Created
April 5, 2020 15:57
-
-
Save mpoeter/926a80eda0c2c2dce8424b1175a24c84 to your computer and use it in GitHub Desktop.
Simple synthetic benchmark comparing a lock-free stack to a lock-based one.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <atomic> | |
| #include <cassert> | |
| #include <chrono> | |
| #include <iostream> | |
| #include <mutex> | |
| #include <thread> | |
| #include <vector> | |
| #if defined(__sparc__) | |
| #include <synch.h> | |
| #elif defined(__x86_64) || defined(_M_AMD64) | |
| #include <emmintrin.h> | |
| #endif | |
| #if defined(_WIN32) | |
| void* aligned_malloc(size_t size, size_t alignment) { | |
| return _aligned_malloc(size, alignment); | |
| } | |
| void aligned_free(void* pointer) { | |
| _aligned_free(pointer); | |
| } | |
| #else | |
| void* aligned_malloc(size_t size, size_t alignment) { | |
| void* result; | |
| posix_memalign(&result, alignment, size); | |
| return result; | |
| } | |
| void aligned_free(void* pointer) { | |
| free(pointer); | |
| } | |
| #endif | |
| void backoff() { | |
| #if defined(__sparc__) | |
| smt_pause(); | |
| #elif defined(__x86_64) || defined(_M_AMD64) | |
| _mm_pause(); | |
| #endif | |
| } | |
| struct spinlock { | |
| void lock() { | |
| for (;;) { | |
| while (locked.load(std::memory_order_relaxed)) | |
| backoff(); | |
| bool expected = false; | |
| if (locked.compare_exchange_weak(expected, true, std::memory_order_acquire, std::memory_order_relaxed)) | |
| return; | |
| backoff(); | |
| } | |
| } | |
| void unlock() { locked.store(false, std::memory_order_release); } | |
| private: | |
| std::atomic<bool> locked{false}; | |
| }; | |
| struct lockfree_stack { | |
| // We intentionally over-align the nodes here, so we can use to lower 16 bits for the version tag. | |
| // This obviously comes with a high memory overhead, but it is the simplest solution that is fully portable. | |
| static constexpr size_t alignment = 1 << 16; | |
| struct node { | |
| static void* operator new(size_t sz) { return aligned_malloc(sz, alignment); } | |
| static void operator delete(void* p) { aligned_free(p); } | |
| node() : data(), next() {} | |
| unsigned data; | |
| std::atomic<node*> next; | |
| }; | |
| lockfree_stack() : head() {} | |
| ~lockfree_stack() { | |
| auto n = get_ptr(head.load()); | |
| while (n) { | |
| auto next = n->next.load(); | |
| delete n; | |
| n = next; | |
| } | |
| } | |
| void push(node* n) { | |
| for (;;) { | |
| auto h = head.load(std::memory_order_relaxed); | |
| n->next.store(get_ptr(h), std::memory_order_relaxed); | |
| auto new_h = make_ptr(n, h); | |
| if (head.compare_exchange_weak(h, new_h, std::memory_order_release, std::memory_order_relaxed)) | |
| return; | |
| backoff(); | |
| } | |
| } | |
| node* pop() { | |
| for (;;) { | |
| auto n = head.load(std::memory_order_acquire); | |
| auto ptr = get_ptr(n); | |
| auto new_h = make_ptr(ptr->next.load(std::memory_order_relaxed), n); | |
| if (head.compare_exchange_weak(n, new_h, std::memory_order_release, std::memory_order_relaxed)) | |
| return ptr; | |
| backoff(); | |
| } | |
| } | |
| private: | |
| static constexpr uintptr_t tag_mask = alignment - 1; | |
| static constexpr uintptr_t tag_inc = 1; | |
| std::atomic<node*> head; | |
| node* make_ptr(node* new_ptr, node* old_ptr) { | |
| uintptr_t new_ptr_val = reinterpret_cast<uintptr_t>(new_ptr); | |
| assert((new_ptr_val & tag_mask) == 0); | |
| auto tag = (reinterpret_cast<uintptr_t>(old_ptr) & tag_mask) + tag_inc; | |
| tag &= tag_mask; | |
| return reinterpret_cast<node*>(new_ptr_val | tag); | |
| } | |
| node* get_ptr(node* n) { | |
| uintptr_t val = reinterpret_cast<uintptr_t>(n); | |
| return reinterpret_cast<node*>(val & ~tag_mask); | |
| } | |
| }; | |
| template <class Lock> | |
| struct threadsafe_stack { | |
| struct node { | |
| node() : data(), next() {} | |
| unsigned data; | |
| node* next; | |
| }; | |
| threadsafe_stack() : head(), lock() {} | |
| ~threadsafe_stack() { | |
| auto n = head; | |
| while (n) { | |
| auto next = n->next; | |
| delete n; | |
| n = next; | |
| } | |
| } | |
| void push(node* n) { | |
| std::lock_guard<Lock> guard(lock); | |
| n->next = head; | |
| head = n; | |
| } | |
| node* pop() { | |
| std::lock_guard<Lock> guard(lock); | |
| auto result = head; | |
| head = head->next; | |
| return result; | |
| } | |
| private: | |
| node* head; | |
| char padding[64]; // avoid false sharing | |
| Lock lock; | |
| }; | |
| static constexpr size_t num_ops = 500000; | |
| template <class T> | |
| void run_benchmark(size_t num_threads, const char* type) { | |
| std::cout << type << " :\t"; | |
| std::vector<std::thread> threads; | |
| threads.reserve(num_threads); | |
| T stack; | |
| std::atomic<bool> start{false}; | |
| std::atomic<size_t> num_threads_ready{0}; | |
| for (size_t i = 0; i < num_threads; ++i) { | |
| threads.push_back( | |
| std::thread( | |
| [&stack, &start, &num_threads_ready]() { | |
| typename T::node* n = new typename T::node(); | |
| ++num_threads_ready; | |
| while (start.load(std::memory_order_relaxed) == false) | |
| backoff(); | |
| for (size_t op = 0; op < num_ops; ++op) { | |
| auto sum = n->data; | |
| stack.push(n); | |
| for (unsigned x = 0; x < 1000; ++x) { | |
| sum += x; // simulate some workload | |
| } | |
| n = stack.pop(); | |
| n->data = sum; | |
| } | |
| stack.push(n); // push the node so the destructor can free it | |
| } | |
| ) | |
| ); | |
| } | |
| while (num_threads_ready.load(std::memory_order_relaxed) < threads.size()) | |
| ; // wait until all threads are ready | |
| auto start_time = std::chrono::high_resolution_clock::now(); | |
| start.store(true); // signal start | |
| // wait for threads to finish... | |
| for (auto& thread : threads) | |
| thread.join(); | |
| auto end_time = std::chrono::high_resolution_clock::now(); | |
| auto duration_ms = std::chrono::duration_cast<std::chrono::milliseconds>(end_time - start_time).count(); | |
| auto total_ops = num_threads * num_ops * 2; | |
| std::cout << duration_ms << "ms\t" << total_ops / duration_ms << " ops/ms" << std::endl; | |
| }; | |
| size_t step_size(size_t n) { | |
| if (n < 2) return 1; | |
| if (n < 8) return 2; | |
| if (n < 24) return 4; | |
| if (n < 48) return 8; | |
| if (n < 160) return 16; | |
| return 32; | |
| } | |
| int main() { | |
| std::cout << "Running concurrent stack bechmarks; each thread performs " << num_ops << " push and pop operations." << std::endl; | |
| const auto max_threads = std::thread::hardware_concurrency() * 2; | |
| for (size_t threads = 1; threads <= max_threads; threads += step_size(threads)) { | |
| std::cout << "\n" << threads << " threads" << std::endl; | |
| run_benchmark<lockfree_stack>(threads, "lockfree_stack "); | |
| run_benchmark<threadsafe_stack<std::mutex>>(threads, "threadsafe_stack<mutex> "); | |
| if (threads <= 64) { | |
| // spinlock performs poorly for large number of threads...! | |
| run_benchmark<threadsafe_stack<spinlock>>(threads, "threadsafe_stack<spinlock>"); | |
| } | |
| } | |
| } |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I have created this benchmark because of the discussion between David Schwartz (alias @JoelKatz) and me in this stackoverflow thread.
Here are some results from different machines:
Linux 4.19.0-8-amd64 #1 SMP Debian 4.19.98-1 (2020-01-26) x86_64 GNU/Linux
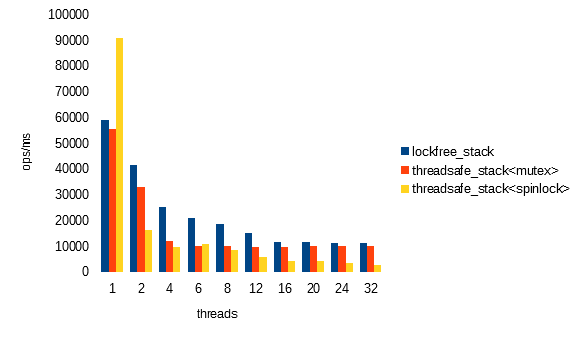
AMD EPYC 7351P 16-Core Processor
16 cores, SMT disabled
Linux 4.19.0-6-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
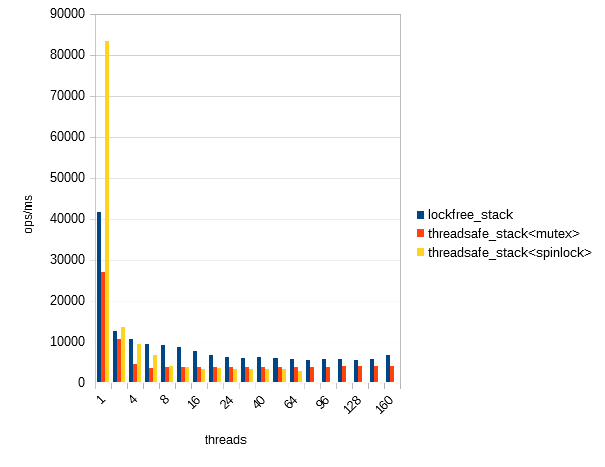
4x Intel(R) Xeon(R) CPU E7- 8850 @ 2.00GHz
80 cores, SMT disabled
SunOS 5.11 11.3 sun4v sparc sun4v
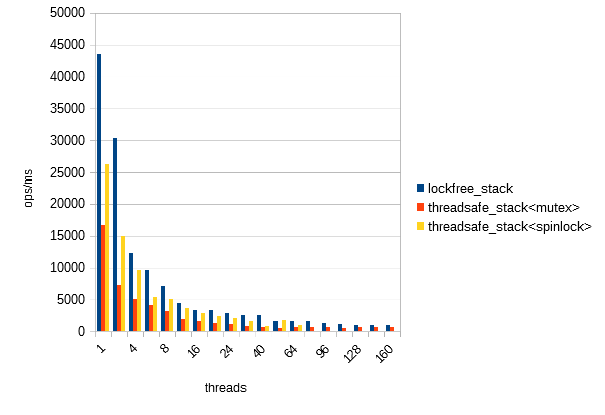
4x SPARC-T5-4
512 hardware threads; 64 cores, 8x SMT