- pyspark.sql module
- pyspark.streaming module
- pyspark.ml package
- pyspark.mllib package
- pyspark.sql.SparkSession: Main entry point for DataFrame and SQL functionality.
- pyspark.sql.DataFrame: A distributed collection of data grouped into named columns.
- pyspark.sql.Column: A column expression in a DataFrame.
- pyspark.sql.Row A row of data in a DataFrame.
- pyspark.sql.GroupedData: Aggregation methods, returned by DataFrame.groupBy().
- pyspark.sql.DataFrameNaFunctions: Methods for handling missing data (null values).
- pyspark.sql.DataFrameStatFunctions: Methods for statistics functionality.
- pyspark.sql.functions: List of built-in functions available for DataFrame.
- pyspark.sql.types: List of data types available.
- pyspark.sql.Window: For working with window functions.
- pyspark.SparkContext: Main entry point for Spark functionality.
- pyspark.RDD: A Resilient Distributed Dataset (RDD), the basic abstraction in Spark.
- pyspark.streaming.StreamingContext: Main entry point for Spark Streaming functionality.
- pyspark.streaming.DStream: A Discretized Stream (DStream), the basic abstraction in Spark Streaming.
- pyspark.sql.SparkSession: Main entry point for DataFrame and SQL functionality.
- pyspark.sql.DataFrame: A distributed collection of data grouped into named columns.
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q https://www-us.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
!tar xf spark-2.4.5-bin-hadoop2.7.tgz
!pip install -q findspark
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-2.4.5-bin-hadoop2.7"
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
- In practice, the cluster will be hosted on a remote machine that's connected to all other nodes.
- There will be one computer, called the master that manages splitting up the data and the computations.
- The master is connected to the rest of the computers in the cluster, which are called worker.
- The master sends the workers data and calculations to run, and they send their results back to the master.
View Dataframe
df.show()
df.show(5)
Inspect Column and Data Types
df.columns
df.dtypes
Rename Columns
df.toDF('a', 'b', 'c')
df.withColumnRenamed(old, new)
Drop Columns
df.drop('mpg')
Filtering
df[df.mpg < 20]
df[(df.mpg < 20) & (df.cyl == 6)]
Add Column
df.withColumn('gpm', 1 / df.mpg)
Fill Nulls
df.fillna(0)
Aggregation
df.groupby(['cyl', 'gear']) \
.agg({'mpg': 'mean', 'disp': 'min'})
Standard Transformation
import pyspark.sql.functions as F
df.withColumn('logdisp', F.log(df.disp))
PySpark
left.join(right, on='key')
left.join(right, left.a == right.b)
Pivot Table
df.groupBy("A", "B").pivot("C").sum("D")
Summary Statistics (only count, mean, stddev, min, max)
df.describe().show()
df.selectExpr(
"percentile_approx(mpg, array(.25, .5, .75)) as mpg"
).show()
Histogram
df.sample(False, 0.1).toPandas().hist()
SQL
df.createOrReplaceTempView('foo')
df2 = spark.sql('select * from foo')
Things To Remember
. Use pyspark.sql.functions and other built in functions.
. Use the same version of python and packages on cluster as driver.
. Check out the UI at http://localhost:4040
. Learn about SSH port forwarding
. Check out Spark MLib
. RTFM: https://spark.apache.org/docs/latest/
Don't
- Try to iterate through rows
- Hard code a master in your driver
- Use spark-submit for that
- df.toPandas().head()
- df.limit(5).toPandas()
file_location = "{{upload_location}}"
file_type = "{{file_type}}"
infer_schema = "{{infer_schema}}"
first_row_is_header = "{{first_row_is_header}}"
delimiter = "{{delimiter}}"
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
display(df)
temp_table_name = "{{file_name}}"
df.createOrReplaceTempView(temp_table_name)
%sql
/* Query the created temp table in a SQL cell */
select * from `{{file_name}}`
permanent_table_name = "{{table_name}}"
import pyspark sc = pyspark.SparkContext(appName="maps_and_lazy_evaluation_example")
log_of_songs = [ "Despacito", "Nice for what", "No tears left to cry", "Despacito", "Havana", "In my feelings", "Nice for what", "despacito", "All the stars" ]
distributed_song_log = sc.parallelize(log_of_songs)
This next code cell defines a function that converts a song title to lowercase. Then there is an example converting the word "Havana" to "havana".
def convert_song_to_lowercase(song): return song.lower()
convert_song_to_lowercase("Havana")
The following code cells demonstrate how to apply this function using a map step. The map step will go through each song in the list and apply the convert_song_to_lowercase() function.
distributed_song_log.map(convert_song_to_lowercase)
You'll notice that this code cell ran quite quickly. This is because of lazy evaluation. Spark does not actually execute the map step unless it needs to.
"RDD" in the output refers to resilient distributed dataset. RDDs are exactly what they say they are: fault-tolerant datasets distributed across a cluster. This is how Spark stores data.
To get Spark to actually run the map step, you need to use an "action". One available action is the collect method. The collect() method takes the results from all of the clusters and "collects" them into a single list on the master node.
distributed_song_log.map(convert_song_to_lowercase).collect()
Note as well that Spark is not changing the original data set: Spark is merely making a copy. You can see this by running collect() on the original dataset.
distributed_song_log.collect()
You do not always have to write a custom function for the map step. You can also use anonymous (lambda) functions as well as built-in Python functions like string.lower().
Anonymous functions are actually a Python feature for writing functional style programs.
distributed_song_log.map(lambda song: song.lower()).collect()
distributed_song_log.map(lambda x: x.lower()).collect()
Apache Kafka® is a distributed streaming platform.
A producer can be any application who can publish messages to a topic.
A consumer can be any application that subscribes to a topic and consume the messages.
Topics are broken up into ordered commit logs called partitions.
Kafka vluster is a set of servers, each of which is called a broker.
A topic is a category or feed name to which records are published.
ZooKeeper is used for managing and coordinating Kafka broker.
A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system. Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka is generally used for two broad classes of applications:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
Few Concepts
- Kafka is run as a cluster on one or more servers that can span multiple datacenters.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
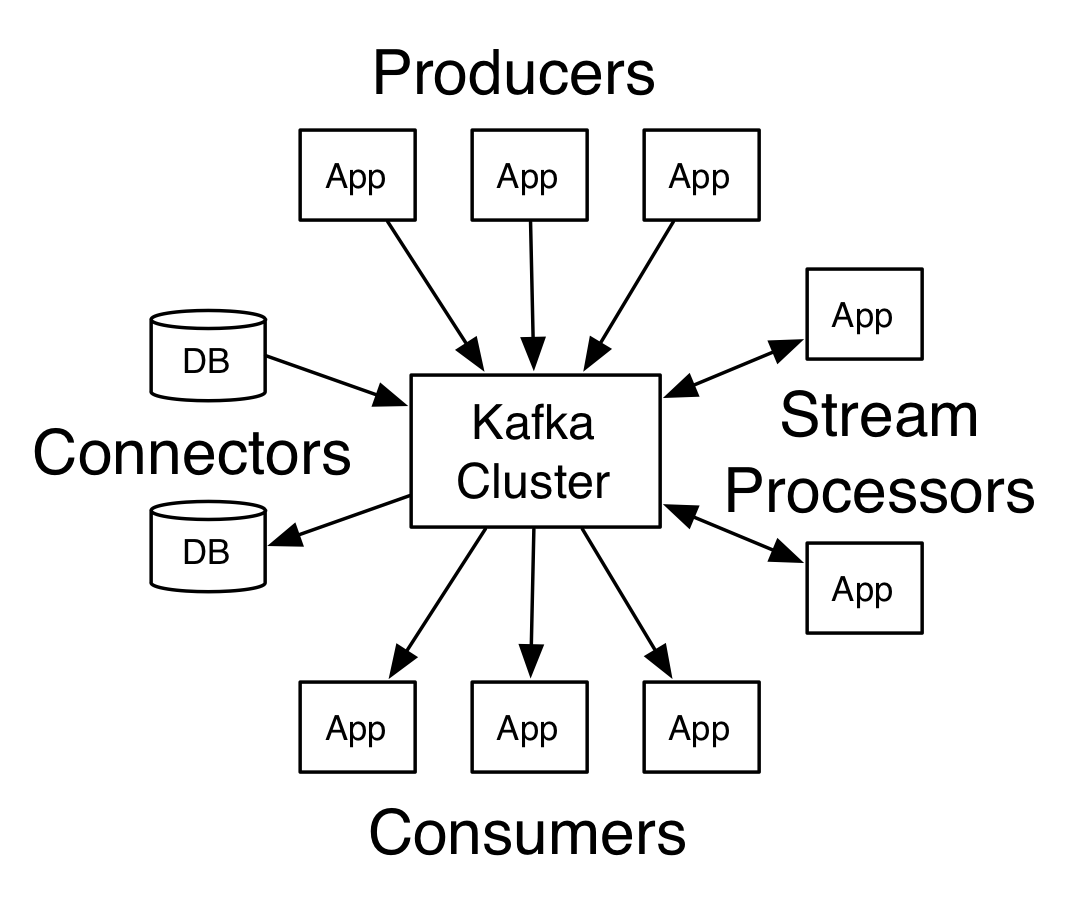
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
- The Admin API allows managing and inspecting topics, brokers and other Kafka objects.
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol.
The core abstraction Kafka provides for a stream of records—the topic.
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
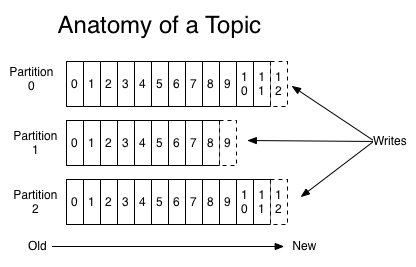
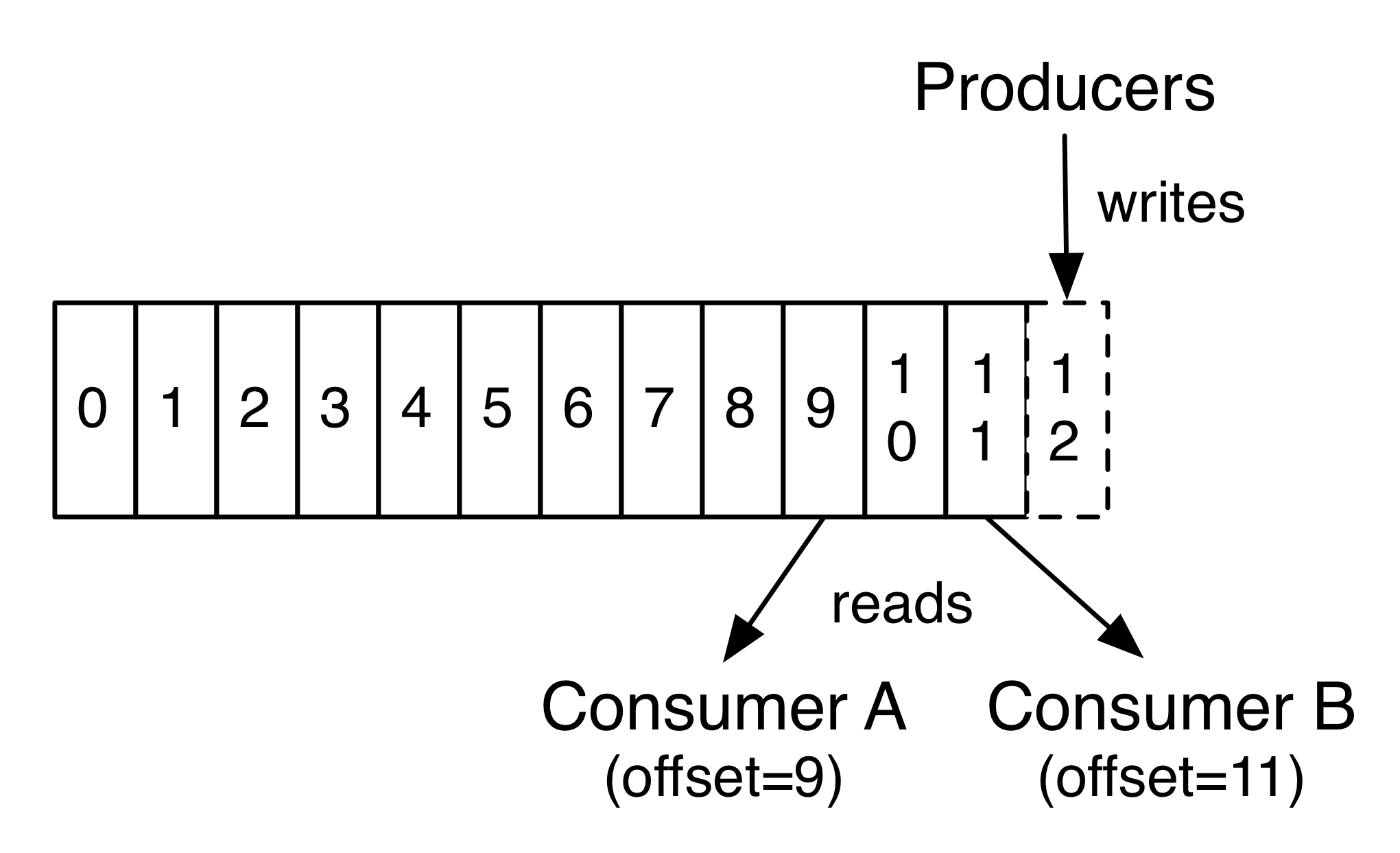
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
The Kafka cluster durably persists all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space.
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record).
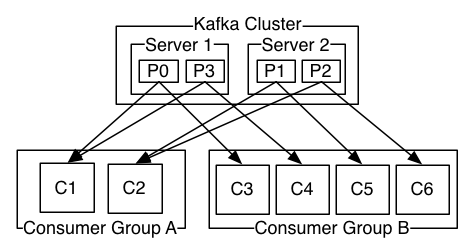
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
You can deploy Kafka as a multi-tenant solution. Multi-tenancy is enabled by configuring which topics can produce or consume data.
Add ZOOKEEPER_HOME = C:\zookeeper-3.4.7 to the System Variables. add ;%ZOOKEEPER_HOME%\bin; to path
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
.\bin\windows\kafka-server-start.bat .\config\server.properties
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytopic
Validate if the topic was created
.\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic mytopic
We can send messages to the Kafka cluster from the console even except the standard file inputs. Just type the message in the console.
This is a message
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic mytopic--from-beginning
.\bin\windows\kafka-server-stop.bat
.\bin\windows\zookeeper-server-stop.bat
from pyspark import SparkContext sc = SparkContext(master = 'local[2]')
- Retrieve SparkContext version
sc.version - Retrieve Python version
sc.pythonVer - Master URL to connect to
sc.master - Path where Spark is installed on worker nodes
str(sc.sparkHome) - Retrieve name of the Spark User running SparkContext
str(sc.sparkUser()) - Return application name
sc.appName - Retrieve application ID
sc.applicationId - Return default level of parallelism
sc.defaultParallelism - Default minimum number of partitions for RDDs
sc.defaultMinPartitions
from pyspark import SparkConf, SparkContext
conf = (SparkConf("local")
.setMaster("My app")
.setAppName( )
.set("spark.executor.memory", "1g"))
sc = SparkContext(conf = conf)
In the PySpark shell, a special interpreter aware SparkContext is already created in the variable called sc.
$ ./bin/spark shell --master local[2]
$ ./bin/pyspark --master local[4] --py files code.py
Set which master the context connects to with the --master argument, and add Python .zip, .egg or .py files to the runtime path by passing a comma separated list to --py-files.
rdd = sc.parallelize([('a',7),('a',2),('b',2)])
rdd2 = sc.parallelize([('a',2),('d',1),('a',1)])
rdd3 = sc.parallelize(range(100))
rdd4 = sc.parallelize([("a",["x","y","z"]), ("b",["p","r"])])
Read either one text file from HDFS, a local file system or or any Hadoop supported file system URI with textFile(), or read in a directory of text files with wholeTextFiles()
textFile = sc.textFile("/my/directory/*.txt")
textFile2 = sc.wholeTextFiles("/my/directory/")