Python / 40.3K lines of code. Start building LLM-empowered multi-agent applications in an easier way.
URL: https://github.com/modelscope/agentscope
▲ Explain the major function of the project and how it works by referencing the most important and relevant code snippets.
AgentScope is a multi-agent platform designed to empower developers to build LLM-powered multi-agent applications with ease, reliability, and high performance. It features three high-level capabilities:
-
Easy-to-Use: AgentScope provides a user-friendly interface for developers to build multi-agent applications using Python. It offers various prebuilt components, such as agents, pipelines, and services, that can be easily integrated into applications.
-
High Robustness: AgentScope supports customized fault-tolerance controls and retry mechanisms to enhance application stability. It handles errors gracefully and provides mechanisms for developers to build customized fault-tolerant strategies.
-
Actor-Based Distribution: AgentScope enables developers to build distributed multi-agent applications in a centralized programming manner. It introduces an actor-based distributed mechanism that enables centralized programming of complex distributed workflows and automatic parallel optimization.
Here's how AgentScope works:
-
Initialization: The
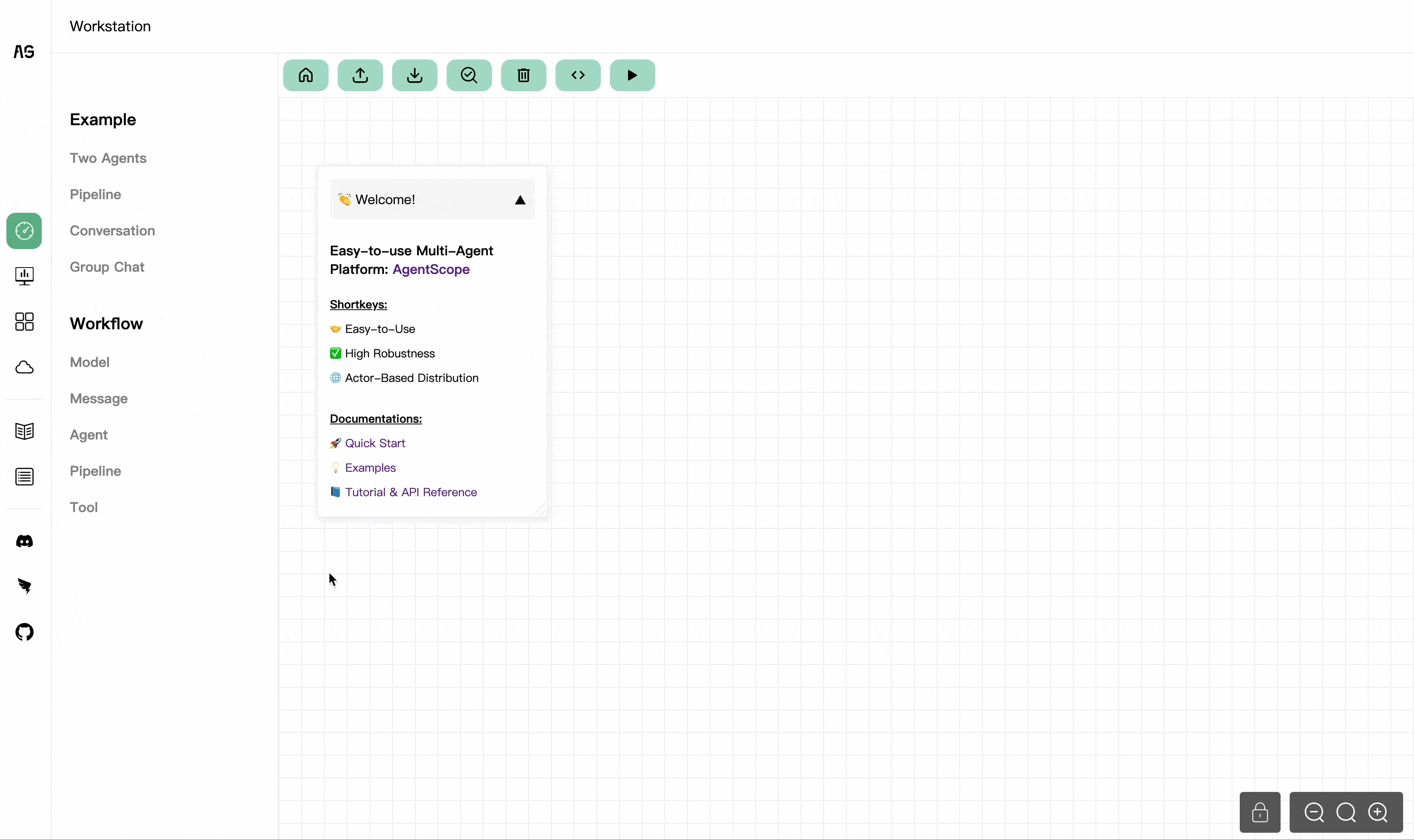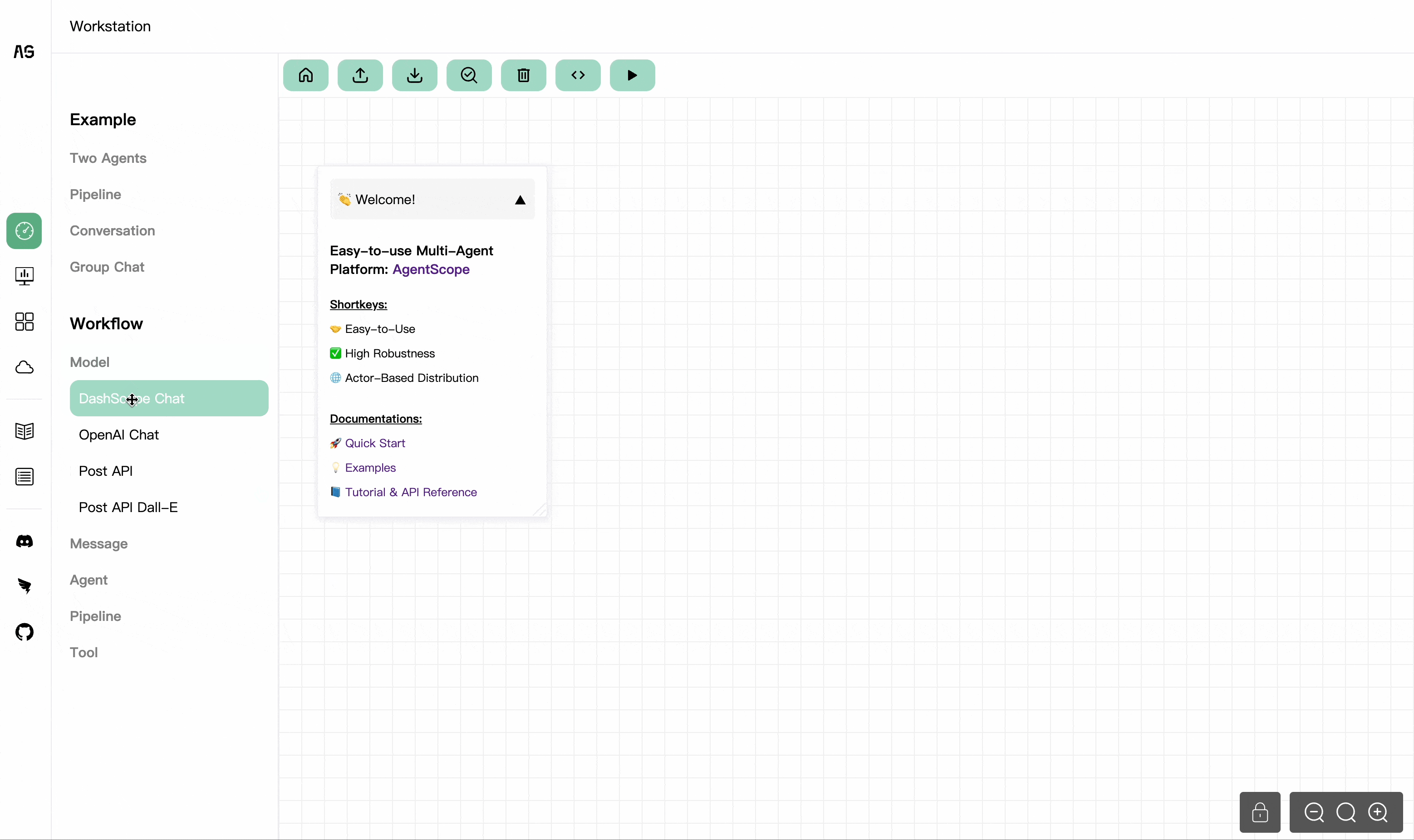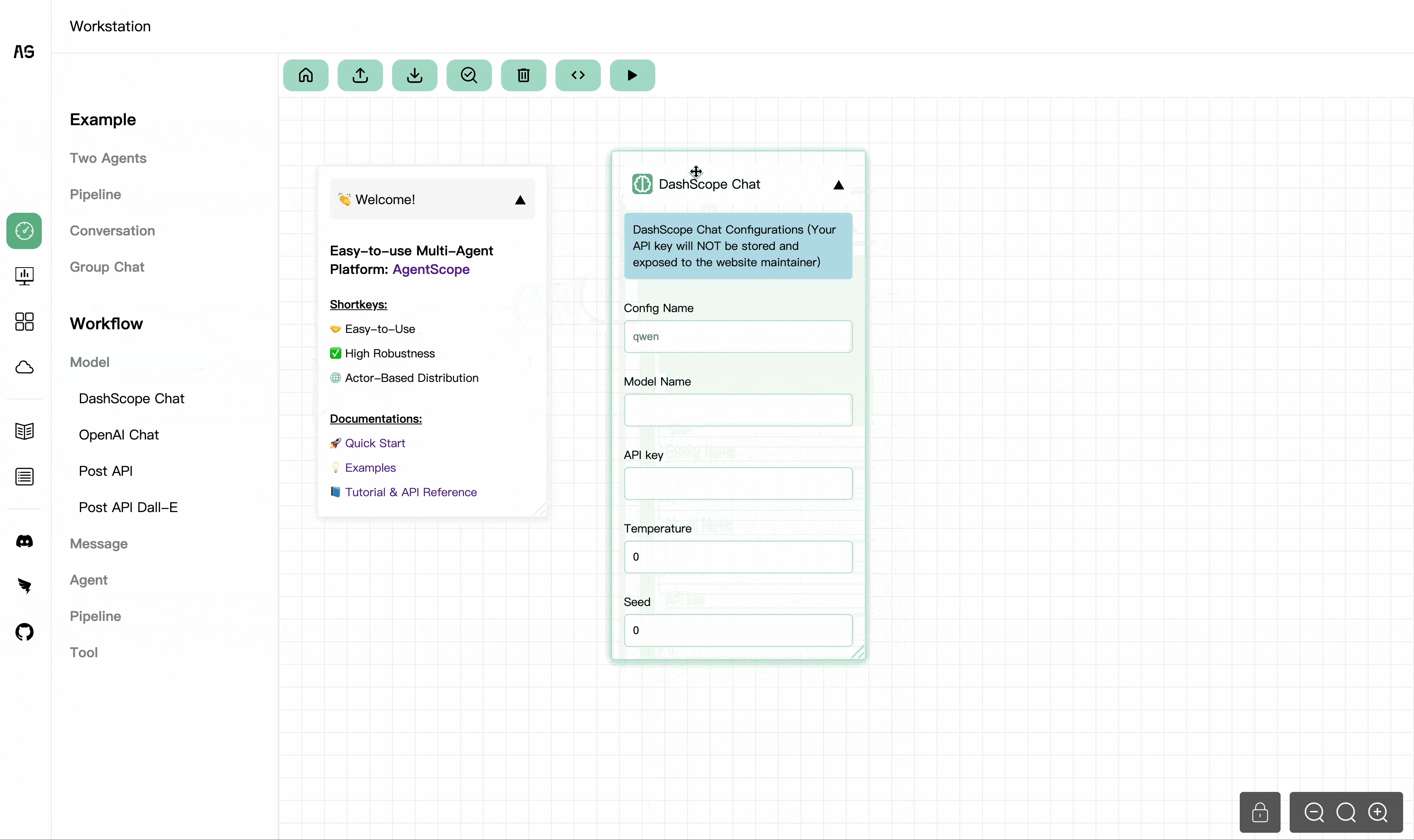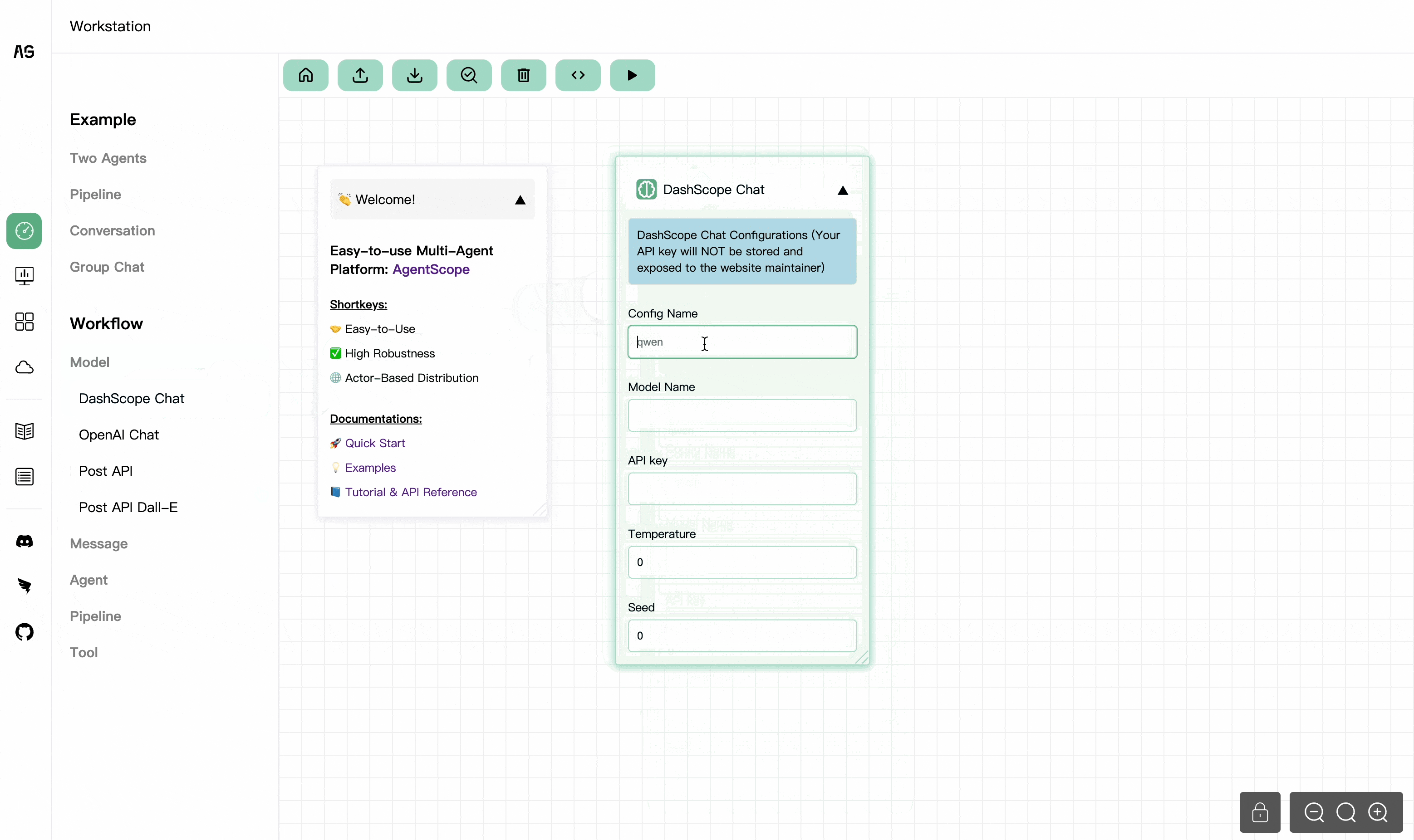
agentscope.init()function initializes the AgentScope environment. It loads model configurations, sets up logging, and initializes the monitor.import agentscope agentscope.init( model_configs="./model_configs.json", logger_level="INFO", save_dir="./runs", save_log=True, save_code=True, save_api_invoke=False, use_monitor=True, )
-
Creating Agents: Developers can create agents using AgentScope's built-in agent classes or by customizing their own agent classes.
from agentscope.agents import DialogAgent, UserAgent dialog_agent = DialogAgent( name="assistant", model_config_name="my_openai_config", sys_prompt="You are a helpful AI assistant", ) user_agent = UserAgent()
-
Message Passing: Agents communicate with each other through messages, which are represented as Python dictionaries.
from agentscope.message import Msg message_from_alice = Msg("Alice", "Hi!") message_from_bob = Msg("Bob", "What about this picture I took?", url="/path/to/picture.jpg")
-
Pipelines: Pipelines define the flow of messages between agents. AgentScope provides various pipeline types, such as
SequentialPipeline,IfElsePipeline, andSwitchPipeline, to manage complex interactions.from agentscope.pipelines import SequentialPipeline pipe = SequentialPipeline([dialog_agent, user_agent]) x = pipe(x)
-
Services: Services provide functional APIs that enable agents to perform specific tasks, such as executing Python code, web search, file operations, and more.
from agentscope.service import execute_python_code result = execute_python_code(code="print('Hello world!')")
-
Distribution: AgentScope supports distributed deployment of agents. Developers can convert agents to their distributed versions using the
to_dist()method.dialog_agent = DialogAgent( name="assistant", model_config_name="my_openai_config", sys_prompt="You are a helpful AI assistant", ).to_dist()
-
Monitoring: AgentScope provides a monitor to track API usage and costs. This helps developers prevent overutilization and ensure compliance with rate limits.
from agentscope.utils import MonitorFactory monitor = MonitorFactory.get_monitor() monitor.register("token_num", metric_unit="token", quota=1000)
-
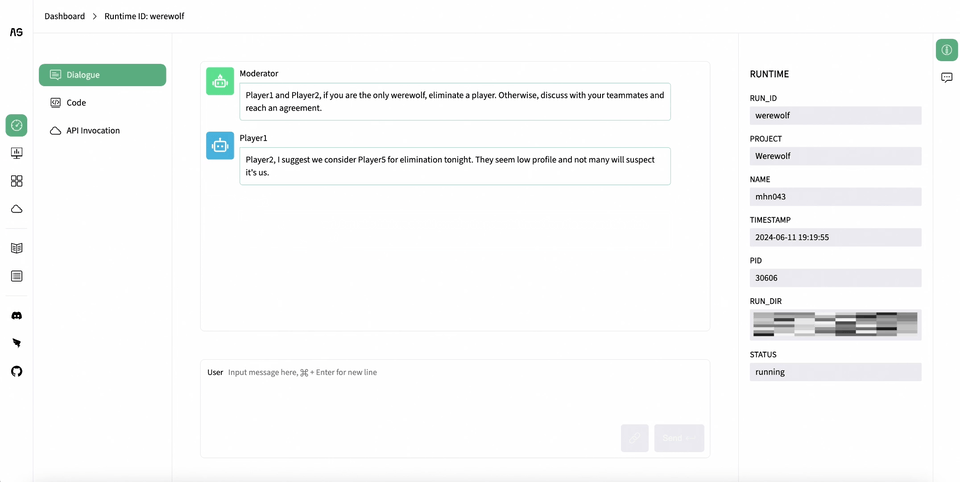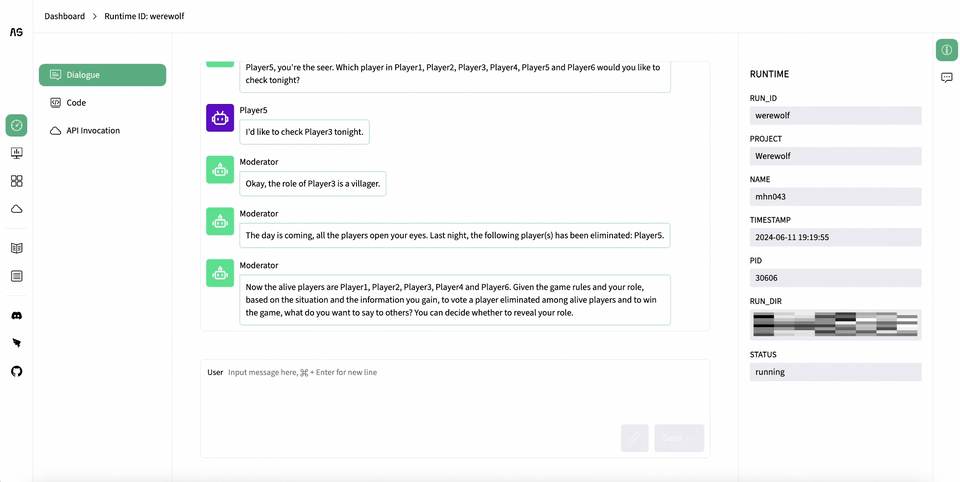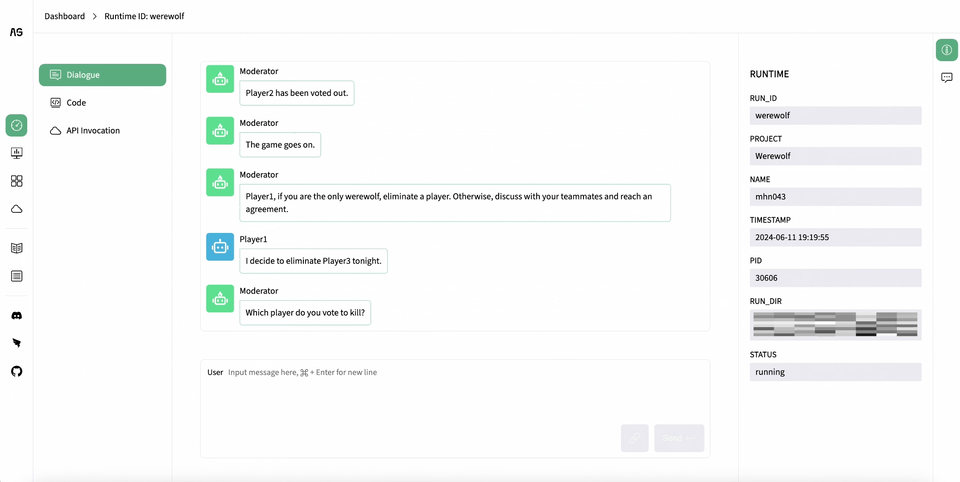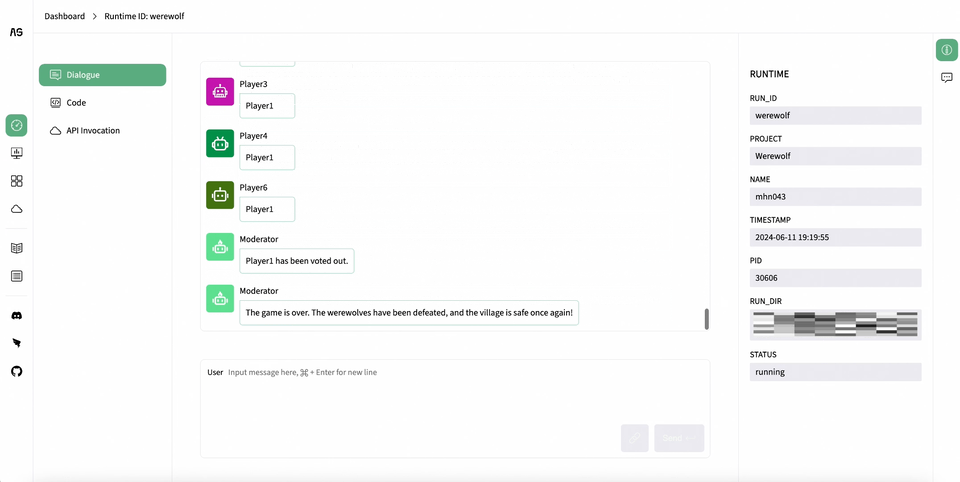
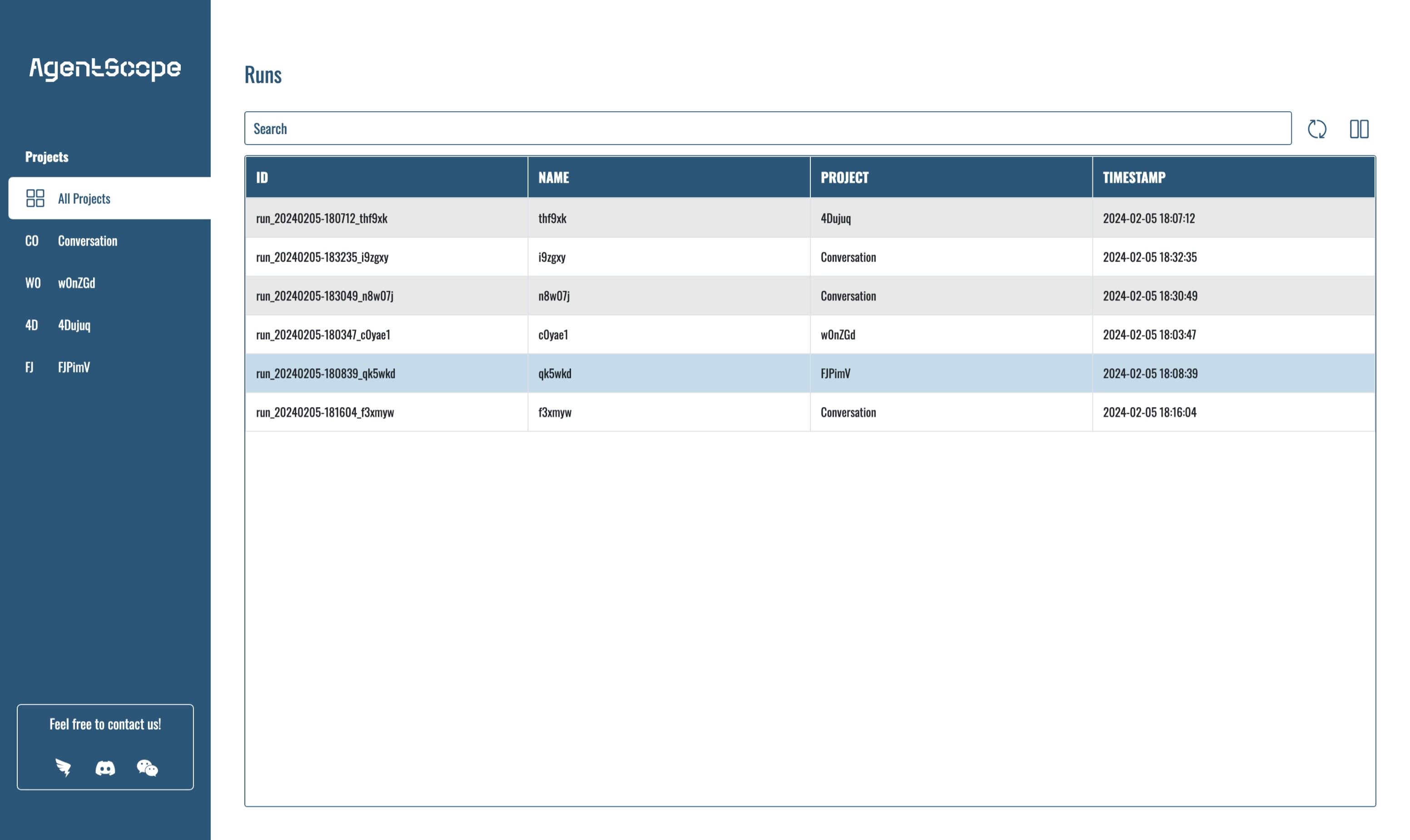
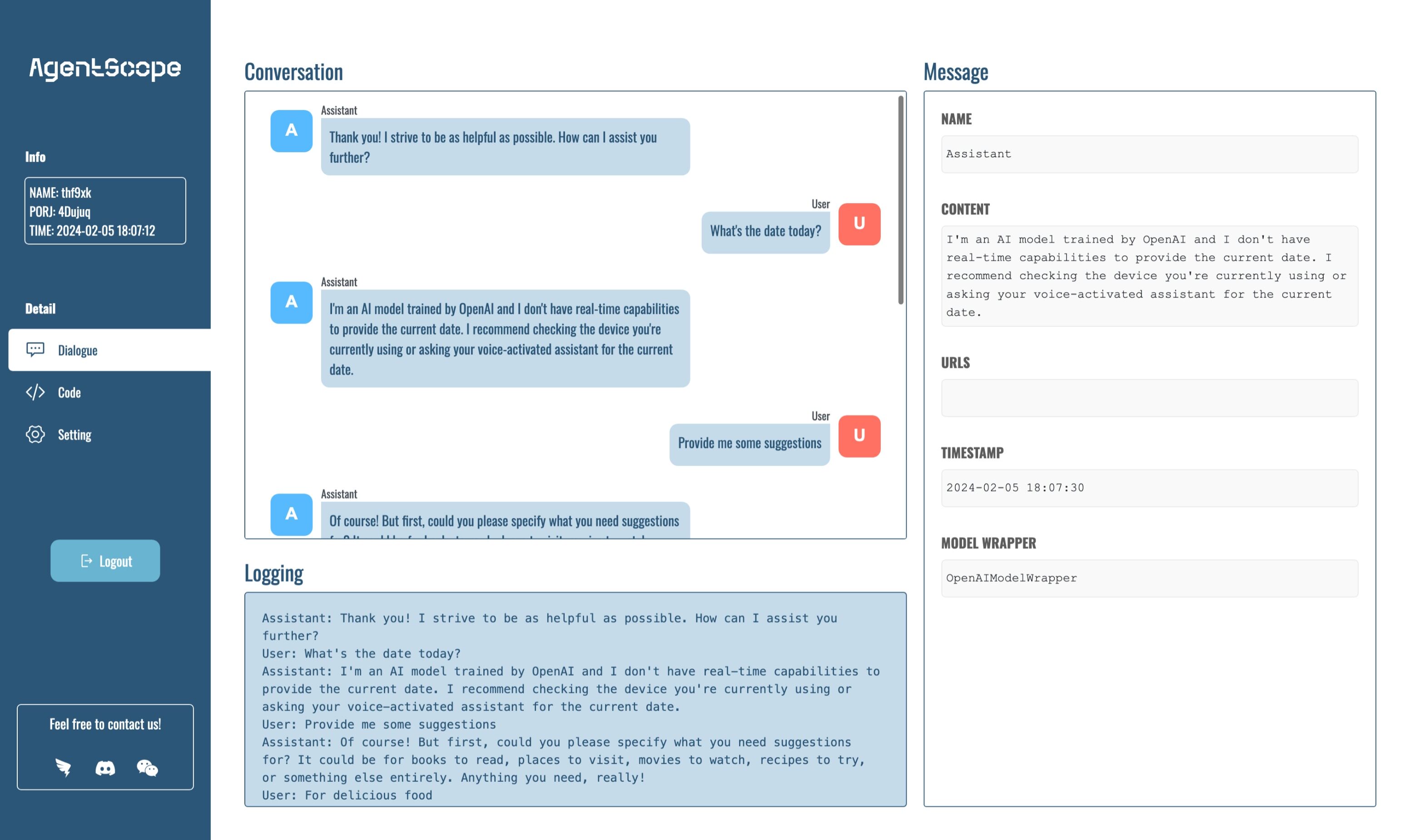
AgentScope Studio: AgentScope Studio is a web UI toolkit for building and monitoring multi-agent applications. It provides a user-friendly interface for building applications with drag-and-drop functionality and a dashboard for monitoring running applications.
AgentScope is a powerful and flexible platform for building LLM-powered multi-agent applications. Its ease of use, robustness, and support for distributed deployment make it an ideal choice for developers looking to build complex and sophisticated applications.





](https://modelscope.cn/studios?name=agentscope&page=1&sort=latest){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}