As you may know from my other blog posts I am mainly working with Django and React at the moment. In this article we are going to take a look on how to solve one bothering problem - the cases mismatch.
- We have working frontend that uses only React
- We are migrating to full Single Page Application (SPA) now
- We maintain the APIs of the app's mobile application
Having this in mind, our backend is used by 3 different endpoints at the same time.
- Python uses
snake_case(mainly) - JavaScript uses
camelCase - Having
obj.snake_case_key.forEach(...)is ugly and lowers the quality of your codebase - Our APIs are built with Django REST Framework (DRF). , they expect
snake_caseddata and return data in the same way
We went through several solutions I want to share with you. I'm sure this architecture is common for a lot of web applications these days so your project might use some of them.
The first solution we've come up with was to implement 2 JavaScript utils - snakeCaseToCamelCase and camelCaseToSnakeCase. You can understand what they did from their names. We used them every time we created POST request and every time we received data from the backend. They actually worked well but introuced a couple of problems themselves:
- It's really easy to forget adding them and end up debugging for a significant amount of time
- Where exactly do you use the util and why? We used the
snakeCaseToCamelCasein the reducers where we actually mutated the data that is comming. We used thecamelCaseToSnakeCasein the functions that made the actualaxiosrequest. - Why didn't we use them only in the sagas or anywhere else? Why do we use 2 pretty much equivalent utils in 2 totally different places?
As you may have noticed I didn't really like the solution with the JS utils. They worked at least!
We've got better with the whole Flux way of thinking and realised that we can use a Redux middleware to solve our problem.
It introduced some "hard-to-debug" bugs and problems so we decided to fall back to the previous schema with the utils.
Recently, I read the DRF docs and noticed a part that I hadn't paid attention to before. They have somethng called Renderers and Parsers. We decided that they are the best place where we should put our camelCase transformation logic.
Let's dive into the main goal of this article - to implement camelCase tranformation in the most elegant way.
Renderers and Parsers stand before and after the serialization of the data. DRF matches which parser and renderer to use by the Content-Type of the request. For example, JSONRenderer and JSONParser are used by default for application/json requests.
This is the perfect place where we can build our logic to mutate the requests and responses data keys.
Our custom renderer and parser must transform the data in depth. This means taht if you have nested lists and dictionaries in the data, their keys will also be affected by the transformation. If you want to take a look at an implementation of such functions, check here
To implement a custom Renderer you need to inherit from BaseRenderer or other Renderer class (JSONRenderer in our case). Every Renderer must define the render method. Here is how our CamelCaseRenderer looks like:
from rest_framework import renderers
from project_name.common.cases import deep_camel_case_transform
class CamelCaseRenderer(renderers.JSONRenderer):
def render(self, data, *args, **kwargs):
camelized_data = deep_camel_case_transform(data)
return super().render(camelized_data, *args, **kwargs)It was easy, wasnt't it? Going further, one thing I really like about DRF is the templates of the responses they have. This is from the DRF docs:
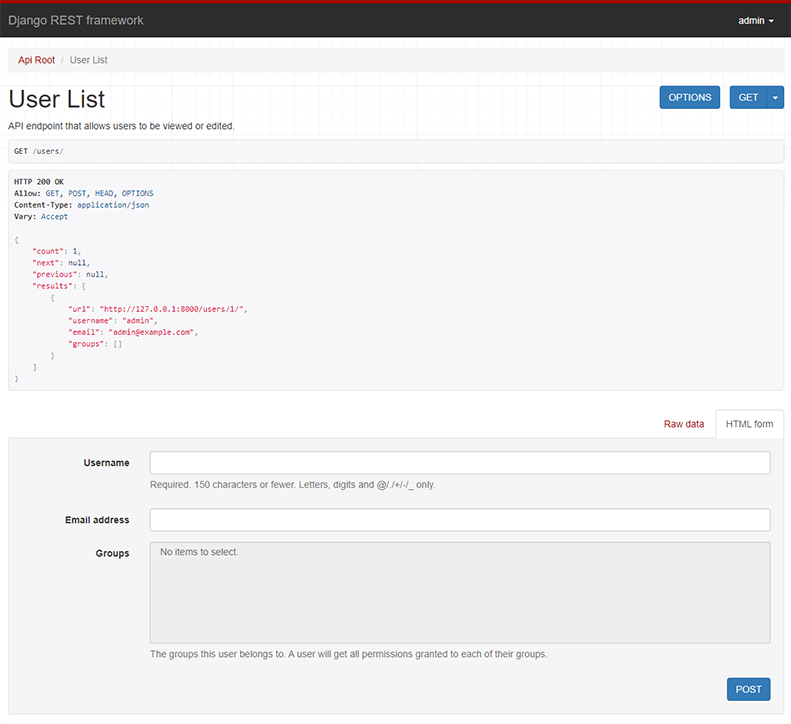
This can be achived by writing your own BrowsableAPIRenderer. Here is how is looks like in our case:
class BrowsableCamelCaseRenderer(renderers.BrowsableAPIRenderer):
def get_default_renderer(self, view):
return CamelCaseRenderer()It was a little bit tricky to use it because it has different interface that is not that good documented. Further on, I will show you how.
Writing a custom JSON parser is easy as well. To implement a custom Parser you need to inherit from BaseParser or other Parser class (JSONParser in our case). Every Parser must define the parse method. Here is how our CamelCaseRenderer looks like:
from rest_framework import parsers
from colab.common.cases import deep_snake_case_transform
class SnakeCaseParser(parsers.JSONParser):
def parse(self, stream, *args, **kwargs):
data = super().parse(stream, *args, **kwargs)
return deep_snake_case_transform(data)Something to notice here: The stream argument is a bytes representation of the data that is comming (the request's body). You could have some problems with parsing it so I recommend you to check the DRF's repository and implementation.
That was actually everything we need in order to transform a snake_case to camelCase and vise versa.
You can use them by putting them to the renderer_classes and parser_classes of your API.
Since we will repeat this code for a lot of our APIs and they are class-based we introduced two mixins:
from rest_framework import renderers
from .renderers import BrowsableCamelCaseRenderer, CamelCaseRenderer
from .parsers import SnakeCaseParser
class ToCamelCase(renderers.BrowsableAPIRenderer):
renderer_classes = (BrowsableCamelCaseRenderer, CamelCaseRenderer, )
class FromCamelCase:
parser_classes = (SnakeCaseParser, )DRF proposes to use these classes as a middleware instead of adding them to the renderer and parser classes by hand. That's actually really smart since you mainly need to use the same renderer and parser every time you get a request with the same Content-Type. In our case we needed something more flexible.
As I mentioned in the beginning, our APIs are used from multiple endpoints. Each of them expects and passes the data in its own manner. We needed to think of a quick solution that doesn't break all of them.
We've decided to build something like a proxy that decides whether to transform the data or not. This is how it looks like:
from rest_framework import renderers
from rest_framework.settings import api_settings
from django.http import QueryDict
from projecct_name.common.cases import deep_snake_case_transform
class ShouldTransform:
def dispatch(self, request, *args, **kwargs):
if not request.GET.get('_transform', False):
"""
The purpose of this mixin is to add the `case-transformation` renderers and parsers
only in case it's forced from the client (putting the '_transform' GET kwarg). If the client
wants the data in the `snake_case` format we just put the default renderers and parsers.*
* Check: https://github.com/encode/django-rest-framework/blob/master/rest_framework/views.py#L97
"""
self.renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES
self.parser_classes = api_settings.DEFAULT_PARSER_CLASSES
else:
# Make request's GET QueryDict mutable
request.GET._mutable = True
# Delete `_transofrm` key since we don't need it
del request.GET['_transform']
# Convert query params to snake_case
request_get_dict = deep_snake_case_transform(request.GET.dict())
# The following lines puts the snake_cased params back to the request.GET
# https://docs.djangoproject.com/en/2.0/ref/request-response/#django.http.QueryDict.update
request_get = QueryDict('', mutable=True)
request_get.update(request_get_dict)
request_get._mutable = False
request.GET = request_get
return super().dispatch(request, *args, **kwargs)This mixin will transform all requests that have _transform GET parameter. As you may have noticed, it also handles the GET params camelCase transformation.
Now add it to our camelCase mixins:
class ToCamelCase(renderers.BrowsableAPIRenderer, ShouldTransform):
renderer_classes = (BrowsableCamelCaseRenderer, CamelCaseRenderer, )
class FromCamelCase(ShouldTransform):
parser_classes = (SnakeCaseParser, )Now we are ready to use them in our APIs.
NOTE Mind the Python's MRO! Put the mixins before your
APIViewin the inheritance order. Otherwise, theAPIViewwill override therenderer_classesandparser_classesproperties
from rest_framework import serializers
from rest_framework.generics import RetrieveAPIView
from project_name.apis.mixins import ToCamelCase
class ObjectRetrieveSerializer(serializers.ModelSerializer):
class Meta:
modal = Object
fields = (snake_case_field_name, )
class ObjectRetrieveAPI(ToCamelCase, RetrieveAPIView):
serializer_class = ObjectRetrieveSerializer
queryset = Object.objects.all()
lookup_url_kwarg = 'object_id'
# Will return `{'snakeCaseFieldName': 'value'}` in it's Responsefrom rest_framework import serializers
from rest_framework.generic import CreateAPIView
from project_name.apis.mixins import FromCamelCase
class ObjectCreateSerializer(serializers.ModelSerializer):
class Meta:
modal = Object
fields = (snake_case_field_name, )
class ObjectCreateAPI(FromCamelCase, CreateAPIView):
serializer_class = ObjectCreateSerializer
queryset = Object.objects.all()
# Will expect `{'snakeCaseFieldName': 'value'}` in the Requestfrom rest_framework import serializers, status
from rest_framework.response import Response
from rest_framework.views import APIView
from project_name.apis.mixins import FromCamelCase, ToCamelCase
class ObjectCreateAPI(FromCamelCase, ToCamelCase, APIView):
def post(self, request, *args, **kwargs):
serializer = ObjectCreateSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
data = serializer.validated_data
# perform create here ...
output_data = ObjectRetrieveSerializer(created_instance).data
return Response(output_data, status=status.HTTP_201_CREATED)
# Will expect `{'snakeCaseFieldName': 'value'}` in the Request
# Will return the created object in the format `{'snakeCaseFieldName': 'value'}`That's everything for this article. I hope it was helpful. If so, subscribe to our blog for more useful articles!