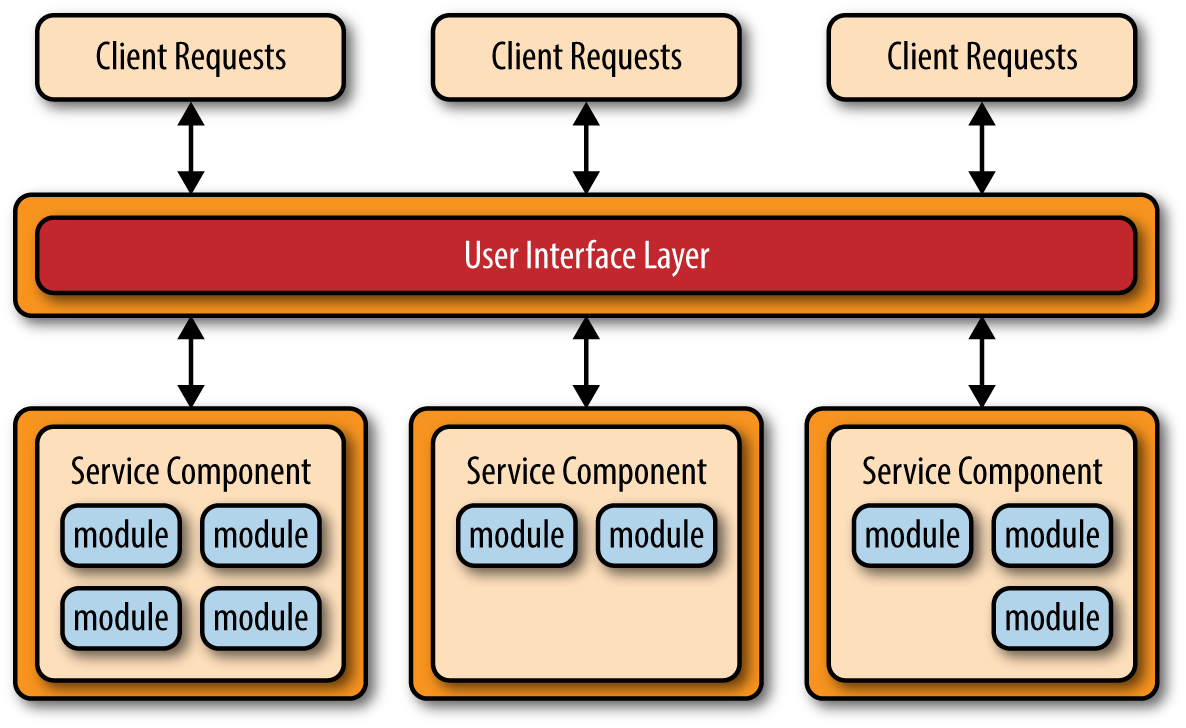
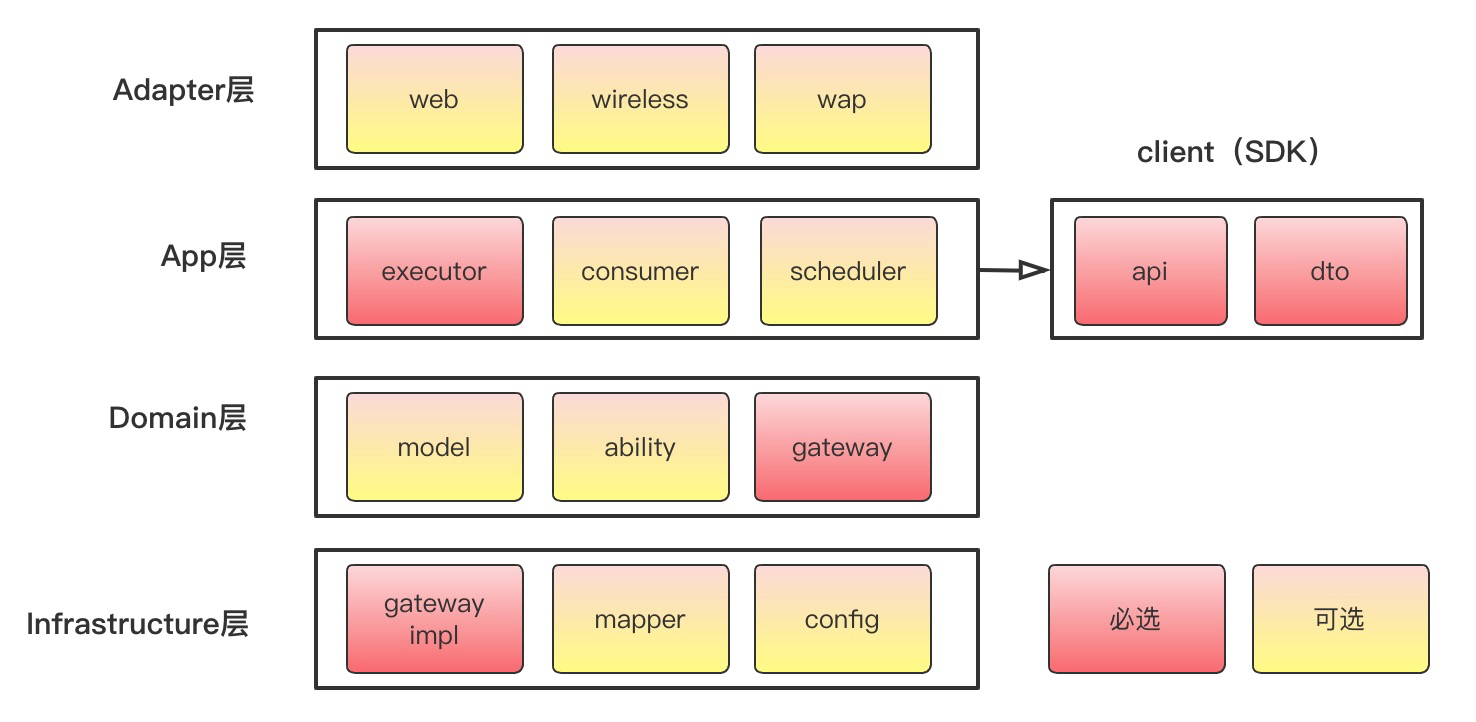
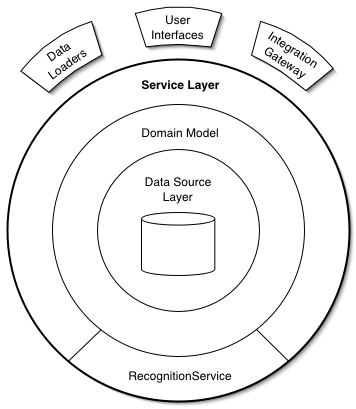
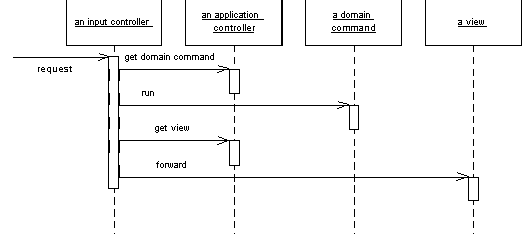
Typically, an application is composed of multiple components, with each component supporting UI, business logic, and database functions. The core principles that need to be followed when designing microservices-based codebase are single responsibility, high cohesion, and loose coupling. Each service has a single purpose and includes all the functions to carry out that single purpose.
Modern distributed applications have needs around lifecycle, networking, binding, and state management that cloud-native platforms must provide.
Kubernetes has great support around lifecycle management but relies on other platforms using the sidecar and operator concepts to satisfy the networking, binding, and state management primitives.
Future distributed systems on Kubernetes will be composed of multiple runtimes where the business logic forms the core of the application, and sidecar “mecha” components offer powerful out-of-the-box distributed primitives.
This decoupled mecha architecture offers the benefits of cohesive units of business logic and improves day-2 operations, such as patching, upgrades, and long-term maintainability.
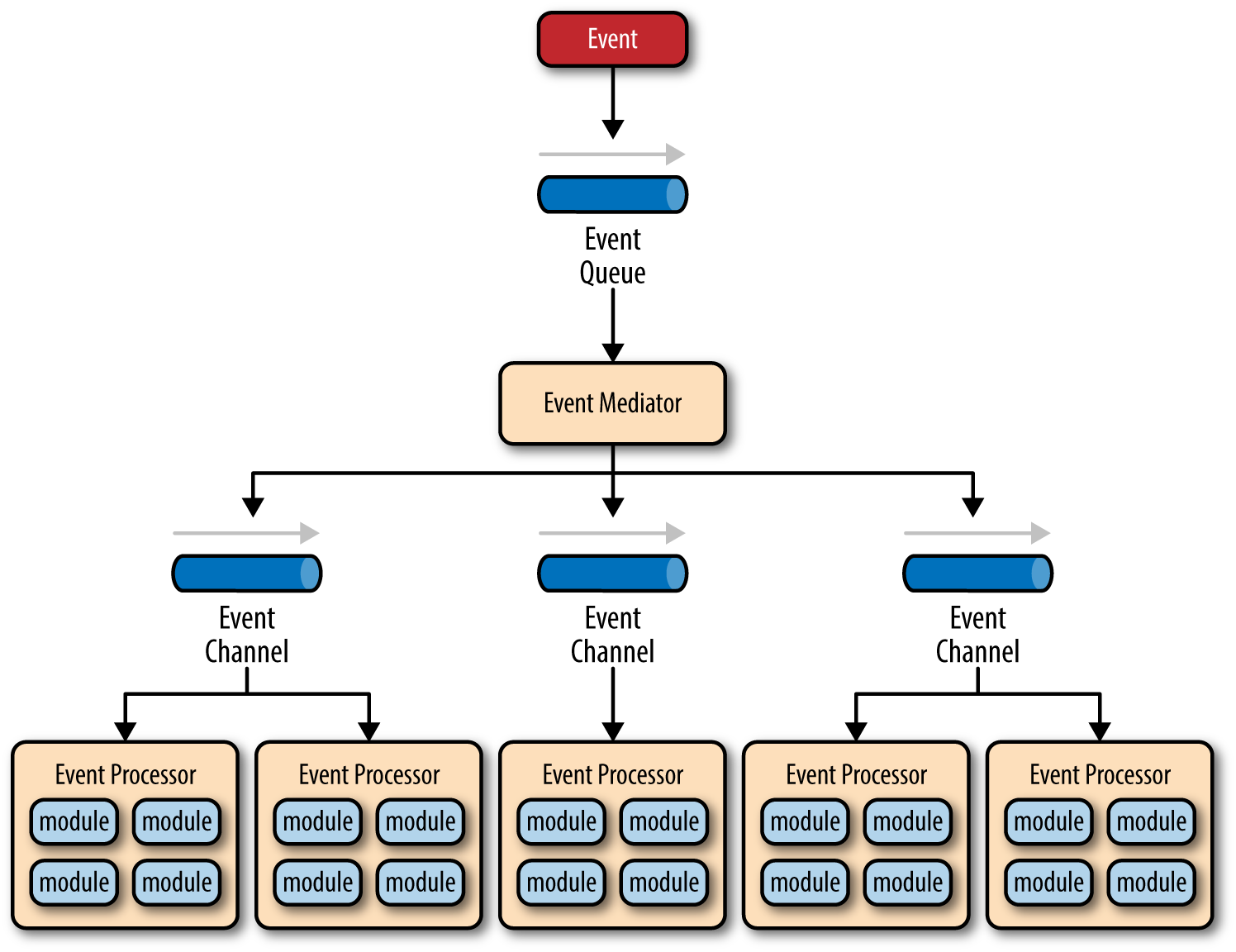
20200714 Gartner’s Advice on How to Choose an Event Broker | Solace, EN, ★★★★★
There are three basic types of event brokers:
queue-oriented (like Solace PubSub+, RabbitMQ, Azure Service Bus, etc.),
Gartner does an adequate job describing the basic principles of queue-based brokers like RabbitMQ, ActiveMQ, Solace PubSub+ and others in that the pub-sub mechanism is typically based on creating queues for each consumer (or shared consumer group) and a routing mechanism to deliver published message to the appropriate queues.
log-oriented (like Apache Kafka or Amazon Kinesis), and
Gartner describes log-oriented brokers as based on the concept of an append-only logs of messages. Neither consumers nor the broker will remove messages when processed. Instead the log is retained and messages are purged as they age or as the log reaches a pre-determined size limit. This allows for what is called “message replay”.
subscription-oriented (such as Amazon EventBridge and Azure Event Grid).
Subscription-based brokers were born out of the need to support cloud-native function platform as a service and serverless architectures.
These design patterns are all about class instantiation. This pattern can be further divided into class-creation patterns and object-creational patterns. While class-creation patterns use inheritance effectively in the instantiation process, object-creation patterns use delegation effectively to get the job done.
These design patterns are all about Class and Object composition. Structural class-creation patterns use inheritance to compose interfaces. Structural object-patterns define ways to compose objects to obtain new functionality.
These design patterns are all about Class's objects communication. Behavioral patterns are those patterns that are most specifically concerned with communication between objects.
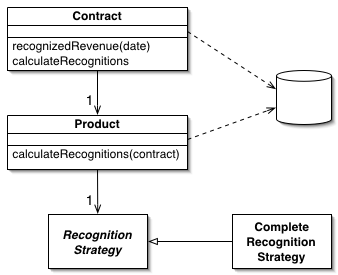
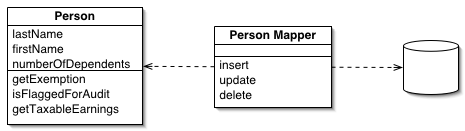
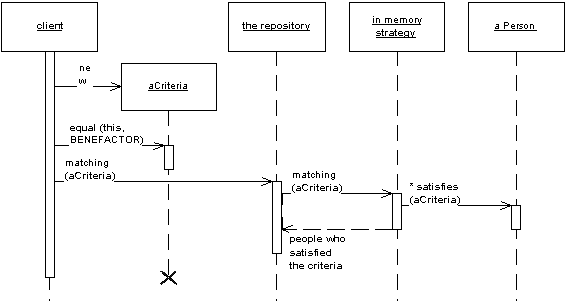
An object that acts as a Gateway (466) to a database table. One instance handles all the rows in the table.
discusses the Data Access Object pattern, which is a Table Data Gateway. They show returning a collection of Data Transfer Objects (401) on the query methods. It’s not clear whether they see this pattern as always being table based; the intent and discussion seems to imply either Table Data Gateway or Row Data Gateway (152).
I’ve used a different name, partly because I see this pattern as a particular usage of the more general Gateway (466) concept and I want the pattern name to reflect that. Also, the term Data Access Object and its abbreviation DAO has its own particular meaning within the Microsoft world.
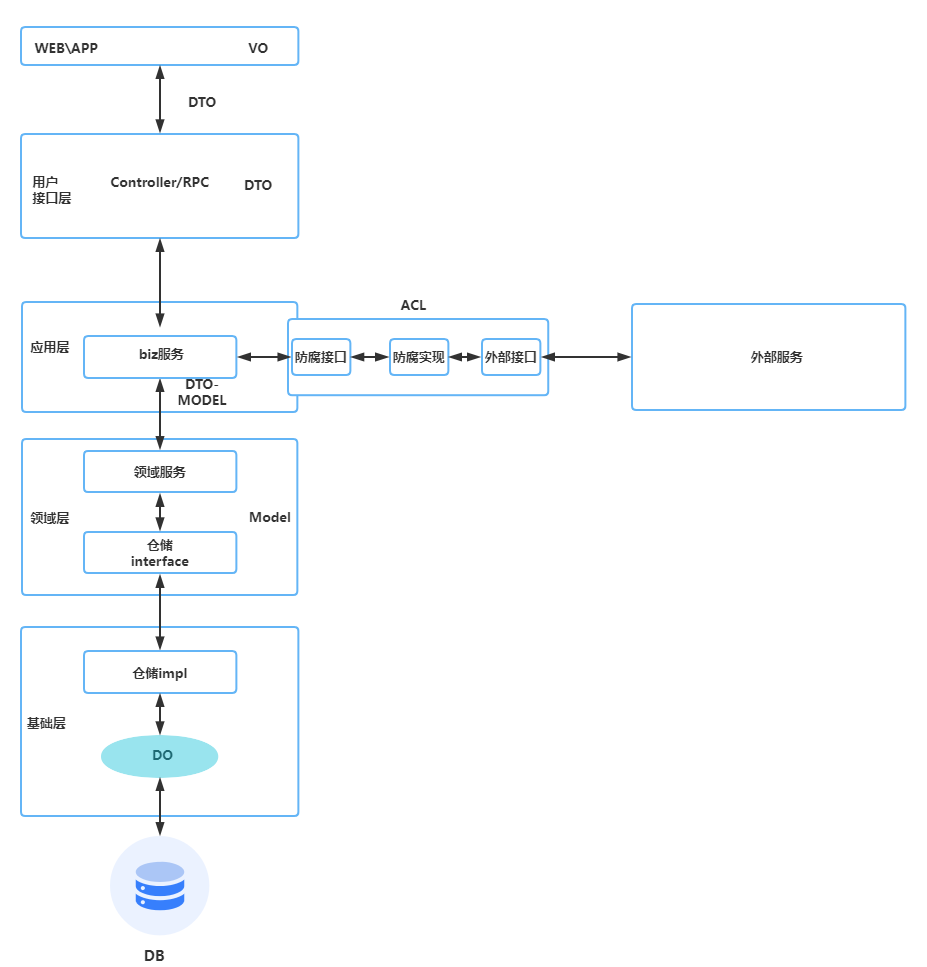
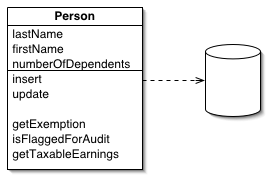
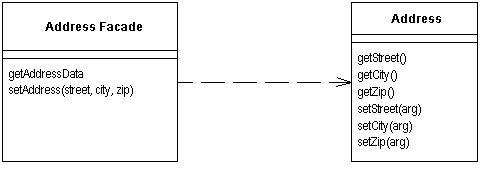
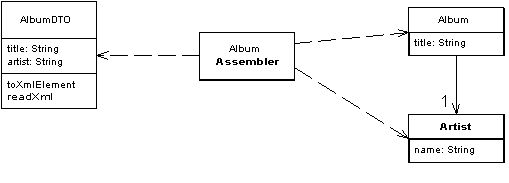
PO ((bean, entity, Persistent object, etc.): which forms a one-to-one mapping relationship with the data structure of the persistence layer (usually a relational database).
DO (Domain Object): A domain object is a tangible or intangible business entity abstracted from the real world.
DTO (Data Transfer Object): is a software application system for transferring data between design patterns.
VO (View Object): A view object used to display layers. Its purpose is to encapsulate all the data of a specified page (or component).
On the Amazon Web Services (AWS) Cloud, you can use AWS Secrets Manager to rotate, manage, and retrieve database credentials throughout their lifecycle. Users and applications retrieve secrets with a call to the Secrets Manager API, removing the need to hardcode sensitive information in plaintext.
If you’re using containers for microservice workloads, you can securely store credentials in AWS Secrets Manager. To separate out configuration from code, these credentials are commonly injected into the container. However, it's important to rotate your credentials periodically and automatically. It’s also important to support the ability to refresh credentials after revocation. At the same time, applications require the ability to rotate credentials while reducing any potential downstream availability impact.
This pattern describes how to rotate your secrets that are secured with AWS Secrets Manager within your containers without requiring your containers to restart. In addition, this pattern reduces the number of credential lookups to Secrets Manager by using the Secrets Manager client-side caching component. When you use the client-side caching component to refresh the credentials within the application, the container doesn't need to be restarted to fetch a rotated credential.
This approach works for Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Elastic Container Service (Amazon ECS).
Two scenarios are covered. In the single-user scenario, the database credential is refreshed on secret rotation by detecting the expired credential. The credential cache is instructed to refresh the secret, and then the application re-establishes the database connection. The client-side caching component caches the credential within the application and helps avoid reaching out to Secrets Manager for each credential lookup. The credential is rotated within the application without the need to force the credential refresh by restarting the container.
---
title: Order example
---
erDiagram
CUSTOMER {
int customer_id PK "IDENTITY"
string name
string sector
}
ORDER {
int order_id PK "IDENTITY"
int customer_id FK "refer to CUSTOMER.customer_id"
string deliveryAddress
}
LINE-ITEM {
int product_id PK "IDENTITY"
int order_id FK "refer to ORDER.order_id"
int quantity
float pricePerUnit
}
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ LINE-ITEM : contains
Loading
TO-BE
Add one nullable UUID (PK) column to the existing tables which will be used as the PK.
Update the values of UUID (PK) column based on the existing PK column.
(Optional) Add one or more nullable UUID (FK) columns to the existing tables which will be used to refer to the PK in other tables.
(Optional) Update the values of UUID (FK) columns based on the existing FK columns.
---
title: Order example
---
erDiagram
CUSTOMER {
int customer_id PK "IDENTITY"
string customer_uuid UK "# based on customer_id"
string name
string sector
}
ORDER {
int order_id PK "IDENTITY"
string order_uuid UK "# based on order_id"
int customer_id FK "refer to CUSTOMER.customer_id"
string customer_uuid "# based on customer_id"
string deliveryAddress
}
LINE-ITEM {
int product_id PK "IDENTITY"
string product_uuid UK "# based on product_id"
int order_id FK "refer to ORDER.order_id"
string order_uuid "# based on order_id"
int quantity
float pricePerUnit
}
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ LINE-ITEM : contains
Delete the existing PRIMARY KEY constraint and then re-create it with the new definition. See Modify Primary Keys for more details.
Recreate the FK constrains on the UUID (FK) columns which refre to the new UUID (PK) in other tab les.
---
title: Order example
---
erDiagram
CUSTOMER {
int customer_id UK "IDENTITY"
string customer_uuid PK "# based on customer_id"
string name
string sector
}
ORDER {
int order_id UK "IDENTITY"
string order_uuid PK "# based on order_id"
int customer_id "refer to CUSTOMER.customer_id"
string customer_uuid FK "# refer to CUSTOMER.customer_uuid"
string deliveryAddress
}
LINE-ITEM {
int product_id UK "IDENTITY"
string product_uuid PK "# based on product_id"
int order_id "refer to ORDER.order_id"
string order_uuid FK "# refer to ORDER.customer_uuid"
int quantity
float pricePerUnit
}
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ LINE-ITEM : contains
Describing Software Architecture Using C4 Model & Structurizr
Presentation Takeaways and Transcripts
Presenter: Leorick Lin Duration: 40 minutes Date: November 10, 2025
3 Key Takeaways
Number 1. C4 Model Provides Clarity and Structure Through Hierarchical Abstraction
The C4 model introduces a simple, hierarchical approach to visualizing software architecture using four levels: System Context, Container, Component, and Code.
Number 2. Evolution from "Diagrams as Code" to "Models as Code" Ensures Single Source of Truth
Structurizr shifts the process from manually drawing diagrams to defining architecture as code, which enhances consistency, enables version control, and supports automation.
Number 3. Shared Vocabulary Bridges Technical and Non-Technical Stakeholders
The C4 model creates a common language that both technical and non-technical stakeholders can understand, ensuring better communication and alignment across teams.
Presentation Transcripts
Slide 4: Construction Blueprints (2 minutes)
"Let's start with an analogy from the building industry. When architects design buildings, they don't create just one drawing. They create a comprehensive set of blueprints and construction documents. Each document serves a specific purpose and targets a specific audience.
Why do they do this? Because contractors, electricians, plumbers, and other specialists need different views of the same building to do their work effectively.
Slide 5:
A site plan shows how the building fits into its environment.
Slide 6:
A foundation plan details the substructure.
Slide 7:
An electrical plan shows wiring and outlets.
Slide 8: Architecture and Architectural Artifacts (2 minutes)
This same principle applies to software architecture. We need different views of our systems for different audiences and purposes. Here, I would to share some definitions. The TOGAF framework defines architecture as 'the structure of components, their inter-relationships, and the principles and guidelines governing their design and evolution over time.'
Notice the key elements here: structure, relationships, and evolution. Architecture isn't static—it evolves.
TOGAF also defines an architectural artifact as 'an architectural work product that describes an aspect of the architecture.' This is important because it acknowledges that we need multiple artifacts—multiple views—to fully describe a system.
The question is: how do we create these artifacts in a way that's consistent, maintainable, and useful to all stakeholders?"
Slide 9: The "Boxes and Lines" Dilemma (3 minutes)
But unfortunately, in software, we often fall into the trap of creating ad-hoc diagrams without this kind of structure."
"This brings us to a common problem in software architecture documentation. Many teams rely on simple 'boxes and lines' diagrams. You've probably seen these before. A few rectangles, some arrows, maybe some labels.
These diagrams create several issues:
First, inconsistent visuals. Different people draw boxes differently. Is a rounded rectangle different from a square? Does color mean something? Without standards, every diagram becomes a puzzle to decode.
Second, lack of clarity. What does each box represent? Is it a server? A process? A class? A team? Without clear definitions, viewers make assumptions—often wrong ones.
Third, mismatched detail. One diagram might show high-level systems while another shows individual classes. Mixing abstraction levels creates confusion about what's important.
Fourth, undefined purpose. Who is this diagram for? What question does it answer? Without a clear purpose, diagrams end up being just for show rather than actually useful.
The result is a loss of visual communication effectiveness. We create diagrams that confuse rather than clarify. We need a better approach."
Slide 10: A Clear, Simple, and Organized Group of Maps (1 minute)
"What we need is something like this—a clear, simple, and organized group of maps. Just as a road atlas provides different zoom levels and different types of maps for different purposes, we need a structured approach to software architecture diagrams.
This is exactly what the C4 model provides. Let's explore how."
Slide 11: The C4 Model: A Shared Vocabulary (3 minutes)
"The C4 model is an 'abstraction-first' approach to visualizing software architecture. Created by Simon Brown, it provides a simple, hierarchical way to map software architecture different levels of detail.
Let me be clear about what C4 is and isn't. It's not a replacement for UML or ArchiMate. Those are comprehensive modeling languages with specific use cases. Instead, C4 is a simpler, more intuitive starting point that most teams can adopt immediately.
The core idea is elegant: create a small, common set of abstractions and diagram types that are easy for everyone—developers and non-developers—to learn and use.
Think of it as a shared vocabulary. When everyone on your team—from product managers to developers to operations—uses the same terms and understands the same diagram types, communication becomes dramatically more effective.
The model uses just four levels of abstraction, which we'll explore in detail. But first, let's understand the core abstractions themselves."
Slide 12: The C4 Core Abstractions (Visual) (1 minute)
"Here's a visual representation of the C4 core abstractions. Notice the hierarchical structure—each level zooms into the previous one. This is the foundation of the entire model.
Let's break down what each of these abstractions means."
Slide 13: The C4 Core Abstractions (Definitions) (3 minutes)
"The C4 model uses four core abstractions:
First, Software System—the highest level of abstraction. A software system is something that delivers value to users. This could be your system—the one you're building—or an external dependency like a payment gateway or authentication service.
Second, Container—and this is not a Docker container. In C4, a container is a deployable or runnable unit within a software system. Think of it as something that needs to be running for your system to work. Examples include a web application, an API service, a mobile app, or a database. Each container typically represents a separate process or deployment unit.
Third, Component—a grouping of related functionality within a container. If a container is a web application, components might include the authentication controller, the user service, or the data repository. Components represent the major structural building blocks inside a container.
Fourth, Code—the implementation details. This is the actual classes, interfaces, and functions that make up your components. This is the most detailed level, and as we'll see, it's often better to use automated tools to visualize this level rather than maintaining manual diagrams.
These four abstractions give us a consistent vocabulary for discussing architecture at different levels of detail."
Slide 14: C4 System Context Diagram (2 minutes)
"Now let's look at the first diagram type: the System Context diagram.
Purpose: This shows the big picture. It answers the question: 'What does our system do, and how does it fit into the world?'
Scope: Your software system sits in the center, surrounded by the people who use it and the external systems it interacts with. You're showing the forest, not the trees.
Audience: Everyone. This diagram should be understandable by technical and non-technical stakeholders. Your project lead or I4 should be able to look at this and understand what the system does and who uses it.
This is typically the first diagram you create when documenting a system, and it's often the most important for communication with business stakeholders."
Slide 15: C4 Container Diagram (2 minutes)
"The Container diagram zooms into the System Context. Now we're looking inside our software system.
Purpose: This shows the high-level technical architecture. It answers: 'What are the major technical building blocks, and how do they communicate?'
Scope: The containers—the deployable units—inside your software system. You're showing high-level technology choices and inter-container communication. For example, you might show a React web application talking to a Node.js API, which connects to a PostgreSQL database.
Audience: Architects, developers, and operations teams. This diagram helps technical teams understand the deployment architecture and technology stack.
This is often the most useful diagram for development teams because it shows the major technical decisions without getting lost in implementation details."
Slide 16: C4 Component Diagram (2 minutes)
"The Component diagram zooms into a single container. Now we're looking at the internal structure of one deployable unit.
Purpose: This shows the internal components and their interactions. It answers: 'How is this container organized internally?'
Scope: The major components inside one container. If you're looking at an API container, you might show controllers, services, repositories, and how they interact.
Audience: Architects and developers working on that specific container. This level of detail is usually too much for business stakeholders but essential for developers.
You typically create one Component diagram for each significant container in your system. Not every container needs one—only those with sufficient complexity to warrant the documentation."
Slide 17: C4 Code Diagram (2 minutes)
"The Code diagram zooms into a single component, showing the implementation details.
Purpose: This shows the actual implementation—the classes, interfaces, or functions that make up a component.
Scope: The code-level details of a specific component.
Audience: Developers working on that specific component.
However, here's an important note: It's often better to use automated tools like IDEs or to generate UML class diagrams directly from the code itself. Why? Because code changes frequently, and manually maintaining these diagrams becomes a burden.
The real value of C4 is in the higher-level abstractions—System Context, Container, and Component diagrams. These change less frequently and provide more strategic value. Code-level diagrams are best generated on-demand when needed."
Slide 18: C4 Dynamic Diagram (2 minutes)
"Beyond the four core levels, C4 includes supplementary diagram types. The Dynamic diagram is one of the most useful.
Dynamic diagrams show how elements from the static model collaborate at runtime to fulfill a specific use case. For example, you might create a Dynamic diagram showing the sequence of interactions when a user signs in.
This is similar to a UML sequence diagram but uses C4 elements. It helps teams understand runtime behavior and can be invaluable for debugging complex interactions or onboarding new team members.
You create Dynamic diagrams for critical use cases or complex workflows that need explanation."
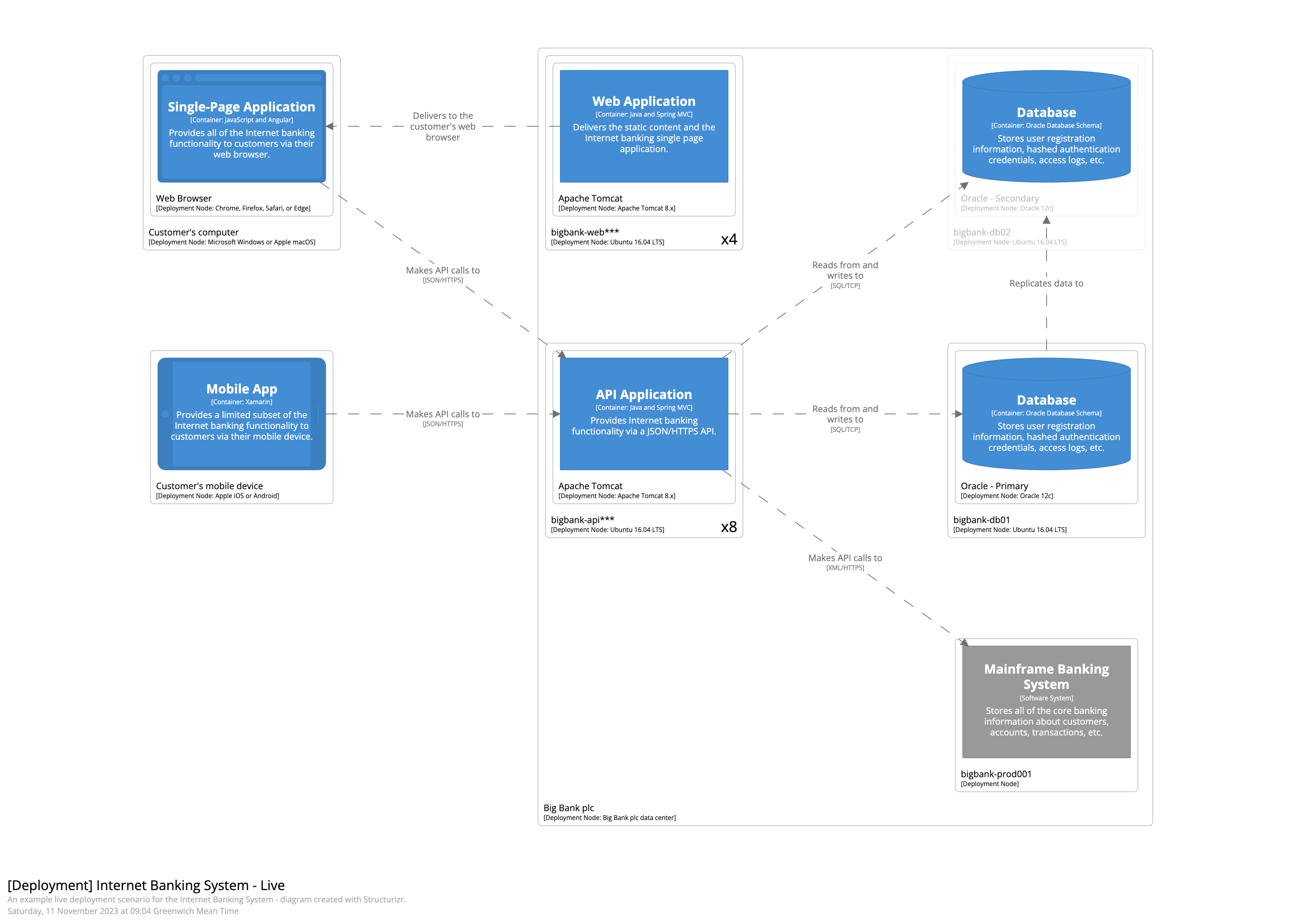
Slide 19: C4 Deployment Diagram (2 minutes)
"The Deployment diagram maps container instances to infrastructure.
This shows where your containers actually run. Are they on physical servers? In the cloud? In Docker containers on Kubernetes? How many instances of each container are running?
For example, you might show that your web application runs in an Azure App Service, your API runs in a Kubernetes cluster with three replicas, and your database runs in Azure SQL Database.
This diagram is essential for operations teams and helps everyone understand the deployment architecture and infrastructure dependencies."
Slide 20: Diagrams as Code (3 minutes)
"Now we've seen what diagrams we need. The question is: how do we create and maintain them?
Manually drawing these in tools like Visio or Lucidchart creates a significant problem. These diagrams become outdated almost immediately. Someone makes a code change, but the diagram doesn't get updated. Soon, your documentation is worse than useless—it's misleading.
The 'Diagrams as Code' movement solves this by letting us define diagrams in text format. This enables several critical capabilities:
Version control: Your diagrams live in Git alongside your code. You can see when they changed and why.
Easy diffing in pull requests: Reviewers can see exactly what changed in the architecture, just like they review code changes.
Integration into CI/CD pipelines: You can automatically generate and publish diagrams as part of your build process.
Common tools in this space include PlantUML, Mermaid, and Graphviz. These are all excellent tools, and many teams use them successfully.
However, they have a limitation that we need to address."
Slide 22: The Problem with "Diagrams as Code 1.0" (3 minutes)
"Most 'Diagrams as Code' tools follow what we might call a '1.0' model. The pattern is simple: 1 Diagram = 1 Source File.
If you need five diagrams, you create five separate files. Each file defines its own elements.
Let's think about what this means in practice. Suppose you have an 'API' component that appears in your System Context diagram, your Container diagram, and your Component diagram. With the 1.0 approach, you define the 'API' box three times—once in each file.
This leads to several problems:
Duplication: Elements are defined repeatedly across multiple files. This is tedious and error-prone.
Inconsistency: How do you ensure the 'API' box in the Context diagram matches the one in the Container diagram? What if someone updates one but not the other? What if they use slightly different names or descriptions?
Manual syncing: You have to manually keep all N files in sync. Change the name of a system? Update it in five places. Add a new relationship? Make sure it's reflected everywhere it should be.
This approach is better than manual diagrams, but it still creates a maintenance burden. We need something better."
Slide 24: Diagrams as Code 2.0 (aka: Models as Code) (3 minutes)
"The solution is to shift our thinking away from 'diagrams' and towards 'views of a model.'
Instead of 1 Diagram = 1 Source File, we use 1 Model = 1 Source File.
Here's how it works: You define your model—all your Persons, Systems, Containers, Components, and their relationships—in a single place. This is your single source of truth.
Then, you simply ask the tool to render different views of that model. Want a System Context diagram? It's a view of the model. Want a Container diagram? Another view of the same model. Want to show just the authentication flow? Another view.
The key insight is that the model is separate from the views. You define each element once, and it can appear in multiple views automatically.
This eliminates duplication, ensures consistency, and makes maintenance dramatically easier. Change the name of a system in the model, and it updates in all views automatically.
This is the 'Diagrams as Code 2.0' approach, and it's what Structurizr implements."
Slide 25: Models as Code: Structurizr (3 minutes)
"Structurizr is a suite of tools built by Simon Brown, the creator of the C4 model, specifically to solve this problem.
It's a C4 modeling tool that implements the 'Diagrams as Code 2.0' approach we just discussed.
The tooling suite includes:
DSL: A simple, text-based Domain Specific Language to define your model. The syntax is intuitive and readable. You define your systems, containers, components, and relationships in plain text.
CLI: A command-line tool to upload your model to a Structurizr workspace. This integrates easily into your build pipeline.
Lite / On-Premises / Cloud: Various options for rendering and exploring your diagrams. Structurizr Lite is a free, Docker-based option perfect for local development. On-premises and cloud options provide additional features for teams.
The beauty of Structurizr is that it's designed specifically for C4. It understands the abstractions natively, enforces consistency, and makes it easy to create professional-looking diagrams."
Slide 26: How Structurizr Works: The "Workspace" (3 minutes)
"In Structurizr, you define a Workspace. This is the single source of truth that contains everything about your architecture.
A workspace has four main sections:
The Model: This is where you define your Persons, Software Systems, Containers, and Components, along with the relationships between them. This is your architectural model—the single source of truth.
The Views: Definitions of which diagrams to render. For example, 'Create a System Context diagram' or 'Create a Container diagram for my E-commerce System.' Each view is a window into the model, showing specific elements and relationships.
Documentation: Built-in support for embedding Markdown or AsciiDoc documentation alongside your diagrams. You can write architectural documentation that lives right next to the visual models, ensuring they stay in sync.
Decisions: A log for Architecture Decision Records, or ADRs. This lets you document why you made specific architectural choices, providing crucial context for future team members.
You define this once, check it into Git, and Structurizr generates all views, ensures consistency, and attaches your documentation. Everything is version-controlled, everything is in sync, and everything is maintainable.
This is the power of the 'Models as Code' approach—a single source of truth that generates multiple consistent views."
Timing Breakdown for 40-Minute Presentation
Slide(s)
Topic
Duration
Cumulative
1-3
Title, Agenda, Key Takeaways
3 min
3 min
4
Construction Blueprints
2 min
5 min
5-7
Blueprint Examples (Site, Foundation, Electrical)
2 min
7 min
8
Architecture and Artifacts
2 min
9 min
9
"Boxes and Lines" Dilemma
3 min
12 min
10
Clear Maps Analogy
1 min
13 min
11
C4 Model Introduction
3 min
16 min
12
C4 Core Abstractions (Visual)
1 min
17 min
13
C4 Core Abstractions (Definitions)
3 min
20 min
14
System Context Diagram
2 min
22 min
15
Container Diagram
2 min
24 min
16
Component Diagram
2 min
26 min
17
Code Diagram
2 min
28 min
18
Dynamic Diagram
2 min
30 min
19
Deployment Diagram
2 min
32 min
20
Diagrams as Code
3 min
35 min
22
Diagrams as Code 1.0 Problem
3 min
38 min
24
Diagrams as Code 2.0
3 min
41 min
25
Structurizr Introduction
3 min
44 min
26
Structurizr Workspace
3 min
47 min
27-29
Demos
10 min
57 min
30
Thank You / Questions
3 min
60 min
Note: The presentation is designed for 40 minutes of core content (slides 1-26), with 10 minutes allocated for demos and 10 minutes for questions and discussion. If time is limited, demos can be shortened or moved to a follow-up session.
Presentation Flow Summary
Introduction (7 minutes)
Set context with construction blueprint analogy
Establish the problem: inconsistent architecture documentation
Problem Definition (5 minutes)
Define architecture and artifacts
Explain the "boxes and lines" dilemma
Solution: C4 Model (14 minutes)
Introduce C4 as a shared vocabulary
Explain the four core abstractions
Walk through each diagram type with purpose, scope, and audience
Implementation: Structurizr (12 minutes)
Introduce "Diagrams as Code" concept
Explain the evolution to "Models as Code"
Demonstrate how Structurizr implements this approach
Demonstrations (10 minutes)
Live examples showing the concepts in practice
Wrap-up (2 minutes)
Reinforce key takeaways
Open for questions
Recommended Delivery Tips
Use the construction analogy throughout: Reference back to building blueprints when explaining different C4 diagram types to reinforce the concept.
Emphasize the pain points: Make sure the audience feels the problems with current approaches before presenting solutions.
Show, don't just tell: Use the demos to make abstract concepts concrete. Live demonstrations are more memorable than slides.
Pause for questions: After explaining the C4 core abstractions (slide 13) and after introducing Structurizr (slide 25), pause briefly to check for understanding.
Connect to audience experience: Ask if anyone has experienced the "boxes and lines" problem or struggled with outdated architecture diagrams.
End with action items: Encourage the audience to try Structurizr Lite with a small project or to review their current architecture documentation using C4 principles.
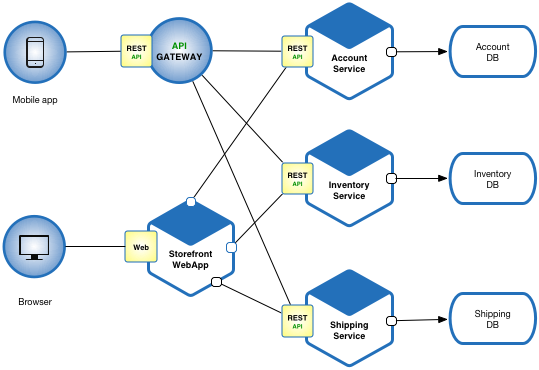
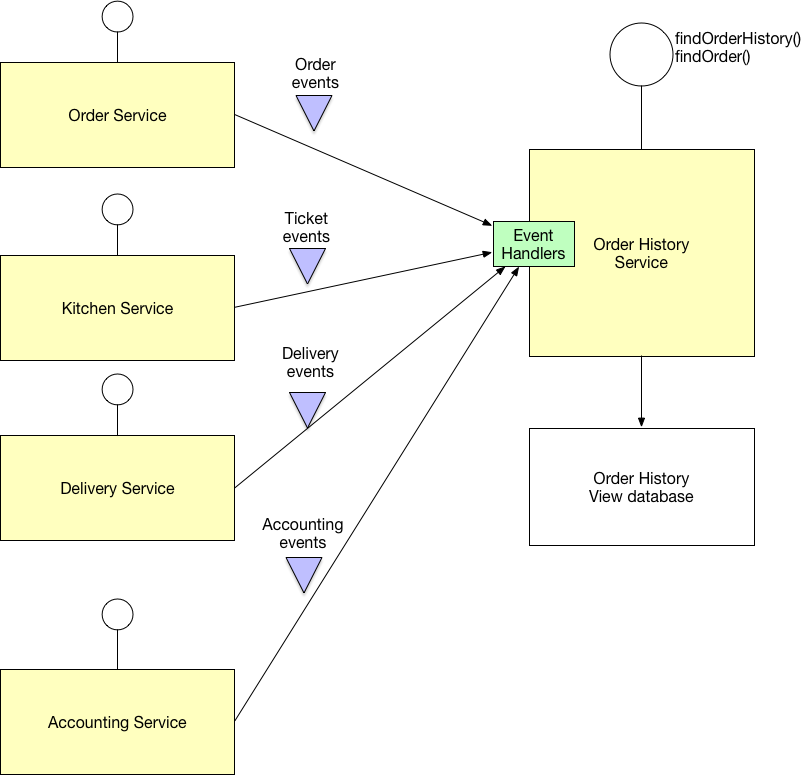
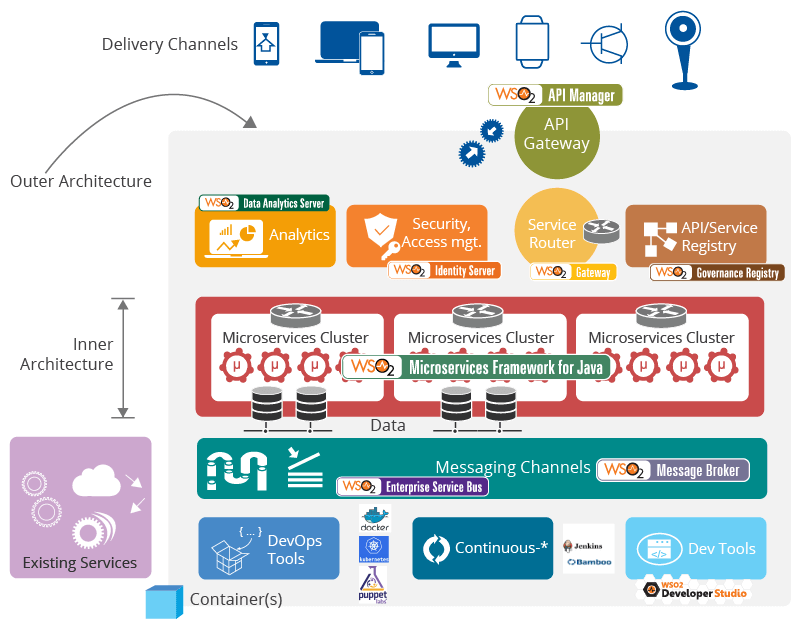
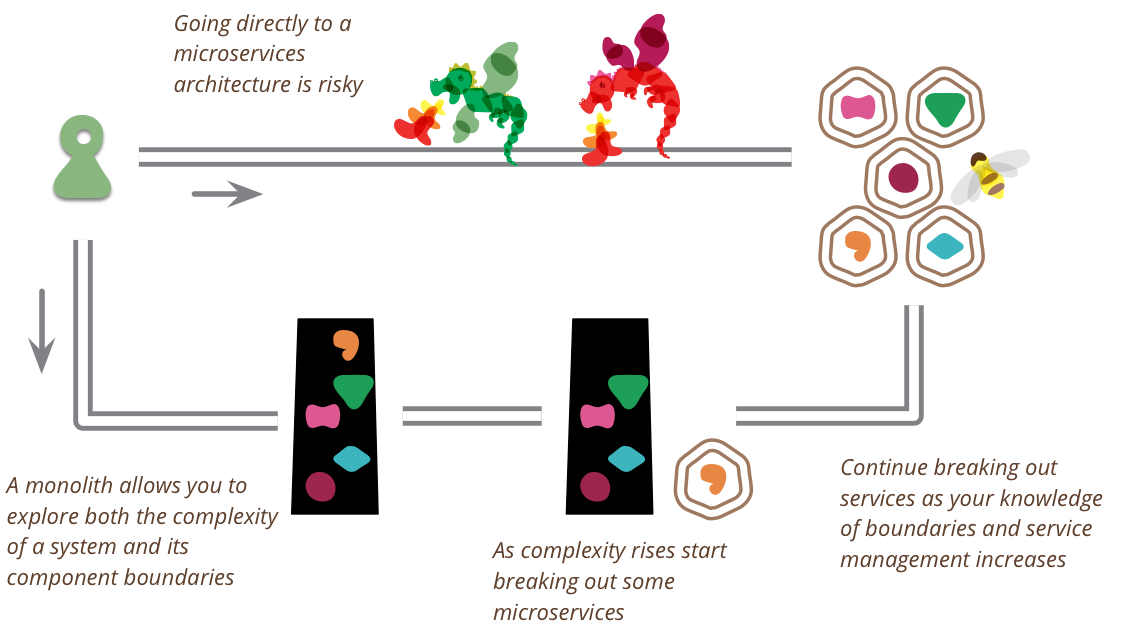

/filters:no_upscale()/articles/C4-architecture-model/en/resources/1c4-4-copy-1529935843163.jpeg)
/filters:no_upscale()/articles/C4-architecture-model/en/resources/1c4-5-1529934730472.jpg)
/filters:no_upscale()/articles/C4-architecture-model/en/resources/2c4-6-1529935332322.jpg)
/filters:no_upscale()/articles/C4-architecture-model/en/resources/1c4-7-1529935328091.jpg)


















AS-IS
--- title: Order example --- erDiagram CUSTOMER { int customer_id PK "IDENTITY" string name string sector } ORDER { int order_id PK "IDENTITY" int customer_id FK "refer to CUSTOMER.customer_id" string deliveryAddress } LINE-ITEM { int product_id PK "IDENTITY" int order_id FK "refer to ORDER.order_id" int quantity float pricePerUnit } CUSTOMER ||--o{ ORDER : places ORDER ||--|{ LINE-ITEM : containsTO-BE
Add one nullable UUID (PK) column to the existing tables which will be used as the PK.
Update the values of UUID (PK) column based on the existing PK column.
(Optional) Add one or more nullable UUID (FK) columns to the existing tables which will be used to refer to the PK in other tables.
(Optional) Update the values of UUID (FK) columns based on the existing FK columns.
--- title: Order example --- erDiagram CUSTOMER { int customer_id PK "IDENTITY" string customer_uuid UK "# based on customer_id" string name string sector } ORDER { int order_id PK "IDENTITY" string order_uuid UK "# based on order_id" int customer_id FK "refer to CUSTOMER.customer_id" string customer_uuid "# based on customer_id" string deliveryAddress } LINE-ITEM { int product_id PK "IDENTITY" string product_uuid UK "# based on product_id" int order_id FK "refer to ORDER.order_id" string order_uuid "# based on order_id" int quantity float pricePerUnit } CUSTOMER ||--o{ ORDER : places ORDER ||--|{ LINE-ITEM : containsDrop the FK constraints of the existing tables. See Delete foreign key relationships for more details.
Delete the existing PRIMARY KEY constraint and then re-create it with the new definition. See Modify Primary Keys for more details.
Recreate the FK constrains on the UUID (FK) columns which refre to the new UUID (PK) in other tab les.
--- title: Order example --- erDiagram CUSTOMER { int customer_id UK "IDENTITY" string customer_uuid PK "# based on customer_id" string name string sector } ORDER { int order_id UK "IDENTITY" string order_uuid PK "# based on order_id" int customer_id "refer to CUSTOMER.customer_id" string customer_uuid FK "# refer to CUSTOMER.customer_uuid" string deliveryAddress } LINE-ITEM { int product_id UK "IDENTITY" string product_uuid PK "# based on product_id" int order_id "refer to ORDER.order_id" string order_uuid FK "# refer to ORDER.customer_uuid" int quantity float pricePerUnit } CUSTOMER ||--o{ ORDER : places ORDER ||--|{ LINE-ITEM : contains