-
-
Save linwoodc3/0306734dfe17076dfd34e09660c198c0 to your computer and use it in GitHub Desktop.
| # Author: | |
| # Linwood Creekmore III | |
| # email: valinvescap@gmail.com | |
| # Acknowledgements: | |
| # http://programmingadvent.blogspot.com/2013/06/kmzkml-file-parsing-with-python.html | |
| # http://gis.stackexchange.com/questions/159681/geopandas-cant-save-geojson | |
| # https://gist.github.com/mciantyre/32ff2c2d5cd9515c1ee7 | |
| ''' | |
| Sample files to test (everything doesn't work, but most do) | |
| -------------------- | |
| Google List of KMZs: https://sites.google.com/a/mcpsweb.org/google-earth-kmz/kmz-files | |
| NOAA KMZ: https://data.noaa.gov/dataset/climate-reconstructions/resource/13f35d9b-a738-4c3b-8ba3-a22e3192e7b6 | |
| Washington DC GIS Data/Quadrants: http://opendata.dc.gov/datasets/02923e4697804406b9ee3268a160db99_11.kml | |
| Examples | |
| ---------- | |
| # output to geopandas | |
| a = keyholemarkup2x('LGGWorldCapitals.kmz',output='gpd') | |
| # plot this new file, use %matplotlib inline if you are in a notebook | |
| #%matplotlib inline | |
| a.plot() | |
| # convert to shapefile | |
| a = keyholemarkup2x('DC_Quadrants.kml',output='shp') | |
| ''' | |
| import pandas as pd | |
| from io import BytesIO,StringIO | |
| from zipfile import ZipFile | |
| import re,os | |
| import numpy as np | |
| import xml.sax, xml.sax.handler | |
| from html.parser import HTMLParser | |
| import pandas as pd | |
| from html.parser import HTMLParser | |
| class MyHTMLParser(HTMLParser): | |
| def __init__(self): | |
| # initialize the base class | |
| HTMLParser.__init__(self) | |
| self.inTable=False | |
| self.mapping = {} | |
| self.buffer = "" | |
| self.name_tag = "" | |
| self.series = pd.Series() | |
| def handle_starttag(self, tag, attrs): | |
| if tag == 'table': | |
| self.inTable = True | |
| def handle_data(self, data): | |
| if self.inTable: | |
| self.buffer = data.strip(' \n\t').split(':') | |
| if len(self.buffer)==2: | |
| self.mapping[self.buffer[0]]=self.buffer[1] | |
| self.series = pd.Series(self.mapping) | |
| class PlacemarkHandler(xml.sax.handler.ContentHandler): | |
| def __init__(self): | |
| self.inName = False # handle XML parser events | |
| self.inPlacemark = False | |
| self.mapping = {} | |
| self.buffer = "" | |
| self.name_tag = "" | |
| def startElement(self, name, attributes): | |
| if name == "Placemark": # on start Placemark tag | |
| self.inPlacemark = True | |
| self.buffer = "" | |
| if self.inPlacemark: | |
| if name == "name": # on start title tag | |
| self.inName = True # save name text to follow | |
| def characters(self, data): | |
| if self.inPlacemark: # on text within tag | |
| self.buffer += data # save text if in title | |
| def endElement(self, name): | |
| self.buffer = self.buffer.strip('\n\t') | |
| if name == "Placemark": | |
| self.inPlacemark = False | |
| self.name_tag = "" #clear current name | |
| elif name == "name" and self.inPlacemark: | |
| self.inName = False # on end title tag | |
| self.name_tag = self.buffer.strip() | |
| self.mapping[self.name_tag] = {} | |
| elif self.inPlacemark: | |
| if name in self.mapping[self.name_tag]: | |
| self.mapping[self.name_tag][name] += self.buffer | |
| else: | |
| self.mapping[self.name_tag][name] = self.buffer | |
| self.buffer = "" | |
| def spatializer(row): | |
| """ | |
| Function to convert string objects to Python spatial objects | |
| """ | |
| ############################# | |
| # coordinates field | |
| ############################# | |
| try: | |
| # look for the coordinates column | |
| data = row['coordinates'].strip(' \t\n\r') | |
| except: | |
| pass | |
| try: | |
| import shapely | |
| from shapely.geometry import Polygon,LineString,Point | |
| except ImportError as e: | |
| raise ImportError('This operation requires shapely. {0}'.format(e)) | |
| import ast | |
| lsp = data.strip().split(' ') | |
| linestring = map(lambda x: ast.literal_eval(x),lsp) | |
| try: | |
| spatial = Polygon(LineString(linestring)) | |
| convertedpoly = pd.Series({'geometry':spatial}) | |
| return convertedpoly | |
| except: | |
| try: | |
| g = ast.literal_eval(data) | |
| points = pd.Series({'geometry':Point(g[:2]), | |
| 'altitude':g[-1]}) | |
| return points | |
| except: | |
| pass | |
| try: | |
| # Test for latitude and longitude columns | |
| lat=float(row['latitude']) | |
| lon=float(row['longitude']) | |
| point = Point(lon,lat) | |
| convertedpoly = pd.Series({'geometry':point}) | |
| return convertedpoly | |
| except: | |
| pass | |
| def htmlizer(row): | |
| htmlparser = MyHTMLParser() | |
| htmlparser.feed(row['description']) | |
| return htmlparser.series | |
| def keyholemarkup2x(file,output='df'): | |
| """ | |
| Takes Keyhole Markup Language Zipped (KMZ) or KML file as input. The | |
| output is a pandas dataframe, geopandas geodataframe, csv, geojson, or | |
| shapefile. | |
| All core functionality from: | |
| http://programmingadvent.blogspot.com/2013/06/kmzkml-file-parsing-with-python.html | |
| Parameters | |
| ---------- | |
| file : {string} | |
| The string path to your KMZ or . | |
| output : {string} | |
| Defines the type of output. Valid selections include: | |
| - shapefile - 'shp', 'shapefile', or 'ESRI Shapefile' | |
| Returns | |
| ------- | |
| self : object | |
| """ | |
| r = re.compile(r'(?<=\.)km+[lz]?',re.I) | |
| try: | |
| extension = r.search(file).group(0) #(re.findall(r'(?<=\.)[\w]+',file))[-1] | |
| except IOError as e: | |
| logging.error("I/O error {0}".format(e)) | |
| if (extension.lower()=='kml') is True: | |
| buffer = file | |
| elif (extension.lower()=='kmz') is True: | |
| kmz = ZipFile(file, 'r') | |
| vmatch = np.vectorize(lambda x:bool(r.search(x))) | |
| A = np.array(kmz.namelist()) | |
| sel = vmatch(A) | |
| buffer = kmz.open(A[sel][0],'r') | |
| else: | |
| raise ValueError('Incorrect file format entered. Please provide the ' | |
| 'path to a valid KML or KMZ file.') | |
| parser = xml.sax.make_parser() | |
| handler = PlacemarkHandler() | |
| parser.setContentHandler(handler) | |
| parser.parse(buffer) | |
| try: | |
| kmz.close() | |
| except: | |
| pass | |
| df = pd.DataFrame(handler.mapping).T | |
| names = list(map(lambda x: x.lower(),df.columns)) | |
| if 'description' in names: | |
| extradata = df.apply(PlacemarkHandler.htmlizer,axis=1) | |
| df = df.join(extradata) | |
| output = output.lower() | |
| if output=='df' or output=='dataframe' or output == None: | |
| result = df | |
| elif output=='csv': | |
| out_filename = file[:-3] + "csv" | |
| df.to_csv(out_filename,encoding='utf-8',sep="\t") | |
| result = ("Successfully converted {0} to CSV and output to" | |
| " disk at {1}".format(file,out_filename)) | |
| elif output=='gpd' or output == 'gdf' or output=='geoframe' or output == 'geodataframe': | |
| try: | |
| import shapely | |
| from shapely.geometry import Polygon,LineString,Point | |
| except ImportError as e: | |
| raise ImportError('This operation requires shapely. {0}'.format(e)) | |
| try: | |
| import fiona | |
| except ImportError as e: | |
| raise ImportError('This operation requires fiona. {0}'.format(e)) | |
| try: | |
| import geopandas as gpd | |
| except ImportError as e: | |
| raise ImportError('This operation requires geopandas. {0}'.format(e)) | |
| geos = gpd.GeoDataFrame(df.apply(PlacemarkHandler.spatializer,axis=1)) | |
| result = gpd.GeoDataFrame(pd.concat([df,geos],axis=1)) | |
| elif output=='geojson' or output=='json': | |
| try: | |
| import shapely | |
| from shapely.geometry import Polygon,LineString,Point | |
| except ImportError as e: | |
| raise ImportError('This operation requires shapely. {0}'.format(e)) | |
| try: | |
| import fiona | |
| except ImportError as e: | |
| raise ImportError('This operation requires fiona. {0}'.format(e)) | |
| try: | |
| import geopandas as gpd | |
| except ImportError as e: | |
| raise ImportError('This operation requires geopandas. {0}'.format(e)) | |
| try: | |
| import geojson | |
| except ImportError as e: | |
| raise ImportError('This operation requires geojson. {0}'.format(e)) | |
| geos = gpd.GeoDataFrame(df.apply(PlacemarkHandler.spatializer,axis=1)) | |
| gdf = gpd.GeoDataFrame(pd.concat([df,geos],axis=1)) | |
| out_filename = file[:-3] + "geojson" | |
| gdf.to_file(out_filename,driver='GeoJSON') | |
| validation = geojson.is_valid(geojson.load(open(out_filename)))['valid'] | |
| if validation == 'yes': | |
| result = ("Successfully converted {0} to GeoJSON and output to" | |
| " disk at {1}".format(file,out_filename)) | |
| else: | |
| raise ValueError('The geojson conversion did not create a ' | |
| 'valid geojson object. Try to clean your ' | |
| 'data or try another file.') | |
| elif output=='shapefile' or output=='shp' or output =='esri shapefile': | |
| try: | |
| import shapely | |
| from shapely.geometry import Polygon,LineString,Point | |
| except ImportError as e: | |
| raise ImportError('This operation requires shapely. {0}'.format(e)) | |
| try: | |
| import fiona | |
| except ImportError as e: | |
| raise ImportError('This operation requires fiona. {0}'.format(e)) | |
| try: | |
| import geopandas as gpd | |
| except ImportError as e: | |
| raise ImportError('This operation requires geopandas. {0}'.format(e)) | |
| try: | |
| import shapefile | |
| except ImportError as e: | |
| raise ImportError('This operation requires pyshp. {0}'.format(e)) | |
| geos = gpd.GeoDataFrame(df.apply(PlacemarkHandler.spatializer,axis=1)) | |
| gdf = gpd.GeoDataFrame(pd.concat([df,geos],axis=1)) | |
| out_filename = file[:-3] + "shp" | |
| gdf.to_file(out_filename,driver='ESRI Shapefile') | |
| sf = shapefile.Reader(out_filename) | |
| import shapefile | |
| sf = shapefile.Reader(out_filename) | |
| if len(sf.shapes())>0: | |
| validation = "yes" | |
| else: | |
| validation = "no" | |
| if validation == 'yes': | |
| result = ("Successfully converted {0} to Shapefile and output to" | |
| " disk at {1}".format(file,out_filename)) | |
| else: | |
| raise ValueError('The Shapefile conversion did not create a ' | |
| 'valid shapefile object. Try to clean your ' | |
| 'data or try another file.') | |
| else: | |
| raise ValueError('The conversion returned no data; check if' | |
| ' you entered a correct output file type. ' | |
| 'Valid output types are geojson, shapefile,' | |
| ' csv, geodataframe, and/or pandas dataframe.') | |
| return result | |
Okay @lkwalke4, I'll take a look.
Setting the Stage and Expectations
Upfront, I apologize for the lengthy explanations. This response provides instruction in detail because I want to make sure you have everything you need, but I also want to have this instruction for anyone that would come after you. If the help seems overly simple or extensive, keep in mind the purpose. I'm want to write this so any level of Python user can understand.
Also, understand it will be difficult for me to debug your exact issue since I don't have the file; it's like I'm trying to reach a door on the other side of a dark room that I vaguely remember. Expect some stumbles along the way :-) . Some details below may not apply to you, but I'll give it my best go. Let's get to your solution!
The First Solution: Adding a New Line to Skip the Error
Based on your error, there's one bad key. You can skip it to see if you're getting the result you need. You'll make an edit at one specitic line; line 103-105. Just add this to skip:
elif self.inPlacemark:
if self.name_tag != "" and name in self.mapping[self.name_tag]:
self.mapping[self.name_tag][name] += self.buffer
elif self.name_tag != ""
self.mapping[self.name_tag][name] = self.buffer
self.buffer = ""Try that, and if it works, awesome! If not, paste the stack trace.
Another Solution: Use geopandas
There's another option too! You could just use geopandas. The instructions on how to read a KML/KMZ in geopandas were inspired from this post.
First you need to install geopandas and make sure it's installed in the Python interpreter that you use for ArcGIS. Based on your stack trace, you're on a Windows machine to installs can be tricky. Use wheels to make it simpler. geopandas requires fiona,pyproj and shapely, and those libraries require GDAL and GEOS (You may know about these libraries as they are core libraries in GIS. You also may need to install from here if below doesn't work). l Visit this page which has Python wheels for windows machines, and install wheels for (links below are clickable):
Make sure you download the correct wheel for your version of Python and architecture of Windows.
Installing the Wheels after downloading
Installing those wheels is easy.
- Download the wheels and remember the folder where you saved them.
- Open up a command prompt on your Windows machine. T
- Navigate, in your command prompt, to the folder/directory where you downloaded the wheels. You can use this easy shortcut to open the prompt quickly without using the command line if you're unfamiliar with command line syntax.
- Then just pip install that wheel file like so:
pip install Fiona‑1.7.12‑cp34‑cp34m‑win_amd64.whl - Do that for each wheel
- Then try to import geopandas; if it works without error, you're good!!
import geopandas as gpd
The next step is enabling KML reading in fiona (fiona is the Python library to read and write geospatial files).
fiona.drvsupport.supported_drivers['kml'] = 'rw' # enable KML support which is disabled by default
fiona.drvsupport.supported_drivers['KML'] = 'rw' # enable KML support which is disabled by defaultAnd now you just read in your KML (if you had a KMZ, extract it first to get your KML file, which is usually named doc.kml):
import geopandas as gpd
a = gpd.read_file("/path/to/your/doc.kml")As a warning, this method is easy but sometimes you lose data (not all lines read in). Because it's so easy, I think it's at least worth a shot.
That code will load up your KML as a geopandas.GeoDataFrame; geopandas is a POWERFUL geospatial analysis library in Python. It eliminates your need for PostGIS; with a stack of geopandas, shapely (for geosptial ops), pysal (for advanced geospatial analytics), rasterio (raster analysis), datashader (visualize large datasets in milliseconds such as lidar) and fiona, you eliminate the need for ArcGIS or any other GIS tool.
Moving on, the last step is writing your data to a shapefile. geopandas can write to any file that fiona writes to and that list is extensive. This line of code exports the GeoDataFrame as an ESRI Shapefile named test.shp.
a.to_file('test.shp',driver='ESRI Shapefile')That line also creates the dbf, prj,cpg,shx and gif files.
Final Suggestion if All Else Fails: use QGIS
If you're having trouble reading KMZ/KML in ArcGIS, I honestly suggest using QGIS. QGIS is, in my humble opinion, better than ArcGIS at dealing with different types of data formats and it is better at handling large data files (ArcGIS will choke on data sets that QGIS handles easily). And, best of all, QGIS is free.
Just follow download/install instructions here: https://qgis.org/en/site/forusers/download.html#
A zoologist in South Africa used this same code I'm helping you with. We got his errors fixed so I'm confident we can do the same for your KML. If not, there's QGIS. QGIS would require manual loading and saving, but his complex tracking data loaded in QGIS with zero issues. You'd just load, right click and download as a shapefile:

Get back to me when you can. Sorry it took a few days to respond but hopefully you can try some of the things above and get back to me in the next week or so.
Hi Linwood!
Woah! Phenomenal answer and I really appreciate you writing it out for me.
I have built a tool that utilizes built in ArcMap "KML to Layer" functionality and then parses out the "Pop-up Info" field. This works on most KMZs - but I still get KMZs that this won't work with. Typically it's because the built in Arc functionality doesn't preserve the "Pop-up Info" field for some reason.
Anyway, that's why I've been trying to get your tool to work - to use on these problem KMLs. The suggestion you gave for skipping / adding a new line did not work and gave a new error, but it may be that I'm working with crummy KMLs. To just read a KML, I typically use BeautifulSoup which seems to work pretty well. I already have Geopandas installed, but I'm at a bit of a loss as to how I could read a KML and then spit it out as a SHP utilizing Geopandas. Perhaps read with Geopandas and then export using GDAL/ogr2ogr? I'm not that familiar with GDAL, so there'd be a learning curve for me.
BUT! Your suggestion of QGIS was PHENOMENAL! So, get this - the KML layers that my tool doens't work with can be parsed just fine by QGIS... but the layers that my tool does work with can't be parsed by QGIS.
Any insight into that interesting phenomenon?
Anyway, thank you so much for all your help,
-Lindsay
If you don't mind, what does the following section accomplish? It seems to be handling a specific case.
kmz = ZipFile(file, 'r')
vmatch = np.vectorize(lambda x:bool(r.search(x)))
A = np.array(kmz.namelist())
sel = vmatch(A)
buffer = kmz.open(A[sel][0],'r')
I would have written that as
kmz = ZipFile(file, 'r')
buffer = kmz.open(kmz.namelist()[0],'r')
but obviously you're doing that extra work in order to accommodate a certain scenario.
Thanks for your time (and code!)
sweet! in case this happens to anyone else, it gave me an error along the lines of "this requires pyshp" running
!pip install pyshp
fixed it. thank you very much
Hey, Is there any way to have the csv export more date. Right now Im only getting a 6 columns, but there are about 36 different columns in the kml. Any ideas?
Hi Linwood,
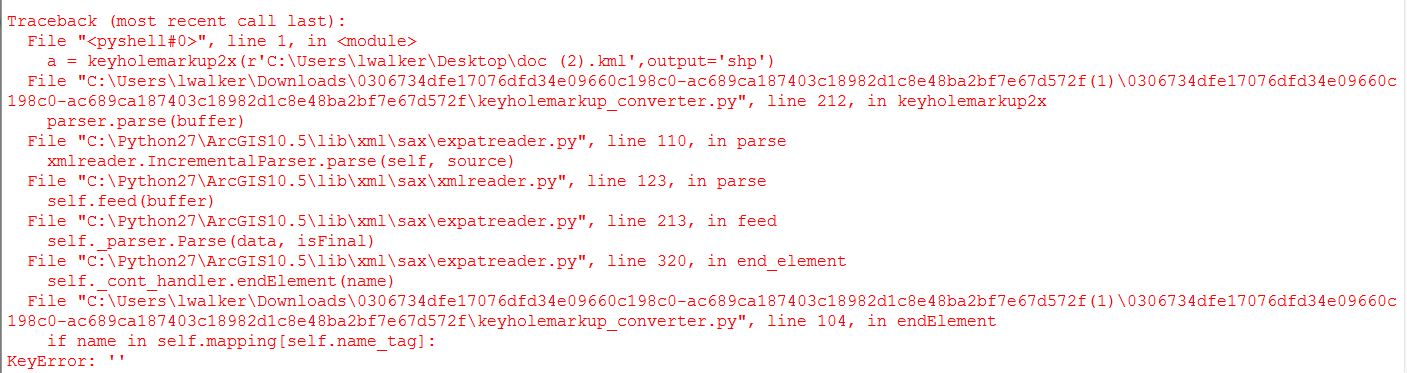
Attached is the error that I receive when trying to run this code. I believe I have all of the prerequisites you call on installed correctly and I'm having trouble figuring out what could be wrong. Any help is much appreciated,
-Lindsay