This analysis will allow a user to aggregate deliveries between origin and destination pairs. After applying, style and filter a map based on trips between origins and destinations.
Requirements:
-
A dataset (without geometries) of deliveries between origins and destinations. The deliveries schema should include at minimum:
- origin id (numeric or string)
- destination id (numeric or string)
- at least one aggregation column such as cost or pallets (numeric)
-
A dataset (with geometries) of locations. The locations schema should include at minimum:
- the_geom (point geometry)
- id (numeric or string)
-
Custom SQL nodes must be enabled and one custom SQL functions is needed: DEP_EXT_ODCounts
For the following example, use this .carto file. It contains the required datasets and analysis & widgets setup. large_fake_bxb_locations map 1 (on 2017-11-27 at 17.36.04).carto.zip
Steps for creating map and analysis with (fake) sample datasets:
-
From the CARTO dashboard, select "New Map"
-
Upload the sample BXB .carto file (which contains the needed sample datasets for deliveries and locations)
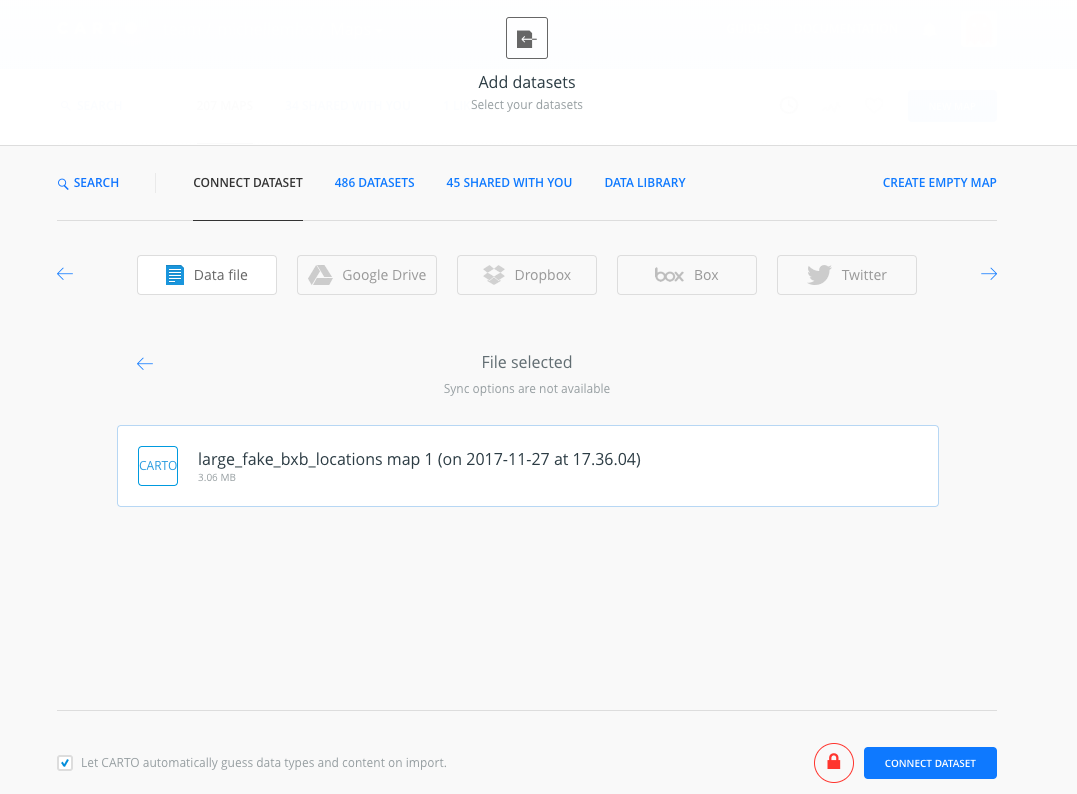 At this point, the map should not render. This is because the custom SQL function does not exist yet.
At this point, the map should not render. This is because the custom SQL function does not exist yet.
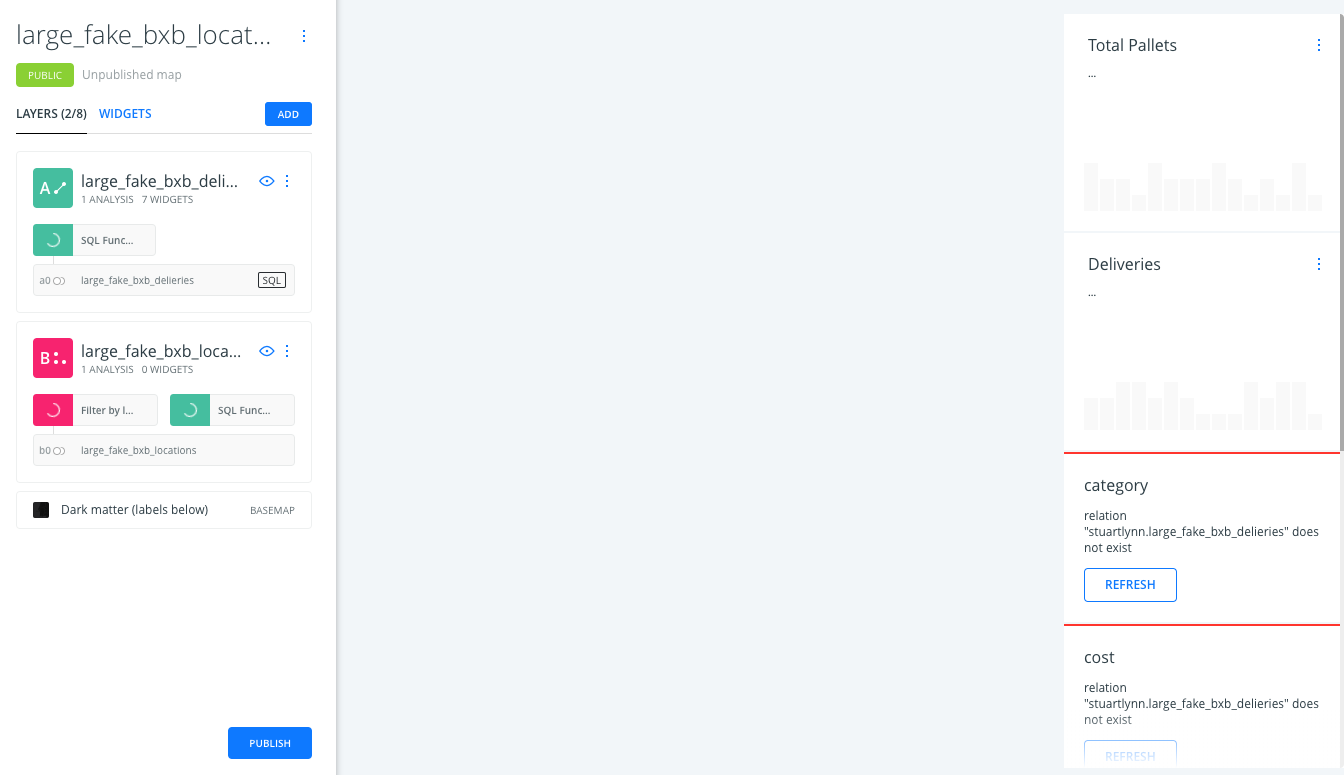
-
To create the custom SQL function, open any dataset SQL pane.
-
Copy-paste the DEP_EXT_ODCounts
CREATE OR REPLACESQL code and apply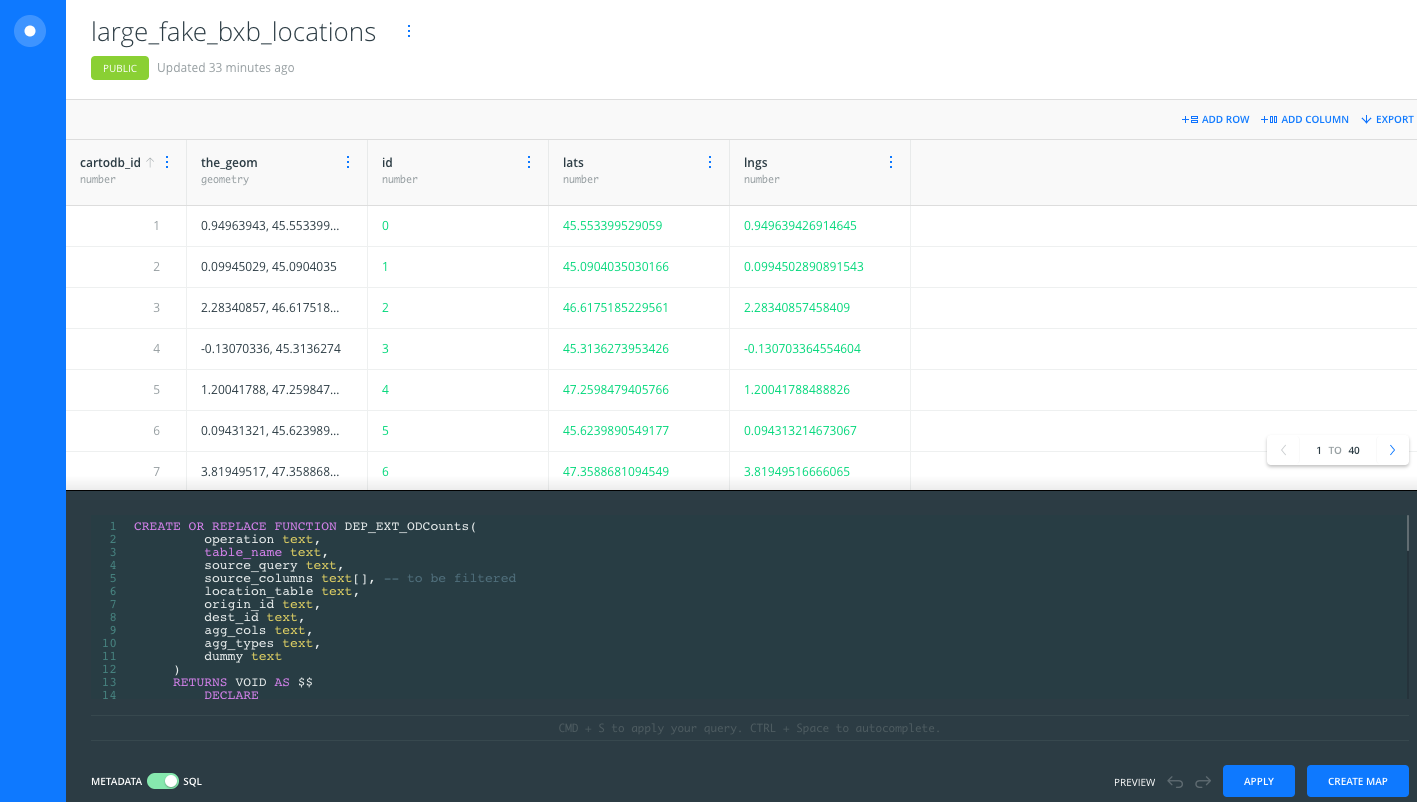
-
Returning to the map, lines should connect the fake sample points in the rectangle, representing deliveries
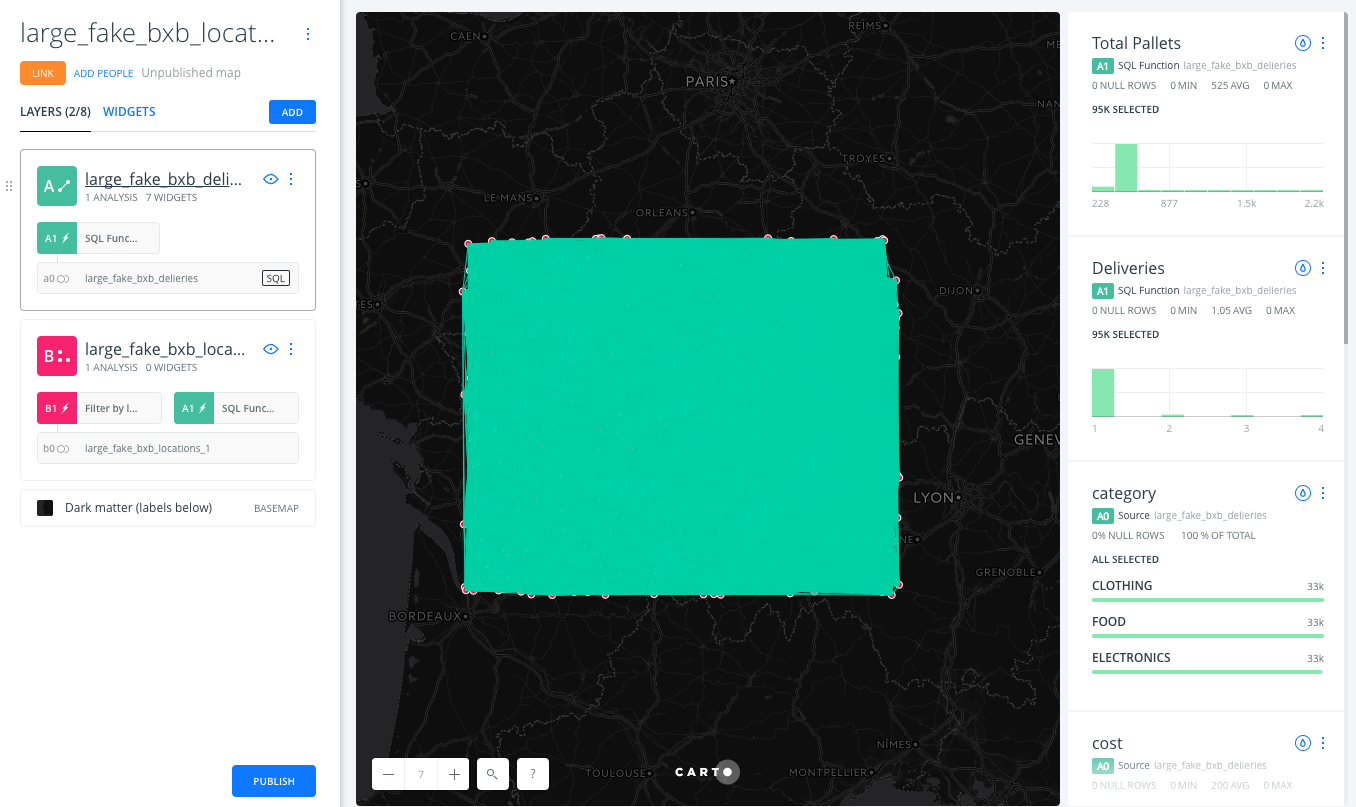
-
Notice the input parameters of the SQL function node on the deliveries layer:
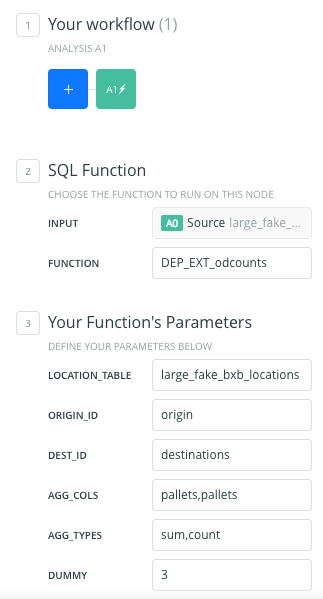
- Location_table: large_fake_bxb_locations (the locations table with point geometries)
- ORIGIN_ID: origin (the column with origin IDs in the delivery table)
- DEST_ID: destinations (the column with destination IDs in the delivery table)
- AGG_COLS: pallets,pallets (a comma separated list of columns to aggregate by, such as cost or pallets)
- AGG_TYPES: sum,count (a comma separated list of aggregation methods. Same length as AGG_COLS)
- DUMMY: 3
This analysis returns two aggregations: the sum and the count of pallets. The dummy variable is to override any cached results and has no effect on the output.
-
Explore the deliveries dataset using widgets.
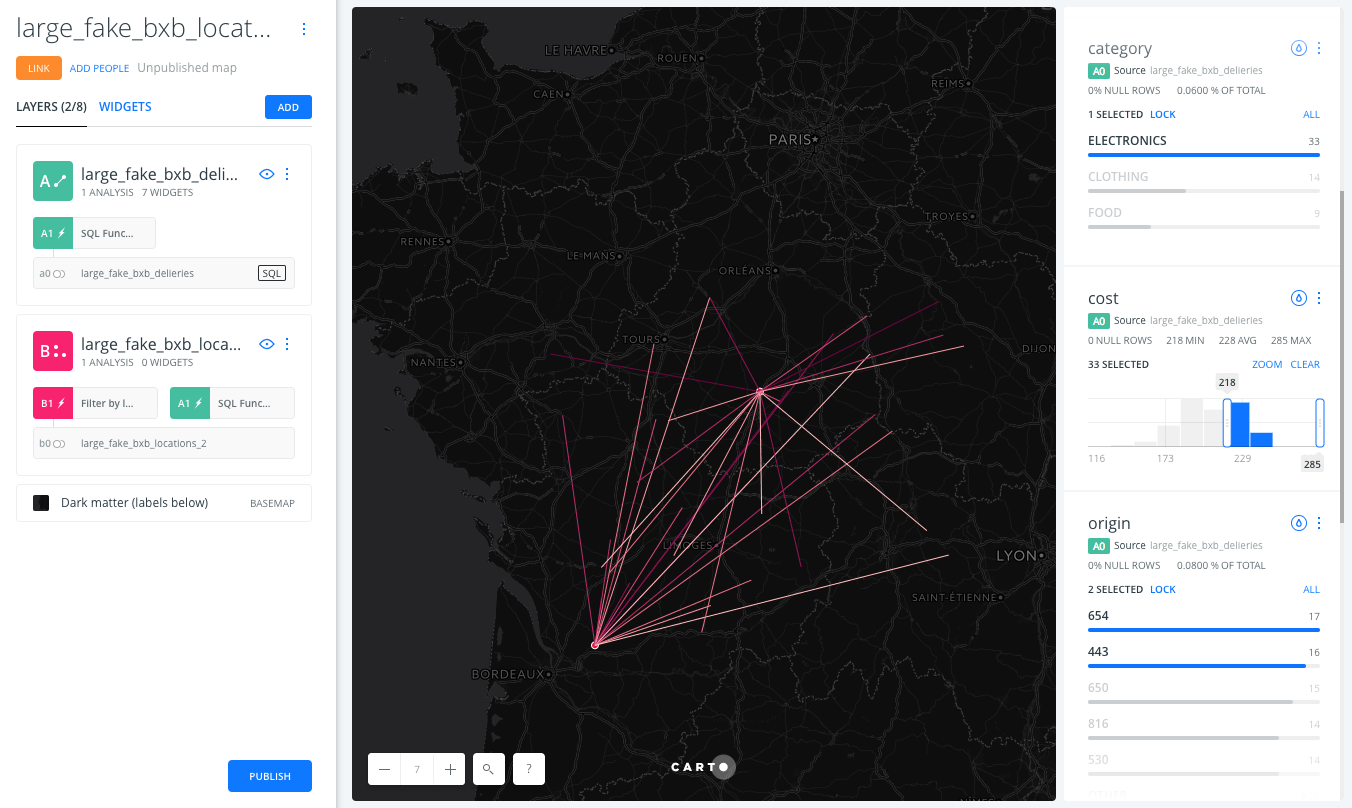
-
Add styling, more widgets, pop-ups, change name and titles, and add legends as desired.